Abstract
In a series of papers, we suggested a non-statistical method for the detection of structural breaks in a time series. It is based on the applications of special fuzzy modeling methods, namely Fuzzy transform (F-transform) and selected methods of Fuzzy Natural Logic (FNL). In this paper, we combine our method with the principles of the classical Chow test, which is a well-known statistical method for testing the presence of a structural break. The idea is to construct testing statistics similar to that of the Chow test which is formed from components of the first-degree F-transform. These components contain an estimation of the average values of the tangents (slopes) of the time series over an imprecisely specified time interval. In this paper, we illustrate our method and its statistical test on a real-time series and compare it with three classical statistical methods.
1. Introduction
Structural breaks in time series are sudden unexpected changes in their course triggered by a structural change in the system (for example, opening a new factory), by an attack from outside, or by some other outer cause. Unlike single outliers, structural breaks are characterized by a longer duration. There are various statistical methods for detection and testing whether a structural break occurs in the given time point, see [1,2,3,4,5], and also non-statistical methods such as genetic algorithms [6].
However, a structural break hardly occurs just at one point. It is a phenomenon lasting usually over several time points. Hence, we argue that techniques based on methods of fuzzy modeling are better suited for this purpose. In [7] and elsewhere, we presented an effective non-statistical method for finding structural breaks. It is based on the application of the so-called fuzzy transform (F-transform) in combination with methods of fuzzy natural logic (FNL). They enable us to detect intervals of specific monotonic behavior and to discover existing structural breaks in a time series. The main idea consists of the fact that the F-transform provides an estimation of the average value of the slope in an imprecisely specified time interval (cf. [8]). The former is then evaluated using a specific evaluative linguistic expression whose semantics is modeled inside FNL (for the details, see [9]). The method is very effective and we argue that it can find the real structural breaks. However, it is non-statistical and so it is a challenge to prove that the detected structural breaks can also be statistically verified. This is the topic of this paper. We modify the classical Chow test [1]. First, we form a modified null hypothesis stating that there is no structural break in the given area and then prove that it is rejected if a structural break is indeed present and detected using our fuzzy method.
The paper is structured as follows. Section 2 contains preliminaries in which we recall the principles of the Chow test, fuzzy transform, and the theory of evaluative linguistic expressions (as a part of FNL). In Section 3, we introduce the algorithm for finding structural breaks using our method, suggest modification of Chow test, and prove that if a structural break is detected then the null hypothesis stating that there is no structural break is rejected. Section 4 contains experimental verification of our results and also a comparison with three statistical techniques, namely the classical Chow, Bai-Perron, and Pettitt’s tests.
2. Preliminaries
2.1. Chow Test
This is one of the first statistical tests (see [1,4]) using which it is possible to decide whether we are facing a structural break or not. Its idea consists of splitting the data having n observations into two parts: observations before the break in time and observations after it. Then we construct two linear regressions models
which are compared with the general regression model
().
The ordinary least squares method is applied to the models above and then we form squares of residuals
- RSS1 which is the residual of squares before the break:
- RSS2 is the residual of squares after the break:
- RSS3 is the residual of squares of the general regression model:
The test of hypothesis related to the test of structural break is conducted by testing the null hypothesis
The structural change is caused due to different intercept terms as well as different regression coefficients. Under the assumption that the probability distribution of is normal, we can test the null hypothesis by the statistics
which has the F-distribution . The null hypothesis is rejected if
where is a critical value of the F-distribution for a corresponding significance level (as usual, we consider ).
2.2. Fuzzy Transform (F-Transform)
The fuzzy transform is a technique for the approximation of continuous functions. In our case, it can be effectively applied to analysis and forecasting of time series. Let a bounded real continuous function be given, where .
Definition 1.
Let be fixed nodes in the interval where , with and . The set of fuzzy sets on is called a fuzzy partition of if the following conditions are fulfilled:
- , ;
- if (for and );
- is continuous;
- strictly increases on for and strictly decreases on for ;
- for all;
- If, where, then fuzzy partitionis called uniform and the following holds for the fuzzy sets forming it:, , , whereand.
The fuzzy sets are often called basic functions. Their shape can be arbitrary (but fulfilling Definition 1). Most often they are simple triangles. The F-transform has two phases: direct and inverse.
Definition 2.
Let the setbe a uniform fuzzy partition with triangular basic functions, h be the distance between nodes andbe a continuous function on. The-tupleis a direct fuzzy transform of f where the elementsare called components.
- The zero-degree fuzzy transform has components of the form
- The first-degree fuzzy transform has components of the formwhere
The coefficient provides estimation of an average value of the tangent (slope) of f over the area characterized by the fuzzy set .
Remark 1.
Note that the coefficients are identical with the components (2) of the zero-degree F-transform.
Definition 3.
Letbe a direct F-transform of f due to Definition 2, where. (In fact, we can define F-transform of arbitrary degree. For our purposes, however, zero and first degrees are sufficient). The inverseF-transform of f is a function
It can be proved that approximates the original function f with arbitrary precision (depending on h). We can set the parameters so that the approximating function has desired properties. The computational complexity of the F-transform is linear. More details can be found in [8,9,10].
2.3. Fuzzy Natural Logic
Our applications to time series require selected methods of Fuzzy Natural Logic (FNL). This is a class of mathematical models characterizing some parts of human common sense thinking that is based on the use of natural language. It includes, besides others, the theory of evaluative linguistic expressions and their semantics and fuzzy/linguistic IF-THEN rules. In a form suitable for time series processing is FNL described in [9]. In this section, we will recall some of the main points needed below.
Evaluative Linguistic Expressions (We will often omit the adjective “linguistic”.) are special expressions of natural language in the form
where ⟨linguistic hedge⟩ is a special adverb standing before ⟨TE-adjective⟩, that makes the adjective more or less specific. We will consider linguistic hedges extremely (Ex), significantly (Si), very (Ve), rather (Ra), more or less (ML), roughly (Ro), very roughly (VR). The TE-adjectives are canonical adjectives zero (Ze), small (Sm), medium (Me), big (Bi). Note that they can be replaced by many other adjectives, for example shallow, medium deep, deep, etc.
Remark 2.
Evaluative linguistic expressions (7) are called simple. We can introduce also complex ones that are formed using connective (and, or). Their syntax and semantics, however, are more complicated since they are not just boolean expressions. We need not consider them in this paper.
The model of the semantics of evaluative expressions requires the concept of context. In our case, this is the interval where . The numbers have the following meaning: is the left bound, is a typical middle value, and is the right bound.
Let be an evaluative linguistic expression. The mathematical model of its meaning is a function where W is a set of all contexts. Such a function is called intension of . If a context is given then extension of w.r.t. w is a fuzzy set from . The details of this model are described in [9].
Let a value be given. We may now ask, what is a proper evaluative linguistic expression using which we can characterize linguistically the value x? Of course, this depends on the context . For example, 100 USD may be a big money in a poor country but very small in a rich one. Therefore, we consider a special function of local perception
which assigns an evaluative expression to the value x w.r.t. the context . (Lperc is implemented in the special software LFL Forecaster described, e.g., in [9,11]).
A special class of evaluative expressions are those characterizing the trend of time series:
where
- := stagnating ,
- := increasing ∣ decreasing,
- : = ∅∣ negligibly ∣ slightly ∣ somewhat ∣ clearly ∣ roughly ∣ sharply ∣ quite largely ∣ fairly large∣ hugely∣ significantly.
We must also consider the context for tangent that is here extended to have two parts: positive for the increase in time series and negative for its decrease.
3. Processing of Time Series Using Methods of Fuzzy Modeling
3.1. Processing of Time Series Using F-transform
A time series X is a mapping [12,13,14,15]
where
is a set of numbers interpreted as time moments, is a nonempty set of elementary random events and is a probability space, where is a -algebra over and P is a probability measure. In general, can be an arbitrary set. For our purposes, we will consider to be a finite set of natural numbers .
We assume that the time series can be decomposed into 4 components, namely
where and are trend and cyclic components of the time series. These two components are usually combined into one component called trend-cycle .
The is the seasonal component and is a random noise. The trend, cycle and seasonal components are ordinary functions not having stochastic character. The noise is assumed to be a sequence of independent random variables with the mean and variance .
It has been proved (see [9,16,17]) that using the F-transform, we can estimate trend Tr or trend-cycle TC with high fidelity which means that the seasonal component S is almost “wiped out” (i.e., its inverse F-transform is close to zero) and the noise R is significantly reduced [18].
3.2. Detection of Structural Breaks in a Time Series
Detection of a structural break in a time series means to determine a time interval in which the course of the time series abnormally changes in comparison with its previous/subsequent development. Our detection method presented in [7] is based on finding short intervals with a steep slope of trend (big tangent) preceded or followed by an interval with a small slope.
Let X be a time series, be a time interval. Let be a basic function due to Definition 1 with the support over which is the slope of the trend of X computed using (5). Let be the corresponding negative and positive parts of the context, respectively. Then, the evaluative expression obtained using the function of local perception (8)
evaluates the trend of the time series X in the interval . Using evaluation (11), we can decompose the time domain T into a set of intervals
in which the slope is evaluated by specific evaluative expressions. The intervals need not necessarily be disjointed.
Definition 4.
Letbe evaluative expressions computed using (11). An intervalis an area of a structural break in the course of X ifand, whereor.
This definition is the basis for the following algorithm for finding structural breaks in a time series X.
Algorithm for finding structural breaks
- Set the distance and determine a uniform fuzzy partition over the time domain due to Definition 1.
- Set the context for evaluation of the trend in the areas determined by the basic functions.
- Compute the direct first-degree fuzzy transform over the fuzzy partition .
- Localize all pairs of components (,) (cf. (3)) with the following properties:
- –
- , , i.e., the coefficient is close to zero.
- –
- , i.e., the coefficient is unexpectedly big.
Alternatively, k and can be interchanged, i.e., is close to zero and is unexpectedly big. - The interval (or ) which is a support of the basic function (or ) is the area of a structural break due to Definition 4.
Without loss of generality, we will in the sequel assume that is close to zero and is unexpectedly big.
3.3. Combination of Fuzzy Techniques and Chow Test
Suppose that a time series X contains a structural break that occurs in the intersection of two adjacent areas represented by the triangular basic functions (fuzzy sets) , in the sense of the algorithm presented in the previous section. Moreover, we also consider a third triangular basic function denoted by over the nodes where the node
is added. Note that the fuzzy set is defined over nodes with the distance . The situation is depicted in Figure 1 (the fuzzy set is depicted upside-down for better visibility).
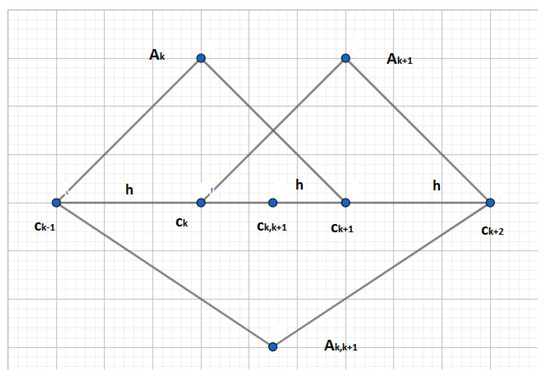
Figure 1.
Fuzzy sets covering the structural break occurring in the interval (the support of the fuzzy set ).
Remark 3.
The triangular fuzzy set w.r.t. the node is defined by the equation
and analogously also the fuzzy sets and . Note also that
Lemma 1.
Proof.
It is enough to consider only the interval . By simple computation, we verify that for and for . For the inequality follows from the property . □
Let us now consider the following F1-transform components:
where the coefficients are determined by the corresponding basic functions due to Figure 1.
Lemma 2.
Let the triangular fuzzy sets depicted in Figure 1 be given. Then
Proof.
Using (4) and Lemma 1 we obtain
□
Lemma 3.
Let the triangular fuzzy sets depicted in Figure 1 be given. Then
Proof.
Using (5) and Lemma 1 we obtain
□
Lemma 4.
Proof.
It is sufficient to consider the interval , in which the fuzzy set and, therefore, it cannot affect the size of and (cf. formula (5)).
Put . By the assumption, if there is a structural break over then and it should be large since the corresponding are not covered by the fuzzy set over which by the assumption. Then,
After computation, we obtain and which means that . Consequently, . □
Let us now define the following sums of squares of differences between values of the time series and the F1-transform components corresponding to the basic functions from Figure 1:
Then, analogously to the classical Chow test (1) we construct the statistics
where n is the number of time points between and p is the number of parameters (note that in our case). The statistics (18) has the F-distribution . The structural break is tested by the null hypothesis:
The null hypothesis is rejected if where is a critical value.
The statistics (17) can be rewritten as
Theorem 1.
Let be a time series over the time domain and be a uniform triangular fuzzy partition of with the distance h between nodes. Then
Proof.
By ([8], Corollary 2), for . Then,
for some constant M and arbitrary h. Similar inequality holds also for and . Hence,
for some constant and . Considering a wider fuzzy partition with , in a similar way we obtain that
(in both cases we can consider the same constant ). We argue that
Indeed, let the opposite inequality hold. Then we choose h so that and, by the assumption and (22), we obtain
which is a contradiction. □
Theorem 2.
Let be a time series over the time domain and be a uniform triangular fuzzy partition of with the distance h between the nodes. Let be two components identifying structural break in the areas characterized by according to the algorithm presented in Section 3.2 (cf. Figure 1). Let
If
where is the number of time points between two nodes, then .
Proof.
Let us consider formula (20) and denote the formulas after the sum symbol in (15)–(17) by , , , respectively.
(a) Let . Then
i.e., . Similarly we obtain
(b) Let . Then
Consequently,
Using the assumption, we thus obtain
Realizing that for , the multiplicative constant in (20) can be fairly high, the value of is also high. □
So far, we did not see whether our method for detection of the structural breaks has an impact on the statistics (20). In the following theorem we will show that when detecting a structural break using the algorithm from Section 3.2, the nominator of (20) significantly increases. For this purpose, we consider two time series which differ only in the interval where the structural break occurs, i.e., for . We will denote the formulas (15)–(17) for the time series by , respectively.
In the proof of the following theorem, we meet the formula
Theorem 3.
Let be the number of time points between two nodes. Furthermore, we will assume:
- (a)
- ,
- (b)
- the inequalities (24) hold for some ,
- (c)
- ,
- (d)
- there are minimal such that the following holds:
If the slope fulfills the inequality
then
Proof.
Note that and so, it follows from the assumptions (c), (d) that because (c) says that there is a structural break in . Therefore, there must be such that .
In the same way as is in the proof of ([10], Theorem 5), we can show that
for . Then we have
The third inequality is assured if
which implies that
This assures inequality (27). □
In this theorem, assumption (b) says that and well approximate X and , respectively. Note that due to assumption (a), we may consider only instead of . Note that Lemma 4 justifies assumption (c); assumption (d) is justified by the results of [8,10].
Corollary 1.
There is a context such that and LPerc and the null hypothesis using the fuzzy Chow-test for the time series is rejected.
4. Experiments
4.1. Detection of Structural Breaks
We will demonstrate our results on real data taken from a Micro subset of time series from M4-Competition published on the Internet. For computations of the F-transform components, we used the experimental software FT-studio. (It was developed in the Institute for Research of Applications of Fuzzy Modeling of the University of Ostrava, Czech Republic. Its author is Radek Valášek. Let us remark that in the R-repository is available R-package lfl providing algorithms used in this paper, see [19].).
In Figure 2, a real time series is depicted together with two fuzzy partitions with equidistant triangular basic functions. The structural breaks are detected using our method. Namely, the time series contains structural breaks occurring in areas characterized by couples of fuzzy sets , ), (, ), (, ).
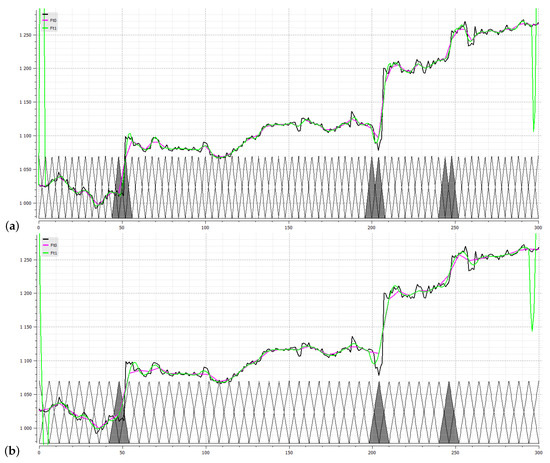
Figure 2.
The time series is depicted together with fuzzy partitions with the basic functions of the width: (a) and (b) . In both images are marked basic functions over which the structural breaks are detected.
We apply Fuzzy Chow test to the found structural breaks using fuzzy technique. The first one is obtained from two F1-transform components
To verify the found structural break also statistically, we will test the null hypothesis
The squares of residuals , , are computed as follows:
The Fuzzy Chow test is based on the statistics
where and .
We obtain for and so, we reject the null hypothesis. This means that we have sufficient evidence to say that a structural break detected using our method indeed occurs in the interval .
We apply the same algorithm with two subsequent by fuzzy sets (, ) and (, ), the structural breaks confirmed by testing the null hypothesis:
The results are summarized in Table 1.

Table 1.
Fuzzy Chow Test results.
All of the results show that we have sufficient evidence to demonstrate that structural breaks occur in the data in the time intervals stated above.
4.2. When Fuzzy Chow Test Does Not Reject the Null Hypothesis?
Our method for detection of structural breaks is non-statistical. Therefore, we should also check whether the fuzzy Chow test does not falsely accept the null hypothesis about the existence of a structural break in place where our method detects none.
For example, lets us check time intervals , , , characterized by fuzzy sets (, ), (, ), (, ), (, ) where no structural break is detected. We apply Fuzzy Chow test and so, we compute two F-transform components:
and form the null hypothesis:
The statistics of the Fuzzy Chow test is
where and .
We may verify that for . Hence, we cannot reject the null hypothesis. This means that we have no sufficient evidence to say that a structural break occurs in the interval .
Let us apply same algorithm with fuzzy sets (, ), (, ) and (, ) and form the following null hypotheses:
The results are summarized in Table 2.
Table 2.
Fuzzy Chow Test results and Decisions.
We conclude that the fuzzy Chow test indeed statistically verifies structural breaks only on places in which our method described in Section 3.2 detects them.
4.3. Comparison with Classical Statistical Tests
In this section, we will compare our method with three classical statistical methods for the detection of structural breaks. Namely, we will consider the classical Chow test described in Section 2.1, Pettitt’s, and Bai-Perron tests.
4.3.1. Pettitt’S Test (1979)
The Pettitt’s test [20,21] is a way to find out when there was a big change in the mean of a set of numbers over time when the exact time of the change is unknown. The data collect n observations, and if it contains a change point at time t, then the change point will split the data into two parts, each of which has a distinct distribution and . The test statistic K is defined by where
The confidence level for n samples is . The null hypothesis is rejected if the value of p does not exceed the given confidence level.
4.3.2. Bai-Perron Test (1998)
Another well known test for identification of several structural breaks in a time series is Bai-Perron one [22,23,24].
With the null hypothesis: There is no structural break in the time series, the Bai-Perron proccess suggests a multiple linear regression with k changes. The change points are and are explicitly handled as unknown:
where is the dependent variable, and are coefficients corresponding to covariates and , and is the residue term. The purpose is to estimate the unknown regression coefficients and the break dates when T observations on are given.
4.3.3. Comparison of Statistical Methods with Fuzzy Chow Test
The results of the comparison can be seen in Figure 3. The computations have been performed using R. The classical Chow test detected change points in and Bai-Perron test in . Thus, the differences in the graph in Figure 3 are invisible. The Pettitt test found only three points in .
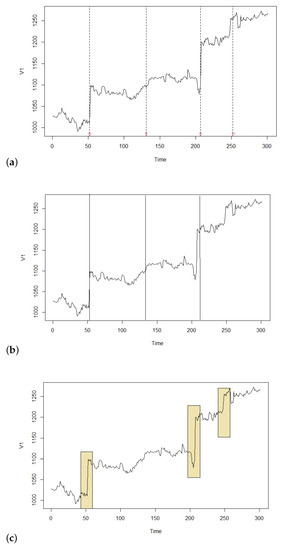
Figure 3.
Results of statistical tests as well as of our method to finding structural breaks in the real time series: (a) Chow and Bai-Perron tests (in the graph, there is no visible difference between them), (b) Pettitt’s test, and (c) our method verified by the fuzzy Chow test.
Our method detected three structural breaks in the intervals , , which, as shown in Section 4.1, are also statistically significant by the fuzzy Chow test. Note that these intervals cover the points found by Chow and Bai-Perron tests with the exception of () where, however, there is no structural break. We argue that, as is apparent from Figure 3, our method correctly detected real structural breaks occurring in the time series. The following conclusions imply from the comparison with our method:
- Statistical methods detect the breaks as if occurring in one time point. However, it is clear from the practice that this rarely happens; the break usually shows in a wider area. Hence, the result of a statistical test should be taken as a point around which the break occurs. But this is equal to what our fuzzy method provides explicitly, and thus we argue that more realistically.
- Statistical methods are less robust and thus, more sensitive to the data. Hence, they are prone to the detection of non-existing breaks. In our example, this happened to all three statistical methods in point () where apparently there is no structural break. Let us emphasize that our fuzzy method ignored this point/area due to its robustness.
- Statistical methods require optimization and therefore, they are computationally expensive. Our method is very simple and computationally effective since the fuzzy transform has linear complexity.
It is important to emphasize that our goal is not to beat statistical methods. Vice-versa, we want to employ maximally the synergy of both approaches.
5. Conclusions
In this paper, we focus on methods for the detection of structural breaks in time series. In [7], we suggested a method based on the fuzzy transform (F-transform) and selected methods of Fuzzy Natural Logic. In this paper, we suggested a combination of our method with a statistical text that stems from the well-known Chow test [1]. Statistical significance is demonstrated on the data. We have shown that our technique is effective in spotting abnormalities and gives statistically significant results. Further research will be focused on the combination of our fuzzy method with other kinds of statistical testing.
Author Contributions
Methodology, V.N.; Software, computations T.T.P.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Chow, G.C. Tests of Equality Between Sets of Coefficients in Two Linear Regressions. Econometrica 1960, 28, 591–605. [Google Scholar] [CrossRef]
- De Wachter, S.; Tzavalis, D. Detection of structural breaks in linear dynamic panel data models. Comput. Stat. Data Anal. 2012, 56, 3020–3034. [Google Scholar] [CrossRef]
- Fischer, P.; Hilbert, A. Fast detection of structural breaks. In Proceedings of the 21th International Conference on Computational Statistics, Geneva, Switzerland, 19–22 August 2014; pp. 9–16. [Google Scholar]
- Nielsen, B.; Whitby, A. A Joint Chow Test for Structural Instability. Econometrics 2015, 3, 156–186. [Google Scholar] [CrossRef]
- Preuss, P.; Puchstein, R.; Detter, H. Detection of multiple structural breaks in multivariate time series. J. Am. Stat. Assoc. 2015, 110, 654–668. [Google Scholar] [CrossRef]
- Doerr, B.; Fischer, P.; Hilbert, A.; Witt, C. Detecting structural breaks in time series via genetic algorithms. Soft Comput. 2017, 21, 4707–4720. [Google Scholar] [CrossRef]
- Truong, P.; Novák, V. An Improved Forecasting and Detection of Structural Breaks in Time Series using Fuzzy Techniques. In Theory and Applications of Time Series Analysis and Forecasting; Valenzuela, O., Rojas, F., Herrera, L., Pomares, H., Rojas, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Perfilieva, I.; Daňková, M.; Bede, B. Towards a Higher Degree F-transform. Fuzzy Sets Syst. 2011, 180, 3–19. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I.; Dvořák, A. Insight into Fuzzy Modeling; Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Perfilieva, I. Fuzzy Transforms: Theory and applications. Fuzzy Sets Syst. 2006, 157, 993–1023. [Google Scholar] [CrossRef]
- Novák, V.; Mirshahi, S.; Pavliska, V. LFL Forecaster: Analysis, Forecasting and Mining Information from Time Series. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2019, New Orleans, LA, USA, 23–26 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Anděl, J. Statistical Analysis of Time Series; SNTL: Praha, Czech Republic, 1976. (In Czech) [Google Scholar]
- Bovas, A.; Ledolter, J. Statistical Methods for Forecasting; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Kedem, B.; Fokianos, K. Regression Models for Time Series Analysis; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Hamilton, J. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Nguyen, L.; Novák, V.; Holčapek, M. Gold Price: Trend-cycle Analysis Using Fuzzy Techniques. In Information Processing and Management of Uncertainty in Knowledge-Based Systems, Part III; Lesot, M.-J., Vieira, S., Reformat, M.Z., Carvalho, J.P., Wilbik, A., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer Nature: Cham, Switzerland, 2020; pp. 254–266. [Google Scholar]
- Novák, V. Fuzzy vs. Probabilistic Techniques in Time Series Analysis. In Econometrics for Financial Applications; Anh, L., Dong, L., Kreinovich, V., Thach, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 213–234. [Google Scholar]
- Nguyen, L.; Holčapek, M. Suppression of High Frequencies in Time Series Using Fuzzy Transform of Higher Degree. In Information Processing and Management of Uncertainty in Knowledge-Based Systems: 16th International Conference, IPMU 2016; Carvalho, J., Lesot, M.-J., Kaymak, U., Vieira, S., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 2, pp. 705–716. [Google Scholar]
- Burda, M.; Stěpnička, M. lfl: An R Package for Linguistic Fuzzy Logic. Fuzzy Sets Syst. 2022, 431, 1–38. [Google Scholar] [CrossRef]
- Pettitt, A. A non-parametric approach to the change-point problem. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 126–135. [Google Scholar] [CrossRef]
- Conte, L.; Bayer, D.; Bayer, F. Bootstrap Pettitt test for detecting change points in hydroclimatological data: Case study of Itaipu Hydroelectric Plant, Brazil. Hydrol. Sci. J. 2019, 64, 1312–1326. [Google Scholar] [CrossRef]
- Bai, J.; Perron, P. Estimating and Testing Linear Models with Multiple Structural Changes. Econometrica 1998, 66, 47–78. [Google Scholar] [CrossRef]
- Bai, J.; Perron, P. Computation and Analysis of Multiple Structural Change Models. J. Appl. Econom. 2003, 18, 1–22. [Google Scholar] [CrossRef]
- Hall, A.R.; Han, S.; Boldea, O. Inference regarding multiple structural changes in linear models with endogenous regressors. J. Econom. 1998, 170, 281–302. [Google Scholar] [CrossRef] [PubMed]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).