Abstract
In this article, we introduce a new extension of the power Lomax (PLo) model by combining the type II exponentiated half-logistic class of statistical models and the PLo model. The new suggested statistical model called type II exponentiated half-logistic-PLo (TIIEHL-PLo) model. However, the new TIIEHL-PLo model is more flexible and applicable than the PLo model and some extensions of THE PLo model, especially those in environmental and medical fields. Some general statistical properties of the TIIEHL-PLo model are computed. Six different estimation approaches, namely maximum likelihood (ML), least-square (LS), weighted least-squares (WLS), maximum product spacing (MPS), Cramér–von Mises (CVM), and Anderson–Darling (AD) estimation approaches, are utilized to estimate the parameters of the TIIEHL-PLo model. The simulation experiment examines the accuracy of the model parameters by employing six different methodologies of estimation. In this study, we analyze three real datasets from the environmental and medical fields to highlight the relevance and adaptability of the proposed approach. The newly suggested model is exceptionally adaptable and outperforms several well-known statistical models.
1. Introduction and Motivation
In recent years, the Lomax (Lo) model presented in [1] has been shown to be the gold standard for a wide range of applications in applied sciences. To mention a few, we recommend the works of [2,3,4,5] for applications in life testing, personal wealth, queue service discipline, and Internet traffic. The probability density function (pdf) and the cumulative distribution function (cdf) for the Lo model are shown below
and
Based on the previous pdf (1) and cdf (2), we observe that the Lo model naturally arises as a sub-model of other familiar statistical models, including the Fisher, Pareto (P) type IV, P-type II, Feller-P, and the second type of beta models.
Furthermore, the Lo model has several limitations: besides the data with heavy-tailed characteristics, the associated model may lack flexibility and be worthless for a full examination. As a result, several initiatives were initiated to generalize these statistical models as best as possible. We desire to highlight some generalizations of the PLo model such as: the Marshall–Olkin extended Lo model [6]; the exponentiated Lo model [7]; the transmuted Lo model [8]; the McDonald Lo model [9]; the Poisson Lo model [10]; the exponential Lo (ELo) model [11]; the gamma Lo model [12]; the Weibull Lo (WLo) model [13]; the weighted Lo model, [14]; the Gompertz Lo model [15]; type II half-logistic Lo model [16]; Gumbel-Lo (GLo) model [17]; and the power Lo (PLo) model [18].
Ref. [18] lets the random variable obtain the PLo model and it has the following cdf
where and are two shape parameters and is a scale parameter. Here, we are interested in putting the scale parameter . Then, the cdf of the PLo model becomes
and the corresponding pdf to (4) is
The PLo model has many different applications including medical, biological, income, engineering, and wealth inequality sciences. Many researchers improved various extensions of the PLo model such as the transmuted PLo model [19]; the exponentiated PLo model [20]; the odds generalized exponential PLo model [21]; inverse PLo model [22]; Type II Topp Leone PLo model [23]; and sine PLo model [24].
Recently, Ref. [25] introduced the TIIEHL class of distributions. The cdf and pdf of the TIIEHL class of distributions are
and
where and are the pdf and cdf for the baseline distribution, respectively, and is the vector of parameters for the baseline distribution.
A similar technique was used in this study, but with an emphasis on the PLo model. Moreover, we expand the PLo model through the TIIEHL class of distributions, taking into account the particular member of the TIIEHL class of distributions defined using the PLo model as a baseline distribution.
The innovation and contribution made by this research is the development of a new four-parameter lifetime model known as the TIIEHL-PLo model. Below are the study’s primary contributions:
- Using the TIIEHL class of distributions to improve the properties and versatility of the PLo model (as motivated above). This assumption is shown by the observation of the uni-modal, decreasing, right skewness, and heavy-tailed forms of the pdf. The hazard rate function (hrf) can be decreasing, up-side-down, and J-shaped.
- To provide a new generalized version of the PLo model with a closed-form quantile function (QF).
- To investigate the essential statistical aspects of the TIIEHL-PLo model, such as the median, mean (), variance (var), skewness (S), kurtosis (K), raw moments, moment generating function, and order statistics.
- To investigate the statistical inference of the TIIEHL-PLo model using six different techniques of estimation such as the maximum likelihood (ML), the least square (LS) and weighted least square (WLS), maximum product spacing (MPS), Cramer-von–Mises (CVM), and the Anderson and Darling (AD) estimates.
- To bring good fits rather than rival modified statistical models. In this work, a comprehensive list of such competing models was investigated (such as those presented [11,13,17,26,27,28], to mention a few), with some good findings for the TIIEHL-PLo model.
All of the above ideas are discussed in depth throughout the paper, including comparisons and discussions with other published works.
The rest of this manuscript is organized as follows: The formulation of the TIIEHL-PLo model is discussed in Section 2. Some fundamental statistical properties of the TIIEHL-PLo model including the quantile function, median, raw moments, incomplete moments, moment-generating function, Lorenz and Bonferroni curves, and order statistics are studied in Section 3. Six different estimation techniques, namely ML, LS, WLS, MPS, CVM, and AD are studied in Section 4. In Section 5, simulation analysis of the performances of the ML, LS, WLS, MPS, CVM, and AD estimators is conducted. In Section 6, we study three real-world datasets from the engineering and medical fields to show the flexibility of the TIIEHL-PLo model. Finally, in Section 7, the conclusion and summary are mentioned.
2. Model Formulation
In this section, we create a new four-parameter statistical model with parameters called the TIIEHL-PLo model by inserting (4) and (5) into (6) and (7), and then the cdf, pdf, reliability function, and hrf of the TIIEHL-PLo model are
and
The cumulative hrf of the TIIEHL-PLo model is
Figure 1 shows that the pdf for the TIIEHL-PLo model can be uni-modal, decreasing, right-skewed, and heavy-tailed. However, Figure 2 demonstrates that the hrf of the TIIEHL-PLo model can be decreasing, upside-down, and J-shaped.
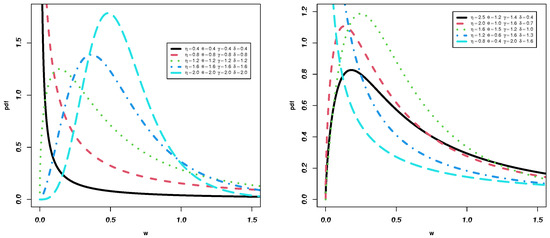
Figure 1.
The pdf for the TIIEHL-PLo model.
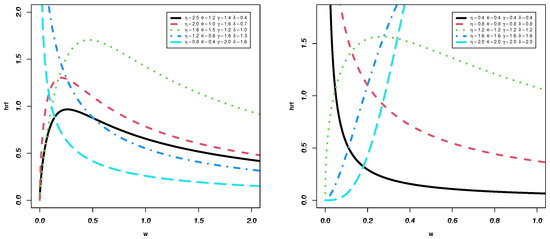
Figure 2.
The hrf for the TIIEHL-PLo model.
3. Basic Statistical Properties
The structural characteristics of the TIIEHL-PLo model are described in this part, including the QF, the nth raw moments, mean, variance, skewness, kurtosis, the moment-generating function, many graphical and numerical results of moments, and order statistics.
3.1. Quantile Function and MacGillivray’s Skewness
Suppose that the random variable W ∼ TIIEHL-PLo(, then its QF is provided in Equation (10) as
where . By putting in Equation (10), we obtain the median (M) of the TIIEHL-PLo model as below
The MacGillivray’s skewness () [29] is derived from the following expression.
3.2. Moments
Suppose that W ∼ TIIEHL-PLo() for and , then the nth raw moments can be computed from the formula below
By using the next two binomial expansions
and
Again, using expansion (13) in the last formula, then
where
Let , then
By using the beta prime function Then, the nth raw moments of the TIIEHL-PLo model is provided via
The , var, S and K are computed, respectively, from the following formulas and .
The moment-generating function for the TIIEHL-PLo model is
Table 1 shows some numerical values of , , , , var, S, K, and CV for the TIIEHL-PLo model using different values of .

Table 1.
Some numerical values of , , , , var, S, K, and CV.
3.3. Order Statistics
Suppose that is a random sample from the TIIEHL-PLo model with order statistics . The pdf of of order statistics can be computed from the next formula
4. Six Different Approaches of Estimation
The parameters of the TIIEHL-PLo distribution are estimated in this section using the ML, MPS, AD, CVM, LS, and WLS approaches of estimation.
4.1. Maximum Likelihood Approach of Estimation
Let be a random sample from the TIIEHL-PLo model, then the ML estimation (MLE) function can be supplied as below:
and the natural log-likelihood function of the TIIEHL-PLo model is provided via
With regard to , the natural log-likelihood function’s first derivatives are provided below
4.2. Maximum Product Spacing Approach of Estimation
A good substitute for the greatest likelihood approach is the maximum product spacing method, which approximates the Kullback–Leibler information measure. Let us now suppose that the data are ordered in an increasing manner. Then, the maximum product spacing for the TIIEHL-PLo distribution is given as follows
where , .
Similarly, one can also choose to maximize the function
By taking the first derivative of the function with respect to , , , and , and solving the resulting nonlinear equations, at = 0, = 0, = 0, and = 0, where , we obtain the value of the parameter estimates.
4.3. Anderson and Darling Approach of Estimation
The function regarding to the model parameters is minimized to obtain the AD estimates, which are written as
where .
4.4. Cramer-von-Mises Approach of Estimation
Another significant estimating approach commented upon in Ref. [30] is the CVM. By minimizing the function with respect to the unknown parameters , the parameters in the CVM estimation technique can be estimated.
4.5. Least Square and Weighted Least Square Approaches of Estimation
To estimate the parameters of the beta model, Ref. [31] offers LS and WLS techniques of estimation. The LS function regarding the unknown parameters can be minimized in the LS estimation (LSE) approach to provide the estimates of the parameters of the proposed model, where
Similarly to this, the WLS function was minimized to compute the WLS estimation (WLSE) of the unknown parameters:
5. Simulation
The ML, AD, CVM, MPS, LS, and WLS techniques are combined with a Monte Carlo simulation to estimate the parameters in this section. Using the R package and the following:
- Simulation techniques for various parameters with varied actual values of the parameters, datum w is distributed as a TIIEHL-PLo distribution: Using the R package and the following:In Table 2, and 0.7, and 1.8;
Table 2. Different estimations for .In Table 3, and 0.85 and 2;
Table 3. Different estimations for .In Table 4, and 1.2 and 3;
Table 4. Different estimations for .In Table 5, and 0.5 and 1.2.
Table 5. Different estimations for .
- Set different samples sizes and 150.
- Use the numerical analysis to obtain the estimator based on different estimation methods.
- Monte Carlo trials were run using a random sample of .
- Generate a sample of the TIIEHL-PLo distribution using QF which is provided in Equation (10).
- Calculate the mean squared error (MSE) and bias of the estimator.
Table 2, Table 3, Table 4 and Table 5: discuss the bias and MSE for six estimation methods as MLE, LS, WLS, MPS, CVM, and AD, with a different sample size. Figure 3, Figure 4, Figure 5 and Figure 6 discuss the MSE of the parameters for each estimation method, which shows the general downward trend with sample size increases and used to compare the estimation method. Figure 7, Figure 8, Figure 9 and Figure 10 obtained the heat-map of MSE for parameters based on each estimation method, where the X-label contains an MSE such as: Table 2, Table 3, Table 4 and Table 5 discuss the bias and MSE for six estimation methods including MLE, LS, WLS, MPS, CVM, and AD, with different sample sizes. Figure 3, Figure 4, Figure 5 and Figure 6 discuss the MSE of parameters for each estimation method, which shows a general downward trend with an increasing sample size and is used to compare the estimation method. Figure 7, Figure 8, Figure 9 and Figure 10 obtained the heat-map of MSE for the parameters based on each estimation method, where the X-label contains the MSE as: Table 2, Table 3, Table 4 and Table 5 discuss the bias and MSE for six estimation methods, namely MLE, LS, WLS, MPS, CVM, and AD, with different sample size. Figure 3, Figure 4, Figure 5 and Figure 6 discuss the MSE of parameters for each estimation method, which showed a general downward trend with an increasing sample size and used to compare the estimation method. Figure 7, Figure 8, Figure 9 and Figure 10 obtained the heat-map of MSE for parameters based on each estimation method, where the X-label contains an MSE such as: MLE1: MSE() based on MLE, MLE2: MSE() based on MLE, MLE3: MSE() based on MLE, MLE4: MSE() based on MLE, LS1: MSE() based on LS, LS2: MSE() based on LS, LS3: MSE() based on LS, LS4: MSE() based on LS, WLS1: MSE() based on WLS, WLS2: MSE() based on WLS, WLS3: MSE() based on WLS, WLS4: MSE() based on WLS, MPS1: MSE() based on MPS, MPS2: MSE() based on MPS, MPS3: MSE() based on MPS, MPS4: MSE() based on MPS, AD1: MSE() based on AD, AD2: MSE() based on AD, AD3: MSE() based on AD, AD4: MSE() based on AD, CVM1: MSE() based on CVM, CVM2: MSE() based on CVM, CVM3: MSE() based on CVM, and CVM4: MSE() based on CVM. However, the Y-label contains a sample case and size as C1n50 is MSE when n = 50 in the first sub-Table result (for example, in Table 2, = 0.7), C2n50 is MSE when n = 50 in the second sub-Table result (for example, in Table 2, = 1.8), C2n100 is MSE when n = 100 in the second sub-Table result, C2n150 is MSE when n = 150 in the second sub-Table result, C1n100 is MSE when n = 100 in first sub-Table result, C1n150 is MSE when n = 150 in first sub-Table result. We look for rectangles that have the darkest colors to determine which sets of categories have the highest values of MSE and which sets have the lowest MSE which have the right colors.
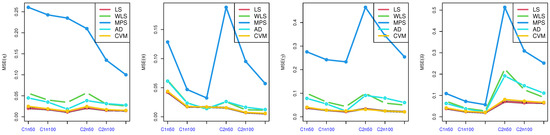
Figure 3.
MSE of parameters in Table 2.
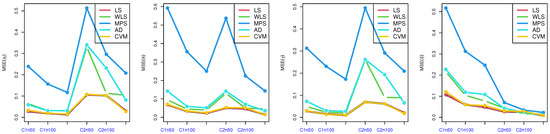
Figure 4.
MSE of parameters in Table 3.

Figure 5.
MSE of parameters in Table 4.
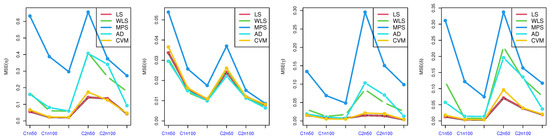
Figure 6.
MSE of parameters in Table 5.
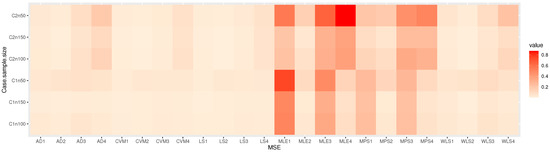
Figure 7.
Heat-map of MSE for the parameters in Table 2.
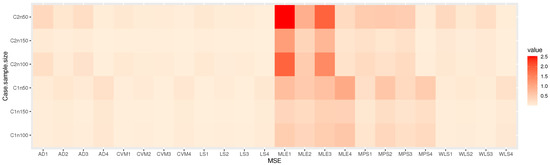
Figure 8.
Heat-map of MSE for the parameters in Table 3.
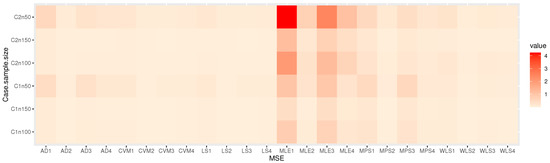
Figure 9.
Heat-map of MSE for the parameters in Table 4.
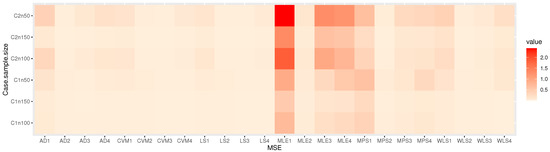
Figure 10.
Heat-map of MSE for the parameters in Table 5.
- The results in the tables show that the TIIEHL-PLo distribution is stable since the range of bias and MSE for the four parameters of the TIIEHL-PLo distribution is fairly modest.
- As the sample size increases, we occasionally observe a decrease in the bias and MSE for all estimations.
- This indicates that, for high sample sizes, several estimating methodologies yield a correct bias and MSE findings.
- The LS and CVM estimation approach are the most accurate means of estimating the TIIEHL-PLo distribution parameter.
- Better metrics than the MLE approaches are provided by the LS, WLS, CVM, MPS, and AD estimation methods.
Through the previous tables and conclusions, we noticed that the two methods LS and CVM are very close, and we want to suggest the best method, so that the averages of the MSE values were calculated in Table 6. From Table 6, we noticed that the best way to estimate the parameters of the TIIEHL-PLo distribution is LS.
Table 6.
Average MSE for the parameters of each estimation method.
6. Modeling of Environmental and Medical Data
The TIIEHL-PLo distribution is used in this section to model several real data examples from many scientific domains. Different distributions, including the extended odd Weibull inverse Nadarajah–Haghighi (EOWINH) [26], Kumaraswamy Weibull (KW) [27], MOAPLo, Marshall–Olkin alpha power extended Weibull (MOAPEW) [28], ELo, IWLoPS, WLo, and GLo models, are offered for comparison with the TIIEHL-PLo model.
For all datasets, we compute the terms “Akaike information criterion (), correct Akaike information criterion (), Bayesian information criterion (), and Hannan–Quinn information criterion ()” were used to analyze the MLE with the standard error (SE) and various measures (, , , and ). The Kolmogorov–Smirnov goodness-of-fit test is used for real data, and the results show that the TIIEHL-PLo, EOWINH, GLo, MOAPLo, MOAPEW, ELo, KW, IWLoPS, and WL distributions fit each of the datasets according to the Kolmogorov–Smirnov distance (KS) and Kolmogorov–Smirnov p-value (PVKS).
6.1. Environmental Data
Data-I. Acid rain is a frequent environmental occurrence caused by the high concentrations of nitric and sulfuric acids in the atmosphere that are carried to Earth and have an impact on a variety of ecological factors, including the diversity of species, the abundance of worms, the size of crabs, the quality of water, the physiological state of individual animals, etc. The oxidation of sulfur and nitrogen in coal and other fossil fuels leads to the creation of acidic pollutants in the atmosphere. Acid rain has seriously destroyed forests in several industrialized nations. Utilizing coal and low-sulfur fuel will help prevent acid rain. In this section, environmental calamities are discussed. On a pH scale, which ranges from one (very acidic) to seven, acidity is measured (neutral). A pH of less than 5.7 is thought to be the threshold for acid rain. The first set of data examines the acidity of Minnesota’s rains during a forty-day period. The values of this dataset, which was published by [32], are as follows: “3.71, 4.23, 4.16, 2.98, 3.23, 4.67, 3.99, 5.04, 4.55, 3.24, 2.80, 3.44, 3.27, 2.66, 2.95, 4.70, 5.12, 3.77, 3.12, 2.38, 4.57, 3.88, 2.97, 3.70, 2.53, 2.67, 4.12, 4.80, 3.55, 3.86, 2.51, 3.33, 3.85, 2.35, 3.12, 4.39, 5.09, 3.38, 2.73, and 3.07”. Figure 11 describes Environmental data-I using box plot, strip plot, and Violine plot of data to check that the data do not have outlier problems and whether the data have symmetric ships. Environmental data-I was reported to be asymmetrical, and uncertain outlier observations were confirmed.
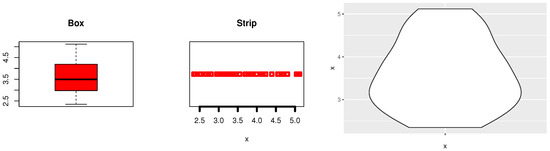
Figure 11.
Box, strip and Violin plots of Environmental data-I.
Table 7 obtained the MLE with SE values of parameters of each comparative model as TIIEHL-PLo, EOWINH, KW, MOAPLo, MOAPEW, ELo, IWLoPS, WLo, and GLo distribution. Furthermore, different measures of the goodness of fit were obtained to compare these models. Figure 12 discusses the estimation of the TIIEHL-PLo distribution for Environmental data-I, where I is the empirical cdf of Environmental data-I, II is the estimated pdf with the histogram of Environmental data-I, III is the QQ plot of data and generates a sample of the TIIEHL-PLo distribution for Environmental data-I, and IV is the plotted PP plot of the TIIEHL-PLo distribution for Environmental data-I. From the results in Table 7 and Figure 12, the TIIEHL-PLo distribution fit of Environmental data-I is confirmed. Figure 13 discusses the profile likelihood of TIIEHL-PLo of Environmental data-I and confirmed the estimators have maximum points. Table 8 discusses the estimation of parameters based on a different estimation method. From the results in Table 8, the LS and WLS method are the best estimation method, whereas the KS distance is small and PVKSs are larger than another methods.
Table 7.
MLE estimators with goodness-of-fit measures: Environmental data-I.
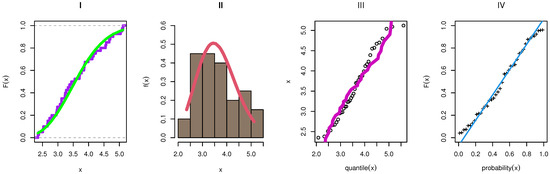
Figure 12.
The estimation of the TIIEHL-PLo distribution: Environmental data-I.
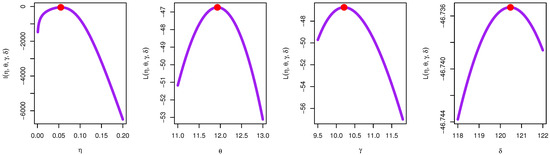
Figure 13.
Profile likelihood of TIIEHL-PLo: Environmental data-I.
Table 8.
Estimation methods and KS test: Environmental data-I.
6.2. Medical Data
Data-I: Barco et al. [33] used this dataset as “1.1, 1.4, 1.3, 1.7, 1.9, 1.8, 1.6, 2.2, 1.7, 2.7, 4.1, 1.8, 1.5, 1.2, 1.4, 3.0, 1.7, 2.3, 1.6, 2.0”, which the information displays how quickly 20 people felt better after taking an analgesic. Figure 14 discusses the description of Medical data-I using the box plot, strip plot, and Violine plot of the data to check that Medical data-I does not have outlier problems and whether the data have symmetric ships. Medical data-I was reported to be asymmetrical, and certain outlier observations were confirmed.
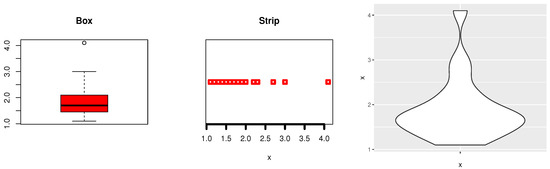
Figure 14.
Box, strip and Violin plot of Medical data-I.
Table 9 obtained an MLE with the SE values of the parameters of each comparative model as TIIEHL-PLo, EOWINH, KW, MOAPLo, MOAPEW, ELo, IWLoPS, WLo, and GLo distribution. Furthermore, different goodness-of-fit measures were obtained to compare these models. Figure 15 discusses the estimation of the TIIEHL-PLo distribution for Medical data-I, where I is the empirical cdf of Medical data-I, II is the estimated pdf with the histogram of Medical data-I, III is the QQ plot of the data and generates a sample of the TIIEHL-PLo distribution for Medical data-I, and IV is the PP plot of the TIIEHL-PLo distribution for Medical data-I. From the results in Table 9 and Figure 15, the TIIEHL-PLo distribution fit of Medical data-I is confirmed. Figure 16 discusses the profile likelihood of the TIIEHL-PLo of Medical data-I and confirms that the estimators have maximum points. Table 10 discusses the estimation of parameters based on different estimation methods. The results in Table 10 evidence that the CVM method is the best estimation method when the KS distance is small and the PVKS is larger than another methods.
Table 9.
MLE estimators with goodness-of-fit measures: Medical data-I.
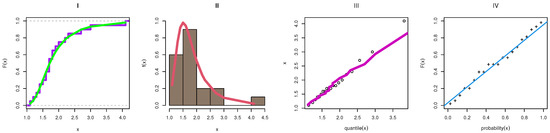
Figure 15.
The estimation of the TIIEHL-PLo distribution: Medical data-I.
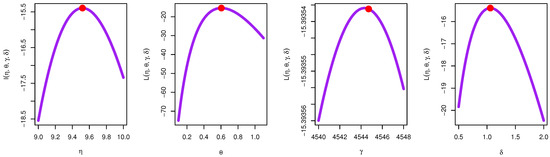
Figure 16.
Profile likelihood of TIIEHL-PLo: Medical data-I.
Table 10.
Estimation methods and KS test: Medical data-I.
Data-II: The most recent data, cited by [34], which shows the number of daily confirmed death cases linked to COVID-19. The dataset is given as follows: “1.00, 1.00, 2.00, 4.00, 5.00, 1.00, 1.00, 3.00, 6.00, 6.00, 4.00, 1.00, 5.00, 6.00, 6.00, 8.00, 5.00, 7.00, 7.00, 9.00, 9.00, 15.00, 17.00, 11.00, 13.00, 5.00, 14.00, 5.00, 13.00, 9.00, 19.00, 15.00, 11.00, 14.00, 12.00, 11.00, 7.00, 13.00, 10.00, 20.00, 22.00, 21.00, 12.00, 14.00, 9.00, 14.00, 7.00, 16.00, 17.00, 13.00, 21.00, 11.00, 11.00, 8.00, 11.00, 12.00, 15.00, 21.00, 20.00, 18.00, 15.00, 14.00, 21.00, 16.00, 11.00, 28.00, 29.00, 19.00, 14.00, 19.00, 29.00, 34.00, 34.00, 46.00, 46.00, 47.00, 36.00, 38.00, 40.00, 32.00, 39.00, 34.00, 35.00, 36.00, 35.00, 45, 62” The data consists of 89 observed values. Figure 17 describes Medical data-II using box plot, strip plot, and Violine plot of the data to verify whether Medical data-II has any outlier problems and whether the data have symmetric ships. Medical data-II was reported to be asymmetrical, and certain outlier observations were confirmed.
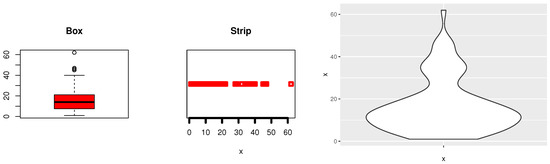
Figure 17.
Box, strip and Violin plot of Medical data-II.
Table 11 shows the MLE with the SE values of the parameters of each comparative model as TIIEHL-PLo, EOWINH, KW, MOAPLo, MOAPEW, ELo, IWLoPS, WLo, and GLo distribution. Furthermore, different goodness-of-fit measures are obtained to compare these models. Figure 18 discusses the estimation of the TIIEHL-PLo distribution for Medical data-II, where I is the empirical cdf of Medical data-II, II is the estimated pdf with the histogram of Medical data-II, III is the QQ plot of data and generates a sample of the TIIEHL-PLo distribution for Medical data-II, and IV is the PP plot of the TIIEHL-PLo distribution for Medical data-II. The results in Table 11 and Figure 18 confirm the TIIEHL-PLo distribution fit of Medical data-II. Table 12 discusses the estimation of parameters based on different estimation methods. The results in Table 12 evidence that the LS method is the best estimation method when the KS distance is small and the PVKS is larger than other methods.
Table 11.
MLE estimators with goodness-of-fit measures: COVID-19 data.
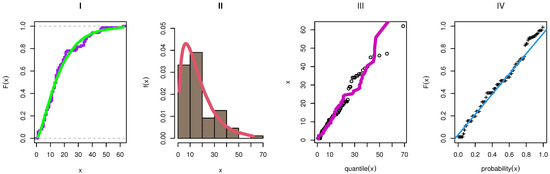
Figure 18.
The estimated of TIIEHL-PLo distribution: Medical data-II.
Table 12.
Estimation methods and KS test: Medical data-II.
7. Conclusions and Summary
In this article, we introduced and studied the type II exponentiated half-logistic-PLo (TIIEHL-PLo) model as a new extension of the PLo model. The new TIIEHL-PLo model is more flexible and applicable than the PLo model and some well-known statistical models, especially in environmental and medical sciences. The pdf for the TIIEHL-PLo model can be uni-modal, decreasing, right skewed, and heavy-tailed. However, the hrf can be decreasing, upside-down, and J-shaped. Some fundamental statistical characteristics of the TIIEHL-PLo model such as the QF, the nth raw moments, mean, variance, skewness, kurtosis, moment-generating function, many graphical and numerical results of moments, and order statistics were calculated. Six different estimation approaches—namely the ML, LS, WLS, MPS, CVM, and AD estimation approaches—were utilized to estimate the parameters of the TIIEHL-PLo model. The simulation experiment examined the accuracy of the model parameters by employing six various estimation techniques. In this study, we analyzed three real datasets from the environmental and medical sciences to show the relevance and adaptability of the TIIEHL-PLo model. The new TIIEHL-PLo model achieves the best fit and performance when we compared it with several well-known statistical models.
Author Contributions
Conceptualization, E.A.A.H., E.M.A., E.A.A. and M.E.; methodology, E.A.E., O.H.M.H., E.M.A., E.A.A.H. and M.E.; software, E.M.A. and M.E.; validation, E.A.A.H., E.M.A., E.A.A. and M.E.; formal analysis, E.A.E., O.H.M.H., E.M.A., E.A.A.H. and M.E.; investigation, E.A.A.H., E.M.A., E.A.A. and M.E.; resources, E.A.E., O.H.M.H., E.M.A., E.A.A.H. and M.E.; data curation, E.A.E., O.H.M.H., E.M.A., E.A.A.H. and M.E.; writing—original draft preparation, E.A.E., O.H.M.H., E.M.A., E.A.A.H. and M.E.; writing—review and editing, E.A.E., O.H.M.H., E.M.A., E.A.A.H. and M.E.; visualization, E.A.E. and O.H.M.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by The Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia grant number INST 051.
Data Availability Statement
Data is available in this paper.
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number INST 051.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lomax, K.S. Business failures: Another example of the analysis of failure data. J. Am. Stat. Assoc. 1954, 49, 847–852. [Google Scholar] [CrossRef]
- Hassan, A.; Al-Ghamdi, A. Optimum step stress accelerated life testing for Lomax distribution. J. Appl. Sci. Res. 2009, 5, 2153–2164. [Google Scholar]
- Atkinson, A.; Harrison, A. Distribution of Personal Wealth in Britain; Cambridge University Press: Cambridge, UK, 1978. [Google Scholar]
- Harris, C. The Pareto distribution as a queue service discipline. Oper. Res. 1968, 16, 307–313. [Google Scholar] [CrossRef]
- Chen, J.; Addie, R.G.; Zukerman, M.; Neame, T.D. Performance evaluation of a queue fed by a Poisson Lomax Burst Process. IEEE Commun. Lett. 2015, 19, 367–370. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Awadhi, F.A.; Alkhalfan, L.A. Marshall Olkin extended Lomax distribution and its application to censored data. Commun. Stat. Theory Methods 2007, 36, 1855–1866. [Google Scholar] [CrossRef]
- Abdul-Moniem, I.B.; Abdel-Hameed, H.F. On exponentiated Lomax distribution. Int. J. Math. Arch. 2012, 3, 2144–2150. [Google Scholar]
- Ashour, S.K.; Eltehiwy, M.A. Transmuted Lomax distribution. Am. J. Appl. Math. Stat. 2013, 1, 121–127. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Cordeiro, G.M. An extended Lomax distribution. Statistics 2013, 47, 800–816. [Google Scholar] [CrossRef]
- Al-Zahrani, B.; Sagor, H. The Poisson-Lomax distribution. Rev. Colomb. Estad. 2014, 37, 225–245. [Google Scholar] [CrossRef]
- El-Bassiouny, A.H.; Abdo, N.F.; Shahen, H.S. Exponential Lomax distribution. Int. J. Comput. Appl. 2015, 121, 24–29. [Google Scholar]
- Cordeiro, G.M.; Ortega, E.M.; Popovíc, B.V. The gamma Lomax distribution. J. Stat. Comput. Simul. 2015, 85, 305–319. [Google Scholar] [CrossRef]
- Tahir, M.H.; Cordeiro, G.M.; Mansoor, M.; Zubair, M. The Weibull-Lomax distribution: Properties and applications. Hacet. J. Math. Stat. 2015, 44, 461–480. [Google Scholar] [CrossRef]
- Kilany, N.M. Weighted Lomax distribution. SpringerPlus 2016, 5, 1862. [Google Scholar] [CrossRef]
- Oguntunde, P.E.; Khaleel, M.A.; Ahmed, M.T.; Adejumo, A.O.; Odetunmibi, O.A. A New Generalization of the Lomax Distribution with Increasing, Decreasing and Constant Failure Rate. Model. Simul. Eng. 2017, 2017, 6043169. [Google Scholar] [CrossRef]
- Hassan, A.S.; Elgarhy, M.; Mohamed, R.E. Statistical Properties and Estimation of Type II Half Logistic Lomax Distribution. Thail. Stat. 2020, 18, 290–305. [Google Scholar]
- Tahir, M.H.; Hussain, M.A.; Cordeiro, G.M.; Hamedani, G.G.; Mansoor, M.; Zubair, M. The Gumbel-Lomax distribution: Properties and applications. J. Stat. Theory Appl. 2016, 15, 61–79. [Google Scholar] [CrossRef]
- Rady, E.A.; Hassanein, W.A.; Elhaddad, T.A. The power Lomax distribution with an application to bladder cancer data. SpringerPlus 2016, 5, 1838. [Google Scholar] [CrossRef]
- Moltok, T.T.; Dikko, H.G.; Asiribo, O.E. A transmuted Power Lomax distribution. Afr. J. Nat. Sci. 2017, 20, 67–78. [Google Scholar]
- Al-Marzouki, S. A new generalization of power Lomax distribution. Int. J. Math. Math. Sci. 2018, 7, 59–68. [Google Scholar]
- Assar, S.M. On odds generalized exponential-power Lomax distribution. J. Math. Stat. 2018, 14, 167–174. [Google Scholar] [CrossRef]
- Hassan, A.S.; Abd-Allah, M. On the inverse power Lomax distribution. Ann. Data Sci. 2019, 6, 259–278. [Google Scholar] [CrossRef]
- Al-Marzouki, S.; Jamal, F.; Chesneau, C.; Elgarhy, M. Type II Topp Leone Power Lomax Distribution with Applications. Mathematics 2020, 8, 4. [Google Scholar] [CrossRef]
- Algarni, A. Sine Power Lomax Model with Application to Bladder Cancer Data. Nanosci. Nanotechnol. Lett. 2020, 12, 677–684. [Google Scholar]
- Al-Mofleh, H.; Elgarhy, M.; Afify, A.Z.; Zannon, M.S. Type II exponentiated half logistic generated family of distributions with applications. Electron. J. Appl. Stat. Anal. 2020, 13, 36–561. [Google Scholar]
- Almetwally, E.M. Extended odd weibull inverse Nadarajah-Haghighi distribution with application on COVID-19 in Saudi Arabia. Math. Sci. Lett. Int. J. 2021, 10, 85–99. [Google Scholar]
- Cordeiro, G.M.; Ortega, E.M.; Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
- Almetwally, E.M. Marshall olkin alpha power extended Weibull distribution: Different methods of estimation based on type i and type II censoring. Gazi Univ. J. Sci. 2022, 35, 293–312. [Google Scholar]
- MacGillivray, H.L. Skewness and asymmetry: Measures and orderings. Ann. Stat. 1986, 14, 994–1011. [Google Scholar] [CrossRef]
- Macdonald, P.D.M. Comments and queries comment on “an estimation procedure for mixtures of distributions” by choi and bulgren. J. R. Stat. Soc. Ser. B (Methodol.) 1971, 33, 326–329. [Google Scholar] [CrossRef]
- Swain, J.J.; Venkatraman, S.; Wilson, J.R. Least-squares estimation of distribution functions in Johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Ross, M.S. Introductory Statistics, 3rd ed.; Elsevier: Oxford, UK, 2010; p. 365. [Google Scholar]
- Barco, K.V.P.; Mazucheli, J.; Janeiro, V. The inverse power Lindley distribution. Commun. Stat.-Simul. Comput. 2017, 46, 6308–6323. [Google Scholar] [CrossRef]
- Alyami, S.A.; Elbatal, I.; Alotaibi, N.; Almetwally, E.M.; Okasha, H.M.; Elgarhy, M. Topp-Leone Modified Weibull Model: Theory and Applications to Medical and Engineering Data. Appl. Sci. 2022, 12, 10431. [Google Scholar] [CrossRef]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).