
Breast Dense Tissue Segmentation with Noisy Labels: A Hybrid Threshold-Based and Mask-Based Approach

 , ,
, ,  , , , ,
, , , ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
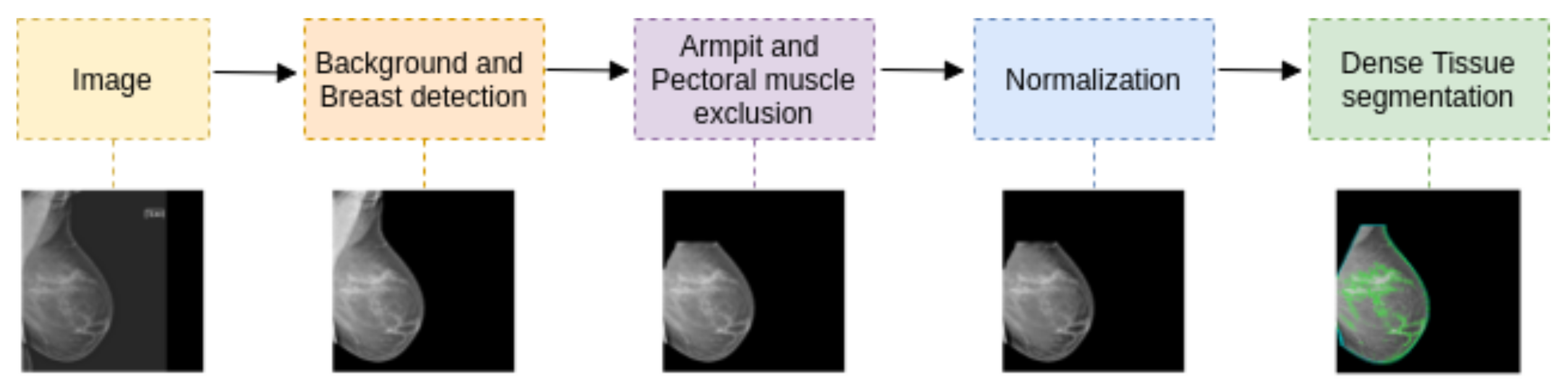
2.2. Segmentation Pipeline
2.2.1. Background and Breast Detection
2.2.2. Armpit and Pectoral Muscle Exclusion
2.2.3. Histogram Normalization
- 1.
- Normalize the pixel values of the image between .
- 2.
- Shift the histogram to set the minimum breast tissue pixel to 0.
- 3.
- Normalize the pixel values again between .
- 4.
- Standardize the breast pixel values to a normal distribution Z∼.
- 5.
- Adjust the pixel values so that the mode is 0.
- 6.
- Assuming that most typical percent density values are below (above the 70th percentile), and values under the 30th percentile only belong to fatty tissue, apply a linear stretching from percentile 30 to and from percentile 70 to 1.
- 7.
- Apply oa normalization once more to ensure the inputs for the deep neural network are between .
2.3. Dense Tissue Segmentation
2.3.1. ECNN: Parameter Estimation
2.3.2. U-Net: Mask Estimation
2.3.3. Y-Net: Hybrid Approach
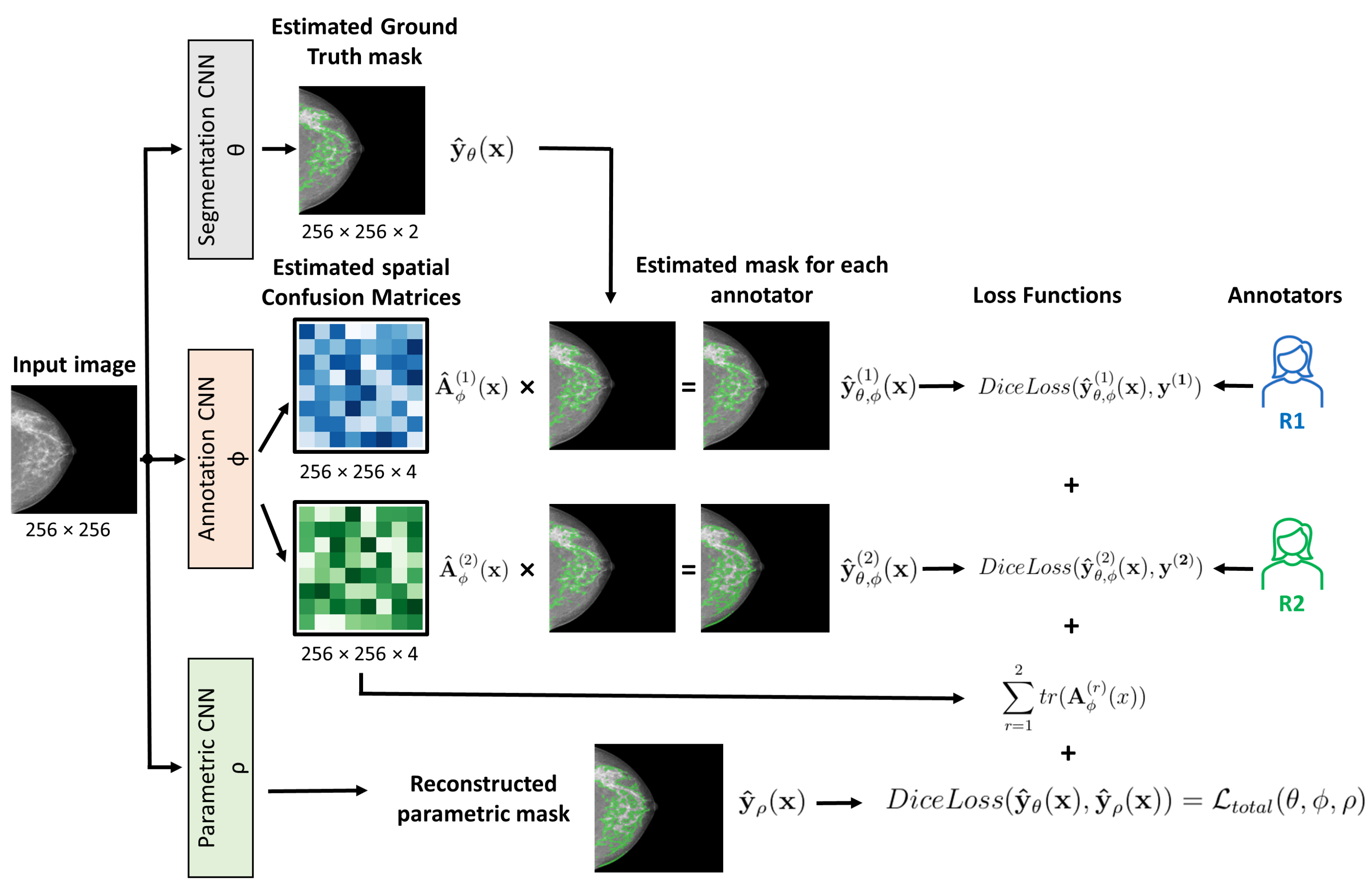
2.3.4. CM-Segmentation: Learning Noisy Labels
- 1.
- The first is the segmentation network that estimates the true segmentation.
- 2.
- The second is the annotation network that models the characteristics of individual experts by estimating the pixel-wise confusion matrices (CM).
2.3.5. CM-YNet: Proposed Network
2.4. Implementation Details
- Using the segmentation of both radiologists as independent annotations. Each image is seen twice during training with this approach, thus doubling the training corpus.
- Using the AND mask as the ground-truth label, obtained as the pixel-wise intersection of both annotations.
- Using the CM approach described in Section 2.3.4.
2.5. Evaluation
3. Results
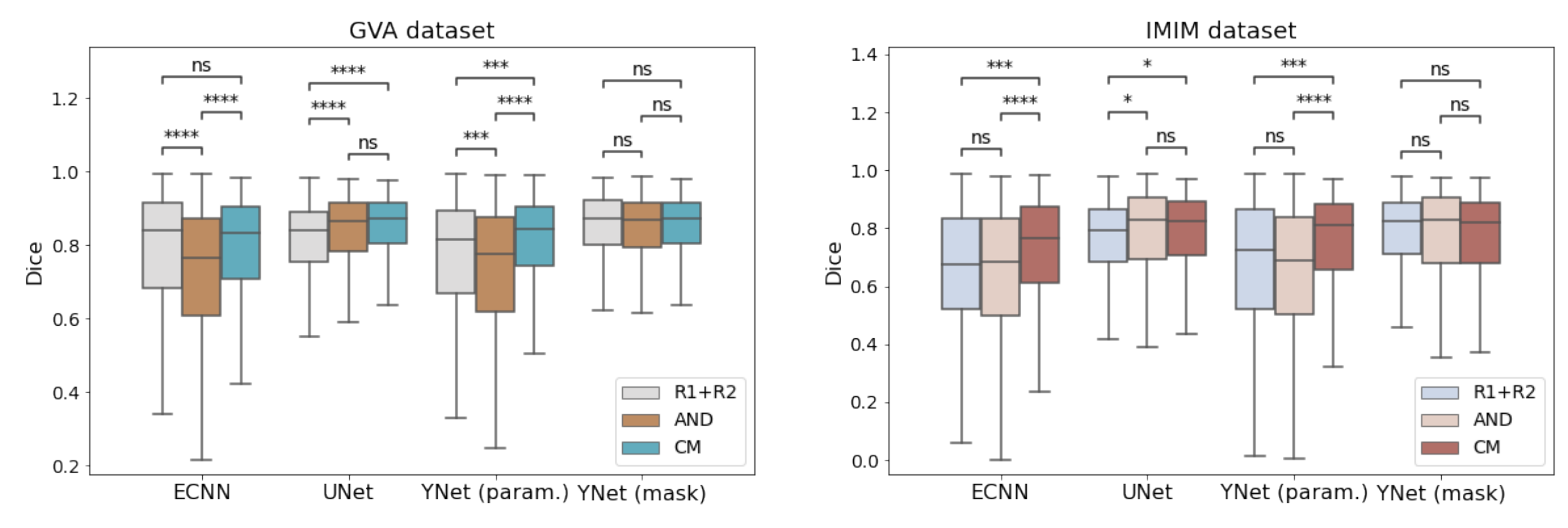
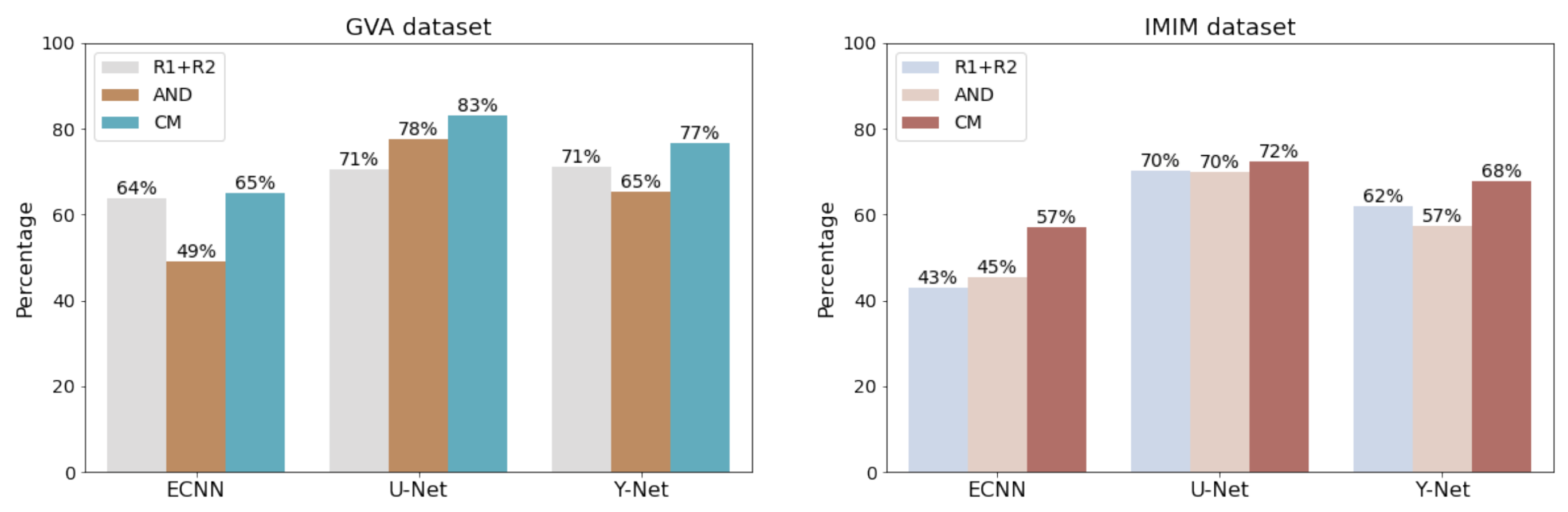
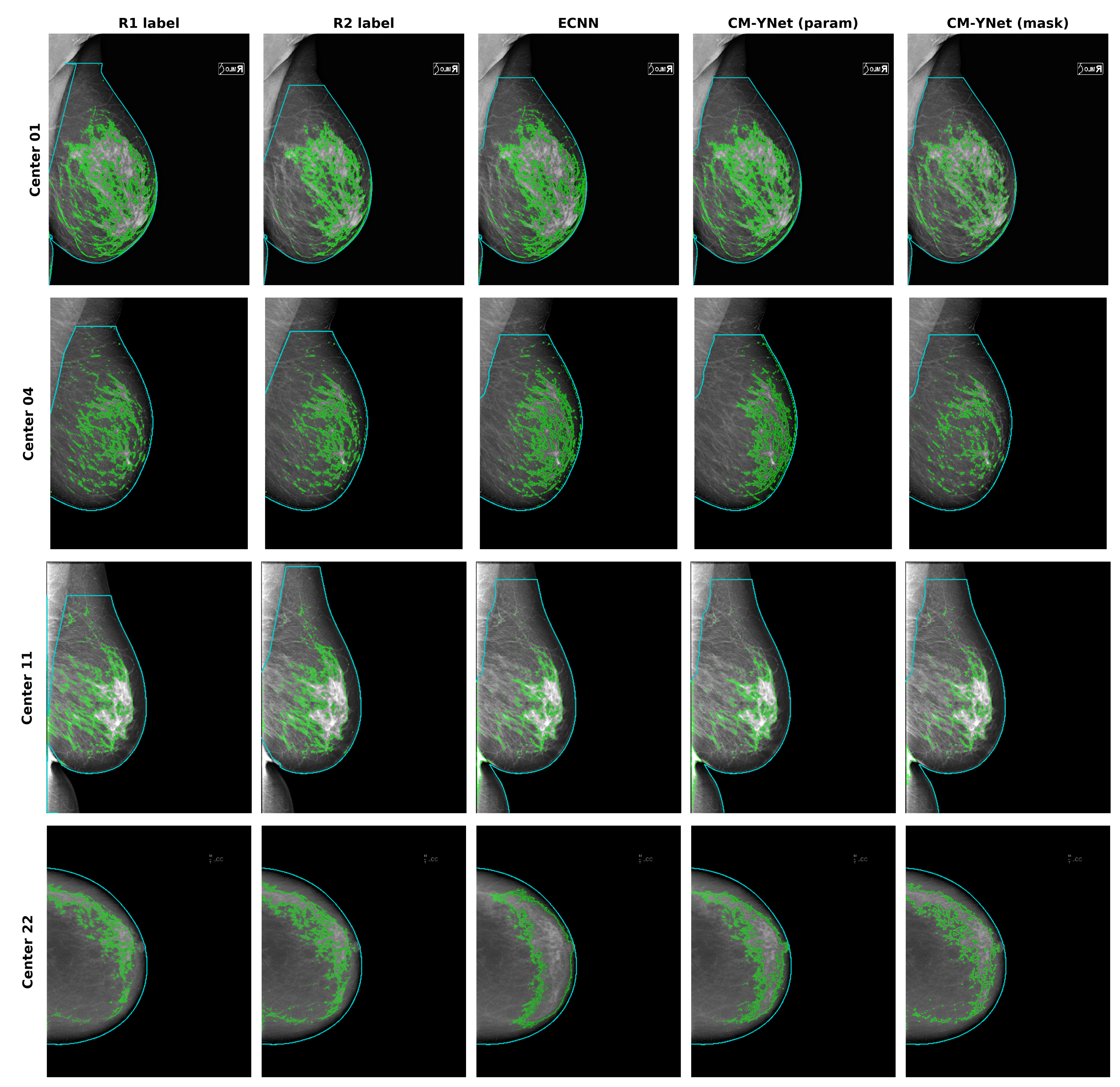
3.1. Comparison of Different Models
- 1.
- The CM versions for ECNN, U-Net and Y-Net were more stable as they showed lower errors.
- 2.
- Including more images for training with labels from different annotators is straightforward due to the network configuration. This functionality allows for easy improvement of the model generalization by adding images from other centers in “for presentation” or “for processing” formats.
- 3.
- The overall performance (parametric and mask outputs) was better than for the other methods as shown in Figure 5.
3.2. Comparison per Acquisition Device
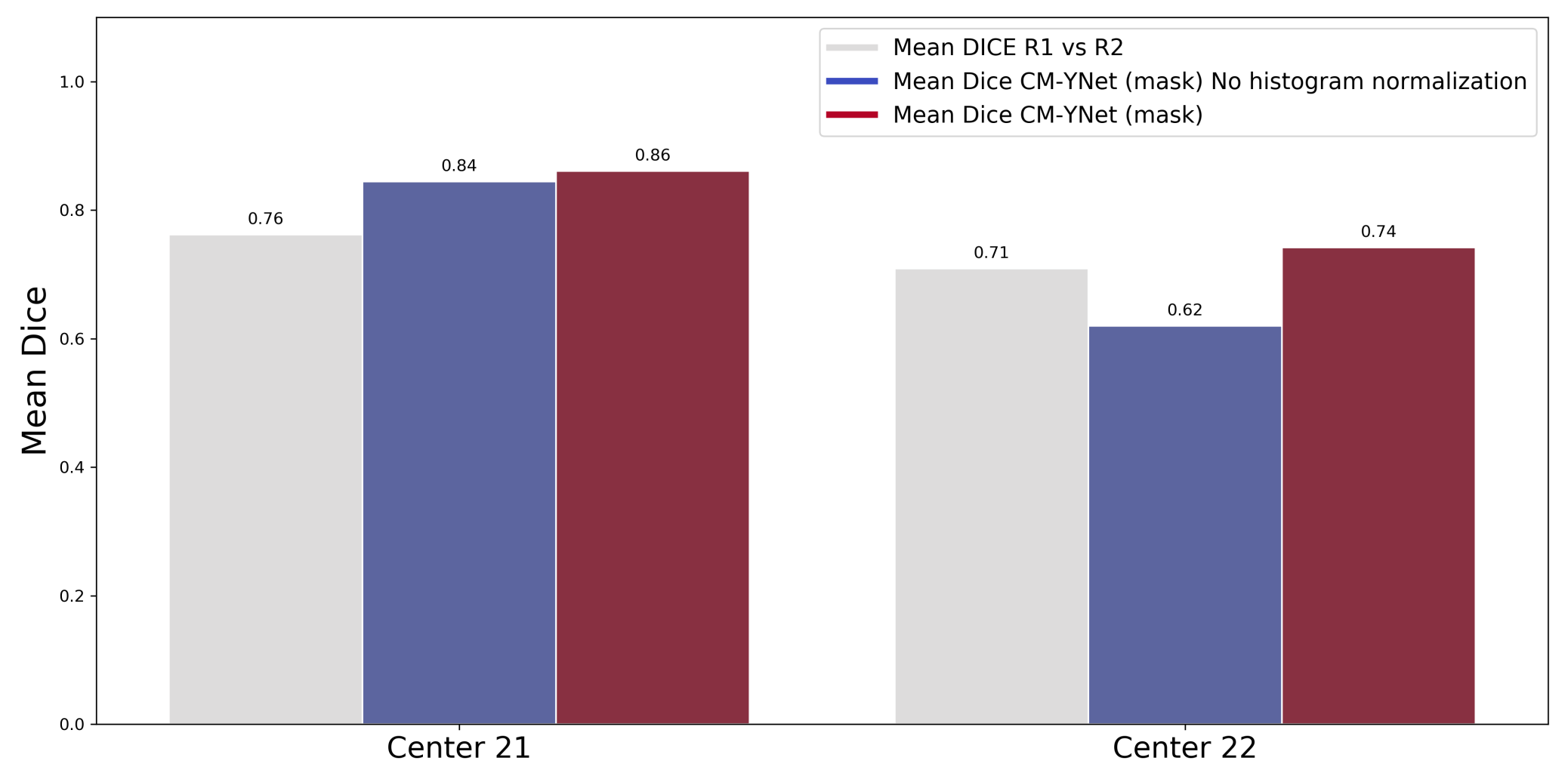
3.3. Histogram Normalization Importance
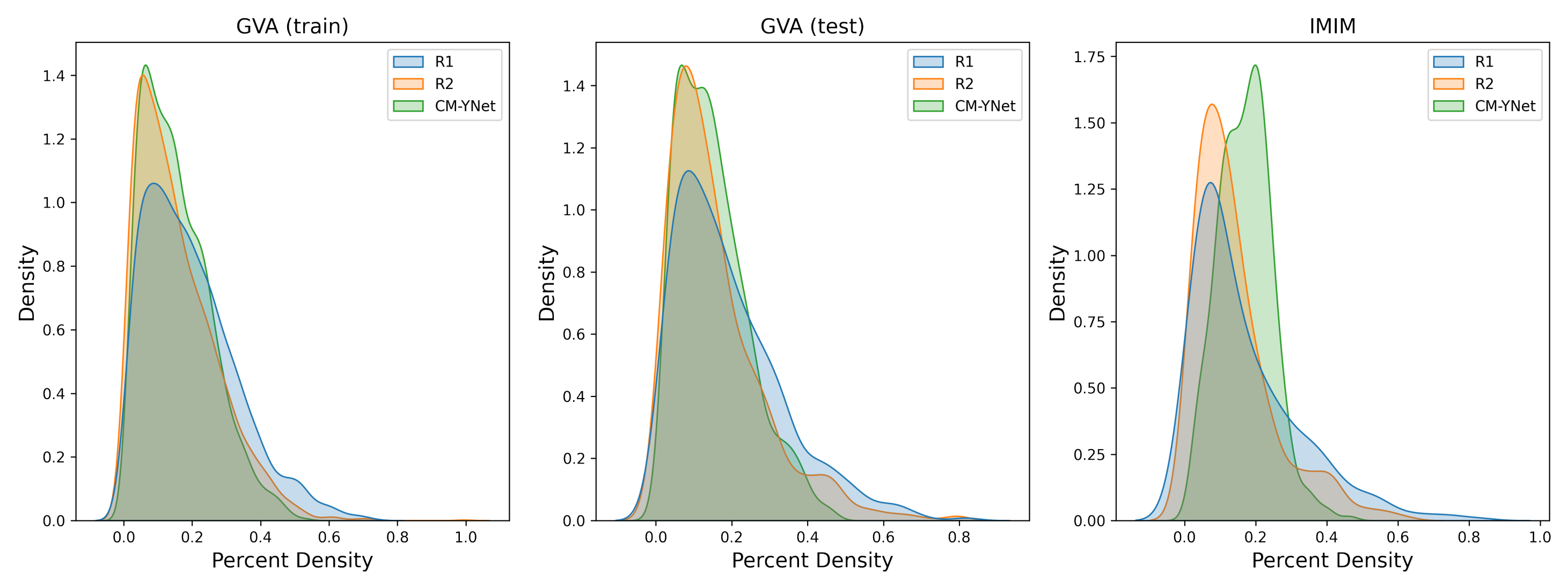
3.4. Percent Density Estimation
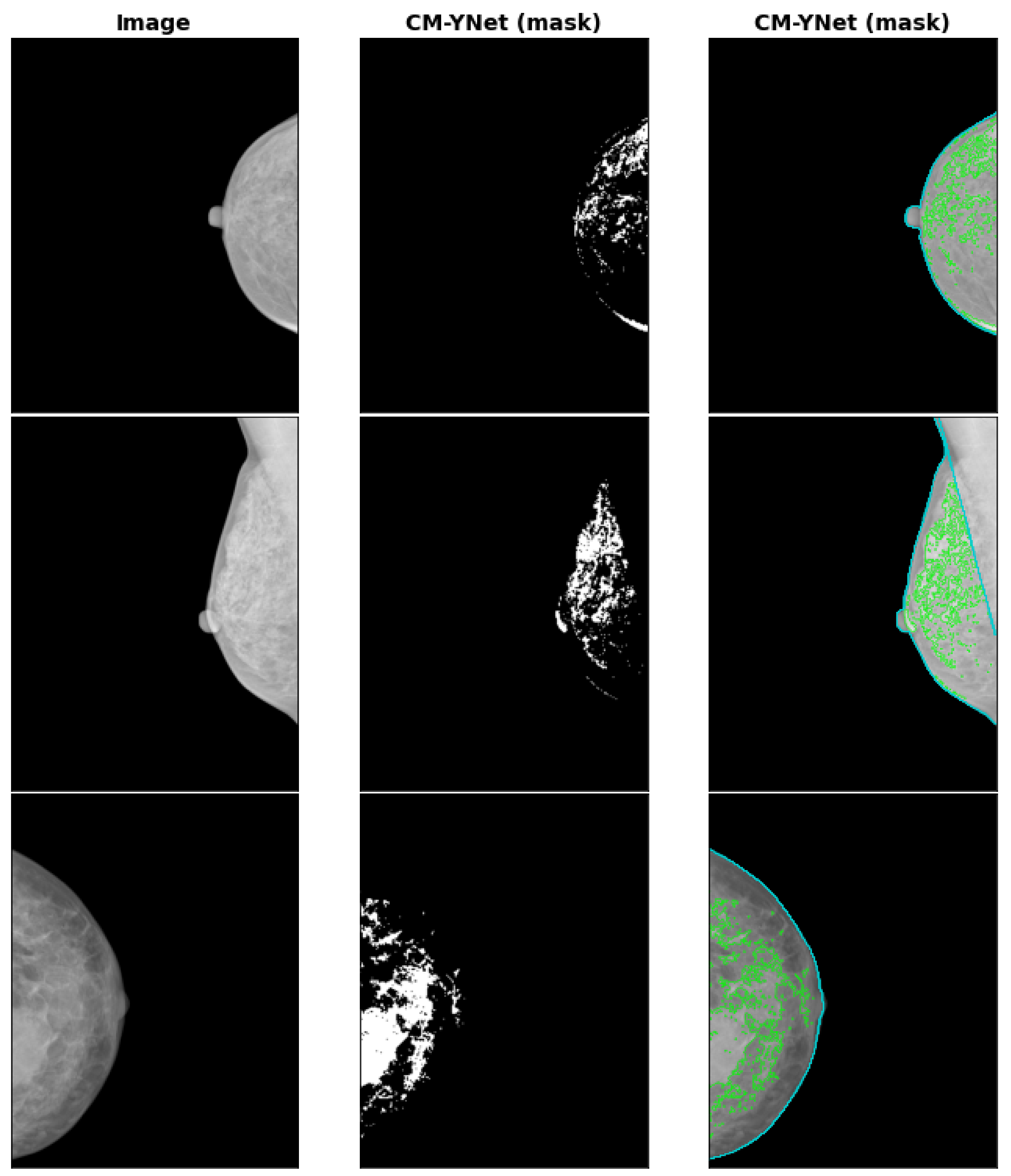
3.5. INbreast Dataset
4. Discussion
- 1.
- Improvement of the previously presented ECNN model with the CM-YNet architecture that jointly estimates the segmentation parameters, segmentation mask at the pixel level, and the confusion matrices of each expert annotator.
- 2.
- Validation of the importance of the preprocessing protocol that standardizes the histograms of breast images. This preprocessing reduces the impact of using different acquisition devices, especially when images acquired with a specific device were never seen during training.
- 3.
- The inclusion of a totally independent dataset used only for testing. This dataset allowed us to further corroborate the validity of our multi-center study showing that the generalization performance was still acceptable () even for low-quality images, such as those of Center 22.
- 4.
- The approach followed achieves higher performance than the concordance between the radiologists and also makes it easy for a radiologist to perform a fine-tuning of the results by interactively modifying the segmentation parameters using a threshold-based tool.
Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kuhl, C.K. The Changing World of Breast Cancer: A Radiologist’s Perspective. Investig. Radiol. 2015, 50, 615–628. [Google Scholar] [CrossRef] [PubMed]
- Boyd, N.F.; Rommens, J.M.; Vogt, K.; Lee, V.; Hopper, J.L.; Yaffe, M.J.; Paterson, A.D. Mammographic breast density as an intermediate phenotype for breast cancer. Lancet Oncol. 2005, 6, 798–808. [Google Scholar] [CrossRef]
- Assi, V.; Warwick, J.; Cuzick, J.; Duffy, S.W. Clinical and epidemiological issues in mammographic density. Nat. Rev. Clin. Oncol. 2012, 9, 33–40. [Google Scholar] [CrossRef]
- D’Orsi, C.J.; Sickles, E.; Mendelson, E.; Morris, E. ACR BI-RADS® Atlas, Breast Imaging Reporting and Data System; American College of Radiology: Reston, VA, USA, 2013. [Google Scholar]
- Oliver, A.; Freixenet, J.; MartÍ, R.; Pont, J.; PÉrez, E.; Denton, E.R.E.; Zwiggelaar, R. A Novel Breast Tissue Density Classification Methodology. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 55–65. [Google Scholar] [CrossRef]
- Pérez-Benito, F.J.; Signol, F.; Pérez-Cortés, J.C.; Pollán, M.; Pérez-Gómez, B.; Salas-Trejo, D.; Casals, M.; Martínez, I.; Llobet, R. Global parenchymal texture features based on histograms of oriented gradients improve cancer development risk estimation from healthy breasts. Comput. Methods Programs Biomed. 2019, 177, 123–132. [Google Scholar] [CrossRef]
- Ciatto, S.; Houssami, N.; Apruzzese, A.; Bassetti, E.; Brancato, B.; Carozzi, F.; Catarzi, S.; Lamberini, M.; Marcelli, G.; Pellizzoni, R.; et al. Categorizing breast mammographic density: Intra- and interobserver reproducibility of BI-RADS density categories. Breast 2005, 14, 269–275. [Google Scholar] [CrossRef]
- Skaane, P. Studies comparing screen-film mammography and full-field digital mammography in breast cancer screening: Updated review. Acta Radiol. 2009, 50, 3–14. [Google Scholar] [CrossRef]
- Van der Waal, D.; den Heeten, G.J.; Pijnappel, R.M.; Schuur, K.H.; Timmers, J.M.; Verbeek, A.L.; Broeders, M.J. Comparing visually assessed BI-RADS breast density and automated volumetric breast density software: A cross-sectional study in a breast cancer screening setting. PLoS ONE 2015, 10, e0136667. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.H.; Lee, E.H.; Jun, J.K.; Kim, Y.M.; Chang, Y.W.; Lee, J.H.; Kim, H.W.; Choi, E.J.; the Alliance for Breast Cancer Screening in Korea. Interpretive Performance and Inter-Observer Agreement on Digital Mammography Test Sets. Korean J. Radiol. 2019, 20, 218–224. [Google Scholar] [CrossRef]
- Geras, K.J.; Mann, R.M.; Moy, L. Artificial Intelligence for Mammography and Digital Breast Tomosynthesis: Current Concepts and Future Perspectives. Radiology 2019, 293, 246–259. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Tompson, J.; Goroshin, R.; Jain, A.; LeCun, Y.; Bregler, C. Efficient object localization using Convolutional Networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 648–656. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. arXiv 2014, arXiv:1312.6229. [Google Scholar]
- Pérez-Benito, F.J.; Signol, F.; Perez-Cortes, J.C.; Fuster-Baggetto, A.; Pollan, M.; Pérez-Gómez, B.; Salas-Trejo, D.; Casals, M.; Martínez, I.; Llobet, R. A deep learning system to obtain the optimal parameters for a threshold-based breast and dense tissue segmentation. Comput. Methods Programs Biomed. 2020, 195, 105668. [Google Scholar] [CrossRef]
- Zhang, L.; Tanno, R.; Xu, M.C.; Jin, C.; Jacob, J.; Ciccarelli, O.; Barkhof, F.; Alexander, D.C. Disentangling Human Error from the Ground Truth in Segmentation of Medical Images. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS’20, Online, 6–12 December 2020; Curran Associates Inc.: Red Hook, NY, USA, 2020; pp. 15750–15762. [Google Scholar]
- Mehta, S.; Mercan, E.; Bartlett, J.; Weaver, D.; Elmore, J.G.; Shapiro, L. Y-Net: Joint Segmentation and Classification for Diagnosis of Breast Biopsy Images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI, 16–20 September 2018; Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer: Granada, Spain, 2018; pp. 893–901. [Google Scholar]
- Pollán, M.; Llobet, R.; Miranda-García, J.; Antón, J.; Casals, M.; Martínez, I.; Palop, C.; Ruiz-Perales, F.; Sánchez-Contador, C.; Vidal, C.; et al. Validation of DM-Scan, a computer-assisted tool to assess mammographic density in full-field digital mammograms. Springerplus 2013, 2, 242. [Google Scholar] [CrossRef]
- Llobet, R.; Pollán, M.; Antón, J.; Miranda-García, J.; Casals, M.; Martínez, I.; Ruiz-Perales, F.; Pérez-Gómez, B.; Salas-Trejo, D.; Pérez-Cortés, J.C. Semi-automated and fully automated mammographic density measurement and breast cancer risk prediction. Comput. Methods Programs Biomed. 2014, 116, 105–115. [Google Scholar] [CrossRef]
- Wu, K.; Otoo, E.; Suzuki, K. Optimizing two-pass connected-component labeling algorithms. Pattern Anal. Appl. 2009, 12, 117–135. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance Normalization: The Missing Ingredient for Fast Stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Dice, L.R. Measures of the amount of ecologic association between species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. INbreast: Toward a Full-field Digital Mammographic Database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef]
- Wu, N.; Geras, K.J.; Shen, Y.; Su, J.; Kim, S.G.; Kim, E.; Wolfson, S.; Moy, L.; Cho, K. Breast Density Classification with Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6682–6686. [Google Scholar]
- Lehman, C.D.; Yala, A.; Schuster, T.; Dontchos, B.; Bahl, M.; Swanson, K.; Barzilay, R. Mammographic breast density assessment using deep learning: Clinical implementation. Radiology 2018, 290, 52–58. [Google Scholar] [CrossRef] [PubMed]
- Kallenberg, M.; Petersen, K.; Nielsen, M.; Ng, A.Y.; Diao, P.; Igel, C.; Vachon, C.M.; Holland, K.; Winkel, R.R.; Karssemeijer, N.; et al. Unsupervised Deep Learning Applied to Breast Density Segmentation and Mammographic Risk Scoring. IEEE Trans. Med. Imaging 2016, 35, 1322–1331. [Google Scholar] [CrossRef]
- Lee, J.; Nishikawa, R.M. Automated mammographic breast density estimation using a fully convolutional network. Med. Phys. 2018, 45, 1178–1190. [Google Scholar] [CrossRef]
- Saffari, N.; Rashwan, H.A.; Abdel-Nasser, M.; Singh, V.K.; Arenas, M.; Mangina, E.; Herrera, B.; Puig, D. Fully Automated Breast Density Segmentation and Classification Using Deep Learning. Diagnostics 2020, 10, 988. [Google Scholar] [CrossRef] [PubMed]
- Haji Maghsoudi, O.; Gastounioti, A.; Scott, C.; Pantalone, L.; Wu, F.F.; Cohen, E.A.; Winham, S.; Conant, E.F.; Vachon, C.; Kontos, D. Deep-LIBRA: An artificial-intelligence method for robust quantification of breast density with independent validation in breast cancer risk assessment. Med. Image Anal. 2021, 73, 102138. [Google Scholar] [CrossRef] [PubMed]
- Boyd, N.F.; Guo, H.; Martin, L.J.; Sun, L.; Stone, J.; Fishell, E.; Jong, R.A.; Hislop, G.; Chiarelli, A.; Minkin, S.; et al. Mammographic Density and the Risk and Detection of Breast Cancer. N. Engl. J. Med. 2007, 356, 227–236. [Google Scholar] [CrossRef] [PubMed]
- Williams, A.D.; So, A.; Synnestvedt, M.; Tewksbury, C.M.; Kontos, D.; Hsiehm, M.K.; Pantalone, L.; Conant, E.F.; Schnall, M.; Dumon, K.; et al. Mammographic breast density decreases after bariatric surgery. Breast Cancer Res. Treat. 2017, 165, 565–572. [Google Scholar] [CrossRef]
- Wood, M.E.; Sprague, B.L.; Oustimov, A.; Synnstvedt, M.B.; Cuke, M.; Conant, E.F.; Kontos, D. Aspirin use is associated with lower mammographic density in a large screening cohort. Breast Cancer Res. Treat. 2017, 162, 419–425. [Google Scholar] [CrossRef]
- Aiello, M.; Cavaliere, C.; D’Albore, A.; Salvatore, M. The Challenges of Diagnostic Imaging in the Era of Big Data. J. Clin. Med. 2019, 8, 316. [Google Scholar] [CrossRef] [PubMed]
- Warfield, S.K.; Zou, K.H.; Wells, W.M. Simultaneous truth and performance level estimation (staple): An algorithm for the validation of image segmentation. IEEE Trans. Med. Imaging 2004, 23, 903–921. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Center | Device | #Women | #Images |
|---|---|---|---|---|
| 01 | Castellón | FUJIFILM | 191 | 382 |
| 02 | Fuente de San Luis | FUJIFILM | 190 | 380 |
| 04 | Alcoi | IMS s.r.l./Giotto IRE (*) | 66 | 132 |
| 05 | Xàtiva | FUJIFILM | 159 | 318 |
| 07 | Requena | HOLOGIC/Giotto IRE (*) | 28 | 56 |
| 10 | Elda | SIEMENS/Giotto IRE (*) | 311 | 622 |
| 11 | Elche | FUJIFILM | 278 | 556 |
| 13 | Orihuela | FUJIFILM | 117 | 234 |
| 18 | Denia | IMS s.r.l./Giotto IRE (*) | 38 | 76 |
| 20 | Serrería | (**) | 177 | 354 |
| 99 | Burjassot | Senography 2000D | 230 | 230 |
| 21 | IMIM-1 | FUJIFILM | 98 | 98 |
| 22 | IMIM-2 | Lorad/Hologic Selenia | 283 | 283 |
| Total | 2166 | 3721 |
| GVA Dataset | ||||
|---|---|---|---|---|
| Model | R1 vs. Model | R2 vs. Model | AND vs. Model | Closest Radiologist |
| ECNN | 0.71 ± 0.23 | 0.72 ± 0.23 | 0.72 ± 0.23 | 0.77 ± 0.21 |
| UNet | 0.76 ± 0.15 | 0.76 ± 0.15 | 0.76 ± 0.16 | 0.81 ± 0.12 |
| YNet (param.) | 0.70 ± 0.21 | 0.70 ± 0.21 | 0.70 ± 0.22 | 0.75 ± 0.20 |
| YNet (mask) | 0.80 ± 0.14 | 0.78 ± 0.15 | 0.78 ± 0.16 | 0.84 ± 0.12 |
| AND-ECNN | 0.68 ± 0.21 | 0.64 ± 0.21 | 0.62 ± 0.22 | 0.72 ± 0.20 |
| AND-UNet | 0.76 ± 0.15 | 0.79 ± 0.15 | 0.81 ± 0.14 | 0.83 ± 0.12 |
| AND-YNet (param.) | 0.65 ± 0.22 | 0.68 ± 0.22 | 0.69 ± 0.23 | 0.72 ± 0.21 |
| AND-YNet (mask) | 0.77 ± 0.15 | 0.79 ± 0.15 | 0.82 ± 0.14 | 0.84 ± 0.12 |
| CM-ECNN | 0.71 ± 0.20 | 0.72 ± 0.20 | 0.73 ± 0.20 | 0.78 ± 0.18 |
| CM-UNet | 0.80 ± 0.13 | 0.80 ± 0.13 | 0.79 ± 0.15 | 0.85 ± 0.10 |
| CM-YNet (param.) | 0.73 ± 0.18 | 0.75 ± 0.17 | 0.77 ± 0.17 | 0.80 ± 0.15 |
| CM-YNet (mask) | 0.79 ± 0.13 | 0.80 ± 0.13 | 0.79 ± 0.15 | 0.84 ± 0.10 |
| IMIM Dataset | ||||
| Model | R1 vs. Model | R2 vs. Model | AND vs. Model | Closest Radiologist |
| ECNN | 0.58 ± 0.24 | 0.59 ± 0.23 | 0.55 ± 0.25 | 0.65 ± 0.23 |
| UNet | 0.67 ± 0.22 | 0.69 ± 0.18 | 0.64 ± 0.23 | 0.74 ± 0.18 |
| YNet (param.) | 0.60 ± 0.27 | 0.60 ± 0.24 | 0.56 ± 0.27 | 0.66 ± 0.25 |
| YNet (mask) | 0.69 ± 0.24 | 0.69 ± 0.20 | 0.64 ± 0.24 | 0.76 ± 0.20 |
| AND-ECNN | 0.58 ± 0.26 | 0.57 ± 0.23 | 0.51 ± 0.26 | 0.64 ± 0.24 |
| AND-UNet | 0.68 ± 0.24 | 0.72 ± 0.21 | 0.68 ± 0.25 | 0.76 ± 0.20 |
| AND-YNet (param.) | 0.58 ± 0.26 | 0.60 ± 0.24 | 0.57 ± 0.26 | 0.65 ± 0.24 |
| AND-YNet (mask) | 0.68 ± 0.24 | 0.71 ± 0.21 | 0.68 ± 0.24 | 0.76 ± 0.21 |
| CM-ECNN | 0.63 ± 0.25 | 0.65 ± 0.21 | 0.60 ± 0.25 | 0.71 ± 0.21 |
| CM-UNet | 0.69 ± 0.22 | 0.72 ± 0.18 | 0.66 ± 0.24 | 0.77 ± 0.17 |
| CM-YNet (param.) | 0.67 ± 0.23 | 0.69 ± 0.20 | 0.65 ± 0.23 | 0.74 ± 0.19 |
| CM-YNet (mask) | 0.68 ± 0.23 | 0.70 ± 0.19 | 0.64 ± 0.24 | 0.76 ± 0.18 |
| Center Id | #Images | R1 vs. R2 | ECNN | CM-YNet (param.) | CM-YNet (mask) |
|---|---|---|---|---|---|
| 01 | 96 | 079 ± 0.16 | 0.81 ± 0.16 | 0.75 ± 0.19 | 0.81 ± 0.11 |
| 02 | 96 | 0.79 ± 0.14 | 0.83 ± 0.15 | 0.81 ± 0.15 | 0.83 ± 0.13 |
| 04 | 34 | 0.75 ± 0.17 | 0.57 ± 0.23 | 0.74 ± 0.20 | 0.83 ± 0.08 * |
| 05 | 80 | 0.64 ± 0.17 | 0.84 ± 0.13 | 0.81 ± 0.16 | 0.84 ± 0.10 |
| 07 | 14 | 0.88 ± 0.15 | 0.85 ± 0.15 | 0.73 ± 0.18 | 0.82 ± 0.14 |
| 10 | 156 | 0.77 ± 0.16 | 0.68 ± 0.24 | 0.79 ± 0.15 | 0.85 ± 0.10 * |
| 11 | 140 | 0.82 ± 0.12 | 0.87 ± 0.10 | 0.84 ± 0.10 | 0.87 ± 0.07 |
| 13 | 60 | 0.78 ± 0.12 | 0.86 ± 0.12 | 0.82 ± 0.13 | 0.86 ± 0.11 |
| 18 | 20 | 0.74 ± 0.14 | 0.51 ± 0.27 | 0.80 ± 0.13 | 0.86 ± 0.08 * |
| 20 | 90 | 0.78 ± 0.16 | 0.61 ± 0.27 | 0.78 ± 0.16 | 0.83 ± 0.12 * |
| 99 | 58 | 0.79 ± 0.13 | 0.78 ± 0.20 | 0.83 ± 0.13 | 0.89 ± 0.09 * |
| 21 | 98 | 0.76 ± 0.14 | 0.80 ± 0.15 | 0.82 ± 0.17 | 0.86 ± 0.10 |
| 22 | 283 | 0.71 ± 0.22 | 0.59 ± 0.22 | 0.72 ± 0.19 | 0.74 ± 0.19 * |
| Total | 1225 | 0.76 ± 0.17 | 0.73 ± 0.22 | 0.78 ± 0.17 | 0.82 ± 0.14 |
| Dataset | #Images | R1 vs. R2 | PD-R1 | PD-R2 | %(R1 > R2) | GED |
|---|---|---|---|---|---|---|
| GVA(train) | 2496 | 0.76 ± 0.17 | 0.19 ± 0.13 * | 0.16 ± 0.12 | 73.31 | 3.13 ± 0.44 |
| GVA(test) | 844 | 0.77 ± 0.15 | 0.19 ± 0.14 * | 0.16 ± 0.13 | 68.36 | 3.16 ± 0.40 |
| IMIM | 381 | 0.72 ± 0.20 | 0.17 ± 0.15 | 0.14 ± 0.11 | 62.2 | 2.80 ± 0.56 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larroza, A.; Pérez-Benito, F.J.; Perez-Cortes, J.-C.; Román, M.; Pollán, M.; Pérez-Gómez, B.; Salas-Trejo, D.; Casals, M.; Llobet, R. Breast Dense Tissue Segmentation with Noisy Labels: A Hybrid Threshold-Based and Mask-Based Approach. Diagnostics 2022, 12, 1822. https://doi.org/10.3390/diagnostics12081822
Larroza A, Pérez-Benito FJ, Perez-Cortes J-C, Román M, Pollán M, Pérez-Gómez B, Salas-Trejo D, Casals M, Llobet R. Breast Dense Tissue Segmentation with Noisy Labels: A Hybrid Threshold-Based and Mask-Based Approach. Diagnostics. 2022; 12(8):1822. https://doi.org/10.3390/diagnostics12081822
Chicago/Turabian StyleLarroza, Andrés, Francisco Javier Pérez-Benito, Juan-Carlos Perez-Cortes, Marta Román, Marina Pollán, Beatriz Pérez-Gómez, Dolores Salas-Trejo, María Casals, and Rafael Llobet. 2022. "Breast Dense Tissue Segmentation with Noisy Labels: A Hybrid Threshold-Based and Mask-Based Approach" Diagnostics 12, no. 8: 1822. https://doi.org/10.3390/diagnostics12081822