Abstract
The world’s population is increasing and so is the challenge on existing healthcare infrastructure to cope with the growing demand in medical diagnosis and evaluation. Although human experts are primarily tasked with the diagnosis of different medical conditions, artificial intelligence (AI)-assisted diagnoses have become considerably useful in recent times. One of the critical lung infections, which requires early diagnosis and subsequent treatment to reduce the mortality rate, is pneumonia. There are different methods for obtaining a pneumonia diagnosis; however, the adoption of chest X-rays is popular since it is non-invasive. The AI systems for a pneumonia diagnosis using chest X-rays are often built on supervised machine-learning (ML) models, which require labeled datasets for development. However, collecting labeled datasets is sometimes infeasible due to constraints such as human resources, cost, and time. As such, the problem that we address in this paper is the unsupervised classification of pneumonia using unsupervised ML models including the beta-variational convolutional autoencoder (β-VCAE) and other variants, such as convolutional autoencoders (CAE), denoising convolutional autoencoders (DCAE), and sparse convolutional autoencoders (SCAE). Namely, the pneumonia classification problem is cast into an anomaly detection to develop the aforementioned ML models. The experimental results show that pneumonia can be diagnosed with high recall, precision, f1-score, and f2-score using the proposed unsupervised models. In addition, we observe that the proposed models are competitive with the state-of-the-art models, which are trained on a labeled dataset.
1. Introduction
The lung is a very crucial organ of the human body. It is situated in the thorax region and primarily responsible for respiration [1]. All the cells in the body require oxygen to carry out various activities. Humans typically have two lungs, one on the left and the other on the right. They continuously provide the body with the oxygen that it requires for performing different important biochemical processes [2]. The results of these biochemical processes often include carbon dioxide (CO2) as a by-product [3]. The human body is not conditioned for accumulating CO2; such an accumulation in the body is harmful. Interestingly, the lungs are also tasked with extracting the produced CO2 from the body [3]. The alveoli and capillaries are the specific sites where the air exchange occurs.
The right lung is slightly larger than the left lung since the heart is also situated in the left section of the chest. Precisely, the right lung occupies 56% of the total lung volume [4]. Furthermore, the lung is involved in other functions such as the absorption and removal of water, alcohol, nitrous oxide, and drugs [5]. As such, a healthy lung is indispensable for the proper functioning of the human body. Unfortunately, there are different diseases that can plague the lungs. Some of these diseases include asthma, bronchitis, tuberculosis (TB), chronic obstructive pulmonary disease (COPD), and pneumonia [6]. Different causes including bacteria, viruses, fungi, and cigarettes may be responsible for the aforementioned diseases.
Pneumonia is an infection of the lungs involving the bronchioles and alveoli [7]. Specifically, pneumonia causes the inflammation of the alveoli. Subsequently, the alveoli collect pus and fluid so that respiration becomes problematic. Pneumonia is contagious, and, therefore, can be transmitted via airborne droplets when an infected individual coughs or sneezes [7]. Popular bacteria that cause pneumonia are Mycoplasma pneumoniae, Legionella pneumophila and Hemophilus influenzae [8]. Common viruses that cause pneumonia are influenza (flu), respiratory syncytial virus, rhinoviruses, and a coronavirus infection [9]. Popular symptoms of pneumonia include coughing, fever, shortness of breath at (near) resting state and chest pain. Considering the importance of the lung, an accurate and fast diagnosis of pneumonia has become very crucial. A wrong or late diagnosis can result in a high mortality rate [10] or expensive and long treatment procedures.
Traditionally, the diagnosis of pneumonia involves a medical specialist who evaluates the chest X-ray, CT scan, blood sample, or sputum sample of a patient [11]. A chest X-ray is perhaps the most-used method for pneumonia diagnosis. This observation may be related to the fact that X-ray acquisition is non-invasive, easy, relatively non-expensive, and fast. Consequently, it will be our focus for pneumonia diagnosis in the paper. The recent related works, along with summarized descriptions of the recent approaches for classifying chest X-rays for pneumonia, which can be found in the literature, are presented in Table 1. Like many other medical conditions [12,13,14], the assisted diagnosis of pneumonia via artificial intelligence (AI) systems can improve the accuracy of diagnosis. However, these machine-learning (ML)-based classification systems, which perform well, are often supervised models that require labeled datasets for training. One drawback, which the earlier works in Table 1 share, is the reliance on labeled datasets for learning. The work in [15] relied on the knowledge transfer from state-of-the-art deep neural networks (DNNs) for the supervised classification of pneumonia using X-rays. The knowledge from pre-trained DNNs such as AlexNet, DenseNet121, Inceptionv3, ResNet18, and GoogleNet was used as the base features for learning. The transferred layers were frozen, and new classification layers were stacked at the end of the aforementioned DNNs. Subsequently, the proposed models were fine-tuned for classifying data as ‘no pneumonia’ or ‘pneumonia’.

Table 1.
Related works summary for the classification of pneumonia using chest X-ray.
In [16], pre-trained DNNs including AlexNet, ResNet18, DenseNet201, SqueezeNet were used for the knowledge transfer. However, the problem was formulated as a multiclass problem, where chest X-rays were classified as having ‘no pneumonia’, ‘bacteria pneumonia’, or ‘viral pneumonia’. Another work [17] proposed the supervised classification of chest X-rays using a CNN and dynamic capsule routing units; competitive results were reported in the work. The work in [19] proposed training a CNN for feature extraction and, then, using different classifiers such as SVM, k-NN and RF to improve classification accuracy. Several experimental results were reported in the work for validating the claim. However, all the works mentioned above use labeled datasets for learning. Unfortunately, the collection of labeled datasets is not always feasible due to reasons such as cost, time, and human resources. Given the problems mentioned above, this paper proposes the unsupervised classification of pneumonia using chest X-rays. The classification task is reformulated as an anomaly detection task using different types of autoencoder models. The results of the models are especially compared against other unsupervised learning models and certain supervised models.
As such, the major expositions in this paper are the following:
- (i)
- (Investigate unsupervised ML models such as the beta-variational convolutional autoencoder (β-VCAE) [21] and other variants, such as the plain convolutional autoencoder (PCAE) [22], denoising convolutional autoencoder (DCAE) [22], sparse convolutional autoencoder (SCAE) [23] for pneumonia diagnosis.
- (ii)
- Study how the choice of the class that the DNN is trained on impacts the generalization performance of the aforementioned models.
- (iii)
- Provide comparative analysis with state-of-the-art supervised models for pneumonia diagnosis. Our evaluation metrics include recall, precision, f1-score, and f2-score, which particularly takes into account false negatives and false positives.
In the remaining parts of this paper, there are the following sections: Section 2 discusses the background and problem statement. In Section 3, the proposed unsupervised ML models for the diagnosis of pneumonia are presented. In Section 4, the results of experiments from the different models investigated are given and discussed, including comparison with some state-of-the-art supervised ML models. We conclude the paper in Section 5 by summarizing the main findings from the experimental results.
2. Background and Problem Statements
2.1. Background
Given a chest X-ray, the traditional approach for pneumonia diagnosis requires a trained medical specialist to examine and evaluate the X-ray to determine if the patient has pneumonia or not. However, such a procedure can sometimes result in erroneous diagnosis due to human fatigue or random attention loss. Moreover, the time for diagnosis can quickly increase when only a few medical specialists are available to evaluate many X-ray scans. As an alternative, an AI-based computer program can be developed to aid diagnosis. Such a computer program processes the chest X-ray and searches for patterns that may reflect the presence of pneumonia. Such a computer program that is based on AI is data-driven for knowledge acquisition. The AI program is tasked to classify X-rays as having pneumonia or not, that is, to act as a binary classifier.
Since computer programs cannot be impacted by fatigue or distractions, they are generally reliable once properly trained for the given task. Furthermore, it is possible with AI programs to evaluate several chest X-ray records over a short period; a human examiner usually requires more time to evaluate the same number of chest X-ray records due to fatigue. The ML model that that is investigated in this work is the β-VCAE and its variants. Figure 1 shows some samples of the chest X-rays used in this work.
Figure 1.
Chest X-ray samples used in this paper [24]. Top row: X-ray samples with no pneumonia. Bottom row: X-ray samples with pneumonia.
2.2. Problem Statements
Although there are existing DNN approaches for classifying chest X-rays for pneumonia, they are often supervised DNN models [25,26,27]. This means that these approaches require labeled datasets. However, collecting and labeling datasets can sometimes be very costly. At other times, we were only able to collect datasets with all samples (examples) belonging to only one class, e.g., with no pneumonia. This can occur when the disease that we are interested in diagnosing is rare so that data samples for the positive class (i.e., with pneumonia) are difficult or outrightly impossible to collect. In this scenario, most supervised DNN models such as VGG [28], ResNet [29], DenseNet [30], etc., cannot be employed. Consequently, the problem statement is the development of pneumonia classification models using unlabeled data, that is, unsupervised models.
3. Proposed Unsupervised Classification of Pneumonia
The objective of this work is to investigate the unsupervised classification of pneumonia using chest X-rays. What particularly distinguishes this work from the related works on the diagnosis of chest pneumonia is that the classification of pneumonia is formulated as an anomaly detection problem. That is, the developed models are trained on only samples that belong to one class and tested on samples that belong to both classes. The hypothesis is that a model that is successfully trained on only a particular class takes any sample that does not belong to the class that it was trained on as an anomalous data sample. The family of unsupervised DNNs that we explored is the CAE, which is either generative or non-generative based on the training algorithm. Generative CAEs learn the training data generation process and interpretable latent space (hidden representation), which can be sampled to generate novel data samples. In contrast, non-generative CAE do not model the training data generation process, and therefore, its latent space cannot be sampled from to generate novel samples; they simply learn a compressed representation in the latent space. In this paper, for generative CAE, we will explore the beta-variational convolutional autoencoder (β-VCAE) [21], which is a generalization of the variational convolutional autoencoder (VCAE) [31] when β = 1. In addition, we experiment with other CAEs such as the conventional CAE referred to as plain CAE (PCAE) [22], the denoising convolutional autoencoder (DCAE) [22], and the sparse convolutional autoencoder (SCAE) [23].
The developed unsupervised pneumonia classification system that is based on autoencoders can provide fast, considerably accurate, and cost-effective diagnoses without the need for a labeled dataset. This section details the proposed diagnosis system that employs different unsupervised ML models. The main stages in the classification framework are data processing and model training set up, which are discussed in the rest of the section.
3.1. Data and Data Processing
The chest X-ray images obtained from the database [24] have samples that reflect X-rays without pneumonia and those with pneumonia. The X-rays with pneumonia are referred to positive (+ve) samples or class, while X-rays without pneumonia are referred to as negative (−ve) samples or class. Subsequently, the positive and negative training data are abbreviated as Train(pos) and Train(neg), respectively. Similarly, the positive and negative testing data are abbreviated as Test(pos) and Test(neg), respectively. Figure 2 shows the overall diagnosis framework. The X-ray images have different sizes. However, the ML models employed in this paper accept input images of fixed size. As such, the X-ray images are resized to a fixed size of 64 × 64 pixels. This has the additional advantage of reducing computing hardware requirements for training and testing the ML models.
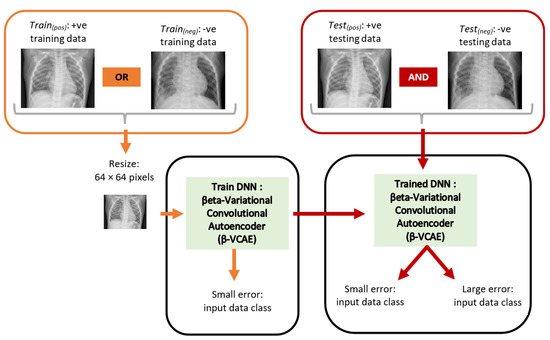
Figure 2.
Proposed unsupervised framework for the diagnosis of pneumonia using chest X-ray. The orange items and red items show the training and testing paths, respectively. The DNN is trained using only data from Train(pos) or Train(neg), while the model is tested using data from both Test(pos) and Test(neg).
3.2. Proposed Unsupervised Models
The problem of pneumonia classification is formulated as an anomaly detection problem based on the autoencoder model family, where the model is trained on either only the positive class or negative. A model that is trained on the positive class is expected to have successfully learned the reconstruction of X-ray samples from the positive class, namely, giving small reconstruction errors for positive samples but high errors for negative samples during testing. Similarly, a model successfully trained on only negative samples is expected to give small reconstruction errors when tested with negative samples but a high reconstruction error when tested with positive samples. It is on this concept that the proposed models are based for diagnosing pneumonia in an unsupervised fashion.
In the paper, four different convolutional autoencoders are investigated. The motivation is to study how the formulation of the models impacts their classification performances. It is well-known that the latent space properties of autoencoders significantly contribute to their regularization characteristics and, therefore, modeling power. An autoencoder is essentially tasked to reconstruct the supplied input data in the output layer [32]. This is expected to foster the learning of interesting latent representations in the hidden layer. The hidden units learn a mapping function for reproducing the input data in the output layer. It is noteworthy that the major challenge in learning autoencoders is capturing important features in the training data, that is, learning good latent representations for the training data [33]. Although the different autoencoders used in this work employ convolution operations, we describe their operations in this section using fully connected networks (multilayer perceptrons) for the sake of simplicity. However, similar formulations can be directly extended to the autoencoders with convolution operations.
3.2.1. Plain Autoencoder
The plain autoencoder is shown in Figure 3, where for a supplied input pattern, , the autoencoder is tasked with the learning of good hidden representation, , essential for the successful reconstruction of the input data in the output layer as . Here, is the dimensionality of the input data, and h is the number of hidden units. The notation, , was used to denote the first hidden layer representation (or codes), since autoencoders can be stacked to obtain a deep network (with many hidden layers). Generally, autoencoders are learned in two stages, referred to as encoding and decoding. Let the training set be of the form: and (as obtained in the input and output data for autoencoding) and .
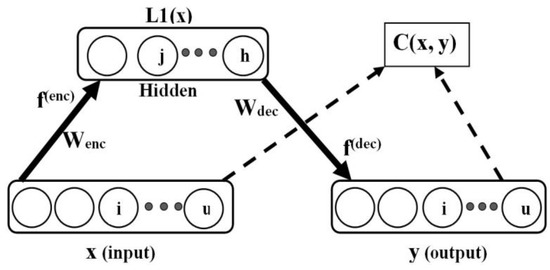
Figure 3.
Plain autoencoder.
- −
- Encoding: the autoencoder learns the mapping of input data, , to the hidden layer codes as a function . This is described as given below:where is the hidden layer output, is the input-hidden weight matrix, is the bias vector for the hidden layer, and is the activation function. The encoding phase can be conceived of as maximizing the mutual information between the input data, , and hidden layer, [33].
- −
- Decoding: the decoder learns the mapping of the learned hidden layer representations (activations), , to input data, , in the output layer as y; this is learned as a mapping function .
Note that the actual autoencoder output is y, while the target output is x, i.e., Figure 3. The decoding phase is described as follows:
where y is the actual network output, is the hidden-output weight matrix, is the hidden layer activations matrix, is the bias vector for the output layer, and is the activation function. The autoencoder weights, and , are learned by minimizing a cost function, , for the model; where denotes model parameters weights and biases, that is, . For real-valued inputs, the obvious choice is the mean squared error, as defined below:
Note that for autoencoders, the output unit denoted is tasked to reconstruct the input . Furthermore, the number of output units is equal to the number of input units, ; is the number of training patterns or samples. For binary inputs, the sum of Bernoulli cross entropies can be used as the cost function, as follows:
It is important to note that the autoencoder described with the convolution operations, which is used in the paper, is referred to as the plain convolutional autoencoder (PCAE).
3.2.2. Denoising Autoencoder
Given sufficient model capacity (i.e., number of parameters), the plain autoencoder can undesirably learn to copy the input as the output without learning useful latent representations. As such, autoencoders can be learned with important and additional constraints that encourage the network to learn better hidden representations that are useful for subsequent discriminative tasks, e.g., improve model optimization and regularization [34]. An interesting constraint is the denoising training criterion, where input data are stochastically corrupted to some specified degree (usually 5–50%), and the autoencoder is tasked with the reconstruction of the clean (uncorrupted) data in the output layer; this model is referred to as a denoising autoencoder (DAE) [35]. The way the denoising autoencoder is learned can provide an interpretation as a generative model. Let the stochastic process where the noisy input data is generated from clean input data be represented as . Then, the denoising training criterion is a way to approximate the stochastic operator . In this work, we implement the zero-masking noise, where input data are randomly set to zero with some pre-defined probability, . The DAE with the convolution operations is referred to as a convolutional autoencoder (CDAE).
3.2.3. Sparse Autoencoder
An obvious concern with autoencoders is the possibility of the model to simply duplicate (without learning useful hidden representations) the input data in the output layer in view of maximizing the mutual information of input data, , and hidden representation, [22]. Hence, the application of sparsity can be employed as a way to constrain autoencoders to learn useful hidden representations for input data [22]. The hidden units are constrained to have a small pre-defined activation value, [36]. From Figure 3, the computed sparsity parameter, , for a hypothetical hidden unit, , can be obtained using
where is the output (or activation) of hidden unit , is the training input pattern vector (sample) with index , and is the number of training samples. The main motivation behind sparsity is to constrain the hidden unit such that .
An inspection of (5) reveals that such a constraint enforces the average activations of hidden unit j to have small values over training samples to realize small values of . The Kullback Leibler (KL) divergence described in (6) can be used to measure the deviation of distribution z from [34] and, hence, optimize the whole model.
It is important to note that ) = 0 for = z. For the overall model cost minimization, the KL divergence is added to the mean squared error. Hence, the new overall cost function C() is expressed in (7), whereas emphasizes the effect of the sparsity constraint.
The SAE with the convolution operations is referred to as a sparse convolutional autoencoder (SCAE).
3.2.4. Beta-Variational Autoencoder
The beta-variational autoencoder (β-VAE) [21] is a generative model, and it is well-known for its structured latent space property, which makes the sampling of novel plausible samples interesting. This is an attribute that the other autoencoders lack, since their latent spaces are not structured or continuous (i.e., smooth) such that sampling from them is not guaranteed to generate semantically meaningful samples. Interestingly, the continuous latent space was argued to regularize the model even for tasks that do not require generating novel samples. Namely, the latent space of the β-VAE is constrained to be continuous manifolds so that the data reconstructed from it are more plausible. The second term in (8) is responsible for the smoothness constraint. This, in turn, is expected to improve its performance for anomaly detection and, therefore, the diagnosis of chest pneumonia.
In simple terms, this autoencoder has two terms in its cost function, as shown in the following expression:
where is the model encoder that is used to approximate the intractable , which is generally chosen to have the isotropic unit Gaussian distribution. The first term in the cost function is the typical reconstruction error, and the other term is the latent space regularization that encourages smoothness and structure. It can be noted that the β-VAE is a generalization of the conventional VAE proposed in work [31], where we can set β = 1. The β-VAE with the convolution operation is referred to as β-VCAE.
3.3. Model Evaluation Metrics
The evaluation metrics for the models in this work are recall, precision, f1-score, and f2-score. The chosen metrics ensure that the model evaluation is thorough. For example, class distribution impact, false positive, and false negative results are reasonably evaluated. Considering that the misdiagnosis of pneumonia can be life-threatening, the main metric for results comparison will be the f2-score. The f2-score especially highlights the false negatives predicted by the model, which are very undesirable in this application. The definitions of the evaluation metrics are as follows, where TP, FN, and FP are true positive, false negative, and false positive, respectively.
4. Experiments
The dataset details and experimental settings, along with results and discussion, are presented here. The experiments were carried out using a workstation with 32 GB random access memory (RAM), intel core-i7 CPU, Nvidia GTX1080Ti GPU, which runs Windows 10 OS.
4.1. Dataset Preparation
There are 3875 positive data (chest X-ray) samples and 1341 negative data samples in the dataset used in this paper. The two data preparation scenarios in the work are the following.
- (i)
- Train and validate the model on only positive data samples, that is, using only Train(pos) and Val(pos). Test the trained models on both positive and negative data samples, that is, using Test(pos) and Test(neg).
- (ii)
- Train and validate the models on only negative data samples, that is, using only Train(neg) and Val(neg). Test the trained models on both negative and positive data samples, that is, using Test(neg) and Test(pos).
For Train(pos), the data samples from the positive class are divided into training, validation, and testing sets in the ratio 60%:20%:20%, respectively. All the negative class data samples are used as testing data. For Train(neg), the data samples from the negative class are partitioned into training, validation, and testing sets in the ratio 60%:20%:20%, respectively. All the data samples from the positive class are taken as taken as testing data. The details of the data preparation for model training are given in Table 2, where positive and negative classes are abbreviated as +ve and −ve, respectively. The pixels in the images are normalized to the range 0 to 1.
Table 2.
Chest X-ray dataset preparation.
4.2. Model Architecture and Training Settings
Herein, the details of the training settings for the different models are discussed. All models have a single filter in the input and output layers that allow the reconstruction of the input images in the output layers of the different models. All the constructed models have either two or four hidden layers, which are convolution layers. As such, we can observe how the number of hidden layers impact model performance. The models with two hidden layers have 16 filters in both hidden layers. The models with four hidden layers have 32, 16, 16, and 32 filters, consecutively. All filters are of spatial size 3 × 3. The hidden layers use the rectified linear activation function, while the output layer uses the sigmoid function. The model hyperparameters are chosen by heuristics using the validation data. The initial learning rate is set at 0.1 and momentum rate at 0.9. The learning rate is decayed during model training every 3 epochs by a factor of 0.2 to facilitate model convergence to one of the good local optima. The batch size is 32, and the models are trained for 10 epochs. The threshold for class association is taken as the maximum reconstruction error on the validation data.
4.3. Results and Discussion
The results of the different models obtained using Train(pos) and Train(neg) are reported in this section. Furthermore, we compare the results of our model, which employ unsupervised learning with the state-of-the-art models that use supervised learning. Table 3, Table 4, Table 5 and Table 6 show the testing results for the different data preparation settings discussed in Section 4.1 (i.e., Table 2) on evaluation metrics such as recall, precision, f1-score, and f2-score. Table 3 shows the results of the models with two hidden layers trained using Train(pos) settings, that is, only positive samples as input but tested using both positive and negative samples. Table 4 reports similar experimental results with models that have four hidden layers.
Table 3.
Testing results of DNN models with two hidden layers obtained using Train(pos).
Table 4.
Testing results of the DNN models with four hidden layers obtained using Train(pos).
Table 5.
Testing results of DNN models with two hidden layers obtained using Train(neg).
Table 6.
Testing results of the DNN models with four hidden layers obtained using Train(neg).
It is seen in Table 3 that the β-VCAE models provides the best results based on both f1-score and f2-score, β-VCAE with β = 5, which enforces a more structured latent space that slightly outperforms β-VCAE with β = 1. The DCAE with σ = 0.1 outperforms the DCAE with σ = 0.05; we conjecture that using σ = 0.1 imposes more regularization on the model and, therefore, better performance. The SCAE model with z = 0.3 performs better than when z = 0.5.
Table 3 can be observed. First, it is seen that increasing the number of hidden layers results in some performance improvements on the models when comparing Table 3 and Table 4. Again, the β-VCAE models give the best results. Using training settings Train(neg), Table 5 and Table 6 show the results of the models with two and four hidden layers. The models are trained on only the negative class samples but tested on both negative and positive class samples. Importantly, it is seen in the experiments that the performances of these models lag behind the corresponding models trained using Train(pos); compare Table 3 with Table 5 and Table 4 with Table 6. Similarly, Table 5 and Table 6 show that the β-VCAE models give the best results in comparison with other models. Again, this reflects the crucial importance of the structured latent space property of β-VCAE, which the other autoencoders lack. Overall, it is seen that the β-VCAE model gives the best performance in comparison to the other autoencoders. We posit that the nature of the latent space of the β-VCAE model discussed in Section 3.2.4 can be related to its success. Namely, the structured latent space ensures that data points are constrained within a plausible manifold from which the output of the model is reconstructed. The other autoencoders do not possess this interesting attribute, as the manifold for the latent representations is not constrained. Consequently, they can generate implausible data, which reflects in lower generalization performance.
Finally, the comparison of our best results obtained using β-VCAE with supervised models is considered. Namely, popular supervised DNNs such as the VGG-16, ResNet-56, ResNet-110, and DenseNet-40 are used for the study. The results, including the number of model parameters and depth, are shown in Table 7, where the β-VCAE models are trained using Train(pos) settings, and thus, the results are taken from Table 4. The supervised models are trained and tested by combining the same positive samples used for β-VCAE and the negative samples in Table 2. It is seen in Table 7 that the supervised models slightly outperform the proposed β-VCAE models that are unsupervised. However, when the different costs associated with collecting labeled data for training are taken into consideration, our unsupervised models are competitive and can be successfully employed for the diagnosis of pneumonia using chest X-rays. The training curve for β-VCAE with β = 5, which is reported in Table 7, is given in Figure 4. Furthermore, in comparison to the supervised models, the proposed models have significantly fewer layers and parameters, and thus, training the β-VCAE model is many times faster than the supervised models. Importantly, the inference times of the different models are especially important, since these reflect the maximum number of diagnoses that can be made within a given period. As such, the inference times of the different models are shown in Figure 5. It is observed that the proposed β-VCAE model has significantly smaller latency during testing compared to the supervised models. This is an additional advantage for the proposed model in comparison to the supervised models.
Table 7.
Results comparison with supervised models.
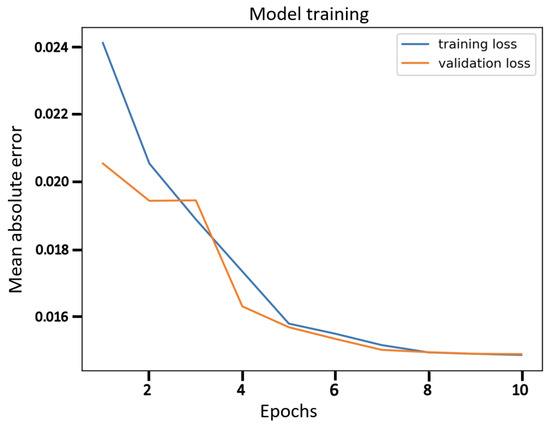
Figure 4.
The training curve for β-VCAE with β = 5 as reported in Table 7.
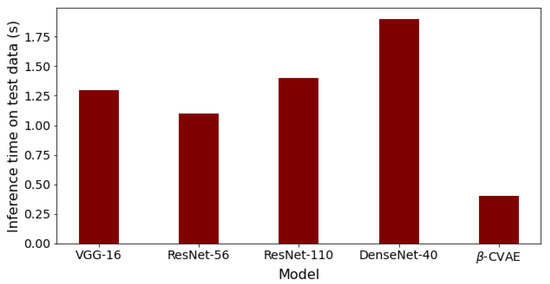
Figure 5.
Inference times for the different models on the testing data. The results follow from the comparison results reported in Table 7.
The results of the unsupervised models are quite surprisingly competitive when compared with the supervised learning models in Table 7. Our explanation is that by casting the classification problem into an anomaly detection task that autoencoders are known to perform well, the classification problem becomes easy. The autoencoder only has to learn good latent representations that partition the decoded (reconstructed) output into the two data classes, positive and negative pneumonia cases. The limitation of the proposed solution that is formulated as an anomaly detection problem in the paper is that it limits diagnosis to two classes, i.e., binary classification problems. For problems with multiple classes, the proposed solution cannot be directly applied. However, supposing that training data for all classes in a multiple classification task are available, it would be interesting to study if training an autoencoder model for each class and then ranking the errors of all the autoencoders for a given data sample during testing gives interesting results.
The major challenge in the investigation is computational resources for training the models in a reasonable time. A workstation with a GPU that has a memory of over 6 Gigabytes was found sufficient for the experiments. The training time can be further improved by using high-end GPUs that allow a larger batch size.
5. Conclusions
This work investigates the diagnosis of pneumonia in the scenario where the available dataset is unlabeled using a beta-variational convolutional autoencoder (β-VCAE). The work also considers the plain convolutional autoencoder (PCAE), convolutional denoising autoencoder (CDAE), and convolutional sparse autoencoder (CSAE) for the diagnosis problem. The diagnosis problem is formulated as an anomaly detection problem so that the models are trained on either only the data from the positive or negative class. The findings show that the autoencoders can be successfully applied to the problem, especially when they are trained on the positive class samples. All the models achieve an over 97% f2-score performance. We note that the β-VCAE consistently gives the best results among the different autoencoder models investigated. A comparison with supervised models such as VGG-16, ResNet-56, ResNet-110, and DenseNet-100 shows that the proposed β-VCAE, which is unsupervised, gives very competitive results and requires a significantly shorter time for testing. As such, a considerably larger number of diagnoses can be performed with the β-VCAE in comparison to the supervised models.
Author Contributions
Conceptualization, S.M.A., E.I. and K.A.; methodology, S.M.A.; software, S.M.A.; validation, S.M.A. and K.A.; formal analysis, S.M.A., E.I. and K.A.; investigation, S.M.A., E.I. and K.A.; resources, S.M.A., E.I. and K.A.; data curation, S.M.A.; writing—original draft preparation, S.M.A.; writing—review and editing, S.M.A., E.I. and K.A.; visualization, S.M.A.; supervision, E.I. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in the paper are publicly available for download via the weblink: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia, accessed on 20 March 2023.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tran, M.C.; Crockett, D.C.; Cronin, J.N.; Borges, J.B.; Hedenstierna, G.; Larsson, A.; Farmery, A.D.; Formenti, F. Bedside monitoring of lung volume available for gas exchange. Intensiv. Care Med. Exp. 2021, 9, 3. [Google Scholar] [CrossRef] [PubMed]
- Crosby, L.M.; Waters, C.M. Epithelial repair mechanisms in the lung. Am. J. Physiol.-Lung Cell. Mol. Physiol. 2010, 298, L715–L731. [Google Scholar] [CrossRef] [PubMed]
- Manickavel, S. Pathophysiology of respiratory failure and physiology of gas exchange during ECMO. Indian J. Thorac. Cardiovasc. Surg. 2021, 37, 203–209. [Google Scholar] [CrossRef] [PubMed]
- Rypens, F.; Metens, T.; Rocourt, N.; Sonigo, P.; Brunelle, F.; Quere, M.P.; Guibaud, L.; Maugey-Laulom, B.; Durand, C.; Avni, F.E.; et al. Fetal lung volume: Estimation at MR imaging—Initial results. Radiology 2001, 219, 236–241. [Google Scholar] [CrossRef]
- Bryson, E.O.; Frost, E.A. Marijuana, nitrous oxide, and other inhaled drugs. In Perioperative Addiction; Springer: New York, NY, USA, 2012; pp. 163–177. [Google Scholar]
- Gupta, A.; Shah, A. Bronchial anthracofibrosis: An emerging pulmonary disease due to biomass fuel exposure. Int. J. Tuberc. Lung Dis. 2011, 15, 602–612. [Google Scholar] [CrossRef]
- Alcón, A.; Fàbregas, N.; Torres, A. Pathophysiology of pneumonia. Clin. Chest Med. 2005, 26, 39–46. [Google Scholar] [CrossRef]
- Blanquer, J.; Borras, R.; Nauffal, D.; Morales, P.; Menendez, R.; Subias, I.; Herrero, L.; Redon, J.; Pascual, J. Aetiology of community acquired pneumonia in Valencia, Spain: A multicentre prospective study. Thorax 1991, 46, 508–511. [Google Scholar] [CrossRef]
- Falsey, A.R.; Walsh, E.E. Viral pneumonia in older adults. Clin. Infect. Dis. 2006, 42, 518–524. [Google Scholar] [CrossRef]
- Restrepo, M.I.; Mortensen, E.M.; Rello, J.; Brody, J.; Anzueto, A. Late admission to the ICU in patients with community-acquired pneumonia is associated with higher mortality. Chest 2010, 137, 552–557. [Google Scholar] [CrossRef]
- Han, W.; Zhu, M.; Chen, J.; Zhang, J.; Zhu, S.; Li, T.; Cai, H.; Fang, Q.; Wei, G.; Liang, T. Lung transplantation for elderly patients with end-stage COVID-19 pneumonia. Ann. Surg. 2020, 272, e33–e34. [Google Scholar] [CrossRef]
- Aslam, N.; Khan, I.U.; Bashamakh, A.; Alghool, F.A.; Aboulnour, M.; Alsuwayan, N.M.; Alturaif, R.K.; Brahimi, S.; Aljameel, S.S.; Al Ghamdi, K. Multiple Sclerosis Diagnosis Using Machine Learning and Deep Learning: Challenges and Opportunities. Sensors 2022, 22, 7856. [Google Scholar] [CrossRef] [PubMed]
- Schulte-Rüther, M.; Kulvicius, T.; Stroth, S.; Wolff, N.; Roessner, V.; Marschik, P.B.; Kamp-Becker, I.; Poustka, L. Using machine learning to improve diagnostic assessment of ASD in the light of specific differential and co-occurring diagnoses. J. Child Psychol. Psychiatry 2022, 64, 16–26. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Wang, F.; Zhang, J.; Cui, X.; Jiang, F.; Chen, N.; Zhou, J.; Chen, J.; Lin, S.; Zou, J. Using machine learning to predict atrial fibrillation diagnosed after ischemic stroke. Int. J. Cardiol. 2022, 347, 21–27. [Google Scholar] [CrossRef] [PubMed]
- Chouhan, V.; Singh, S.K.; Khamparia, A.; Gupta, D.; Tiwari, P.; Moreira, C.; Damaševičius, R.; de Albuquerque, V.H.C. A novel transfer learning based approach for pneumonia detection in chest X-ray images. Appl. Sci. 2020, 10, 559. [Google Scholar] [CrossRef]
- Rahman, T.; Chowdhury, M.E.H.; Khandakar, A.; Islam, K.R.; Islam, K.F.; Mahbub, Z.B.; Kadir, M.A.; Kashem, S. Transfer learning with deep convolutional neural network (CNN) for pneumonia detection using chest X-ray. Appl. Sci. 2020, 10, 3233. [Google Scholar] [CrossRef]
- Mittal, A.; Kumar, D.; Mittal, M.; Saba, T.; Abunadi, I.; Rehman, A.; Roy, S. Detecting pneumonia using convolutions and dynamic capsule routing for chest X-ray images. Sensors 2020, 20, 1068. [Google Scholar] [CrossRef]
- Elshennawy, N.M.; Ibrahim, D.M. Deep-pneumonia framework using deep learning models based on chest x-ray images. Diagnostics 2020, 10, 649. [Google Scholar] [CrossRef]
- Masad, I.S.; Alqudah, A.; Alqudah, A.M.; Almashaqbeh, S. A hybrid deep learning approach towards building an intelligent system for pneumonia detection in chest X-ray images. Int. J. Electr. Comput. Eng. 2021, 11, 5530–5540. [Google Scholar] [CrossRef]
- Singh, S.; Tripathi, B.K. Pneumonia classification using quaternion deep learning. Multimedia Tools Appl. 2022, 81, 1743–1764. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-vae: Learning basic visual concepts with a constrained variational framework. In Proceedings of the International Conference on Learning Representation 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Makhzani, A.; Frey, B. K-sparse autoencoders. In Proceedings of the International Conference on Learning Representation 2013, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Pneumonia Chest X-ray Dataset. Available online: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia (accessed on 12 August 2022).
- Umer, M.; Ashraf, I.; Ullah, S.; Mehmood, A.; Choi, G.S. COVINet: A convolutional neural network approach for predicting COVID-19 from chest X-ray images. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 535–547. [Google Scholar] [CrossRef] [PubMed]
- Sarki, R.; Ahmed, K.; Wang, H.; Zhang, Y.; Wang, K. Automated detection of COVID-19 Through Convolutional Neural Network Using Chest X-ray Images. PLoS ONE 2022, 17, e0262052. [Google Scholar] [CrossRef] [PubMed]
- Kundu, R.; Das, R.; Geem, Z.W.; Han, G.T.; Sarkar, R. Pneumonia detection in chest X-ray images using an ensemble of deep learning models. PLoS ONE 2021, 16, e0256630. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the International Conference on Learning Representation 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Chen, M.; Weinberger, K.; Sha, F.; Bengio, Y. Marginalized denoising auto-encoders for nonlinear representations. In Proceedings of the International Conference on Machine Learning 2014, Beijing, China, 21–26 June 2014; pp. 1476–1484. [Google Scholar]
- Erhan, D.; Manzagol, P.A.; Bengio, Y.; Bengio, S.; Vincent, P. The difficulty of training deep architectures and the effect of unsupervised pre-training. In Proceedings of the Artificial Intelligence and Statistics 2009, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 153–160. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Bengio, Y.; Yao, L.; Alain, G.; Vincent, P. Generalized denoising auto-encoders as generative models. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Meng, L.; Ding, S.; Xue, Y. Research on denoising sparse autoencoder. Int. J. Mach. Learn. Cybern. 2017, 8, 1719–1729. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).