
Estimating Unknown Parameters and Disturbance Term in Uncertain Regression Models by the Principle of Least Squares


Abstract
1. Introduction
- This paper constructed a statistical invariant with symmetric uncertainty distribution based on the observation data and disturbance term, and applied the least squares principle to estimate unknown parameters and the uncertain disturbance term in the uncertain regression model.
- A numerical algorithm was designed to solve the specific estimator.
- Two numerical examples and an empirical case study of forecasting of electrical power output were provided to illustrate the method proposed in this paper.
2. Estimating Unknown Parameters and Disturbance Term in Uncertain Regression Model
2.1. Least Squares Estimator
2.2. Least Squares Estimation of Uncertain Regression Model
| Algorithm 1: Numerical solutions of least squares estimators. |
| Step 0: Input observational data
|
| Step 2: For each and , compute by
|
| Step 4: Set
|
| Step 5: If , then go to Step 4. |
| Step 6: Find and such that reaches its minimum value. |
| Step 7: Output and . |
3. Hypothesis Test and Forecast
3.1. Uncertain Hypothesis Test
3.2. Point Forecast and Interval Forecast
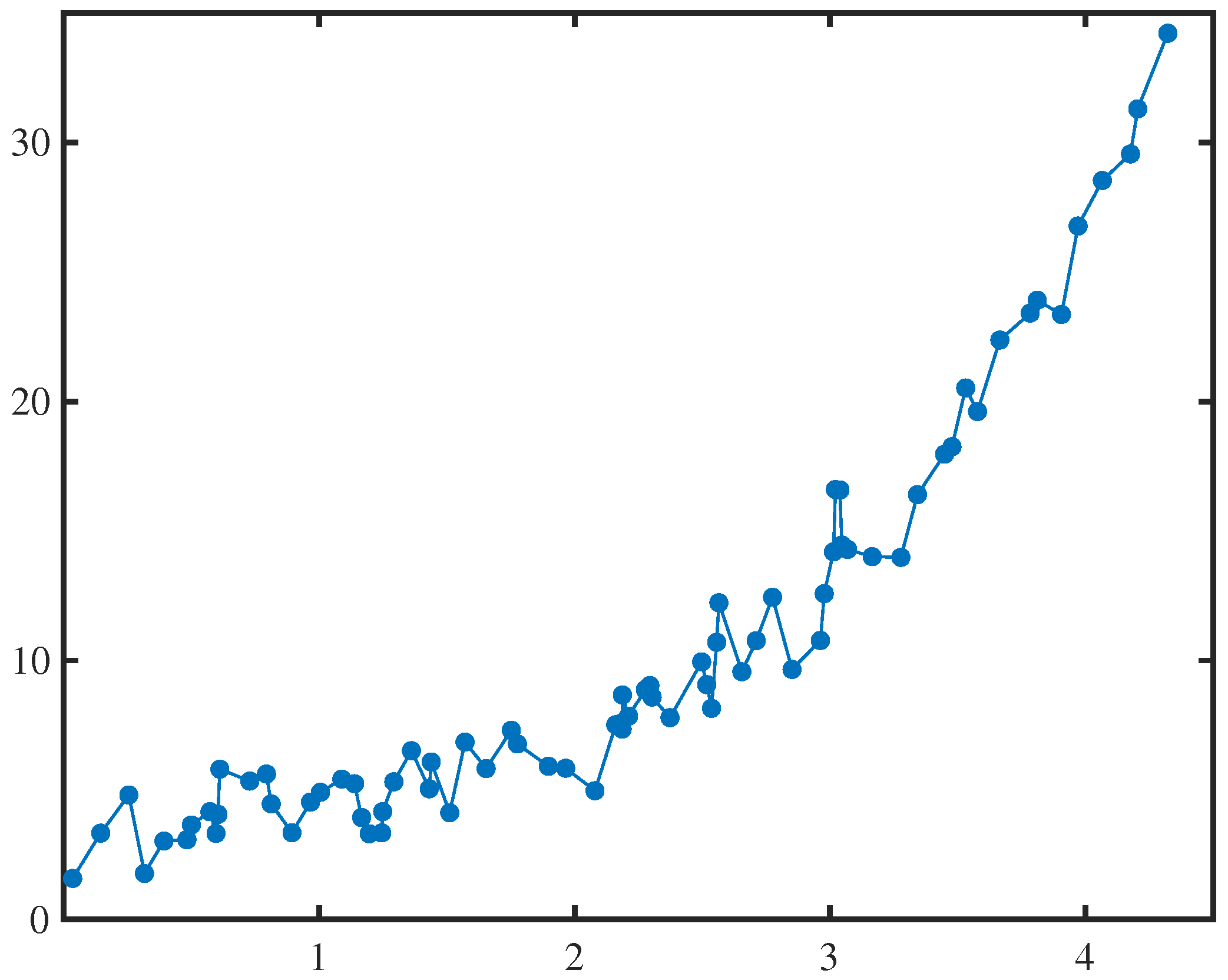
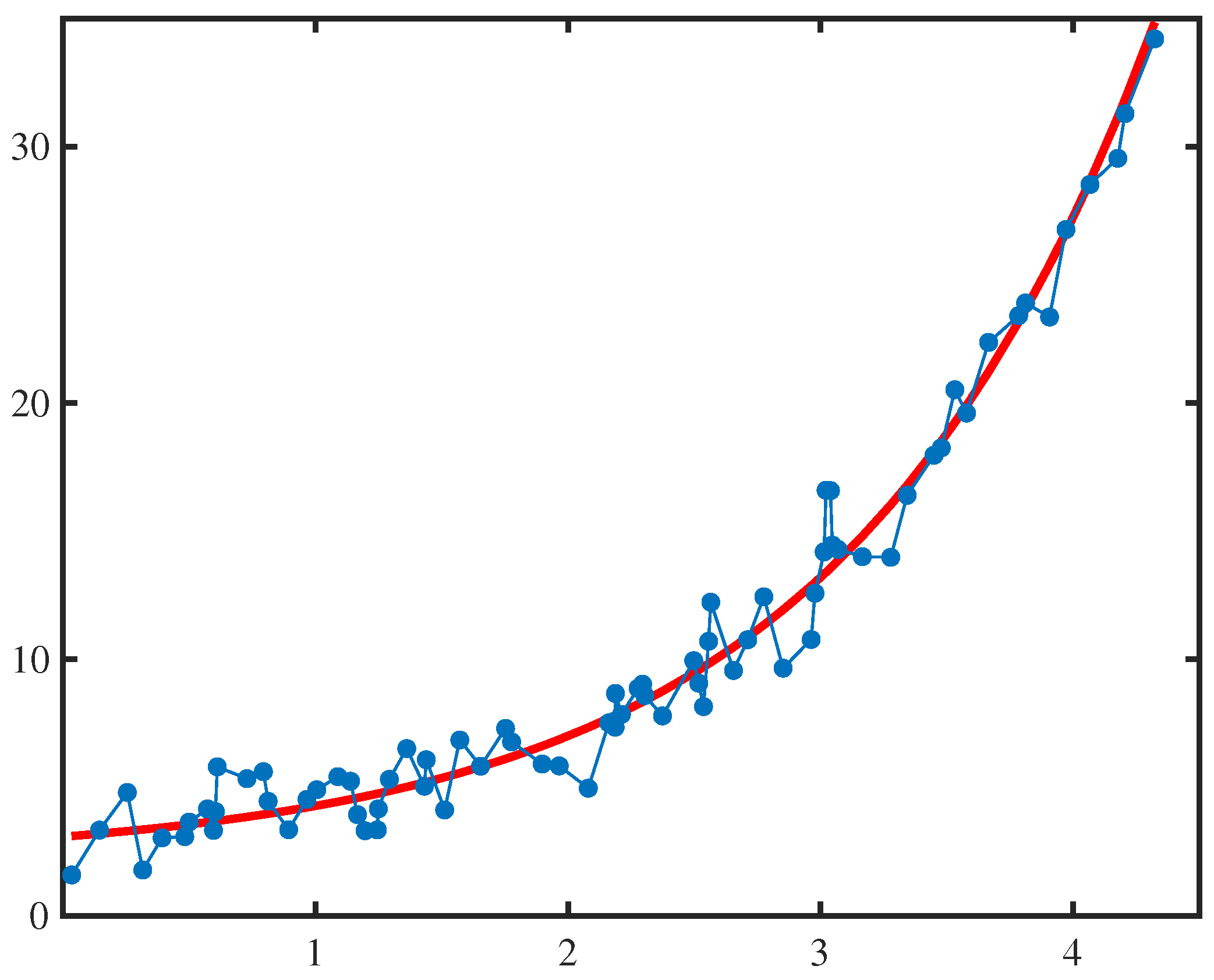
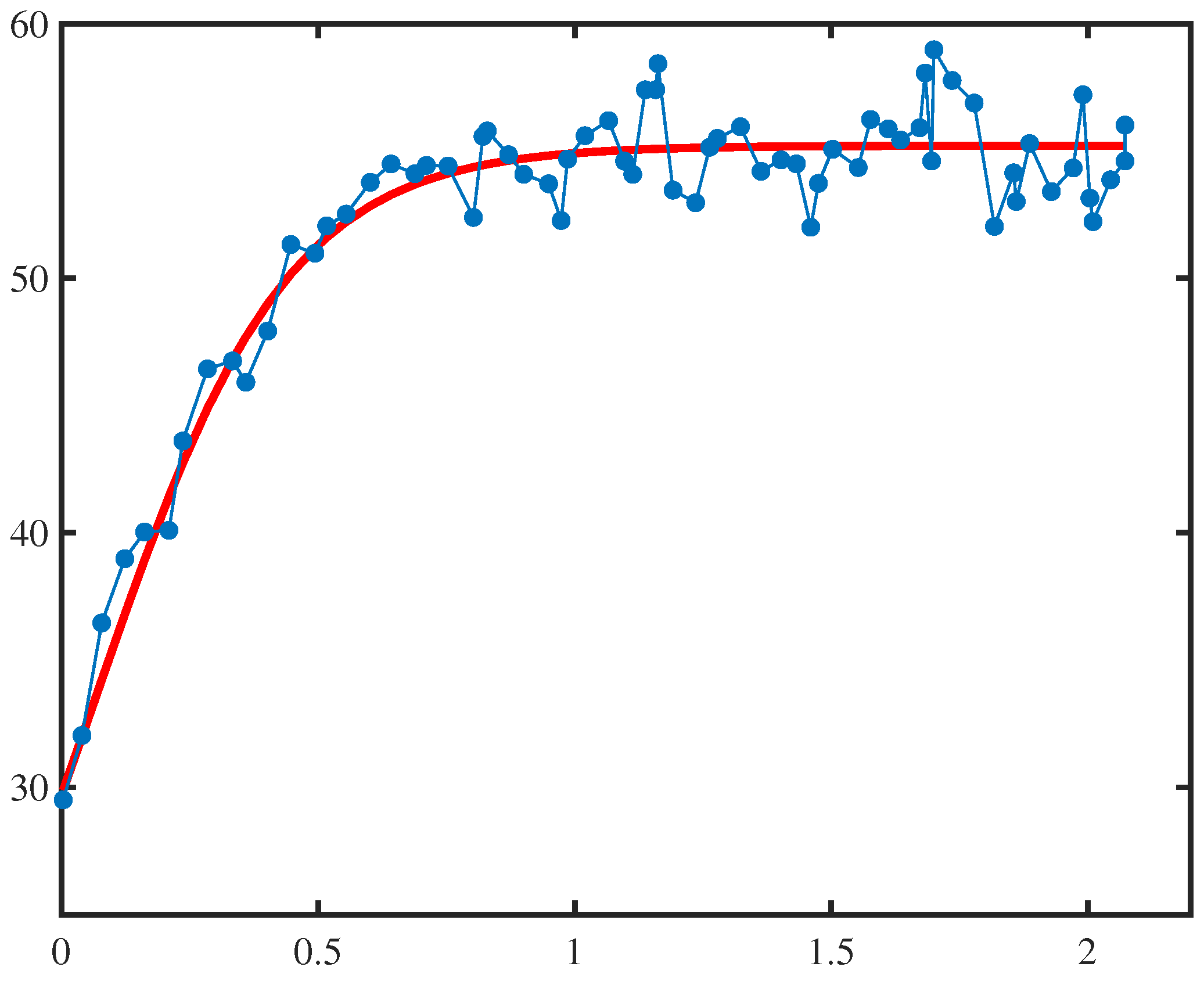
4. Numerical Examples
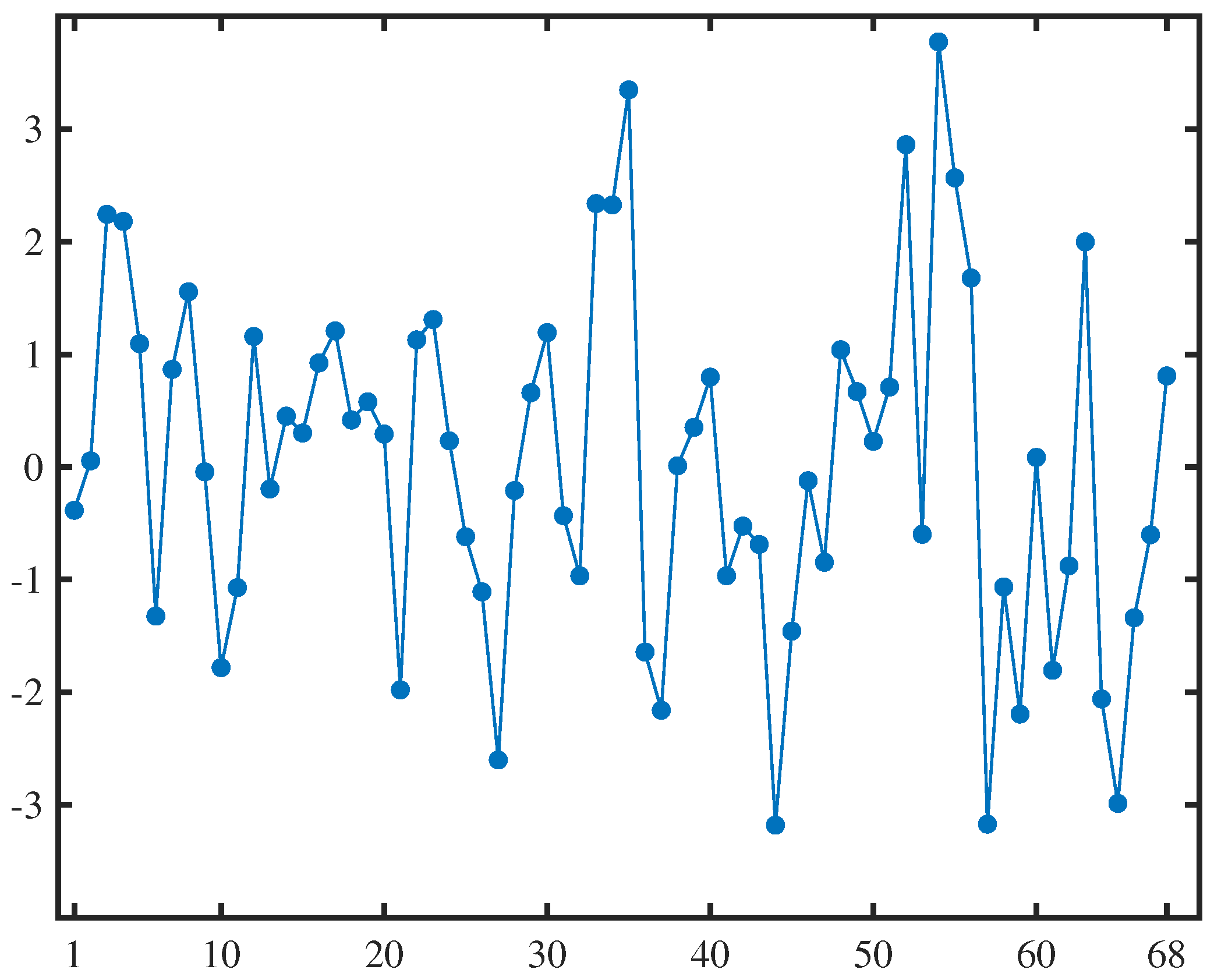
5. Case Study: Forecast of Electrical Power Output
5.1. Uncertain Electrical Power Output Model
5.2. Uncertain Hypothesis Test and Electrical Power Output Forecast
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Galton, F. Family likeness in stature. Proc. R. Soc. Lond. 1886, 40, 42–73. [Google Scholar]
- Berkson, J. Application of the logistic function to bio-assay. J. Am. Stat. Assoc. 1944, 39, 357–365. [Google Scholar]
- Hoerl, A.; Kennard, R. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Stat. Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Freund, R.; Wilson, W.; Sa, P. Regression Analysis; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Sen, A.; Srivastava, M. Regression Analysis: Theory, Methods, Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Chatterjee, S.; Simonoff, J. Handbook of Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Liu, B. Uncertainty Theory, 2nd ed.; Springer: Berlin, Germany, 2007. [Google Scholar]
- Liu, B. Some research problems in uncertainty theory. J. Uncertain Syst. 2009, 3, 3–10. [Google Scholar]
- Yao, K.; Liu, B. Uncertain regression analysis: An approach for imprecise observations. Soft Comput. 2018, 22, 5579–5582. [Google Scholar] [CrossRef]
- Ye, T.; Liu, Y.H. Multivariate uncertain regression model with imprecise observations. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 4941–4950. [Google Scholar] [CrossRef]
- Chen, D. Uncertain regression model with autoregressive time series errors. Soft Comput. 2021, 25, 14549–14559. [Google Scholar] [CrossRef]
- Chen, D. Uncertain regression model with moving average time series errors. Commun. Stat. Theory Methods 2023, 52, 7632–7646. [Google Scholar] [CrossRef]
- Jiang, B.; Ye, T. Uncertain panel regression analysis with application to the impact of urbanization on electricity intensity. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 13017–13029. [Google Scholar] [CrossRef]
- Ding, J.; Zhang, Z. Statistical inference on uncertain nonparametric regression model. Fuzzy Optim. Decis. Mak. 2021, 20, 451–469. [Google Scholar] [CrossRef]
- Liu, Z.; Yang, Y. Least absolute deviations estimation for uncertain regression with imprecise observations. Fuzzy Optim. Decis. Mak. 2020, 19, 33–52. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Uncertain maximum likelihood estimation with application to uncertain regression analysis. Soft Comput. 2020, 24, 9351–9360. [Google Scholar] [CrossRef]
- Chen, D. Tukey’s biweight estimation for uncertain regression model with imprecise observations. Soft Comput. 2020, 24, 16803–16809. [Google Scholar] [CrossRef]
- Liu, Y. Moment estimation for uncertain regression model with application to factors analysis of grain yield. Commun. Stat. Simul. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Xie, W.; Wu, J.; Sheng, Y. Uncertain regression model based on Huber loss function. J. Intell. Fuzzy Syst. 2023, 45, 1169–1178. [Google Scholar] [CrossRef]
- Lio, W.; Liu, B. Residual and confidence interval for uncertain regression model with imprecise observations. J. Intell. Fuzzy Syst. 2018, 35, 2573–2583. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, B. A modified uncertain maximum likelihood estimation with applications in uncertain statistics. Commun. Stat. Theory Methods 2024, 53, 6649–6670. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, B. Estimation of uncertainty distribution function by the principle of least squares. Commun. Stat. Theory Methods 2023, 1–18. [Google Scholar] [CrossRef]
- Liu, Z. Uncertain growth model for the cumulative number of COVID-19 infections in China. Fuzzy Optim. Decis. Mak. 2021, 20, 229–242. [Google Scholar] [CrossRef]
- Yang, L. Analysis of death toll from COVID-19 in China with uncertain time series and uncertain regression analysis. J. Uncertain Syst. 2022, 15, 2243007. [Google Scholar] [CrossRef]
- Ding, C.; Ye, T. Uncertain logistic growth model for confirmed COVID-19 cases in Brazil. J. Uncertain Syst. 2022, 15, 2243008. [Google Scholar] [CrossRef]
- Li, H.; Yang, X.; Ni, Y. Uncertain yield-density regression model with application to parsnips. Int. J. Gen. Syst. 2023, 52, 777–801. [Google Scholar] [CrossRef]
- Liu, Y. Analysis of China’s population with uncertain statistics. J. Uncertain Syst. 2022, 15, 2243001. [Google Scholar] [CrossRef]
- Gao, C.; Liu, Y.; Ning, Y.; Gao, H.; Hu, B. Analysis of the number of students in general colleges and universities in China with uncertain statistics. Soft Comput. 2023. [Google Scholar] [CrossRef]
- Chen, D.; Yang, X. Maximum likelihood estimation for uncertain autoregressive model with application to carbon dioxide emissions. J. Intell. Fuzzy Syst. 2021, 40, 1391–1399. [Google Scholar] [CrossRef]
- Ye, T.; Liu, B. Uncertain significance test for regression coefficients with application to regional economic analysis. Commun. Stat.-Theory Methods 2023, 52, 7271–7288. [Google Scholar] [CrossRef]
- Jia, Y.; Tang, H. Modeling China’s per capita disposable income by uncertain statistics. J. Uncertain Syst. 2023. [Google Scholar] [CrossRef]
- Ye, T.; Liu, B. Uncertain hypothesis test with application to uncertain regression analysis. Fuzzy Optim. Decis. Mak. 2022, 21, 157–174. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | y | x | y | x | y | x | y |
|---|---|---|---|---|---|---|---|
| 0.0350 | 1.5892 | 1.1663 | 3.9409 | 2.1875 | 8.6692 | 3.0388 | 16.5826 |
| 0.1450 | 3.3379 | 1.1963 | 3.3124 | 2.2113 | 7.8528 | 3.0463 | 14.4552 |
| 0.2550 | 4.8082 | 1.2450 | 3.3465 | 2.2775 | 8.8732 | 3.0688 | 14.2875 |
| 0.3163 | 1.7829 | 1.2488 | 4.1678 | 2.2950 | 9.0323 | 3.1650 | 14.0064 |
| 0.3925 | 3.0347 | 1.2925 | 5.3190 | 2.3038 | 8.5864 | 3.2775 | 13.9808 |
| 0.4825 | 3.0839 | 1.3613 | 6.5189 | 2.3738 | 7.7935 | 3.3425 | 16.4002 |
| 0.5000 | 3.6518 | 1.4313 | 5.0478 | 2.4975 | 9.9483 | 3.4488 | 17.9623 |
| 0.5725 | 4.1642 | 1.4388 | 6.0847 | 2.5175 | 9.0674 | 3.4775 | 18.2491 |
| 0.5963 | 3.3266 | 1.5113 | 4.1250 | 2.5363 | 8.1565 | 3.5313 | 20.5180 |
| 0.6038 | 4.0595 | 1.5713 | 6.8535 | 2.5563 | 10.7031 | 3.5775 | 19.6079 |
| 0.6113 | 5.8057 | 1.6538 | 5.8316 | 2.5650 | 12.2296 | 3.6650 | 22.3669 |
| 0.7288 | 5.3459 | 1.7525 | 7.3063 | 2.6550 | 9.5657 | 3.7838 | 23.4053 |
| 0.7938 | 5.6176 | 1.7763 | 6.7783 | 2.7113 | 10.7657 | 3.8113 | 23.9019 |
| 0.8125 | 4.4627 | 1.8975 | 5.9172 | 2.7750 | 12.4397 | 3.9063 | 23.3548 |
| 0.8938 | 3.3543 | 1.9650 | 5.8426 | 2.8513 | 9.6549 | 3.9713 | 26.7689 |
| 0.9663 | 4.5373 | 2.0800 | 4.9724 | 2.9625 | 10.7734 | 4.0663 | 28.5248 |
| 1.0050 | 4.9135 | 2.1613 | 7.5202 | 2.9775 | 12.5799 | 4.1763 | 29.5484 |
| 1.0888 | 5.4231 | 2.1800 | 7.5710 | 3.0138 | 14.1928 | 4.2050 | 31.2873 |
| 1.1388 | 5.2447 | 2.1863 | 7.3537 | 3.0213 | 16.5998 | 4.3225 | 34.2073 |
| x | y | x | y | x | y | x | y |
|---|---|---|---|---|---|---|---|
| 0.0030 | 29.5059 | 0.6885 | 54.1126 | 1.1620 | 58.4385 | 1.6830 | 58.0711 |
| 0.0395 | 32.0362 | 0.7110 | 54.4404 | 1.1915 | 53.4652 | 1.6955 | 54.6119 |
| 0.0780 | 36.4589 | 0.7530 | 54.4186 | 1.2355 | 52.9707 | 1.7000 | 58.9852 |
| 0.1230 | 38.9807 | 0.8025 | 52.3946 | 1.2630 | 55.1536 | 1.7355 | 57.7782 |
| 0.1615 | 40.0327 | 0.8210 | 55.5801 | 1.2780 | 55.4998 | 1.7785 | 56.8902 |
| 0.2090 | 40.0993 | 0.8295 | 55.7937 | 1.3230 | 55.9606 | 1.8180 | 52.0411 |
| 0.2360 | 43.6076 | 0.8710 | 54.8597 | 1.3630 | 54.2075 | 1.8555 | 54.1480 |
| 0.2840 | 46.4421 | 0.9005 | 54.0925 | 1.4020 | 54.6567 | 1.8605 | 53.0196 |
| 0.3330 | 46.7559 | 0.9490 | 53.7172 | 1.4320 | 54.4987 | 1.8865 | 55.2992 |
| 0.3590 | 45.9164 | 0.9735 | 52.2714 | 1.4600 | 52.0097 | 1.9290 | 53.4092 |
| 0.4015 | 47.9307 | 0.9860 | 54.6858 | 1.4750 | 53.7355 | 1.9715 | 54.3374 |
| 0.4465 | 51.3303 | 1.0200 | 55.6078 | 1.5025 | 55.0737 | 1.9905 | 57.2144 |
| 0.4935 | 50.9886 | 1.0660 | 56.1994 | 1.5525 | 54.3553 | 2.0040 | 53.1554 |
| 0.5165 | 52.0612 | 1.0970 | 54.6051 | 1.5765 | 56.2438 | 2.0100 | 52.2278 |
| 0.5545 | 52.5257 | 1.1130 | 54.0854 | 1.6110 | 55.8744 | 2.0445 | 53.8768 |
| 0.6015 | 53.7737 | 1.1375 | 57.4118 | 1.6350 | 55.4344 | 2.0725 | 54.6140 |
| 0.6420 | 54.4962 | 1.1580 | 57.4150 | 1.6725 | 55.9188 | 2.0726 | 56.0243 |
| y | y | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 14.96 | 41.76 | 1024.07 | 73.17 | 463.26 | 10.54 | 34.03 | 1018.71 | 74 | 478.77 |
| 25.18 | 62.96 | 1020.04 | 59.08 | 444.37 | 27.71 | 74.34 | 998.14 | 71.85 | 434.2 |
| 5.11 | 39.4 | 1012.16 | 92.14 | 488.56 | 23.11 | 68.3 | 1017.83 | 86.62 | 437.91 |
| 20.86 | 57.32 | 1010.24 | 76.64 | 446.48 | 7.51 | 41.01 | 1024.61 | 97.41 | 477.61 |
| 10.82 | 37.5 | 1009.23 | 96.62 | 473.9 | 26.46 | 74.67 | 1016.65 | 84.44 | 431.65 |
| 26.27 | 59.44 | 1012.23 | 58.77 | 443.67 | 29.34 | 74.34 | 998.58 | 81.55 | 430.57 |
| 15.89 | 43.96 | 1014.02 | 75.24 | 467.35 | 10.32 | 42.28 | 1008.82 | 75.66 | 481.09 |
| 9.48 | 44.71 | 1019.12 | 66.43 | 478.42 | 22.74 | 61.02 | 1009.56 | 79.41 | 445.56 |
| 14.64 | 45 | 1021.78 | 41.25 | 475.98 | 13.48 | 39.85 | 1012.71 | 58.91 | 475.74 |
| 11.74 | 43.56 | 1015.14 | 70.72 | 477.5 | 25.52 | 69.75 | 1010.36 | 90.06 | 435.12 |
| 17.99 | 43.72 | 1008.64 | 75.04 | 453.02 | 21.58 | 67.25 | 1017.39 | 79 | 446.15 |
| 20.14 | 46.93 | 1014.66 | 64.22 | 453.99 | 27.66 | 76.86 | 1001.31 | 69.47 | 436.64 |
| 24.34 | 73.5 | 1011.31 | 84.15 | 440.29 | 26.96 | 69.45 | 1013.89 | 51.47 | 436.69 |
| 25.71 | 58.59 | 1012.77 | 61.83 | 451.28 | 12.29 | 42.18 | 1016.53 | 83.13 | 468.75 |
| 26.19 | 69.34 | 1009.48 | 87.59 | 433.99 | 15.86 | 43.02 | 1012.18 | 40.33 | 466.6 |
| 21.42 | 43.79 | 1015.76 | 43.08 | 462.19 | 13.87 | 45.08 | 1024.42 | 81.69 | 465.48 |
| 18.21 | 45 | 1022.86 | 48.84 | 467.54 | 24.09 | 73.68 | 1014.93 | 94.55 | 441.34 |
| 11.04 | 41.74 | 1022.6 | 77.51 | 477.2 | 20.45 | 69.45 | 1012.53 | 91.81 | 441.83 |
| 14.45 | 52.75 | 1023.97 | 63.59 | 459.85 | 15.07 | 39.3 | 1019 | 63.62 | 464.7 |
| 13.97 | 38.47 | 1015.15 | 55.28 | 464.3 | 32.72 | 69.75 | 1009.6 | 49.35 | 437.99 |
| 17.76 | 42.42 | 1009.09 | 66.26 | 468.27 | 18.23 | 58.96 | 1015.55 | 69.61 | 459.12 |
| 5.41 | 40.07 | 1019.16 | 64.77 | 495.24 | 35.56 | 68.94 | 1006.56 | 38.75 | 429.69 |
| 7.76 | 42.28 | 1008.52 | 83.31 | 483.8 | 18.36 | 51.43 | 1010.57 | 90.17 | 459.8 |
| 27.23 | 63.9 | 1014.3 | 47.19 | 443.61 | 26.35 | 64.05 | 1009.81 | 81.24 | 433.63 |
| 27.36 | 48.6 | 1003.18 | 54.93 | 436.06 | 25.92 | 60.95 | 1014.62 | 48.46 | 442.84 |
| 27.47 | 70.72 | 1009.97 | 74.62 | 443.25 | 8.01 | 41.66 | 1014.49 | 76.72 | 485.13 |
| 14.6 | 39.31 | 1011.11 | 72.52 | 464.16 | 19.63 | 52.72 | 1025.09 | 51.16 | 459.12 |
| 7.91 | 39.96 | 1023.57 | 88.44 | 475.52 | 20.02 | 67.32 | 1012.05 | 76.34 | 445.31 |
| 5.81 | 35.79 | 1012.14 | 92.28 | 484.41 | 10.08 | 40.72 | 1022.7 | 67.3 | 480.8 |
| 30.53 | 65.18 | 1012.69 | 41.85 | 437.89 | 27.23 | 66.48 | 1005.23 | 52.38 | 432.55 |
| 23.87 | 63.94 | 1019.02 | 44.28 | 445.11 | 23.37 | 63.77 | 1013.42 | 76.44 | 443.86 |
| 26.09 | 58.41 | 1013.64 | 64.58 | 438.86 | 18.74 | 59.21 | 1018.3 | 91.55 | 449.77 |
| 29.27 | 66.85 | 1011.11 | 63.25 | 440.98 | 14.81 | 43.69 | 1017.19 | 71.9 | 470.71 |
| 27.38 | 74.16 | 1010.08 | 78.61 | 436.65 | 23.1 | 51.3 | 1011.93 | 80.05 | 452.17 |
| 24.81 | 63.94 | 1018.76 | 44.51 | 444.26 | 10.72 | 41.38 | 1021.6 | 63.77 | 478.29 |
| 12.75 | 44.03 | 1007.29 | 89.46 | 465.86 | 29.46 | 71.94 | 1006.96 | 62.26 | 428.54 |
| 24.66 | 63.73 | 1011.4 | 74.52 | 444.37 | 8.1 | 40.64 | 1020.66 | 89.04 | 478.27 |
| 16.38 | 47.45 | 1010.08 | 88.86 | 450.69 | 27.29 | 62.66 | 1007.63 | 58.02 | 439.58 |
| 13.91 | 39.35 | 1014.69 | 75.51 | 469.02 | 17.1 | 49.69 | 1005.53 | 81.82 | 457.32 |
| 23.18 | 51.3 | 1012.04 | 78.64 | 448.86 | 11.49 | 44.2 | 1018.79 | 91.14 | 475.51 |
| 22.47 | 47.45 | 1007.62 | 76.65 | 447.14 | 23.69 | 65.59 | 1010.85 | 88.92 | 439.66 |
| 13.39 | 44.85 | 1017.24 | 80.44 | 469.18 | 13.51 | 40.89 | 1011.03 | 84.83 | 471.99 |
| 9.28 | 41.54 | 1018.33 | 79.89 | 482.8 | 9.64 | 39.35 | 1015.1 | 91.76 | 479.81 |
| 11.82 | 42.86 | 1014.12 | 88.28 | 476.7 | 25.65 | 78.92 | 1010.83 | 86.56 | 434.78 |
| 10.27 | 40.64 | 1020.63 | 84.6 | 474.99 | 21.59 | 61.87 | 1011.18 | 57.21 | 446.58 |
| 22.92 | 63.94 | 1019.28 | 42.69 | 444.22 | 27.98 | 58.33 | 1013.92 | 54.25 | 437.76 |
| 16 | 37.87 | 1020.24 | 78.41 | 461.33 | 18.8 | 39.72 | 1001.24 | 63.8 | 459.36 |
| 21.22 | 43.43 | 1010.96 | 61.07 | 448.06 | 18.28 | 44.71 | 1016.99 | 33.71 | 462.28 |
| 13.46 | 44.71 | 1014.51 | 50 | 474.6 | 13.55 | 43.48 | 1016.08 | 67.25 | 464.33 |
| 9.39 | 40.11 | 1029.14 | 77.29 | 473.05 | 22.99 | 46.21 | 1010.71 | 60.11 | 444.36 |
| 31.07 | 73.5 | 1010.58 | 43.66 | 432.06 | 23.94 | 59.39 | 1014.32 | 74.55 | 438.64 |
| 12.82 | 38.62 | 1018.71 | 83.8 | 467.41 | 13.74 | 34.03 | 1018.69 | 67.34 | 470.49 |
| 32.57 | 78.92 | 1011.6 | 66.47 | 430.12 | 21.3 | 41.1 | 1001.86 | 42.75 | 455.13 |
| 8.11 | 42.18 | 1014.82 | 93.09 | 473.62 | 27.54 | 66.93 | 1017.06 | 55.2 | 450.22 |
| 13.92 | 39.39 | 1012.94 | 80.52 | 471.81 | 24.81 | 63.73 | 1009.34 | 83.61 | 440.43 |
| 23.04 | 59.43 | 1010.23 | 68.99 | 442.99 | 4.97 | 42.85 | 1014.02 | 88.78 | 482.98 |
| 27.31 | 64.44 | 1014.65 | 57.27 | 442.77 | 15.22 | 50.88 | 1014.19 | 100.12 | 460.44 |
| 5.91 | 39.33 | 1010.18 | 95.53 | 491.49 | 23.88 | 54.2 | 1012.81 | 64.52 | 444.97 |
| 25.26 | 61.08 | 1013.68 | 71.72 | 447.46 | 33.01 | 68.67 | 1005.2 | 51.41 | 433.94 |
| 27.97 | 58.84 | 1002.25 | 57.88 | 446.11 | 25.98 | 73.18 | 1012.28 | 85.78 | 439.73 |
| 26.08 | 52.3 | 1007.03 | 63.34 | 442.44 | 28.18 | 73.88 | 1005.89 | 75.41 | 434.48 |
| 29.01 | 65.71 | 1013.61 | 48.07 | 446.22 | 21.67 | 60.84 | 1017.93 | 81.63 | 442.33 |
| 12.18 | 40.1 | 1016.67 | 91.87 | 471.49 | 17.67 | 45.09 | 1014.26 | 51.92 | 457.67 |
| 13.76 | 45.87 | 1008.89 | 87.27 | 463.5 | 21.37 | 57.76 | 1018.8 | 70.12 | 454.66 |
| 25.5 | 58.79 | 1016.02 | 64.4 | 440.01 | 28.69 | 67.25 | 1017.71 | 53.83 | 432.21 |
| 28.26 | 65.34 | 1014.56 | 43.4 | 441.03 | 16.61 | 43.77 | 1012.25 | 77.23 | 457.66 |
| 21.39 | 62.96 | 1019.49 | 72.24 | 452.68 | 27.91 | 63.76 | 1010.27 | 65.67 | 435.21 |
| 7.26 | 40.69 | 1020.43 | 90.22 | 474.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Liu, Y.; Shi, H. Estimating Unknown Parameters and Disturbance Term in Uncertain Regression Models by the Principle of Least Squares. Symmetry 2024, 16, 1182. https://doi.org/10.3390/sym16091182
Wang H, Liu Y, Shi H. Estimating Unknown Parameters and Disturbance Term in Uncertain Regression Models by the Principle of Least Squares. Symmetry. 2024; 16(9):1182. https://doi.org/10.3390/sym16091182
Chicago/Turabian StyleWang, Han, Yang Liu, and Haiyan Shi. 2024. "Estimating Unknown Parameters and Disturbance Term in Uncertain Regression Models by the Principle of Least Squares" Symmetry 16, no. 9: 1182. https://doi.org/10.3390/sym16091182
APA StyleWang, H., Liu, Y., & Shi, H. (2024). Estimating Unknown Parameters and Disturbance Term in Uncertain Regression Models by the Principle of Least Squares. Symmetry, 16(9), 1182. https://doi.org/10.3390/sym16091182