
Symmetrical Convergence Rates and Asymptotic Properties of Estimators in a Semi-Parametric Errors-in-Variables Model with Strong Mixing Errors and Missing Responses


Abstract
1. Introduction
2. Assumptions
- Missing Completely at Random (MCAR): The probability of missingness is independent of both the observed and unobserved data values.
- Missing at Random (MAR): The probability of missingness depends on the observed values, but not on the unobserved (missing) values themselves.
- Not Missing at Random (NMAR): Missingness depends on the unobserved (missing) values themselves.
- (H0)
- Consider the sequence of random variables which are both stationary and exhibit strong mixing properties with mixing coefficients . Additionally, consider the sequence of independent random variables that satisfy the following:
- (i)
- , , , ;
- (ii)
- , for some ;
- (iii)
- The sequences and are mutually independent.
- (H1)
- Let be a sequence as defined in (2) satisfying the following:
- (i)
- As , , where .
- (ii)
- As , , denotes any order of 1 to n.
- (H2)
- On , both and are continuous and Lipschitz continuous of order one.
- (H3)
- For each integer k with , there exists a weight function that is confined to the domain [0, 1] and satisfies the following:
- (i)
- Let . Then, .
- (ii)
- Assume for all : .
- (iii)
- .
- (H4)
- Let , for , denote the probability weight functions defined over the interval , which are subject to the following conditions:
- (i)
- Let . Then, .
- (ii)
- Assume for all : .
- (iii)
- (H5)
- (i)
- Given , it holds that .
- (ii)
- Given , it holds that .
- (H6)
- (i)
- for any .
- (ii)
- for any .
- (H7)
- Positive integers and exist, satisfying the following:
- (i)
- , , , , .
- (ii)
- Let ; it follows that as .
3. Main Results
3.1. Building Estimators: Methods and Techniques
3.1.1. Direct Deletion Method
3.1.2. Modified Least Squares Estimation (LSE)
3.1.3. Imputation Method
3.1.4. Regression Substitution Method
3.1.5. Summary of Computational Complexities
3.2. Strong Consistency in Estimator Behavior
- (a)
- (b)
- (a)
- (b)
- (a)
- (b)
3.3. Asymptotic Normality in Estimator Behavior
- (a)
- Given , it follows that
- (b)
- Under the condition as , it holds that
- (a)
- Given , it follows that
- (b)
- Under the condition as , it holds that
- (a)
- Given , it follows that
- (b)
- Under the condition as , it holds that
4. Simulation Study
- (i)
- To evaluate the efficacy of three estimators for and three estimators for . For the estimators, the performance metric utilized in this study is the MSE. For the estimators of , the assessment is carried out using the GMSE as the evaluation criterion.
- (ii)
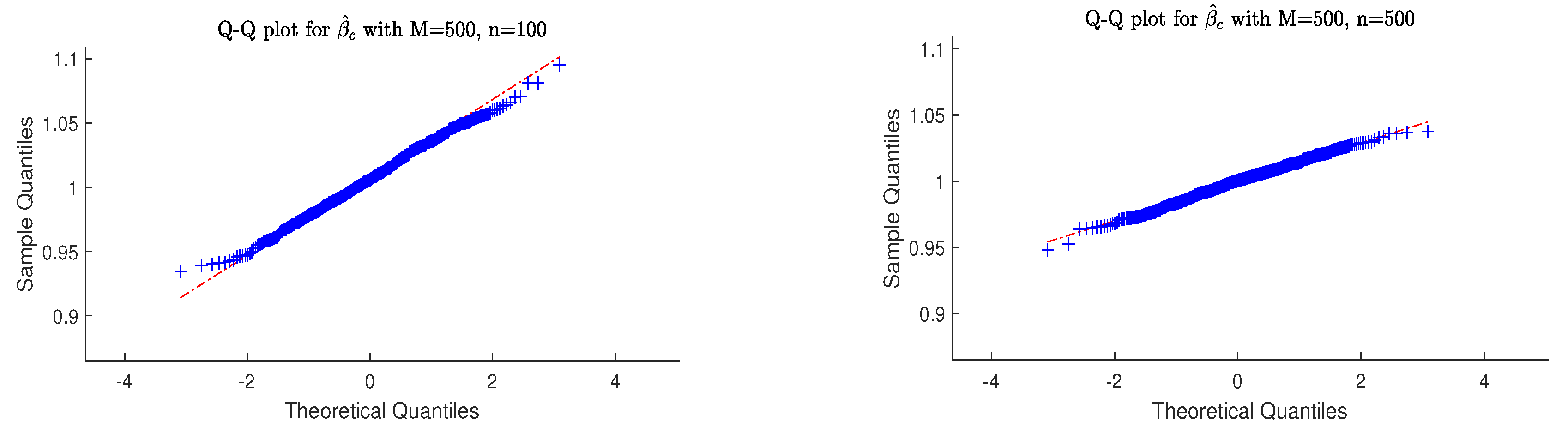
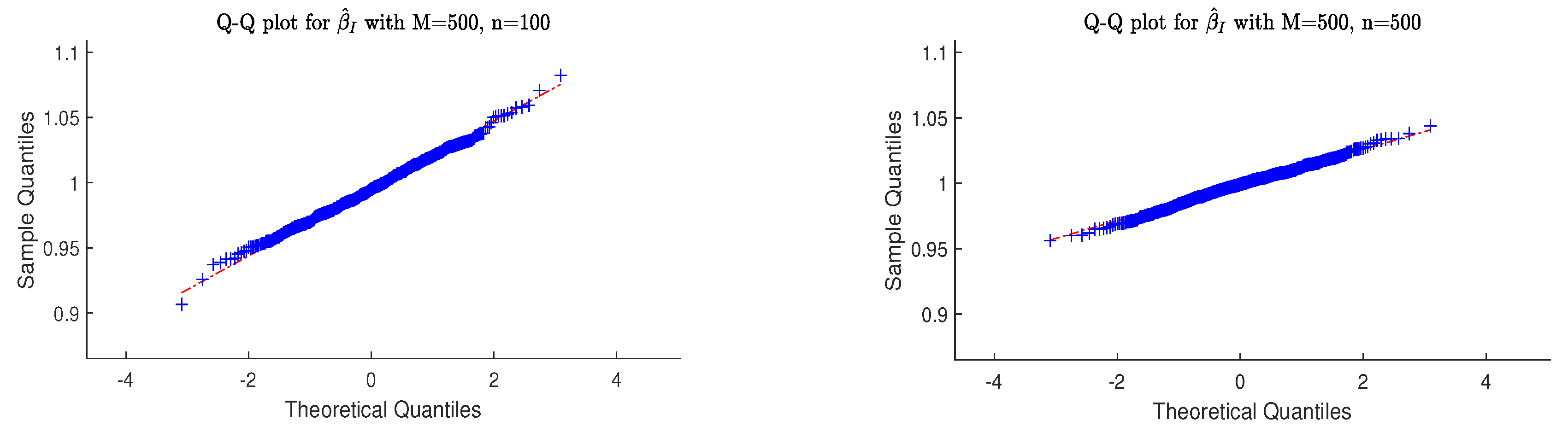
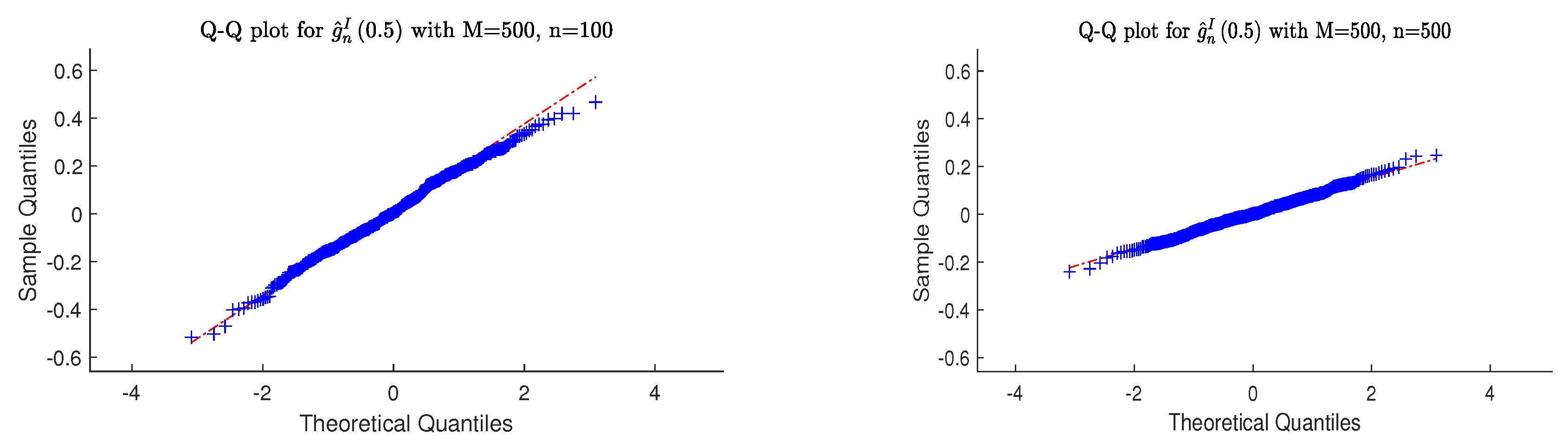
- Q-Q plots are utilized to graphically represent and compare the distributional properties of the three estimators for and are presented.
4.1. MSE/GMSE Evaluation for and Estimators
- (i)
- All estimators demonstrated notably strong consistency.
- (ii)
- For every fixed n, a higher missing probability led to an increased MSE or GMSE for every estimator considered.
- (iii)
- For every fixed p, a larger sample size n brought about a reduction in both the MSE and GMSE for every estimator considered.
- (iv)
- Compared to , almost all estimators showed a rise in both MSE and GMSE when .
- (v)
- In comparison to , the estimated values of and exhibited a greater proximity to the real value, suggesting that addressing incomplete data is indeed beneficial. A similar result was observed for the estimators of .
4.2. Simulation Evidence for Asymptotic Normality
- (i)
- Derived from a sample size of 500, the estimated values for and closely resemble a normal distribution, indicating asymptotic normality.
- (ii)
- As sample size increases from 100 to 500, all estimators’ sample variances decrease, reflecting improved precision and stability in larger datasets.
- (iii)
- The simulation outcomes corroborated the findings predicted by our theory.
5. Preliminary Lemmas
- (a)
- Given , , the assumptions and as well as and , it follows that for any arbitrarily small positive number η, a constant exists, which is dependent on , such that the following inequality holds:
- (b)
- Assume that and when , we haveIn this case, by setting , the proof for (b) is directly obtainable from the Lemma 4.
- (a)
- Let , where can be eithor or . Let , where or . According to conditions (H0)–(H4), it follows that and .
- (b)
- Based on (H0)–(H4), we conclude that , , , and .
6. Proof of Main Results
6.1. Proof of Strong Consistency
6.2. Proof of Asymptotic Normality
7. Appendix Proofs of Lemmas
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Engle, R.F.; Granger, C.W.J.; Rice, J.; Weiss, A. Semiparametric estimates of the relation between weather and electricity sales. J. Am. Stat. Assoc. 1986, 81, 310–320. [Google Scholar] [CrossRef]
- Roozbeh, M.; Arashi, M. Least-trimmed squares: Asymptotic normality of robust estimator in semiparametric regression models. J. Stat. Comput. Simul. 2017, 87, 1130–1147. [Google Scholar] [CrossRef]
- Ding, L.W.; Chen, P.; Zhang, Q.; Li, Y.M. Asymptotic normality for wavelet estimators in heteroscedastic semi-parametric model with random errors. J. Syst. Sci. Complex. 2020, 33, 1212–1243. [Google Scholar] [CrossRef]
- Wei, C.; Wu, X. Error variance estimation in partially linear varying coefficient models. Math. Appl. 2008, 21, 378–383. [Google Scholar]
- Fu, F.; Zeng, Z.; Liu, X. Difference-based M-estimator of generalized semiparametric model with NSD errors. J. Inequal. Appl. 2019, 2019, 61. [Google Scholar] [CrossRef]
- Deaton, A. Panel data from time series of cross-sections. J. Econom. 1985, 30, 109–126. [Google Scholar] [CrossRef]
- Chen, P.; Kong, N.; Sung, S.H. Complete convergence for weighted sums of i.i.d. random variables with applications in regression estimation and EV model. Commun. Stat. 2016, 3599–3613. [Google Scholar] [CrossRef]
- You, J.; Zhou, X.; Zhou, Y. Statistical inference for panel data semiparametric partially linear regression models with heteroscedastic errors. J. Multiv. Anal. 2010, 101, 1079–1101. [Google Scholar] [CrossRef]
- Zhang, J.J.; Liang, H.Y.; Amei, A. Asymptotic normality of estimators in heteroscedastic errors-in-variables model. AStA Adv. Stat. Anal. 2014, 98, 165–195. [Google Scholar] [CrossRef]
- Emami, H. Ridge estimation in semiparametric linear measurement error models. Lin. Algebra Appl. 2018, 552, 127–146. [Google Scholar] [CrossRef]
- Miao, Y.W. Moderate deviations for LS estimator in simple linear EV regression model. J. Stat. Plan. Inference 2009, 139, 2263–2272. [Google Scholar] [CrossRef]
- Hu, D.; Chen, P.Y.; Sung, S.H. Strong laws for weighted sums of -mixing random variables and applications in errors-in-variables regression models. Stat. Methods Appl. 2017, 26, 600–617. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Yu, Y.; Hu, H. Asymptotic normality and mean consistency of LS estimators in the errors-in-variables model with dependent errors. Open Math. 2020, 18, 930–947. [Google Scholar] [CrossRef]
- Zou, Y.Y.; Wu, C.X.; Fan, G.L.; Zhang, R.Q. Estimation for a hybrid model of functional and linear measurement errors regression with missing response. Statistics 2022, 56, 271–296. [Google Scholar] [CrossRef]
- Xiao, Y.T.; Li, F.X. Estimation in partially linear varying-coefficient errors-in-variables models with missing response variables. Comput. Stat. 2020, 35, 1637–1658. [Google Scholar] [CrossRef]
- Zou, Y.Y.; Wu, C.X. Statistical inference for the heteroscedastic partially linear varying-coefficient errors-in-variables model with missing censoring indicators. Discret. Dyn. Nat. Soc. 2021, 2021, 1141022. [Google Scholar] [CrossRef]
- Xi, M.M.; Wang, R.; Yu, W.; Shen, Y.; Wang, X.Y. Asymptotic properties for the estimators in heteroscedastic semiparametric EV models with α-mixing errors. Statistics 2021, 54, 1232–1254. [Google Scholar] [CrossRef]
- Zhang, J.J.; Liu, C.L. Asymptotic properties for estimators in a semiparametric EV model with NA errors and missing responses. Discret. Dyn. Nat. Soc. 2022, 2022, 4862820. [Google Scholar] [CrossRef]
- Zhang, J.J.; Yang, X. Statistical inference for estimators in a semiparametric EV model with linear process errors and missing responses. Math. Probl. Eng. 2023, 2023, 2547329. [Google Scholar] [CrossRef]
- Liang, H.Y.; Fan, G.L. Berry-Esseen type bounds of estimators in a semiparametric model with linear process errors. J. Multiv. Anal. 2009, 100, 1–15. [Google Scholar] [CrossRef]
- Liang, H.Y.; Baek, J.I. Convergence for weighted sums of negatively associated random variables. Stat. Probab. Lett. 2004, 41, 883–894. [Google Scholar] [CrossRef]
- Wang, Q.H.; Sun, Z.H. Estimation in partially linear models with missing responses at random. J. Multiv. Anal. 2007, 98, 1470–1493. [Google Scholar] [CrossRef]
- Härdle, W.; Liang, H.; Gao, J.T. Partial Linear Models; Physica-Verlag: Heidelberg, Germany, 2000. [Google Scholar]
- Xu, B. The convergence of the weighted sum for strong mixing dependent variable and its application. J. Math. 2002, 45, 1025–1034. [Google Scholar]
- Volkonskii, V.A.; Rozanov, Y.A. Some limit theorems for random functions. Theory Probab. 1959, 4, 178–197. [Google Scholar] [CrossRef]
- Hall, P.; Heyde, C.C. Martingale Limit Theory and Its Applications; Academic Press: Cambridge, MA, USA, 1980. [Google Scholar]
- Miao, Y.; Yang, G.; Shen, L. The central limit theorem for LS estimator in simple linear EV regression models. Theory Methods 2007, 36, 2263–2272. [Google Scholar] [CrossRef]
- Zhang, J.J.; Liang, H.Y. Asymptotic normality of estimators in heteroscedastic semi-parametric model with strong mixing errors. Commun. Stat. Theory Methods 2012, 41, 2172–2201. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | p | ||||||
|---|---|---|---|---|---|---|---|
| 100 | 0.1 | ||||||
| 300 | 0.1 | ||||||
| 500 | 0.1 | ||||||
| 100 | 0.25 | ||||||
| 300 | 0.25 | ||||||
| 500 | 0.25 | ||||||
| 100 | 0.5 | ||||||
| 300 | 0.5 | ||||||
| 500 | 0.5 |
| n | p | ||||||
|---|---|---|---|---|---|---|---|
| 100 | 0.1 | ||||||
| 300 | 0.1 | ||||||
| 500 | 0.1 | ||||||
| 100 | 0.25 | ||||||
| 300 | 0.25 | ||||||
| 500 | 0.25 | ||||||
| 100 | 0.5 | ||||||
| 300 | 0.5 | ||||||
| 500 | 0.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Yan, H.; Hu, T. Symmetrical Convergence Rates and Asymptotic Properties of Estimators in a Semi-Parametric Errors-in-Variables Model with Strong Mixing Errors and Missing Responses. Symmetry 2024, 16, 1544. https://doi.org/10.3390/sym16111544
Zhang J, Yan H, Hu T. Symmetrical Convergence Rates and Asymptotic Properties of Estimators in a Semi-Parametric Errors-in-Variables Model with Strong Mixing Errors and Missing Responses. Symmetry. 2024; 16(11):1544. https://doi.org/10.3390/sym16111544
Chicago/Turabian StyleZhang, Jingjing, Haiqin Yan, and Tingting Hu. 2024. "Symmetrical Convergence Rates and Asymptotic Properties of Estimators in a Semi-Parametric Errors-in-Variables Model with Strong Mixing Errors and Missing Responses" Symmetry 16, no. 11: 1544. https://doi.org/10.3390/sym16111544
APA StyleZhang, J., Yan, H., & Hu, T. (2024). Symmetrical Convergence Rates and Asymptotic Properties of Estimators in a Semi-Parametric Errors-in-Variables Model with Strong Mixing Errors and Missing Responses. Symmetry, 16(11), 1544. https://doi.org/10.3390/sym16111544