
Automated Segmentation of Median Nerve in Dynamic Sonography Using Deep Learning: Evaluation of Model Performance

 , ,
, ,
Abstract
:
1. Introduction
2. Materials and Methods
2.1. Model Principles
2.1.1. U-Net
2.1.2. DeepLabv3+
2.1.3. FPN
2.1.4. Mask R-CNN
2.2. Subject Recruitment and Dataset of Dynamic US Images
2.3. Model Implementation
2.4. Morphology Metrics
2.5. Performance Evaluation
3. Results
3.1. Effects of Model and Backbone Variation on Inference Performance
3.2. Effects of Various Training Conditions on Model Performance
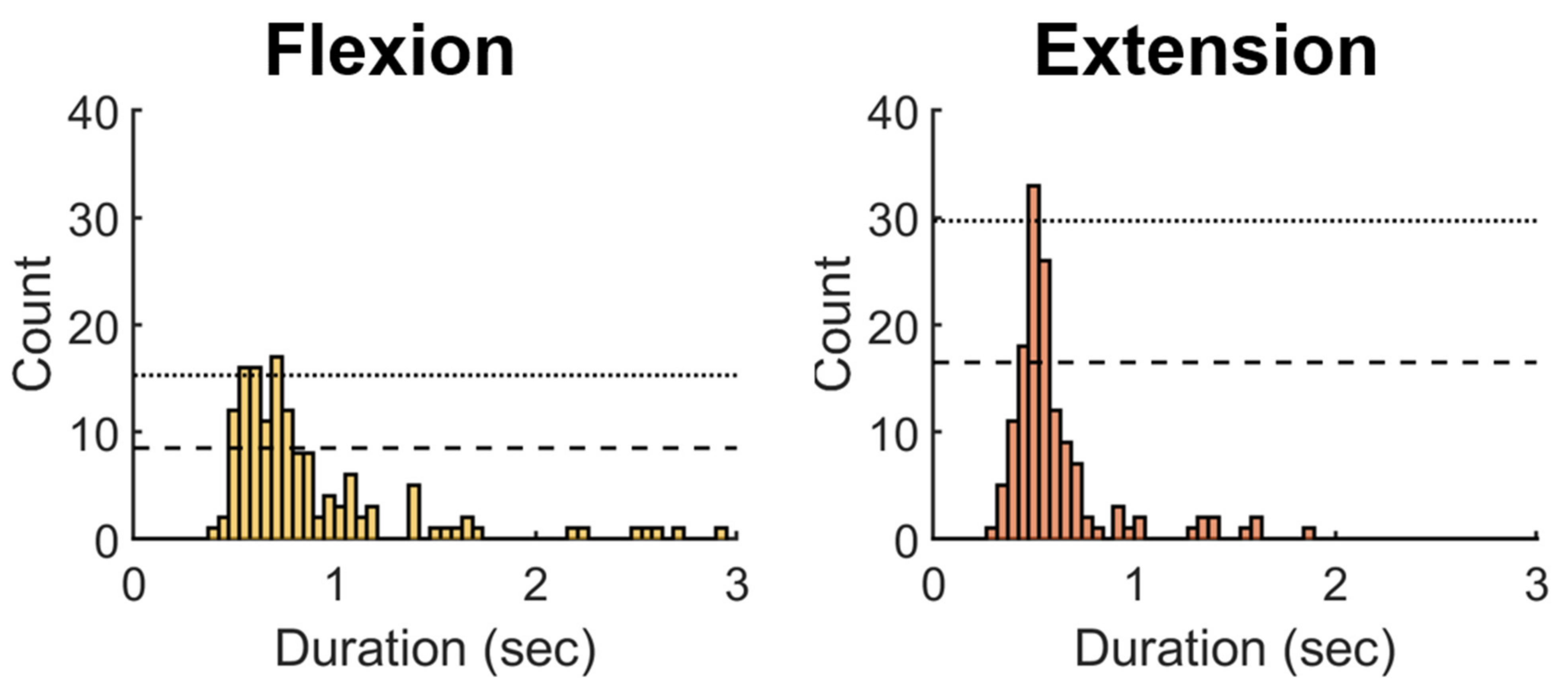
3.3. Conditions Affect the Model Inference
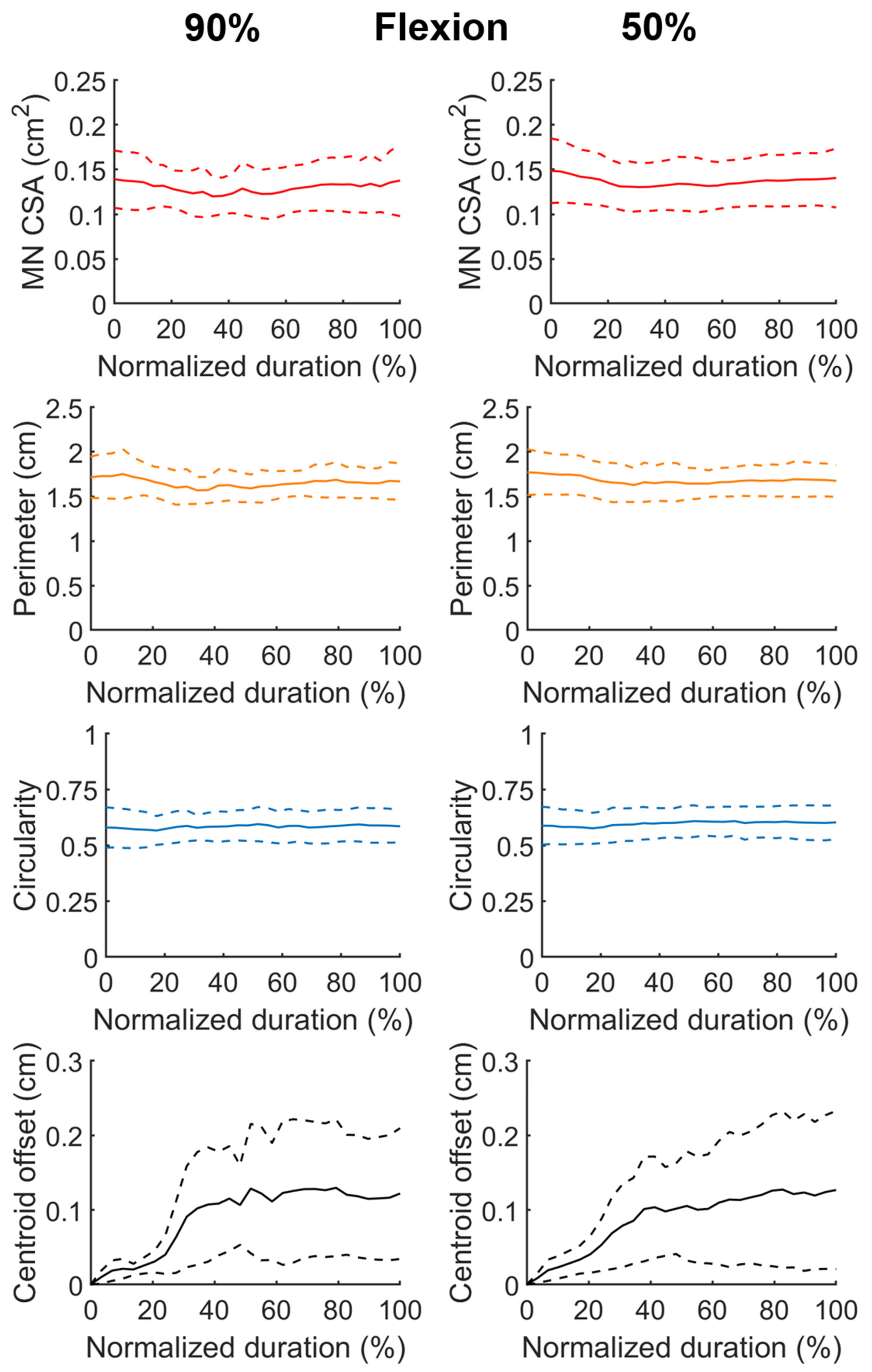
3.4. Morphological Characteristics of the Inferred Median Nerve
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviation
References
- Alfonso, C.; Jann, S.; Massa, R.; Torreggiani, A. Diagnosis, treatment and follow-up of the carpal tunnel syndrome: A review. Neurol. Sci. 2010, 31, 243–252. [Google Scholar] [CrossRef] [Green Version]
- Dale, A.M.; Harris-Adamson, C.; Rempel, D.; Gerr, F.; Hegmann, K.; Silverstein, B.; Burt, S.; Garg, A.; Kapellusch, J.; Merlino, L.; et al. Prevalence and incidence of carpal tunnel syndrome in US working populations: Pooled analysis of six prospective studies. Scand. J. Work. Environ. Health 2013, 39, 495–505. [Google Scholar] [CrossRef]
- Witt, J.C.; Hentz, J.G.; Stevens, J.C. Carpal tunnel syndrome with normal nerve conduction studies. Muscle Nerve 2004, 29, 515–522. [Google Scholar] [CrossRef]
- Chen, Y.-T.; Williams, L.; Zak, M.J.; Fredericson, M. Review of Ultrasonography in the Diagnosis of Carpal Tunnel Syndrome and a Proposed Scanning Protocol. J. Ultrasound Med. 2016, 35, 2311–2324. [Google Scholar] [CrossRef]
- McDonagh, C.; Alexander, M.; Kane, D. The role of ultrasound in the diagnosis and management of carpal tunnel syndrome: A new paradigm. Rheumatology 2014, 54, 9–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Al-Hashel, J.Y.; Rashad, H.M.; Nouh, M.R.; Amro, H.A.; Khuraibet, A.J.; Shamov, T.; Tzvetanov, P.; Rousseff, R.T. Sonography in carpal tunnel syndrome with normal nerve conduction studies. Muscle Nerve 2015, 51, 592–597. [Google Scholar] [CrossRef] [PubMed]
- Aseem, F.; Williams, J.W.; Walker, F.O.; Cartwright, M.S. Neuromuscular ultrasound in patients with carpal tunnel syndrome and normal nerve conduction studies. Muscle Nerve 2017, 55, 913–915. [Google Scholar] [CrossRef] [PubMed]
- Roghani, R.S.; Holisaz, M.T.; Norouzi, A.A.S.; Delbari, A.; Gohari, F.; Lokk, J.; Boon, A.J. Sensitivity of high-resolution ultrasonography in clinically diagnosed carpal tunnel syndrome patients with hand pain and normal nerve conduction studies. J. Pain Res. 2018, 11, 1319–1325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torres-Costoso, A.; Martínez-Vizcaíno, V.; Álvarez-Bueno, C.; Morales, A.F.; Cavero-Redondo, I. Accuracy of Ultrasonography for the Diagnosis of Carpal Tunnel Syndrome: A Systematic Review and Meta-Analysis. Arch. Phys. Med. Rehabil. 2018, 99, 758–765.e10. [Google Scholar] [CrossRef]
- Cartwright, M.S.; Hobson-Webb, L.D.; Boon, A.J.; Alter, K.E.; Hunt, C.; Flores, V.H.; Werner, R.A.; Shook, S.J.; Thomas, T.D.; Do, S.J.P.; et al. Evidence-based guideline: Neuromuscular ultrasound for the diagnosis of carpal tunnel syndrome. Muscle Nerve 2012, 46, 287–293. [Google Scholar] [CrossRef] [Green Version]
- Filius, A.; Scheltens, M.; Bosch, H.G.; van Doorn, P.A.; Stam, H.J.; Hovius, S.E.R.; Amadio, P.C.; Selles, R.W. Multidimensional ultrasound imaging of the wrist: Changes of shape and displacement of the median nerve and tendons in carpal tunnel syndrome. J. Orthop. Res. 2015, 33, 1332–1340. [Google Scholar] [CrossRef] [Green Version]
- Kuo, T.-T.; Lee, M.-R.; Liao, Y.-Y.; Chen, J.-P.; Hsu, Y.-W.; Yeh, C.-K. Assessment of Median Nerve Mobility by Ultrasound Dynamic Imaging for Diagnosing Carpal Tunnel Syndrome. PLoS ONE 2016, 11, e0147051. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Filius, A.; Zhao, C.; Passe, S.M.; Thoreson, A.R.; An, K.-N.; Amadio, P.C. Altered Median Nerve Deformation and Transverse Displacement during Wrist Movement in Patients with Carpal Tunnel Syndrome. Acad. Radiol. 2014, 21, 472–480. [Google Scholar] [CrossRef] [Green Version]
- Park, D. Ultrasonography of the Transverse Movement and Deformation of the Median Nerve and Its Relationships with Electrophysiological Severity in the Early Stages of Carpal Tunnel Syndrome. PM&R 2017, 9, 1085–1094. [Google Scholar] [CrossRef]
- Roomizadeh, P.; Eftekharsadat, B.; Abedini, A.; Ranjbar-Kiyakalayeh, S.; Yousefi, N.; Ebadi, S.; Babaei-Ghazani, A. Ultrasonographic Assessment of Carpal Tunnel Syndrome Severity. Am. J. Phys. Med. Rehabil. 2019, 98, 373–381. [Google Scholar] [CrossRef]
- Festen, R.T.; Schrier, V.J.; Amadio, P.C. Automated Segmentation of the Median Nerve in the Carpal Tunnel using U-Net. Ultrasound Med. Biol. 2021, 47, 1964–1969. [Google Scholar] [CrossRef]
- Chen, X.; Xie, C.; Chen, Z.; Li, Q. Automatic Tracking of Muscle Cross-Sectional Area Using Convolutional Neural Networks with Ultrasound. J. Ultrasound Med. 2019, 38, 2901–2908. [Google Scholar] [CrossRef] [PubMed]
- Loram, I.; Siddique, A.; Sanchez, M.B.; Harding, P.; Silverdale, M.; Kobylecki, C.; Cunningham, R.; Puccini, M.B.S. Objective Analysis of Neck Muscle Boundaries for Cervical Dystonia Using Ultrasound Imaging and Deep Learning. IEEE J. Biomed. Health Inform. 2020, 24, 1016–1027. [Google Scholar] [CrossRef]
- Hafiane, A.; Vieyres, P.; Delbos, A. Deep learning with spatiotemporal consistency for nerve segmentation in ultrasound images. arXiv 2017, arXiv:1706.05870. [Google Scholar]
- Horng, M.-H.; Yang, C.-W.; Sun, Y.-N.; Yang, T.-H. DeepNerve: A New Convolutional Neural Network for the Localization and Segmentation of the Median Nerve in Ultrasound Image Sequences. Ultrasound Med. Biol. 2020, 46, 2439–2452. [Google Scholar] [CrossRef] [PubMed]
- Baby, M.; Jereesh, A.S. Automatic nerve segmentation of ultrasound images. In Proceedings of the 2017 International conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; pp. 107–112. [Google Scholar]
- Huang, C.; Zhou, Y.; Tan, W.; Qiu, Z.; Zhou, H.; Song, Y.; Zhao, Y.; Gao, S. Applying deep learning in recognizing the femoral nerve block region on ultrasound images. Ann. Transl. Med. 2019, 7, 453. [Google Scholar] [CrossRef] [PubMed]
- Smistad, E.; Johansen, K.F.; Iversen, D.H.; Reinertsen, I. Highlighting nerves and blood vessels for ultrasound-guided axillary nerve block procedures using neural networks. J. Med. Imaging 2018, 5, 044004. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Sun, N. Improved U-Net Model for Nerve Segmentation. In Proceedings of the Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 496–504. [Google Scholar]
- Abraham, N.; Illanko, K.; Khan, N.; Androutsos, D. Deep Learning for Semantic Segmentation of Brachial Plexus Nervesin Ultrasound Images Using U-Net and M-Net. In Proceedings of the 2019 3rd International Conference on Imaging, Signal Processing and Communication (ICISPC), Singapore, 27–29 July 2019; pp. 85–89. [Google Scholar]
- Baka, N.; Leenstra, S.; Walsum, T.V. Ultrasound Aided Vertebral Level Localization for Lumbar Surgery. IEEE Trans. Med. Imaging 2017, 36, 2138–2147. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Greenspan, H.; van Ginneken, B.; Summers, R.M. Guest Editorial Deep Learning in Medical Imaging: Overview and Future Promise of an Exciting New Technique. IEEE Trans. Med. Imaging 2016, 35, 1153–1159. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional Neural Networks for Medical Image Analysis: Full Training or Fine Tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep Learning in Medical Ultrasound Analysis: A Review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 6399–6408. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Mishra, D.; Chaudhury, S.; Sarkar, M.; Soin, A.S. Ultrasound Image Segmentation: A Deeply Supervised Network with Attention to Boundaries. IEEE Trans. Biomed. Eng. 2018, 66, 1637–1648. [Google Scholar] [CrossRef]
- Huang, K.; Zhang, Y.; Cheng, H.; Xing, P.; Zhang, B. Semantic segmentation of breast ultrasound image with fuzzy deep learning network and breast anatomy constraints. Neurocomputing 2021, 450, 319–335. [Google Scholar] [CrossRef]
- Guo, Y.; Duan, X.; Wang, C.; Guo, H. Segmentation and recognition of breast ultrasound images based on an expanded U-Net. PLoS ONE 2021, 16, e0253202. [Google Scholar] [CrossRef]
- Poudel, P.; Illanes, A.; Sheet, D.; Friebe, M. Evaluation of Commonly Used Algorithms for Thyroid Ultrasound Images Segmentation and Improvement Using Machine Learning Approaches. J. Health Eng. 2018, 2018, 8087624. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Irfan, R.; Almazroi, A.; Rauf, H.; Damaševičius, R.; Nasr, E.; Abdelgawad, A. Dilated Semantic Segmentation for Breast Ultrasonic Lesion Detection Using Parallel Feature Fusion. Diagnostics 2021, 11, 1212. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Gómez-Flores, W.; Pereira, W.C.D.A. A comparative study of pre-trained convolutional neural networks for semantic segmentation of breast tumors in ultrasound. Comput. Biol. Med. 2020, 126, 104036. [Google Scholar] [CrossRef] [PubMed]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Wu, Y.; Zhang, R.; Zhu, L.; Wang, W.; Wang, S.; Xie, H.; Cheng, G.; Wang, F.L.; He, X.; Zhang, H. BGM-Net: Boundary-Guided Multiscale Network for Breast Lesion Segmentation in Ultrasound. Front. Mol. Biosci. 2021, 8. [Google Scholar] [CrossRef] [PubMed]
- Chiao, J.-Y.; Chen, K.-Y.; Liao, K.Y.-K.; Hsieh, P.-H.; Zhang, G.; Huang, T.-C. Detection and classification the breast tumors using mask R-CNN on sonograms. Medicine 2019, 98, e15200. [Google Scholar] [CrossRef]
- Atroshi, I.; Flondell, M.; Hofer, M.; Ranstam, J. Methylprednisolone Injections for the Carpal Tunnel Syndrome. Ann. Intern. Med. 2013, 159, 309–317. [Google Scholar] [CrossRef]
- Chang, C.W.; Wang, Y.C.; Chang, K.F. A practical electrophysiological guide for non-surgical and surgical treatment of carpal tunnel syndrome. J. Hand. Surg. Eur. Vol. 2008, 33, 32–37. [Google Scholar] [CrossRef]
- Wada, K. Labelme: Image Polygonal Annotation with Python. 2016. Available online: https://github.com/wkentaro/labelme (accessed on 13 September 2021).
- Massa, F.; Girshick, R. Maskrcnn-Benchmark: Fast, Modular Reference Implementation of Instance Segmentation and Object Detection Algorithms in PyTorch. Available online: https://github.com/facebookresearch/maskrcnn-benchmark (accessed on 13 September 2021).
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Kwak, D.; Ali, A.; Imran, M.; Kwak, K.-S. A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion. Inf. Fusion 2020, 63, 208–222. [Google Scholar] [CrossRef]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting Objects by Locations. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 649–665. [Google Scholar]
- Srinivasu, P.; SivaSai, J.; Ijaz, M.; Bhoi, A.; Kim, W.; Kang, J. Classification of Skin Disease Using Deep Learning Neural Networks with MobileNet V2 and LSTM. Sensors 2021, 21, 2852. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yu, L.Q.; Wu, L.G.; Wang, Y.; Ni, D.; Qin, J.; Heng, P.-A. Fine-grained recurrent neural networks for automatic prostate segmentation in ultrasound images. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1633–1639. [Google Scholar]
- Ijaz, M.F.; Attique, M.; Son, Y. Data-Driven Cervical Cancer Prediction Model with Outlier Detection and Over-Sampling Methods. Sensors 2020, 20, 2809. [Google Scholar] [CrossRef] [PubMed]
- Ijaz, M.F.; Alfian, G.; Syafrudin, M.; Rhee, J. Hybrid Prediction Model for Type 2 Diabetes and Hypertension Using DBSCAN-Based Outlier Detection, Synthetic Minority Over Sampling Technique (SMOTE), and Random Forest. Appl. Sci. 2018, 8, 1325. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | Segmentation Type | Average IoU | Average Inference Time (s) |
|---|---|---|---|---|
| U-Net | ResNet-101 | Semantic | 0.7873 ± 0.0882 | 0.0623 |
| U-Net | ResNext-101-32x8d | Semantic | 0.8031 ± 0.0668 | 0.1239 |
| FPN | ResNet-101 | Semantic | 0.8016 ± 0.0647 | 0.0556 |
| FPN | ResNext-101-32x8d | Semantic | 0.8132 ± 0.0608 | 0.1146 |
| DeepLabv3+ | ResNet-101 | Semantic | 0.8045 ± 0.0628 | 0.0794 |
| DeepLabv3+ | Xception-65 | Semantic | 0.8243 ± 0.0527 | 0.0984 |
| Mask R-CNN | ResNet-101 | Instance | 0.8216 ± 0.0564 | 0.0849 |
| Model | Backbone | Training Output Stride | Test Output Stride | Training Image Size | Multi-Scale Input | Average IoU | Average Inference Time (s) |
|---|---|---|---|---|---|---|---|
| DeepLabv3+ | Xception-65 | 16 | 16 | 721,961 | No | 0.8249 ± 0.0533 | 0.0982 |
| DeepLabv3+ | Xception-65 | 16 | 8 | 721,961 | No | 0.8278 ± 0.0508 | 0.3651 |
| DeepLabv3+ | Xception-65 | 16 | 16 | 481,481 | No | 0.8247 ± 0.0569 | 0.1002 |
| DeepLabv3+ | Xception-65 | 16 | 8 | 481,481 | No | 0.8244 ± 0.0513 | 0.3539 |
| DeepLabv3+ | Xception-65 | 8 | 8 | 481,481 | No | 0.8179 ± 0.0673 | 0.3644 |
| DeepLabv3+ | Xception-65 | 16 | 16 | 721,961 | Yes | 0.8315 ± 0.0562 | 0.1018 |
| DeepLabv3+ | Xception-65 | 16 | 8 | 721,961 | Yes | 0.8285 ± 0.0533 | 0.3700 |
| DeepLabv3+ | Xception-65 | 16 | 16 | 481,481 | Yes | 0.8342 ± 0.0480 | 0.1024 |
| DeepLabv3+ | Xception-65 | 16 | 8 | 481,481 | Yes | 0.8283 ± 0.0454 | 0.3706 |
| DeepLabv3+ | Xception-65 | 8 | 8 | 481,481 | Yes | 0.8356 ± 0.0481 | 0.3718 |
| Mask R-CNN | ResNet-101 | No | 0.8242 ± 0.0541 | 0.0845 | |||
| Mask R-CNN | ResNet-101 | Yes | 0.8317 ± 0.0555 | 0.0846 | |||
| Mask R-CNN | ResNext-101-32x8d | No | 0.8252 ± 0.0580 | 0.1525 | |||
| Mask R-CNN | ResNext-101-32x8d | Yes | 0.8300 ± 0.0570 | 0.1536 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, C.-H.; Syu, W.-T.; Lin, M.-T.; Yeh, C.-L.; Boudier-Revéret, M.; Hsiao, M.-Y.; Kuo, P.-L. Automated Segmentation of Median Nerve in Dynamic Sonography Using Deep Learning: Evaluation of Model Performance. Diagnostics 2021, 11, 1893. https://doi.org/10.3390/diagnostics11101893
Wu C-H, Syu W-T, Lin M-T, Yeh C-L, Boudier-Revéret M, Hsiao M-Y, Kuo P-L. Automated Segmentation of Median Nerve in Dynamic Sonography Using Deep Learning: Evaluation of Model Performance. Diagnostics. 2021; 11(10):1893. https://doi.org/10.3390/diagnostics11101893
Chicago/Turabian StyleWu, Chueh-Hung, Wei-Ting Syu, Meng-Ting Lin, Cheng-Liang Yeh, Mathieu Boudier-Revéret, Ming-Yen Hsiao, and Po-Ling Kuo. 2021. "Automated Segmentation of Median Nerve in Dynamic Sonography Using Deep Learning: Evaluation of Model Performance" Diagnostics 11, no. 10: 1893. https://doi.org/10.3390/diagnostics11101893