
Deep Learning Technology Applied to Medical Image Tissue Classification

Abstract
:1. Introduction
- Compare the classification accuracy rate of different CNN models.
- Find the best performing deep learning technique.
- Compare it with the results of existing techniques and methods.
2. Related Works
2.1. Predicting Colorectal Cancer Slice Categories
2.2. Weakly Supervised Classification of Chest X-ray Diseases
2.3. Different Dermoscopic Images
2.4. Retinopathy Identification
2.5. Detection of Pneumonia
2.6. Detection of Breast Ultrasound Images
3. Research Method
3.1. Experimental Steps
3.1.1. Finding the Best Architecture
- (1)
- AlexNet
- (2)
- ResNet
- (3)
- Inception V3
- (4)
- DenseNet
- (5)
- MobileNet
- (6)
- XceptionNet
3.1.2. Data Availability
- (1)
- Colorectal Cancer Tissue
- (2)
- Chest X-ray
- (3)
- Common skin lesions
- (a)
- Apiece: actinic keratoses (solar keratoses) and intraepithelial carcinoma (Bowen’s disease) are common noninvasive variants of squamous cell carcinoma that can be treated locally without surgery.
- (b)
- Bcc: basal cell carcinoma is a common variant of epithelial skin cancer that rarely metastasizes.
- (c)
- Bkl: horny growth, especially on the skin, is a generic class that includes seborrheic keratosis and solar lentigo.
- (d)
- Df: dermatofibroma is a benign skin lesion which is regarded as either benign proliferation or minimal trauma.
- (e)
- NV: melanocytic nevi are benign neoplasms of melanocytes.
- (f)
- Mel: melanoma is a malignant neoplasm derived from melanocytes that may appear in different variants.
- (g)
- Vasc: vascular skin lesions.
- (4)
- Diabetic retinopathy
- (5)
- Pediatric chest X-ray
- (6)
- Breast ultrasound image
3.1.3. Model Testing
3.2. Software and Tools Platform
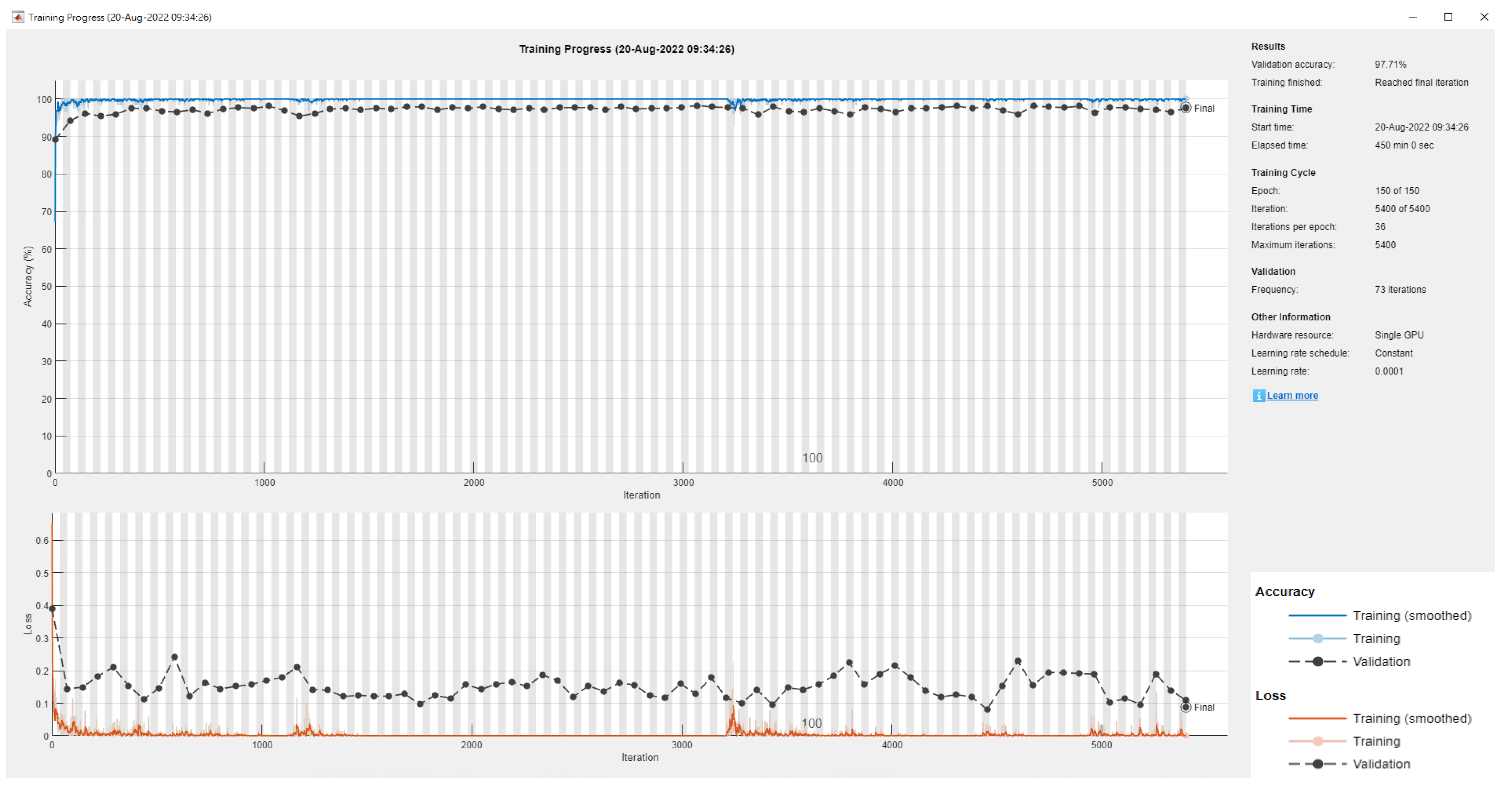
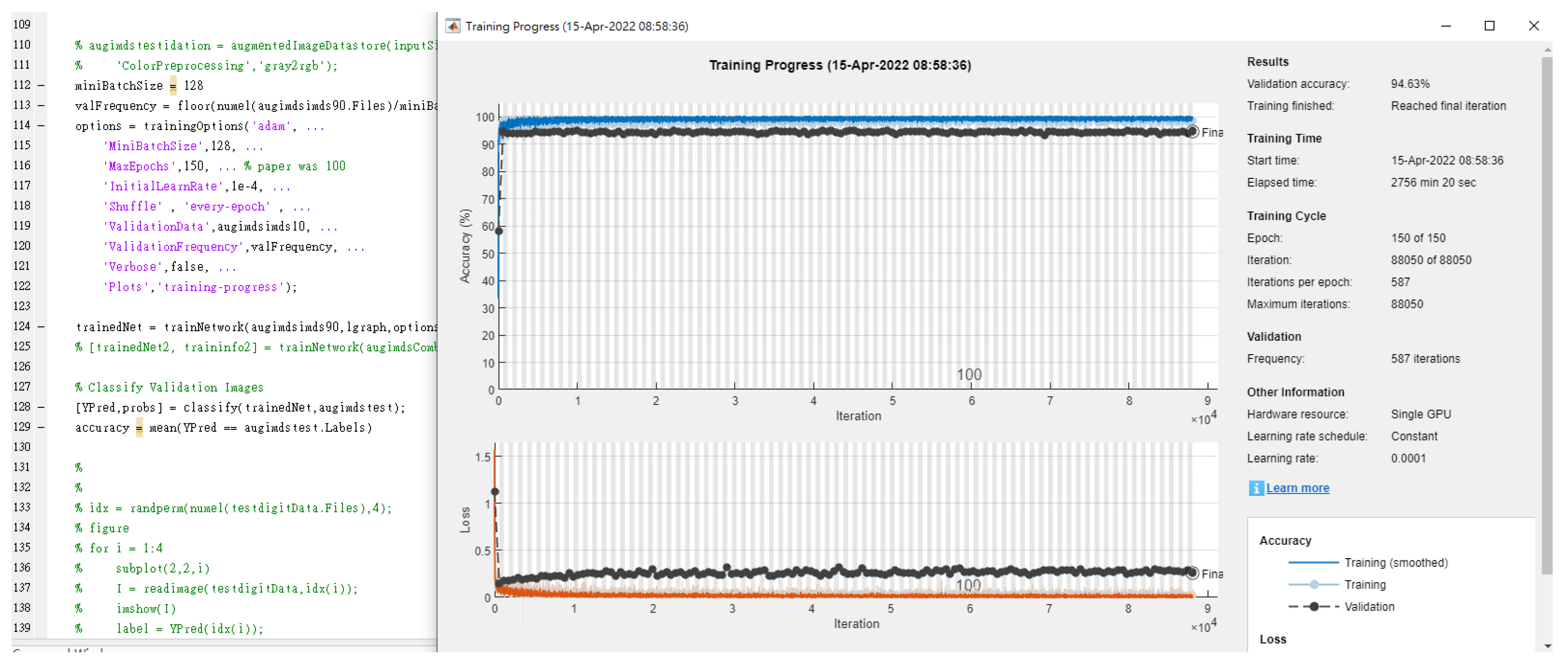
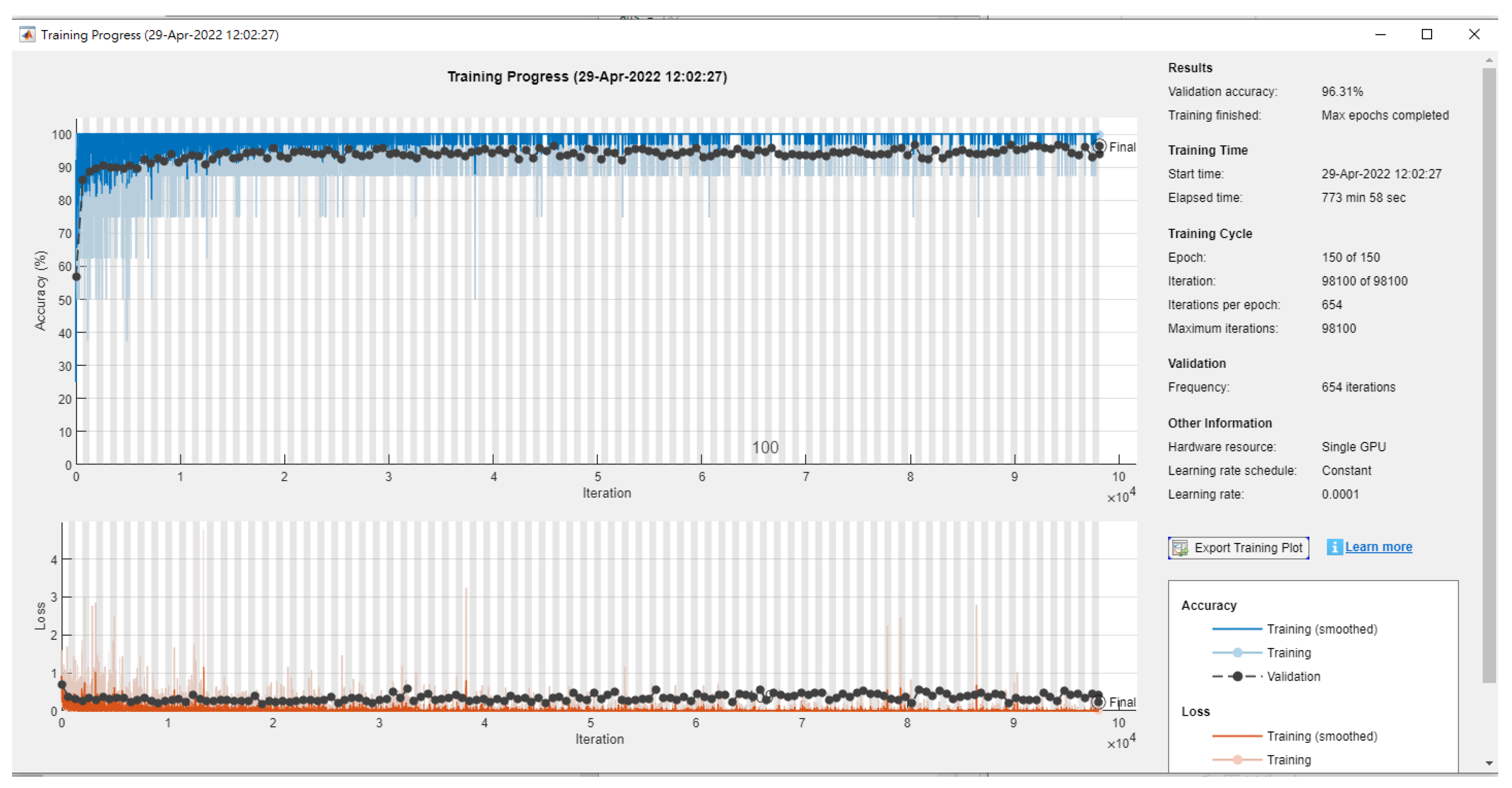
4. Experimental Results
4.1. Colorectal Cancer Tissue
4.2. Chest X-ray
4.3. Common Skin Lesions
4.4. Diabetic Retinopathy
4.5. Pediatric Chest X-ray
4.6. Breast Ultrasound Image
4.7. Data Analysis Section
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-Level Classification of Skin Cancer with Deep Neural Networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic Assessment of Deep Learning Algorithms for Detecting Lymph Node Metastases in Women with Breast Cancer. JAMA Natl. Libr. Med. 2017, 542, 2199–2210. [Google Scholar]
- Kleppe, A.; Albregtsen, F.; Vlatkovic, L.; Pradhan, M.; Nielsen, B.; Hveem, T.S.; Askautrud, H.A.; Kristensen, G.B.; Nesbakken, A.; Trovik, J.; et al. Chromatin Organisation and Cancer Prognosis: A Pan-Cancer Study. Lancet Oncol. 2018, 19, 356–369. [Google Scholar] [CrossRef] [Green Version]
- Bychkov, D.; Linder, N.; Turkki, R.; Nordling, S.; Kovanen, P.E.; Verrill, C.; Walliander, M.; Lundin, M.; Haglund, C.; Lundin, J. Deep Learning-Based Tissue Analysis Predicts Outcome in Colorectal Cancer. Sci. Rep. 2018, 8, 2045–2322. [Google Scholar]
- Goldbaum, M.; Moezzi, S.; Taylor, A.; Chatterjee, S.; Boyd, J.; Hunter, E.; Jain, R. Automated diagnosis and image understanding with object extraction, object classification, and inferencing in retinal images. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996; Volume 3, pp. 695–698. [Google Scholar]
- Chaudhuri, S.; Chatterjee, S.; Katz, N.; Nelson, M.; Goldbaum, M. Detection of blood vessels in retinal images using two-dimensional matched filters. IEEE Trans. Med. Imaging 1989, 8, 263–269. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoover, A.; Goldbaum, M. Locating the optic nerve in a retinal image using the fuzzy convergence of the blood vessels. IEEE Trans. Med. Imaging 2003, 22, 951–958. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoover, A.; Kouznetsova, V.; Goldbaum, M. Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans. Med. Imaging 2000, 19, 203–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 818–833. [Google Scholar]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655. [Google Scholar]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 512–519. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks. Adv. Neural Inf. Process. Syst. 2014, 2, 3320–3328. [Google Scholar]
- Terrance, D.V.; Graham, W.T. Improved Regularization of Convolutional Neural Networks with Cutout. Comput. Sci. Comput. Vis. Pattern Recognit. 2017, 8, 4401–4410. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. Proc. AAAI Conf. Artif. Intell. 2020, 34, 13001–13008. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning Augmentation Strategies from Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 15–20. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical Data Augmentation with No Separate Search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 14–19. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual’ transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2016; pp. 18–23. [Google Scholar]
- Tan, M.; Quoc, V.L. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Lin, T.Y.; Goyal, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Berman, M.; Rannen, A.; Matthew, B. The Lovasz-Softmax Loss: A Tractable Surrogate for Optimizing the Intersection over-Union Measure in Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 18–23. [Google Scholar]
- Kather, J.N.; Krisam, J.; Charoentong, P.; Luedde, T.; Herpel, E.; Weis, C.A.; Gaiser, T.; Marx, A.; Valous, N.A.; Ferber, D.; et al. Predicting Survival from Colorectal Cancer Histology Slides Using Deep Learning: A Retrospective Multicenter Study. PLoS Med. 2019, 16, e1002730. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 7–12. [Google Scholar]
- Karen, S.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1409–1429. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-Level Accuracy with 50× Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-ray8 Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 21–26. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 20–25. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Magenet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Tschandl, P.; Rosendahl, C.; Kittler, R. The HAM10000 Dataset, a Large Collection of Multi-Source Dermatoscopic Images of Common Pigmented Skin Lesions. Nature 2018, 5, 180161. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 27–30. [Google Scholar]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Fahmy, A. Dataset of Breast Ultrasound Images. Data Brief 2021, 28, 2352–3409. [Google Scholar] [CrossRef] [PubMed]
- Swanson, E.A.; James, G.F. The Ecosystem that Powered the Translation of OCT from Fundamental Research to Clinical and Commercial Impact. Biomed. Opt. Express 2017, 8, 1638–1664. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McLuckie, A. (Ed.) Respiratory Disease, and Its Management; Springer: Berlin/Heidelberg, Germany, 2017; pp. 45–53. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2016; pp. 10–16. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 777–787. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Kermany, D.S.; Goldbaum, M.; Cai, W.; Valentim, C.C.; Liang, H.; Baxter, S.L.; McKeown, A.; Yang, G.; Wu, X.; Yan, F.; et al. Identifying Medical Diagnoses and Treatable Diseases by Image-Based Deep Learning. Cell 2018, 172, 1122–1131. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Research Objective | Classification Technique | The Best Classification Technique | Accuracy Rate (%) |
|---|---|---|---|---|
| [14] | Predicting survival from colorectal cancer histology slides using deep learning, a retrospective multicenter study | VGG19, AlexNet, SqueezeNet, GoogLeNet, Resnet50 | VGG19 | 98.7 |
| [20] | ChestX-ray8 hospital-scale chest X-ray database and benchmarks on weakly supervised classification and localization of common thorax diseases | AlexNet, GoogLeNet, VGGNet-16, ResNet-50 | ResNet-50 | 69.67 |
| [23] | The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions | Inception V3 | Inception V3 | 95 |
| [9] | Identifying medical diagnoses and treatable diseases with image-based deep learning | Inception V3 for Octmnist | Inception V3 | 96.6 |
| [9] | Identifying medical diagnoses and treatable diseases with image-based deep learning | Inception V3 for Pneumoniamnist | Inception V3 | 92.8 |
| [24] | Dataset of breast ultrasound images | - | - | - |
| Dataset | Image Number | Training | Validation | Testing | Number of Classes | Image Size |
|---|---|---|---|---|---|---|
| NCT-CRC-HE-100K [14] | 107,180 | 89,996 | 10,004 | 7180 | 9 | 224 × 224 |
| ChestX-ray8 [20] | 112,120 | 78,468 | 11,219 | 22,433 | 8 | 512 × 512 |
| Human Against Machine with 10,000 training images [23] | 10,015 | 7007 | 1003 | 2005 | 7 | 600 × 450 |
| Optical coherence tomography (OCT) images [9] | 109,309 | 97,477 | 10,832 | 1000 | 4 | 512 × 496 |
| Chest X-Ray Images [9] | 5856 | 4708 | 524 | 624 | 2 | 944 × 940 |
| Breast ultrasound images [24] | 780 | 546 | 78 | 156 | 3 | 562 × 471 |
| Model | Accuracy Rate% (Times) | |
|---|---|---|
| Adam | SGDM | |
| AlexNet | 68.86% (395 min) | 67.48% (412 min) |
| ResNet 50 | 99.39% (720 min) | 99.01% (733 min) |
| ResNet 18 | 99.37% (422 min) | 99.15% (458 min) |
| Inception V3 | 99.43% (2658 min) | 99.19% (2683 min) |
| DenseNet | 81.25% (1964 min) | 81.07% (1990 min) |
| MobileNet | 80.51% (508 min) | 80.25% (533 min) |
| XceptionNet | 81.49% (2643 min) | 81.04% (2697 min) |
| Model | Accuracy Rate% (Times) | |
|---|---|---|
| Adam | SGDM | |
| AlexNet | 76.99% (177 min) | 76.91% (182 min) |
| ResNet 50 | 77.28% (447 min) | 77.24% (430 min) |
| ResNet 18 | 77.89% (194 min) | 77.84% (188 min) |
| Inception V3 | 77.31% (1256 min) | 77.26% (1283 min) |
| DenseNet | 75.18% (2025 min) | 75.17% (2034 min) |
| MobileNet | 75.25% (2018 min) | 75.17% (2034 min) |
| XceptionNet | 75.37% (2017 min) | 75.17% (2034 min) |
| Model | Accuracy Rate% (Times) | |
|---|---|---|
| Adam | SGDM | |
| AlexNet | 83.42% (45 min) | 83.37% (53 min) |
| ResNet 50 | 86.6% (170 min) | 86.42% (185 min) |
| ResNet 18 | 86.6% (170 min) | 86.39% (193 min) |
| Inception V3 | 88.3% (481 min) | 86.00% (497 min) |
| DenseNet | 88.19% (473 min) | 88.24% (495 min) |
| MobileNet | 88.02% (468min) | 88.13% (490 min) |
| XceptionNet | 88.17% (502min) | 88.21% (499 min) |
| Model | Accuracy Rate% (Times) | |
|---|---|---|
| Adam | SGDM | |
| AlexNet | 93.11% (2651 min) | 92.07% (2666 min) |
| ResNet 50 | 93.89% (1506 min) | 93.68% (1532 min) |
| ResNet 18 | 94.24% (1831 min) | 94.09% (1857 min) |
| Inception V3 | 96.63% (3383 min) | 95.35% (3392 min) |
| DenseNet | 68.12% (2473 min) | 68.04% (2485 min) |
| MobileNet | 68.31% (973 min) | 68.18% (996 min) |
| XceptionNet | 68.69% (2595 min) | 68.26% (2657 min) |
| Model | Accuracy Rate% (Times) | |
|---|---|---|
| Adam | SGDM | |
| AlexNet | 85.29% (104 min) | 85.22% (114 min) |
| ResNet 50 | 92.66% (141 min) | 92.47% (167 min) |
| ResNet 18 | 90.84% (98 min) | 90.64% (103 min) |
| Inception V3 | 96.27% (762 min) | 96.31% (774 min) |
| DenseNet | 90.21% (251 min) | 90.20% (257 min) |
| MobileNet | 88.12% (45 min) | 88.03% (49 min) |
| XceptionNet | 89.94% (130 min) | 89.77% (145 min) |
| Model | Accuracy Rate% (Times) | |
|---|---|---|
| Adam | SGDM | |
| AlexNet | 75.73% (12 min) | 75.65% (14 min) |
| ResNet 50 | 81.88% (18 min) | 81.67% (21 min) |
| ResNet 18 | 72.73% (14 min) | 72.59% (17 min) |
| Inception V3 | 92.31% (29 min) | 92.17% (33 min) |
| DenseNet | 70.91% (27 min) | 70.86% (30 min) |
| MobileNet | 61.86% (6 min) | 61.72% (7 min) |
| XceptionNet | 72.11% (15 min) | 72.03% (17 min) |
| Dataset | Sensitivity | Specificity | F1 Score | Balanced Accuracy (%) |
|---|---|---|---|---|
| NCT-CRC-HE-100K | 0.99 | 0.99682 | 1.8965 | 99.42 |
| ChestX-ray8 | 0.76 | 0.64192 | 1.0143 | 76.98 |
| Human Against Machine with 10,000 training images | 0.97368 | 0.83333 | 1.3528 | 87.9 |
| Optical coherence tomography (OCT) images | 0.96 | 0.96225 | 1.3018 | 96.62 |
| Chest X-Ray images | 0.96 | 0.96891 | 1.2541 | 96.34 |
| Breast ultrasound images | 0.95 | 0.95556 | 1.1339 | 93.59 |
| Existing Researches | Our Research | |||||
|---|---|---|---|---|---|---|
| Dataset | Classification Technique | The Best Classification Technique | Accuracy Rate (%) | Classification Technique | The Best Classification Technique | Accuracy Rate (%) |
| NCT-CRC-HE-100K [14] | VGG19, AlexNet, SqueezeNet, GoogLeNet, Resnet50 | VGG19 | 98.7 | AlexNet, ResNet 50, ResNet 18, Inception V3, DenseNet, MobileNet, XceptionNet | Inception V3 | 99.43 |
| ChestX-ray8 [20] | AlexNet, GoogLeNet, VGGNet-16, ResNet-50 | ResNet-50 | 69.67 | Inception V3 | 77.31 | |
| Human Against Machine with 10000 training images [23] | Inception V3 | Inception V3 | 95 | Inception V3 | 88.3 | |
| Optical coherence tomography (OCT) images [9] | Inception V3 | Inception V3 | 96.6 | Inception V3 | 96.63 | |
| Chest X-Ray Images [9] | Inception V3 | Inception V3 | 92.8 | Inception V3 | 96.31 | |
| Breast ultrasound images [24] | - | - | - | Inception V3 | 92.31 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, M.-J.; Tao, Y.-H. Deep Learning Technology Applied to Medical Image Tissue Classification. Diagnostics 2022, 12, 2430. https://doi.org/10.3390/diagnostics12102430
Tsai M-J, Tao Y-H. Deep Learning Technology Applied to Medical Image Tissue Classification. Diagnostics. 2022; 12(10):2430. https://doi.org/10.3390/diagnostics12102430
Chicago/Turabian StyleTsai, Min-Jen, and Yu-Han Tao. 2022. "Deep Learning Technology Applied to Medical Image Tissue Classification" Diagnostics 12, no. 10: 2430. https://doi.org/10.3390/diagnostics12102430
APA StyleTsai, M.-J., & Tao, Y.-H. (2022). Deep Learning Technology Applied to Medical Image Tissue Classification. Diagnostics, 12(10), 2430. https://doi.org/10.3390/diagnostics12102430