1. Introduction
Respiratory diseases endanger the ability of the respiratory system to supply the body with oxygen and to eliminate carbon dioxide sufficiently, potentially causing life-threatening consequences. These conditions are caused on one hand primarily by damaging the pulmonary tissue through, for instance, infection, toxic effects of inhaled gases or fluids or trauma. On the other hand, the lung can be affected indirectly as a side-effect of diseases of other organs [
1]. Early diagnosis and treatment are essential to achieve positive outcomes for patients [
2,
3,
4,
5]. Critically ill patients who require treatment in an Intensive Care Unit (ICU) are at high risk of developing respiratory disease, one of the most serious of which is Acute Respiratory Distress Syndrome (ARDS), a condition that was first described by Ashbaugh et al. [
6]. ARDS is still the subject of intensive research due to its high incidence in ICU patients as reported by Confalonieri et al. (10.4% of total ICU admissions) and high mortality rate as highlighted by Le et al. (30–55% of affected patients) [
3,
5].
ARDS is further characterised by its heterogeneity and the difficulty with respect to diagnosing it, leading clinicians and researchers to establish the “Berlin Definition” by which ARDS onset is defined as a ratio of Partial Pressure of Arterial Oxygen (P
aO
2) to Fraction of Inspired Oxygen (F
iO
2) (P/F ratio) of less than 300 mmHg in combination with bilateral opacities in pulmonary imaging and absence of hypervolemia and heart failure [
7]. Furthermore, this definition classifies the severity of the condition to be inversely proportional to the value of the P/F ratio. Despite widespread research activities in this field, which were even intensified during the COVID-19 pandemic, effective treatment methods of ARDS are still lacking, resulting in a high mortality rate [
3,
5]. In fact, Bellani et al. highlight that ARDS diagnosis is still delayed or missed in two thirds of patients, leading to severe outcomes [
8]. The management of ARDS patients, thus, usually remains supportive with lung-protective mechanical ventilation, prone positioning and extracorporeal membrane oxygenation (ECMO) treatment as
ultima ratio [
9,
10,
11,
12].
In developing the Nottingham Physiology Simulator (NPS), Hardman et al. launched an in silico tool for modeling pulmonary disease progression and determining the potential effectiveness of treatment methods [
13]. This model was later improved upon by Das et al. and Saffaran et al. to include elements of the cardiovascular system and to improve its performance, which extended its usefulness even further [
14,
15]. The resulting virtual patient simulator was validated through generating outputs for initial conditions similar to real-world ARDS patients and it was found that these model outputs were consistently comparable with the source clinical data [
16]. With a tool such as the NPS, clinicians and biomedical engineers can consistently and accurately model individual patient states, predict the onset of disease and formulate and validate potential treatment methods to guarantee the best outcomes for patients.
The development of models such as the NPS was simplified with the advent of Electronic Health Records (EHRs). Making large amounts of clinical data easily accessible has enabled a lot of research in healthcare, and has helped highlight pathological patterns and uncover treatment methods, but has also sparked discussions about patient privacy and data security [
17,
18,
19]. As these records grow into the realm of Medical Big Data, the need to develop more efficient storage for the data and more capable computing resources to process them grows at a similar rate [
20,
21,
22,
23]. Thus, it is essential to make High-Performance Computing (HPC) available for biomedical applications and to develop the algorithms to take advantage of these resources in order to clean, process, analyse and extract information from the available data.
It follows that several teams have already employed available HPC resources in the storage and analysis of Medical Big Data or in training Machine Learning (ML) and Deep Learning (DL) models. Kesselheim et al. applied the Jülich Wizard for European Leadership Science (JUWELS) (
https://www.fz-juelich.de/en/ias/jsc/systems/supercomputers/juwels (accessed on 3 February 2023)) supercomputing cluster and booster to perform pre-training of the ResNet-152 DL network. Their goal was to highlight the speed-up achieved using the HPC resources and to eventually perform large-scale transfer learning using the publicly available COVIDx (
https://www.kaggle.com/datasets/andyczhao/covidx-cxr2 (accessed on 3 February 2023)) dataset to develop a tool for rapid COVID-19 detection from Chest X-rays (CXRs) [
24]. The researchers also discussed using their supercomputing resources to improve the available ML methods for RNA structure prediction. In a similar vein, Baek et al. and Jumper et al. concurrently published their results for the Artificial Intelligence (AI) models RoseTTAFold and AlphaFold, which make use of the HPC clusters available at the University of Washington and at Google, respectively [
25,
26]. Both teams used an implementation of multi-track DL networks in an attempt to solve the protein-folding problem and in both cases the results were highly accurate. Finally, Zhang et al. made use of HPC to perform hyperparameter tuning on an ML model for Alzheimer’s disease detection [
27]. Their work highlights the speed-up that can be achieved by making use of HPC, especially in situations where many trials need to be performed with minute changes in order to find the optimal parameter combination that produces the best results.
This paper describes the process by which an ML and data science platform that takes advantage of Modular Supercomputing Architecture (MSA) available from the Jülich Supercomputing Centre (JSC) is used to build a surrogate model of the NPS with the intention of implementing it for streamlined ARDS-diagnosis support [
28,
29,
30]. In order to achieve this primary goal, several steps need to be completed as follows:
Medical data collection, cleaning, analysis and visualisation.
Data augmentation through statistical analysis of the available clinical data.
Parallel simulation of patient states using a ported NPS.
Parallel hyperparameter optimisation of the developed DL model using Ray Tune [
31].
Final training of the DL-based surrogate model and validation of the results with the original simulation.
As Gherman et al. highlighted, several researchers have already developed ML surrogate models from complex mechanistic models [
32]. These surrogates benefit greatly from the high accuracy of the mechanistic models they emulate, while avoiding the computation overhead associated with equilibrating multiple complex differential equations. This aspect coupled with the use of a pre-established HPC-enabled data science and ML platform that was validated in previously published work represent the core innovations of the research described in this manuscript [
28,
29]. In this way, the HPC resources are instrumental to the accelerated development and testing of the surrogate.
This work is conducted as part of the use case Algorithmic Surveillance of Intensive Care Unit patients with ARDS (ASIC) which is part of the Smart Medical Information Technology for Healthcare (SMITH) project under the guidance of the German Federal Ministry of Education and Research (BMBF) [
33,
34]. Furthermore, the work described here paves the way for the future development of surrogate models from pre-established mechanistic disease representations, thus providing valuable tools to accelerate diagnosis in critical situations.
2. Materials and Methods
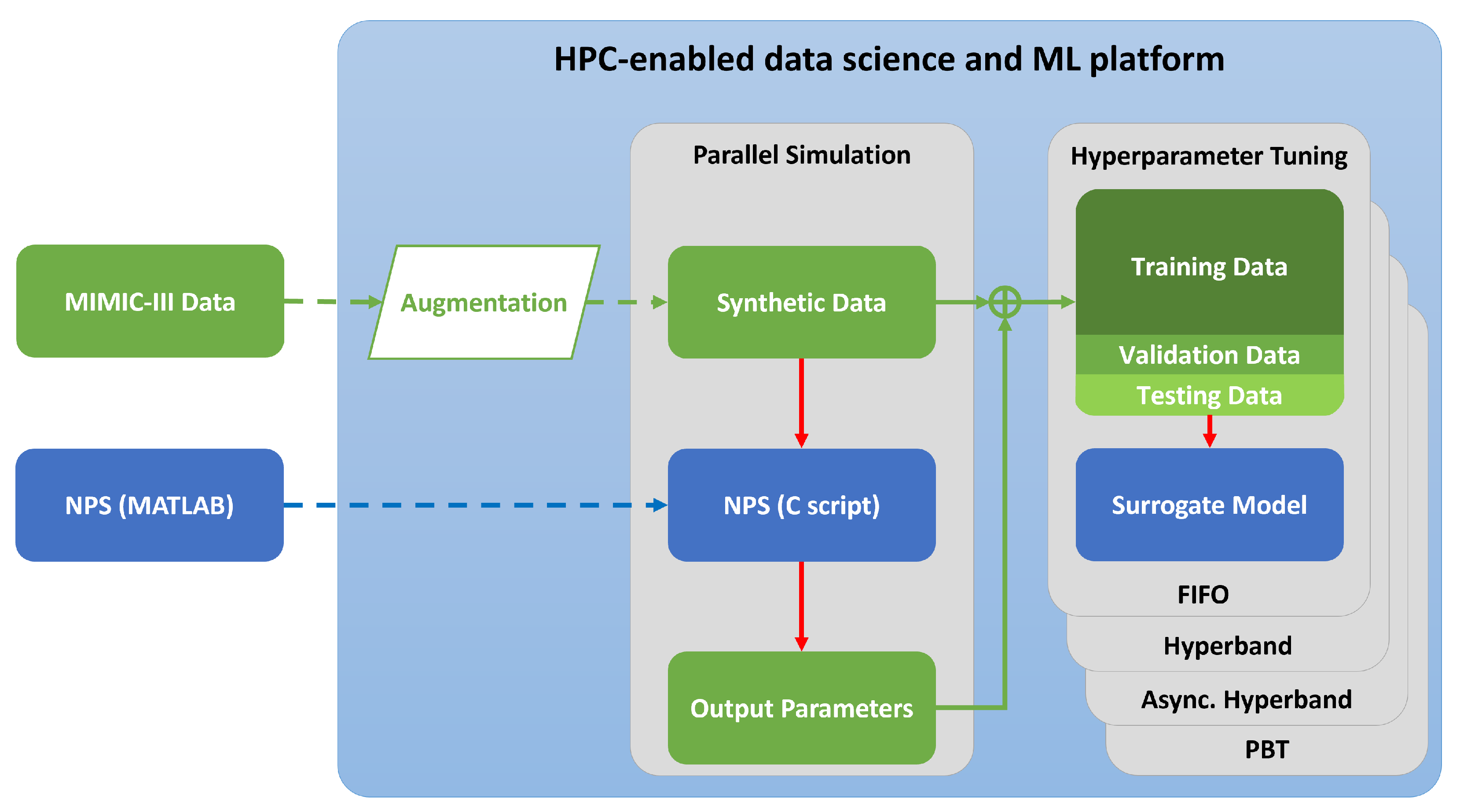
The experimental process leading towards completion of the research objective described in the Introduction is represented in
Figure 1. The subsections below go further into the details of each step of the experimental process as well as the hardware and software implemented within them.
2.1. HPC Resources
The Dynamic Exascale Entry Platform (DEEP) series of projects (
https://www.deep-projects.eu/ (accessed on 3 February 2023)) was set up to highlight the benefits of using heterogeneous architectures in HPC to pave the way towards exascale computing by introducing boosters alongside traditional supercomputing clusters [
35,
36]. The boosters, which run independently of the cluster nodes used for traditional supercomputing tasks, offer the option of expanding storage and compute power for specific tasks, including large-memory nodes for image-processing tasks and multi-GPU nodes for accelerated DL tasks. Thus, the DEEP projects introduced the Modular Supercomputing Architecture (MSA) concept that would later be used in development systems such as the JUWELS cluster and booster, unveiled in 2018 and 2020, respectively [
37]. The specific configuration of the cluster-booster prototype set up in the DEEP project and its subsequent projects, DEEP-Extended Reach (DEEP-ER) and DEEP-Extreme Scale Technologies (DEEP-EST), is presented in
Table 1.
2.2. Software and Libraries
2.2.1. Nottingham Physiology Simulator
The NPS is made available as part of the SMITH project as a central MATLAB (
https://www.mathworks.com/products/matlab.html (accessed on 3 February 2023)) script accompanied by peripheral functions written either in MATLAB or in C-script and converted at initial startup into the MATLAB executable (.mex) format. Version 1.4 of the simulator was made available for this research as part of the SMITH project. Further updates to the NPS have already been implemented which improve its performance [
15]; however, all of the experiments described in this manuscript concern the version mentioned above. The simulator loads patient data from prepared input files, then runs a preset number of cycles during which it solves a series of differential equations that model the gas exchange occurring during a breathing cycle.
Disease states can be modeled in the simulator through adjusting the input parameters, such as reducing oxygenation, reducing lung compliance or changing the acid–base balance of the blood [
16,
38], which are typical pathophysiological alterations in ARDS patients [
39]. Previous research has validated the performance of the NPS compared to the responses of real patients in the ICU [
13,
15,
40].
Given all of the above, the NPS is certainly a valuable tool in the hands of clinicians aiming to understand medical conditions such as ARDS and to analyse potential treatment methods. It does, however, have specific shortcomings:
The time required to run individual simulations makes it unfeasible to use the NPS in diagnosis support, especially for more time-critical clinical situations.
The outputs are broad and extremely detailed, requiring users to filter through them in order to extract the information useful for their specific task.
It uses proprietary and license-based software, which is a limiting factor for applications on a large scale, especially in remote clinics that would not have proper funding for it.
These shortcomings highlight the need to convert the NPS and to develop the surrogate model as described in the remainder of this manuscript.
2.2.2. Software Used in Model Conversion
As mentioned above, the NPS is built in MATLAB and thus is implemented on a local machine running MATLAB version R2019a within Windows 10 version 22H2. Additionally, the MATLAB Coder (
https://www.mathworks.com/products/matlab-coder.html (accessed on 3 February 2023)) software plugin is used in order to export the simulation as a C-script and package it for implementation on the HPC cluster.
The remainder of the programming done for this project uses the Python (
https://www.Python.org/ (accessed on 3 February 2023)) programming language with additional packages installed through the built-in pip function or loaded from the list of pre-installed modules available on the HPC cluster. The packages include Numerical Python (NumPy) (
https://numpy.org/ (accessed on 3 February 2023)) and Pandas (
https://pandas.pydata.org/ (accessed on 3 February 2023)) for data structure manipulation, MatPlotLib (
https://matplotlib.org/ (accessed on 3 February 2023)) for data visualisation, Keras (
https://keras.io/ (accessed on 3 February 2023)) (running from within TensorFlow (
https://www.tensorflow.org/ (accessed on 3 February 2023))) and Scikit-Learn (
https://scikit-learn.org/ (accessed on 3 February 2023)) for performing the ML tasks and mpi4py to bind to the Message Passing Interface (MPI) and handle the parallelisation aspect of some of the data-manipulation tasks [
41]. Hyperparameter tuning is done using Ray Tune, which in turn employs different scheduling algorithms in order to simplify the task of finding the optimal parameters for training the final model [
31]. Finally, the HPC cluster employs the Simple Linux Utility for Resource Management (SLURM) scheduler (
https://slurm.schedmd.com/ (accessed on 3 February 2023)) in order to distribute the submitted training and tuning jobs onto the available computing resources. The submission of jobs is done using shell scripts that define the environments to load and the resources to recruit for each specific job.
2.3. Model Preparation
In order to build the surrogate model, it is necessary to convert the NPS to a format that can more easily be run in parallel, which would then be used to generate data to train the DL model with. Exporting the model in C-script would be a simple task given its similarity to the MATLAB programming language, as well as the availability of the MATLAB Coder plugin. Accordingly, the various peripheral function files that make up the NPS are grouped into a single script as per the requirements of the MATLAB Coder and the input parameters are defined according to the variables provided in the patient data.
Additionally, the original model outputs an array containing several parameters recorded over every time step of the simulation, which made exporting values difficult. Therefore, the output parameters are reduced to only include the final values of markers for a pulmonary impairment, which can be consistent with an ARDS onset (PaO2, Partial Pressure of Arterial Carbon Dioxide (PaCO2), pH and Bicarbonate).
This converted model is tested locally on several patients and its outputs are compared to those from the original simulation in order to verify its integrity. The duration of each simulation is also recorded in order to evaluate the speed-up achieved through this conversion. Moreover, the same patient simulations are performed on the HPC cluster to both validate the outputs and to highlight the speed-up that can be achieved when running several instances concurrently.
2.4. Data
The data used in this research were collected from the open-source Medical Information Mart for Intensive Care - III (MIMIC-III) database as part of the research done by Sharafutdinov et al. also within the scope of the SMITH project [
42,
43,
44]. Due to the limited number of patients and the inconsistent representation of their parameters, it was decided to generate simulated data based the statistical distribution of the original data extracted from the MIMIC-III database. In order to perform this data augmentation, the statistical distribution of each parameter listed in
Table 2 is analysed and a generator is developed that outputs randomised snapshots of patient states emulating a wide range of real-world parameter combinations. The choice of these parameters was based on the input parameters required for proper functioning of the NPS. Matching the parameters from the simulation to their equivalent values in the MIMIC-III database was done by Sharafutdinov et al. in previous work [
43,
44].
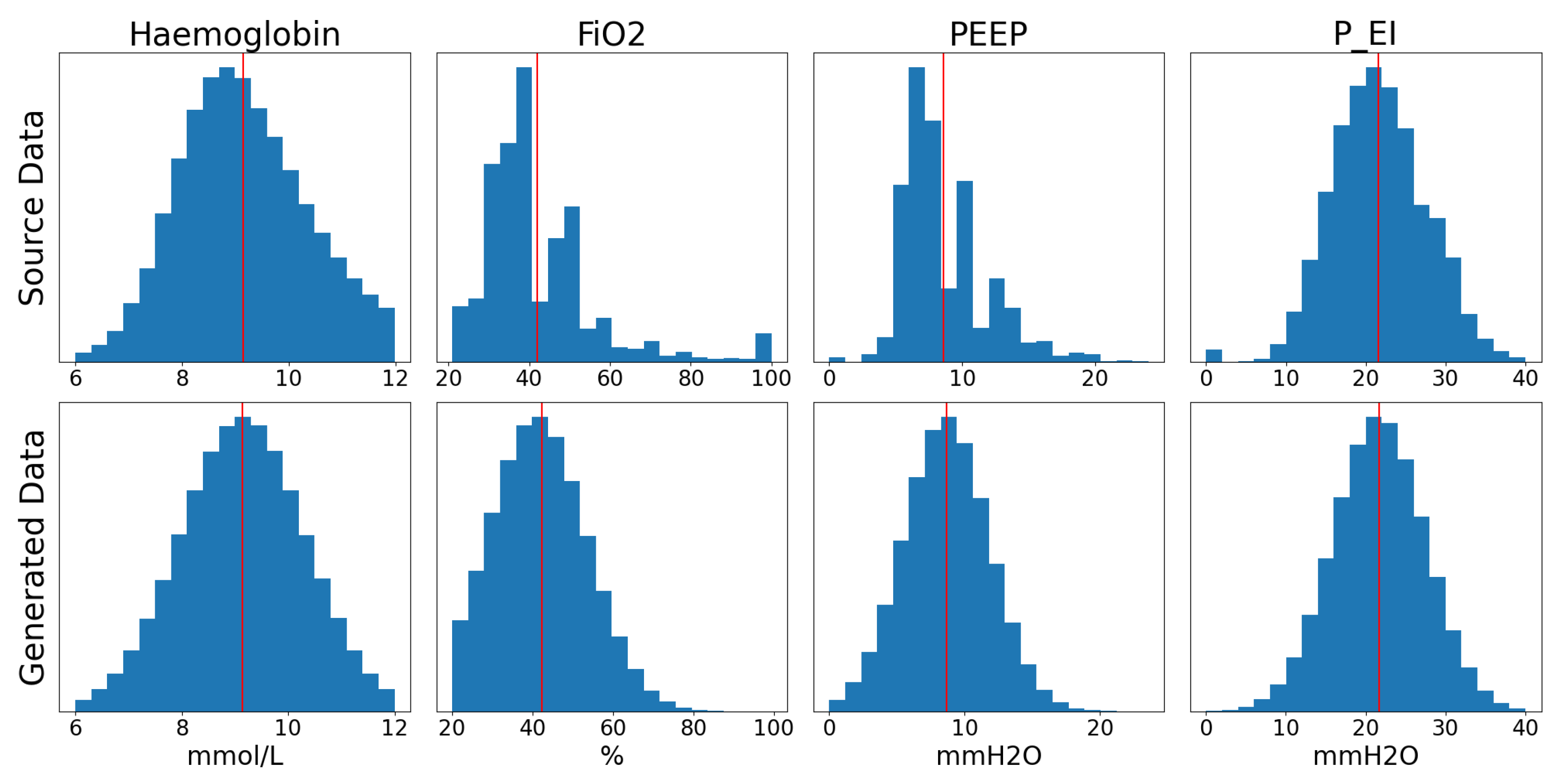
Table 3 provides a statistical description of the data extracted from the source dataset while
Figure 2 presents a comparison of the distributions of the source data and the generated data. In this case, the minimum and maximum cutoff values were chosen based on discussions with clinicians.
As these data are fed into the reduced simulation, the aforementioned markers of ARDS onset of these patients are generated. The end result of this data-manipulation step is a collection of 1,000,000 initial states of patients made up of 19 input parameters and 4 associated expected outputs. The output parameters were chosen based on a sensitivity analysis done by Sharafutdinov et al. in previously published research [
44] and are presented in
Table 2. The generated patient states are further subdivided into 80% training/10% validation/10% testing datasets to be used to train the DL-based model described in the next section.
2.5. Model Design and Training
In order to select the model architecture that offers the greatest potential training performance, several different approaches are tested. However, the choice was limited by two major factors: first, the architecture does not need to be adapted for timeseries data since the inputs chosen are snapshots of patients’ states, as described above; therefore, Recurrent Neural Networks (RNNs) are excluded. Second, no advanced neural network architectures, such as residual layers or transformers, are to be used in order to maintain a reduced model complexity. Accordingly, the models tested out in this step were made up of stacked fully connected layers, convolutional layers or a combination of both.
Several models of both architectures were tested, with varying depths and types of layers, including regularisation, dropout and normalisation layers and with different layer sizes, dropout rates, regularisation factors, learning rates, batch sizes and loss functions. This was done in order to uncover the hyperparameters that have a significant effect on the training process. Each of these architectures was trained for 50 epochs. After this initial testing phase, a provisional best performing model structure is decided on based on a statistical comparison of the four output parameters listed in
Table 2 (P
aO
2, P
aCO
2, pH and HCO
3) with the outputs generated by the original simulation. Further improvements of this model are done through hyperparameter optimisation as described in the next section.
2.6. Hyperparameter Tuning
Hyperparameters are the variables that affect the way in which a model is built or its training process and can be altered either through a process of trial and error or automatically using optimisation algorithms [
45,
46]. In order to uncover potential hyperparameter combinations through which model training and performance can be improved, the Ray (
https://www.ray.io/ (accessed on 3 February 2023)) framework is employed to perform hyperparameter tuning [
31,
47]. This framework can also take advantage of available HPC resources by distributing the tuning process over several nodes, thus reducing the time needed to run the trials and making the process more efficient.
The schedulers used by Ray Tune in the optimisation process described in this manuscript are HyperBand, Asynchronous HyperBand, Population-Based Training (PBT) and the default First-In, First-Out (FIFO) [
48,
49,
50]. These algorithms distribute the tuning task over the available resources and may interfere with the process by introducing perturbations as is the case for PBT or by shutting down under-performing tasks as is the case for HyperBand and Asynchronous HyperBand. Aside from FIFO, which was chosen to serve as a control in this experiment, the remaining schedulers were chosen based on their purported resource efficiency and accuracy. The comparison of the different algorithms is thus intended to highlight the most successful both in terms of resource use and accuracy of results for this specific application.
In this experiment, the tuned parameters are the learning rate, the batch size, the dropout rate, the loss function and the presence of an intermediate fully connected layer before the output layer in the network architecture. The choice of tuning these specific hyperparameters stemmed from the initial testing carried out in the model design and training phase described in
Section 2.5 where changing these parameters had a significant effect on how the models performed. The tuning process is carried out to minimise the validation error value, which serves to reduce the possibility of an overfitting model being selected as the best performing trial. After tuning, the best performing parameters for each scheduler are used to retrain the ML-based model and to highlight the improvement in its prediction performance. Best performance is thus based on the models with the most effective loss reduction and where the output R
2 scores are closest to 1 for all output parameters. These scores quantify the deviation of the model results from the outputs generated by the original simulation.
4. Discussion
Converting the NPS to C helped highlight the speed-up that can be achieved through the use of HPC resources. Running multiple simulations simultaneously as well as the increased efficiency and reduced overhead of C code reduced the code execution times and made it possible to generate more data with which to train the proposed ML models. In the end, the average duration of simulations was less than half the average duration of simulations in MATLAB. Additionally, processing and storing the output data was a computation- and communication-intensive process which was greatly simplified through the availability of online storage on the pre-established HPC-enabled platform for medical ML and data science [
30].
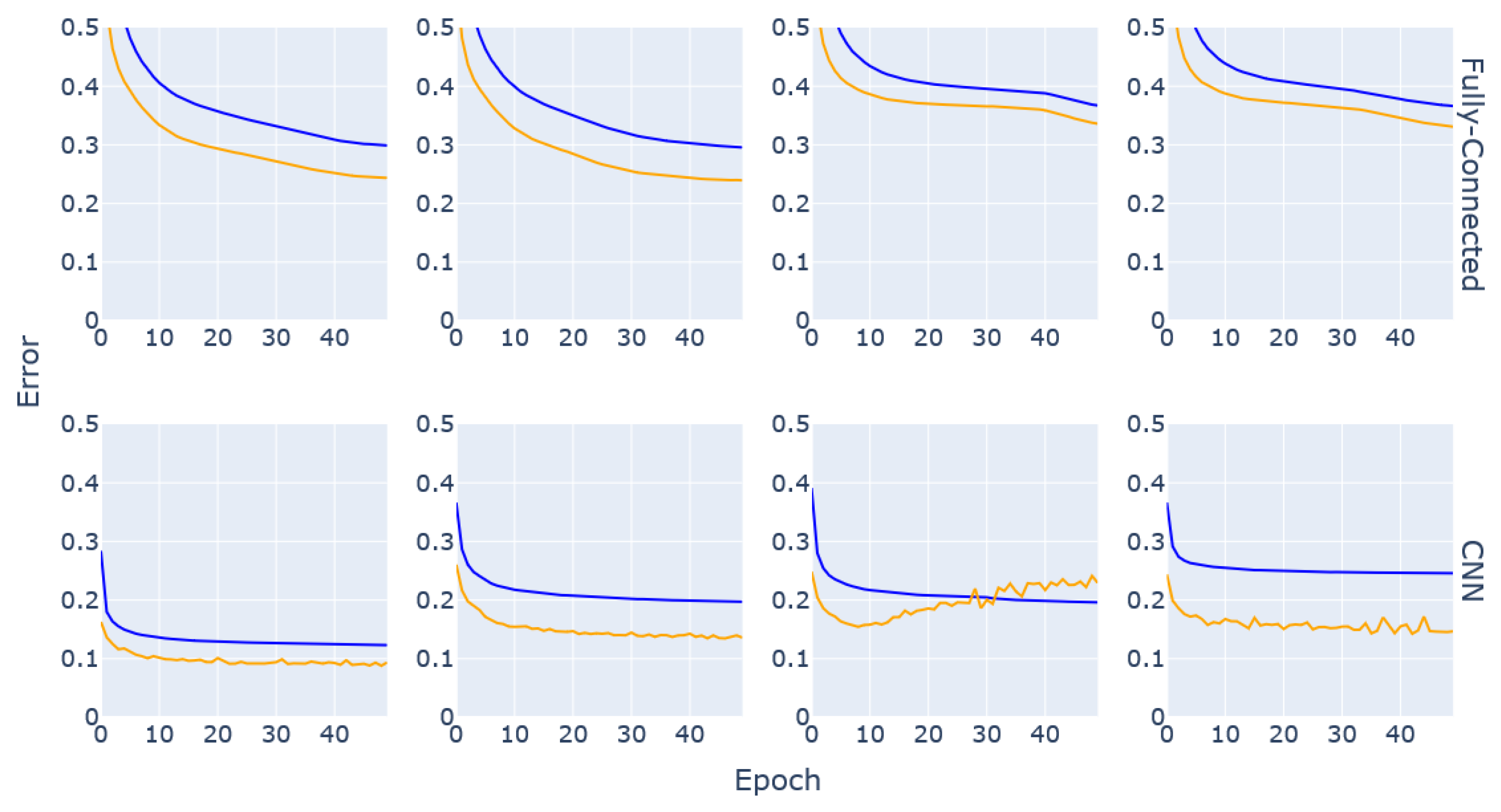
The results of the DL model training step of this research highlighted the inherent differences between a fully connected (i.e., traditional Artificial Neural Network (ANN)) architecture and a convolution-based approach. While ANNs are more likely to give value to every input parameter, CNNs are more adapted to uncover connections between the inputs and infer meaning from them, which might explain why these networks consistently performed better. The results in
Figure 3 show that CNNs might overfit the data if the layers are not well tuned, but in most cases the performance surpassed that of ANNs and lower MAE values were reached in shorter training periods, which ultimately makes the convolutional approach more resource-efficient. Additionally, the curves consistently show the validation error being lower than the training error; this is due to the regularisation and dropout layers introduced in the network architectures to reduce overfitting. These layers are active during the training process but inactive by design during validation and testing (
https://keras.io/getting_started/faq/ (accessed 10 February 2023)).
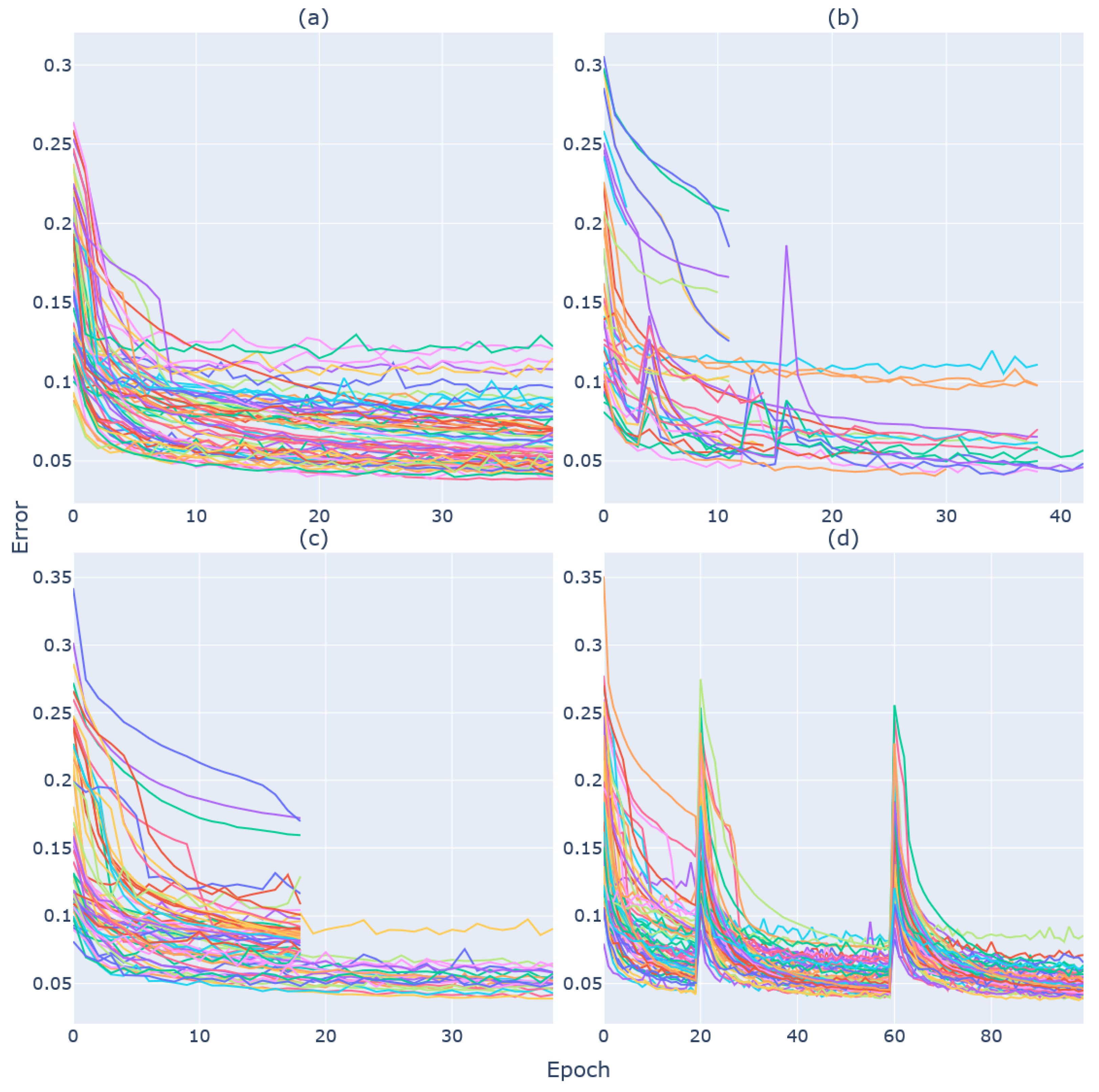
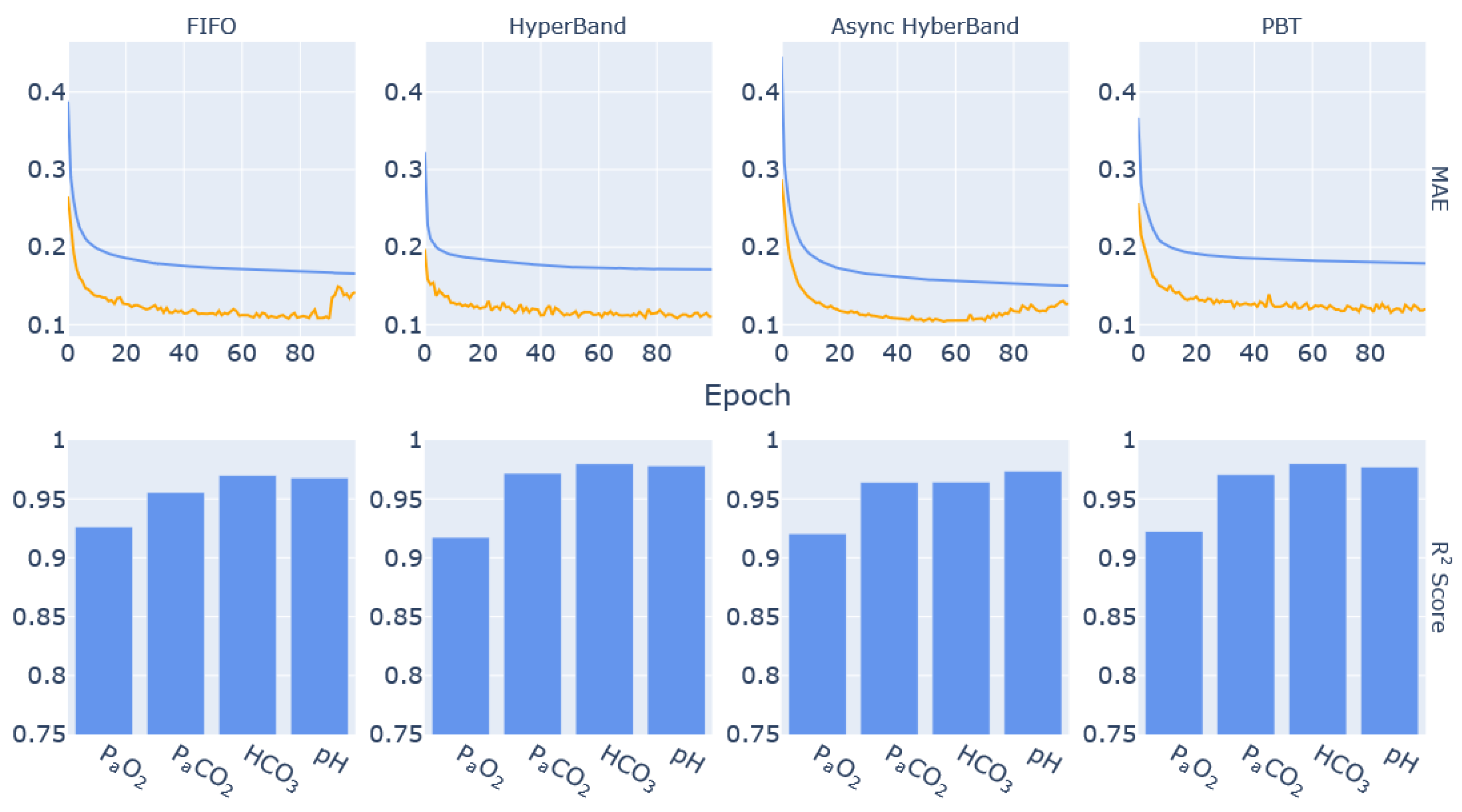
Similarly, when considering resource efficiency, HyperBand and its successor Asynchronous HyperBand make the best use of the available resources to distribute the available tasks. Besides the reduction in computation time, these two approaches minimise stragglers, that is the number of allocated resources that are not effectively being used for computational tasks. Furthermore, the recommendations from the Ray framework highlight Asynchronous HyperBand as a more capable and efficient scheduler than the original HyperBand (
https://docs.ray.io/en/latest/tune/api_docs/schedulers.html (accessed 10 February 2023)). In the case of PBT, resource efficiency is secondary to uncovering more effective approaches through parameter perturbations. Although this approach could be beneficial for applications where minor changes of parameters might greatly alter the outcome of the experiment, the computational overhead necessary for PBT to complete the trials was judged too great for the research purposes described in this manuscript.
The performance of these models is comparable to the performance of the first CNN model in
Figure 3, which shows that the best combination of parameters can be reached through a process of trial and error, although it required running several trials to find the best parameters and was extremely time- and resource-consuming and the many combinations were difficult to keep track of. Making use of the hyperparameter-tuning methods streamlined the process and had the added benefit of managing the computation resources and distributing the trials without much interference.
The models trained on the best parameters generated from the tuning process highlight the need to take advantage of early stopping during training. Such an approach might produce better predictive performance from the models trained on the parameters selected by FIFO and Asynchronous HyperBand where overfitting was a clear issue. The model trained on the parameters selected by HyperBand took the longest time to train due to the lower batch size but still had a performance similar to that of the PBT model in terms of R2 scores for PaCO2, bicarbonate concentration and pH. Moreover, it is clear from the results that all models have high prediction accuracy for the four output parameters (R2 > 0.90), although the prediction of PaO2 was consistently lower. This could be due to possible physiological patterns that were not effectively represented within the data, although future tests with larger data sizes might shed more light on the issue.
These results highlight the fact that the surrogate model manages to accurately emulate the performance of the NPS within a statistically acceptable range. Although the performance of the models developed through this approach has not been compared with existing diagnostic support models, the surrogate model benefits greatly from the accuracy that is inherent to the original mechanistic simulation. On the other hand, in replacing the NPS with the DL-based surrogate model, the computational overhead due to nested calculation and equilibration loops is reduced. Additionally, following the experimental procedure described herein, further surrogate models can easily be developed from the NPS with the intent of diagnosing other conditions.
The results described in this research further showcase the benefits of building specialised surrogate models from existing complex medical mechanistic models, a process that is well established in many scientific fields as described by Gherman et al. [
32]. Through this process, significantly representative, more easily applicable and more lightweight models can be made available within hospital ICUs. This has the added benefit of not exposing ICUs to unnecessary external threats of data breaches, not requiring specialised and closed-source software and at the same time not exposing the specific inner workings of the models themselves. Furthermore, this approach benefits from the portability of the developed models, as they can be trained within the platform and exported as offline regressors to be implemented within a container environment. These benefits come at the price of slightly reduced accuracy, although the resulting model predictions are still adequate for supporting clinicians in diagnosing potential disease onset and identifying the need for extra medical attention for a given patient. Another shortcoming of the research described herein is the fact that our surrogate is effectively a black box model. This goes against the current
modus operandi of model development for clinical applications where explainable AI methods are recommended. It follows that developing explainable AI models for clinical diagnosis is one of the research focus points within the developed ML and data science platform described in this manuscript.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}