Using Knowledge Transfer and Rough Set to Predict the Severity of Android Test Reports via Text Mining



Abstract
:1. Introduction
- We propose a KTC approach based on text mining and machine learning methods to predict the severity of test reports from crowdsourced testing. Our approach obtains labeled training data from bug repositories and uses knowledge transfer to predict the severity of Android test reports.
- We use an IDR strategy based on rough set to extract characteristic keywords, reduce the noise in the integrated labels, and, consequently, enhance the training data and model quality.
- We use two bug repository datasets (Eclipse, Mozilla) for knowledge transfer to predict the severity of Android test reports. Several experiments demonstrate the prediction accuracy of our approach in various cases.
2. Methodology
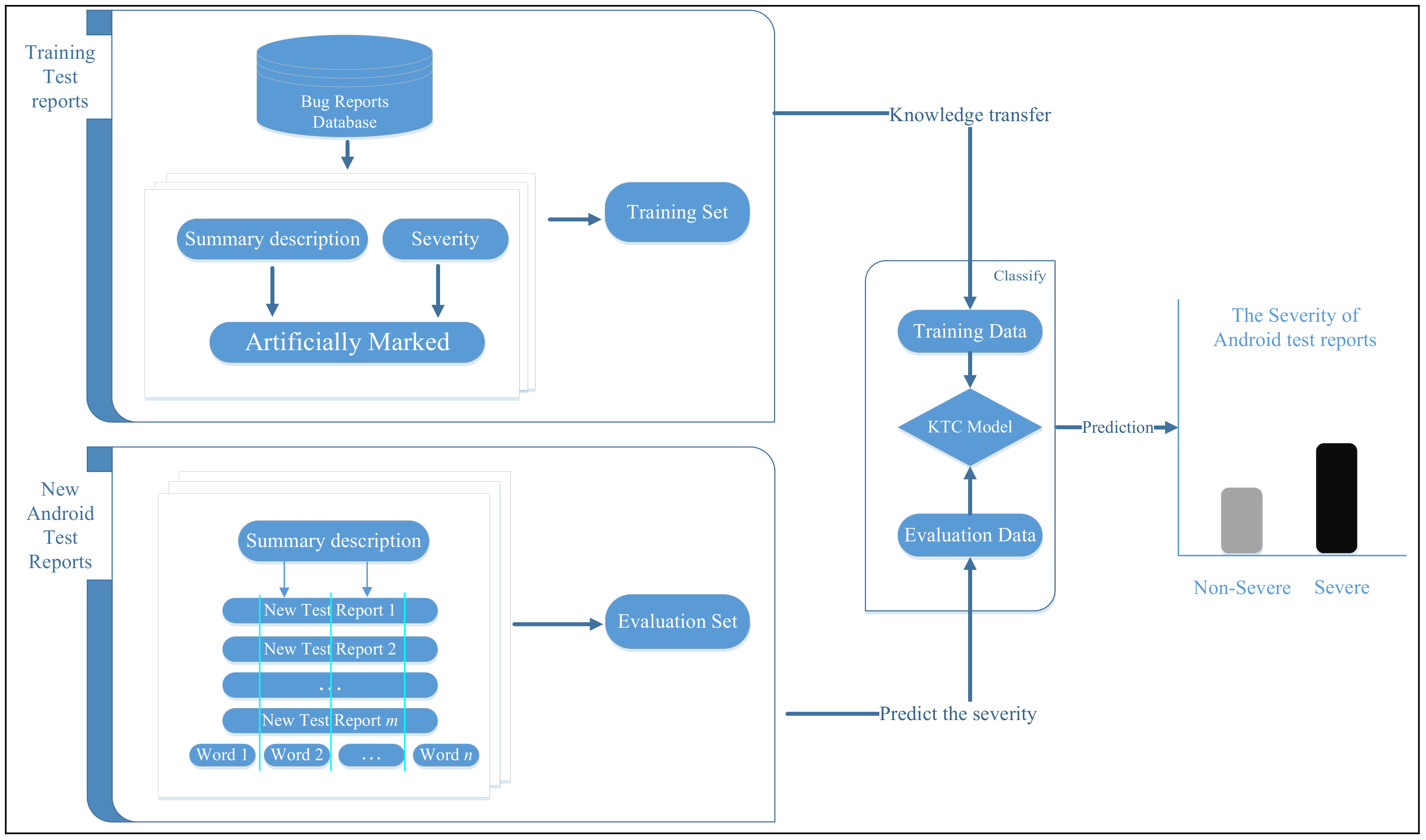
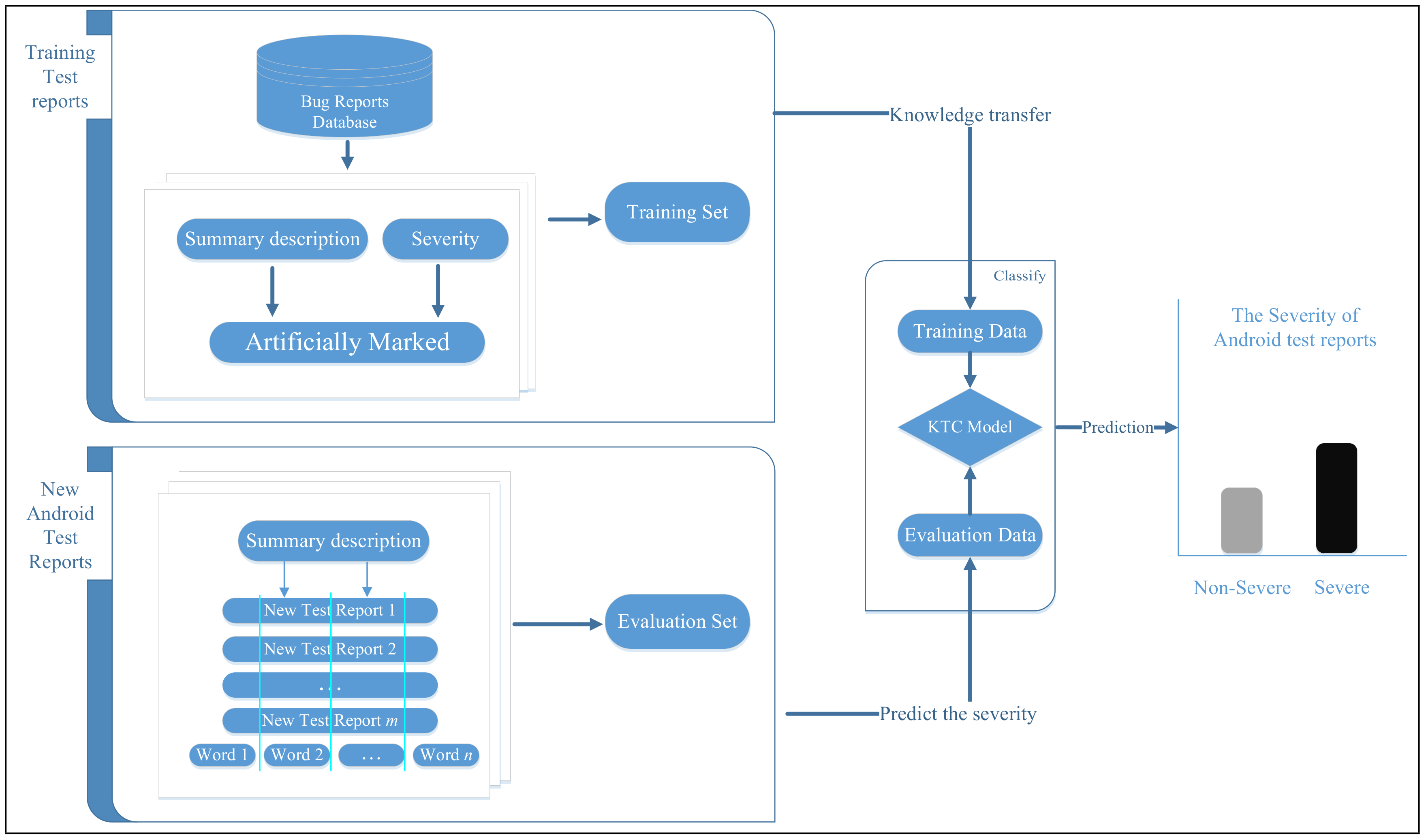
2.1. Overview
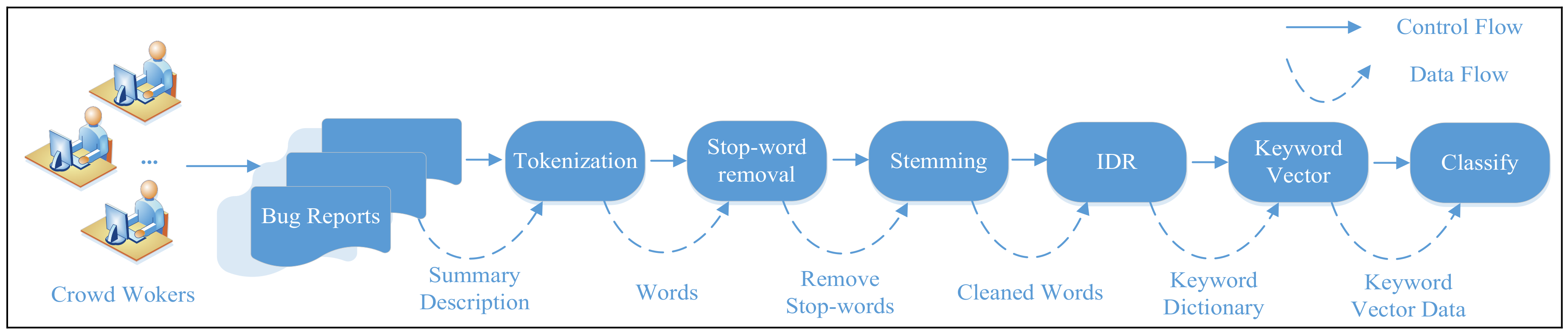
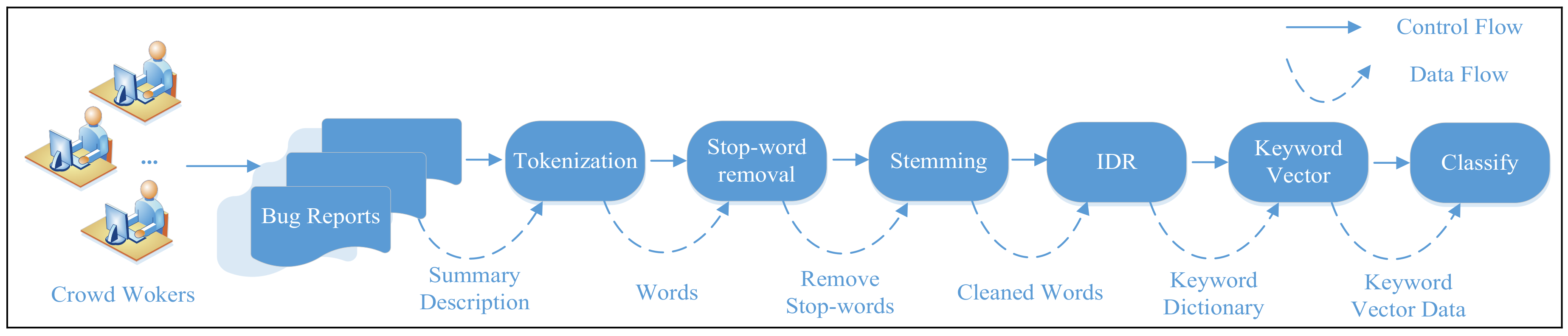
2.2. Model Description
- (1).
- Tokenization: The process of tokenization consists of dividing a large textual string into a set of tokens, where a single token corresponds to a single term. This step also includes filtering out all meaningless symbols such as punctuation because these symbols do not contribute to the classification task. Also, all capitalized characters are replaced with their lower-case versions.
- (2).
- Stop-word removal: Human languages commonly use constructive terms such as conjunctions, adverbs, prepositions and other language structures for the building of sentences. Terms such as “the”, “in” and “that”, also known as stop words, carry little specific information in the context of a bug report. Moreover, these terms appear frequently in bug report descriptions and thus increase the dimensionality of the data, which could, in turn, cause the performance of classification algorithms to decrease. This is sometimes referred to as the curse of dimensionality. Therefore, all stop words are removed from the set of tokens, based on a list of known stop words.
- (3).
- Stemming: The purpose of the stemming step is to reduce each term appearing in a description to its most basic form. Each single term can be expressed in various forms while still carrying the same specific information. For example, the terms “computerized”, “computerize”, and “computation” all share the same morphological base: “computer”. A stemming algorithm such as the Porter stemmer [12] transforms each term into its basic form.
- (4).
- IDR: Keywords extracted from test reports play an important role in the prediction of test report severity. To summarize the information contained within the keywords, we count their frequencies (i.e., numbers of occurrences) to estimate their degrees of importance. However, the keywords are described in natural language by crowdsourced workers, who may have various different backgrounds (i.e., expertise, reliability, performance, location). This can result in a large number of keyword dimensions and considerable noise. In this study, an IDR strategy based on rough set is used to extract characteristic keywords, reduce the noise in the integrated labels, and, consequently, enhance the training data and model quality. The IDR strategy is described in detail in the next section. In this way, a keyword dictionary is built.
- (5).
- Keyword vector modeling: This step involves the construction of a keyword vector model (KV). Based on the keyword dictionary, we construct a keyword vector for each test report, tri = (ei1, ei2, …, eim), where m is the number of keywords in the keyword dictionary. We set eij = 1 if the ith test report contains the j-th keyword in the keyword dictionary and eij = 0 otherwise.
- (6).
- Classification results: A variety of classification algorithms have been proposed in the data mining community. In this study, we apply the four most important of these algorithms (Naïve Bayes (NB), K-Nearest Neighbour (KNN), Support Vector Machines (SVM), and Decision Tree (J48)) to our problem to verify the accuracy of our approach.
2.3. Description of IDR Strategy
| Algorithm 1. Importance Degree Reduction (IDR) Algorithm |
| Input: KV = {U, C D, V, f} |
| Output: The reduction set B ((B C) (B REDC(D))) of KV |
|
3. Experimental Design
3.1. Experimental Setup
3.2. Evaluation Metrics
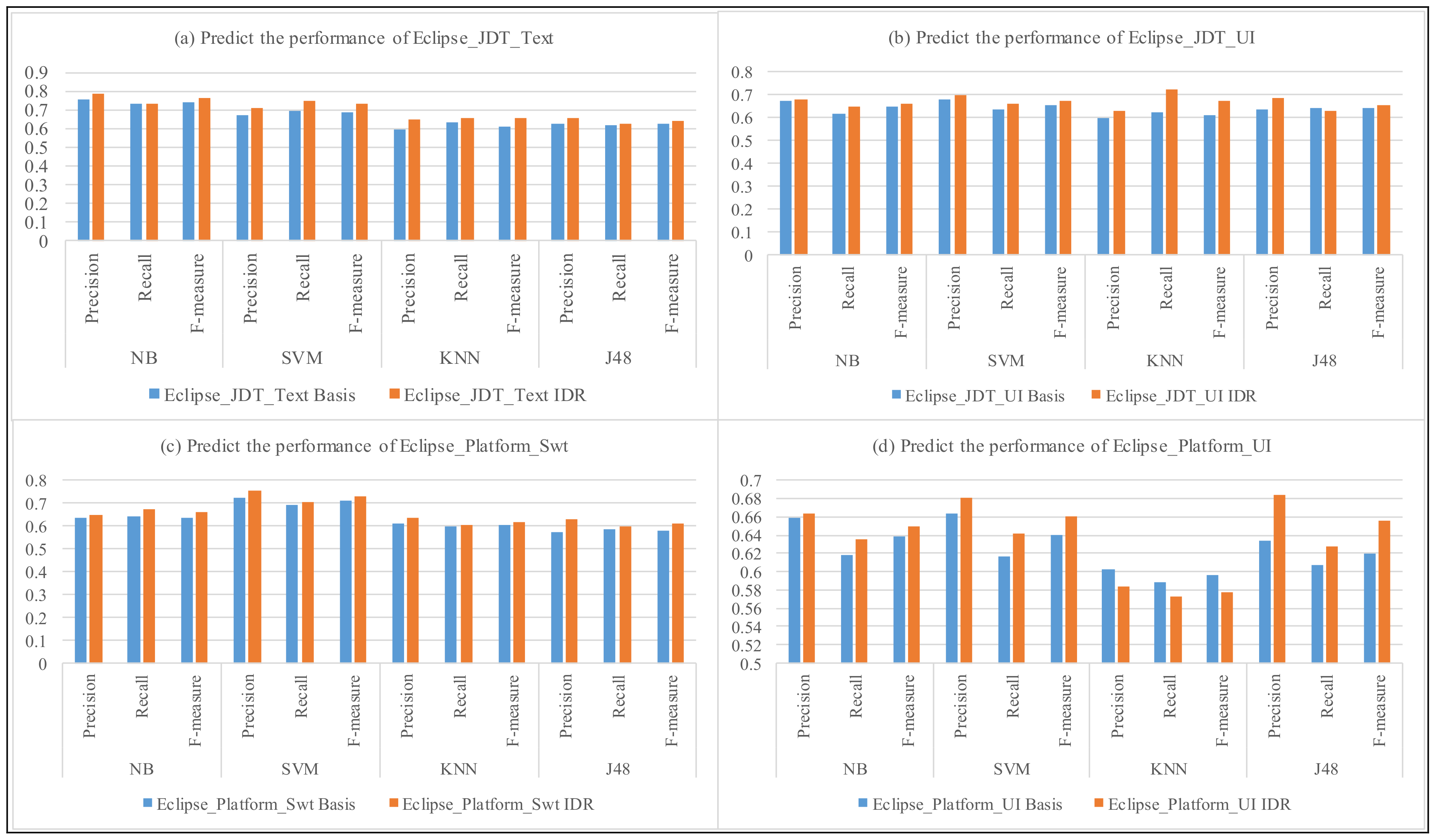
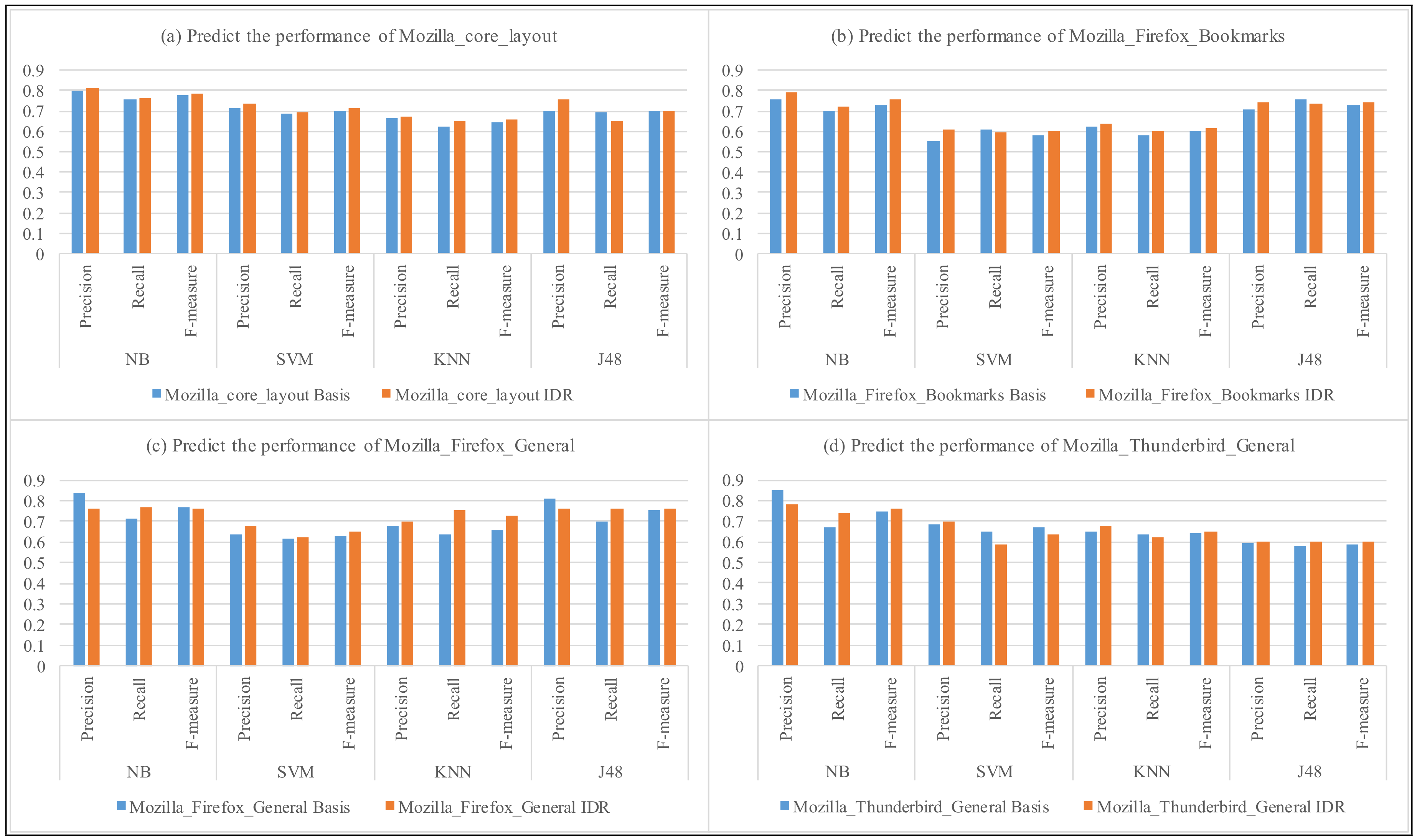
4. Experimental Results
5. Related Work
5.1. Automatic Bug Classification in Software Engineering
5.2. Crowdsourced Software Testing
6. Threats to Validity
- Conclusion Validity: Since we use the bug reports submitted by the community both as training data, it is not guaranteed that the severities in these reports are entered correctly. Users fill in the reports according to their understanding and therefore assess severities corresponding to their experience, which does not necessarily correspond with the guidelines. We explicitly omitted the bugs reported with severity “normal” since this category corresponded to the default option when submitting a bug and thus likely to be unreliable [20]. In addition, we manually labeled their severity according to the rules defined for the bug repositories. Then, we use the majority vote to ensure the severity of Android bug reports. Finally, we selected the Android bug reports to relabel because the labeling results of Android bug reports are vary widely. The tools we used to process the data might contain errors. We implemented our approach using the widely used open-source data mining tool WEKA (http://www.cs.waikato.ac.nz/ml/weka/).
- Internal Validity: Our approach relies heavily on the presence of a causal relationship between the contents of the fields in the bug report and the severity of the bug. There is empirical evidence that this causal relationship indeed holds [4]. We only use the short summary descriptions of the test report to build our classifiers, without including other features of bug reports (e.g., the product of the bug report). However, we will consider adding the others’ features to investigate the influence of these features on model performance.
- Construct Validity: We have trained our classifier for each component, assuming that special terminology used for each component will result in a better prediction. However, bug reporters have confirmed that providing the “component” field in a bug report is notoriously difficult [21], hence we risk that the users interpreted these categories in different ways than intended. We alleviated the risk by selecting those components with a significant number of bug reports. In addition, we use standard metrics used in classification and prediction, namely: precision, recall, and F-measure. These measures have been used before by Menzies and Marcus to evaluate SEVERIS [27].
- External Validity: In this study, we focused on the bug reports of two software projects: Eclipse and Mozilla. Like in other empirical studies, the results obtained from our presented approach are therefore not guaranteed to hold with other software projects. However, we selected the cases to represent worthwhile points in the universe of software projects, representing sufficiently different characteristics to warrant comparison. For instance, Eclipse was selected because its user base exists mostly of developers hence it is likely to have “good” bug reports. Our experimental evaluation data consisted of randomly selected test reports from the Android bug tracker system. We cannot assume a priori that the results of our study can be generalized beyond the environment in which it was conducted. However, the diverse nature of the projects and the size of the datasets somewhat reduce this risk.
7. Conclusions and the Further Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Mao, K.; Capra, L.; Harman, M.; Jia, Y. A Survey of the Use of Crowdsourcing in Software Engineering; Technical Report RN/15/01; Department of Computer Science, University College London: London, UK, 10 May 2015. [Google Scholar]
- Dolstra, E.; Vliegendhart, R.; Pouwelse, J. Crowdsourcing gui tests. In Proceedings of the 2013 IEEE Sixth International Conference on Software Testing, Verification and Validation (ICST), Luxembourg, 18–22 March 2013; pp. 332–341. [Google Scholar]
- Google Code. Available online: https://code.google.com (accessed on 16 August 2017).
- Ko, A.J.; Myers, B.A.; Chau, D.H. A linguistic analysis of how people describe software problems. In Proceedings of the Visual Languages and Human-Centric Computing, Brighton, UK, 4–8 September 2006; pp. 127–134. [Google Scholar]
- Tian, Y.; Lo, D.; Sun, C. Drone: Predicting priority of reported bugs by multi-factor analysis. In Proceedings of the 29th IEEE International Conference on Software Maintenance (ICSM 2013), Eindhoven, The Netherlands, 22–28 September 2013; pp. 200–209. [Google Scholar]
- Wang, X.; Zhang, L.; Xie, T.; Anvik, J.; Sun, J. An approach to detecting duplicate bug reports using natural language and execution information. In Proceedings of the 30th International Conference on Software Engineering (ICSE 2008), Leipzig, Germany, 10–18 May 2008; pp. 461–470. [Google Scholar]
- Zhou, Y.; Tong, Y.; Gu, R.; Gall, H. Combining text mining and data mining for bug report classification. In Proceedings of the 30th IEEE International Conference on Software Maintenance (ICSM 2014), Victoria, BC, Canada, 29 September–3 October 2014; pp. 311–320. [Google Scholar]
- Feng, Y.; Chen, Z.; Jones, J.A.; Fang, C.; Xu, B. Test report prioritization to assist crowdsourced testing. In Proceedings of the 10th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on The Foundations of Software Engineering (FSE 2015), Bergamo, Italy, 30 August–4 September 2015; pp. 225–236. [Google Scholar]
- Kao, A.; Poteet, S.R. Natural Language Processing and Text Mining; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Wang, J.; Cui, Q.; Wang, Q.; Wang, S. Towards effectively test report classification to assist crowdsourced testing. In Proceedings of the ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM 2016), Ciudad Real, Spain, 8–9 September 2016. [Google Scholar]
- Wang, J.; Wang, S.; Cui, Q.; Wang, Q. Local-Based Active Classification of Test Report to Assist Crowdsourced Testing. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 190–201. [Google Scholar]
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Wang, G.Y. Calculation Methods for Core Attributes of Decision Table. Chin. J. Comput. 2003, 26, 611–615. [Google Scholar]
- Pawlak, Z. Rough Sets-Theoretical Aspects of Reasoning about Data; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1991; pp. 11–52. [Google Scholar]
- Lei, S.; Weng, M.; Ma, X.M.; Xi, L. Rough Set Based Decision Tree Ensemble Algorithm for Text Classification. J. Comput. Inf. Syst. 2010, 6, 89–95. [Google Scholar]
- Herraiz, I.; German, D.M.; Gonzalez-Barahona, J.; Robles, G. Towards a Simplification of the Bug Report Form in Eclipse. In Proceedings of the 5th International Working Conference on Mining Software Repositories, Leipzig, Germany, 10–11 May 2008; pp. 145–148. [Google Scholar]
- Weka. Available online: http://www.cs.waikato.ac.nz/ml/weka/ (accessed on 16 August 2017).
- Weng, C.G.; Poon, J. A new evaluation measure for imbalanced datasets. In Proceedings of the Seventh Australasian Data Mining Conference, Glenelg, Australia, 27–28 November 2008; Volume 87, pp. 27–32. [Google Scholar]
- Ling, C.; Huang, J.; Zhang, H. Auc: A better measure than accuracy in comparing learning algorithms. In Advances in Artificial Intelligence; Lecture Notes in Computer Science; Xiang, Y., Chaib-draa, B., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2671, p. 991. [Google Scholar]
- Ahmed, L.; Serge, D.; David, S.Q.; Tim, V. Comparing mining algorithms for predicting the severity of a reported bug. In Proceedings of the European Conference on Software Maintenance and Reengineering, Oldenburg, Germany, 1–4 March 2011; pp. 249–258. [Google Scholar]
- Bettenburg, N.; Just, S.; Schröter, A.; Weiss, C.; Premraj, R.; Zimmermann, T. What makes a good bug report? In Proceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Atlanta, GA, USA, 9–14 November 2008; pp. 308–318. [Google Scholar]
- Zanetti, M.S.; Scholtes, I.; Tessone, C.J.; Schweitzer, F. Categorizing bugs with social networks: A case study on four open source software communities. In Proceedings of the International Conference on Software Engineering (ICSE 2013), San Francisco, CA, USA, 18–26 May 2013; pp. 1032–1041. [Google Scholar]
- Wang, S.; Zhang, W.; Wang, Q. FixerCache: Unsupervised caching active developers for diverse bug triage. In Proceedings of the International Symposium on Empirical Software Engineering and Measurement (ESEM 2014), Torino, Italy, 18–19 September 2014. [Google Scholar]
- Mao, K.; Yang, Y.; Wang, Q.; Jia, Y.; Harman, M. Developer recommendation for crowdsourced software development tasks. In Proceedings of the IEEE Symposium on Service-Oriented System Engineering (SOSE 2015), San Francisco Bay, CA, USA, 30 March–3 April 2015; pp. 347–356. [Google Scholar]
- Yu, L.; Tsai, W.T.; Zhao, W.; Wu, F. Predicting defect priority based on neural networks. In Proceedings of the Advanced Data Mining and Applications—6th International Conference Lecture (ADMA 2010), Chongqing, China, 19 November 2010; pp. 356–367. [Google Scholar]
- Antoniol, G.; Ayari, K.; di Penta, M.; Khomh, F.; Guéhéneuc, Y.-G. Is it a bug or an enhancement? A text based approach to classify change requests. In Proceedings of the CASCON ’08 Conference of the Center for Advanced Studies on Collaborative Research, Richmond Hill, ON, Canada, 27–30 October 2008; ACM: New York, NY, USA, 2008; pp. 304–318. [Google Scholar]
- Menzies, T.; Marcus, A. Automated severity assessment of software defect reports. In Proceedings of the IEEE International Conference on Software Maintenance (ICSM 2008), Beijing, China, 28 September–4 October 2008; pp. 346–355. [Google Scholar]
- Hooimeijer, P.; Weimei, W. Modeling bug report quality. In Proceedings of the 22nd IEEE/ACM International Conference on Automated Software Engineering (ASE), Atlanta, GA, USA, 5–9 November 2007; pp. 34–43. [Google Scholar]
- Runeson, P.; Alexandersson, M.; Nyolm, O. Detection of duplicate defect reports using natural language processing. In Proceedings of the International Conference on Software Engineering (ICSE), Minneapolis, MN, USA, 20–26 May 2007; pp. 499–510. [Google Scholar]
- Sun, C.; Lo, D.; Wang, X.; Jiang, J.; Khoo, S.C. A discriminative model approach for accurate duplicate bug report retrieval. In Proceedings of the 32nd International Conference on Software Engineering (ICSE), Cape Town, South Africa, 1–8 May 2010; pp. 45–54. [Google Scholar]
- Sun, C.; Lo, D.; Khoo, S.C.; Jiang, J. Towards more accurate retrieval of duplicate bug reports. In Proceedings of the 26th IEEE/ACM International Conference on Automated Software Engineering (ASE), Lawrence, KS, USA, 6–10 November 2011; pp. 253–262. [Google Scholar]
- Chen, N.; Kim, S. Puzzle-based automatic testing: Bringing humans into the loop by solving puzzles. In Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering (ASE 2012), Essen, Germany, 3–7 September 2012; pp. 140–149. [Google Scholar]
- Musson, R.; Richards, J.; Fisher, D.; Bird, C.; Bussone, B.; Ganguly, S. Leveraging the crowd: How 48,000 users helped improve lync performance. IEEE Softw. 2013, 30, 38–45. [Google Scholar] [CrossRef]
- Gomide, V.H.M.; Valle, P.A.; Ferreira, J.O.; Barbosa, J.R.G.; da Rocha, A.F.; Barbosa, T. Affective crowdsourcing applied to usability testing. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 575–579. [Google Scholar]
- Gomez, M.; Rouvoy, R.; Adams, B.; Seinturier, L. Reproducing context-sensitive crashes of mobile apps using crowdsourced monitoring. In Proceedings of the IEEE/ACM International Conference on Mobile Software Engineering and Systems (MOBILESoft), Austin, TX, USA, 16–17 May 2016; pp. 88–99. [Google Scholar]
- Liu, D.; Bias, R.G.; Lease, M.; Kuipers, R. Crowdsourcing for usability testing. Proc. Am. Soc. Inf. Sci. Technol. 2012, 49, 1–10. [Google Scholar] [CrossRef]
- Pastore, F.; Mariani, L.; Fraser, G. Crowdoracles: Can the crowd solve the oracle problem? In Proceedings of the 2013 IEEE Sixth International Conference on Software Testing, Verification and Validation (ICST), Luxembourg, 18–22 March 2013; pp. 342–351. [Google Scholar]
- Nebeling, M.; Speicher, M.; Grossniklaus, M.; Norrie, M.C. Crowdsourced web site evaluation with crowdstudy. In Proceedings of the 12th International Conference on Web Engineering, Berlin, Germany, 23–27 July 2012; pp. 494–497. [Google Scholar]
- Feng, Y.; Chen, Z.; Jones, J.A.; Fang, C. Multi-objective Test Report Prioritization using Image Understanding. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 202–213. [Google Scholar]
- Wohlin, C.; Runeson, P.; Host, M.; Ohlsson, M.C.; Regnell, B.; Wesslen, A. Experimentation in Software Engineering; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Summary Description | Android Studio crashes upon launch on Linux |
| After stop-words removal | Android Studio crashes launch Linux |
| After stemming | android studio crash launch linux |
| Project | Non-Severe Bugs | Severe Bugs |
|---|---|---|
| Android | 289 | 311 |
| Project | Product-Component | Non-Severe Bugs | Severe Bugs |
|---|---|---|---|
| Eclipse | Platform-UI | 1173 | 2982 |
| JDT-UI | 1216 | 1436 | |
| JDT-Text | 712 | 515 | |
| Platform-SWT | 521 | 2565 | |
| Mozilla | Core-Layout | 960 | 2747 |
| Firefox-General | 2142 | 6378 | |
| Firefox-Bookmarks | 511 | 656 | |
| Thunderbird-General | 313 | 1268 |
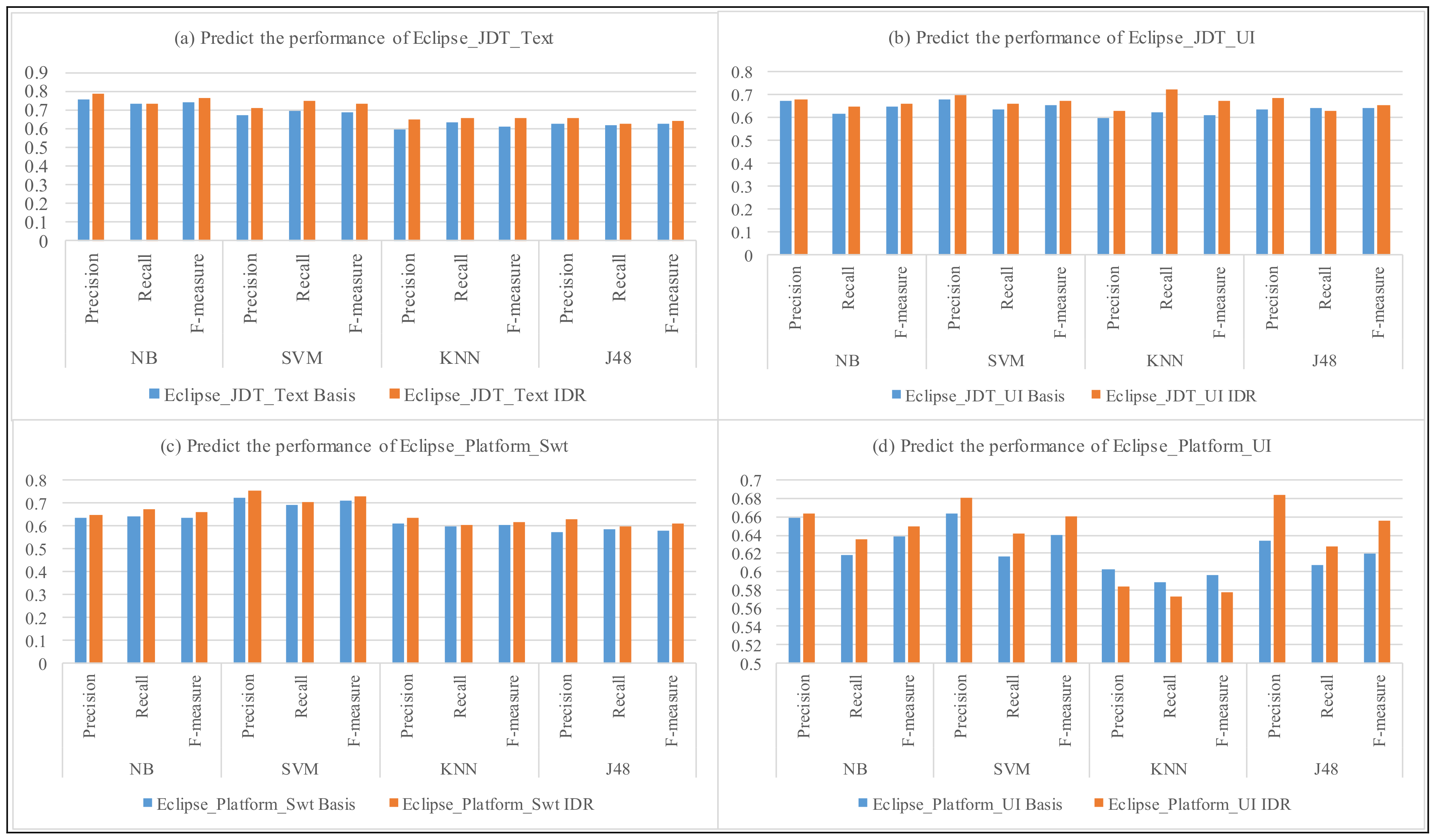
| Project | Product + Component | NB | IDR + NB | SVM | IDR + SVM | KNN | IDR + KNN | J48 | IDR + J48 |
|---|---|---|---|---|---|---|---|---|---|
| Eclipse | JDT_Text | 0.717 | 0.713 | 0.68 | 0.698 | 0.62 | 0.634 | 0.684 | 0.654 |
| JDT_UI | 0.632 | 0.683 | 0.641 | 0.667 | 0.605 | 0.625 | 0.627 | 0.657 | |
| Platform_Swt | 0.785 | 0.825 | 0.831 | 0.827 | 0.834 | 0.834 | 0.738 | 0.734 | |
| Platform_UI | 0.708 | 0.721 | 0.717 | 0.724 | 0.731 | 0.748 | 0.633 | 0.627 | |
| Eclipse_Avg. | 0.725 | 0.758 | 0.721 | 0.739 | 0.632 | 0.647 | 0.643 | 0.66 | |
| Mozilla | Core_Layout | 0.711 | 0.764 | 0.741 | 0.761 | 0.736 | 0.725 | 0.749 | 0.749 |
| Firefox_Bookmarks | 0.708 | 0.738 | 0.562 | 0.678 | 0.631 | 0.697 | 0.684 | 0.695 | |
| Firefox_General | 0.745 | 0.749 | 0.748 | 0.743 | 0.756 | 0.672 | 0.769 | 0.794 | |
| Thunderbird_General | 0.774 | 0.794 | 0.802 | 0.812 | 0.786 | 0.826 | 0.602 | 0.683 | |
| Mozilla_Avg. | 0.723 | 0.748 | 0.715 | 0.739 | 0.712 | 0.720 | 0.686 | 0.699 | |
| All_Avg. | 0.715 | 0.735 | 0.716 | 0.731 | 0.721 | 0.734 | 0.659 | 0.663 |
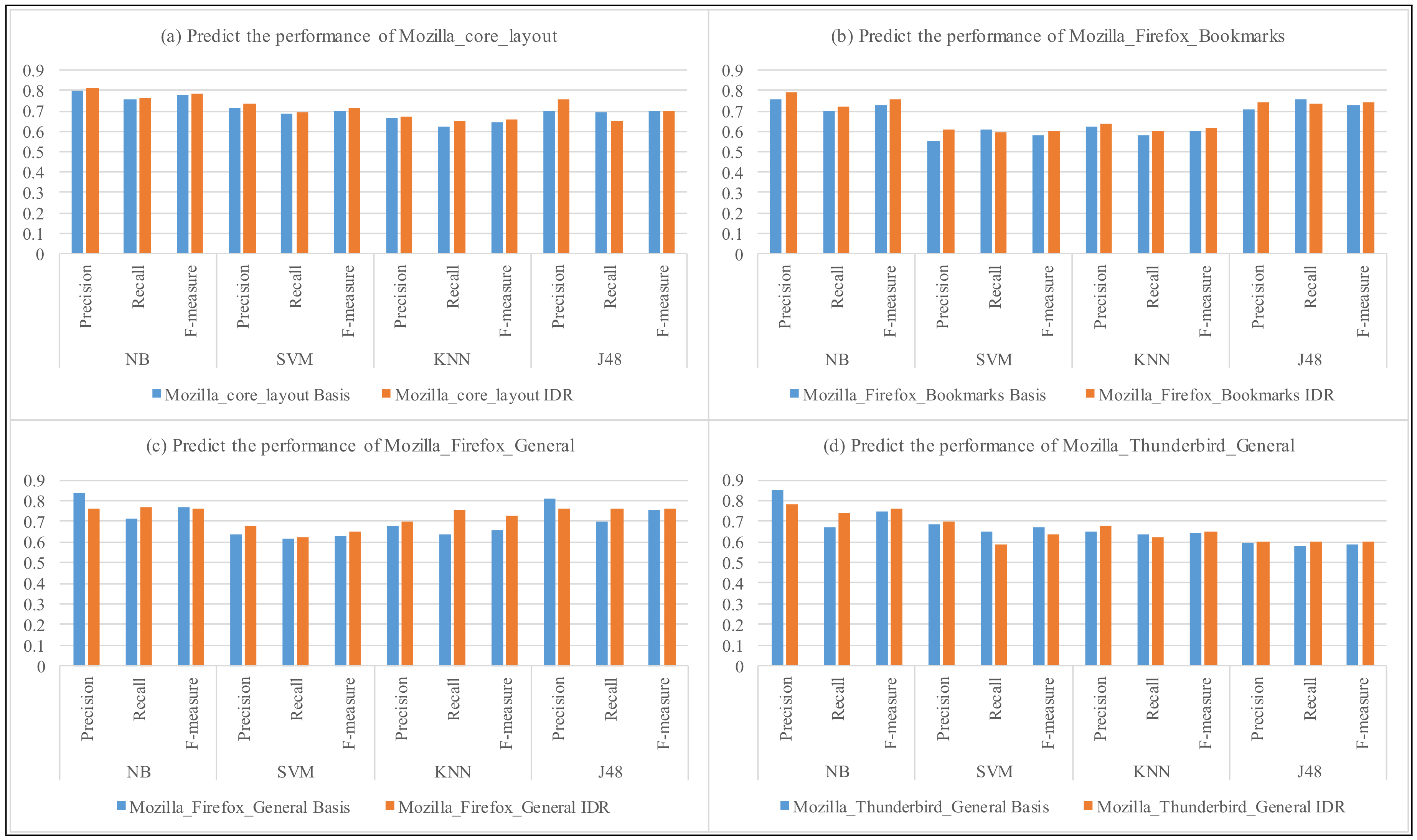
| Project | Product + Component | NB | IDR +NB | SVM | IDR + SVM | KNN | IDR + KNN | J48 | IDR + J48 |
|---|---|---|---|---|---|---|---|---|---|
| Eclipse | JDT_Text | 0.781 | 0.775 | 0.756 | 0.759 | 0.69 | 0.713 | 0.707 | 0.738 |
| JDT_UI | 0.686 | 0.793 | 0.69 | 0.711 | 0.634 | 0.664 | 0.651 | 0.625 | |
| Platform_Swt | 0.732 | 0.744 | 0.74 | 0.767 | 0.597 | 0.606 | 0.542 | 0.631 | |
| Platform_UI | 0.702 | 0.721 | 0.701 | 0.717 | 0.607 | 0.603 | 0.674 | 0.645 | |
| Eclipse_Avg. | 0.725 | 0.758 | 0.722 | 0.739 | 0.632 | 0.647 | 0.643 | 0.66 | |
| Mozilla | Core_Layout | 0.774 | 0.792 | 0.72 | 0.736 | 0.675 | 0.759 | 0.749 | 0.759 |
| Firefox_Bookmarks | 0.772 | 0.783 | 0.593 | 0.695 | 0.695 | 0.724 | 0.74 | 0.721 | |
| Firefox_General | 0.787 | 0.775 | 0.684 | 0.782 | 0.703 | 0.763 | 0.763 | 0.773 | |
| Thunderbird_General | 0.762 | 0.778 | 0.73 | 0.725 | 0.635 | 0.647 | 0.596 | 0.621 | |
| Mozilla_Avg. | 0.75 | 0.77 | 0.702 | 0.737 | 0.655 | 0.685 | 0.678 | 0.689 | |
| All_Avg. | 0.737 | 0.764 | 0.712 | 0.738 | 0.643 | 0.666 | 0.661 | 0.674 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, S.; Chen, R.; Li, H. Using Knowledge Transfer and Rough Set to Predict the Severity of Android Test Reports via Text Mining. Symmetry 2017, 9, 161. https://doi.org/10.3390/sym9080161
Guo S, Chen R, Li H. Using Knowledge Transfer and Rough Set to Predict the Severity of Android Test Reports via Text Mining. Symmetry. 2017; 9(8):161. https://doi.org/10.3390/sym9080161
Chicago/Turabian StyleGuo, Shikai, Rong Chen, and Hui Li. 2017. "Using Knowledge Transfer and Rough Set to Predict the Severity of Android Test Reports via Text Mining" Symmetry 9, no. 8: 161. https://doi.org/10.3390/sym9080161
APA StyleGuo, S., Chen, R., & Li, H. (2017). Using Knowledge Transfer and Rough Set to Predict the Severity of Android Test Reports via Text Mining. Symmetry, 9(8), 161. https://doi.org/10.3390/sym9080161