
Automated Laryngeal Invasion Detector of Boluses in Videofluoroscopic Swallowing Study Videos Using Action Recognition-Based Networks
 , , , and
, , , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Video Fluoroscopic Swallowing Study
2.2. Dataset
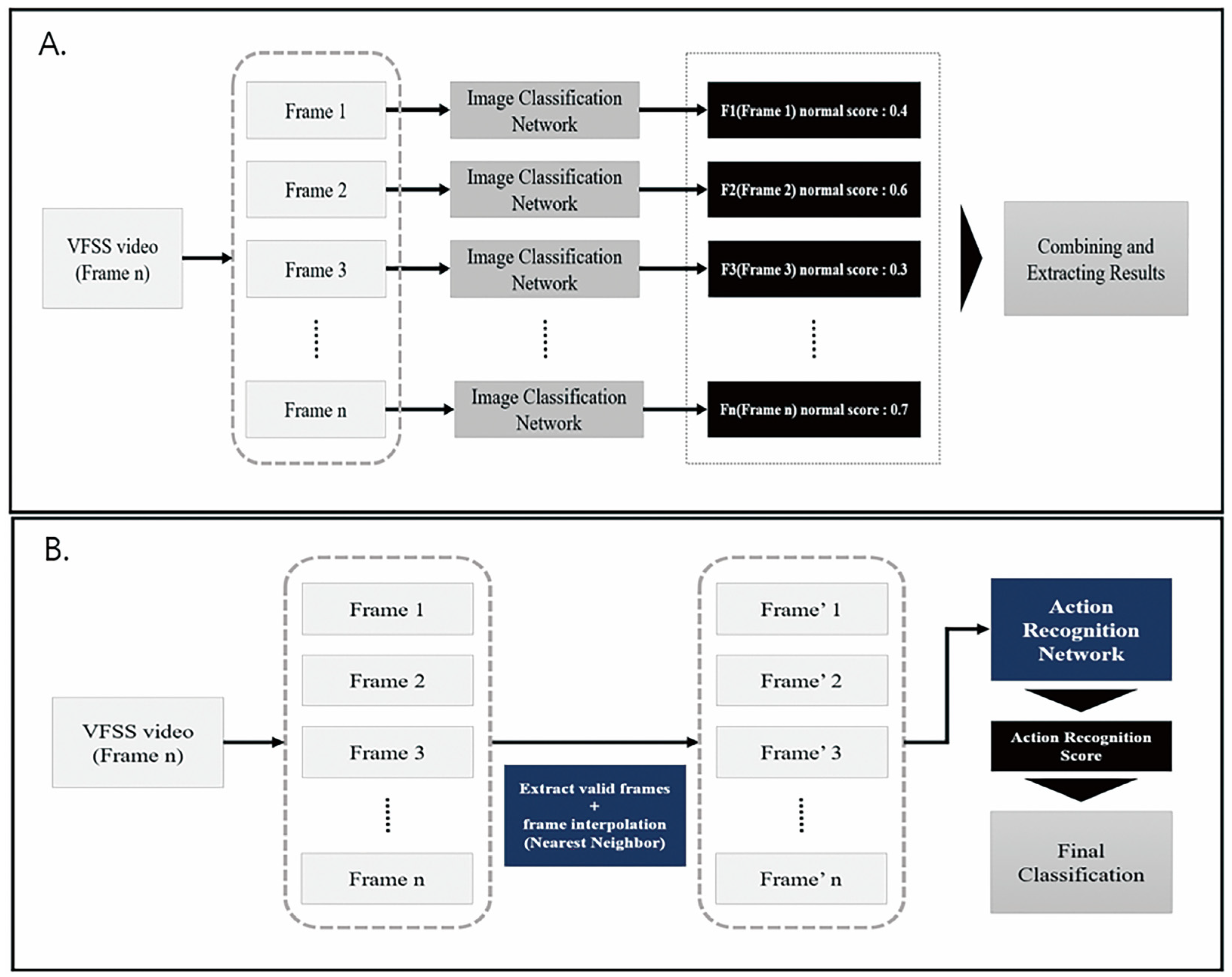
2.3. Deep Learning Architecture for Action Recognition
2.4. Application of Architecture for Action Recognition on VFSS
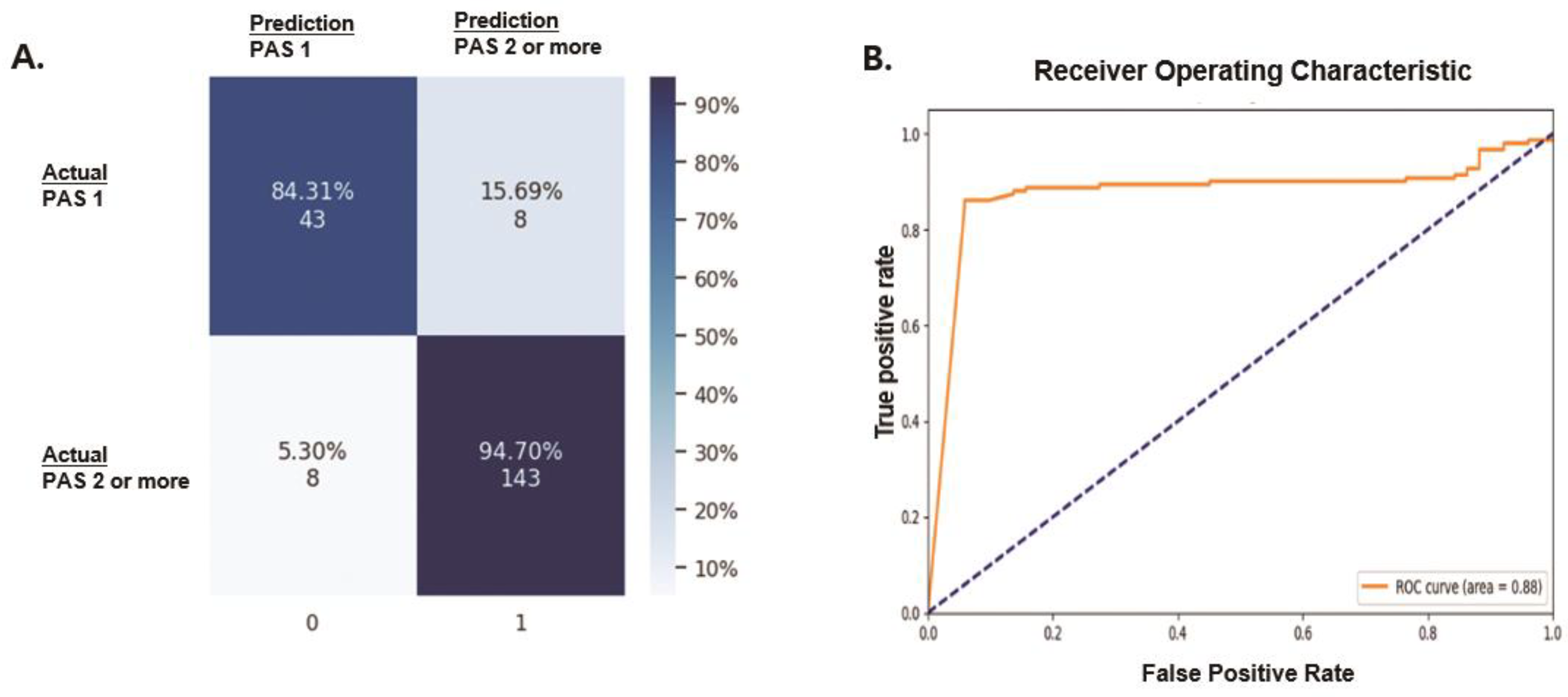
3. Results
Performance
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matsuo, K.; Palmer, J.B. Anatomy and physiology of feeding and swallowing: Normal and abnormal. Phys. Med. Rehabil. Clin. N. Am. 2008, 19, 691–707. [Google Scholar] [CrossRef]
- Pauloski, B.R. Rehabilitation of dysphagia following head and neck cancer. Phys. Med. Rehabil. Clin. N. Am. 2008, 19, 889–928. [Google Scholar] [CrossRef]
- Martin-Harris, B.; Jones, B. The videofluorographic swallowing study. Phys. Med. Rehabil. Clin. N. Am. 2008, 19, 769–785. [Google Scholar] [CrossRef]
- Gramigna, G.D. How to perform video-fluoroscopic swallowing studies. GI Motil. Online 2006. [Google Scholar] [CrossRef]
- Edwards, A.; Froude, E.; Sharpe, G. Developing competent videofluoroscopic swallowing study analysts. Curr. Opin. Otolaryngol. Head Neck Surg. 2018, 26, 162–166. [Google Scholar] [CrossRef]
- Bhinder, B.; Gilvary, C.; Madhukar, N.S.; Elemento, O. Artificial Intelligence in Cancer Research and Precision Medicine. Cancer Discov. 2021, 11, 900–915. [Google Scholar] [CrossRef]
- Miller, D.D.; Brown, E.W. Artificial Intelligence in Medical Practice: The Question to the nswer? Am. J. Med. 2018, 131, 129–133. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef]
- Wang, R.; Chen, S.; Ji, C.; Fan, J.; Li, Y. Boundary-aware context neural network for medical image segmentation. Med. Image Anal. 2022, 78, 102395. [Google Scholar] [CrossRef]
- Lee, S.J.; Ko, J.Y.; Kim, H.I.; Choi, S.-I. Automatic Detection of Airway Invasion from Videofluoroscopy via Deep Learning Technology. Appl. Sci. 2020, 10, 6179. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data. 2021, 8, 53. [Google Scholar] [CrossRef]
- Yang, Q.; Lu, T.; Zhou, H. A spatio-temporal motion network for action recognition based on spatial attention. Entropy 2022, 24, 368. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the 2014 IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ramanathan, M.; Yau, W.-Y.; Teoh, E.K. Human action recognition with video data: Research and evaluation challenges. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 650–663. [Google Scholar] [CrossRef]
- Li, T.; Foo, L.G.; Ke, Q.; Rahmani, H.; Wang, A.; Wang, J.; Liu, J. (Eds.) Dynamic spatio-temporal specialization learning for fine-grained action recognition. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Park, J.W.; Oh, J.C.; Lee, J.W.; Yeo, J.S.; Ryu, K.H. The effect of 5Hz high-frequency rTMS over contralesional pharyngeal motor cortex in post-stroke oropharyngeal dysphagia: A randomized controlled study. Neurogastroenterol. Motil. 2013, 25, 324-e250. [Google Scholar] [CrossRef]
- Rosenbek, J.C.; Robbins, J.A.; Roecker, E.B.; Coyle, J.L.; Wood, J.L. A penetration–aspiration scale. Dysphagia 1996, 11, 93–98. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Rukundo, O.; Cao, H. Nearest neighbor value interpolation. arXiv 2012, arXiv:12111768. [Google Scholar]
- Lin, C.-J.; Lin, C.-W. Using Three-dimensional Convolutional Neural Networks for Alzheimer’s Disease Diagnosis. Sens. Mater. 2021, 33, 3399–3413. [Google Scholar] [CrossRef]
- Liao, Y.; Lu, S.; Yang, Z.; Liu, W. Depthwise grouped convolution for object detection. Mach. Vision Appl. 2021, 32, 1–13. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xu, H.; Das, A.; Saenko, K. Two-stream region convolutional 3D network for temporal activity detection. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2319–2332. [Google Scholar] [CrossRef]
- Feng, Z.; Sivak, J.A.; Krishnamurthy, A.K. Two-stream attention spatio-temporal network for classification of echocardiography videos. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Pham, H.H.; Khoudour, L.; Crouzil, A.; Zegers, P.; Velastin, S.A. Video-based human action recognition using deep learning: A review. arXiv 2022, arXiv:220803775. [Google Scholar]
- Huang, X.; Cai, Z. A review of video action recognition based on 3D convolution. Comput. Electr. Eng. 2023, 108, 108713. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, X.; Liu, C.; Zolfaghari, M.; Xiong, Y.; Wu, C.; Zhang, Z.; Tighe, J.; Manmatha, R.; Li, M. A comprehensive study of deep video action recognition. arXiv 2020, arXiv:201206567. [Google Scholar]
- Liu, H.; Tu, J.; Liu, M. Two-stream 3d convolutional neural network for skeleton-based action recognition. arXiv 2017, arXiv:170508106. [Google Scholar]
- Jeong, S.Y.; Kim, J.M.; Park, J.E.; Baek, S.J.; Yang, S.N. Application of deep learning technology for temporal analysis of videofluoroscopic swallowing studies. Sci. Rep. 2023, 13, 17522. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Classification | Precision | Recall | F1 Score |
|---|---|---|---|
| Absence of laryngeal invasion (PAS 1) | 0.8431 | 0.8431 | 0.8431 |
| Presence of laryngeal invasion (PAS 2 or higher) | 0.9470 | 0.9470 | 0.9470 |
| Type | Model | Valid Accuracy |
|---|---|---|
| Image | resnet101 | 60.39% (122/202) |
| swin-transformer | 60.19% (125/202) | |
| efficientnet-b2 | 63.36% (128/202) | |
| HRnet-w32 | 61.38% (124/202) | |
| Video | Our model | 92.10% (186/202) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nam, K.; Lee, C.; Lee, T.; Shin, M.; Kim, B.H.; Park, J.-W. Automated Laryngeal Invasion Detector of Boluses in Videofluoroscopic Swallowing Study Videos Using Action Recognition-Based Networks. Diagnostics 2024, 14, 1444. https://doi.org/10.3390/diagnostics14131444
Nam K, Lee C, Lee T, Shin M, Kim BH, Park J-W. Automated Laryngeal Invasion Detector of Boluses in Videofluoroscopic Swallowing Study Videos Using Action Recognition-Based Networks. Diagnostics. 2024; 14(13):1444. https://doi.org/10.3390/diagnostics14131444
Chicago/Turabian StyleNam, Kihwan, Changyeol Lee, Taeheon Lee, Munseop Shin, Bo Hae Kim, and Jin-Woo Park. 2024. "Automated Laryngeal Invasion Detector of Boluses in Videofluoroscopic Swallowing Study Videos Using Action Recognition-Based Networks" Diagnostics 14, no. 13: 1444. https://doi.org/10.3390/diagnostics14131444
APA StyleNam, K., Lee, C., Lee, T., Shin, M., Kim, B. H., & Park, J.-W. (2024). Automated Laryngeal Invasion Detector of Boluses in Videofluoroscopic Swallowing Study Videos Using Action Recognition-Based Networks. Diagnostics, 14(13), 1444. https://doi.org/10.3390/diagnostics14131444