As the name implies, deepfakes employ artificial intelligence and deep learning to manipulate or generate inexistent visual or audio content. The breakthroughs in deepfake generation offer both benefits and drawbacks. The 2019 video footage of former US President Barack Obama, where he was faked into improper usage of language, was released as public awareness of the would-be-weapon of the near future by filmmaker Jordan Peele [
1]. The outreach of the terminology deepfakes hit its maximum when video footage of Facebook CEO Mark Zuckerberg announcing the closure of Facebook to the public went viral, which was a deep fake. Though the concept of forging and manipulating visual content is not new, the advent of highly realistic indistinguishable fake content is quite challenging since they call for efficient models for their detection. The face is a person’s most distinguishing characteristic. Face modification poses a growing security issue due to the rapid advancement of face synthesis technology. Frequently, people’s faces can be replaced with those of others who seem real.
We tend to trust what we see. The common public is well aware of generating fake images through easily accessible software such as Photoshop. However, we are yet to be informed about the possibilities of generating fake videos and their convincing nature due to their highly realistic output. Deepfake content is disseminating more quickly than ever in the twenty-first century due to the growth of multiple social networking sites, making it a global threat. It explains how deepfake technology could be one of the digital weapons facing future generations, producing extremely unacceptable ethical, moral, and legal concerns [
2]. Through digital impersonation, it would be considered easy to cyberattack a person, a public figure, or a cause. Moreover, convenient and discrete public access to digital content can only elevate the effects. On the other hand, deepfake technology has a brighter side to the positive application in the entertainment industry. There may soon come a time when an eligible actor’s physical looks and vocals may be deep faked and inserted into video recordings of films acted out by another talented individual. Deepfakes are cutting-edge technology that eventually produces smart applications that can enable someone to be a part of the trend. The traditional image forgery detection approaches have yet to prove efficient in detecting deepfake content.
The recent inclination of deepfake research can be split into two main categories: (1) Deepfake generation, which focuses on synthesizing and improving existing state-of-the-art techniques with respect to computational complexities and training time, and (2) Deepfake detection, which concentrates on developing reliable and universal classifiers that can be deployed in the wild.
The promise of current deepfake generation and detection research lies solely in facial deepfake recognition. There are various datasets containing millions of images for face recognition tasks, which are utilized for face deepfake synthesis. The Visual Geometry Group Face dataset (VGGFace) and the CelebFaces Attributes Dataset (Celeb-A) are huge datasets comprising over 200,000 images. The deciphering gap, however, largely potentiates medical deepfake synthesis and detection that should call for much attention.
Extensive research is being encouraged in medical diagnostics, and disease detection using machine learning, deep learning, and ensemble techniques [
3,
4,
5]. Pre-trained networks such as MobileNet and EfficientNets have been preferred over handcrafted features for healthcare diagnosis due to their capacity to adapt to new data by transferring the learned representations from one domain to another [
6,
7]. Given that medical fakes pose a future hazard, the identification of medical deepfakes prior to a medical diagnosis would only be extremely intuitive. In the case of manipulated facial data, the artificial visual irregularities in the skin tone were initially recognizable to the human eye [
8]. On the contrary, new and improved modified GANs are still being released in rapid succession.
1.1. Generation of Synthesized Images
Depending on the degree of alteration, synthesized images may be divided into three categories: face-swapping, face-reenactment or attribute manipulation, and inexistent whole face synthesis [
9]. Face-swap is a technique where the subject’s face from the source image is automatically swapped out with that of the subject from the target face. Face-reenactment is the manipulation of facial expressions, such as adding the attributes of a source person, which includes eyes, emotions, and facial features, onto an output image. Face generation aims to create lifelike representations of a human face that might or might not exist in reality. The ability of human eyes to distinguish between fake and genuine content has become increasingly challenging due to the high quality of these synthetic images.
Table 1 briefs the state-of-the-art in each of the generation categories.
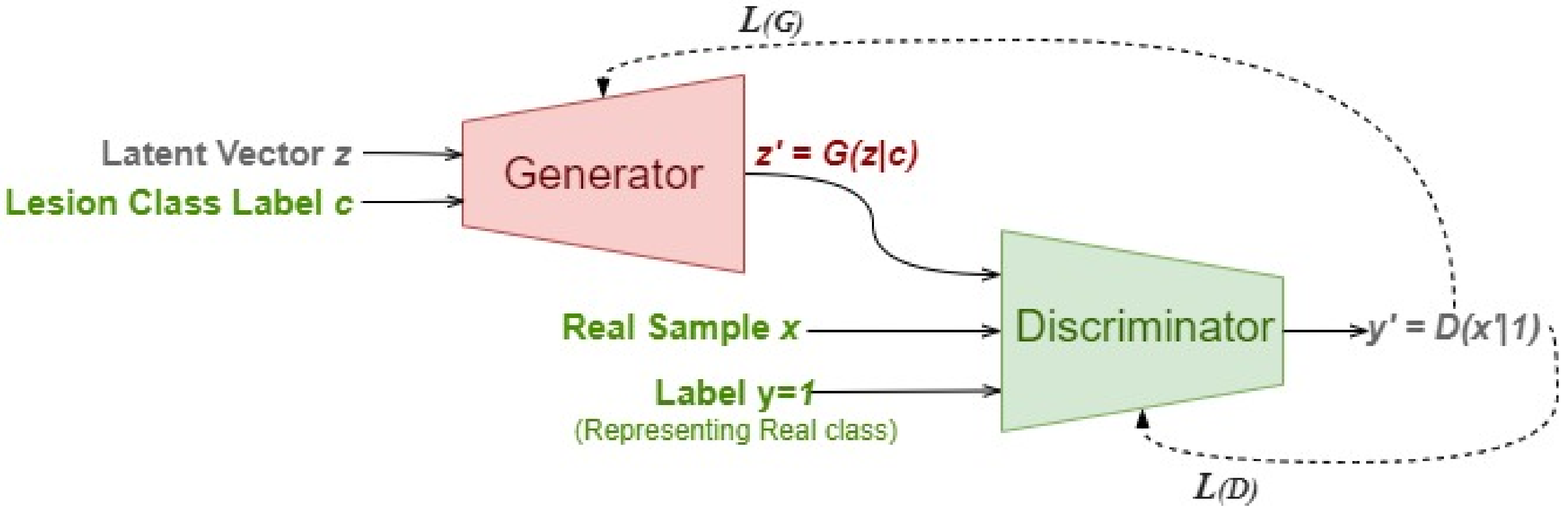
The basis of synthesized multimedia is the mathematical formulations of Generative Adversarial Networks (GANs) [
10]. Deepfakes are generated using several variants of GANs by generating new samples that imitate an existing data set. In the vanilla GAN model, a low-dimension random noise is transformed into photorealistic images using the adversarial training behavior of a generative model and the classification nature of a discriminative model. Briefly, while the generator trains its network to generate realistic fake content from a set of training images, the discriminator distinguishes an incoming image as real or fake.
where
z is the random noise vector,
is the training samples from the real dataset, and
are the generated fake datapoints. Technically,
z gets molded into highly realistic images
by the model in a min-max pull of the cost functions of generator
and discriminator
(Equations (
1) and (
2)). Here, The generator attempts to reduce the likelihood that the discriminator will accurately categorize images, and the discriminator tries to maximize the probability of its efficient classification where real images are classified as real and fake images are classified as fake [
11].
Table 1.
Overview of Image Generation Models.
Table 1.
Overview of Image Generation Models.
| Reference | Mode | Model | Data | Synthesized Quality |
|---|
| Korshunova et al. [12] | Face Swap | GAN | VGGFace | 256 × 256 |
| Natsume et al. [13] | Face Swap | GAN | CelebA | 128 × 128 |
| Li et al. [14] | Face Reeanctment | GAN | VGG Face CelebA | 256 × 256 |
| Kim et al. [15] | Face Reenactment | cGAN | customized | 1024 × 1024 |
| Liu et al. [16] | Face Synthesis | CoGAN | CelebA | 64 × 64 |
| Karras et al. [17] | Face Synthesis | PGGAN | CelebA | 1024 × 1024 |
| Karras et al. [18] | Face Synthesis | StyleGAN | ImageNet | 1024 × 1024 |
| Brock et al. [19] | Face Synthesis | BigGAN | ImageNet | 512 × 512 |
| Frid-Adar et al. [20] | CT images | DCGAN | Own data | 64 × 64 |
| Thambawita et al. [21] | ECG | WaveGAN | Own data | 10 s ECG |
| Mirsky et al. [22] | CT Lung Nodules | CTGAN | LIDC-IDRI | 3 × 64 × 64 |
An enhanced deepfake generation method employing GAN was suggested in [
12], which added a perceptual loss to the VGGface synthesis. They created texture-less, smooth images. Natsume et al. [
13] employed two different GANs to encode the latent dynamics of facial and hair attributes. However, the approach was sensitive to occlusions and lighting effects. In order to maintain the desired properties such as stance, expression, and occlusion, Li et al. [
14] produced facial images by employing two real face datasets. Nevertheless, the imperfections created during synthesis were projected because of the stripping effect and inadequate resolution.
Instead of only changing the target individual’s facial expression, in [
15], GANs were conditioned using a conditional GAN (cGAN) to mimic human expressions, including blinking and smiling. In [
23], GANs were then effectively employed for face synthesis by integrating a perceptual loss with conditional GANs. The resolutions, however, remained poor compared to real-face photographs. Instead of training only one GAN, Liu et al. [
16] suggested Coupled GAN (CoGAN), where each of the two GANs was in charge of synthesizing images in a specific domain. Low picture resolution is a challenge for the majority of these deep learning-based image synthesis approaches. Karras et al. [
17] proposed the Progressive Growing GANs (PG-GAN) to demonstrate high-quality face synthesis with enhanced image quality by progressively adding layers to the networks during the training process. Checker effects and blob-like effects were quite common in the aforementioned methods of synthesis, leaving visible traces of manipulation. In [
18], PGGANs were improved to propose Style GAN by learning to transform a latent noise (Z) to an intermediate latent vector (W), rather than mapping latent code z to an image resolution, as in the vanilla GAN architecture. This controlled different visual characteristics to be transferred to another domain. The BigGAN architecture [
19] used residual networks and an increased batch size to improve resolution.
Recently, GANs have been used to create deep medical fakes and machine learning-based diagnosis tools to trick medical professionals by erasing or adding symptoms and signs of medical illnesses. However, this method was largely used to provide more medical data for study and research innovations. A Deep Convolutional GAN (DCGAN) was suggested by Frid-Adar et al. to synthesize high-definition CT (Computed Tomography) images [
20]. The artificial creation of brain tumors, cancerous cell structures, and challenging-to-reproduce histopathological data is suggested [
24,
25,
26]. The generation of complicated Electrocardiograms (ECG) using a WaveGAN was suggested by Thambawita et al. [
21].
Recently, the technology has been made available to anybody interested in creating new data for a positive study. Indeed, synthetic data has piqued the interest as a potential road ahead for increased reproducibility in research. However, this technology’s detection has yet to be extensively investigated, and it may become a weapon in the medical arena in the future. The Jekyll framework was the first to demonstrate a style transfer mechanism for medical deepfake attacks in X-rays and retinal fundus modalities [
27]. A conditional generative adversarial network (cGAN) called CT-GAN was developed by Mirsky et al. to add or remove malignant nodules from lung CT data that over 90% of the clinicians failed to spot [
22]. The motivations and reasons for such attacks could be many, for instance, fabricating research, a misdiagnosis on falsified medical data leading to permanent physical or mental effects on patients due to wrong medications, and even insurance frauds claiming huge payouts.
1.2. Detection of Synthesized Images
Existing approaches target either the spatial inconsistencies left during the generation or are based on pure content classification. The spatial artifacts include background artifacts and GAN fingerprints. Deep neural models can capture intrinsic characteristics and, thus, are used in data-driven techniques to classify and identify modifications. On studying several existing deep neural network models for the detection of deepfake attacks, we observed that most researches are presented by generating their own dataset.
The scientific community had forecasted the threats involved with the advent of GANs and had come up with open-sourced datasets such as the Deepfake Detection Challenge (DFDC) [
28], Diverse Fake Face Dataset (DFFD) [
29], FaceForensics++ [
30] and many more. Research on detection mechanisms is mostly focused on exploring the pre-trained models so as to leverage already learned feature maps onto a new domain. This seems to work well with self-synthesized datasets rather than benchmarked ones. In [
31], an ensemble of EfficientNets was fine-tuned on DFDC to achieve results comparable to the challenge-winning team. However, the winning solution could only achieve an accuracy of ∼65%. A light weighted CNN was proposed in [
32] with as much as only two and three convolution layers. On the DFDC data, their model outperformed the state-of-the-art VGG-19, Inception-ResNet-v2, and Xception Networks. Suganthi et al. [
33] proposed a statistical approach where fisher faces were extracted from texture components using the local binary pattern algorithm. A Deep Belief Network (DBN) could classify the DFFD dataset with 88.9% sensitivity and 93.76% specificity.
Since medical deepfakes are fairly recent, few detection techniques have been used to lessen their impact. On CT-GAN-produced data, Solaiyappan et al. tested numerous machine learning and pre-trained Convolution Neural Networks (CNNs) [
34]. Limited data and model simplicity both had a negative impact on the success of detection. The detection rate of the models was quite low when the experiments were conducted as a multi-class categorization of tampered versus untampered injected and removed nodules. The various pre-trained networks attained a maximum of 80% classification accuracy when considering the DenseNet121 variant. In [
35], we learned a more sophisticated 3-dimensional neural architecture on localized nodules from CT-GAN generated data and could attain a marginal accuracy gain of over 10%. The temporal feature extraction across multiple slices performed by a 3DCNN had more significance than the spatial content learning of individual slices. This led us to think that utilizing Vision Transformers to leverage the attention processes weighing the relevance of each element of the input data separately could replace the feature learning procedures through convolutions [
36].
1.3. Motivation
We opted to research the dermoscopic avenue of medical deepfakes, as this modality is the easiest technique for capturing skin cancer diagnosis data due to easier targeted attacks.
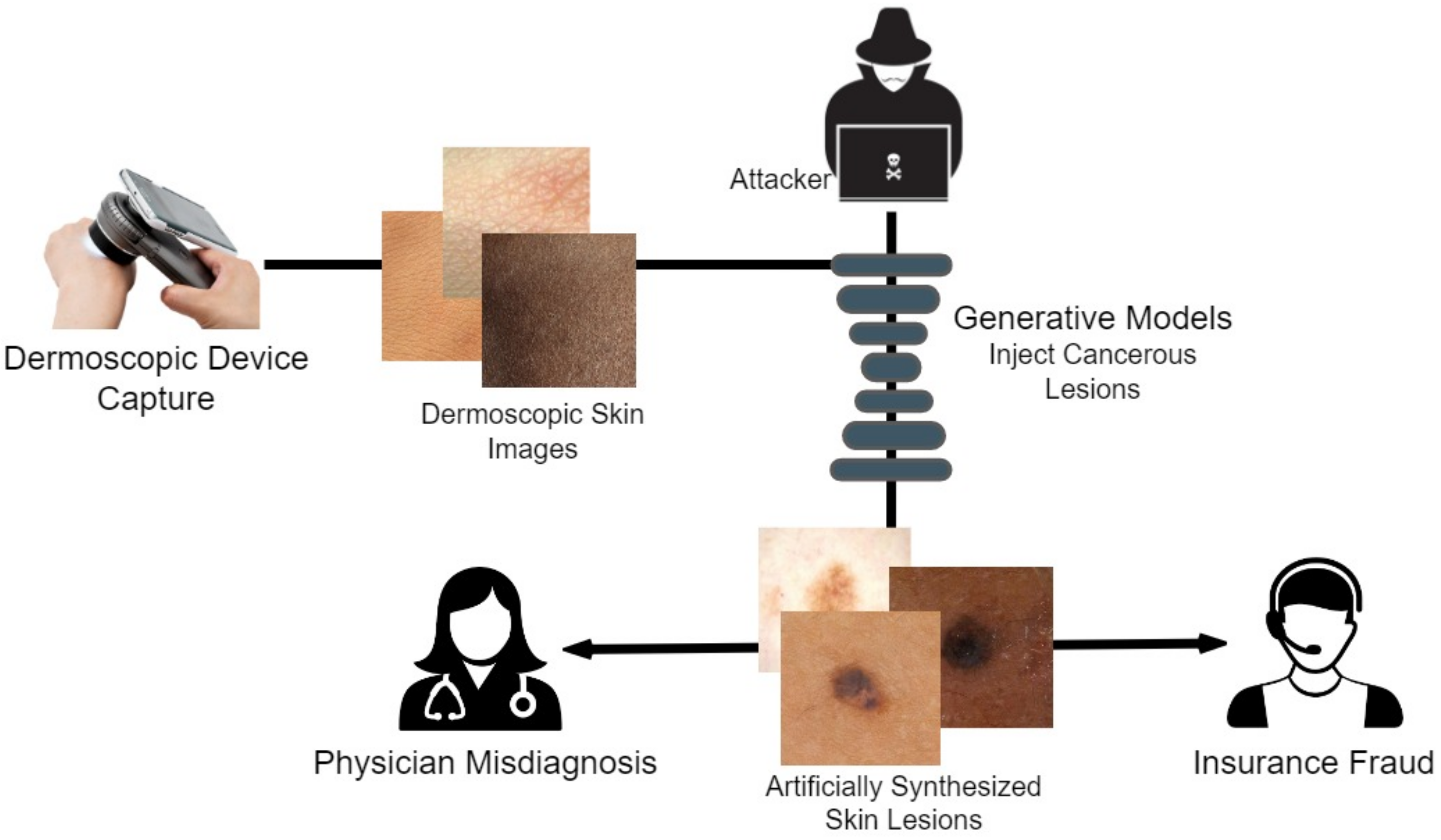
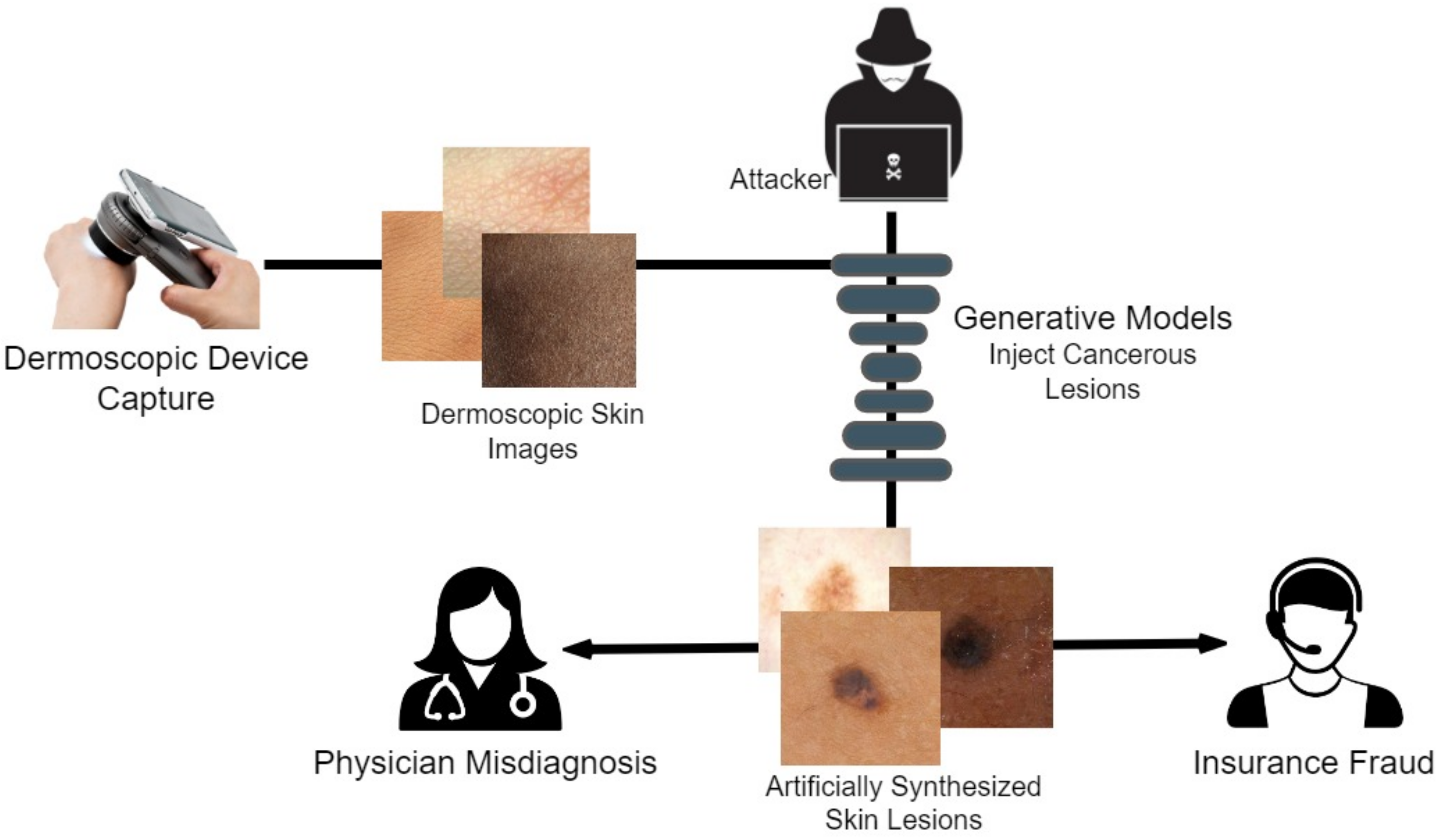
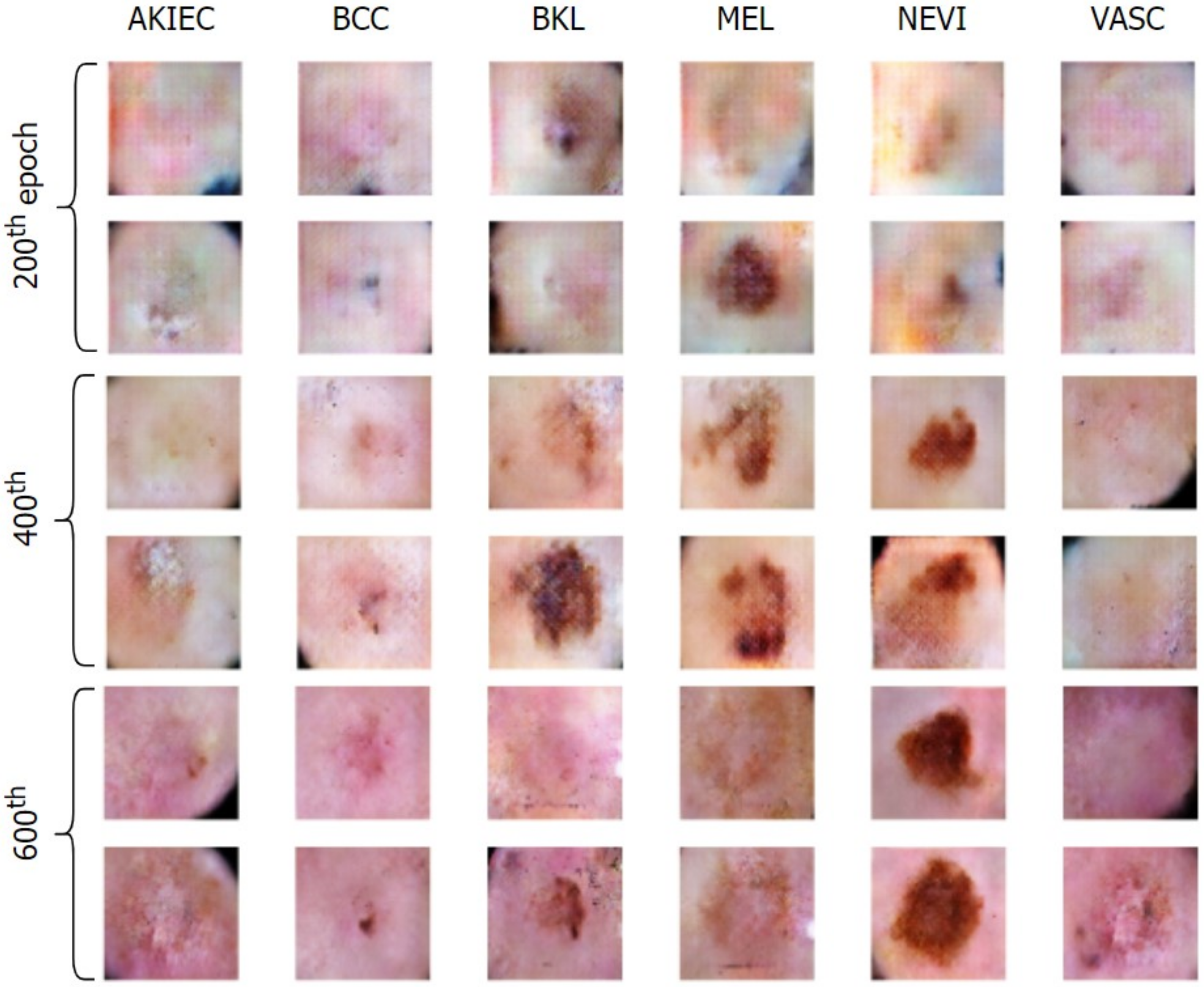
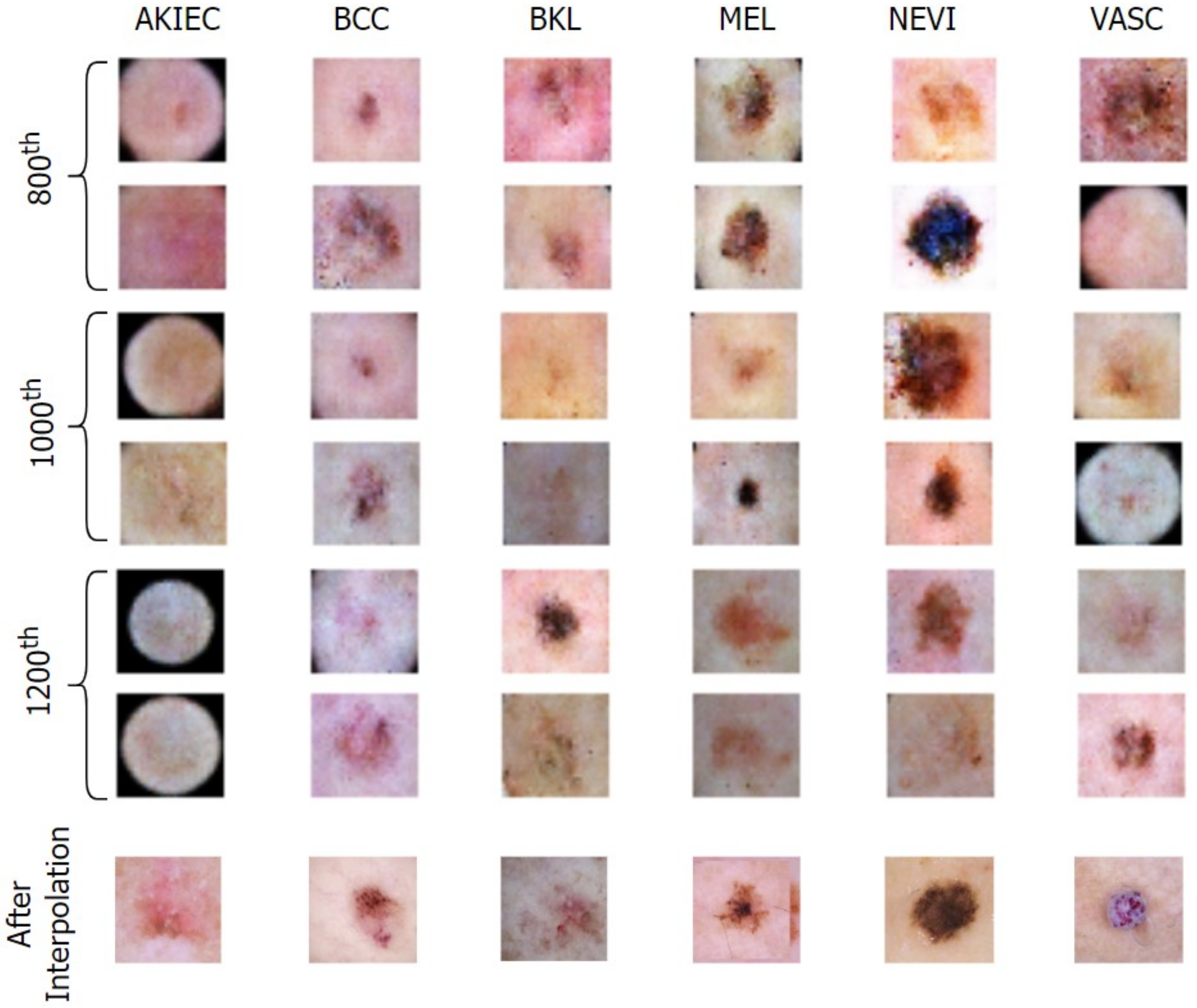
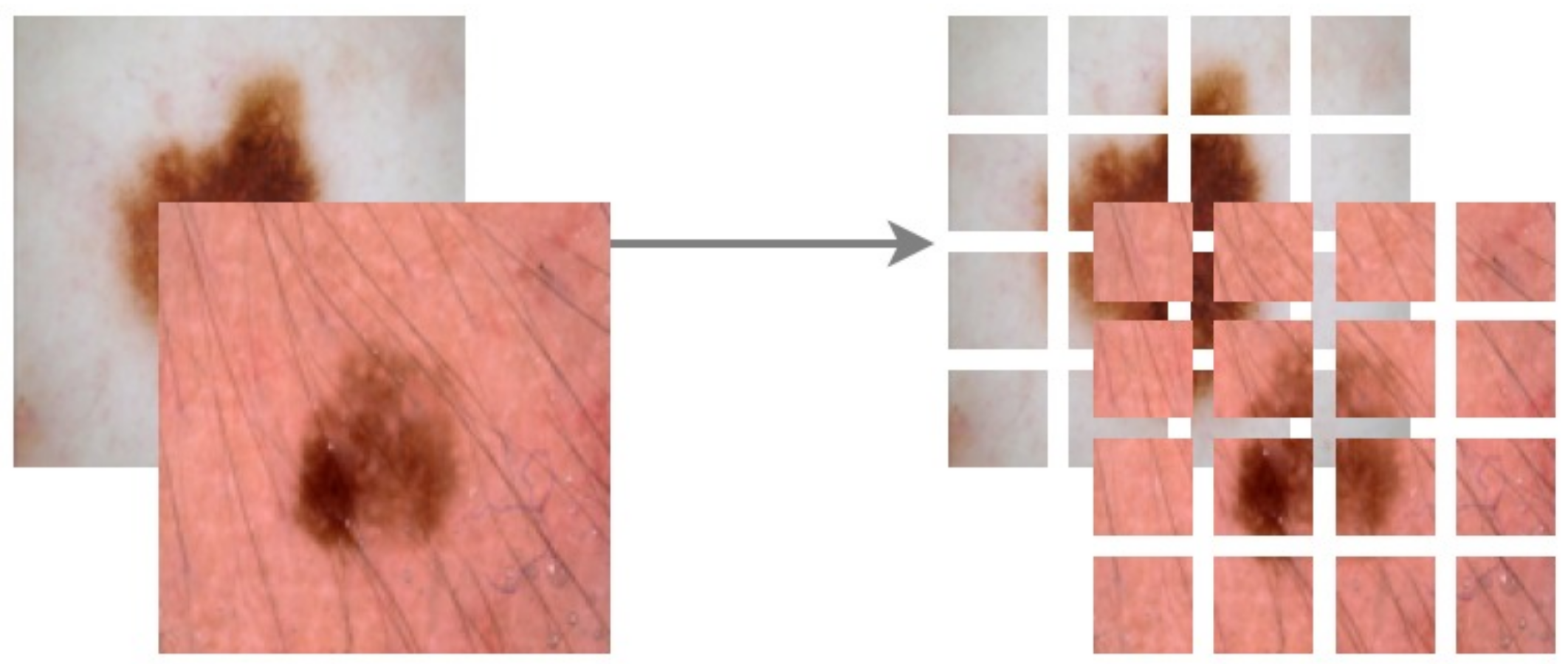
Figure 1 illustrates how an attacker can easily manipulate healthcare and other biomedical imagery. Dermoscopic devices are standard handheld, non-invasive machines capable of capturing high-resolution skin images. Most often, skin-prone diseases are initially diagnosed by a physician from these images. Using a generative framework, a black hat expert could easily maneuver different skin cancers from mere human skin image samples. The generative model could either generate new fake lesions or transform existing non-dangerous tumors into late-stage malignant lesions. The current healthcare system is designed to provide insurance schemes based on a doctor’s diagnosis and biomedical imaging modalities as proof. Consequently, both the physician and the inspection agent at the insurance end are likely to believe the attacker’s fallacy of tampering and manipulating the medical images during the inquiry and diagnostic stages.
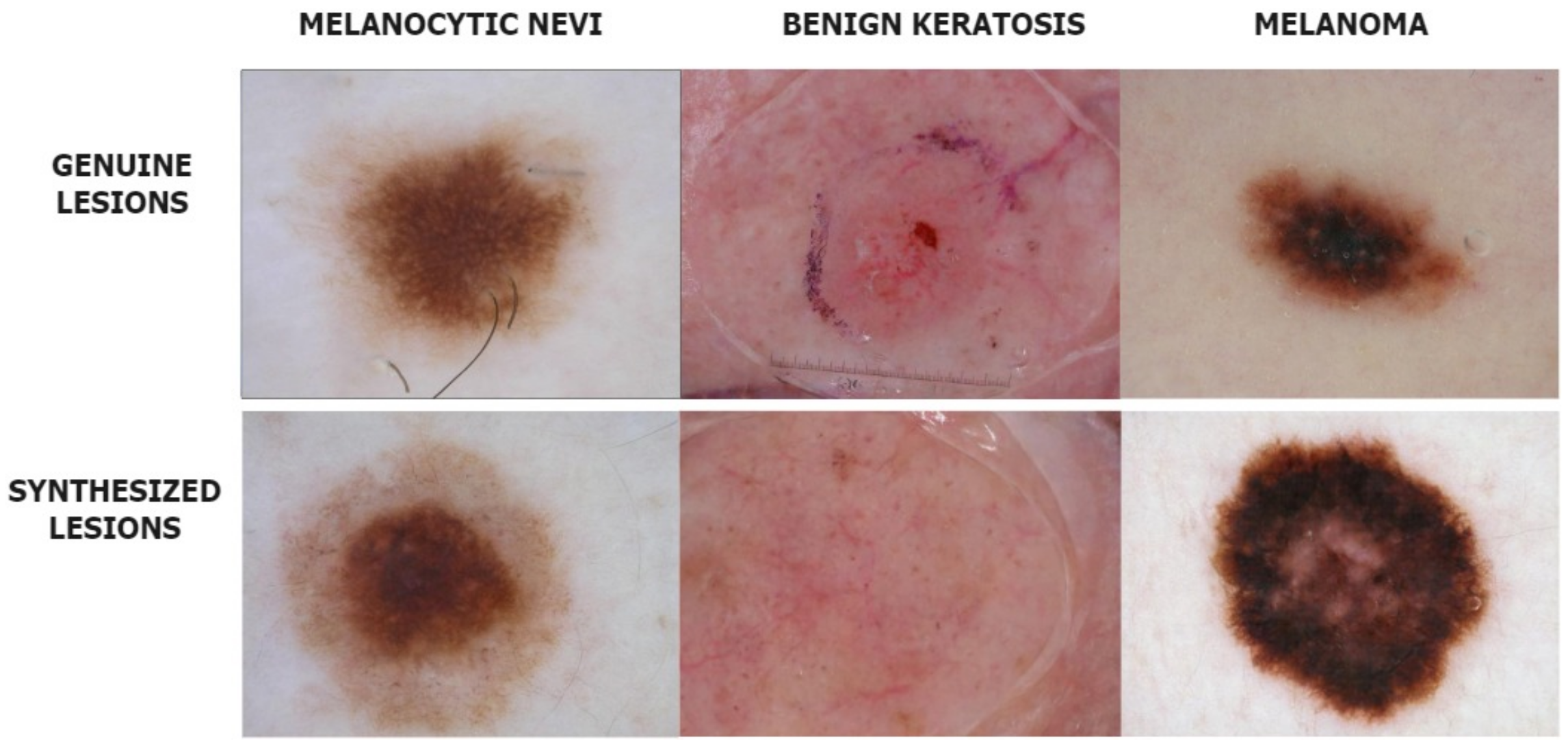
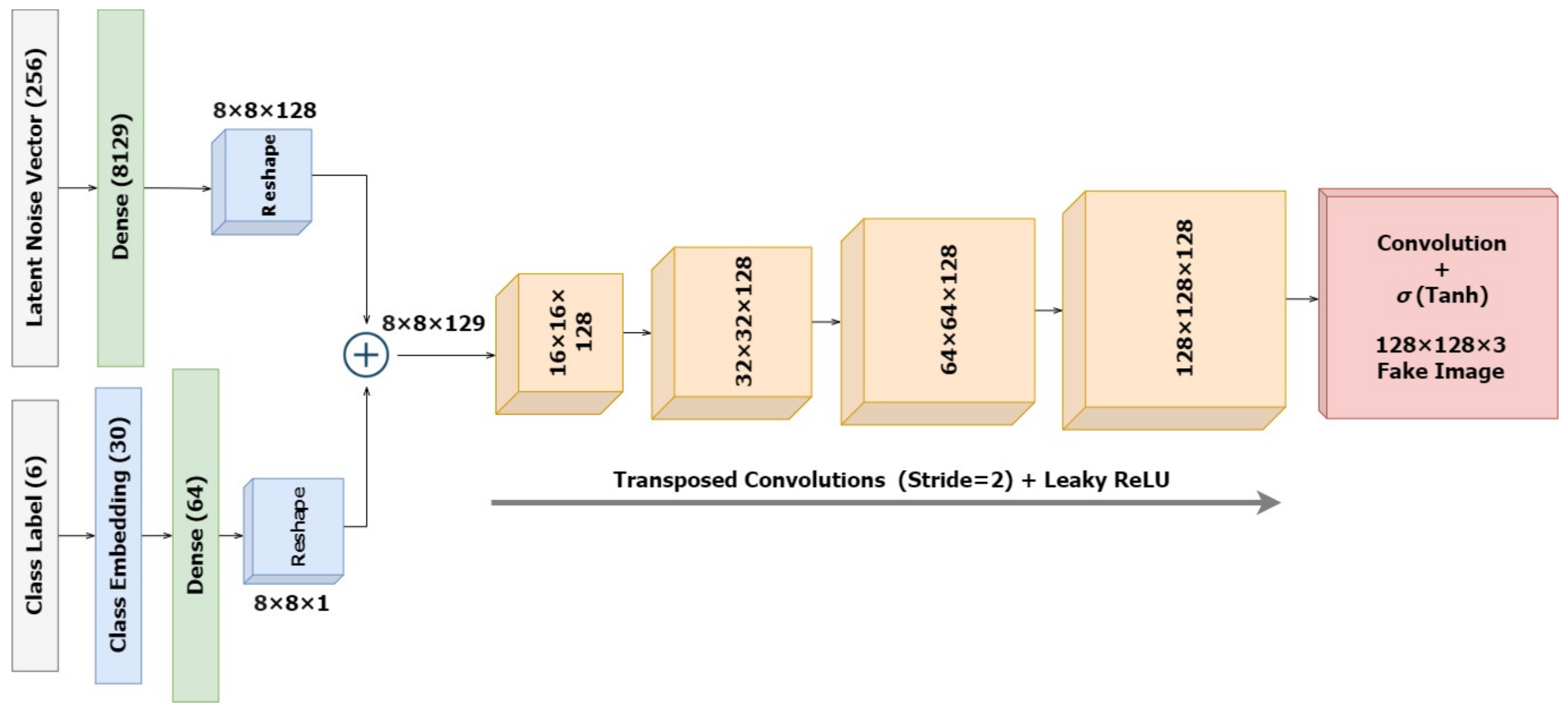
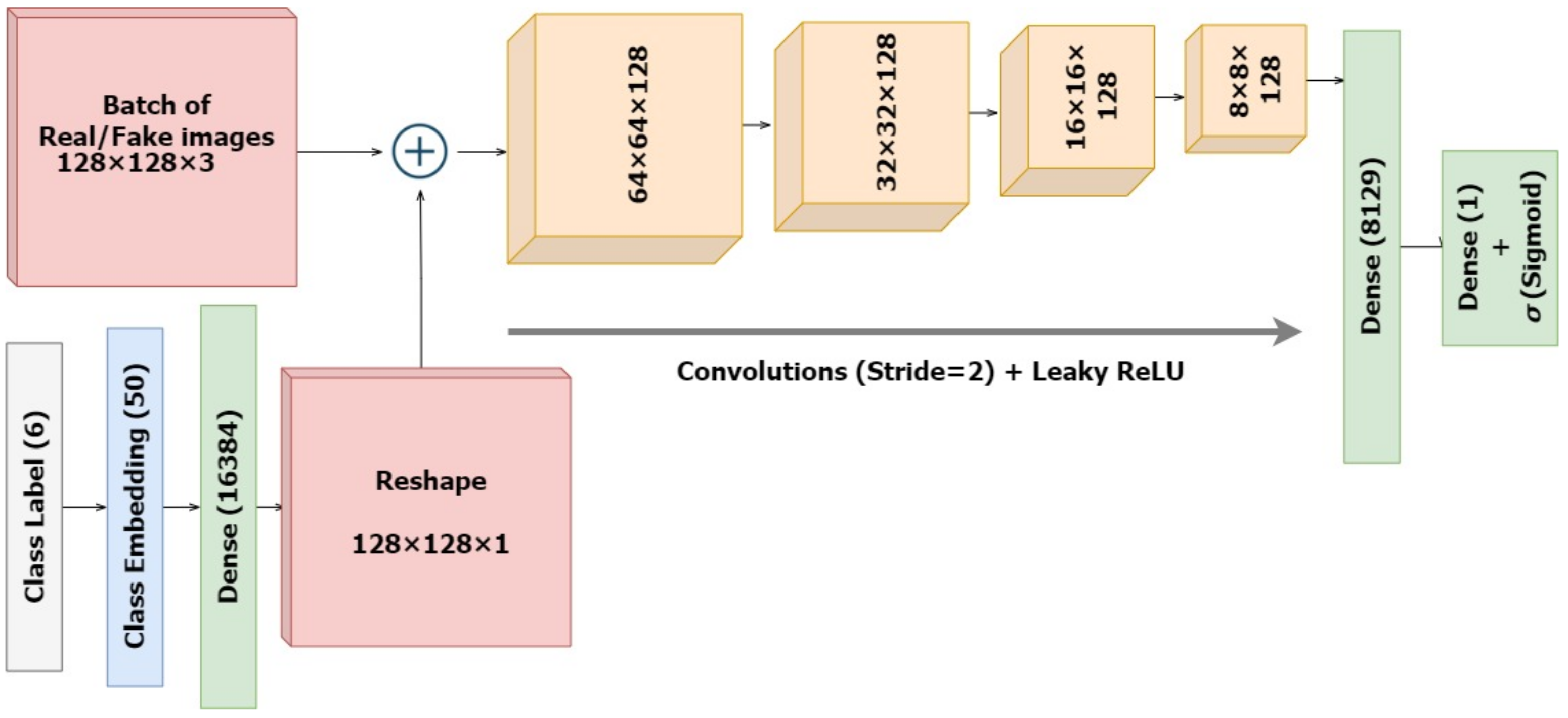
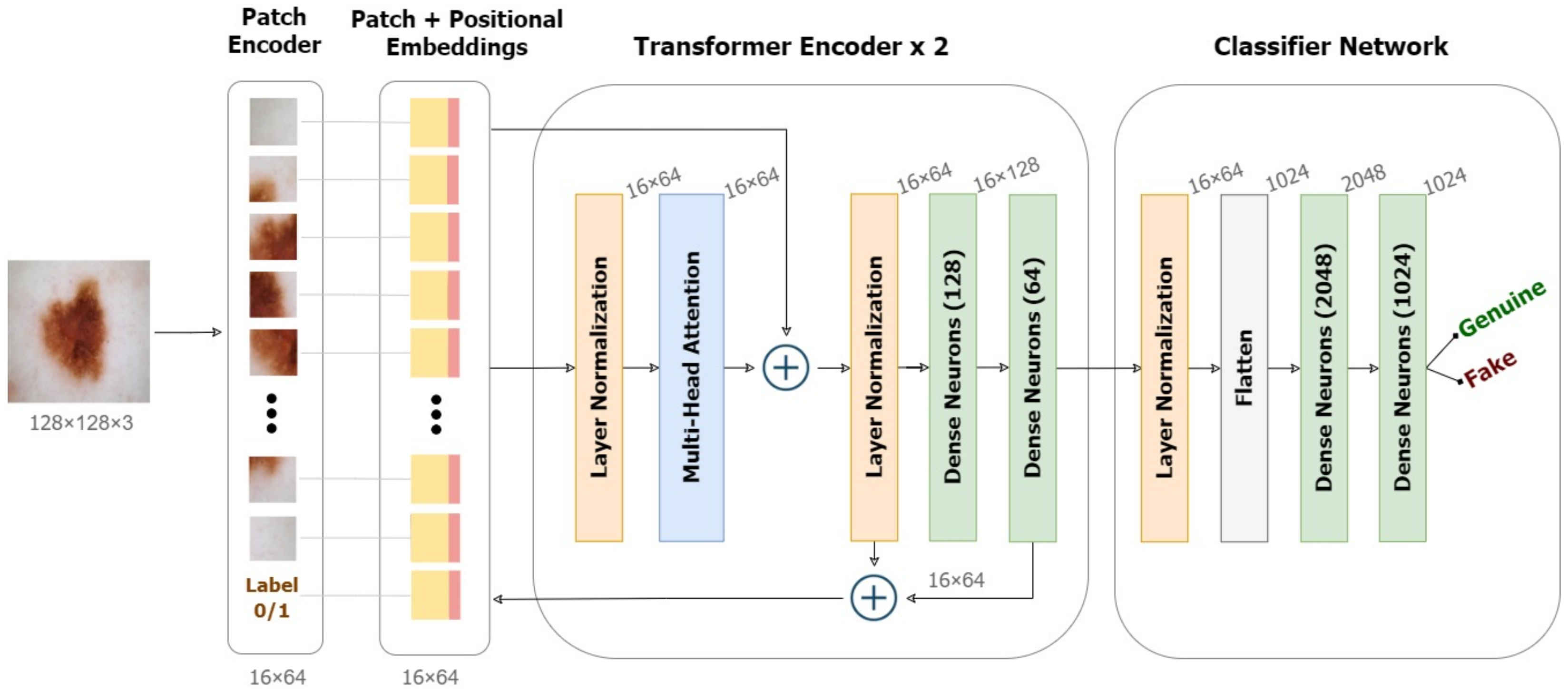
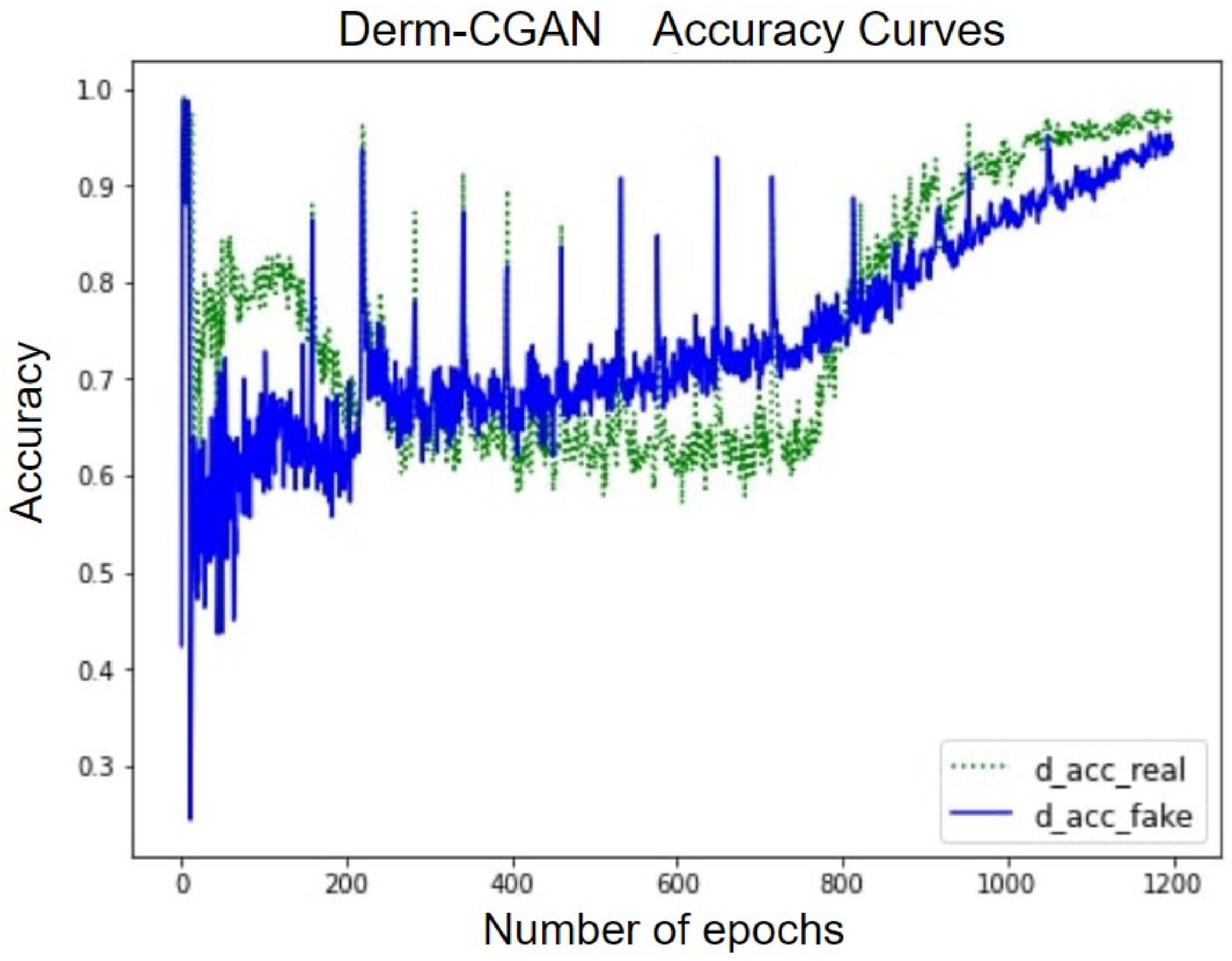
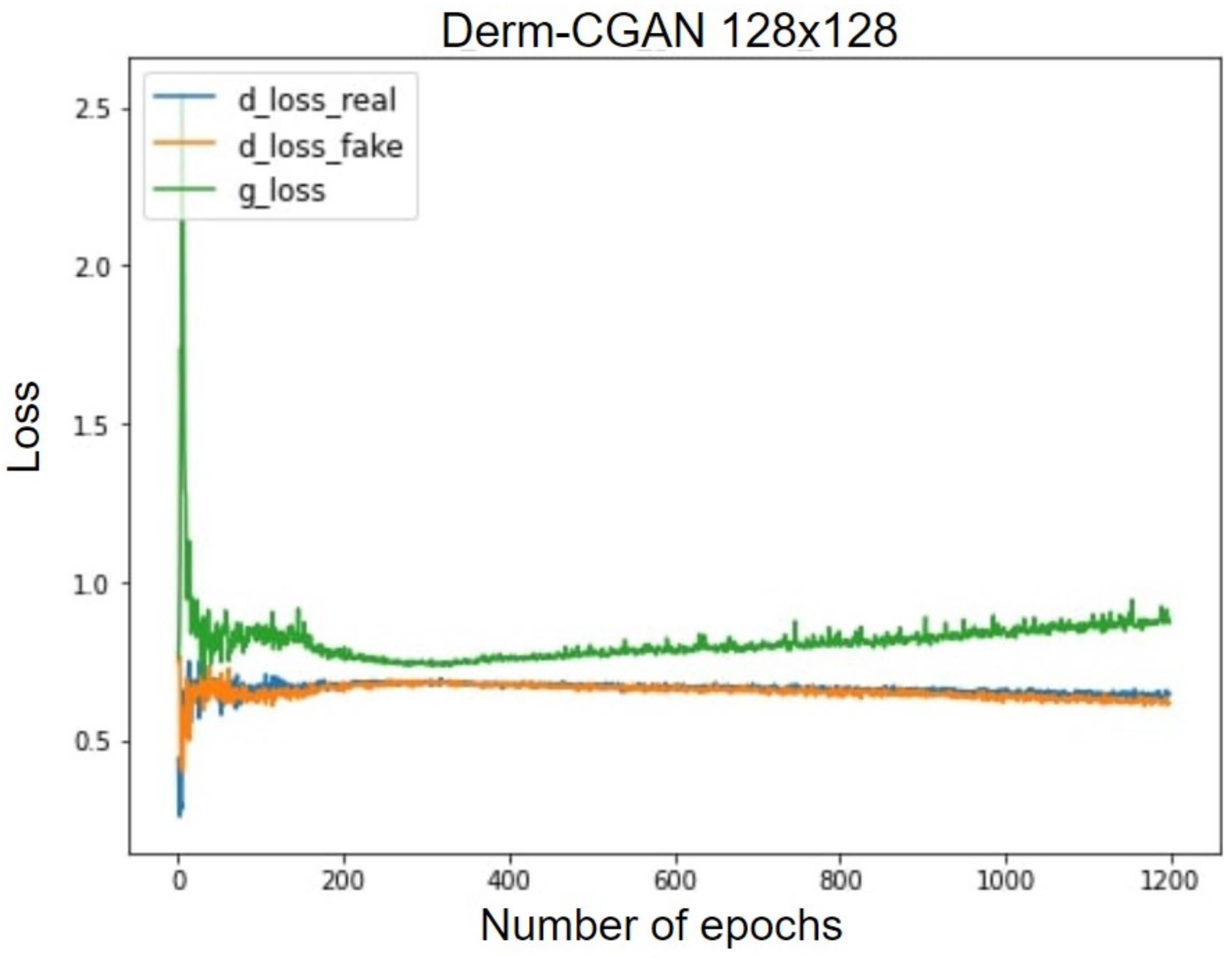
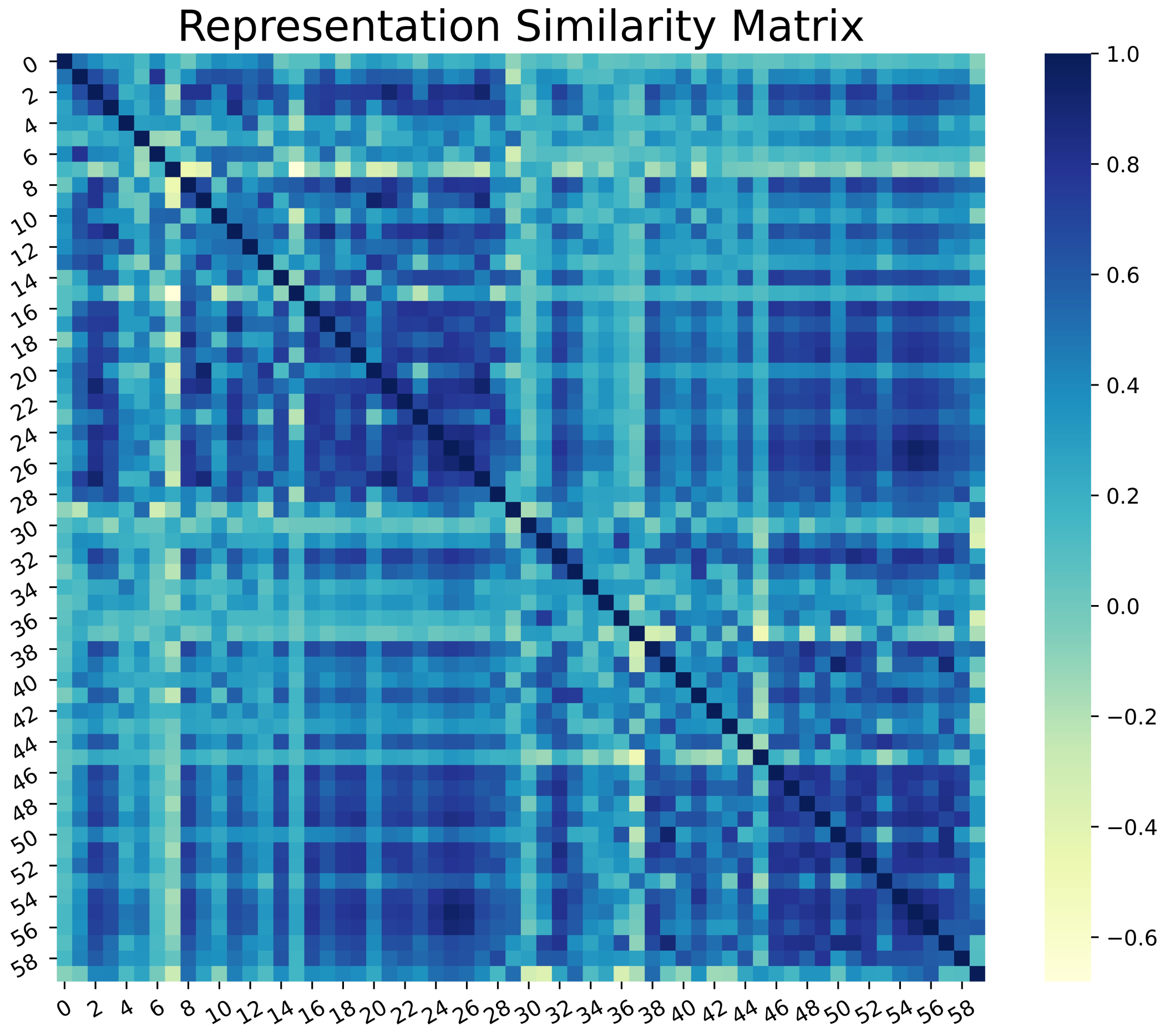
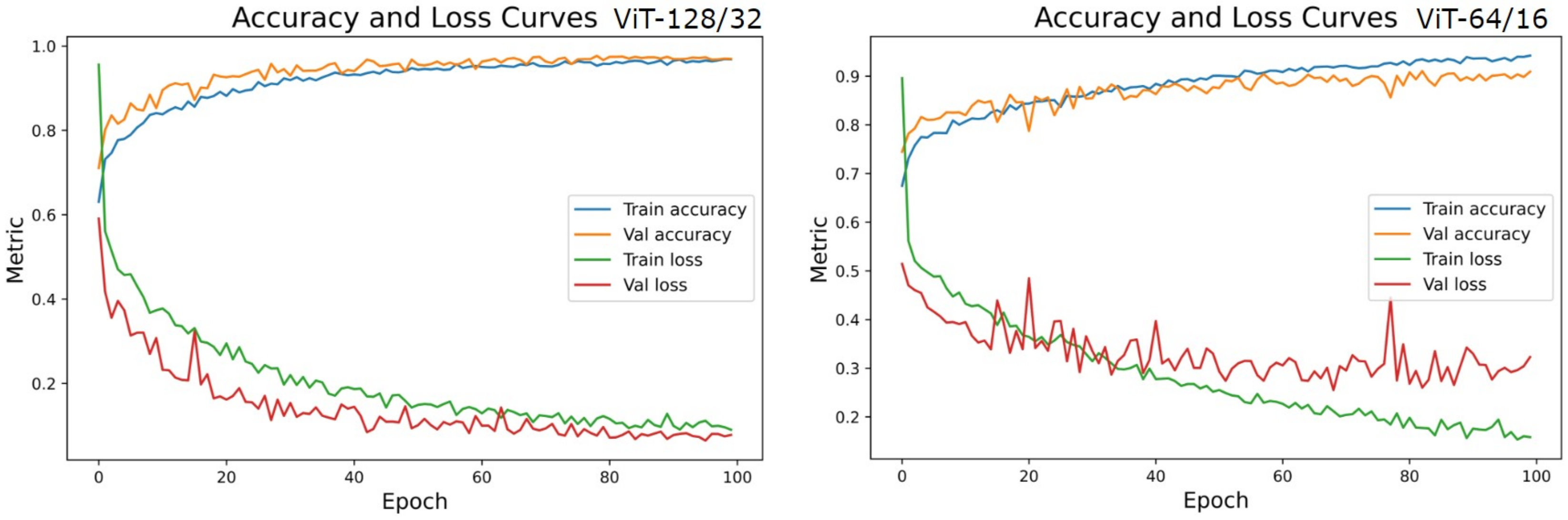
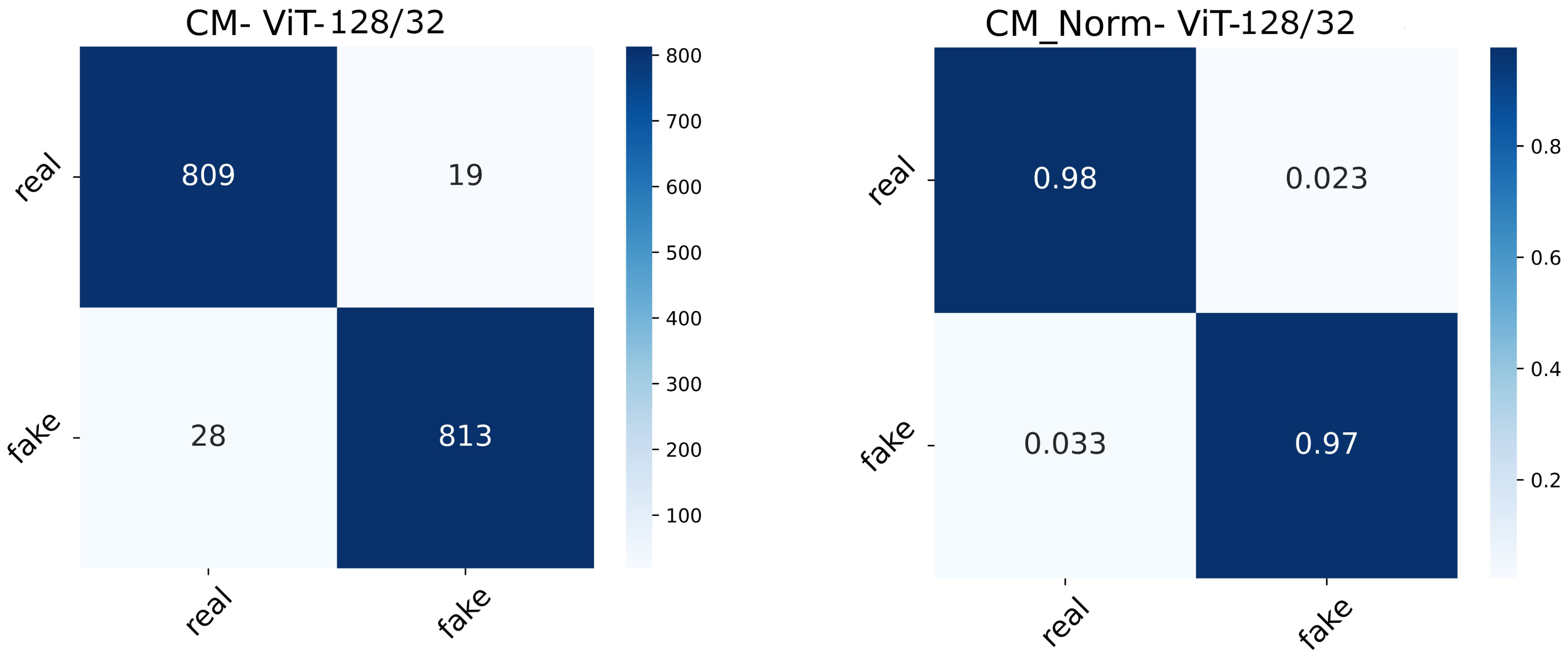
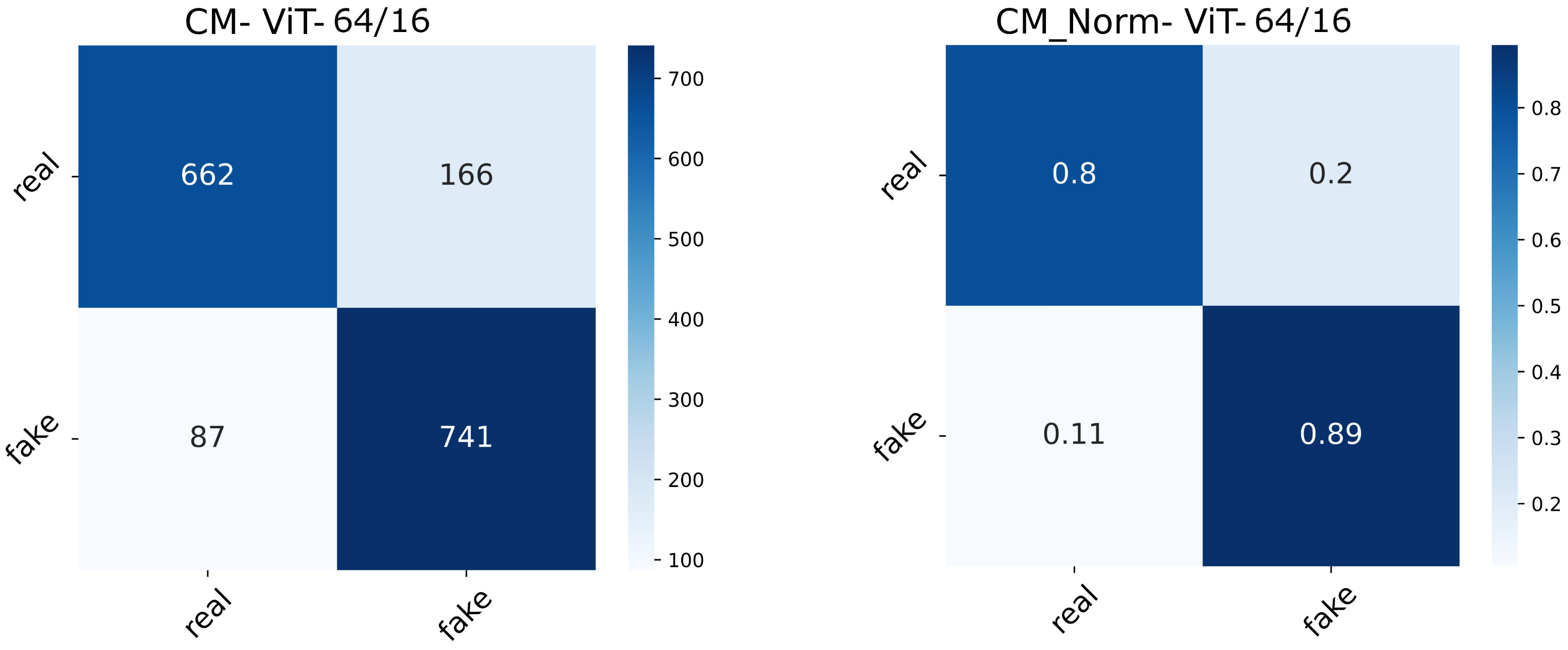
With this in the lead, we propose a modified conditional GAN named Derm-CGAN to generate high-definition dermoscopic images of skin lesions. Analyzing the synthesized data with real cancerous data reveals high resemblance and realism. We compute the Representation Similarity Matrix (RSM) to project the resemblance. Further, the state-of-the-art Vision Transformers (ViT) are explored in the feature learning and categorization of real and fake dermoscopic data. The best-performing ViT configuration was further analyzed by testing on synthesized face images from the DFFD dataset as well as on selected pre-trained networks to consolidate the findings.
The novelty of the research work is contributed as:
Designed a dermatology-conditioned generative adversarial network named Derm-CGAN for the artificial synthesis of dermoscopic images.
A similarity analysis technique is illustrated that compares the realism of deepfakes to genuine data.
Proposed an architecture for dermoscopic deepfake image detection based on a modified vision attention transformer.
Critical analysis has been performed on the detection mechanism in Diverse Fake Face Dataset (DFFD) and state-of-the-art pre-trained networks.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}