
On a Randomly Censoring Scheme for Generalized Logistic Distribution with Applications


Abstract
1. Introduction
2. Random Censoring Model
3. Classical Estimation
3.1. Point Estimation
3.2. Asymptotic Confidence Interval
4. Bayesian Estimation
4.1. Priors Information
4.2. MCMC Posterior Computation
- Set and begin with the initial values for the parameters , , and , which are denoted as , , and , respectively. Select a value for M, which represents the burn-in period.
- Utilizing a gamma distribution with parameters , determine the value of .
- Utilizing a gamma distribution with parameters , determine the value of .
- The posterior densities for in Equation (23) do not analytically simplify into any well-known distributions, making direct sampling with conventional methods infeasible. Therefore, we recommend using the M-H technique with a normal proposal distribution to generate random numbers from these distributions (see Neal [29]).
- (i)
- Determine the probability of acceptance:
- (ii)
- Using a uniform distribution over the interval , create random numbers u.
- (iii)
- Accept the suggestion and put if . If not, set and keep the previous value.
- Set .
- To acquire the parameter values , where , repeat Steps 2 through 5 a total of N times.
- In order to find the CRIs for , , and , sort the parameter values , and , where , in ascending order. Therefore, are the CRIs where .
- Under the SE loss function, the Bayes estimate for the parameter can be calculated using the following formula:The estimates are obtained using the GE loss function as follows:
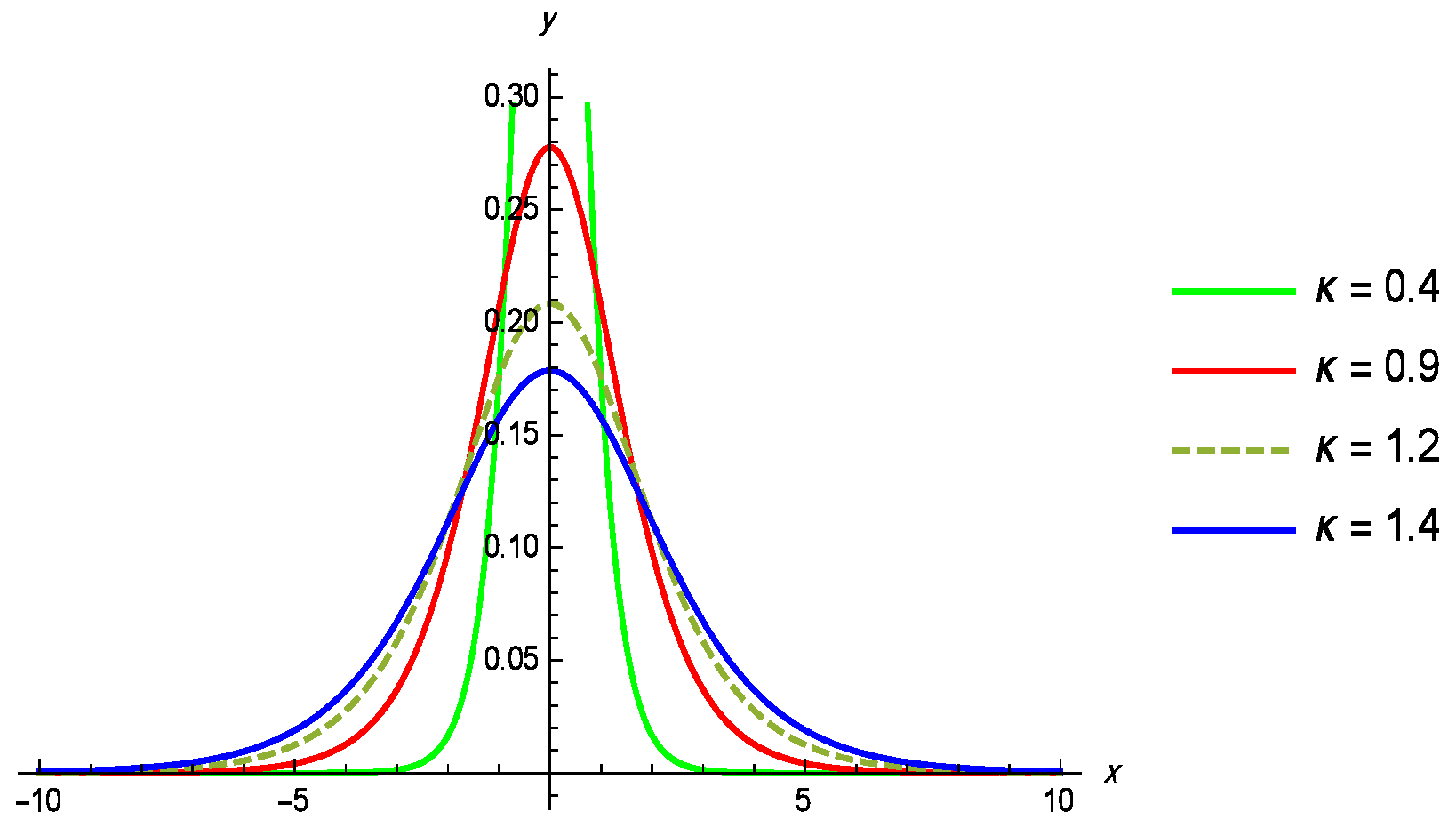
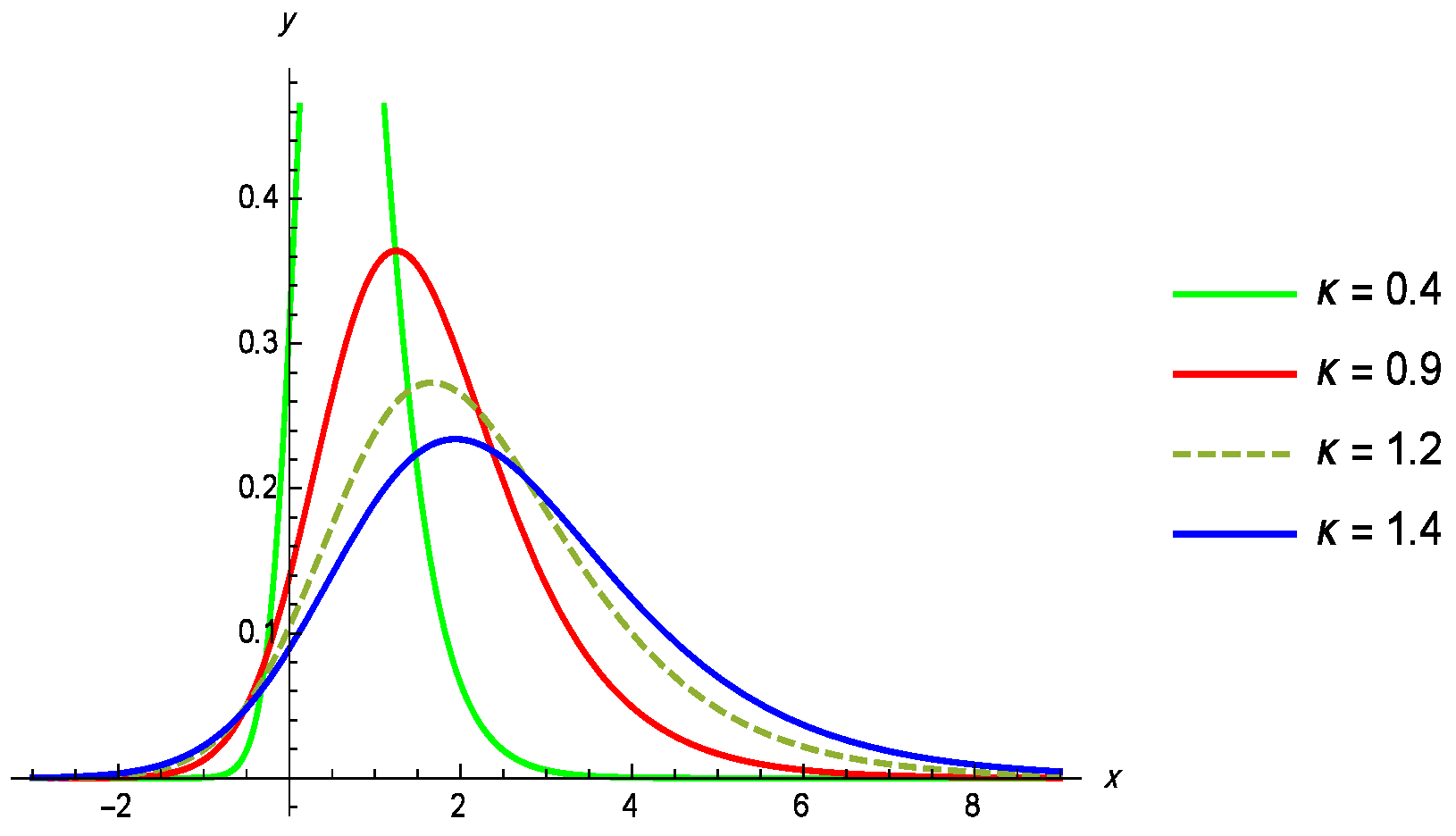
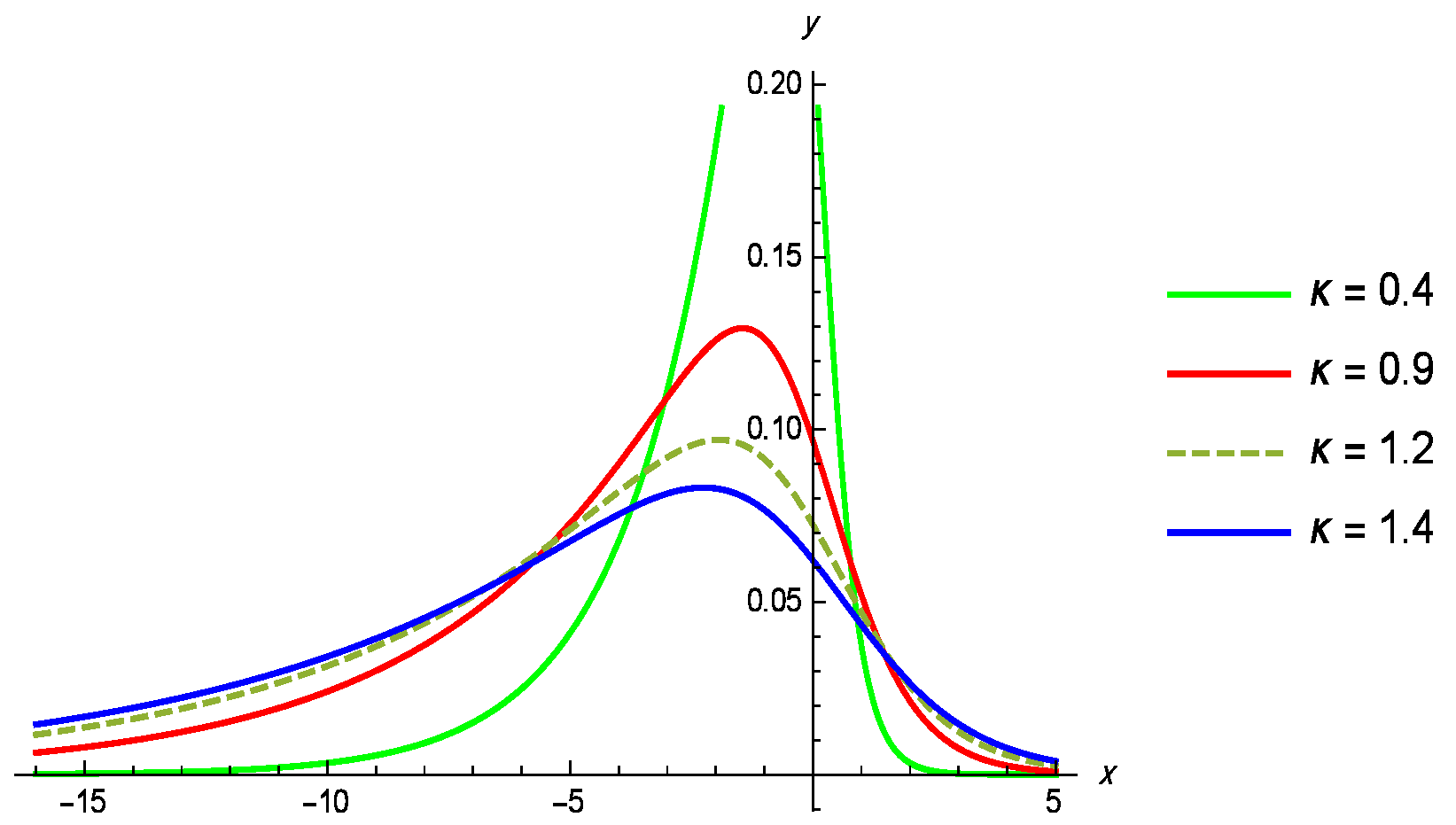
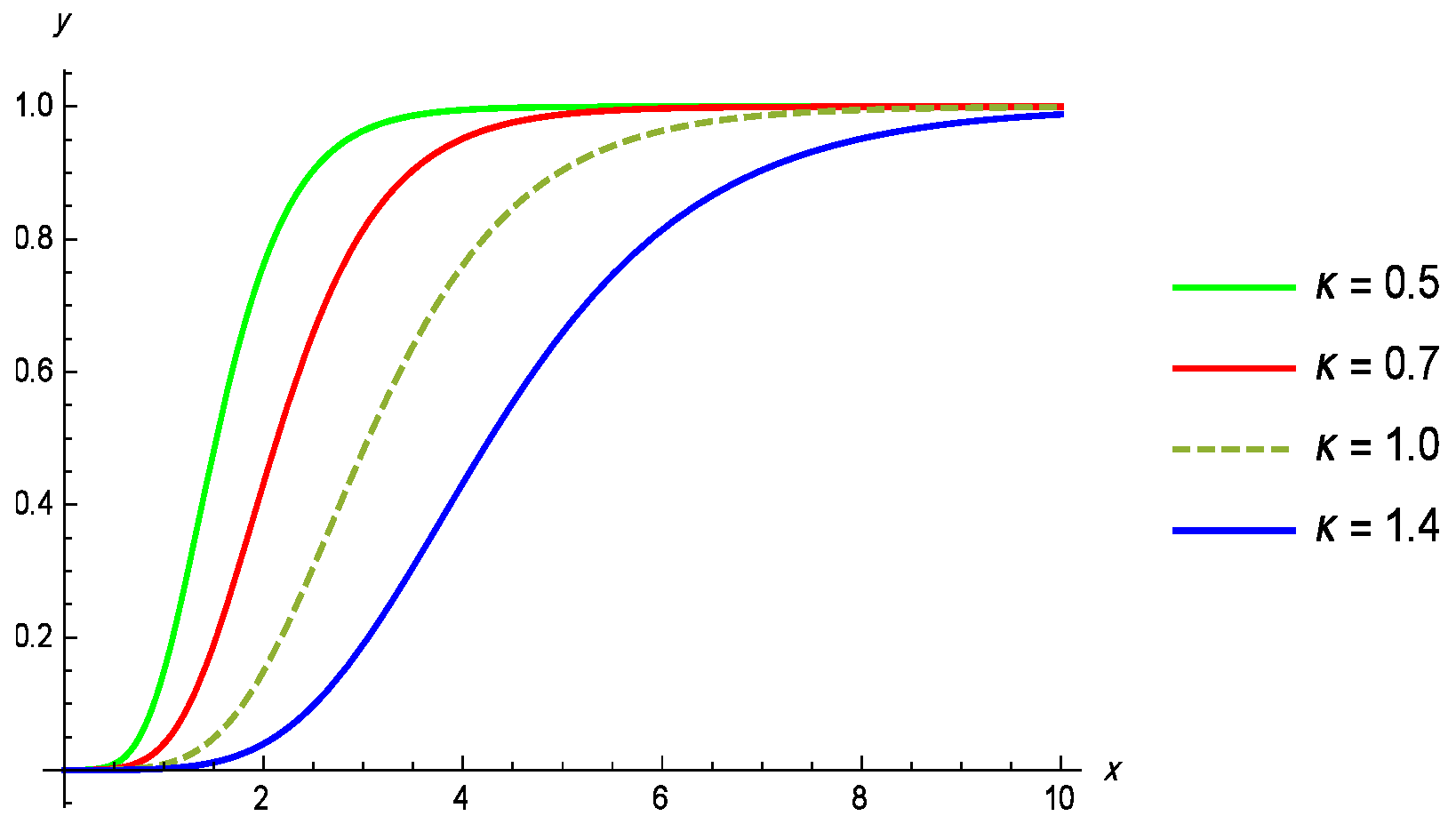
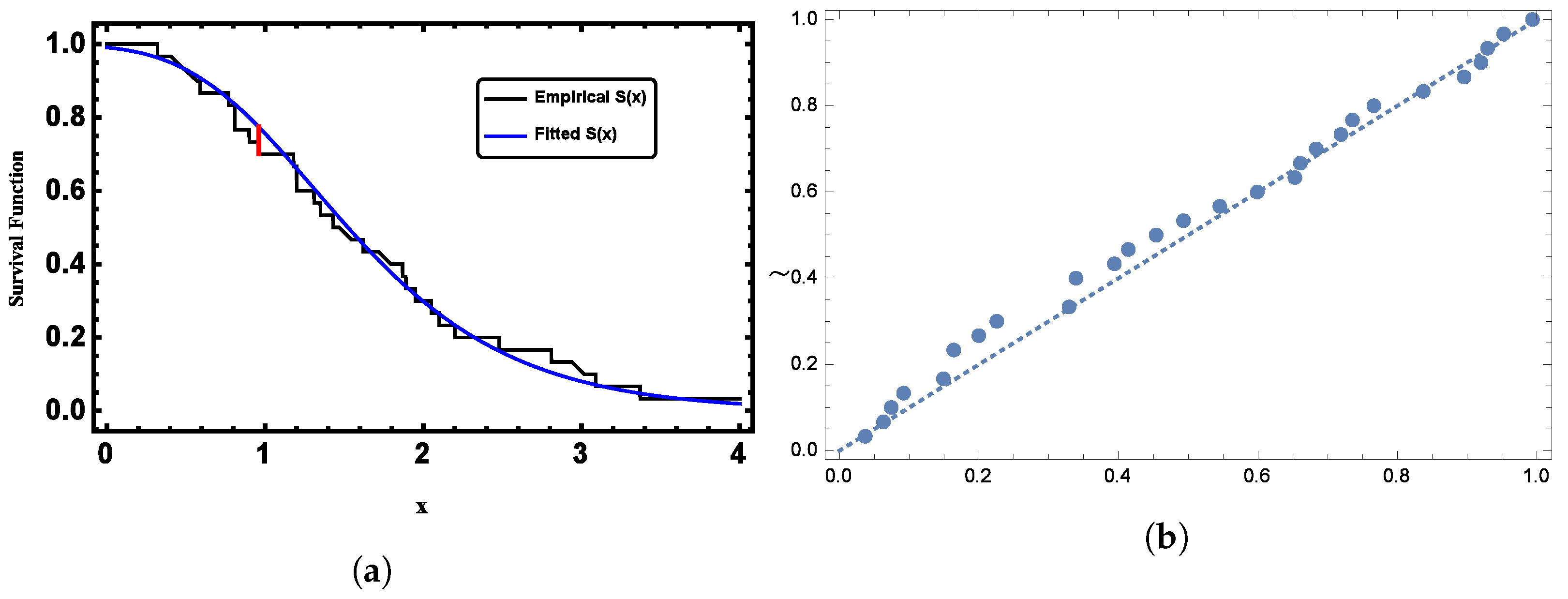
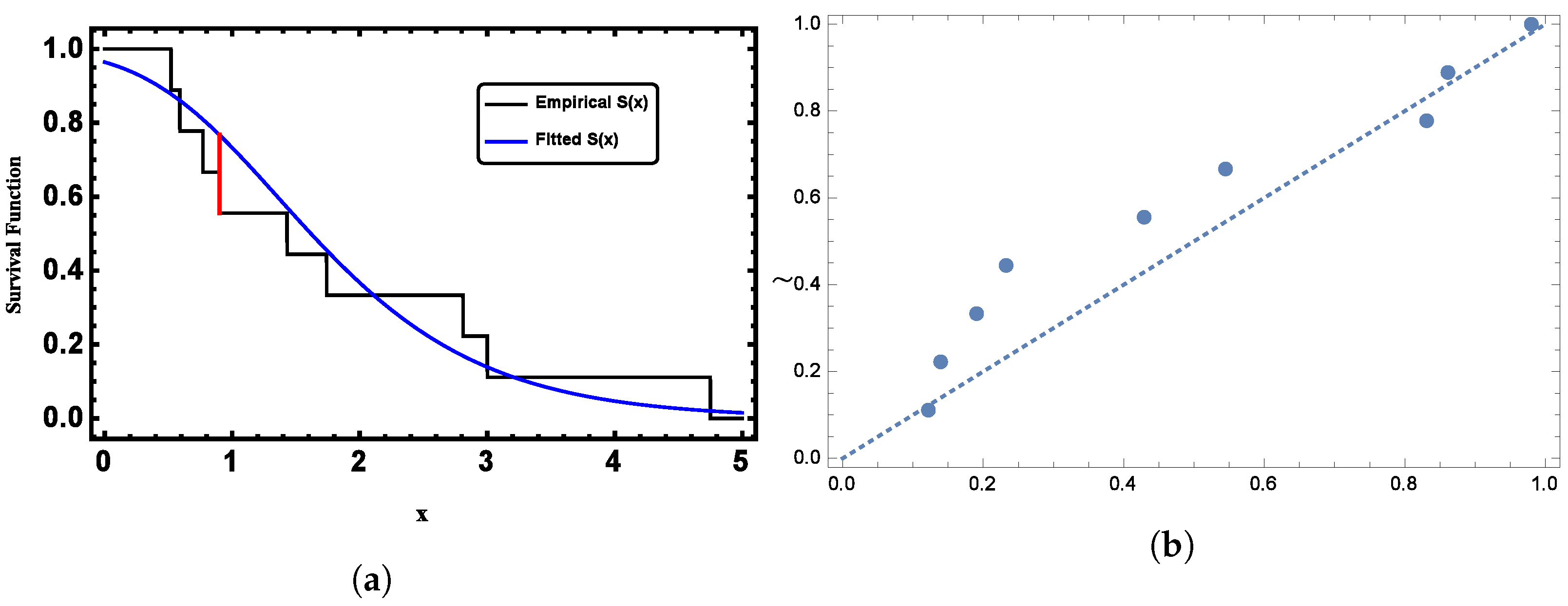
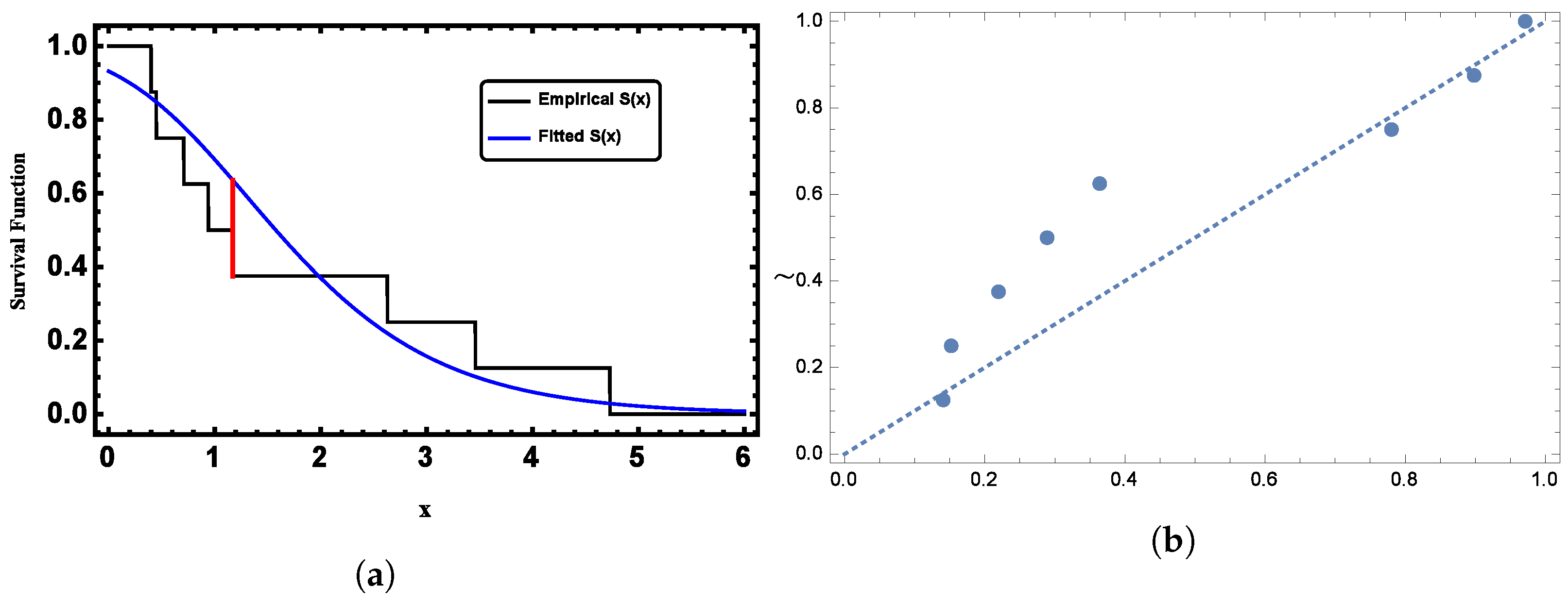
5. Application to Random Censored Data
5.1. Dataset I
5.2. Dataset II
6. Simulation Study
- The ARB decreases as the sample size increases.
- The ARB is lower in the Bayesian approach compared to the classical approach, indicating that the MCMC method performs better than MLE.
- It was observed that the length of the ACI was greater than that of the Bayesian intervals.
- The ARB was lower in the Bayesian approach under the GE loss function compared to the SE loss function, suggesting that the GE method outperforms the SE method.
7. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gilbert, J.P. Random Censorship. Ph.D. Thesis, University of Chicago, Chicago, IL, USA, 1962. [Google Scholar]
- Breslow, N.; Crowley, J. A large sample study of the life table and product limit estimates under random censorship. Ann. Stat. 1974, 2, 437–453. [Google Scholar] [CrossRef]
- Koziol, J.; Green, S. A Cramer–von Mises statistic for randomly censored data. Biometrika 1976, 633, 465–474. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Awadhi, S. Maximum likelihood estimation of Burr XII distribution parameters under random censoring. J. App. Stat. 2002, 29, 955–965. [Google Scholar] [CrossRef]
- Liang, T. Empirical Bayes testing for uniform distributions with random censoring. J. Stat. Theory Pract. 2008, 2, 633–649. [Google Scholar] [CrossRef]
- Saleem, M.; Aslam, M. On Bayesian analysis of the Rayleigh survival time assuming the random censor time. Pak. J. Stat. 2009, 25, 71–82. [Google Scholar]
- Danish, M.Y.; Aslam, M. Bayesian inference for the randomly censored Weibull distribution. J. Stat. Comput. Simul. 2014, 84, 215–230. [Google Scholar] [CrossRef]
- Vivekanand, H.K.; Kumar, K. Estimation in Maxwell distribution with randomly censored data. J. Stat. Comput. Simul. 2015, 85, 3560–3578. [Google Scholar]
- Garg, R.; Dube, M.; Kumar, K.; Krishna, H. On randomly censored generalized inverted exponential distribution. Am. J. Math. Manag. Sci. 2016, 35, 361–379. [Google Scholar] [CrossRef]
- Krishna, H.; Goel, N. Maximum likelihood and Bayes estimation in randomly censored geometric distribution. J. Probab. Stat. 2017, 2017, 4860167. [Google Scholar] [CrossRef]
- Krishna, H.; Goel, N. Classical and Bayesian inference in two parameter exponential distribution with randomly censored data. Comput. Stat. 2018, 33, 249–275. [Google Scholar] [CrossRef]
- Kumar, K.; Kumar, I. Estimation in inverse Weibull distribution based on randomly censored data. Statistica 2019, 79, 47–74. [Google Scholar]
- Garg, R.; Dube, M.; Krishna, H. Estimation of parameters and reliability characteristics in Lindley distribution using randomly censored data. Stat. Opt. Inform. Comput. 2020, 8, 80–97. [Google Scholar] [CrossRef]
- Ajmal, M.; Danish, M.Y.; Arshad, I.A. Objective Bayesian analysis for Weibull distribution with application to random censorship model. J. Stats. Comput. Simul. 2022, 92, 43–59. [Google Scholar] [CrossRef]
- Goel, N.; Krishna, H. Different methods of estimation in two parameter Geometric distribution with randomly censored data. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 1652–1665. [Google Scholar] [CrossRef]
- Hasaballah, M.M.; Al-Babtain, A.A.; Hossain, M.M.; Bakr, M.E. Theoretical Aspects for Bayesian Predictions Based on Three-Parameter Burr-XII Distribution and Its Applications in Climatic Data. Symmetry 2023, 15, 1552. [Google Scholar] [CrossRef]
- Hasaballah, M.M.; Tashkandy, Y.A.; Balogun, O.S.; Bakr, M.E. Bayesian inference for the inverse Weibull distribution based on symmetric and asymmetric balanced loss functions with application. Eksploat. Niezawodn. Maint. Reliab. 2024, 26, 187158. [Google Scholar] [CrossRef]
- Hasaballah, M.M.; Tashkandy, Y.A.; Balogun, O.S.; Bakr, M.E. Statistical inference of unified hybrid censoring scheme for generalized inverted exponential distribution with application to COVID-19 data. AIP Adv. 2024, 14, 045111. [Google Scholar] [CrossRef]
- Hasaballah, M.M.; Balogun, O.S.; Bakr, M.E. Point and interval estimation based on joint progressive censoring data from two Rayleigh-Weibull distribution with applications. Phys. Scr. 2024, 99, 8. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Leung, M.Y. Order statistics from the type I generalized logistic distribution. Commun. Stat. Simul. Comput. 1988, 17, 25–50. [Google Scholar] [CrossRef]
- Balakrishnan, N. Handbook of the Logistic Distribution, 2nd ed.; Marcel Dekker: New York, NY, USA, 2010; pp. 50–77. [Google Scholar]
- Gupta, R.D.; Kundu, D. Generalized logistic distributions. J. Appl. Stat. Sci. 2010, 18, 51–66. [Google Scholar]
- Alkasasbeh, M.R.; Raqab, M.Z. Estimation of the generalized logistic distribution parameters: Comparative study. Stat. Methodol. 2009, 6, 262–279. [Google Scholar] [CrossRef]
- Asgharzadeh, A. Point and interval estimation for a generalized logistic distribution under progressive type-II censoring. Commun. Stat. Theory Methods 2006, 35, 1685–1702. [Google Scholar] [CrossRef]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions, 2nd ed.; Wiley and Sons: New York, NY, USA, 1995; Volume 2. [Google Scholar]
- Li, M.; Yan, L.; Qiao, Y.; Cai, X.; Said, K.K. Generalized Fiducial Inference for the Stress–Strength Reliability of Generalized Logistic Distribution. Symmetry 2023, 15, 1365. [Google Scholar] [CrossRef]
- Asgharzadeh, A.; Valiollahi, R.; Raqab, M.Z. Estimation of the stress–strength reliability for the generalized logistic distribution. Stat. Methodol. 2013, 15, 73–94. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1091. [Google Scholar] [CrossRef]
- Neal, R.M. Slice sampling. Ann. Stat. 2003, 31, 705–767. [Google Scholar] [CrossRef]
- Hinkley, D. On quick choice of power transformations. Appl. Stat. 1977, 26, 67–69. [Google Scholar] [CrossRef]
- Murthy, D.N.P.; Xie, M.; Jiang, R. Weibull models. In Wiley Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | MLE | MCMC | ||||
|---|---|---|---|---|---|---|
| Mean | Length | SE | GE | Length | ||
| 6.7388 | 4.3964 | 3.3807 | 3.5517 | 3.052 | 2.9426 | |
| 1.2077 | 0.8179 | 1.4098 | 1.4514 | 1.3339 | 0.9597 | |
| 1.9703 | 2.9016 | 1.4441 | 1.2777 | 0.9546 | 1.1590 | |
| Parameters | MLE | MCMC | ||||
|---|---|---|---|---|---|---|
| Mean | Length | SE | GE | Length | ||
| 5.6053 | 3.4173 | 3.1897 | 3.3337 | 2.9106 | 2.6732 | |
| 1.2749 | 0.9024 | 1.2943 | 1.3288 | 1.2303 | 0.8077 | |
| 1.8565 | 2.7112 | 1.0529 | 1.1514 | 0.8706 | 1.2587 | |
| n | MLE | MCMC | ||||
|---|---|---|---|---|---|---|
| Mean | Length | SE | GE | Length | ||
| 30 | 2.1608 | 1.4883 | 1.6984 | 1.7413 | 1.621 | 1.3497 |
| (0.7357) | (0.3206) | (0.3035) | (0.3516) | |||
| 35 | 2.4911 | 1.347 | 2.1529 | 2.1970 | 2.0706 | 1.2092 |
| (0.6036) | (0.2688) | (0.2212) | (0.2718) | |||
| 45 | 2.6678 | 1.3204 | 1.8509 | 1.8816 | 1.7932 | 0.9275 |
| (0.5671) | (0.2597) | (0.2474) | (0.2466) | |||
| 55 | 2.4055 | 1.0928 | 1.9053 | 1.9311 | 1.8551 | 0.8669 |
| (0.5078) | (0.2379) | (0.2276) | (0.2579) | |||
| 65 | 2.622 | 1.0621 | 2.0253 | 2.0500 | 1.9779 | 0.8688 |
| (0.4488) | (0.2199) | (0.2191) | (0.2089) | |||
| 75 | 2.7086 | 1.0765 | 2.0835 | 2.1046 | 2.0429 | 0.8155 |
| (0.4235) | (0.2066) | (0.2081) | (0.2028) | |||
| 85 | 2.5626 | 0.9429 | 2.1141 | 2.1351 | 2.0741 | 0.8076 |
| (0.4151) | (0.2043) | (0.2059) | (0.2004) | |||
| 95 | 2.7228 | 0.9294 | 2.1670 | 2.1851 | 2.132 | 0.7695 |
| (0.4091) | (0.1932) | (0.1926) | (0.1972) | |||
| 105 | 2.4087 | 0.7825 | 1.8364 | 1.8502 | 1.8093 | 0.6276 |
| (0.3365) | (0.1654) | (0.1599) | (0.1763) | |||
| 115 | 2.6026 | 0.7167 | 2.0464 | 2.0606 | 2.0189 | 0.6132 |
| (0.3111) | (0.1514) | (0.1458) | (0.1425) | |||
| n | MLE | MCMC | ||||
|---|---|---|---|---|---|---|
| Mean | Length | SE | GE | Length | ||
| 30 | 3.6186 | 2.5604 | 2.2174 | 2.2845 | 2.0805 | 1.7035 |
| (0.8339) | (0.3665) | (0.3473) | (0.4056) | |||
| 35 | 4.2924 | 2.4981 | 2.5072 | 2.5777 | 2.3653 | 1.6407 |
| (0.7264) | (0.2836) | (0.2635) | (0.3242) | |||
| 45 | 3.1662 | 1.6388 | 1.9893 | 2.0306 | 1.9065 | 1.1317 |
| (0.6954) | (0.2316) | (0.2198) | (0.2553) | |||
| 55 | 3.5482 | 1.6268 | 2.3282 | 2.3699 | 2.2435 | 1.1218 |
| (0.5138) | (0.2248) | (0.2129) | (0.2290) | |||
| 65 | 3.3718 | 1.4416 | 2.2436 | 2.2763 | 2.1780 | 1.0605 |
| (0.4266) | (0.2159) | (0.2096) | (0.2077) | |||
| 75 | 4.0464 | 1.3465 | 2.4913 | 2.5247 | 2.4241 | 1.0328 |
| (0.3561) | (0.2082) | (0.2087) | (0.2074) | |||
| 85 | 3.7482 | 1.3281 | 2.4507 | 2.4802 | 2.3911 | 1.0109 |
| (0.3409) | (0.2028) | (0.2014) | (0.2018) | |||
| 95 | 3.5422 | 1.2378 | 2.3801 | 2.4051 | 2.3303 | 0.9581 |
| (0.3121) | (0.1932) | (0.1828) | (0.1912) | |||
| 105 | 3.3041 | 1.1063 | 2.2305 | 2.2515 | 2.1883 | 0.8396 |
| (0.3056) | (0.1627) | (0.1567) | (0.1608) | |||
| 115 | 3.6497 | 1.0549 | 2.3962 | 2.4174 | 2.3537 | 0.8208 |
| (0.1528) | (0.1540) | (0.1493) | (0.1475) | |||
| n | MLE | MCMC | ||||
|---|---|---|---|---|---|---|
| Mean | Length | SE | GE | Length | ||
| 30 | 1.1860 | 1.7966 | 0.7858 | 0.8634 | 0.6473 | 0.9941 |
| (0.5093) | (0.4762) | (0.4244) | (0.4085) | |||
| 35 | 1.2735 | 1.7000 | 0.8466 | 0.9221 | 0.7126 | 0.9855 |
| (0.4951) | (0.4356) | (0.3853) | (0.4249) | |||
| 45 | 1.1590 | 1.3621 | 0.6437 | 0.6864 | 0.5634 | 0.6468 |
| (0.4273) | (0.3708) | (0.3424) | (0.3244) | |||
| 55 | 1.1035 | 1.1560 | 0.6959 | 0.7345 | 0.6242 | 0.6296 |
| (0.3644) | (0.3361) | (0.3103) | (0.3039) | |||
| 65 | 1.0371 | 1.0073 | 0.6347 | 0.6655 | 0.5761 | 0.5413 |
| (0.3386) | (0.3069) | (0.3064) | (0.3015) | |||
| 75 | 1.6173 | 1.0049 | 0.7967 | 0.8276 | 0.7383 | 0.5126 |
| (0.3282) | (0.2988) | (0.2483) | (0.2478) | |||
| 85 | 1.1491 | 0.9650 | 0.7025 | 0.7278 | 0.6536 | 0.5252 |
| (0.2339) | (0.2617) | (0.2348) | (0.2343) | |||
| 95 | 1.0893 | 0.8689 | 0.6548 | 0.6762 | 0.6134 | 0.4626 |
| (0.2138) | (0.2135) | (0.2092) | (0.2011) | |||
| 105 | 1.0506 | 0.7989 | 0.6083 | 0.6267 | 0.5730 | 0.4116 |
| (0.1996) | (0.1944) | (0.1822) | (0.1810) | |||
| 115 | 1.1886 | 0.6625 | 0.6745 | 0.6926 | 0.6395 | 0.4096 |
| (0.1476) | (0.1303) | (0.1383) | (0.1237) | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasaballah, M.M.; Balogun, O.S.; Bakr, M.E. On a Randomly Censoring Scheme for Generalized Logistic Distribution with Applications. Symmetry 2024, 16, 1240. https://doi.org/10.3390/sym16091240
Hasaballah MM, Balogun OS, Bakr ME. On a Randomly Censoring Scheme for Generalized Logistic Distribution with Applications. Symmetry. 2024; 16(9):1240. https://doi.org/10.3390/sym16091240
Chicago/Turabian StyleHasaballah, Mustafa M., Oluwafemi Samson Balogun, and Mahmoud E. Bakr. 2024. "On a Randomly Censoring Scheme for Generalized Logistic Distribution with Applications" Symmetry 16, no. 9: 1240. https://doi.org/10.3390/sym16091240
APA StyleHasaballah, M. M., Balogun, O. S., & Bakr, M. E. (2024). On a Randomly Censoring Scheme for Generalized Logistic Distribution with Applications. Symmetry, 16(9), 1240. https://doi.org/10.3390/sym16091240