1. Introduction
The Coronavirus 2019 (COVID-19) pandemic adversely affected people’s daily lives as well as the economies of countries all over the world. The psychosocial environment was altered significantly because of economic shutdowns, isolation, and social distancing, among other restrictions, and these alterations had a considerable negative impact on countries. Families, young people, and children were particularly hard hit. Due to the requirements for social distancing, there was less opportunity for people to participate in leisure activities, schools and kindergartens were shut down, and fewer opportunities existed for people to interact with one another socially. In contrast, parents were overburdened with work, helping their children with schoolwork, and many of them were working from their homes. In addition to the challenges caused by the economic collapse, unemployment had a substantial influence on the mental health of individuals. In light of the above, it is important to accurately predict COVID-19 data and come up with a plan for the next wave of the pandemic in order to ameliorate the public’s losses. With the help of machine learning tools, we may be able to achieve an accurate forecast for COVID-19 and formulate strategies before confronting the challenges that may arise during the next phase of the pandemic. This, in turn, may lead to a healthy economy for the nation.
Machine learning (ML) is a branch of artificial intelligence that studies and develops ways for computers to learn on their own. ML has been successful in many areas, such as computer vision, detecting fraud, online advertising, automatic driving, and robotics [
1]. The success of ML applications in fields, such as treatment, disease diagnosis, patient monitoring, epidemiology, and drug discovery, among others, makes it possible to predict the potential and influence of ML tools in designing and implementing new and better solutions in these areas [
2,
3]. For instance, Ref. [
4] reviewed the significance of using drones, the Internet of Things, artificial intelligence, and blockchain, among other emerging technologies, to combat the pandemic. Similarly, in [
5], blockchain is used to propose a method that circumvents the manipulation of information, such as COVID-19 test results.
One of the areas where ML algorithms have implications is the field of health. ML has inspired numerous researchers to approach the study of COVID-19 using a set of ML tools. COVID-19 is an infectious virus that spreads easily and belongs to the family of coronaviruses. The illness produces flu-like signs and symptoms, such as coughing, fever, exhaustion, and shortness of breath. The origin of the virus is still a matter of debate. According to genomic analyses [
1], however, this virus is part of the bat- and rodent-hosting coronavirus family and is therefore classified as a member of the Beta-CoV (Corona Virus) genus group. Variants of the virus, including Delta and Omicron, have been responsible for various waves (high peaks) of infections and fatalities across the globe [
6]. The Omicron variant, which is considered to be more transmissible but less lethal, was detected in 61.5% of women who reported infections. As of 3 April 2022, more than 491 million confirmed cases and more than 6.1 million deaths had been reported as part of the current COVID-19 pandemic [
7,
8]. Additionally, it was stated that the pandemic might be over by 2022 and fully under control by 2024 [
9]. The scientific community is developing techniques, vaccines, and procedures utilizing various ICT-based technologies and investigating problems to enhance the performance of ML algorithms for survival analysis studies.
Nowadays, time series methods are widely used in statistics, medicine, health science, financial mathematics, pattern recognition, communications engineering, astronomy, and many other fields of applied science and economics that involve time-based measurements. Time series models are an important part of forecasting in the medical field because they have their own unique properties [
10]. For example, Ref. [
11] used the autoregressive integrated moving average model (ARIMA) to predict the number of COVID-19 deaths and recoveries in Pakistan. The authors in [
12] predict the future spread of COVID-19 by exploiting lead–lag effects identified in different countries. Specifically, they first determine the past relationships between nations with the help of dynamic time loops. The method presented applies to confirmed coronavirus cases from 1 January 2020 to 28 March 2020. The results show that China leads all other countries in the range of 29 days for South Korea and 44 days for the United States. Ref. [
13] forecasted the epidemic peak of COVID-19 in Turkey, Brazil, and South Africa using an age-structured SEIR system. Some researchers predicted the continuation of COVID-19 using the exponential smoothing method. For example, Ref. [
14] explored the development of informational efficacy in cryptocurrency and international stock markets before and during the pandemic caused by COVID-19. They found that the crypto markets were more unstable during the COVID-19 pandemic than international stock markets. Thus, investing in digital assets during pandemic times might be riskier.
Few authors used machine learning models for forecasting COVID-19 [
15,
16,
17,
18]. The work [
19] investigated the spread of COVID-19 using the case of Malaysia and scrutinized its linkage with some external factors, e.g., inadequate medical resources and incorrect diagnosis problems. They used an epidemiological model and a dynamical systems technique and observed that this might misrepresent the evaluation of the severity of COVID-19 under complexities. Ref. [
20] discusses a comprehensive review of studies applying deep learning (DL) models for the diagnosis of COVID-19 and lung segmentation. In addition, an overview of work on predicting coronavirus prevalence in different parts of the world with DL is presented. Finally, challenges in detecting COVID-19 using DL techniques and directions for future research are discussed. Based on the spreading behavior of COVID-19 in the population, Ref. [
21] estimated three novel quarantine epidemic models. They found that isolation at home and quarantine in hospitals are the two most effective control strategies under the current circumstances when the disease has no known available treatment. In the work [
22], using positive cases over 50 days of disease progression for Pakistan, the authors analyzed the graphical trend and forecasted the behavior of disease progression through exponential growth for the next 30 days. They assumed different possible trajectories and projected an estimated 20k–456k positive cases within 80 days of disease spread in Pakistan.
Yaqoob et al. [
23] introduced two-dimensional reduction procedures, feature extraction, and feature selection, as well as a systematic comparison of various dimension reduction procedures for the analysis of high-dimensional gene expression biomedical data. This paper can assist researchers in selecting the most efficient algorithm for cancer classification and prognosis in order to analyze high-dimensional biomedical data satisfactorily.
The proposed technique and support vector classification model beat the other models in terms of accuracy, whereas deep learning along with the proposed optimization approach beat the random forest model with 99.71% versus 98.33% performance [
24]. Sagu et al. [
25] introduced new dual metaheuristic optimization algorithms for adjusting the weights of DL models. Using DL may assist in the unmasking and prevention of cyberattacks. In addition, dual hybrid DL classifiers, i.e., convolutional neural network + deep belief network and bidirectional long short-term memory + gated recurrent network, were devised and tuned utilizing the previously proposed optimization algorithms, resulting in improved model accuracy. Iftikhar et al. [
26] conducted a study using the chronic kidney disease dataset and attempted a comparison of various machine-learning techniques. Results show that in all three scenarios, the SVM-LAP model is superior to rival approaches.
1.1. An Overview of the COVID-19 Pandemic
COVID-19 is an infectious disease that is spreading rapidly in populated areas. The World Health Organization declared COVID-19 a global pandemic that has affected at least 99% of the countries in the world, first identified in the city of Wuhan, Hubei Province of China [
27]. The humanitarian costs of the COVID-19 outbreak have been rising since 31 December 2019, as it affected more than 10,710,005 people and resulted in a death count of 517,877 through 3 July 2020 globally [
28]. The countries that share borders with Pakistan were infected by COVID-19, including Iran and China, which were the major influencing factors for Pakistanis. The first two cases were confirmed on 26 February 2020 in Islamabad and Karachi [
29]. Due to the weak healthcare system of the country, many people were affected, and careless public attitudes and mega shopping made the coming days worst. On 13 March, the government of Pakistan imposed a complete lockdown on the whole country. In the continuation of the lockdown, authorities took the initial steps to reduce the spread of the virus: canceling conferences to disrupt supply chains, imposing travel restrictions, closing borders, canceling flights, and closing shopping malls, schools, colleges, and universities, To raise awareness, different TV programs, commercials, and advertisements were organized, and face masks and sanitizers were used by everyone [
30]. After the partial lifting of the lockdown on 15 April 2020 and further relaxation on 12 May 2020, the number of cases increased dramatically. During May, more than fifty thousand new cases were reported. The rise did not stop there, and the month of June proved to be worse. The total number of cases and confirmed deaths in the country as of 3 July 2020, was 198,883 and 4035, respectively. Sindh reported the highest number of cases, which was 76,318, followed by Punjab at 72,880. At the same time, Punjab had the highest number of deaths in the country, with 1656, followed by Sindh with 1205 [
31]. A continuous struggle is required to reduce the spread of COVID-19 so that the healthcare sector can deal with COVID-19 patients in the future [
32].
Due to the mutated nature of the virus, the situation has become graver as little is known about the cure, and the probable timeline of this disease remains highly uncertain. Hence, forecasting for the short-term is immensely important in finding a clue for predicting the flattening of curves and the revival of routine social and economic life [
33,
34]. Statistical models using evidence from real-world data can help predict the location, timing, and size of outbreaks, allowing governments to allocate resources more effectively, conduct scenario and signal analysis, and determine policy approaches. Epidemiological tools are applied to limit the scope and spread of outbreaks; however, these approaches are sensitive to the underlying assumptions, and their impact varies [
35,
36]. It is essential to ensure oversight by checking assumptions in modeling and ensuring the veracity, reliability, and accountabilities these tools use to address bias and other potential harms. This work attempts to look at the projections for COVID-19 infections in Pakistan using several univariate time series methods along with an artificial neural network (ANN) approach.
1.2. Contribution of the Study
This study contributes to the literature on forecasting COVID-19 in several ways: The study considers two kinds of tools: parametric and non-parametric, including an artificial neural network. In a similar way, our study uses three kinds of data on COVID-19, i.e., confirmed cases, confirmed deaths, and recovered cases in Pakistan. Third, the study compares parametric and non-parametric techniques, including ANN, statistically as well as graphically and selects the best technique. The best technique is then used for future forecasting of the confirmed, deceased, and recovered cases.
1.3. Organization of the Study
The rest of the article is organized as follows:
Section 2 describes the materials and methods.
Section 3 discusses training, testing, and prediction model results and discusses future forecasts. Finally,
Section 4 contains conclusions, limitations, and future directions.
3. Experimental Results and Discussion
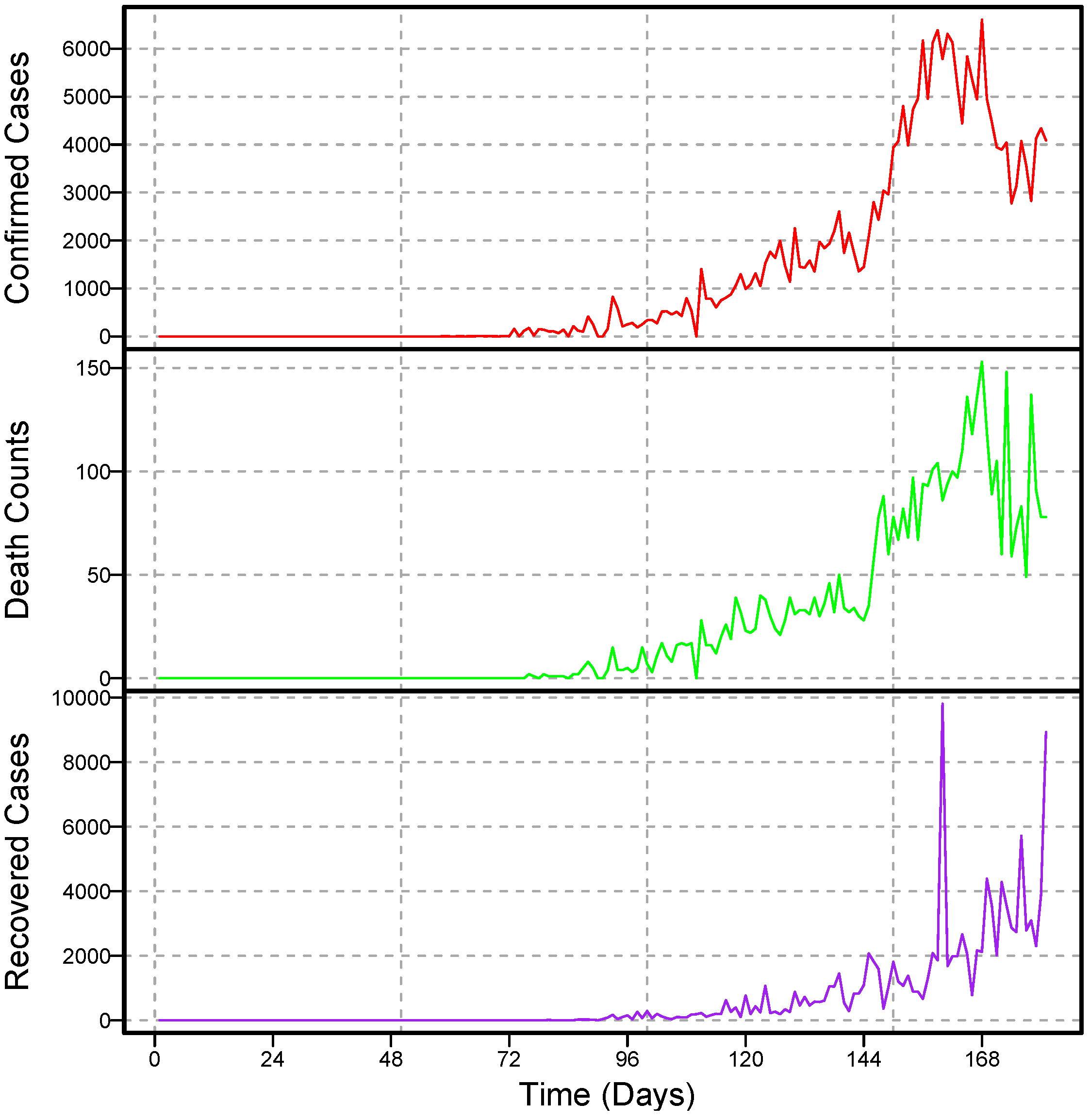
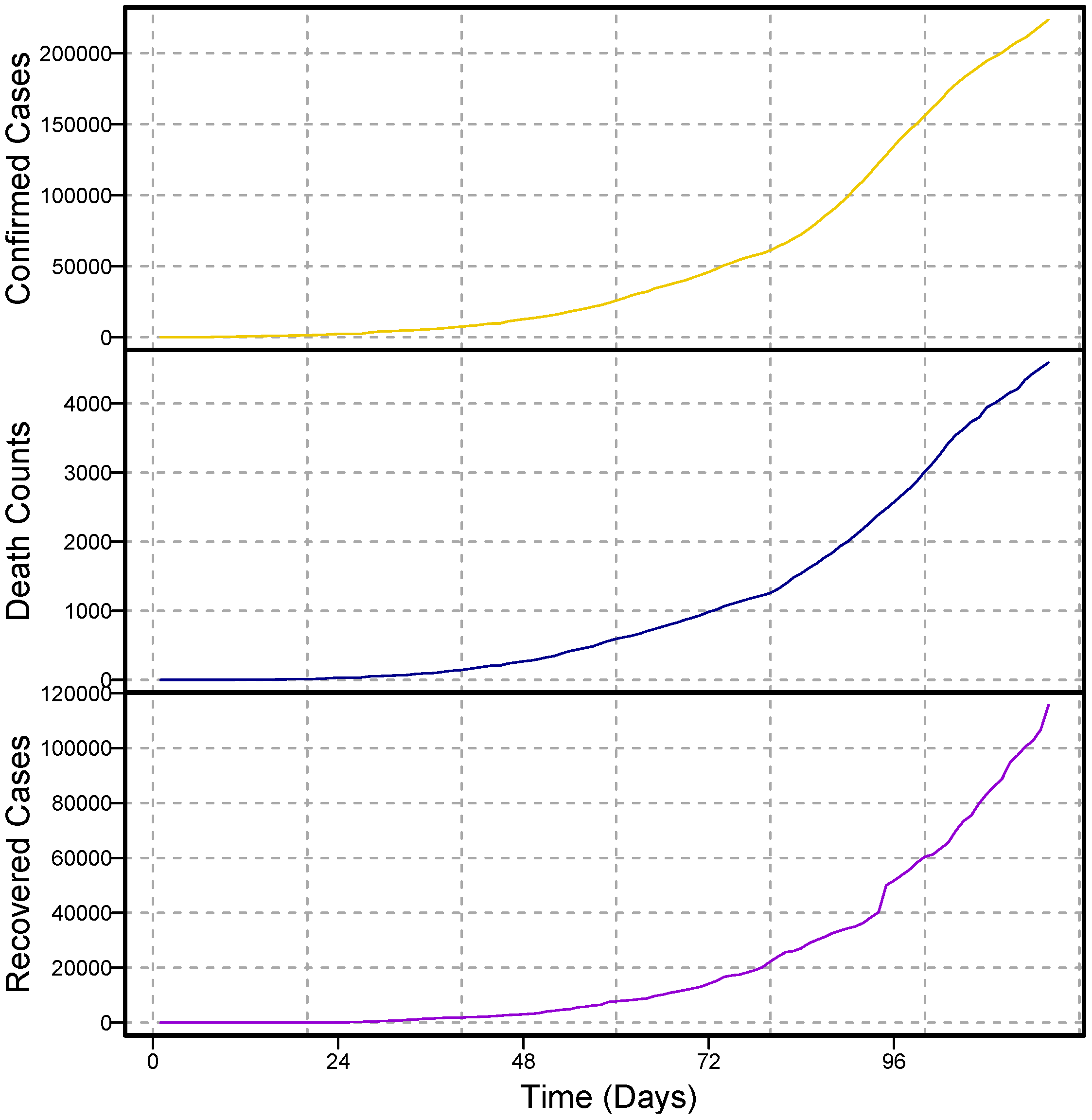
The study used daily data from confirmed COVID-19 cases, deaths, and recovered cases from Pakistan. The dataset was obtained from the World Health Organization; each series ranges from 10 March 2020 to 3 July 2020. The descriptive statistics of the considered datasets are given in
Table 2. For practical and rational modeling through time series models, at least 30 observations were required [
43]. To do this, approximately 116 data points from each series were considered. The complete dataset covers 116 days, of which 10 March 2020 to 19 May 2020 (71 days) were used for model training, and 21 May to 3 July 2020 (45 days) were used for one-day-ahead post sample (testing) predictions.
We used two accuracy measures (MAE and RMSE) to figure out which model for each series is the best. The results of these accuracy measures are shown in
Table 3 and
Table 4.
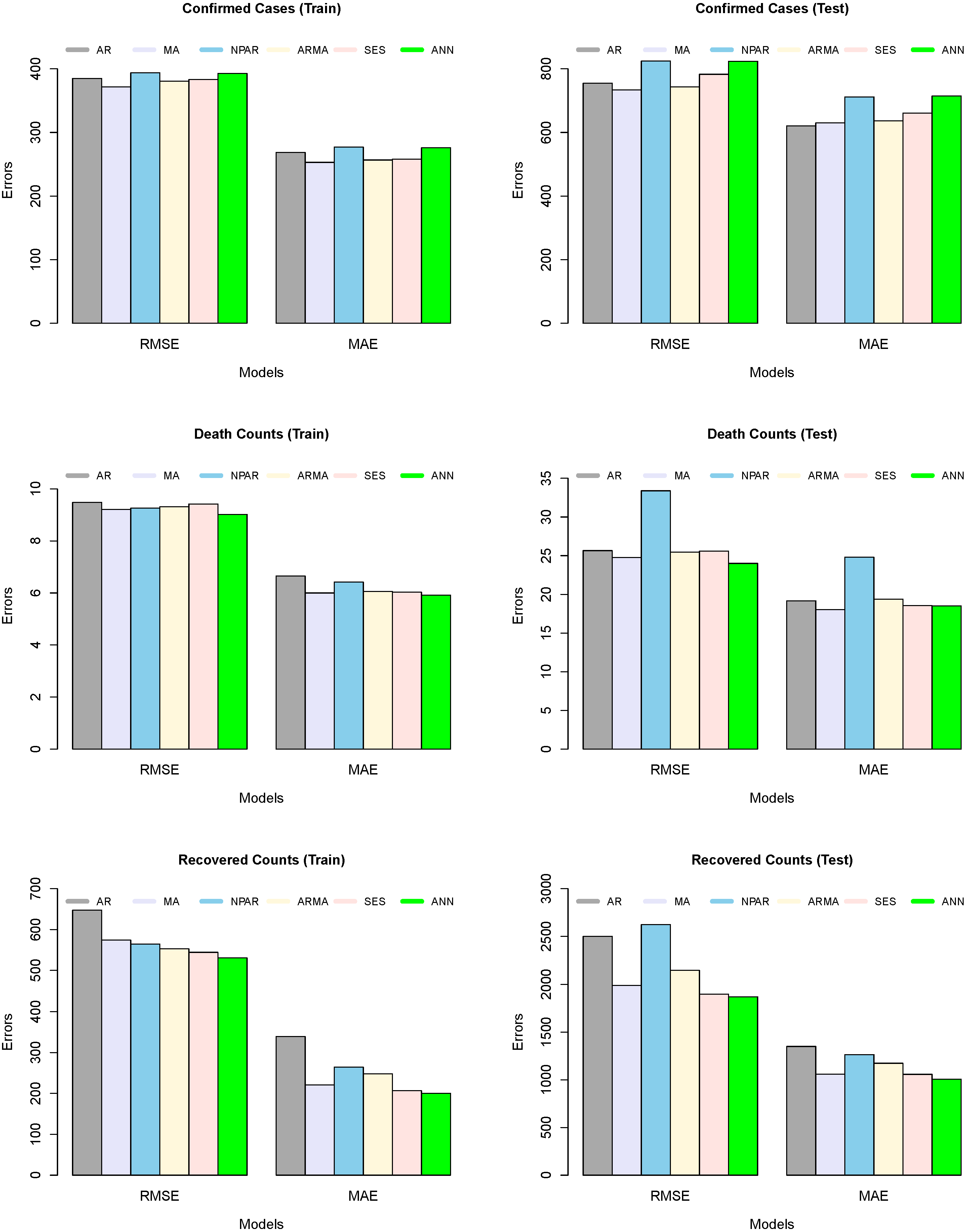
Table 3 shows the numerical description of the trained model’s accuracy mean errors for the all-considered model, such as five time series models and a machine learning model. On the other hand, the table presented a numerical description of the tested model’s accuracy and mean errors for all considered models. From the output of both
Table 3 and
Table 4, we can observe that the MA model produced low forecast errors, in contrast to all other competitors for confirmed predictions. The RMSE and MAE values for the MA model are 733.92 and 629.95, respectively, for confirmed cases. However, the ARMA model remains a good competitor. In the case of predicted death counts and recovered patients due to COVID-19, the ANN algorithm shows better results than the rest of the models, while the MA and SES models are the second- and third-best models, respectively. In addition, a graphical analysis of the RMSE and MAE values for confirmed cases, death counts, and recovered patients is plotted in
Figure 4. However,
Figure 4 (left column) shows the graphical representation of the trained model’s accuracy mean errors for all considered models. On the other side,
Figure 4 (right column) shows the graphical representation of the test model’s accuracy mean errors for all considered models. The superiority of the MA (confirmed cases) and ANN (death counts and recovered patients) models can be seen in both training and testing exercises.
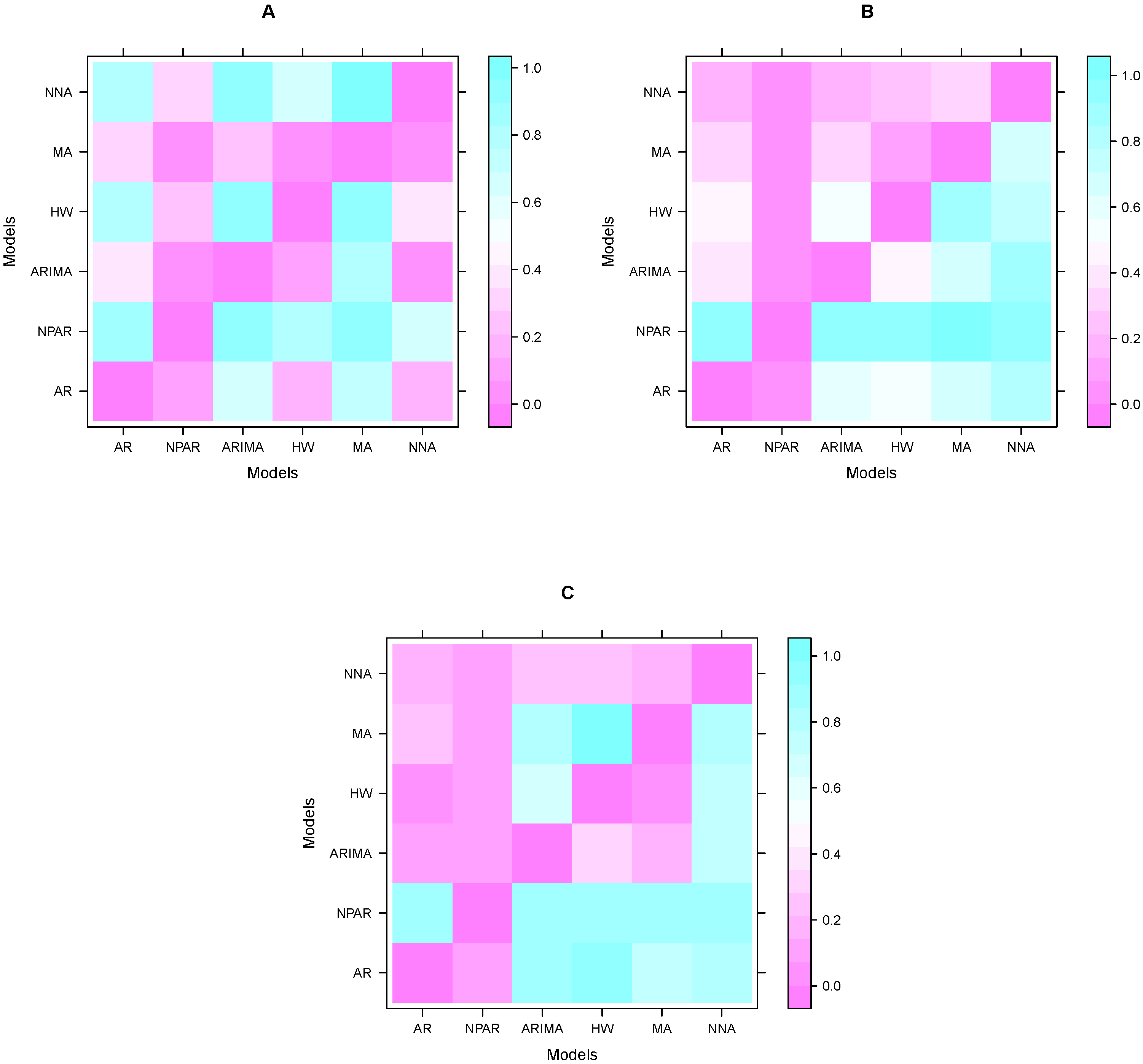
Once the performance of models is calculated by accuracy mean errors. The next step is to assess the dominance of these results. For this purpose, many researchers in the literature performed the Diebold and Mariano test (DM). In this work, we performed a DM test on each pair of models to verify the superiority of the model results (performance indicators) shown in
Table 4. The DM test results (
p-values) for confirmed cases are shown in
Table 5. The null hypothesis is displayed as a predictor in contrast to the alternative where all entries in the table are
p, and the accuracy of the column/row predictors are more accurate than the column/row predictors of the hypothesis system. This table shows that among all the models in
Table 4 (confirmed cases), the MA model is statistically superior to the other models at the 5% significance level. The DM test results (
p-values) for the number of deaths are shown in
Table 6. This table confirms that among all the models in
Table 4 (death counts), the ANN and MA models are statistically superior to the other at 5% significance level models. In addition, DM test results (
p-values) for recovered cases are shown in
Table 7. The results in these tables show that among all the models in
Table 4 (recovered cases), the ANN and SES models are statistically superior to the other models at the 5% significance level. On the other hand, the graphic representation of these results (
p-values) is presented in
Figure 5. The sky blue color in
Figure 5, is close to one, which means that the difference between the two models is significant; in contrast, the purple color indicates that the two models are not statistically significant at the 5% significance level. Thus, the superiority of the models in each case is easily seen in the figures. Therefore, from the descriptive statistics, graphical interpretation, and a statistical test, the superiority of the models in each case is confirmed.
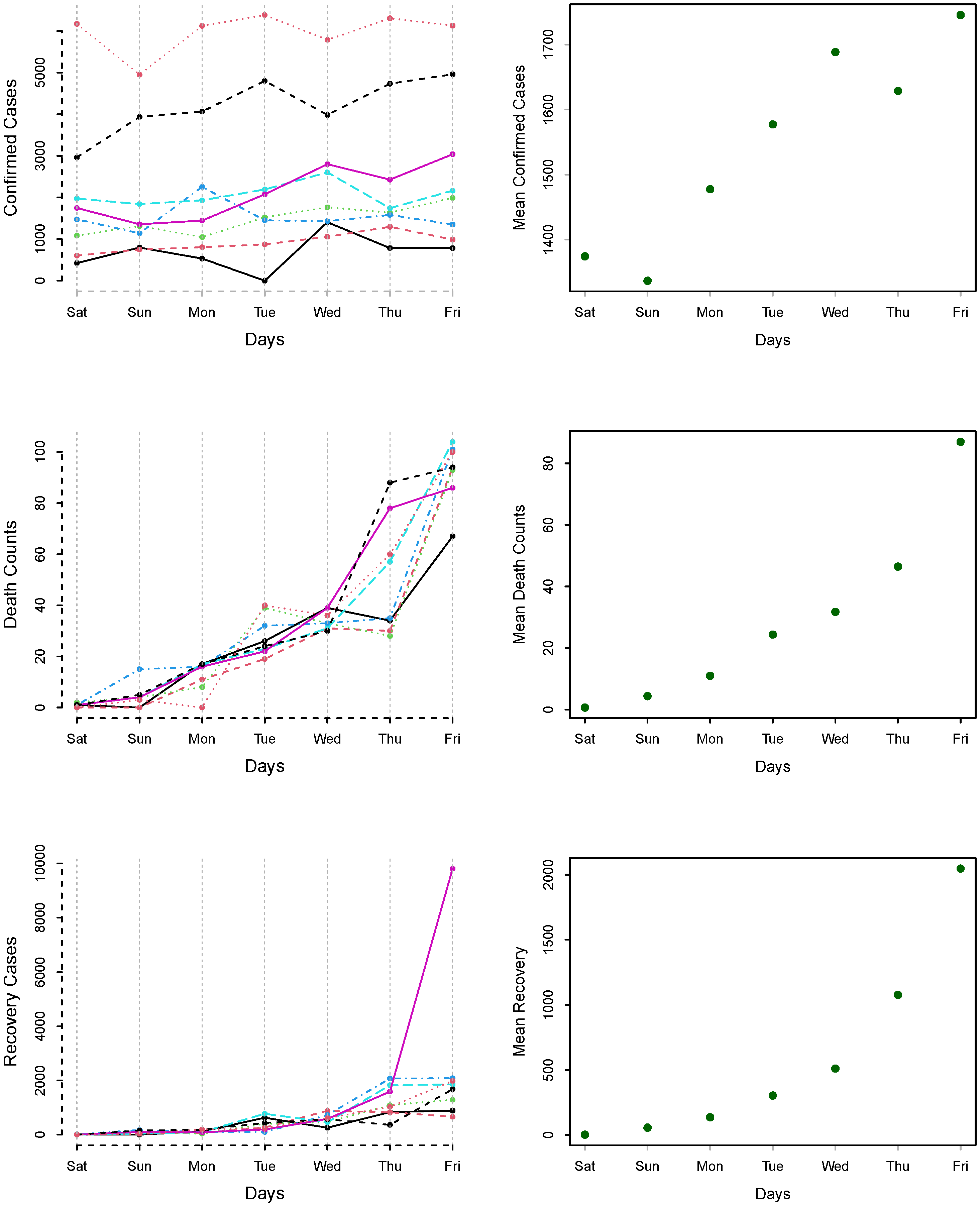
The day-specific confirmed cases, deaths, and recovered counts are plotted in
Figure 6 for 21 March to 19 June 2020.
Figure 6 (left column) shows that there is variation among the different weeks, while in
Figure 6 (right-column), the mean of days are plotted for confirmed cases, deaths, and recovered cases. We can see an increasing pattern from Saturday to Friday, which shows the effect of working and non-working days.
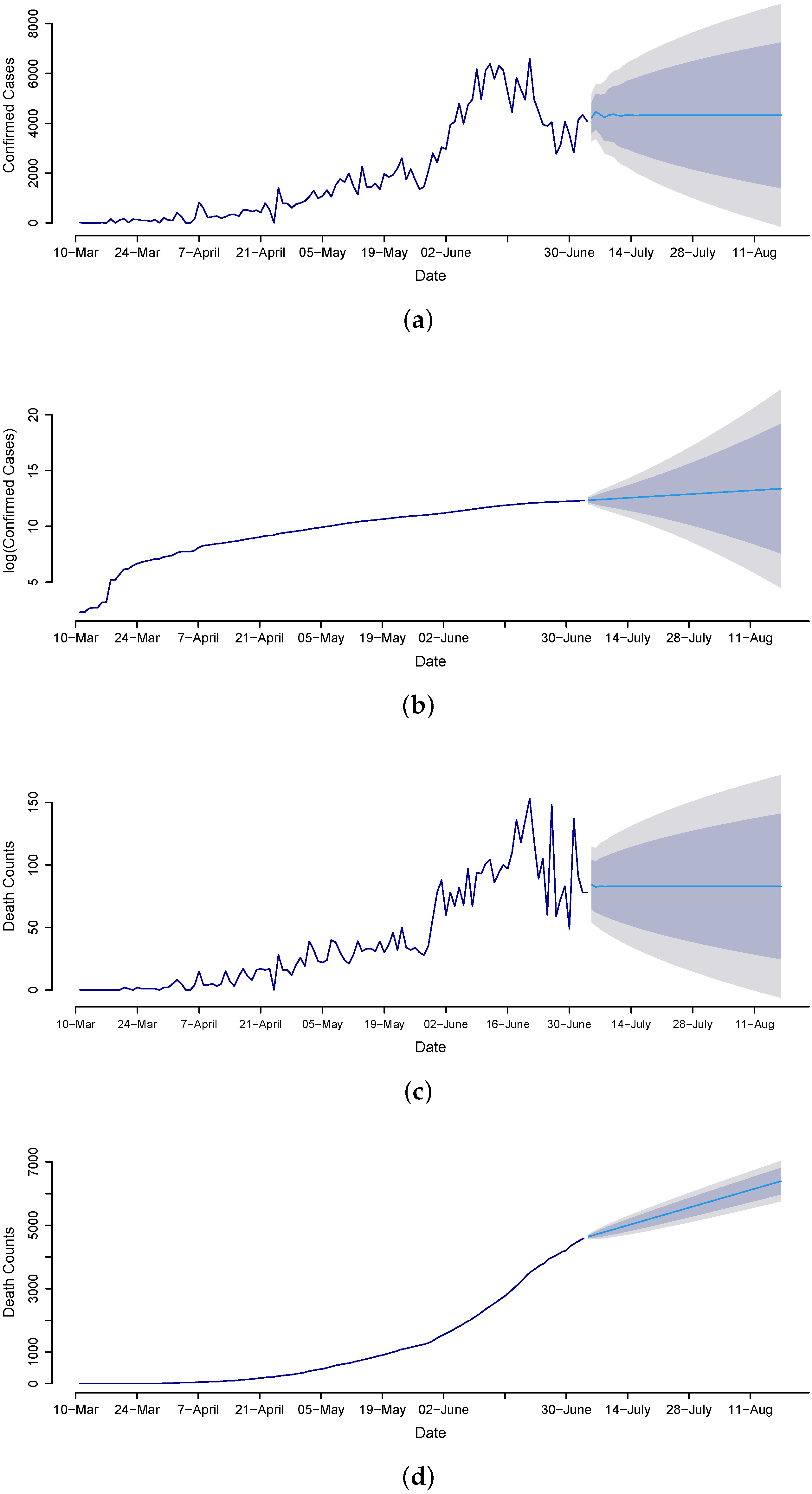
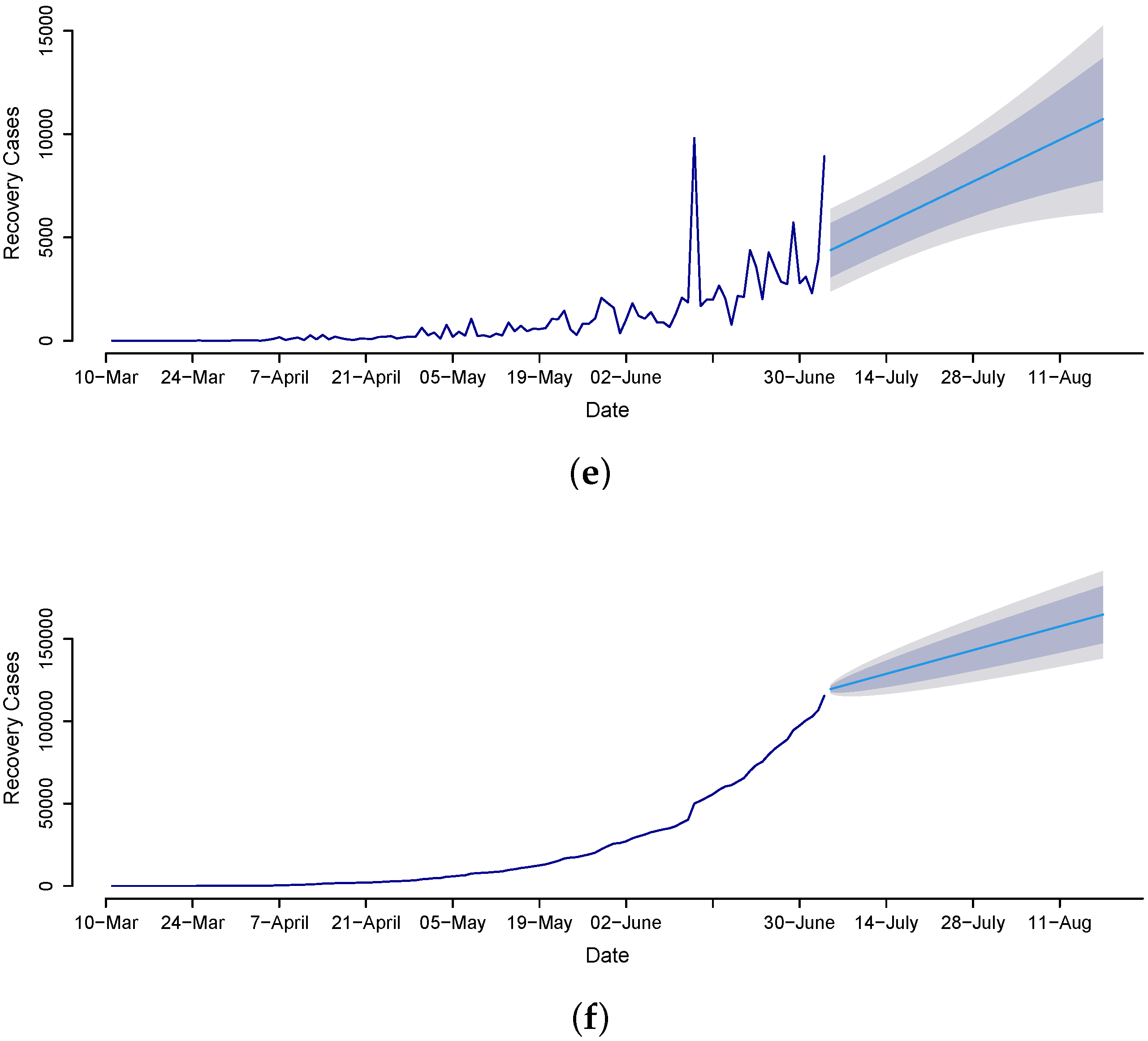
Once the best models are assessed through the out-of-sample mean errors (RMSE, MAE), a statistical test (DM test), and graphical analysis, we proceed to the future forecasting of confirmed cases, death counts, and recovered cases. Therefore, we implement the MA model for confirmed cases and the ANN model for the death count and recovered cases to forecast from 4 July to 14 August 2020, for the daily and cumulative number of cases. The forecasted values are presented in
Figure 7, clearly revealing that death counts and recovered cases are monotonically increasing while confirmed cases are not. The confirmed cases on 14 August 2020 are expected to be 7325, and the cumulative is 413,639. The death counts during late August are expected to be 121, and the cumulative counts are 9279. The recovered cases are 10,730, and the cumulative count is 455,661. Overall, the results suggest that the trend in confirmed cases gradually decreased over time, which is the outcome of the earlier steps that the government imposed, such as canceling conferences to disrupt supply chains; imposing travel restrictions; closing borders; canceling flights; closing workplaces; closing shopping malls, schools, colleges, and universities; and raising awareness through different TV programs, commercials, and advertisements, as well as having everyone use face masks and sanitizers.
4. Conclusions
The main purpose of this work was to forecast confirmed cases, death counts, and recovered cases of coronavirus in Pakistan using a machine learning model and five different univariate time series models, such as autoregressive, moving average, autoregressive moving average, nonparametric autoregressive, and simple exponential smoothing models. These models were applied to Pakistan’s daily records of confirmed cases, death counts, and recovered cases from 10 March 2020 to 3 July 2020. To evaluate the performances of the fitted models, a statistical test and two mean errors were considered. Experimental results showed that the ANN model outperformed the time series models considered in this study. Using the recovered cases, for the ANN model, the values of RMSE and MAE were 1870.07 and 1006.91, respectively. Using the death cases, for the ANN model, the values of RMSE and MAE were 24.00 and 17.89, respectively. On the other hand, using the confirmed cases, the MA model outperformed the ANN and other time series models. Using the confirmed cases, for the MA model, the values of RMSE and MAE were 733.92 and 629.95, respectively. Furthermore, the performances of the fitted models were assessed using the Diebold and Mariano test. The Diebold and Mariano’s test results (p-values) showed that among all models (confirmed cases), the MA model was statistically superior to the other models at the 5% significance level. On the other hand, for predicting mortality and recovery cases, the ANN model was statistically superior to the rest of all models at the 5% significance level. Based on the best-selected models, we forecasted confirmed cases and death counts from 4 July to 14 August 2020, which will be helpful for the decision making of public healthcare and other sectors in Pakistan.
This work only compares univariate models; no multivariate time series models are used. In the future, considering the covariates that affect COVID-19 can improve the forecasting performance of the models. In addition, machine learning models, such as random forest and support vector regression, can be used to obtain more accurate and efficient predictions in the future.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}