Abstract
An intense level of academic pressure causes students to experience stress, and if this stress is not addressed, it can cause adverse mental and physical effects. Since the pandemic situation, students have received more assignments and other tasks due to the shift of classes to an online mode. Students may not realize that they are stressed, but it may be evident from other factors, including sleep deprivation and changes in eating habits. In this context, this paper presents a novel ensemble learning approach that proposes an architecture for stress level classification. It analyzes certain factors such as the sleep hours, productive time periods, screen time, weekly assignments and their submission statuses, and the studying methodology that contribute to stress among the students by collecting a survey from the student community. The survey data are preprocessed to categorize stress levels into three categories: highly stressed, manageable stress, and no stress. For the analysis of the minority class, oversampling methodology is used to remove the imbalance in the dataset, and decision tree, random forest classifier, AdaBoost, gradient boost, and ensemble learning algorithms with various combinations are implemented. To assess the model’s performance, different metrics were used, such as the confusion matrix, accuracy, precision, recall, and F1 score. The results showed that the efficient ensemble learning academic stress classifier gave an accuracy of 93.48% and an F1 score of 93.14%. Fivefold cross-validation was also performed, and an accuracy of 93.45% was achieved. The receiver operating characteristic curve (ROC) value gave an accuracy of 98% for the no-stress category, while providing a 91% true positive rate for manageable and high-stress classes. The proposed ensemble learning with fivefold cross-validation outperformed various state-of-the-art algorithms to predict the stress level accurately. By using these results, students can identify areas for improvement, thereby reducing their stress levels and altering their academic lifestyles, thereby making our stress prediction approach more effective.
Keywords:
stress; students; academic; routine; mitigate; tension; conventional; boosting; metrics; practical analysis; model; performance 1. Introduction
The pandemic has played its role to keep classes for students online, and it has significantly increased the stress levels of the students because they must look at devices such as laptops, PCs (personal computers), and mobiles throughout the day, complete assignments, and handle exams online. This is the primary reason for an increase in stress amongst college students in the United States [1]. This physically affects the students because they sit in one place, and there is less physical activity compared to how it would have been if the classes were conducted in schools and colleges on campus [2]. To identify certain academic factors that affect students, a survey was conducted across various schools and colleges about their workloads and collected their responses. With the use of machine learning models, which play a significant role in recognizing patterns that are not visible to the naked eye, this paper aims to predict the stress levels of the students based on the responses collected from them.
There are many factors that contribute to stress such as personal relationships, worrying about something, uncertainty in taking decisions, and so on [3], but the focus here will be on the academic factors that contribute to the stress. After brainstorming various ideas, certain key features were picked that may contribute to academic stress, and those questions were asked of students in the teenage group, and the responses were collected along with the stress levels, which will be used as the training data for the purpose of predicting stress levels for other students in future using the model. The model thus provides insights to the students to find the ideal habits that they need to follow in day-to-day life in order to keep their stress levels under control. Machine learning models such as the decision tree classification algorithm, random forest algorithm (bagging), AdaBoost algorithm, and gradient boosting algorithm have been developed on the collected data to obtain various insights, thus maximizing the efficiency of the output for predicting stress levels and determining a student’s ideal workload and daily habits to live a stress-free student life. A challenge faced before building the model was the bias in the collected survey. The students who responded to the survey mostly responded that their stress levels were either in a manageable state or that they were highly stressed; hence, the numbers of responses for the no-stress category were fewer, which in turn caused an imbalance in the dataset. In order to solve this issue, the oversampling method was used to bring the count of the minority class, that is, the no-stress responses, to the other two majority classes. This ensured that there was no bias in the trained machine learning models that would be used to predict the stress levels on the testing data.
To overcome the challenges, the key contributions involved in the paper are as follows:
- (i)
- The research proposes a unique ensemble learning strategy designed primarily for classifying students’ levels of stress. While earlier research focused on stress prediction as outlined in Section 2, the work presented here ingeniously blends decision trees, random forest classifiers, AdaBoost, gradient boost, and ensemble learning techniques to provide a thorough model for precisely classifying stress levels.
- (ii)
- In contrast to other approaches outlined in Section 2, the article incorporates survey data from the student population to thoroughly analyze stress causes. The method also uses oversampling methods to correct the imbalance in the dataset of stress levels. A more reliable and accurate stress prediction model is produced because of the integration of survey-based insights with imbalance management.
- (iii)
- The work uses a number of performance assessment criteria, such as accuracy, precision, recall, and F1 score, to go beyond intuitive measurements. The results’ validity is further strengthened by the use of fivefold cross-validation. The addition of receiver operating characteristic (ROC) curve analysis also offers a full review of the model’s performance for each category of stress level, demonstrating a comprehensive and in-depth examination of the suggested strategy.
Bagging and boosting techniques have been used to increase the efficiency of the predictions. The objective of boosting is to combine weak learners together to form an overall strong model. However, it is important to note that bagging is computationally more effective than boosting because it can train ‘n’ models in parallel, while boosting cannot do that. If we do not have a high bias and there is only a need to reduce overfitting, bagging was the best option to choose, which was another challenge that had to be overcome for the analysis of the survey data.
Academics play an important role in determining the future of a student, and this can cause mental pressure by testing their coping skills [4]. Keeping this in mind, management of stress plays a crucial role while navigating through challenges faced by the students in their academic coping lifestyles. The COVID-19 pandemic caused many struggles in a student’s life when classes and assignments were given in online modes [5]. This caused an increase in screentime and working hours, thereby imposing more pressure on the students. Thus, this paper aims to analyze which factors affect the way students cope with academics by obtaining responses from them and building a model that can predict how well they manage their stress levels. This enables them to adapt and improvise their lifestyles to keep their stress levels in check.
The Section 2 of the paper talks about the various related work conducted in the field of stress prediction and the models used for that purpose; the Section 3 explains the proposed work and the models used to obtain the results, followed by the Section 4 and Section 5 that explain the experimental setup and the results obtained in comparison with the other works, with a summary of the various performance metrics that determine the efficiency of the model.
2. Related Works
In this section, related papers are referenced and surveyed. It is noted that different authors used different methodologies in implementing their solutions to similar stress-level balancing problems. Some used deep learning using neural networks and long short-term memory (LSTM) models, while many used supervised learning classification methods such as random forests, decision trees, and other ensemble learning algorithms.
2.1. Deep Learning Algorithms
The authors in [6] tried to predict stress levels using LSTM. The dataset is obtained from a student life app, which collects passive and automatic data from the sensors available in mobiles. The data were collected from students of Dartmouth for a 10-week spring term. They concluded that they were 62.83% confident in determining if the student was stressed or not by observing their last 2–12 h of usage of their mobiles. They stated that if the number of epochs were increased, the training accuracy reached a maximum of 99%, but a drop in the performance of the testing set was noticed. The authors in [7,8,9,10,11,12] proposed a method to predict personalized stress in students using a deep multitask network. They received the dataset from a SmartLife study of 48 students in Dartmouth. They concluded that the best model that predicted stress levels accurately was the CALM network model with an F1 score of 0.594.
2.2. Supervised and Ensemble Learning
There are works that address a similar problem to ours, and the authors of those research projects use different methods to arrive at a conclusion for their specific problems. Some used deep learning algorithms to classify the data they collected. Others used various machine learning algorithms such as ensemble algorithms, boosting algorithms, etc. In [10,11,12], the authors took the Open Sourcing Mental Illness (OSMI) Mental Health in Tech 2017 survey as their dataset. They initially performed one-hot encoding after cleaning the data, and they took 14 of the most relevant attributes out of 68. One-hot encoding is a popular encoding method to utilize when processing datasets containing categorical variables [13]. They finally concluded that stress is highly correlated to gender among the selected parameters, i.e., women are generally found to experience greater stress than men in the same department. The authors in [14] researched about detecting anxiety, depression, and stress using the dataset obtained from the Depression, Anxiety, and Stress Scale (DASS 21) questionnaire. Their results show that the highest accuracy for all three classes, depression, anxiety, and stress, is achieved in the naïve Bayes classifier; however, the F1 score for stress was highest in the random forest algorithm, and for depression, it was highest in the naïve Bayes classifier with the F1 score for anxiety being low in all tested models. They also stated that the patients without diseases, i.e., negative cases, were also classified appropriately. In [15], the authors researched the prevalence and the predicting causes of stress among university students in Bangladesh. They surveyed students from 28 different universities using questions regarding academic-, health-, and lifestyle-related information, which in turn was referred to the perceived stress status of the students. They stated that the most important factors that were selected for the prediction of stress were academic background, blood pressure, pulse rate, sleep status, etc. The highest performance was observed from the random forest algorithm with an accuracy of nearly 80%, and the lowest was observed by logistic regression with an accuracy of 75%. They concluded that their model predicts the psychological problem of students more accurately, and this can help stakeholders, families, management, and authorities to understand the health problems faced by the students.
The authors in [16] tried to model students’ happiness by using machine learning methods on data collected from students who were monitored for a month via mobile phone logs and sensors. They stated that modeling and predicting the happiness of the students can help to detect individuals who are either prone to or at risk of depression, and then, they can intervene and help the student.
They finally stated that they had achieved 70% classification accuracy of the happiness of students on the test data. In [17,18], perceived stress caused by the COVID-19 pandemic on adults were modeled and predicted through machine learning models and psychological traits. They collected data from around 2000 Italian adults via online surveying methods concerning their stress factors, psychological traits, demographics, etc. They stated that higher levels of distress were observed in the parts of society where people earn less. It was also found that women were comparatively more stressed, and those who lived with others also faced more distress. They finally said that the machine learning models identified people with high stress with a sensitivity of more than 76%.
The authors in [19,20] tried to predict stress in the students who are transitioning from teenagers to adults in a few institutions of India, and the data were collected from them. The top-most contributors of stress in those people were found to be social media, academic pressure, workload, and anxiety, among others. The data showed that B. Tech students are under more high stress as compared to bachelor of computer application (BCA) students. Their research also showed that academics, work stress, and unhealthy social media consumption contributed much toward stress among generation Z students. Finally, their algorithm resulted in an R-squared value of 0.8042 after elimination of around 30% of the initial features obtained. In [21], the authors tried to detect and predict high-resolution stress as a tool for electronic or mobile health systems supporting personalized treatments both clinically and remotely. The dataset they used to train their models was the Wearable Stress and Affect Detection (WESAD) dataset, and they calculated stress scores based on various questionnaires from it. Their results show that the specific algorithms of random forests, least-squares gradient boosting, and nonlinear auto-regressive network with exogenous inputs offered the best predictions of high-resolution stress, and they also proposed that this can be integrated with a decision support system to aid in the decision-making for stress management and monitoring.
2.3. Analysis of Stress Factors
In [22,23], the authors tried to find the interrelationship between stressors, i.e., stress-causing agents, and coping strategies. They used self-collected data from various students from five colleges in the city of Shillong. They reported that academic stress had a high degree of correlation with social and financial stress, and positive stress-coping mechanisms such as prayer, sleep, and meditation were helpful to combat academic stress. The authors in [24] tried to predict stress in pre-registration nursing students using self-collected data from all the pre-registration nursing students in a top English university. They finally stated that the work–life balance of pre-registration nursing students, especially those who must take care of children, should be considered important while designing the curriculum of nursing education. They also said that the main predictors of caseness are pressure, whether they had children or not, coping method employed, and scores on their personal problems, and the caseness rate was around 33% of the population. Table 1 shows the summary of the key contributions and algorithms used in the various surveyed works.

Table 1.
Key contributions and algorithms used in different fields of scope.
In [11], the authors discussed that the global pandemic was a cause of fear and stress being instigated among the people, with students especially becoming stressed over their studies in various forms. Their analysis showed that there was a key importance in certain features affecting academic stress such as prolonged use of digital tools for education purposes, lack of physical learning on campus contributing to improper education, and the psychological elements at play. In [1], the authors surveyed students from Texas A&M University regarding stress. Over 40% of surveyed students reported an increase in stress due to online classes and then, concerns over grades. Participants had difficulty concentrating and had an increased workload that contributed to their stress. Some also stated that their sleep schedules have also been impacted, causing stress. In [25], the authors said that students suddenly feel less motivated to focus on academics due to the sudden switch from traditional teaching to an online mode. Students also believe they are wasting a lot of time indulging in social media as they do not have anything interesting to do and as a diversion from academia.
Four stress parameters are taken into consideration in distinguishing each work analyzed, namely academic/student-related stress (S1), workplace-related stress (S2), personal stress (S3), and stress caused by the COVID-19 pandemic (S4). For each of the authors mentioned below in Table 2, the stress factors they have considered in their work are represented.
Table 2.
Depiction of stress parameters considered in various works.
The various works related to the management and prediction of stress were surveyed and analyzed. A standard benchmark for the prediction of stress levels caused by the impact of academics is proposed and implemented in this paper with this trend in mind.
3. Problem Statement
The primary focus of the problem is to classify the students’ stress levels and classify them into three categories: whether they are extremely stressed, experiencing manageable stress, or are completely free from any mental pressure brought on by analyzing particular academic factors. Ensemble learning models such as random forest and boosting algorithms such as the AdaBoost and gradient boost have been utilized after a traditional approach such as the decision tree classifier to determine if there is any improvement in the efficacy of the findings so acquired. The data used for this purpose were collected from the student community using a survey questionnaire. The attributes of the model and the methods used to construct it are described in the following sections.
4. Proposed Work
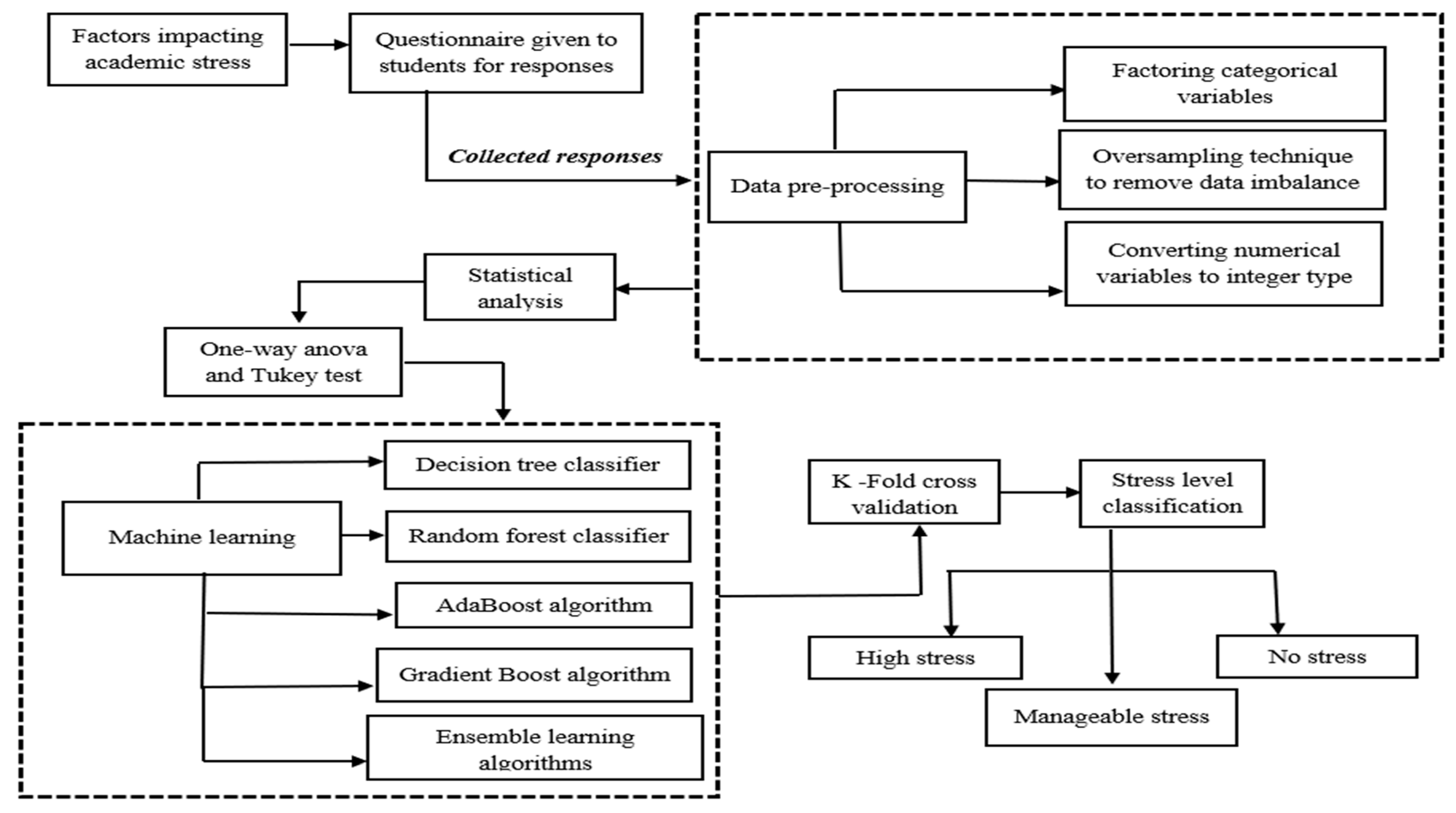
After collecting the survey data, preprocessing work and various machine learning models are applied to classify the stress levels into three categories: highly stressed, manageable stress, and no stress. The oversampling method is used to remove the imbalance in the dataset caused by the minority class. Decision tree, random forest classification, AdaBoost, and the gradient boost algorithm are used as the ML models for the analysis. Figure 1 represents the architecture of the entire process that is followed.
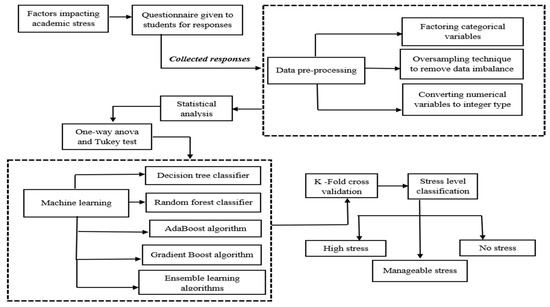
Figure 1.
Architectural workflow for academic stress level classification.
The oversampling methodology used to balance the dataset is described in Algorithm 1.
| Algorithm 1: Oversampling the minority class in survey data to remove bias | |
| Step 1 | The minority class, “No stress” class, is oversampled to remove bias. |
| Step 2 | Oversampling the data due to the imbalance in the dataset for the “No stress” class. No stress data ← take subset (data, where stress level = “No stress”) Sampling “no stress” subset data to generate duplicate rows ← Sample ‘n’ rows (no-stress data, specify additional data point count) |
| Step 3 | Merge the additional duplicate records created with the initial data New data ← Row binding the data frame (data, Sampled “no stress” data) Shuffled data ← new data (sample (1: total data point count of new obtained data)) |
| Step 4 | Use the obtained data to train machine learning models |
The algorithm takes the imbalanced dataset and adds more samples to replicate the “No stress” class, and it is merged with the initial dataset to form the data that will be provided as input to the models.
4.1. Decision Tree Classification to Classify Stress Levels
Decision trees use the concept of entropy and information gain to build trees from a root node. Entropy is defined as the measure of randomness of a variable, while the information gain computes the difference between the entropy value before and after the splitting of the tree and specifies the impurity in the class elements [26]. Here, the stress levels are classified by using both criteria to extract information from the dataset.
The entropy of an attribute is calculated by using Equation (1).
where E(S) is the entropy of attribute S, and pi is the probability of event i or the percentage of class i in a node of S.
Each node in the tree yields a maximum amount of data in each split, which could be achieved using the information gain (IG) provided by Equation (2).
The parameters used to train the decision tree classifier are described in Algorithm 2.
| Algorithm 2: Implementing decision tree classifier to classify stress levels | |
| Step 1 | Read the surveyed dataset |
| Step 2 | Transforming data to feed them to the machine learning model Data ← transform (data, sleep = convert as integer (sleep), productivity ← convert as factor (productivity), screentime ← convert as factor (screentime), assignments ← convert as integer (assignments), deadline ← convert as factor(deadline), study ← convert as factor (study), stress ← convert as factor (stress)) |
| Step 3 | Training the decision tree model using the unbiased dataset Sample ← sample rows (1: total data point count (data), split into 80–20 ratio) Train ← data[sample,] Test ← data[-sample,] Decision tree model ← feed data (stress ~., data = training data) |
| Step 4 | Interpreting the results |
The algorithm takes the dataset as the input and converts the categorical variables such as the productivity and study-time columns into factors and the assignment column into an integer, which act as the preprocessing steps before splitting the training and testing data and feeding them into the decision tree classifier.
4.2. Random Forest Classification to Classify Stress Levels
The random forest algorithm is an ensemble learning method that uses the concept of bagging. The random forests select a subset of the features in the survey dataset, and the final classification of the stress levels is obtained by training the model using multiple decision trees as base learners [27]. It uses the concepts of the Gini index and entropy, which are calculated using Equations (3) and (4).
where pi is the probability of event i or the percentage of class i in a node of S.
The parameters used to train the random forest model are described in Algorithm 3.
| Algorithm 3: Feeding the data to random forest classifier | |
| Step 1 | Implement the similar transformation steps used in decision tree classifier |
| Step 2 | Random forest model ← random forest (stress~., data = training data, mtry = 2) |
| Step 3 | Evaluate the model using performance metrics |
| Step 4 | Interpreting the results |
The algorithm follows the preprocessing steps described in the previous algorithm and feeds the data to the random forest classifier.
4.3. Stress Level Classification Using Adaboost Algorithm
This is another ensemble learning technique that uses the concept of boosting [28]. Decision tree “stumps” are used as base learners, and each time a wrong classification is made on the base learners, those weak links are alone passed to the next stump, and this process keeps happening until the error is minimized. Weights are assigned to all the data points, and after each time a wrong classification happens, higher weights are assigned to those points.
Equation (5) calculates the weights of the data points.
where n is the total number of data points.
The performance of each stump is calculated by the formula in Equation (6).
Then, the new weights after each iteration are updated using Equation (7).
The parameters used to train the AdaBoost model are described in Algorithm 4.
| Algorithm 4: Feeding the data to the AdaBoost classifier | |
| Step 1 | Implement the similar transformation steps used in decision tree classifier |
| Step 2 | Model ← boosting (stress~., data = training data, boost = TRUE, mfinal = 100) predictions ← predict (model, test) |
| Step 3 | Evaluate the model using performance metrics |
| Step 4 | Interpreting the results |
The algorithm follows the preprocessing steps described in the previous algorithm and feeds the data to the AdaBoost algorithm with the parameters mentioned above.
4.4. Stress Level Classification Using Gradient Boost Algorithm
The gradient boost algorithm is another boosting technique under the ensemble learning method. It also uses the concept of decision stumps. It increases the weight of the records that are incorrectly classified and decreases the weight of the ones that are correctly classified. It works on the principle that the weak learners combine together to form a strong model [29]. It is described in Equation (8).
where yi is the observed value of each observation, L is the loss function, and gamma is the value for log (odds).
The derivative of the loss function is provided by Equation (9).
The gamma value that minimizes the loss function can be written in a generalized equation, as below:
And finally, the predictions are updated using Equation (11).
The parameters used to train the gradient boost algorithm are described in Algorithm 5.
| Algorithm 5: Feeding the data to gradient boost classifier | |
| Step 1 | Implement the similar transformation steps used in decision tree classifier |
| Step 2 | Model gbm = gbm (stress~., data = training_data, distribution = “multinomial”, cv.folds = 10, shrinkage = 0.01, n.minobsinnode = 10, n.trees = 200) |
| Step 3 | Evaluate the model using performance metrics |
| Step 4 | Interpreting the results |
The algorithm follows the preprocessing steps described in the previous algorithm and feeds the data to the gradient boost algorithm with the parameters mentioned above, and the combinations of the above algorithms are analyzed for ensemble learning. The next section describes the exploratory analysis of the factors involved in determining the academic stress level of students and the application of these algorithms with the results obtained.
5. Experimental Setup and Analysis
5.1. Exploratory Analysis
The survey data were collected from the student community in the teenage group, and the experiments were conducted using the RStudio environment, version 1.4.1717-3. R-programming version 4.1.1 was used to do the preprocessing and the building of machine learning models.
The following questions were the parts of the survey that were answered by the students and were used as the dataset for training the models:
- Number of hours of sleep every night;
- Most productive time in the day—early bird/night owl;
- Screen time per day;
- Number of weekly assignments assigned to the student;
- Submission status of the weekly assignments;
- Study plan—regular or procrastinated;
- Stress level as assessed by the student.
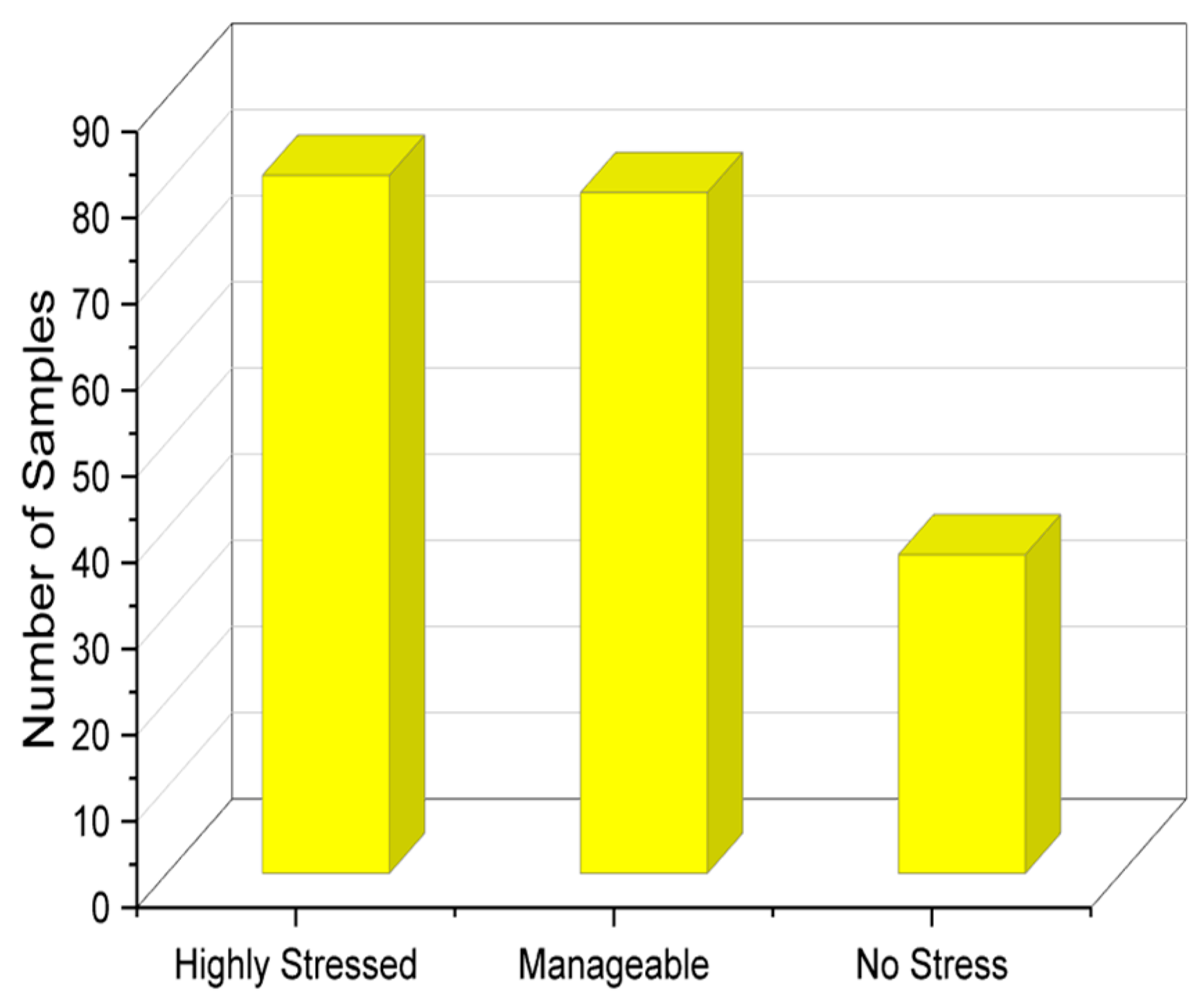
The variables that are categorical are as follows: most productive time, submission status of weekly assignments, study plan, and stress level. The remaining variables are numeric; 197 responses were collected from the community, and exploratory analysis of the results was performed to analyze the responses. In the given problem statement, we have multiple columns representing different variables related to student stress levels. We performed the Tukey test [30], which allows for multiple comparisons between the levels of each variable, providing valuable insights into the differences and relationships among these variables. This capability is particularly useful when trying to identify which variables have a significant impact on the stress levels of students. On top of this, the test is known for its ability to handle small sample sizes effectively. It does not rely on strict assumptions about the underlying data distribution, making it suitable for datasets with relatively limited observations. The number of samples with respect to each stress class is analyzed in Figure 2. It shows that most students were highly stressed or were able to manage stress; however, a fraction of the students answered by saying that they experienced no stress as well.
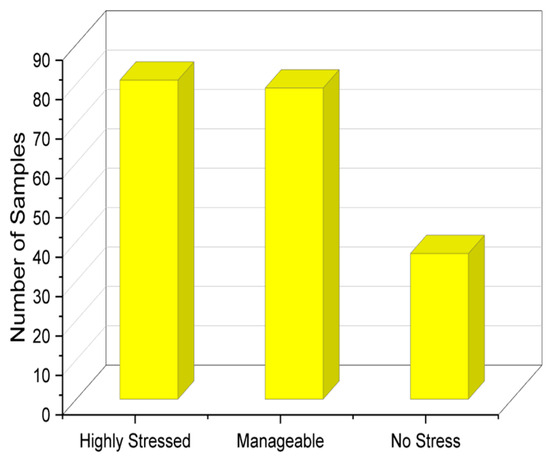
Figure 2.
Stress level distribution of students.
The average sleeping hours of a student fall more or less between the range of 6 to 8 h, which is a healthy sign; however, there is still a fraction of people sleeping fewer hours than ideal, which is not good for our bodies. It can be seen that the people who are observed to be highly stressed have a sleep time of less than the ideal amount of 6 h a day.
From Table 3, it is inferred that out of the 197 responses, 144 students sleep for at least a minimum of six hours, which is the recommended minimum sleeping time for a person. It also shows that the people who sleep for less than 6 h are more likely to be highly stressed than not. The data for highly stressed students can be seen toward the top left of the table, which implies that there is a correlation between sleep hours and stress levels. The absolute value for the highly stressed might be higher in the 6 h range, but this is because there are more entries, i.e., more people who achieve around 6 h of sleep compared to the other data points.
Table 3.
Analysis of stress with sleeping hours of students.
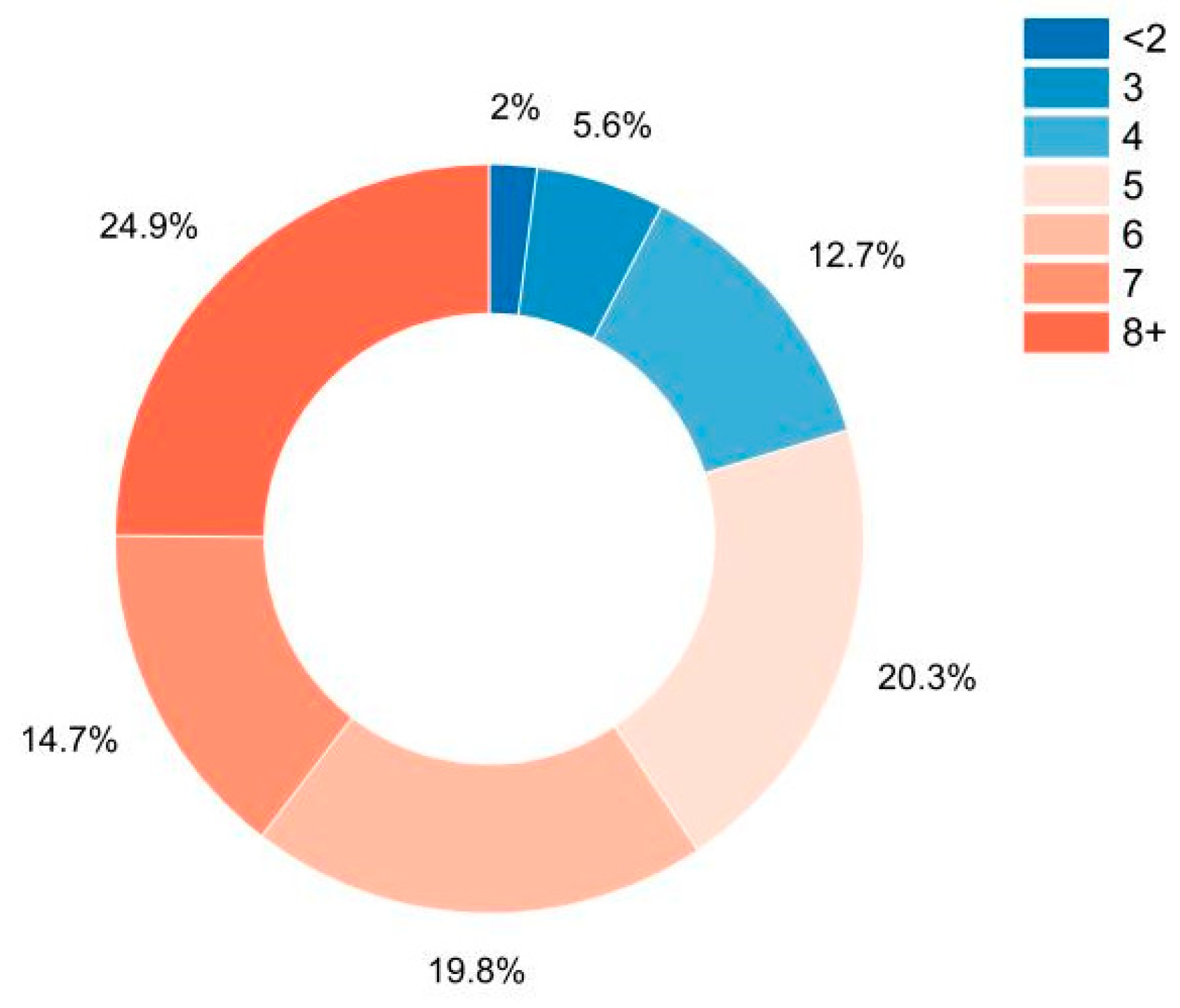
The following figures and tables focus on how screen time plays an integral part in determining the stress levels of students. Figure 3 shows a donut graph that displays the percentage of students exposed to screen time on their phones or laptops.
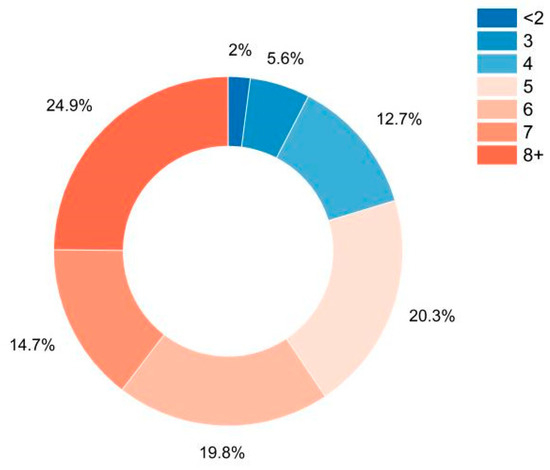
Figure 3.
Hours of exposure to screen time.
Table 4 compares the screen time of the students and the number of weekly assignments they receive, and from it, we can see that many people who obtain more than five weekly assignments have an alarming screen time of more than 8 h a day.
Table 4.
Screen time on a daily basis vs. weekly assignments.
It is evident that the amount of screen time has shot up considerably, considering that the classes for the students have shifted online, and nearly 160 students have screen time greater than or equal to 5 h. Table 5 shows how the stress levels are impacted with respect to the number of weekly assignments given to the students with respect to each stress level classification.
Table 5.
Impact of assignments on stress levels of the students.
It can be inferred that most of the students manage stress as long as the assignments per week are fewer than or equal to 3, and it as goes beyond 4, the stress levels become higher, indicating that the students find it difficult to manage the workload of the academics. Table 6 shows the representation of how sleep hours are affected with respect to the productive time period of each student.
Table 6.
Analyzing impact of sleep hours on the productivity of a student.
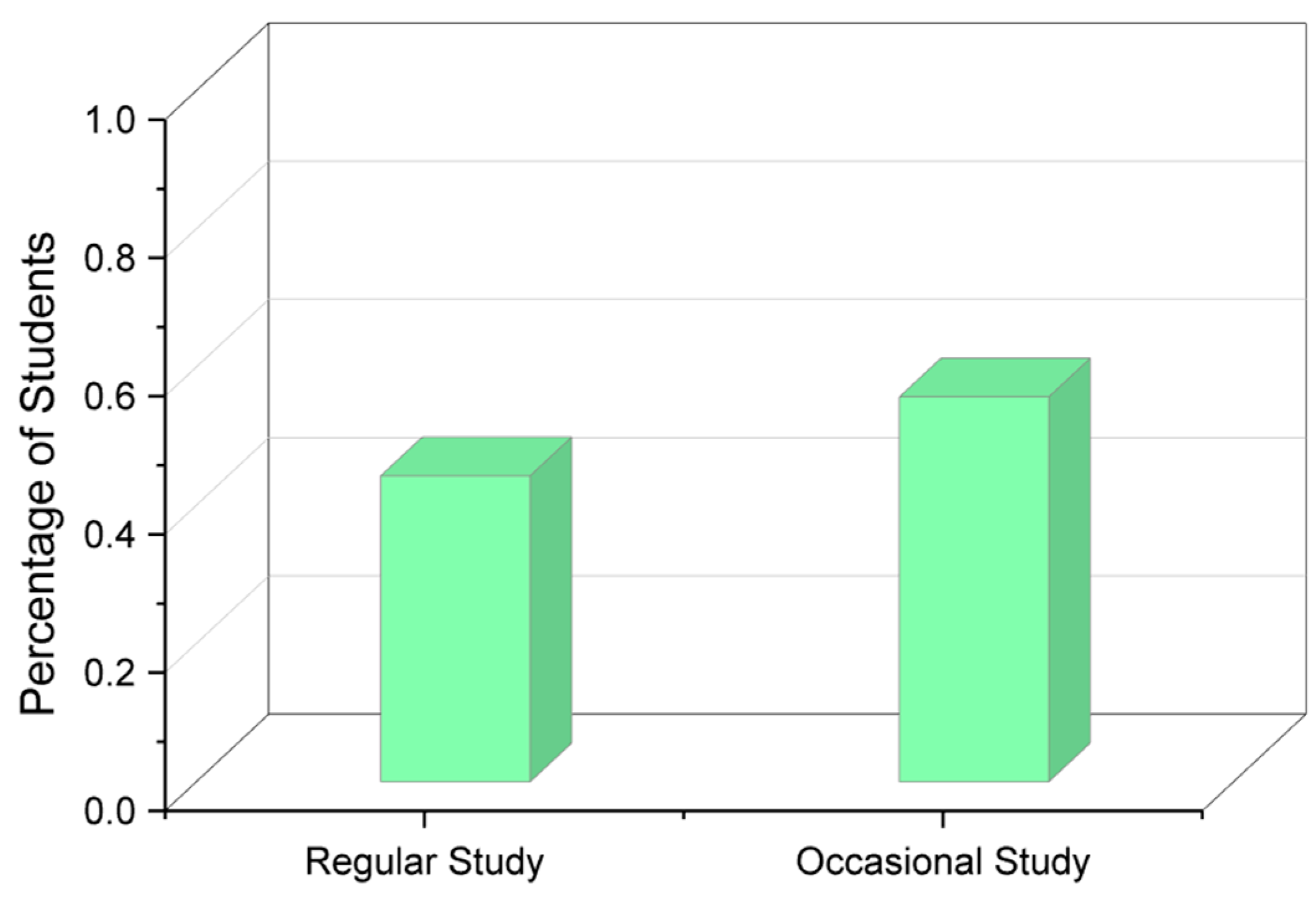
It is clearly visible that the students who sit up late at night tend to sleep for fewer hours than the ones who are productive early in the morning. The late-night workers tend to sleep as little as 4 h, while the ones who wake up early in the morning obtain at least a minimum of 6 h of sleep. Figure 4 shows which methods students adopt when it comes to studying, and more than half the responses state that the students study occasionally rather than regularly.
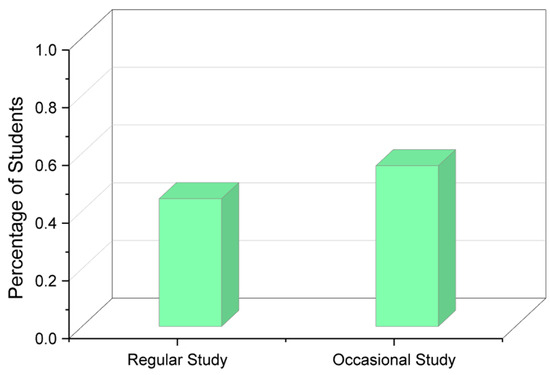
Figure 4.
Studying methodology of students.
5.2. Data Preprocessing
After the exploratory analysis is completed, data preprocessing is performed to prepare the data for use in training machine learning models. Symbols such as +, <, and > are removed by using the inbuilt libraries and packages in R, as explained in the algorithm section. An important step in the process is to remove the imbalance in the dataset. Table 7 shows the number of responses under each class of stress level.
Table 7.
Classification of stress levels in initial data response.
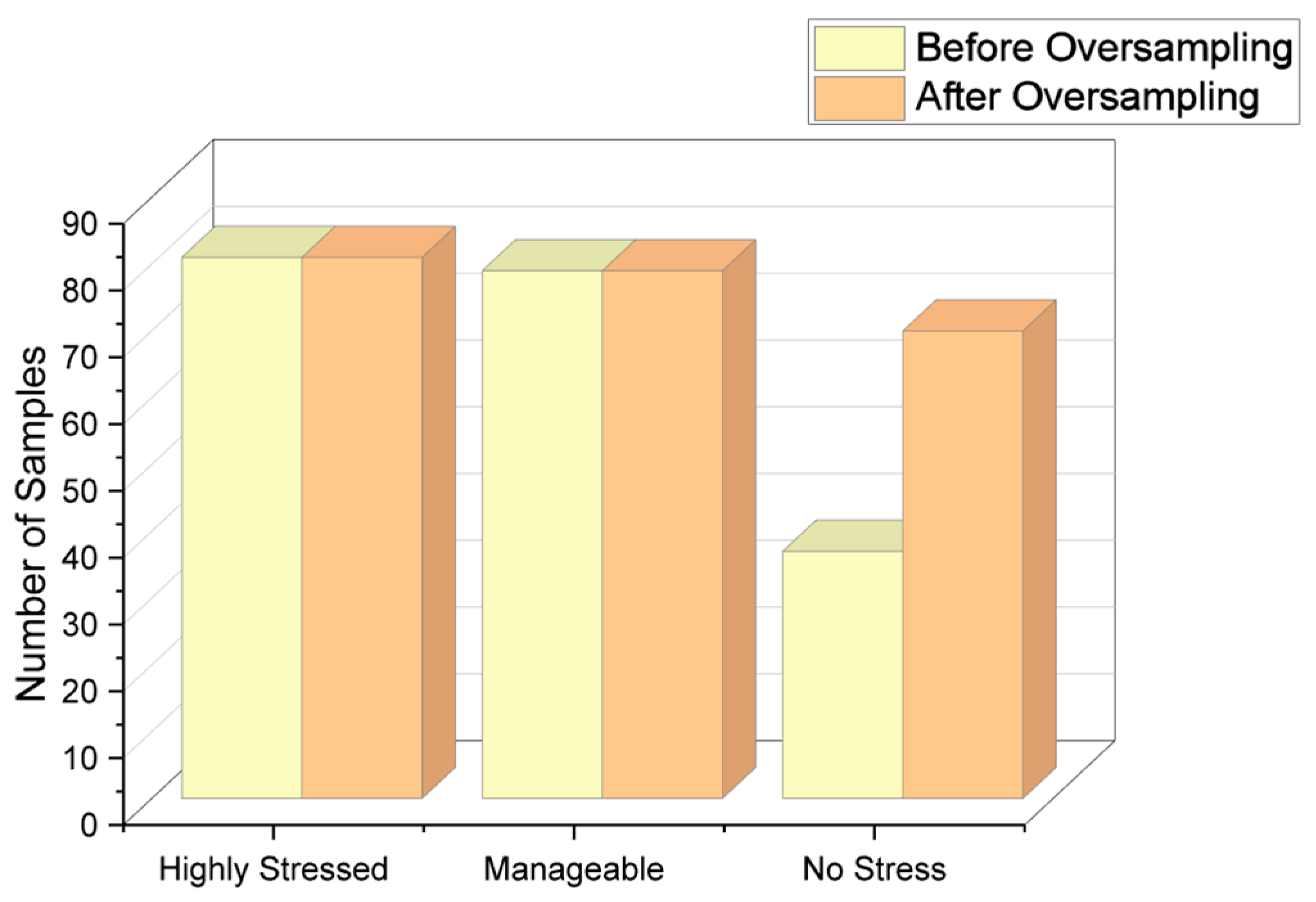
Since there is a large number of responses for “Highly stressed” and “Manageable” stress levels, the oversampling method has been used to bring the count of the “No stress” class closer to the count of the other two majority classes. The count of each class after applying the oversampling method is shown in Table 8. Figure 5 shows the visual representation of responses before and after applying the oversampling technique.
Table 8.
Classification of stress-level responses after oversampling.
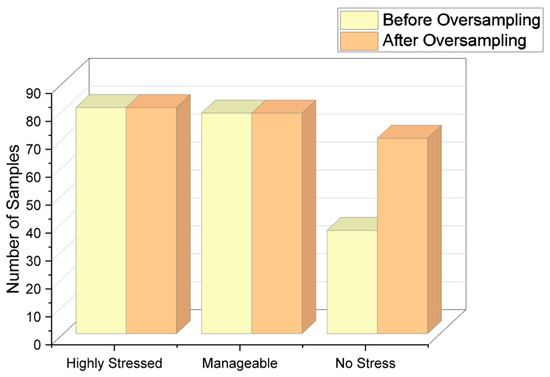
Figure 5.
Responses after applying oversampling technique.
5.3. Evaluation Metrics
To evaluate the performance of each algorithm we have used by the same methods, we have chosen confusion matrices as the best way to move forward as they directly provide a numerical representation of what was predicted compared to its actual value. In a classification consisting of more than two predictable values, the confusion matrix is a k × k matrix, where k is the number of possible predictable values. The main diagonal of the confusion matrix shows the count of the right predictions, and the other elements show the wrong predictions. Consider the k × k confusion matrix to be X and each element of the matrix to be xij. The accuracy of the algorithm can be calculated as in Equation (12).
where N represents the total number of predicted values, and xii are the true positives, i.e., the values in the main diagonal. Accuracy can also be represented as the following Equation (13):
The other metric that is useful to analyze the performance of an algorithm is the F1 score, which is defined as the harmonic mean of precision and recall. Here, precision quantifies the number of positive class predictions that actually belong to the positive class, and recall quantifies the number of positive class predictions formulated out of all positive examples in the dataset, and these are described in Equations (14)–(16).
6. Results
6.1. Statistical Test Results
Two statistical tests, the analysis of variance (ANOVA) and the Tukey test, have been implemented and analyzed on the data. The purpose of the tests is to check if the statistical analysis proceeds to show that there exists a difference between the means of different populations, i.e., the stress-level classes in this scenario. The numerical variables, namely the sleep hours, the number of assignments, and the average screentime of students, have been taken into consideration for the tests to check the impact of the factors. A one-way ANOVA test was initially conducted using the three parameters, keeping the stress-level classes as the factors. Table 9 shows the F score for each parameter with respect to the factor variable.
Table 9.
F-score value for each parameter in a one-way ANOVA test.
It was inferred that there was a significant difference between the population at the 0.05 significance level when tested with all three numeric parameters. Following the one-way ANOVA test, a Tukey test was conducted on the dataset to analyze the difference in means for the parameters with respect to the factor variable.
When tested with the sleep hour parameter, it was inferred that there was a significant mean difference in those who were highly stressed but no difference between those who managed the stress well or were under no stress. Table 10 and Table 11 show the Tukey test mean comparisons by taking the sleep hours parameter into consideration.
Table 10.
Tukey test mean comparison grouping letters table with respect to sleep hours.
Table 11.
Tukey test mean comparison with respect to sleep hours.
When the test was conducted using the assignment parameter, it was inferred that there existed a significant difference between all three groups. Table 12 and Table 13 show the Tukey test mean comparison by taking the assignment parameter into consideration.
Table 12.
Tukey test mean comparisons grouping letters table with respect to assignments.
Table 13.
Tukey test mean comparison with respect to assignments.
When tested with the screen-time parameter, it was inferred that there was a significant mean difference in those who were highly stressed but no difference between those who managed the stress well or were under no stress. Table 14 and Table 15 show the Tukey test mean comparison by taking the sleep hours parameter into consideration.
Table 14.
Tukey test mean comparison grouping letters table with respect to screen time.
Table 15.
Tukey test mean comparison with respect to screen time.
6.2. Experimental Results
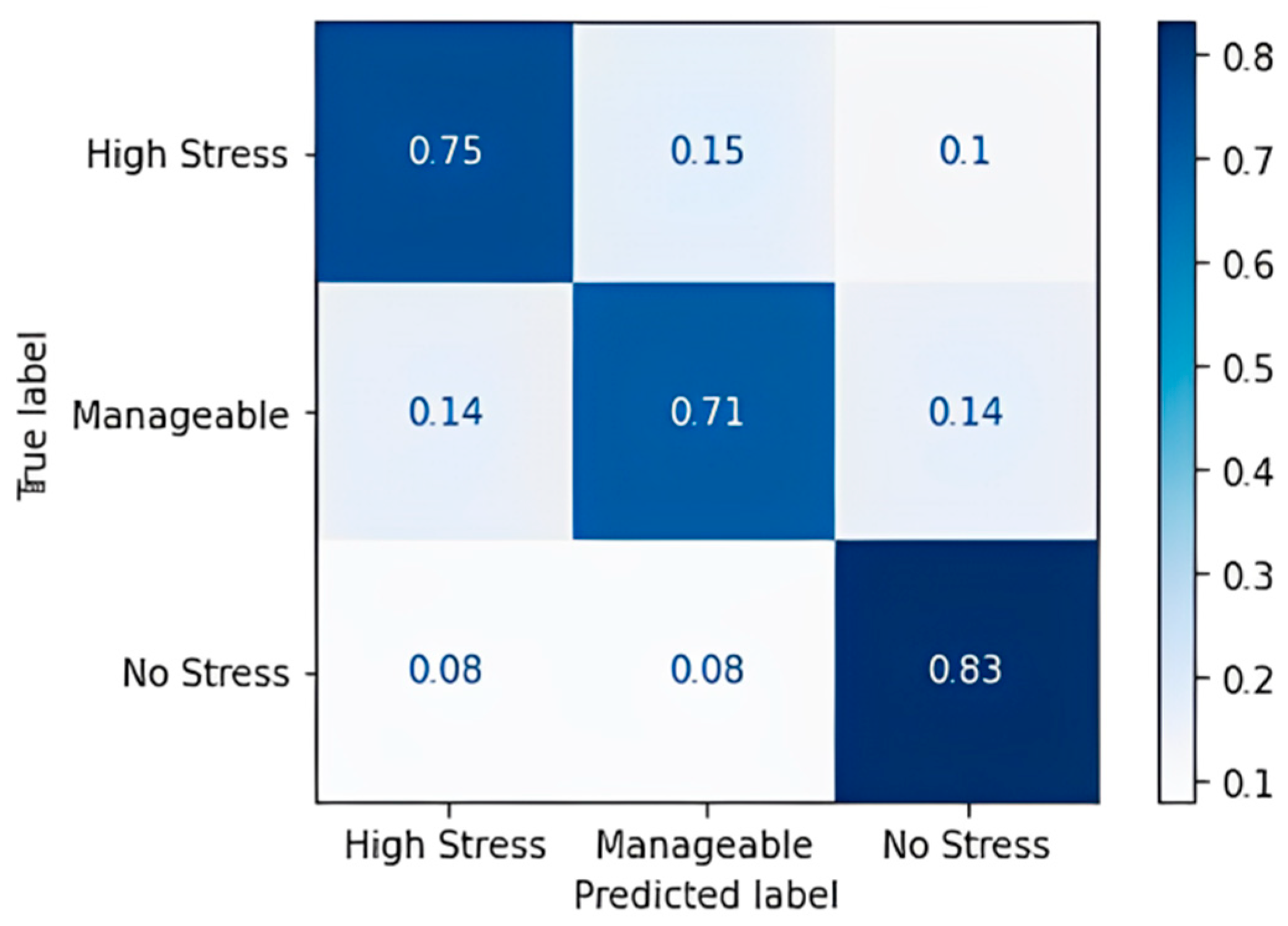
The data are split into 80% training data and 20% testing data and provided to various ML algorithms to classify the stress levels. From the decision tree obtained, it was observed that those who study regularly are under no stress—even more so when the assignments given to them per week are fewer than or equal to 4. As the assignments keep increasing, the screen time increases and goes up to 7 or 8 h as well, and that, in turn, has led to the prediction of the class to be “Highly stressed”, while other cases are mostly predicting manageable stress levels. Table 16 shows the confusion matrix obtained for the decision tree classifier, and Figure 6 shows the accuracy in terms of the classification percentage.
Table 16.
Confusion matrix for decision tree algorithm.
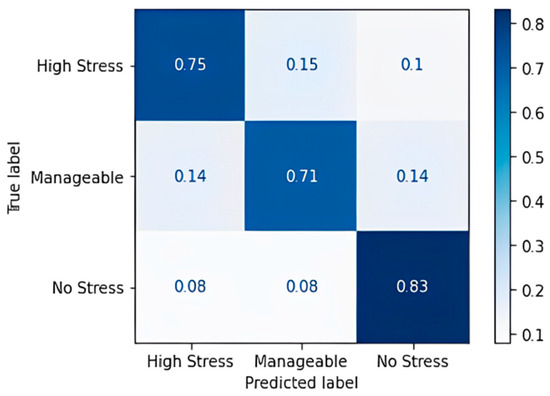
Figure 6.
Confusion matrix accuracy for decision tree classifier.
For the most part, the algorithm has predicted correctly, except for a few cases of the high-stress class for which it predicted “Manageable” and “No Stress”. A classification accuracy of 76.09% and an F1 score of 75.67% were obtained upon applying the decision tree classification algorithm. Table 17 shows the confusion matrix obtained for the random forest algorithm, and Figure 7 shows the accuracy in terms of the classification percentage.
Table 17.
Confusion matrix for random forest algorithm.
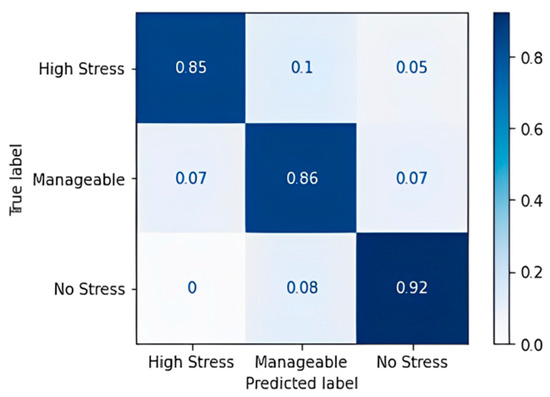
Figure 7.
Confusion matrix accuracy for random forest classifier.
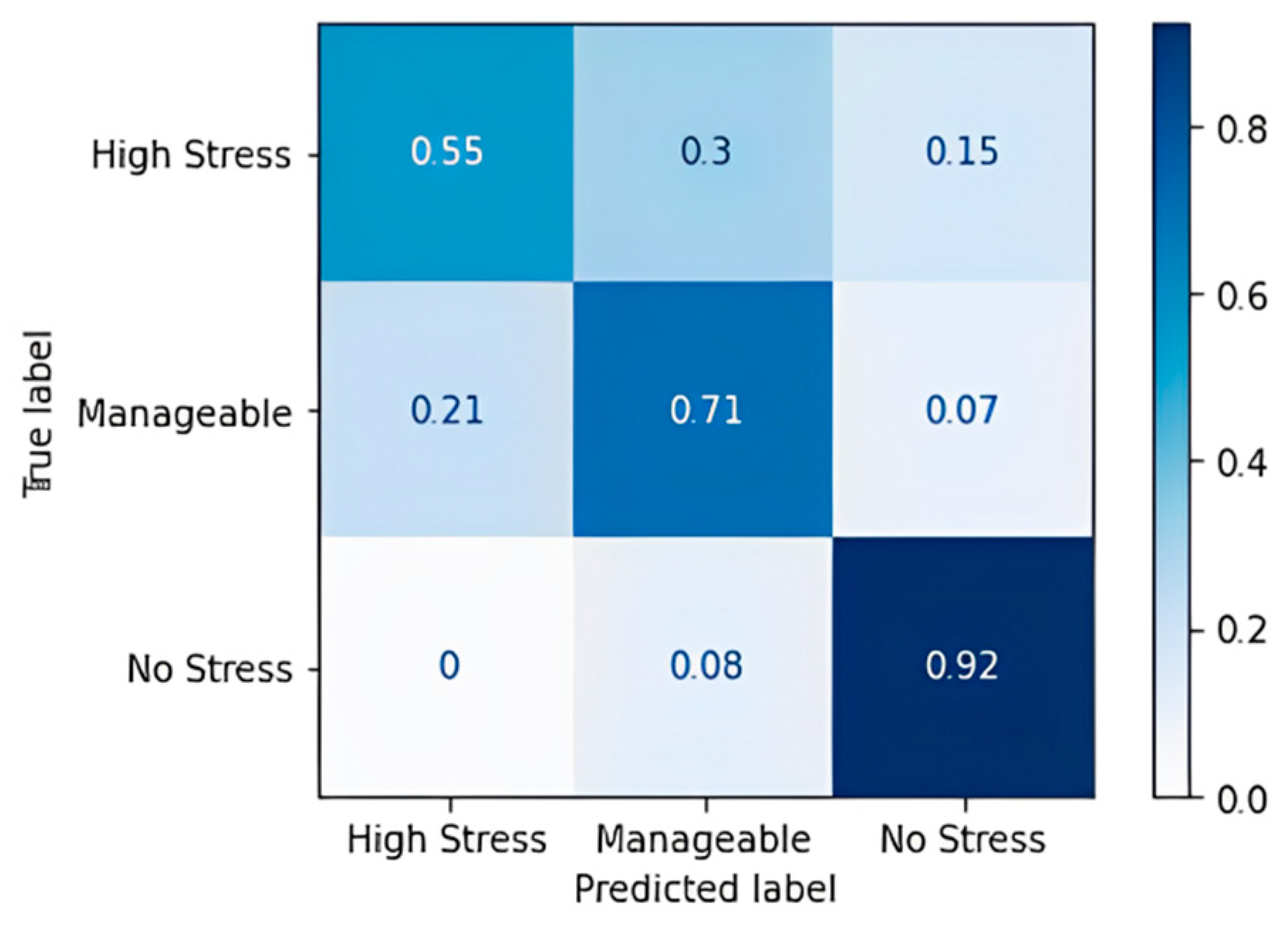
The random forest algorithm performs better in comparison to the decision tree. Noticeable wrong predictions are in the high and manageable stress classes. An accuracy of 86.96% and an F1 Score of 86.67% were obtained, which implies that the random forest model has more true positives and true negatives when it classifies and a smaller number of false positives and false negatives than the decision tree model that we obtained. Table 18 shows the confusion matrix obtained for the gradient boost algorithm, and Figure 8 shows the accuracy in terms of the classification percentage.
Table 18.
Confusion matrix for gradient boost algorithm.
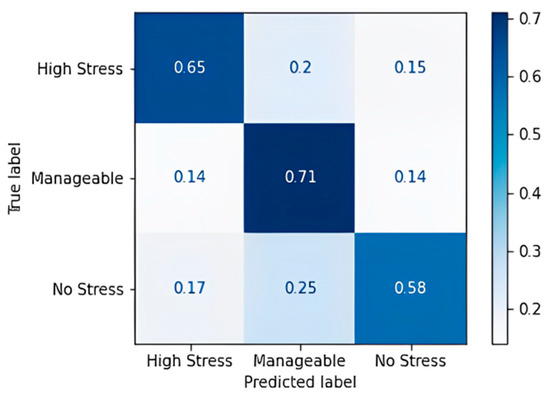
Figure 8.
Confusion matrix accuracy for gradient boost algorithm.
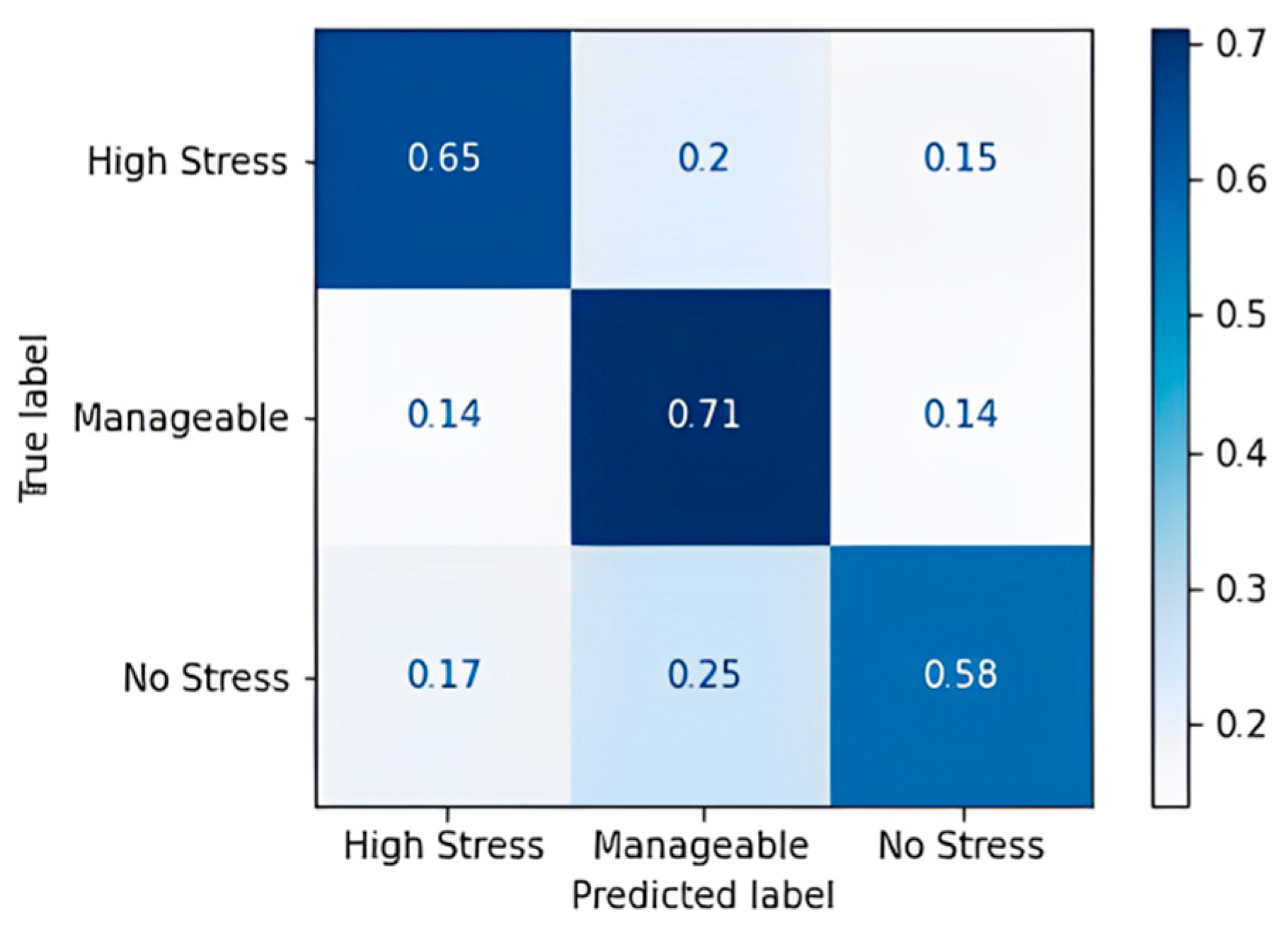
The gradient boost algorithm has some imperfections in predicting all three classes. The gradient boost model was trained with the multinomial loss function, and an accuracy of 65.22% and an F1 score of 64.3% were obtained. Table 19 shows the confusion matrix obtained for the AdaBoost algorithm, and Figure 9 shows the accuracy in terms of the classification percentage.
Table 19.
Confusion matrix for AdaBoost algorithm.
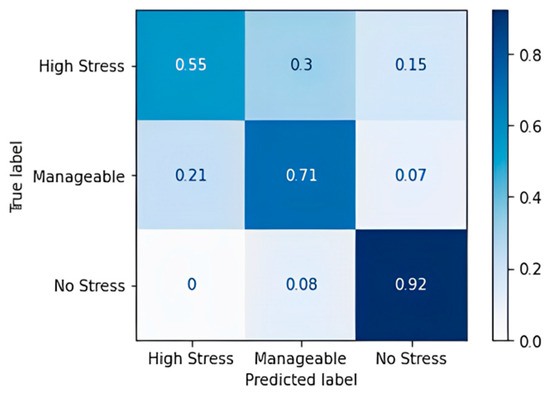
Figure 9.
Confusion matrix accuracy for AdaBoost algorithm.
The AdaBoost algorithm performs a little better than the gradient boost algorithm. The algorithm yielded results with an accuracy of 69.57% and an F1 score of 70.3%.
6.3. Comparison of Algorithms
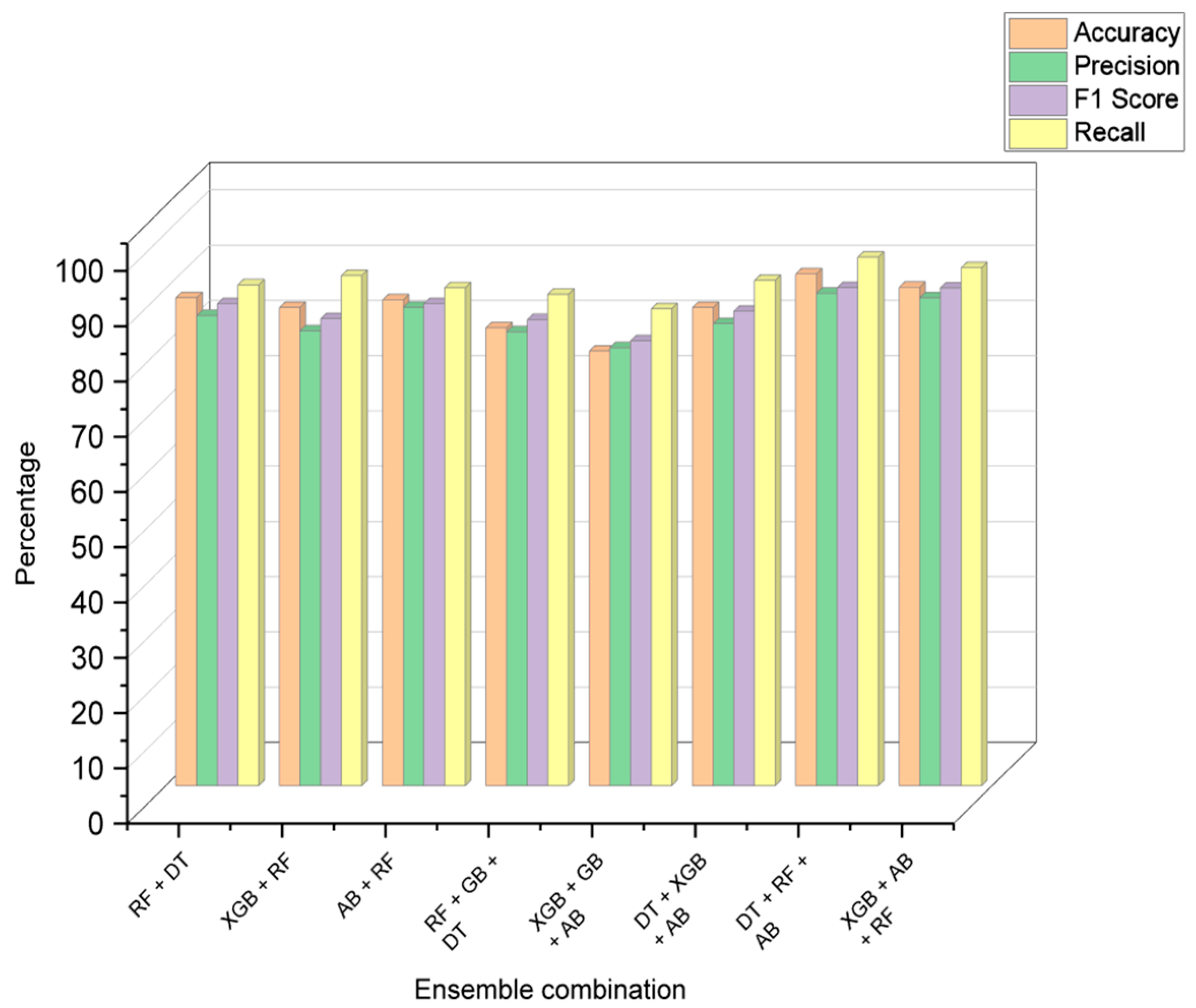
After analyzing the performance of each model individually, a combination of models was used to predict the stress level. The ensemble learning methods were judged by the combined performance of accuracy, precision, F1 score, and recall. Table 20 and Table 21 consist of the results of the performance metrics of the decision models and ensemble learning models, respectively, and Figure 10 shows the visual comparison of the evaluation metrics of each combination of ensemble models.
Table 20.
Performance metrics of decision models.
Table 21.
Performance metrics of ensemble models.
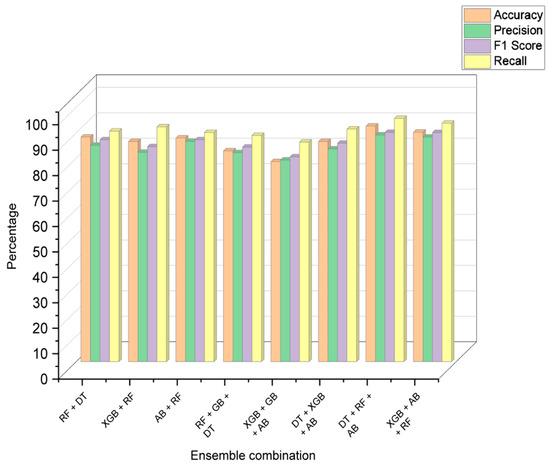
Figure 10.
Comparison of ensemble learning performance metrics.
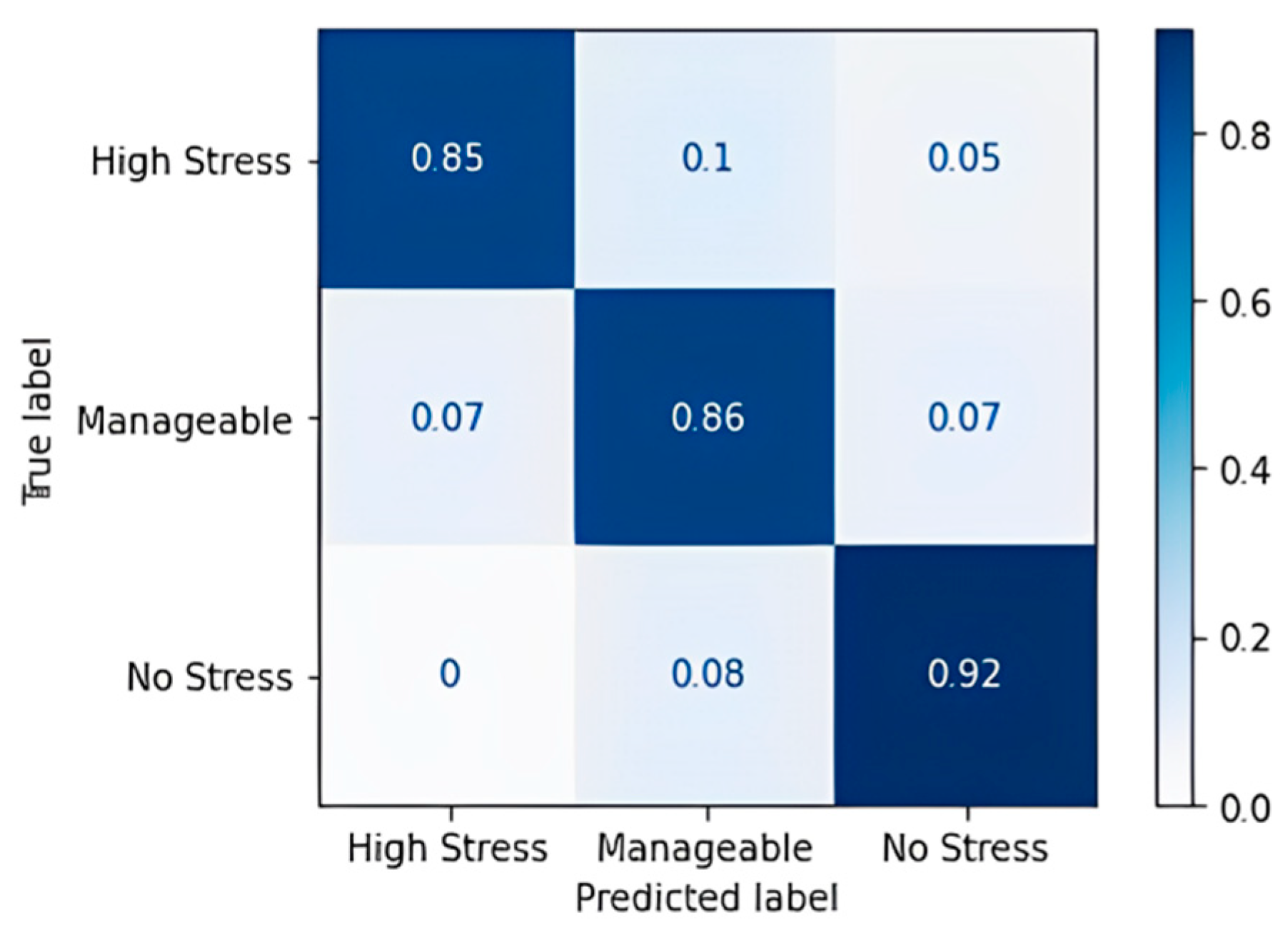
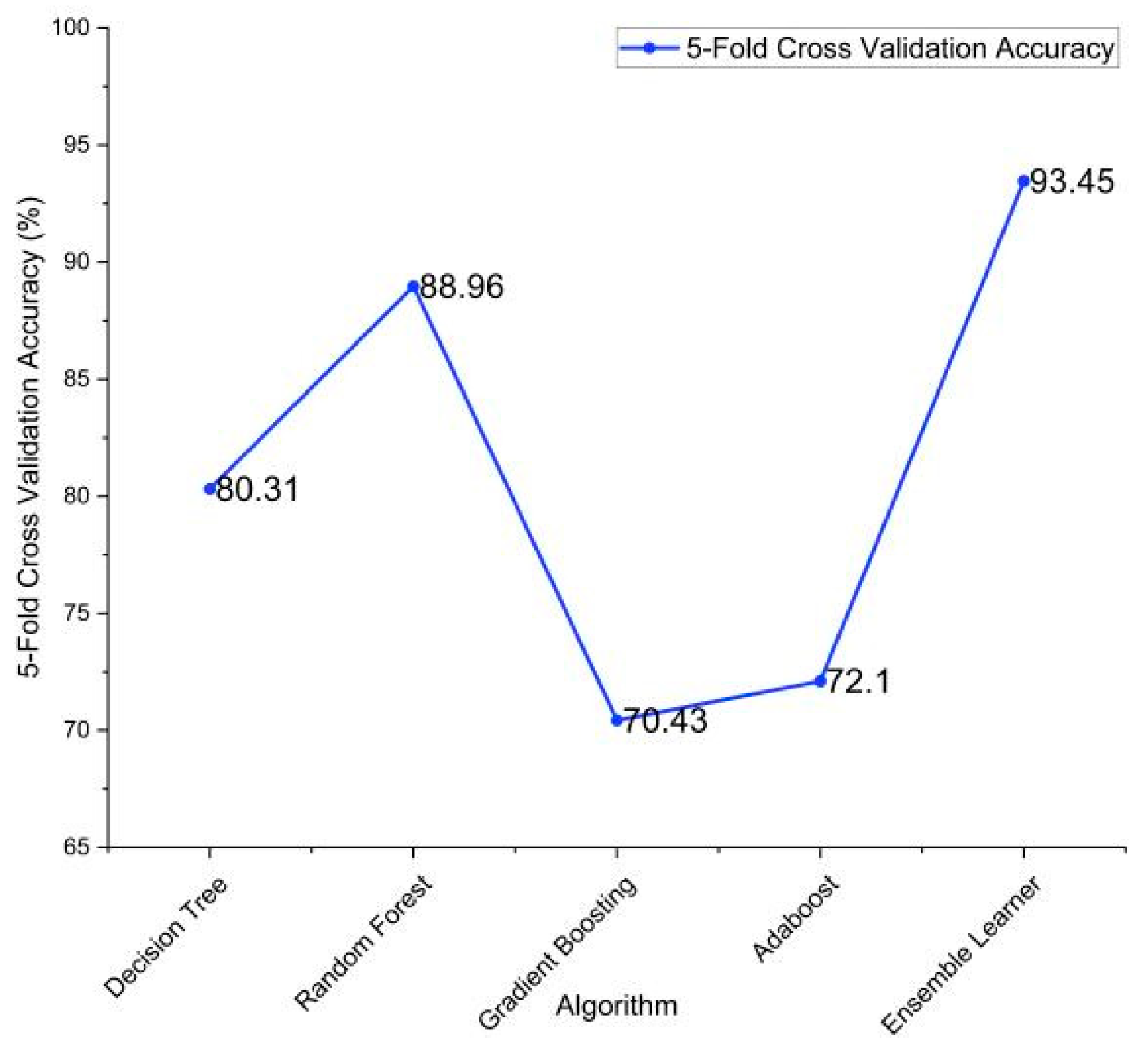
In the table, DT—decision tree, RF—random forest, XGB—XG boost classifier, and AB—AdaBoost classifier. The combination of DT + RF + AB provided the best results with an accuracy of 93.48%. The confusion matrix of this is listed below in Table 22. This essentially highlights the importance of using ensemble methodology to improve the overall performance. Fivefold cross-validation was performed on the individual models and the ensemble model, and the results are described in Table 23 and visualized in Figure 11.
Table 22.
Confusion matrix of ensemble algorithm DT + RF + AB.
Table 23.
Fivefold cross-validation accuracies.
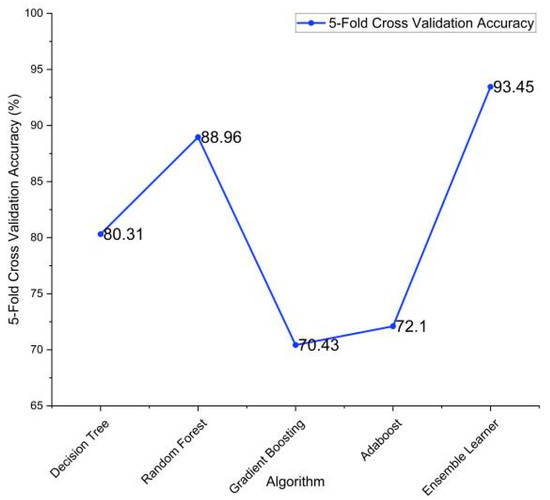
Figure 11.
Fivefold cross-validation accuracies of the implemented algorithms.
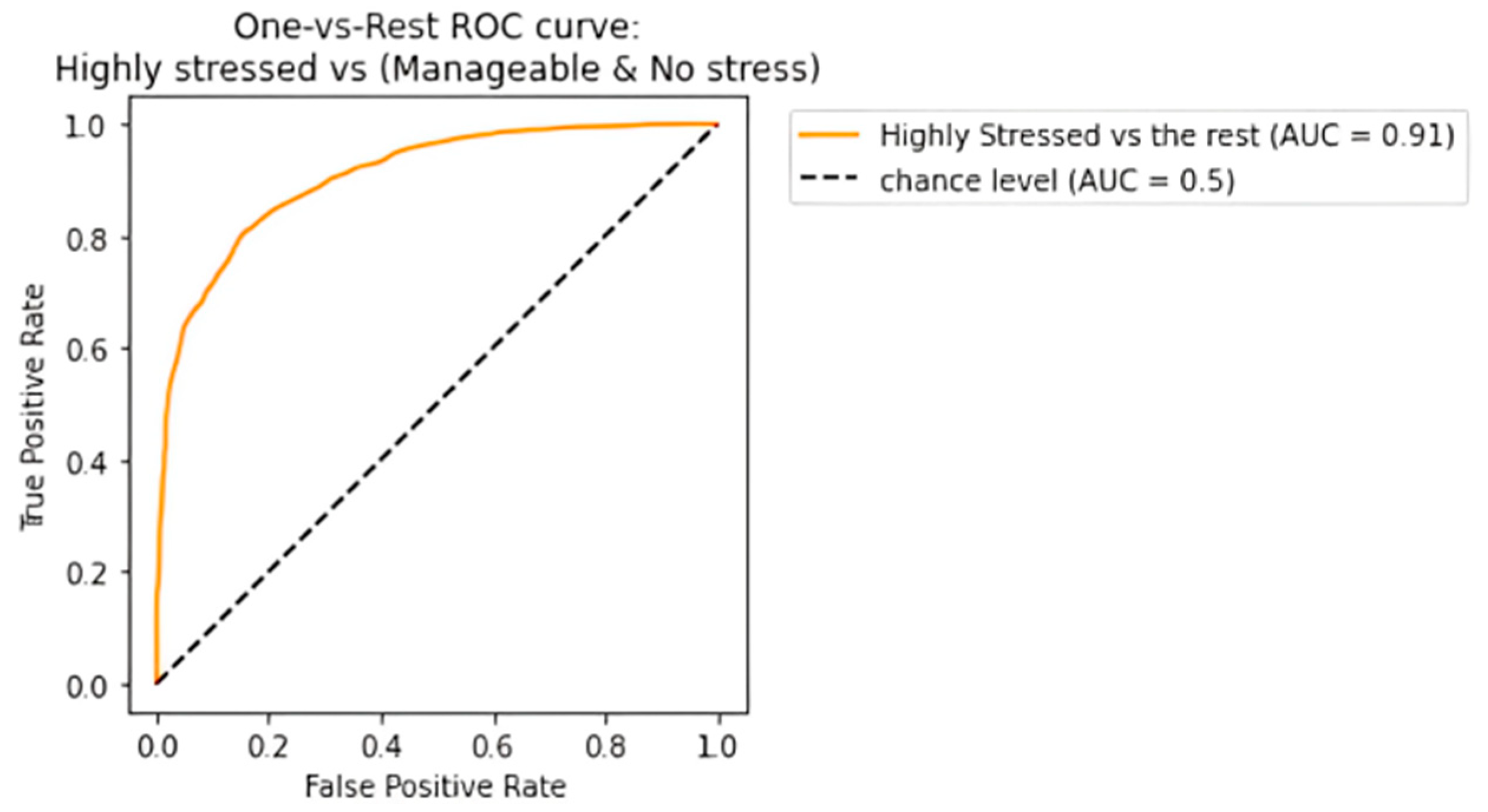
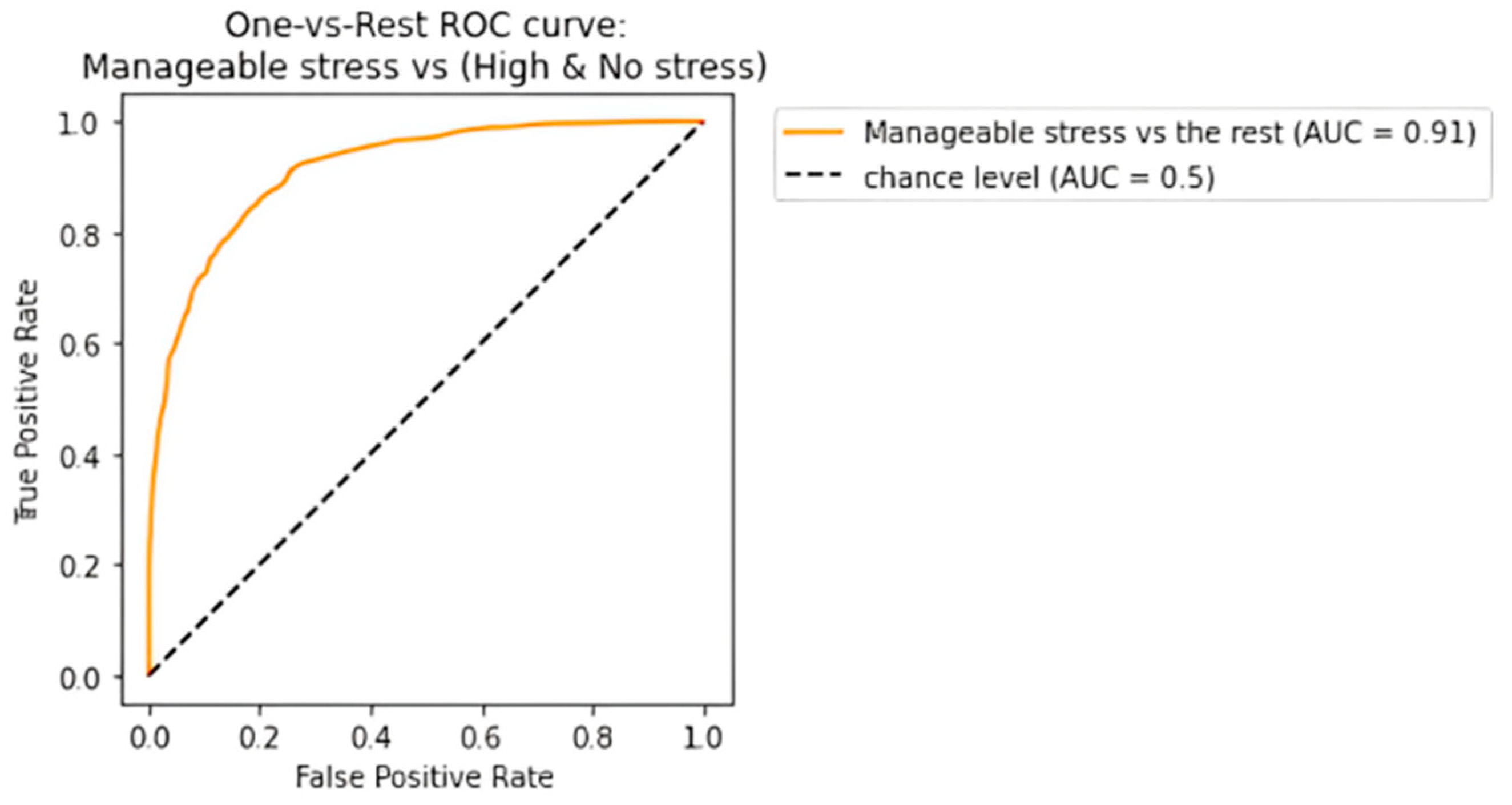
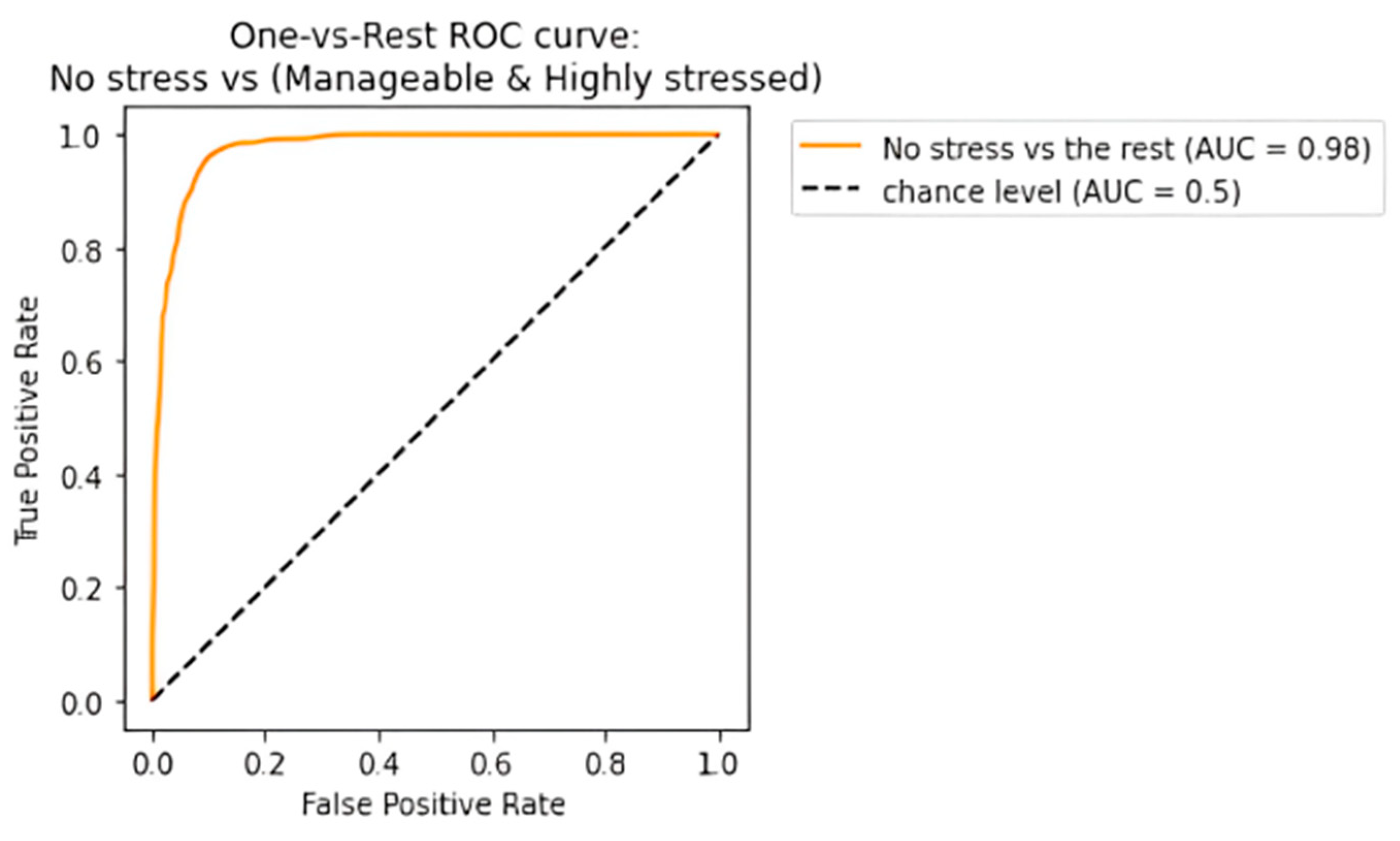
The receiving operating characteristic (ROC) curve has been plotted for the efficient ensemble learning algorithm (DT + RF + AB), which provided the best results. Figure 12, Figure 13 and Figure 14 show an area under the curve (AUC) for each predicted class. The high-stress and manageable-stress categories had true-positive rates of 91%, while the no-stress category had a rate of 98%.
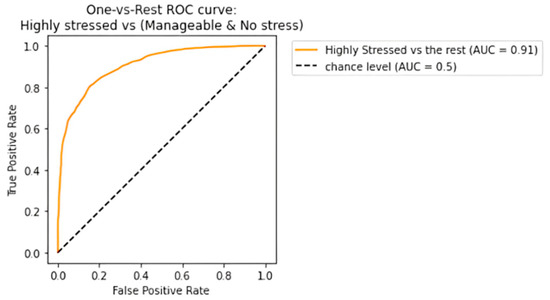
Figure 12.
ROC-AUC curve for high-stress class.
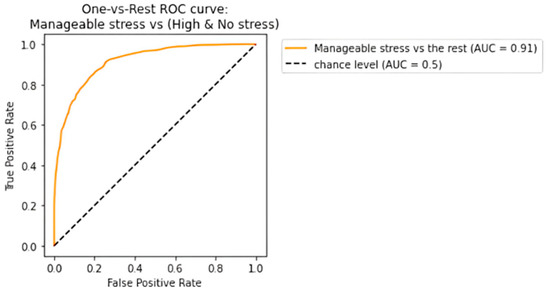
Figure 13.
ROC-AUC curve for manageable-stress class.
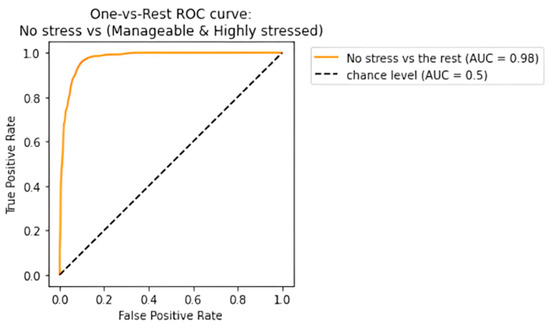
Figure 14.
ROC-AUC curve for no-stress class.
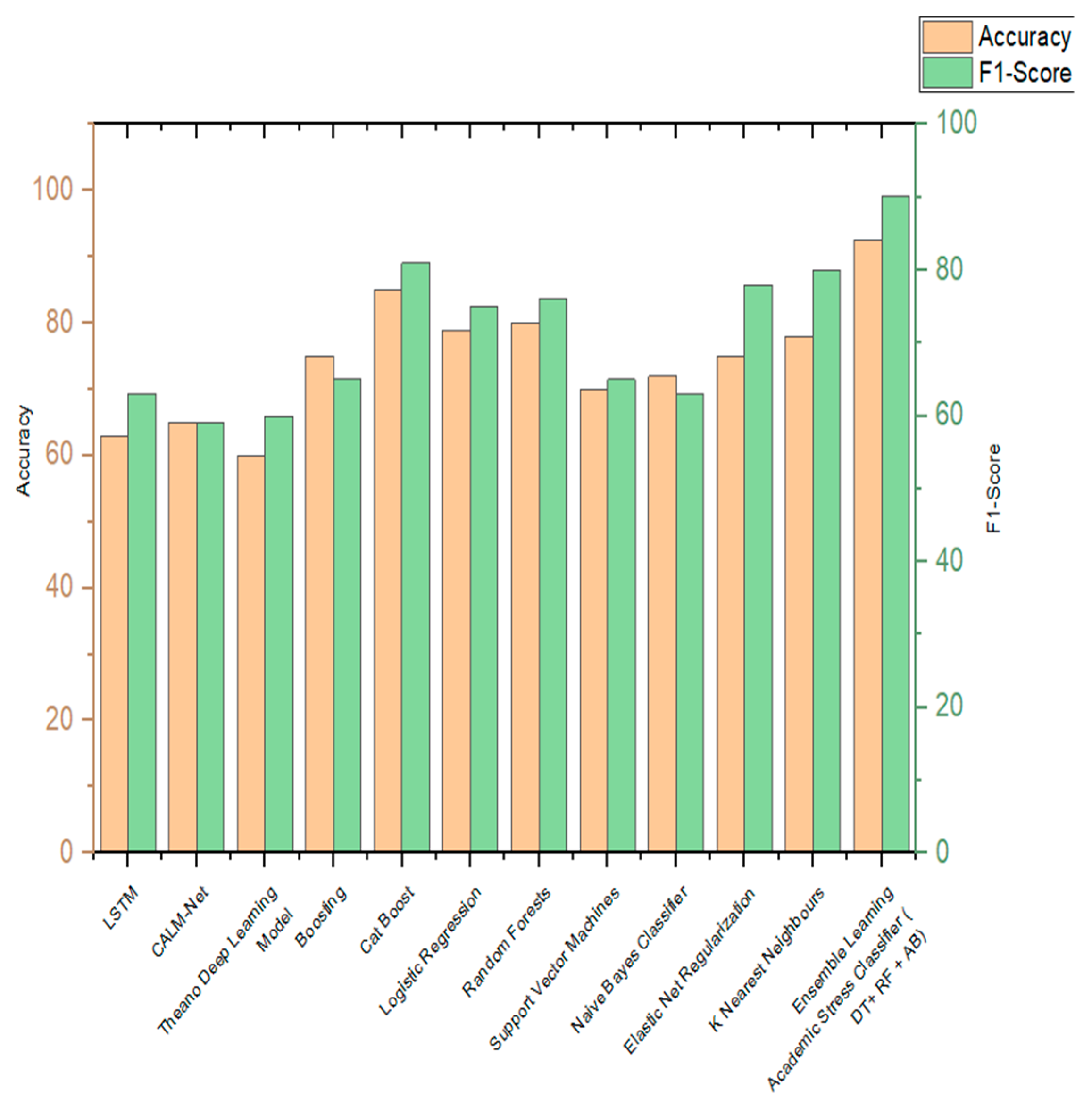
The efficient ensemble learning stress classifier developed in this paper has been compared with the various state-of-the-art algorithms. Table 24 shows the comparisons of algorithms incorporated by various authors in the classification of stress and is being compared to the ensemble learning academic stress classifier implemented in this paper. Figure 15 shows the visual representation of the same. The parameters of comparison are accuracy and F1 score.
Table 24.
Comparison results of proposed work and other works.
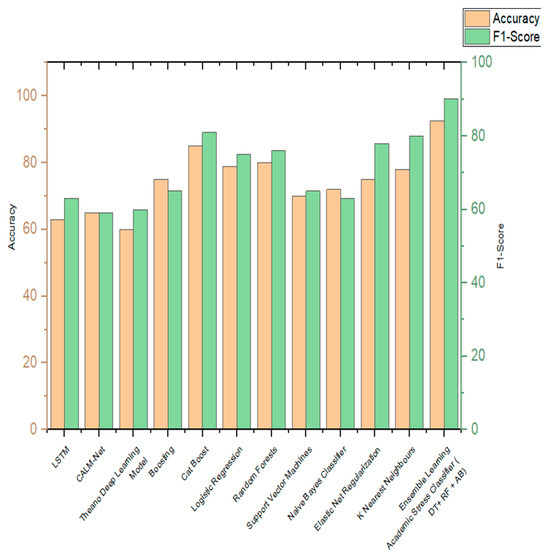
Figure 15.
Comparison graph of proposed work with other existing works.
7. Discussion and Future Work
This paper analyzes surveyed data in order to classify the stress levels of a student based on different machine learning models. To remove the imbalance in the minority class, an oversampling method was used to sample responses with “no stress” classification. To measure the performance of the models, confusion matrix, accuracy, precision, recall, and the F1 score was used. Based on the results, the ensemble learning academic stress classifier provided the best results with an accuracy of 93.48% and an F1 score of 93.14%. Fivefold cross-validation was also performed, and an accuracy of 93.45% was achieved. The individual machine learning models also provided good results with random forest alone achieving an accuracy of 88.96%. This highlights the importance of enhanced prediction using the ensemble learning techniques. As a result of this analysis, students are able to gain insights into where their daily habits can be improved in order to maintain a stress-free academic lifestyle.
Importantly, this research extends beyond the immediate results and paves the way for further exploration in the field of stress prediction and mitigation. Previous studies have delved into stress prediction across various domains, offering valuable insights into the broader landscape of human well-being. However, our work distinguishes itself by focusing exclusively on students and their academic stressors, shedding light on a crucial facet of stress prediction. By narrowing the scope to academic factors, we bridge the gap in existing research, ensuring that the unique stressors faced by students are comprehensively addressed. The future work involves analyzing patterns of the responses across different classes in terms of the stress level and developing a personalized assistant where students can enter the value for each attribute and obtain strategies that may help them improve their academic performances based on the predictions that the model provides, and the model will be able to learn from the responses of the students with lower stress levels. It is also possible to perform conventional statistical analysis with the dependent variable as stress and keeping the predictors as other variables. Analyses such as binary logistic regression, method enter, and method backward conditional can be performed. With the advancement of technology, electronic devices have become an integral part of our daily lives, providing an opportunity to gather valuable information without direct user involvement. By incorporating sensors or logging mechanisms into electronic devices such as smartphones or smartwatches, it is possible to passively collect data on various factors related to student stress levels, such as physical activity, screen time, location, and communication patterns. This passive data-collection approach eliminates the need for manual data entry through forms, reducing the potential for self-reporting biases and enhancing the ecological validity of the dataset. In this way, students can receive better insights into how to advance academically while keeping stress levels in check. The broader implications of this work resonate with the concept of predictive analytics for stress management, not only within the academic realm but also across diverse domains. Our findings underscore the potential for a personalized assistant that allows students to input their attributes and receive tailored strategies to enhance their academic performances, leveraging the predictive capabilities of our model. This approach presents an innovative paradigm in stress mitigation, one that learns from the experiences of students with lower stress levels, thereby contributing to the development of more effective stress management techniques.
Author Contributions
Conceptualization, R.V.A. and A.Q.M.; formal analysis, A.Q.M. and R.V.A.; funding acquisition, S.U.; investigation, A.Q.M., R.V.A., A.C., S.U. and M.A.A.; methodology, A.Q.M. and S.U.; project administration, S.U.; validation, A.Q.M., M.A.A. and S.M.; writing—original draft, A.Q.M. and R.V.A.; writing—review and editing, S.U. and S.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2023R79), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2023R79), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, X.; Hegde, S.; Son, C.; Keller, B.; Smith, A.; Sasangohar, F. Investigating Mental Health of US College Students During the COVID-19 Pandemic: Cross-Sectional Survey Study. J. Med. Internet 2020, 22, e22817. [Google Scholar] [CrossRef]
- Bedewy, D.; Gabriel, A. Examining perceptions of academic stress and its sources among university students: The Perception of Academic Stress Scale. Health Psychol. Open 2015, 2, 2055102915596714. [Google Scholar] [CrossRef]
- Kulkarni, S.; O’Farrell, I.; Erasi, M.; Kochar, M.S. Stress and hypertension. WMJ Off. Publ. State Med. Soc. Wis. 1998, 97, 34–38. [Google Scholar]
- Chemers, M.M.; Hu, L.T.; Garcia, B.F. Academic self-efficacy and first year college student performance and adjustment. J. Educ. Psychol. 2001, 93, 55. [Google Scholar] [CrossRef]
- Aristovnik, A.; Keržič, D.; Ravšelj, D.; Tomaževič, N.; Umek, L. Impacts of the COVID-19 pandemic on life of higher education students: A global perspective. Sustainability 2020, 12, 8438. [Google Scholar] [CrossRef]
- Acikmese, Y.; Alptekin, S.E. Prediction of stress levels with LSTM and passive mobile sensors. Procedia Comput. Sci. 2019, 159, 658–667. [Google Scholar] [CrossRef]
- Shaw, A.; Simsiri, N.; Deznaby, I.; Fiterau, M.; Rahaman, T. Personalized student stress prediction with deep multitask network. arXiv 2019, arXiv:1906.11356. [Google Scholar]
- Wang, R.; Chen, F.; Chen, Z.; Li, T.; Harari, G.; Tignor, S.; Zhou, X.; Ben-Zeev, D.; Campbell, A.T. StudentLife. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing–UbiComp ’14 Adjunct, Washington, DC, USA, 13–17 September 2014. [Google Scholar] [CrossRef]
- Raichur, N.; Lonakadi, N.; Mural, P. Detection of Stress Using Image Processing and Machine Learning Techniques. Int. J. Eng. Technol. 2017, 9, 1–8. [Google Scholar] [CrossRef]
- Reddy, U.S.; Thota, A.V.; Dharun, A. Machine Learning Techniques for Stress Prediction in Working Employees. In Proceedings of the 2018 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 13–15 December 2018. [Google Scholar] [CrossRef]
- Gamage, S.N.; Asanka, P.P.G.D. Machine Learning Approach to Predict Mental Distress of IT Workforce in Remote Working Environments. In Proceedings of the 2022 International Research Conference on Smart Computing and Systems Engineering (SCSE), Colombo, Sri Lanka, 1 September 2022; pp. 211–216. [Google Scholar] [CrossRef]
- Rahman, A.A.; Siraji, M.I.; Khalid, L.I.; Faisal, F.; Nishat, M.M.; Ahmed, A.; Al Mamun, M.A. Perceived Stress Analysis of Undergraduate Students during COVID-19: A Machine Learning Approach. In Proceedings of the 2022 IEEE 21st Mediterranean Electrotechnical Conference (MELECON), Palermo, Italy, 14–16 June 2022; pp. 1129–1134. [Google Scholar]
- El Affendi, M.A.; Al Rajhi, K.H. Text encoding for deep learning neural networks: A reversible base 64 (Tetrasexagesimal) Integer Transformation (RIT64) alternative to one hot encoding with applications to Arabic morphology. In Proceedings of the 2018 Sixth International Conference on Digital Information, Networking, and Wireless Communications (DINWC), Beirut, Lebanon, 25–27 April 2018; pp. 70–74. [Google Scholar]
- Priya, A.; Garg, S.; Tigga, N.P. Predicting Anxiety, Depression and Stress in Modern Life using Machine Learning Algorithms. Procedia Comput. Sci. 2020, 167, 1258–1267. [Google Scholar] [CrossRef]
- Rois, R.; Ray, M.; Rahman, A.; Roy, S.K. Prevalence and predicting factors of perceived stress among Bangladeshi university students using machine learning algorithms. J. Health Popul. Nutr. 2021, 40, 50. [Google Scholar] [CrossRef] [PubMed]
- Jaques, N.; Taylor, S.; Azaria, A.; Ghandeharioun, A.; Sano, A.; Picard, R. Predicting students’ happiness from physiology, phone, mobility, and behavioral data. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015. [Google Scholar] [CrossRef]
- Flesia, L.; Monaro, M.; Mazza, C.; Fietta, V.; Colicino, E.; Segatto, B.; Roma, P. Predicting Perceived Stress Related to the COVID-19 Outbreak through Stable Psychological Traits and Machine Learning Models. J. Clin. Med. 2020, 9, 3350. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Zheng, E.; Zhong, Z.; Xu, C.; Roma, N.; Lamkin, S.; Von Visger, T.T.; Chang, Y.-P.; Xu, W. Stress prediction using micro-EMA and machine learning during COVID-19 social isolation. Smart Health 2022, 23, 100242. [Google Scholar] [CrossRef]
- Pabreja, K.; Singh, A.; Singh, R.; Agnihotri, R.; Kaushik, S.; Malhotra, T. Stress Prediction Model Using Machine Learning. In Proceedings of International Conference on Artificial Intelligence and Applications; Bansal, P., Tushir, M., Balas, V., Srivastava, R., Eds.; Advances in Intelligent Systems and Computing; Springer: Singapore, 2021; Volume 1164. [Google Scholar] [CrossRef]
- Bisht, A.; Vashisth, S.; Gupta, M.; Jain, E. Stress Prediction in Indian School Students Using Machine Learning. In Proceedings of the 2022 3rd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 27–29 April 2022; pp. 770–774. [Google Scholar] [CrossRef]
- Martino, F.D.; Delmastro, F. High-Resolution Physiological Stress Prediction Models based on Ensemble Learning and Recurrent Neural Networks. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020. [Google Scholar] [CrossRef]
- Pariat, M.L.; Rynjah, M.A.; Joplin, M.; Kharjana, M.G. Stress Levels of College Students: Interrelationship between Stressors and Coping Strategies. IOSR J. Humanit. Soc. Sci. 2014, 19, 40–45. [Google Scholar] [CrossRef]
- Kim, J.; McKenzie, L. The Impacts of Physical Exercise on Stress Coping and Well-Being in University Students in the Context of Leisure. Health 2014, 6, 2570–2580. [Google Scholar] [CrossRef]
- Pryjmachuk, S.; Richards, D.A. Predicting stress in preregistration nursing students. Br. J. Health Psychol. 2007, 12, 125–144. [Google Scholar] [CrossRef] [PubMed]
- Agrawal, S.; Sharma, N.; Singh, M. Employing CBPR to understand the well-being of higher education students during COVID-19 lockdown in India. SSRN Electron. J. 2020. [Google Scholar] [CrossRef]
- Myles, A.J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Zhang, C., Ma, Y., Eds.; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining AdaBoost. In Empirical Inference; Schölkopf, B., Luo, Z., Vovk, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Newman-Keuls test and Tukey test. Encycl. Res. Des. 2010, 2, 897–902. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).