



Evaluation of Machine Learning Classification Models for False-Positive Reduction in Prostate Cancer Detection Using MRI Data
 , , ,
, , ,
Abstract
1. Introduction
- Is the classification performance affected by incorporating localization information using the ROI?
- Is classical machine learning or deep learning more beneficial in solving the issue?
- Can the pipeline performance be improved by adding a classification algorithm?
2. Materials and Methods
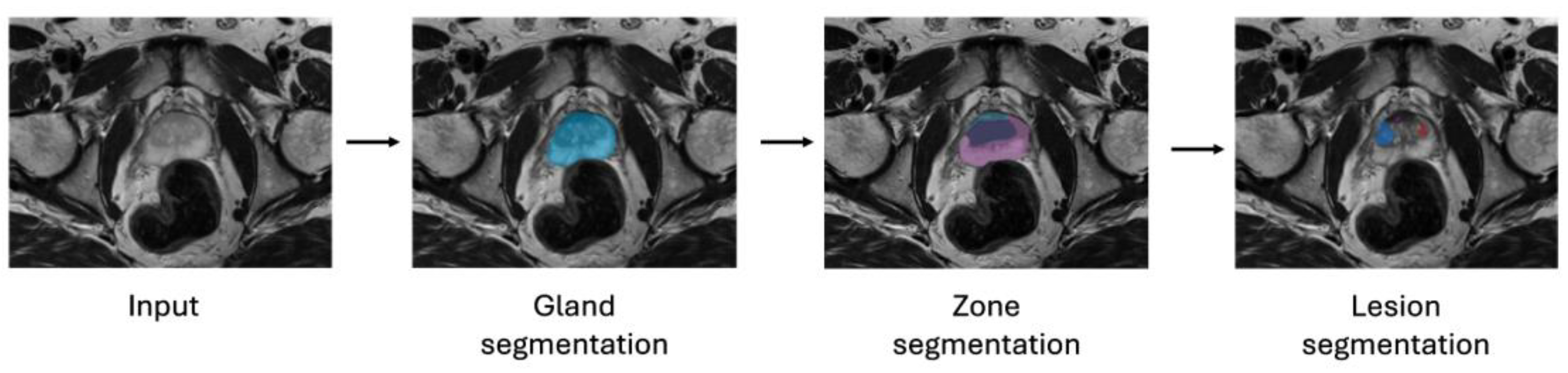
2.1. Image Data and Labels
- Patients younger than 45 years;
- Patients who had undergone previous prostate surgeries (ICD-10-PCS 0VT0 Resection of Prostate, 0VB0 Excision of the Prostate);
- Patients (ICD 0VB-03ZX) who had a prostate biopsy less than six months ago.
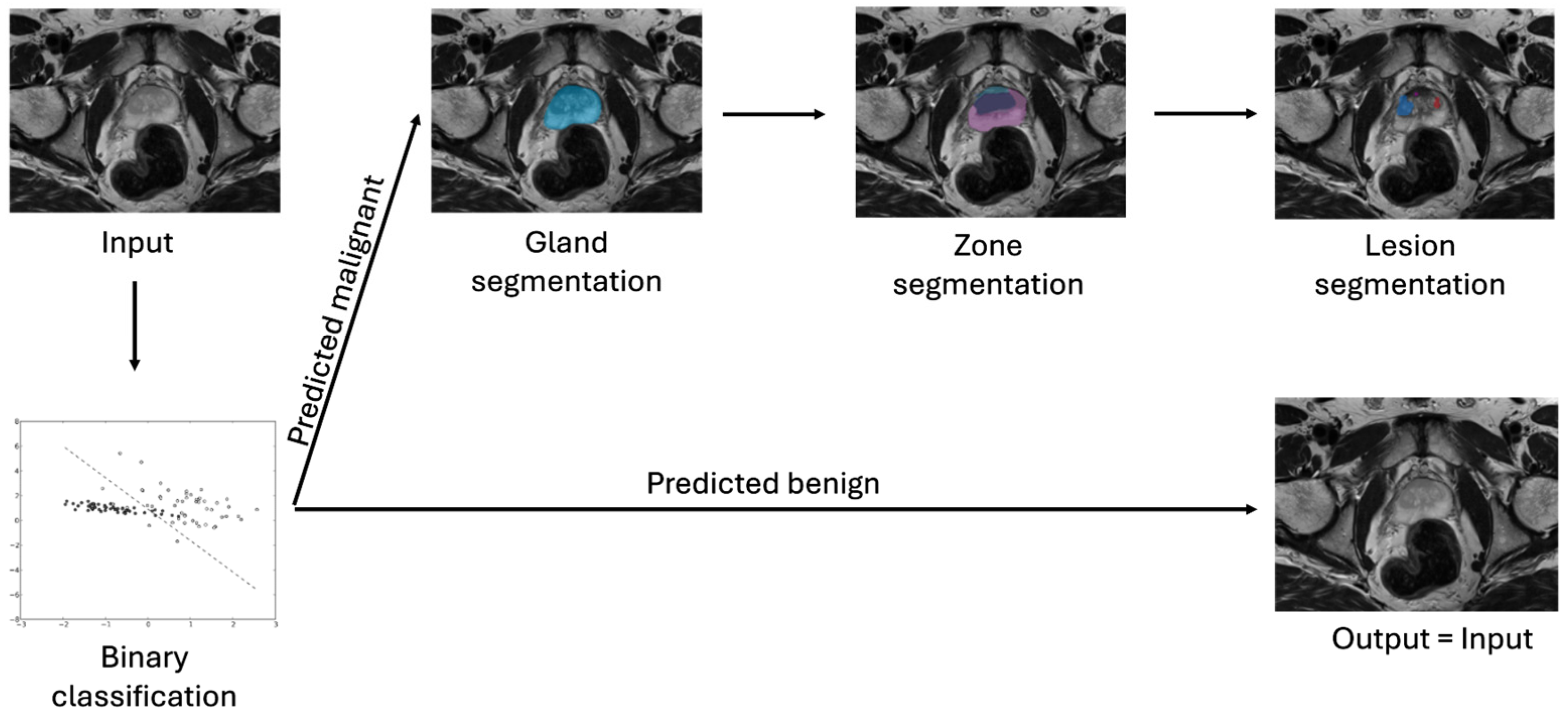
2.2. Models
2.3. Methods
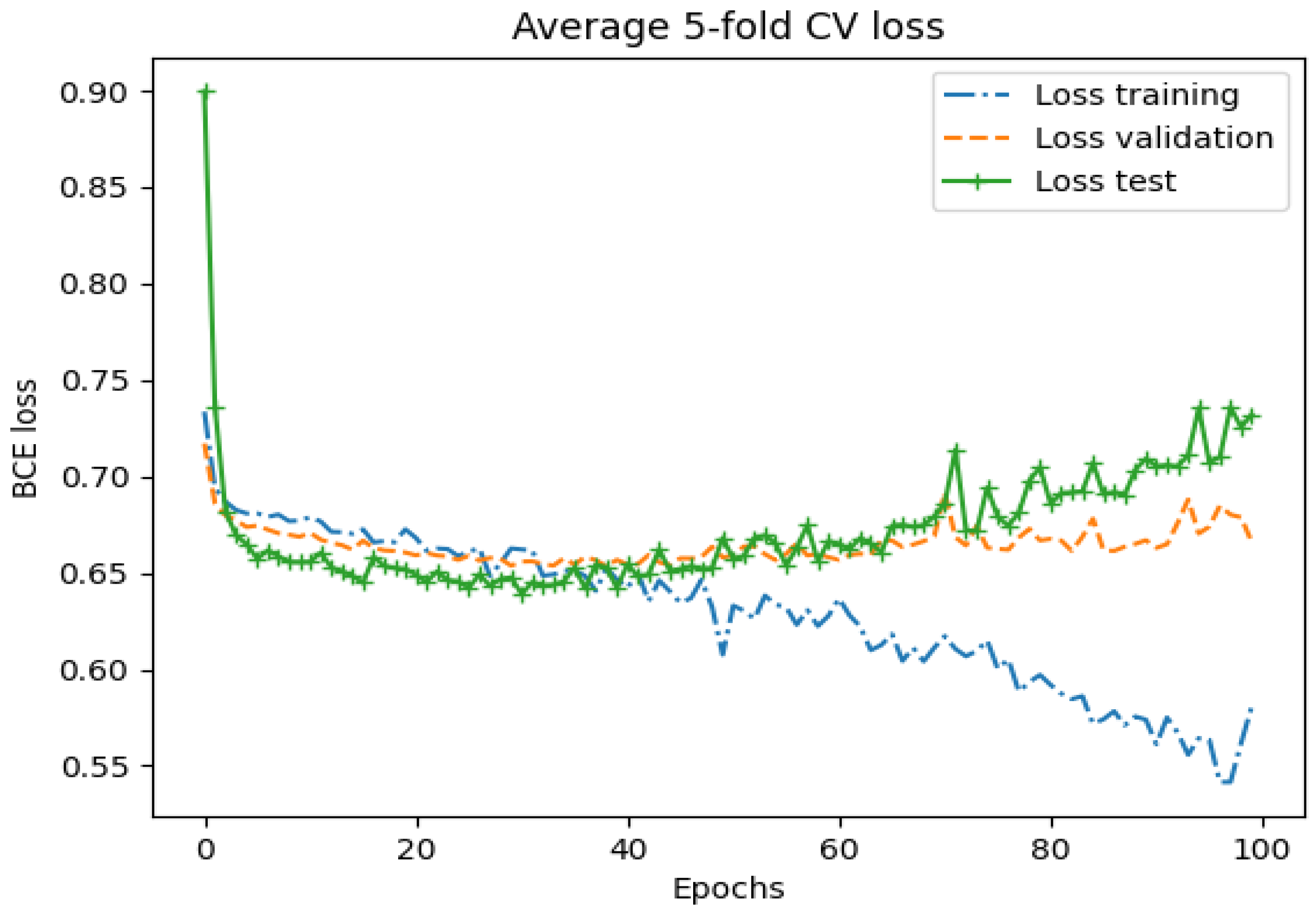
2.4. Experiment Setup
3. Results
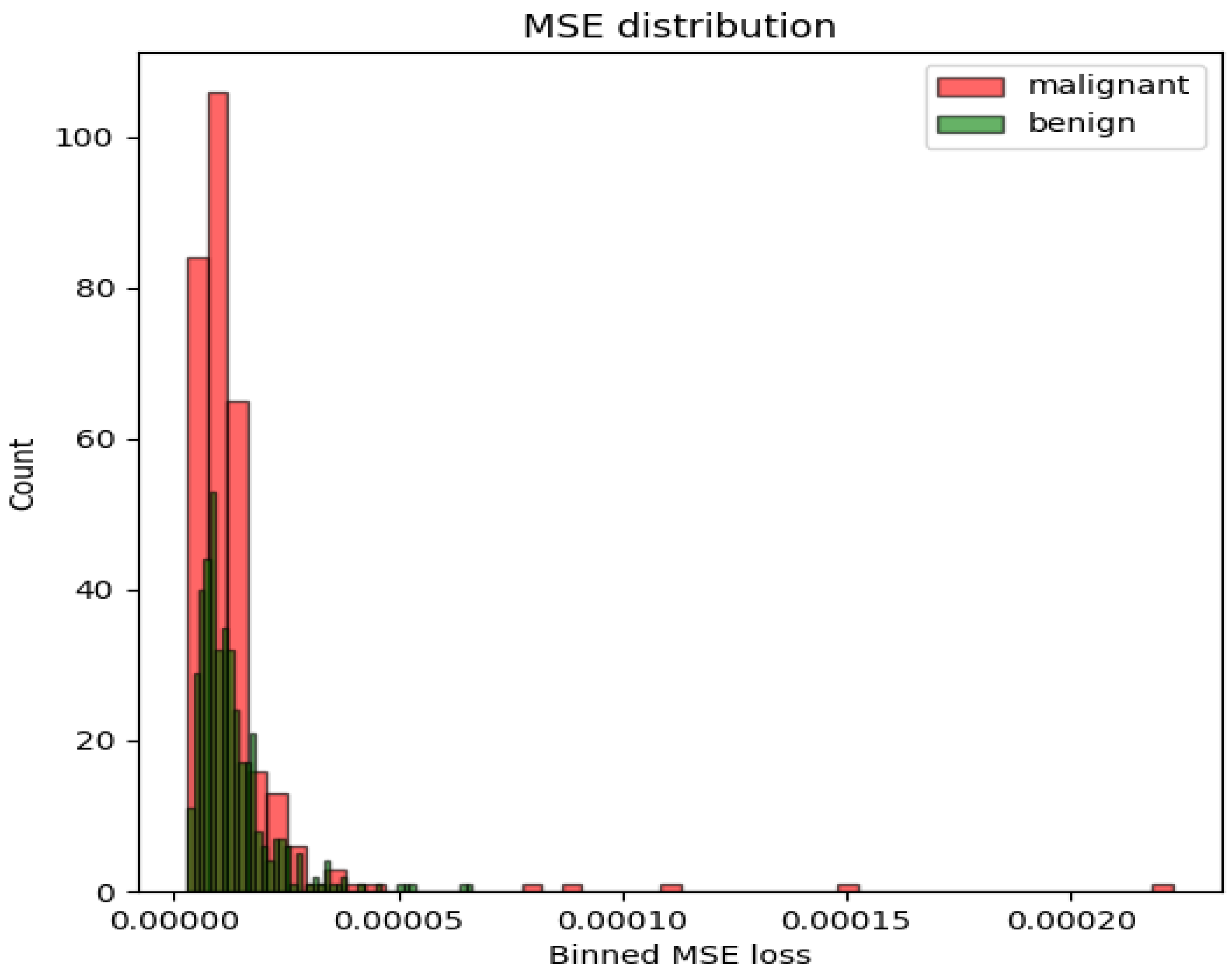
3.1. Whole-Image Results
3.2. Region-Based Results
3.3. Performance Measurement in the Segmentation Pipeline
4. Discussion
4.1. Discussion of Methods
4.2. Discussion of Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Ferlay, J.; Ervik, M.; Lam, F.; Laversanne, M.; Mery, L.; Piñeros, M.; Znaor, A.; Soerjomataram, I.; Bray, F. Global Cancer Observatory: Cancer Today; International Agency for Research on Cancer: Lyon, France, 2024; Available online: https://gco.iarc.who.int/today (accessed on 30 July 2024).
- Siegel, R.L.; Miller, K.D.; Wagle, N.S.; Jemal, A. Cancer statistics. CA Cancer J. Clin. 2023, 73, 17–48. [Google Scholar] [CrossRef] [PubMed]
- Kufel, J.; Bargieł-Łączek, K.; Kocot, S.; Koźlik, M.; Bartnikowska, W.; Janik, M.; Czogalik, Ł.; Dudek, P.; Magiera, M.; Lis, A.; et al. What Is Machine Learning, Artificial Neural Networks and Deep Learning?—Examples of Practical Applications in Medicine. Diagnostics 2023, 13, 2582. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Lee, C.H.; Chia, D.; Lin, Z.; Huang, W.; Tan, C.H. Machine learning in prostate MRI for prostate cancer: Current status and future opportunities. Diagnostics 2022, 12, 289. [Google Scholar] [CrossRef] [PubMed]
- Schelb, P.; Kohl, S.; Radtke, J.P.; Wiesenfarth, M.; Kickingereder, P.; Bickelhaupt, S.; Kuder, T.A.; Stenzinger, A.; Hohenfellner, M.; Schlemmer, H.P.; et al. Classification of cancer at prostate MRI: Deep learning versus clinical PI-RADS assessment. Radiology 2019, 293, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Arif, M.; Schoots, I.G.; Tovar, J.C.; Bangma, C.H.; Krestin, G.P.; Roobol, M.J.; Niessen, W.; Veenland, J.F. Clinically significant prostate cancer detection and segmentation in low-risk patients using a convolutional neural network on multi-parametric MRI. Eur. Radiol. 2020, 30, 6582–6592. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Debats, O.; Barentsz, J.; Karssemeijer, N.; Huisman, H. SPIE-AAPM PROSTATEx Challenge Data (Version 2) [dataset]. The Cancer Imaging Archive. Cancer Imaging Arch. 2017, 10, K9TCIA. [Google Scholar] [CrossRef]
- Gordetsky, J.; Epstein, J. Grading of prostatic adenocarcinoma: Current state and prognostic implications. Diagn. Pathol. 2016, 11, 25. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Zhou, Z.; Sodha, V.; Pang, J.; Gotway, M.B.; Liang, J. Models genesis. Comput. Vis. Pattern Recognit. 2020, 67, 101840. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef]
- Dupre, R.; Argyriou, V.; Greenhill, D.; Tzimiropoulos, G. A 3d scene analysis framework and descriptors for risk evaluation. In Proceedings of the 2015 International Conference on 3D Vision, Lyon, France, 19–22 October 2015. [Google Scholar] [CrossRef]
- Min, X.; Li, M.; Dong, D.; Feng, Z.; Zhang, P.; Ke, Z.; You, H.; Han, F.; Ma, H.; Tian, J.; et al. Multi-parametric MRI-based radiomics signature for discriminating between clinically significant and insignificant prostate cancer: Cross-validation of a machine learning method. Eur. J. Radiol. 2019, 115, 16–21. [Google Scholar] [CrossRef]
- Lindauer, M.; Eggensperger, K.; Feurer, M.; Biedenkapp, A.; Deng, D.; Benjamins, C.; Ruhopf, T.; Sass, R.; Hutter, F. Smac3: A versatile bayesian optimization package for hyperparameter optimization. Mach. Learn. (Stat.ML) 2022, 23, 1–9. [Google Scholar] [CrossRef]
- Guo, Y.; Liao, W.; Wang, Q.; Yu, L.; Ji, T.; Li, P. Multidimensional time series anomaly detection: A gru-based gaussian mixture variational autoencoder approach. Proc. Mach. Learn. Res. 2018, 95, 97–112. Available online: https://proceedings.mlr.press/v95/guo18a.html (accessed on 30 July 2024).
- Blendowski, M.; Nickisch, H.; Heinrich, M.P. How to learn from unlabeled volume data: Self-supervised 3d context feature learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 649–657. [Google Scholar] [CrossRef]
- Noroozi, M.; Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- McNeal, J.E.; Redwine, E.A.; Freiha, F.S.; Stamey, T.A. Zonal distribution of prostatic adenocarcinoma. Am. J. Surg. Pathol. 1988, 12, 897–906. [Google Scholar] [CrossRef]
- Murphy, G.; Haider, M.; Ghai, S.; Sreeharsha, B. The expanding role of MRI in prostate cancer. Am. J. Roentgenol. 2013, 201, 1229–1238. [Google Scholar] [CrossRef] [PubMed]
- Han, S.M.; Lee, H.J.; Choi, J.Y. Computer-aided prostate cancer detection using texture features and clinical features in ultrasound image. J. Digit. Imaging 2008, 21, 121–133. [Google Scholar] [CrossRef] [PubMed]
- Abraham, B.; Nair, M.S. Computer-aided classification of prostate cancer grade groups from MRI images using texture features and stacked sparse autoen coder. Comput. Med. Imaging Graph. 2018, 69, 60–68. [Google Scholar] [CrossRef]
- Jensen, C.; Carl, J.; Boesen, L.; Langkilde, N.C.; Østergaard, L.R. Assessment of prostate cancer prognostic gleason grade group using zonal-specific features extracted from biparametric MRI using a KNN classifier. J. Appl. Clin. Med. Phys. 2019, 20, 146–153. [Google Scholar] [CrossRef]
- Toivonen, J.; Perez, I.M.; Movahedi, P.; Merisaari, H.; Pesola, M.; Taimen, P.; Bostrom, P.J.; Pohjankukka, J.; Kiviniemi, A.; Pahikkala, T.; et al. Radiomics and machine learning of multisequence multiparametric prostate MRI: Towards improved non-invasive prostate cancer characterization. PLoS ONE 2019, 14, e0217702. [Google Scholar] [CrossRef]
- Cameron, A.; Khalvati, F.; Haider, M.A.; Wong, A. MAPS: A quantitative radiomics approach for prostate cancer detection. IEEE Trans. Biomed. Eng. 2015, 63, 1145–1156. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, H.; Feng, Y.; Li, W. Prostate cancer diagnosis using deep learning with 3d multiparametric MRI. Comput. Vis. Pattern Recognit. 2017, 10134, 581–584. [Google Scholar] [CrossRef]
- Blendowski, M.; Bouteldja, N.; Heinrich, M.P. Multimodal 3d medical image registration guided by shape encoder–decoder networks. Int. J. Comput. Assist. Radiol. Surg. 2019, 15, 269–276. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Li, L.; Tang, M.; Huan, Y.; Zhang, X.; Zhe, X. A new approach to diagnosing prostate cancer through magnetic resonance imaging. Alex. Eng. J. 2020, 60, 897–904. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | AUC-ROC | Sensitivity | Specificity | Feature Set | Selection (# Features) |
|---|---|---|---|---|---|
| SVM | 0.6016 | 0.3611 | 0.8421 | LBP + HOG | PCA (95) |
| XGB | 0.5782 | 0.2223 | 0.9342 | LBP + HOG + Haralick | None (891) |
| MLP | 0.5762 | 0.3056 | 0.8158 | LBP + HOG + Haralick | None (891) |
| Architecture | AUC-ROC | Sensitivity | Specificity |
|---|---|---|---|
| ConvNet | 0.4808 | 0.4172 | 0.5808 |
| ConvNeXt | 0.5038 | 0.3659 | 0.6353 |
| ResNet | 0.4958 | 0.4832 | 0.5159 |
| Convolutional autoencoder (Softmax classifier) | 0.6553 | 0.4722 | 0.7763 |
| ConvNeXt (with Jigsaw Puzzle Pretraining) | 0.5461 | 0.1500 | 0.9105 |
| ConvNet (Encoding branch from Models Genesis) | 0.5946 | 0.3611 | 0.6895 |
| Region | Model | AUC-ROC | Sensitivity | Specificity |
|---|---|---|---|---|
| Gland | XGB | 0.5972 | 0.6111 | 0.5833 |
| PZ (on ADC) | XGB | 0.5467 | 0.4483 | 0.6452 |
| Lesion | XGB | 0.6897 | 0.5333 | 0.8462 |
| Sliding Window | XGB | 0.5291 | 0.1974 | 0.8608 |
| Gland | Genesis | 0.7192 | 0.6318 | 0.6578 |
| PZ (on ADC) | Genesis | 0.6393 | 0.5982 | 0.6502 |
| Lesion | Genesis | 0.7343 | 0.7656 | 0.7300 |
| Sliding Window | Genesis | 0.6598 | 0.5805 | 0.8004 |
| Model | Region | Sensitivity | Specificity |
|---|---|---|---|
| Baseline UNet | Lesion | 0.6170 | 0.4727 |
| ConvNeXt | While Image | 0.4231 | 0.4198 |
| SVM | Gland | 0.5106 | 0.4815 |
| SVM | Zone | 0.4894 | 0.4561 |
| Genesis | Lesion | 0.4808 | 0.3551 |
| Genesis | Sliding window | 0.6170 | 0.4952 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rippa, M.; Schulze, R.; Kenyon, G.; Himstedt, M.; Kwiatkowski, M.; Grobholz, R.; Wyler, S.; Cornelius, A.; Schindera, S.; Burn, F. Evaluation of Machine Learning Classification Models for False-Positive Reduction in Prostate Cancer Detection Using MRI Data. Diagnostics 2024, 14, 1677. https://doi.org/10.3390/diagnostics14151677
Rippa M, Schulze R, Kenyon G, Himstedt M, Kwiatkowski M, Grobholz R, Wyler S, Cornelius A, Schindera S, Burn F. Evaluation of Machine Learning Classification Models for False-Positive Reduction in Prostate Cancer Detection Using MRI Data. Diagnostics. 2024; 14(15):1677. https://doi.org/10.3390/diagnostics14151677
Chicago/Turabian StyleRippa, Malte, Ruben Schulze, Georgia Kenyon, Marian Himstedt, Maciej Kwiatkowski, Rainer Grobholz, Stephen Wyler, Alexander Cornelius, Sebastian Schindera, and Felice Burn. 2024. "Evaluation of Machine Learning Classification Models for False-Positive Reduction in Prostate Cancer Detection Using MRI Data" Diagnostics 14, no. 15: 1677. https://doi.org/10.3390/diagnostics14151677
APA StyleRippa, M., Schulze, R., Kenyon, G., Himstedt, M., Kwiatkowski, M., Grobholz, R., Wyler, S., Cornelius, A., Schindera, S., & Burn, F. (2024). Evaluation of Machine Learning Classification Models for False-Positive Reduction in Prostate Cancer Detection Using MRI Data. Diagnostics, 14(15), 1677. https://doi.org/10.3390/diagnostics14151677