Abstract
In this work, we introduce an extension of the so-called beta autoregressive moving average (ARMA) models. ARMA models consider a linear dynamic structure for the conditional mean of a beta distributed variable. The conditional mean is connected to the linear predictor via a suitable link function. We propose modeling the relationship between the conditional mean and the linear predictor by means of the asymmetric Aranda-Ordaz parametric link function. The link function contains a parameter estimated along with the other parameters via partial maximum likelihood. We derive the partial score vector and Fisher’s information matrix and consider hypothesis testing, diagnostic analysis, and forecasting for the proposed model. The finite sample performance of the partial maximum likelihood estimation is studied through a Monte Carlo simulation study. An application to the proportion of stocked hydroelectric energy in the south of Brazil is presented.
Keywords:
βARMA models; double bounded data; forecasting; non-Gaussian time series; parametric link function MSC:
62Fxx; 62J12; 62M10; 62M20
1. Introduction
Gaussianity is by far the most commonly used hypothesis in statistics. It is easy to find in the literature applications of Gaussian time series in contexts where it is neither natural nor adequate to suppose normality of the underlying data distribution. Simple examples are strictly positive data such as prices, counting phenomena or double bounded data, such as rates and proportions whose support is . In these situations, normality is obviously not an adequate hypothesis to assume. The consequences of using a Gaussian time series model were it is not reasonable may be grave, especially when the focus lies on forecasting. In these cases, it is a common problem to obtain predicted values that lie outside the natural bounds of the data.
To overcome these issues, non-Gaussian time series models have been extensively explored in the literature. For instance, autoregressive models for integer valued time series were introduced in [1]. A broad class of dynamic models for non-Gaussian time series based on generalized linear models (GLM) [2] was considered in [3], which called them generalized autoregressive moving average (GARMA) models. Traditional GLM methods can serve as an inspiration for time series models, but there are important distinctions and technicalities to keep in mind [4]. Other studies in this direction can be found in [5,6,7,8].
Modeling rates and proportions observed over time is a common problem in many areas of application. By nature, such time series are limited to the interval and, hence, Gaussianity is an assumption that should be avoided [9]. In this direction, the class of beta autoregressive moving average (ARMA) models, proposed by [10], introduces a GLM-like dynamic model for time series restricted to . The ARMA model assume that, conditionally to its past, the variable of interest follows a beta distribution while the conditional mean is modeled through a dynamical time dependent linear structure accommodating an ARMA-like term and a linear combination of exogenous covariates. The conditional mean is connected to the linear predictor through a suitable fixed link function.
The beta distribution is well known for its flexibility, being able to model asymmetric behaviors such as bathtub and J-shaped and inverted J-shaped densities, among other. For this reason, the literature has seen a growing interest in beta-based models in the last decade and several improvements and generalizations of the ARMA model have been proposed. For instance, some generalizations propose the use of different specifications for the systematic component. Ref. [11] proposed the class of SARMA models which introduces a seasonal ARMA structure in the systematic components. Ref. [12] proposed the class of ARFIMA models by considering a long range dependent specification for the systematic component. Some goodness-of-fit tests for ARMA are proposed in [13], while prediction intervals and model selection criteria are recently explored in [14,15], respectively. In [16], the inflated ARMA model was introduced for modeling time series data that assume values in the intervals , or .
A common feature in the aforementioned models, i.e., the connection between the conditional mean with the linear predictor is made by a suitable link function, ensures that the modeled conditional mean values do not fall outside its natural bounds. Typical choices for responses taking values in are the logit and cloglog fixed links. However, misspecification of the link function may cause distortions in parameter estimation [2]. A simple solution to this problem is to apply a parametric link function. This adds flexibility to the model and improves the finite sample performance of maximum likelihood estimation in the context of GLM [17], compared to the canonical ones. In the literature, we can find some models that apply parametric link functions in the context of regression models. For instance, for binary response problems, [18] proposed the use a modified Box-Cox transformation as link function, while [19] introduced a modified two parameter link that allows free manipulation of both tails of the link. More flexible approaches, which treat the entire link function to be estimated from the data, were considered in [20,21,22]. In the context of beta regression with variable dispersion, [23] proposed the use of parametric link function for the specification of both, mean and dispersion. Recently, ref. [24] proposed the use of the Aranda-Ordaz parametric link function [25] in the context of Kumaraswamy regression. Other applications of parametric link functions in regression models can be found in [26,27,28,29].
Despite the relative growth of the literature on parametric link function in regression models, to the best of our knowledge, there are no time series models considering parametric link functions. In this direction, this works generalizes the ARMA model by introducing a parametric link function in the conditional mean specification. Given that a time series following a ARMA lies on , a suitable and widely known link (as discussed in [23]) is the Aranda-Ordaz asymmetric link function, introduced in [25]. The Aranda-Ordaz link function depends on a parameter which must be known, or, ideally, estimated from the data. To do that, we propose a partial maximum likelihood approach to estimate along with all other parameters in the model.
Different from time series analysis, in regression analysis, the interpretability of the fitted model is of great interest. Some commonly applied link functions, such as the logit and logarithm, allow for a simple interpretation of model parameters, which is no longer the case when we consider a parametric specification for the link function. However, in time series models, prediction is usually considered more important than model interpretability, which favors the use of a parametric link function, since it usually allows for a better model fitting and, often, a superior forecasting performance. In this sense, the proposed ARMA with Aranda-Ordaz link function provides two advantages over the standard ARMA model: (i) better model fitting due to more flexibility when considering the relationship between the mean and the linear predictor and (ii) robustness against inferential distortions usually attributed to link misspecification.
The paper is organized as follows. In the next section, we introduce the ARMA model with the Aranda-Ordaz link function. In Section 3, we propose a partial maximum likelihood approach to estimate the model parameters and discuss some of its properties. In Section 4, we present some diagnostic and goodness-of-fit tools and discuss forecasting in the context of the proposed model. A Monte Carlo simulation study is presented in Section 5, while a real data application is presented in Section 6. Our conclusions are presented in Section 7 and some technical details are discussed in the Appendix A and Appendix B.
2. Proposed Model
Let denote a time series of interest and let denote a set of k-dimensional exogenous covariates, possibly time dependent and random. Let denote the -field representing the history of the model known to the researcher up to time t, that is, the sigma-field generated by . We assume that the conditional distribution of given is parameterized as in [9], with density:
where is the Gamma function, and . It is easy to show that:
Observe that the parameter acts as a precision parameter, since the higher the , the smaller the variance of , for a fixed . Note that the variance of changes for each t, so the model is naturally heteroscedastic. Although, in principle, it could be possible to consider a variable dispersion parameter, as in [23]; however, the majority of works in the literature assume a constant precision/dispersion parameter ([3,9,10,11,15,30], to name just a few) so, for simplicity, we shall do the same.
Let be a twice continuously differentiable one to one link function, possibly depending on a parameter . Consider the following specification for the model’s systematic component:
where is an intercept, is a k-dimensional vector of parameter associated with the covariates, and and are p and q-dimensional vectors of parameters associated with the autoregressive and moving average components, respectively. The error term is defined as . Observe that if we substitute for a fixed (non-parametric) link function , such as logit or probit links, then we obtain the ARMA model of [10].
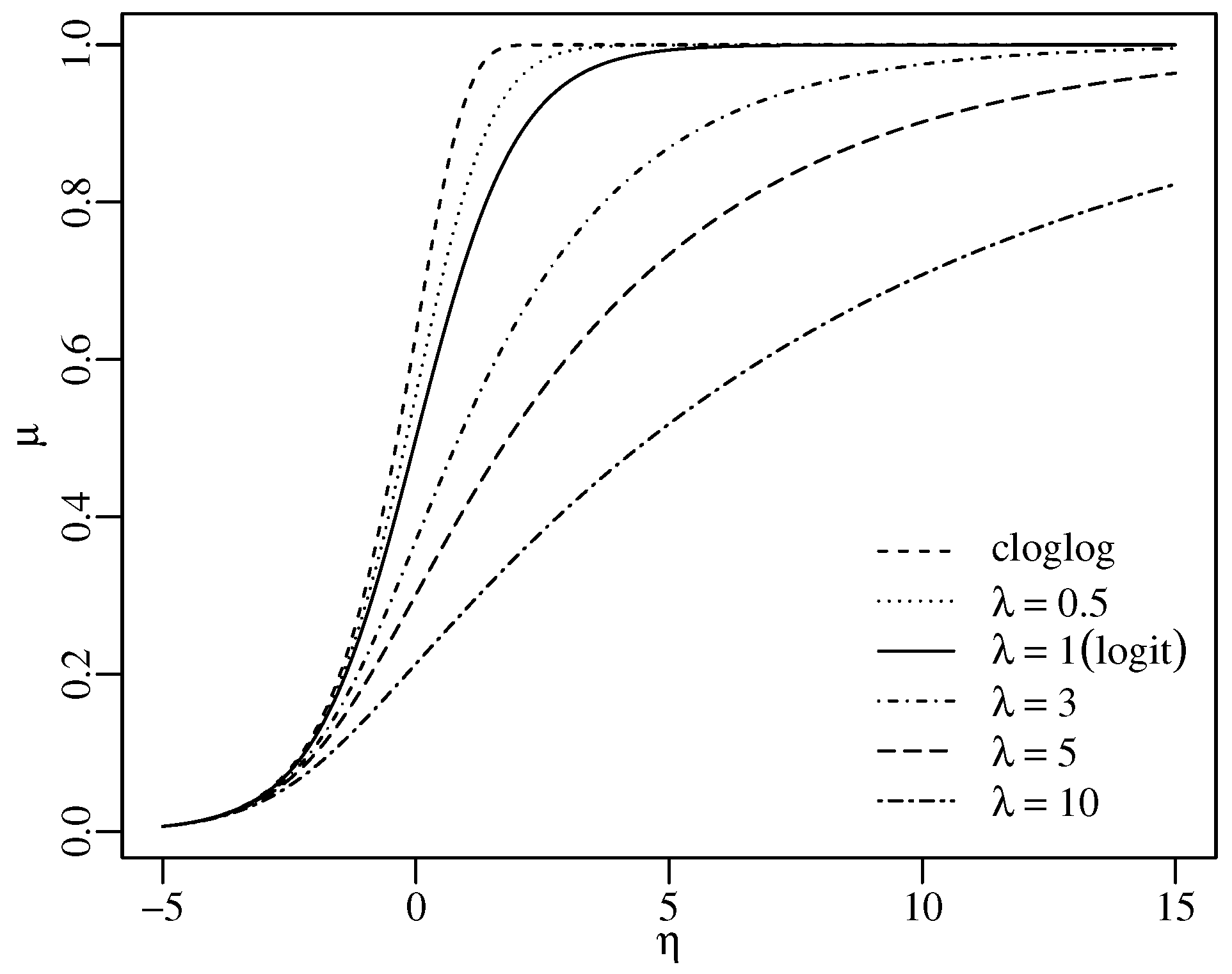
In (2), when g indeed depends on we have a parametric link function. The choice of the parametric link is an important one and due to its flexibility, we shall apply the asymmetric Aranda-Ordaz family of link functions in (2), which has the form:
for . Observe that and that g is infinitely differentiable away from zero on and . Figure 1 shows the Aranda-Ordaz link function for several values of , highlighting its asymmetric behavior, which allows an asymmetric relationship between and . We note that it is an increasing and monotonic function, where positive (or negative) changes in the linear predictor imply a positive (or negative) effect on the response mean. The traditional logit is a particular case obtained when and the cloglog is obtained as a limiting case for .
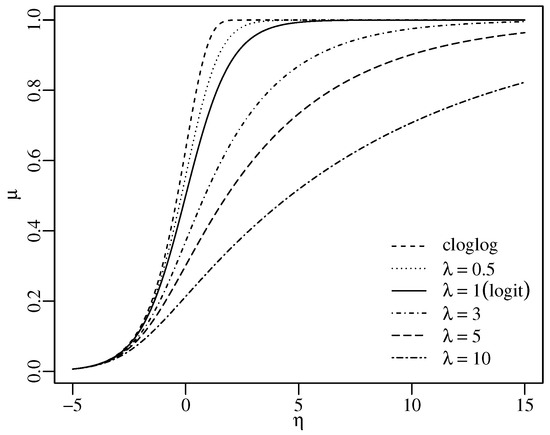
Figure 1.
The Aranda-Ordaz link function for different values of .
The proposed ARMA model with Aranda-Ordaz link function, hereafter referred to as , is defined by (1), (2), and (3). The Aranda-Ordaz parameter influences the conditional mean , which affects the response through . Figure 1 illustrates how the parameter affects as a function of . For , the effect on is mild compared to clolog and logit, primarily impacting values between 0 and 4 by slightly accelerating or decelerating the increase of relative to . For , the impact of is more pronounced, with larger values dampening the speed at which changes in affect . Thus, for , becomes less sensitive to variations in , smoothing ’s conditional mean compared to the logit and cloglog functions.
3. Partial Likelihood Inference
Let be a sample from the proposed model and let be the -dimensional vector of unknown parameters in the model, and is the parametric space, such that . In this section, we derive a partial maximum likelihood estimation (PMLE) approach to estimate . Given , the partial log-likelihood function is given by:
where and
The estimator is defined as:
The solution of (5) is obtained by solving , where is the partial score vector and . Closed-form expressions of the partial score vector are presented in Appendix A.
The non-linear system has no closed-form solution. To obtain approximate solutions, it is necessary to numerically maximize the partial log-likelihood function given in (4). In this work, we consider the so-called BFGS method [31] with analytical first derivatives to do so. The procedure requires initialization. We initialize (logit particular case) and in all cases. Parameters , , and are initialized as the ordinary least squares estimates of the regression problem:
where denotes an error term. Let denote the initial value of , the starting value of is given by:
where and .
In addition to point inference, it is also interesting to build confidence intervals and carry out hypothesis tests. In this sense, we need the asymptotic distribution of the partial maximum likelihood estimator. The seminal work of [32] established the asymptotic theory of the maximum likelihood in the context of traditional GLM under mild conditions. These results were generalized for the case of GLM with parametric link functions in [33]. For GARMA-like models, a rigorous asymptotic theory was established in [34,35]. Ref. [12] presented the asymptotic theory for the PMLE in the context of ARFIMA models. Recently, Ref. [24] established the asymptotic theory of the MLE for GLM-like models with the Aranda-Ordaz parametric link based on the Kumaraswamy distribution, which is not a member of the exponential family.
In the context of model, specification (1) and the fact that the information matrix is not block diagonal imply that the parameter estimation must be jointly performed via the log-likelihood function. To derive the asymptotic theory for the PMLE in the context of the present work, a similar argument as in [33,34] can be applied, with a few modifications. Under suitable conditions, closely related to the ones presented in [34], it can be shown that the partial maximum likelihood estimator is consistent and:
as n tends to infinity, where denotes the -variate normal distribution with mean vector and variance-covariance matrix . The matrix is a positive definite and invertible matrix, the analogous to the information matrix per observation in the context of i.i.d. samples. Under suitable conditions, in probability, where is the cumulative conditional information matrix presented in the Appendix B.
Let denote the r-th component of , and with the previous results, it is possible to obtain approximate confidence interval to and standard Z statistics to test hypothesis like vs. [36]. Versions of other commonly applied test statistics, such as the Wald [37], likelihood ratio [38], Rao’s score [39], and the gradient [40] statistic, can be similarly defined. Their asymptotic distributions will be with the corresponding degrees of freedom imposed by the restrictions under . More general forms of these hypothesis tests can be performed similarly to traditional regression models.
4. Diagnostics and Forecasting
In this section, we consider some diagnostic tools useful in determining whether a fitted model succeeded in capturing the data dynamics. Also, we detail a method to produce forecasts based on a fitted model. Besides the joint significance of the parameters obtained using the tests presented in the previous section, we can also discuss residual analysis. A priori, there is no imposed distributional structure for the error term in (2), but it is quite common to look at some goodness-of-fit statistics.
The so-called deviance statistics is commonly applied as a goodness-of-fit measure of a given model [4]. It can be shown that, if the model is correctly specified, then the deviance statistics is asymptotically distributed [3,4]. Model selection can be performed by using adapted versions of the AIC [41] and BIC [42]. A lower AIC and BIC values are associated with more suitable models. Residual analysis is a fundamental diagnostic tool in statistical modeling. There are several ways to define the residuals for the proposed model, such as standardized, quantile [43], and deviance residuals. As considered in [13], for the ARMA, and in [9], for the beta regression model, we suggest using the standardized ordinary residual.
Another useful tool in diagnostic analysis are Portmanteau tests. If the model is correctly specified, it is expected that the residuals behave like a white noise [4]. Portmanteau tests for ARMA models were rigorously studied by [13]. In this context, similar arguments to those in [13] can be applied to show that the Ljung–Box statistics to test the null hypothesis that the first s residual autocorrelations are zero will be asymptotically distributed, under mild assumptions.
Since the proposed model is an extension of the ARMA, -step ahead forecasts can be obtained similarly. Let be a sample from the proposed model. Let be the PMLE based on the sample and be evaluated at and . For , h-step ahead forecasts are given by:
where
5. Numerical Experiments
In this section, we present a Monte Carlo simulation study to assess the finite sample properties of the PMLE for the proposed model parameters. We consider 10,000 simulated replications of a process , for following the . The following two scenarios were considered in the simulation:
- with two covariates, where the parameters are set as , , , , , and ;
- with one covariate, where the parameters are , , , , , and .
In order to induce a deterministic seasonality into the model, we consider in Scenario 1 and in Scenario 2. All simulations were performed using R version 3.5.2 [44]. Table 1 and Table 2 present the simulation results for Scenario 1, while Table 3 and Table 4 for Scenario 2 by varying the precision parameter . Presented are the mean estimate, relative bias (RB), standard error (SE), and mean square error (MSE).

Table 1.
Simulation results for the proposed PMLE under Scenario 1 with .
Table 2.
Simulation results for the proposed PMLE under Scenario 1 with .
Table 3.
Simulation results for the proposed PMLE under Scenario 2 with .
Table 4.
Simulation results for the proposed PMLE under Scenario 2 with .
As expected, in general, as n increases, the mean of the estimated values converges to the true value of the parameter and the RB, SE, and MSE decrease. Note that for , the relative bias and standard errors are higher than the ones when . This behavior is expected since decreasing precision implies an increase in the variability of . For small sample sizes such as , there is considerable bias in all scenarios. Just as in the case of the beta regression [45] and ARFIMA [12], is slightly biased, especially in small samples.
Overall, all parameters are reasonably estimated even in small samples. In all scenarios, the MSE uniformly decreases as n increases, which represents numerical evidence of the PMLE’s consistency. Among all parameters, the estimation of is the one presenting the highest relative bias. The simulation results provide numerical evidence supporting the theory discussed in Section 3.
6. Application
In this section, we showcase the usefulness of the proposed model in a real data application. The data comprehend the monthly proportion of stocked hydroelectric energy in the south of Brazil from January 2000 to May 2022, yielding a total of 269 observations. The last six months of data were reserved for out-of-sample forecasting purposes, and hence, for modeling purposes the sample size is . This is an updated time series that was also modeled in [13]. The data are freely available at the Operador Nacional do Sistema Elétrico repository (http://www.ons.org.br/paginas/resultados-da-operacao/historico-da-operacao/dados-gerais/, accessed on 29 October 2024). The hydrological study is essential for the adequate distribution of energy and to supply the consumption demand of the population. Forecasts are widely used by institutions to prevent energy shortages. All the results presented in this section can be accessed by a friendly web application available at http://ufsm.shinyapps.io/appBARMA/, accessed on 29 October 2024. In this online application, users can upload any time series data to fit using the proposed model.
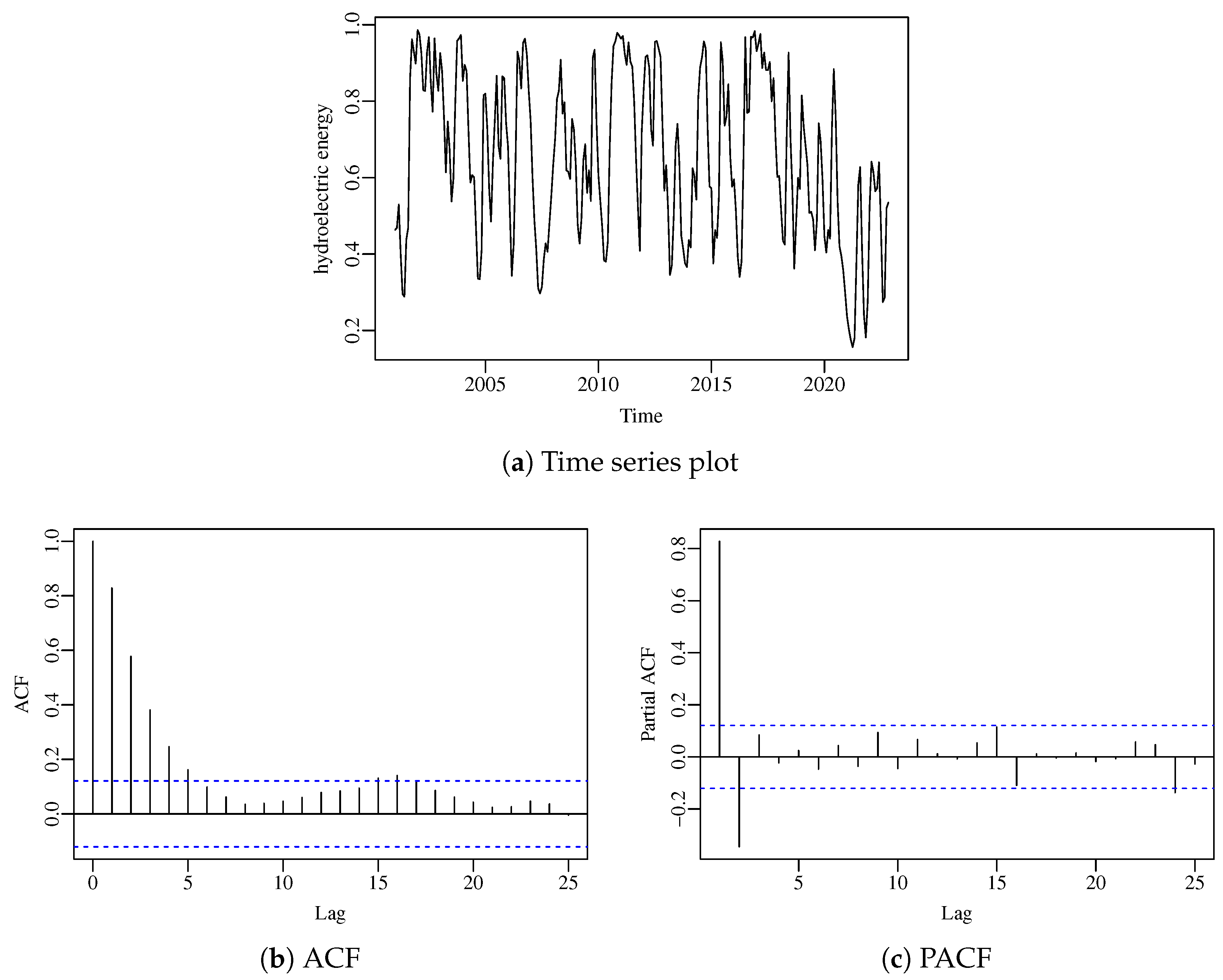
Figure 2 presents the time series plot of the data, as well as its sample autocorrelation (ACF) and partial autocorrelation (PACF) functions. From the time series plot, a clear yearly seasonal pattern can be observed. In order to capture this seasonality, we shall employ as covariate in the model.
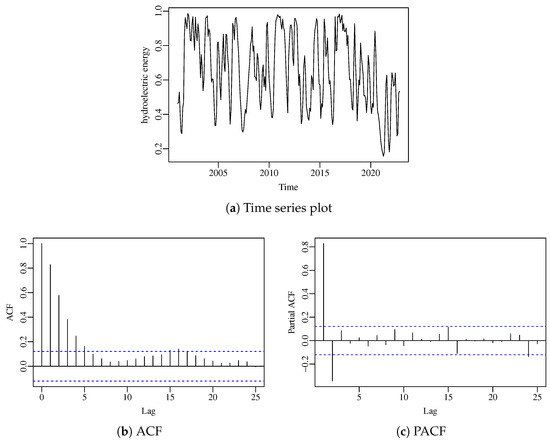
Figure 2.
Time series and related plots for the hydroelectric energy.
Additionally, we consider a further step in the optimization procedure that explores different initial values of (Aranda-Ordaz parameter); this step selects the model that has the smallest AIC value. The algorithm is described by:
- Let be a vector of initial values associated with the Aranda-Ordaz link function parameter.
- Fit L models, one for each , for .
- Calculate the AIC for each fitted model and choose the one with the lowest value.
For this application, we considered .
Model selection is carried out in a similar fashion to the iterative Box and Jenkins methodology [46]. To select the model, first we compare the AIC of the following competing models: , , , , , , , , , , , , , , and . The model selected by the AIC was a given by:
The parameter was not significant. Table 5 presents a summary of the fitted model with estimated parameters, standard errors, Z-statistics, and p-values, as well as AIC, BIC, deviance, and Ljung–Box test for the residuals. We also test the null hypothesis (logit), rejecting the null hypothesis at the 1% significance level, indicating that the logit function is not adequate for the data.
Table 5.
Summary statistics for the fitted .
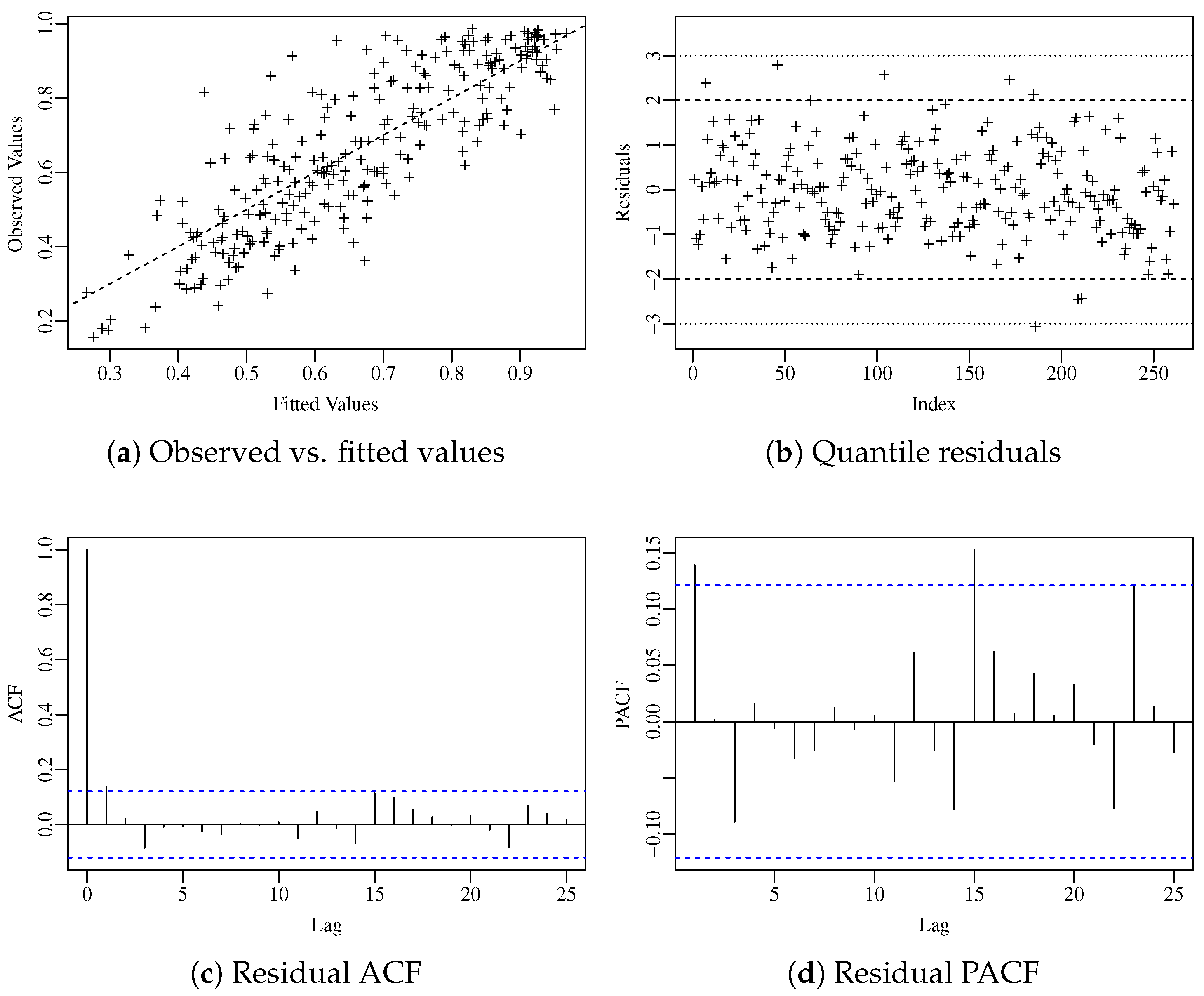
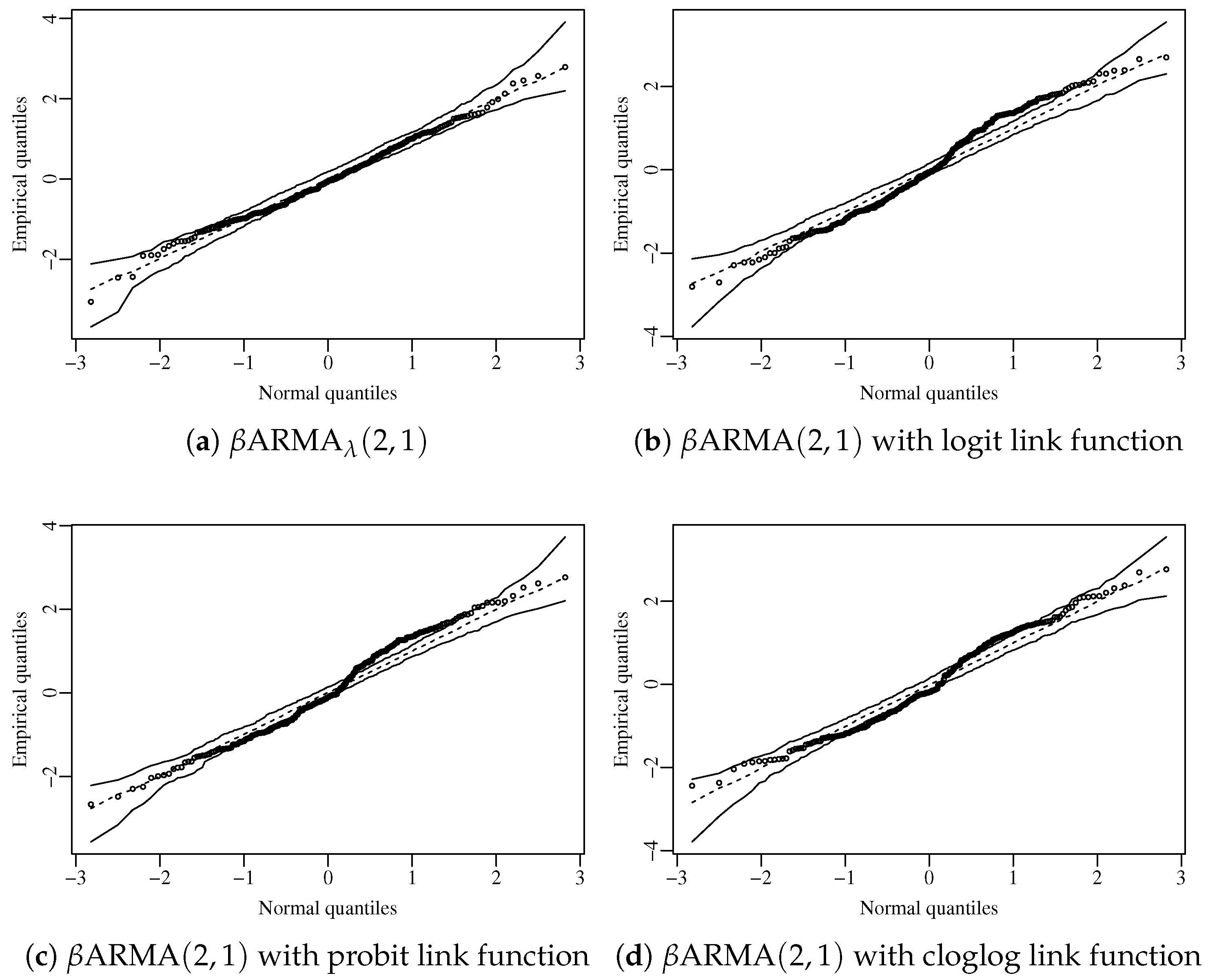
To carry on the residual analysis, we consider the standardized ordinary residual. The diagnostic plots presented in Figure 3 suggest that the residuals do not exhibit any pattern and are uncorrelated, as confirmed by the Ljung–Box test [13]. Figure 4 shows the normal plot with simulated envelope of the residuals considering the proposed model and the standard ARMA model with different fixed link functions. Among all competitors, the proposed model was the only one capable of fitting the data adequately, with the residuals lying uniformly within the confidence region. The plots and tests further support the hypothesis that the model is correctly specified.
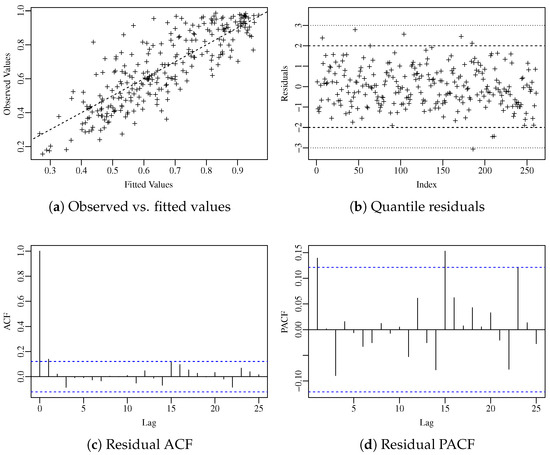
Figure 3.
Diagnostic plots for the residuals.
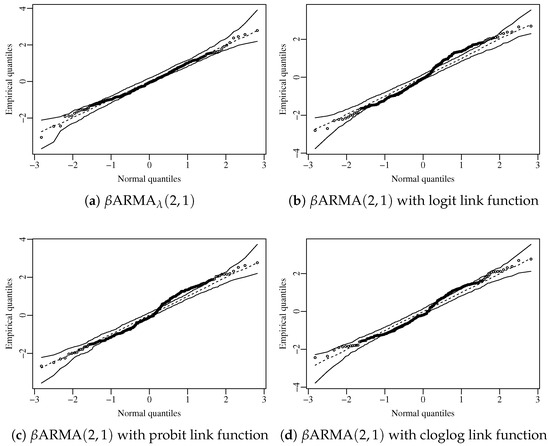
Figure 4.
Normal plot with simulated envelope for different fitted models.
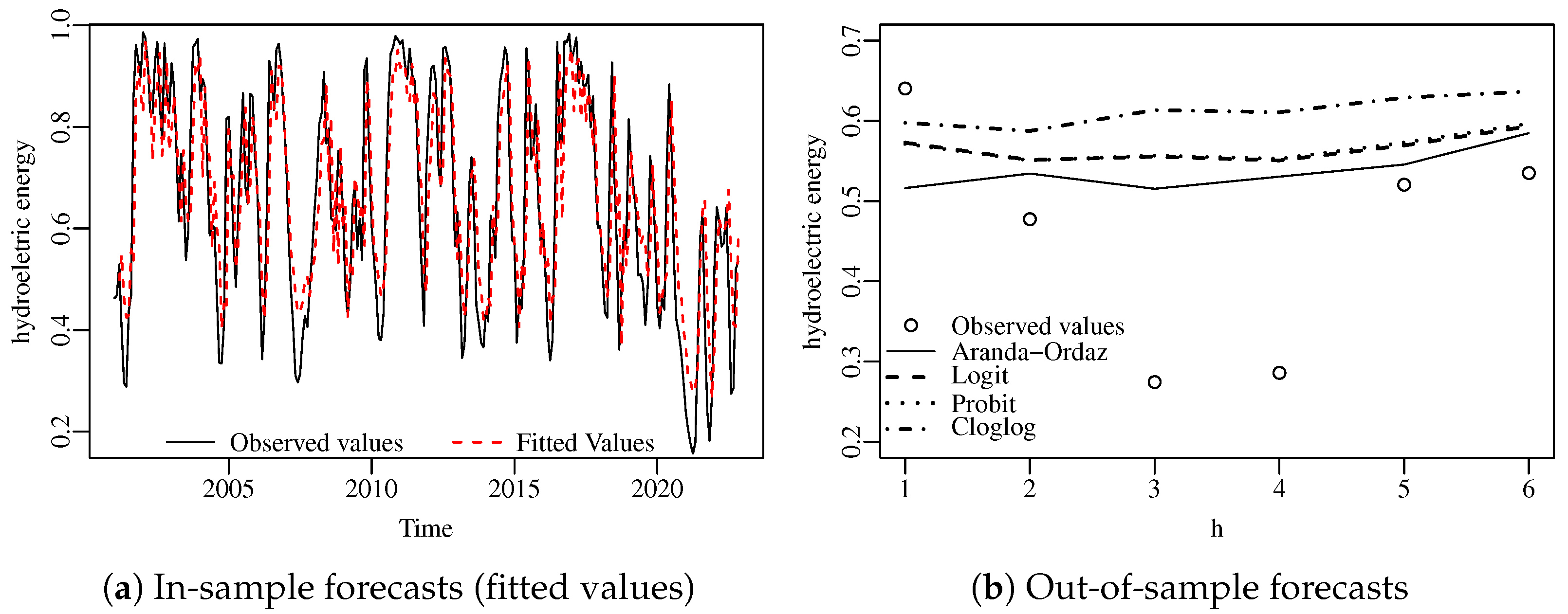
Figure 5a presents the time series plot of the data and the predicted values (in-sample forecasts), while Figure 5b presents the six-step out-of-sample forecasts. In order to make a comparison, we have added to the plot out-of-sample forecasts for the fitted ARMA model coupled with four different link functions, namely, the fitted Aranda-Ordaz (), the logit, the probit, and the cloglog. It is noteworthy that the model yielded more accurate out-of-sample forecasts than the competitors.
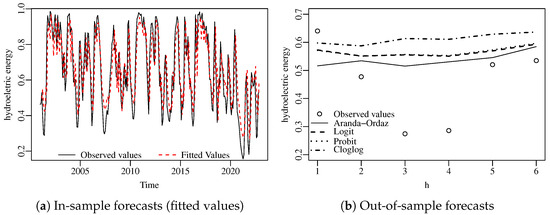
Figure 5.
Observed in-sample and out-of-sample forecasts for the hydroelectric energy data.
Table 6 presents in-sample and out-of-sample forecasting root mean square error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) measures between observed and fitted values, for all t, for the four fitted models. In addition, we present the forecast measures by modeling the time series with smaller periods, namely . We observe that the proposed model outperforms the competitor models in all metrics in the in-sample case. Considering out-of-sample forecasting, the proposed model outperforms in most cases, with lower performance only in MAPE for the logit and probit link functions, and in RMSE for the logit link function when considering . The usual logit link function performs better than our proposal only in two metrics of one prediction scenario. Our proposal performs better in most cases, and when it does not, it is still very competitive. The Aranda-Ordaz link function with has a heavier right tail compared to the other links, which may explain its superior forecasting performance.
Table 6.
In-sample and out-of-sample () forecasting measures for the model compared to the ARMA model with other fixed links (best figures are in bold).
Moreover, besides presenting the best forecast performance, the flexibility of the Aranda-Ordaz link allows for the proposed model to circumvent problems steaming from link function misspecification, being more robust and facilitating the construction of an adequate model for practitioners.
7. Conclusions
In this work, we considered an alternative way to model bounded time series by extending the relationship between the random component and linear predictors in the context of ARMA models. To do that, we introduced the Aranda-Ordaz parametric link function in place of the traditional fixed links. The parameter on the Aranda-Ordaz link is estimated along the other ARMA parameters by partial maximum likelihood. We discussed large sample inferences and presented a Monte Carlo simulation study showcasing the estimator’s performance in finite sample sizes. Based on the proposed methodology, we discussed residual analysis, hypothesis testing, and forecasting. Finally, a real data application to the proportion of stocked hydroelectric energy in the south of Brazil was presented, showcasing the usefulness of the proposed model, which has outperformed the competing ones.
Author Contributions
Conceptualization, D.R.C. and F.M.B.; methodology, C.E.F.M., D.R.C., G.P. and F.M.B.; software, C.E.F.M., D.R.C. and F.M.B.; formal analysis, C.E.F.M., D.R.C., G.P. and F.M.B.; investigation, C.E.F.M., D.R.C., G.P. and F.M.B.; resources, C.E.F.M., D.R.C., G.P. and F.M.B.; writing—original draft preparation, C.E.F.M., D.R.C., G.P. and F.M.B.; writing—review and editing, C.E.F.M., D.R.C., G.P. and F.M.B.; supervision, D.R.C. and F.M.B.; project administration, F.M.B.; funding acquisition, F.M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially funded by CAPES, CNPq, and FAPERGS, Brazil.
Data Availability Statement
The data presented in this study are available in the Operador Nacional do Sistema Elétrico repository at http://www.ons.org.br/paginas/resultados-da-operacao/historico-da-operacao/dados-gerais/, accessed on 29 October 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Score Vector
The conditional score vector will be derived in this appendix. In what follows, all equalities should be understood to hold almost surely. Let , we have:
It is easy to see that , and , where is the digamma function. Proceeding similarly as in [10,30], the derivatives are given by:
where is the r-th coordinate of . Finally:
where
The score vector is given by , which can be compactly rewritten in matrix form as:
where , , , , , , and are , and matrices, respectively, with -th entry given by , , and .
Appendix B. Information Matrix
In this appendix, we derive the cumulative conditional information matrix and all equalities should be understood to hold almost surely. The cumulative conditional information matrix is given by:
Let and be proxies for or . We have:
Upon defining , we have:
The derivative of with respect to is given by:
where . Observe further that:
where . The derivative of with respect to is given by:
We then arrive at:
The derivatives with respect to and are given by:
The derivatives with respect to and , are given by:
and, hence:
Let , , , the conditional cumulative information matrix can be written as:
where , , , , , , , , , , , , , , , , , , , , and , with 1 denoting a vector of ones. From the cumulative conditional information matrix we conclude that the model parameters are not orthogonal, contrarily to some linear and some GARMA models [3].
References
- McKenzie, E. Some simple models for discrete variate time series. J. Am. Water Resour. Assoc. 1985, 21, 645–650. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J. Generalized Linear Models, 2nd ed.; Chapman and Hall: Boca Raton, FL, USA, 1989. [Google Scholar]
- Benjamin, M.A.; Rigby, R.A.; Stasinopoulos, D.M. Generalized autoregressive moving average models. J. Am. Stat. Assoc. 2003, 98, 214–223. [Google Scholar] [CrossRef]
- Kedem, B.; Fokianos, K. Regression Models for Time Series Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Janacek, G.; Swift, A. A class of models for non-normal time series. J. Time Ser. Anal. 1990, 11, 19–31. [Google Scholar] [CrossRef]
- Tiku, M.L.; Wong, W.K.; Vaughan, D.C.; Bian, G. Time series models in non-normal situations: Symmetric innovations. J. Time Ser. Anal. 2000, 21, 571–596. [Google Scholar] [CrossRef]
- Jung, R.C.; Kukuk, M.; Liesenfeld, R. Time series of count data: Modeling, estimation and diagnostics. Comput. Stat. Data Anal. 2006, 51, 2350–2364. [Google Scholar] [CrossRef]
- Ribeiro, T.F.; Peña-Ramírez, F.A.; Guerra, R.R.; Alencar, A.P.; Cordeiro, G.M. Forecasting the proportion of stored energy using the unit Burr XII quantile autoregressive moving average model. Comput. Appl. Math. 2024, 43, 27. [Google Scholar] [CrossRef]
- Ferrari, S.L.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Rocha, A.V.; Cribari-Neto, F. Beta autoregressive moving average models. TEST 2009, 18, 529, Erratum in TEST 2017, 26, 451–459. [Google Scholar] [CrossRef]
- Bayer, F.M.; Cintra, R.J.; Cribari-Neto, F. Beta seasonal autoregressive moving average models. J. Stat. Comput. Simul. 2018, 88, 2961–2981. [Google Scholar] [CrossRef]
- Pumi, G.; Valk, M.; Bisognin, C.; Bayer, F.M.; Prass, T.S. Beta autoregressive fractionally integrated moving average models. J. Stat. Plan. Inference 2019, 200, 196–212. [Google Scholar] [CrossRef]
- Scher, V.T.; Cribari-Neto, F.; Pumi, G.; Bayer, F.M. Goodness-of-fit tests for βARMA hydrological time series modeling. Environmetrics 2020, 31, e2607. [Google Scholar] [CrossRef]
- Palm, B.G.; Bayer, F.M.; Cintra, R.J. Prediction intervals in the beta autoregressive moving average model. Commun. Stat.-Simul. Comput. 2023, 52, 3635–3656. [Google Scholar] [CrossRef]
- Cribari-Neto, F.; Scher, V.T.; Bayer, F.M. Beta autoregressive moving average model selection with application to modeling and forecasting stored hydroelectric energy. Int. J. Forecast. 2023, 39, 98–109. [Google Scholar] [CrossRef]
- Bayer, F.M.; Pumi, G.; Pereira, T.L.; Souza, T.C. Inflated beta autoregressive moving average models. Comput. Appl. Math. 2023, 42, 183. [Google Scholar] [CrossRef]
- Czado, C. On selecting parametric link transformation families in generalized linear models. J. Stat. Plan. Inference 1997, 61, 125–140. [Google Scholar] [CrossRef]
- Guerrero, V.M.; Johnson, R.A. Use of the Box-Cox transformation with binary response models. Biometrika 1982, 69, 309–314. [Google Scholar] [CrossRef]
- Czado, C. Parametric link modification of both tails in binary regression. Stat. Pap. 1994, 35, 189–201. [Google Scholar] [CrossRef]
- Mallick, B.K.; Gelfand, A.E. Generalized Linear Models with Unknown Link Functions. Biometrika 1994, 81, 237–245. [Google Scholar] [CrossRef]
- Newton, M.A.; Czado, C.; Chappell, R. Bayesian Inference for Semiparametric Binary Regression. J. Am. Stat. Assoc. 1996, 91, 142–153. [Google Scholar] [CrossRef]
- Muggeo, V.M.; Ferrara, G. Fitting generalized linear models with unspecified link function: A P-spline approach. Comput. Stat. Data Anal. 2008, 52, 2529–2537. [Google Scholar] [CrossRef]
- Canterle, D.R.; Bayer, F.M. Variable dispersion beta regressions with parametric link functions. Stat. Pap. 2019, 60, 1541–1567. [Google Scholar] [CrossRef]
- Pumi, G.; Rauber, C.; Bayer, F.M. Kumaraswamy regression model with Aranda-Ordaz link function. TEST 2020, 29, 1051–1071. [Google Scholar] [CrossRef]
- Aranda-Ordaz, F.J. On two families of transformations to additivity for binary response data. Biometrika 1981, 68, 357–363. [Google Scholar] [CrossRef]
- Koenker, R.; Yoon, J. Parametric links for binary choice models: A Fisherian–Bayesian colloquy. J. Econom. 2009, 152, 120–130. [Google Scholar] [CrossRef]
- Ramalho, E.A.; Ramalho, J.J.; Murteira, J.M. Alternative estimating and testing empirical strategies for fractional regression models. J. Econ. Surv. 2011, 25, 19–68. [Google Scholar] [CrossRef]
- Flach, N. Generalized Linear Models with Parametric Link Families in R. Ph.D. Thesis, Department of Mathematics, Technische Universität München, München, Germany, 2014. [Google Scholar]
- Dehbi, H.M.; Cortina-Borja, M.; Geraci, M. Aranda-Ordaz quantile regression for student performance assessment. J. Appl. Stat. 2016, 43, 58–71. [Google Scholar] [CrossRef]
- Bayer, F.M.; Bayer, D.M.; Pumi, G. Kumaraswamy autoregressive moving average models for double bounded environmental data. J. Hydrol. 2017, 555, 385–396. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Fahrmeir, L.; Kaufmann, H. Consistency and asymptotic normality of the maximum likelihood estimator in generalized linear models. Ann. Stat. 1985, 13, 342–368. [Google Scholar] [CrossRef]
- Czado, C.; Munk, A. Noncanonical links in generalized linear models—When is the effort justified? J. Stat. Plan. Inference 2000, 87, 317–345. [Google Scholar] [CrossRef]
- Fokianos, K.; Kedem, B. Partial likelihood inference for time series following generalized linear models. J. Time Ser. Anal. 2004, 25, 173–197. [Google Scholar] [CrossRef]
- Fokianos, K.; Kedem, B. Prediction and Classification of non-stationary categorical time series. J. Multivar. Anal. 1998, 67, 277–296. [Google Scholar] [CrossRef]
- Pawitan, Y. In All Likelihood: Statistical Modelling and Inference Using Likelihood; Oxford University Press: Oxford, UK, 2001. [Google Scholar]
- Wald, A. Tests of statistical hypotheses concerning several parameters when the number of observations is large. Trans. Am. Math. Soc. 1943, 54, 426–482. [Google Scholar] [CrossRef]
- Neyman, J.; Pearson, E.S. On the use and interpretation of certain test criteria for purposes of statistical inference: Part I. Biometrika 1928, 20, 175–240. [Google Scholar]
- Rao, C.R. Large sample tests of statistical hypotheses concerning several parameters with applications to problems of estimation. Math. Proc. Camb. Philos. Soc. 1948, 44, 50–57. [Google Scholar]
- Terrell, G.R. The gradient statistic. Comput. Sci. Stat. 2002, 34, 206–215. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Dunn, P.K.; Smyth, G.K. Randomized quantile residuals. J. Comput. Graph. Stat. 1996, 5, 236–244. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Ospina, R.; Cribari-Neto, F.; Vasconcellos, K.L.P. Improved point and intervalar estimation for a beta regression model. Comput. Stat. Data Anal. 2006, 51, 960–981. [Google Scholar] [CrossRef]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).