1. Introduction
Depression is a global public health concern with an alarming rise in prevalence [
1]. In fact, the global prevalence of depression was estimated at 28% in 2021 [
2]. Furthermore, depression is one of the most common comorbidities in patients with severe physical disorders [
3] (e.g., cancer, cardiovascular, neurological, and inflammatory disorders). Comorbid depression has a significant negative impact on a patient’s quality of life (QoL) [
4,
5,
6] and is associated with poor adherence to medical treatments. Additionally, it involves higher rates of healthcare expenditure [
3,
7].
Although depression is common in comorbidity and multimorbidity patterns, it is often underestimated and greatly undertreated [
8], even in higher-income countries [
9]. Since depression is often associated with other clinical conditions such as anxiety and pain syndromes, the signs are often overlooked during daily medical care by professionals without specific training in mental health [
10]. There are also structural barriers related to the availability, affordability, time constraints, and attitudinal factors of patients, e.g., non-treatment-seeking behavior [
11], which significantly contribute to late diagnosis.
Smartphones and ‘mHealth’ apps can overcome several of the barriers mentioned above There is growing evidence that remote sign and symptom monitoring of various diseases and disorders can significantly improve health outcomes [
12]. The ‘mHealth’ apps represent the foundation of digital biomarkers such as risk, diagnostic, monitoring, prognostic, predictive, or response markers [
13]. Since measurements can be performed in real time, as a momentary assessment, these biomarkers can be less subjected to recall bias than retrospective questionnaires completed at the clinic [
14]. The latter are also prone to reporting bias; for instance, self-reports of negative mood states experienced in the past tend to be exaggerated in a negative direction [
15]. Moreover, social desirability and adherence can further distort the quality of the information provided by using self-report questionnaires [
16]. Hence, psychiatry and other relevant fields may improve their screening processes and care by complementing subjective indicators (such as validated clinical questionnaires) with objective measures (such as those gathered via ‘mHealth’ apps) [
17].
There is growing interest regarding the exploitation of observable cues [
18], such as language use, speech, and facial expressions, in the screening and prediction of mental health problems [
19]. It is a well-known fact that a variety of observable cues are affected by being in a depressed state [
20,
21]. Among non-verbal cues, facial muscle movements [
22], slower pupil dilation [
23], changes in vocal tract dynamics [
24], and various other cues are characteristic of depression [
22]. Since these cues are generated spontaneously, the use of AI-supported classification can contribute to improving the objectivity of the assessment and monitoring of the signs of depression [
22] and other psychiatric disorders [
25].
The main motivation of this scoping review was to identify and evaluate the existing algorithms for the classification of signs of depression from multiple observable cues, simultaneously expressed using the three conversational modalities [
26]—language (i.e., verbal), speech (i.e., vocal), and facial expressions (i.e., visual)—to complement data gathered with self-report questionnaires. The work within this paper is driven to address the following research questions: (Q1) “What artificial models for depression classification analyse all three groups of observable cues?” (Q2) “How do the multimodal algorithms perform compared to unimodal and bimodal implementations?” (Q3) “How, if at all, does the use of multiple multimodalities mitigate the performance degradation in unfavorable datasets?” While the findings of our review represent an important contribution to the literature in the broadest sense, they will also be applied in digital interventions implemented in the multicentric single-case experimental prospective study of the PERSIST project [
27]. The overall objective of PERSIST is to leverage the potential of big data and advanced data analytics, which can improve cancer survivors’ treatment and follow-up decision-making and engagement. PERSIST is particularly concerned with patient-reported outcomes, patient satisfaction scoring, identifying high-risk patients and giving them the appropriate treatment, and supporting patients who are at high risk of reoccurrence. Depression classification algorithms, the central topic of this review, will be used in PERSIST to derive complementary information about the mental health of patients and to offer personalized feedback by analyzing the videos of diary recordings, which will be recorded by patients via smartphone. We build our research on the assumption that depression is likely expressed through all three modalities of communication continuously and simultaneously [
18]. Hence, the prevailing unimodal and bimodal approaches to the AI-based recognition of signs of depression may be inadequate [
28] Depression has a complex structure in general due to having a wide array of potential symptoms that can manifest slightly differently for each individual, depending on their current and past personal psychosocial context. Thus, the fusion of multimodal features is needed to create a discriminative and explanatory approach able to deal with the complex nature of depression. However, to our knowledge, the existing reviews have focused on biochemical studies [
29], mental health applications and monitoring systems [
8,
30,
31], and single observable cues or bimodal approaches [
22,
25,
32]. Furthermore, the existing studies have revealed relatively high accuracy [
31,
33]. However, they should only be considered as proof-of-concept studies, without addressing any specific issues such as decision errors, data bias and transparency, and other ethical concerns. The data have the main role as far as biases in the process are concerned. Decision errors (especially false negatives) and data bias are some of the main issues of machine learning algorithms. From a clinical perspective, those biases could lead to improper clinical decisions and may cause severe consequences. The main sources of unwanted biases are either choosing the wrong subjects for the training dataset or the wrong factors for training. In any case, both situations may cause fatal errors and challenges in medical situations [
34].
The outline of this scoping review is as follows. The six-stage methodological framework is introduced in
Section 2. The illustration and analyses of the experimental results are presented in
Section 3. Finally, the key findings, challenges, and limitations are explained in
Section 4.
2. Materials and Methods
2.1. Overview
In the preparation of the study, we followed the six-stage methodological framework for scoping reviews outlined by Arksey and O’Malley [
35], as follows: identifying the research questions; searching for relevant studies; selecting the relevant studies; charting the data; collating, summarizing, and reporting the results; consulting the study findings. PRISMA-ScR (Preferred Reporting Items for Systematic Reviews and Meta-Analyses—Extension for Scoping Reviews) [
36] guidelines were followed to guarantee that the scoping review was systematic, transparent, and complete.
Beyond the scoping review framework, we applied the identified algorithms (with the available code) to two depression datasets to evaluate the accuracy of the AI-based processing of multimodal features for the classification of depression. The performance of the algorithms was evaluated using standard metrics.
2.2. Research Questions
Our scoping review was guided by these research questions derived from the main aim of the review:
To what extent do the papers include the different types of modalities for depression classification?
What types of algorithms currently exist for depression classification for observable cues and what is the performance of those algorithms?
What is the effect of data bias on the results of existing algorithms and the contributions of the multimodal approach to decrease the bias?
2.3. Search Strategy
Four large and commonly used databases, Web of Science (WOS), IEEE Xplore, SCOPUS, and ACM Digital Library, were used to identify the relevant papers. After a preliminary search in all databases, which helped us to refine the search strategy and ensure that the databases provided adequate coverage of the research topic, we conducted the main search between 14 October and 21 October 2021.
Our search strategy combined terms related to depression (depression, depressed), cues (cue, feature, indicator, marker, sign, signal, symbol, pattern, style, clue, manifestation, expression), features (“feature extraction”, speech, text, audio, video, face, visual), emotion (emotion, “emotion recognition”), algorithms (“explainable AI”, “deep learning”, “machine learning”, supervised, unsupervised), and data fusion (“feature fusion”, “data fusion”, “decision fusion”) (
Box 1).
Box 1. The exact search string for Scopus.
TITLE-ABS-KEY (“Depression”) AND TITLE-ABS-KEY (“Feature extraction” OR speech OR text OR audio OR video OR face OR visual) AND TITLE-ABS-KEY (cue OR feature OR indicator OR marker OR sign OR signal OR symbol OR pattern OR style OR clue OR manifestation OR expression OR emotion OR “emotion recognition” OR “Feature fusion” OR “data fusion” OR “decision fusion”) AND TITLE-ABS-KEY (“Explainable AI” OR “Deep learning” OR “machine learning” OR “supervised” OR “unsupervised”) AND (LIMIT-TO (LANGUAGE, “English”)) AND (LIMIT-TO (DOCTYPE, “ar”) OR LIMIT-TO (DOCTYPE, “cp”) OR LIMIT-TO (DOCTYPE, “ch”))
The inclusion criteria (being available in English and being published, i.e., pre-prints and other unpublished papers were not considered) were derived from the research questions guiding this scoping review and were set a priori. The exclusion criteria included non-technical papers including reviews, studies that included human participants who suffered from other disorders that affect behavior and displays of emotions (i.e., dementia, Parkinson’s disease, autism, schizophrenia, Alzheimer’s disease, neurological disorder, stroke, Huntington’s disease, paralysis, autism, multiple sclerosis, cerebral palsy, Down syndrome), studies that focused on psychological disorders other than depression (e.g., anxiety, insomnia), and studies that offered classifications based on other observable features of depression (i.e., ECG, EEG, fMRI). Additionally, for the qualitative synthesis or experimental part of the paper, studies that included algorithms not operating over all three channels of communication simultaneously were excluded.
2.4. Study Selection
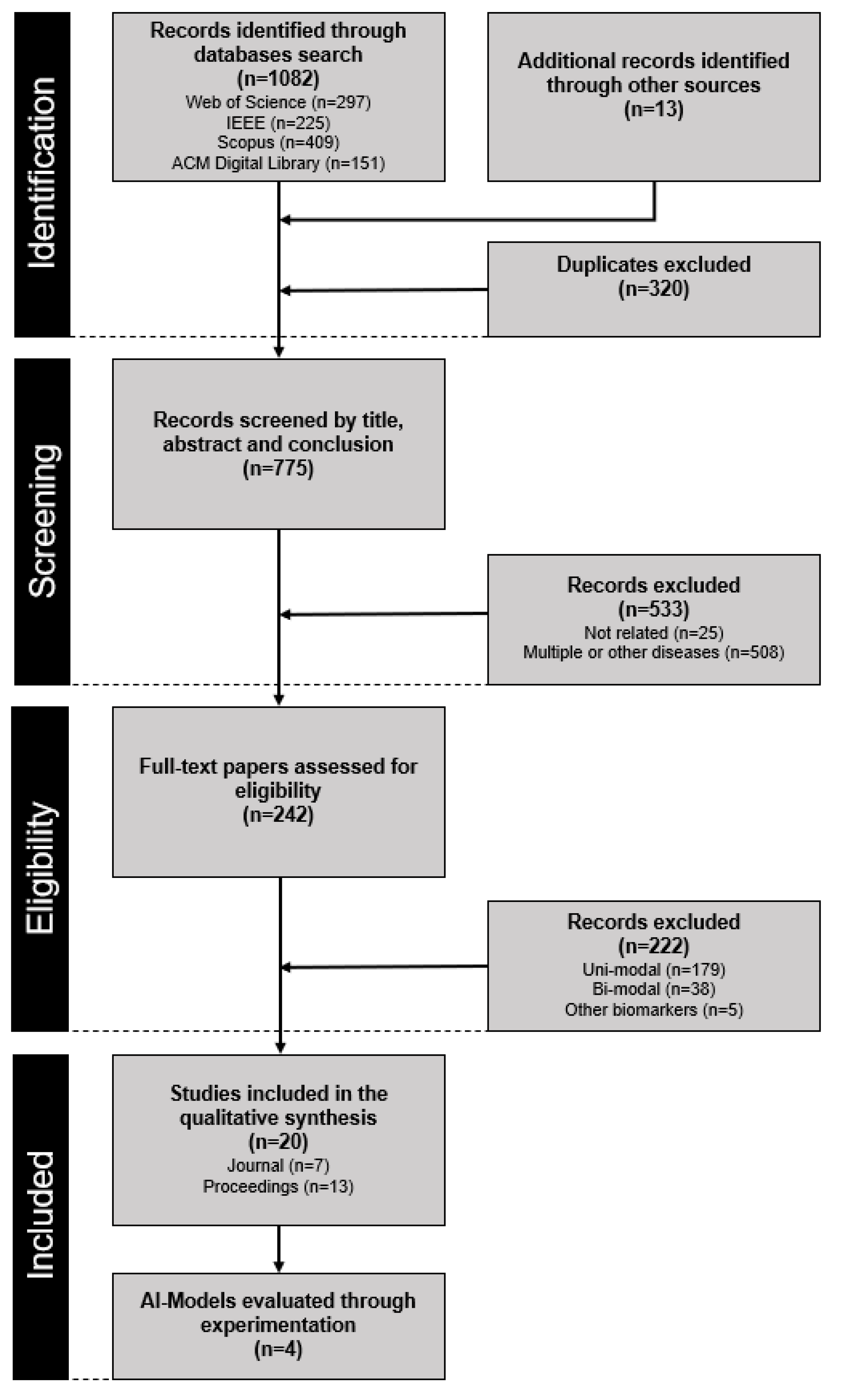
All citations identified in the electronic databases were exported to Excel spreadsheets. The database searches yielded a total of 1082 papers, and 13 additional papers were identified through other sources (
Figure 1). After duplicates were removed, 775 titles and abstracts were screened in three stages. In the first stage, the authors (I.M. and U.A.) individually excluded highly irrelevant papers. In the second stage, all authors (U.A., I.M., U.S., and N.P.) independently reviewed the titles and abstracts of the remaining citations and settled disagreements through discussion. After this step, 245 papers underwent a thorough full-text review independently by two authors (I.M. and U.A.). Disagreements in this phase were settled through discussion and adjudication by the remaining authors (U.S. and N.P.). In the end, 20 papers fulfilled the pre-determined criteria and were included in the scoping review. In the 20 papers, we identified four different approaches that processed the three communication channels simultaneously and corresponding pre-trained models that were found on public repositories (i.e., GitHub). The four approaches were implemented and evaluated by three authors (I.M., U.A., and U.S.) in experiments using DAIC-WOZ [
37] and Media datasets [
38] to assess the data bias.
2.5. Data Collection and Charting
We developed a spreadsheet to determine variables to be extracted from the reviewed papers. Two authors (I.M. and U.A.) then extracted the following data from each paper, as follows: (1) authors; (2) year of publication; (3) type of paper; (4) targeted diseases; (5) exclusion criteria; (6) modality (e.g., text, audio, visual cues); (7) AI/ML technique (e.g., CNN, LSTM, RF, SVM). During this process, the results were categorized into the following categories: (1) unimodal; (2) bimodal; (3) multimodal. The processes for data extraction and the categorization of results were refined and updated in an iterative process as the papers were reviewed. The resulting chart was used for the analysis.
2.6. Collating, Summarizing, and Reporting Results
We did not follow a well-structured meta-analytic approach in comparing and summarizing the results given the aim and nature of the scoping review. Since the aim of a scoping review includes mapping the existing findings on a topic, providing a descriptive overview, and (re)evaluating the algorithms on a proprietary dataset [
39], the results were analyzed by I.M. and U.A. using a thematic analysis [
40] for the multimodal category. To maintain rigor in collating and summarizing the results, this process was reviewed by U.S. and N.P.
2.7. Consultation Exercises
The review protocol of the study was developed with the help of the expertise from psychological (U.S., N.P.), technological (I.M., U.A.), and methodological (I.M., U.S., N.P.) fields. Relevant inclusion and exclusion criteria (e.g., specific conditions or comorbidities that could impact the expression of depression) were determined by consulting the healthcare professionals in the PERSIST and HosmartAI project.
4. Discussion
4.1. Key Findings
The aim of this study was two-fold: first, to review the extent to which papers exploit different types of modalities in the implementation of depression classifications together with the types of AI models currently existing and the percentages of multimodal (text, audio, and video) data usage in the AI models in the literature (i.e., research question Q1); second, to explore the effects of multimodality and data bias with an experimental study as complementary work to the scoping review and to explain the need for explainable AI models (i.e., research questions Q2 and Q3).
Although there are some scoping reviews in the literature about the use of AI for mental health (including depression) [
90,
91] and depression recognition [
92,
93], to our knowledge, our scoping review is the first review investigating the different types of modalities used for depression classification with different AI models. Beyond our scoping review, we also conducted an experimental study and described its results. As such, our study has a unique position in the literature. The existing scoping reviews about depression recognition are mainly focused on using only one modality (facial [
22], speech [
25]) or using different observation techniques (rather than audio, text, and video) [
94].
To address research question Q1, we identified 242 research papers or studies in total, of which only 20 (8.26%) analyzed all three groups of observable cues during depression classification. Most of the identified studies (179, 73.96%) in the literature still used a unimodal architecture that could detect only one aspect of depression. On the other hand, 38 (15.7%) studies used a bimodal architecture and 5 (2.06%) studies used a multimodal approach with physiological features.
Another important finding from the scoping review was related to the features that are used in multimodal classifications. The majority of the algorithms explore similar features, as AI algorithms for multimodal depression classification studies need to have a large volume dataset to obtain more accurate and less biased results. Powerful and accurate AI algorithms need more parameters and variables to feed their models, which means more data. Combining more data into your model helps in two ways: first, it provides more raw variables to be used as features, and second, it allows for new derived variables to be made by combining existing ones [
95]. On the other hand, including all features in the models that we can find is not the aim of AI studies. The best possible feature set should be selected for the best result, but this discussion is beyond the scope of our review. All reviewed studies except two of them used the same dataset (DAIC-WOZ) for training and testing. This dataset has only 189 sessions. On the other hand, the variety of AI/ML techniques should be increased to increase the accuracy and decrease the error rate.
Another issue with multimodal depression classification studies is not having enough open-source codes for researchers, app developers, and product teams. Open source in an AI algorithm means that it is available for both commercial and non-commercial usage under certain licenses. Open source is the key element for innovation through collaboration. Open-source AI systems may include datasets, algorithms, and user interfaces. According to the latest technology report [
96], nowadays 48% of enterprises are using open-source codes, and this number will increase to 65% within two years. Within our reviewed studies, only 3 (15%) studies provided their codes via GitHub. This may be one of the main reasons for the smaller number of multimodal depression classification studies in the literature.
A similar issue occurs regarding the types of reviewed studies. Only 7 (35%) studies were published in scientific journals, while the rest were published in conference proceedings. This result shows that there are still opportunities and open areas to contribute scientifically to multimodal depression classification.
To address research questions Q2 and Q3, we carried out experiments on the most widely used multimodal architectures, i.e., LSTMs, SVMs, and RFs. In the experimental study, we performed the depression classification process with four different models (SVM, RF, LSTM with gating, and LSTM without gating models) and four different modalities (T + A, T + V, A + V, and T + A + V).
The key finding of the experimental study was that there was an obvious benefit of analyzing multiple modalities during depression classification. The results clearly showed that multimodal approaches have the potential to outperform uni- and bimodal approaches. Overall, to answer research question Q2, the results showed that all multimodal architectures give superior or at least similar results to bimodal models (
Table 6,
Table 7 and
Table 8).
It is easily observed that the negative effect of the small volume of datasets (data bias) is apparent and valid for all models. This is the main reason behind having lower performance rates and higher error rates. We provide a comparison table about the reported performance values of uni-, bi-, and multimodalities to emphasize the contribution of each modality to the depression classification process. According to the reported results, multimodal feature sets provide the best performance against the use of uni- or bimodal features in all studies (
Table 9). To answer research question Q3, the results clearly show that the accuracy of the algorithms, especially those operating on uni- or bimodal assumptions, tends to degrade when introduced to recordings outside the nature of the training dataset. A more detailed analysis of the impact of using multiple modalities, especially in unfavorable datasets, is represented in the following section.
4.2. Challenges
4.2.1. Decision Errors (Type I and Type II)
Misinterpretations or mistakes always exist within scientific studies because of their nature. The complete elimination of those decision errors is impossible, but controlling them is possible. There are two types of decision errors: false positives (type I errors), which show the decision as true while the actual case is false; and false negatives (type II errors), which show the decision as false when the actual case as true. To control and optimize these errors, we must understand the roles of false negatives and false positives specifically within our cases; while false negatives are preferable in some cases (e.g., criminal counts [
97]), those errors can be very dangerous in different cases (e.g., clinical decisions [
98], like in our case). If a patient with depression is not classified as depressed (false negative), then that patient may not get the proper clinical treatment and the mental disorder may get worse because of decision errors. False-positive cases for automatic depression classification have a less detrimental effect on people who have no depression at all and can be easily verified by other standardized tools such as questionnaires [
99].
The F1-score is a more useful metric than other metrics because it considers the false negatives and is more meaningful when you have a non-symmetric dataset (
Section 3.2.3.). On the other hand, the accuracy score gives the best performance when the burdens of the false negatives and false positives are similar. However, false negatives are more important than false positives concerning the consequences of different types of decisions in our case.
From the performance and error metrics tables (
Table 3,
Table 4,
Table 5 and
Table 6), the favorability of the datasets, variability between datasets, and variability among models can be compared according to the variability of the F1-scores. The A + T bimodal features were the only features that showed improvements for all four models between datasets. The A+V bimodal features showed the most variation (more data bias) in a negative direction, with the results varying depending on the favorability of the dataset. Our testing dataset, the SymptomMedia dataset, which is a high-quality dataset with high expressivity of the features, might be favorable for the bimodal features for SVM and RF approaches (higher F1-scores), and this shows that if the features are not so distinct within the dataset (the SymptomMedia dataset has higher F1-scores than the DAIC-WOZ dataset), the F1-score will significantly decrease, which is not reliable at all. On the other hand, the multimodal features showed minimal F1-score variations for all four models, which means that the usage of multimodal features gives more resilient and reliable results. When we compare the models, the SVM and RF models generated less variability than the other models.
4.2.2. Data Bias
The data bias is one of the important challenges for machine learning models. These models lack visibility because of having a ‘black box’ structure. If we are trying to solve a problem in the healthcare sector and want to use AI, the paramount factor to consider is the data itself. The data are the main and only source of bias, which tends to be influenced by multiple factors such as the patient population and the correlation between parameters [
58]. Training without considering those factors results in the misrepresentation and misunderstanding of the phenomenon. The other source of data bias is not having enough data in the health domain, as in other fields such as computer vision and data mining. Even in our scoping review, the sizes of the datasets were not sufficient (DAIC-WOZ, 189 subjects; BDC WB, 51 subjects; AViD-C, 84 subjects). We selected those studies because they contained only multimodal depression features. Besides those features, other features can be gathered and added to the model from different devices such as EEG, ECG, and fMRI devices. If we take into account all of those features, then those may lead to another problem called ‘the curse of dimensionality’ [
100]. In
Section 3.1.1 and
Section 3.1.2 methods, the LDA, PCA, clustering, and RELIEFF approaches are highlighted as practical solutions to at least partially overcome the challenge of dimensionality and to generate optimal sets of features.
Beyond those issues, another problem that causes bias with the DAIC-WOZ dataset is having binary labels based on PHQ-8 scores from the participants’ self-reports. These self-reports may depend on social, subjective, and other kinds of biases, and may affect the annotation accuracy [
101]. Thus, taking the DAIC-WOZ dataset as a ground truth may not be the most accurate way to measure the depression status. As a result, those issues can be counted as additional potential reasons for the low performance values.
One of the ways to overcome these challenges is to use explainable and interpretable models. Explainable AI models provide transparency, fairness, and reliability in the process and results. The mitigation of bias in the model includes removing the effect of the bias. There are different techniques for mitigation that can be applied in each phase of the model (pre-processing, in-processing, and post-processing). For example, while the reweighing technique [
102] involves changing the weights of the features before the training in the pre-processing phase, the adversarial debiasing technique [
103] involves applying an optimization process using a GAN during the training process. On the other hand, the techniques used after the training phase have less pronounced effects. For example, the equalized odds [
104] technique involves adjusting the thresholds to obtain smaller differences between the true and false results. In summary, it is shown that explainable AI techniques can be used for bias detection and that there are some useful tools that can be used for this, such as a fairness report [
105], SHAP [
106], and CERTIFAI [
107].
4.3. Limitations of the Scoping Review
While this scoping review provides comprehensive insight into the cues of depression, which are observable from text, audio, and video sources, and contributes to the literature by presenting an additional experimental study to show the importance and effects of the use of multimodal features for depression classification, it does not provide a complete picture of the current state of the research on depression classification due to certain limitations. First, our scoping review did not include other observable features of depression from different devices (i.e., ECG, EEG, fMRI). Although those features may also contribute to the classification of depression, we may again be faced some problems related to the existing dataset and feature dimensionality. Second, we focused only on papers written in English. The studies in other languages may include additional information about the classification of depression. Third, we tried to show which method tends to be more resilient to data collected outside the training datasets in the experimental part of our study. Although the SymptomMedia recordings are not exactly categorized as real-world data, the data are of a different nature, and from the psychological perspective represent a high-quality simulation of real-world data. Fourth, as specified in the Discussion, one of the main issues of ML in the health domain is the volume of available datasets. In our experiments, we trained our models with 142 cases and tested them with 75 cases. Thus, our results, just like those of the reviewed studies, need to be validated with larger datasets. In the future, if new depression datasets emerge and are available as open-source data, we will try to increase the sizes of both the training and testing sets.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}