This section contains the results of the literature review, starting with the optimization methods for analysis and decision making and continuing with the multi-criteria methods—those that precede the metaheuristics. The section ends with the particle swarm optimization algorithm (PSO), addressing its concept, uses, and implementations, and the structure of the algorithm for its implementation.
3.1. Analysis and Decision-Making
Businesses have been transformed over the years since their first revolution in the mid-17th century; going through mechanization, electricity, automation, and the use of information technologies until we reach what we know as industry 4.0—where innovation is the main promoter for technological development and knowledge management [
1].
In this sense, technological development requires data analysis processes. Due to the amount of data that is being generated, a range of technologies, tools, strategies, and techniques have been created. These are not only affecting the organization and conduct of the industry, but also the data collection, digitization, and analysis for decision making [
2,
10].
In this way, it can be pointed out that technologies are making data analysis more efficient, for which they used strategies and techniques that integrate the collection, processing, modeling, and visualization of said data [
32], converting information into results that help identify problems, risks, or competitive advantages, contributing to more efficient and faster decision making [
33,
34]. Efficiency in data analysis has led decision makers to face increasingly complex situations [
3], and with dynamic data [
35].
However, the decision maker not only faces the aforementioned situations, but also the need to obtain increasingly precise and reliable results [
36,
37], in addition to handling data with uncertainty [
4,
8]. This is why the strategies created for data analysis help decision makers obtain the best solution. Among these strategies are the multi-criteria methods and the optimization methods, which are detailed in the following sections.
3.2. Multi-Criteria Methods
Decision makers have a great responsibility that comes from analyzing the data to arrive at the best solution [
32]. The decision maker’s success increases when he considers multiple criteria or outcomes [
8]. This leads to advantages and disadvantages of each alternative that reduce costs and increase benefits [
8]. Multi-criteria decision-making (MCDM) problems are part of the most used strategies for decision making [
38,
39]. With these methods, a set of finite alternatives is compared, evaluated, and classified with respect to a set of attributes that are also finite [
8].
In other words, the MCDM are designed to help the decision maker choose the best option among a group of possibilities [
38]. These possibilities are called alternatives, and form the choice set [
40]. To choose from this choice set, the decision maker must consider a variety of conflicting points of view, called criteria [
8,
39]. The MCDM is used in problems that have several solutions and the answer is not determined with a true or false [
41]. Otherwise, with a variety of answers that evaluate multiple conditions with algorithms and mathematical tools to obtain the best solution [
42,
43].
Therefore, the main objective of the MCDM is to provide, to the decision maker, solutions to a problem with multiple criteria, which are often contradictory [
43,
44]. This makes MCDM efficient strategies to obtain the best solution, using strategies to evaluate multiple criteria [
6,
42].
Below are two tables with MCDM methods.
Table 7 contains some of the more popular methods, while
Table 8 shows MCDM methods with fuzzy logic. The tables contain the abbreviation MCDM, the author(s), and the year it was first published. Subsequently, the strategies contained in these tables are detailed.
The first method corresponds to elimination and choice translating reality (ELECTRE), and comprises a family of classification methods. The similarities of this family of methods lie in the pairwise comparison of the alternatives, based on the primary notions of agreement and disagreement sets. In addition, they use ranking charts to point out the best alternative. Bernard Roy is credited as the creator of ELECTRE [
45].
For 1981, two methods appear. The technique for order preference by similarity to an ideal solution (TOPSIS), compares the distance of all alternatives with the best and worst solutions [
46,
47]. The analytical hierarchy process (AHP) decomposes the elements in all hierarchies and determines the priority of the elements through quantitative judgment for integration and evaluation [
36,
48].
In 1988, the multiple criteria compromise and optimization solution (VIKOR) method appears, seeking multi-criteria optimization by classifying a set of alternatives against several conflicts [
48,
49]. Later, in 2005, the preference ranking organization method for evaluation enrichment (PROMETHEE) appeared, which calculates the dominant flows of alternatives [
50,
51]. Meanwhile, in 2006, the multi-objective optimization method based on ratio analysis (MOORA) appeared, which evaluates the ranking of each alternative based on ratio analysis [
52,
53]. The most recent of this group are the combinatorial distance-based evaluation (CODAS) models that use the alternative Euclidean distance of the negative ideal and the Taxicab distance [
54,
55].
A disadvantage of the MCDM lies in the subjective determination of the weights by the decision makers, presenting complexity and uncertainty when evaluating the information [
40,
63]. Due to this complexity, in 1965, Lotfi Zadeh introduced fuzzy sets (FS), allowing the analysis of a wide variety of situations that resemble decision making in situations of uncertainty or inaccuracy [
45,
53]. Since that year, there has been an increase in the development of new methods or improvements, among which is the intuitionist fuzzy set (IFS), developed in 1986, which considers the function of the degree of membership and that of non-members [
56]. Meanwhile, in 1994, it evolved, becoming the bipolar fuzzy set (BFS) with positive and negative membership function degree [
56,
57].
Later, in 2006, the Fuzzy PSO method appeared, solving the convergence conflict of group particles, in addition to maintaining a faster speed and convergence precision [
58]. Meanwhile, in 2008, the Fuzzy TOPSIS method found positive and negative ideal solutions as a comparison criterion for each choice. Later, it compares the Euclidean distance between the alternatives and the ideal solution to obtain the proximity of the alternatives and perform the classification of the pros and cons of the alternatives [
59].
After some time, by 2013, the IFS evolved, modeling uncertainty and vagueness through linguistic terms, called Pythagorean fuzzy sets (PFS) [
41,
60].
Among the most recent methods of 2017, is the q-rung orthopair (q-ROF) fuzzy set, which is based on IFS and PFN, which presents, in parallel, the degrees of membership, non-membership, and indeterminacy of decision makers [
51,
52]. Meanwhile, the T-spherical fuzzy set, from 2019, has the flexibility to unite the sum of the q-th power of membership, abstinence, and non-membership between one and zero [
61,
62].
Although the use of optimization methods as a decision making strategy has shown efficiency, many of them require a lot of time to perform the calculations [
2,
37]. Just as the application of a single algorithm does not guarantee having the best solution, comparing several algorithms or a hybrid increases the efficiency and effectiveness of the result [
36,
64]. An example of this is the combination of interval analytical hierarchy process (IAHP) and combinative distance-based assessment (CODAS) to prioritize alternative energy storage technologies [
65].
3.3. Metaheuristics
The objective of this section is to make a classification of metaheuristic algorithms. Therefore, the origin of the metaheuristics within the optimization methods must first be identified.
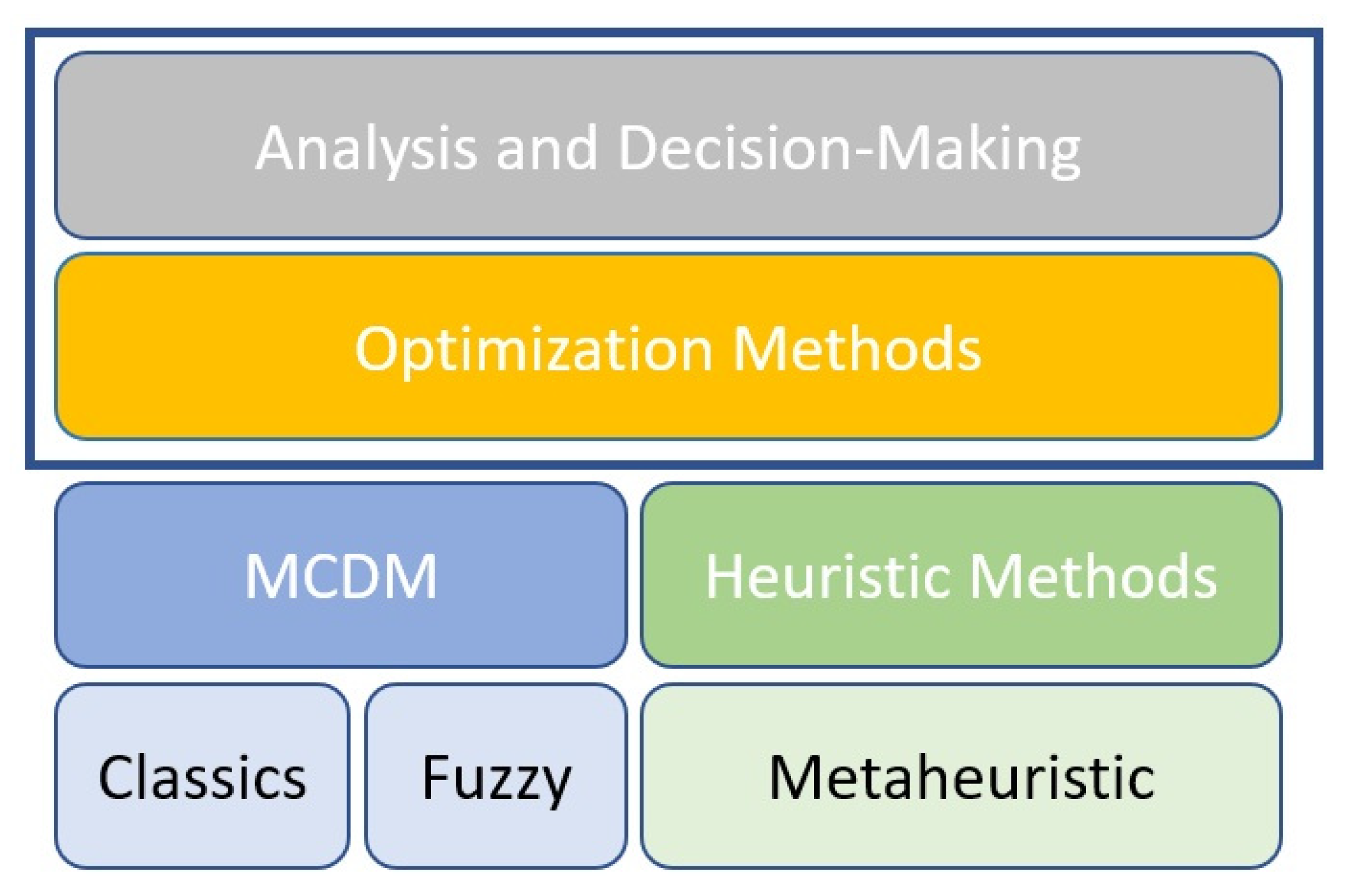
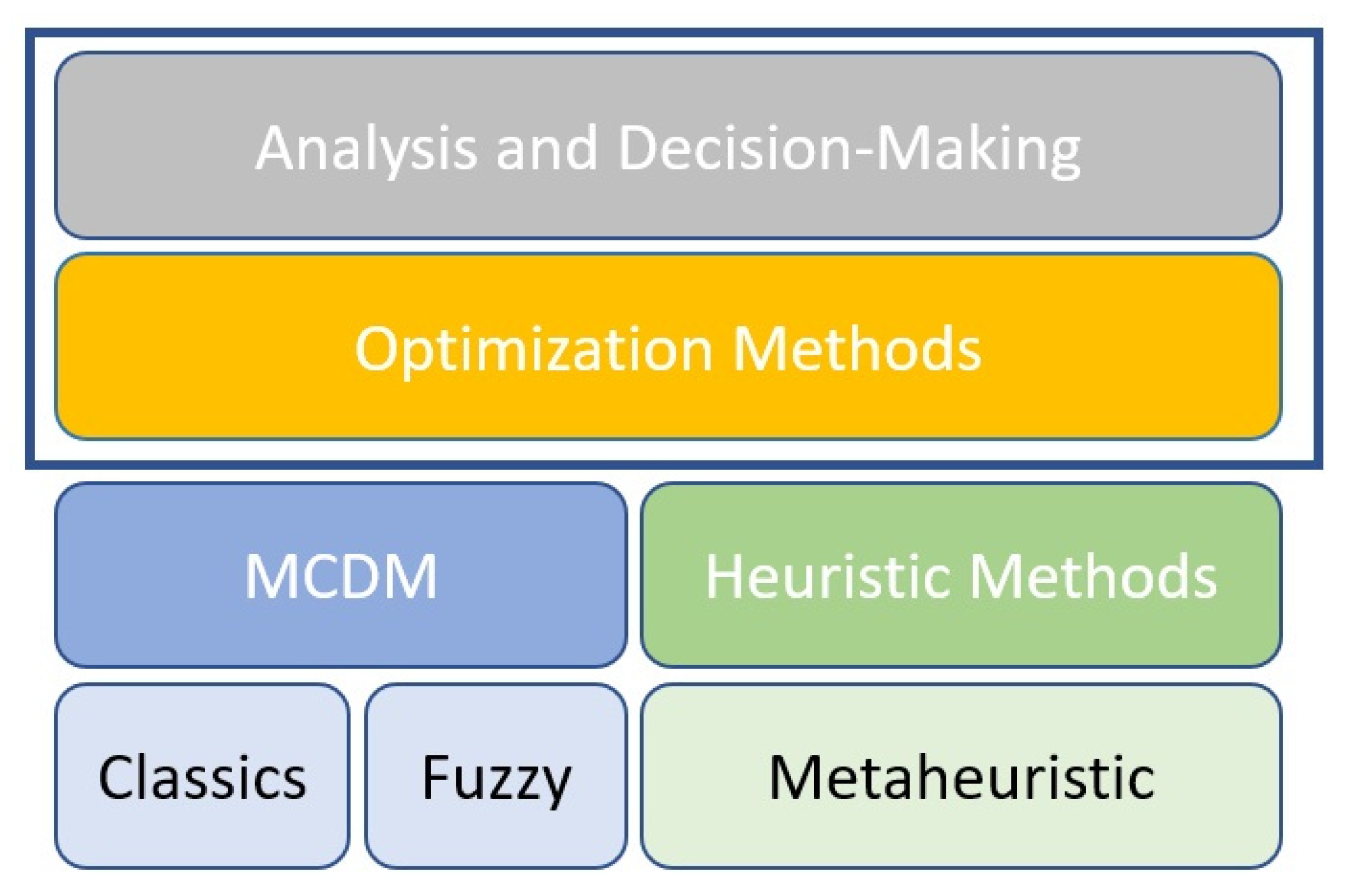
Optimization methods (OM) are one of the strategies for data analysis. OM involves a series of mathematical steps to visualize wins, gains, losses, risks, or errors [
66,
67], where the location of the decision variables is by maximizing or minimizing their objective function [
68].
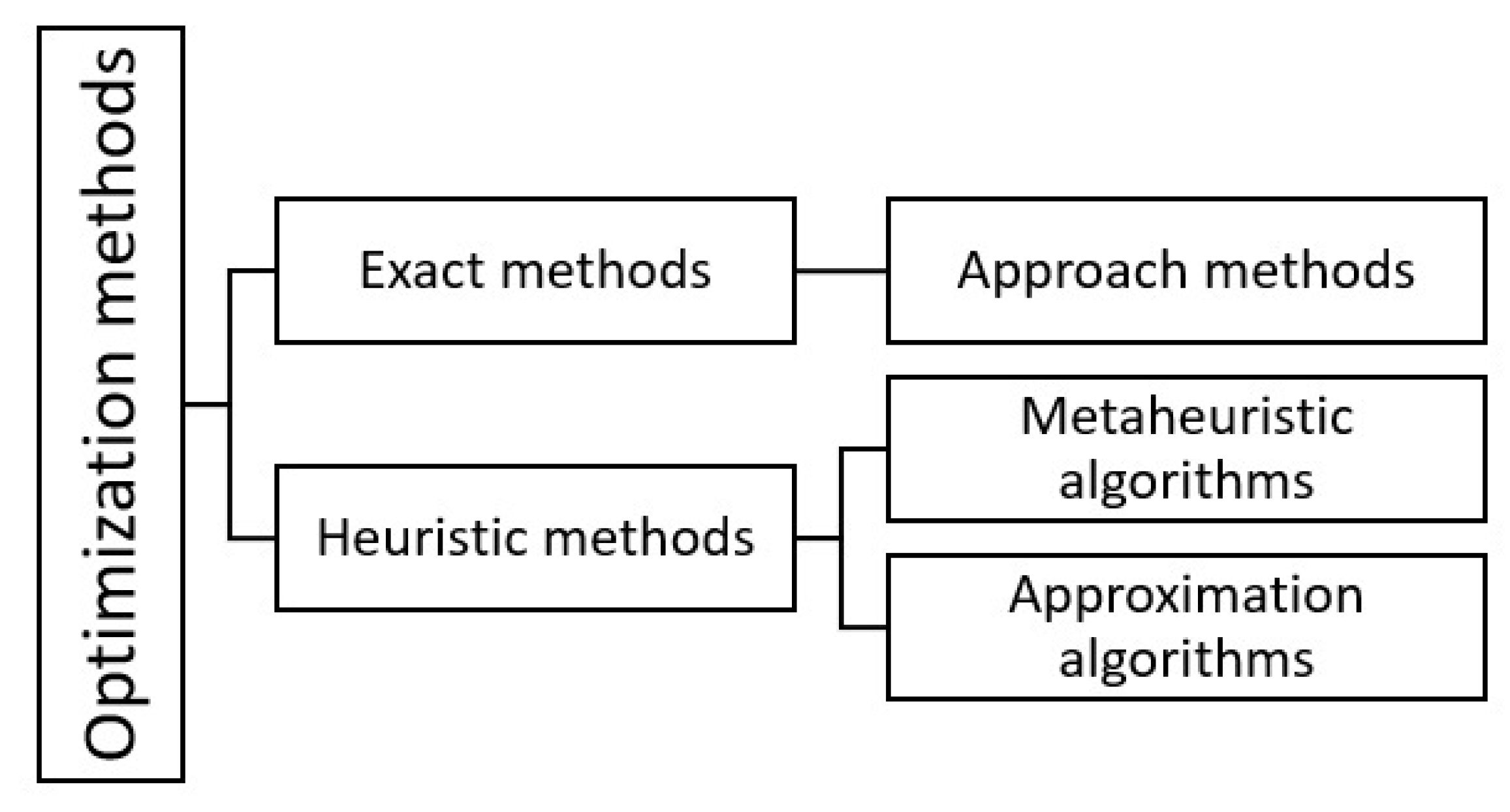
Figure 11 shows a classification that the authors visualize between exact and heuristic methods, where the exact methods give an optimal solution, while the heuristics compute the fastest result, getting closer to the optimal solution [
67,
69]. Among the heuristic methods are the approximation and metaheuristic algorithms, where their main difference lies in the number of iterations used in their process [
49,
66].
The metaheuristic algorithms apply rules with a sequential ordering in the processes in a simpler, more precise, and faster way [
38,
63]. These algorithms improve the solutions because they are based on the intelligence of the population [
66,
67]. The use of these algorithms has been found to reduce costs, assign tasks, distribute times, and find the best path or location [
37,
70]. Currently, metaheuristic algorithms have solved problems in the field of engineering, economics, science, and computer security [
38].
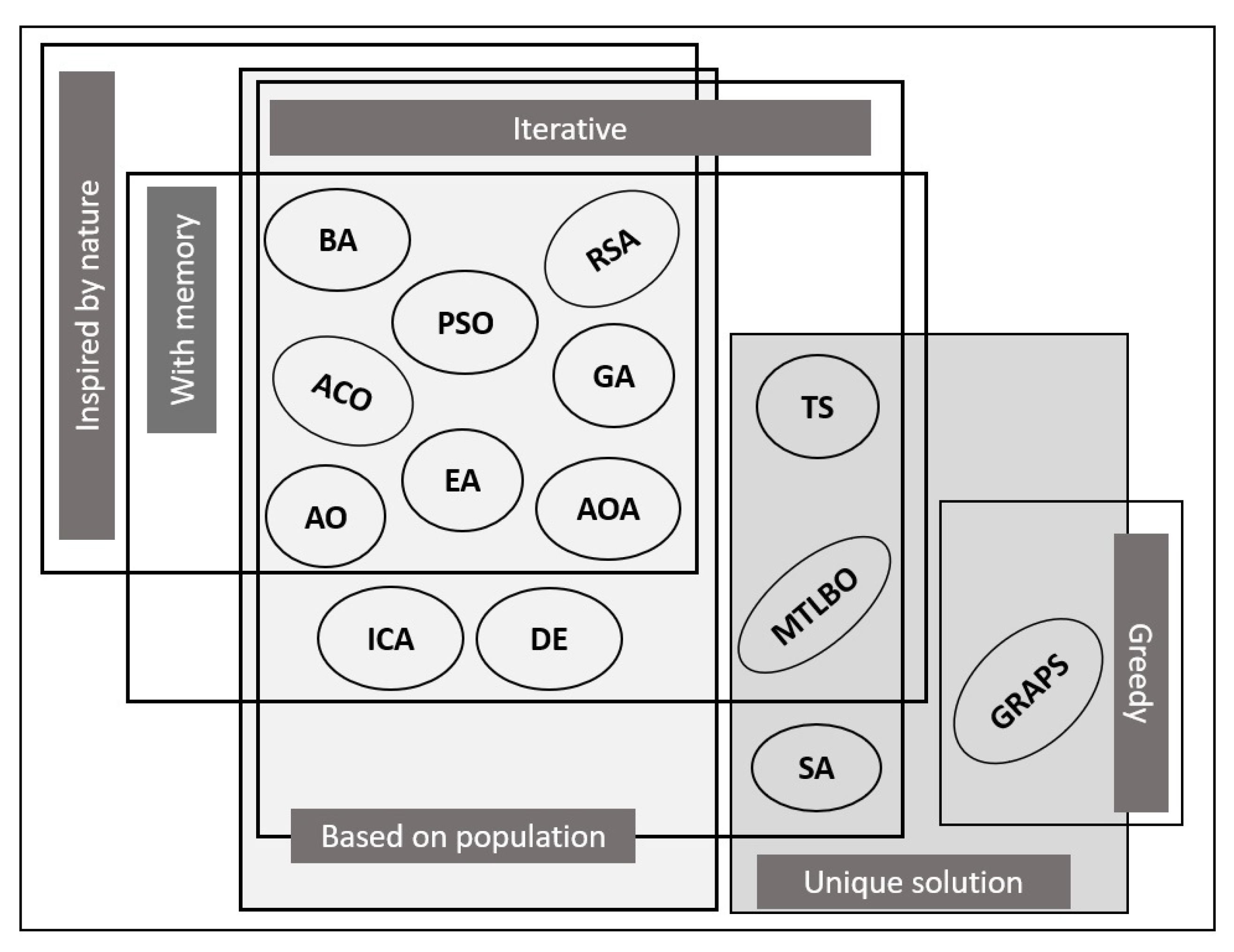
There is a wide variety of algorithms within metaheuristics, including novel algorithms and hybridization of several algorithms, which makes it difficult to determine which of them provides the most efficient solution [
68,
71]. That is why the authors have made four categories according to behaviors and characteristics, see
Figure 12. These categories correspond to: (1) those based on unique or population solutions, (2) inspired or not by nature, (3) iterative or greedy, and (4) with or without memory.
In the first category are population-based algorithms that provide a set of solutions, improving local search with the ability to explore solutions close to the optimum [
6,
66]. The vast majority of these algorithms are initialized with random solutions, which improve with each iteration [
72]. These algorithms include the arithmetic optimization algorithm (AOA) [
68] and the evolutionary algorithms (EA) [
73,
74], among which are the genetic algorithms (GA) [
66], and the swarm optimization of particles (PSO) [
73,
75]. These methods are based on one path at a time and this solution may not be within the search neighborhood, they are the single solution algorithms, among which are the simulated annealing algorithm (SA) [
67] and Taboo (TS) [
40].
Then, there is the category of algorithms inspired by nature that establish rules for the behavior of a population in a situation that occurs in nature [
33,
70]. Some authors, such as Abualigah et al. [
68], name these as swarm intelligence algorithms. Tzanetos in 2021, located 256 algorithms in this category, of which 125 have demonstrated their efficiency in solving a real-life problem [
70]. Within this category, they are classified into swarm intelligence algorithms and those based on organisms. In the swarm intelligence algorithms are the: PSO [
37,
40], ant colony algorithm (ACO) [
37,
76], bat algorithm (BA) [
38,
70], and among the most recent, the reptile search algorithm (RSA) [
77,
78]. While in the algorithms based on organisms, one finds the algorithms of coyotes [
79,
80], dolphins [
81,
82], penguins [
83,
84], and moths [
85,
86].
On the other hand, there are algorithms that do not incorporate the elements of nature, showing two classifications. The first comprises algorithms based on the behavior of physical or chemical laws, such as the SA [
70,
87], the multiverse optimizer (MVO) [
68,
73], and the differential evolution algorithm (DE) [
66]. The second classification bases its processes on cultural or emotional behavior, including social theory [
33,
68]. An example is the imperialist competitive algorithm (ICA) based on human sociopolitical growth [
88,
89] and the optimization algorithm based on teaching learning (MTLBO) [
90,
91].
Another category of metaheuristic algorithms comprises the iterative and the greedy. Iterative algorithms perform repetitions within their procedure to find the best solution, for example, the PSO [
37,
72] and AOA [
68]. While greedy algorithms start with an empty solution and in their search process, the decision variable finds the result, an example of this type of algorithm is the greedy random adaptive search procedure (GRASP) [
70].
Memory algorithms, however, store previous and present information during the search process, these include AOA [
68] and PSO [
92,
93]. On the other hand, there are algorithms without memory, which only use the present data of the search, among the examples of these algorithms this SA [
87] and GRASP [
70].
In
Figure 13, we see the topics addressed so far, showing the vision of the authors and the connection they have between them.
In the next section, we focus on the PSO algorithm, explaining its concept, advantages and disadvantages, applications, and the mathematical structure for its implementation.
3.4. Particle Swarm Algorithm (PSO)
Within the family of metaheuristic algorithms is the mathematical model called particle swarm optimization (PSO) [
52]. PSO finds the best spot, based on the group intelligence of flocks of birds and schools of fish, during predation and foraging [
15,
94].
The PSO works within a set of solutions (swarm) that contain a working sequence with a series of solutions (particles), where each particle updates its speed, considering past and present locations, to compare them with those of the swarm and thus establish the best global position [
52,
95].
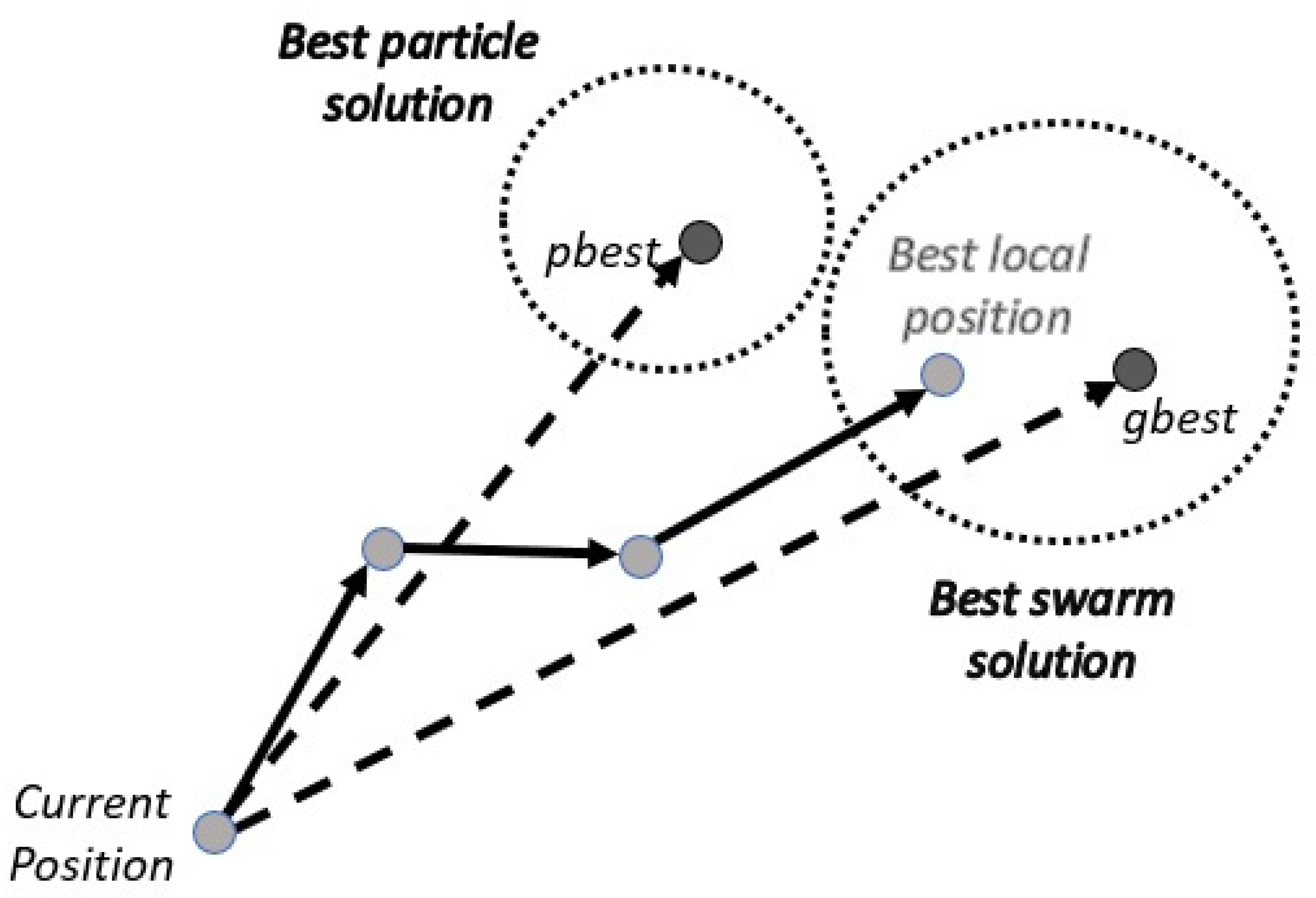
Figure 14 shows the movement of the particle in the swarm, with the solid line, while the dotted line indicates the best position (pbest) and the best global position (gbest) [
21,
95].
Russell Eberhart and James Kennedy, in 1995, first presented the PSO algorithm, starting with the current position and the change produced by each particle within the swarm [
25]. Three years later, Russell Eberhart, together with Yuhui Shi, announced a modification of the PSO, in which they introduced the inertial weight and the best state found at the moment by the particle and the swarm [
68].
Among the advantages of PSO is the ease of application to solve problems in different areas of agricultural, engineering, and materials, health, natural, and social sciences [
2,
5,
13]. It is applied in the engineering sciences, which include industrial processes, transportation, electrical, and computer engineering [
17,
96]. In addition to applications in health sciences, including medical sciences and bioinformatics [
29,
94]. However, although PSO is effective in complex optimization problems, its disadvantages include premature stalling [
97,
98], fast convergence [
94], and stochastic excess problem [
97].
3.4.1. PSO Applications
The PSO algorithm in its classical form has proven to be efficient for solving complex problems [
11,
99], achieving an approximation of the particles to the optimum of the problem—that is, a fast convergence [
52,
100]. Even so, PSO has some drawbacks, as mentioned. When combined with other algorithms, it generates hybrid algorithms that increase the validation of the results [
11,
75].
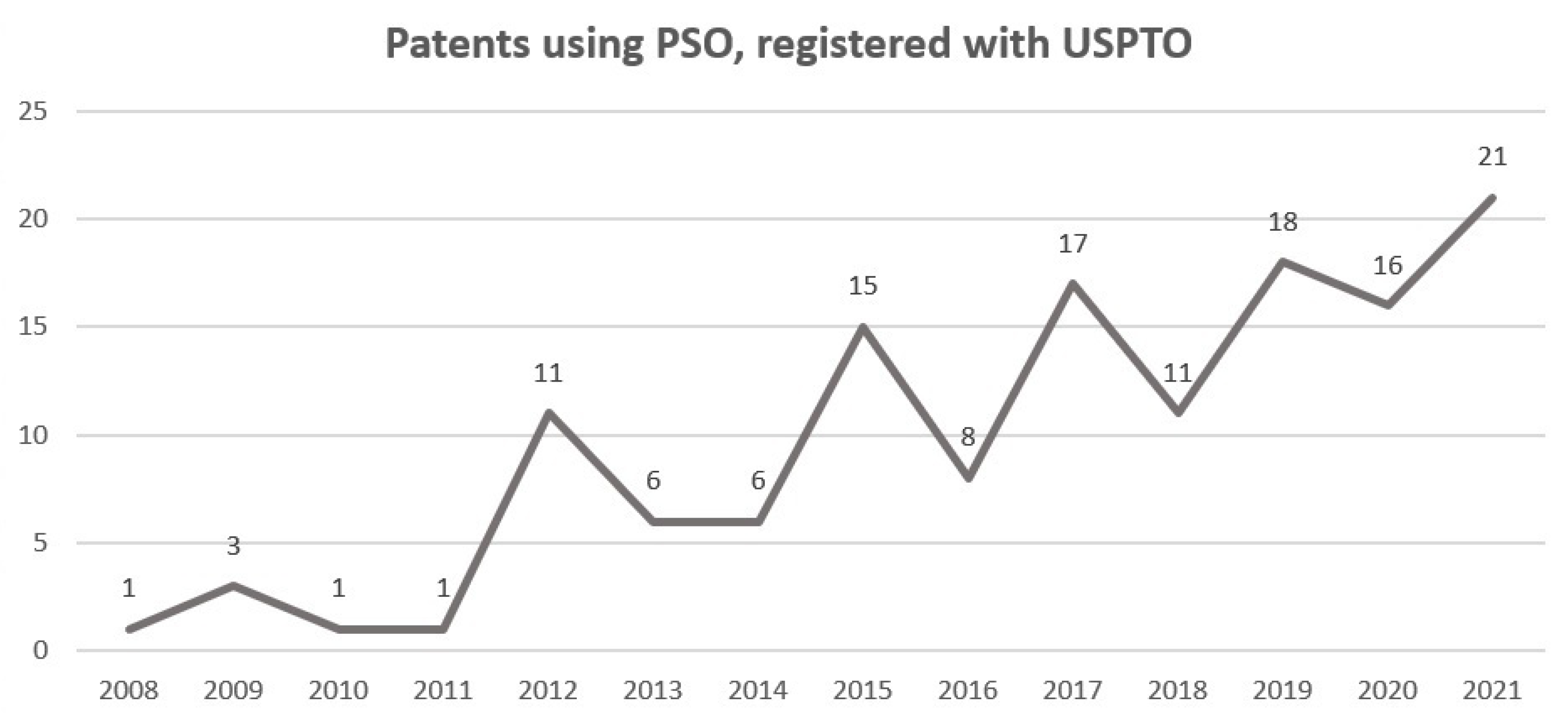
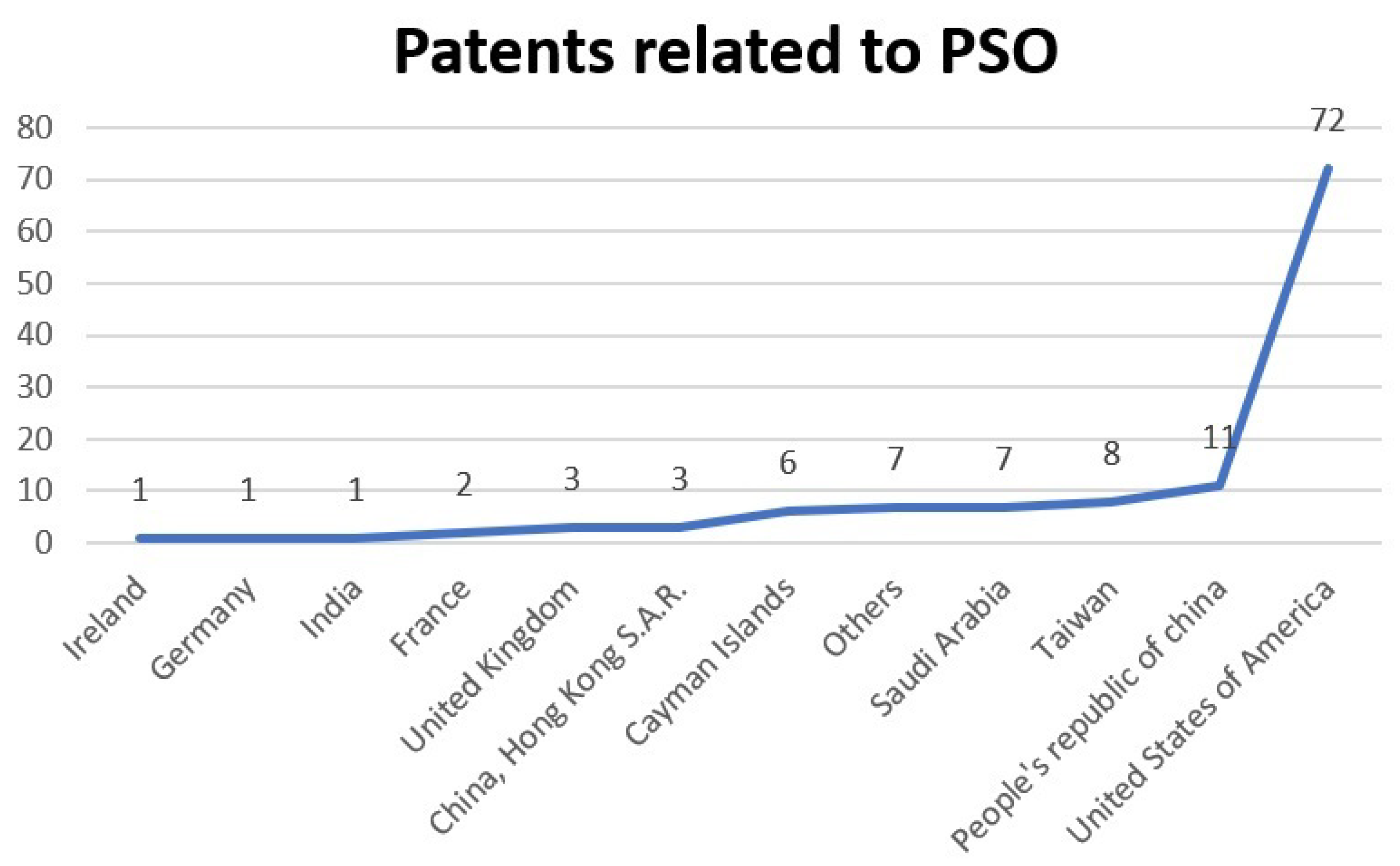
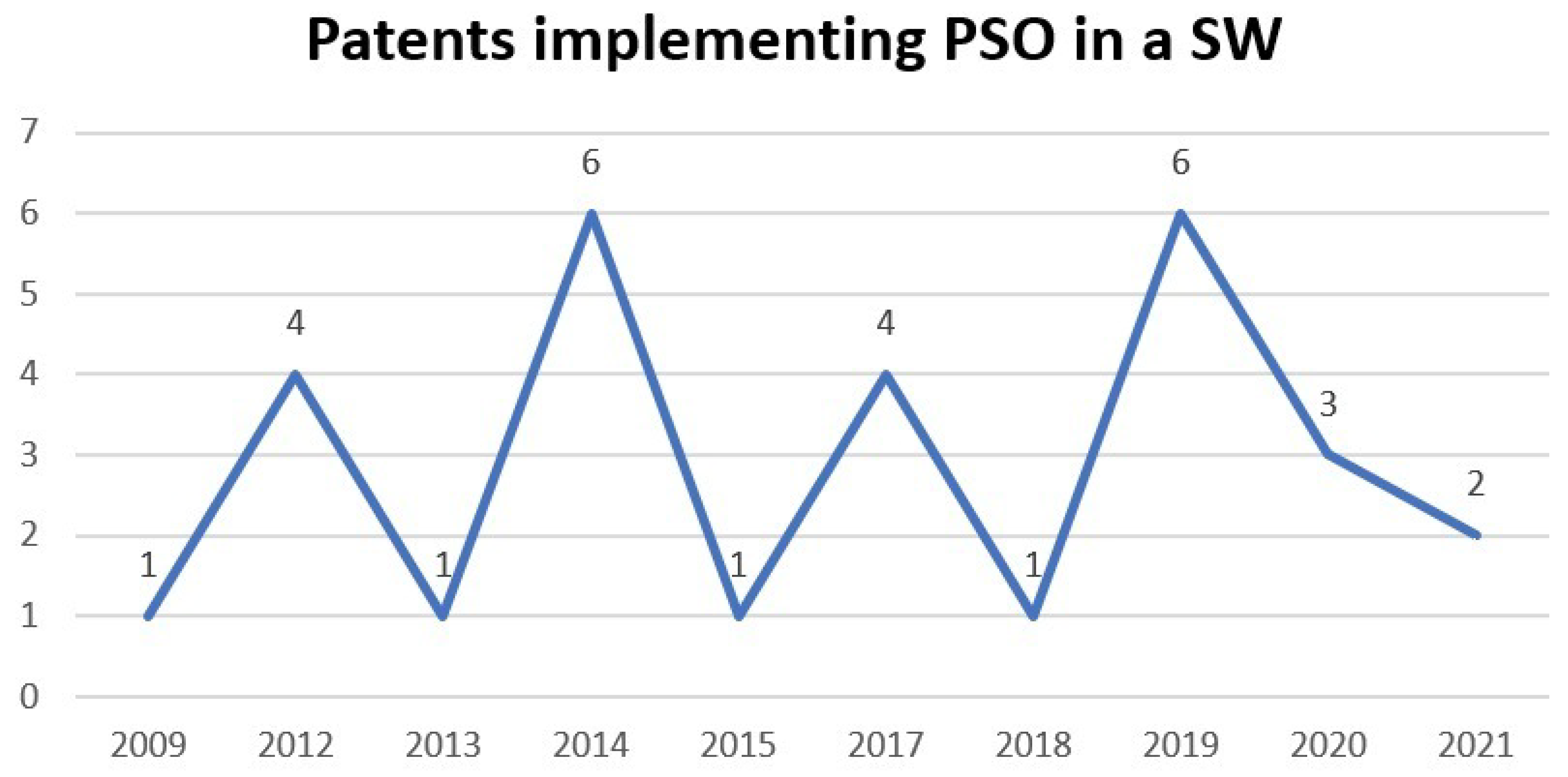
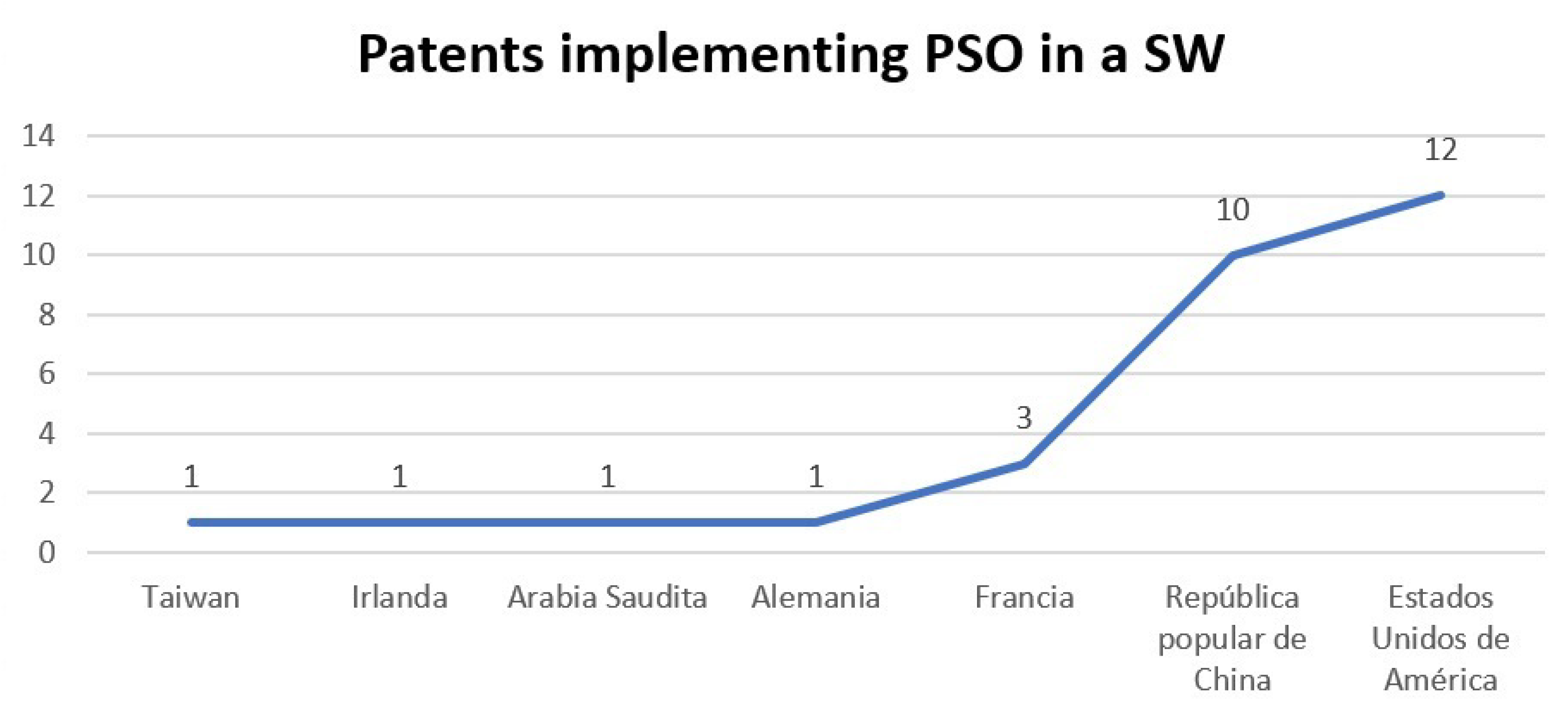
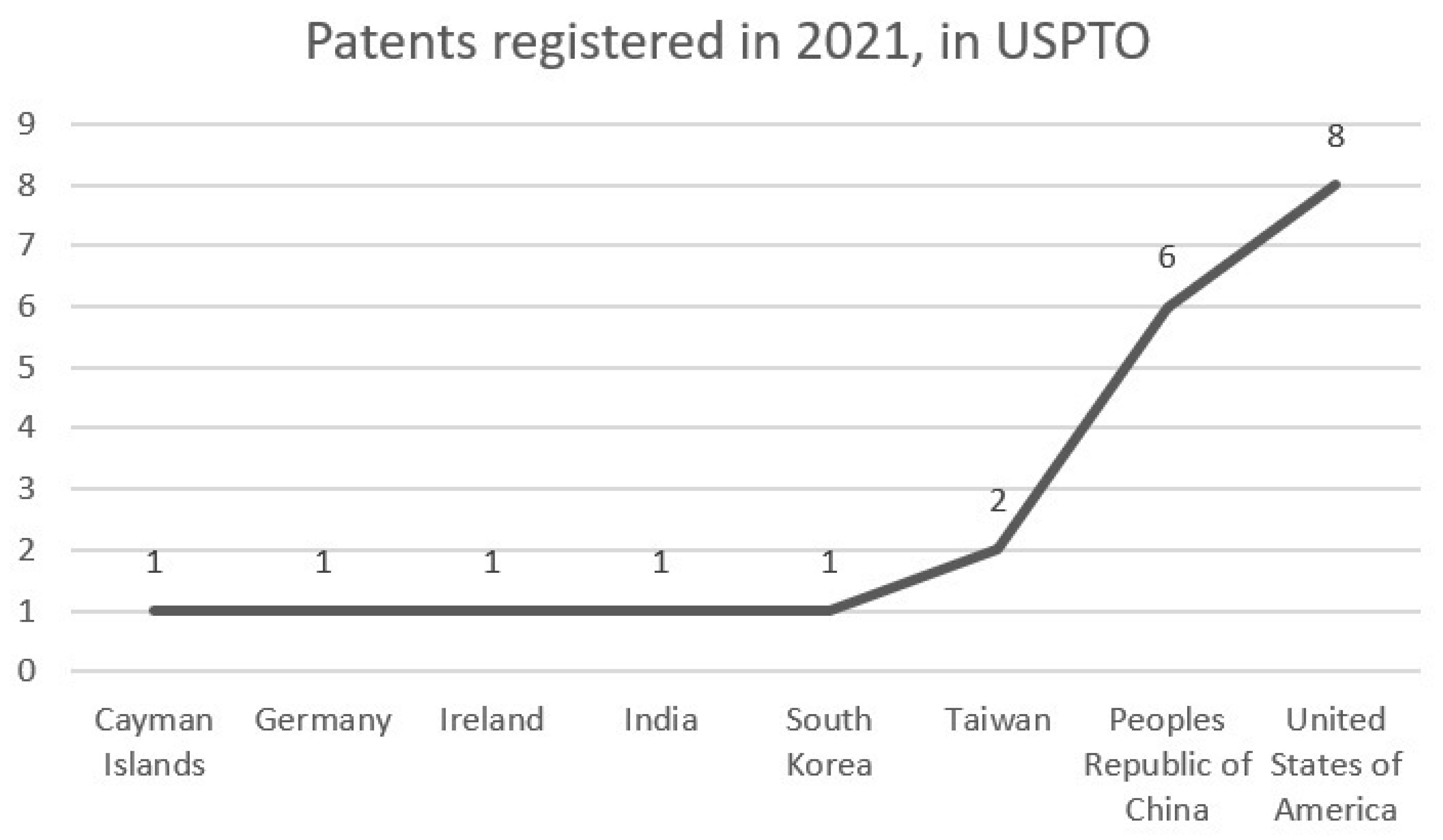
In 2008, the first patent using PSO was registered, that is, 13 years after PSO was first published. In this patent, the position of the access node between multiple paths, between the main path and the estimation result, is located by means of PSO [
14].
In 2009, PSO was applied in recognition of 3D objects seen from multiple points of view [
21]. PSO is also incorporated in the classifiers with attention mechanisms [
22]. Additionally, an object recognition SW with PSO and the possibilistic particle swarm algorithm (PPSO) is developed. In said SW, PSO performs the search and classification in a multidimensional solution space. While PPSO determines the size and optimizes the parameters of the classifier, with the simultaneous work of the particles [
23]. In another implementation that year, PSO trained a neural network to monitor the input to a network, making comparisons of input and known frequency spectra [
19].
Around 2010, applications in recognition of structured objects and groups of images were performed by fuzzy attribute relational graphics (FARG) and PSO, where PSO matches the graphics [
24]. In 2012, PSO performed the searches and classifications of visual images in a directed area, while cognitive Bayesian reasoning makes the decision with uncertainty in the data [
26].
In 2013, a method and apparatus for the optimal placement of responsible actuators, shaping elastically deformable structures, was developed. Making the coincidence and location of the optimal actuator solution with PSO [
27] occurred in 2013. In that same year, PSO was implemented in two software, one for the detection and verification of objects in a region and the hierarchical representation scheme for the grouping and indexing of images in the database [
29]. Another method for the recognition of behavior between objects in a video sequence uses the fuzzy attribute relational graph (FARG) for the organization of the scene in the organization module and classifies objects in video data with PSO [
28].
Meanwhile, in 2014, systems implementing PSO were developed. The first for image registration with a new PSO approach makes a comparison of test image features with references unnecessary. This new approach improves the convergence rate and reduces the cost of calculations in the comparison [
25], and the second one achieves a true optimal solution and avoids premature convergence, allowing a random walk process for PSO [
20].
Among the applications reported in 2018, PSO, together with ABC (artificial bee colony algorithm), optimizes the calculations of the mechanical performance of wireless sensors of a bicycle disc rotor [
93]. In another implementation, PSO is used in a rational function model (RFM) to extract geometric information from images [
101]. Likewise, it is implemented to improve a robot welder, reduce costs, and increase productivity, implementing PSO with discrete particles together with the genetic algorithm GA, which they called DPSO [
11].
By 2019, MCPSO, a modified centralized algorithm based on PSO, was generated in which the MCPSO assigns tasks to supply medicine and food for the victims in specific places using unmanned aerial vehicles [
15]. Another application of that year is the artificial neural network (ANN) training to find the weights of the network, implementing PSO and quasi-Newton (QN) on the CPU-GPU platform with OpenCL [
102].
On the other hand, in 2020, PSO performed better than GA by using an integral squared error as an objective function, employing a nano-network that uses three resources: the photovoltaic array, the wind turbine, and the fuel cell [
103]. In this same year, the GLPSOK algorithm provided better results than the classical or latest generation of clustering algorithms. GLPSOK implements the Gaussian distribution method and Lévy flight to help search for PSO [
104].
In 2021, an improved fractional-order Darwinian particle swarm optimization technique called FODPSO was developed, which improves the fractional-order calculation to identify the electrical parameters of photovoltaic solar cells and modules. FOSPSO allows an additional degree of freedom in the speed change of the position [
75]. Furthermore, three systems that implement PSO were generated. One system prints the route planning method for autonomous vehicles, determining the PSO parameters by the complete simplex sequence [
16], and another controls the movement of biomimetric robotic fish, improving the speed and stability of swimming forward and backward with PSO [
12], and a third party makes online decisions for generator start-up, optimizing the maximum total generation capacity in a power system situation through PSO [
17].
Among the most recent applications of PSO in 2022 is the optimization of parameters in the calibration of camera image quality [
96], as well as the application to determine the minimum insulin for a type 1 diabetic patient, using the analytical convergence of the fractional calculation particle swarm optimization algorithm (FOPSO), which improves PSO stagnation [
94]. In addition to the harvesting of agricultural products by means of a robot, using PSO to segment green images [
13].
3.4.2. Structure of the Classic PSO Algorithm
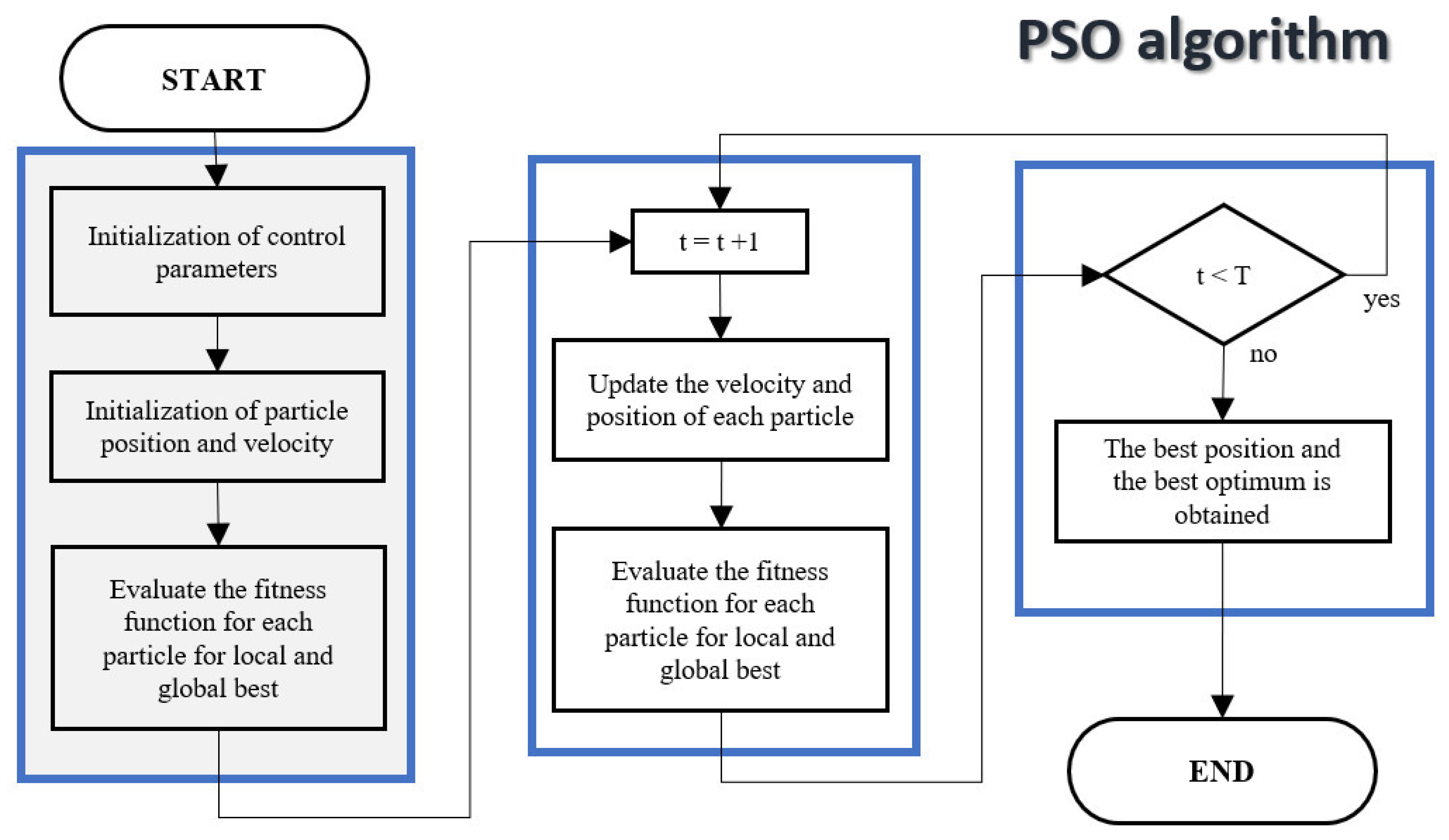
The authors present a vision of three main steps for the process of the classical PSO algorithm: initialization, update of the local optimum-position, and obtaining the best global optimum-position [
105,
106]. These most important steps can be seen in the flowchart in
Figure 15.
The following paragraphs details the classic PSO mathematical model, using the corresponding formulas for its implementation.
Next, some notations that are used both in
Figure 15 and in the formulas that will be shown after the table are explained in
Table 9.
- Steps 1.
Initialization
- 1.
Set the control parameters: N, ω, , , , , and T (definition in Table 9), the number current number of iterations with a value of 1 () because it is the first iteration, and the fitness function to initialize the swarm. The variable ω makes convergence happen in fewer iterations and maintains the balance between local and global searches. A smaller value of ω leads to a local search and a larger value than a global search. If ω has a large value, the algorithm starts the search globally and ends with a local search [108,109]. - 2.
Determine the first local position of the particles randomly, considering : - 3.
Randomly set the first local velocity of the particles (from 1 to N): - 4.
Evaluate the fitness function with the first position (Equation (1)), to obtain the best current optimum: - 5.
To establish the best local position (LBP), we use the first local position (Equation (1)). While, for the first best local optimum (LBF), we use the current best optimum (Equation (3)): - 6.
To obtain the best global optimum with the maximum value of the best local optimum (Equation (5)); that is, the maximum value of the dataset of the best local optimum (LBF): - 7.
To obtain the best global position, we extract the particle position in i from the best global optimum (Equation (6)). Position (z) provides the value of the best local position and becomes the best global position: To continue with step 2, we increment the current number of iterations ().
- Steps 2.
Position updating and local optimal
- 1.
Update speed and position of the particle.
From this step, () indicates the value of the previous iteration, while (t) is the current iteration.
To update the velocity, we use the inertial weight coefficient (ω), the learning factors ( and ), and the particle circulation values ( and ), as well as the values of the previous iteration of the speed, local position, and best local and global positions.
Meanwhile, for the current position, we add the previous current position and the new speed: - 2.
To obtain the best current optimum, evaluating the fitness function with the current position (Equation (9)): - 3.
Update best local position with current position (Equation (9)): - 4.
To obtain the best local position, we select the maximum value between the best current optimum (Equation (10)) and the best local optimum of the previous iteration (Equation (5)): - 5.
Obtain the best global optimum with the maximum value of the best local optimum (Equation (12)). That is, the maximum value of the dataset of the best local optimum (LBF): - 6.
To obtain the best global position, we extract the particle position in i from the best global optimum (Equation (11)). That position (z) provides the value of the best local position and becomes the best global position:
- Steps 3.
Obtaining the best global-optimal position
- 1.
If the current iteration is less than the total iterations, it is convergent; therefore, we increment the iteration and continue from step 2
: Continue from step 2
(Equation (8)) - 2.
The process ends when the total iteration is equal to or greater than the current iteration. We obtain the best position and the best optimum from the last values of the best global position and the best global optimum:


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}