2.1. Facial Attractiveness Dataset
Two datasets were used in this study. The first dataset comes from the facial images of patients scanned by 3D imaging in Chang Gung Memorial Hospital from 2016 to 2019. Fifteen doctors attracted 210 facial images. Each pictured face contains fifteen scores.
We averaged all the scores and calculated each picture’s standard deviation based on each picture’s score. Then, based on normal distribution statistics, we initially excluded unqualified pictures based on three times the standard deviation and calculated the average and standard of the score. This is to check whether the scores of the fifteen doctors have too many deviations, so the pictures and scores have no reference value.
Since most of the original pictures are
pixels in size, most of the areas in the pictures are gray or black backgrounds. Suppose that these pictures are directly input to the model training. In that case, it will greatly affect the learning effect of the model and add a lot of unnecessary data. To calculate the amount, first use the program to uniformly cut the background on both sides to retain the middle face, and then manually adjust to retain the least part of the background. According to the face size in the picture, most manually adjusted picture sizes are the same. It falls between
and
. A second screening will make the model more accurate when manually adjusting the image size. For example, in a picture with a high attractiveness score, if there is a blur or a broken image, manually delete the image or fill in the gaps in the middle of the image with color patches of the same color. At the same time, the model learned to manually delete some pictures with blurred scores in different score intervals so that the characteristics between different scores can be more obvious, and there were a total of 189 pictures after the final screening.
Figure 1 is a schematic diagram of the original picture and the processed picture.
Another dataset used in this research is called SCUT-FBP5500, which was proposed by the Human–Computer Intelligent Interaction Laboratory of the South China University of Technology. It is a diversified benchmark dataset for facial beauty prediction. The dataset has a total of 5500 sheets. Frontal face images of pixels. These images have different attributes, such as men and women from different parts of the world, and of different age groups. The 5500 image dataset can be divided into four types. A subset of different races and genders, including 2000 Asian men (AM), 2000 Asian women (AF), 750 European and American men (CM), and 750 European and American women (CF). These 5500 pictures will be randomly shown to 60 people aged 18–27, and the score range is the lowest from 1 to the highest, and 10% of the pictures will appear twice. A second score will be required if the correlation between the two scoring results is less than 0.7. The 3-fold scoring ensures that the score has a reference value, and finally, the average score of all the picture scores is calculated as the final attractiveness score of this picture.
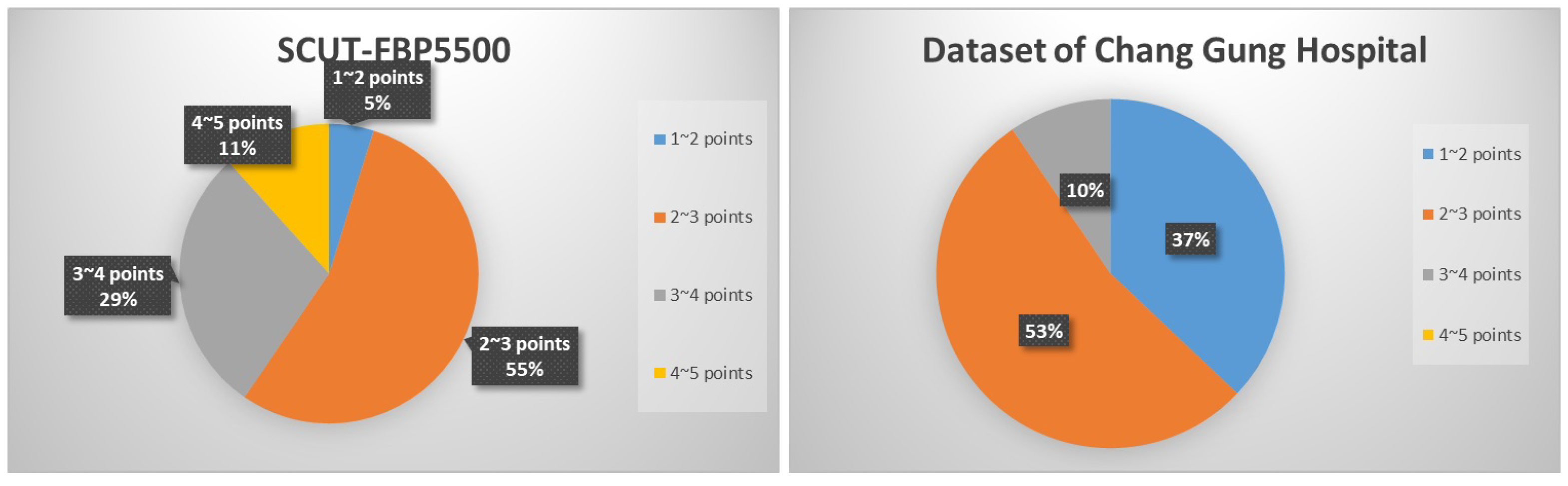
Before conducting experimental research, we first need to analyze the data. When the machine is performing feature learning, it completely relies on the existing dataset information to learn, so the choice of the dataset is very important. The detail of two distribution scores and the number of data are in different sections of the dataset.
a. SCUT-FBP5500 distribution score:
From 1 to 2 points—265;
From 2 to 3 points—3011;
From 3 to 4 points—1582;
From 4 to 5 points—642.
b. Chang Gung Hospital distribution score:
From 1 to 2 points—70;
From 2 to 3 points—101;
From 3 to 4 points—18;
From 4 to 5 points—0.
From
Figure 2, it can be seen that the proportion of the two datasets has more than 50% for 2–3 points. While the SCUT-FBP dataset has 11% of the data in the interval 4–5, provided in Chang Gung Memorial Hospital. The Chang Gung dataset does not have data with the same score. Therefore, we need to manually downgrade the image data with a score higher than 4. This process aims to avoid low-level data transfer to the data in the Chang Gung dataset after the initial training of the model is completed and the weights are frozen. The same issues also happened for the score range of 1–2 points. The SCUT-FBP dataset only accounts for 5%, but Chang Gung Memorial Hospital has 37%. Therefore, we also need to manually downgrade it to avoid the same problems in the transfer model training.
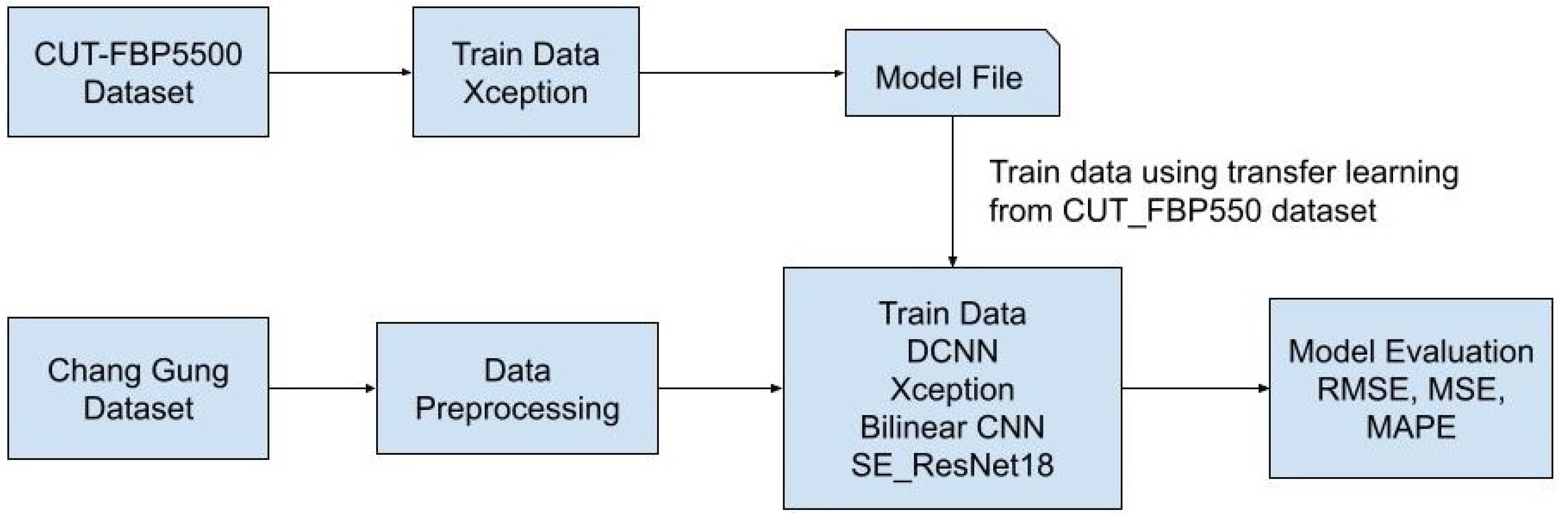
Since the image dataset and its corresponding scores are on different files, if the Python program is to merge the two and input them into the model for reading training, it will take a lot of time to merge the DataFrame. Thus, manually, the picture numbers and their corresponding scores are unified in a txt file.
2.2. Transfer Learning
Transfer learning is an effective technique in computer vision since it makes it possible to quickly construct precise models [
11]. Transfer learning begins with the learned patterns when solving a different problem, instead of starting the learning process from scratch. Doing so can make use of prior knowledge and prevent having to begin from scratch. Transfer learning is typically demonstrated in computer vision by using trained models. A model that has already been trained on a sizable benchmark dataset to address a problem resembling the one we are trying to solve is known as a pre-trained model.
Transfer learning is a machine learning method that transfers the knowledge of the original domain to a new domain [
12]. As such, the domain can achieve good learning results, and we can divide the data used for migration learning into two categories: one is the source data, and the other is the target data. Source data refer to other data and are not directly related to the task to be solved, while target data are data which are directly related to the task. According to whether the purpose of the two samples is the same, the work of transfer learning is divided into transfer learning, direct push transfer learning, and unsupervised transfer learning [
13,
14]. According to the technology used in the transfer learning method, the transfer learning method can be roughly divided into (1) transfer learning based on feature selection; (2) transfer learning based on feature mapping; and (3) weight-based transfer learning.
2.3. Attention Mechanism
The concept of attention mechanism was first proposed in the field of computer vision in the 1990s. The main inspiration comes from the fact that many different objects may appear simultaneously in the human field of vision, but people’s eyes will be more focused on their interests. Areas or important areas automatically blur the unimportant areas to reduce attention to the rest of the area and focus the limited attention on key information, thereby saving resources and quickly obtaining the most effective information [
15]. However, like deep learning, its popularity is limited by hardware computing power and other reasons and gradually fell silent. Until 2014, the Google Mind team used the attention mechanism on the RNN model for image classification [
16]. Subsequently, the attention mechanism was widely used in natural language processing tasks based on neural network models such as RNN/CNN. In 2017, Google published Self-Attention, which has also become an important part of the NLP research field. In 2018, Google again proposed two language models, BERT and GPT, making the attention mechanism a popular research avenue. The attention mechanism can be divided into categories according to the calculated area, structure, and model.
The calculation area of attention can be divided into the three following types:
Soft Attention: This is a relatively common attention method. The weighted probability of all keys is calculated. Each key has a corresponding weight. It is a global calculation method which can also be called Global Attention. This method refers to the content of all keys and then weights them, but the amount of calculation may increase further.
Hard Attention: This method directly locates a certain key, and the other keys are not considered. The probability equivalent to this key is 1, and the remaining keys are all 0, or part of all keys is selected for use in a set selection method.
Local Attention: This method is a compromise between the two above methods. An area is calculated first, and the Hard Attention method is used to locate a certain point. With this point as the center, a window area can be obtained in this small area. Then, the soft method is used to calculate attention.
They use different models:
CNN + Attention: The convolution operation of CNN can extract important features, but the convolution perception field of CNN is partial, and it is necessary to expand the field of view by superimposing multi-layer convolution areas. In addition, max pooling directly extracts the feature with the largest value, similarly to the hard attention method, and directly selects a feature. There are three ways to use attention on CNN: (1) Attention is performed before the convolutional layer, and attention is performed on the two input sequence vectors at the same time, and the feature vector is calculated, and then spliced into the original vector as the input of the convolutional layer. (2) Perform attention after the convolutional layer as the input to the pooling layer. (3) Perform attention on the pooling layer instead of max pooling.
LSTM + Attention: LSTM usually needs to obtain a vector and then make predictions based on the problem. (1) Directly using the last hidden state, this method may lose some shallow information, making it difficult for the model to understand the full text. (2) Perform a weighted average of the hidden state under all steps. (3) Attention mechanism weights the hidden state of all steps, and focuses on the text’s more important hidden state messages. The performance of this method is better than the previous two, and it is convenient to observe which steps are important visually. Still, it is more prone to overfitting and increases the amount of calculation, so additional attention is required.
2.5. Related Works
Before conducting this research, we read the research results in the fields related to the research topic, including theoretical foundations, experimental ideas, implementation processes, etc. These results greatly helped in enabling us to have clearer concepts, avoid many difficulties, and smoothly obtain better research results smoothly.
There have been many studies on facial attractiveness since the 1990s. At first, some standards were formulated based on the ratio of facial features, such as the golden ratio (1:0618) [
18], the facial rule of thirds [
19], and the new golden ratio [
20], and so on. The aforementioned standard ratios evaluate facial attractiveness by using the correlation between the various parts of the face. According to the research of Holland et al., [
21], the golden ratio can be applied to evaluating plastic surgery. A universal standard for strength. According to past research, [
22,
23], it is feasible to use machine learning technology to analyze facial attractiveness based on facial features using standard ratio rules to train models to evaluate facial attractiveness. The experimental results show a significant correlation between the estimated score of the model trained on the standard scale and the score of human subjects. However, since the machine learning model first needs to label the data, it will require higher labor and time costs. Rothe et al. [
24] built a convolutional neural network model to learn facial attractiveness from thousands of pictures and applied it to facial beauty recommendations. According to the experimental results, the deep learning model can learn more features that help evaluate facial attractiveness than manually labeled data and features. Sunitha et al. [
25] distinguished and classified ethnicity based on facial photos. The feature extractor in the proposed models is an exception network. The feature reduction approach uses the principal component analysis (PCA) technique to overcome the “curse of dimensionality” because the retrieved features are high-dimensional. Additionally, the process of classifying people by their ethnicity is carried out using an ideal kernel extreme learning machine (KELM), with the KELM model’s parameters being tuned using the glow worm swarm optimization (GSO) method.
According to the research of Jinsheng Ji [
26] and others, they proposed a new multi-level attention model (MLA-CNN) to classify fine-grained images, and first select feature maps of three sizes through the visual attention mechanism. After entering the model for identification and making final predictions from different feature maps, the experimental results are better than those of other methods in the three challenging fine-grained classification datasets. In the publication of Ting Sun et al. [
27], a fine classification system based on CNN was proposed by extracting and interpreting the hierarchical hidden layer features learned by CNN. When evaluating the Caltech-UCSD Birds-200-2011, FGVC-Aircraft car, and Stanford dog datasets, this method uses only labels for training, and no other labeling information can be used for training and testing, and it reaches 83.6% accuracy. In the publication by Qiule Sun et al. [
28], they proposed an optimized architecture of a bilinear CNN model. Bilinear CNN performs outer product combinations through the output of the convolutional layer of two CNN models. Nonetheless, generally, bilinear CNN cannot use the inherent information in different convolutional layers, so they proposed a super-layer bilinear pooling CNN (HLBP). In the final test, the accuracy rate can be increased from 88.6% to 91.4%. According to the above conclusions, there are more references for us to choose models from in the experiment.
According to the publication by Zhang et al. [
29,
30], the degree of facial symmetry is judged through transfer learning, the contour map of the face is used as training data, and the system can be constructed to classify and score the symmetry of the face. Through the transfer of the Xception model, the classification can achieve an accuracy of 90.6%. In the publication of Niu et al. [
31], they proposed a new end-to-end fine-grained image classification structure. They added an attention shift mechanism (AS-DNN), automatically locating distinguishable regions and iteratively encoding semantic relevance. According to experimental results, AS-DNN outperforms CNN-based weakly supervised or strongly supervised FGVC algorithms on multiple fine-grained datasets, thus obtaining the best results. Through the visualization of the attention area, this method can locate the area in a complex background. Through the above papers, we need to pay attention to and discuss the use of transfer learning and the transfer of weights and provide references for constructing our system and webpage.
Based on recent research, we found that the use of transfer learning is limited to enhancing the performance of the models in terms of facial recognition models. Therefore, we experimented with the transfer learning methods and fine-grained image classification on our model.
2.7. Data Preprocessing
Every picture must contain noise, but only the difference in severity, such as the noise heard by traditional radio walkie-talkies and radios; or the black and white flickering snowflakes seen on old TVs, are all interfered with by noise. In the field of image processing, noise can be understood as a random change in gray value caused by one or a combination of multiple reasons, such as the current angle of light and shadow, intensity, etc., and the noise may not be directly visible to the naked eye. To distinguish from the picture, picture filtering technology will need to be used at this time. The filter is usually a square matrix with odd sides called mask or kernel. Similarly to the main concept and convolution operation, the filter is calculated with each picture pixel. The filter can be divided into two types according to different application functions:
Smoothing filter: used to blur and remove noise, including a low-pass filter and Gaussian filter.
Sharpening filter: strengthen the edge position of the object, including the high pass filter (high pass filter).
In this experiment, in addition to the use of filters for preprocessing, according to Zhang et al.’s experiment, the brightness and contrast of the images of the Chang Gung Memorial Hospital were adjusted. Using the original dataset for direct training may lead to model learning because the features are not clear enough. Poor or over-fitting, so we will make four different datasets for transfer training and test the model’s performance. The first is without any filtering, only the cropped face images, the second one is the picture processed by the Gaussian filter, the third is the picture after brightness and contrast enhancement, and the fourth is a combination of the second and third methods. Gaussian filtering is performed before brightness and contrast enhancement, as can be seen in dataset in
Figure 5.
2.10. Evaluation Model
After completing the construction and training of the machine learning model, we need to evaluate the model to understand its effectiveness. There are many ways to evaluate the model. The simple split method mentioned in the previous section is one of them. It is an evaluation method, but only knowing the predicted and real values cannot intuitively reach an understanding of how the model performs. Therefore, we need to have several model evaluation indicators for comparison.
In the second chapter, we mentioned some model evaluation indicators. This study uses RMSE as the loss function when training the model. This will calculate the error value of the model’s training results at each step and assist in learning the model. In the final evaluation of the model, we chose to use MAPE, MAE, and RMSE as the indicators for model evaluation in this study, and use the above three indicators to evaluate the predictive effect of the model.
MAPE is one of the most commonly used evaluation indicators. It can be seen from the following formula that the average absolute percentage error (
) is an error obtained by subtracting the actual value (
) from the predicted value (
). Then, the error value is divided by the actual value, so when the actual value is low, and the error is large, it will greatly impact the value of
. The following is the formula of
:
Mean absolute error (
) is a commonly used predictive evaluation index, but it has a disadvantage in that it does not consider the average of the actual value. Although an evaluation value can be obtained after calculation, there is no way to know the model. The pros and cons can only be compared by comparison. The following is the formula of
:
The root mean square error (
) measures the error between the observed and true values. The calculation method does not consider the value of the actual value. Therefore, as long as there is a large error in the prediction result, the value of RMSE will be very poor, and the following formula of
is:
The mean square error (
) is the most common indicator in regression problems because it is calculated faster. It measures the average of the squared difference between the predicted value and the actual value. The following is the formula for
:
where
n = number of times the summation iteration happens and
= actual value
= forecast value.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}