
Cross-Silo, Privacy-Preserving, and Lightweight Federated Multimodal System for the Identification of Major Depressive Disorder Using Audio and Electroencephalogram

 ,
,  , and
, and
Abstract
:1. Introduction
- To develop and analyze baseline EEG and audio-based multimodal systems for the classification of MDD.
- To implement and analyze privacy-preserved FL multimodal systems for the classification of MDD using EEG and audio databases.
- To analyze the impact of identical and non-identical multimodal Cross-Silo databases on the FL-based MDD classification system.
2. Materials and Methods
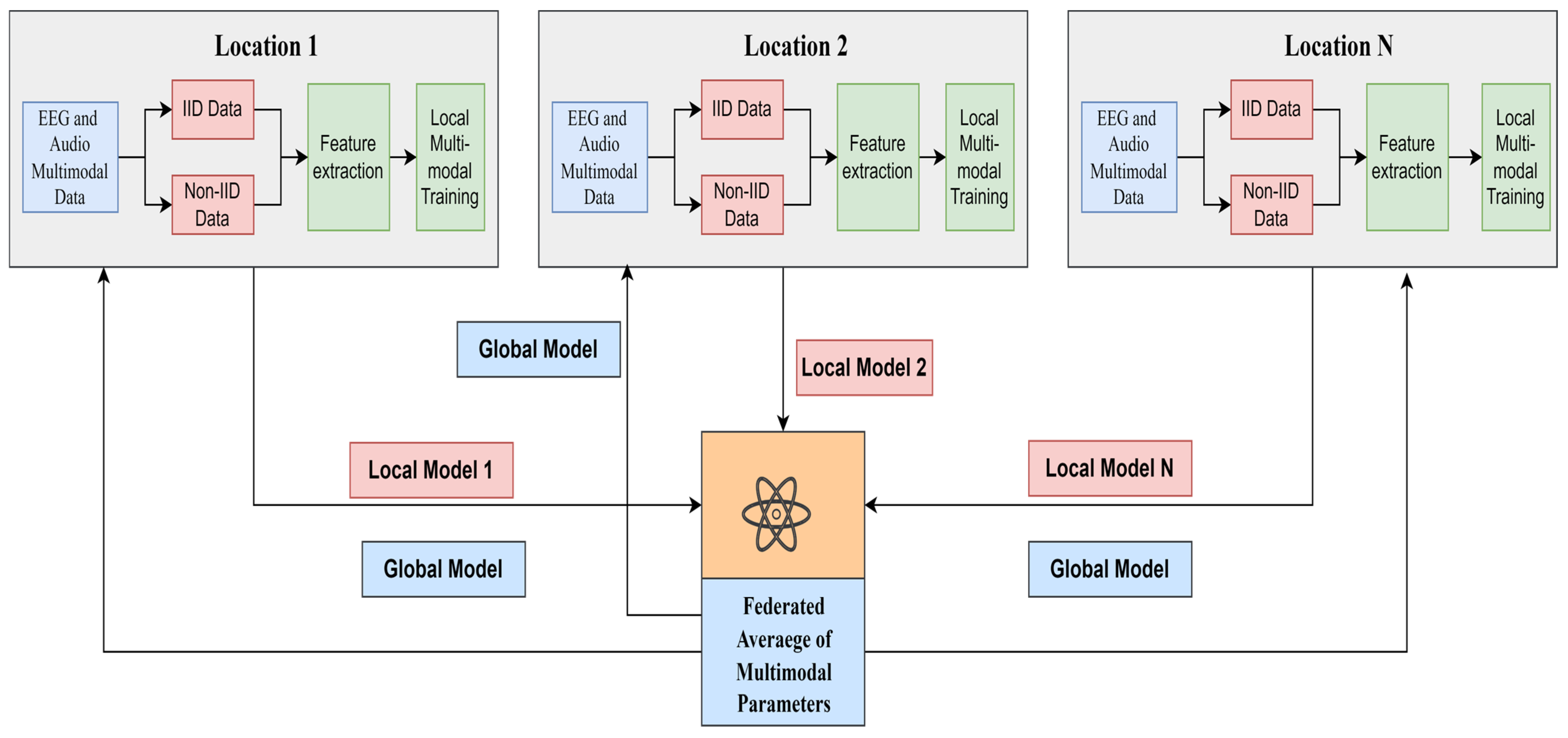
2.1. Proposed Multimodal Federated Learning Framework for MDD Classification
| Algorithm 1. Federated Averaging |
| K—number of clients from 1 to n B—minimum batch size E—number of epochs F—fractions of clients Server function—FedAvg Initialize global weights for round i = 1, 2…do ← max (F.K, 1) ← (random sets of M clients) for client k € do parallel ClientUpdate(k, ) end end Client function—ClientUpdate(k, ) B ← Split data into batches For each local epoch i from1 to E do Update client Return to server |
2.2. Deep Learning Methods
2.3. Multimodal Architecture
2.4. Data Acquisition
2.5. IIDs and Non-IIDs
3. Results
3.1. Deep Learning for Audio Dataset



3.2. Deep Learning for EEG Dataset
3.3. Deep Learning Using Multimodal Audio and EEG Datasets
3.4. Federated Learning Multimodal Using Audio and EEG Datasets
4. Discussion
5. Conclusions and Future Trends
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yasin, S.; Hussain, S.A.; Aslan, S.; Raza, I.; Muzammel, M.; Othmani, A. EEG Based Major Depressive Disorder and Bipolar Disorder Detection Using Neural Networks: A Review. Comput. Methods Programs Biomed. 2021, 202, 106007. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Depressive Disorder (Depression). 2023. Available online: https://www.who.int/news-room/fact-sheets/detail/depression (accessed on 21 November 2023).
- Uyulan, C.; Ergüzel, T.T.; Unubol, H.; Cebi, M.; Sayar, G.H.; Nezhad Asad, M.; Tarhan, N. Major Depressive Disorder Classification Based on Different Convolutional Neural Network Models: Deep Learning Approach. Clin. EEG Neurosci. 2021, 52, 38–51. [Google Scholar] [CrossRef] [PubMed]
- de Aguiar Neto, F.S.; Rosa, J.L.G. Depression Biomarkers Using Non-Invasive EEG: A Review. Neurosci. Biobehav. Rev. 2019, 105, 83–93. [Google Scholar] [CrossRef] [PubMed]
- Lam, G.; Dongyan, H.; Lin, W. Context-Aware Deep Learning for Multi-Modal Depression Detection. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1–5. [Google Scholar]
- Orabi, A.H.; Buddhitha, P.; Orabi, M.H.; Inkpen, D. Deep Learning for Depression Detection of Twitter Users. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, New Orleans, LA, USA, 5 June 2018; Loveys, K., Niederhoffer, K., Prud’hommeaux, E., Resnik, R., Resnik, P., Eds.; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 88–97. [Google Scholar]
- Ansari, L.; Ji, S.; Chen, Q.; Cambria, E. Ensemble Hybrid Learning Methods for Automated Depression Detection. IEEE Trans. Comput. Soc. Syst. 2023, 10, 211–219. [Google Scholar] [CrossRef]
- Xu, R.; Hua, A.; Wang, A.; Lin, Y. Early-Depression-Detection-for-Young-Adults-with-a-Psychiatric-and-Ai-Interdisciplinary-Multimodal-Framework. Int. J. Psychol. Behav. Sci. 2021, 15, 219–225. [Google Scholar]
- Barberis, A.; Petrini, E.M.; Mozrzymas, J.W. Impact of synaptic neurotransmitter concentration time course on the kinetics and pharmacological modulation of inhibitory synaptic currents. Front. Cell. Neurosci. 2011, 5, 6. [Google Scholar] [CrossRef]
- Cai, H.; Han, J.; Chen, Y.; Sha, X.; Wang, Z.; Hu, B.; Yang, J.; Feng, L.; Ding, Z.; Chen, Y.; et al. A Pervasive Approach to EEG-Based Depression Detection. Complexity 2018, 2018, 5238028. [Google Scholar] [CrossRef]
- Gupta, C.; Khullar, V. Contemporary Intelligent Technologies for Electroencephalogram-Based Brain Computer Interface. In Proceedings of the 2022 10th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions), ICRITO 2022, Noida, India, 13–14 October 2022. [Google Scholar]
- Tsouvalas, V.; Ozcelebi, T.; Meratnia, N. Privacy-preserving Speech Emotion Recognition through Semi-Supervised Federated Learning. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and Other Affiliated Events (PerCom Workshops), Pisa, Italy, 21–25 March 2022; pp. 359–364. [Google Scholar] [CrossRef]
- Fan, Z.; Su, J.; Gao, K.; Peng, L.; Qin, J.; Shen, H.; Hu, D.; Zeng, L.-L. Federated Learning on Structural Brain MRI Scans for the Diagnostic Classification of Major Depression. Biol. Psychiatry 2021, 89, S183. [Google Scholar] [CrossRef]
- Luo, J.; Wu, S. FedSLD: Federated Learning with Shared Label Distribution for Medical Image Classification. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- Ain, Q.u.; Khan, M.A.; Yaqoob, M.M.; Khattak, U.F.; Sajid, Z.; Khan, M.I.; Al-Rasheed, A. Privacy-Aware Collaborative Learning for Skin Cancer Prediction. Diagnostics 2023, 13, 2264. [Google Scholar] [CrossRef]
- Agbley, B.L.Y.; Li, J.; Hossin, M.A.; Nneji, G.U.; Jackson, J.; Monday, H.N.; James, E.C. Federated Learning-Based Detection of Invasive Carcinoma of No Special Type with Histopathological Images. Diagnostics 2022, 12, 1669. [Google Scholar] [CrossRef]
- Subashchandrabose, U.; John, R.; Anbazhagu, U.V.; Venkatesan, V.K.; Thyluru Ramakrishna, M. Ensemble Federated Learning Approach for Diagnostics of Multi-Order Lung Cancer. Diagnostics 2023, 13, 3053. [Google Scholar] [CrossRef] [PubMed]
- Ju, C.; Gao, D.; Mane, R.; Tan, B.; Liu, Y.; Guan, C. Federated Transfer Learning for EEG Signal Classification. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Montreal, QC, Canada, 20–24 July 2020; pp. 3040–3045. [Google Scholar]
- Khullar, V.; Singh, H.P. Privacy Protected Internet of Unmanned Aerial Vehicles for Disastrous Site Identification. Concurr. Comput. 2022, 34, e7040. [Google Scholar] [CrossRef]
- Wadhwa, S.; Saluja, K.; Gupta, S.; Gupta, D. Blockchain Based Federated Learning Approach for Detection of COVID-19 Using Io MT. SSRN Electron. J. 2022, 25, 760–764. [Google Scholar] [CrossRef]
- Sharma, S.; Guleria, K. A Comprehensive Review on Federated Learning Based Models for Healthcare Applications. Artif. Intell. Med. 2023, 146, 102691. [Google Scholar] [CrossRef] [PubMed]
- Sheu, R.K.; Chen, L.C.; Wu, C.L.; Pardeshi, M.S.; Pai, K.C.; Huang, C.C.; Chen, C.Y.; Chen, W.C. Multi-Modal Data Analysis for Pneumonia Status Prediction Using Deep Learning (MDA-PSP). Diagnostics 2022, 12, 1706. [Google Scholar] [CrossRef] [PubMed]
- Othmani, A.; Kadoch, D.; Bentounes, K.; Rejaibi, E.; Alfred, R.; Hadid, A. Towards Robust Deep Neural Networks for Affect and Depression Recognition from Speech. In Pattern Recognition: Proceedings of the ICPR International Workshops and Challenges, ICPR 2021, Virtual, 10–15 January 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 5–19. [Google Scholar]
- Zogan, H.; Razzak, I.; Wang, X.; Jameel, S.; Xu, G. Explainable Depression Detection with Multi-Modalities Using a Hybrid Deep Learning Model on Social Media. World Wide Web 2022, 25, 281–304. [Google Scholar] [CrossRef] [PubMed]
- Diwakar, A.; Kaur, T.; Ralekar, C.; Gandhi, T.K. Deep Learning Identifies Brain Cognitive Load via EEG Signals. In Proceedings of the 2020 IEEE 17th India Council International Conference, INDICON 2020, New Delhi, India, 10–13 December 2020. [Google Scholar]
- Saeedi, A.; Saeedi, M.; Maghsoudi, A.; Shalbaf, A. Major Depressive Disorder Diagnosis Based on Effective Connectivity in EEG Signals: A Convolutional Neural Network and Long Short-Term Memory Approach. Cogn. Neurodyn 2021, 15, 239–252. [Google Scholar] [CrossRef]
- Amanat, A.; Rizwan, M.; Javed, A.R.; Abdelhaq, M.; Alsaqour, R.; Pandya, S.; Uddin, M. Deep Learning for Depression Detection from Textual Data. Electronics 2022, 11, 676. [Google Scholar] [CrossRef]
- Escorcia-Gutierrez, J.; Beleño, K.; Jimenez-Cabas, J.; Elhoseny, M.; Dahman Alshehri, M.; Selim, M.M. An Automated Deep Learning Enabled Brain Signal Classification for Epileptic Seizure Detection on Complex Measurement Systems. Measurement 2022, 196, 111226. [Google Scholar] [CrossRef]
- Bhat, P.; Anuse, A.; Kute, R.; Bhadade, R.S.; Purnaye, P. Mental Health Analyzer for Depression Detection Based on Textual Analysis. J. Adv. Inf. Technol. 2022, 13, 67–77. [Google Scholar] [CrossRef]
- Adarsh, V.; Arun Kumar, P.; Lavanya, V.; Gangadharan, G.R. Fair and Explainable Depression Detection in Social Media. Inf. Process. Manag. 2023, 60, 103168. [Google Scholar] [CrossRef]
- Tutun, S.; Johnson, M.E.; Ahmed, A.; Albizri, A.; Irgil, S.; Yesilkaya, I.; Ucar, E.N.; Sengun, T.; Harfouche, A. An AI-Based Decision Support System for Predicting Mental Health Disorders. Inf. Syst. Front. 2023, 25, 1261–1276. [Google Scholar] [CrossRef] [PubMed]
- Mousavian, M.; Chen, J.; Traylor, Z.; Greening, S. Depression Detection from SMRI and Rs-FMRI Images Using Machine Learning. J. Intell. Inf. Syst. 2021, 57, 395–418. [Google Scholar] [CrossRef]
- Shen, G.; Jia, J.; Nie, L.; Feng, F.; Zhang, C.; Hu, T.; Chua, T.-S.; Zhu, W. Depression Detection via Harvesting Social Media: A Multimodal Dictionary Learning Solution. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3838–3844. [Google Scholar]
- Li, B.; Zhu, J.; Wang, C. Depression Severity Prediction by Multi-Model Fusion. In Proceedings of the HEALTHINFO 2018, the Third International Conference on Informatics and Assistive Technologies for Health-Care, Medical Support and Wellbeing, Nice, France, 14 October 2018; pp. 19–24. [Google Scholar]
- Wang, Y.; Wang, Z.; Li, C.; Zhang, Y.; Wang, H. A Multimodal Feature Fusion-Based Method for Individual Depression Detection on Sina Weibo. In Proceedings of the 2020 IEEE 39th International Performance Computing and Communications Conference, IPCCC 2020, Austin, TX, USA, 6–8 November 2020; pp. 1–8. [Google Scholar]
- Pessanha, F.; Kaya, H.; Akdag Salah, A.A.; Salah, A.A. Towards Using Breathing Features for Multimodal Estimation of Depression Severity. In Proceedings of the 2022 International Conference on Multimodal Interaction, Bengaluru, India, 7–11 November 2022; pp. 128–138. [Google Scholar]
- Zhou, L.; Liu, Z.; Shangguan, Z.; Yuan, X.; Li, Y.; Hu, B. TAMFN: Time-Aware Attention Multimodal Fusion Network for Depression Detection. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 669–679. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Peng, H.; Bhuiyan, M.Z.A.; Hao, Z.; Liu, L.; Sun, L.; He, L. Privacy-Preserving Federated Depression Detection from Multisource Mobile Health Data. IEEE Trans. Ind. Inform. 2022, 18, 4788–4797. [Google Scholar] [CrossRef]
- Bn, S.; Abdullah, S. Privacy Sensitive Speech Analysis Using Federated Learning to Assess Depression. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6272–6276. [Google Scholar]
- Cui, Y.; Li, Z.; Liu, L.; Zhang, J.; Liu, J. Privacy-Preserving Speech-Based Depression Diagnosis via Federated Learning. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, Glasgow, UK, 11–15 July 2022; pp. 1371–1374. [Google Scholar]
- Pranto, M.A.M.; Al Asad, N. A Comprehensive Model to Monitor Mental Health Based on Federated Learning and Deep Learning. In Proceedings of the 2021 IEEE International Conference on Signal Processing, Information, Communication and Systems, SPICSCON 2021, Dhaka, Bangladesh, 3–4 December 2021; pp. 18–21. [Google Scholar]
- Asad, N.A.; Pranto, A.M.; Afreen, S.; Islam, M. Depression Detection by Analyzing Social Media Posts of User. In Proceedings of the 2019 IEEE International Conference on Signal Processing, Information, Communication & Systems (SPICSCON), Dhaka, Bangladesh, 28–30 November 2019; pp. 13–17. [Google Scholar]
- Alsagri, H.S.; Ykhlef, M. Machine Learning-Based Approach for Depression Detection in Twitter Using Content and Activity Features. IEICE Trans. Inf. Syst. 2020, E103D, 1825–1832. [Google Scholar] [CrossRef]
- Prakash, A.; Agarwal, K.; Shekhar, S.; Mutreja, T.; Chakraborty, P.S. An Ensemble Learning Approach for the Detection of Depression and Mental Illness over Twitter Data. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development, INDIACom 2021, New Delhi, India, 17–19 March 2021; pp. 565–570. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 423–443. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wang, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Cai, H.; Gao, Y.; Sun, S.; Li, N.; Xiao, H.; Li, J.; Yang, Z.; Li, X.; Zhao, Q.; Liu, Z.; et al. MODMA Dataset: A Multi-Modal Open Dataset for Mental-Disorder Analysis. arXiv 2020, arXiv:2002.09283. [Google Scholar]
- Shi, Q.; Liu, A.; Chen, R.; Shen, J.; Zhao, Q.; Hu, B. Depression Detection Using Resting State Three-Channel EEG Signal. arXiv 2020, arXiv:2002.09175. [Google Scholar]
- Li, Y.; Shen, Y.; Fan, X.; Huang, X.; Yu, H.; Zhao, G.; Ma, W. A Novel EEG-Based Major Depressive Disorder Detection Framework with Two-Stage Feature Selection. BMC Med. Inform. Decis. Mak. 2022, 22, 209. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wang, D.; Zhang, L.; Hu, B. A Novel Decision Tree for Depression Recognition in Speech. arXiv 2020, arXiv:2002.12759. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Data Type | Method Applied | Multi-Modality | Data Privacy | Parameters |
|---|---|---|---|---|---|
| [23] | Speech data | Deep Neural Network Architecture | No | No | 96.7% |
| [24] | X, formerly Twitter data | Hybrid DL Model | No | No | F1 score 89% |
| [25] | EEG data | 1D CNN Model | No | No | Accuracy 90.5% |
| [26] | EEG data | DL Models | No | No | Accuracy 99.24% |
| [27] | Text data | Deep Learning Model | No | No | Accuracy 99% |
| [28] | EEG data | Deep Belief Network (DBN) Model | No | No | Accuracy 83.16%, 86.09% under binary and multiple classes |
| [29] | X, formerly Twitter data | DL Models | No | No | Got high accuracy of 98% with CNN |
| [30] | Reddit data | EL Model | No | No | Accuracy 98.05% |
| [31] | Questionnaire data | AI-based Decision Support System | No | No | Accuracy 89% |
| References | Features Extracted | Method Applied | Data Privacy | Parameters |
|---|---|---|---|---|
| [33] | Social networks, visual, emotional, and user profile | A Multimodal Dictionary Learning | No | F1-measure is 85% |
| [34] | Audio, video, and text data | Multi-model Fusion | No | Root Mean Square Error is 5.98 |
| [35] | Text, picture, and behaviour | Multimodal Feature Fusion Network | No | F1-score is 0.9685 |
| [36] | Audio and text | Cross Dataset Prediction | No | Root Mean Square Error is 5.62 using Lenear Regression model |
| [37] | Audio and image | Time-Aware Attention-based Multimodal Fusion Depression Detection Network | No | F1-score is 0.75 |
| References | Data Type | Method Applied | Multi-Modality | Data Privacy | Parameters |
|---|---|---|---|---|---|
| [38] | Multi-source mobile health data | FL Model | No | Yes | Accuracy 85.13% |
| [39] | Speech data | FL Method | No | Yes | Accuracy 87% |
| [40] | Audio data | FL Model | No | Yes | Accuracy with IID 86.3% and with non-IID 85.3% |
| [41] | Text data | FL Framework | No | Yes | Accuracy 93.46% |
| Subject Type | Age (in Years) | Gender | |
|---|---|---|---|
| Male | Female | ||
| Has Depression | 16–56 | 15 | 11 |
| No Depression | 18–55 | 19 | 10 |
| Parameters | Bi LSTM | CNN | LSTM |
|---|---|---|---|
| Accuracy | 99.08333 | 99.66667 | 99.33333 |
| Val Accuracy | 91 | 85 | 89 |
| Precision | 99.08333 | 99.66667 | 99.33333 |
| Val Precision | 91 | 85 | 89 |
| Recall | 99.08333 | 99.66667 | 99.33333 |
| Val Recall | 91 | 85 | 89 |
| Loss | 0.032376 | 0.012926 | 0.015737 |
| Val Loss | 0.349078 | 0.439554 | 0.347897 |
| Parameters | BiLSTM | CNN | LSTM |
|---|---|---|---|
| Accuracy | 99.28598 | 98.99417 | 99.19285 |
| Val Accuracy | 98.95704 | 96.92078 | 98.93221 |
| Precision | 99.28598 | 98.99417 | 99.19285 |
| Val Precision | 98.95704 | 96.92078 | 98.93221 |
| Recall | 99.28598 | 98.99417 | 99.19285 |
| Val Recall | 98.95704 | 96.92078 | 98.93221 |
| Loss | 0.019303 | 0.02646 | 0.023499 |
| Val Loss | 0.043929 | 0.09795 | 0.047406 |
| Parameters | DL Multimodal |
|---|---|
| Accuracy | 99.99411 |
| Validation Accuracy | 100 |
| Precision | 99.97054 |
| Validation Precision | 100 |
| Recall | 99.95877 |
| Validation Recall | 100 |
| Loss | 0.00047 |
| Validation Loss | 0.000117 |
| IID Settings | |
|---|---|
| Parameters | FL Multimodal |
| Accuracy | 99.94 |
| Validation Accuracy | 99.93 |
| Precision | 99.97 |
| Validation Precision | 99.9 |
| Recall | 99.88 |
| Validation Recall | 99.94 |
| Loss | 0 |
| Validation Loss | 0 |
| Non-IID Settings | |
|---|---|
| Parameters | FL Multimodal |
| Accuracy | 99.99 |
| Validation Accuracy | 99.97 |
| Precision | 99.99 |
| Validation Precision | 99.96 |
| Recall | 99.99 |
| Validation Recall | 99.95 |
| Loss | 0 |
| Validation Loss | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gupta, C.; Khullar, V.; Goyal, N.; Saini, K.; Baniwal, R.; Kumar, S.; Rastogi, R. Cross-Silo, Privacy-Preserving, and Lightweight Federated Multimodal System for the Identification of Major Depressive Disorder Using Audio and Electroencephalogram. Diagnostics 2024, 14, 43. https://doi.org/10.3390/diagnostics14010043
Gupta C, Khullar V, Goyal N, Saini K, Baniwal R, Kumar S, Rastogi R. Cross-Silo, Privacy-Preserving, and Lightweight Federated Multimodal System for the Identification of Major Depressive Disorder Using Audio and Electroencephalogram. Diagnostics. 2024; 14(1):43. https://doi.org/10.3390/diagnostics14010043
Chicago/Turabian StyleGupta, Chetna, Vikas Khullar, Nitin Goyal, Kirti Saini, Ritu Baniwal, Sushil Kumar, and Rashi Rastogi. 2024. "Cross-Silo, Privacy-Preserving, and Lightweight Federated Multimodal System for the Identification of Major Depressive Disorder Using Audio and Electroencephalogram" Diagnostics 14, no. 1: 43. https://doi.org/10.3390/diagnostics14010043
APA StyleGupta, C., Khullar, V., Goyal, N., Saini, K., Baniwal, R., Kumar, S., & Rastogi, R. (2024). Cross-Silo, Privacy-Preserving, and Lightweight Federated Multimodal System for the Identification of Major Depressive Disorder Using Audio and Electroencephalogram. Diagnostics, 14(1), 43. https://doi.org/10.3390/diagnostics14010043