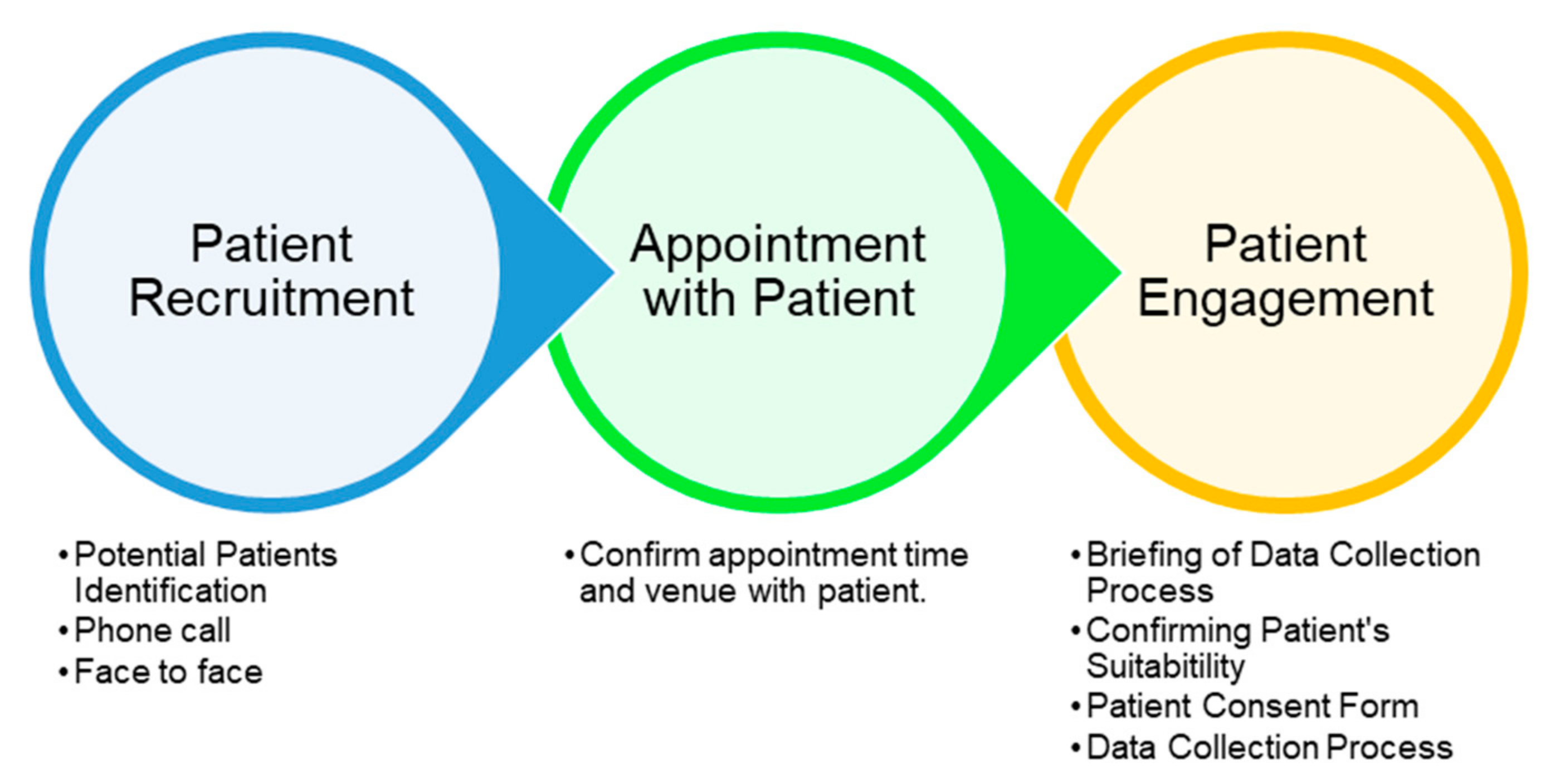
Figure 1.
Process of Patient Recruitment and Engagement.
Figure 1.
Process of Patient Recruitment and Engagement.
Figure 2.
Sensors in data acquisition system: twin-axis goniometer (left), sEMG sensor (middle), and wireless-adapted myometer (right).
Figure 2.
Sensors in data acquisition system: twin-axis goniometer (left), sEMG sensor (middle), and wireless-adapted myometer (right).
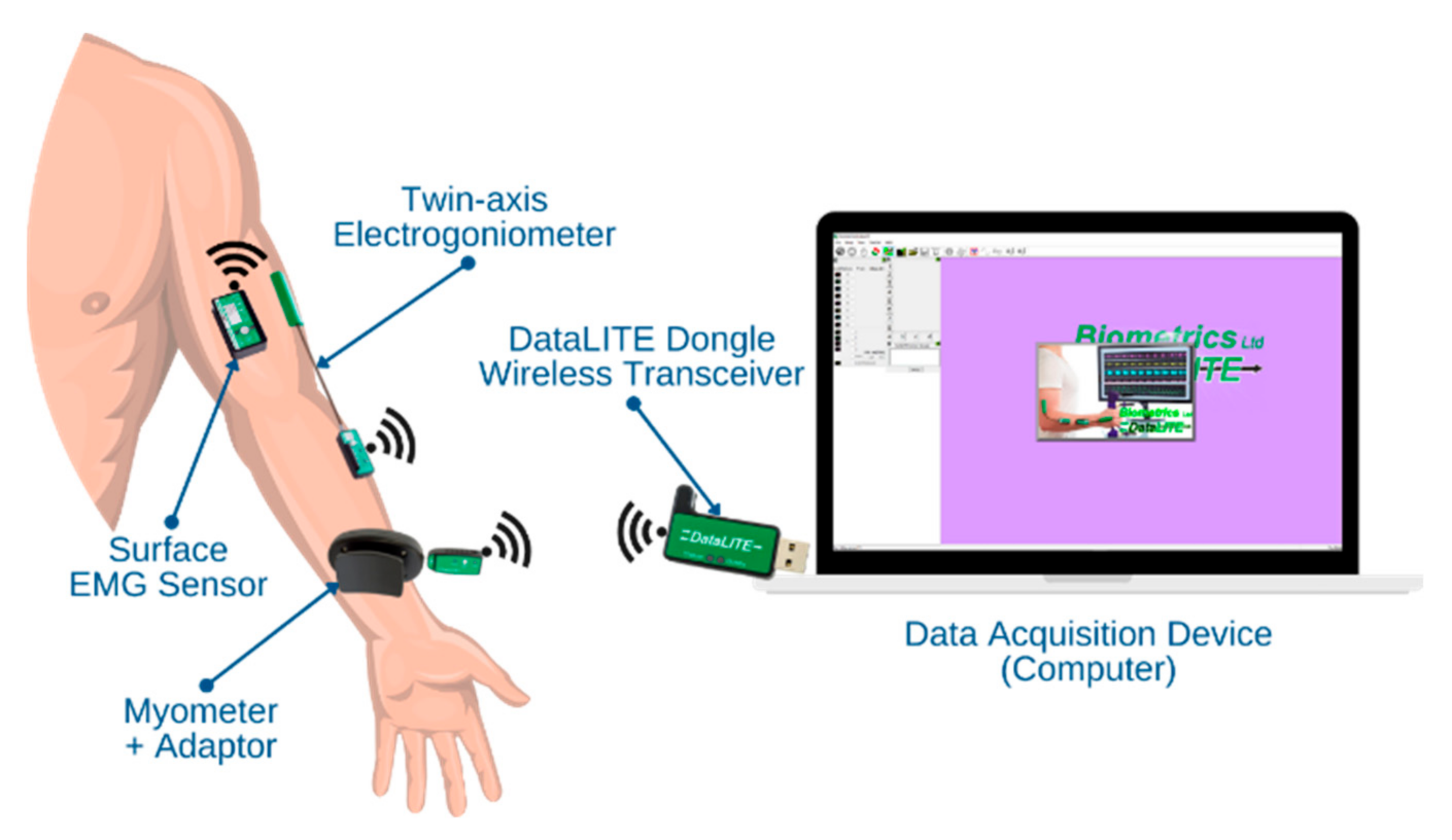
Figure 3.
Connectivity between the DataLITE sensors and the computer.
Figure 3.
Connectivity between the DataLITE sensors and the computer.
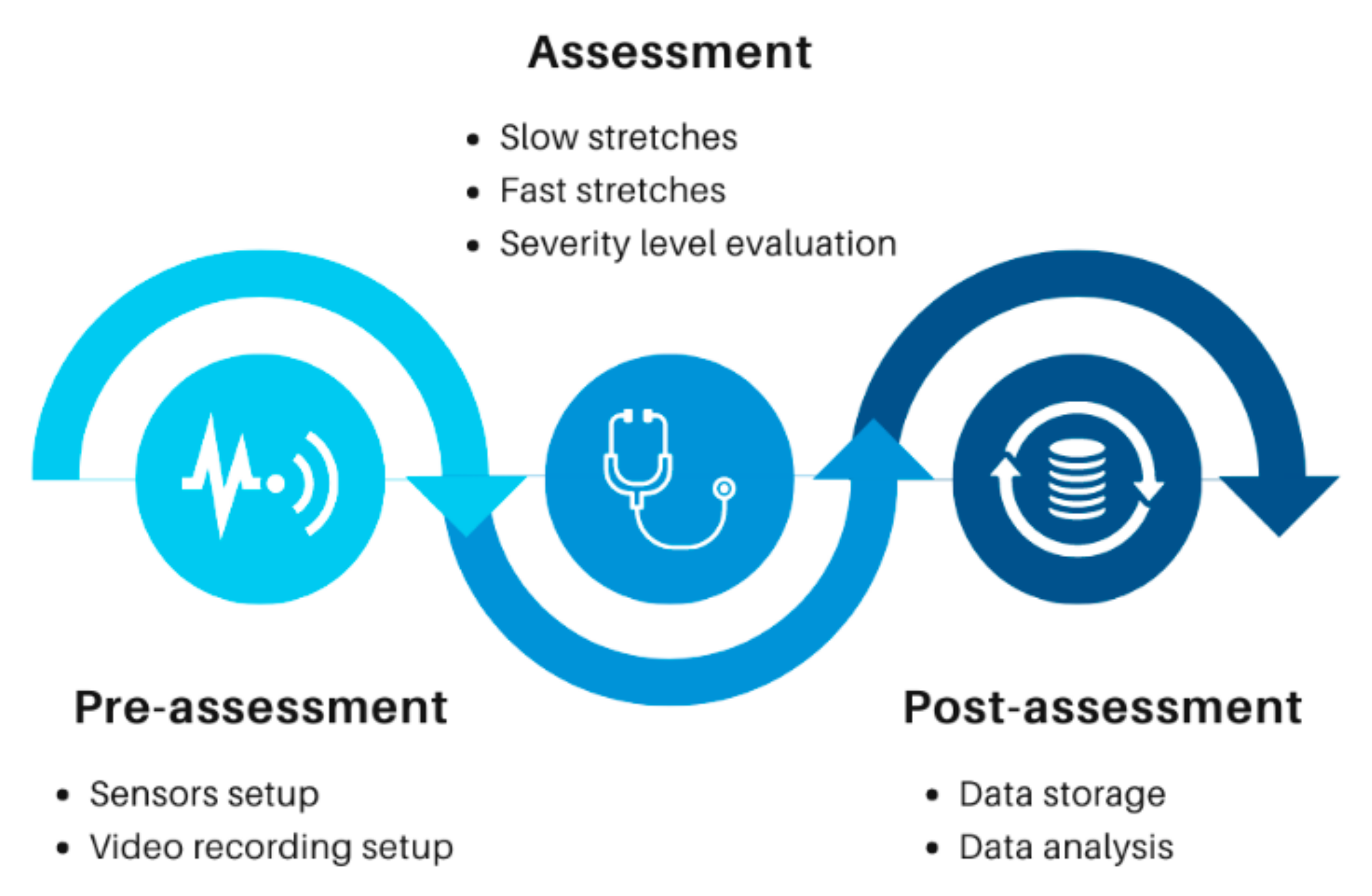
Figure 4.
Flow chart showing the stages in clinical data collection.
Figure 4.
Flow chart showing the stages in clinical data collection.
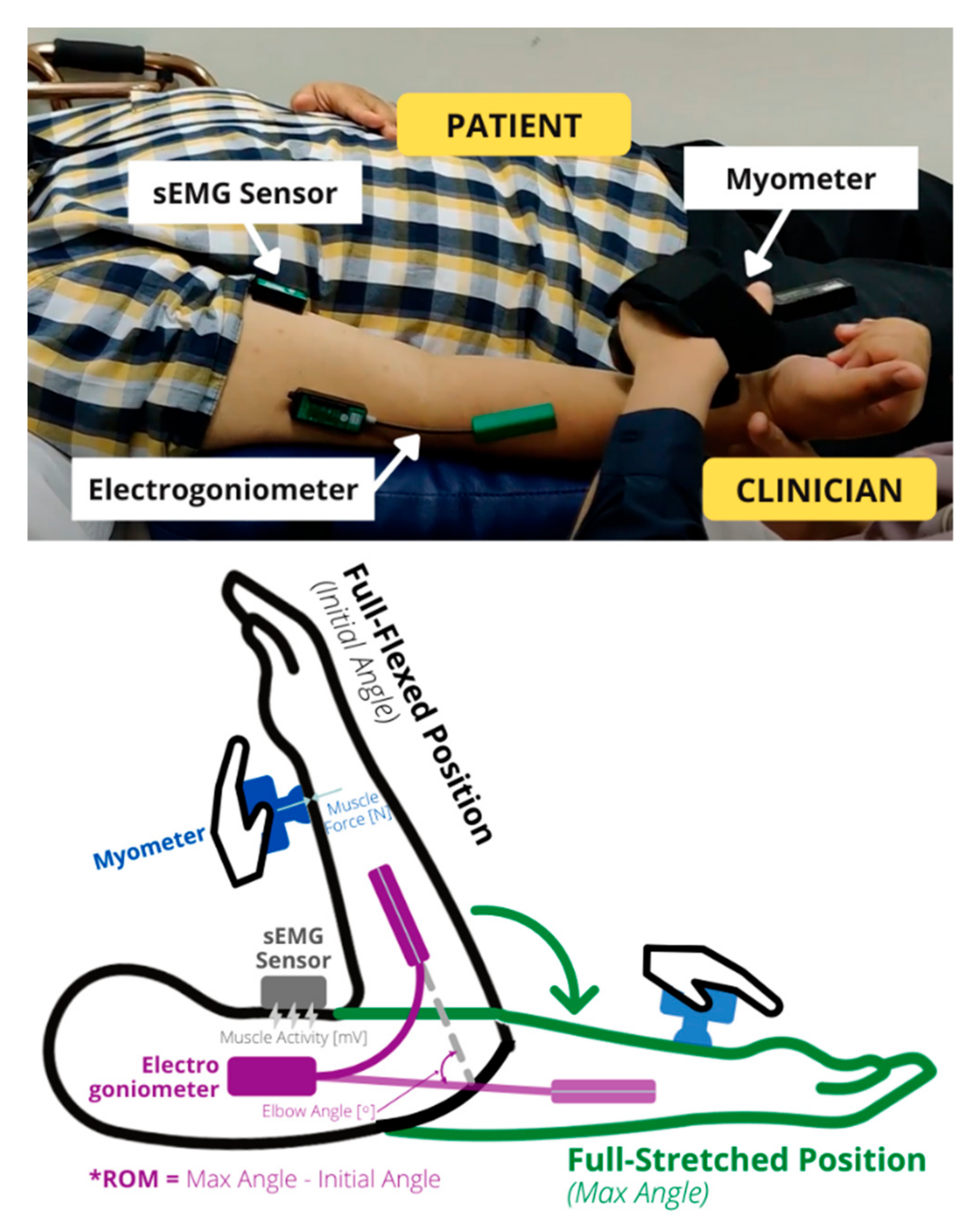
Figure 5.
Illustration of the sensor’s positions and the passive stretch of the forearm. The forearm is stretched from a fully flexed position to a fully stretched position, and this difference in elbow angle is the range of motion (* ROM). The elbow angle, muscle force, and muscle signal are measured simultaneously during this motion.
Figure 5.
Illustration of the sensor’s positions and the passive stretch of the forearm. The forearm is stretched from a fully flexed position to a fully stretched position, and this difference in elbow angle is the range of motion (* ROM). The elbow angle, muscle force, and muscle signal are measured simultaneously during this motion.
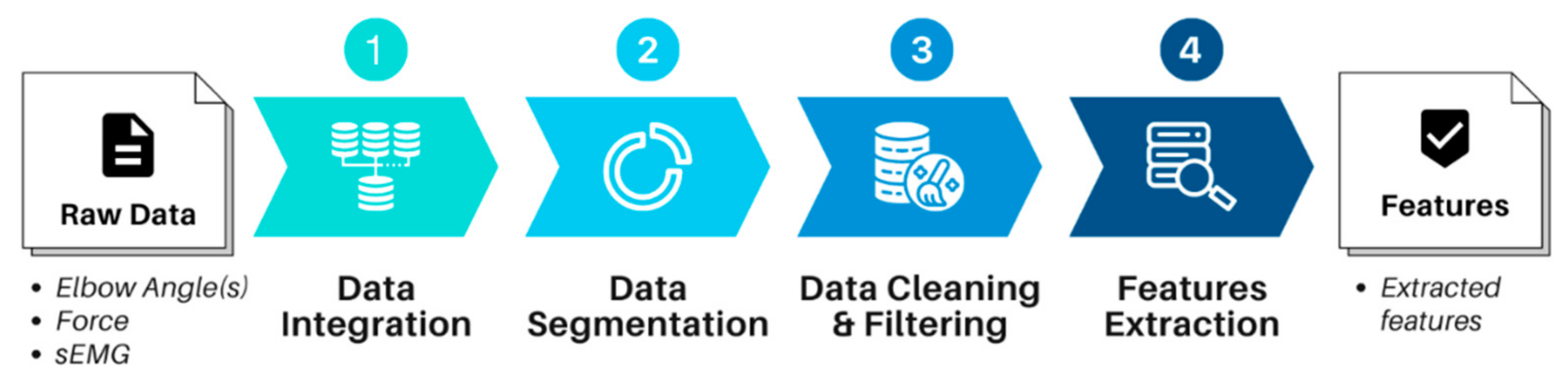
Figure 6.
Data preprocessing stages to convert the raw data into extracted features.
Figure 6.
Data preprocessing stages to convert the raw data into extracted features.
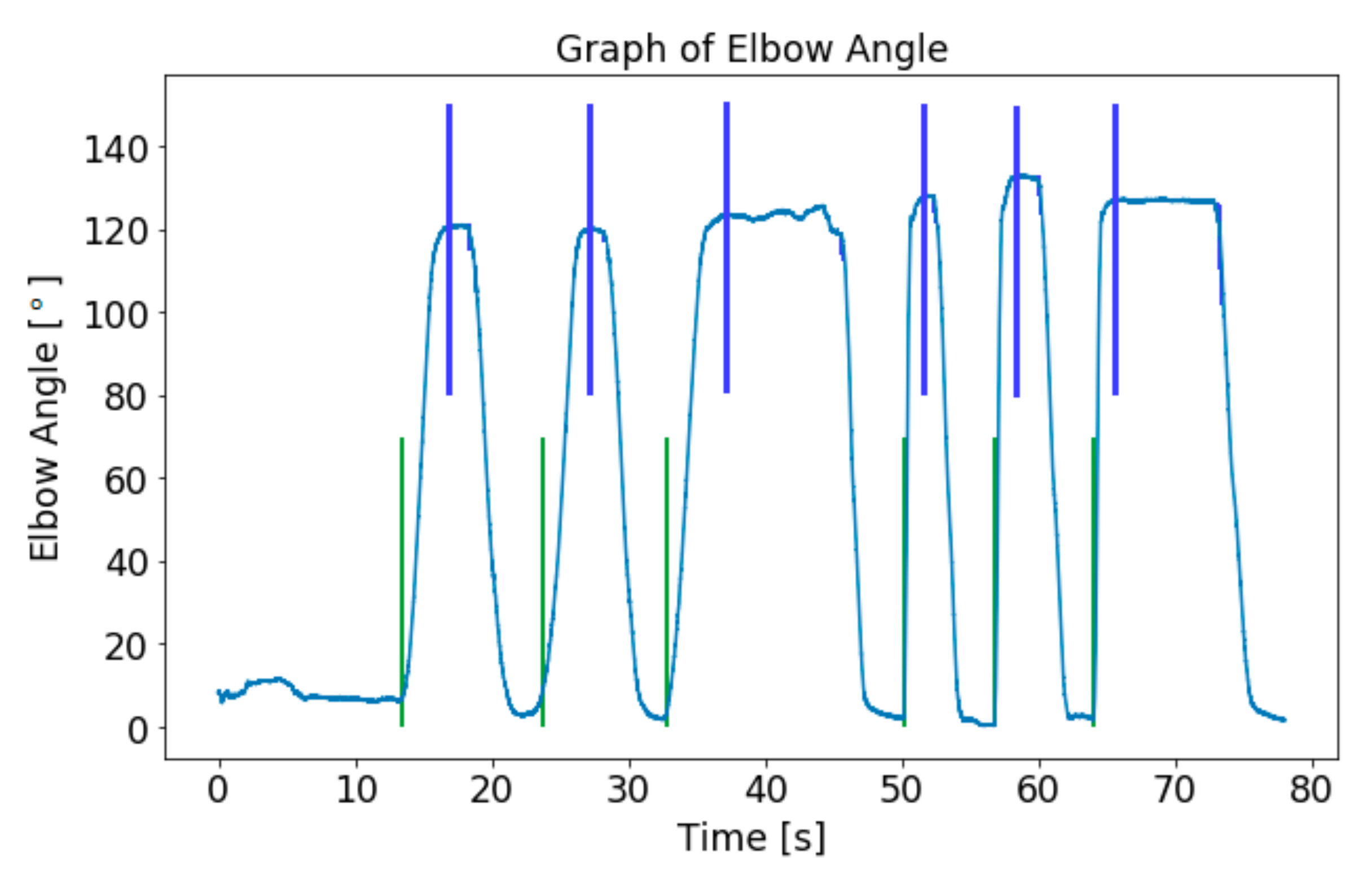
Figure 7.
Detection of local minima (green line) and local maxima (blue line) of the elbow angle.
Figure 7.
Detection of local minima (green line) and local maxima (blue line) of the elbow angle.
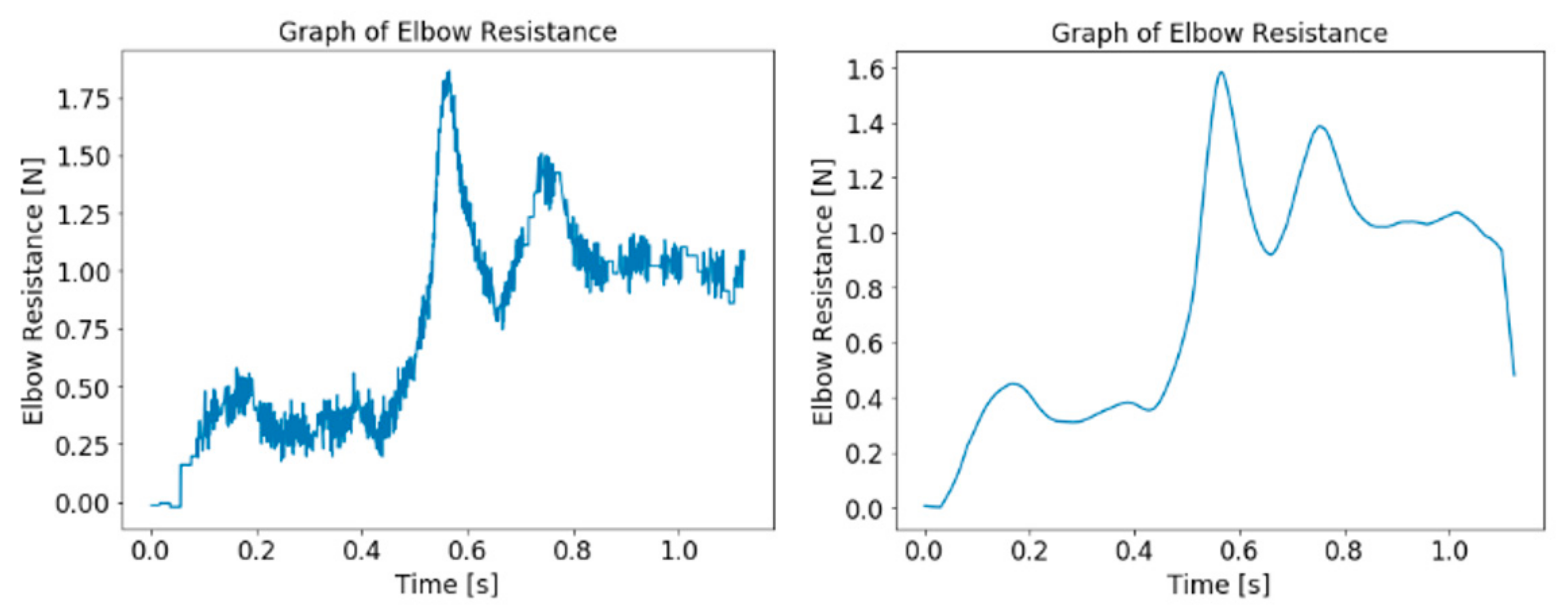
Figure 8.
Graph of elbow resistance data before (left) and after (right) processing.
Figure 8.
Graph of elbow resistance data before (left) and after (right) processing.
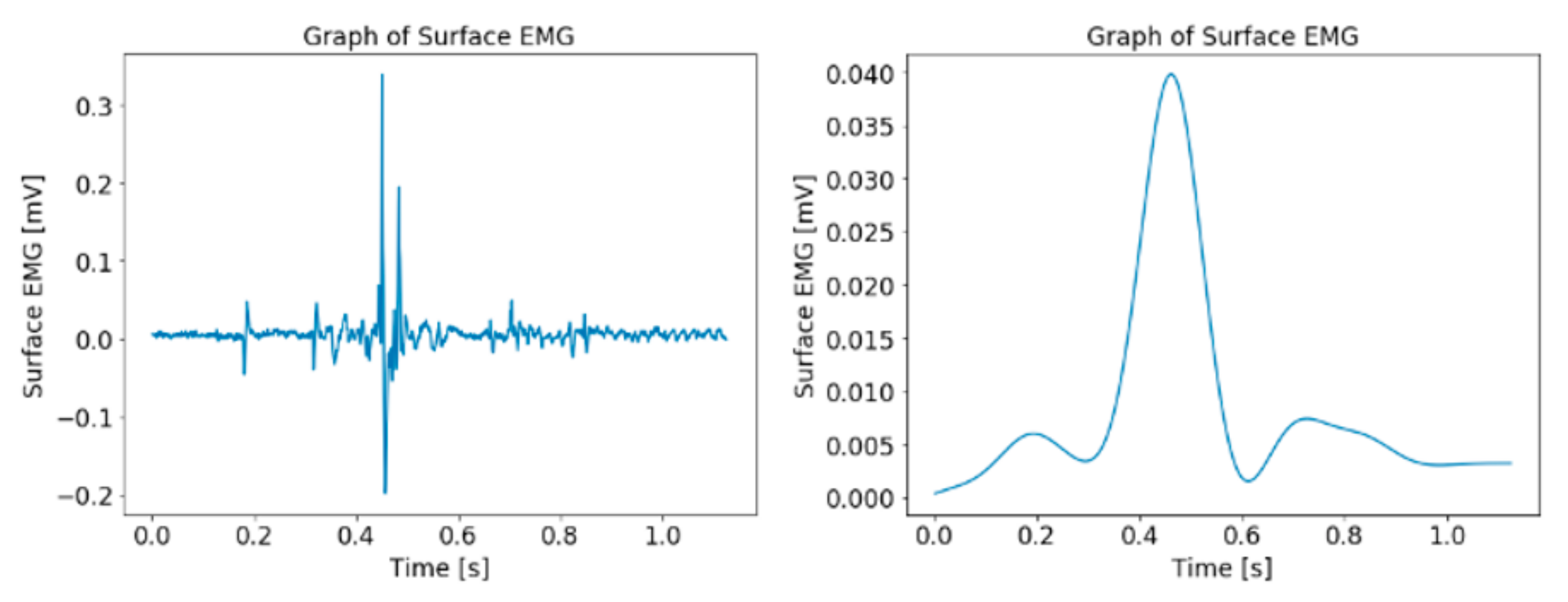
Figure 9.
Graph of sEMG data before (left) and after (right) preprocessing.
Figure 9.
Graph of sEMG data before (left) and after (right) preprocessing.
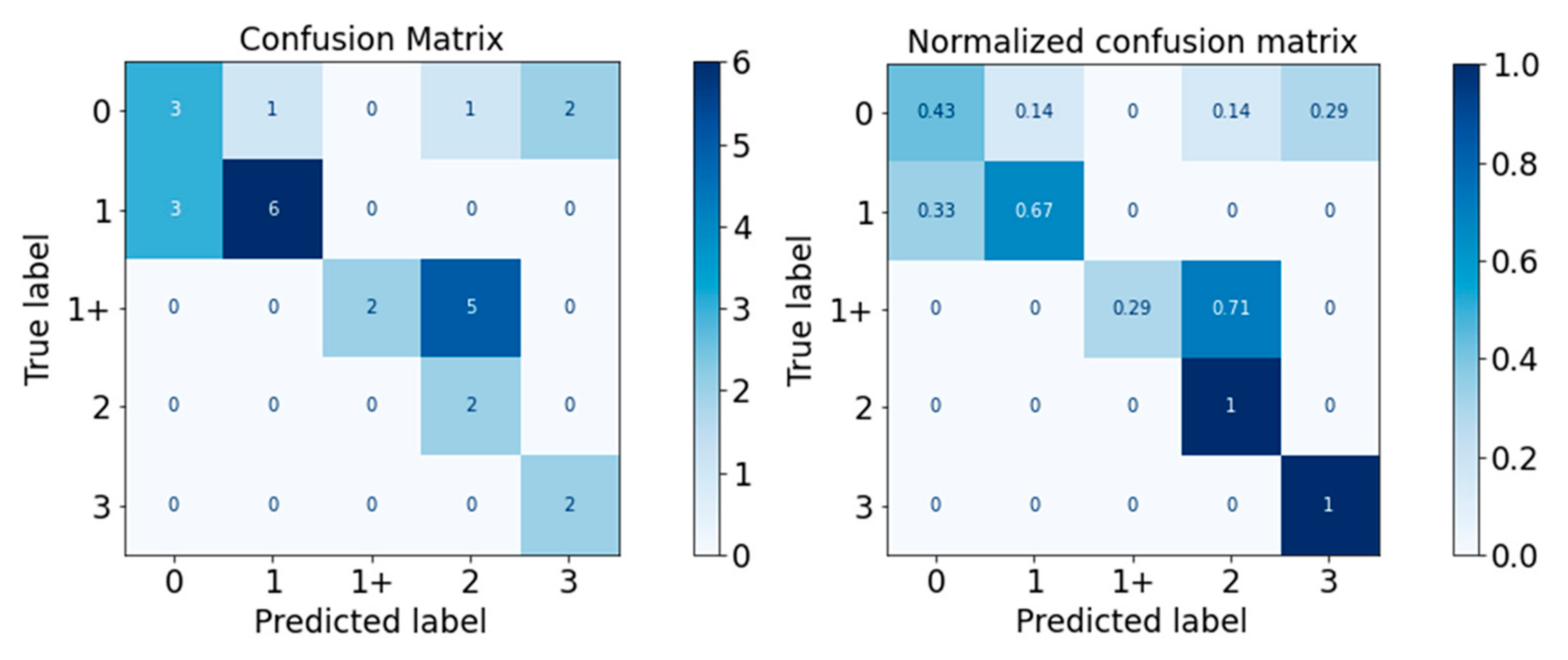
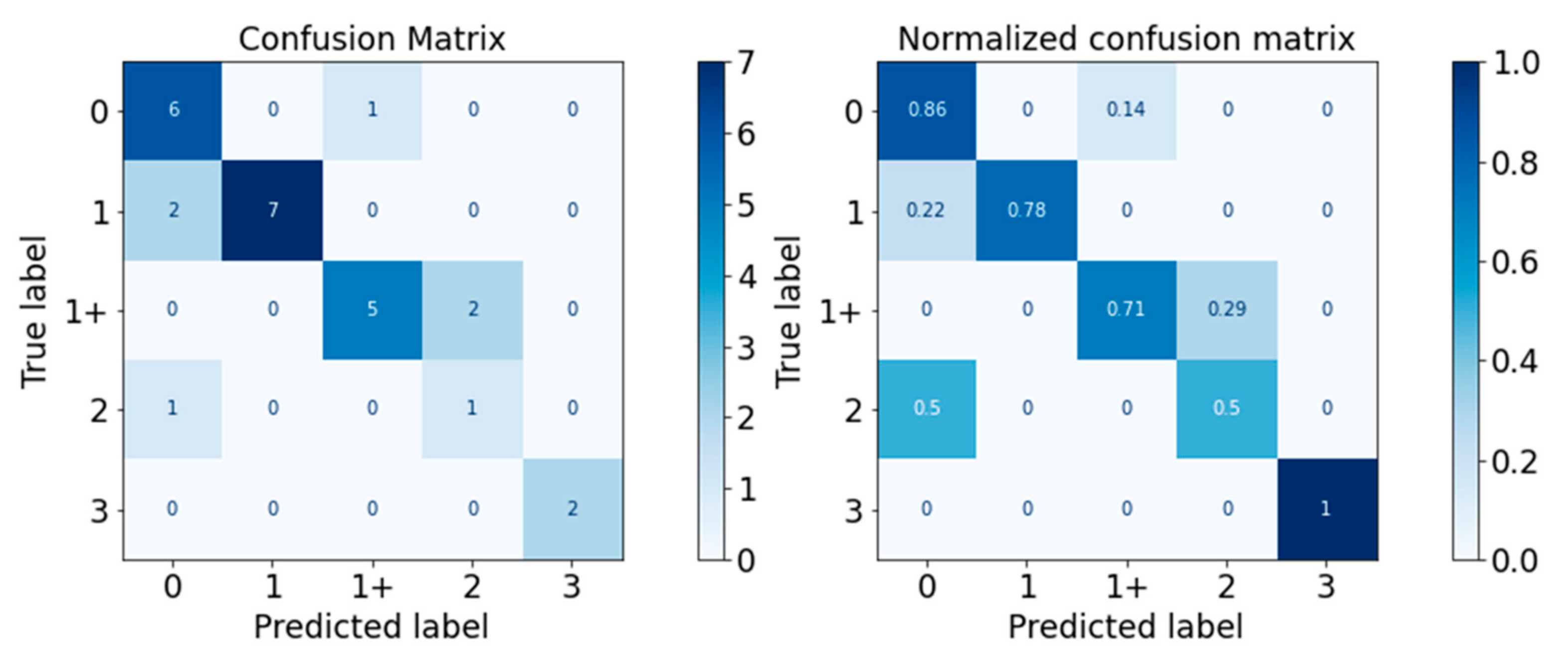
Figure 10.
Confusion Matrix of Gaussian Naïve Bayes Classifier.
Figure 10.
Confusion Matrix of Gaussian Naïve Bayes Classifier.
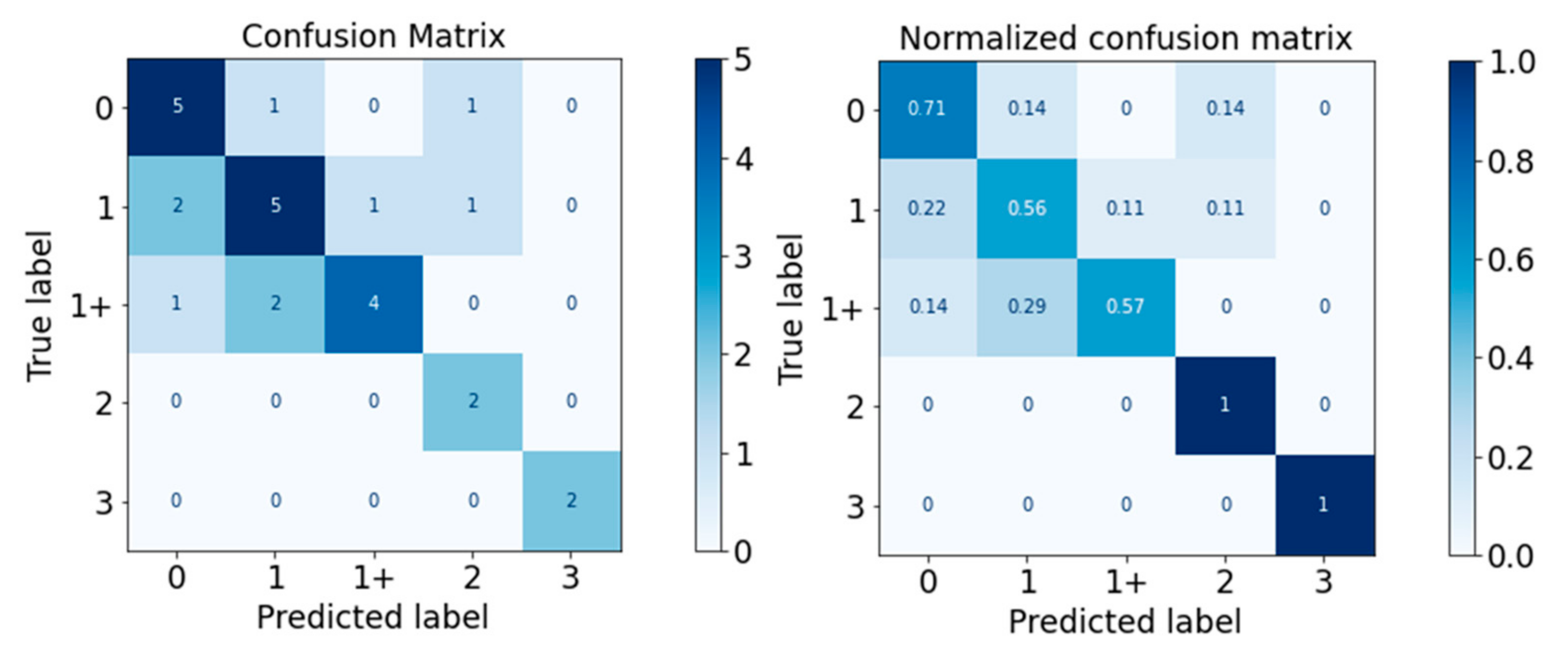
Figure 11.
Confusion Matrix of Decision Tree Classifier.
Figure 11.
Confusion Matrix of Decision Tree Classifier.
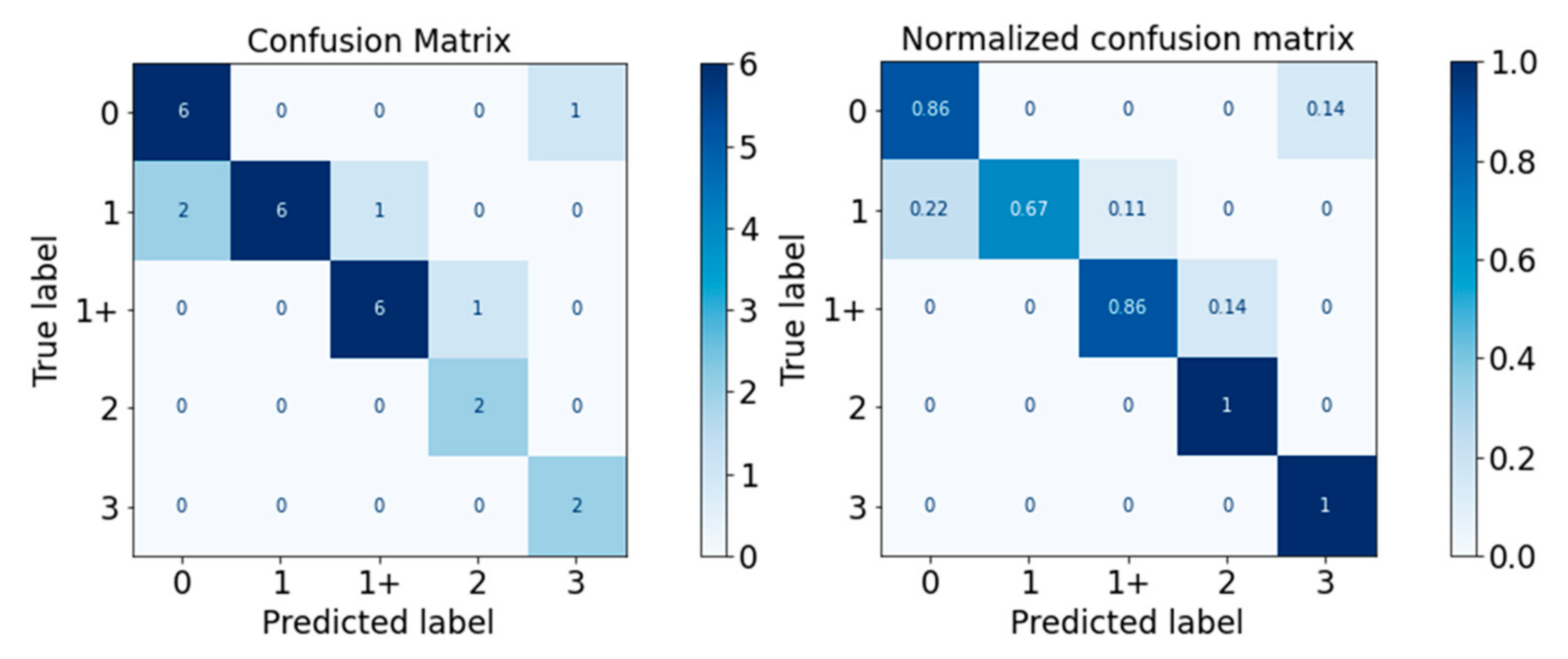
Figure 12.
Confusion Matrix of Random Forest Classifier.
Figure 12.
Confusion Matrix of Random Forest Classifier.
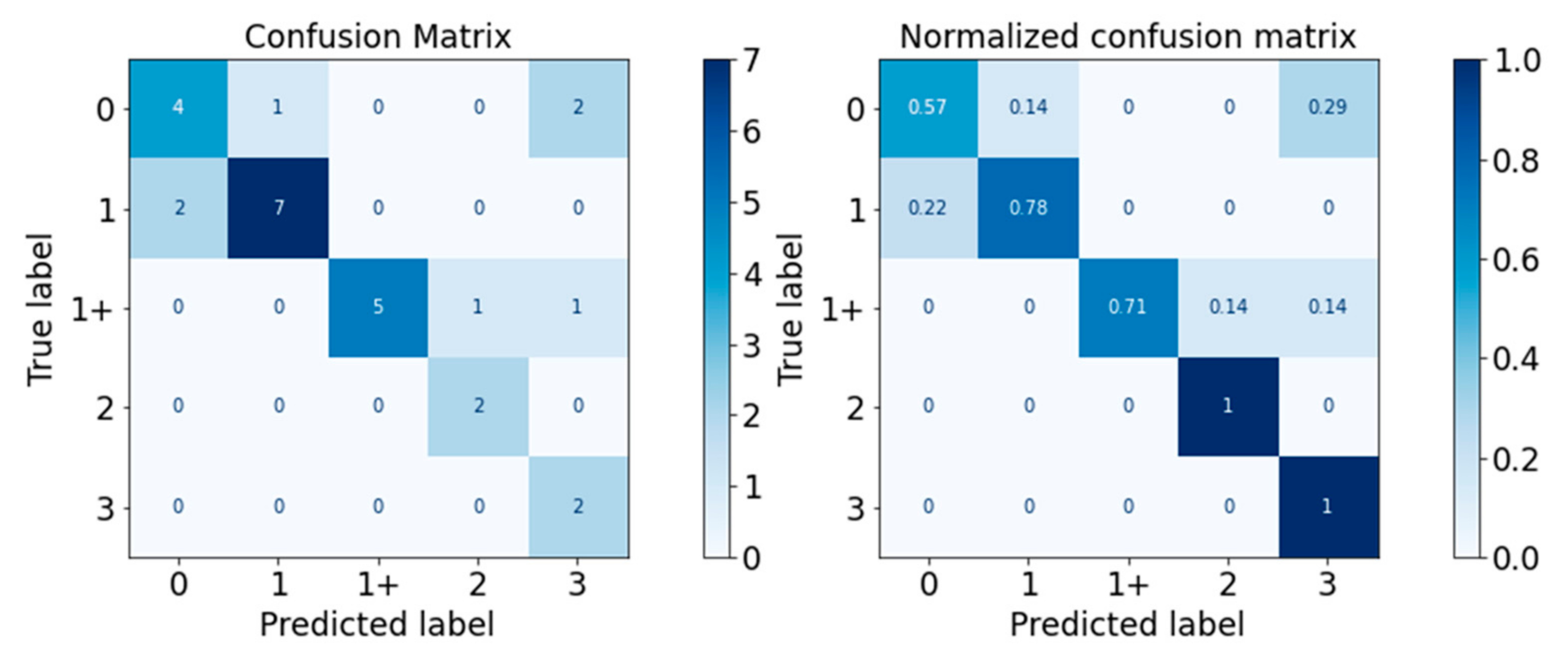
Figure 13.
Confusion Matrix of XGBoost Classifier.
Figure 13.
Confusion Matrix of XGBoost Classifier.
Figure 14.
Confusion Matrix of SVM Classifier.
Figure 14.
Confusion Matrix of SVM Classifier.
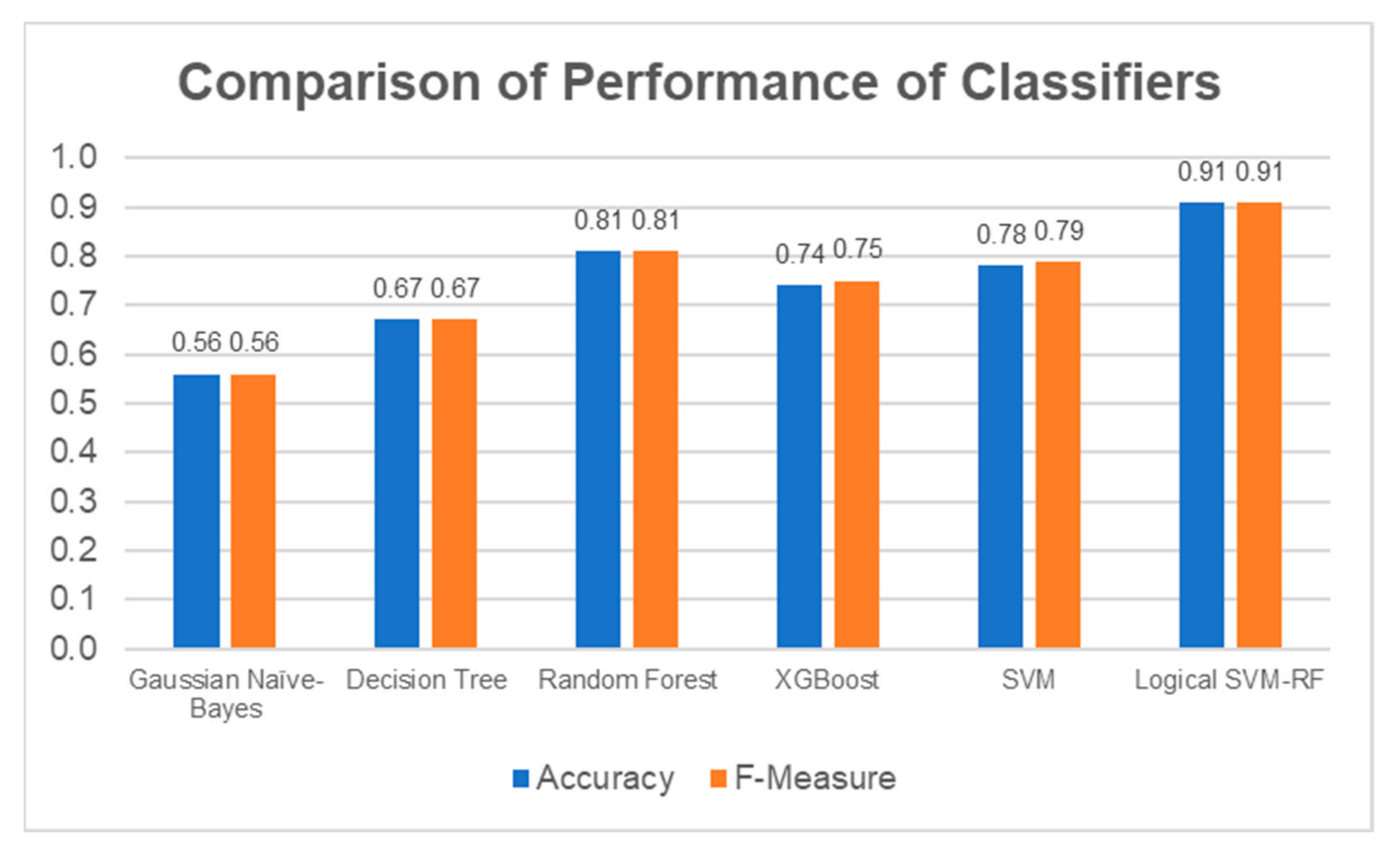
Figure 15.
Accuracy and F-Measure Scores of Each Classifier.
Figure 15.
Accuracy and F-Measure Scores of Each Classifier.
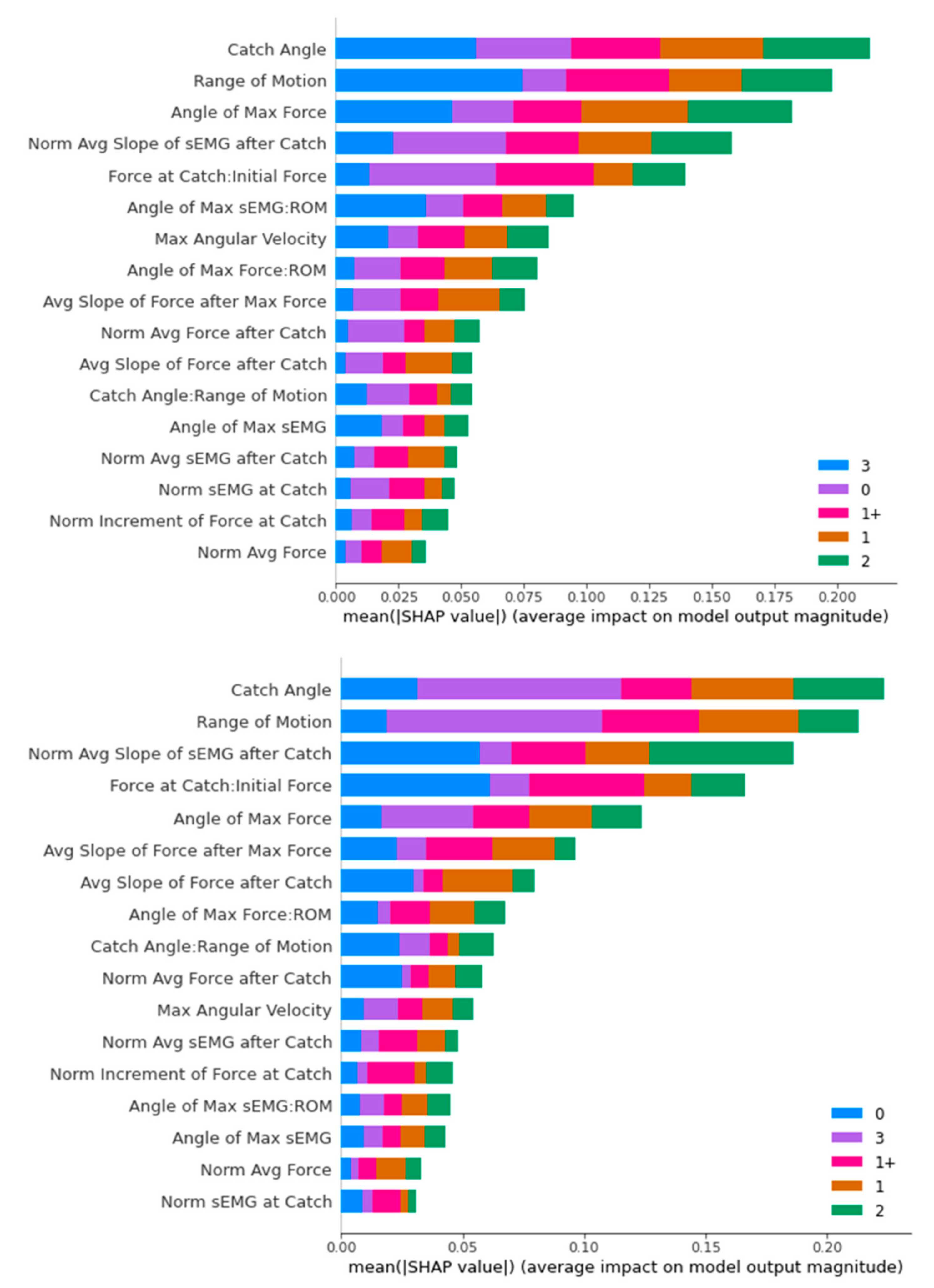
Figure 16.
SHAP Analysis Result for Decision Tree: ROS-upsampled (above) and SMOTE-upsampled (below).
Figure 16.
SHAP Analysis Result for Decision Tree: ROS-upsampled (above) and SMOTE-upsampled (below).
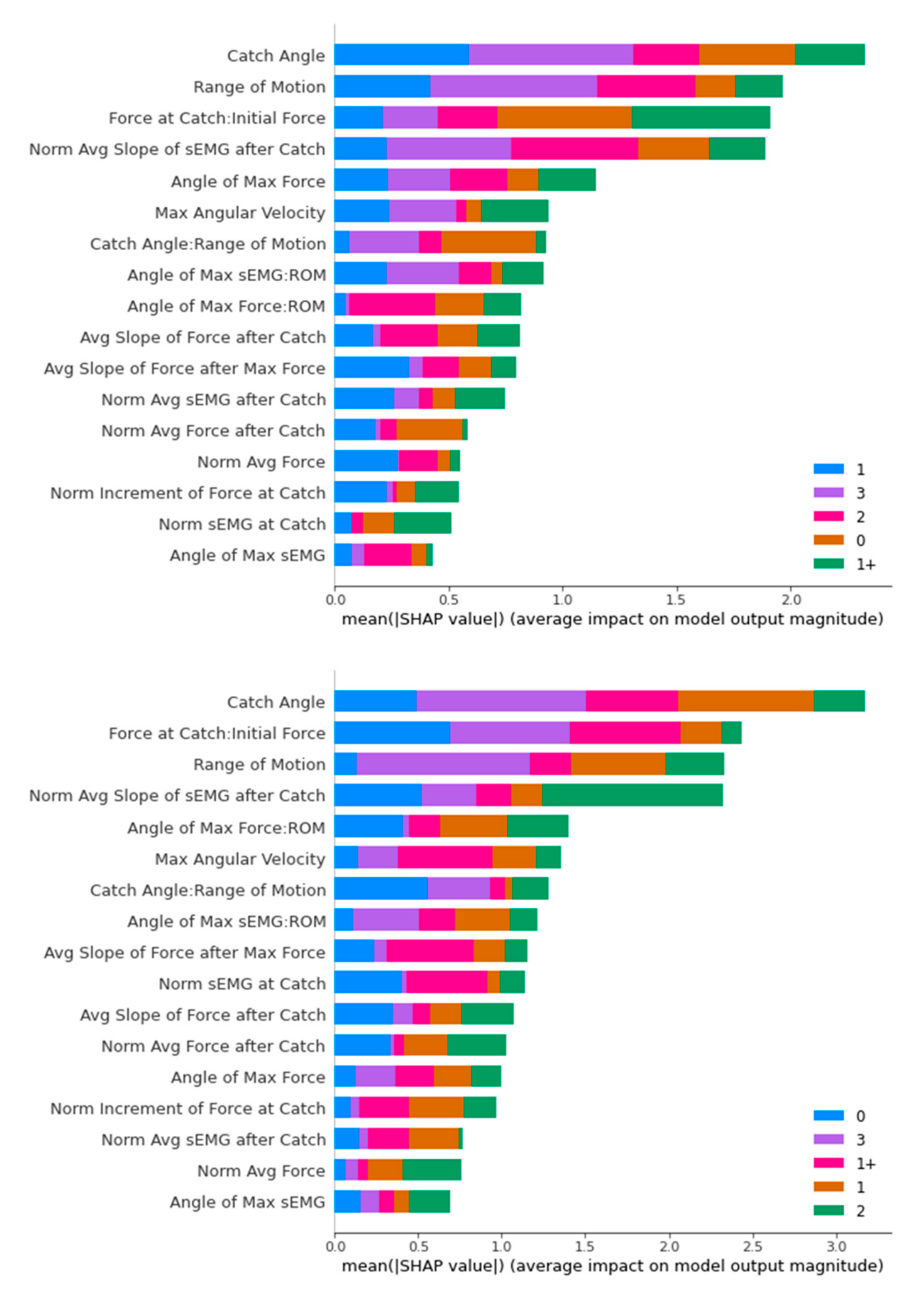
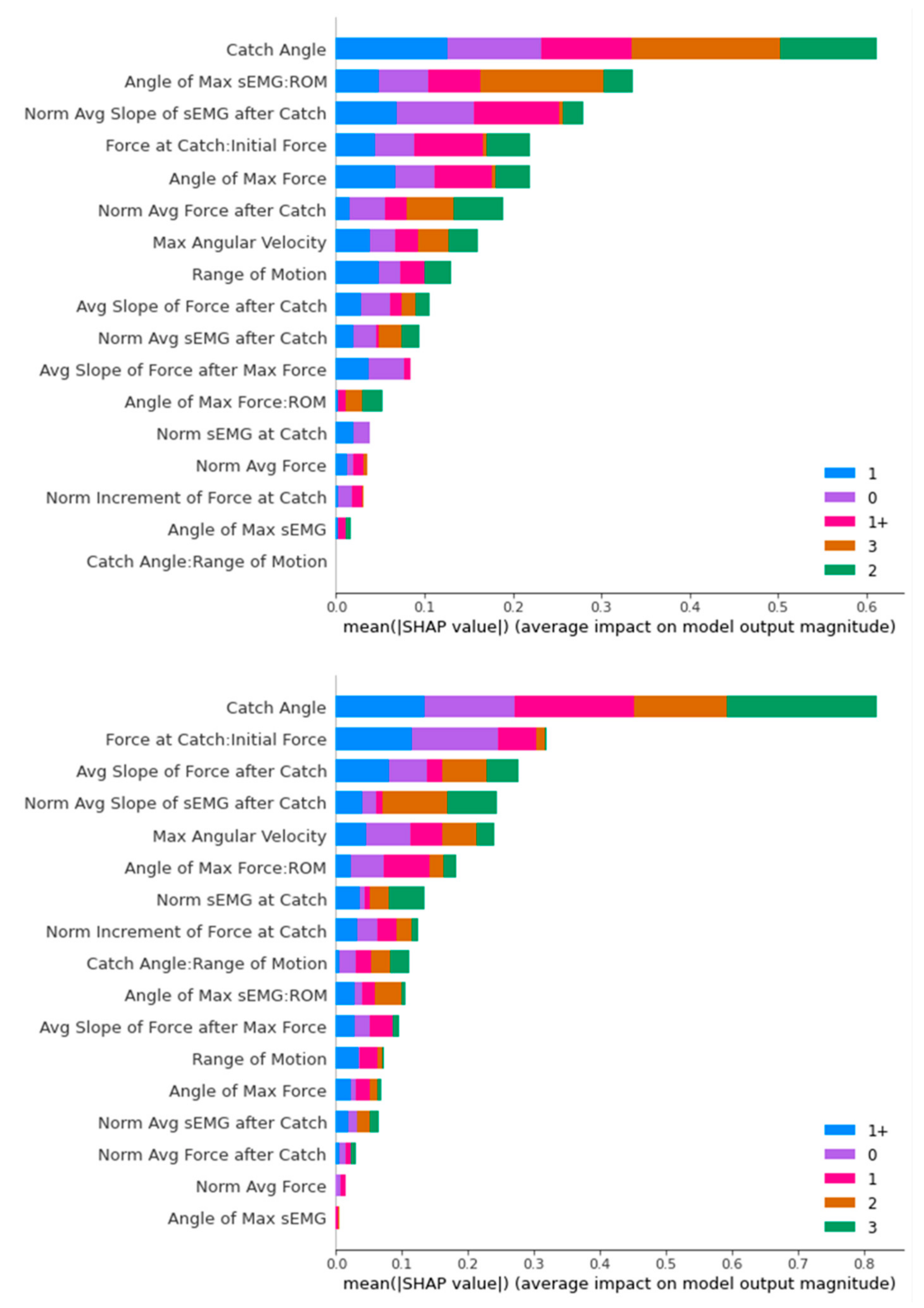
Figure 17.
SHAP Analysis Result for Random Forest: ROS-upsampled (above) and SMOTE-upsampled (below).
Figure 17.
SHAP Analysis Result for Random Forest: ROS-upsampled (above) and SMOTE-upsampled (below).
Figure 18.
SHAP Analysis Result for XGBoost: ROS-upsampled (above) and SMOTE-upsampled (below).
Figure 18.
SHAP Analysis Result for XGBoost: ROS-upsampled (above) and SMOTE-upsampled (below).
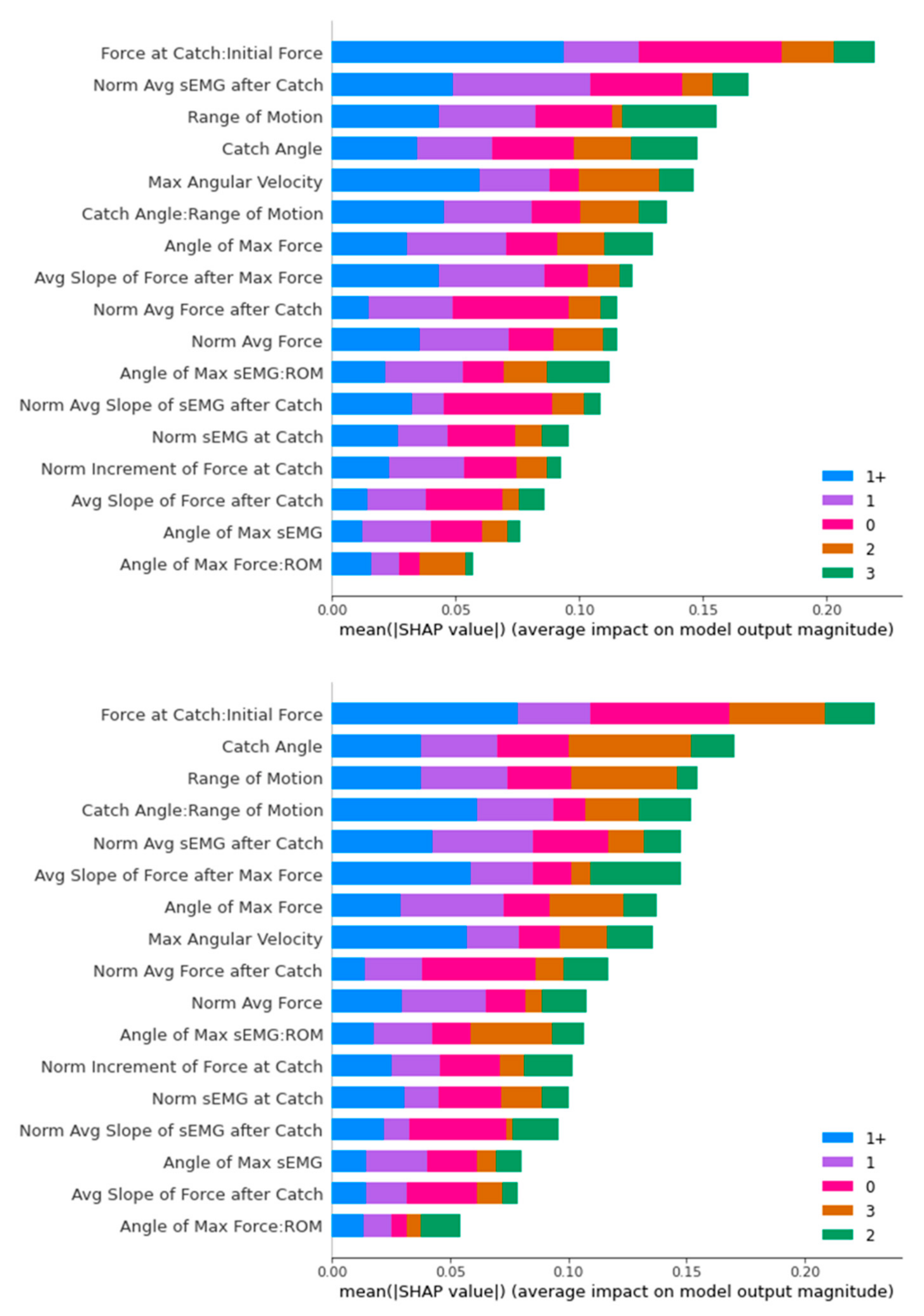
Figure 19.
SHAP Analysis Result for SVM: ROS-upsampled (above) and SMOTE-upsampled (below).
Figure 19.
SHAP Analysis Result for SVM: ROS-upsampled (above) and SMOTE-upsampled (below).
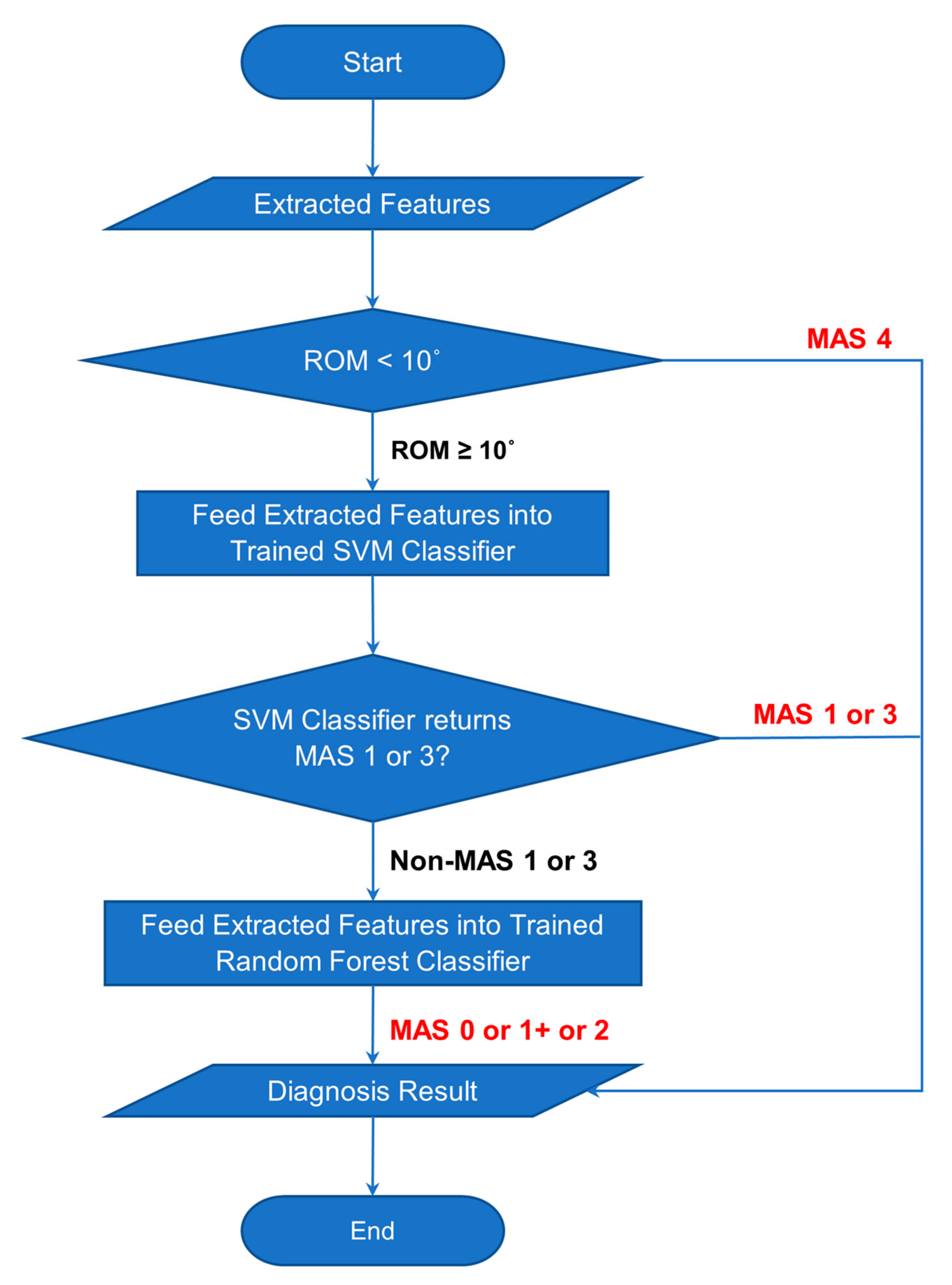
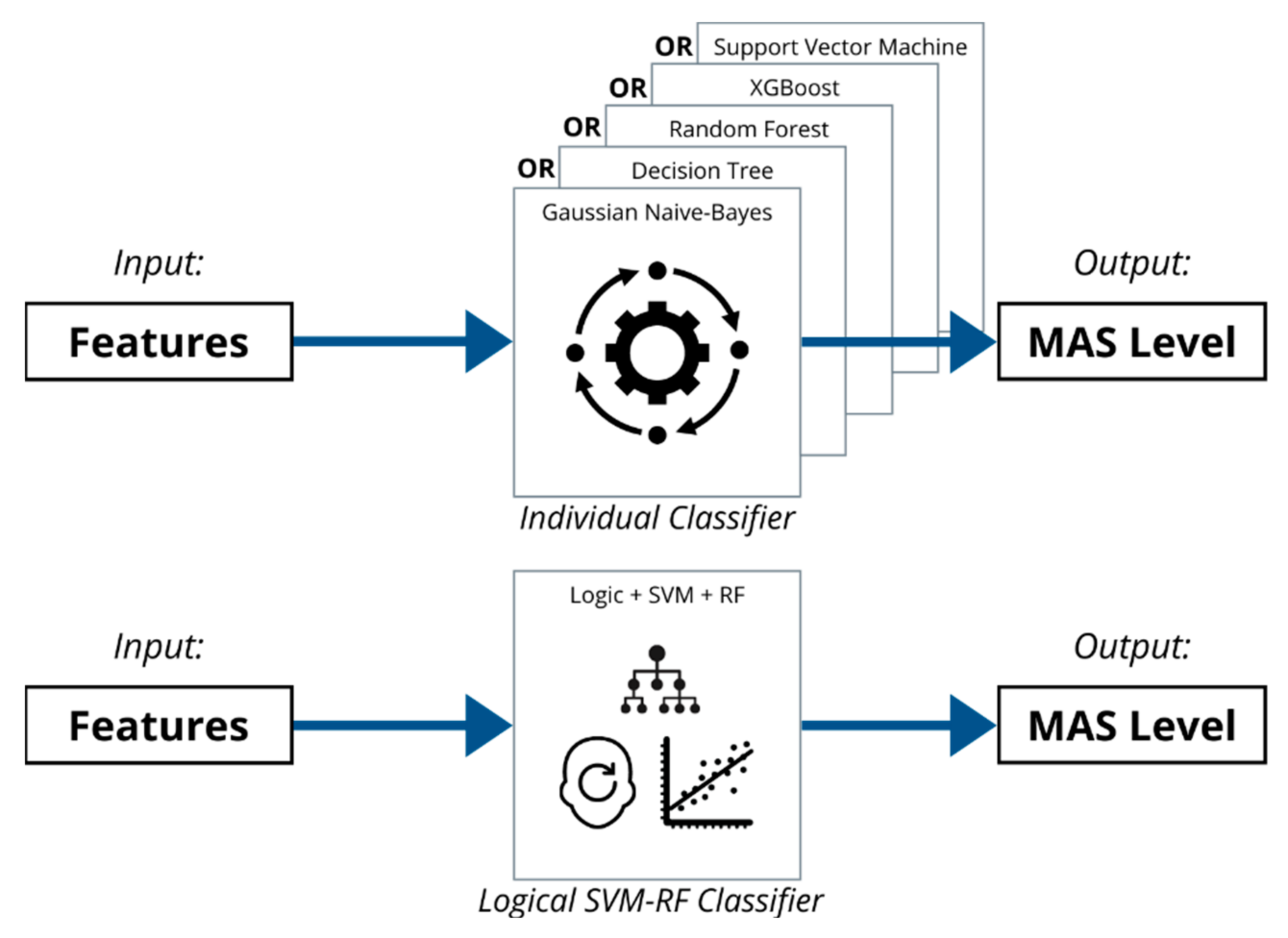
Figure 20.
Flowchart of Classification Process of Combined Classifier.
Figure 20.
Flowchart of Classification Process of Combined Classifier.
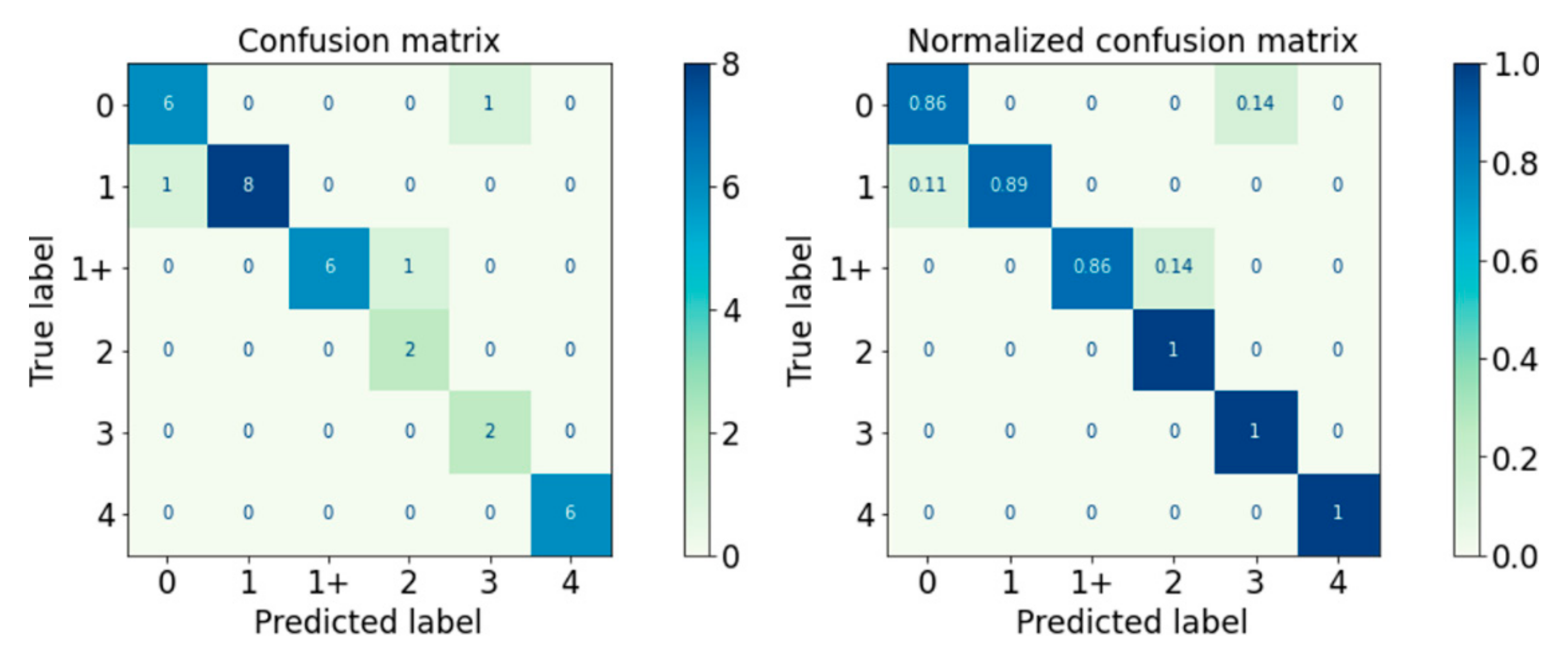
Figure 21.
Confusion Matrix of Logical–SVM–RF Classifier.
Figure 21.
Confusion Matrix of Logical–SVM–RF Classifier.
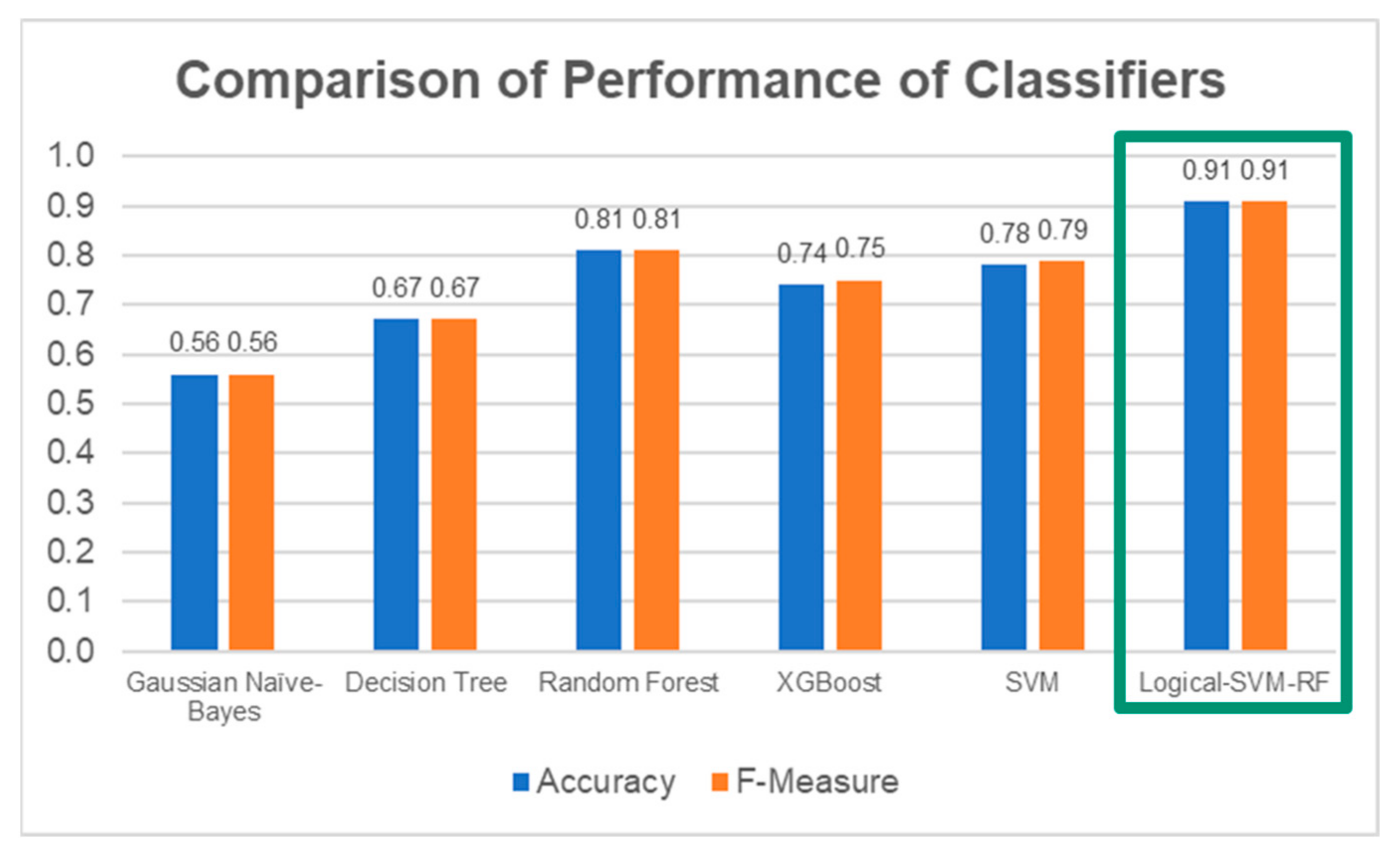
Figure 22.
Comparison of performance between the individual classifiers and the Logical–SVM–RF classifier. The performance of Logical-SVM-RF classifier (in green box) is the highest among all.
Figure 22.
Comparison of performance between the individual classifiers and the Logical–SVM–RF classifier. The performance of Logical-SVM-RF classifier (in green box) is the highest among all.
Figure 23.
Logical–SVM–RF Classifier can better classify the MAS level based on the extracted features than the individual classifiers working alone.
Figure 23.
Logical–SVM–RF Classifier can better classify the MAS level based on the extracted features than the individual classifiers working alone.
Table 1.
Visualisation of MAS Grades.
Table 2.
Sensors in Data Acquisition System.
Table 2.
Sensors in Data Acquisition System.
| Sensor | Specifications |
|---|
| DataLITE Wireless Twin-Axis Goniometers | Range | 0–340° (±170°) |
| Accuracy | ±2° measured over a range of ±90° |
| Resolution | +0.1° in a range of 180° |
| OperatingTemperature | +10 to +40 [°C] |
| DataLITE Handheld Myometer | Rated Load | 0 to 50 [kg] (for compression only) |
| Accuracy | Better than 1% rated load |
| DataLITE Wireless Surface EMG Sensor | Bandwidth | 10–490 [Hz] |
| Amplifier | Standard Unit × 1000 |
| Accuracy | ±1.0 [%] |
| Noise | <5 [µV] |
| Sampling Rate | Up to 2000 [Hz] |
Table 3.
Distributions of Subjects’ MAS Level.
Table 3.
Distributions of Subjects’ MAS Level.
| MAS Level | Number of Trials |
|---|
| 0 | 28 |
| 1 | 28 |
| 1+ | 22 |
| 2 | 9 |
| 3 | 7 |
| 4 | 2 |
| TOTAL | 96 |
Table 4.
Details of Sensors Data.
Table 4.
Details of Sensors Data.
| Sensors | Data | Unit |
|---|
| Twin-Axis Electrogoniometer | Elbow angle (x-axis) | Degree [°] |
| Elbow angle (y-axis) | Degree [°] |
| Handheld Myometer | Elbow resisting force | Newton [N] |
| Wireless sEMG Sensor | Surface EMG | Millivolt [mV] |
Table 5.
Filter and Cleaning Processes for Different Data.
Table 5.
Filter and Cleaning Processes for Different Data.
| Data | Filter/Cleaning Processes |
|---|
| Elbow Angle | Median Filter (5th order) |
| Mean Filter (5th order) |
| Elbow Resistance | Median Filter (5th order) |
| Mean Filter (5th order) |
| Fix Zero Data Levelling |
| Surface Electromyography | Zero Mean Value Data Levelling |
| Value Rectification |
| Butterworth Filter (4th order, 10 Hz Low-Pass Filter) |
Table 6.
Distributions of Datasets According to MAS Levels.
Table 6.
Distributions of Datasets According to MAS Levels.
| MAS Level | Train Set | Test Set | Total |
|---|
| 0 | 65 | 7 | 72 |
| 1 | 75 | 9 | 84 |
| 1+ | 59 | 7 | 66 |
| 2 | 25 | 2 | 27 |
| 3 | 19 | 2 | 21 |
| 4 | 5 | 1 | 6 |
| Total | 248 | 28 | 276 |
Table 7.
Grid search value range of each hyperparameter.
Table 7.
Grid search value range of each hyperparameter.
| Classifier Type | Hyperparameter | Value Range |
|---|
| Gaussian Naïve Bayes | Variance Smoothing | From 10−9 to 1 |
| Decision Tree | Criterion | [Gini, Entropy] |
| Min Samples in Leaf | From 2 to 20 |
| Min Samples for Split | From 2 to 20 |
| Splitter | [Best, Random] |
| Max Feature | From 2 to 10 |
| Random Forest | Criterion | [Gini, Entropy] |
| Min Samples in Leaf | From 2 to 20 |
| Min Samples for Split | From 2 to 20 |
| Splitter | [Best, Random] |
| Max Feature | From 2 to 10 |
| N Estimators | [25, 50, 75, 100] |
| XGBoost | Booster | [gbtree] |
| Gamma | [0.5, 1.5, 2, 5] |
| Learning Rate | [0.01, 0.05, 0.1, 0.5] |
| Min Child Weight | [5, 10] |
| N Estimators | [50, 100, 200] |
| SVM | Kernel | [Linear, Radial Basis Function] |
| Gamma | Scale, Auto |
| C | 0.01–100 |
Table 8.
Optimised Hyperparameters for Gaussian Naïve Bayes.
Table 8.
Optimised Hyperparameters for Gaussian Naïve Bayes.
| Hyperparameter | Value |
|---|
| ROS | SMOTE |
|---|
| Variance Smoothing | 0.1203 | 0.1203 |
Table 9.
Optimised Hyperparameters for Decision Tree.
Table 9.
Optimised Hyperparameters for Decision Tree.
| Hyperparameter | Value |
|---|
| ROS | SMOTE |
|---|
| Criterion | Entropy | Entropy |
| Min Samples in Leaf | 3 | 3 |
| Min Samples for Split | 6 | 6 |
| Splitter | Best | Random |
| Max Feature | 8 | 8 |
Table 10.
Optimised Hyperparameters for Random Forest.
Table 10.
Optimised Hyperparameters for Random Forest.
| Hyperparameter | Value |
|---|
| ROS | SMOTE |
|---|
| Criterion | Gini | Entropy |
| Min Samples in Leaf | 3 | 6 |
| Min Samples for Split | 6 | 18 |
| Splitter | Best | Best |
| Max Feature | 3 | 4 |
| N Estimators | 25 | 25 |
Table 11.
Optimised Hyperparameters for XGBoost.
Table 11.
Optimised Hyperparameters for XGBoost.
| Hyperparameter | Value |
|---|
| ROS | SMOTE |
|---|
| Booster | gbtree | gbtree |
| Gamma | 0.1 | 0.1 |
| Learning Rate | 0.1 | 0.1 |
| Min Child Weight | 5 | 5 |
| N Estimators | 100 | 100 |
| Objective | Multiclass:softprob | Multiclass:softprob |
Table 12.
Optimised Hyperparameters for Support Vector Machine
Table 12.
Optimised Hyperparameters for Support Vector Machine
| Hyperparameter | Value |
|---|
| ROS | SMOTE |
|---|
| C | 15 | 15 |
| Gamma | Gamma | Scale |
| Kernel | RBF | RBF |
Table 13.
Performance of Classifiers on Train Set.
Table 13.
Performance of Classifiers on Train Set.
| Classifier | Accuracy ± Standard Deviation |
|---|
| ROS | SMOTE |
|---|
| Gaussian Naïve Bayes | 0.59 ± 0.11 | 0.60 ± 0.16 |
| Decision Tree | 0.71 ± 0.16 | 0.60 ± 0.16 |
| Random Forest | 0.83 ± 0.13 | 0.72 ± 0.16 |
| XGBoost | 0.79 ± 0.18 | 0.75 ± 0.17 |
| SVM | 0.83 ± 0.14 | 0.79 ± 0.13 |
Table 14.
Performance of Gaussian Naïve Bayes Classifier.
Table 14.
Performance of Gaussian Naïve Bayes Classifier.
| MAS Level | Precision | Recall | F-Measure |
|---|
| 0 | 0.50 | 0.43 | 0.46 |
| 1 | 0.86 | 0.67 | 0.75 |
| 1+ | 1.00 | 0.29 | 0.44 |
| 2 | 0.25 | 1.00 | 0.40 |
| 3 | 0.50 | 1.00 | 0.67 |
| Accuracy | - | - | 0.56 |
| Weighted Average | 0.73 | 0.56 | 0.56 |
Table 15.
Performance of Decision Tree Classifier.
Table 15.
Performance of Decision Tree Classifier.
| MAS Level | Precision | Recall | F-Measure |
|---|
| 0 | 0.63 | 0.71 | 0.67 |
| 1 | 0.63 | 0.56 | 0.59 |
| 1+ | 0.80 | 0.57 | 0.67 |
| 2 | 0.50 | 1.00 | 0.67 |
| 3 | 1.00 | 1.00 | 1.00 |
| Accuracy | - | - | 0.67 |
| Weighted Average | 0.69 | 0.67 | 0.67 |
Table 16.
Performance of Random Forest Classifier.
Table 16.
Performance of Random Forest Classifier.
| MAS Level | Precision | Recall | F-Measure |
|---|
| 0 | 0.75 | 0.86 | 0.80 |
| 1 | 1.00 | 0.67 | 0.80 |
| 1+ | 0.86 | 0.86 | 0.86 |
| 2 | 0.67 | 1.00 | 0.80 |
| 3 | 0.67 | 1.00 | 0.80 |
| Accuracy | - | - | 0.81 |
| Weighted Average | 0.85 | 0.81 | 0.81 |
Table 17.
Performance of XGBoost Classifier.
Table 17.
Performance of XGBoost Classifier.
| MAS Level | Precision | Recall | F-Measure |
|---|
| 0 | 0.67 | 0.57 | 0.62 |
| 1 | 0.88 | 0.78 | 0.82 |
| 1+ | 1.00 | 0.71 | 0.83 |
| 2 | 0.67 | 1.00 | 0.80 |
| 3 | 0.40 | 1.00 | 0.57 |
| Accuracy | - | - | 0.74 |
| Weighted Average | 0.80 | 0.74 | 0.75 |
Table 18.
Performance of SVM Classifier.
Table 18.
Performance of SVM Classifier.
| MAS Level | Precision | Recall | F-Measure |
|---|
| 0 | 0.67 | 0.86 | 0.75 |
| 1 | 1.00 | 0.78 | 0.88 |
| 1+ | 0.83 | 0.71 | 0.77 |
| 2 | 0.33 | 0.50 | 0.40 |
| 3 | 1.00 | 1.00 | 1.00 |
| Accuracy | - | - | 0.78 |
| Weighted Average | 0.82 | 0.78 | 0.79 |
Table 19.
Performance of Logical–SVM–RF Classifier.
Table 19.
Performance of Logical–SVM–RF Classifier.
| MAS Level | Precision | Recall | F-Measure |
|---|
| 0 | 0.86 | 0.86 | 0.86 |
| 1 | 1.00 | 0.89 | 0.94 |
| 1+ | 1.00 | 0.86 | 0.92 |
| 2 | 0.67 | 1.00 | 0.80 |
| 3 | 0.67 | 1.00 | 0.80 |
| 4 | 1.00 | 1.00 | 1.00 |
| Accuracy | - | - | 0.91 |
| Weighted Average | 0.93 | 0.91 | 0.91 |
Table 20.
Comparison of Logical–SVM–RF classifier and other existing works.
Table 20.
Comparison of Logical–SVM–RF classifier and other existing works.
| Aspect | Yee et al. (This Work) | Ahmad Puzi et al. [6] | Park et al. [7] | Zhang et al. [8] | Chen et al. [9] |
|---|
| Stretching Method | Passive | Passive | Passive | Passive | Active |
Clinical
Scale | MAS
0, 1, 1+, 2, 3, 4 | MAS 0, 1, 2 | MAS 0, 1, 1+, 2, 3 | MAS 0, 1, 1+, 2, 3 | MAS 0, 1, 1+, 2 |
| MAS Classes | 6 | 3 | 5 | 5 | 4 |
No. of
Subjects | 50 | 25 | 34 | 24 | 13 |
| Sensors Data | Angle, Force, sEMG | Angle, Torque | Angle, Torque | IMU, sEMG | IMU, sEMG |
| Classification Methods | SVM + RF + Logical Decision | SVM, Linear Discriminant, Weighted-KNN | MLP | Support Vector Regressor | KNN, SVM, RF, MLP |
| Reported Performance | Accuracy & F1: 91% | Accuracy: 76–84% | Accuracy: 82.2% | MSE: 0.059 | F1: 70.5–95.2% |
Table 21.
Comparison of current clinical practice and assisted diagnosis system.
Table 21.
Comparison of current clinical practice and assisted diagnosis system.
| Aspect | Conventional Clinical Practice | Assisted Diagnosis System |
|---|
| Setup time | No setup required | <5 min |
| Measurement Data | Elbow Angle | Elbow Angle, Elbow Resisting Force, sEMG |
| Data Format | Recorded with pen and paper | Recorded as numerical data in digital format |
| Diagnosis Method | Manual | Assisted by data-driven machine learning model |
| Diagnosis Outcome | Inter-rater and intra-rater variability issues | Transparency in decision making |


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




























