
Automatic Detection of Mandibular Fractures in Panoramic Radiographs Using Deep Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. Related Works
2.1.1. Medical Diagnosis Based on YOLO Deep Learning
2.1.2. The Structure of YOLO
2.2. Proposed Methods
2.2.1. Data Augmentation
2.2.2. Training and Detection Process
2.2.3. Performance Evaluation Metrics
3. Results
3.1. Deep Learning System and Dataset
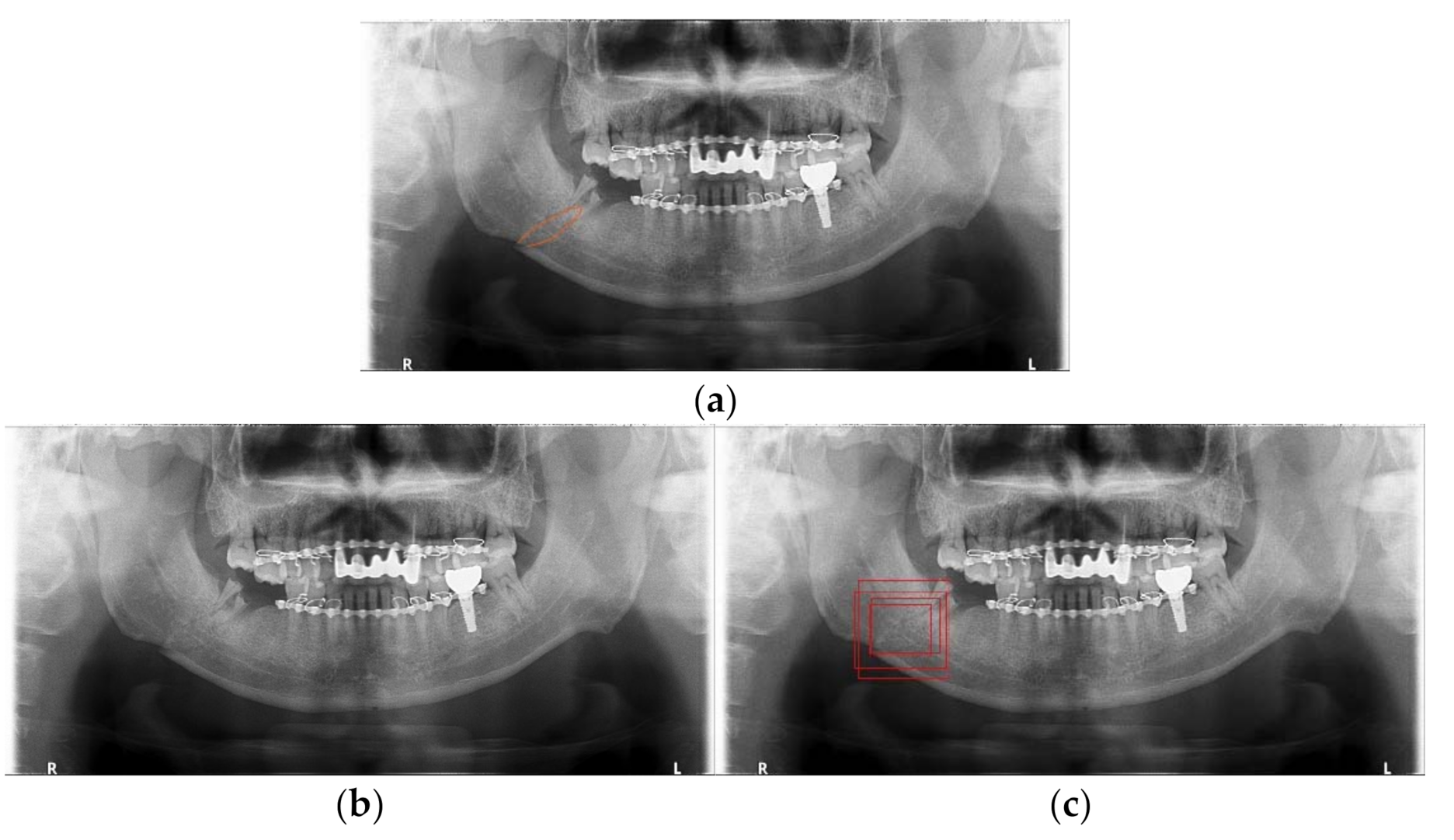
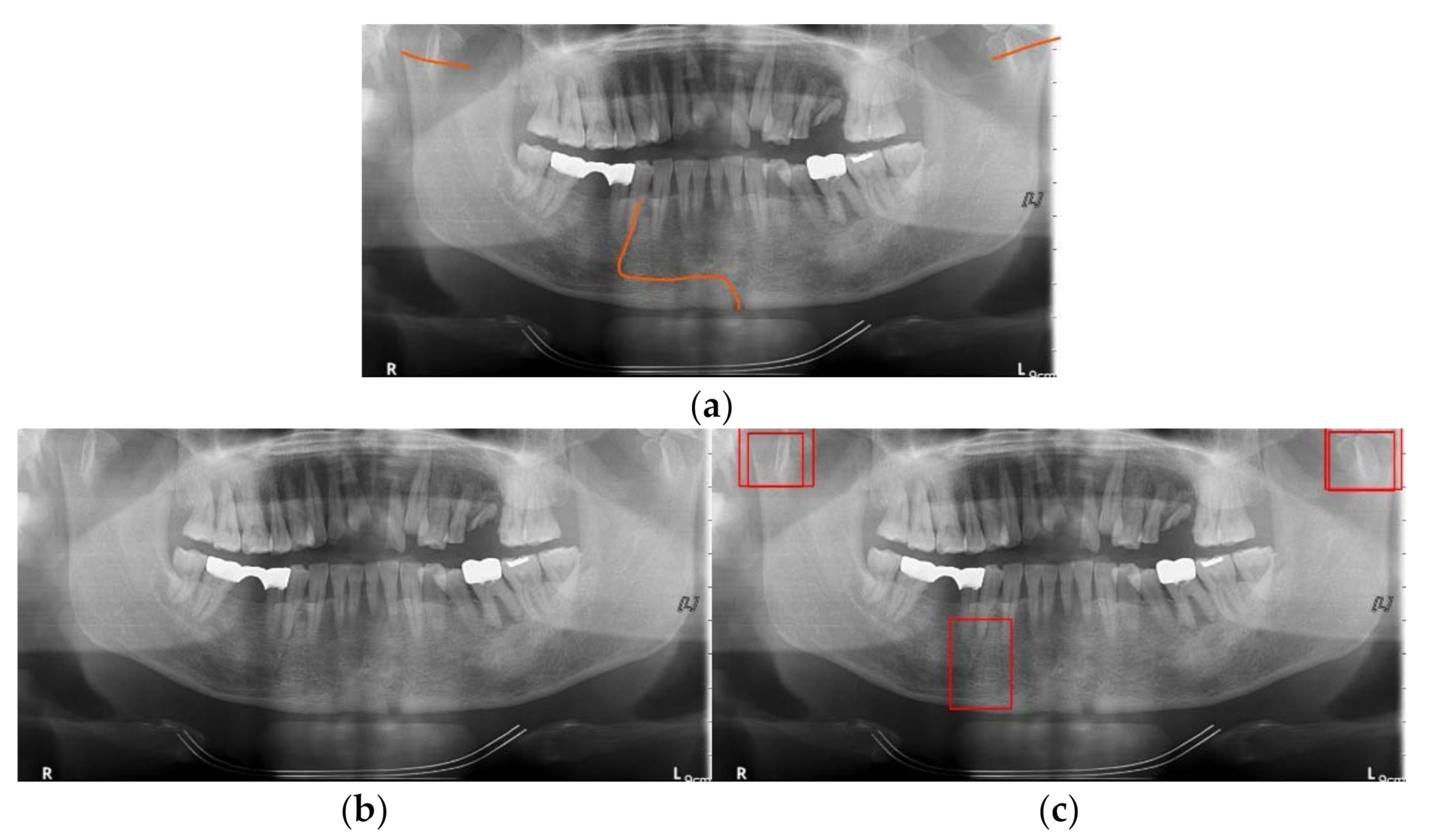
3.2. Detection Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- King, R.E.; Scianna, J.M.; Petruzzelli, G.J. Mandible fracture patterns: A suburban trauma center experience. Am. J. Otolaryngol. 2004, 25, 301–307. [Google Scholar] [CrossRef] [PubMed]
- Nardi, C.; Vignoli, C.; Pietragalla, M.; Tonelli, P.; Calistri, L.; Franchi, L.; Preda, L.; Colagrande, S. Imaging of mandibular fractures: A pictorial review. Insights Imaging 2020, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tams, J.; Van Loon, J.P.; Rozema, F.R.; Otten, E.; Bos, R.R.M. A three-dimensional study of loads across the fracture for different fracture sites of the mandible. Br. J. Oral Maxillofac. Surg. 1996, 34, 400–405. [Google Scholar] [CrossRef]
- Neves, F.S.; Nascimento, M.C.C.; Oliveira, M.L.; Almeida, S.M.; Bóscolo, F.N. Comparative analysis of mandibular anatomical variations between panoramic radiography and cone beam computed tomography. Oral Maxillofac. Surg. 2014, 18, 419–424. [Google Scholar] [CrossRef] [PubMed]
- Lindh, C.; Petersson, A. Radiologic examination for location of the mandibular canal: A comparison between panoramic radiography and conventional tomography. Int. J. Oral Maxillofac. Implants 1989, 4, 249–253. [Google Scholar] [PubMed]
- Farman, A. Panoramic Radiology; Springer: Berlin/Heidelberg, Germany, 2007; ISBN 9783540462293. [Google Scholar] [CrossRef]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, C.; Kim, D.; Jeong, H.G.; Yoon, S.J.; Youm, S. Automatic tooth detection and numbering using a combination of a CNN and heuristic algorithm. Appl. Sci. 2020, 10, 5624. [Google Scholar] [CrossRef]
- Lee, J.H.; Han, S.S.; Kim, Y.H.; Lee, C.; Kim, I. Application of a fully deep convolutional neural network to the automation of tooth segmentation on panoramic radiographs. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2020, 129, 635–642. [Google Scholar] [CrossRef] [PubMed]
- Al-Masni, M.A.; Al-Antari, M.A.; Park, J.M.; Gi, G.; Kim, T.Y.; Rivera, P.; Valarezo, E.; Choi, M.T.; Han, S.M.; Kim, T.S. Simultaneous detection and classification of breast masses in digital mammograms via a deep learning YOLO-based CAD system. Comput. Methods Programs Biomed. 2018, 157, 85–94. [Google Scholar] [CrossRef] [PubMed]
- Ünver, H.M.; Ayan, E. Skin lesion segmentation in dermoscopic images with combination of yolo and grabcut algorithm. Diagnostics 2019, 9, 72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, H.; Jo, E.; Kim, H.J.; Cha, I.; Jung, Y.-S.; Nam, W.; Kim, J.-Y.; Kim, J.-K.; Kim, Y.H.; Oh, T.G.; et al. Deep Learning for Automated Detection of Cyst and Tumors of the Jaw in Panoramic Radiographs. J. Clin. Med. 2020, 9, 1839. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Kwon, H.J.; Lee, S.H.; Lee, G.Y.; Sohng, K.I. Luminance adaptation transform based on brightness functions for LDR image reproduction. Digit. Signal Process. A Rev. J. 2014, 30, 74–85. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 30th IEEE Conference on Computer Vision Pattern Recognition, (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNET: A new backbone that can enhance learning capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar]
- Msonda, P.; Uymaz, S.A.; Karaaǧaç, S.S. Spatial pyramid pooling in deep convolutional networks for automatic tuberculosis diagnosis. Trait. Signal 2020, 37, 1075–1084. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. Cvpr 2018, arXiv:1803.01534. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the IEEE Interantional Conference Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar] [CrossRef] [Green Version]
- Bartleson, C.J.; Breneman, E.J. Brightness Perception in Complex Fields. J. Opt. Soc. Am. 1967, 57, 953–957. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Liu, B.; Wang, S.P.; Wang, Y.N. Computed densitometry of panoramic radiographs in evaluation of bone healing after enucleation of mandibular odontogenic keratocysts. Chin. J. Dent. Res. 2010, 13, 123–126. [Google Scholar] [PubMed]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original | Gamma Modulation | Luminance Adaptation Transform | Proposed Pre-Processing | |
|---|---|---|---|---|
| Precision | 0.375 | 0.341 | 0.441 | 0.570 |
| recall | 0.048 | 0.222 | 0.474 | 0.714 |
| Option | Set Value |
|---|---|
| Batch size | 64 |
| Subdivision | 16 |
| Resolution | 608 × 608 |
| Momentum | 0.949 |
| Decay | 0.0005 |
| Learning rate | 0.0001 |
| Angle | 180 |
| Saturation | 1 |
| Exposure | 1.5 |
| Hue | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Son, D.-M.; Yoon, Y.-A.; Kwon, H.-J.; An, C.-H.; Lee, S.-H. Automatic Detection of Mandibular Fractures in Panoramic Radiographs Using Deep Learning. Diagnostics 2021, 11, 933. https://doi.org/10.3390/diagnostics11060933
Son D-M, Yoon Y-A, Kwon H-J, An C-H, Lee S-H. Automatic Detection of Mandibular Fractures in Panoramic Radiographs Using Deep Learning. Diagnostics. 2021; 11(6):933. https://doi.org/10.3390/diagnostics11060933
Chicago/Turabian StyleSon, Dong-Min, Yeong-Ah Yoon, Hyuk-Ju Kwon, Chang-Hyeon An, and Sung-Hak Lee. 2021. "Automatic Detection of Mandibular Fractures in Panoramic Radiographs Using Deep Learning" Diagnostics 11, no. 6: 933. https://doi.org/10.3390/diagnostics11060933