
Predicting the Severity of Lockdown-Induced Psychiatric Symptoms with Machine Learning

 , , ,
, , , 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Clinical Measures and Data Collection
2.3. Data Pre-Processing
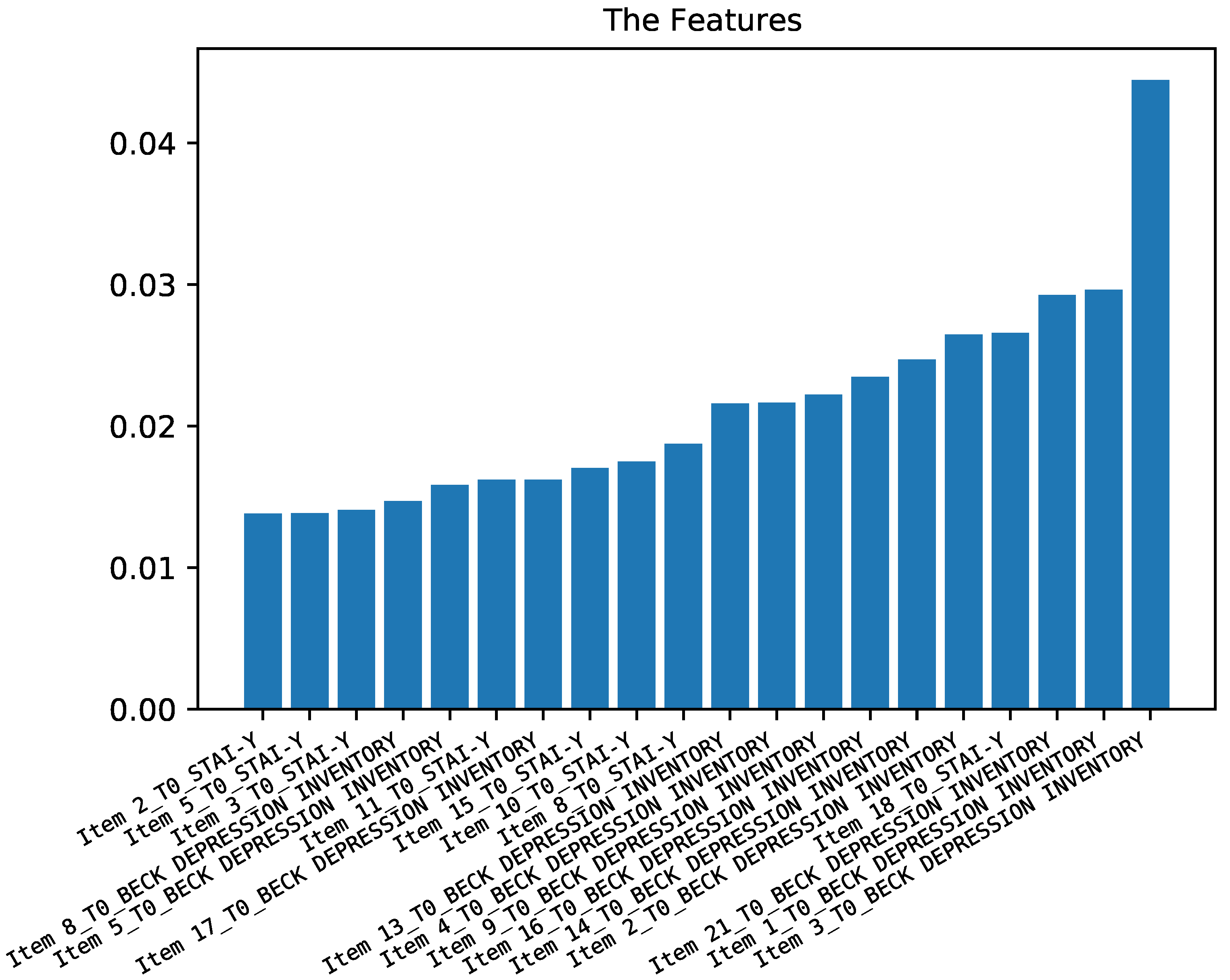
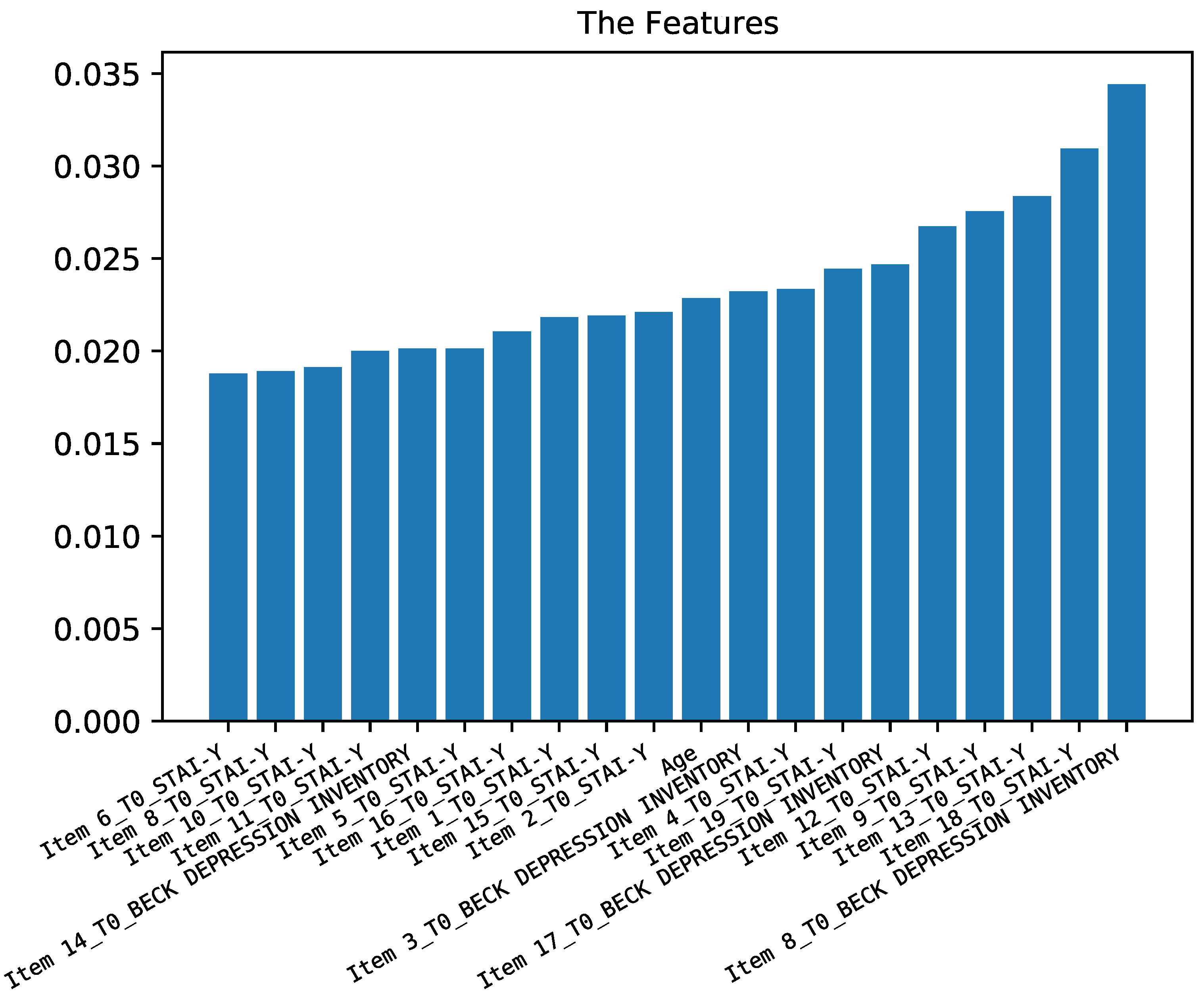
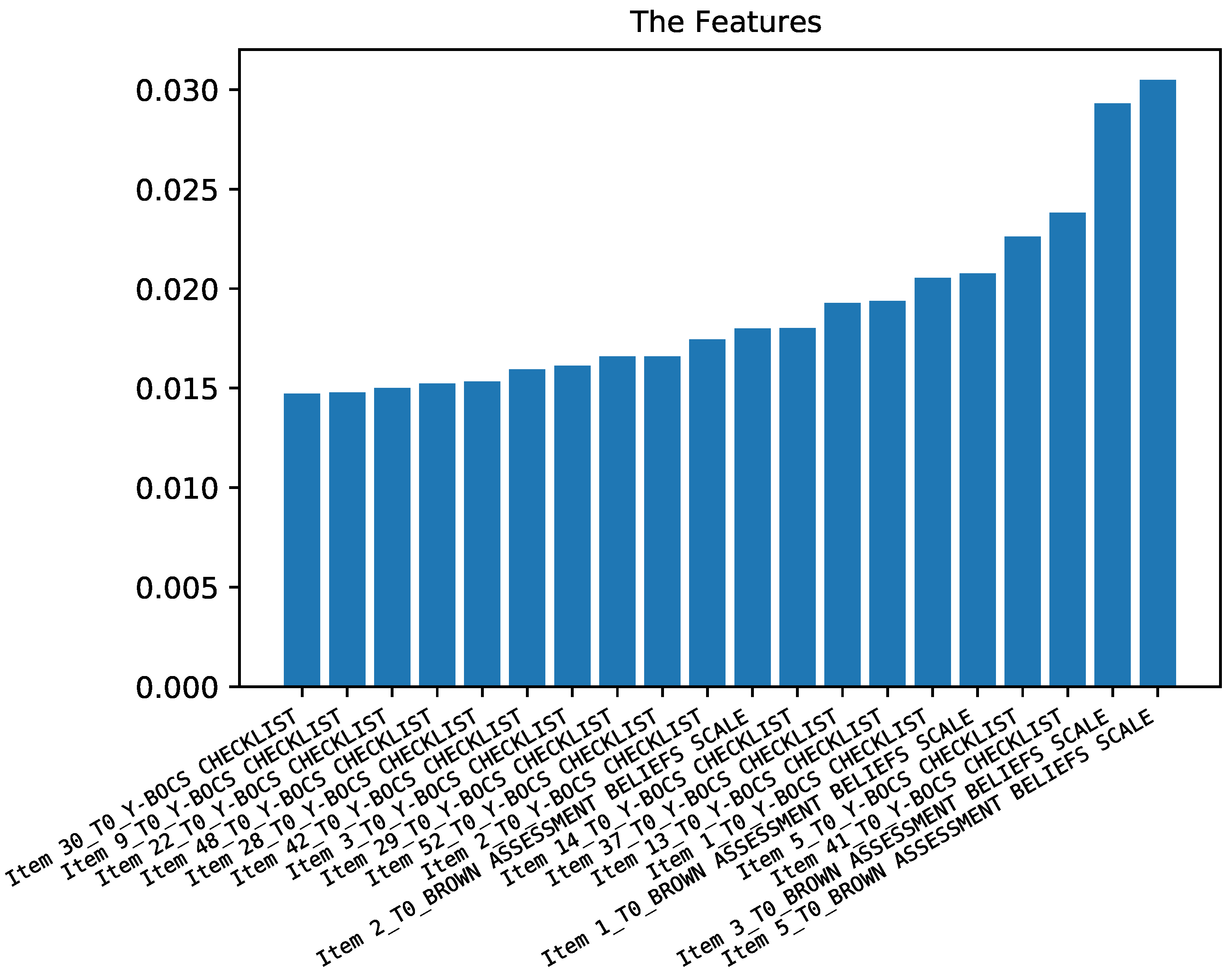
2.4. Feature Importance
2.5. Prediction
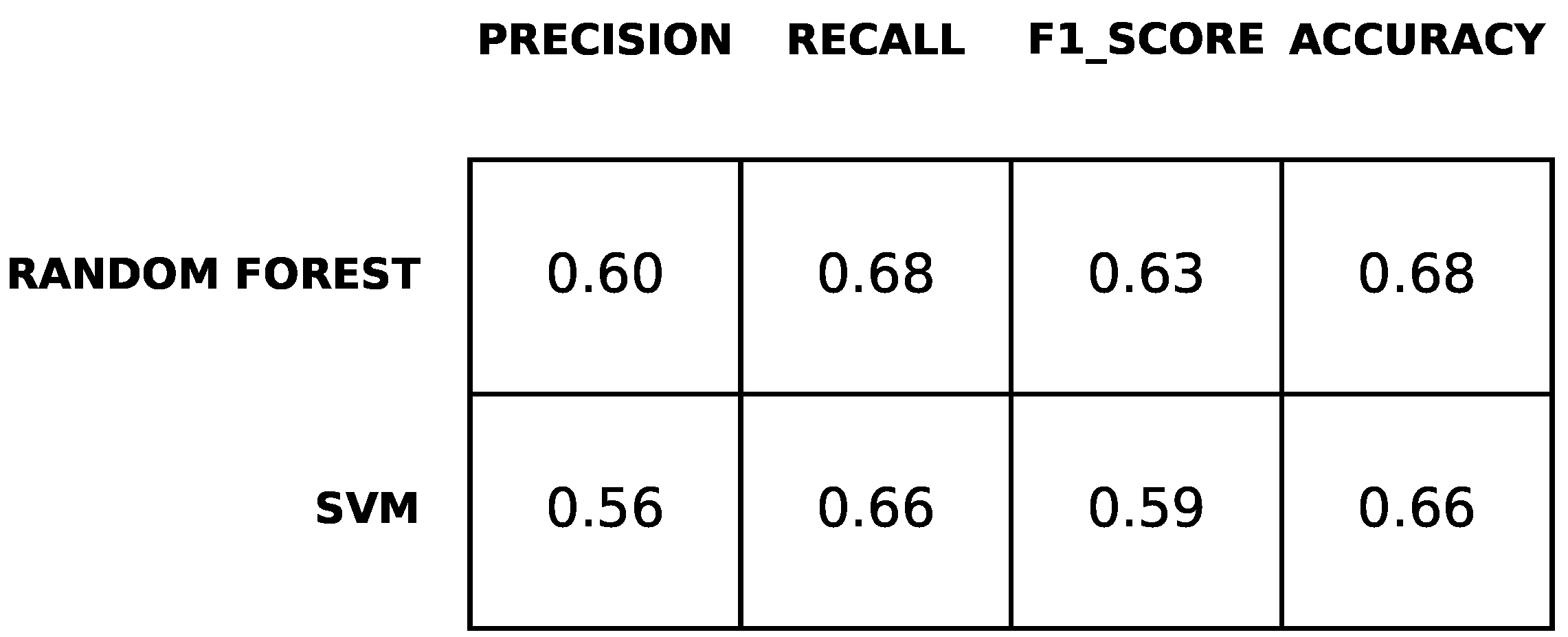
2.6. Performance Metrics
3. A Preliminary Study on a Real Dataset
3.1. Data Used
3.2. Results Obtained
3.2.1. Predicting Depression Symptoms
3.2.2. Predicting Anxiety Symptoms
3.2.3. Predicting Obsessive and Compulsive Symptoms
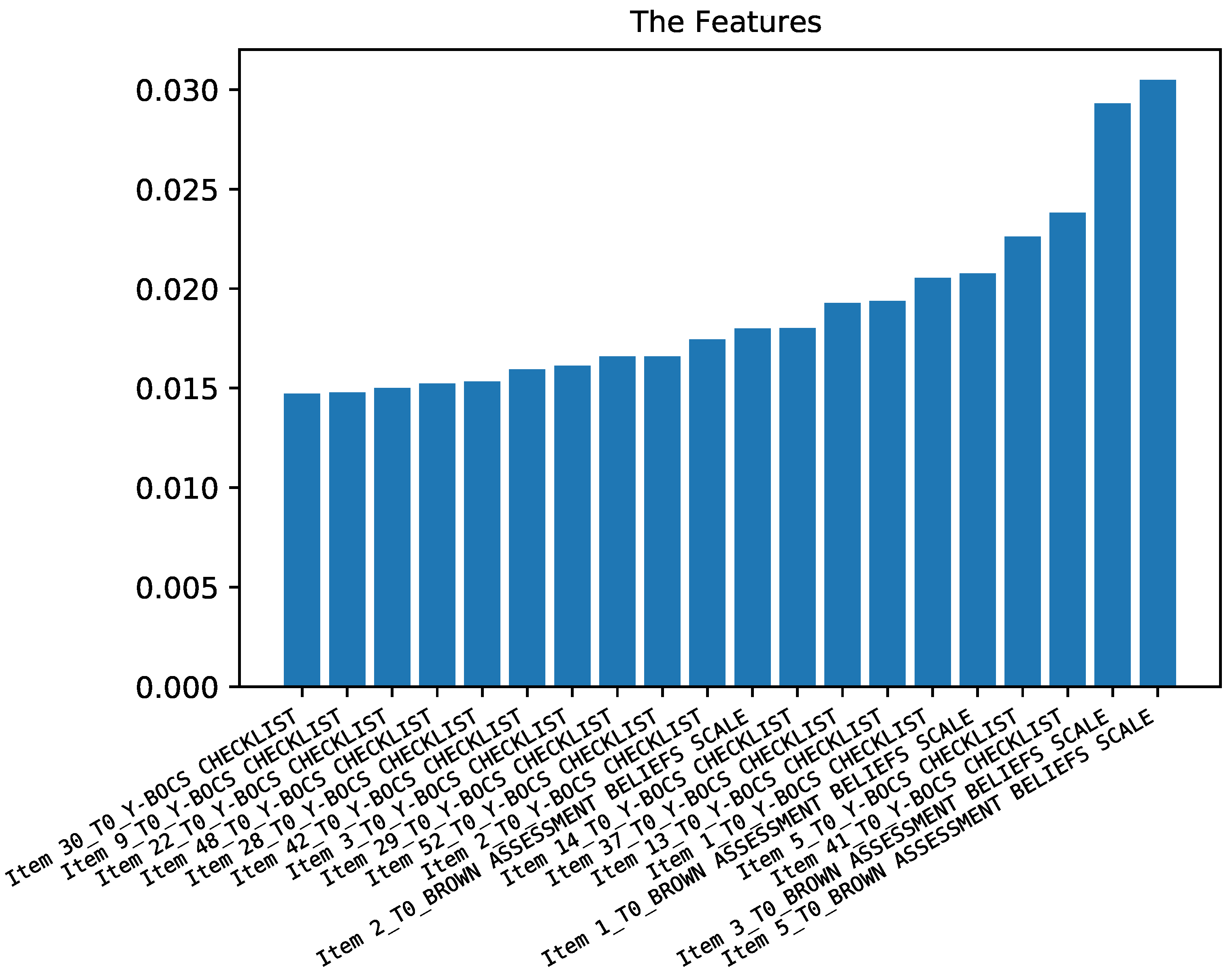
3.2.4. Predicting Belief Symptoms
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kesner, L.; Horáček, J. Three challenges that the COVID-19 pandemic represents for psychiatry. Br. J. Psychiatry 2020, 217, 475–476. [Google Scholar] [CrossRef]
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; McIntyre, R.S.; Choo, F.N.; Tran, B.; Ho, R.; Sharma, V.K.; et al. A longitudinal study on the mental health of general population during the COVID-19 epidemic in China. Brain, Behav. Immun. 2020, 87, 40–48. [Google Scholar] [CrossRef]
- Rossi, R.; Socci, V.; Talevi, D.; Mensi, S.; Niolu, C.; Pacitti, F.; Di Marco, A.; Rossi, A.; Siracusano, A.; Di Lorenzo, G. COVID-19 pandemic and lockdown measures impact on mental health among the general population in Italy. Front. Psychiatry 2020, 11, 790. [Google Scholar] [CrossRef]
- Fiorillo, A.; Sampogna, G.; Giallonardo, V.; Del Vecchio, V.; Luciano, M.; Albert, U.; Carmassi, C.; Carrà, G.; Cirulli, F.; Dell’Osso, B.; et al. Effects of the lockdown on the mental health of the general population during the COVID-19 pandemic in Italy: Results from the COMET collaborative network. Eur. Psychiatry 2020, 63, e87. [Google Scholar] [CrossRef]
- Giuntella, O.; Hyde, K.; Saccardo, S.; Sadoff, S. Lifestyle and mental health disruptions during COVID-19. Proc. Natl. Acad. Sci. USA 2021, 118, e2016632118. [Google Scholar] [CrossRef]
- Li, S.; Zhang, Y. Mental healthcare for psychiatric inpatients during the COVID-19 epidemic. Gen. Psychiatry 2020, 33, e100216. [Google Scholar] [CrossRef] [Green Version]
- Hao, F.; Tan, W.; Jiang, L.; Zhang, L.; Zhao, X.; Zou, Y.; Hu, Y.; Luo, X.; Jiang, X.; McIntyre, R.S.; et al. Do psychiatric patients experience more psychiatric symptoms during COVID-19 pandemic and lockdown? A case-control study with service and research implications for immunopsychiatry. Brain, Behav. Immun. 2020, 87, 100–106. [Google Scholar] [CrossRef]
- Iasevoli, F.; Fornaro, M.; D’Urso, G.; Galletta, D.; Casella, C.; Paternoster, M.; Buccelli, C.; de Bartolomeis, A.; in Psychiatry Study Group, C.; the COVID-19 in Psychiatry Study Group. Psychological distress in patients with serious mental illness during the COVID-19 outbreak and one-month mass quarantine in Italy. Psychol. Med. 2021, 51, 1054–1056. [Google Scholar] [CrossRef]
- Ready, R.E.; Watson, D.; Clark, L.A. Psychiatric patient–and informant-reported personality: Predicting concurrent and future behavior. Assessment 2002, 9, 361–372. [Google Scholar] [CrossRef]
- Rosenström, T.; Jylhä, P.; Cloninger, C.R.; Hintsanen, M.; Elovainio, M.; Mantere, O.; Pulkki-Råback, L.; Riihimäki, K.; Vuorilehto, M.; Keltikangas-Järvinen, L.; et al. Temperament and character traits predict future burden of depression. J. Affect. Disord. 2014, 158, 139–147. [Google Scholar] [CrossRef]
- Wang, Y.; Bhaskaran, J.; Sareen, J.; Bolton, S.L.; Chateau, D.; Bolton, J.M. Clinician prediction of future suicide attempts: A longitudinal study. Can. J. Psychiatry 2016, 61, 428–432. [Google Scholar] [CrossRef] [Green Version]
- Basu, S.; Verma, S.; Abdin, E. The evolution of depression in first-episode psychosis: A naturalistic database study. Clin. Psychol. Psychother. 2020, 27, 611–620. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.X.; Huang, H.; Li, J.; Antonelli-Ponti, M.; Paiva, S.F.d.; da Silva, J.A. Predictors of Depression and Anxiety Symptoms in Brazil during COVID-19. Int. J. Environ. Res. Public Health 2021, 18, 7026. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, H.; Zhang, Z.; Liu, T.; Xiong, N.N. Learning knowledge graph embedding with heterogeneous relation attention networks. IEEE Trans. Neural Netw. Learn. Syst. 2021. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zheng, C.; Li, D.; Shen, X.; Lin, K.; Wang, J.; Zhang, Z.; Zhang, Z.; Xiong, N.N. EDMF: Efficient Deep Matrix Factorization with Review Feature Learning for Industrial Recommender System. IEEE Trans. Ind. Inf. 2021. [Google Scholar] [CrossRef]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric Relation-aware Representation Learning for Head Pose Estimation in Industrial Human–machine Interaction. IEEE Trans. Ind. Inf. 2022. [Google Scholar] [CrossRef]
- Stein, D.J.; Costa, D.L.; Lochner, C.; Miguel, E.C.; Reddy, Y.; Shavitt, R.G.; van den Heuvel, O.A.; Simpson, H.B. Obsessive–compulsive disorder. Nat. Rev. Dis. Prim. 2019, 5, 1–21. [Google Scholar] [CrossRef] [Green Version]
- O’Donnell, M.L.; Agathos, J.A.; Metcalf, O.; Gibson, K.; Lau, W. Adjustment disorder: Current developments and future directions. Int. J. Environ. Res. Public Health 2019, 16, 2537. [Google Scholar] [CrossRef] [Green Version]
- Guzick, A.G.; Candelari, A.; Wiese, A.D.; Schneider, S.C.; Goodman, W.K.; Storch, E.A. Obsessive–Compulsive Disorder During the COVID-19 Pandemic: A Systematic Review. Curr. Psychiatry Rep. 2021, 23, 71. [Google Scholar] [CrossRef]
- Goodman, W.K.; Price, L.H.; Rasmussen, S.A.; Mazure, C.; Fleischmann, R.L.; Hill, C.L.; Heninger, G.R.; Charney, D.S. The Yale-Brown obsessive compulsive scale: I. Development, use, and reliability. Arch. Gen. Psychiatry 1989, 46, 1006–1011. [Google Scholar] [CrossRef]
- Eisen, J.L.; Phillips, K.A.; Baer, L.; Beer, D.A.; Atala, K.D.; Rasmussen, S.A. The brown assessment of beliefs scale: Reliability and validity. Am. J. Psychiatry 1998, 155, 102–108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beck, A.; Steer, R.; Brown, G. Beck Depression Inventory; The Psychological Corporation: San Antonio, TX, USA, 1987. [Google Scholar]
- Spielberger, C. State-trait anxiety inventory for adults (STAI-AD)[Database record]. APA PsycTests. 1983.
- Michalski, R.; Bratko, I.; Bratko, A. Machine Learning and Data Mining; Methods and Applications; John Wiley & Sons, Inc.: Chichester, UK, 1998. [Google Scholar]
- Luo, L.; Feng, B.; Yang, S.; Zhang, N.; Qiu, S. Clinical characteristics of moderate–severe obsessive–compulsive disorder in children and adolescents in China. J. Int. Med. Res. 2020, 48, 0300060520922679. [Google Scholar] [CrossRef]
- Kayikcioglu, O.; Bilgin, S.; Seymenoglu, G.; Deveci, A. State and trait anxiety scores of patients receiving intravitreal injections. Biomed. Hub 2017, 2, 478993. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 1–26. [Google Scholar] [CrossRef]
- Kim, Y.J.; Jeon, J.S.; Cho, S.E.; Kim, K.G.; Kang, S.G. Prediction Models for Obstructive Sleep Apnea in Korean Adults Using Machine Learning Techniques. Diagnostics 2021, 11, 612. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support vector machine versus random forest for remote sensing image classification: A meta-analysis and systematic review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly Media, Inc.: Newton, MA, USA, 2016. [Google Scholar]
- Dwyer, D.B.; Falkai, P.; Koutsouleris, N. Machine Learning Approaches for Clinical Psychology and Psychiatry. Annu. Rev. Clin. Psychol. 2018, 14, 91–118. [Google Scholar] [CrossRef]
- Urtnasan, E.; Joo, E.Y.; Lee, K.H. AI-Enabled Algorithm for Automatic Classification of Sleep Disorders Based on Single-Lead Electrocardiogram. Diagnostics 2021, 11, 2054. [Google Scholar] [CrossRef]









Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Urso, G.; Magliacano, A.; Rotbei, S.; Iasevoli, F.; de Bartolomeis, A.; Botta, A. Predicting the Severity of Lockdown-Induced Psychiatric Symptoms with Machine Learning. Diagnostics 2022, 12, 957. https://doi.org/10.3390/diagnostics12040957
D’Urso G, Magliacano A, Rotbei S, Iasevoli F, de Bartolomeis A, Botta A. Predicting the Severity of Lockdown-Induced Psychiatric Symptoms with Machine Learning. Diagnostics. 2022; 12(4):957. https://doi.org/10.3390/diagnostics12040957
Chicago/Turabian StyleD’Urso, Giordano, Alfonso Magliacano, Sayna Rotbei, Felice Iasevoli, Andrea de Bartolomeis, and Alessio Botta. 2022. "Predicting the Severity of Lockdown-Induced Psychiatric Symptoms with Machine Learning" Diagnostics 12, no. 4: 957. https://doi.org/10.3390/diagnostics12040957
APA StyleD’Urso, G., Magliacano, A., Rotbei, S., Iasevoli, F., de Bartolomeis, A., & Botta, A. (2022). Predicting the Severity of Lockdown-Induced Psychiatric Symptoms with Machine Learning. Diagnostics, 12(4), 957. https://doi.org/10.3390/diagnostics12040957