
Explainable Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease



Abstract
:1. Introduction
1.1. Gastrointestinal Disease
1.2. Explainable Artificial Intelligence
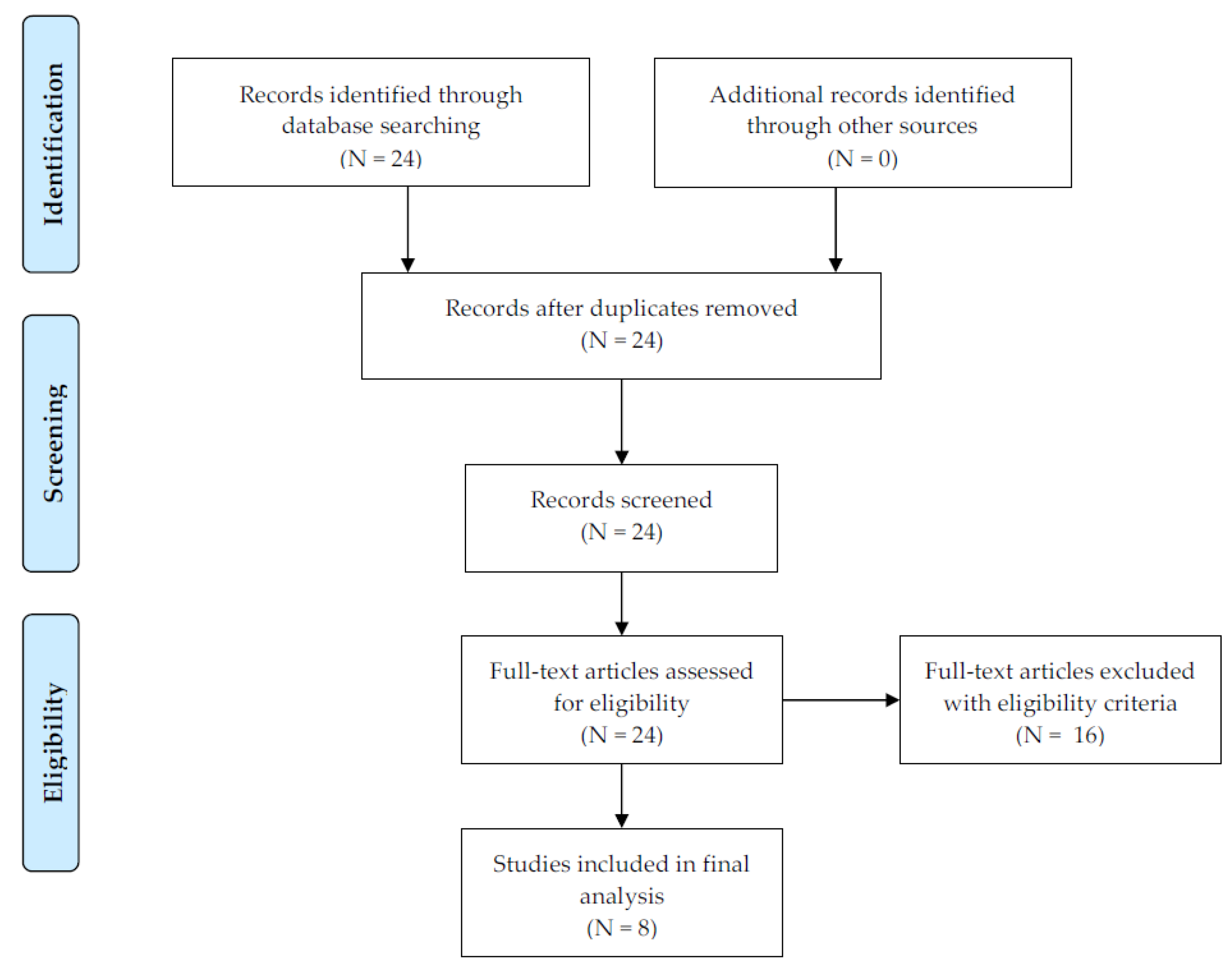
2. Methods
3. Results
3.1. Summary
3.2. Numeric Data
3.3. Genomic and Radiomic Data
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Johns Hopkins Medicine. Health: Digestive Disorders. Available online: https://www.hopkinsmedicine.org/health/wellness-and-prevention/digestive-disorders (accessed on 28 September 2022).
- Milivojevic, V.; Milosavljevic, T. Burden of Gastroduodenal Diseases from the Global Perspective. Curr. Treat. Options Gastroenterol. 2020, 18, 148–157. [Google Scholar] [CrossRef] [PubMed]
- Peery, A.F.; Crockett, S.D.; Murphy, C.C.; Jensen, E.T.; Kim, H.P.; Egberg, M.D.; Lund, J.L.; Moon, A.M.; Pate, V.; Barnes, E.L.; et al. Burden and Cost of Gastrointestinal, Liver, and Pancreatic Diseases in the United States: Update 2021. Gastroenterology 2022, 162, 621–644. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.-E.; Park, H.; Jo, M.-W.; Oh, I.-H.; Go, D.-S.; Jung, J.; Yoon, S.-J. Trends and Patterns of Burden of Disease and Injuries in Korea Using Disability-Adjusted Life Years. J. Korean Med Sci. 2019, 34 (Suppl. S1), e75. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.-K.; Jang, B.; Kim, Y.H.; Park, J.; Park, S.Y.; Nam, M.-H.; Choi, M.-G. Health Care Costs of Digestive Diseases in Korea. Korean J. Gastroenterol. 2011, 58, 323–331. [Google Scholar] [CrossRef] [Green Version]
- Cleveland Clinic. Health: Gastrointestinal Diseases. Available online: https://my.clevelandclinic.org/health/articles/7040-gastrointestinal-diseases (accessed on 28 September 2022).
- Lee, K.-S.; Ahn, K.H. Application of Artificial Intelligence in Early Diagnosis of Spontaneous Preterm Labor and Birth. Diagnostics 2020, 10, 733. [Google Scholar] [CrossRef]
- Lee, K.-S.; Jung, S.; Gil, Y.; Son, H.S. Atrial fibrillation classification based on convolutional neural networks. BMC Med. Informatics Decis. Mak. 2019, 19, 1–6. [Google Scholar] [CrossRef]
- Lee, K.-S.; Korean Society of Ultrasound in Obstetrics and Gynecology Research Group; Kim, H.Y.; Lee, S.J.; Kwon, S.O.; Na, S.; Hwang, H.S.; Park, M.H.; Ahn, K.H. Prediction of newborn’s body mass index using nationwide multicenter ultrasound data: A machine-learning study. BMC Pregnancy Childbirth 2021, 21, 1–10. [Google Scholar] [CrossRef]
- Lee, K.-S.; Song, I.-S.; Kim, E.S.; Kim, H.-I.; Ahn, K.H. Association of preterm birth with medications: Machine learning analysis using national health insurance data. Arch. Gynecol. Obstet. 2022, 305, 1369–1376. [Google Scholar] [CrossRef]
- Lee, J.Y.; Lee, K.S.; Seo, B.K.; Cho, K.R.; Woo, O.H.; Song, S.E.; Kim, E.K.; Lee, H.Y.; Kim, J.S.; Cha, J. Radiomic machine learning for pre-dicting prognostic biomarkers and molecular subtypes of breast cancer using tumor heterogeneity and angiogenesis prop-erties on MRI. Eur. Radiol. 2022, 32, 650–660. [Google Scholar] [CrossRef]
- Lee, K.-S.; Jang, J.-Y.; Yu, Y.-D.; Heo, J.S.; Han, H.-S.; Yoon, Y.-S.; Kang, C.M.; Hwang, H.K.; Kang, S. Usefulness of artificial intelligence for predicting recurrence following surgery for pancreatic cancer: Retrospective cohort study. Int. J. Surg. 2021, 93, 106050. [Google Scholar] [CrossRef]
- Lee, K.S.; Park, K.W. Social determinants of association among cerebrovascular disease, hearing loss and cognitive impair-ment in a middle-aged or old population: Recurrent-neural-network analysis of the Korean Longitudinal Study of Aging (2014–2016). Geriatr. Gerontol. Int. 2019, 19, 711–716. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, K.-S.; Kim, G.; Ham, B.-J. Original Article: Associations of antidepressant medication with its various predictors including particulate matter: Machine learning analysis using national health insurance data. J. Psychiatr. Res. 2022, 147, 67–78. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.D.; Lee, K.S.; Kim, J.; Ryu, J.H.; Lee, J.G.; Lee, K.W.; Kim, B.W.; Kim, D.S.; Korean Organ Transplantation Registry Study Group. Artificial intelligence for predicting survival following deceased donor liver transplantation: Retrospective multi-center study. Int. J. Surg. 2022, 105, 106838. [Google Scholar] [CrossRef] [PubMed]
- Ryu, K.-J.; Yi, K.W.; Kim, Y.J.; Shin, J.H.; Hur, J.Y.; Kim, T.; Seo, J.B.; Lee, K.-S.; Park, H. Machine Learning Approaches to Identify Factors Associated with Women’s Vasomotor Symptoms Using General Hospital Data. J. Korean Med. Sci. 2021, 36, e122. [Google Scholar] [CrossRef]
- Ryu, K.J.; Yi, K.W.; Kim, Y.J.; Shin, J.H.; Hur, J.Y.; Kim, T.; Seo, J.B.; Lee, K.S.; Park, H. Artificial intelligence approaches to the determi-nants of women’s vaginal dryness using general hospital data. J. Obstet. Gynaecol. 2022, 42, 1518–1523. [Google Scholar] [CrossRef]
- Lee, K.S.; Kwak, H.J.; Oh, J.M.; Jha, N.; Kim, Y.J.; Kim, W.; Baik, U.B.; Ryu, J.J. Automated detection of TMJ osteoarthritis based on artificial intelligence. J. Dent. Res. 2020, 99, 1363–1367. [Google Scholar] [CrossRef]
- Lee, K.-S.; Jha, N.; Kim, Y.-J. Risk factor assessments of temporomandibular disorders via machine learning. Sci. Rep. 2021, 11, 1–11. [Google Scholar] [CrossRef]
- R Package Randomforest. Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 28 September 2022).
- Python Package sklearn.ensemble. Random Forest Classifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (accessed on 28 September 2022).
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Python Package Shap. Available online: https://github.com/slundberg/shap (accessed on 10 August 2021).
- Mokhtari, K.E.; Higdon, B.P.; Basar, A. Interpreting financial time series with SHAP values. In Proceedings of the 29th Annual International Conference on Computer Science and Software Engineering, Markham, ON, Canada, 4–6 November 2019; pp. 166–172. [Google Scholar]
- Mangalathu, S.; Hwang, S.-H.; Jeon, J.-S. Failure mode and effects analysis of RC members based on machine-learning-based SHapley Additive exPlanations (SHAP) approach. Eng. Struct. 2020, 219, 110927. [Google Scholar] [CrossRef]
- Parsa, A.B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A. (Kouros) toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accid. Anal. Prev. 2020, 136, 105405. [Google Scholar] [CrossRef]
- Kha, Q.-H.; Le, V.-H.; Hung, T.N.K.; Le, N.Q.K. Development and Validation of an Efficient MRI Radiomics Signature for Improving the Predictive Performance of 1p/19q Co-Deletion in Lower-Grade Gliomas. Cancers 2021, 13, 5398. [Google Scholar] [CrossRef] [PubMed]
- Manikis, G.; Ioannidis, G.; Siakallis, L.; Nikiforaki, K.; Iv, M.; Vozlic, D.; Surlan-Popovic, K.; Wintermark, M.; Bisdas, S.; Marias, K. Multicenter DSC–MRI-Based Radiomics Predict IDH Mutation in Gliomas. Cancers 2021, 13, 3965. [Google Scholar] [CrossRef] [PubMed]
- Laios, A.; Kalampokis, E.; Johnson, R.; Munot, S.; Thangavelu, A.; Hutson, R.; Broadhead, T.; Theophilou, G.; Leach, C.; Nugent, D.; et al. Factors predicting surgical effort using explainable artificial intelligence in advanced stage epithelial ovarian cancer. Cancers 2022, 14, 3447. [Google Scholar] [CrossRef]
- Buergel, T.; Steinfeldt, J.; Ruyoga, G.; Pietzner, M.; Bizzarri, D.; Vojinovic, D.; Zu Belzen, J.U.; Loock, L.; Kittner, P.; Christmann, L.; et al. Metabolomic profiles predict individual multidisease outcomes. Nat. Med. 2022, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Song, S.I.; Hong, H.T.; Lee, C.; Lee, S.B. A machine learning approach for predicting suicidal ideation in post stroke patients. Sci. Rep. 2022, 12, 15906. [Google Scholar] [CrossRef] [PubMed]
- Kruk, M.; Goździejewska, A.M.; Artiemjew, P. Predicting the effects of winter water warming in artificial lakes on zooplankton and its environment using combined machine learning models. Sci. Rep. 2022, 12, 16145. [Google Scholar] [CrossRef]
- Lee, K.-S.; Song, I.-S.; Kim, E.-S.; Ahn, K.H. Determinants of Spontaneous Preterm Labor and Birth Including Gastroesophageal Reflux Disease and Periodontitis. J. Korean Med. Sci. 2020, 35, e105. [Google Scholar] [CrossRef] [Green Version]
- Deshmukh, F.; Merchant, S.S. Explainable Machine Learning Model for Predicting GI Bleed Mortality in the Intensive Care Unit. Am. J. Gastroenterol. 2020, 115, 1657–1668. [Google Scholar] [CrossRef]
- Shinn, L.M.; Li, Y.; Mansharamani, A.; Auvil, L.S.; Welge, M.E.; Bushell, C.; Khan, N.A.; Charron, C.S.; Novotny, J.A.; Baer, D.J.; et al. Fecal Bacteria as Biomarkers for Predicting Food Intake in Healthy Adults. J. Nutr. 2020, 151, 423–433. [Google Scholar] [CrossRef]
- Kang, E.A.; Jang, J.; Choi, C.H.; Kang, S.B.; Bang, K.B.; Kim, T.O.; Seo, G.S.; Cha, J.M.; Chun, J.; Jung, Y.; et al. Development of a clinical and genetic prediction model for early intestinal resection in pa-tients with Crohn’s disease: Results from the IMPACT Study. J. Clin. Med. 2021, 10, 633. [Google Scholar] [CrossRef]
- Esposito, A.A.; Zannoni, S.; Castoldi, L.; Giannitto, C.; Avola, E.; Casiraghi, E.; Catalano, O.; Carrafiello, G. Pseudo-pneumatosis of the gastrointestinal tract: Its incidence and the accuracy of a checklist supported by artificial intelligence (AI) techniques to reduce the misinterpretation of pneumatosis. Emerg. Radiol. 2021, 28, 911–919. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.-S.; Kim, E.S.; Kim, D.-Y.; Song, I.-S.; Ahn, K.H. Association of Gastroesophageal Reflux Disease with Preterm Birth: Machine Learning Analysis. J. Korean Med. Sci. 2021, 36. [Google Scholar] [CrossRef] [PubMed]
- Lipták, P.; Banovcin, P.; Rosoľanka, R.; Prokopič, M.; Kocan, I.; Žiačiková, I.; Uhrik, P.; Grendar, M.; Hyrdel, R. A machine learning approach for identification of gastrointestinal predictors for the risk of COVID-19 related hospitalization. PeerJ 2022, 10, e13124. [Google Scholar] [CrossRef] [PubMed]
- Liptak, P.; Duricek, M.; Rosolanka, R.; Ziacikova, I.; Kocan, I.; Uhrik, P.; Grendar, M.; Hrnciarova, M.; Bucova, P.; Galo, D.; et al. Gastrointestinal sequalae months after severe acute respiratory syndrome corona virus 2 infection: A prospective, observational study. Eur. J. Gastroenterol. Hepatol. 2022, 34, 925–932. [Google Scholar] [CrossRef] [PubMed]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Why should I trust you? Explaining the predictions of any classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Gheisari, S.; Shariflou, S.; Phu, J.; Kennedy, P.J.; Agar, A.; Kalloniatis, M.; Golzan, S.M. A combined convolutional and recurrent neural network for enhanced glaucoma detection. Sci. Rep. 2021, 11, 1945. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Hambly, B.; Xu, R.; Yang, H. Recent advances in reinforcement learning in finance. arXiv 2022, arXiv:2112.04553. [Google Scholar] [CrossRef]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement learning in healthcare: A survey. arXiv 2020, arXiv:1908.08796. [Google Scholar] [CrossRef]
- Puiutta, E. Veith EMSP. Explainable reinforcement learning: A survey. arXiv 2020, arXiv:2005.06247. [Google Scholar]


{kind=link}
{kind=link}
| ID | Method | Sample Size | Data Type | Performance | Important Predictor |
|---|---|---|---|---|---|
| [33] | ANN DT LR * NB RF * SVM | 731 | Numeric | Accuracy 0.79–0.87 AUC 0.54–0.76 | RFVI for the prediction of preterm birth, which has a strong association with GERD: Age, education, upper gastrointestinal tract symptom, Helicobacter pylori, region |
| [34] | APACHE XGB * | 5691 | Numeric | Sensitivity 1.00 Specificity 0.04–0.27 AUC 0.80–0.85 | SHAP for the prediction of mortality from gastrointestinal bleeding in the intensive care unit: mean arterial pressure (max), bicarbonate (min), creatinine (max), PMN, heart rate (mean), Glasgow Coma Scale, age, respiratory rate (mean), prothrombin time (max), aminotransferase aspartate (max), albumin (min), oxygen saturation (mean), white blood cell, AlkPhos (max), platelet (min), lactate (max), intubation, bilirubin (max), international normalized ratio (max), vasopressor, glucose (max), blood urea nitrogen (max), PTT (max), hemoglobin (min), potassium |
| [35] | RF * | 340 | Genomic | Accuracy 0.70 AUC 0.92 | RFVI for the prediction of food intake (almond, avocado, broccoli, walnut, whole-grain barley, whole-grain oat): Roseburia undefined, Lachnospira spp., Oscillibacter undefined, Subdoligranulum spp., Streptococcus salivarius subsp. thermophiles, Parabacteroides distasonis, Roseburia spp., Anaerostipes spp., Lachnospiraceae ND3007 group undefined, Ruminiclostridium spp. |
| [36] | CB * | 337 | Genomic | AUC 0.81–0.84 | SHAP for the prediction of early intestinal resection with Crohn’s disease: age, disease behavior (clinical predictors), rs28785174, rs60532570, rs13056955, rs7660164 (single nucleotide polymorphisms) |
| [37] | RF * | 71 | Radiomic | Accuracy 0.78–0.94 | RFVI for the prediction of pneumatosis: dissecting gas in the bowel wall, intramural gas beyond a gas-fluid/fecal level, a circumferential gas pattern |
| [38] | ANN * LR * RF * | 405,586 | Numeric | Accuracy 0.93–0.98 | RFVI for the prediction of preterm birth, which has a strong association with GERD: socioeconomic status, age, region (city) |
| [39] | RF * | 710 | Numeric | AUC 0.76–0.80 | RFVI for the prediction of COVID-19 hospitalization based on gastrointestinal factors: aspartate transaminase, diabetes mellitus, chronic liver disease, alanine transaminase, diarrhea, age, bloating |
| [40] | RF * | 590 | Numeric | AUC 0.68 | RFVI for the prediction of gastrointestinal sequelae months after COVID-19 infection: acute diarrhea, antibiotics administration |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.-S.; Kim, E.S. Explainable Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease. Diagnostics 2022, 12, 2740. https://doi.org/10.3390/diagnostics12112740
Lee K-S, Kim ES. Explainable Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease. Diagnostics. 2022; 12(11):2740. https://doi.org/10.3390/diagnostics12112740
Chicago/Turabian StyleLee, Kwang-Sig, and Eun Sun Kim. 2022. "Explainable Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease" Diagnostics 12, no. 11: 2740. https://doi.org/10.3390/diagnostics12112740
APA StyleLee, K.-S., & Kim, E. S. (2022). Explainable Artificial Intelligence in the Early Diagnosis of Gastrointestinal Disease. Diagnostics, 12(11), 2740. https://doi.org/10.3390/diagnostics12112740