1. Introduction
With the continuous advancement of financial integration and the increasingly apparent global financial risks, the stability and sustainable development of financial markets are facing unprecedented challenges. The profound lessons learned from the 2008 financial crisis have led regulatory authorities to recognize the importance of systemic financial risks for financial stability. Countries worldwide are urgently seeking ways to strengthen macroprudential regulatory frameworks and address various vulnerabilities to ensure national financial security. As the world’s second-largest economy, China’s financial market stability directly impacts global economic dynamics and financial system stability [
1]. Currently, the Chinese government is facing the dual challenges of addressing the complex economic and financial environment and various unforeseen events, including the Sino–U.S. trade tensions and the COVID-19 pandemic. In such a context, effectively conducting comprehensive and accurate early warnings of China’s systemic financial risk has become an urgent and critical issue to address. Therefore, we aimed to accurately and comprehensively measure China’s systemic financial risk by exploring and proposing effective early warning methods to address various risk challenges that may arise now and in the future. By conducting a comprehensive assessment and early warning of systemic risk in China’s financial system, it can better protect the interests of investors, maintain the stability of global financial markets, and promote sustainable economic development.
Preventing and resolving financial risk has always been a perennial theme in financial work. In the early stages, any situation that threatened the stability of the financial system or undermined public confidence in the financial system was classified as systemic financial risk [
2]. However, after the 2008 financial crisis, the academic community defined systemic financial risk as a form of risk contagion and conducted extensive discussions.
Currently, there are two main categories of measurement methods for systemic financial risk. One is the comprehensive index method based on the risk measurement indicator system [
3], using the financial stress index as the mainstream method [
4]. The other focuses on reflecting the interconnectivity between financial institutions, with metrics mainly including the systemic risk index and marginal expected shortfall [
5]. Adrian and Brunnermeier [
6] proposed the conditional value at risk (CoVaR) and conditional expected shortfall (MES) to measure the contribution of individual institutions to the overall risk of the financial system. Acharya et al. [
7] introduced the marginal expected shortfall (MES) based on expected loss theory to measure the contribution of individual financial institutions to risk. Subsequently, some scholars combined the DCC-GARCH and Copula models, further extending the CoVaR-related indicators [
8,
9,
10,
11]. Other researchers considered the impact of leverage and further improved MES, adopting the risk index SRISK, which measures risk in the capital gap [
12]. In addition, some scholars explored the contagion of systemic financial risk from a network perspective [
13].
A system for providing financial risk warnings is a prerequisite for preventing and controlling systemic financial risks. Currently, in the academic community, models for systemic financial risk warning can be broadly categorized into three types. The first type is early warning models that use binary indicators (1 and 0) to define crisis and non-crisis situations. These models construct regression equations to select warning indicators and assess the likelihood of a crisis outbreak. Common models in this category include the STV cross-sectional regression model, KLR model, etc. Due to drawbacks such as information loss and subjectivity, scholars have sought improvements using the second type of traditional statistical methods. Mainstream methods include autoregressive integrated moving average (ARIMA), generalized autoregressive conditional heteroskedasticity (GARCH), etc. [
14,
15]. However, these models still face challenges when dealing with nonlinear and non-stationary time series. The third type involves artificial intelligence models. Numerous studies suggest that machine learning and artificial neural networks (ANNs) can effectively enhance the predictive accuracy of traditional statistical methods [
16,
17]. Subsequently, recurrent neural networks (RNNs) became an important approach in time-series problem research due to their advantages in capturing sequential information [
18]. However, RNNs are prone to issues like vanishing or exploding gradients. To address this, scholars introduced gate mechanisms in RNN to control information flow, creating models such as long short-term memory (LSTM) and gated recurrent unit (GRU). These models significantly improve the accuracy of financial time-series warnings [
19,
20]. At the same time, Shen et al. [
21] reported the advantages of convolutional neural networks in stock price prediction. Moreover, scholars have extended these models to bidirectional long short-term memory (BiLSTM) and demonstrated their superiority in forecasting [
22,
23,
24].
Extensive practice has shown that individual artificial intelligence prediction models come with both advantages and disadvantages, making it challenging to achieve optimal predictive performance using a single model. Therefore, most scholars are currently focusing on using ensemble methods to improve the forecasting accuracy of time series. The main approaches can be broadly classified into two categories. The first category involves combining various single models to form a new model. Attention mechanism, which can compute attention probability distributions to extract crucial information and optimize predictive models, is widely used in this context. For example, Ouyang et al. [
5] found that attention mechanism significantly improves the predictive accuracy in systemic financial risk warning research. Lu et al. [
25] combined convolutional neural network (CNN) and BiLSTM, embedding attention mechanism for stock price prediction, achieving favorable forecasting results.
The second category involves data preprocessing based on the “decomposition–reconstruction–integration” concept. This approach decomposes and reconstructs data into different subsequences, using deep learning models to predict each subsequence separately, finally integrating these parts for an overall analysis [
26,
27]. Representative decomposition techniques include wavelet decomposition (WD) and empirical mode decomposition (EMD) and its variants, with EMD and its variants being more suitable for the decomposition of nonlinear data [
28,
29].
Most studies indicate that stock market fluctuations are driven by collective behavior, with investor sentiment playing a particularly significant role in stock market changes [
30,
31]. This influence not only involves the correlation between investor sentiment and the stock market [
32], but also the crucial role of investor sentiment in financial forecasting [
33,
34]. For example, Gao et al. [
35] revealed the significant role of investor sentiment in predicting stock market volatility. As a crucial component of the financial market, stock market volatility can trigger financial risk, and some scholars have demonstrated that investor sentiment has a nonlinear effect in financial risk prediction [
36]. Therefore, further exploring the role of investor sentiment in the prediction of systemic financial risk is of significant importance.
By reviewing the above literature, it is evident that individual risk measurement indicators can only assess a certain aspect of systemic financial risk. Moreover, investor sentiment plays a driving role in systemic financial risk, yet few studies have considered investor sentiment as a predictive factor for systemic financial risk. Additionally, obtaining optimal predictive results with a single predictive model is challenging. The widely applied “decomposition–reconstruction–integration” forecasting approach has shown significant improvements in predictive performance. However, there is room for improvement in the methods of “decomposition–reconstruction” [
37], and further optimization is needed for deep learning predictive models. Therefore, this paper proposes a systemic financial risk prediction method based on the ESMD-HFastICA-BiLSTM-Attention model. Firstly, four systemic financial risk indicators, CoVaR, ∆CoVaR, MES, and SRISK, are constructed. These indicators are decomposed using extreme-point symmetric empirical mode decomposition (ESMD). Next, a combination of hierarchical clustering and fast independent component analysis (HFastICA) is employed to reconstruct the decomposed data into new subsequences. Finally, investor sentiment measures, such as the network sentiment index and the new subsequences, are used as inputs. The systemic financial risk is predicted through a combination of bidirectional long short-term memory (BiLSTM) and attention mechanism.
This paper’s innovations lie in three aspects. First, the use of the empirical symmetric mode decomposition method effectively overcomes the mode mixing phenomenon encountered in EMD. It does so without the need for additional steps like adding noise, denoising, or smoothing methods, enabling a direct decomposition of the data. Second, the application of hierarchical clustering and fast independent component analysis for data reconstruction results in mutually independent subsequences. This approach avoids subjective reconstruction of subsequences and reduces prediction errors caused by inter-subsequence correlations. Third, the consideration of the network sentiment index is a crucial indicator in forecasting. Additionally, an attention mechanism is incorporated on top of the BiLSTM model, enhancing the focus on important information in the prediction process and improving prediction accuracy.
The remaining structure of this paper is as follows: the second part covers the methodology, the third part deals with indicator calculation and analysis, and the empirical analysis and research conclusion are presented in the fourth and fifth parts, respectively.
2. Methods
2.1. Dynamic Conditional Correlation-Generalized Autoregressive Conditional Heteroskedasticity
We adopted the DCC-GARCH model to calculate the dynamic correlation coefficient between two financial variables. The specific model is as follows:
where
represents the matrix of conditional correlation coefficients,
represents the matrix of conditional covariance
,
represents the diagonal matrix of conditional standard deviations, and the conditional variance
is fitted by a univariate GARCH or TGARCH model.
is the covariance matrix,
is the matrix of unconditional variances of residuals,
is the standardized residual coefficients of lag
n,
is the coefficients of conditional variances at lag order, all of which are negative and simultaneously satisfy the condition
.
represents the disturbance term, and
j follows a specific distribution.
2.2. Extreme-Point Symmetric Empirical Mode Decomposition
Wang and Li [
38] proposed the extreme-point symmetric empirical mode decomposition (ESMD), which addresses the issue of mode mixing in traditional empirical mode decomposition by interpolating the midpoints of line segments connecting local maxima and minima. The ESMD process involves three steps:
Step 1: Identify all local extrema points of the systemic financial risk X (including maxima and minima), connect all adjacent points , and label the midpoints of the line segments as . Then, supplement a left boundary midpoint and a right boundary midpoint by linear interpolation. Utilize n+1 midpoints to construct p interpolation curves , and concurrently calculate the average curve .
Step 2: Repeat Step 1 for . If the iteration reaches the maximum preset value K or satisfies (where is the preset error, is the standard deviation of data X, and is typically chosen), obtain the first mode . Repeat the above steps for to successively obtain . Stop when the number of extreme points contained in the residual function reaches the preset value.
Step 3: Sequentially change the value of K within a pre-defined integer interval . Determine based on the minimum variance ratio (where and represent the standard deviations of X − R and X, respectively). Repeat Steps 1 and 2 to obtain the final decomposition result.
2.3. Hierarchical Clustering and Fast Independent Component Analysis
Hierarchical clustering creates a hierarchical tree-like clustering structure by calculating the similarity between different clusters. It is generally divided into agglomerative (bottom–up) and divisive (top–down) approaches. This paper chose the agglomerative hierarchical clustering algorithm. Initially, it assumes each sample is a separate cluster. It then calculates the Manhattan distance between each pair of clusters:
Subsequently, employing the single linkage method, the two sets with the minimum distance are identified, and they are merged into a new set. This process is repeated iteratively until only one set remains. Hierarchical clustering categorizes different intrinsic modes into
n classes, forming
n random observed signals
X. Independent component analysis treats these
n random signals as a linear combination of
mutually independent signals
s, satisfying:
Here
X is the known observed signal matrix,
S is the unknown independent source vector, and
A is the unknown mixing matrix. Then, a separation matrix
W is constructed, transforming Equation (3) into
. Thus, the problem becomes the solution for the separation matrix
W. Following the research by Hyvärinen and Oja [
39], this paper chose the FastICA method, which maximizes non-Gaussian criteria according to
solving the separation matrix
W. It constructs the optimization problem of maximizing negative entropy as follows:
where
g is a nonlinear function satisfying
,
y is a subvector in signal
Y,
b = 1,
is negative entropy,
represents the mean function, and
m is a Gaussian random variable after centering and whitening. According to the Kuhn–Tucker conditions, with the constraint
, given
as the derivative of
,
as the optimized value of
W, and
as a constant, the final optimal value is expressed as:
2.4. Bidirectional Long Short-Term Memory
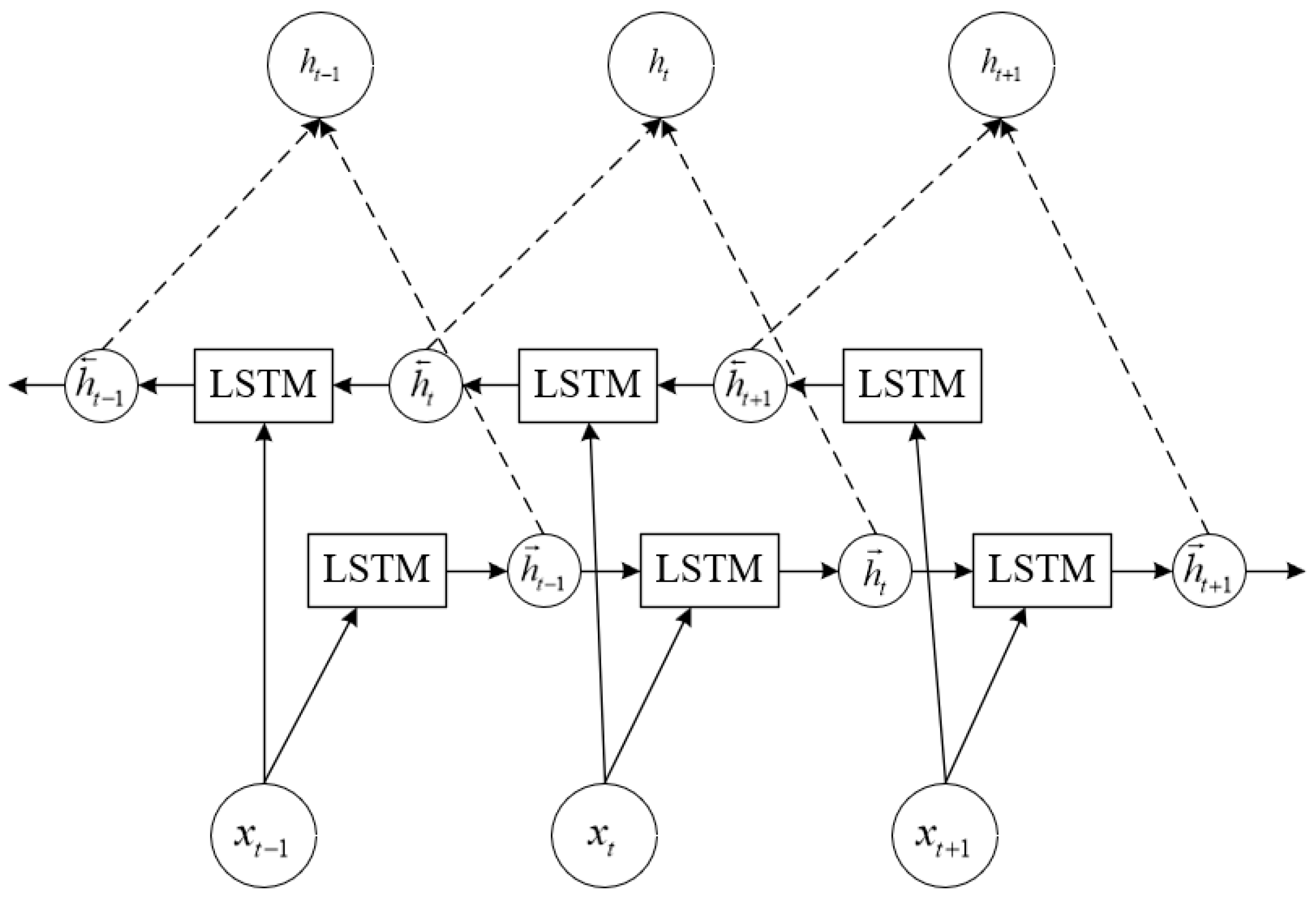
The BiLSTM constructed in this paper consists of two independent LSTMs, namely the forward LSTM and the backward LSTM. Simultaneously considering information from past and future sequences, the final learning result is obtained by combining the forward input sequence and the reverse input sequence with certain weights. The specific model structure is illustrated in
Figure 1. To be specific, if
,
and
are input variables, after going through the forward LSTM, we obtain hidden vectors
,
and
. At the same time, the same input sequences undergo the backward LSTM, yielding hidden vectors
,
and
. Further, concatenating the forward hidden vectors with the backward hidden vectors results in the output of the BiLSTM, represented by
,
and
.
The LSTM cell unit depicted in
Figure 1 is primarily composed of a forget gate, an input gate, and an output gate. The forget gate regulates the extent of information to be discarded, while the input and output gates are responsible for receiving and outputting parameters. The specific operational principles are outlined below.
The formula for the forget gate is , where denotes the output at time t−1, is the input to the current layer at time t, is the weights of various variables, and is the bias term. The activation function determines the retention or omission of information. In this context, the sigmoid function is chosen, with the form , where ranges between 0 and 1.
The formula for the input gate is , where and ranges between 0 and 1, and represents the updated cell state value. is the cell state value at time t − 1, represents the information extracted from the input at time t, and tanh is the hyperbolic tangent activation function. Other types of activation functions can be used as well. And the formula for the output gate is , where is the output.
Therefore, LSTM can accomplish internal processing of a neuron through three control gates, forming a memory of long-term past data.
2.5. Attention Mechanism
The attention mechanism can simulate the resource allocation mechanism formed by human attention, allocating probabilistic weights to input elements to reduce the interference of irrelevant information and enhance the significance of key information. If
represents the input to the BiLSTM,
is the output of each hidden layer after learning,
is the attention allocation value to the input of the BiLSTM hidden layer in the attention mechanism, and
y is the output value of the BiLSTM with the attention mechanism. The calculation formula is:
Here, and represents the energy value determined by the hidden layer state vector at time t in the BiLSTM. And and are the weight coefficient matrices at time t, and is the bias. The activation function is tan h.
2.6. Prediction Framework and Evaluation Metrics
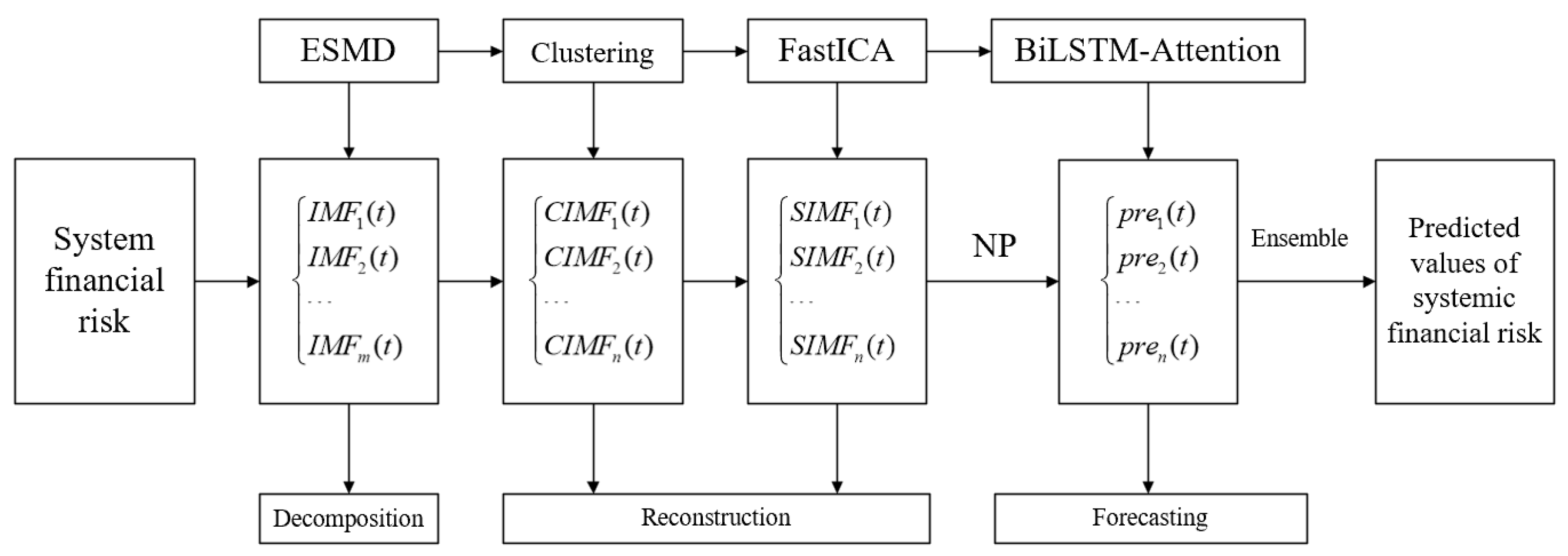
We combined extreme-point symmetric empirical mode decomposition (ESMD), hierarchical clustering and fast independent component analysis (HFastICA), bidirectional long short-term memory (BiLSTM), and attention mechanism, taking into account the crucial indicator of network public opinion. It constructs a novel “decomposition–clustering-ensemble” model for systematic risk prediction.
Figure 2 illustrates the structure of the prediction model.
Therefore, the forecasting process of this paper is divided into four steps:
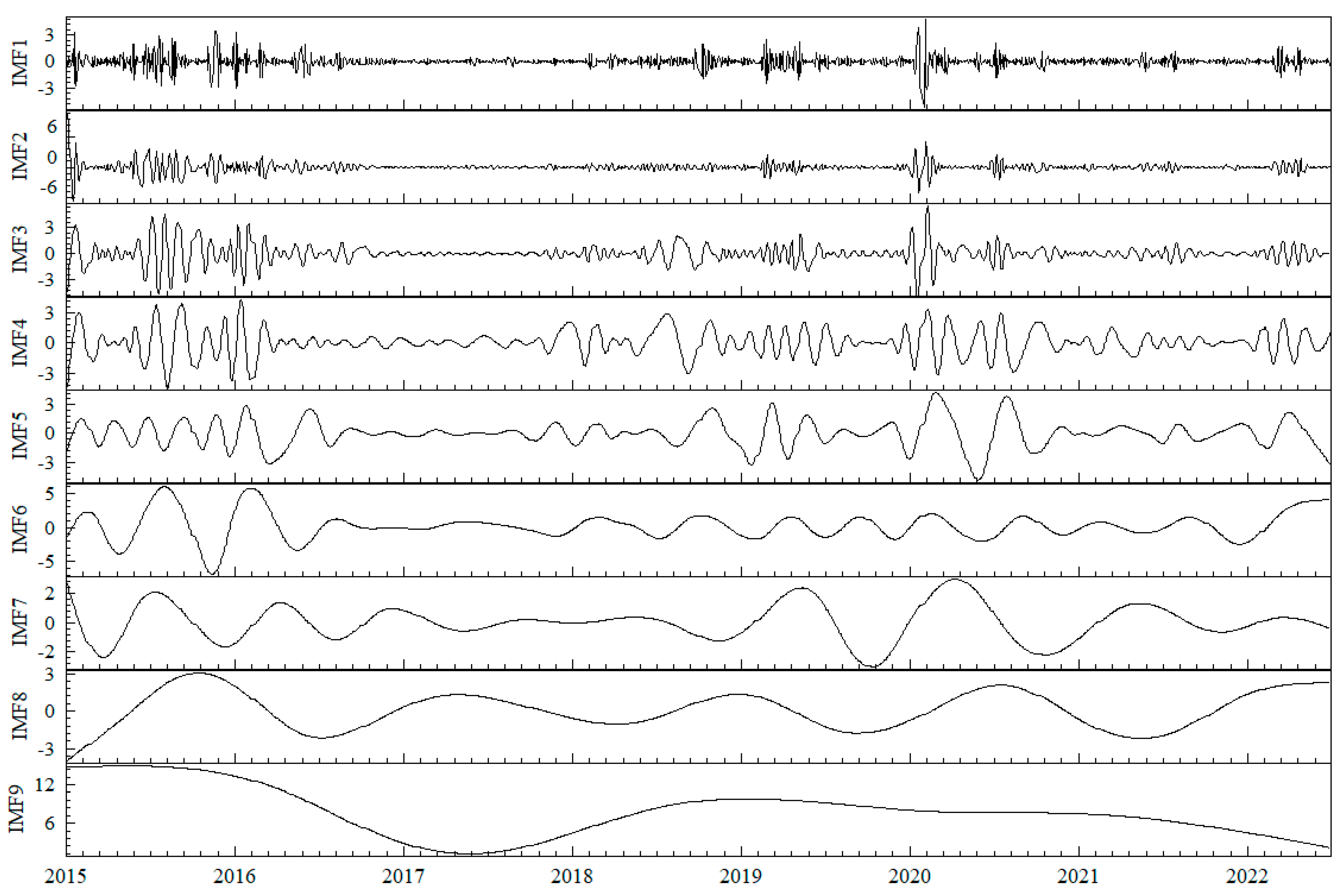
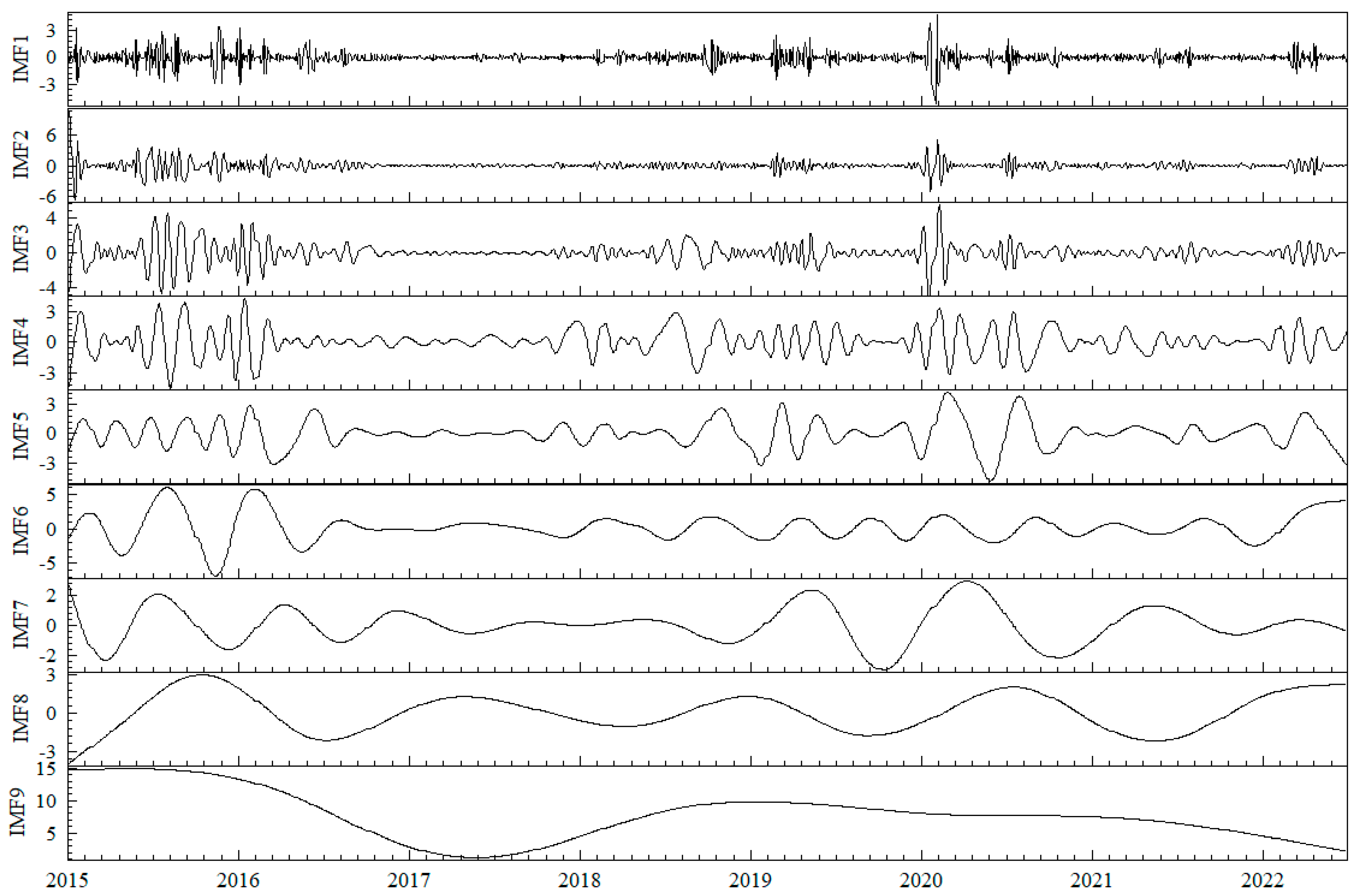
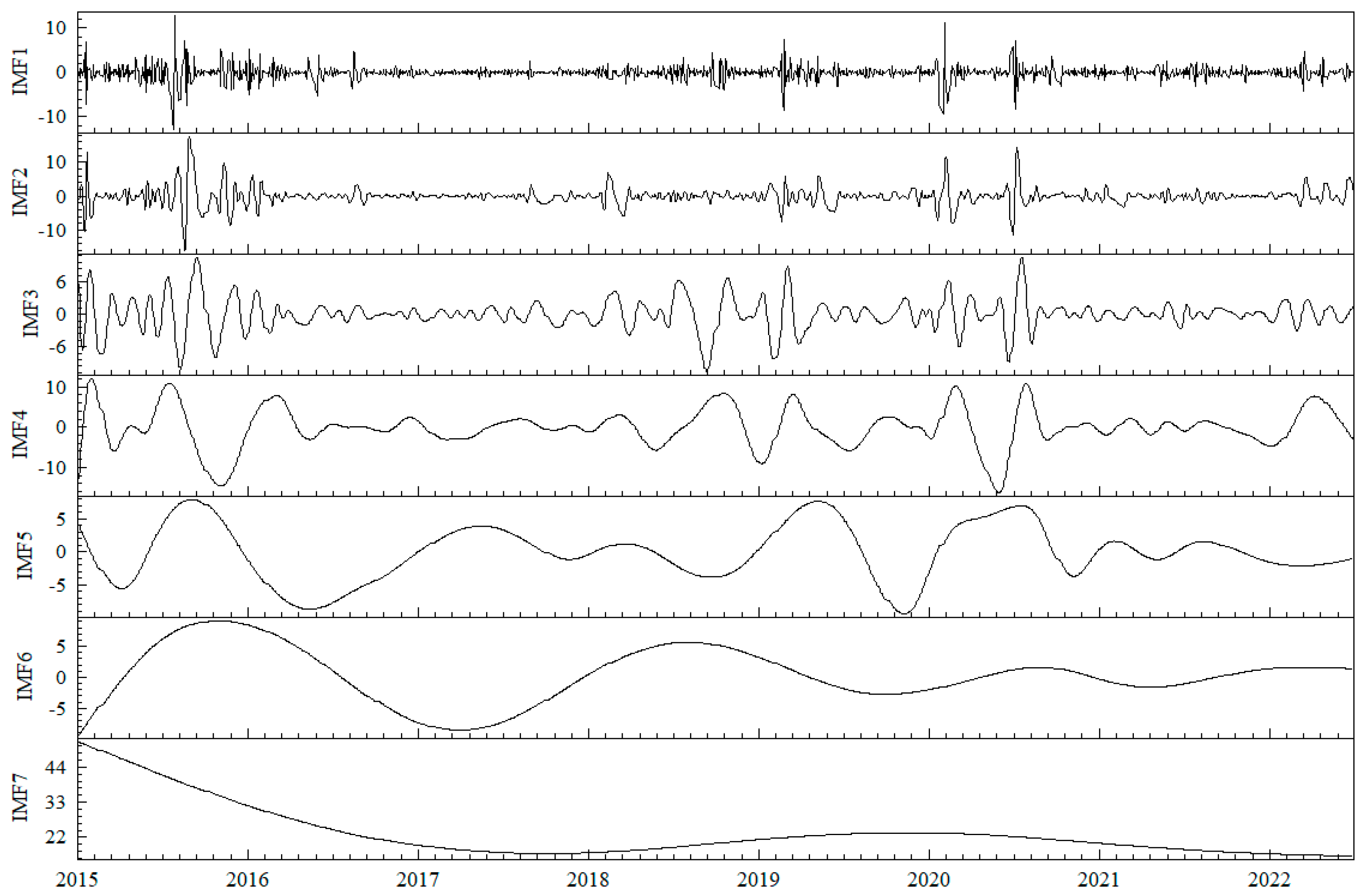
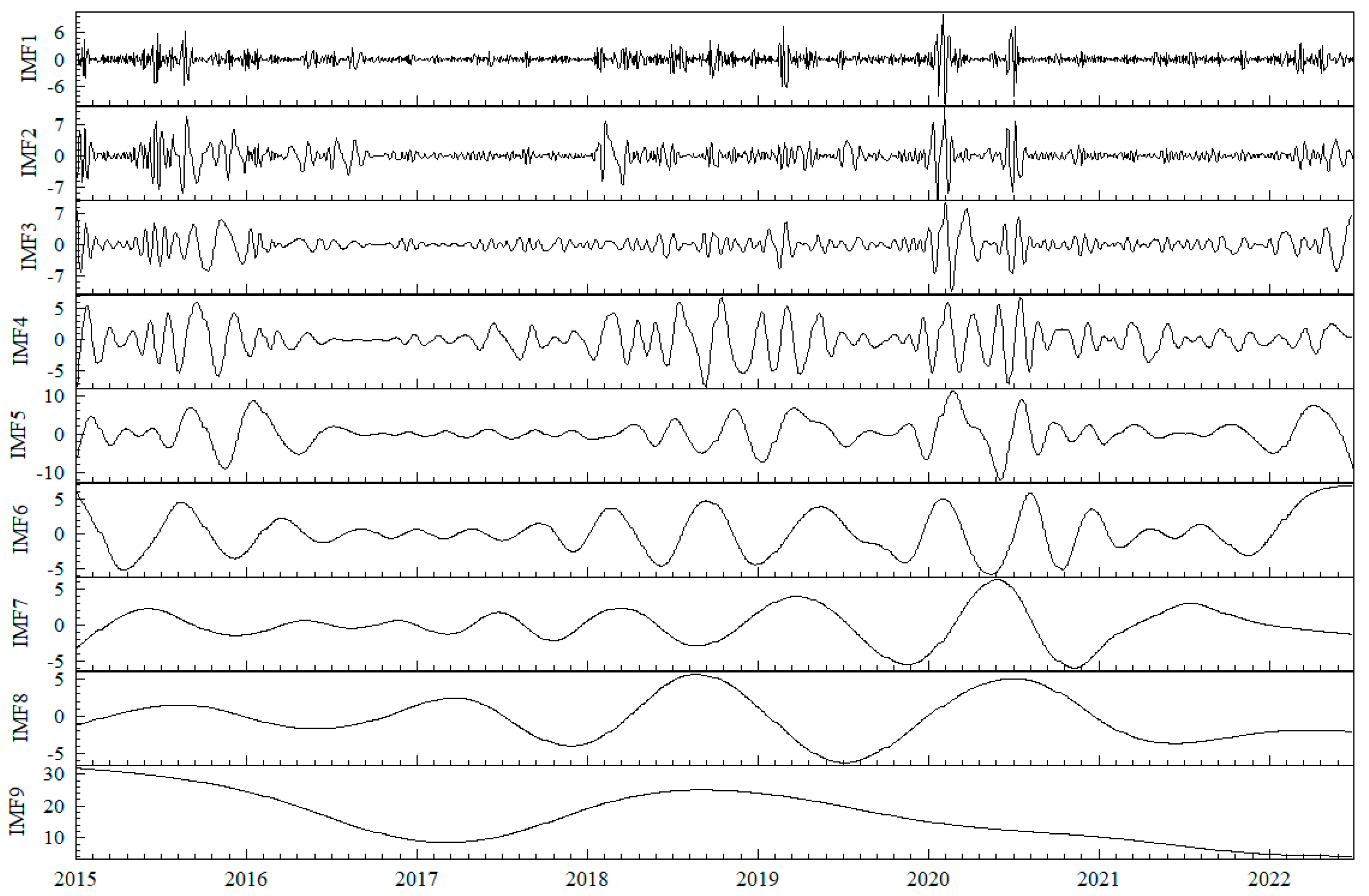
Step 1: Input the forecast indicators of systemic financial risk , and use the ESMD to decompose the observed data into m intrinsic mode functions (IMFs), with (the residual sequence is defined as the last mode in this paper).
Step 2: Classify the obtained m mode functions using hierarchical clustering and sum the mode functions of the same category to obtain a new reconstructed sequence, with .
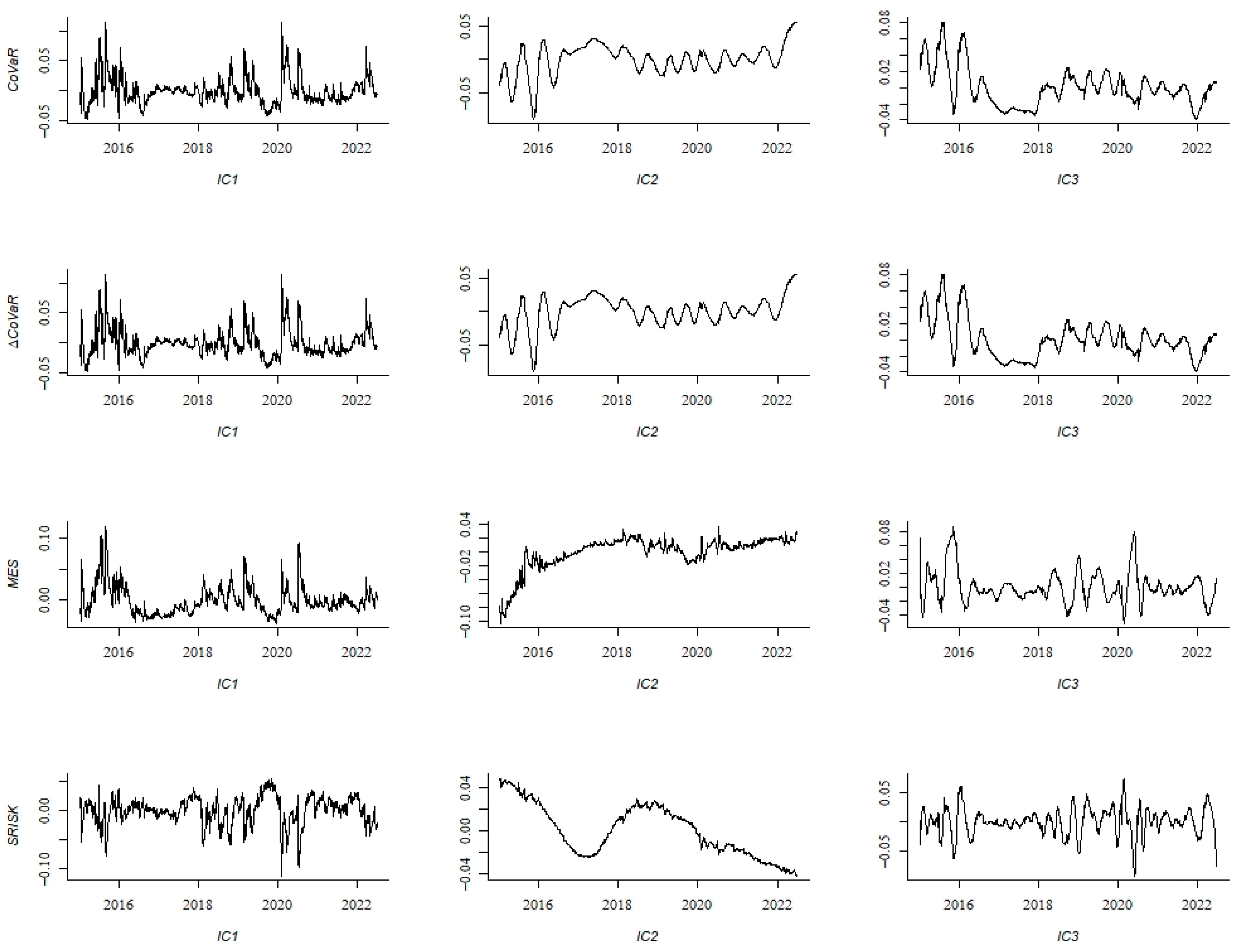
Step 3: Perform FastICA on the reconstructed sequence obtained in Step 2 to obtain mutually independent reconstructed sequences, with , where is the sum of columns of the mixing matrix and is the estimated signal.
Step 4: Multiply the network public opinion index and the reconstructed sequences from Step 3 by weights as new inputs. Through BiLSTM and attention mechanism, obtain the predicted values of each reconstructed sequence. Integrate all predicted values to obtain the forecast values of systemic financial risk indicators and calculate the evaluation metrics (the specific calculation methods are detailed in
Table 1).
3. Indicator Calculation and Analysis
3.1. Calculation of Systemic Financial Risk Indicators
To ensure the universality and representativeness of the research results, we selected all financial institutions listed on the A-share market before 2014 as our research sample. We excluded institutions with missing data and considered the availability of text data from the East Money Stock Bar. Eventually, we identified 47 financial institutions, all of which have a market share exceeding 70% and thus play a dominant role in the financial market. We calculated their daily logarithmic return, and the market index was measured using the daily logarithmic returns of the CSI 300 index. The sample period extended from 2 January 2015 to 30 June 2022, and all data were sourced from CSMAR.
We measured China’s systemic financial risk from various perspectives using conditional value at risk (CoVaR), conditional value at risk difference (∆CoVaR), marginal expected shortfall (MES), and the capital shortfall risk index (SRISK). CoVaR emphasizes the risk spillover of individual financial institutions to others or the entire market. ∆CoVaR reflects the difference between CoVaR when a single institution is in an extreme state and when the system is normal. MES reflects the marginal contribution of individual financial institutions to systemic risk during a significant market return decline. SRISK reflects systemic risk from the expected capital shortfall perspective.
(1) CoVaR Calculation: CoVaR is defined as
by Adrian and Brunnermeier [
6], representing the risk value level of the financial system at confidence level
q when financial institution
i experiences a crisis, where
represents the financial system’s return. We chose
q = 0.05 and used the CSI 300 index logarithmic return to represent the financial system’s return. Equation (1) was used to calculate the dynamic CoVaR value for individual financial institution
i.
(2) ∆CoVaR Calculation: setting q = 0.05 and q = 0.5 as extreme and normal states, respectively, we calculated the CoVaR value for individual financial institutions in different states. ∆CoVaR was calculated by computing .
(3) MES Calculation: Acharya et al. [
7] defined MES as
, where
is the CSI 300 index logarithmic return and
is the logarithmic return of individual financial institutions. We set
q = 0.05 and calculated the dynamic MES using Equation (1).
(4) SRISK Calculation: Based on the MES calculation results, setting k = 0.08, we computed , where the long-term marginal expected loss , where and represent the book value of debt and equity, sourced from CSMAR.
Based on the calculation of systemic financial risk values for individual financial institutions, we computed the weighted average of CoVaR, ∆CoVaR, MES, and SRISK for 47 institutions using market capitalization as weights. These values represent the overall systemic financial risk for China, serving as the basis for subsequent research in this paper. Due to the small scale of these four systemic financial risk indicators, we multiplied all indicators by 1000 for subsequent research.
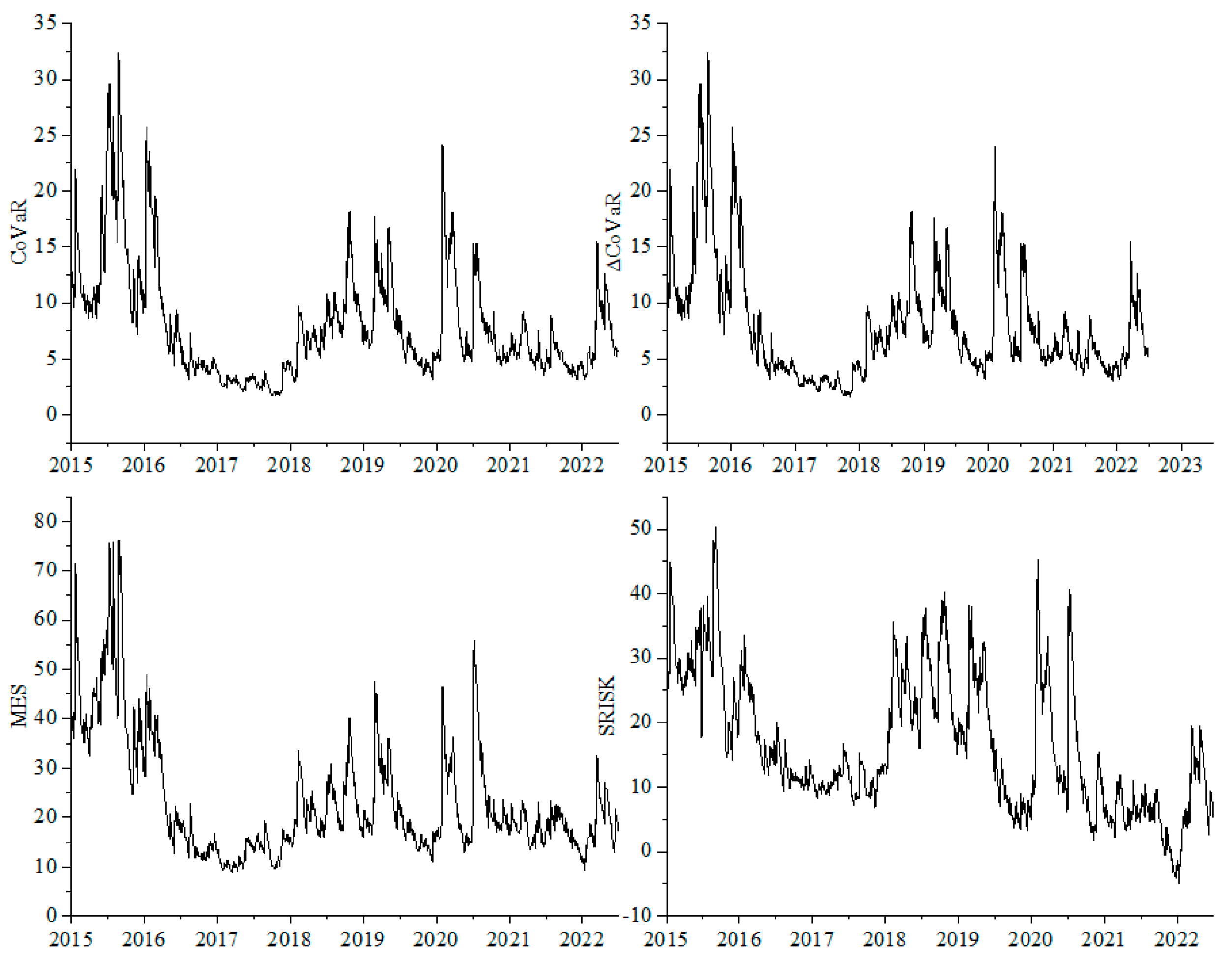
Figure 3 shows the time series of systemic financial risk, indicating similar trends in the four indicators. In the second half of 2015, the abnormal fluctuations in the A-share market significantly impacted the Chinese economy, leading to a drastic fluctuation in systemic financial risk. The sustained high level of risk exacerbated the transmission and diffusion of risks, causing substantial harm to both financial markets and the real economy. This warrants close attention from regulatory authorities and proactive preventive measures. The second significant fluctuation occurred in 2018, driven by the ongoing trade tensions between the U.S. and China, financial reforms domestically, and the release of certain risks into the market, inducing panic. However, due to the proactive response from relevant Chinese authorities, the systemic risk gradually declined to a relatively stable state after the initial rise. The third major fluctuation emerged after 2020, coinciding with the outbreak of the COVID-19 pandemic in China. This event had a significant impact on the Chinese and global economies. Nevertheless, the Chinese government promptly implemented effective epidemic control measures and introduced a series of policies to stabilize the market. This allowed businesses to resume operations quickly, leading to a gradual recovery of the economy after a brief shock.
3.2. Calculation of Network Public Opinion Index
Drawing on the research methodology of Ouyang Zisheng et al. [
36], this paper utilized python to crawl comment data for 47 listed companies on East Money’s website from 5 January 2015 to 30 June 2022. The collected data included post titles, click-through rates, reply counts, usernames, posting times, and post content. As stock market forums serve as open platforms for information exchange, containing both emotional expressions of investors facing market changes and a certain amount of irrelevant information, the obtained data underwent thorough cleaning. This process involved removing advertising posts from the scraped information and eliminating duplicate sentences and words.
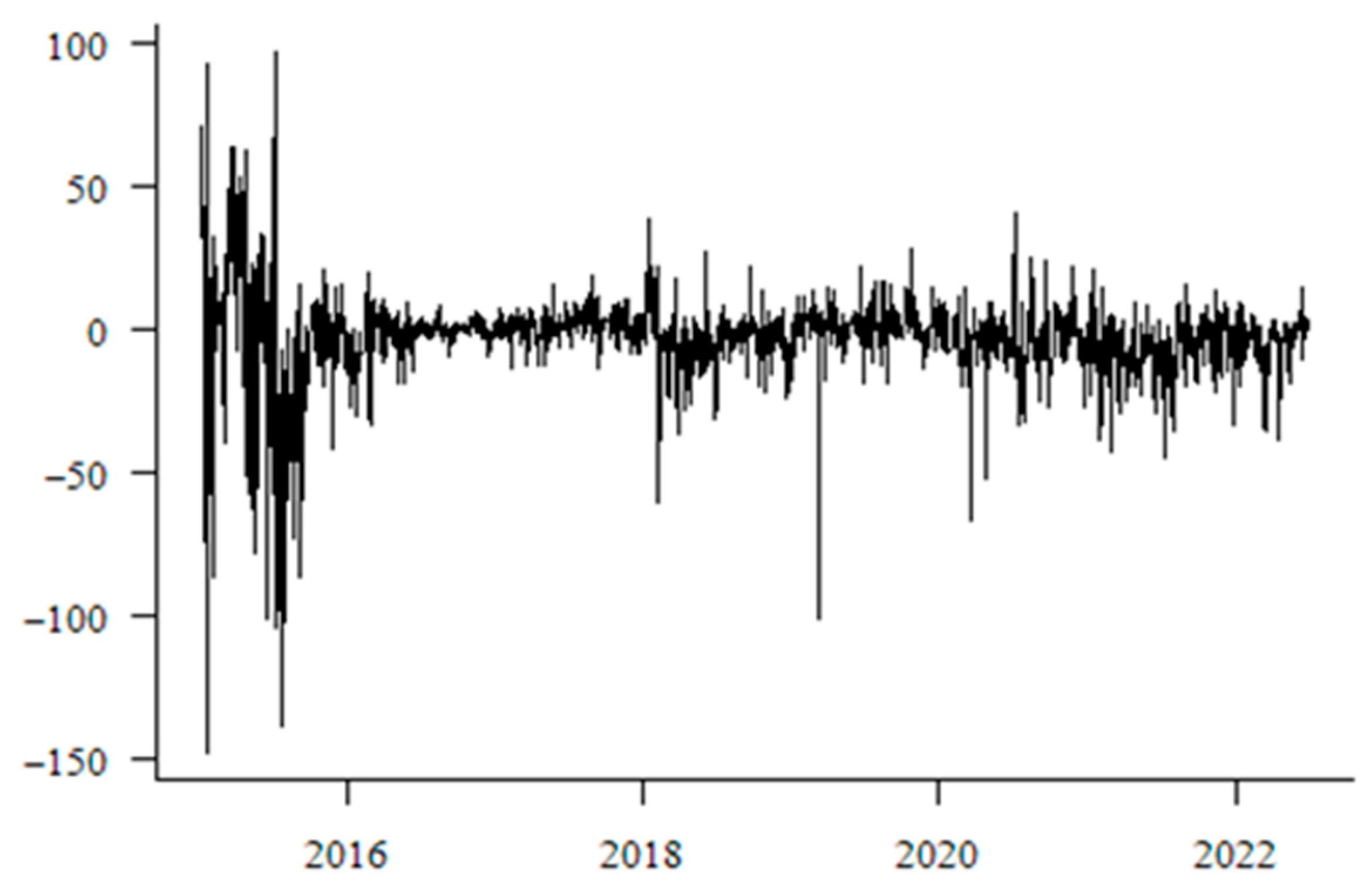
Following data cleaning, the text data underwent segmentation, a common method for Chinese text segmentation that combines rule-based and statistical approaches. Leveraging python’s Jieba, Dalian University of Technology, Sogou lexicons, as well as specialized sentiment lexicons for the stock market and stock forums, we achieved text segmentation and feature extraction. Additionally, sentiment analysis categorized network sentiment into optimistic, neutral, and pessimistic sentiments. Each comment was analyzed, and the quantities of positive, neutral, and negative vocabulary were calculated. Positive sentiment words were assigned a value of 1, negative sentiment words −1, and neutral sentiment words 0. The sum of these three sentiment categories for each day resulted in the daily network public opinion index (NP), acting as a proxy indicator for investor sentiment, with its trend depicted in
Figure 4. Clearly, after 2016, the fluctuation range of the network public opinion index is relatively small, except for occasional times when the variation range is basically within the [−50, 50] interval. However, during the period from 2015 to 2016, the network public opinion index showed extreme volatility. The reason for this is that in 2015, the “stock market crash” caused the Chinese stock market to experience drastic fluctuations of collapse, rebound, and subsequent adjustments, leading to repeated changes in investor sentiment between optimism and panic. Combined with the herd effect and emotion-driven behavior of investors, this resulted in exceptionally violent fluctuations in the network public opinion index during this period.
3.3. Data Description and Interrelationship Analysis
Figure 3 and
Figure 4 depict the temporal characteristics of China’s systemic financial risk and network public opinion index. To further understand the distributional properties of the data,
Table 2 provides descriptive statistics for both datasets, including the sample size (Number), minimum value (Min), maximum value (Max), mean (Mean), and standard deviation (St). The standard deviation of the network public opinion index is 16.1111, indicating a large variability within the sample period, with a mean of −2.4110, suggesting a prevailing negative sentiment among investors in the Chinese financial system during the sample period. We observe that MES exhibits the greatest fluctuation among the four systemic financial risk indicators, while ∆CoVaR has the smallest standard deviation. The minimum value of SRISK is negative, indicating that the debt of the financial system exceeded its assets during those periods. The distinct statistical characteristics of the four systemic financial risk indicators illustrate their varied perspectives on China’s systemic financial risk.
The interrelationship between network public opinion and systemic financial risk manifests in two aspects. On the one hand, investors, as the mediators influencing systemic financial risk through network public opinion, can gather and interpret information from online sentiment, understand various investors’ expectations for the financial market, engage in information exchange, and share insights. However, such sentiment-laden information can lead investors to make irrational judgments, causing market overfluctuations, investment bubbles, and triggering systemic financial risk. On the other hand, in the era of digital information, the rapid and diverse dissemination of public sentiment information may result in varying qualities of information. Due to limited investor attention, this can lead to the transmission of false or erroneous information, creating an asymmetry of information in the market. Consequently, in situations of rapid market changes, investors might make inaccurate decisions, causing significant market fluctuations and exacerbating systemic financial risk. Therefore, the network public opinion index can serve as a crucial indicator for predicting systemic financial risk.
We employed the generalized forecast error variance decomposition method proposed by Diebold and Yilmaz [
40] to construct the spillover matrices between the network public opinion index and systemic financial risk. The interrelationship between the network public opinion index and systemic financial risk was examined, and the rationality of using the network public opinion index as a predictor for systemic financial risk was tested.
Table 3 presents the spillover matrices calculated through vector autoregression and variance decomposition, where “To” indicates spillovers, and “From” indicates inward spillovers. Overall, the information spillover of the network public opinion index was as high as 232.39%, while the inward spillover was only 0.08%. This suggests that the impact of network public opinion on the four categories of systemic financial risk is far greater than the impact of systemic risk on network public opinion index. Among them, CoVaR, ∆CoVaR, and SRISK, the three types of systemic financial risk, receive information spillovers mainly from the network public opinion index, accounting for 76.48%, 76.49%, and 51.75%, respectively. The information spillover of the network public opinion index to MES is 27.68%, ranking second in the spillover into MES. Nevertheless, this still indicates the significant role of network public opinion in predicting systemic risk. There are asymmetric information spillovers and spillovers among the four types of systemic financial risk, indicating that these indicators have certain correlations but also differences. Therefore, different dimensions of the systemic financial risk indicators should be considered in predictions.
5. Conclusions and Discussion
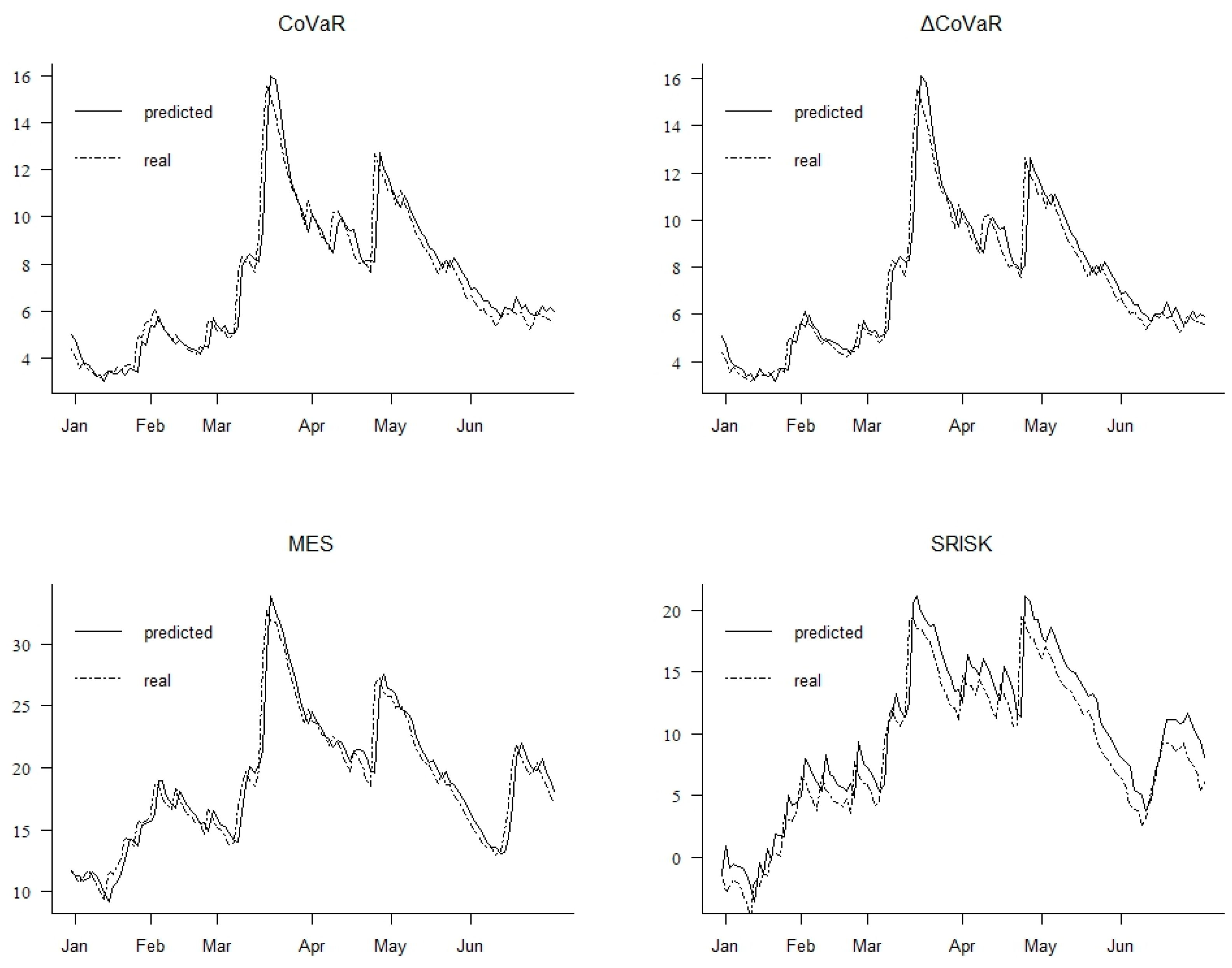
We proposed a novel ensemble model for predicting systemic financial risk. Firstly, we selected financial institutions as the research sample, measured multidimensional systemic financial risk indicators in China, and employed text mining techniques to construct a Chinese financial network public opinion index as a driving factor for predicting systemic financial risk. Subsequently, we used the ESMD method to decompose the systemic financial risk into different sub-series, and after decomposition, we reconstructed the sub-series through hierarchical clustering and FastICA methods. Finally, using the network public opinion index as input, we employed a BiLSTM-Attention ensemble model to predict different sub-series and integrate them. By evaluating the learning results, we verified the superiority of our proposed model in financial time series prediction. Our research conclusions are as follows:
Firstly, there is an interrelationship between the network public opinion index and systemic financial risk, and this interrelationship exhibits asymmetry. Specifically, the influence of the network public opinion index on systemic financial risk is much greater than the influence of systemic financial risk on the network public opinion index, indicating that the network public opinion index can serve as a driving factor for predicting systemic financial risk.
Secondly, combining data decomposition–reconstruction with deep learning methods can improve the prediction accuracy of systemic financial risk. Compared to empirical mode decomposition and variational mode decomposition, ESMD can overcome disadvantages such as mode mixing and parameter selection, making it more effective in exploring nonlinear data. Additionally, reconstructing the decomposed sub-series not only enhances prediction accuracy but also shortens the prediction time, providing a new research approach for financial time series prediction.
Thirdly, the ensemble model is more effective in predicting systemic financial risk compared to single machine learning models and traditional statistical models. Traditional statistical models fail to capture the nonlinear relationships of systemic financial risk, while single machine learning models such as support vector regression and decision tree regression, as well as single neural network models, have limitations in handling complex financial sequences. By combining bidirectional long short-term memory neural networks with attention mechanism, our predictive model gains discriminative capabilities, thus improving prediction accuracy.
Although our study has achieved certain results, there are still two main limitations. Firstly, there are limitations in the scope of the research. We selected Chinese financial institutions as the research sample, without considering different economies, various financial markets, different types of financial risks, or multidimensional influencing factors other than the network public opinion index, which may affect the research results. Secondly, there are limitations in the research methods. We constructed deep learning models for predicting systemic financial risk from a point prediction perspective based on historical time series, but the evaluation perspective can be further expanded. Therefore, as a research extension, we plan to select different economies and markets as research samples to predict various financial risks such as systemic financial risks, imported financial risks, and credit risks. We also intend to include interval prediction, model sensitivity analysis, model effectiveness evaluation, and statistical demonstration of the significance of predictive models to improve the research on financial risk prediction.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}