This section introduces the different areas used by the proposed model and further describes them by explaining the input and output of the various modules. The work proposed in this paper deals with three major areas: image capturing and output feed, privacy and security, object detection and classification, and relative depth estimation. The technical details of these modules are elaborated on in the following subsections.
4.4.1. Image Capturing and Output Feed: IoT and Cloud
The problem at hand necessitates the transmission of the images of the surroundings to the cloud and the subsequent delivery of the processed results from the cloud back to the user in an audio format, all facilitated by a compact, portable device. These functions can be suitably carried out by an IoT device: Raspberry Pi 4 Model B. Another requirement to enhance the capability of the model is the utilisation of a camera lens that possesses an expanded field of view. This leads to the deep learning model being able to detect objects, which can be a possible obstacle to the user, even if they are not in the direct line of sight of the user.
Figure 7 provides an overview of the control flow in the model. The camera lens, with a horizontal field of view of 155 degrees, is connected to the Raspberry Pi through the camera serial interface (CSI). It captures video frames and these images are subsequently resized to a smaller size to facilitate faster transfer to the cloud [
42]. These resized images are then transmitted to Firebase Storage, a cloud-based storage service, as depicted in
Figure 8.
Figure 8 shows that each image link is stored in a real-time database. The blockchain module then takes over to perform further processing. Upon the completion of the deep learning model’s output transmission to the Firestore database, a change in the document snapshot is detected, prompting the Raspberry Pi to retrieve and return the corresponding result from the Firestore. The generated output is delivered to the user in an audio format, as illustrated in
Figure 7.
Although the frames of the video are reduced to a smaller size in the IoT device, when frames are saved at such a fast rate, they occupy memory in the Raspberry Pi device as well. To avoid the memory of Raspberry Pi being utilised completely, the images are deleted from the device as soon as they are sent to the cloud, since they are not used again by the device. The final output received by the user is of the following format: [Object] detected at your [Position]. For example, an output inference could say “Chair detected at your left”.
Algorithm 1 elaborates the process of taking the input of a real-time video feed from the camera lens and sending it over to the Firebase Storage and the metadata to the real-time database. The algorithm initializes Firebase and creates a PiCamera object. It then loops forever, capturing a frame and saving it locally. The image is then smoothed and uploaded to Firebase Storage. The URL of the uploaded image is then retrieved and pushed to Firebase Realtime Database. The local copy of the image is then removed and the captured frame buffer is cleared. If an error occurs, the camera is closed.
Algorithm 2 first initializes the Firebase app and Firestore client. This allows the algorithm to access Firebase’s cloud database. Next, it creates a thread synchronization event to notify the main thread when the document changes. Then, it sets up a listener to watch the document. This listener will be called whenever the document changes. When the listener is called, it will retrieve the result from the document and set the callback. Finally, the audio output is given to the user.
| Algorithm 1: Image Capture and Upload to Firebase |
![Symmetry 15 01627 i001]() |
| Algorithm 2: Result retrieval from Firestore |
- 1
Initialise the Firebase app and Firestore client - 2
Create a thread synchronization event to notify the main thread - 3
Set up a listener to watch the document - 4
On change to the document, retrieve the result and set the callback - 5
Give the audio output to user
|
4.4.2. Privacy and Security: Blockchain
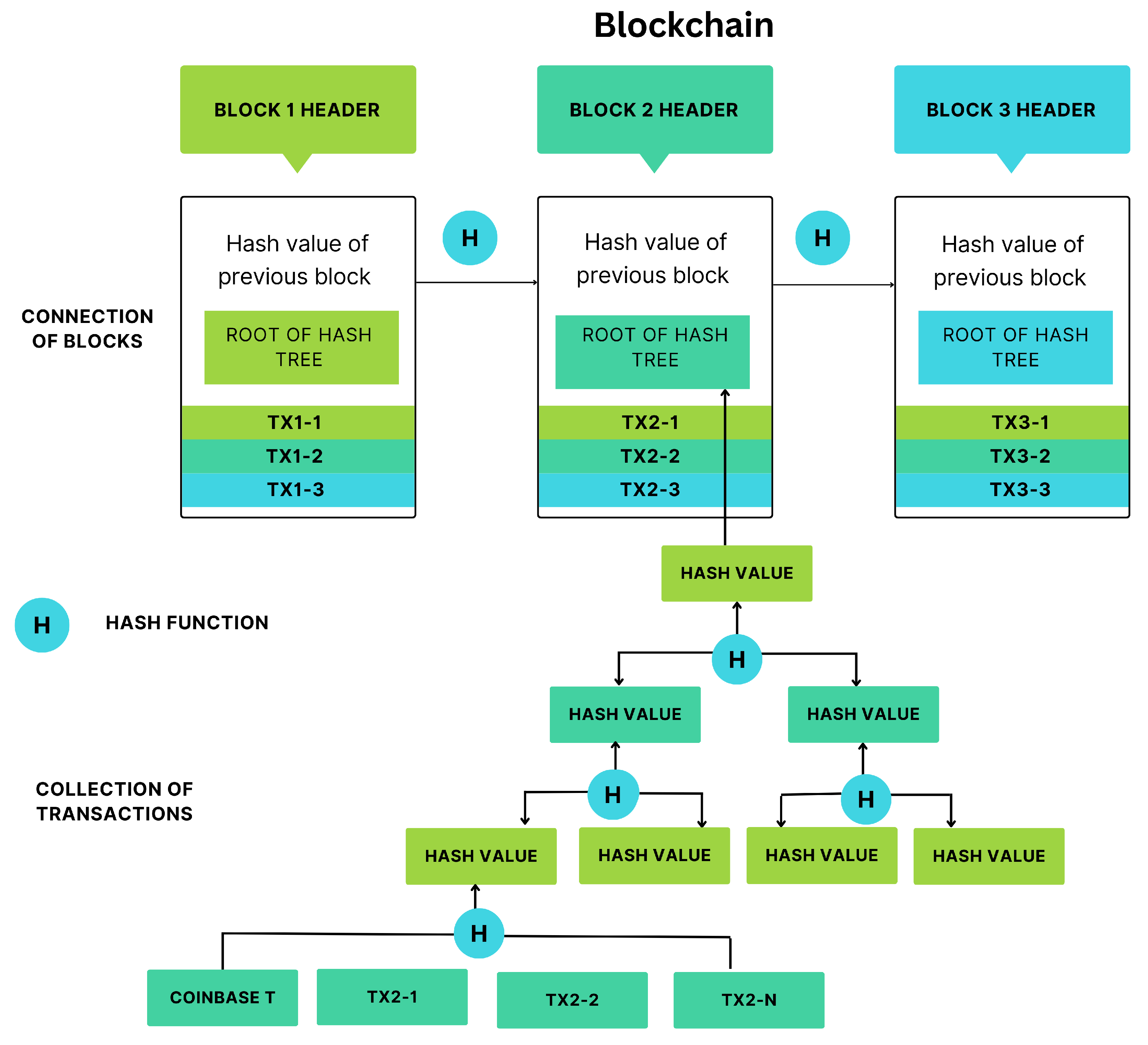
In the previous section, the authors convey how the IoT configuration is actively acquiring real-time video frames. The captured images encompass sensitive user data, including location information and depictions of other individuals present within the environment. A significant challenge encountered within this system pertains to determining a secure and efficient method for storing such sensitive information.
Blockchain is a technology that can facilitate fine-grained access control through smart contracts [
43]. This ensures that only authorized entities have access to specific data, improving data privacy and reducing the risk of unauthorized data usage or breaches [
44]. Hence, the authors proposed the concept of a private blockchain network for the purpose of storing the captured images.
However, storing images in a blockchain network is expensive due to data replication across all nodes, high transaction fees for large data uploads and rapid and excessive growth of a blockchain’s data size due to the accumulation of large amounts of data which can impact network performance and resource requirements. This is referred to as “Blockchain Bloat”.
In response to this challenge, the authors decided to address it by utilizing a secure storage space for images, coupled with the integration of a blockchain network to ensure streamlined and secure access control to the data. Therefore, the authors adopted a two-fold approach: images were stored in the cloud using Firebase for secure storage, and a private blockchain network was employed to record the links to these images as transactions within the network.
Blockchain also provides immutability so it guarantees that once the image link data is recorded on the blockchain, it cannot be altered without consensus from the network. Furthermore, should any image become corrupted, tampered or be removed from the Firebase storage, the hash link associated with the image will no longer correspond to the one stored within the blockchain network. As a result, such an alteration can be readily detected. This ensures an additional level of security.
In real-time systems such as the proposed project, continuous data acquisition is crucial for maintaining up-to-date and accurate information. Having a single point of failure, where data collection or distribution relies on a sole component, poses a significant risk. If that component fails, the entire system can collapse, leading to data gaps, delays, or disruptions.
To ensure uninterrupted data flow, blockchain provides decentralization by distributing data and control among multiple authorized participants [
45,
46]. Further, identical copies of the blockchain ledger are maintained across multiple nodes. This redundancy ensures that if one node fails or experiences issues, others can seamlessly take over, preserving data integrity and continuous operation.
The current framework employs Firebase for image storage within the proposed system. Nonetheless, should the need arise to transition to a different storage platform, the existing setup remains adaptable due to the blockchain’s role as an abstraction layer, ensuring portability. The process involves using the link of the new platform for image storage onto the blockchain network with minimal alterations to the initial code. This streamlined approach effectively diminishes the degree of interdependence among system components, mitigating tight coupling.
A suitable consensus mechanism has to be chosen for the proposed private blockchain network. The consensus mechanism is used to validate the nodes that are added to the blockchain network. There are two commonly used consensus mechanisms [
47]:
Proof of Work (PoW)
In the present consensus algorithm, the integration of fresh blocks into the blockchain network is achieved by mining, which involves resolving intricate computational challenges to add a legitimate block to the blockchain. The determination of a block’s validity is contingent upon the longest sequence of blocks, thus resolving any potential conflicts that may arise.
Proof of Stake (PoS)
This mechanism depends on cryptocurrency holders who pledge their coins as collateral in order to participate in the block validation process, whereby a subset of them is chosen randomly to serve as validators. Cryptocurrency refers to a form of digital or virtual currency utilised to ensure the security of transactions conducted on the blockchain. Only when a consensus is reached among multiple validators regarding the accuracy of a transaction is it deemed valid and allowed to proceed.
For the given real-time model, instant processing and transferring of data is required. PoW requires high energy and is computationally expensive, so it is not suitable for the proposed model. PoS eliminates the requirement of high energy and computational power, but in this mechanism [
48], although two or more validators might stake the same amount of coins, the value of stake differs depending on their individual assets.
To address this constraint, a modified version of Proof of Stake (PoS) called the Proof of Authority (PoA) consensus mechanism has been employed. PoA functions by assigning significance to the validator’s identity rather than a stake associated with monetary value [
49,
50].
In the private blockchain network model, the servers that run the deep learning model act as nodes in the blockchain as depicted in
Figure 9. A new deep learning server can join as a node of the blockchain only after being approved by the network administrator. Nodes can add blocks to the blockchain once it is validated using the PoA consensus mechanism.
In the proposed work, the private blockchain network is deployed using Ganache, a local blockchain development tool. Ganache provides a fast and convenient environment for testing and deploying Ethereum smart contracts. It offers a personal Ethereum network for developers, allowing them to simulate various blockchain behaviors without the need for a public network. Smart contracts are utilized within this setup to automate and enforce predefined agreements, offering a secure and efficient decentralized application environment.
Algorithm 3 provides a general overview of the process of image link retrieval from the cloud-based Firebase Realtime Database and the application of blockchain where the image link is being stored through smart contract in the private network. The deep learning servers continuously retrieve the last image link from blockchain network using the reference of same smart contract used while uploading the link. The algorithm for the same is shown in Algorithm 4.
The nodes within the blockchain are computational units that run the deep learning algorithms of the proposed model. These algorithms process images and produce textual results, which will be further elaborated in the subsequent section.
| Algorithm 3: Image link retrieval from Firebase and Upload to Blockchain |
![Symmetry 15 01627 i002]() |
| Algorithm 4: Retrieval of image link from Blockchain by Deep learning server |
- 1
Initiate connection with the Private Blockchain Network - 2
Get a reference to the Smart Contract using its address - 3
Retrieve the last pending block data from using Smart Contract reference - 4
Send the image data to the Deep learning server for further processing
|
4.4.3. Object Detection and Relative Depth Estimation: Deep Learning
The present study focuses on exploring object detection and relative depth estimation using a deep neural network architecture. The study investigates the use of the object detection framework based on the widely recognised and popular convolutional neural network (CNN) [
51] model known as YOLOv7. This real-time object detection system was developed by researchers at the University of Maryland and represents an enhanced version of the original YOLO (You Only Look Once) system, initially introduced in 2015. YOLOv7 has been specifically designed to identify objects quickly and precisely in both images and videos. By performing a single pass through the input data, it efficiently predicts bounding boxes and class probabilities for the detected objects within the input data. Furthermore, YOLOv7 exhibits efficiency and scalability, having been trained on a substantial dataset comprising annotated images from the MS COCO dataset [
52]. The selection of YOLOv7 for this study stems from its advantageous properties; in particular, it exhibits a significantly reduced inference time in comparison to other object detection models, e.g., RCNN, Faster RCNN, and SPP-Net. This characteristic renders YOLOv7 highly suitable for real-time applications, including the requirements of this study.
To identify the closest identifiable objects, the research incorporates a monocular depth estimation model referred to as MiDaS (Monocular Depth Scaling). MiDaS is an approach that enables the estimation of object depths in an image using a single camera. The foundation of MiDaS lies in the concept of utilising a CNN to predict the depth of objects by analysing their visual appearance, as well as the patterns of light and shadow within the scene. MiDaS underwent training using ten distinct datasets. These datasets, namely ReDWeb, DIML, Movies, MegaDepth, WSVD, TartanAir, HRWSI, ApolloScape, BlendedMVS, and IRS, were utilised in the training process. To optimise the performance of MiDaS, a multi-objective optimisation technique was employed. In order to strike a balance between time constraints and accuracy, the authors adopted MiDaS v3.1 Swin2 Large.
The identification of objects within the image is facilitated by the YOLO system, as shown in
Figure 10, which detects objects and constructs the corresponding bounding boxes. Concurrently, the relative depth map is extracted from the input image. The determination of the nearest object involves a comparison of the depth values across the bounding boxes associated with each object. The step-by-step procedure to perform depth estimation on an input image retrieved from the Firebase cloud and acquiring the extracted depth map through the MiDaS model is elucidated in Algorithm 5.
| Algorithm 5: Depth Estimation |
Input: Image from Firebase Cloud Output: Relative Depthmap of Input Image - 1
Read image and convert the colour space from BRG to RGB - 2
Load MiDaS from TorchHub and Move model to GPU if available - 3
Load transforms to resize and normalise the image for the model - 4
Load the image and apply the transform - 5
Predict depthmap and save image
|
Algorithm 6 elaborates on the process of evaluating the closest obstacle and its corresponding class by leveraging the object detection and depth map obtained from Algorithm 5. To maintain accuracy, object detections with confidence levels below 30% are ignored due to the likelihood of distant or partially visible objects. The position of the nearest object is categorised into one of three regions situated in front of the user, namely, left, middle, or right. The resulting output encompasses the appropriate region and the class of the object.
| Algorithm 6: Nearest Object Detection |
Input: Image from Firebase Cloud and Relative Depth Map Output: Nearest Object Type with Location - 1
Load YOLOv7 model and yolov7 weights from TorchHub - 2
Read image and convert colour space from BRG to RGB - 3
Obtain result dataframe and filter out objects with less than 0.3 confidence - 4
If result is empty (No detectable objects in image)—return empty string - 5
Obtain bounding box coordinates for each object in result - 6
Obtain depthmap values in each object bounding box from Depth Estimation Algorithm - 7
Store maximum depthmap value for each object - 8
Compare maximum values and select the highest—Closest object - 9
Divide image frame into 3 regions—left/middle/right - 10
Select region where closest object is detected - 11
Return closest object class and region
|


 ,
, 




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}