1. Introduction
The World Health Organization (WHO) announced that hypertension affects one billion people worldwide and causes 9 million deaths each year [
1]. It is widely known that high blood pressure is the primary cause of death from cardiovascular disease (CVD) [
1,
2]. Hence, the accurate blood pressure (BP) measurement can have important public health implications. Recently, BP monitoring has been vital for people with CVD, especially the elderly living alone. Rapid changes in blood pressure in these people can mean that they have a severe illness because it is constantly changing due to intrinsic physiological changes for many causes, such as food, outside temperature, exercise, disease, and stress. Hence, precision, uncertainty, and accuracy in blood pressure measurements of physiological parameters have been a continuing concern for clinicians and practitioners [
3,
4,
5]. Therefore, research on accurate BP measurement techniques is continuously needed.
Since about a decade ago, machine learning (ML) algorithms have been commonly used to estimate data in biomedical fields [
4,
6]. The ML algorithms, including support vector machine (SVM) [
7], were utilized to estimate BP [
8]. Wang et al. [
9] introduced a method for BP estimation using a novel artificial neural network (ANN) and photoplethysmography (PPG) signals. Massaro et al. [
10] proposed a decision support system for estimating health status based on artificial intelligence algorithms. A novel smart healthcare monitoring system using ML and the Internet of Things was developed by [
11], which created an automated artifact detection method for BP and PPG signals. Tan et al. [
12] introduced an artificial intelligence-enhanced BP monitoring wristband. The wristband’s sensors are based on piezoelectric nanogenerators. Nandi et al. [
13] introduced a new long short-term memory and convolutional neural network using cuffless BP estimation based on the PPG and ECG signals. Recently, multi-channel PPGs were introduced using SVM ensemble-based continuous blood pressure estimation in [
14]. Qiu et al. [
8] proposed a new method for estimating BP using a window function-based piecewise neural network. This paper evaluated the random forest-based regression network and the three-layer ANN-based regression network as well as the SVM model as a less complex algorithm using the PPG signal in order to perform the accurate cuffless BP estimation. Here, valuable features were extracted using the PPG signal’s first and second derivative waveforms and used as input data for BP estimation. The critical issue to increasing ML algorithms’ reliability is extracting features essential to the response variable [
15,
16,
17]. The two most popular methods for cuffless BP estimation are obtained using the extracted features and pulse transit time (PTT) from the PPG and electrocardiogram (ECG) signal pulses [
8,
18,
19,
20]. The feature extraction method using PTT effectively estimates BP because PTT is closely correlated with blood pressure [
21]. Based on this principle, we can determine arterial pressure by measuring the pulse wave velocity (PWV) because PTT change corresponds to a change in PWV at a fixed distance, an indicator of BP variation [
20,
22].
Another issue for improving the performance of ML algorithms is feature selection to use as input data by replacing the original features [
23,
24,
25,
26,
27]. Feature selection is an essential part of the learning algorithm’s performance, which selects a subset of features with high weights for the response variable, and eliminates duplicate features [
15,
16]. This process increases the reliability of ML, enhances predictive accuracy, and improves understanding. Irrelevant features provide no helpful information, and redundant features offer no more information than the currently selected feature [
28]. In general, feature selection algorithms are classified into the filter, wrapper, and embedded algorithms.
First, the filter algorithm uses the available attributes of the training data independently of the learning algorithm [
23,
28]. Yang et al. [
24] proposed neighbor component analysis (NCA) to learn feature weight vectors, which is efficient and computationally fast. However, the NCA algorithm may miss helpful features, so it can be combined with other methods to enhance performance. In addition, robust NCA (RNCA), which enhanced the performance of NCA, was introduced [
29]. However, RNCA also has a problem: the number of features or weights may be specified and used as a fixed threshold heuristically when selecting the weight features.
Second, wrapper algorithms usually use learning algorithms to gain features and outperform filter algorithms in most cases. A wrapper algorithm demands one learning algorithm for feature selection and utilizes its performance to measure the superiority of a selected subset of features. However, wrapper algorithms are computationally intensive and sometimes difficult to handle in high-dimensional feature selection problems because the learning algorithm always needs to train each subset of features [
24,
28].
Third, the embedded algorithm is built into the learning algorithm. For example, the gradient descent algorithm is usually utilized to optimize the feature weights, indicating the relevance between the corresponding features and the target value. In particular, many embedded algorithms based on SVM have been introduced [
24,
25,
26].
Various algorithms have been used to select valuable features [
27]. Ding et al. [
30,
31] proposed minimum overlap-maximum relatedness (MRMR) to obtain optimal subsets of multiple genes. Szabo et al. [
32] introduced an algorithm that applies v-fold cross-validation combined with a randomly selected feature selection. Another algorithm that combines k-nearest neighbors with genetic algorithms was developed by Li et al. [
33]. Guyon et al. [
34] introduced an SVM-based approach called recursive feature elimination (RFE) to discover informative features.
In these regards, we propose a new methodology that combines the Gaussian process with hybrid optimal feature decision (CGHOFD) in cuffless blood pressure estimation. This study aims to accurately estimate systolic blood pressure (SBP) and diastolic blood pressure (DBP), which improves the reliability of cuffless BP estimation. Moreover, the Gaussian process (GP) algorithms are those that, like other kernel methods, can be precisely optimized for given hyperparameter values. Hence, it performs well due to well-optimized parameter values, especially on small datasets [
35,
36]. Another advantage of the GP is that it is robust to noisy signal and naturally regularizes [
37]. Hence, the proposed CGHOFD algorithm uses a combined hybrid approach, such as minimum redundancy maximum relevance (MRMR) [
30], ANOVA F-test (F-test) [
38], and robust neighbor component analysis (RNCA) [
29], to select weighted features among the original features. Although the MRMR, F-test, and RNCA algorithms can select features quickly, they also have the disadvantage of missing valuable features mentioned above. Therefore, the combined hybrid approach is to overcome this limitation. We then find the best feature set using the GP algorithm. The role of the GP as a learning algorithm is to determine feature subsets as the subset with the minimum root mean square error (RMSE). Here, we use a weighted feature subset as initial input through the feature selection method. The GP algorithm utilizes the input data to generate k-folds and perform cross-validation [
29]. However, the GP algorithm uses more computer resources than other filter-based feature selection methods [
24,
28]. We intend to overcome the performance limitation of filter-based feature selection methods by combining the CGHOFD algorithm based on the biometric (PPG and ECG signals). We conduct extensive experiments to compare the conventional algorithms with the proposed CGHOFD algorithm on the public dataset for cuffless BPs estimation. The experimental results confirm that the proposed CGHOFD algorithm is very effective. To the authors’ knowledge, this is the first study of the proposed CGHOFD algorithm to estimate cuffless BPs. The CGHOFD algorithm is shown in the block diagram in
Figure 1.
This paper is composed as follows.
Section 2 contains the collection of PPG and ECG signals and preprocessing for feature extraction. The proposed combining Gaussian process with hybrid optimal feature decision (CGHOFD) algorithm is shown in
Section 3.
Section 4 denotes the experimental results and statistical analysis. Finally, the discussion and conclusion are denoted in
Section 5 and
Section 6.
5. Discussion
This is the first study to propose combining the Gaussian process with hybrid optimal feature decision (HOFD) in cuffless blood pressure estimation.
Table 3 shows the high-scoring features selected using the F-test and RNCA algorithms [
29,
38]. Here, we can see that the ranked features rely on the feature selection algorithm. In addition, the ranked features were changed depending on the SBP or DBP target variable. Hence, we confirm the best feature decision using the proposed HOFD algorithm. Therefore, the proposed HOFD algorithm was more conducive to improving the performance of ML than using the threshold of the conventional RNCA algorithm.
Table 5 confirms that the proposed algorithm is more complex than the GP algorithm in terms of computational complexity. This indicates that during the HOFD process, computing resources were consumed in deciding the weight feature subset according to evaluation criteria.
Based on the results of evaluations according to the AAMI/ESH/ISO protocols [
46], we show the SDEs of MEs for the SBP (13.33 mmHg) and DBP (11.50 mmHg) acquired using the SVM algorithm compared with the reference BPs. The ANN algorithm represents the SDEs of MEs for the SBP (13.04 mmHg) and DBP (10.32 mmHg). The GP algorithm shows the SDEs of MEs for the SBP (11.80 mmHg) and DBP (9.61 mmHg). In addition, we show the SDEs of MEs for the SBP (10.85 mmHg) and DBP (8.42 mmHg) obtained using the GP with the RNCA algorithm. As given in
Table 7, we observe the SDEs of MEs for the SBP (11.62 mmHg) and DBP (9.44 mmHg) obtained using the CGP with F-test algorithm, and we show the SDEs of MEs for the SBP (11.31 mmHg) and DBP (8.89 mmHg) acquired using the CGP with MRMR algorithm. Furthermore, the proposed CGPRNCA algorithm is obtained in the lower SDEs of MEs for the SBP (10.79 mmHg) and DBP (8.07 mmHg) compared with the conventional SVM, ANN, GP, and GP with RNCA algorithms. Although the proposed methodology does not meet the AAMI/ESH/ISO protocols [
46] in the SBP results, it is superior to the conventional methods. Furthermore, it shows the possibility of future development, and the DBP results are very close to the protocol criteria.
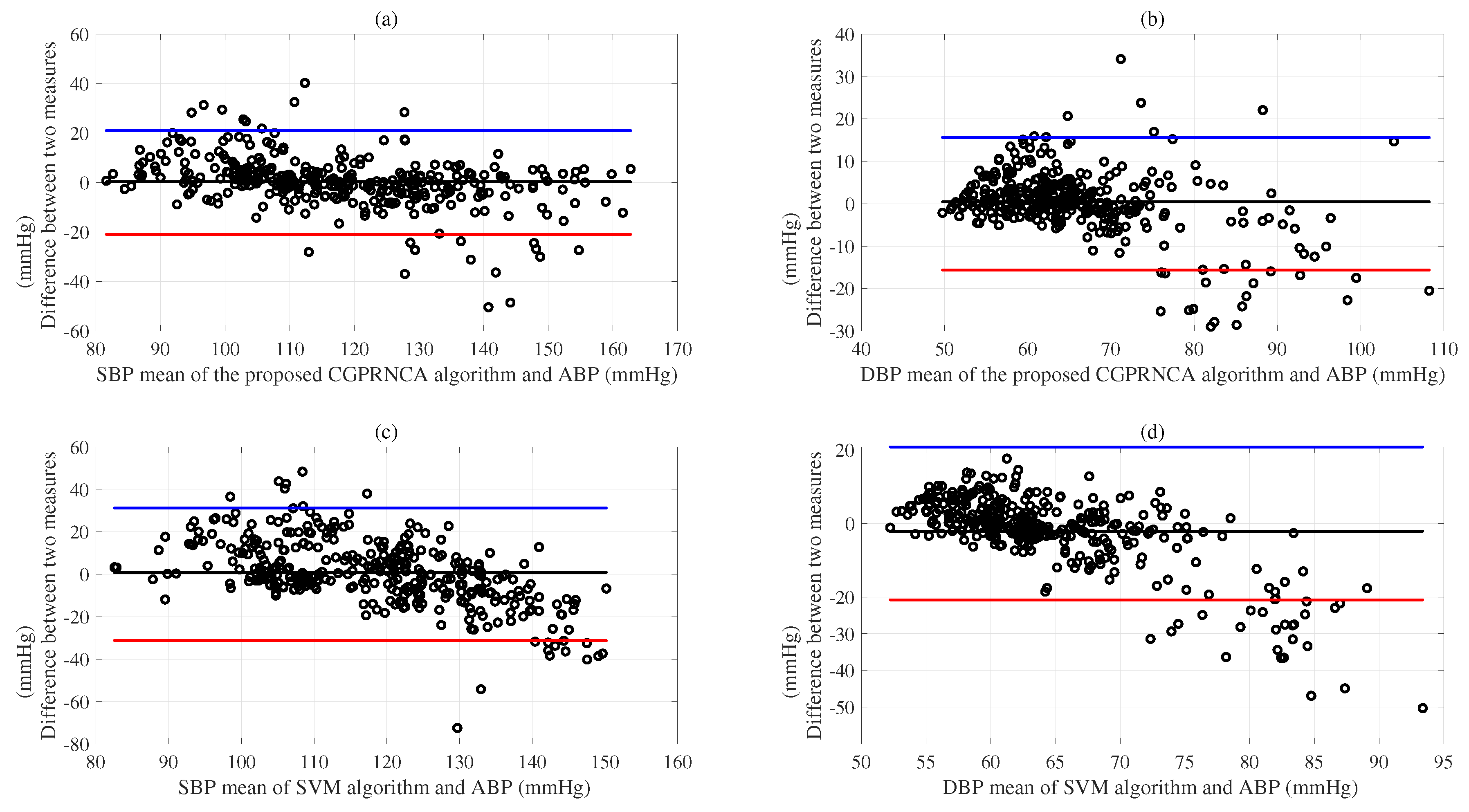
Figure 7a was well represented to compare the performance of the proposed CGPRNCA algorithm with the reference ABP (mmHg) concerning the SDE of ME for SBP.
Figure 7b compares the performance of the proposed CGPRNCA algorithm with the reference ABP (mmHg) concerning the SDE of ME for DBP. The Bland–Altman plots (c) and (d) compare the performance of the SVM algorithm with the reference ABP (mmHg) concerning the SDEs of MEs for SBP and DBP, as represented in
Figure 7.
The MAEs of SBP (9.84 mmHg) and DBP (8.30 mmHg) acquired using the SVM algorithm are compared to the reference BPs given in
Table 8. The ANN algorithm shows the MAEs of SBP (9.75 mmHg) and DBP (7.23 mmHg) compared with reference BPs. The GP algorithm represents the MAEs of SBP (8.39 mmHg) and DBP (6.45 mmHg) compared with reference BPs.
Table 8 also shows the MAEs of SBP (8.93 mmHg) and DBP (6.45 mmHg) acquired using the GP with the RNCA algorithm (GPRNCA). We show the MAEs of SBP (7.83 mmHg) and DBP (5.97 mmHg) obtained using the CGP with the F-test algorithm and observe the MAEs of SBP (7.85 mmHg) and DBP (5.82 mmHg) obtained using the CGP with MRMR algorithm. Regarding estimation accuracy, the proposed CGPRNCA algorithm exhibits the lowest MAE for SBP (7.22 mmHg) and DBP (5.18 mmHg) compared with the reference BPs given in
Table 8. In particular, SBP 2.2% =
and DBP 6.2% =
were improved compared to the MAEs of SBP (7.38 mmHg) and DBP (5.50 mmHg) in the GPRNCA algorithm, proving that the proposed CGPRNCA algorithm is effective in estimating SBP and DBP. We confirm the effect of the HOFD process that finally determines the weighted feature subset. In addition, when the proposed CGPRNCA algorithm is compared with the GP algorithm, it shows an improved performance of 16.2% =
for SBP and 24.5% =
for DBP. On the other hand, the SDEs of MAEs in all algorithms show stable values except for the SVM, as given in
Table 8. The comparison between the SBP estimation result of the proposed CGPRNCA algorithm and the estimation result of the conventional SVM is well confirmed in
Figure 8.
Moreover, we compared the CGPRNCA algorithm with the SVM, ANN, GP, GPRNCA, CGPF-Test, and CGPMRMR algorithms following the British hypertension protocol (BHS) [
3]. We evaluated the mean absolute error (MAE) for three groups of less than five mmHg, less than ten mmHg, and 15 less than mmHg, respectively. The readings using the proposed CGPRNCA algorithm were 54.58% (≤5 mmHg), 75.31% (≤10 mmHg), and 86.21% (≤15 mmHg) for the SBP in the test scenario, and 65.78 % (≤5 mmHg), 84.83% (≤10 mmHg), and 93.21% (≤15 mmHg) for the DBP in the test scenario. The probabilities of the proposed CGPRNCA algorithm based on the BHS are higher than those obtained by the conventional SVM, ANN, GP, and GPRNCA, CGPF-Test, and CGPMRMR algorithms, as given in
Table 9. Compared to the BHS protocol, the proposed CGPRNCA algorithm obtained a grade of C in SBP and B in DBP [
3]; it sets a standard for improving the performance of the future algorithm as shown in
Table 9. The MAEs were 54.58% (≤5 mmHg), 75.31% (≤10 mmHg), and 86.21% (≤15 mmHg), respectively, for SBP and 65.78% (≤5 mmHg), 84.83% (≤10 mmHg), and 93.21% (≤15 mmHg), respectively, for DBP as expressed in
Table 9. Furthermore, we observe that the proposed CGPRNCA algorithm indicates better accuracy than the conventional algorithms for the cuffless BP estimations.
As shown in
Figure 6, we display the ANOVA experiments from RMSEs between the conventional and proposed algorithms for the SBP and DBP. Here, since the
F values follow the
F distribution, it can be concluded that the
F values obtained from the observations can be compared with the threshold value
(=0.05) in the
F table. The RMSEs of SVM, ANN, and GP are significantly different, as given in
Figure 6a. The
p-value of 0.0009 is lower than the critical value (0.05). Box (b) shows that the RMSE of the GP with RNCA (GPRNCA) is lower than that of the CGP with F-test (CGPF-TEST). There is a statistically significant difference between the GPRNCA and CGPF-TEST, according to comparisons
p(=9.0 × 10
). The results of the CGP with RNCA (CGPRNCA) show a statistically significant difference
p(=0.0014) from that of the CGP with MRMR (CGPMRMR), according to comparison
p(=0.05) value, as shown in
Figure 6b. However, there is no statistically significant difference between the GPRNCA and CGPRNCA, according to comparisons
p(=0.77), as shown in
Figure 6b. The result of the GP is statistically different from that of the SVM and ANN, according to comparison
p(=3.35 × 10
), as given in
Figure 6c.
Figure 6d also shows the RMSEs for the GPRNCA and CGPF-TEST regarding the reference DBP values. Again, the GPRNCA is statistically different
p(=9.4 × 10
) from the CGPF-TEST, according to comparison
p(=0.05). A statistically significant difference
p(=1.7 × 10
) in the RMSEs of the CGPMRMR and CGPRNCA is observed concerning the reference DBP values. A statistically significant difference
p(=0.02) in the GPRNCA and the proposed CGPRNCA is observed concerning the reference DBP values, as shown in
Figure 6d.
In addition, the
values of the GP algorithm for SBP (0.80) and DBP (0.67) indicate a stronger relationship with the response than those of the ANN algorithm for SBP (0.74) and DBP (0.59), as given in
Table 10. The
s of the GPRNCA algorithm for SBP (0.83) and DBP (0.75) show higher relationships for the response variable compared to the CGPF-Test algorithms, as given in
Table 10. The
s of the CGPMRMR algorithm for SBP (0.82) and DBP (0.72) represent a lower relationship with the response variable than that of the CGPRNCA algorithm. The
s of the proposed CGPRNCA algorithm for the SBP (0.83) and DBP (0.77) also indicate a higher relationship with the response variable than that of the conventional SVM, ANN, GP, and CGPMRMR algorithms, as given in
Table 10.
Figure 9a shows the
value between the proposed CGPRNCA and reference SBP (mmHg). The
value between the proposed CGPRNCA and reference DBP (mmHg) is given in
Figure 9b. Based on the results, the
values of the CGPRNCA algorithm for SBP and DBP indicate a stronger relationship with the response than those of the SVM algorithm for SBP and DBP, as given in
Figure 9.
The RMSEs of the GP algorithm for the SBP (11.75 mmHg) are lower than that of the SVM algorithm for the SBP (13.27 mmHg). The RMSEs of the GP algorithm for DBP (9.55 mmHg) are lower than that of the SVM algorithm for DBP (11.46 mmHg). However, the RMSEs of the GPRNCA algorithm for the SBP (10.79 mmHg) and DBP (8.38 mmHg) are slightly lower than those of the CGPF-Test algorithm for the SBP (11.59 mmHg) and DBP (9.41 mmHg), as given in
Table 10. We also confirm the RMSEs of SBP (11.25 mmHg) and DBP (8.85 mmHg) obtained using the CGPMRMR algorithm. The RMSE results were compared with reference ABP using the proposed CGPRNCA algorithm for SBP (10.75 mmHg) and DBP (8.02 mmHg). These results represent 9.3% =
and 19.1% =
performance improvements for SBP (11.75 mmHg) and DBP (9.55 mmHg), respectively, compared to a conventional GP algorithm. The results confirm that the proposed CGPRNCA algorithm is more accurate than conventional algorithms for cuffless BPs estimation. In addition, the proposed methodology can constantly monitor BP change through the continuous variability of RMSE’s SDEs and MAE’s SDEs to estimate hypertension risk. The proposed HOFD process based on the GP algorithm may effectively be used for BP estimation.
Limitation
Although we experimented with a public MIMIC-II dataset, this study showed limitations in that patient distribution and experimental results did not satisfy the AAMI/ESH/ ISO protocols [
46]. Based on the AAMI/ESH/ISO protocol, we evaluated the validity of the proposed method. The MIMIC II satisfies the standard of 85 subjects in general, the MIMIC II dataset does not meet the AAMI/ESH/ISO protocol at SBP >160 mmHg 5%, >140 mmHg 20%, and DBP >100 mmHg 5%, >85 mmHg 20% [
46]. The high blood pressure part shows a small distribution, and the low blood pressure part shows a large distribution as 17.9% for SBP 100 mmHg or less and 38.0% for DBP 60 mmHg or less. Moreover, obtaining inter- and intra-individual BP variations is crucial for cuffless device evaluation but challenging to acquire [
54]. Finally, the subject population should exhibit a wide BP range for calibration-free algorithms, such as those required by universal standards. However, identifying these populations can be difficult and costly, and meeting many of these criteria will require much work, especially in lab-scale studies of popular cuffless devices [
54]. We believed that MIMIC II data were obtained from long-term monitoring of patients. However, further research should be considered when obtaining data based on the AAMI/ESH/ISO protocol. Therefore, our laboratory will conduct a confidence interval of BP estimation to track the inter-and intra-individual BP variations to observe the cardiovascular functions’ variance over 24 h. In addition, we should obtain more BP data and conduct experiments to verify intra-individual blood pressure changes according to the AAMI/ESH/ISO protocol [
54]. Moreover, since calibration-free algorithms often use age and gender as inputs to ML models, this causes the accuracy of the experimental results to be unclear [
54]. However, in this study, age and gender were not used as input values for the proposed algorithm. Nevertheless, the following study should improve the performance of the CGPRNCA algorithm by reducing the SDE of ME to pass the AAMI criteria [
50]. Another disadvantage is that the complexity of the HOFD algorithm should be improved for BPs estimation.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}