Abstract
Diabetic retinopathy (DR) is an ophthalmological disease that causes damage in the blood vessels of the eye. DR causes clotting, lesions or haemorrhage in the light-sensitive region of the retina. Person suffering from DR face loss of vision due to the formation of exudates or lesions in the retina. The detection of DR is critical to the successful treatment of patients suffering from DR. The retinal fundus images may be used for the detection of abnormalities leading to DR. In this paper, an automated ensemble deep learning model is proposed for the detection and classification of DR. The ensembling of a deep learning model enables better predictions and achieves better performance than any single contributing model. Two deep learning models, namely modified DenseNet101 and ResNeXt, are ensembled for the detection of diabetic retinopathy. The ResNeXt model is an improvement over the existing ResNet models. The model includes a shortcut from the previous block to next block, stacking layers and adapting split–transform–merge strategy. The model has a cardinality parameter that specifies the number of transformations. The DenseNet model gives better feature use efficiency as the dense blocks perform concatenation. The ensembling of these two models is performed using normalization over the classes followed by maximum a posteriori over the class outputs to compute the final class label. The experiments are conducted on two datasets APTOS19 and DIARETDB1. The classifications are carried out for both two classes and five classes. The images are pre-processed using CLAHE method for histogram equalization. The dataset has a high-class imbalance and the images of the non-proliferative type are very low, therefore, GAN-based augmentation technique is used for data augmentation. The results obtained from the proposed method are compared with other existing methods. The comparison shows that the proposed method has higher accuracy, precision and recall for both two classes and five classes. The proposed method has an accuracy of 86.08 for five classes and 96.98% for two classes. The precision and recall for two classes are 0.97. For five classes also, the precision and recall are high, i.e., 0.76 and 0.82, respectively.
1. Introduction
Diabetes is a chronic disease that occurs either when the pancreas does not produce enough insulin or when the body cannot effectively use the insulin it produces. In this case, the glucose level in the blood becomes high, leading to multiple problems. It is reported that about 10% of the total world’s population is suffering from diabetes (WHO). This number is increasing rapidly and is expected to increase manifold in the coming years. Diabetes affects other body organs and systems. Specifically, the nerves and the blood vessels are most affected. The vision of diabetic persons is often affected due to diabetic retinopathy (DR). This is an eye condition that leads to vision loss and blindness. The blood vessels of the retina are damaged leading to the formation of exudates. These exudates lead to a loss in the vision of the affected person. In the early stages of DR, the symptoms may go unnoticed or be misinterpreted. A few patients may feel a minor alteration in their vision, for example, difficulty in reading or seeing objects that are far away. However, in the advanced stages of DR, the blood vessels of the retina start bleeding and, thus, a gel-like fluid fills up the eyes. Due to this, spots or streaks appear in the eyes, leading to loss of vision. There are two main stages of diabetic retinopathy, known as non-proliferative and proliferative diabetic retinopathy. The early stage of DR is known as non-proliferative diabetic retinopathy (NPDR). In this stage, tiny blood vessels leak, leading to swelling in the retina. In case of NPDR, the vision becomes blurry due to the presence of exudates. The advanced stage is known as proliferative diabetic retinopathy (PDR). In this condition, the blood vessels bleed. If the bleeding is high, the vision becomes blocked. Figure 1 shows the images of a normal eye and an eye affected with DR.
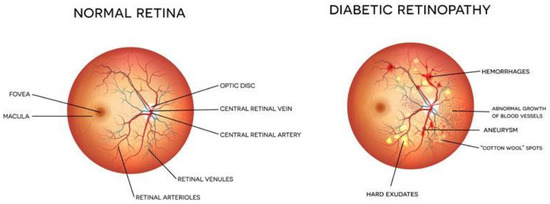
Figure 1.
Eye structure and presence of DR [Image credit https://www.eyeops.com/, accessed on 20 September 2022].
The early detection of DR in patients helps in their treatment. Thus, various automated tools and advanced techniques are available in the literature for automated detection of DR from retinal images. In this paper, a deep learning-based approach is proposed for the detection and classification of DR from retinal images. In the next section, a literature review of the existing techniques for exudate detection is discussed.
2. Literature Review
Detection of diabetic retinopathy is critical in the treatment of patients. Presently, a trained ophthalmologist performs manual analysis of the fundus images to detect the presence of DR. This method requires the availability of trained individual and is prone to human errors. Thus, there is a need for automated methods that can analyse fundus images. The automated methods are fast and accurate. In the literature, many methods based on image processing and machine learning are available for DR detection and classification. Many researchers have used segmentation techniques for the identification of exudates and discs. Maximum principal curvature is used for the segmentation of exudates or any other abnormality in the eye [1]. Another author presented a blood vessel segmentation technique for analysis of the retinal image vessels. Image morphological operators along with K-means clustering are utilized for the segmentation of blood vessels [2]. Many other authors have proposed different image segmentation-based techniques for detection of DR [3,4,5]. The literature review reveals that mostly Gaussian methods [6], mathematical morphology [7] and multi-scale analysis [8] are being widely used for detection of DR. All these methods based on image processing do not show very high accuracy for the detection of DR. Thus, more efficient methods are required that can identify and classify the retinal images more accurately. Nowadays, deep learning is being widely used for image classification problems. Many researchers have made use of various deep learning models for detection and classification of DR [8]. Convolutional neural networks have been widely used for DR detection and classification [9,10,11]. The performance of these networks was further improved using transfer learning along with CNN [12]. With transfer learning, the pretrained models can be tuned as per the medical image database consisting of retinal images. These models demonstrated improved accuracy as compared to the traditional CNN [13,14]. Many researchers proposed ensemble methods that combined the advantages from different classifiers and produced highly accurate results. The ensemble models have a higher information gain, as the information from standalone models is combined [15]. There are many ensembling techniques that can be used for the combining of complementary information amongst models. Many ensemble classifiers are reported in the literature that are presented for the DR problem [15,16,17,18,19]. The literature review reveals that there are certain limitations in the existing methods. Due to a limited database of medical images, the accuracy of machine learning models is not high. In addition, the traditional methods have the efficiency of a single model. However, the proposed method performs augmentation; thus, the model is immune to orientation variations.
In this paper, to further improve the accuracy and speed of DR detection and classification DRRest is proposed. DRRest is a deep learning ensemble model that uses ResNext architecture. The ResNeXt architecture comprises a shortcut from the previous block to the next block, stacking layers and adapting split–transform–merge strategy. The model has a cardinality parameter that specifies the number of transformations. The model is trained on the third largest dataset APTOS19 which includes more than 5000 retinal images. The images are pre-processed using CLAHE method for histogram equalization. The dataset has a high-class imbalance, and the images of the non-proliferative type are very low, therefore, GAN-based augmentation technique is used for data augmentation. The results obtained are accurate and outperform the other existing methods.
3. Proposed Method
In this paper, a deep learning ensemble model is used for detection and classification of diabetic retinopathy. The flowchart of the proposed method is shown in Figure 2.
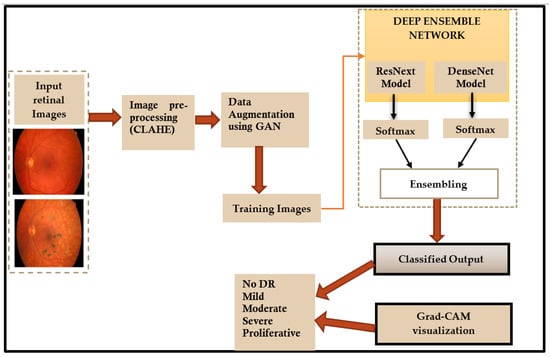
Figure 2.
Flowchart of the proposed method.
The following sections present a detailed description of each step shown in the flowchart (Figure 2).
3.1. Input Retinal Images
The retinal images used are fundus images that are acquired under heterogeneous imaging conditions. The images are rated by a clinician indicating the level of diabetic retinopathy on a scale of 0 to 4 for five classes. The images with two classes are graded as DR and No DR. These images are used for testing and training the model.
3.2. Pre-Processing of Images
The images obtained are taken under different lighting conditions. These images need to be pre-processed before these can be used for model training. The retinal images have low contrast and therefore CLAHE is used for histogram equalization. The histogram equalization algorithm is as follows (Algorithm 1):
| Algorithm 1: Histogram equalization algorithm. |
| Input—Retinal images |
| Output—Preprocessed histogram equalized image |
| Method: CLAHE |
| Begin |
| For each image compute: |
| where is the pixel value at location for the |
| image |
| End |
The pre-processed images obtained from this step are used as input to the proposed deep learning network.
3.3. Data Augmentation
The bottleneck while developing an effective classification model for retinal images is the lack of adequate quantity of relevant class-specific data. Positive examples of disease conditions tend to be rare. Therefore, in this work, data augmentation is used to enhance the class-specific data. Many methods of data augmentation are available. Generative adversarial networks (GAN) are effective for data augmentation [20]. In GAN-based augmentation, the model is first trained using all the classes and thereafter fine tuning for rare classes occurs. In this paper, a MixGAN model is used for augmenting the data. This model performs better for data augmentation, since the model can capture mix-type data information as well as continuous data generation. Real images are given as input to the MixGAN model, and synthetic images are generated. Then the synthetically generated images are augmented in the available dataset. The process followed for generating the synthetic images is shown in Figure 3.
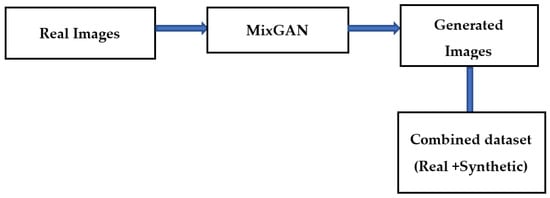
Figure 3.
Data augmentation technique.
3.4. ResNeXt Model
ResNeXt is a variant of ResNet it extends the concept of the residual network to the “split transform merge” technique. In this model, the convolutions are not performed on the full input feature map. Rather, the convolutions are performed on lower dimensional representations. These blocks are later merged after applying some convolutions. The ResNeXt block is shown in Figure 4.
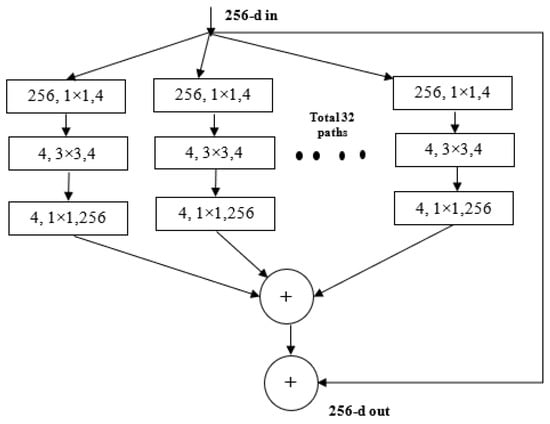
Figure 4.
ResNeXt Block.
3.5. DenseNet Model
The DenseNet comprises dense connections that outperform the simple ResNet and highway model. DenseNet solves the vanishing gradient problem by using the concatenation operation over the different blocks [21]. This network enables the maximum amount of information transfer amid the internal layers of the network. The complete architecture of the ResNeXt is shown in Figure 5. The dense block is shown in Figure 6. As it is observed, in this block, every layer is connected to all the proceeding layers. The output of a layer is derived from the outputs of all the previous layers. This dense connection overcomes the vanishing gradient problem. The network convergence becomes high, and the performance is also improved.
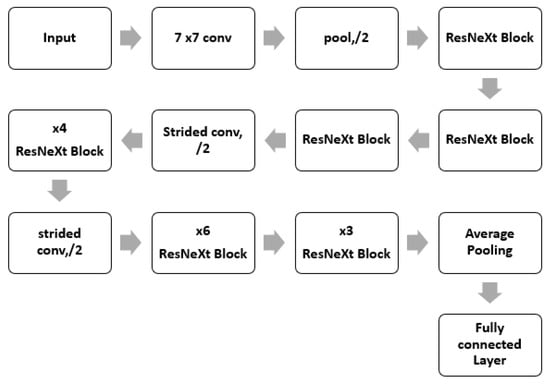
Figure 5.
ResNeXt Architecture.
Figure 6.
DenseNet block architecture.
The architecture of the model used is shown in Table 1.

Table 1.
Architecture of DenseNet model.
3.6. Ensemble Architecture
Ensemble networks combines several individual models to obtain a more efficient output. Deep ensemble learning models combine the advantages of both the deep learning models as well as the ensemble learning such that the final model has better generalization performance. In this work, ResNeXt v2 architecture is used [22]. This model is ensembled with the modified DenseNet, as shown in Figure 7.
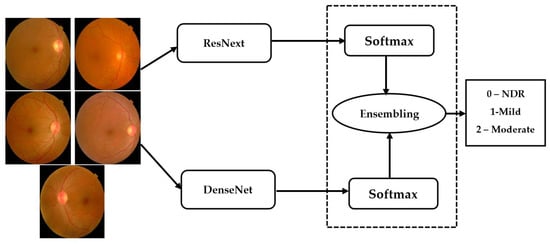
Figure 7.
Ensembling architecture.
The ensemble model inputs the outputs () obtained from the individual models () for a class . The ensembling technique normalizes the output over each class. Thereafter, these are combined using the softmax layer to obtain the final output from the ensemble network.
Equation (1) performs the softmax over the class scores and Equation (2) performs a maximum a posteriori over the class outputs to compute the final class label. The loss function used is maximum probability cross entropy. The value of n is 2 and C is 5.
- (a)
- Maximum probability-based cross entropy loss: For improving the training of the model, MPCE loss function is used. It reduces the back propagation error and makes the convergence fast. The mathematical formulation of MPCE is shown in Equation (3).
3.7. Model Training
The training of a deep neural network (DNN) requires two major components, i.e., a loss function or training objective and an optimization algorithm. Loss function is used to estimate the loss of the model by comparing target value with predicted value of DNN. The optimization algorithm minimizes the loss function by updating the weights of the network. We have used categorical cross entropy loss function available in keras library. It is a softmax activation plus a cross entropy loss. It is used for multi-class classification problems to output the probabilities over the n number of classes for each image. In medical datasets, an imbalanced dataset is a frequent problem for building a deep learning model due to lack of a sufficient amount of the training data or uneven class distribution within the dataset. For handling an imbalanced dataset problem, we have used the strategy of data augmentation, as discussed above. For efficient memory utilization, we use mini-batches, in which a small subset of all samples is propagated through the network during training. After relevant experiments, the number of samples per batch was set to eight. The epoch is the model hyper parameter which is defined as the number of times the network will be trained over the entire training dataset. The performance of the models is assessed with different evaluation metrics such as F1-score, Precision, Validation Accuracy, Sensitivity, Specificity, etc., which is detailed in the Results section.
3.8. Rectified Adam Optimization
In this paper, a rectified Adam optimization algorithm is used. It is a variant of the Adam optimizer that introduces a term to rectify the variance of the adaptive learning rate. It seeks to tackle the bad convergence problem suffered by the Adam optimizer.
3.9. Grad-CAM Visualization
The gradient-based class activation map (Grad-CAM) is a class-discriminative localization map which highlights the relevant regions of image by computing gradient of class score yc for class c in reference to feature map activations Ak of a convolutional layer, i.e., ∂yc/∂Ak. These gradients flows back and are then global-average-pooled to obtain the importance of weights of neurons, i.e., ack [17].
Grad-CAM is basically a weighted combination of forward activation maps followed by the ReLU operation, as follows:
We have plotted the Grad-CAM visualization heatmap of sample test images of the three classes predicted by our model. The Grad-CAM visualization heatmap highlights the relevant regions in the image, which the final convolution layer of the model uses to discriminate among different classes. We can observe that the Grad-CAM visualization heatmap produces different highlighting patterns for normal and DR images. The class activation map of a normal eye highlights the full image, focusing on the middle region, whereas, in the case of DR images, the upper region of the image is highlighted with greater density. The highlighted part in the class activation map is the important region in the image, used by the model for predicting the concept. The gradcam visualizations for different classes are shown in Figure 8.
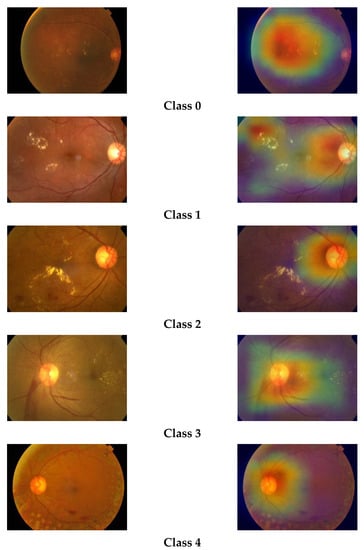
Figure 8.
Grad-CAM visualizations of retinal images.
4. Results and Discussion
The experiments are conducted in Python with GPU acceleration. The keras module is used for implementing the deep learning model.
4.1. Dataset Used
4.1.1. Two Class Databases
The first dataset used is DIARETDB1 database which is available publicly, for use by researchers. This dataset is used for two class detection, i.e., DR and no DR [23]. The dataset contains ground truth data marked by experts. It comprises of 89 color fundus images; the dataset has two gradings: Diabetic Retinopathy (DR) and No Diabetic Retinopathy (NDR).
4.1.2. APTOS 2019
The data are collected from the APTOS 2019 diabetic retinopathy dataset. The dataset is available on Kaggle [24]. The dataset is collected by Aravind Eye Hospital in India’s rural areas for the development of automated tools for DR detection. The dataset comprises a large set of retina images taken using fundus photography under a variety of imaging conditions. Each image is rated for the severity of diabetic retinopathy on a scale of 0 to 4. The images are either No DR, Mild, Moderate, severe or Proliferative DR. The grading from 1–3 is conducted based on the frequency, location, and severity. The distribution of training images is shown in Table 2.
Table 2.
Distribution of training images.
The dataset comprises a total of 3662 training images and 1928 testing images. The distribution of these images is shown in Figure 9.
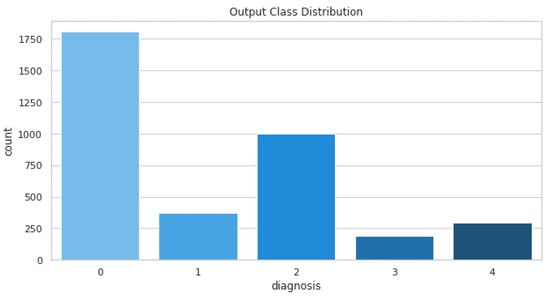
Figure 9.
Training images distribution.
The sample images from the database are shown in Figure 10.

Figure 10.
Retinal images for (a) Normal (b) Mild DR (c) Moderate DR (d) Severe DR (e) Proliferative DR.
The performance of the proposed method is evaluated using the various evaluation metrics. The following metrics are used:
- Precision is defined as the number of misclassifications. This can be computed by
- Recall is a measure of the actual positives a model computes. The formula for computing the recall is shown in Equation (6):
- The overall accuracy is also computed using
4.1.3. Two Class Detection
The experiments were also conducted for two class detections. The two classes are normal and abnormal. The confusion matrix for the two classes is shown in Table 3. The 89 images were manually assigned into categories representing the progressive states of retinopathy. Using the categories, the images were divided into the representative training (28 images) and test sets (61 images).
Table 3.
Confusion Matrix for two classes.
4.1.4. Five Class Detection
The dataset comprises of five classes of DR images that are represented by the numbers 0 to 4.
- 0
- No DR (NDR)
- 1
- Mild
- 2
- Moderate
- 3
- Severe
- 4
- Proliferative DR (PDR)
The testing was conducted on 733 testing images from different grades. The grade-wise distribution of images is shown in Table 4.
Table 4.
Testing image distribution.
The confusion matrix for five classes is shown in Table 5.
Table 5.
Confusion matrix for five classes.
The precision, recall and accuracy of the method is calculated and compared with other state-of-the-art methods.
The results obtained for different methods for two classes and five classes are shown in Table 6 and Table 7, respectively.
Table 6.
Results comparison, two classes.
Table 7.
Results comparison, five classes.
The results show that the proposed method performs better than the existing methods for both two classes and five classes. For five classes, the model accuracy is less than that for two classes. This cam be further improved by using a more balanced dataset for five classes. Thus, the limitation of the model is the imbalanced and limited medical data for five classes.
5. Conclusions and Future Work
Diabetic retinopathy is affecting millions of individuals worldwide. Early detection of DR aids in the treatment of the affected individuals. In this paper, a deep ensembled model for detection and classification of DR from retinal fundus images is presented. The proposed method follows an ensemble approach using ResNeXt and a modified DenseNet deep learning model. The model is trained on the APTOS dataset that consists of five classes of images. Another dataset, used for two classes, is DIARET DB1. The input images are pre-processed to equalize the histogram using the CLAHE method. The class imbalance is handled using MixGAN data augmentation. The augmented dataset is used to train the model. The performance of the proposed method is compared with other state-of-the-art methods. The results show that the proposed method outperforms the other methods. In future, it will be beneficial if the efficiency of the proposed model is increased. In addition, the classification of DR in various classes can be improved. A device can be developed using the proposed method that can completely automate the disease detection and classification.
Author Contributions
Conceptualization, N.M., K.K.S. and A.S.; Methodology, S.S.M.; Investigation, S.S.M. and I.I.; Writing—original draft, S.S.M.; Writing—review & editing, A.S.; Supervision, N.M. and K.K.S.; Funding acquisition, I.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
Publicly Available (https://www.kaggle.com/c/aptos2019-blindness-detection).
Conflicts of Interest
The authors declare that there are no conflict of interest.
References
- Kumar, N.C.S.; Radhika, Y. Optimized maximum principal curvatures based segmentation of blood vessels from retinal images. Biomed. Res. 2019, 30, 2. [Google Scholar] [CrossRef]
- Hassan, G.; El-Bendary, N.; Hassanien, A.E.; Fahmy, A.; Snasel, V. Retinal blood vessel segmentation approach based on mathematical morphology. Procedia Comput. Sci. 2015, 65, 612–622. [Google Scholar] [CrossRef]
- Orlando, J.I.; Prokofyeva, E.; Blaschko, M.B. A discriminatively trained fully connected conditional random field model for blood vessel segmentation in fundus images. IEEE Trans. Biomed. Eng. 2016, 64, 16–27. [Google Scholar] [CrossRef] [PubMed]
- Mondal, S.S.; Mandal, N.; Singh, A.; Singh, K.K. Blood vessel detection from Retinal fundas images using GIFKCN classifier. Procedia Comput. Sci. 2020, 167, 2060–2069. [Google Scholar] [CrossRef]
- Memari, N.; Ramli, A.R.; Saripan, M.; Mashohor, S.; Moghbel, M. Retinal blood vessel segmentation by using matched filtering and fuzzy c-means clustering with integrated level set method for diabetic retinopathy assessment. J. Med. Biol. Eng. 2019, 39, 713–731. [Google Scholar] [CrossRef]
- Budai, A.; Bock, R.; Maier, A.; Hornegger, J.; Michelson, G. Robust vessel segmentation in fundus images. Int. J. Biomed. Imaging 2013, 2013, 154860. [Google Scholar] [CrossRef] [PubMed]
- Tian, Z.; Liu, L.; Zhang, Z.; Fei, B. Superpixel-based segmentation for 3D prostate MR images. IEEE Trans. Med. Imaging 2015, 35, 791–801. [Google Scholar] [CrossRef] [PubMed]
- Shankar, K.; Sait, A.R.W.; Gupta, D.; Lakshmanaprabu, S.K.; Khanna, A.; Pandey, H.M. Automated detection and classification of fundus diabetic retinopathy images using synergic deep learning model. Pattern Recognit. Lett. 2020, 133, 210–216. [Google Scholar] [CrossRef]
- Ghosh, R.; Ghosh, K.; Maitra, S. Automatic detection and classification of diabetic retinopathy stages using CNN. In Proceedings of the 2017 4th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 2–3 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 550–554. [Google Scholar]
- Gayathri, S.; Gopi, V.P.; Palanisamy, P. A lightweight CNN for Diabetic Retinopathy classification from fundus images. Biomed. Signal Process. Control 2020, 62, 102115. [Google Scholar]
- Reguant, R.; Brunak, S.; Saha, S. Understanding inherent image features in CNN-based assessment of diabetic retinopathy. Sci. Rep. 2021, 11, 9704. [Google Scholar] [CrossRef] [PubMed]
- Benson, J.; Carrillo, H.; Wigdahl, J.; Nemeth, S.; Maynard, J.; Zamora, G.; Barriga, S.; Estrada, T.; Soliz, P. Transfer learning for diabetic retinopathy. In Proceedings of the Medical Imaging 2018: Image Processing, Houston, TX, USA, 10–15 February 2018; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10574. [Google Scholar]
- Gadekallu, T.R.; Khare, N.; Bhattacharya, S.; Singh, S.; Maddikunta, P.K.R.; Ra, I.H.; Alazab, M. Early detection of diabetic retinopathy using PCA-firefly based deep learning model. Electronics 2020, 9, 274. [Google Scholar] [CrossRef]
- Kandel, I.; Castelli, M. Transfer learning with convolutional neural networks for diabetic retinopathy image classification. A review. Appl. Sci. 2020, 10, 2021. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Khare, N.; Bhattacharya, S.; Singh, S.; Maddikunta, P.K.R.; Srivastava, G. Deep neural networks to predict diabetic retinopathy. J. Ambient. Intell. Humaniz. Comput. 2020, 1–14. [Google Scholar] [CrossRef]
- Shen, Z.; Wu, Q.; Wang, Z.; Chen, G.; Lin, B. Diabetic Retinopathy Prediction by Ensemble Learning Based on Biochemical and Physical Data. Sensors 2021, 21, 3663. [Google Scholar] [CrossRef] [PubMed]
- Reddy, G.T.; Bhattacharya, S.; Ramakrishnan, S.S.; Chowdhary, C.L.; Hakak, S.; Kaluri, R.; Reddy, M.P.K. An ensemble based machine learning model for diabetic retinopathy classification. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Ali, R.; Hardie, R.C.; Narayanan, B.N.; Kebede, T.M. IMNets: Deep Learning Using an Incremental Modular Network Synthesis Approach for Medical Imaging Applications. Appl. Sci. 2022, 12, 5500. [Google Scholar] [CrossRef]
- Kobat, S.G.; Baygin, N.; Yusufoglu, E.; Baygin, M.; Barua, P.D.; Dogan, S.; Orhan, Y.; Celiker, U.; Yildirim, H.; Tan, R.-S.; et al. Automated diabetic retinopathy detection using horizontal and vertical patch division-based pre-trained DenseNET with digital fundus images. Diagnostics 2022, 12, 1975. [Google Scholar] [CrossRef] [PubMed]
- Lim, G.; Thombre, P.; Lee, M.L.; Hsu, W. Generative Data Augmentation for Diabetic Retinopathy Classification. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1096–1103. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Hitawala, S. Evaluating ResNeXt Model Architecture for Image Classification. arXiv 2018, arXiv:1805.08700. [Google Scholar]
- Kauppi, T.; Kalesnykiene, V.; Kamarainen, J.-K.; Lensu, L.; Sorri, I.; Raninen, A.; Voutilainen, R.; Uusitalo, H.; Kälviäinen, H.; Pietilä, J. The diaretdb1 diabetic retinopathy database and evaluation protocol. BMVC 2007, 1, 1–10. [Google Scholar]
- Aravind Eye Hospital. APTOS 2019 Blindness Detection. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection (accessed on 19 November 2022).
- Kumar, G.; Chatterjee, S.; Chattopadhyay, C. DRISTI: A hybrid deep neural network for diabetic retinopathy diagnosis. Signal Image Video Process. 2021, 15, 1679–1686. [Google Scholar] [CrossRef]
- Sugeno, A.; Ishikawa, Y.; Ohshima, T.; Muramatsu, R. Simple methods for the lesion detection and severity grading of diabetic retinopathy by image processing and transfer learning. Comput. Biol. Med. 2021, 137, 104795. [Google Scholar] [CrossRef] [PubMed]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).