Abstract
This is a discussion article that should raise more questions than answers. We write our own point of view about the concept of axioms. We list several examples, mostly known to readers, and focus on examples where the axioms produce separate areas of studies and applications. The classic definitions are schematically presented since these are well known. We briefly notice how they generated various other fields of development. Set theory is, in our opinion, the fundamental for new areas of development. Our focus is on some recent axioms such as uncertainty, probability, and new concepts and results related to these fields. The emphasis is on the meaning of an undefined concept and on its measuring.
1. Introduction
Let look at this explanation: Any axiom is a statement that is so evident or well-established that it is accepted without controversy or question. It serves as a starting point from which other statements are logically derived. However, single axioms cannot serve as a foundation of any science without pointing out the sets of objects for which they are valid.
In my modest opinion, the axioms are a list of basic rules (postulates) that a population of objects or individuals should follow to save their relationships as an entity and integrity. These rules are accepted as rue riles and no one can be derived from the others. Here is the first question: What is a population? It needs the concept of sets. There is a relatively new theory of sets (late-19th century) that explains some intuitive understanding about it. However, let me give some examples of axioms that do not belong to any concepts, and that have been since ancient times. Each country has a constitution that governs the rules of behavior for its citizens. However, the population (the set that contains no more and no less of all the individuals involved) includes all visitors and new citizens adopted by the country. All the laws that are introduced later are products of this constitution. These are the theorems, lemmas, and corollaries of this list of rules postulated in the constitution. As we can see, there are several countries with constitutions that keep the rules in their countries.
Another example are religious organizations. For instance, the Ten Commandments are like a constitution for Christianity, and the Bible is a development of these recommended rules in a form of verses as a law of behavior.
However, here we will talk about the axioms on historically known examples of how a change in the basic rules of the axiom list might change the future areas of study and propose new developments. In my opinion, this process is an endless source of new theories and new knowledge not yet known to science and society.
An axiomatic system is called complete if for every statement, either itself or its negation, is derivable from the system’s axioms (equivalently, every statement is capable of being proven true or false). In my opinion, an incomplete system of axioms may serve as a source for new discoveries, as in the case of the set theory axioms (see Section 2.1).
Relative consistency is also the mark of a worthwhile axiom system. This describes the scenario where the undefined terms of a first axiom system are provided definitions from a second, so that the axioms of the first are theorems of the second. Relative consistency examples may also serve for new and additional discoveries that may follow from the original axiomatic system (e.g., probability as a measure of uncertainty, see Section 3).
In the next section, I present a selection of axioms from websites, ordered in the way as my concepts of understanding. My references are mostly on these sites. In Section 3, I use my own concepts for axioms on uncertainty and on mathematics for measuring degrees of uncertainty. Most references are in books where axioms are given and most important are the examples/models where we understand what these axioms are offering to readers and researchers in research and applications.
2. Some Classic Examples of Axioms
It is, again, my opinion that set theory should be the first and basis of the formation of any axiomatic approach. The reason for this is that any list of axioms is directed to a set of objects (individuals, basic concepts, population) for which these axioms are valid. Sometimes the axiom itself contains a definition of the elements of these sets and the relationships between individuals and subsets of individuals. Here, I try to prove this regardless of whether it is relatively recent.
2.1. Set Theory Axioms
Set theory is considered as a branch of mathematical logic. It uses a basic concept of sets. There is no definition of set (as any other basic concept in any theory). Later, we will see other basic concepts that only have some intuitive meaning, and have only explanations, sometimes via the axioms. A set can be informally described as collections of objects possessing some common features. Although objects of any kind can be collected into a set, here, we see the replacement of a name “set” by another name “collection”. Many times, we observe explanations of a basic concept with the help (in terms) of others through the axioms, and we will mark such facts in the sequel.
Set theory begins with a fundamental relation between an object ω and a set A. If ω belongs to the set A (or ω is an element of A), the notation ω ∈ A is used. Objects can be undefined concepts that could be explained through the axioms (see e.g., Euclidian axioms). A set is described by listing its elements when possible, or by a characterizing property of its elements. Sets are also objects, and the membership relation also relates sets. A derived binary relation between sets is the subset relation, also called set inclusion. If all the elements of set A are also elements of set B, then A is a subset of B, denoted A ⊆ B. As implied by this definition, a set is a subset of itself. If A ⊆ B, and B ⊆ A, then the two sets are identical. Relationships between sets are also important and used in many models based on set theory. No axioms are known in this relation but that the sets do exist and satisfy some relationships, which were imitating operations with numbers.
The following is a partial list of them:
- -
- The union of sets A and B, denoted A ∪ B, is the set of all elements that are members of A, B, or both.
- -
- The intersection of sets A and B, denoted A ∩ B, is the set of all elements that are members of both A and B.
- -
- Cartesian product of A and B, denoted A × B, is the set whose members are all ordered pairs (a, b), where a is a member of A and b is a member of B.
- -
- The empty set is the unique set containing no elements. For this, the usual symbolic notation is Ø.
- -
- The power set (or powerset) of set A is the set (actually, the number) of all subsets of A including set A itself and the empty set.
These operations with the sets are extended to unions and intersections between more than two sets. The very meaning of the set (as a collection of elements) has led to many philosophical discussions, paradoxes, and new discoveries by many famous mathematicians and philosophers (e.g., Dedekind, Cantor. Russel, Zermelo, Gödel, Peano, Hillbert, Bernstein). One of the most important axioms is the axiom of the choice: From any non-empty set there can be selected at least one element (Zerrmelo-Fraenkel, please see complete set of their axioms at https://plato.stanford.edu/entries/set-theory/ZF.html (accessed on 23 June 2021)
Examples of sets have helped to create the theory of numbers, real numbers, continuity, Boolean algebra, and many others used in computer sciences. The paradoxes of Cantor (is the set of all conceivable sets a set?) or Russel (if a barber shaves everyone who does not shave himself, who shaves the barber; does this barber belong to the set of his clients?) created the theory of cardinality and transcendental numbers like infinity as an element of the set of natural numbers. Obviously, they created the need for the introduction of other concepts that dominate the concept of sets.
We will not go in these details. Those interested should read set theory at https://plato.stanford.edu/entries/set-theory/ (accessed on 19 June 2021) and the references therein.
2.2. Euclidian Geometry Axioms
Despite this system of axioms being created more than 2000 years before set theory, it also uses some concepts of sets of basic concepts/elements on the plane (sets of points, straight lines, circles, angles) and for neither of these elements is there is any definition. They do exist in our imagination, but no definition is available. After multiple use and with the help of drowning, people have started understanding what the axioms are talking about. Again, we do not go into details and statements that follow from these postulations. Here, we list these axioms, which only give descriptions of relationships sufficient to build on geometry since Euclid (details at https://www.sfu.ca/~swartz/euclid.htm) (accessed on 18 June 2021).
Euclid begins by stating his assumptions to help determine the method of solving a problem. These assumptions were known as the five axioms. An axiom is a statement that is accepted without proof. These are:
- A line can be drawn from a point to any other point.
- A finite line can be extended indefinitely.
- A circle can be drawn, given a center and a radius.
- All right angles are ninety degrees.
- If a line intersects two other lines such that the sum of the interior angles on one side of the intersecting line is less than the sum of two right angles, then the lines meet on that side and not on the other side (also known as the parallel postulate).
Axioms 1–3 establish lines and circles as the basic constructs of Euclidean geometry. The fourth axiom establishes a measure for angles and invariability of figures. The fifth axiom basically means that given a point and a line, there is only one line through that point parallel to the given line. This equivalent reformulation of Axiom 5 makes it more acceptable and understandable.
It was sufficient for Lobachevsky to amend Axiom 5 to create a new class of geometry called spherical geometry. He introduced another parallel postulate: There exist two lines parallel to a given line through a given point not on the line. Additionally, it was sufficient to build geometry on a sphere, instead of on a plane https://link.springer.com/chapter/10.1007%2F978-3-319-05669-2_2 (accessed on 21 June 2021).
Some other additions have extended the geometry from the plane to the geometry of the 3-dimensional space, called hyperbolic geometry. Planes are actually defined via these axioms. Here are the axioms (http://www.ms.uky.edu/~droyster/courses/spring02/classnotes/chapter04.pdf (accessed on 8 June 2021), which say that:
- For any two points A and B, there exists a straight line L that passes through each of the points A and B.
- For any two points A and B, there exists no more than one straight line L that passes through both A and B.
- On each straight line L, there exists at least two points. There exists at least three points that do not lie on the same straight line.
- For any three points A, B, C that do not lie on the same straight line, there exists a plane α that contains each of the points A, B, C. For every plane, there always exists a point which it contains.
- For any three points A, B, C that do not lie on one and the same straight line, there exists no more than one plane that passes through each of these three points.
- If two points A, B of a straight line L lie in a plane α, then every point of L lies in plane α. In this case, one says: “the straight line L lies in the plane α”, or “the plane α passes through the straight line L”.
- If two planes α and β have a point A in common, then they have at least one more point B in common.
2.3. About Axioms of Algebra
Before the axioms in geometry, no one could give any definition of point, straight line, or plane. However, everyone may have these concepts in their imagination, drawn figures, or seen things. Something analogous happened in algebra! As for the definition of number, or what is zero, who knows in advance what this is? Small children start answering the question “What is your age?”, and they will show you one, two, or three fingers? People have used numbers since humanity began. Symbols for numbers were also developed using some operations with numbers (Roman symbols I, II, III) to just show “how many”, but IV, VI, VII, VII already include some arithmetic to figure out what they represent. Furthermore, symbols X, L, M, etc. already symbolize certain now known numbers. Their use also includes some arithmetic to find out what that number is in a long chain of symbols. However, these symbols were inappropriate for calculations.
After Arabic symbols for digits were accepted, calculations and symbolization of numbers were made easier. Additionally, algorithms in calculations became easier to use AND teach in school. As matter of fact, ZERO was introduced sometime in the 13th century. However, the theory of algebra (number theory) came later. In 1889, Peano published a simplified version of number theory as a collection of axioms in his book, The principles of arithmetic presented by a new method: Arithmetices principia, nova methodo exposita, https://en.wikipedia.org/wiki/Peano_axioms (accessed on 19 June 2021).
The Peano axioms define the arithmetical properties of natural numbers, usually represented as set N of objects. The first axiom states that the constant 0 is a natural number:
- 0 is a natural number.
- The next four axioms describe the equality.
- For every natural number x, x = x.
- For all natural numbers x and y, if x = y, then y = x.
- For all natural numbers x, y, and z, if x = y and y = z, then x = z.
- For all a and b, if b is a natural number and a = b, then a is also a natural number. That is, the natural numbers are closed under equality.
The remaining axioms define the arithmetical properties of the natural numbers. The naturals are assumed to be closed under a single-valued “Successor function” S.
- 7.
- For every natural number n, S(n) is a natural number. That is, the natural numbers are closed under S.
- 8.
- For all natural numbers m and n, m = n if and only if S(m) = S(n). That is, S is an injection.
- 9.
- For every natural number n, S(n) = 0 is false. That is, there is no natural number whose successor is 0.
Peano’s original formulation of the axioms used 1 instead of 0 as the “first” natural number. This choice is arbitrary, as these axioms do not endow the constant 0 with any additional properties. However, because 0 is the additive identity in arithmetic, most modern formulations of the Peano axioms start from 0.
Axioms 1, 6, 7, and 8 define a unitary representation of the intuitive notion of natural numbers: the number 1 can be defined as S(0), 2 as S(S(0)), etc. However, considering the notion of natural numbers as being defined by these axioms, axioms 1, 6, 7, and 8 do not imply that the successor function generates all the natural numbers different from 0. Put differently, they do not guarantee that every natural number other than zero must succeed some other natural number.
The intuitive notion that each natural number can be obtained by applying successor sufficiently often to zero requires an additional axiom, which is sometimes called the axiom of induction.
- 10.
- If K is a set such that:
- ○
- 0 is in K, and
- ○
- for every natural number n, n being in K implies that S(n) is in K,
then K contains every natural number.
The mathematical induction axiom is sometimes stated in the following form:
- 11.
- If φ is a statement such that:
- ○
- φ(0) is true, and
- ○
- for every natural number n, φ(n) being true implies that φ(S(n)) is true,
then φ(n) is true for every natural number n.
In Peano’s original formulation, the induction axiom is a second order axiom. It is used in many proof of validity of statements in mathematics.
The nine Peano axioms contain three types of statements. The first axiom asserts the existence of at least one member of the set of natural numbers. The next four are general statements about equality. In modern treatments, these are often not taken as part of the Peano axioms, but rather as axioms of the “underlying logic”. The next three axioms are statements about natural numbers expressing the fundamental properties of the successor operation. The ninth axiom is a statement of the principle of mathematical induction over the natural numbers. A weaker first-order system called Peano arithmetic is obtained by explicitly adding the addition and multiplication operation symbols. The mathematical induction method is the most widely used method in the proof of new mathematical rules, and are valid in the world of relationships depending on the numbers of events involved.
3. Uncertainty Axioms and Axioms about Concepts and Its Measurements in Applications
3.1. Preliminary Concepts and Meaning
Now we focus our attention on some recent concepts, related to specific sets of objects and basic concepts without definitions. Most are based on set theory, specifically defined sets of outcomes of an experiment and additional relationships and interpretations. All are related to the definition of uncertainty. Examples show how different models satisfy uncertainty axioms and create descriptions of intuitively clear general situations are met in practice.
To start with uncertainty, we need to introduce some basic concepts for which there are no definitions, similar to the concepts of points, lines, and numbers as referred above. These are experiment, outcomes, and random events.
First is the concept of experiment. This word has many particular determinations, and no general definition. According to probability theory, an experiment is just a collection of conditions that produces results. This is not a definition, just a description. We denote this concept by the symbol E.
Another basic concept is the outcome ω, a simple result from E. It is called a simple event.
Then, we can define the set of all possible events under the E, and denote it with S. This set S contains no more, nor less than the outcome ω, simple results from E. We call S a sure event.
Every subset A of S is called a random event. A random event A occurs only when ω ϵ A.
The empty set Ø is called an impossible event.
The specific situation allows us to introduce some additional extra random events—the complement to a random event A. This is the event that happens only and always when A does not happen. In set theory, there is no concept of complement to a set, and in uncertainty, the operations with events also have specific interpretations.
The union of the events A and B, denoted A ∪ B, is the set of all elementary outcomes ω that favor A, B, and that are members of A, or B, or both. It is read as “at least one of the two events occurs”. Meanings matter.
The intersection of the events A and B, denoted A ∩ B, is the set of all elementary outcomes ω that favor both A and B. It is read as “both events occur” simultaneously in E.
- -
- If A ∩ B = Ø, then the events A and B are called mutually exclusive, and their union will be symbolized as A + B (meaning it is the union of mutually exclusive events).
These meanings and operations with symbols will be used in full scale in the next. For instance,
means “at least one event in the list will occur in E”; also
means that each one event in the list will simultaneously occur in E.
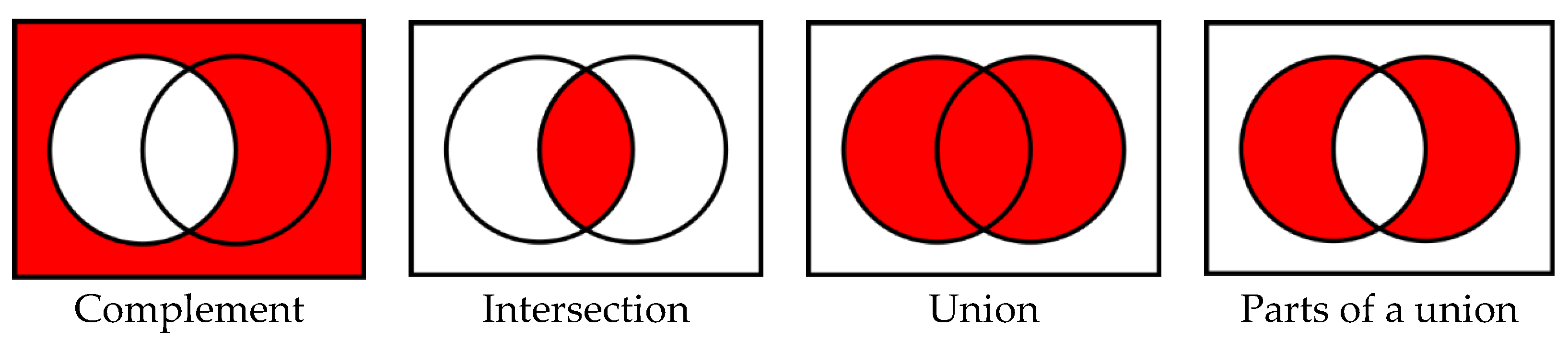
This is how the operations with events, stated in set theory, become important meanings. It is used thorough the entire axiomatic of uncertainty where sets have meaning. For simplicity, we introduced specific symbols in operations with sets that do not change the meaning and include knowledge about their mutual intersections. Graphic illustration of operations between sets/events and their meaning as subsets of set S are called Venn diagrams. The following pictures seem useful in such presentations and makes such an illustration below:
3.2. Axioms of Uncertainty and Examples
Uncertainty is related only with certain experiment, frequently understood in a broad and imaginary sense. For instance, a human being can be considered as a result of many circumstances (conditions) at the place he/she is born, country, parents, growth, friends, ethnicity, politics, etc. Experiment is not well defined, but results are clear, and may undoubtedly serve as a set of possible outcomes.
The axioms of uncertainty should now be clear: This is a system @ of random events, which satisfies the following rules (axioms):
- The sure event S and the impossible event Ø belong to @.
- If the random events A, B, …, C belong to @, then their unions A ∪ B, A ∪ C, …, intersections A ∩ B, A ∩ C, …, and complements , , …, also belong to @.
The following models illustrate the flexibility of this presentation of uncertainty. Each model corresponds to the resolution of what degree one can recognize the random events in an experiment:
- @0 = {S, Ø}. This corresponds to the situation where one sees only the sure and impossible events. This is the model of certainty.
- @A = {S, Ø, A, }. This model corresponds to a situation, where one sees only when a random event A occurs or not (then occurs the complement ).
- The sure event S is partitioned in particular cases (mutually exclusive events A1, A2, …, An), so that S = A1+ A2 + …+ An. This means that in the experiment, only some finite, or countable number of mutually exclusive random events can be recognized. The incertainty system @ consists of any union of events from these in the above partition. As an example, in a roulette game, there are 37 particular positions, but colors, odds, and neighbors make combinations of this partition. In natural numbers (if considered as a particular case), odds, evens, multiple to an integer number k are combined random events. Here are many models we do not discuss in detail, and they represent a better resolution in the set of outcomes of the experiments.
- @∞—the uncertainty consists of any particular outcome in the experiment and contains every subset of the sure event S. This is the maximal resolution one can see in the outcomes of an experiment.
3.3. Measures of Uncertainty. Axioms of Probability
The uncertainty as introduced is only to register the existence and resolution of events in experiments. To study its properties comes the mathematics with all of its power, and mathematics comes with another basic concept still not defined. This is the concept of probability, also introduced with axioms [1]. There is no definition of probability, again just an explanation:
Probability is a measure of the chance that a random event will occur under the conditions of certain experiment. For a random event A, probability is denoted as P(A).
The word measure introduces mathematics in the analysis of uncertainty. Any time one introduces this measure, they should have in mind the conditions of the experiment and the uncertainty model @ associated with this measure. Uncertainty model @ is necessary whenever probability is introduced.
Therefore, we need the uncertainty model @ and only within such a model can probability be introduced. Then, the axioms of probability can be applied. These are:
- For any event A ϵ @ the probability P(A) ≥ 0;
- P(S) = 1;
- If A = A1 + A2 + … + An + …, then P(A) = P(A1) + P(A2)+ … + P(An) + …
The triplet {S, @, P} is then called the probability space.
These axioms [2] do not explain how the probability must be calculated, but they are sufficient to derive all the probability theory mathematical rules and properties that govern any application of this theory. Axioms do not assign any numeric value for P(A), but ensure that any method used to assign such numeric values for which the relationships, like these
are valid. An important interpretation: The probabilities P(A) and P (B) are called marginal probabilities, while P(A ∩ B) is called joint probability. This meaning is essential later on when we introduce measures for the strength of dependence also based on these axioms.
3.3.1. Methods for Establishing Numeric Values of Probability P(A)
Axioms do not provide ways to assign numeric values of P(A) in any probability space {S, @, P}.
However, practical needs and theoretical results of probability theory have created the following approaches: classic definition, statistical approach, and subjective approach. Their use depends on certain assumptions, and we explain it shortly.
Classical probability definition
This is used when the following assumptions are legal to be applied:
The uncertainty model of an experiment shows that the sure event S is equivalent to the occurrence of a finite number of mutually exclusive equally likely outcomes ω1, ω2, …, ωn (i.e., S = ω1 + ω2+… + ωn as in Model 3 of the uncertainty). Every random event is equivalent to the occurrence of some k of these outcomes (i.e., . Then, P(A) is determined as the ratio of the numbers k of the outcomes that favor A and the total number n of possible outcomes, in other words,
P(A) = k/n = #(A)/#(S).
Here, I use the sign “#” as a symbol for the counts of the distinct elements in a set. Then, the classical definition of probability works. However, if S is a finite geometric space (a line segment, a plain region or a multidimensional region with finite volume), and the outcomes of the experiment are equally likely to appear as points in any part of S, then thinking #(S) and #(A) as respective geometric measure (length, area, volume), the same classic definition applies, and the probability introduced by the above rule is then called geometric probability. All rules of combinatorics (counting techniques) and the geometry measures can be used in numeric calculations of the measures of the chances that random events occur in a single experiment.
Statistical determination of probability
This approach is the most real and can be used when the experiment can be repeated without changed conditions many times. When repeated N times and a random event A is observed N(A) times, its relative frequency fN(A) is defined as the ratio of number of times A occurs and the total number N of experiments performed.
fN(A) = N(A)/N
The probability P(A) is then defined as the limit of fN(A) when N tends to infinity, in other words,
P(A) = lim N---> ∞ {fN(A)} = lim N----> ∞ {N(A)/N},
The legality of this approach is proven based on axioms of probability, known as the law of large numbers. It has been used many times in practice to discover frauds in hazard games and is also widely used in simulations. We note that this definition satisfies the three axioms of probability.
- Subjective determination of probability
This approach is usually applied when any experiment cannot be used. It is subjected to future events with known or guessed conditions. Then, experts are used to give their forecasts, and the user may then use the statistical approach to manipulate the expert’s opinions. In the absence of an expert, only one opinion can be used. However, any consequences should be delivered only when the axioms of the probability theory are verified and fulfilled.
- Rules of combinatorics in applying the classic probability approach
These are not axioms, but just rules in counting. I consider this as axioms related to modeling the counting depending on the descriptions of outcomes in sampling.
Sampling is a kind of experiment (considered as selection of groups of elements from non-empty sets). A description of the sample is as ordered and unordered sequence of elements, where description of the sample matters. Two counting rules work:
- Rule of multiplications:
The outcomes ω of an experiment are described as an ordered sample from n sets M1, M2, … Mn.
Then, S is called the Cartesian product of the sets M1, M2, … Mn.
Using the sign “#” as a symbol for the counts of the distinct elements in a set, then the first counting principle of combinatorics is
# (S) = #(M1)# (M2)… #(Mn).
- Rule of addition:
If a set S is partitioned into a mutually exclusive subset M1, M2, … Mn (i.e., if S = M1 + M2+ … + Mn), then
# (S) = #(M1) + # (M2) +… + #(Mn).
These two rules, associated with different appropriate descriptions and two different legal ways of calculations of the elements in one and the same set of components, serve as a source of many combinatorial identities. We do not provide details, but good examples can be found in the book by W. Feller [3], and many textbooks on probability. For instance, when calculating the number of unordered samples of size k with different content from a set of n distinct elements, we present these samples as X—the subsets with different contents, A1 +…+ AX, and then make in each of them k! ordered samples. When counting these in this way, one obtains the number of permutations Pk,n = n(n − 1)(n − 2)…(n − k + 1) of ordered samples without replacements of size k out of a set with n elements, calculated by the rule of multiplication, in other words,
X.k! = n(n − 1)(n − 2)…(n − k + 1).
In this way, one can derive the formula for the number of combinations of size k out of a set with n distinct elements.
Another interesting example is the division of set N of natural numbers in two mutually exclusive parts, odds N1 and even N2 numbers. So, N = N1 + N2, and each of these contains the cardinal infinity. Using the above rules of counting the power of these sets, an interesting question arises: Is the infinity odd or even?
3.3.2. Independence and Dependence Strength Measured
Let us stop for a minute on the concept of independence, its definition, and on the ways of measuring dependence. There are many trials to define this very complicated concept (Declaration of Independence in USA, Memorandum of Independence from various countries in the world, independent people, independent students, etc.). However, the only definition of independency in this world of uncertainty that can be verified is given through probability theory. For two random events A and B, independence is defined as satisfying the mathematical equation:
This means that the joint probability of the two events under the same experiment is equal to the product of their marginal probabilities. Independence is symmetric. It is mutual. Moreover, any pair А and (the complement of В), and B, and are also mutually independent. However, the books stop their discussions here, even though it can be continued. In [4], I used an idea of Bulgarian mathematician N. Obreshkov [5] to introduce several measures of discovering dependence and measure its strength for the case of pairs of random events. Then, it was extended to measure the local dependence between pairs of random variables, regardless of their type (numeric or non-numeric, or mixed). I see here a huge area of future studies, since joint distributions between random variables and their marginal distributions are defined as probabilities of random events. What is worked out for relationships between random events will also be valid for random variables.
Let us see the measures of dependence between two random events as proposed by Obreshkov [5].
Connection between random events. The number
is called the connection between events А and В.
The following properties of the connection hold [5]:
- (δ1)
- The connection equals zero if and only if the events are independent.
- (δ2)
- The connection between events А and В is symmetric.
- (δ3)
- If are mutually exclusive events, then it is fulfilled
The function is additive with respect to either of its arguments. Therefore, it is also a continuous function as the probabilities in its construction are.
- (δ4)
- The connection satisfies , and this is equivalent to the rule for probability of the union for two arbitrary events. Therefore, most of the properties of the probability function for random events can be transferred as properties of the connection function including extensions for the union of any finite number of events.
- (δ5)
- The connection between events А and equals {by magnitude) the connection between events А and В, but has an opposite sign, in other words, it is true that The connection between the complementary events and is the same as between А and В, in other words, it is fulfilled
- (δ6)
- If the occurrence of А implies the occurrence of В, in other words, when we have then it is fulfilled and the connection between events А and В is positive.
- (δ7)
- If А and В are mutually exclusive, in other words, when , then and the connection between events А and В is negative.
- (δ8)
- When the occurrence of one of the two events increases the conditional probability for the occurrence of the other event. The following relation is true:
If (then also ), the occurrence of one of the events decreases the chances for the other one to occur. Equation (5) indicates that the knowledge of the connection is very important, and can be used for calculation of the posteriori probabilities like when we apply the Bayes’ rule!
The connection function just shows the direction of dependence—positive or negative—but it is not good for measuring the strength of dependence. The next measures serve better for the strength of dependence.
- Regression coefficients as measure of dependence
Regression coefficient of event А with respect to event В is called the difference between the conditional probability for event А given event В, and the conditional probability for event А given the complementary event , namely
This measure of the dependence of event А on event В, is directed dependence.
The regression coefficient of event В with respect to event А is defined analogously:
The following statements hold [5]:
- (r1)
- The equality to zero = = 0 holds if and only if the two events are independent.
- (r2)
- The regression coefficients and are numbers with equal signs and this is the sign of their connection . The relationshipholds.
The numerical values of and may not always be equal. There exists an asymmetry in the dependence between random events, and this reflects the nature of real life.
For = to be valid, it is necessary and sufficient to be fulfilled
- (r3)
- When , the occurrence of event B increases the conditional probability for the occurrence of event A. It is true:
The knowledge of the regression coefficients is important, and can be used for the calculation of the posterior probabilities, similar to when applying Bayes’ rule.
- (r4)
- The regression coefficients and are numbers between –1 and 1, in other words, they satisfy the inequalities
- (r4.1)
- The equality holds only when random event А coincides with (or is equivalent to) event В. Тhen, the equality = 1 is also valid;
- (r4.2)
- The equality holds only when random event А coincides with (or is equivalent to) event —the complement of the event В. Тhen, = −1 is also valid, and respectively .
We interpreted the properties (r4) of the regression coefficients in the following way:
The closer the numerical value of to 1, “as denser inside within each other are the events A and B, considered as sets of outcomes of the experiment”. In a similar way, we also interpret the negative values of the regression coefficient: “As closer is the numerical value of to -1, as denser within each other are the events A and considered as sets of outcomes of the experiment”.
It is fulfilled = −, and = −. Additionally, the identities = = − hold.
It is true that for any mutually exclusive sequence of events
The regression function possesses the property
These properties are anticipated to be used in the simulation of dependent random events with the desired values of the regression coefficients, and with given marginal probabilities P(A) and P(B). The restrictions must be satisfied when modeling dependent events by use of regression coefficients.
The asymmetry in this form of dependence of one event on the other can be explained by the different capacity of the events. Events with less capacity (fewer amounts of favorable outcomes) will have less influence on events with larger capacity. Therefore, when is less than , event A is weaker in its influence on B. We accept it as reflecting what indeed exists in the real life. By catching the asymmetry with the proposed measures, we are convinced of their flexibility and utility features.
Correlation between two random events A and B, we call the number
where sign, plus or minus, is the sign of either of the two regression coefficients.
An equivalent representation of the correlation coefficient in terms of the connection holds,
We do not discuss the properties of the correlation coefficient between events А and В. We note that it equals the formal correlation coefficient between the random variables and —the indicators of the two random events A and B. This explains the terminology proposed by Obreshkov in 1963.
The correlation coefficient between two random events is symmetric, located between the numbers and , and possesses the following properties: = = −; = .
The knowledge of allows us to calculate the posterior probability of one of the events under the condition that the other one occurred. For instance, P(A|B) will be determined by the rule
This rule reminds us again of Bayes’ rule for posterior probabilities. The net increase or decrease in the posterior probability compared to the prior probability is equal to the quantity , and depends only on the value of the mutual correlation (positive or negative).
Freshet–Hoefding inequalities for the correlation coefficient [5]:
Its use is of importance in the construction (e.g., for simulation or modeling purposes) of events with given individual probability, and desired mutual correlation.
An interesting new approach in measuring the strength of dependence between random events, based on the use of entropy, was recently introduced to me by another Bulgarian mathematician Dr. Valentin Iliev A preprint of his work can be found at https://www.preprints.org/manuscript/202106.0100/v3 (accessed on 28 June 2021). No official publication of this work is known to me yet. However, lots of research in this direction is needed. One direction is the dependence between two variables in many important situations. The other is about the extension of the dependence measures between more than two variables. Good luck to those who start working on this.
3.3.3. On the Axioms of Statistics and Classes of Variables
Statistics also uses several basic concepts, most of which are explained in terms of sets. These concepts are population, sample, variables, measurement, and dataset. Most of the textbooks on probability and statistics start their introduction to uncertainty with these concepts.
Population—this is the set that contains no more, nor less, but all the individuals targeted in a statistical study.
Sample—this is the set of n individuals selected from the population whose data will be used for information about the properties of various characteristics of the population.
Measurements—this is a sequence of characteristics = (x1, x2, …, xk)i one can obtain after recording the data inspecting the selected individual i, i = 1, 2, …, n.
Dataset—or data matrix is the matrix of all recorded observations Ẍ = {(x1, x2, …, xk)i}i=1,…,n.
Variables—these are the recorded values of the measured/observed characteristics for individuals in the sample, located in any of the columns of the dataset. These can be:
- -
- Non-numerical or nominal, like names, symbols, labels like gander, color, origin, etc.;
- -
- Ordinal, where categories could be ordered (good, better, best), like preference, age groups, etc.; and
- -
- Numeric (relative or absolute), like temperature, weight, scores, income, etc. Here, digital records work.
Actually, no axioms of statistics are known. All statistical manipulations with statistical datasets are based on assumed probability models for the data in a column (i.e., axioms and rules of probability theory start work). Here, we observed a change in the concept of the population, called the sample space. This is a set of all the possible values of the variables in a column (as a population) and parameters of the distributions, presumably presenting what is going on in the original population, are called population parameters. Usually in statistics, the targets are the estimation of these population parameters. Further various hypotheses have been built and tested according to the huge set of algorithms developed in statistics. There we face the concept of risk, related to many, if not to all decisions based on statistical data, or on the probability models applied to real life.
4. Uncertainty and Related Risks in Applications
My extended search for definitions of the concept of risk faced different opinions. One of these https://rolandwanner.com/the-difference-between-uncertainty-and-risk/ (accessed on 12 May 2021) seems reasonable:
A risk is the effect of uncertainty on certain objectives. These can be business objectives or project objectives. A more complete definition of risk would therefore be “an uncertainty that if it occurs could affect one or more objectives”.
A risk is the effect of uncertainty on certain objectives. These can be business objectives or project objectives. A more complete definition of risk would therefore be “an uncertainty that if it occurs could affect one or more objectives”. Objectives are what matter!
This recognizes the fact that there are other uncertainties that are irrelevant in terms of objectives, and that these should be excluded from the risk process. With no objectives, we have no risks.
Linking risk with objectives makes it clear that every facet of life is risky. Everything we do aims to achieve objectives of some sort including personal objectives, project objectives, and business objectives. Wherever objectives are defined, there will be risks to their successful achievement.
The PMBOK guide https://www.amazon.com/Project-Management-Knowledge-PMBOK%C2%AE-Sixth/dp/1628251840 (accessed on 29 May 2021) defines risk as an uncertain event or set of circumstances, and if this occurs, it has a positive or negative effect on the achievement of objectives. There are events and circumstances/conditions mentioned in these definitions, which is obviously something separate from the event. There are uncertain future events that if they occur could affect the achievement of objectives, and that has been the focus. So what does this mean? Where do events correspond to the event risk? This distinction may still be strange.
The above online references built in me the incentives, that the risk is something objective, and it is accepted subjectively. Without measures of the risks, it does not make any sense to discuss it further. I hope that my examples below will explain my feelings, and will raise more things to think about.
4.1. Risks in Hypotheses Testing and Their Measures
In testing hypotheses, we have the following situation: a null hypothesis H0 is tested versus some alternative hypothesis Ha and some appropriate test, based on certain model assumptions, is applied. After the test is performed, the statistician should make a decision as to not reject the null hypothesis, or reject it. Since the nature (uncertainty) is not known, such personal decisions contain some risk, which has the following measures: the probability to admit error of type 1 (usually denoted by the symbol α) meaning to reject the correct null hypothesis; and if the statistician accepts the null hypothesis as being correct, there is another risk for this decision to be incorrect. Its measure is given by the probability β to admit this type 2 error.
Here, we observe the risk of making the wrong decisions of any kind based on uncertain data, so there is no further discussion.
The p-value
Whenever a statistical package is run with a statistical dataset and uses a probability model to test it, at the output, you obtain a list of numerical results. In it, you will find many of these labeled as p-values, either for the model itself, or for the parameters used in them. Each p-value corresponds to specific pairs of hypotheses (formally as described above) and to make decisions, one needs to know their meaning. This meaning is very important and needs to be understood. The book [6] by A. Vickers is an interesting place to start. It offers a fun introduction to the fundamental principles of statistics, presenting the essential concepts in thirty-four brief, enjoyable stories. Drawing on his experience as a medical researcher, Vickers blends insightful explanations and humor, with minimal math, to help readers understand and interpret the statistics they read every day.
My own simple definition-explanation of the p-value should be clear for any user and used in decisions:
The p-value is the measure of the chance for the null hypothesis to survive in the conditions provided by the statistical data used in its evaluation.
You cannot find the explanation of a p-value concept in any textbook or books related to its discussion like in. Lately, the ASA (American Statistical Association) has also had a huge discussion on this issue (https://www.bing.com/search?form=MOZLBR&pc=MOZD&q=asa+p-value (accessed on 23 May 2021)), and gives the following definition:
A p-value is the probability under a specified statistical model that a statistical summary of the data (e.g., the sample mean difference between two compared groups) would be equal to or more extreme than its observed value.
Can you find any useable meaning in this definition? I cannot. Other definitions in the textbooks are focused on the rules of its numeric calculations (since it depends on the null and alternative hypotheses formulations, on the tests applied, targeted parameters, and many other things) and do not give any understandable meaning. However, meaning is the most stable something, which does not depend on any method of calculation and anything else. Measures of the meanings are numbers and should be used as measures of the risk taken in decisions (look at the chance that the null hypothesis is correct in this discussion).
4.2. Other Visions on the Risk and Numeric Measures
Risk is a complex concept and was met in old times mainly in hazard games. Then (and even in now days), it was measured in terms of “odds”.
- Odds
A true definition of the odds should be the ratio of the probability that a random event A will happen in the condition of an experiment, and the probability that another event B will occur. So,
Odds of (A versus B) = P(A)/P(B).
This ratio should be read as the ratio of two integers, therefore, these probabilities are usually multiplied by 10, or 100, or even by a thousand (and then the fractional parts are removed) for easy understanding on behalf of users not familiar to probability. The best example in the case of classic probability is
Odds of (A versus B) = #(A)/#(B).
According to the web information https://www.bing.com/search?form=MOZLBR&pc=MOZD&q=odds or https://www.thefreedictionary.com/odds (accessed on 17 May 2021), odds provide preliminary information about bidders in games on what are their chances to win after the experiment is performed if the player bet is for event A. There, usually for B, stays the complement of A. In my opinion, the odds are kind of hints given by experts to the players of what their risk is in games when they bid for the occurrence of certain random future events.
- Relative Risk
In medicine, biology, and in many usual actuarial, social, and engineering practices, there is a need to apply tests to establish if an individual (or an item) in the population possesses some property (let use terminology “belongs to category B” or does not belong to this category).
Therefore, let B and A be two events where A has the sense of test factor (for example, result of an environment)) to find out if an individual belongs to category B. The relative risk (relative risk, we denote it briefly RR) of event B with respect to event A is defined by the rule
The point is that the larger the RR, the more the test (risk factor A is increasing the probability of occurrence of B) affects category B to be true. For example, if we want to evaluate the influence of some risk factors (obesity, smoking, etc.) on the incidence of a disease (diabetes, cancer, etc.), we need to look at the value of the relative risk when test A is applied and indicates such categorization to be a fact. It is kind of an “odds measure” useful to know. We illustrate this with an example from the biostatistics below.
- Tests for the Truth
It is well known that in medical research and in other experiential sciences, to discover the presence of certain diseases, there are well used tests. When the result of the test is positive, it is considered that the object owns the quality of what it is tested. However, tests are not perfect. They are very likely to give a positive result when the tested objects really have that quality, which are tested. Additionally, it happens to give a negative test result although the object possesses that property. Furthermore there is another possibility, although unlikely, that the test gives a positive result, even when the subject does not possess the property in question. These issues are closely related to the conditional probability. Biostatistics has established specific terminology in this regard, which should be known and used. It is known that in carrying out various tests among the population that suffers from something, it is possible to get a positive test (indicating that the person may be ill) or a negative test. In turn, the latter is an indication that the person is not sick. Unfortunately, there are no tests that are 100% truthful. It is possible that the tested subject is sick, but the test may not show it as well as being positive, although the inspected subject is not sick. Here, the concepts of conditional probabilities play a special role and are important in assessing the results of the tests.
- Screening tests.
Predictive value positive, PV+ of a screening test is called the probability of a tested individual to possess tested quality (such as being sick) when tested positive, (T+), in other words,
PV+ = P(sick| T+);
Predictive value negative, PV- of a screening test, is called the probability that the tested individual does not have the tested quality (is not sick), on the condition that the test was negative (T-), in other words,
PV- = P(healthy|T−).
The sensitivity of the test is determined by the probability that the test will be positive, provided that the individual has the tested quality, in other words,
Sensitivity = P (T+ | sick).
The specificity of the test is determined by the probability that the test gives a negative result, provided that the tested individual does not possess the quality for which is being checked, in other words,
Specificity = P (T−|not sick).
In other words, specificity = P (no symptom detected | no disease).
False negative is determined as the outcome of the test where an individual, who was tested as a negative, is sick (possessing the tested quality).
To be effective, for test prediction, the disease should have high sensitivity and high specificity. The relative risk to be sick if tested positive is then the ratio
RR(risk to be sick when tested positive) = P(sick|T+)/P(sick|T−) = PV+/[1 − PV−].
The use of RR in terms of odds is a very good and useful idea.
4.3. Reliability and Risk
Possibly for many natural reasons, the risk concept is most related to another complex concept—reliability. This is an exciting area of discussions, and in my opinion, not finished yet, and will probably never finish. I studied the web opinions and have had detailed discussions with my Gnedenko Forum colleagues, and still did not come to any determined conclusions. Here are some brief results of my research.
In my modest opinion, the risk is an objective-subjective feeling that something undesirable, a dangerous event, may happen under certain conditions. While one can explain in words what it is to everyone else, this is not sufficient without some general frames and numeric measure of that risk.
Let us see what the wise sources on the risk concept are saying.
- Definition of Risk Related to Reliability (from the web)
Creating a reliable product that meets customer expectations is risky.
What is risk and how does one go about managing risk? The recent set of ISO (International; Organization fos Standards) updates and elevates risk management. Here are some details:
ISO 9000:2015 includes the definition of risk as the “effect of uncertainty on an expected result.”
ISO 31000:2009 includes the definition of risk as the “effect of uncertainty on objectives.”
The origin of the English word ‘risk’ traces back to the 17th century French and Italian words related to danger.
A dictionary definition includes “the possibility that something unpleasant or unwelcome will happen.”
Risk from a business sense may need slightly more refinement. The notes in the ISO standards expand and bind the provided definition as away from unwanted outcomes to include the concept of a deviation from the expected.
Surprise seems to be an appropriate element of risk. Surprise may include good and bad deviations from the expected.
For the purposes of the ISO standards, risk includes considerations of financial, operations, environmental, health, safety, and may impact business or society objectives at strategic, project, product, or process levels.
The discussion about a specific risk should include the events and consequences. While we may discuss the risk of an event occurring, we should also include the ‘so what?’ element.
If an event occurs, then this consequence is the result. Of course, this can quickly become complex as events and associated consequences rarely have a one-to-one relationship.
Finally, the ISO notes on risk include a qualitative element to characterizing risk.
The likelihood (similar to probability, I think) and the value (in terms of money would be common) of the up- or downside of the consequences.
According to me, risk is a concept with many faces. It is possible that the reliability may highlight some of it.
Following this study, it is possible to give the following proposition:
The risk (analogously, the reliability) is a complex notion that is measured by numerous indexes depending on different applications and situations. However, the basic measure should be unique.
- Risk and Reliability Related Risks
As for the reliability professionals, these ISO definitions may seem familiar and comfortable. We have long dealt with the uncertainty of product or process failures. We regularly deal with the probability of unwanted outcomes. We understand and communicate the cost of failures.
What is new is the framework described by the ISO standards for the organization to identify and understand risk as it applies to the organization and to the customer.
Reliability risk now has a place to fit into larger discussions concerning business, market, and societal risk management. I agree that reliability risk is a major component of the risks facing an organization. Witness the news making recalls in recent years (nuclear plant accidents, plane crashes, We threatening that sometimes happen, companies ruined). As reliability professionals, we use the tools to identify risks, to mitigate or eliminate risks, and to estimate future likelihoods and consequences of risks. How do we view the connection between risk and reliability? Why do car companies recall some vehicles from users to replace some parts in order to prevent unexpected failures?
We usually connect the risk to some specific vision of the characteristic on the reliability. Here, I present some points of view of my Gnedenko Forum associates, albeit not an exhaustive review.
Here is the opinion of A. Bochkov, the Gnedenko Forum https://gnedenko.net/ (accessed on 19 June 2021) corresponding secretary and motor:
- Safety and Risk
Risk and safety relate to humanity. Namely, the human assesses the degree of safety and risk considering its own actions during the life or the reliability of systems as a source of potential danger, or risk that such a thing happens. Tools, machines, systems, and technical items do not feel the risk. Risk is felt by people. How do people estimate the risk is a different question. Safety, in most tools that people use, depends on its ergonomic design and its instructions for use. There are ergonomic decisions that help such use and users to follow these instructions and are always in the process of improvement.
Safety is also a complicated concept. It does not have a unique definition nor some unique measure. Everything is specific and is a mixture between objective and personal. There are no numeric measures for safety. However, I agree with the statement that the higher the safety, the lower the risk. Still, the measurement for risk as a number that should make aware people and companies and governments to pay attention to some existing future risks is not clear. According to Bochkov, risk should be measured as a degree of difference of the current estimated state from the ideal. Here, there is no probability to be used. Humans usually assess the probability, but humans do not always understand what they risk. The maximal price of the risk for humans is their own life. For the one who takes such risk, the price has no numeric expression. Such a loss cannot be compensated. However, when a risk is not related to loss of lives, the maximum losses are estimated by the means available by those who make decisions on actions against risks. Usually, human lives are priced by the insurance agencies who are paying for those lost lives.
Hence, this opinion is not far from the ISO specifications listed above, and do not contribute clarity to the questions on how to measure particular risks.
- Risk—a property of a real and modeled process
A slightly different opinion is expressed by V. Kashtanov, another member of the Gnedenko Forum advisory board. Again, I present his vision. Everything is based on the possibility to present the situations by an appropriate mathematical process in development.
A qualitative definition: The risk (danger) is a property of a real or modeled process.
It is common to talk about the political, social, economic, technologic, and other processes that possess risks. Then, in modeling respective models for such processes, it is necessary to determine the sets of states of each process and present them as a random walk within the set of all states. Then, the above definition of the risk makes sense and can be understood. The danger is when the process passes into the set of risky states. Safety is when the process is out of the risky states. Such an approach allows us to understand the concept of risk and the ways to assess the risk (author’s note) as the probability to pass from a safety set into the risky ones with the use of the respective model.
Risk (maybe catastrophe) is to be in that set of Risky states. Assessment of the risk is to measure the chance to get there from one that you currently are.
Therefore, without mathematical models, we may not be able to give good definitions for concepts widely used in our scientific and social life. According to Kashtanov, the following definition should be valid:
Risk as a quantitative indicator assessing the danger is some functional operator calculated on the set of trajectories of the process that describes the evolution (the functional behavior) of the studied system.
By the way, a controller may interfere with the system working, and have some control on the process.
Uncertainty factors (randomness, limited information, impossibility to observe process states, or making measurements with errors) create additional challenges in risk evaluation and control.
I like this approach since it gives an explanation of the models of risky events and allows one to measure the chance to get into it from the safety states.
Risk as a two-dimensional process
One further opinion is that of our RTA chief editor V. A. Ryov, who is an established expert in reliability. In his book [7], he relates almost each system reliability characteristic to some respective risk, with an emphasis on the economic consequences when a risky event takes place, where probability models are used in each situation. My brief review follows.
A variety of risks go with individual people throughout their life. The same things happen with various industrial product lines, agricultural, financial companies, biological, environmental systems, and many other units. Risk appears due to the uncertainty of some events that may occur with respect to which corresponding decisions and actions should be taken. Mathematical risk theory is generated and developed on actuarial science, where the risk is that an insurance company will be ruined and is measured by the probability of ruin.
However, nowadays, the understanding of risk is related to the occurrence of some “risky” event and with its related consequences in terms of material or monetary losses to restore. Numerous examples support this position, as one can read in Rykov’s book [7]. However, we focus on situations related to reliability. Before that, let us present his mathematical definition of the risk given there.
Risk is related to the occurrence of some random (risky) event A, whose probability Pt(A) varies in time t, depending on current conditions. Occurrence of such an event at time t generates some damage measured by the value Xt. In this way, the risk is characterized by two variables (T, XT), where T is the time of the occurrence of the risky event and XT is the measure of the damage then. Both components can be random.
In reliability theory, T can be the time of use of a technical system, which may vary according to the reliability model of management of this system and of its structure. Application of this approach is demonstrated in the analysis of technological risk for popular reliability systems in the framework of some known failure models. The focus is on the measured risk.
As a basic measure, the two dimensional distribution function F(t, x) = P{T ≤ t, XT ≤ x} is proposed. I like this approach. It admits lots of analytical analysis of characteristics and cases as demonstrated in this book and many new research projects.
However, this is just in theoretical frameworks and assumptions. Practical applications need sufficient data for such a function F(t, x) to be estimated. I do not refer to any particular result from the book. Just note that the variable T varies depending on the reliability system model where a catastrophic event may take place. Then, the value of the losses XT will be known. Additionally, the value of losses that extend some critical value Xcritical is achieved or is close to being achieved. Then, the process should be stopped (times to stop are also interesting to analyze in such an approach) to prevent the risk. Such discussion was not used in that book, but deserves attention.
Somehow, I could not see any satisfactory measure of the risk shown to be different from the amount of expected losses. Average characteristics can be found in, but no clear measure of the risk that can be used such as a BELL RINGS THAT THE RISK IS NEARBY could be seen. I believe that if the risk is measured in terms of odds, then when the odds reach a certain level, then the bell’s ring should make an alarm for those who are concerned about that risk.
One more thing for the risks in reliability.
During my work on the “risk issue”, we had a vital discussion with my colleagues on the Gnedenko Forum Advisory Board. As a result of this discussion, I arrived at a general definition of the risk in a random process, and ways for its evaluation.
First, random processes need some realistic probability model where the set of states Ώ of the process are defined, (known mathematically as described, controlled) at any time and the dynamic probabilities of the changes are known. In other words, it is defined as a probability space {Ώ, @t, Pt}. Here, Ώ is the set of all possible states of the process, and it cannot vary in time; @t is the uncertainty at the time t, and Pt is the probability that works in that time. Let Bt be the set of undesired (risky) events, an element of @t, and At be the set of current states, also an element of @t. At could be a result of a test performed at time t.
Definition: Let it be that at time t for a process, there is a set Bt of undesired (risky) events and let At be the set of current states of the process in the probability space {Ώ, @t, Pt}. The risk that describes the evolution of the observed process is measured by the relative risk
in terms of odds.
RR(Bt with respect to At) = P(Bt|At)/P(Bt | complement of At)
This definition is a replicate borrowed from the measurements of risk in biostatistics, as presented above. By the way, in the cases discussed in Bockov terms, where safety and risky sets have nothing in common, this measure = 0; in Kashtanov’s and Rykov’s considerations, it needs calculations. Please note that At and Bt may overlap. As more At is covering Bt, the higher the risk. I think that this is a natural measure.
Another different point of view is presented in the N. Singpurvalla monograph [8]. He says:
The management of risk calls for its quantification, and this in turn entails the quantification of its two elements: the uncertainty of outcomes and the consequences of each outcome. The outcomes of interest are adverse events such as the failure of an infrastructure element (e.g., a dam) or the failure of a complex system (e.g., a nuclear power plant); or the failure of a biological entity (e.g., a human being). ‘Reliability’ pertains to the quantification of the occurrence of adverse events in the context of engineering and physical systems. In the biological context, the quantification of adverse outcomes is done under the label of ‘survival analysis’. The mathematical underpinnings of both reliability and survival analysis are the same; the methodologies can sometimes be very different. A quantification of the consequences of adverse events is done under the aegis of what is known as utility theory. The literature on reliability and survival analysis is diverse, scattered, and plentiful. It ranges over outlets in engineering, statistics (to include biostatistics), mathematics, philosophy, demography, law, and public policy. The literature on utility theory is also plentiful, but is concentrated in outlets that are of interest to decision theorists, economists, and philosophers. However, despite what seems like a required connection, there appears to be a dearth of material describing a linkage between reliability (and survival analysis) and utility. One of the aims of [8] is to help start the process of bridging this gap. This can be done in two ways. The first is to develop material in reliability with the view that the ultimate goal of doing a reliability analysis is to appreciate the nature of the underlying risk and to propose strategies for managing it. The second is to introduce the notion of the ‘utility of reliability’, and to describe how this notion can be cast within a decision theoretic framework for managing risk. To do the latter, he makes a distinction between reliability as an objective chance or propensity, and survivability as the expected value of one’s subjective probability about this propensity. In other words, from the point of view of this book, based mainly on the Bayesian approach. It deserves to be studied, but we do not include more discussion on it here.
I am not sure that the risks in reliability analysis should stop here. Reliability itself is defined as the probability that a system functions at a given time. Therefore, the fact that it does not work is a kind of risky event. The availability coefficient is also the probability of an event that the system is able to function at a certain time. Additionally, many other functions, like failure rates, number of renewals, maintenance costs, effectiveness, expenses for supporting functionality, etc. have quantitative measures that could be used as risky variables. Each of these uses a construction of an appropriate probability space, where the above general definition and evaluation of the risk can be applied. Therefore, the issues for the risk assessments are not finished yet. There are many open questions for researchers to work on.
5. Conclusions
Axioms are the foundation in establishing new areas of theoretical research.
In each theory arises numerous new concepts that have meaning, and the meanings may generate new axioms and areas of studies that need explanation and metrics for evaluation that may be useful in their better understanding, and clear practical directions for their use and applications.
Our article is tracing some ways of developing useful projects for studying life.
Funding
This research received no external funding.
Conflicts of Interest
The author declares no conflict of interest.
References
- Gnedenko, B.V. Theory of Probability, 6th ed.; CRS Press: Boca Raton, FL, USA; New York, NY, USA; London, UK; Taylor & Francis Group: Boca Raton, FL, USA; New York, NY, USA; London, UK, 2005. [Google Scholar]
- Kolmoorov, A. Foundations of the Theory of Probability; Chelsea Publishing Company: New York, NY, USA, 1950. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications; John Wiley and Sons: New York, NY, USA, 1968; Volume 1. [Google Scholar]
- Dimitrov, B. Some Obreshkov Measures of Dependence and Their Use. C. R. Acad. Bulg. Sci. 2010, 63, 15–18. (In Bulgarian) [Google Scholar]
- Orbeshkov, N. Teory of Probability; Naika I Izkustvo: Sofia, Bulgaria, 1963. [Google Scholar]
- Vickers, A. What Is the P-Value Anyway? 34 Stories to Help You Actually Understand Statistics; Pearson UK Higher Education: Pearson, UK, 2010. [Google Scholar]
- Rykov, V.V. Reliability of Engineering Systems and Technological Risks; Wiley and Sons: New York, NY, USA, 2016. [Google Scholar]
- Nozer, D. Singpurwalla, Reliability and Risk a Bayesian Perspective; Wiley and Sons: New York, NY, USA, 2006. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).