1. Introduction
The spinal cord is a long, thin, tubular bundle of nerve fibers that extends from the brain down through the vertebral column. It is a part of the central nervous system and plays a crucial role in relaying information between the brain and the rest of the body. The spinal cord is protected by the bony vertebral column, which provides both support and flexibility. The spinal cord is divided into four regions: the cervical region (neck), thoracic region (upper back), lumbar region (lower back), and sacral region (pelvis). Each of these regions has a specific set of nerves that control different parts of the body. Injury to the spinal cord can cause a range of disabilities, depending on the location and severity of the injury. Some common effects of spinal cord injury include paralysis, loss of sensation, and loss of bowel and bladder control. Treatments for spinal cord injury include medication, physical therapy, and surgery, but there is currently no cure for spinal cord injury [
1].
Spinal cord segmentation is a medical image analysis task that involves the automatic or manual delineation of the spinal cord from magnetic resonance imaging (MRI) data. Accurate segmentation of the spinal cord is essential for many clinical applications, such as diagnosis, treatment planning, and monitoring of spinal cord diseases and injuries. Segmentation of the spinal cord can be performed using various techniques, including manual delineation by experts, threshold-based methods, edge detection, region growing, clustering, machine learning, and deep learning-based methods [
2]. The choice of method depends on the specific application and the available data. Manual delineation by experts is considered the gold standard for spinal cord segmentation. However, it is time-consuming, tedious, and subject to inter- and intra-rater variability. Automated methods based on image processing and machine learning techniques can provide accurate and reproducible segmentations in a fraction of the time required for manual delineation. Deep learning-based methods, in particular, have shown promising results in spinal cord segmentation, using convolutional neural networks (CNNs) and other deep learning architectures. These methods are data-driven and can learn complex patterns and features from the MRI data, enabling them to generalize well to new data and improve segmentation accuracy. Overall, spinal cord segmentation is a challenging task that requires a combination of expert knowledge, image analysis techniques, and machine learning methods. The accurate segmentation of the spinal cord from MRI data has the potential to improve diagnosis and treatment of spinal cord diseases and injuries. A typical spinal cord image processing model is depicted in
Figure 1, wherein different processing components are integrated together for final tumor classification.
Detection of the spinal cord using deep learning algorithms is an active area of research in the field of medical image analysis. Deep learning algorithms are particularly suited to this task, because they can learn complex patterns in large volumes of data, such as medical images, and make accurate predictions. There are different approaches to detecting the spinal cord using deep learning algorithms. One approach is to use convolutional neural networks (CNNs), which are a type of deep learning algorithm that is commonly used for image analysis tasks. CNNs are designed to identify patterns in images by analyzing their local features and spatial relationships. To train a CNN model for spinal cord detection, a large dataset of spinal cord images is needed. This dataset should include images of the spinal cord with different orientations, resolutions, and contrast levels. The images can be obtained from various imaging modalities, such as magnetic resonance imaging (MRI) and computed tomography (CT). Once the dataset is prepared, the CNN can be trained using a supervised learning approach. The CNN learns to classify pixels in the image as either belonging to the spinal cord or not. During training, the CNN adjusts its parameters to minimize the difference between its predicted outputs and the ground truth labels provided in the training dataset. After training, the CNN model can be used to detect the spinal cord in new images. The CNN model takes an image as input and produces a binary mask that highlights the pixels that belong to the spinal cord. The mask can be further processed to extract features of the spinal cord, such as its length, width, and position. Overall, deep learning algorithms such as CNNs have shown promising results for detecting the spinal cord in medical images. However, further research is needed to validate the performance of these algorithms on different datasets and imaging modalities, and to optimize their parameters for clinical use.
It can be observed that segmentation, feature extraction and classification are the major blocks which assist in achieving high-efficiency tumor classification performance [
3]. Based on this model flow, a wide variety of spinal cord tumor classification models have been proposed by researchers, and each of them varies in terms of its applicability and performance. In [
4], the authors used different ML methods including k-nearest-neighbor, a neural network with radial basis functions, and a naive Bayer classifier to classify vertebral compression fractures as either benign or malignant on T1-weighted sequences. They achieved an AUROC of 0.97 in detecting vertebral fractures and of 0.92 in classifying them as benign or malignant. However, their model was limited by their manual segmentation process (introducing intra- and interobserver variability) and their individual analysis of the vertebral bodies, ignoring relevant information such as the presence of epidural masses. Thomas et al. trained a deep CNN to differentiate between tuberculous and pyogenic spondylitis on axial T2-weighted MRI images, concluding that the algorithm’s performance was comparable to that of three radiologists. They suggested that their model could be used to identify spondylitis as an incidental finding on spine MRI obtained for reasons other than for the assessment of a suspected infection. However, the DL method used in the model needs further validation with a larger-scale study that utilizes multiplanar MR images [
5]. The eventual integration of these spinal cord deep learning algorithms into routine clinical practice would open the door to potential improvements in diagnostic sensitivity, treatment monitoring, and patient outcomes, with resultant value added for both clinicians and our patients.
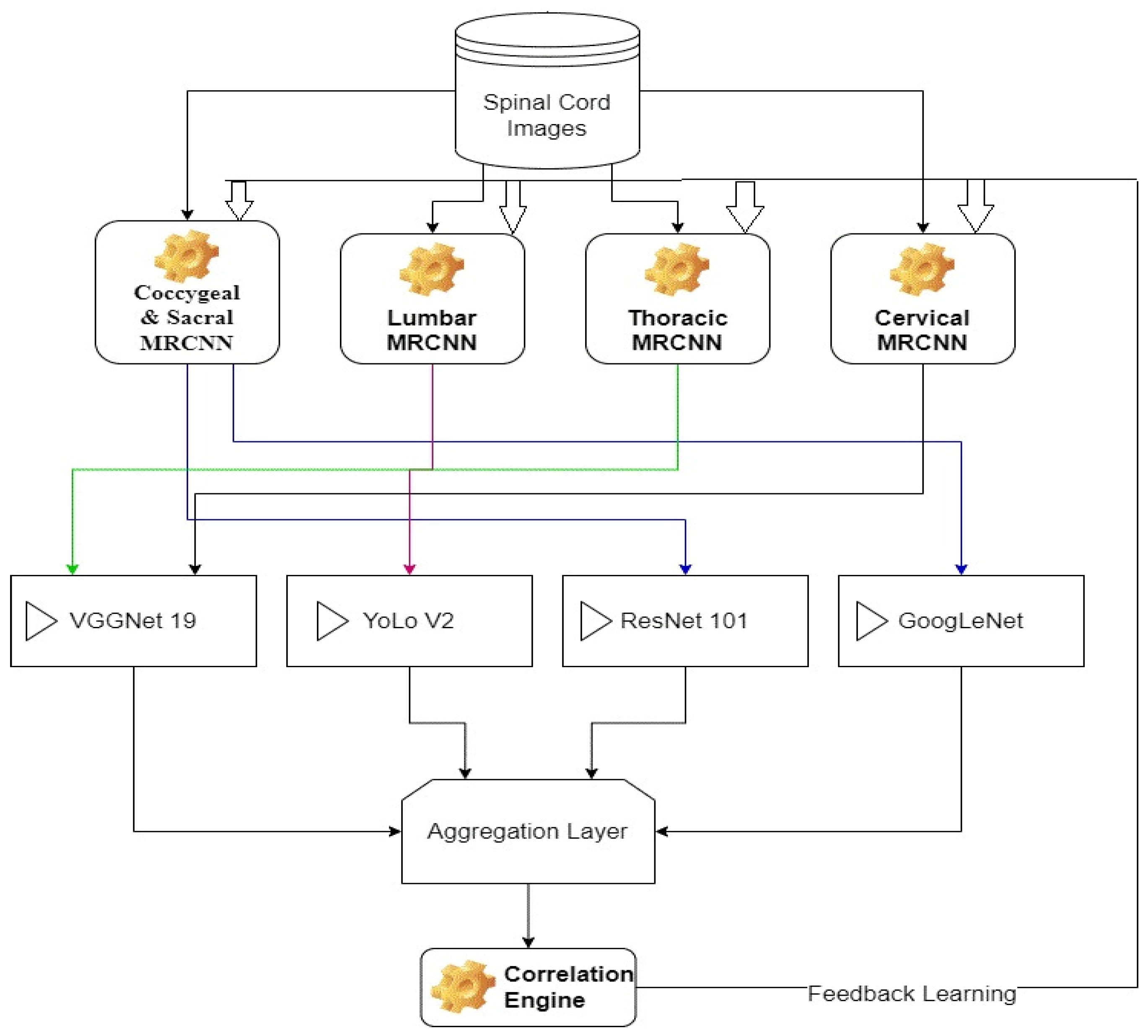
On the basis of the literature described above, this work proposes a new augmented model for spinal cord segmentation and tumor classification using deep nets. The proposed model initially divides each spinal cord image into multiple segments via the MRCNN model and uses these segments to train an ensemble of CNN classifiers. Each of these classifiers is responsible for detecting a particular type of tumor, which assists in improving model scalability and performance. The model initially segments all five spinal cord regions and stores them as separate datasets. These datasets are manually tagged with cancer status and stage based on observations from multiple radiologist experts. Multiple Mask Regional Convolutional Neural Networks (MRCNNs) were trained on various datasets for region segmentation. The results of these segmentations are combined using a combination of VGGNet 19, YoLo V2, ResNet 101, and GoogLeNet models. These models were selected via performance validation on each segment. It was observed that VGGNet-19 was capable of classifying Thoracic and Cervical regions, while YoLo V2 efficiently classified Lumbar regions, ResNet 101 showcased better accuracy for Sacral region classification, and Goog-LeNet classified Coccygeal regions with high accuracy performance. This performance is evaluated in terms of Peak Signal-to-Noise Ratio (PSNR), accuracy, and delay measures in
Section 4, and compared with various state-of-the-art models. Based on this comparison, it can be observed that the proposed model is highly scalable for multiple spinal cord regions and showcases better performance w.r.t. existing classification models. Finally, this text concludes with some interesting observations about the proposed model and recommends various methods to further improve its performance.
2. Related Work
A wide variety of models have been proposed for spinal cord processing and classification, and every one of them has explicit execution. For example, in the work in [
5], limit-based division and Convolutional Neural Network (CNN)-based division models are portrayed. It can be seen that the edge-based model has limited precision, and must be physically tuned for each dataset, while the CNN model is autotuned, and has high division effectiveness, and in this manner can be applied to a wide assortment of datasets. An examination of such models was discussed in [
6], from where it can be seen that AI techniques beat direct division models, and consequently are profoundly liked for clinical applications. This model was additionally examined in [
7], wherein division repeatability of thoracic spinal muscle morphology was performed by means of deep learning-based characterization strategies. A plan of a comparable model was additionally portrayed in [
8], wherein the Statistical Parametric Planning (SPP) structure was depicted. This strategy has great precision and can be utilized for quite a long time with negligible preparation exertions on the client side. In any case, these models require huge delays for preparation, which can be streamlined through utilization of equal handling, or pipelining methods. An illustration of such a high-speed performance model is proposed in [
9,
10,
11], in which scientists utilized a deep learning network with more learning. The fusing of move learning diminishes cold-start issues, and hence, in general, works on Accuracy, Recall, and FMeasure execution. Motivated by this perception, the proposed model additionally utilizes move learning to achieve the profoundly effective division of spinal rope symbolism. Comparatively high-productivity models are proposed in [
12,
13,
14], wherein the analysts utilized scientific change-based completely computerized convolutions, vertebrae division, and Particle Swarm Optimization (PSO) models to achieve high exactness in low postpone division and order tasks. The PSO model will, in general, beat other models because of its minuscule division execution, and capacity to perform order and relapse with high productivity.
The effectiveness of the assessed models should additionally be assessed on bigger datasets. Such examination was discussed in [
15,
16,
17], wherein vertebral estimation, Deep Neural Network (DNN) for injury grouping, and Dense Dilated Convolutions (DDC) are utilized for division and arrangement activities. By displaying different datasets and using the Finite Element Method (FEM) for the division and inspection of spinal lines, the models in [
18,
19] further assist in developing the arrangement and executing the division.
Table 1 shows the main Convolutional Neural Network applications for Deep segmentation models.
3. Proposed Model
Based on the literature review, it can be observed that a wide variety of machine learning models have been proposed by researchers for high-efficiency and low-computational-time spinal cord segmentation and tumor classification scenarios. However, these models were developed for particular portions of the spine, making them applicable only in a specific spinal cord segmentation application scenario. To overcome this limitation, a novel augmented model for spinal cord segmentation and tumor classification using deep nets is discussed in this section, wherein segmentation results from Multiple Mask Regional Convolutional Neural Networks (MRCNNs) are combined with VGGNet 19, YoLo V2, ResNet 101, and GoogLeNet classification models.
Multiple Mask Regional Convolutional Neural Networks (MMRCNN) are a type of deep learning architecture used for image recognition and object detection tasks. It is an extension of the popular Faster R-CNN algorithm, which uses a Region Proposal Network (RPN) to generate region proposals for objects in an image, and a Region of Interest (ROI) pooling layer to extract features from the proposed regions. MMRCNN improves upon Faster R-CNN by introducing multiple masks for each region proposal, instead of a single ROI pooling layer. These masks are used to refine object boundaries and improve the accuracy of object detection. The network also includes an additional branch for predicting object masks, which helps in segmentation tasks. In MMRCNN, the RPN generates region proposals, which are then passed through several convolutional layers to generate features for each proposed region. These features are then fed into multiple ROI pooling layers, each of which generates a mask for the proposed region. The resulting masks are combined to refine the object boundaries, and the final output is a set of object proposals along with their corresponding masks.
Each of these models is trained for a particular segment of spinal cord, which assists in achieving better classification performance. The overall flow of the proposed method is depicted in
Figure 2, wherein different MRCNNs segmentation models are combined with CNN models to achieve final segmentation. From the flow, it can be observed that a tagged database of spinal cord images is segmented via different MRCNN models, which assists in identification of different regions with better segmentation performance. These segmented images are classified using an augmentation of VGGNet 19, YoLo V2, ResNet 101, and GoogLeNet classifiers. Data augmentation is a technique used in deep learning to increase the size of a dataset by generating new samples from existing ones, typically through a series of random transformations. This technique helps to improve the robustness and generalization ability of deep learning models by introducing more variations and diversity into the training data. The results of these classifiers are combined using an aggregation layer, which assists in the final estimation of spinal cord conditions. These conditions are validated via a correlation layer, which is used for continuous database update operations. Due to use of this continuous update layer, the model is capable of incrementally improving its performance with respect to the number of evaluations.
Each of these blocks, along with their internal design details are discussed in separate sub-sections of this text. Researchers can implement these models in part(s) or as a full system depending upon their application requirements.
3.1. Design of the MRCNN Model for Segmentation of Different Spinal Cord Regions
The input spinal cord images are initially segmented using a MRCNN model that uses eXplanation with Ranked Area Integrals (XRAI) for region-based analysis. Ranked area integrals are a type of mathematical technique used to calculate the area under a curve. The basic idea behind this technique is to divide the region under the curve into small strips or rectangles, calculate the area of each strip, and then add up the areas of all the strips to obtain the total area.
Using the XRAI method, medical images are segmented, and their Regions of Interest (RoIs) are extracted from raw images. To perform this task, the entropy for each pixel is evaluated via convolutional processing and bit plane slicing models. To extract these features, convolutional operations are performed, which assist in high-variance feature representation.
A high-variance feature representation refers to a set of features in a dataset that exhibit a wide range of values or variability. In other words, the values of these features can vary significantly from one data point to another. High-variance features can be useful in some machine learning tasks, such as classification or regression, because they may contain important information for distinguishing between different classes or predicting an outcome. However, they can also pose challenges, as they may be more susceptible to overfitting, where a model learns to fit the noise in the training data rather than the underlying patterns. In this paper, we used this technique to reduce redundancies and unique values in image features so high variance feature representation is used. Image pixels are initially processed via an entropy evaluation layer, which estimates energy levels of pixels. Entropy of images is evaluated via Equation (1), wherein pixel levels and their logarithmic intensities are averaged to form final image entropy.
where
represents image pixel value at
location, and
represents slice number of the raw input image. Based on these entropy levels, pixels with values above
are termed foreground, while others are marked as background and supressed from the output. This process is performed at slice level, and these slices are combined to form the final segmented image set. This process is termed Saliency extraction, and an example of it can be observed in
Figure 3, wherein the input image and its corresponding saliency map are visualized.
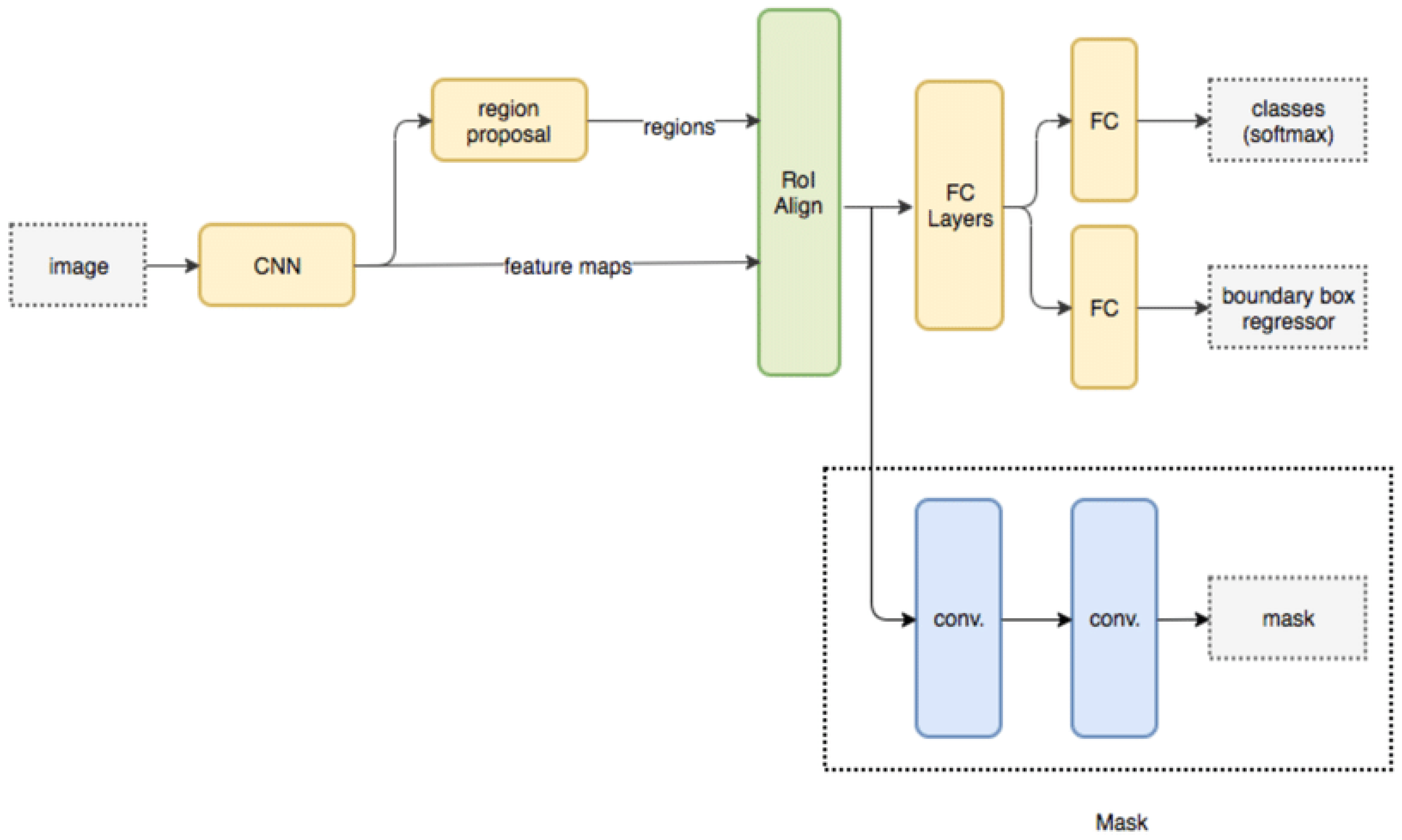
The extracted regions are processed via a Masked Region CNN model, which assists in classification of each pixel set into different spinal cord segments. Masked Region CNN (Convolutional Neural Network) is a type of neural network that is designed to process images or visual data with a particular focus on regions of interest (ROIs) in the image. It is also known as Mask R-CNN. Mask R-CNN is an extension of Faster R-CNN, which is a two-stage object detection algorithm that uses a region proposal network (RPN) to generate candidate regions in an image, followed by a classification and regression network to classify each region and refine the bounding box coordinates. Mask R-CNN builds on top of this architecture by adding a third branch to the network that generates a binary mask for each ROI, indicating which pixels belong to the object and which do not. In addition to object detection and instance segmentation, Mask R-CNN can also be used for semantic segmentation by treating each object in the image as a separate class. This allows the network to assign a semantic label to each pixel in the image, which can be useful for tasks such as image segmentation and scene understanding. Mask R-CNN has achieved state-of-the-art results on several benchmark datasets for object detection and instance segmentation, and it has been widely adopted in computer vision research and applications.
The masked RCNN model is depicted in
Figure 4, wherein different convolutional layers, along with their interconnections, are visualized. It can be observed that the MRCNN Model is trained for different types of spinal cord segments, and then evaluated at pixel level. Due to which individual Region Proposal Networks (RPNs) are trained and evaluated for different spinal cord segments. Each RPN layer consists of different inception and mapping modules, which assist in separating pixels of one segment from others.
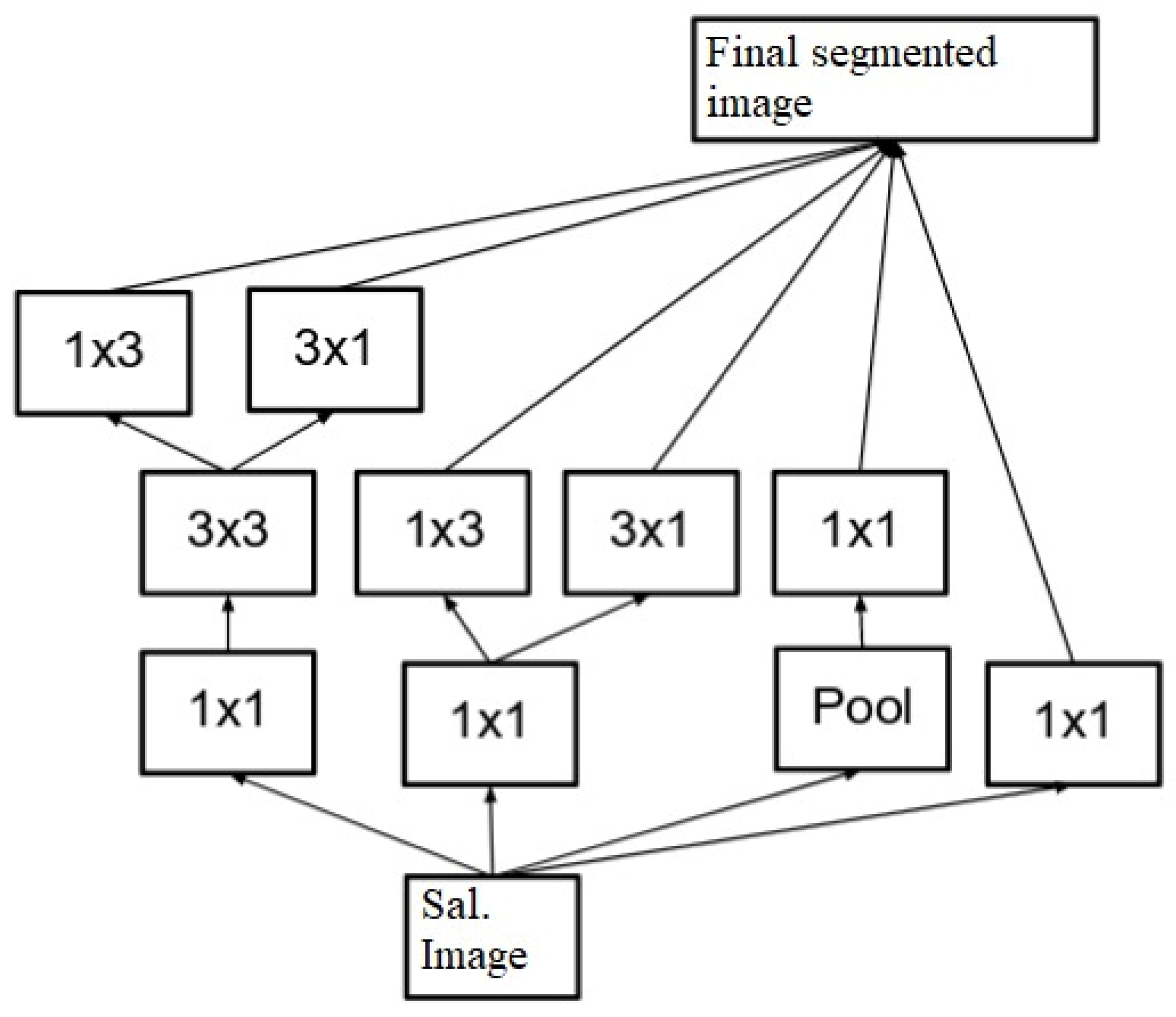
To perform this task, masks for different regions are convoluted with the Saliency Map image, which assists in obtaining segment-level images. This assists in separating the input image into different sub-components, which increases the efficiency of the tumor classification process. The results of RPN are evaluated using Equation (2):
where
represent the Saliency Map image and the Mask for the current part of spine segment, respectively. The equation signifies the summation of the Saliency Map image and the Mask for the current part of spine segment. Due to the complexity of spinal structures, multiple masks are combined to form the final segmented (
) image. These masks, along with their filter-level concatenation process, can be visualized using
Figure 5, where masks of different shapes and sizes are combined to form the final output image set.
The final filter mask can be represented via Equation (3), wherein different smaller sized masks are combined for each region, which assists in achieving better segmentation performance.
where
represent mask-level constants, and can be tuned as per the input dataset,
represent the pixel-level mask and the binary mask for the current part of the spinal cord. These pixel-level masks are pre-set by the MRCNN model and are used for the final segmentation process. Multiple RCNN modules are connected individually, assisting in the extraction of different spinal cord segments. All of these masks and their generated segments are individually given to different CNN models for classification of segment level tumors.
3.2. Design of the CNN Model for Tumor Classification
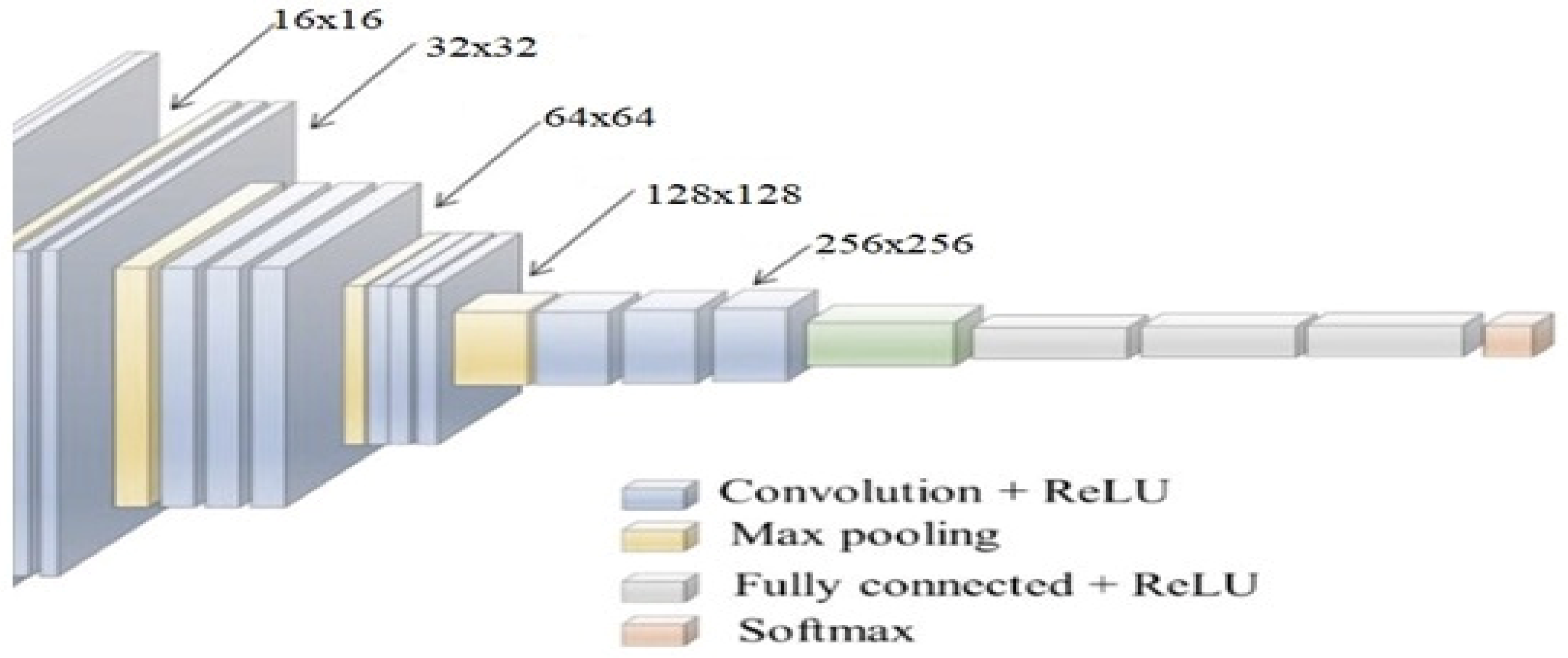
Individual extracted spinal cord segments are given to different CNN models for tumor classification. During evaluation, it was observed that VGGNet-19 showcased higher efficiency for the classification of thoracic tumors and cervical-region tumors, YoLo V2 had better performance for lumbar-region tumors, ResNet 101 achieved higher accuracy for sacral-region tumors, and GoogLeNet performed better for coccygeal-region tumors, achieving high performance accuracy. A typical CNN model is depicted in
Figure 6, wherein different convolutional operations are cascaded with maximum feature pooling (Max Pool) and drop-out layers. A Max Pool layer is a type of pooling layer commonly used in convolutional neural networks (CNNs) for image recognition tasks.
The main function of a max pooling layer is to reduce the spatial dimensionality (i.e., the height and width) of the input volume (i.e., the output of a convolutional layer) while retaining the most important features. It works by sliding a fixed-size window (called the pooling window or filter) over the input volume and outputting the maximum value within each window. In this paper, an elaboration of the design of the max pooling layer is given in order to obtain a clear picture of the convolutional neural network. It works by sliding a fixed-size window (called the pooling window or filter) over the input volume and outputting the maximum value within each window.
To process spinal cord segments, the CNN models extract a large number of convolutional features, which assist in obtaining a high-accuracy image representation of the input images. Based on these convolutions, different statistical measures including mean, max, standard deviation, kurtosis, entropy, variance, and correlation coefficient values are estimated at block level. Thus, each input image segment is divided into different blocks, and each block is processed by means of windowing and padding constants. An instance of these convolutions is evaluated in Equation (4), wherein input image pixels are activated via Leaky ReLU (rectilinear unit) kernels.
where
represents the Leaky ReLU kernel and the spinal cord component, respectively, while
represent the window size across the rows and columns of the input image, respectively. These convolutional features are evaluated for each window size and assist in the estimation of a large number of features. The features extracted from each convolutional layer of the CNN are checked to reveal some internal working mechanisms of the CNN and explain the specific meanings of some features. Due to the variation in different padding, stride, and kernel sizes, this model is able to extract a large number of features from any spinal cord image. However, with increasing numbers of convolutional layers, the total number of features extracted per spinal cord segment also increases.
The number of features extracted by these layers is evaluated using Equation (5):
where
represent the extracted and input features for the given convolutional layer,
represent the padding size used during convolution, the stride size used during convolution, and the kernel size used during convolution in the current layer, respectively.
The features extracted from each convolutional layer of the CNN are checked to reveal some internal working mechanisms of the CNN and explain the specific meanings of some features. Due to the variations in different padding, stride, and kernel sizes, this model is able to extract a large number of features from any spinal cord image. However, with increasing numbers of convolutional layers, the total number of features extracted per spinal cord segment also increases. To cut these redundant positions, each convolutional layer is followed by a Max Pool layer. These layers calculate the variance threshold for each extracted feature set and choose the features with the highest variation levels on the basis of this variance threshold. The variance threshold for each Max Pool layer is evaluated using Equation (6):
where
represents variance for the given feature set,
represents extracted features, and
represents the probability of variance for the given feature set.
This probability is tuned during each iteration and assists in achieving better feature extraction performance. This performance is enhanced through the use of different-sized convolution layers. In this case, layers with sizes of 3 × 3 × 512, 7 × 7 × 256, 16 × 16 × 128, and 32 × 32 × 64 and 64 × 64 × 32 are used by the CNN models to extract a large number of highly variant features. These features are processed via a Fully Connected Neural Network (FCNN), which assists in the identification of tumor classes. The model is able to differentiate between tumor and non-tumor classes, due to which it is used in binary classification mode, which assists in achieving higher classification performance when compared with sparse categorical classifications. To obtain the final class, Equation (7) is used, wherein a Softmax-based activation layer is deployed to improve feature segregation into tumor and non-tumor classes. Softmax is a mathematical function that takes a vector of real numbers as input and returns a probability distribution over the elements of that vector. It is commonly used in machine learning and deep learning to convert a set of scores or logits into probabilities that can be used for classification tasks.
where
represents the values of the extracted convolutional feature vectors,
represents weight,
represents bias, and
represents the total features extracted by the convolutional layers. Each of these classes is evaluated for the coccygeal, sacral, lumbar, thoracic, and cervical regions individually. These classes are given to an aggregation layer, which assists in the identification of the final tumor state for the spinal cord. The design of this layer is discussed in the next section of this text.
3.3. Design of Aggregation Layer with Correlation Engine for Continuous Performance Enhancement
The CNN layer assists in the identification of cancer status for different regions of the spinal cord. These status values are aggregated using Equation (8) to obtain final cancer spreading probability.
where
represents the weight of the current spinal cord segment, and is estimated using Equation (9):
where
represents approximate length of spinal cord region for the given patient, and is estimated using Equation (10):
where
represents the count of the total number of pixels for a given spinal cord segment. On the basis of this evaluation, the probability of cancer spread across the entire spinal cord is evaluated. These results are correlated with the actual spread probability values (C) using Equation (11):
where
represent the actual and obtained values of probability, while
represents the total number of images used to perform this evaluation. If correlation with the actual spread probability value is greater than 0.999, then this image of the spinal cord regions is added to the training set, on the basis of which the model is able to continuously improve its performance in terms of both accuracy and precision. Estimation of this performance is discussed in the next section of this paper, wherein the performance of the proposed model is compared with various state-of-the-art approaches.
4. Results and Comparison
In order to estimate the classification performance of the proposed NAMSTCD model, spinal cord images from multiple Mendeley datasets and their ground truth images were used. These data were obtained from
https://data.mendeley.com/datasets/zbf6b4pttk/2 (accessed on 25 December 2022) [
20] and are freely available under an open-source license. The dataset was evaluated using the proposed NAMSTCD model, and the values for segmentation peak signal-to-noise ratio (PSNR), classification accuracy, and computational delay were evaluated and compared with the values obtained using CNN [
5], SPM [
8], and DNN [
16]. The classification accuracy was evaluated using Equation (12), as follows:
where
N_correct and
N_total represent the total number of correctly classified images and the total number of rated images, respectively. The entire dataset of 5000 images was split 60:10:30 for training, validation and testing, respectively. The accuracy is listed in
Table 2, below.
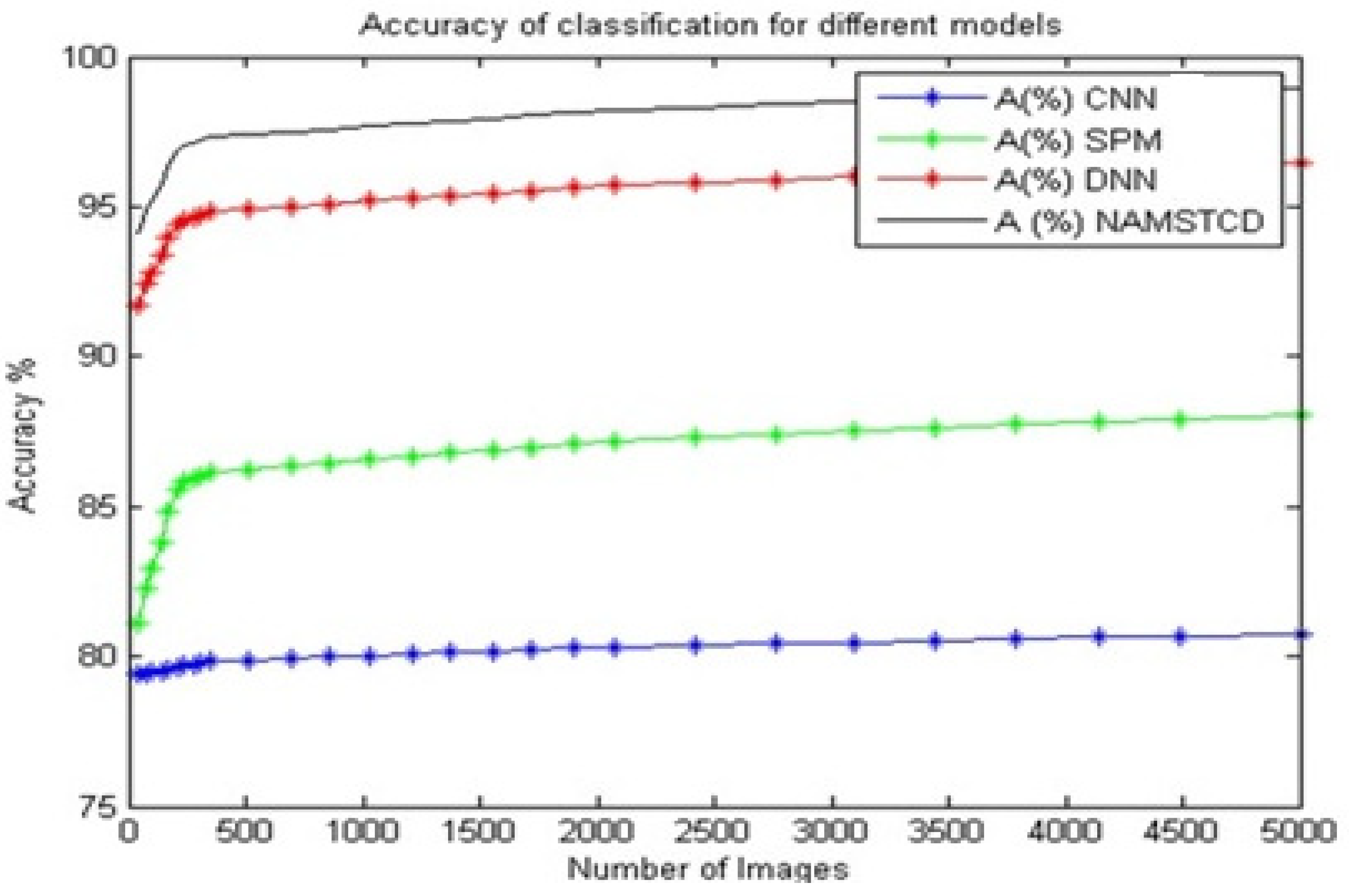
From
Table 3 and
Figure 7, it can be observed that the proposed model has an accuracy that is 18.1% better than that of CNN [
5], 10.5% better than that of SPM [
8], and 2.3% better than that of DNN [
16] on the same dataset.
This suggests that the proposed model is highly efficient for large-scale deployments and can be used in real-time clinical classification applications. Similarly, the PSNR during segmentation was evaluated for CNN [
5], SPM [
8] and DNN [
16], and compared with the values obtained for the proposed model; these values are shown in
Table 3, below.
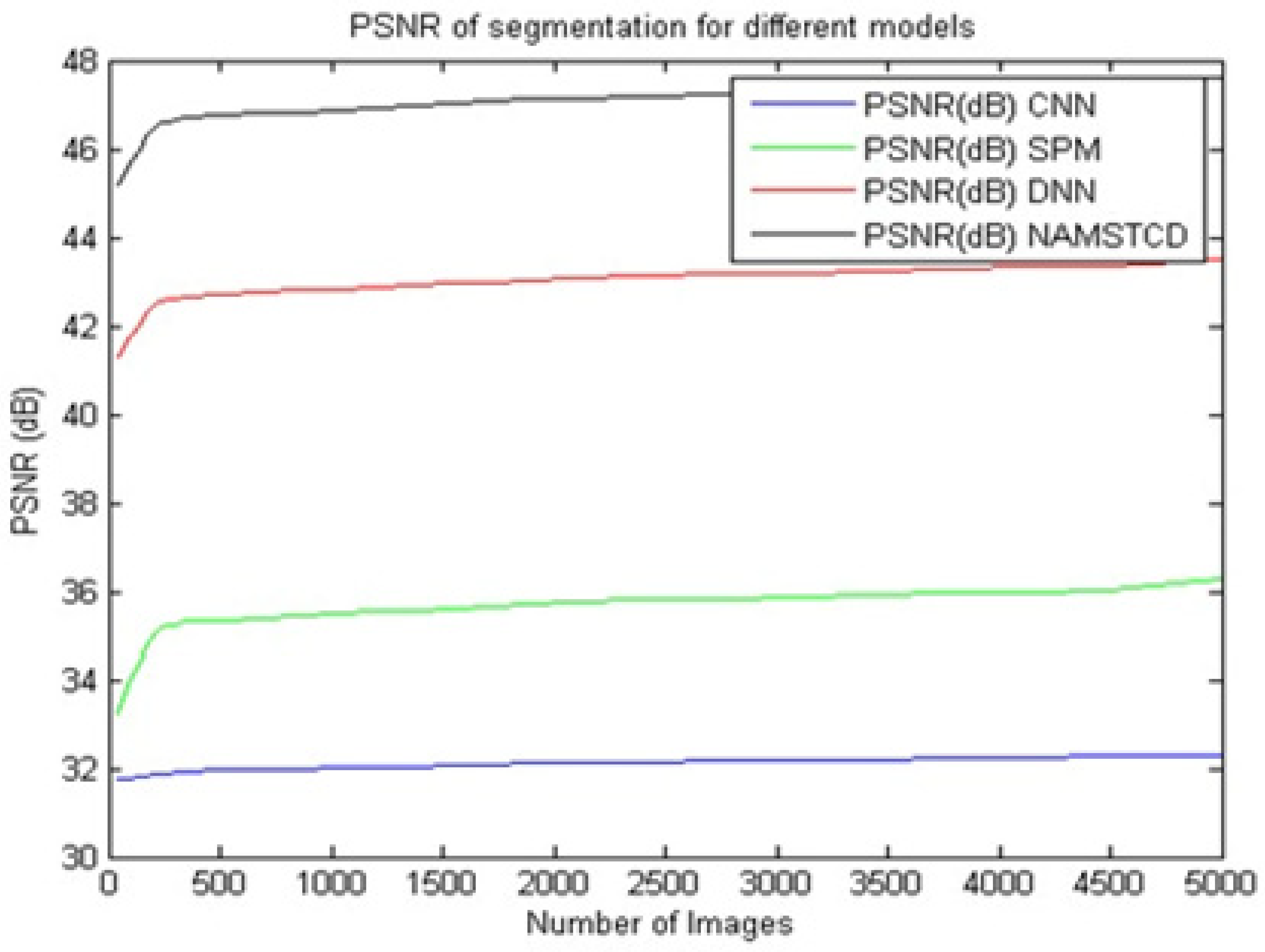
It can be seen from
Table 3 and
Figure 8 that the proposed model presents an improvement in PSNR of 14.6 dB compared to CNN [
5], an improvement of 10.5 dB over SPM [
8] and an improvement of 3.4 dB over DNN [
16] on the same dataset. This improvement in PSNR is due to the combination of XRAI and MRCNN, which helps to perform fine-tuned segmentation. This suggests that the proposed model is highly efficient for large-scale deployment and can be used to perform real-time clinical segmentation.
Similarly, the computational delay during classification was evaluated for CNN [
5], SPM [
8] and DNN [
16], and compared with the proposed model. Using MATLAB 2019 b, the computational delay was taken into account. These values are shown in
Table 4, below.
It can be seen from
Table 4 and
Figure 9 that the proposed model has a computational delay that is 25.1% lower than CNN [
5], 31.4% lower delay than SPM [
8] and 39.3% lower than DNN [
16] on the same data set. This reduction in computational delay is due to the combination of XRAI and MRCNN, which helps to achieve fine-tuned segmentation, thereby reducing the overall computational delay arising from classification and post-processing operations.
These improvements make the proposed model useful for a wide range of real-time clinical classification applications. It also identifies the likelihood of tumor spread, which further helps to improve its scalability and applicability to a wide range of clinical scenarios.
5. Conclusions
The proposed NAMSTCD model uses MRCNN-based segmentation in combination with CNN classification to assist in region-based image extraction and cancer probability analysis. The model also uses a continuous learning mechanism that helps to gradually improve the classification performance. Due to these characteristics, the proposed model is able to achieve a classification accuracy of 98.95%, a segmentation PSNR of 47.62 dB, and a delay of less than 900 s for input sets with a large number of images. This performance was compared with various state-of-the-art models, and it was observed that the proposed model had an accuracy that was 18.1% better than CNN [
5], 10.5% better than SPM [
8] and 2.3% better than DNN [
16] on the same dataset. It also demonstrated an improvement in PSNR of 14.6 dB compared to CNN [
5], an improvement of 10.5 dB compared to SPM [
8] and an improvement of 3.4 dB over DNN [
16], with a delay 25.1% lower than CNN [
5], 31.4% lower than SPM [
8] and 39.3% lower than DNN [
16] on the same dataset. This improvement was achieved through the development of better segmentation, classification and post-processing model designs. In the future, researchers can verify the performance of this model on other datasets, which will help to estimate its scalability and applicability to a wider range of images. In addition, researchers can also replace CNN models with recurrent NN (RNN) models to further improve classification the capabilities for larger datasets. This will help achieve better deployment performance for different clinical scenarios.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}