

Maintaining Symmetry between Convolutional Neural Network Accuracy and Performance on an Edge TPU with a Focus on Transfer Learning Adjustments



Abstract
1. Introduction
- Proposes a methodology for determining the limits of neural network performance on edge devices;
- Analyzes the performance, both runtime and energy, of an edge TPU on both fully connected and convolutional neural networks as compared to a mobile CPU;
- Assesses the performance impact of modifications made to convolutional neural networks as part of transfer learning;
- Provides recommendations for how symmetry between accuracy and performance can be maintained throughout transfer learning adjustments.
2. Background and Related Work
2.1. Deep Neural Networks
2.2. Transfer Learning
2.3. Tensor Processing
2.4. Related Work
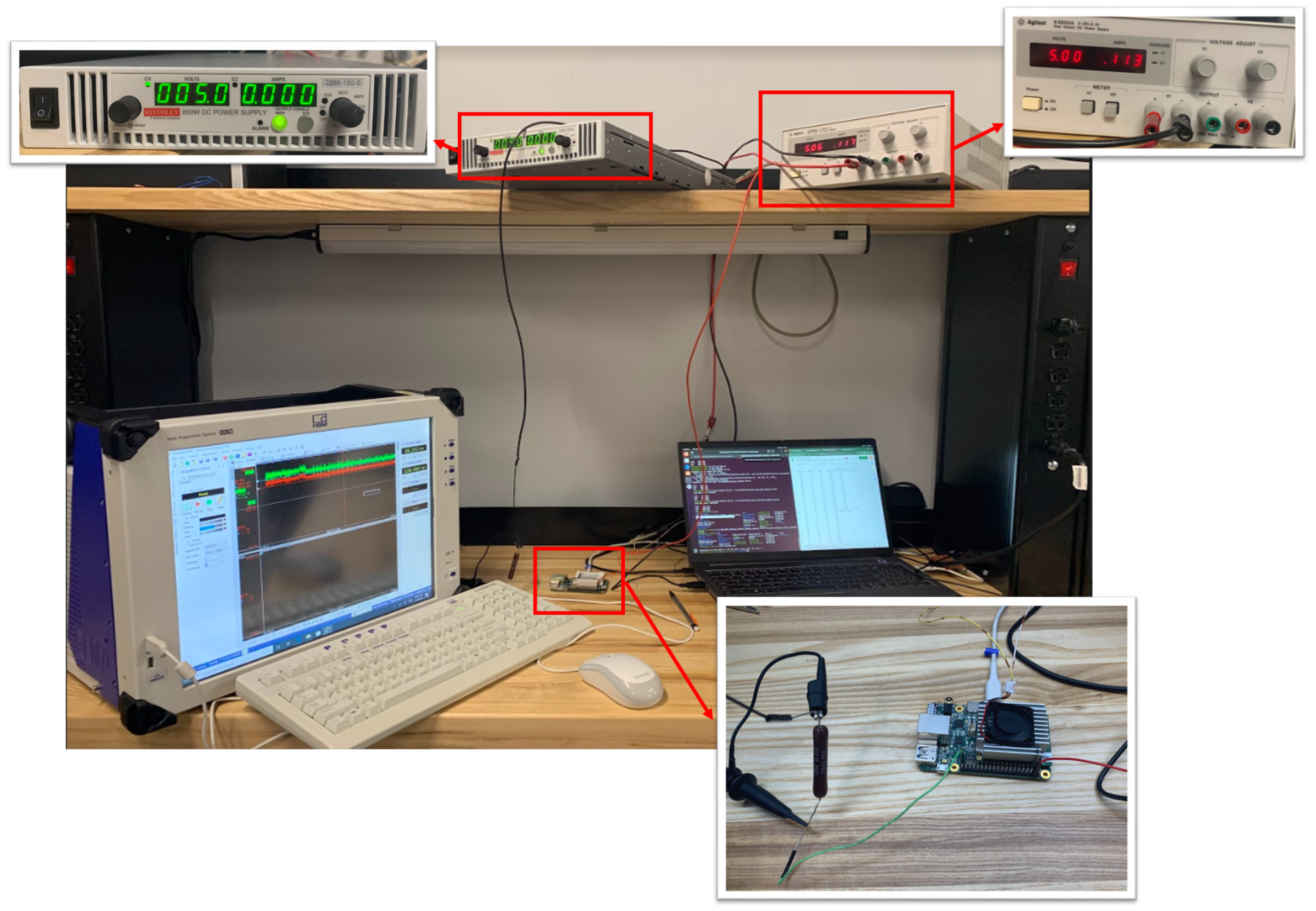
3. Methodology
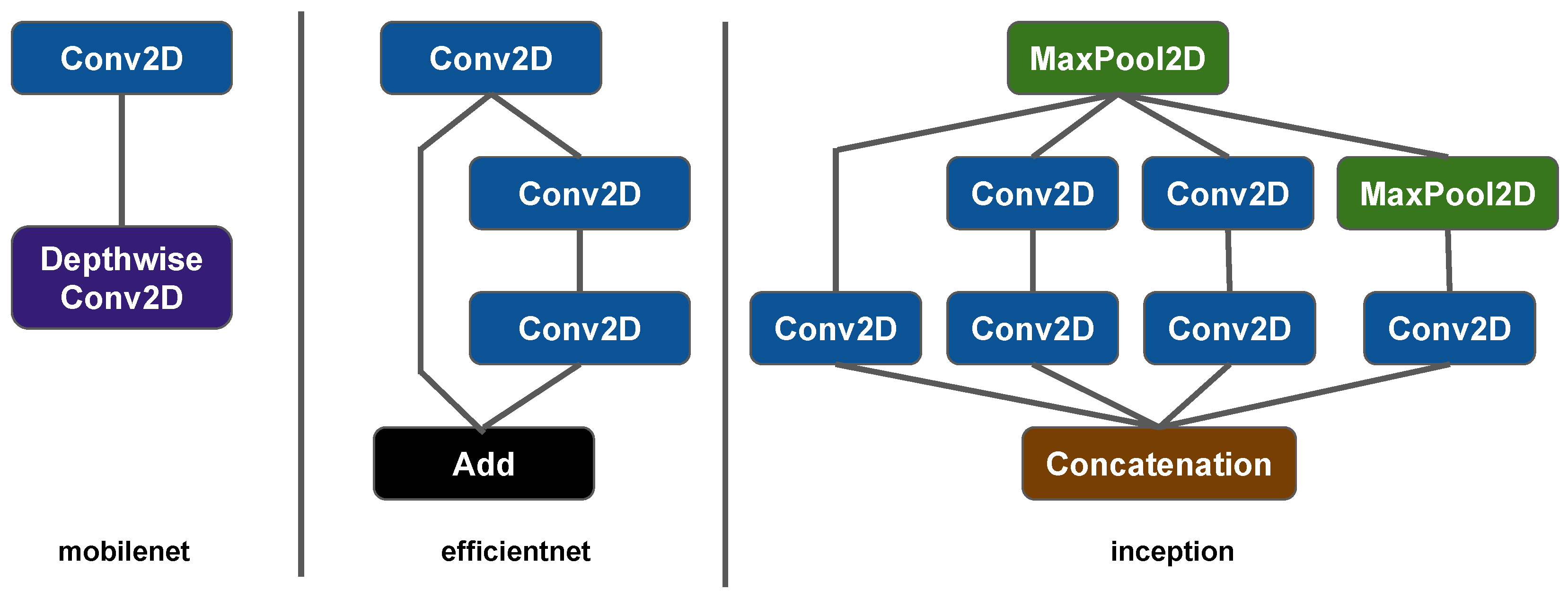
3.1. Convolutional Neural Networks
3.2. Exploring Adjustments to CNN Models
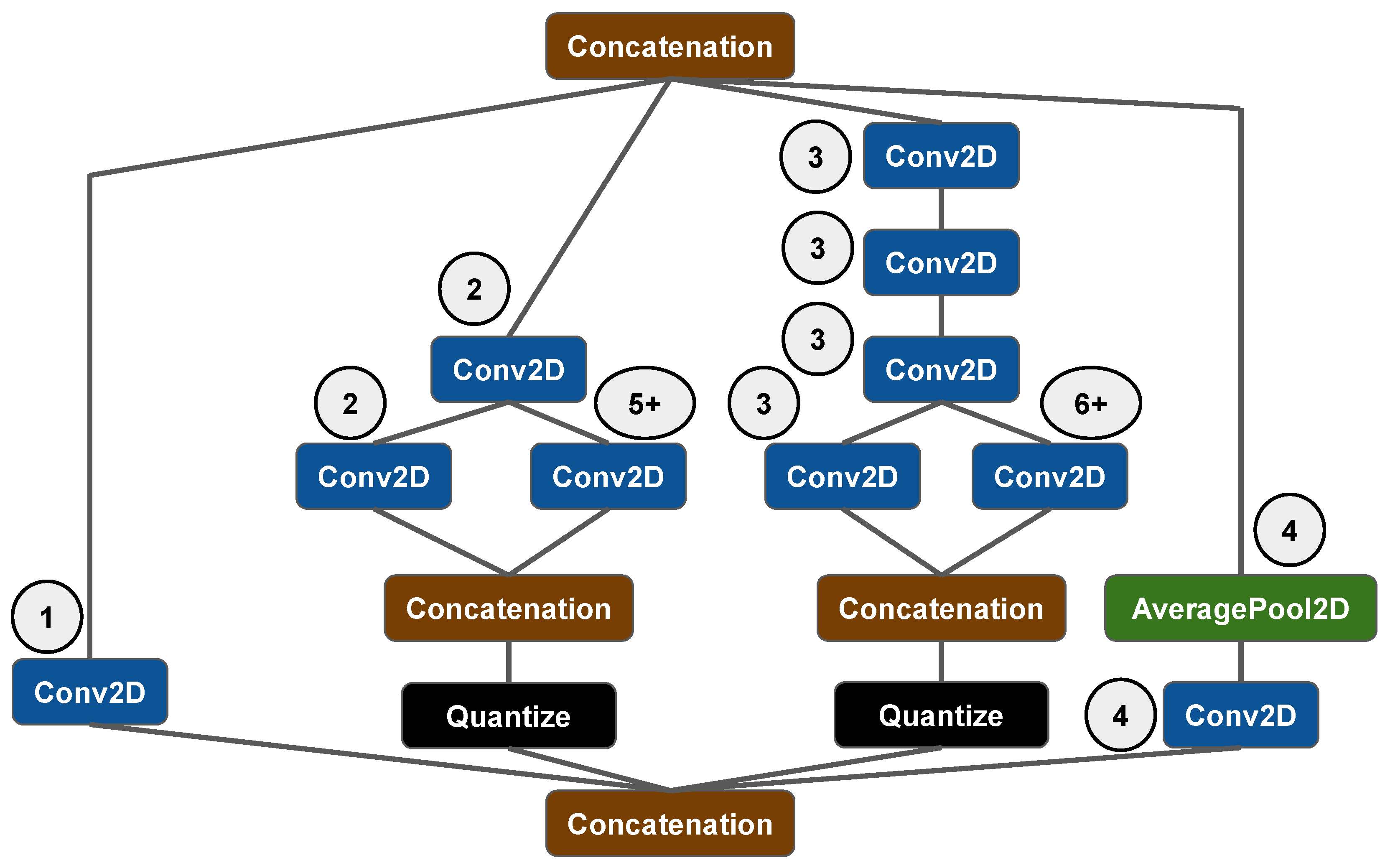
3.2.1. Extracting the Baseline Models from Tensorflow Lite
3.2.2. Generating Deeper Models
3.2.3. Generating Wider Models
4. Experimental Results
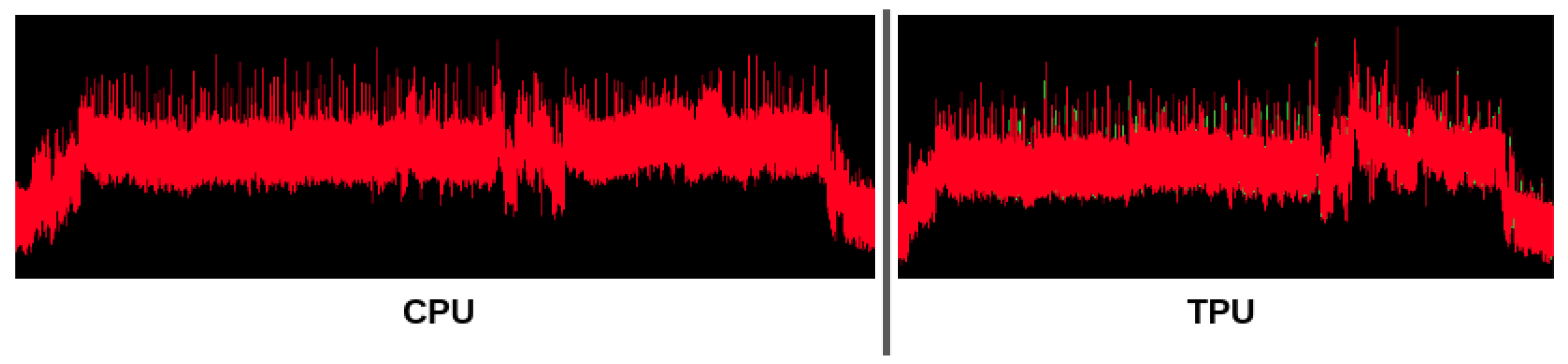
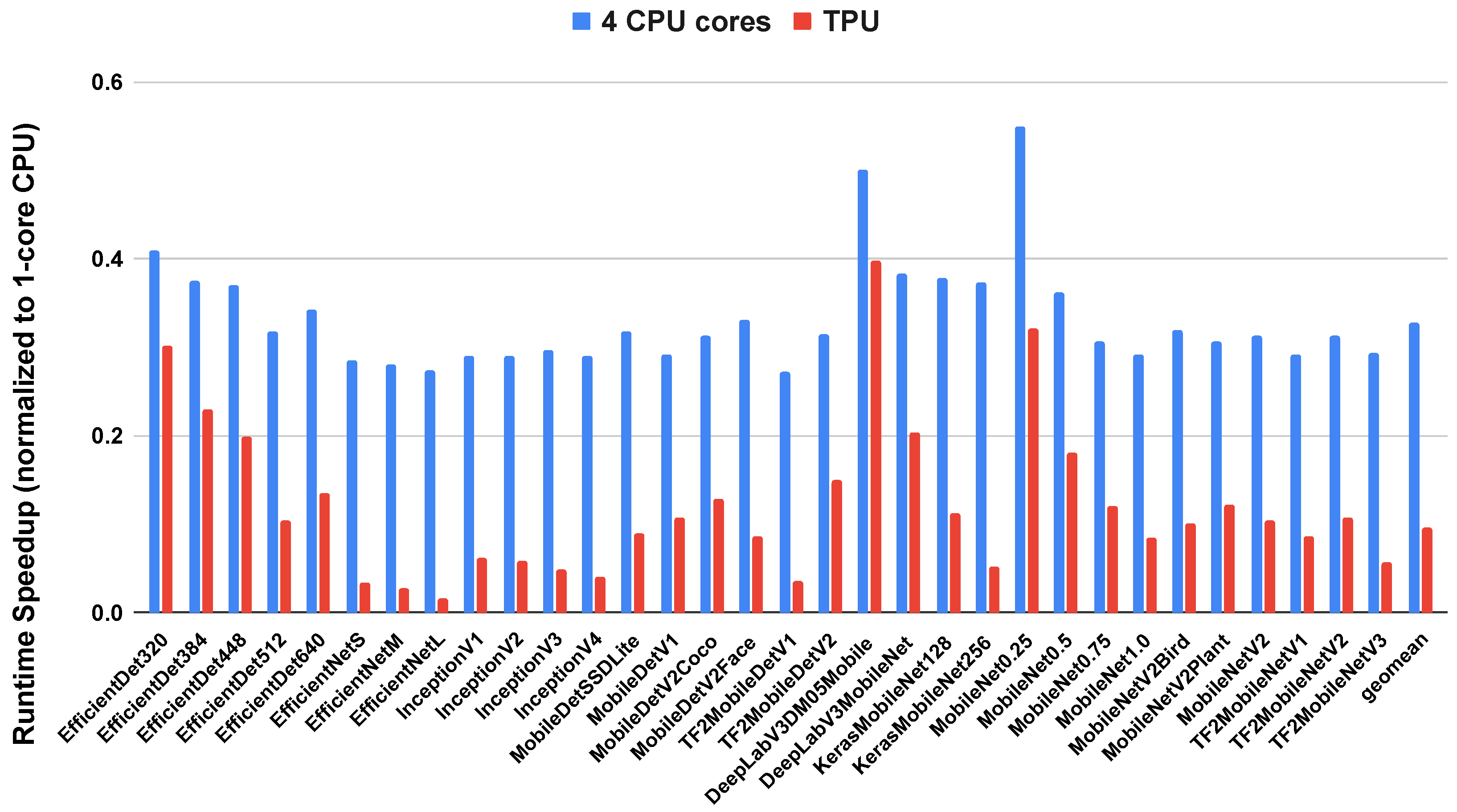
4.1. Convolutional Neural Networks
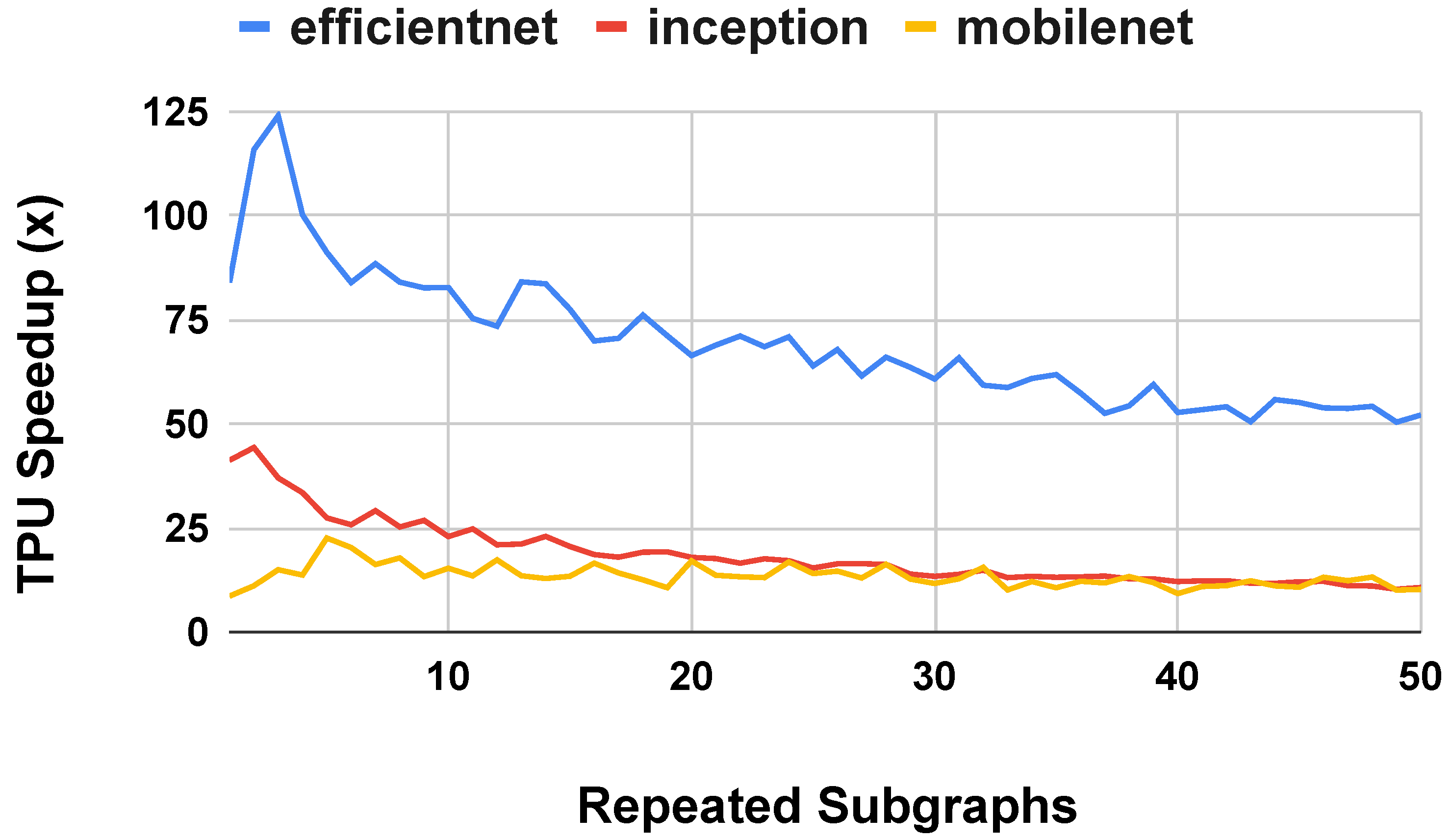
4.2. Transfer Learning
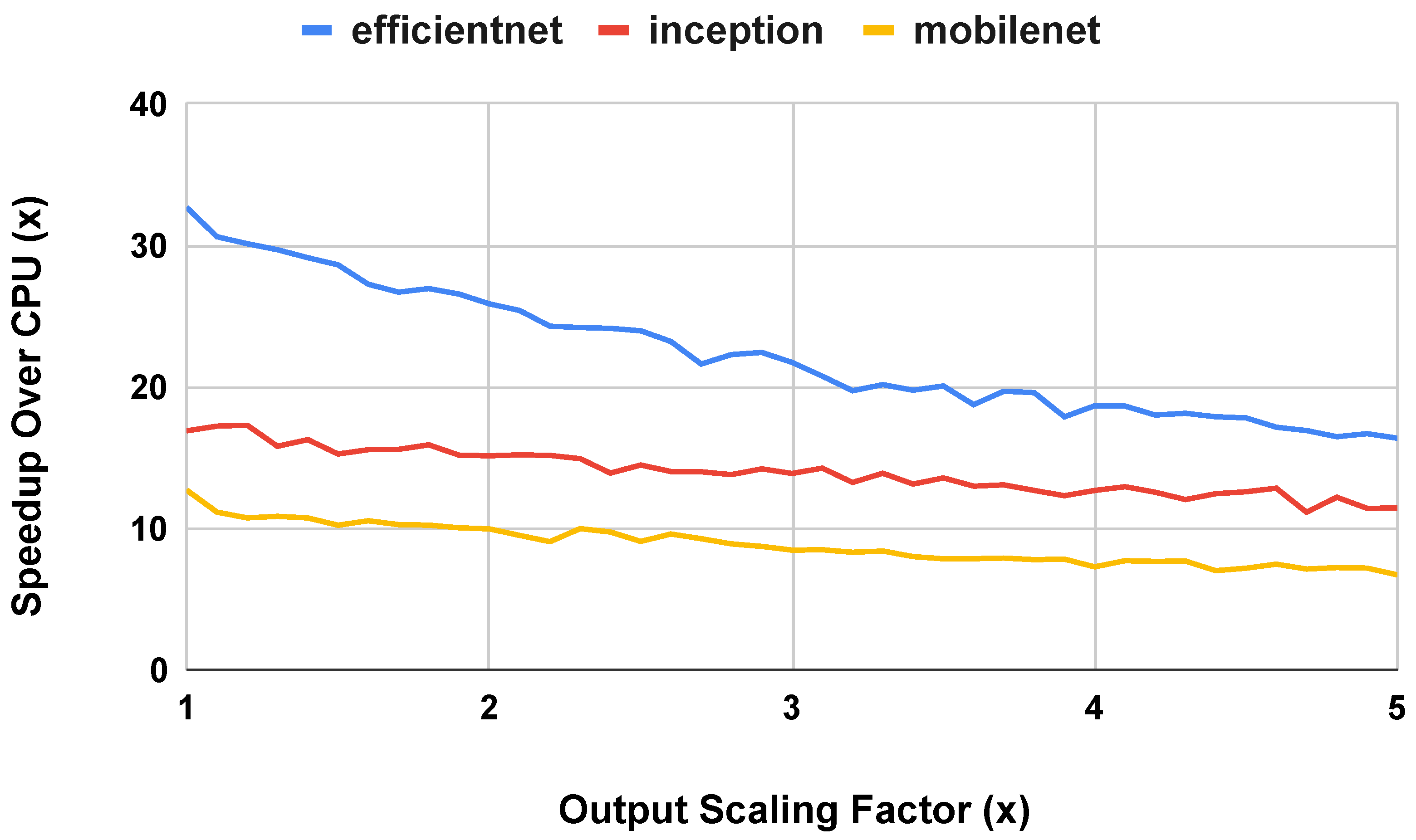
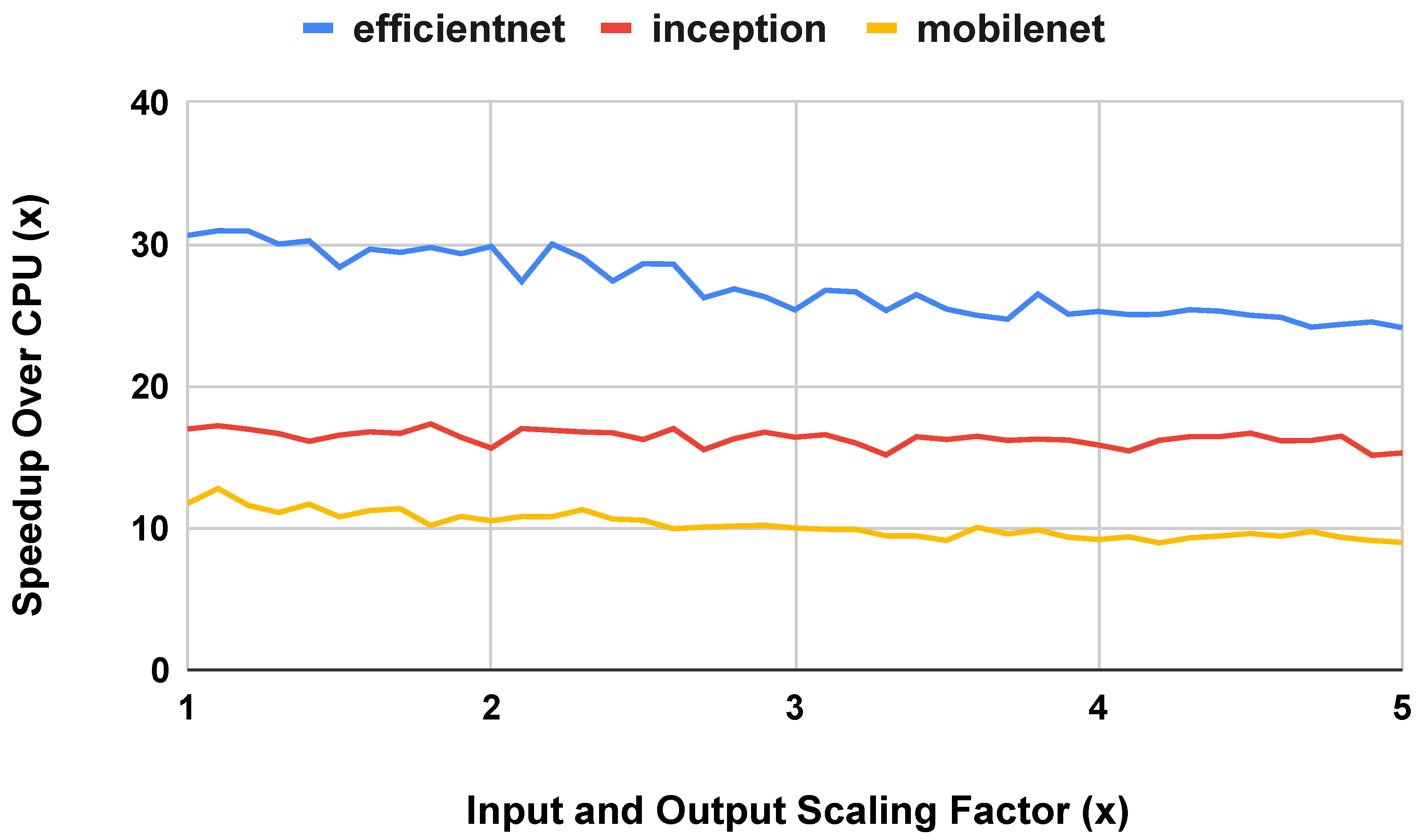
4.3. Input and Output Size
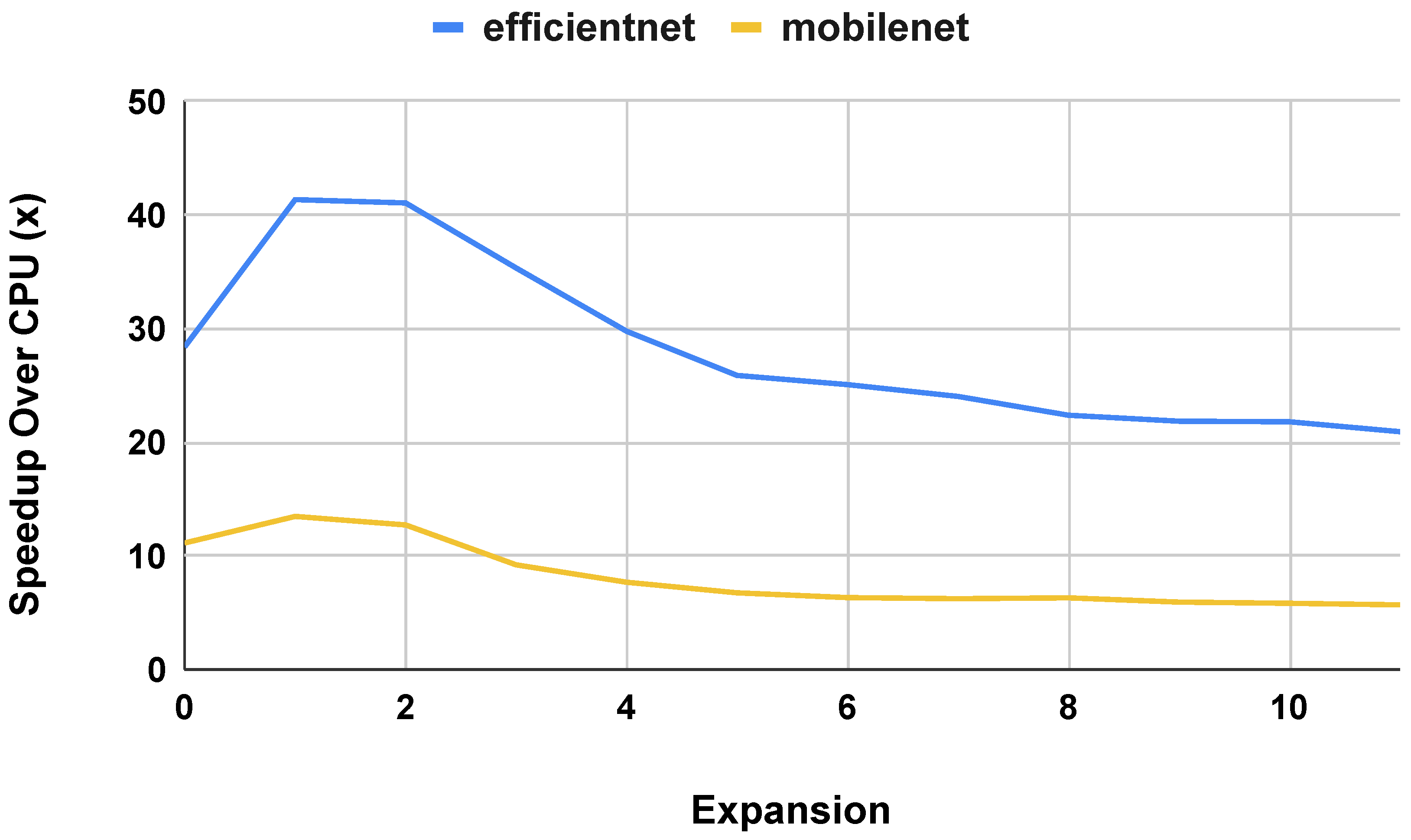
4.3.1. Depth Extensions
4.3.2. Wide Extensions
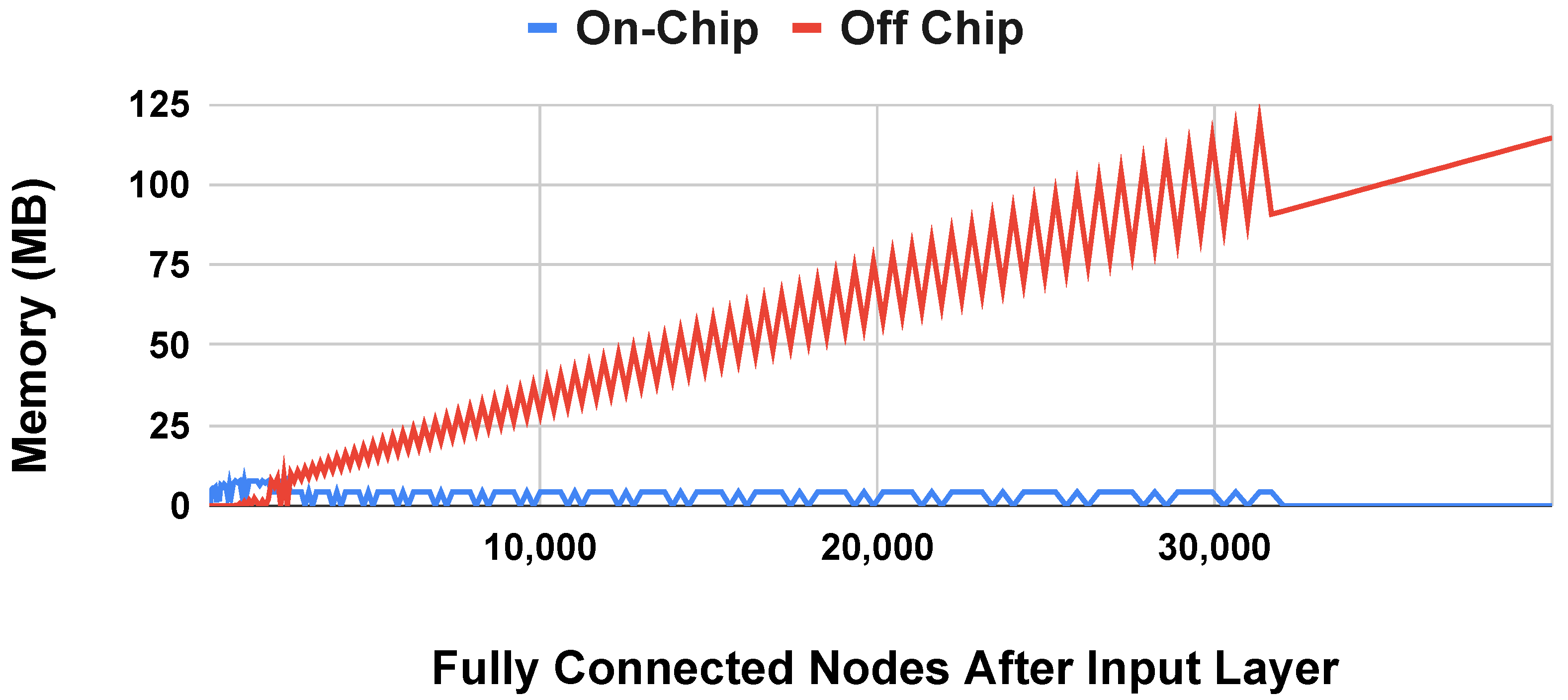
4.3.3. Off-Chip Memory
5. Discussion
5.1. Prefer Single-Core for Long Term Energy Efficiency but Multi-Core for Energy Efficiency Per Inference
5.2. Prefer a TPU for Convolutional Neural Networks
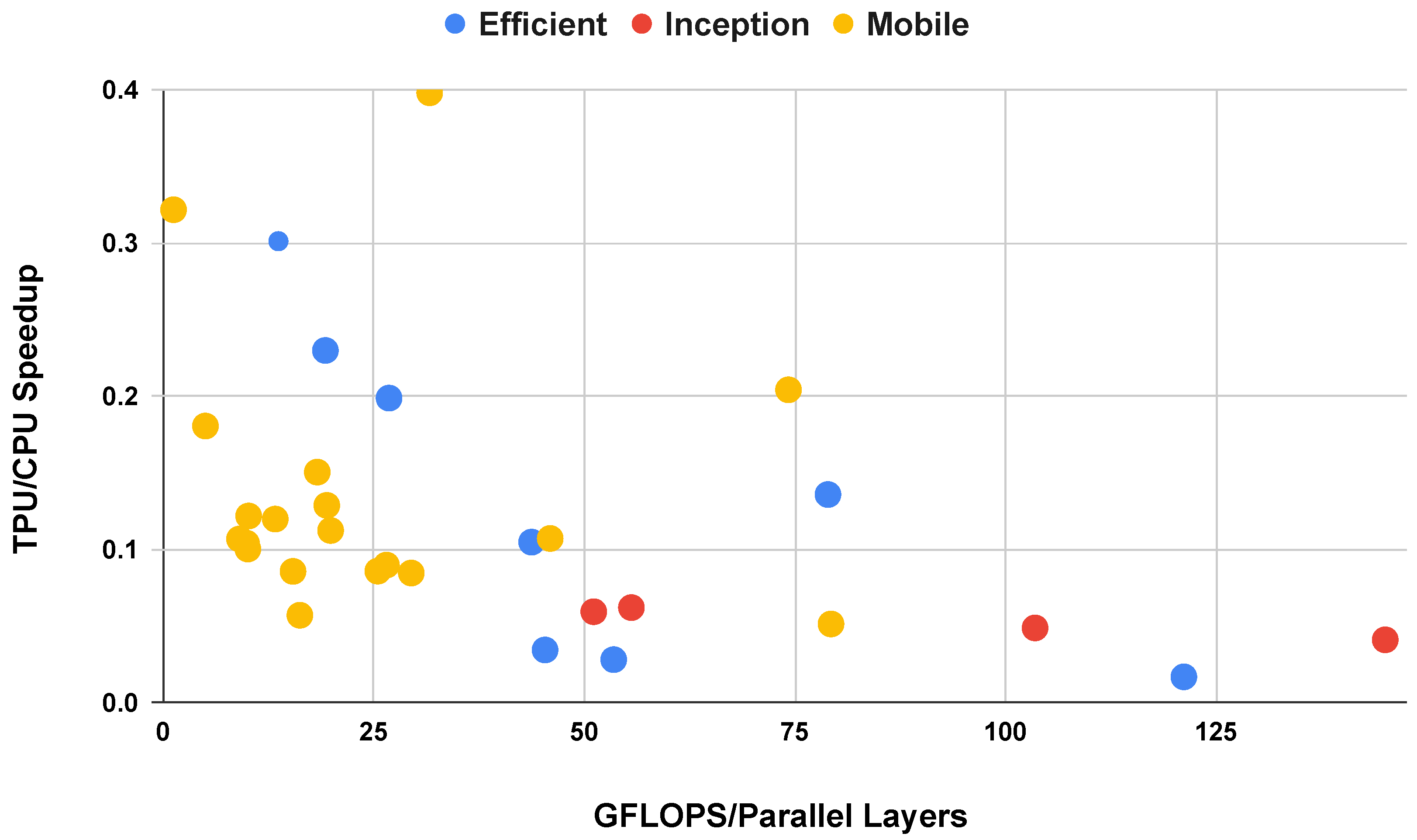
5.3. For Edge TPUs, Prefer Model Depth When Possible for Convolutional Networks
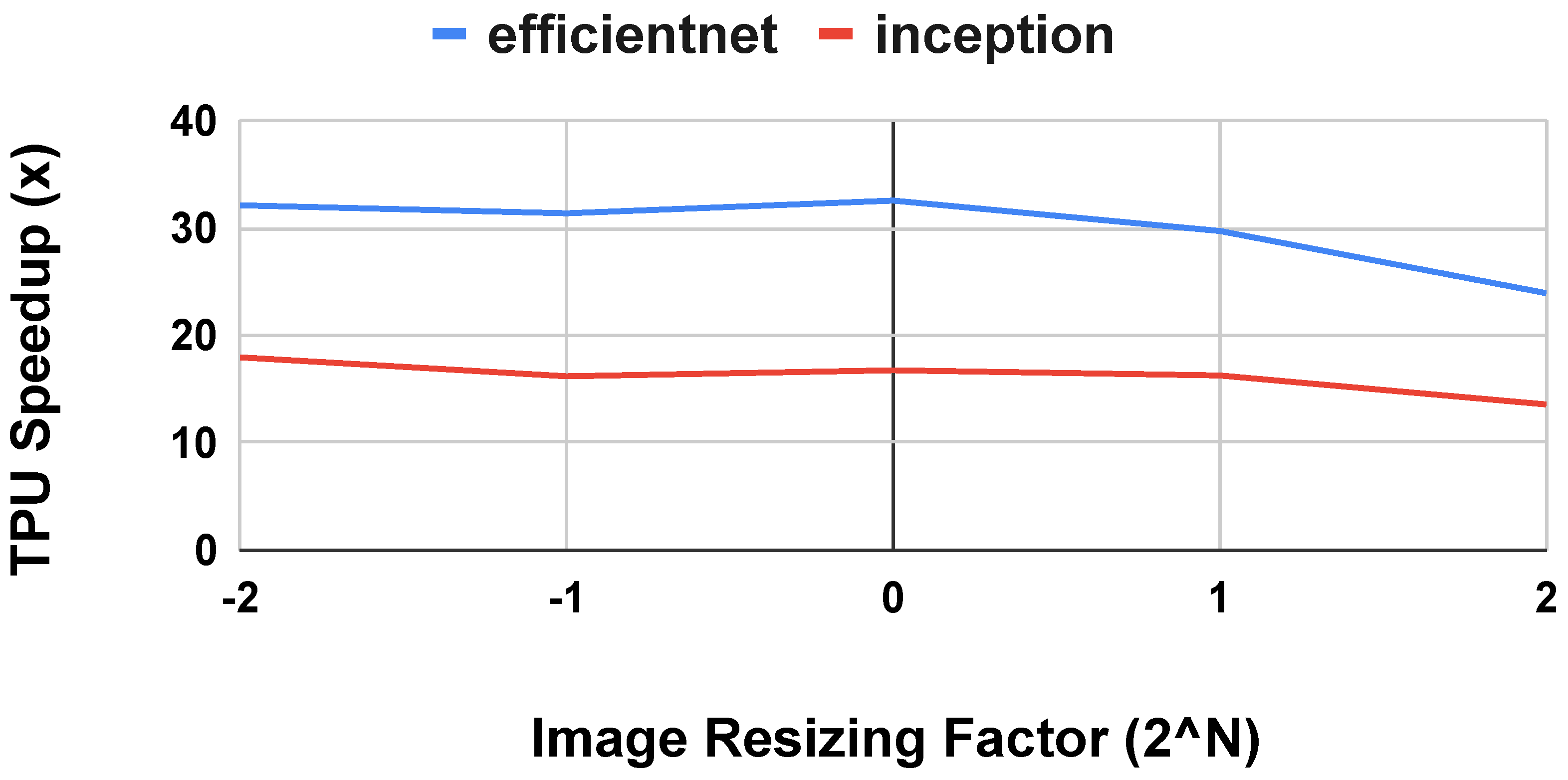
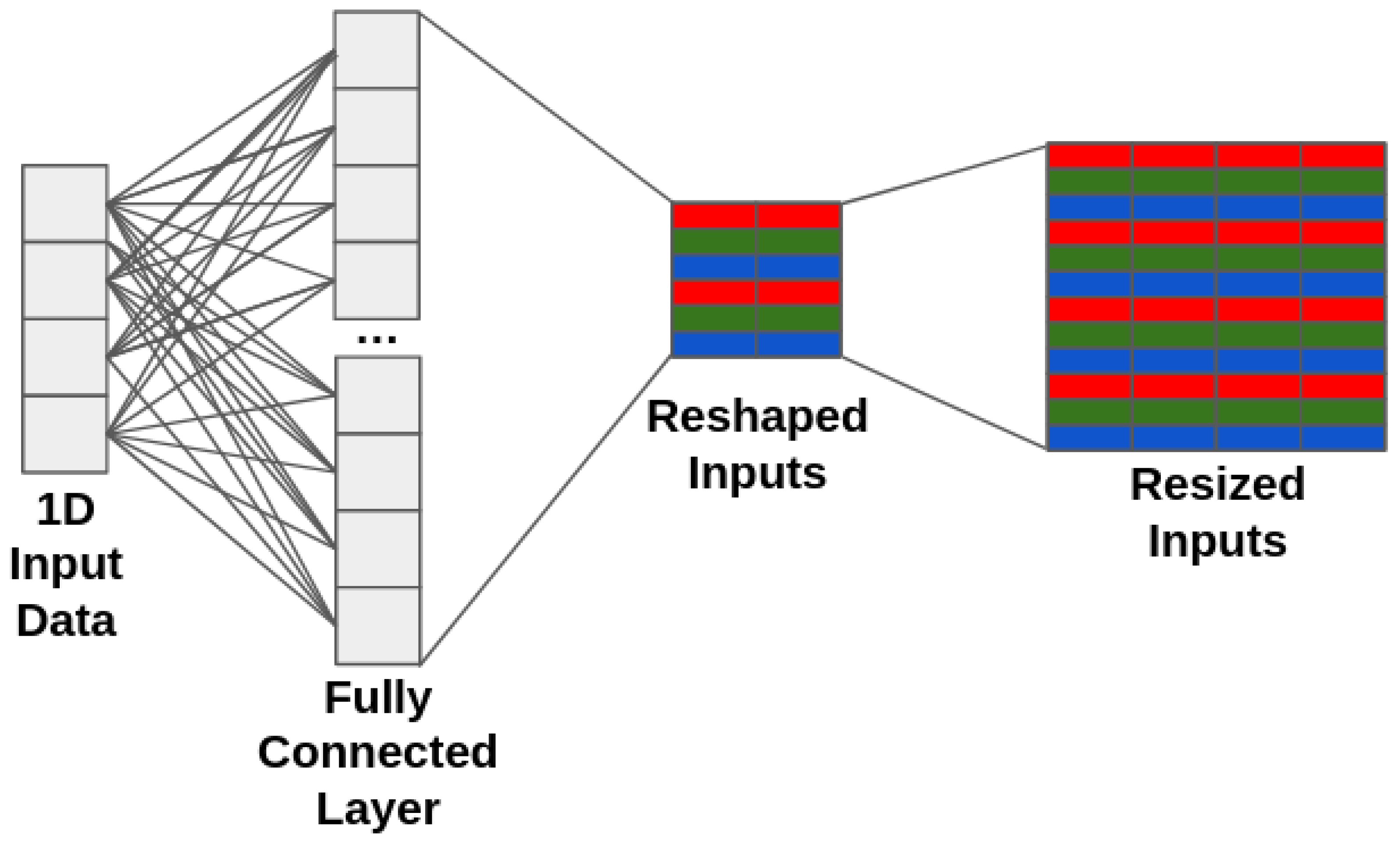
5.4. Avoid Performance Cliffs for Transfer Learning with Fully-Connected Input Layers
5.5. Scale Width at Input Layers to Exploit Parallelism on the Edge TPU
5.6. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CPU | Central Processing Unit |
| TPU | Tensor Processing Unit |
| CNN | Convolutional Neural Network |
References
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- What Makes TPUs Fine-Tuned for Deep Learning? Available online: https://cloud.google.com/blog/products/ai-machine-learning/what-makes-tpus-fine-tuned-for-deep-learning/ (accessed on 7 May 2022).
- Xu, D.; Zheng, M.; Jiang, L.; Gu, C.; Tan, R.; Cheng, P. Lightweight and Unobtrusive Data Obfuscation at IoT Edge for Remote Inference. IEEE Internet Things J. 2020, 7, 9540–9551. [Google Scholar] [CrossRef]
- Dominguez-Morales, J.P.; Duran-Lopez, L.; Gutierrez-Galan, D.; Rios-Navarro, A.; Linares-Barranco, A.; Jimenez-Fernandez, A. Wildlife Monitoring on the Edge: A Performance Evaluation of Embedded Neural Networks on Microcontrollers for Animal Behavior Classification. Sensors 2021, 21, 2975. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Chakravarthy, S.; Nanthaamornphong, A. Energy-Efficient Deep Neural Networks for EEG Signal Noise Reduction in Next-Generation Green Wireless Networks and Industrial IoT Applications. Symmetry 2023, 15, 2129. [Google Scholar] [CrossRef]
- Gen7i Transient Recorder and Data Acquisition System. Available online: https://disensors.com/product/gen7i-transient-recorder-and-data-acquisition-system/ (accessed on 20 June 2022).
- Pouyanfar, S.; Sadiq, S.; Yan, Y.; Tian, H.; Tao, Y.; Reyes, M.P.; Shyu, M.; Chen, S.; Iyengar, S.S. A Survey on Deep Learning: Algorithms, Techniques, and Applications. ACM Comput. Surv. 2019, 51, 92. [Google Scholar] [CrossRef]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A State-of-the-Art Survey on Deep Learning Theory and Architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef]
- Bebis, G.; Georgiopoulos, M. Feed-forward neural networks. IEEE Potentials 1994, 13, 27–31. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- You, K.; Kou, Z.; Long, M.; Wang, J. Co-Tuning for Transfer Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 17236–17246. [Google Scholar]
- Kumar, K.; Khanam, S.; Bhuiyan, M.M.I.; Qazani, M.R.C.; Mondal, S.K.; Asadi, H.; Kabir, H.D.; Khorsavi, A.; Nahavandi, S. SpinalXNet: Transfer Learning with Modified Fully Connected Layer for X-ray Image Classification. In Proceedings of the IEEE International Conference on Recent Advances in Systems Science and Engineering, Shanghai, China, 12–14 December 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Khosravi, M.R.; Rezaee, K.; Moghimi, M.K.; Wan, S.; Menon, V.G. Crowd Emotion Prediction for Human-Vehicle Interaction Through Modified Transfer Learning and Fuzzy Logic Ranking. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15752–15761. [Google Scholar] [CrossRef]
- Sharma, A.K.; Nandal, A.; Dhaka, A.; Zhou, L.; Alhudhaif, A.; Alenezi, F.; Polat, K. Brain tumor classification using the modified ResNet50 model based on transfer learning. Biomed. Signal Process. Control 2023, 86, 105299. [Google Scholar] [CrossRef]
- Kollem, S.; Reddy, K.R.; Prasad, C.R.; Chakraborty, A.; Ajayan, J.; Sreejith, S.; Bhattacharya, S.; Joseph, L.L.; Janapati, R. AlexNet-NDTL: Classification of MRI brain tumor images using modified AlexNet with deep transfer learning and Lipschitz-based data augmentation. Int. J. Imaging Syst. Technol. 2023, 33, 1306–1322. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, X.; Wang, X.; Zhou, T. Modified Convolutional Neural Network with Transfer Learning for Solar Flare Prediction. J. Korean Astron. Soc. 2019, 52, 217–225. [Google Scholar]
- Rahman, J.F.; Ahmad, M. Detection of Acute Myeloid Leukemia from Peripheral Blood Smear Images Using Transfer Learning in Modified CNN Architectures. In Proceedings of International Conference on Information and Communication Technology for Development; Studies in Autonomic, Data-driven and Industrial Computing; Springer: Singapore, 2022. [Google Scholar] [CrossRef]
- Hou, Y.; Ren, H.; Lv, Q.; Wu, L.; Yang, X.; Quan, Y. Radar-Jamming Classification in the Event of Insufficient Samples Using Transfer Learning. Symmetry 2022, 14, 2318. [Google Scholar] [CrossRef]
- Lanjewar, M.G.; Morajkar, P. Modified transfer learning frameworks to identify potato leaf diseases. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Zhao, X.; Qi, S.; Zhang, B.; Ma, H.; Qian, W.; Yao, Y.; Sun, J. Deep CNN models for pulmonary nodule classification: Model modification, model integration, and transfer learning. J. X-ray Sci. Technol. 2019, 27, 615–629. [Google Scholar] [CrossRef] [PubMed]
- Sarang, S.; Sheifali, G.; Deepali, G.; Sapna, J.; Amena, M.; Shaker, E.; Kyung-Sup, K. Transfer learning-based modified inception model for the diagnosis of Alzheimer’s disease. Front. Comput. Neurosci. 2022, 16, 1000435. [Google Scholar] [CrossRef]
- Shin, H.C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Tao, J.; Wu, L.; Mou, C.; Bai, W.; Zheng, X.; Zhu, Z.; Deng, Z. A Recognition Method of Ancient Architectures Based on the Improved Inception V3 Model. Symmetry 2022, 14, 2679. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Q.; Shi, C. Research on Spider Recognition Technology Based on Transfer Learning and Attention Mechanism. Symmetry 2023, 15, 1727. [Google Scholar] [CrossRef]
- Edge TPU Performance Benchmarks. Available online: https://coral.ai/docs/edgetpu/benchmarks/ (accessed on 8 May 2022).
- Kim, B.; Lee, S.; Trivedi, A.R.; Song, W.J. Energy-Efficient Acceleration of Deep Neural Networks on Realtime-Constrained Embedded Edge Devices. IEEE Access 2020, 8, 216259–216270. [Google Scholar] [CrossRef]
- Yazdanbakshsh, A.; Seshadri, K.; Akin, B.; Laudon, J.; Narayanaswami, R. An Evaluation of Edge TPU Accelerators for Convolutional Neural Networks. arXiv 2020, arXiv:2102.10423. Available online: https://arxiv.org/abs/2102.10423 (accessed on 1 September 2023).
- Baller, S.P.; Jindal, A.; Chadha, M.; Gerndt, M. DeepEdgeBench: Benchmarking Deep Neural Networks on Edge Devices. In Proceedings of the 2021 IEEE International Conference on Cloud Engineering, San Francisco, CA, USA, 4–8 October 2021; pp. 20–30. [Google Scholar]
- Jetson Modules. Available online: https://developer.nvidia.com/embedded/jetson-modules (accessed on 27 November 2023).
- Intel Movidius Vision Processing Units (VPUs). Available online: https://www.intel.com/content/www/us/en/products/details/processors/movidius-vpu.html (accessed on 27 November 2023).
- AI on Snapdragon Compute Platforms. Available online: https://www.qualcomm.com/products/mobile/snapdragon/pcs-and-tablets/features/computeai (accessed on 27 November 2023).
- Biglari, A.; Tang, W. A Review of Embedded Machine Learning Based on Hardware, Application, and Sensing Scheme. Sensors 2023, 23, 2131. [Google Scholar] [CrossRef] [PubMed]
- Ni, Y.; Kim, Y.; Rosing, T.; Imani, M. Online Performance and Power Prediction for Edge TPU via Comprehensive Characterization. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, Antwerp, Belgium, 14–23 March 2022; pp. 612–615. [Google Scholar] [CrossRef]
- Jo, J.; Jeong, S.; Kang, P. Benchmarking GPU-Accelerated Edge Devices. In Proceedings of the IEEE International Conference on Big Data and Smart Computing, Busan, Republic of Korea, 19–22 February 2020; pp. 117–120. [Google Scholar] [CrossRef]
- Holly, S.; Wendt, A.; Lechner, M. Profiling Energy Consumption of Deep Neural Networks on NVIDIA Jetson Nano. In Proceedings of the 11th International Green and Sustainable Computing Workshops, Pullman, WA, USA, 19–22 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Sun, H.; Qu, Y.; Wang, W.; Dong, C.; Zhang, L.; Wu, Q. An Experimental Study of DNN Operator-Level Performance on Edge Devices. In Proceedings of the IEEE International Conference on Smart Internet of Things, Xining, China, 25–27 August 2023; pp. 131–138. [Google Scholar] [CrossRef]
- Hosseininoorbin, S.; Layeghy, S.; Sarhan, M.; Jurdak, R.; Portmann, M. Exploring edge TPU for network intrusion detection in IoT. J. Parallel Distrib. Comput. 2023, 179, 104712. [Google Scholar] [CrossRef]
- Liu, H.; Wang, H. Real-Time Anomaly Detection of Network Traffic Based on CNN. Symmetry 2023, 15, 1205. [Google Scholar] [CrossRef]
- Hosseininoorbin, S.; Layeghy, S.; Kusy, B.; Jurdak, R.; Portmann, M. Exploring Edge TPU for deep feed-forward neural networks. Internet Things 2023, 22, 100749. [Google Scholar] [CrossRef]
- Asyraaf Jainuddin, A.; Hou, Y.; Baharuddin, M.; Yussof, S. Performance Analysis of Deep Neural Networks for Object Classification with Edge TPU. In Proceedings of the 8th International Conference on Information Technology and Multimedia, Selangor, Malaysia, 24–26 August 2020; pp. 323–328. [Google Scholar] [CrossRef]
- Assunção, E.; Gaspar, P.D.; Alibabaei, K.; Simões, M.P.; Proença, H.; Soares, V.N.G.J.; Caldeira, J.M.L.P. Real-Time Image Detection for Edge Devices: A Peach Fruit Detection Application. Future Internet 2022, 14, 323. [Google Scholar] [CrossRef]
- Morales-García, J.; Bueno-Crespo, A.; Martínez-España, R.; Posadas, J.L.; Manzoni, P.; Cecilia, J.M. Evaluation of low-power devices for smart greenhouse development. J. Supercomput. 2023, 79, 10277–10299. [Google Scholar] [CrossRef]
- Hou, X.; Guan, Y.; Han, T.; Zhang, N. DistrEdge: Speeding up Convolutional Neural Network Inference on Distributed Edge Devices. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium, Lyon, France, 30 May–3 June 2022; pp. 1097–1107. [Google Scholar] [CrossRef]
- Nukavarapu, S.; Ayyat, M.; Nadeem, T. iBranchy: An Accelerated Edge Inference Platform for loT Devices. In Proceedings of the IEEE/ACM Symposium on Edge Computing, San Jose, CA, USA, 14–17 December 2021; pp. 392–396. [Google Scholar]
- Jiang, B.; Cheng, X.; Tang, S.; Ma, X.; Gu, Z.; Fu, S.; Yang, Q.; Liu, M. MLCNN: Cross-Layer Cooperative Optimization and Accelerator Architecture for Speeding Up Deep Learning Applications. In Proceedings of the 2022 IEEE International Parallel and Distributed Processing Symposium, Lyon, France, 30 May–3 June 2022; pp. 1184–1194. [Google Scholar]
- Guo, J.; Teodorescu, R.; Agrawal, G. Fused DSConv: Optimizing Sparse CNN Inference for Execution on Edge Devices. In Proceedings of the IEEE/ACM 21st International Symposium on Cluster, Cloud and Internet Computing, Melbourne, Australia, 10–13 May 2021; pp. 545–554. [Google Scholar]
- Arish, S.; Sinha, S.; Smitha, K.G. Optimization of Convolutional Neural Networks on Resource Constrained Devices. In Proceedings of the IEEE Computer Society Annual Symposium on VLSI, Miami, FL, USA, 15–17 July 2019; pp. 19–24. [Google Scholar]
- Yang, L.; Zheng, C.; Shen, X.; Xie, G. OfpCNN: On-Demand Fine-Grained Partitioning for CNN Inference Acceleration in Heterogeneous Devices. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 3090–3103. [Google Scholar] [CrossRef]
- Belson, B.; Philippa, B. Speeding up Machine Learning Inference on Edge Devices by Improving Memory Access Patterns using Coroutines. In Proceedings of the IEEE 25th International Conference on Computational Science and Engineering, Wuhan, China, 9–11 December 2022; pp. 9–16. [Google Scholar] [CrossRef]
- Nasrin, S.; Shylendra, A.; Darabi, N.; Tulabandhula, T.; Gomes, W.; Chakrabarty, A.; Trivedi, A.R. ENOS: Energy-Aware Network Operator Search in Deep Neural Networks. IEEE Access 2022, 10, 81447–81457. [Google Scholar] [CrossRef]
- Chen, C.; Guo, W.; Wang, Z.; Yang, Y.; Wu, Z.; Li, G. An Energy-Efficient Method for Recurrent Neural Network Inference in Edge Cloud Computing. Symmetry 2022, 14, 2524. [Google Scholar] [CrossRef]
- Dev Board Datasheet. Available online: https://coral.ai/docs/dev-board/datasheet/ (accessed on 10 May 2022).
- Arm Cortex-A53 MPCore Processor Technical Reference Manual. Available online: https://developer.arm.com/documentation/ddi0500/latest/ (accessed on 10 May 2022).
- Trained TensorFlow Models for the Edge TPU. Available online: https://coral.ai/models/ (accessed on 29 January 2022).
- Tan, M.; Pang, R.; Le, Q. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th Internation Conference on Machine Learning, PMLR 97, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-ResNet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. Available online: http://arxiv.org/abs/1704.04861 (accessed on 1 September 2023).
- Tensorflow 2 Detection Model Zoo. Available online: https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md (accessed on 28 September 2023).
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. arXiv 2018, arXiv:1802.02611. Available online: https://arxiv.org/abs/1802.02611 (accessed on 28 September 2023).
- MobileNet, MobileNetV2, and MobileNetV3. Available online: https://keras.io/api/applications/mobilenet/ (accessed on 28 September 2023).
- DeLozier, C.; Rooney, F.; Jung, J.; Blanco, J.A.; Rakvic, R.; Shey, J. A Performance Analysis of Deep Neural Network Models on an Edge Tensor Processing Unit. In Proceedings of the International Conference on Electrical, Computer and Energy Technologies, Prague, Czech Republic, 20–22 July 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Cloud TPU Performance Guide. Available online: https://cloud.google.com/tpu/docs/performance-guide (accessed on 1 September 2023).
- Charniak, E. Introduction to Deep Learning, 1st ed.; The MIT Press: Cambridge, MA, USA, 2019; pp. 1–192. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks, 1st ed.; The MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. [Google Scholar]
- Nsight Compute Occupancy Calculator. Available online: https://docs.nvidia.com/nsight-compute/NsightCompute/index.html#occupancy-calculator (accessed on 9 June 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coral TPU [53] | Coral CPU [53,54] | |
|---|---|---|
| Processor | Google Edge TPU | Cortex-A53 Quad-core |
| Frequency | 480 MHz | 3.01 GHz |
| RAM | 4 GB DDR4 | 4 GB DDR4 |
| Operation Type | Fixed Point | Floating Point |
| Operations/s | 4 Trillion (8-bit) | 32 Billion (32-bit) |
| Model Name | Input | Output | GFLOP | Layers | % Parallel Layers |
|---|---|---|---|---|---|
| EfficientDet320 [56] | 320 × 320 × 3 | 90 | 2323.1 | 266 | 36% |
| EfficientDet384 [56] | 384 × 384 × 3 | 90 | 4272.3 | 321 | 31% |
| EfficientDet448 [56] | 448 × 448 × 3 | 90 | 6806.7 | 356 | 29% |
| EfficientDet512 [56] | 512 × 512 × 3 | 90 | 13,117.4 | 423 | 29% |
| EfficientDet640 [56] | 640 × 640 × 3 | 90 | 23,671.8 | 423 | 29% |
| EfficientNetS [57] | 244 × 244 × 3 | 1000 | 2991.1 | 66 | 0% |
| EfficientNetM [57] | 240 × 240 × 3 | 1000 | 4598.3 | 86 | 0% |
| EfficientNetL [57] | 300 × 300 × 3 | 1000 | 11,752.0 | 97 | 0% |
| InceptionV1 [58] | 244 × 244 × 3 | 1000 | 2167.2 | 83 | 53% |
| InceptionV2 [59] | 244 × 244 × 3 | 1000 | 2708.2 | 98 | 46% |
| InceptionV3 [59] | 299 × 299 × 3 | 1000 | 7347.8 | 132 | 47% |
| InceptionV4 [60] | 299 × 299 × 3 | 1000 | 15,666.1 | 205 | 32% |
| MobileDetSSDLite [61] | 320 × 320 × 3 | 90 | 2437.3 | 136 | 32% |
| MobileDetV1 [62] | 300 × 300 × 3 | 90 | 1929.1 | 75 | 44% |
| MobileDetV2Coco [61] | 300 × 300 × 3 | 90 | 1494.4 | 110 | 30% |
| MobileDetV2Face [61] | 320 × 320 × 3 | 90 | 1524.6 | 132 | 25% |
| TF2MobileDetV1 [63] | 640 × 640 × 3 | 90 | 67,482.4 | 104 | 56% |
| TF2MobileDetV2 [63] | 300 × 300 × 3 | 90 | 1407.5 | 101 | 24% |
| DLV3DM05MobileNet [64] | 513 × 513 × 3 | 20 | 2276.7 | 72 | 0% |
| DLV3MobileNet [64] | 513 × 513 × 3 | 20 | 5343.5 | 72 | 0% |
| KerasMobileNet128 [65] | 128 × 128 × 3 | 37 | 1350.8 | 76 | 10% |
| KerasMobileNet256 [65] | 256 × 256 × 3 | 37 | 5390.1 | 76 | 10% |
| MobileNet0.25 [62] | 128 × 128 × 3 | 1000 | 37.8 | 31 | 0% |
| MobileNet0.5 [62] | 160 × 160 × 3 | 1000 | 155.1 | 31 | 0% |
| MobileNet0.75 [62] | 192 × 192 × 3 | 1000 | 412.1 | 31 | 0% |
| MobileNet1.0 [62] | 224 × 224 × 3 | 1000 | 912.6 | 31 | 0% |
| MobileNetV2Bird [61] | 224 × 224 × 3 | 900 | 652.3 | 65 | 0% |
| MobileNetV2Plant [61] | 224 × 224 × 3 | 2000 | 658.6 | 65 | 0% |
| MobileNetV2 [61] | 224 × 224 × 3 | 1000 | 652.3 | 66 | 0% |
| TF2MobileNetV1 [63] | 224 × 224 × 3 | 1000 | 840.3 | 33 | 0% |
| TF2MobileNetV2 [63] | 224 × 224 × 3 | 1000 | 614.8 | 68 | 0% |
| TF2MobileNetV3 [63] | 224 × 224 × 3 | 1000 | 1280.9 | 79 | 0% |
| FNN240L810N [66] | 100 × 1 | 9 | 565.3 | 242 | 0% |
| Model | TPU Speedup (14 FC Nodes) | TPU Speedup (224 FC Nodes) |
|---|---|---|
| EfficientNet | 33.0× | 0.99× |
| Inception | 17.9× | 0.94× |
| MobileNet | 13.3× | 0.85× |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
DeLozier, C.; Blanco, J.; Rakvic, R.; Shey, J. Maintaining Symmetry between Convolutional Neural Network Accuracy and Performance on an Edge TPU with a Focus on Transfer Learning Adjustments. Symmetry 2024, 16, 91. https://doi.org/10.3390/sym16010091
DeLozier C, Blanco J, Rakvic R, Shey J. Maintaining Symmetry between Convolutional Neural Network Accuracy and Performance on an Edge TPU with a Focus on Transfer Learning Adjustments. Symmetry. 2024; 16(1):91. https://doi.org/10.3390/sym16010091
Chicago/Turabian StyleDeLozier, Christian, Justin Blanco, Ryan Rakvic, and James Shey. 2024. "Maintaining Symmetry between Convolutional Neural Network Accuracy and Performance on an Edge TPU with a Focus on Transfer Learning Adjustments" Symmetry 16, no. 1: 91. https://doi.org/10.3390/sym16010091
APA StyleDeLozier, C., Blanco, J., Rakvic, R., & Shey, J. (2024). Maintaining Symmetry between Convolutional Neural Network Accuracy and Performance on an Edge TPU with a Focus on Transfer Learning Adjustments. Symmetry, 16(1), 91. https://doi.org/10.3390/sym16010091