1. Introduction
Skin is the largest organ of the human body. It is the only organ that is in constant contact with the external environment. The skin keeps the internal temperature of the body consistent and protects from harmful agents entering the body. Since the skin directly interacts with the environment, many factors affect it significantly, such as friction, pressure, vibration, heat, cold, radiation, virus, bacteria, insects, etc., and a variety of other chemicals.
As the skin is at constant exposure, the chance of obtaining a skin disease is higher. Malignant skin cancer, commonly known as malignant melanoma, is one of the most dangerous types of skin cancer. It is caused by long-term UV exposure, which induces mutations in melanocytes, the cells that make melanin pigment [
1]. When exposed to UV radiation, melanocytic cells create an excessive amount of melanin. As a result, black moles appear on the skin. These moles on the skin can grow into malignant tumors that spread fast to other parts of the body. Melanoma is one of Australia’s most prevalent malignancies. The top cancers contribute to approximately 60% of total cancers diagnosed in the country [
2]. In Australia, an estimated 434,000 persons were diagnosed with one or more non-melanoma skin malignancy in 2008. A total of 679 Australians died in 2016 from non-melanoma skin cancer. According to a report of the American Cancer Society [
3], in 2021, 6% of all diagnosed cancers were melanoma. Melanoma affects one out of every twenty-seven males and one out of every forty females. In 2021, the United States saw 1.9 million new cancer diagnoses and 608,570 cancer deaths. Melanoma cases are very high in sun-exposed areas. By 2020, melanoma is anticipated to be Australia’s third most common cancer, and New Zealand has the highest melanoma incidence rate in the world. In Australia, 16,878 new cases of melanoma are predicted to be discovered in 2021.
Melanoma may appear in a variety of ways. The initial indicator is generally the appearance of a new mole or a change in an existing mole. The dermatologist typically applies the “ABCDE” criterion to diagnose skin cancer: (i) A—Asymmetry (irregular) (ii) B—Border (uneven or scalloped edges), (iii) C—Colour (differing shades and color patches), (iv) D—Diameter (usually over 6mm), (v) E—Evolving (changing and growing). After applying the “ABCDE” criterion, they decide whether the mole is malignant or benign. If the mole is suspected of melanoma, a skin biopsy or other methods are performed for confirmation of melanoma. If it is a benign mole, then the patient needs time to time the “ABCDE” assessment in order to keep track of its condition. In the United States, the 5-year survival rate is 98 percent, but it drops to 18 percent after cancer spreads to distant organs. As a result, the early identification of melanoma is critical for increasing survival rates. Malignant melanoma can be treated if diagnosed early enough [
4,
5] according to experimental research.
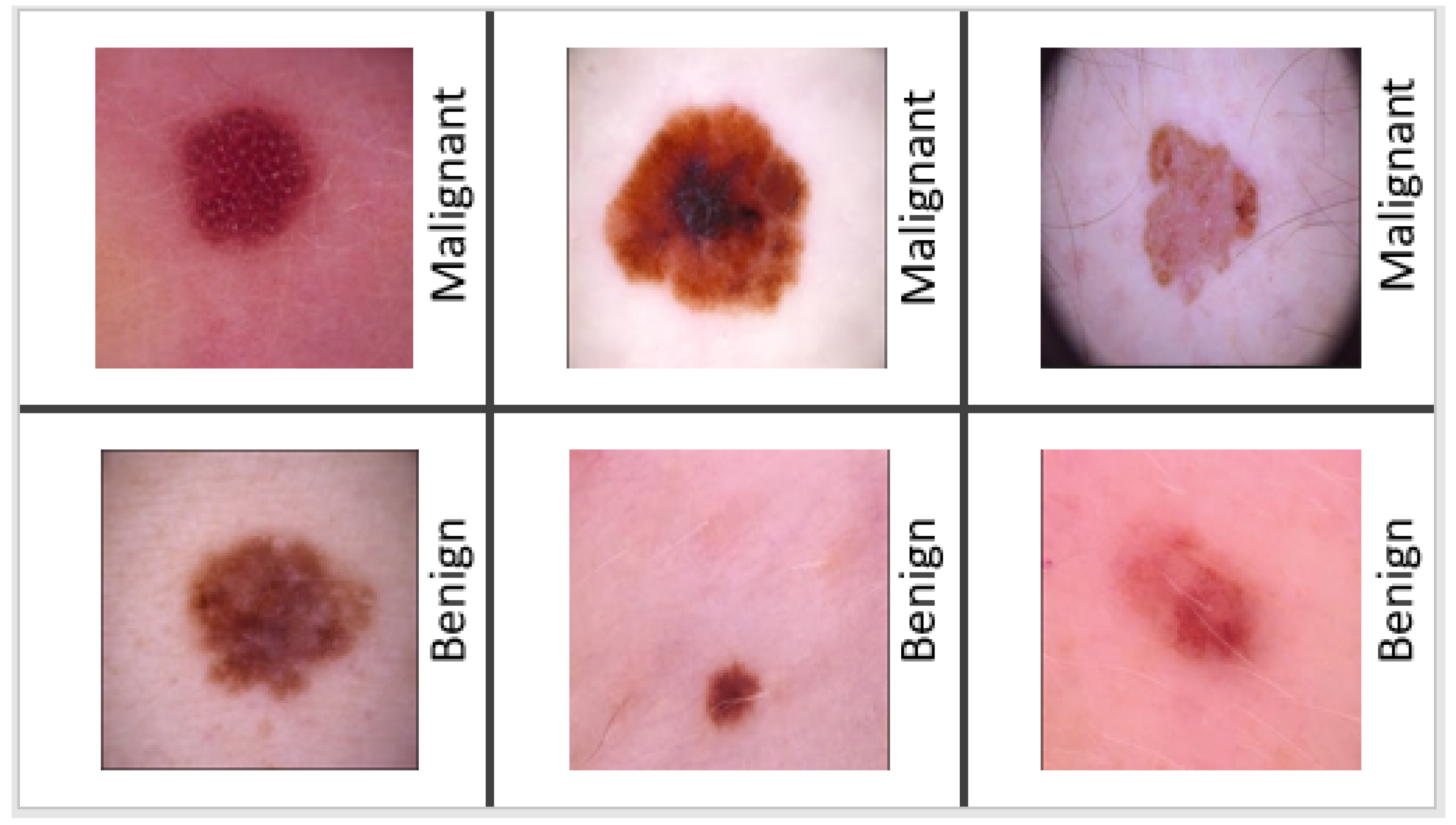
Figure 1 displays examples of a collection of malignant and benign skin lesions.
It can be difficult to recognize melanoma from all melanoma photos because of the variety of features, such as a low contrast, noise, and uneven borders. Moreover, ABCD criteria are not always reliable in determining whether or not an individual has skin cancer, as per the research findings [
6]. Additionally, these procedures require highly trained dermatologists to minimize the possibility of making an incorrect diagnosis, which results in a high rate of false positive and negative instances. To overcome these limitations, this article has focused on developing a deep-learning-based computer-aided method for analyzing lesions on skin to detect potential skin cancer.
Automated melanoma detection algorithms also began to appear in the literature, giving timely services to dermatologists of all levels. Two approaches based on statistical learning are widely used. Firstly, standard classification methods rely on skin lesion features that are typically difficult to generate and require a specific understanding of the domain. The second category of methods are based on deep learning models that can automatically extract disease-related features for skin lesion classification. Nonetheless, accuracies have been hampered thus far due to image occlusions and imbalanced datasets. While deep learning algorithms have demonstrated their superiority to conventional strategies for melanoma identification, the majority of these approaches lack an adequate explainability of the models associated with relevant aspects of pathological symptoms. As a result, the clinical usefulness of these strategies is unknown until more research is conducted to understand the high-level properties collected from these models. Even with highly precise experimental results, dermatologists are unlikely to adopt a black-box categorization approach in the real world.
Hence, the overall objective of this research is to introduce an interpretable method for non-invasive diagnosis melanoma skin cancer using deep learning and ensemble stacking of machine learning models. More specifically, the proposed research has the following four objectives to be achieved: (i) to build a stacked ensemble of various machine models that are trained using hand-crafted features extracted from melanoma images for a non-invasive diagnosis of melanoma skin cancer; (ii) to create an ensemble of deep learning models that are fine-tuned with automated features extracted from melanoma images; (iii) to assess the effectiveness of our proposed models using a publicly available skin lesion dataset over a wide range of parameters; (iv) to construct an interpretability approach that generates heatmaps to identify the parts of a melanoma image that are most suggestive of the illness.
Our statistical hypothesis testing was carried out using the corrected paired Student’s
t-test to see whether the differences in the performances of these models were statistically significant or not [
7]. To accomplish this, the paired
t-test is utilized using the following null and alternative hypotheses: H0, no difference in performance exists between the two deep learning models when comparing them; HA, the two deep learning models exhibit significant differences in performance.
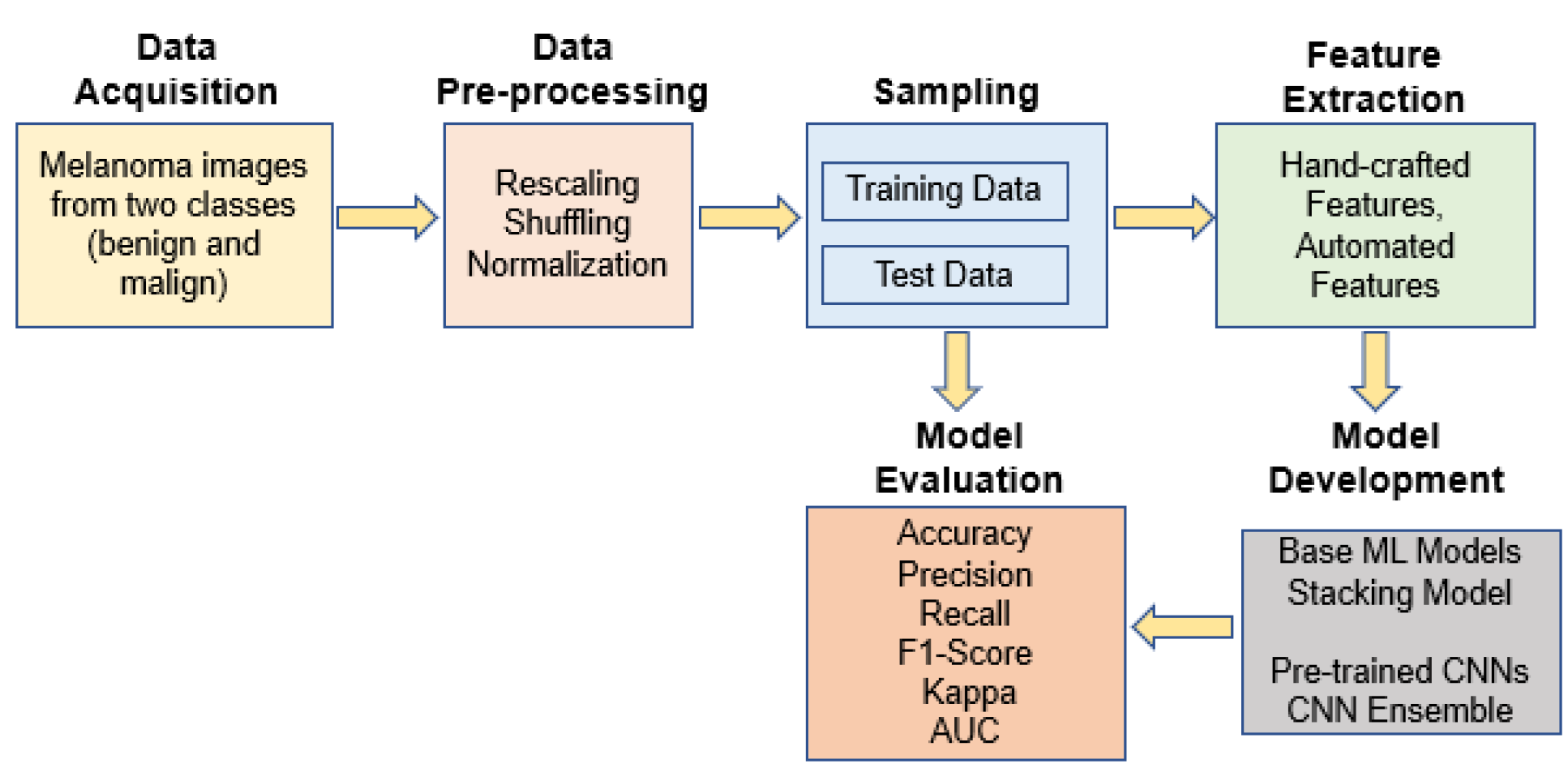
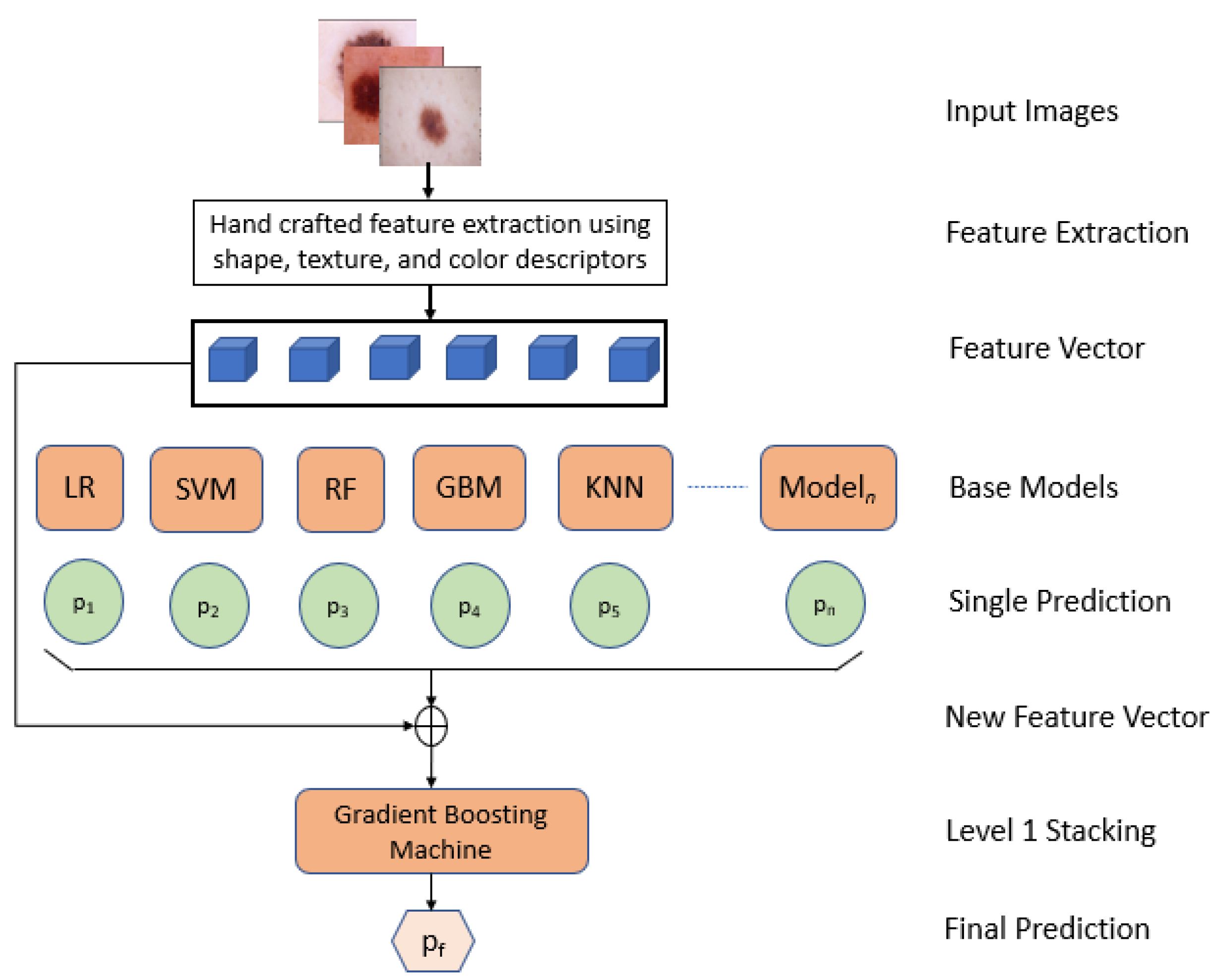
In this paper, we proposed an interpretable approach to melanoma skin cancer diagnosis based on deep learning and ensemble stacking of machine learning models. Hand-crafted features based on shape, texture, and color were used to train the base machine learning models, namely, logistic regression, support vector machine (SVM), random forest, k-nearest neighbor (KNN), and gradient boosting machine. The prediction of these base models was used to train level one model stacking [
8,
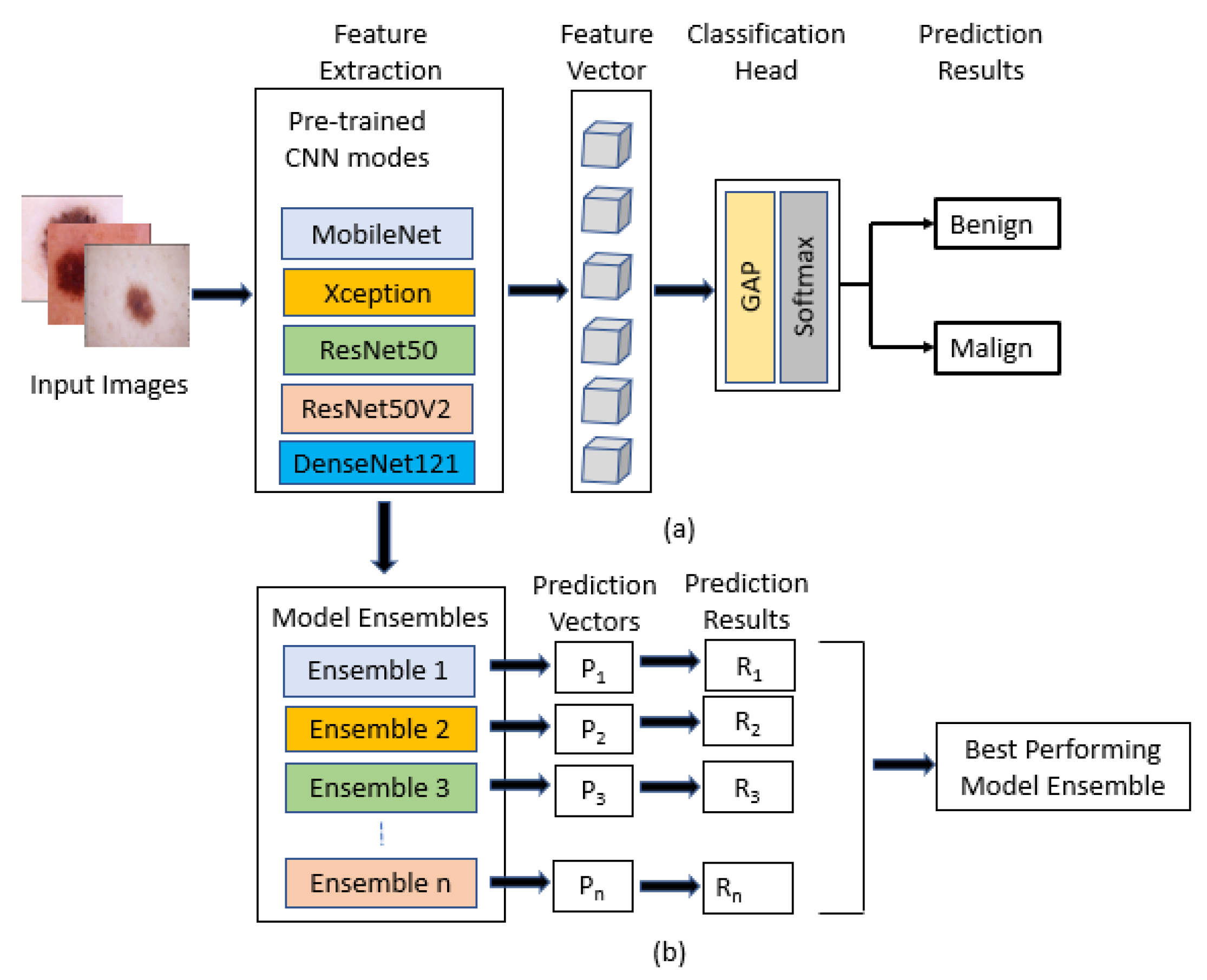
9] using cross-validation on the training set. Deep learning models (MobileNet, Xception, ResNet50, ResNet50V2, and DenseNet121) were used for transfer learning, and were already pre-trained on ImageNet data. The selected base models were trained and tested on a small dataset [
10] of the ISIC 2018 challenge [
11], and the results of each model were compared. The best models were then ensembled to increase the accuracy. The dataset contains only two classes: malignant and benign. However, the methods are also capable of classifying the dataset with more categories. Furthermore, shapely adaptive explanations were used to construct an interpretability approach that generates heatmaps to identify the parts of a melanoma image that are most suggestive of the illness. Our method shows promising results in diagnosing melanoma skin cancer, leading to clinical advantages. To summarize, we have made the following significant contributions in this paper:
Feature extractions were performed using Hu moments, Haralick features, and a color histogram;
Transfer learning was used by fine-tuning the backbones, and the base models were pre-trained on ImageNet data;
A performance comparison was carried out between machine learning and deep learning models;
Level one stacking was performed on machine learning models;
Ensembling was carried out from different combinations of deep learning models;
Extensive experimentation was conducted to illustrate the model’s performance, with a final accuracy of 92.0% and an AUC score of 97.0% for skin lesion classification.
We structure the rest of the paper as follows.
Section 2 includes the related work.
Section 3 describes the dataset used and the model architecture of our two methods.
Section 4 elaborately explains the graphs and results of the models. Finally,
Section 5 concludes the paper with an idea of future work.
4. Results and Discussions
In this paper, two methods were proposed. The first method includes the machine learning models followed by level one stacking, and the second method comprises deep learning models followed by ensembling. For both approaches, we used the miniature version of the ISIC 2018 challenge dataset. The two classes of the dataset were balanced, and it already contained the training set and test set. To compare the models, we evaluated the models with different metrics. These metrics include: accuracy—which measures the proportion of correct predictions, ranging from 0 (worst) to 1 (best); f1-score—the harmonic mean of recall and precision, which measures from 0 (worst) to 1 (best); Cohen’s kappa—measures how agreeable the true label and prediction are, ranging from −1 (completely disagree) to 1 (completely agree); confusion matrix—an overview of prediction results on a classification problem. AUC-ROC curves of the models were also generated to provide a performance measurement at various threshold settings. In fact, ROC curves are widely used to graphically depict the relationship/trade-off between clinical sensitivity and specificity for every conceivable cut-off for a model or a group of models. ROC curves are used to determine the best cut-off value for a model. The most suitable cut-off has a high true positive rate while having a low false positive rate and is determined on the ROC curve that is closest to the graph’s upper left corner. A single measure, the area under the ROC curve (AUC), may summarise all potential configurations of sensitivity and specificity that could be produced by adjusting the cutoff value. Thus, the AUC is a measure of how accurate a model is. The greater the AUC, the more accurate the model. When comparing two models, an AUC greater than or equal to the other’s is a sign that the model with the higher ROC curve is the more accurate of the two. Thus, we have used area under the curves values (AUC) to compare the performance of the deep learning models. The GPU and TPU support from Google Colab were used, and the models were trained.
Table 2 describes our model parameters and setup.
Table 3 and
Table 4 show the result of our first method. A total of 49 classifiers were produced with different hyper parameters from the five base models: logistic regression, random forest, support vector machine, gradient boosting machine and k-nearest neighbor. The best result of each model are recorded. From the following table, it can be seen that the k-nearest neighbor performed last, with an accuracy of 82%, f1-score of 83%, and Cohen’s kappa of 64%. Logistic regression and random forest performed slightly better, with an accuracy and f1-score of 84%, and Cohen’s kappa of 69% and 68%, respectively. The support vector machine performed better than the other three models, with an accuracy and f1-score of 85% and Cohen’s kappa of 69%. Among the base models, the gradient boosting machine performed well, with an accuracy of 87%, f1-score of 87%, and Cohen’s kappa of 74%. We then performed level one stacking on the feature vector where the predictions of all the 49 classifiers were stored, and calculated the final prediction result. After level one stacking, the accuracy rose to 88%, f1-score rose to 88%, and Cohen’s kappa rose to 76%.
While training the deep learning models, the hyper-parameters were tuned with random search. The classification head and all layers were trained up to 100 epochs separately. The batch size and learning rate were set to 32 and 0.001, respectively. The training was halted when the model had no improvements, and the accuracy curve started to converge to a specific limit. The table shows the evaluated results of the models. In TPU, the classification head, on average, took up to 6 min for each epoch; on the other hand, to train all layers, it took an average of 16 min for each epoch. Therefore, if the classifier trained its classification head for 100 epochs and then all layers for another 100 epochs, then the total training time for the classification head would be 600 min and, for all layers, 1600 min, which means that the classifier would take around 2200 min to train in total.
Five deep learning models—MobileNet, Xception, ResNet50, ResNet50V2, and DenseNet121—were pre-trained on ImageNet data, and transfer learning was used by fine-tuning them. When we fed our training data into these classifier models, the following results, shown in
Table 5 and
Table 6, were obtained.
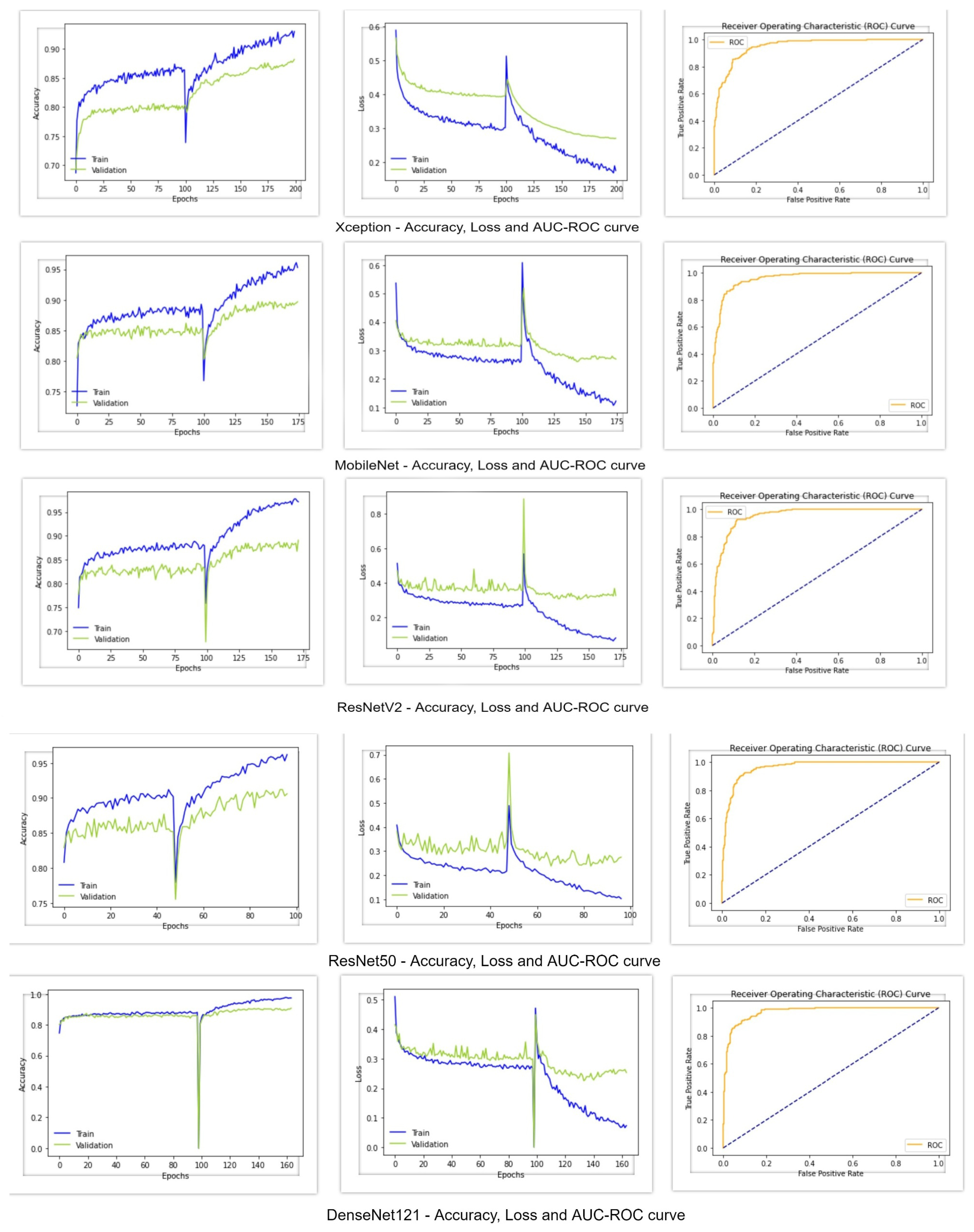
Figure 5 shows the accuracy, loss, and AUC-ROC curve of these deep learning classifiers. From the following table, it can be seen that the Xception architecture performed poorly compared to the other deep learning models, with an accuracy and f1-score of 88%, Cohen’s kappa of 77%, and AUC value of 0.95. On the other hand, all of the other deep learning classifiers achieved an accuracy greater than 90%. MobileNet and ResNet50V2 performed almost similarly, with an accuracy of 90%, f1-score of 90% and Cohen’s kappa of around 80%. However, MobileNet achieved an AUC value of 0.96, whereas the AUC value of ResNet50V2 was 0.95. Regarding the AUC-ROC curve of MobileNet and ResNet50V2, the curve of MobileNet is more rounded at the edges. ResNet50 performed better than the other models, with an accuracy of 91%, f1-score of 91%, Cohen’s kappa of 82%, and AUC of 0.96. DesnetNet121 achieved an accuracy of 91%, f1-score of 90.8%, Cohen’s kappa of 81.7%, and AUC of 0.97, which is better than all of the other base models. The accuracy and loss curves of all of the models in
Figure 5 show a region where there is a massive change in the middle of the curves. The portion of the curve before the massive change shows the training of the classification head of the classifiers, and the portion after the massive change shows the training of all of the other layers of the classifiers. Since the classification head was first trained, and reached a certain accuracy and loss value, when the classifiers shifted to train all of their layers, a massive change in results occurred. From these graphs, it can be seen that the classification head training pushed the accuracy to a certain level and, after training all layers, it further pushed the accuracy to its maximum level.
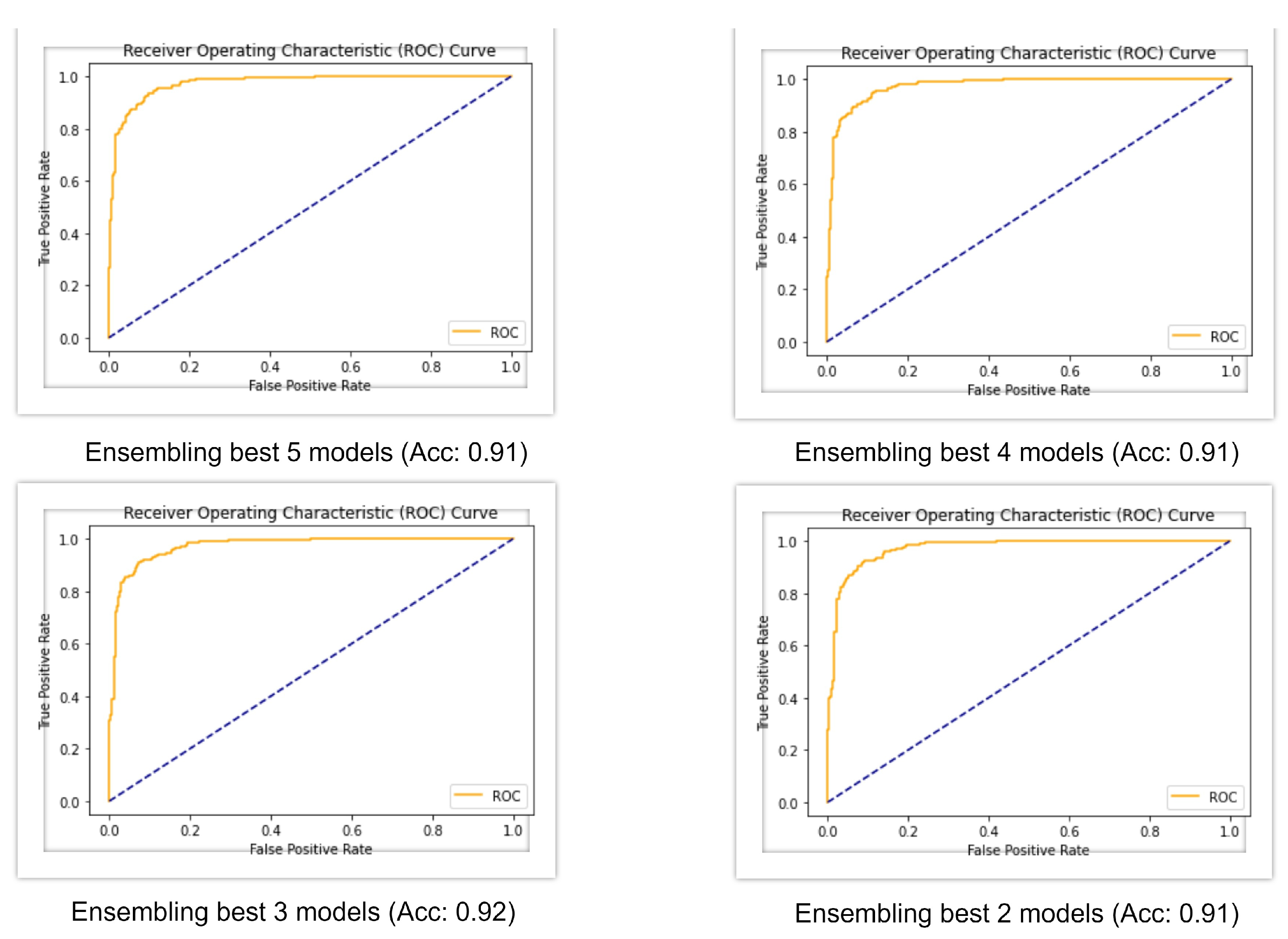
The best base models of deep learning were then ensembled with combinations of five, four, three, and two.
Figure 6 shows the AUC-ROC curve for four ensembled models and, from the table, it can be seen that when all the five models were ensembled, it gave an accuracy of 91%, f1-score of 91%, Cohen’s kappa of 82%, and AUC of 0.97. When the four best models were ensembled, they produced a similar result, but when the three best models were ensembled, the accuracy rose to 92%, f1-score rose to 92%, and Cohen’s kappa rose to 83%, which is greater than all the machine learning and deep learning models. All of the ensembled models produced an AUC value of 0.97.
From the above results, we can compare the models of machine learning and deep learning to classify skin lesions. Almost all the deep learning models showed an accuracy greater than 90%, whereas Xception only achieved 88%. On the other hand, all of the machine learning models showed an accuracy below 90%. After stacking and ensembling, the final results are 88% and 92%, respectively. It can be clearly seen that, among all of the other methods, the ensembling of tthe op three deep learning models performed better, with an accuracy of 92%.
To measure the degree of significance in the difference between the performance of the best ensembling model and other CNN models, the
t statistic as generated in [
7] is combined with a Student-t distribution with a certain degree of freedom. A
p-value below the accepted significance level (i.e., 5%) rejects the null hypothesis, affirming that the models’ performances are different. Furthermore, the null hypothesis will not be rejected if the
p-value is higher than the significance level. We employed this approach to compare the performance metrics of the best ensembling model with each of the base models by computing the paired
t-test results, as shown in
Table 7. The
p-values smaller than the considered threshold level (i.e., 5%) are highlighted in bold, implying that the null hypothesis can be rejected, and the studied models perform differently in such cases. Therefore, the findings statistically show convincing evidence that the performance gain of the ensembling model, especially in terms of the kappa, accuracy, and AUC values over the base models, is significant.
The ISIC 2018 challenge winner MetaOptima [
32], achieved an accuracy of 0.871 on the best single model, 0.882 on the meta ensemble, and 0.885 on the top 10 models averaged. This means that our proposed model’s accuracy is almost 4% greater than that of the ISIC 2018 challenge winners. We also compare the performance of our best performing model with some other existing work from the literature. A comparative summary of these techniques is provided in
Table 8. Due to the fact that different research used distinct datasets and performance indicators, it would be difficult to carry out an effective comparison.
Table 8 shows that our model outperforms many other methods when they use standard datasets. When compared to studies that used the ISIC 2018 dataset, our model outperforms others in terms of accuracy (92.0%), precision (91.0%), and sensitivity (92.0%).
Furthermore, the suggested ensemble model has a high AUC score (0.970), indicating that our approach can appropriately identify the population with melanoma skin cancer problems. Our study is surpassed in terms of all metrics by the models reported by Yuan and Lo [
26], who assessed their models using datasets other than ours. However, the majority of this research in the literature does not provide any or sufficient explanation for their performance results. Our model, on the other hand, gives results that are important for AI models to be accepted by a wide range of health care professionals.
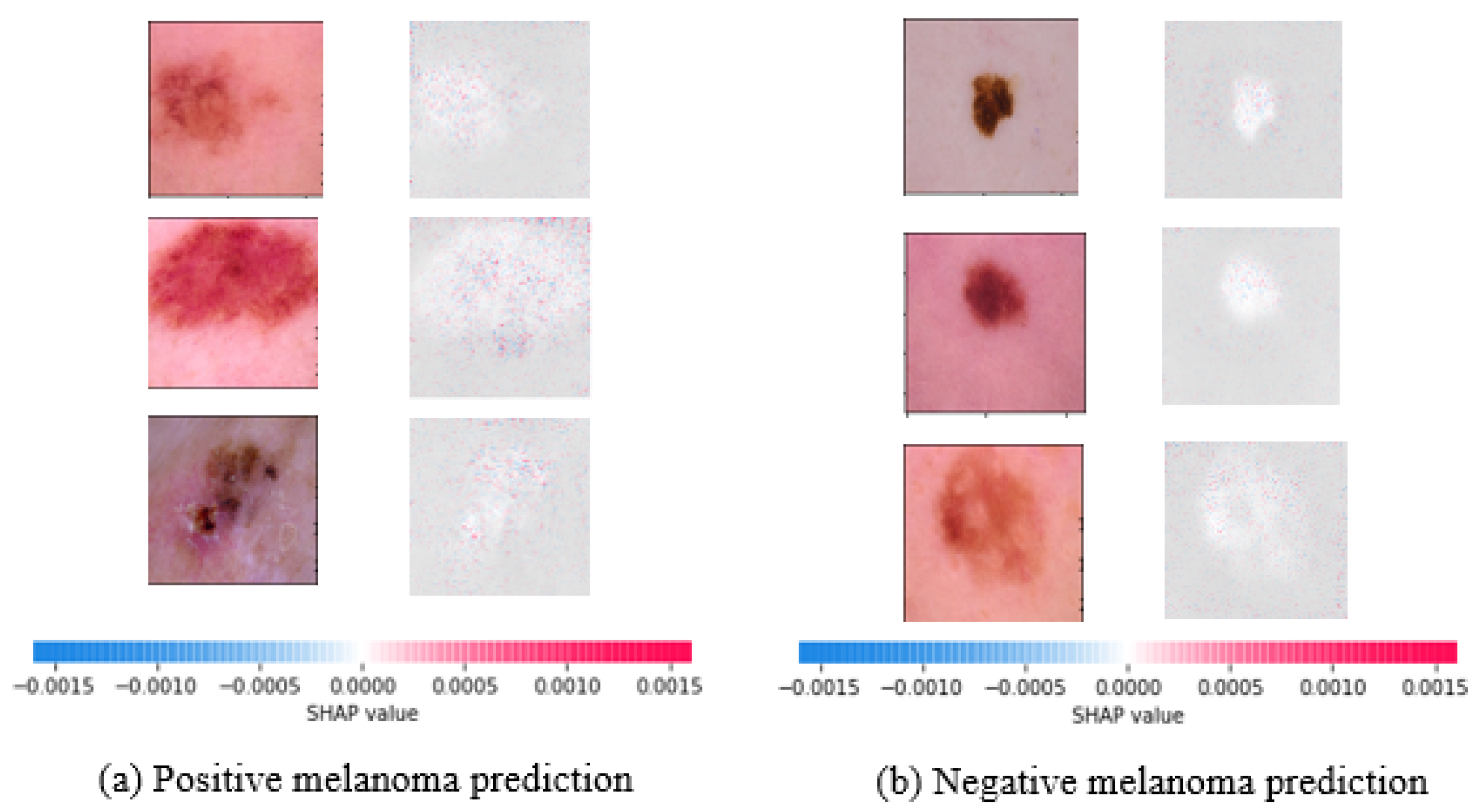
To this end, SHAP values for the best performing DenseNet121 model are shown in
Figure 7. Indicators in red reflect features that increase the malignant melanoma output, whereas indicators in blue show features that decrease it. The saliency of a ROI is measured by the sum of the intensity of its features for a given class. As a result, the robustness of our best performing deep learning strategy for malignant melanoma detection is explained by this explainability strategy.
We can understand how AI can help dermatologists to diagnose potential melanoma skin cancer difficulties more correctly and rapidly, given the amount of effort made so far to employ deep learning models to autonomously assess the severity of the disease. This research takes us closer to a better understanding of the problems that skin cancer causes. In comparison to other studies in the area, it offers an improved deep-learning-based strategy for the automatic and quick detection of prospective skin cancer occurrences.
Our proposed fusion approach, nonetheless, is not intended to replace the knowledge of a dermatologist. Rather, we think that our findings will have a big impact on how AI-assisted technologies are used in the medical field. Health care providers can greatly benefit from automatic advanced scanning to discover positive encounters while waiting for more comprehensive testing to be specified, even if they cannot solely rely on the outcomes of skin lesion images to advise a patient’s treatment plan.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}