
Distantly Supervised Relation Extraction via Contextual Information Interaction and Relation Embeddings


Abstract
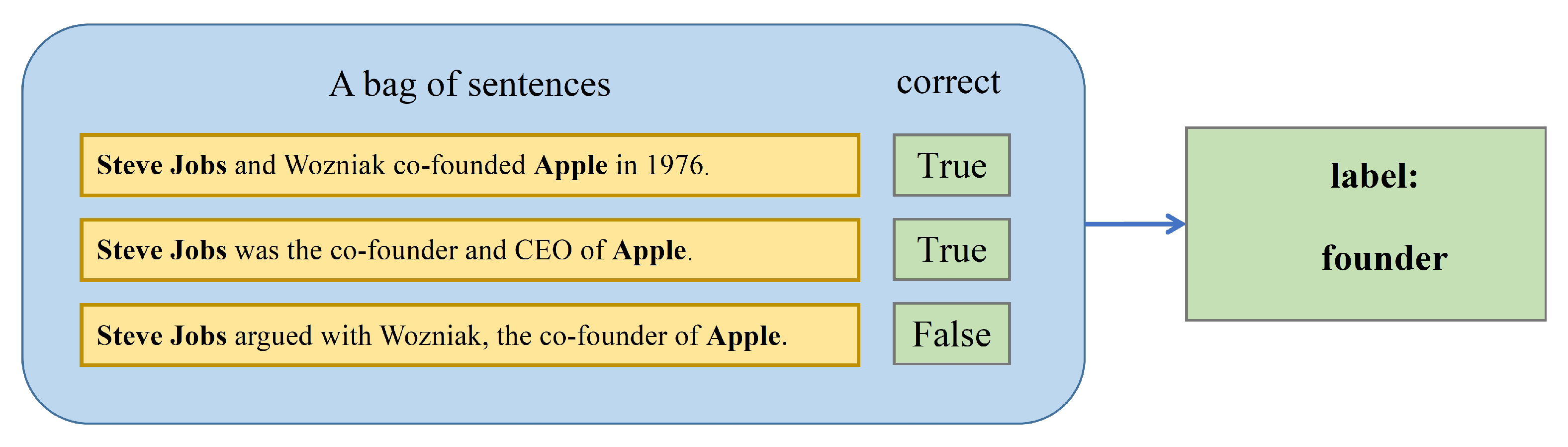
:1. Introduction
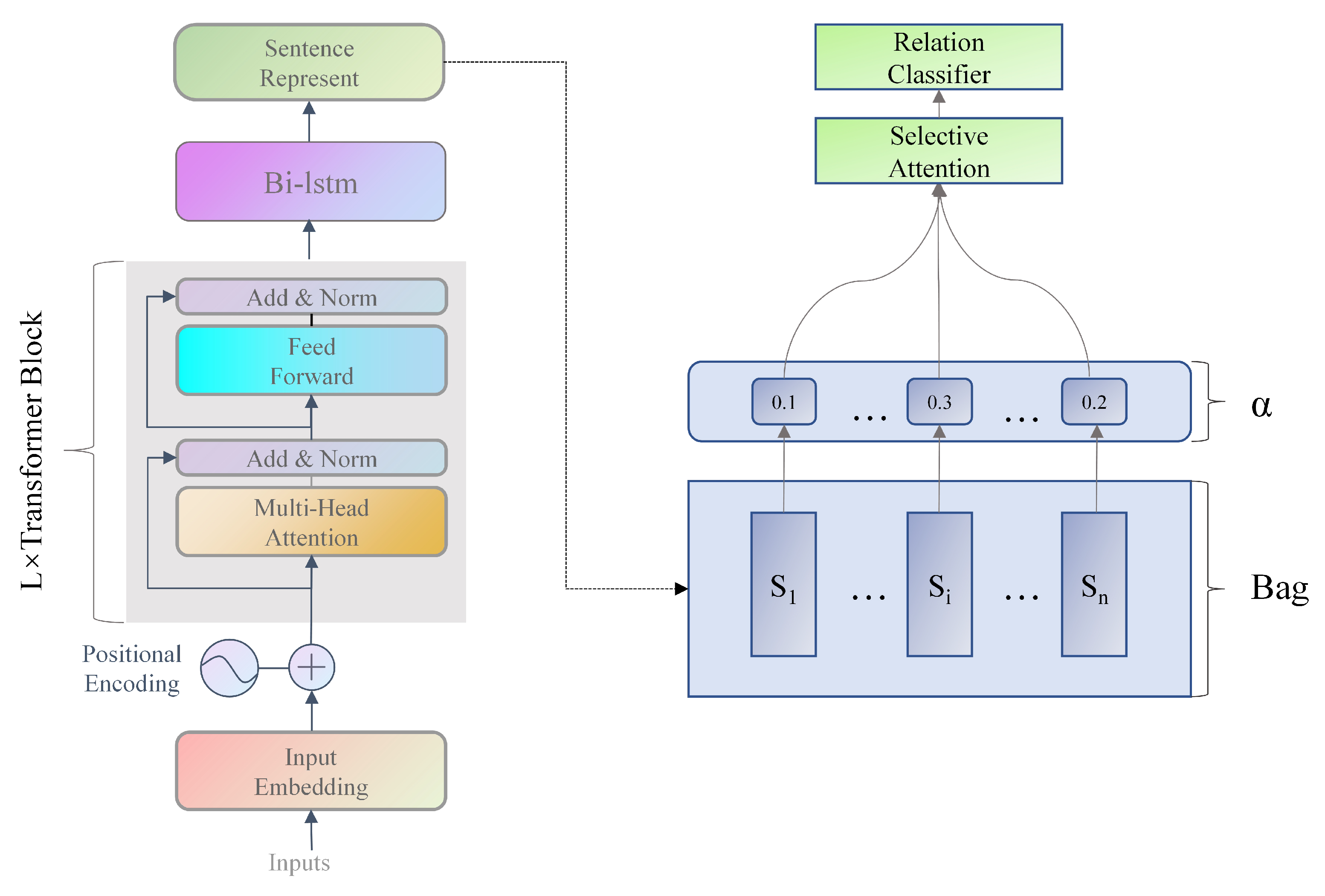
- This paper proposes a novel contextual information interaction and relation embeddings (CIRE) method for DSRE. We utilize BERT and Bi-LSTM to construct a neural network model. Based on acquiring semantic features based on the BERT encoder, we utilize the Bi-LSTM gating mechanism’s error repair ability to filter and supplement the sequence information and further model the text sequence to extract more compact and rich semantic and sequence information.
- We improve the TransE model by building entity-guided augmented relations in a nonlinear layer in a high-dimensional space, which improves the long-tail problem by combining entity pairs and vector differences of entity pairs in the relation embeddings part to form a relation-embedded representation that helps to recognize a broader range of relations.
- We integrate CIRE-based sentence representations, relation representations, and sentence-weighted representations at the semantic fusion layer to produce the final enhanced sentence-level representation. Finally, we use sparse softmax as a classifier, improving the classifier’s ability to control the noise categories by controlling the number of output categories so that the model fitting process reduces the bias and effectively handles the noise category interference.
- By conducting a large number of experiments on the NYT2010 [2] dataset, we proved that our method is effective and reasonable.
2. Related Work
3. Methodology
3.1. Sentence Input
3.1.1. Input Representation
3.1.2. Input Embedding
3.2. BERT
3.3. Enhanced Text Message Processing
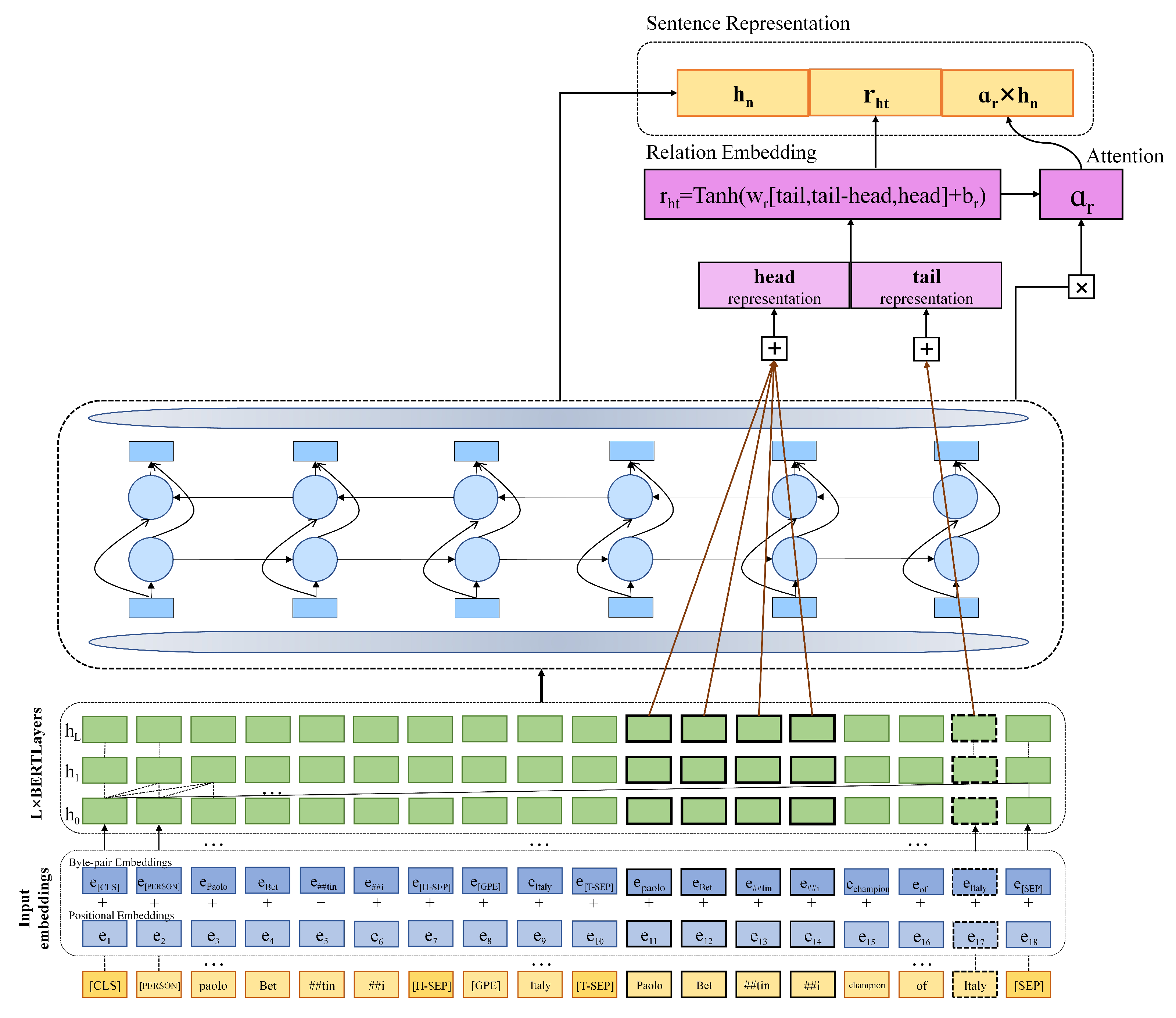
3.4. Improved Constructed Sentence Representation Based on Relation Embeddings
3.4.1. Acquisition of Head and Tail Entities
3.4.2. Methods for Fusing Supplementary Entity Pair Features in the Relation Embeddings Layer
3.4.3. Sentence Representation Based on Relational Attention
3.4.4. Methods for Constructing Final Sentence Representations
3.5. Bag-Level Characterization
3.6. Sparse Softmax Classifier
4. Experiments
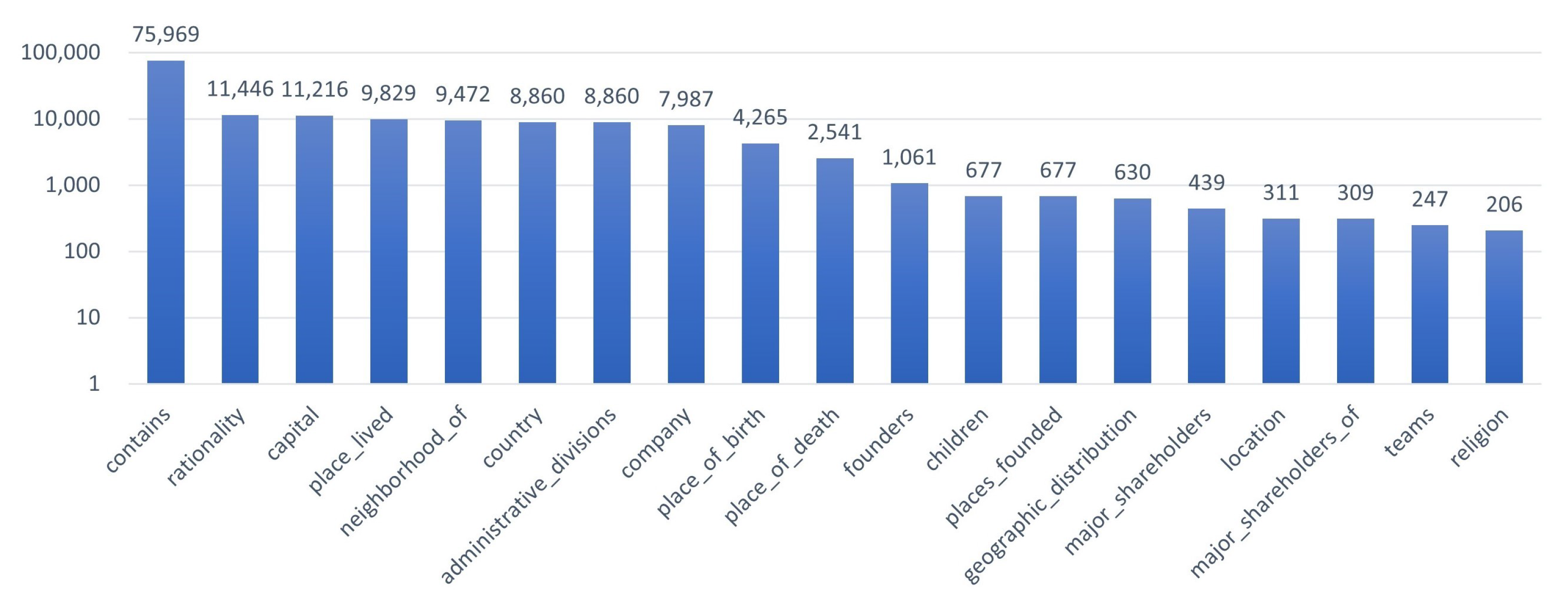
4.1. Datasets
4.2. Hyperparameter Settings
4.3. Comparison Experiment
4.3.1. Advanced Baseline Model
4.3.2. Evaluation Indicators
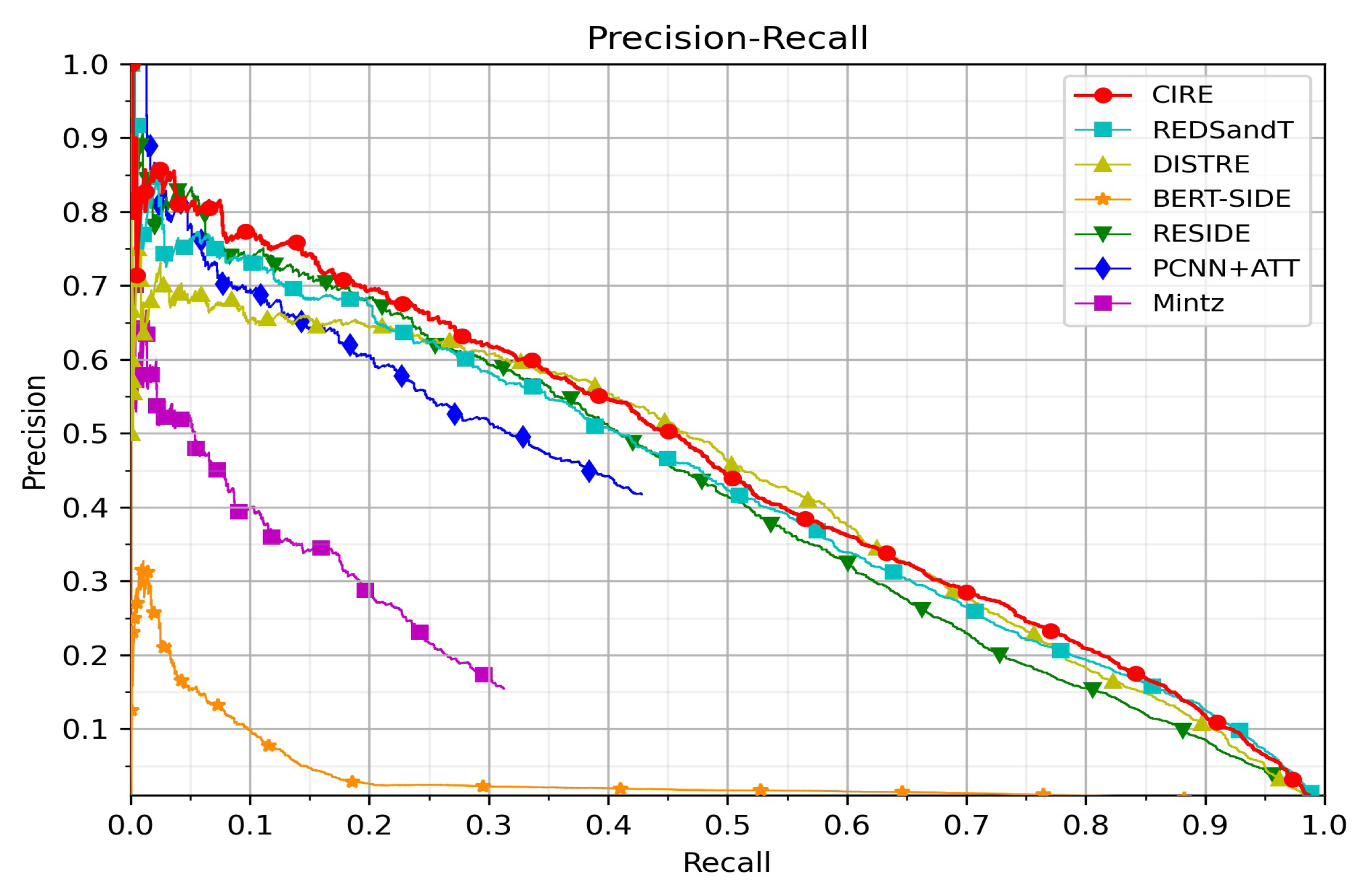
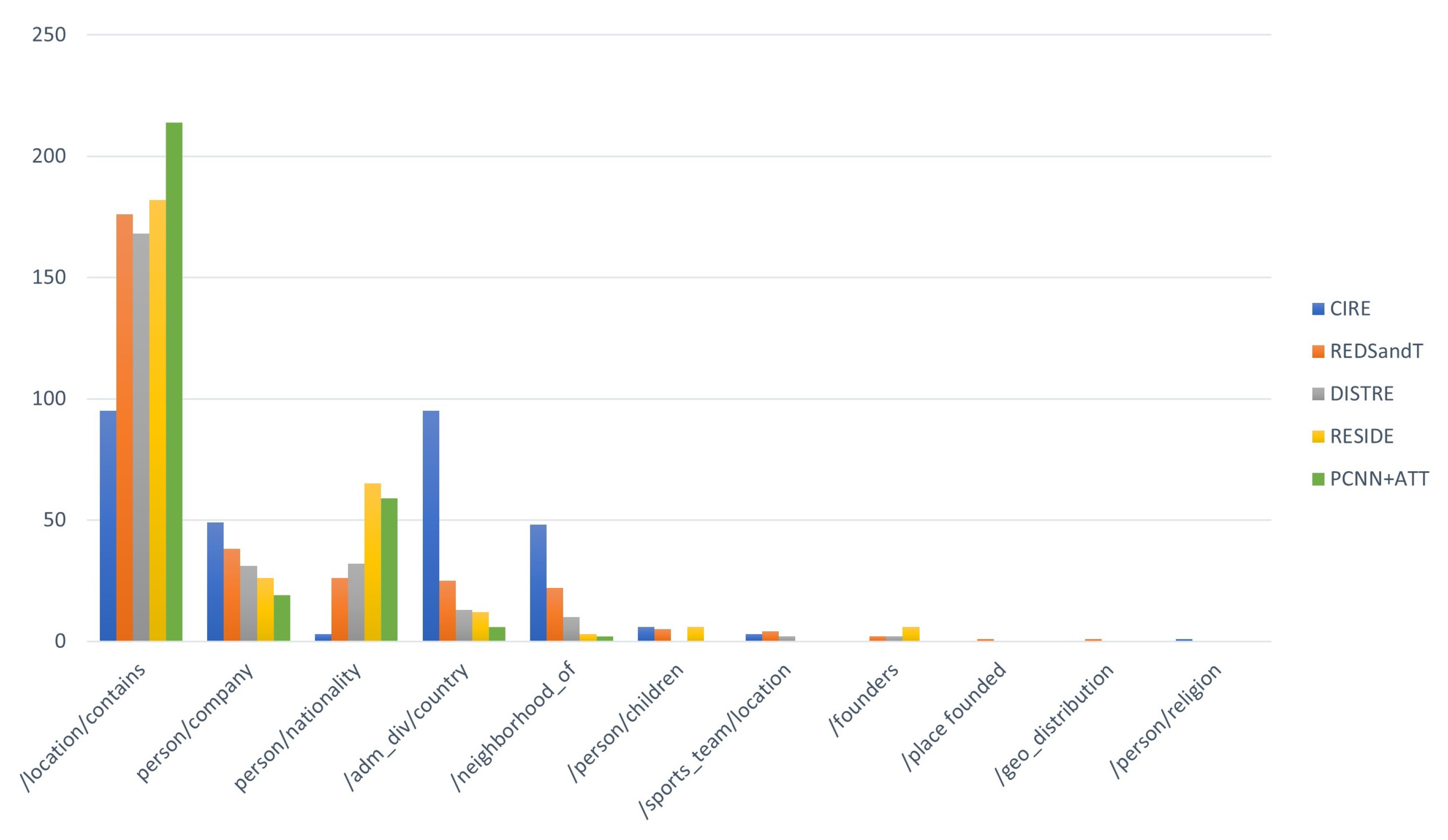
4.3.3. Analytical Comparisons with Benchmark Models
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 1003–1011. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; Proceedings, Part III 21. pp. 148–163. [Google Scholar]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portuga, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Lin, Y.; Shen, S.; Liu, Z.; Luan, H.; Sun, M. Neural relation extraction with selective attention over instances. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2124–2133. [Google Scholar]
- Liu, T.; Zhang, X.; Zhou, W.; Jia, W. Neural relation extraction via inner-sentence noise reduction and transfer learning. arXiv 2018, arXiv:1808.06738. [Google Scholar]
- Yan, D.; Hu, B. Shared representation generator for relation extraction with piecewise-lstm convolutional neural networks. IEEE Access 2019, 7, 31672–31680. [Google Scholar] [CrossRef]
- He, Z.; Chen, W.; Li, Z.; Zhang, M.; Zhang, W.; Zhang, M. See: Syntax-aware entity embedding for neural relation extraction. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Vashishth, S.; Joshi, R.; Prayaga, S.S.; Bhattacharyya, C.; Talukdar, P. Reside: Improving distantly-supervised neural relation extraction using side information. arXiv 2018, arXiv:1812.04361. [Google Scholar]
- Hu, L.; Zhang, L.; Shi, C.; Nie, L.; Guan, W.; Yang, C. Improving distantly-supervised relation extraction with joint label embedding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3821–3829. [Google Scholar]
- Alt, C.; Hübner, M.; Hennig, L. Fine-tuning pre-trained transformer language models to distantly supervised relation extraction. arXiv 2019, arXiv:1906.08646. [Google Scholar]
- Han, X.; Yu, P.; Liu, Z.; Sun, M.; Li, P. Hierarchical relation extraction with coarse-to-fine grained attention. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2236–2245. [Google Scholar]
- Yu, E.; Han, W.; Tian, Y.; Chang, Y. Tohre: A top-down classification strategy with hierarchical bag representation for distantly supervised relation extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Online, 8–13 December 2020; pp. 1665–1676. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Verga, P.; Strubell, E.; McCallum, A. Simultaneously self-attending to all mentions for full-abstract biological relation extraction. arXiv 2018, arXiv:1802.10569. [Google Scholar]
- Christou, D.; Tsoumakas, G. Improving distantly-supervised relation extraction through bert-based label and instance embeddings. IEEE Access 2021, 9, 62574–62582. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; Volume 26. [Google Scholar]
- Viji, D.; Revathy, S. A hybrid approach of Weighted Fine-Tuned BERT extraction with deep Siamese Bi–LSTM model for semantic text similarity identification. Multimed. Tools Appl. 2022, 81, 6131–6157. [Google Scholar] [CrossRef]
- Yao, X.; Van Durme, B. Information extraction over structured data: Question answering with freebase. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MD, USA, 22–27 June 2014; pp. 956–966. [Google Scholar]
- Yu, M.; Yin, W.; Hasan, K.S.; dos Santos, C.; Xiang, B.; Zhou, B. Improved neural relation detection for knowledge base question answering. arXiv 2017, arXiv:1704.06194. [Google Scholar]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel methods for relation extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Culotta, A.; Sorensen, J. Dependency tree kernels for relation extraction. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), Barcelona, Spain, 21–26 July 2004; pp. 423–429. [Google Scholar]
- Wu, F.; Weld, D.S. Autonomously semantifying wikipedia. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 41–50. [Google Scholar]
- Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L.; Weld, D.S. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 541–550. [Google Scholar]
- Surdeanu, M.; Tibshirani, J.; Nallapati, R.; Manning, C.D. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Republic of Korea, 12–14 July 2012; pp. 455–465. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Jäntschi, L.; Bolboacă, S.D. Informational entropy of B-ary trees after a vertex cut. Entropy 2008, 10, 576–588. [Google Scholar] [CrossRef]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Wen, H.; Zhu, X.; Zhang, L.; Li, F. A gated piecewise CNN with entity-aware enhancement for distantly supervised relation extraction. Inf. Process. Manag. 2020, 57, 102373. [Google Scholar] [CrossRef]
- Ye, H.; Luo, Z. Deep ranking based cost-sensitive multi-label learning for distant supervision relation extraction. Inf. Process. Manag. 2020, 57, 102096. [Google Scholar] [CrossRef]
- Xu, J.; Chen, Y.; Qin, Y.; Huang, R.; Zheng, Q. A feature combination-based graph convolutional neural network model for relation extraction. Symmetry 2021, 13, 1458. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Liu, Y.; Liu, K.; Xu, L.; Zhao, J. Exploring fine-grained entity type constraints for distantly supervised relation extraction. In Proceedings of the Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 2107–2116. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified language model pre-training for natural language understanding and generation. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Cabot, P.L.H.; Navigli, R. REBEL: Relation extraction by end-to-end language generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Online, 7–11 November 2021; pp. 2370–2381. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bolboacă, S.D.; Jäntschi, L. Predictivity approach for quantitative structure-property models. Application for blood-brain barrier permeation of diverse drug-like compounds. Int. J. Mol. Sci. 2011, 12, 4348–4364. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Origin | Sparse | |
|---|---|---|
| Softmax | ||
| Cross-Entropy |
| Train | Test | |
|---|---|---|
| Ins | 522,611 | 172,448 |
| EP | 281,270 | 96,678 |
| Rel | 53 | 53 |
| Parameter Name | Value | Candidate Set |
|---|---|---|
| Max_seq_length | 64 | {32, 64, 128} |
| Batch size | 32 | {8, 16, 32, 64} |
| Epochs | 3 | {2, 3, 4, 5} |
| Learning rate | ||
| Dropout | 0.4 | {0.2, 0.4, 0.5} |
| Weight_decay | 0.001 | {0.01, 0.001} |
| DSRE Methods | AUC |
|---|---|
| Mintz | 0.17 |
| PCNN + ATT | 0.341 |
| RESIDE | 0.415 |
| DISTRE | 0.422 |
| REDSandT | 0.424 |
| CIRE (ours) | 0.45 |
| DSRE Methods | P@100 | P@300 | P@500 | P@Mean |
|---|---|---|---|---|
| Mintz | 52.3 | 45.0 | 39.7 | 45.67 |
| PCNN + ATT | 73 | 67.3 | 63.6 | 67.97 |
| RESIDE | 81.8 | 74.3 | 69.7 | 75.26 |
| DISTRE | 68 | 65.3 | 65 | 66.1 |
| REDSandT | 78 | 73 | 67.6 | 72.87 |
| CIRE (ours) | 79 | 77.7 | 71.2 | 75.97 |
| Metrics | AUC |
|---|---|
| CIRE without Merge.ht | 0.429 |
| CIRE without Bi-LSTM | 0.435 |
| CIRE without sparse softmax | 0.436 |
| CIRE without | 0.429 |
| CIRE | 0.45 |
| Metrics | P@100 | P@300 | P@500 | P@Mean |
|---|---|---|---|---|
| CIRE without Merge.ht | 77 | 70 | 68.4 | 71.8 |
| CIRE without Bi-LSTM | 76 | 74.7 | 70.2 | 73.63 |
| CIRE without sparse softmax | 76 | 74 | 69 | 73 |
| CIRE without | 76 | 74 | 66.8 | 72.3 |
| CIRE | 79 | 77.7 | 71.2 | 75.97 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, H.; Liu, S.; Jian, Z. Distantly Supervised Relation Extraction via Contextual Information Interaction and Relation Embeddings. Symmetry 2023, 15, 1788. https://doi.org/10.3390/sym15091788
Yin H, Liu S, Jian Z. Distantly Supervised Relation Extraction via Contextual Information Interaction and Relation Embeddings. Symmetry. 2023; 15(9):1788. https://doi.org/10.3390/sym15091788
Chicago/Turabian StyleYin, Huixin, Shengquan Liu, and Zhaorui Jian. 2023. "Distantly Supervised Relation Extraction via Contextual Information Interaction and Relation Embeddings" Symmetry 15, no. 9: 1788. https://doi.org/10.3390/sym15091788
APA StyleYin, H., Liu, S., & Jian, Z. (2023). Distantly Supervised Relation Extraction via Contextual Information Interaction and Relation Embeddings. Symmetry, 15(9), 1788. https://doi.org/10.3390/sym15091788