

Shifting Pattern Biclustering and Boolean Reasoning Symmetry



Abstract
:1. Introduction
2. Theoretical Background
2.1. Biclustering
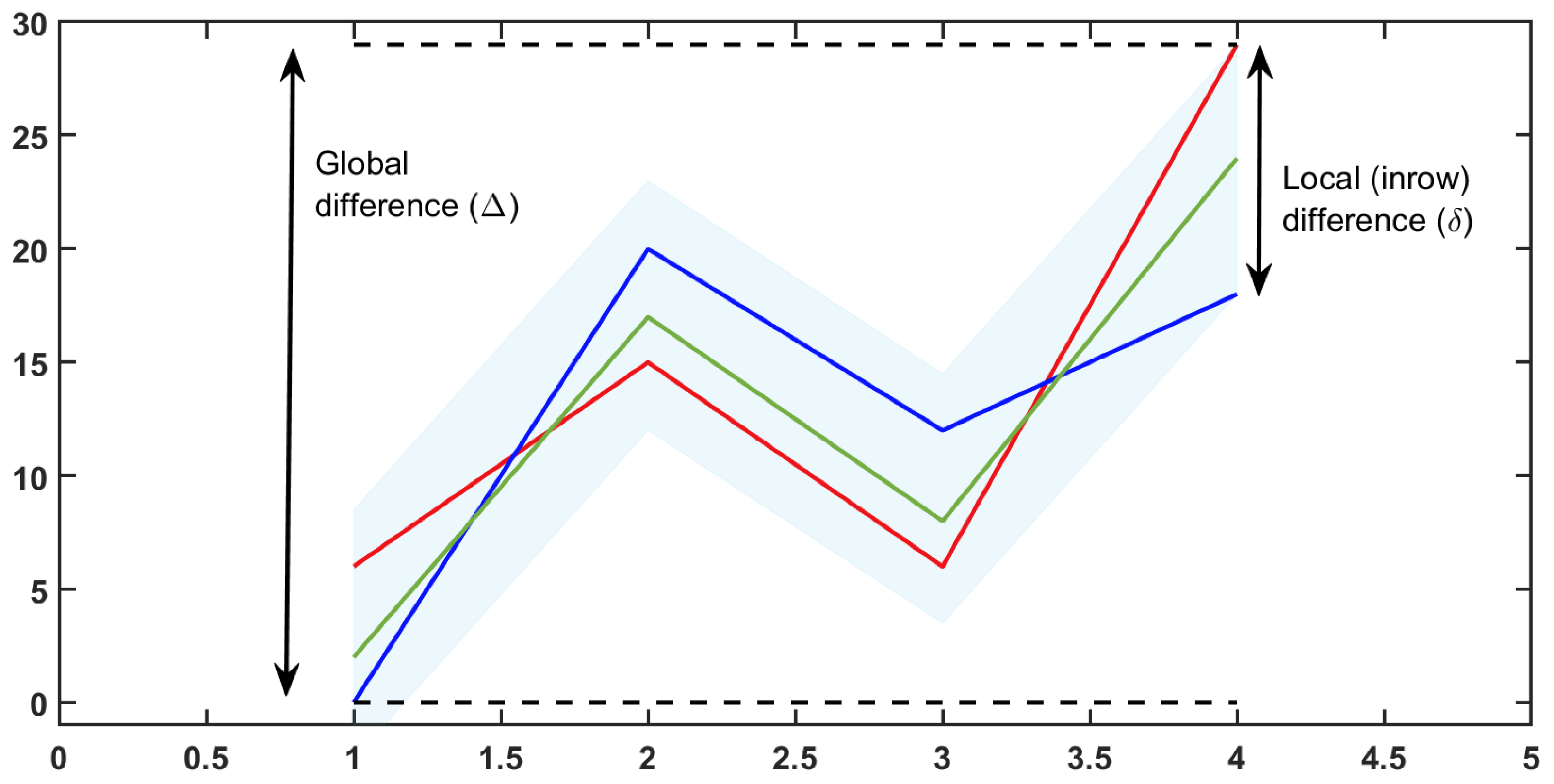
2.2. Bicluster Typology
- Tolerance bicluster
- Center-based bicluster
- Perfect bicluster, satisfying one of the following (the symbol represents addition or multiplication):
- –
- All the values are equal (equivalent to considering continuous data as discrete);
- –
- where is a typical value within the bicluster and is the adjustment for row ;
- –
- where is a typical value within the bicluster and is the adjustment for column ;
- –
- , which is a combination of the above two.
3. Boolean Reasoning and Biclustering
4. Pattern Induction with Boolean Reasoning
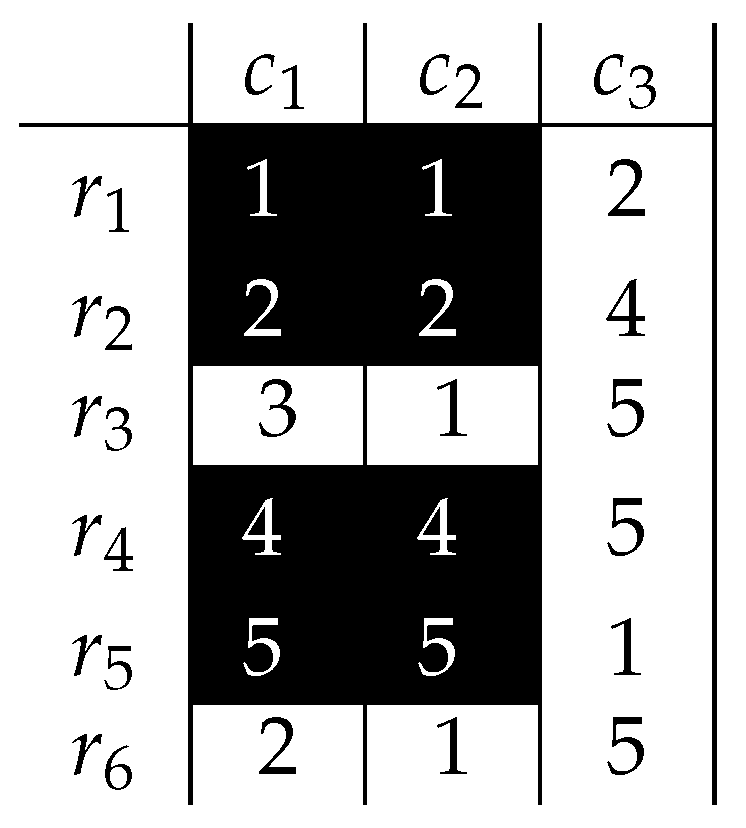
4.1. Constant Patterns
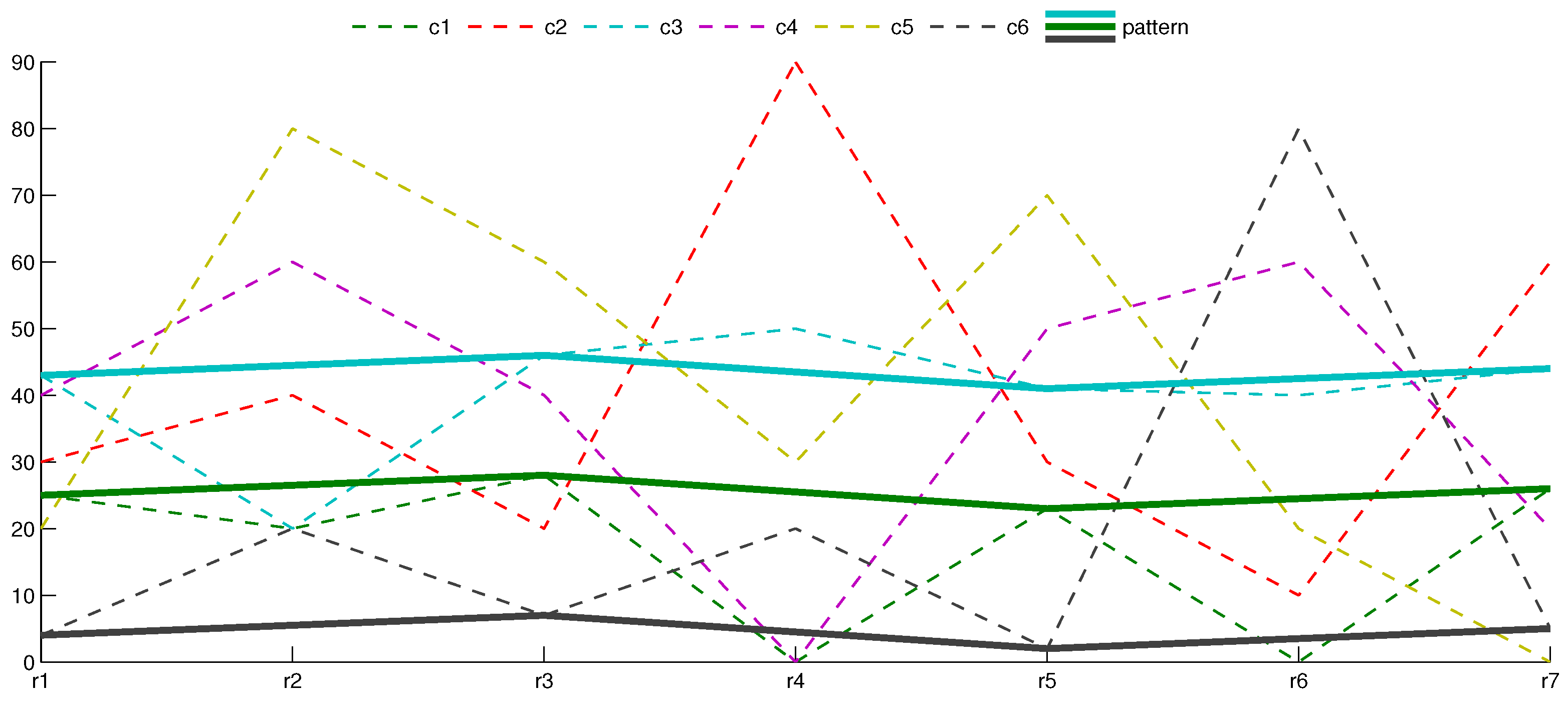
4.2. -Shifting Patterns
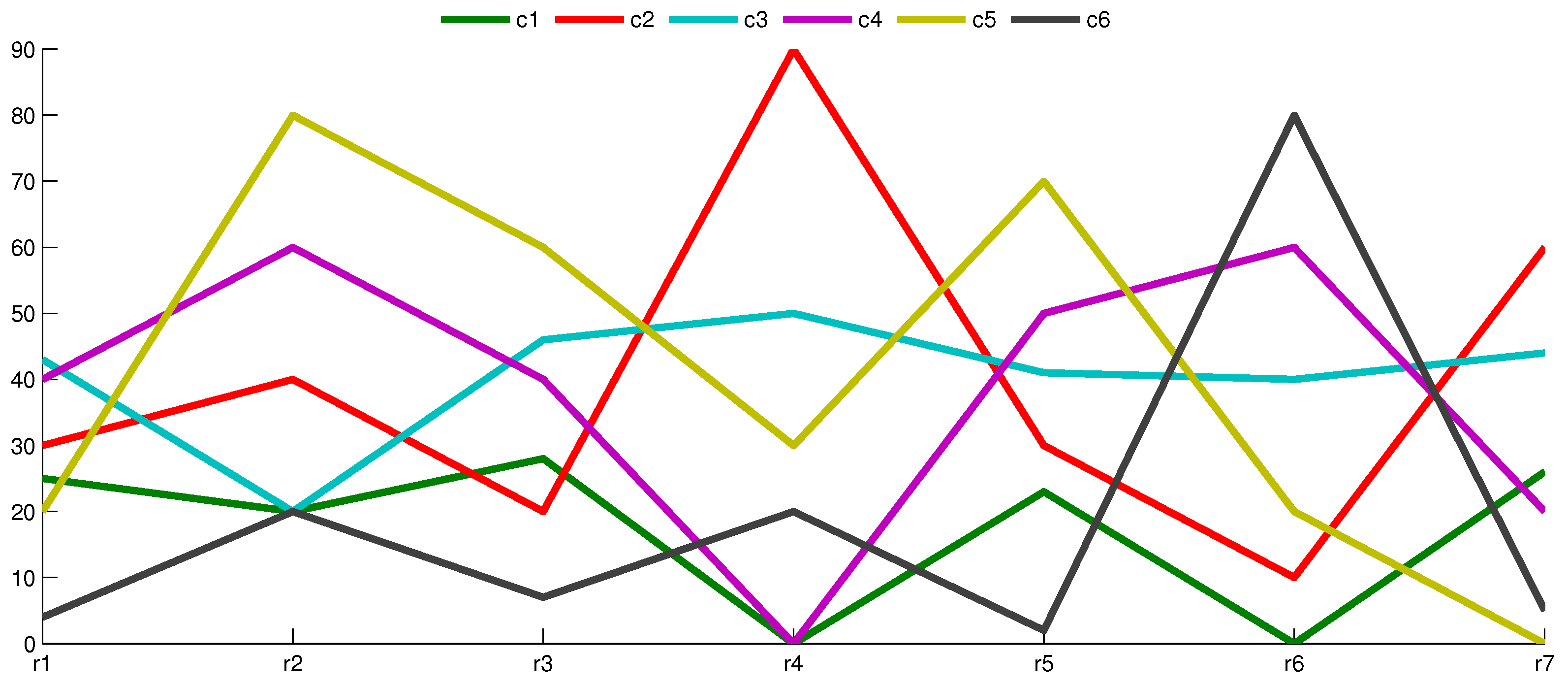
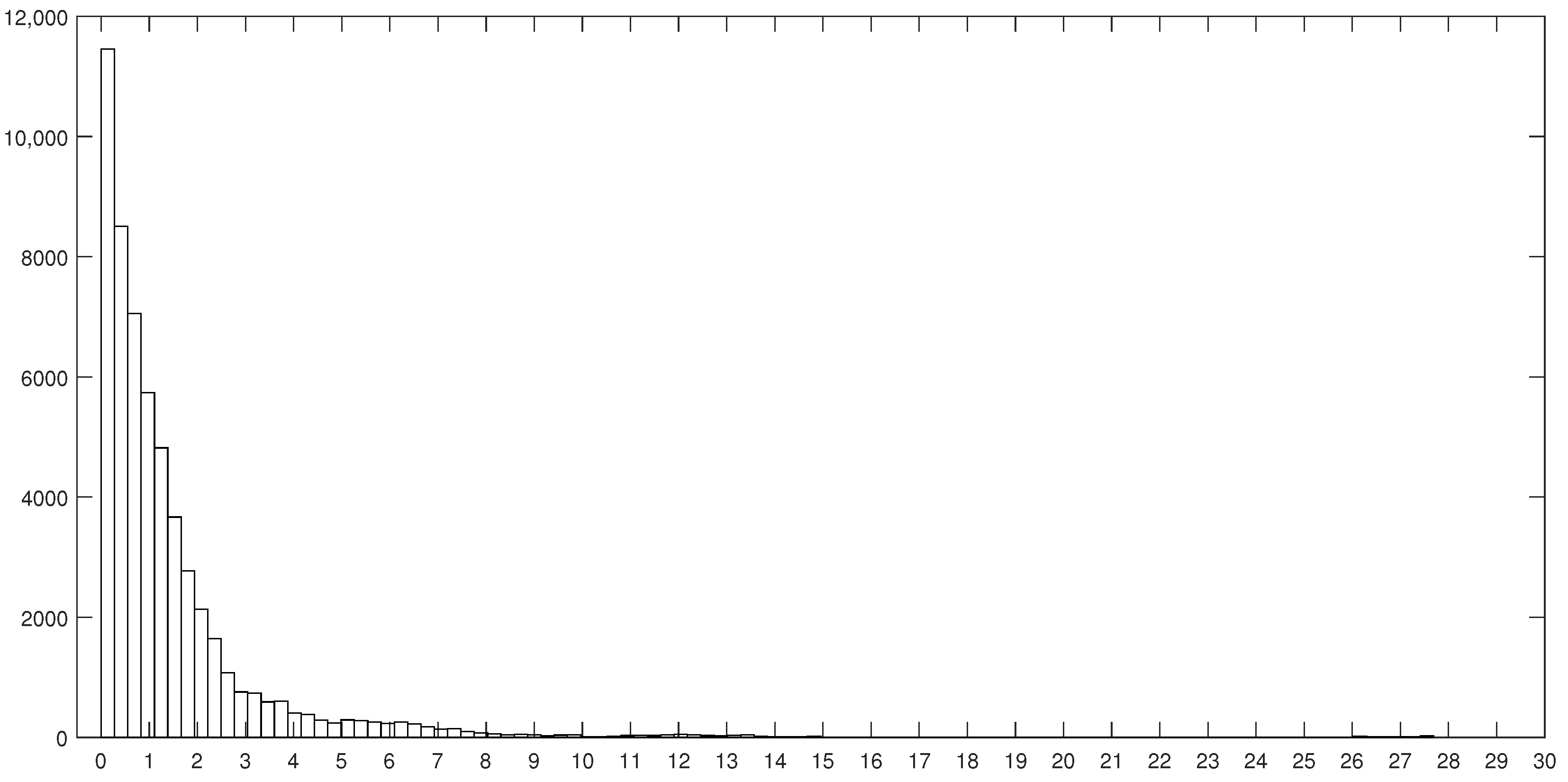
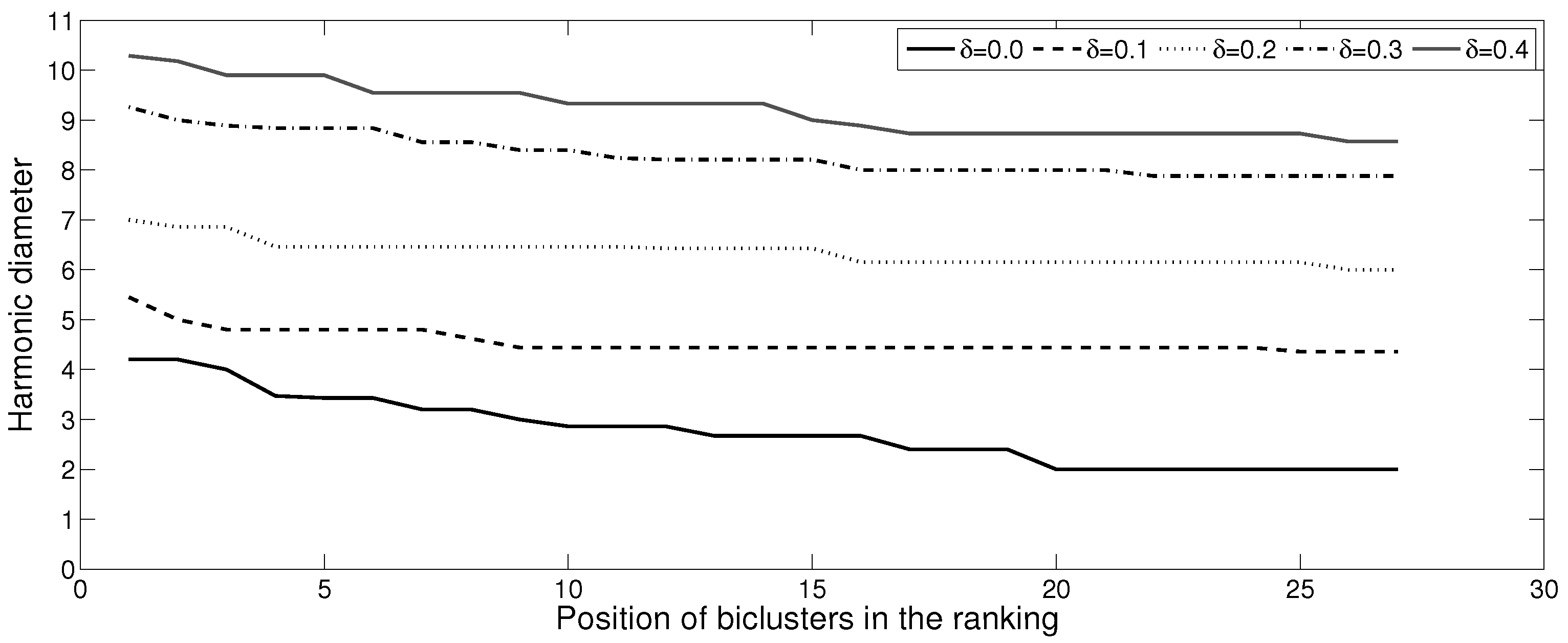
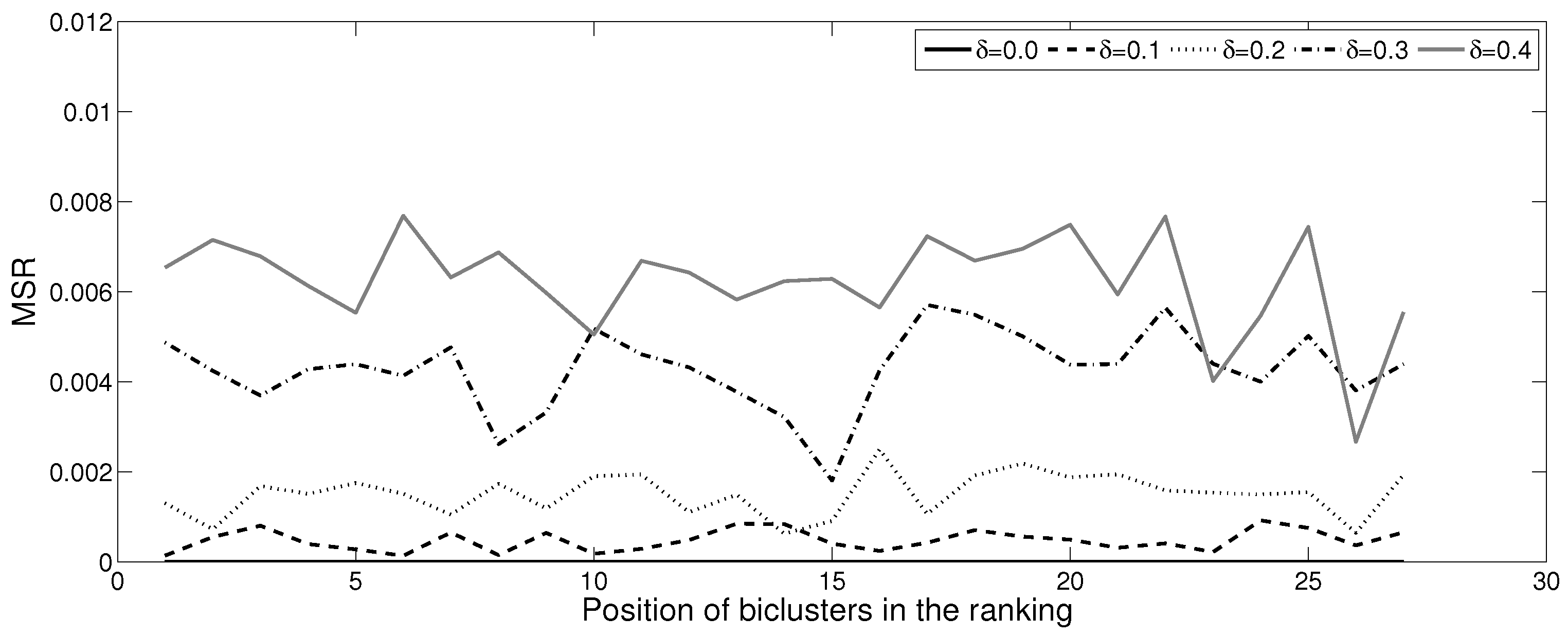
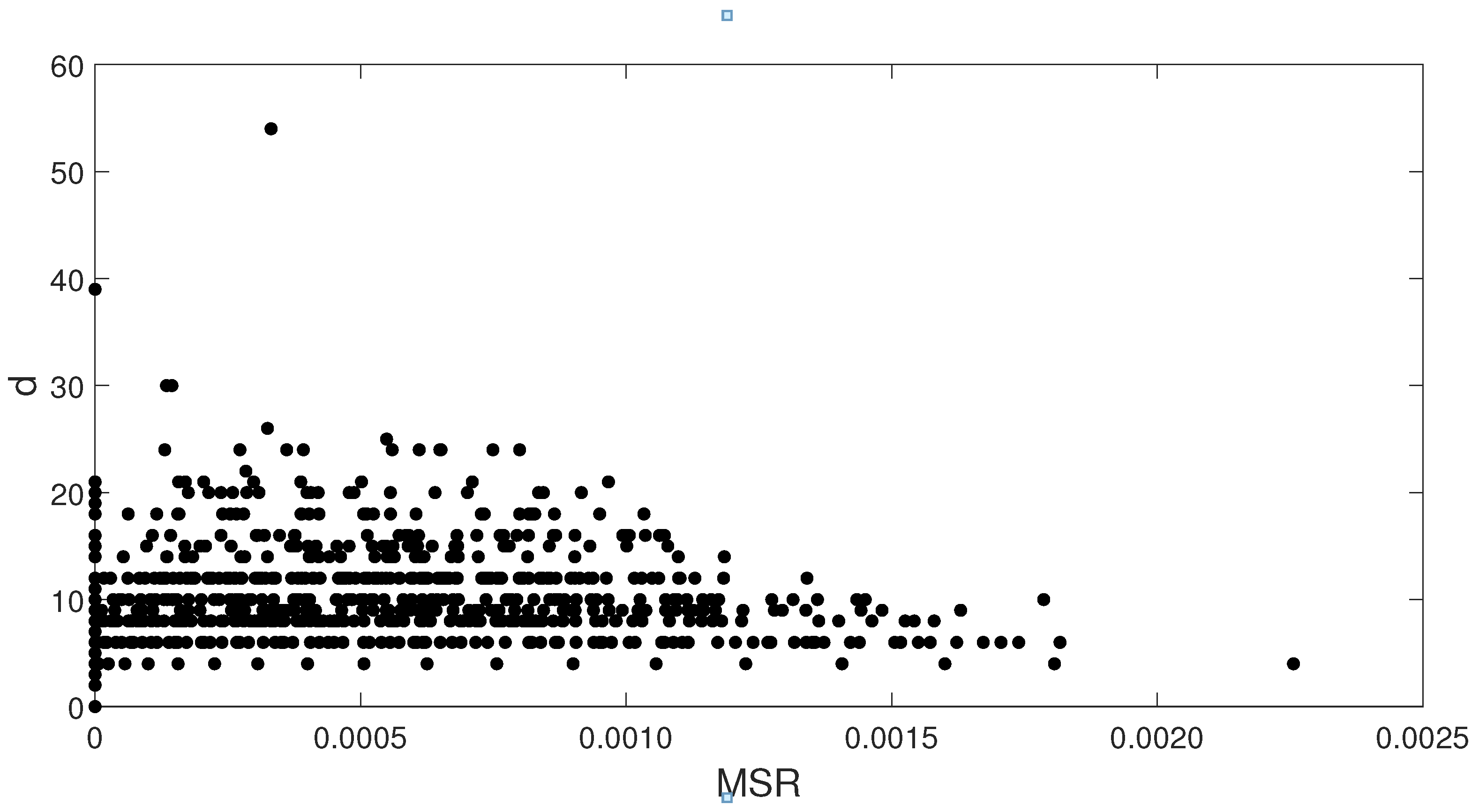
5. Experimental Analysis
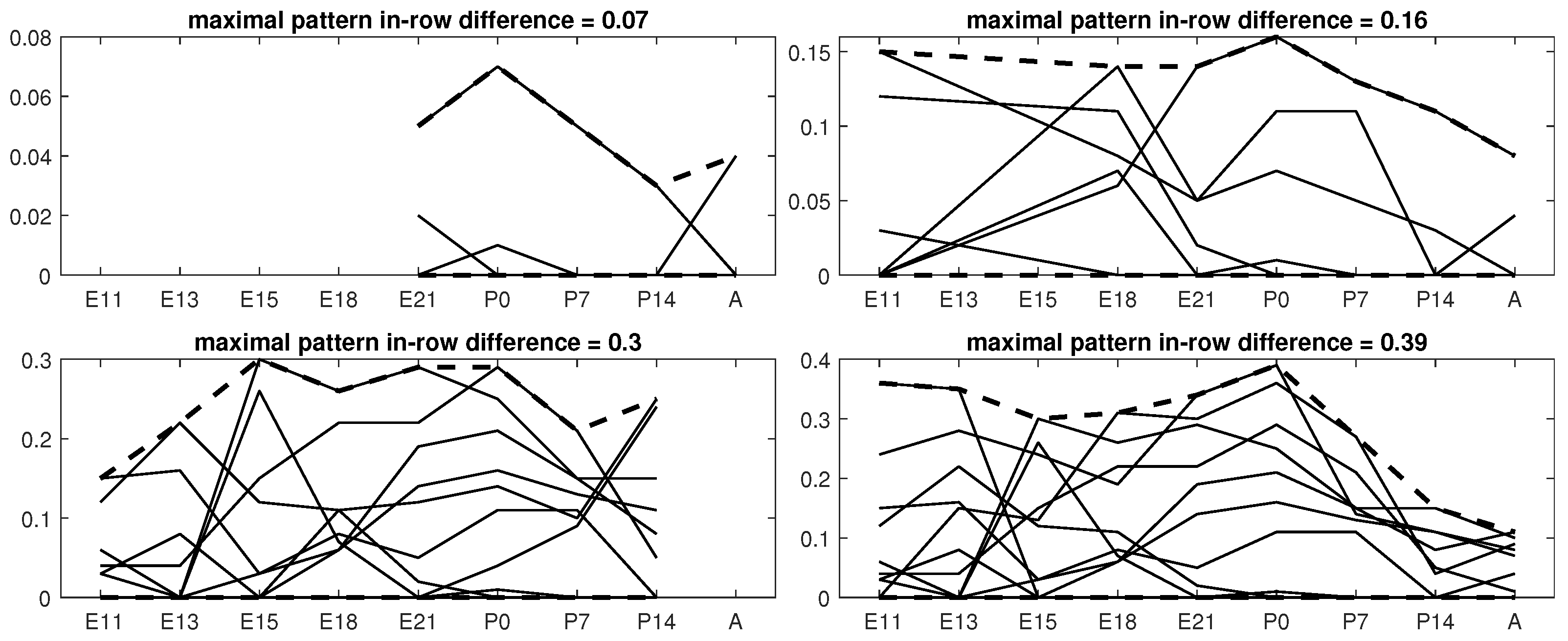
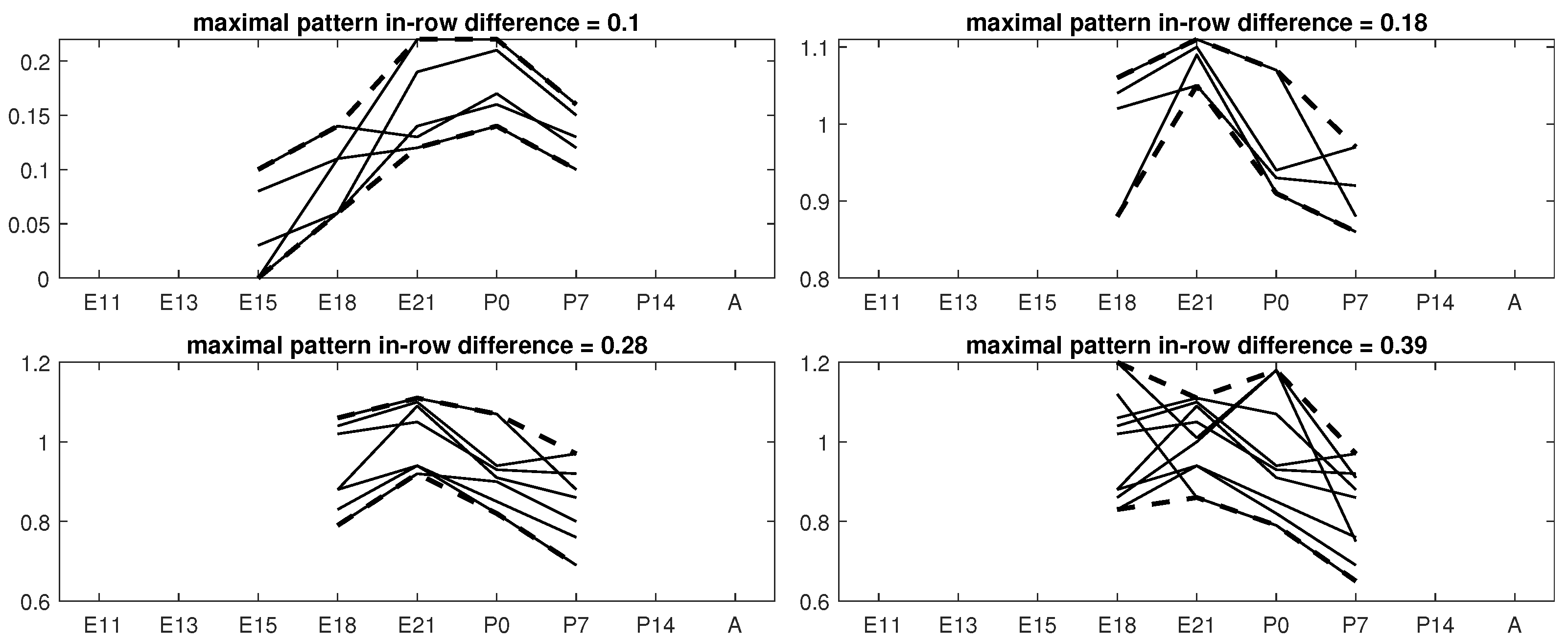
5.1. Boolean Reasoning-Based Experiments
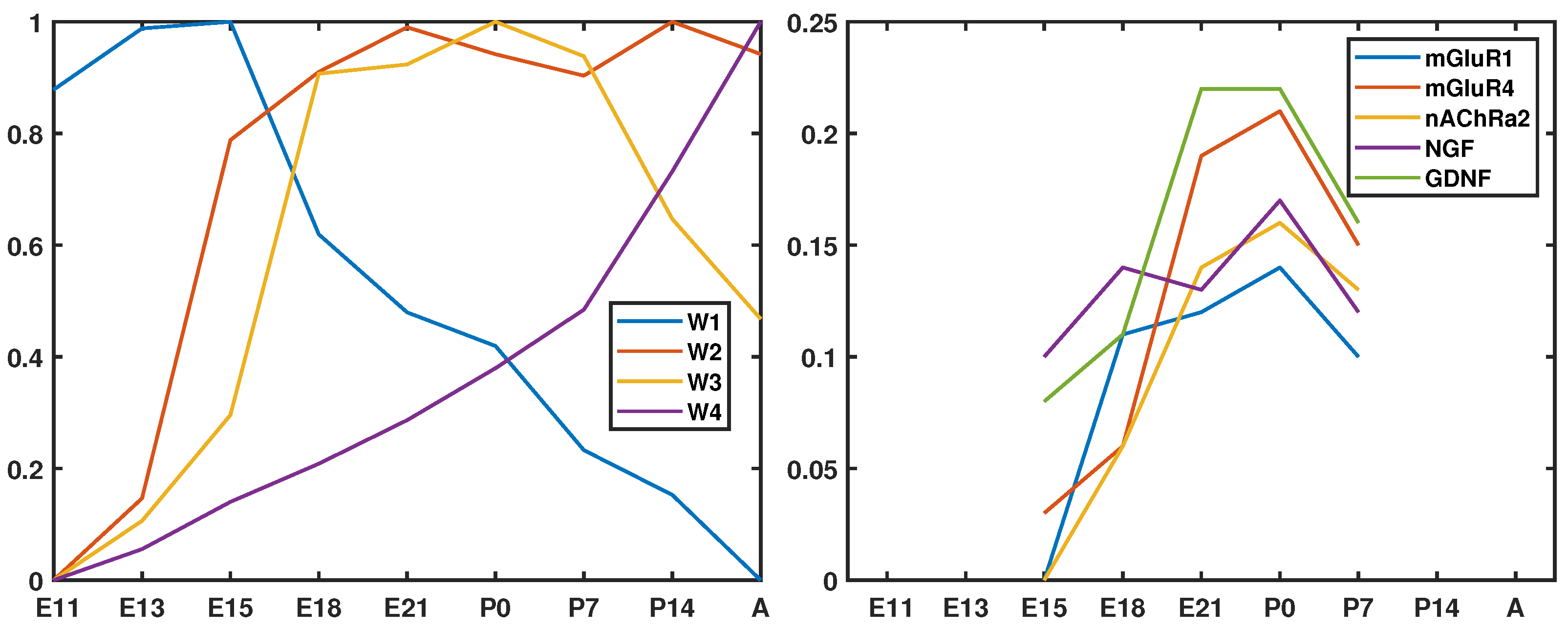
5.2. Biological Interpretation
5.3. Comparative Analysis
6. Conclusions and Further Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Theorems and Proofs
Appendix A.1. Proofs of Theorems for Constant Pattern Induction
Appendix A.2. Proofs of Theorems for δ-Shifting Pattern Induction
References
- Morgan, J.; Sonquist, J. Problems in the analysis of survey data, and a proposal. J. Am. Stat. Assoc. 1963, 58, 415–434. [Google Scholar] [CrossRef]
- Hartigan, J.A. Direct clustering of a data matrix. J. Am. Stat. Assoc. 1972, 67, 123–129. [Google Scholar] [CrossRef]
- Mirkin, B. Mathematical Classification and Clustering; Kluwer: Alphen aan den Rijn, The Netherlands, 1996. [Google Scholar]
- Cheng, Y.; Church, G.M. Biclustering of Expression Data. In Proceedings of the Eighth International Conference on Intelligent Systems for Molecular Biology; AAAI Press: Washington, DC, USA, 2000; pp. 93–103. [Google Scholar]
- Tanay, A.; Sharan, R.; Shamir, R. Discovering statistically significant biclusters in gene expression data. Bioinformatics 2002, 18, S136–S144. [Google Scholar] [CrossRef]
- Fernández, D.; Sram, R.J.; Dostal, M.; Pastorkova, A.; Gmuender, H.; Choi, H. Modeling Unobserved Heterogeneity in Susceptibility to Ambient Benzo[a]pyrene Concentration among Children with Allergic Asthma Using an Unsupervised Learning Algorithm. Int. J. Environ. Res. Public Health 2018, 15, 106. [Google Scholar] [CrossRef]
- Silva, M.G.; Madeira, S.C.; Henriques, R. Water Consumption Pattern Analysis Using Biclustering: When, Why and How. Water 2022, 14, 1954. [Google Scholar] [CrossRef]
- Yazdanparast, A.; Li, L.; Zhang, C.; Cheng, L. Bi-EB: Empirical Bayesian Biclustering for Multi-Omics Data Integration Pattern Identification among Species. Genes 2022, 13, 1982. [Google Scholar] [CrossRef]
- Chagoyen, M.; Carmona-Saez, P.; Shatkay, H.; Carazo, J.M.; Pascual-Montano, A. Discovering semantic features in the literature: A foundation for building functional associations. BMC Bioinform. 2006, 7, 41. [Google Scholar] [CrossRef] [PubMed]
- Orzechowski, P.; Boryczko, K. Text Mining with Hybrid Biclustering Algorithms. Lect. Notes Comput. Sci. 2016, 9693, 102–113. [Google Scholar]
- Busygin, S.; Prokopyev, O.; Pardalos, P.M. Biclustering in data mining. Comput. Oper. Res. 2008, 35, 2964–2987. [Google Scholar] [CrossRef]
- Pontes, B.; Giráldez, R.; Aguilar-Ruiz, J.S. Biclustering on expression data: A review. J. Biomed. Inform. 2015, 57, 163–180. [Google Scholar] [CrossRef]
- Madeira, S.C.; Oliveira, A. Biclustering algorithms for biological data analysis: A survey. IEEE/ACM Trans. Comput. Biol. Bioinform. 2004, 1, 24–45. [Google Scholar] [CrossRef] [PubMed]
- Aguilar-Ruiz, J.S. Shifting and scaling patterns from gene expression data. Bioinformatics 2005, 21, 3840–3845. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, H.; Mahanta, P.; Bhattacharyya, D.; Kalita, J. Shifting-and-scaling correlation based biclustering algorithm. IEEE/ACM Trans. Comput. Biol. Bioinform. 2014, 11, 1239–1252. [Google Scholar] [CrossRef] [PubMed]
- Bryan, K.; Cunningham, P.; Bolshakova, N. Application of Simulated Annealing to the Biclustering of Gene Expression Data. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 519–525. [Google Scholar] [CrossRef] [PubMed]
- Bryan, K.; Cunningham, P. Extending bicluster analysis to annotate unclassified ORFs and predict novel functional modules using expression data. BMC Genom. 2008, 9, S20. [Google Scholar] [CrossRef]
- Reiss, D.J.; Baliga, N.S.; Bonneau, R. Integrated biclustering of heterogeneous genome-wide datasets for the inference of global regulatory networks. BMC Bioinform. 2006, 7, 280. [Google Scholar] [CrossRef]
- Alzahrani, M.; Kuwahara, H.; Wang, W.; Gao, X. Gracob: A novel graph-based constant-column biclustering method for mining growth phenotype data. Bioinformatics 2017, 33, 2523–2531. [Google Scholar] [CrossRef]
- Karim, M.B.; Huang, M.; Ono, N.; Kanaya, S.; Altaf-Ul-Amin, M. BiClusO: A novel biclustering approach and its application to species-VOC relational data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 1955–1965. [Google Scholar] [CrossRef]
- Li, G.; Ma, Q.; Tang, H.; Paterson, A.H.; Xu, Y. QUBIC: A qualitative biclustering algorithm for analyses of gene expression data. Nucleic Acids Res. 2009, 37, e101. [Google Scholar] [CrossRef]
- Denitto, M.; Farinelli, A.; Figueiredo, M.; Bicego, M. A biclustering approach based on factor graphs and the max-sum algorithm. Pattern Recognit. 2017, 62, 114–124. [Google Scholar] [CrossRef]
- Denitto, M.; Bicego, M.; Farinelli, A.; Figueiredo, M. Spike and slab biclustering. Pattern Recognit. 2017, 72, 186–195. [Google Scholar] [CrossRef]
- Kluger, Y.; Basri., R.; Chang, J.T.; Gerstein, M. Spectral biclustering of microarray data: Coclustering genes and conditions. Genome Res. 2003, 13, 703–716. [Google Scholar] [CrossRef]
- Mitra, S.; Banka, H. Multi-objective evolutionary biclustering of gene expression data. Pattern Recognit. 2006, 39, 2464–2477. [Google Scholar] [CrossRef]
- Hanczar, B.; Nadif, M. Ensemble methods for biclustering tasks. Pattern Recognit. 2012, 45, 3938–3949. [Google Scholar] [CrossRef]
- Nepomuceno, J.A.; Troncoso, A.; Aguilar-Ruiz, J.S. Biclustering of Gene Expression Data by Correlation-Based Scatter Search. BioData Min. 2011, 4, 3. [Google Scholar] [CrossRef]
- Banerjee, A.; Dhillon, I.; Ghosh, J.; Merugu, S.; Modha, D.S. A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation. J. Mach. Learn. Res. 2007, 8, 1919–1986. [Google Scholar]
- Gupta, N.; Aggarwal, S. MIB: Using mutual information for biclustering gene expression data. Pattern Recognit. 2010, 43, 2692–2697. [Google Scholar] [CrossRef]
- Pontes, B.; Giráldez, R.; Aguilar-Ruiz, J. Quality Measures for Gene Expression Biclusters. PLoS ONE 2015, 10, e0115497. [Google Scholar] [CrossRef]
- Flores, J.L.; Inza, I.; Larrañaga, P.; Calvo, B. A new measure for gene expression biclustering based on non-parametric correlation. Comput. Methods Programs. Biomed. 2013, 112, 367–397. [Google Scholar] [CrossRef]
- Wille, R. Restructuring Lattice Theory: An Approach Based on Hierarchies of Concepts. In Proceedings of the Ordered Sets, Banff, AB, Canada, 28 August–12 September 1981; Rival, I., Ed.; Springer: Berlin/Heidelberg, Germany, 1982; pp. 445–470. [Google Scholar]
- Serin, A.; Vingron, M. DeBi: Discovering Differentially Expressed Biclusters using a Frequent Itemset Approach. Algorithms Mol. Biol. 2011, 6, 18. [Google Scholar] [CrossRef] [PubMed]
- Aguinis, H.; Forcum, L.E.; Joo, H. Using Market Basket Analysis in Management Research. J. Manag. 2013, 39, 1799–1824. [Google Scholar] [CrossRef]
- Tomescu, M.A.; Jäntschi, L.; Rotaru, D.I. Figures of Graph Partitioning by Counting, Sequence and Layer Matrices. Mathematics 2021, 9, 1419. [Google Scholar] [CrossRef]
- Brown, F.M. Boolean Reasoning; Springer: New York, NY, USA, 1990. [Google Scholar]
- Michalak, M.; Ślȩzak, D. Boolean Representation for Exact Biclustering. Fundam. Inform. 2018, 161, 275–297. [Google Scholar] [CrossRef]
- José-García, A.; Jacques, J.; Sobanski, V.; Dhaenens, C. Metaheuristic Biclustering Algorithms: From State-of-the-Art to Future Opportunities. ACM Comput. Surv. 2023, 56, 1–38. [Google Scholar] [CrossRef]
- van Uitert, M.; Meuleman, W.; Wessels, L.F.A. Biclustering Sparse Binary Genomic Data. J. Comput. Biol. 2008, 15, 1329–1345. [Google Scholar] [CrossRef]
- Chokeshaiusaha, K.; Puthier, D.; Nguyen, C.; Sudjaidee, P.; Sananmuang, T. Factor Analysis for Bicluster Acquisition (FABIA) revealed vincristine-sensitive transcript pattern of canine transmissible venereal tumors. Heliyon 2019, 5, e01558. [Google Scholar] [CrossRef]
- Gonçalves, J.P.; Madeira, S.C. LateBiclustering: Efficient Heuristic Algorithm for Time-Lagged Bicluster Identification. IEEE/ACM Trans. Comput. Biol. Bioinform. 2014, 11, 801–813. [Google Scholar] [CrossRef]
- Michalak, M. Induction of Centre—Based Biclusters in Terms of Boolean Reasoning. Adv. Intell. Syst. Comput. 2020, 1061, 239–248. [Google Scholar]
- Wen, X.; Fuhrman, S.; Michaels, G.S.; Carr, D.B.; Smith, S.; Barker, J.L.; Somogyi, R. Large-scale temporal gene expression mapping of central nervous system development. Proc. Natl. Acad. Sci. USA 1998, 95, 334–339. [Google Scholar] [CrossRef]
- Wang, Z.; Li, G.; Robinson, R.W.; Huang, X. UniBic: Sequential row-based biclustering algorithm for analysis of gene expression data. Sci. Rep. 2016, 6, 23466. [Google Scholar] [CrossRef]
- Liu, X.; Li, D.; Liu, J.; Su, Z.; Li, G. RecBic: A fast and accurate algorithm recognizing trend-preserving biclusters. Bioinformatics 2020, 36, 5054–5060. [Google Scholar] [CrossRef] [PubMed]
- biclust: BiCluster Algorithms. Available online: https://cran.r-project.org/web/packages/biclust/index.html (accessed on 1 October 2023).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Turner, H.; Bailey, T.; Krzanowski, W. Improved biclustering of microarray data demonstrated through systematic performance tests. Comput. Stat. Data Anal. 2005, 48, 235–254. [Google Scholar] [CrossRef]
- Lazzeroni, L.; Owen, A. Plaid Models for Gene Expression Data. Stat. Sin. 2002, 12, 61–86. [Google Scholar]
- Murali, T.M.; Kasif, S. Extracting Conserved Gene Expression Motifs from Gene Expression Data. In Proceedings of the Pacific Symposium Biocomputing, Kauai, HI, USA, 3–7 January 2003; pp. 77–88. [Google Scholar]
- Michalak, M.; Jaksik, R.; Ślȩzak, D. Heuristic Search of Exact Biclusters in Binary Data. Int. J. Appl. Math. Comput. Sci. 2020, 30, 161–171. [Google Scholar]
- Michalak, M. Hierarchical heuristics for Boolean-reasoning-based binary bicluster induction. Acta Inform. 2022, 59, 673–685. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
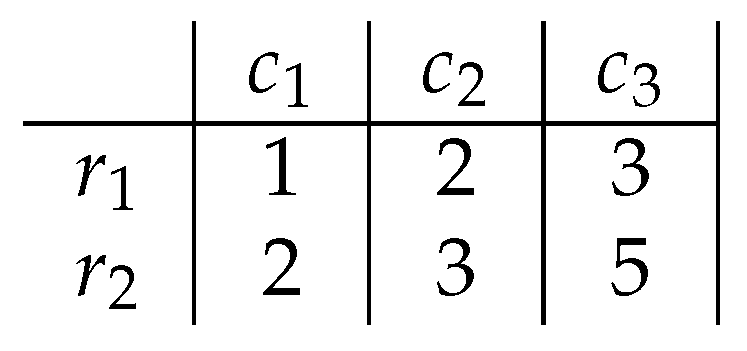{kind=link}
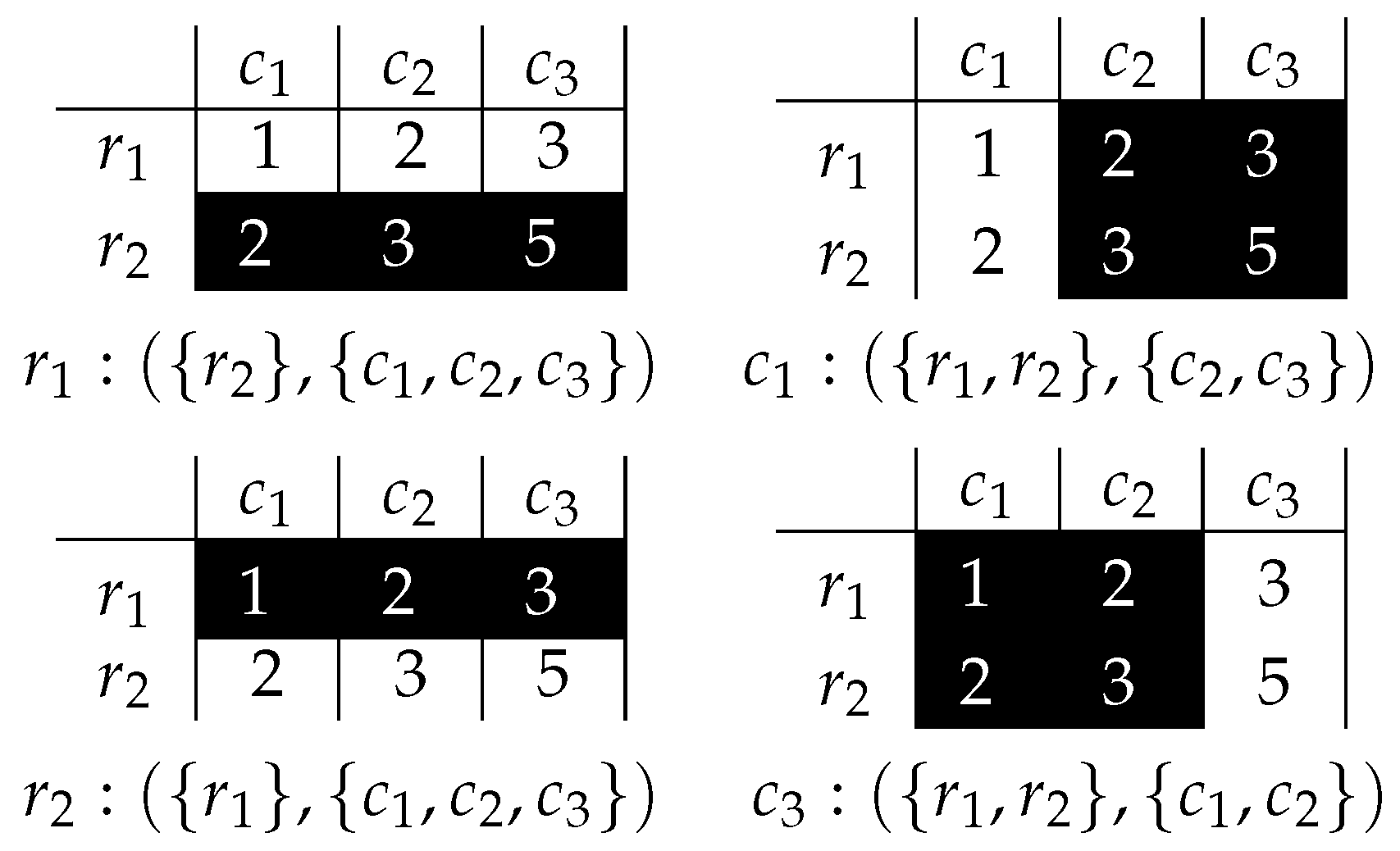{kind=link}
{kind=link}
{kind=link}
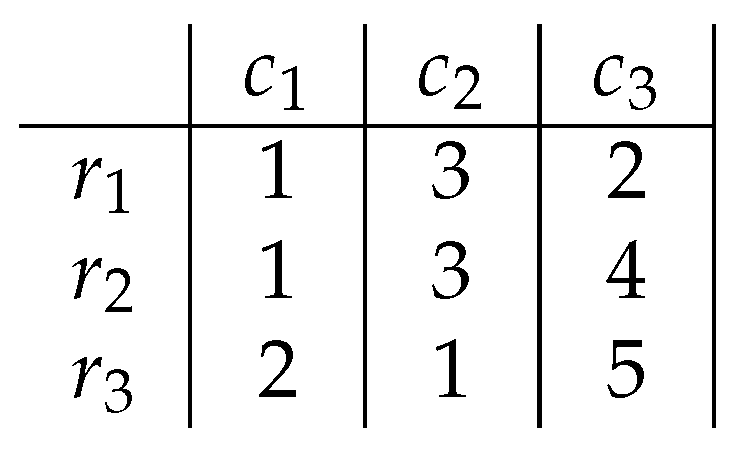{kind=link}
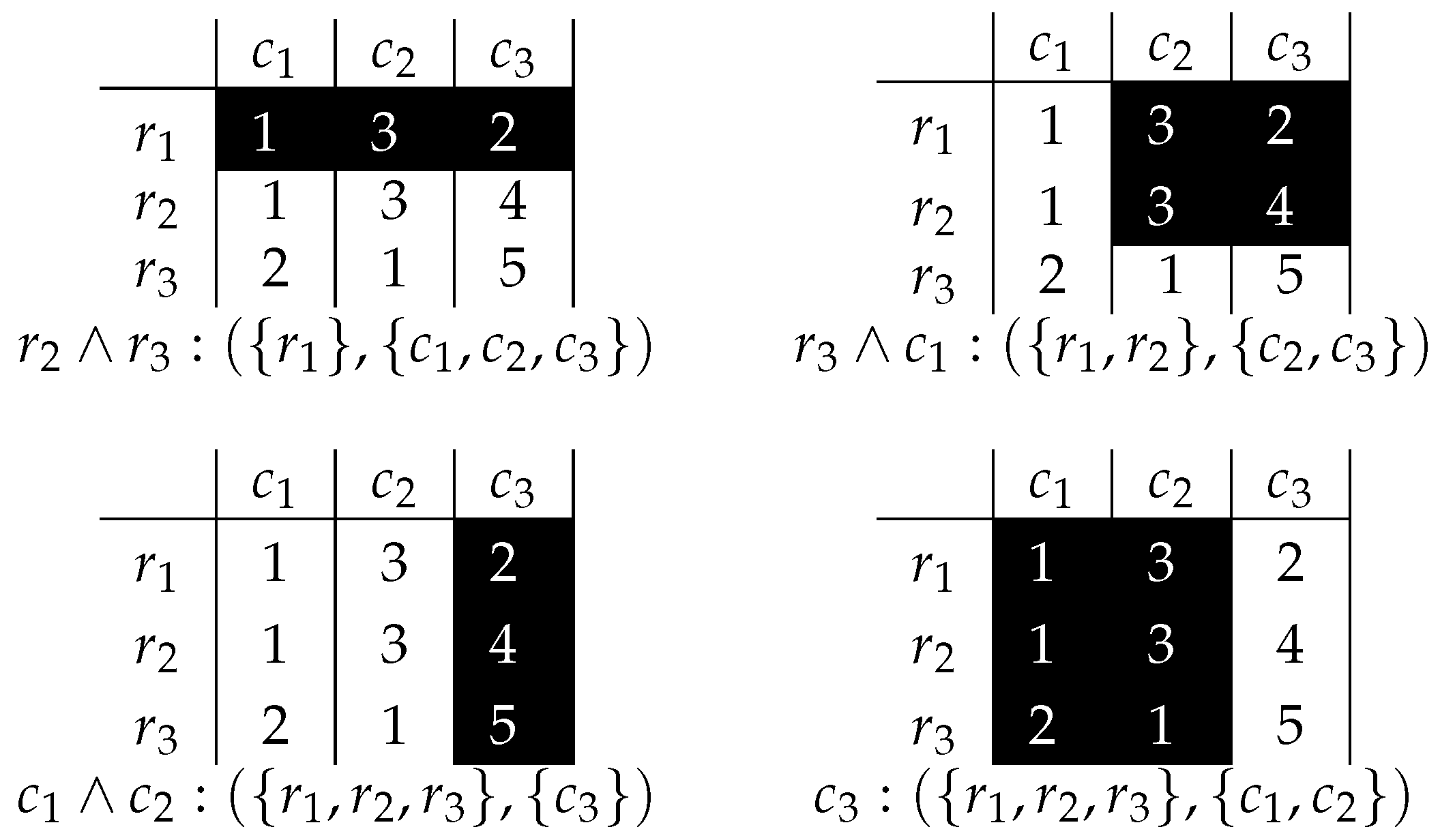{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Patterns | Max () | Max (d) | |
|---|---|---|---|
| 0.0 | 27 | 0.00000 | 4.20 |
| 0.1 | 1027 | 0.00226 | 5.45 |
| 0.2 | 2487 | 0.00951 | 7.00 |
| 0.3 | 4027 | 0.02102 | 9.26 |
| 0.4 | 6943 | 0.02976 | 10.29 |
| N. of Genes | N. of Cond. | Area | d | ||
|---|---|---|---|---|---|
| 6 | 5 | 30 | 0.00013 | 5.45 | |
| 7 | 7 | 49 | 0.00130 | 7.00 | |
| 11 | 8 | 88 | 0.00487 | 9.26 | |
| 12 | 9 | 108 | 0.00653 | 10.29 |
| N. of Genes | N. of Cond. | Area | d | ||
|---|---|---|---|---|---|
| 5 | 5 | 25 | 0.00055 | 5.00 | |
| 4 | 4 | 16 | 0.00151 | 4.00 | |
| 4 | 7 | 28 | 0.00137 | 5.09 | |
| 4 | 9 | 36 | 0.00695 | 5.54 |
| N. of Genes | N. of Cond. | Area | d | ||
|---|---|---|---|---|---|
| 0.00013 | 3 | 5 | 15 | 0.02 | 3.75 |
| 0.00130 | 7 | 6 | 42 | 0.19 | 6.46 |
| 0.00487 | 14 | 8 | 112 | 0.36 | 10.18 |
| 0.00653 | 16 | 9 | 144 | 0.44 | 11.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michalak, M.; Aguilar-Ruiz, J.S. Shifting Pattern Biclustering and Boolean Reasoning Symmetry. Symmetry 2023, 15, 1977. https://doi.org/10.3390/sym15111977
Michalak M, Aguilar-Ruiz JS. Shifting Pattern Biclustering and Boolean Reasoning Symmetry. Symmetry. 2023; 15(11):1977. https://doi.org/10.3390/sym15111977
Chicago/Turabian StyleMichalak, Marcin, and Jesús S. Aguilar-Ruiz. 2023. "Shifting Pattern Biclustering and Boolean Reasoning Symmetry" Symmetry 15, no. 11: 1977. https://doi.org/10.3390/sym15111977
APA StyleMichalak, M., & Aguilar-Ruiz, J. S. (2023). Shifting Pattern Biclustering and Boolean Reasoning Symmetry. Symmetry, 15(11), 1977. https://doi.org/10.3390/sym15111977