

Gray-Scale Extraction of Bone Features from Chest Radiographs Based on Deep Learning Technique for Personal Identification and Classification in Forensic Medicine
 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
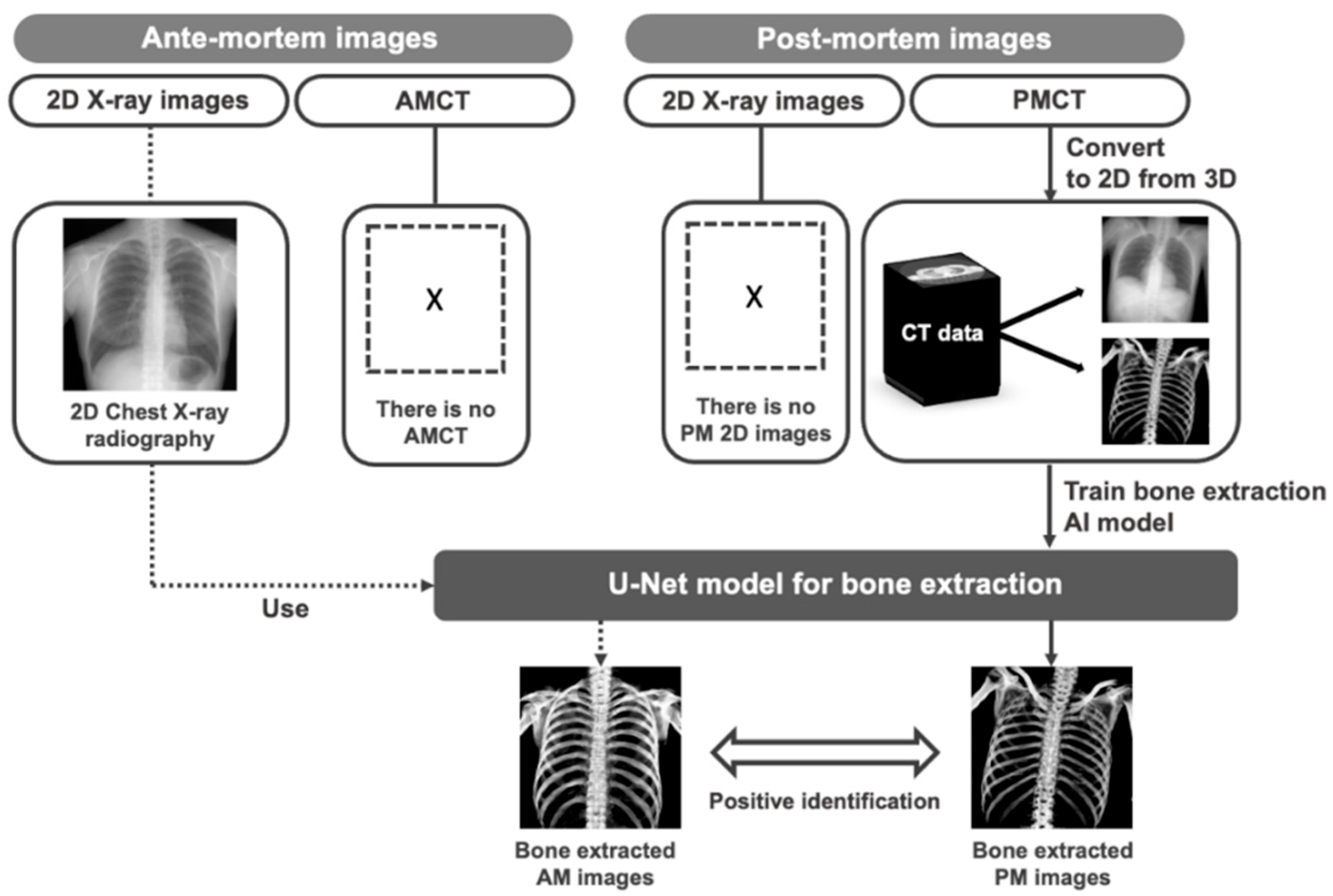
2.1. Overview of Proposed Method
2.2. Image Database
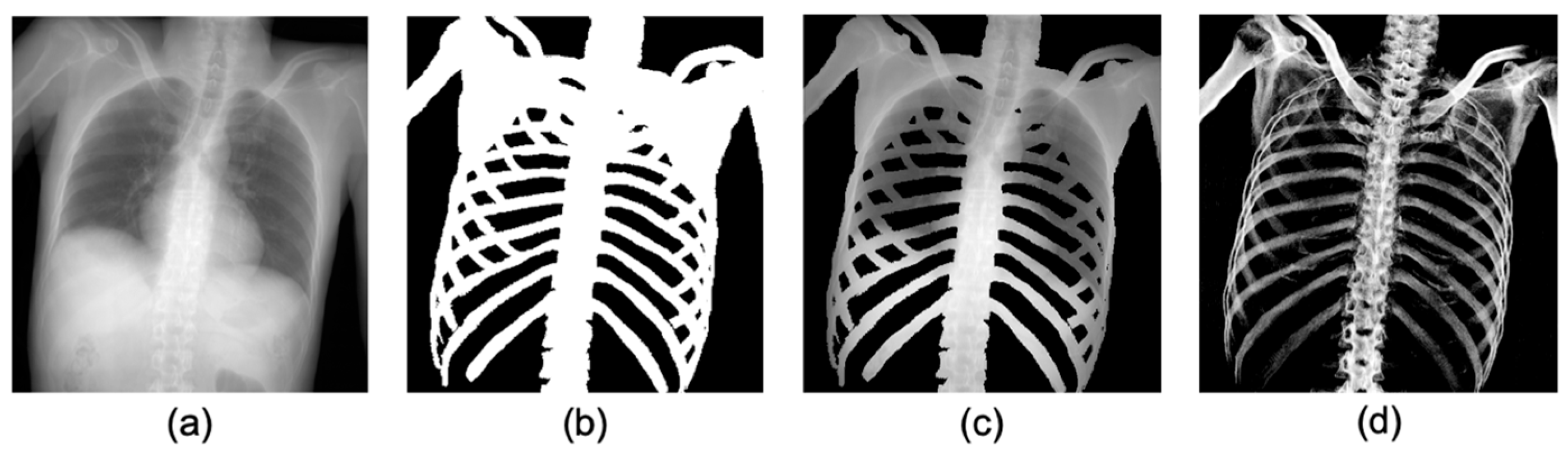
2.3. Pre-Processing: Producing Training Datasets from PMCT Images
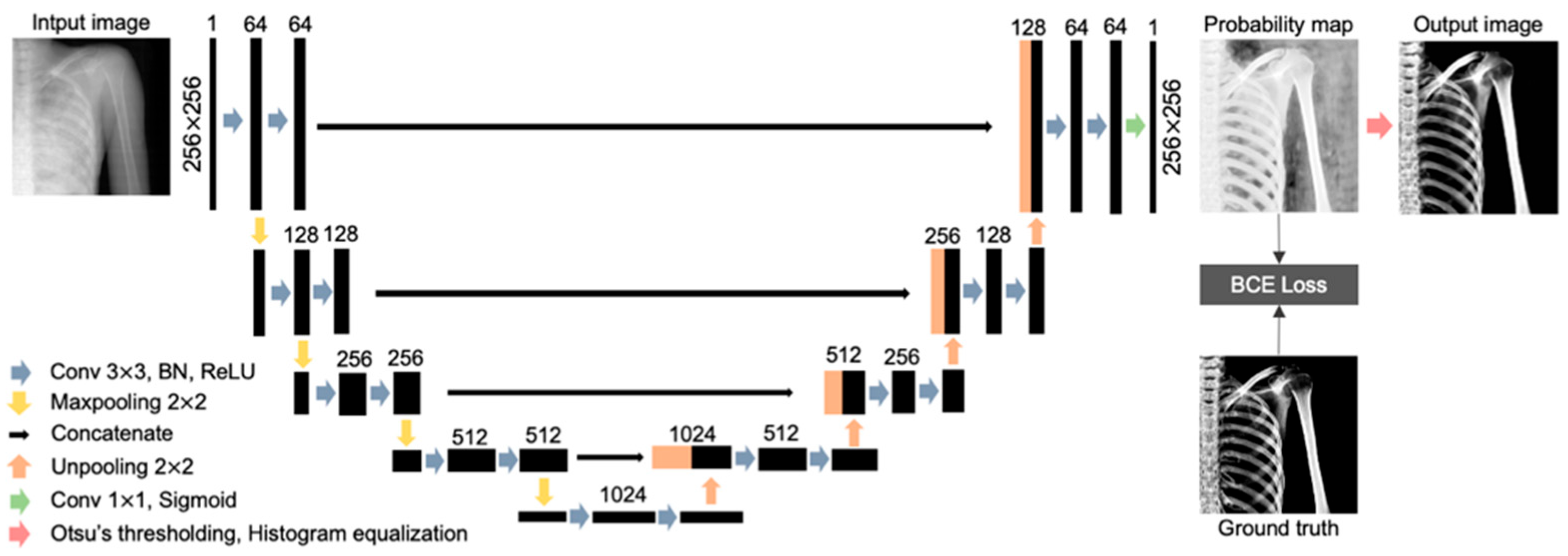
2.4. U-Net Architecture
2.5. Evaluation of Bone Extraction Performance by U-Net
2.5.1. Evaluation on the Extracted Bone Regions
2.5.2. Evaluation of Bone Signal Intensity Distribution
3. Results
3.1. Results of Bone Region Extraction Evaluation
3.2. Results of Bone Signal Intensity Distribution Analysis
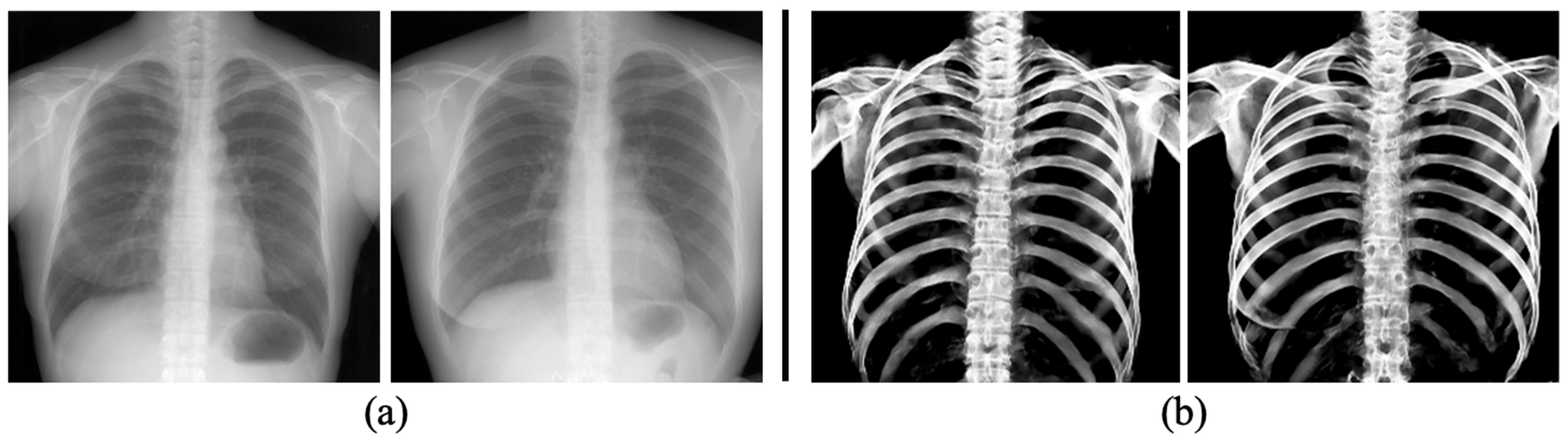
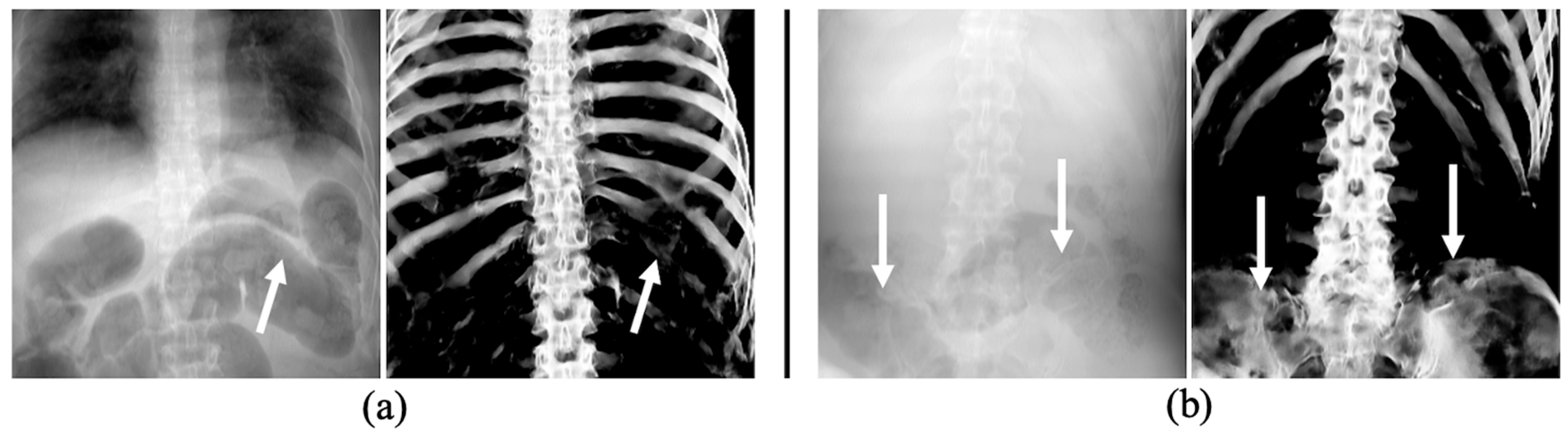
3.3. The Performance of Bone Extraction on Real 2D X-ray Images (CXRs)
4. Discussion
5. Limitations and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Warren, C.P. Personal identification of human remains: An overview. J. Forensic Sci. 1978, 23, 388–395. [Google Scholar] [CrossRef]
- Brough, A.L.; Morgan, B.; Rutty, G.N. Postmortem computed tomography (PMCT) and disaster victim identification. La Radiol. Med. 2015, 120, 866–873. [Google Scholar] [CrossRef]
- Dedouit, F.; Telmon, N.; Costagliola, R.; Otal, P.; Joffre, F.; Rougé, D. Virtual anthropology and forensic identification: Report of one case. Forensic Sci. Int. 2007, 173, 182–187. [Google Scholar] [CrossRef] [PubMed]
- Tatlisumak, E.; Ovali, G.Y.; Aslan, A.; Asirdizer, M.; Zeyfeoglu, Y.; Tarhan, S. Identification of unknown bodies by using CT images of frontal sinus. Forensic Sci. Int. 2007, 166, 42–48. [Google Scholar] [CrossRef] [PubMed]
- Morishita, J.; Ikeda, N.; Ueda, Y.; Yoon, Y.; Tsuji, A. Personal identification using radiological technology and advanced digital imaging: Expectations and challenges. J. Forensic Res. 2021, 12, 472. [Google Scholar]
- Morishita, J.; Ueda, Y. New solutions for automated image recognition and identification: Challenges to radiologic technology and forensic pathology. Radiol. Phys. Technol. 2021, 14, 123–133. [Google Scholar] [CrossRef]
- Pfaeffli, M.; Vock, P.; Dirnhofer, R.; Braun, M.; Bolliger, S.A.; Thali, M.J. Post-mortem radiological CT identification based on classical ante-mortem X-ray examinations. Forensic Sci. Int. 2007, 171, 111–117. [Google Scholar] [CrossRef]
- Wagensveld, I.M.; Blokker, B.M.; Wielopolski, P.A.; Renken, N.S.; Krestin, G.P.; Hunink, M.G.; Oosterhuis, J.W.; Weustink, A.C. Total-body CT and MR features of postmortem change in in-hospital deaths. PLoS ONE 2017, 12, e0185115. [Google Scholar] [CrossRef]
- Varlet, V.; Smith, F.; Giuliani, N.; Egger, C.; Rinaldi, A.; Dominguez, A.; Chevallier, C.; Bruguier, C.; Augsburger, M.; Mangin, P.; et al. When gas analysis assists with postmortem imaging to diagnose causes of death. Forensic Sci. Int. 2015, 251, 1–10. [Google Scholar] [CrossRef]
- Gascho, D.; Thali, M.J.; Niemann, T. Post-mortem computed tomography: Technical principles and recommended parameter setting for high-resolution imaging. Med. Sci. Law 2018, 58, 70–82. [Google Scholar] [CrossRef] [PubMed]
- Matsunobu, Y.; Morishita, J.; Usumoto, Y.; Okumura, M.; Ikeda, N. Bone comparison identification method based on chest computed tomography imaging. Leg. Med. 2017, 29, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Stolojescu-Crisan, C.; Holban, S. A comparison of X-ray image segmentation techniques. Adv. Electr. Comput. Eng. 2013, 13, 85–92. [Google Scholar] [CrossRef]
- Shen, W.; Xu, W.; Zhang, H.; Sun, Z.; Ma, J.; Ma, X.; Zhou, S.; Guo, S.; Wang, Y. Automatic segmentation of the femur and tibia bones from X-ray images based on pure dilated residual U-Net. Inverse Probl. Imaging 2021, 15, 1333. [Google Scholar] [CrossRef]
- Pacal, I.; Alaftekin, M.; Zengul, F.D. Enhancing Skin Cancer Diagnosis Using Swin Transformer with Hybrid Shifted Window-Based Multi-head Self-attention and SwiGLU-Based MLP. J. Imaging Inform. Med. 2024, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Feng, H.; Bu, Q.; Cui, L.; Xie, Y.; Zhang, A.; Feng, J.; Zhu, Z.; Chen, Z. Mdu-net: A convolutional network for clavicle and rib segmentation from a chest radiograph. J. Healthc. Eng. 2020, 2020, 2785464. [Google Scholar] [CrossRef] [PubMed]
- Ding, L.; Zhao, K.; Zhang, X.; Wang, X.; Zhang, J. A lightweight U-Net architecture multi-scale convolutional network for pediatric hand bone segmentation in X-ray image. IEEE Access 2019, 7, 68436–68445. [Google Scholar] [CrossRef]
- Pacal, I.; Celik, O.; Bayram, B.; Cunha, A. Enhancing EfficientNetv2 with global and efficient channel attention mechanisms for accurate MRI-Based brain tumor classification. Clust. Comput. 2024, 1–26. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Chen, Y.; Gou, X.; Feng, X.; Liu, Y.; Qin, G.; Feng, Q.; Yang, W.; Chen, W. Bone suppression of chest radiographs with cascaded convolutional networks in wavelet domain. IEEE Access 2019, 7, 8346–8357. [Google Scholar] [CrossRef]
- Matsubara, N.; Teramoto, A.; Saito, K.; Fujita, H. Bone suppression for chest X-ray using a convolutional neural filter. Phys. Eng. Sci. Med. 2020, 43, 97–108. [Google Scholar] [CrossRef] [PubMed]
- Kawazoe, Y.; Morishita, J.; Matsunobu, Y.; Okumura, M.; Shin, S.; Usumoto, Y.; Ikeda, N. A simple method for semi-automatic readjustment for positioning in post-mortem head computed tomography imaging. J. Forensic Radiol. Imaging 2019, 16, 57–64. [Google Scholar] [CrossRef]
- Shimizu, Y.; Morishita, J. Development of a method of automated extraction of biological fingerprints from chest radiographs as preprocessing of patient recognition and identification. Radiol. Phys. Technol. 2017, 10, 376–381. [Google Scholar] [CrossRef] [PubMed]
- Nishitani, Y.; Nakayama, R.; Hayashi, D.; Hizukuri, A.; Murata, K. Segmentation of teeth in panoramic dental X-ray images using U-Net with a loss function weighted on the tooth edge. Radiol. Phys. Technol. 2021, 14, 64–69. [Google Scholar] [CrossRef] [PubMed]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Xu, X.; Xu, S.; Jin, L.; Song, E. Characteristic analysis of Otsu threshold and its applications. Pattern Recognit. Lett. 2011, 32, 956–961. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Tan, D.S.; Chen, J.-C.; Cheng, W.-H.; Hua, K.-L. Segmenting hepatic lesions using residual attention U-Net with an adaptive weighted dice loss. In Proceedings of the 2019 IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 3322–3326. [Google Scholar] [CrossRef]
- Oliveira, H.; Mota, V.; Machado, A.M.; dos Santos, J.A. From 3d to 2d: Transferring knowledge for rib segmentation in chest X-rays. Pattern Recognit. Lett. 2020, 140, 10–17. [Google Scholar] [CrossRef]
- Candemir, S.; Jaeger, S.; Antani, S.; Bagci, U.; Folio, L.R.; Xu, Z.; Thoma, G. Atlas-based rib-bone detection in chest X-rays. Comput. Med. Imaging Graph. 2016, 51, 32–39. [Google Scholar] [CrossRef] [PubMed]
- Bascou, A.; Dubourg, O.; Telmon, N.; Dedouit, F.; Saint-Martin, P.; Savall, F. Age estimation based on computed tomography exploration: A combined method. Int. J. Leg. Med. 2021, 135, 2447–2455. [Google Scholar] [CrossRef] [PubMed]
- Chiba, F.; Inokuchi, G.; Hoshioka, Y.; Sakuma, A.; Makino, Y.; Torimitsu, S.; Yamaguchi, R.; Saitoh, H.; Kono, M.; Iwase, H. Age estimation by evaluation of osteophytes in thoracic and lumbar vertebrae using postmortem CT images in a modern Japanese population. Int. J. Leg. Med. 2022, 136, 261–267. [Google Scholar] [CrossRef]
- Shimizu, Y.; Matsunobu, Y.; Morishita, J. Evaluation of the usefulness of modified biological fingerprints in chest radiographs for patient recognition and identification. Radiol. Phys. Technol. 2016, 9, 240–244. [Google Scholar] [CrossRef] [PubMed]
- Morishita, J.; Katsuragawa, S.; Kondo, K.; Doi, K. An automated patient recognition method based on an image-matching technique using previous chest radiographs in the picture archiving and communication system environment. Med. Phys. 2001, 28, 1093–1097. [Google Scholar] [CrossRef] [PubMed]
- Morishita, J.; Katsuragawa, S.; Sasaki, Y.; Doi, K. Potential usefulness of biological fingerprints in chest radiographs for automated patient recognition and identification. Acad. Radiol. 2004, 11, 309–315. [Google Scholar] [CrossRef] [PubMed]
- Toge, R.; Morishita, J.; Sasaki, Y.; Doi, K. Computerized image-searching method for finding correct patients for misfiled chest radiographs in a PACS server by use of biological fingerprints. Radiol. Phys. Technol. 2013, 6, 437–443. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Before Augmentation | After Augmentation | |
|---|---|---|
| Training | 80 | 4668 |
| Validation | 20 | 1152 |
| Test | 10 | 582 |
| Total | 110 | 6402 |
| Hyperparameter | Value |
|---|---|
| Epochs | 30 |
| Batch size | 16 |
| Learning rate | 0.001 |
| Activation | Sigmoid |
| Optimizer | Adam |
| Loss function | Binary cross-entropy |
| IoU | Dice | Sensitivity | Specificity | |
|---|---|---|---|---|
| Average | 0.834 | 0.909 | 0.944 | 0.895 |
| Maximum | 0.920 | 0.959 | 0.997 | 0.986 |
| Minimum | 0.638 | 0.779 | 0.857 | 0.688 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.; Yoon, Y.; Matsunobu, Y.; Usumoto, Y.; Eto, N.; Morishita, J. Gray-Scale Extraction of Bone Features from Chest Radiographs Based on Deep Learning Technique for Personal Identification and Classification in Forensic Medicine. Diagnostics 2024, 14, 1778. https://doi.org/10.3390/diagnostics14161778
Kim Y, Yoon Y, Matsunobu Y, Usumoto Y, Eto N, Morishita J. Gray-Scale Extraction of Bone Features from Chest Radiographs Based on Deep Learning Technique for Personal Identification and Classification in Forensic Medicine. Diagnostics. 2024; 14(16):1778. https://doi.org/10.3390/diagnostics14161778
Chicago/Turabian StyleKim, Yeji, Yongsu Yoon, Yusuke Matsunobu, Yosuke Usumoto, Nozomi Eto, and Junji Morishita. 2024. "Gray-Scale Extraction of Bone Features from Chest Radiographs Based on Deep Learning Technique for Personal Identification and Classification in Forensic Medicine" Diagnostics 14, no. 16: 1778. https://doi.org/10.3390/diagnostics14161778
APA StyleKim, Y., Yoon, Y., Matsunobu, Y., Usumoto, Y., Eto, N., & Morishita, J. (2024). Gray-Scale Extraction of Bone Features from Chest Radiographs Based on Deep Learning Technique for Personal Identification and Classification in Forensic Medicine. Diagnostics, 14(16), 1778. https://doi.org/10.3390/diagnostics14161778