1. Introduction
In many applications, such as studies on financial and biomedical data, the response variable is usually positive. For modeling the relationship between the positive response and a set of explanatory variables, the natural idea is to first take an appropriate transformation for the response, e.g., the logarithmic transformation, and then, some common regression models, such as linear regression or quantile regression, which can be employed based on the transformed data. As argued by [
1], the least-squares or least absolute deviation criteria are both based on absolute errors, which is not desirable in many practical applications. Rather, the relative errors are more of concern.
In the early literature, many authors contributed fruitfully to this issue; see [
2,
3,
4], where the relative error is defined as the ratio of the error relative to the target value. Since the work of [
1], where both the ratios of the error relative to both the target value and the predictor are introduced in the loss function, called the least absolute relative error (LARE) criterion, more attention has been focused on the multiplicative regression (MR) model, and various extensions have been investigated. For example, Ref. [
5] considered the estimation problem of the nonparametric MR model; see also [
6,
7] and references therein. In particular, some semi-parametric MR models have been studied. When estimating the nonparametric function
in these models, such as the partially linear MR model ([
8,
9,
10]), single-index MR model ([
11,
12,
13]), varying-coefficient MR model ([
14]), and others ([
15]), almost all researchers use the local linear smoothing technique and approximate it in a neighborhood of
z for obtaining its estimation, where a good choice of the bandwidths is quietly critical and its value is possibly sensitive to the performance of the resulting estimation and inference. Additionally, due to the fact that the value of the function at every observation of
z is estimated separately, the optimal selection of bandwidth for all observations may be not the same. Thus, the computation is cumbersome and the numerical problem becomes untractable when the sample size is large. As a result, researchers have had to compromise and assume that the bandwidths used for estimating the nonparametric function are the same.
When solving nonparametric regression, spline-based methods, such as regression splines, smoothing splines, and penalized splines, are popular and applied extensively in many fields. Recently, Ref. [
16] proposed multiplicative additive models based on the least product relative error criterion (LPRE), where the B-spline basis functions are used to estimate the nonparametric functions. Simulation studies have demonstrated that their approach performs well. It is worth noting that the loss function based on LPRE is smooth enough and differentiable with respect to the regression parameter, in contrast to that based on LARE. Moreover, LPRE inherits the symmetry between the two kinds of relative errors presented in LARE. Using this symmetry makes the computation and derivation of asymptotic properties easier.
A common feature in the above-mentioned literature is that these studies presume that all variables in the model are precisely observed. However, in many applications, some covariates cannot be measured exactly due to various limitations; see [
17] for such examples in econometric, biology, nutrition, and toxicology studies. Extensive studies have been conducted, such as quantile and other traditional robust statistical inference procedures in the measurement error setup. Only recently have we witnessed an interest in applying multiplicative regression when the covariates are contaminated with measurement errors. Ref. [
18] developed a simulation–extrapolation (SIMEX) estimation method for unknown parameters based on the LPRE criterion for the linear and varying coefficient multiplicative models, respectively, with the covariates being measured with additive error, where the measurement error is assumed to follow a normal distribution, and under certain conditions, the large sample properties of the given estimates are proved.
The SIMEX estimation procedure was first developed by [
19] to reduce the estimation bias in the presence of additive measurement errors. Since then, the SIMEX method has gained more attention in the literature, and it has become a standard tool for analyzing complex regression models. A significant feature of SIMEX is that one can rely on standard inferential procedures to estimate the unknown parameters. Since its conception, more researchers have extended the SIMEX method to various applications. Ref. [
20] considered statistical inference for additive partial linear models when the linear covariate is measured with error using attenuation-to-correction and SIMEX methods. Ref. [
21] proposed graphical proportional hazards measurement error models and developed SIMEX procedures for the parameter of interest with complex structured covariates. To the best of our knowledge, there are seldom studies on the partially linear multiplicative regression model with measurement error. To fill this gap, we will address this problem in detail in this paper.
This paper is organized as follows. In
Section 2, we first introduce in detail the simulation–extrapolation method for the partially linear multiplicative regression model with measurement errors. Combining the B-spline approximation and the LPRE criterion, a new estimation method is proposed, and some remarks about the selection of number and location of knots and the asymptotic properties of the proposed estimator are presented. Some simulation studies are carried out to assess the performance of our method under a finite-sample situation in
Section 3. A real example is analyzed to illustrate the practical usage of our proposed method in
Section 4. Finally, some discussions in
Section 5 conclude the paper.
2. Methodology
In this section, we propose the simulation–extrapolation estimation for regression parameters and the nonparametric function in the partially linear multiplicative regression model, where the covariates in the parametric part are measured with additive measurement errors. Computation details are presented, and some asymptotic results are also established.
2.1. Notations and Model
Let
Y denote the positive response variable, which satisfies the following partially linear multiplicative regression model
where
X is the
p-dimensional vector of covariates associated with the regression parameter vector
,
Z is a continuous univariate variable,
is the positive error and independent of
, and
is an unknown smooth link function.
Due to some practical limitations, the covariate
X cannot be observed precisely. Instead, its surrogate,
W, through the additive covariate measurement error structure
is available, where
U is the measurement error with mean zero and the covariance matrix
and independent of
and
. Assume that
is known; otherwise, it can be estimated through the replication experiments technique, as argued in much of the literature such as [
17]. When some components of
X are error-free, the corresponding terms in
are set to be zero. In particular, when
is a zero matrix, i.e.,
U is zero, there is no measurement error.
We combine Models (1) and (2) and refer to it as the partially linear multiplicative regression measurement error (PLMR-ME) model. Let be independent and identical replicates of .
2.2. SIMEX Estimation of PLMR-ME Model
In general, the SIMEX method consists of a simulation step, an estimation step, and an extrapolation step. Before the detailed introduction of our method, we must specify two kinds of parameters; one is the simulation times, denoted by , and the other is the levels of added error, denoted by . Oftentimes, equally spaced values with and are adopted, M ranges from 10 to 20, and B is a given integer lying in [50,200].
In our method, we use the SIMEX algorithm, B-spline approximation, and the LPRE criterion to estimate
and
. First, we approximate
using a B-spline function, i.e.,
, where
is the B-spline basis function of order
d with
internal knots, and
. Then, Model (1), as in [
22,
23], can be rewritten as the spline model
where
,
is the corresponding vector of the spline coefficients. In this way, the estimation problem of unknown function
is transformed into the estimation of
. Next, we employ the LPRE criterion to estimate
and
. Explicitly speaking, the proposed SIMEX algorithm proceeds as follows.
- (1)
Simulation step.
For each
, generate
B independent random samples of size
n from
. That is to say, for the
j-th sample, generate a sequence of pseudo-predictors
where
. Note that the covariance matrix of
given
is
Thus, when
, it follows that
. Combining the fact that
, the conditional mean square error of
, defined as
, converges to zero as
.
- (2)
Estimation step.
For a fixed
, based on the
b-th random sample
, one can obtain the estimator of
, denoted by
, which is the minimizer of the objective function
where
. Then, define the final estimates of
using the average of
over
, defined by
and
, where
. Furthermore, the corresponding estimator of
.
- (3)
Extrapolation step.
Consider two extrapolation models: linear and quadratic. Without loss of generality, denote the extrapolation function by
, where
is the regression parameter vector. At this time, the linear extrapolation function is
, and the quadratic one is
. For the two sequences
and
, we fit a regression model to each of the two sequences from
respectively, where
and
are random errors. Using the least-squares method, one can obtain the estimates of
and
and denote them as
and
, respectively. Then, the SIMEX estimator of
is defined as the predicted value
Meanwhile, the naive estimator of
reduces to
. As for
above, the nonparametric term
can be estimated in the same way. Denote the SIMEX estimator of
by
.
2.3. Asymptotic Results
To derive the asymptotic normality of the SIMEX estimator , some regularity conditions are necessary to be introduced as follows.
- (A1)
.
- (A2)
is a positive definite matrix.
- (A3)
There exists such that , , and .
- (A4)
, where and are some positive constants and is the superior norm. .
Conditions (A1)–(A3) are common requirements in the penalized spline theory. (A4) is the regularization condition used in the study of MR. (A5) is an identification condition for the LPRE estimation, which is similar to the zero-mean condition in the classical linear mean regression.
Before presenting our result, some notations need to be introduced in advance. Let and , where is the true parameter vector estimated in the extrapolation step for the j-th component of . Define and . Let be the minimizer of , where . According to the least-squares theory, satisfies , where . Denote and .
Theorem 1. Assume that the extrapolation function is theoretically exact. Under the conditions (A1)–(A4), it follows that as , we have Proof. Assume that
is the true value based on the model
Using the similar method in Theorem 2 in [
16], we have
where
and
. Because
, it follows that
where
Define
. Some algebraic calculations show that
Then, according to the central limit theorem, it holds that
Write
. In the following, using the standard derivation of the SIMEX method and the definition of
, we have
where
. Finally, using the Delta method and noting the facts
and
, the desirable result is established. □
3. Simulation Studies
Numerical studies were conducted to evaluate the finite sample performance of our proposed SIMEX estimators under various situations. To fairly compare the SIMEX estimator with the naive estimator that ignores measurement errors and the true estimator based on the data without measurement errors, we set the degree of spline basis to be and the number of internal knots to ; these are located on equally spaced quantiles for all methods. All results below are based on 500 replicates, where , , and the sample size , 100, and 200, respectively. All simulations were implemented using the software R.
Now, generate
from the following model
where
,
,
,
,
, and
and is independent of the error
. Further, we assume
, which means that
is error-free. However, for
, three measurement error distributions are considered, namely,
Case 1: ;
Case 2: ;
Case 3: .
These represent the light-level, moderate-level, and heavy-level measurement error, respectively. In the extrapolation step, consider both the linear and quadratic extrapolation functions and, respectively, denote the corresponding method as SIMEX1 and SIMEX2.
For estimators of
, we record their empirical bias (BIAS), sample standard deviation (SD), and mean square error (MSE). For the nonparametric part, we use the averaged integrated absolute bias (IABIAS) and mean integrated square error (MISE), where for one estimator
, obtained from the
j-th sample,
at the fixed grid points
equally spaced in [−2,2] and
. The values in parentheses below them are the associated sample standard deviation.
Table 1,
Table 2 and
Table 3 report the simulation results of different estimators of regression parameter and nonparametric function under cases 1–3 with different sample sizes. For
, we can see that when the measurement error is small as in
Table 1, all methods behave similarly and the proposed SIMEX method gains no obvious advantage over the naive method. Not surprisingly, as the measurement error becomes moderate as seen in
Table 2, the naive estimates are substantially biased and have a larger mean square error (MSE), while the SIMEX estimates, especially when the quadratic function is applied, are unbiased and have a smaller MSE. When the measurement error is large, as seen in
Table 3, all methods except the true one are slightly biased, but the performance of the SIMEX methods is still relatively better than that of the naive method. For
and
, the corresponding covariates
and
are error-free, and it seems that under the same measurement error level and sample size, both the naive and SIMEX estimates have similar performance in terms of the sample standard deviation (SD) and MSE for
, integrated absolute bias (IABIAS), and mean integrated square error (MISE) for
.
On the other hand, for each method and given case, the SD and MSE of estimates of
and the IABIAS and MISE of estimates of
decrease as the sample size increases. Although the MSE of SIMEX2 is smaller that that of SIMEX1 for
, their SD is reversed.
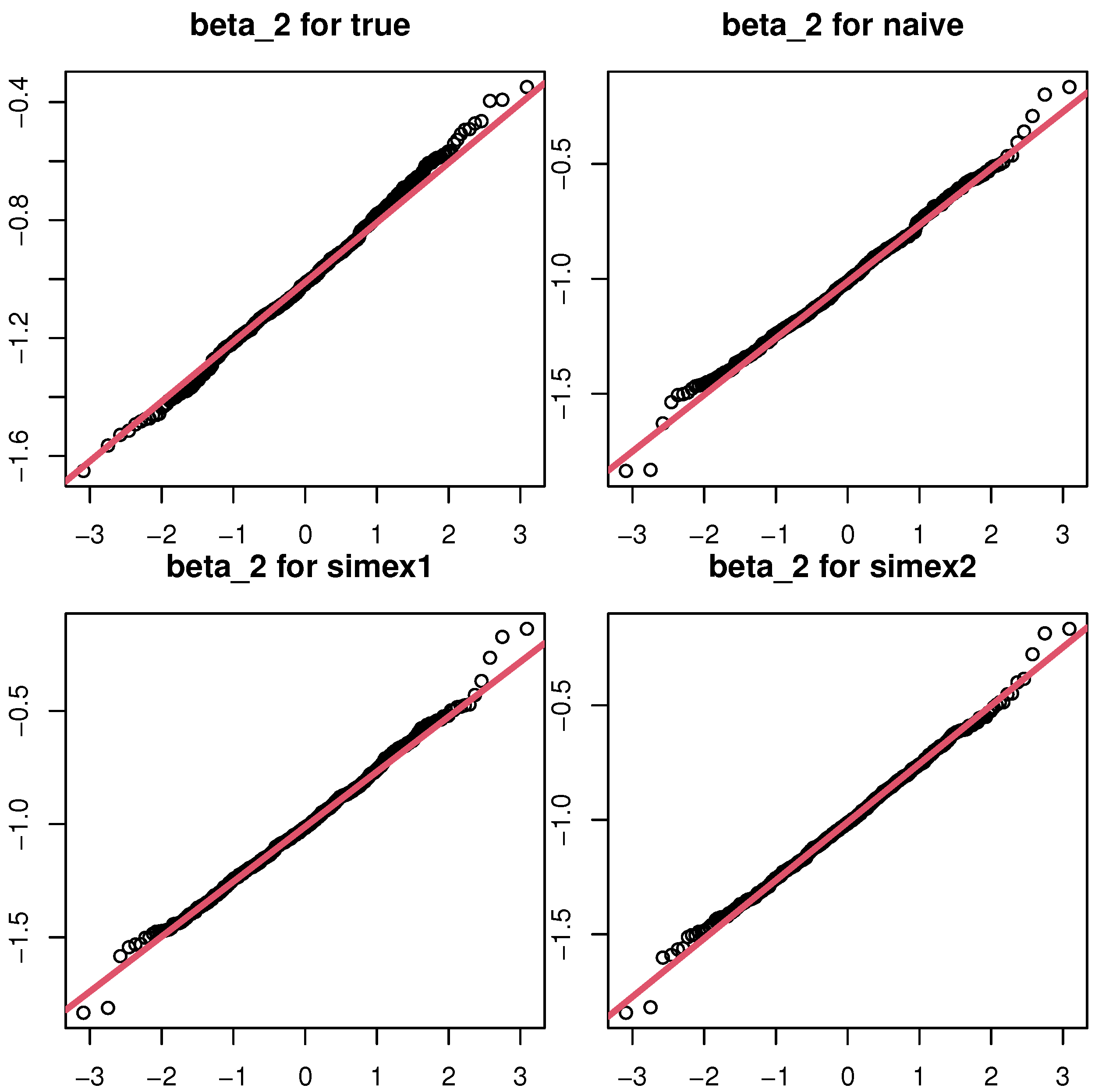
Figure 1 is the Q-Q plots of the estimates of
in case 2 with a sample size
. It can be seen that all points are close to the line, which indicates that the resulting SIMEX estimator is asymptotically normal. This finding is in accordance with the theoretical result in Theorem 1.
Figure 2 and
Figure 3 display the boxplots of estimators of
and
in cases 2 and 3 with a sample size
, respectively, which reveal the similar conclusions obtained above.
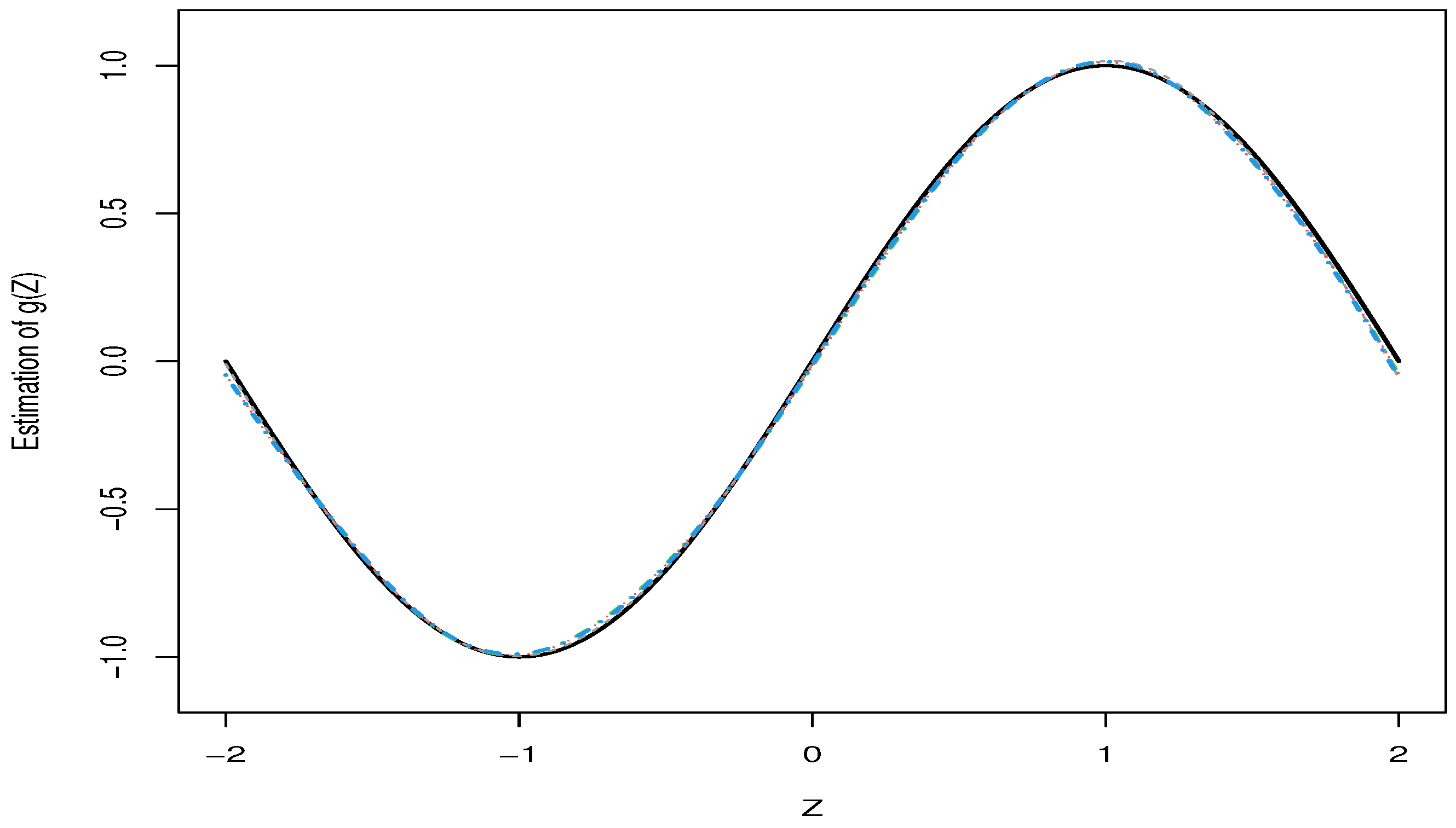
Figure 4 presents the average estimated curves, which are very close to the true one. Similar plots are obtained in other cases and omitted due to the limitation of space.
4. Real Data Analysis
To illustrate the proposed procedure, an application regarding body fat data is provided. These data are available at
http://lib.stat.cmu.edu/datasets/bodyfat (accessed on 1 January 2020) and have been analyzed by several authors in different contexts; see [
8,
10,
24]. There are 252 observations and several variables, including the percentage of body fat as the response variable
Y, and 13 explanatory variables: age (
), weight (
), height (
), neck (
), chest (
), abdomen (
), hip (
), thigh (
), knee (
), ankle (
), biceps (
), forearm (
), and wrist (
). As in [
10], we deleted all possible outliers and obtained a sample size of 248. Following [
8], we selected chest (
) as the nonlinear effect
U, and the other 12 covariates were treated as the linear component
X in Model (1). Motivated by the suggestion in [
24], weight (
) was presumed to be mismeasured, and others were presumed to be error-free. Similar to [
10], before the forthcoming computation, the nonparametric part
U was transformed into [0,1] and the other covariates were standardized.
Estimation results of the regression coefficients
using the naive method and SIMEX methods with linear or quadratic extrapolation functions are shown in
Table 4 and
Table 5, associated with the results presented in [
8] (local linear LARE estimator) and [
10] (local linear LPRE estimator), which are denoted by Naive, SIMEX1, SIMEX2, ZW, and CL, respectively. To evaluate the impact of the measurement error level
and the number of interior knots
, the variance in the measurement error and the number were set to 0.1 and 0.3, 3, and 6, respectively. This means that four cases were considered. In each specific case, the estimates of regression coefficients were close to each other. However, the estimates of the coefficient associated with weight (
) varied greatly. In particular, for the the coefficient of
, the sign of the naive estimate was negative, but the SIMEX estimates were both positive, although their absolute values were small. As the level of measurement error increased, the changes in SIMEX estimates varied steadily.
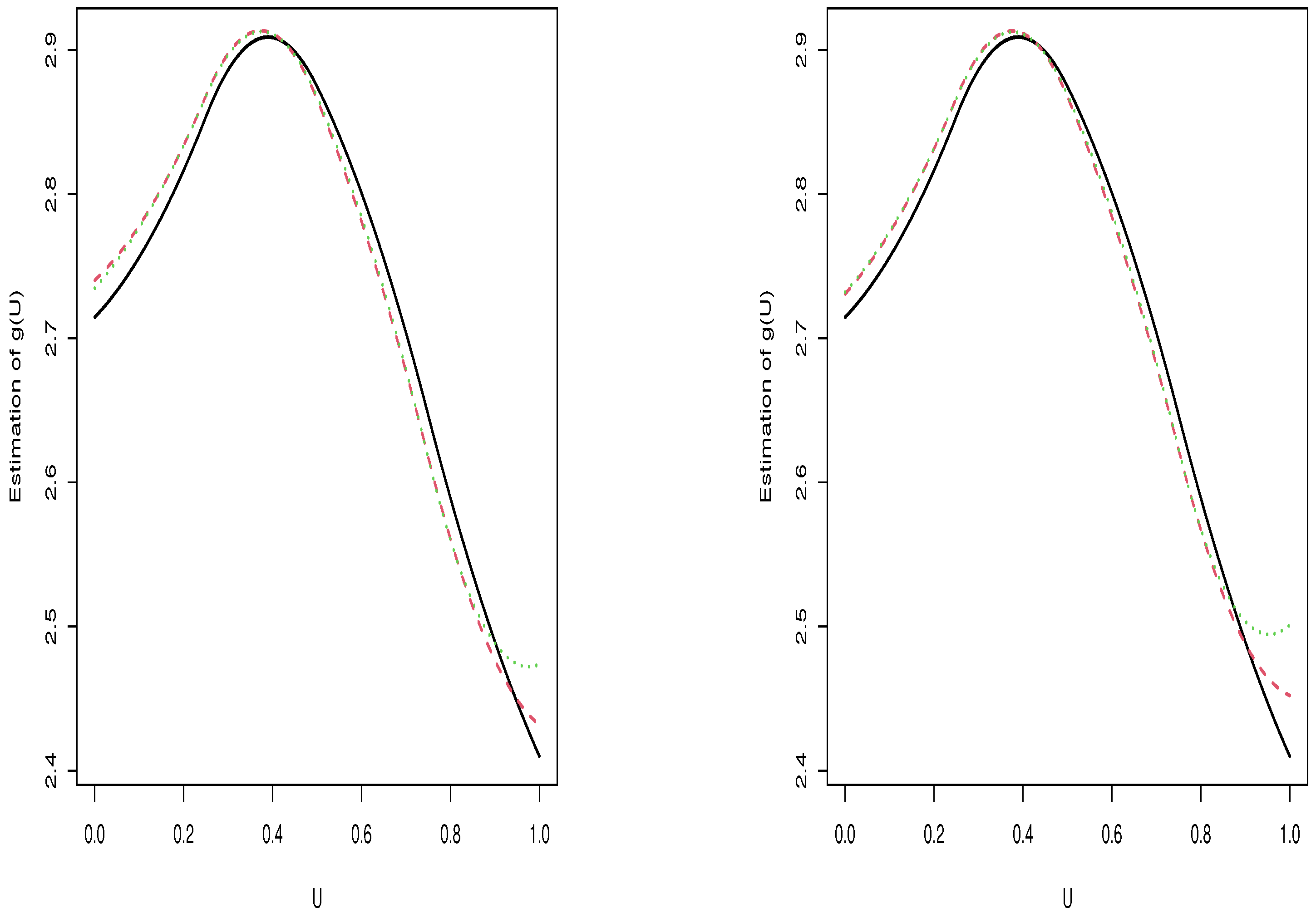
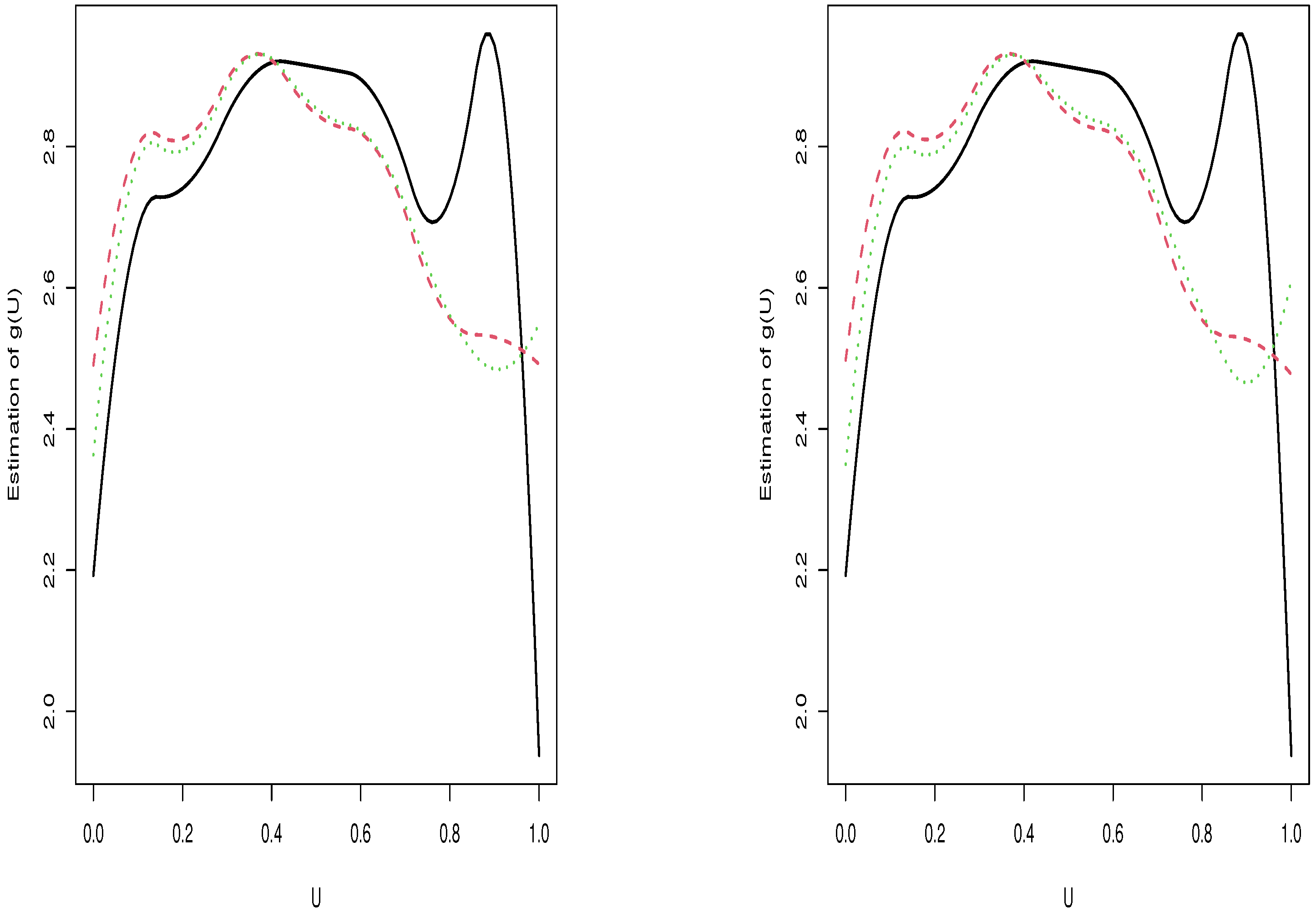
The estimated curves of
are plotted in
Figure 5 and
Figure 6. All curves had a similar trend. In other words,
firstly increased until around
, and then it then decreased. This phenomenon was also found in [
10], but their figures behaved less clearly than ours. For a fixed number of knots, the level of measurement error had little effect on the estimated curves. Instead, the difference between
Figure 5 and
Figure 6 was relatively large, which may have been caused by the overfitting when
was 6 and underfiting when
was 3. It is worth noting that the SIMEX estimates were less sensitive than the naive estimate in all cases.
5. Conclusions
In this study, we used the simulation–extrapolation method to estimate the regression parameters and the nonparametric function in the partially linear multiplicative regression model in Models (1) and (2) based on the LPRE loss function and B-spline approximation, where covariates in the linear part are measured with additive measurement errors, but the nonparametric part is exactly observed. Under some regularity conditions, the SIMEX estimates were asymptotically normal with a more complex covariance matrix structure than naive estimates. Furthermore, extensive numerical studies show that our proposed method performs better than naive estimators when the measurement error is moderate or heavy, and it is comparable with the naive estimators when the measurement error is light. As the covariate in the nonparametric component is error-free, the resulting estimates of the nonparametric function are always well-fitted.
As indicated in
Section 1, the approaches proposed in this paper may be adapted to the other more general models, such as the partially linear additive model as in [
20], or single-index or varying-coefficient multiplicative regression models. Our future work will also consider extensions of them in fields with covariate measurement errors in all covariates, censored data, or longitudinal data analysis, which is meaningful for practitioners. As indicated by one referee, the model in Models (1) and (2) assumed that the measurement error only occurred in the linear part. In fact, the nonlinear part may be measured with error. For the later case, our method can still be implemented as in [
20], except some minor modifications. However, the asymptotic theory becomes troublesome. Furthermore, as in [
16], how to identify which set of covariates lies in the linear part or the nonlinear part is interesting. Additionally, when the dimension of covariates is high, how to effectively select the true important variables deserves to be studied thoroughly. All these issues will be investigated in the future.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}