
Accuracy Evaluation of GPT-Assisted Differential Diagnosis in Emergency Department

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
2.2. Study Design
2.3. Evaluation
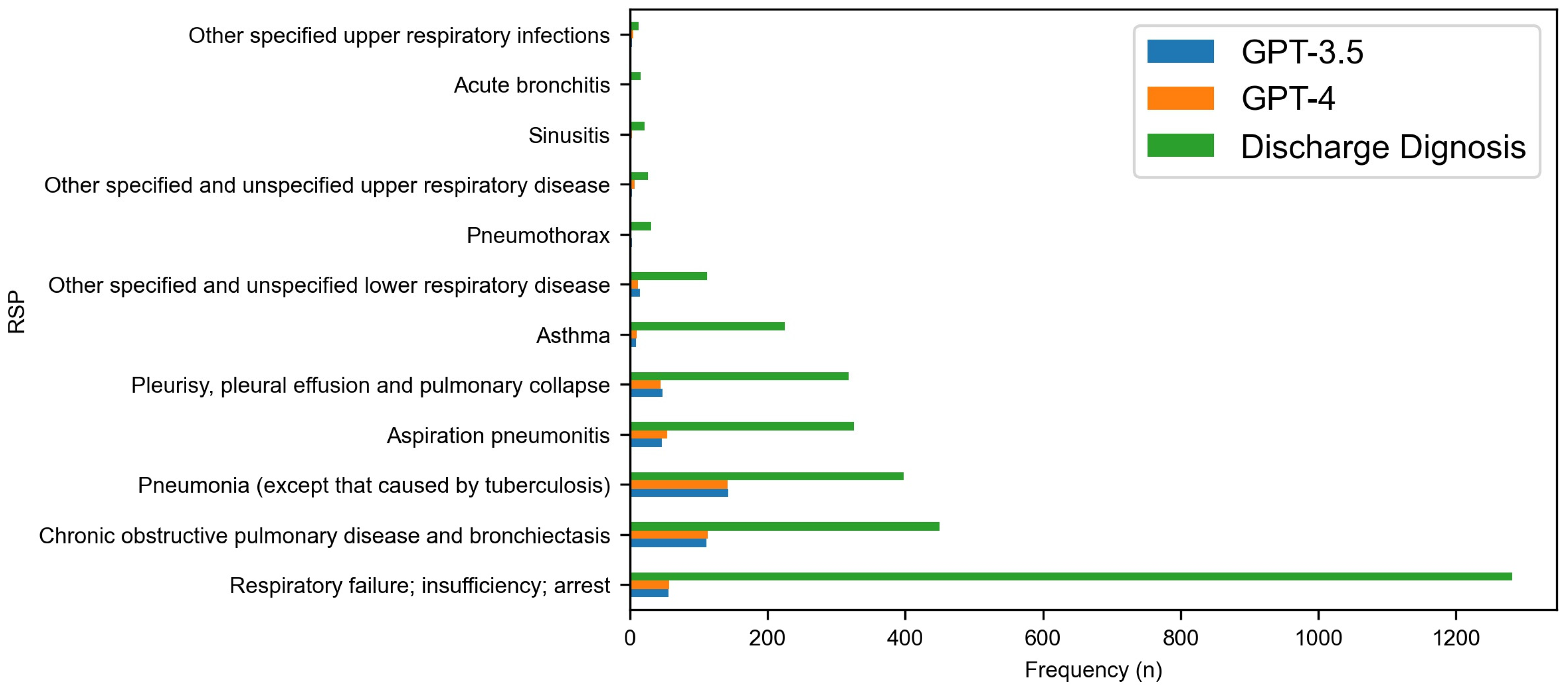
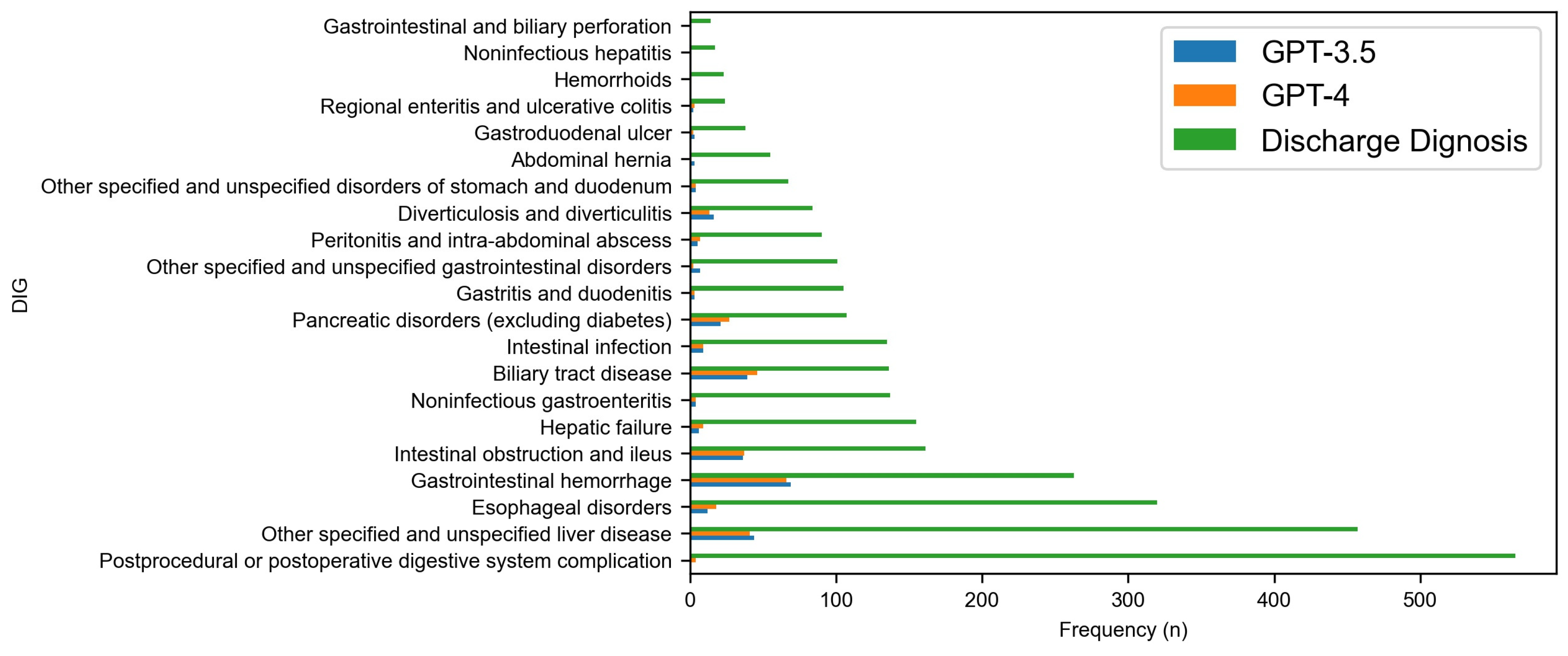
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Newman-Toker, D.E.; Wang, Z.; Zhu, Y.; Nassery, N.; Tehrani, A.S.S.; Schaffer, A.C.; Yu-Moe, C.W.; Clemens, G.D.; Fanai, M.; Siegal, D. Rate of diagnostic errors and serious misdiagnosis-related harms for major vascular events, infections, and cancers: Toward a national incidence estimate using the “Big Three”. Diagnosis 2021, 8, 67–84. [Google Scholar] [CrossRef]
- Newman-Toker, D.E.; Pronovost, P.J. Diagnostic errors—The next frontier for patient safety. JAMA 2009, 301, 1060–1062. [Google Scholar] [CrossRef] [PubMed]
- Gunderson, C.G.; Bilan, V.P.; Holleck, J.L.; Nickerson, P.; Cherry, B.M.; Chui, P.; Bastian, L.A.; Grimshaw, A.A.; Rodwin, B.A. Prevalence of harmful diagnostic errors in hospitalized adults: A systematic review and meta-analysis. BMJ Qual. Saf. 2020, 29, 1008–1018. [Google Scholar] [CrossRef]
- Newman-Toker, D.E.; Tucker, L.J.; on behalf of the Society to Improve Diagnosis in Medicine Policy Committee. Roadmap for Research to Improve Diagnosis, Part 1: Converting National Academy of Medicine Recommendations into Policy Action. 2018. Available online: https://www.improvediagnosis.org/roadmap/ (accessed on 8 July 2024).
- Committee on Diagnostic Error in Health Care; Board on Health Care Services; Balogh, E.P.; Miller, B.T. Technology and tools in the diagnostic process. In Improving Diagnosis in Health Care; National Academies Press (US): Washington, DC, USA, 2015. [Google Scholar]
- Schmieding, M.L.; Kopka, M.; Schmidt, K.; Schulz-Niethammer, S.; Balzer, F.; Feufel, M.A. Triage accuracy of symptom checker apps: 5-year follow-up evaluation. J. Med. Internet Res. 2022, 24, e31810. [Google Scholar] [CrossRef]
- Riches, N.; Panagioti, M.; Alam, R.; Cheraghi-Sohi, S.; Campbell, S.; Esmail, A.; Bower, P. The effectiveness of electronic differential diagnoses (ddx) generators: A systematic review and meta-analysis. PLoS ONE 2016, 11, e0148991. [Google Scholar] [CrossRef]
- Greenes, R. Chapter 2—A brief history of clinical decision support: Technical, social, cultural, economic, governmental perspectives. In Clinical Decision Support, 2nd ed.; Academic Press: London, UK, 2014; pp. 49–109. [Google Scholar]
- Sutton, R.T.; Pincock, D.; Baumgart, D.C.; Sadowski, D.C.; Fedorak, R.N.; Kroeker, K.I. An overview of clinical decision support systems: Benefits, risks, and strategies for success. NPJ Digit. Med. 2020, 3, 17. [Google Scholar] [CrossRef]
- Meunier, P.; Raynaud, C.; Guimaraes, E.; Gueyffier, F.; Letrilliart, L. Barriers and facilitators to the use of clinical decision support systems in primary care: A mixed-methods systematic review. Ann. Fam. Med. 2023, 21, 57–69. [Google Scholar] [CrossRef]
- Wani, S.U.D.; Khan, N.A.; Thakur, G.; Gautam, S.P.; Ali, M.; Alam, P.; Alshehri, S.; Ghoneim, M.M.; Shakeel, F. Utilization of artificial intelligence in disease prevention: Diagnosis, treatment, and implications for the healthcare workforce. Healthcare 2022, 10, 608. [Google Scholar] [CrossRef]
- Haug, C.J.; Drazen, J.M. Artificial intelligence and machine learning in clinical medicine, 2023. N. Engl. J. Med. 2023, 388, 1201–1208. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Wang, C.; Liu, S. Utility of ChatGPT in clinical practice. J. Med. Internet Res. 2023, 25, e48568. [Google Scholar] [CrossRef]
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Saleh, K.B.; Badreldin, H.A.; et al. Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef]
- Collins, C.; Dennehy, D.; Conboy, K.; Mikalef, P. Artificial intelligence in information systems research: A systematic literature review and research agenda. Int. J. Inf. Manage. 2021, 60, 102383. [Google Scholar] [CrossRef]
- Kawamoto, K.; Finkelstein, J.; Del Fiol, G. Implementing Machine Learning in the Electronic Health Record: Checklist of Essential Considerations. Mayo Clin Proc. 2023, 98, 366–369. [Google Scholar] [CrossRef] [PubMed]
- Patrizio, A. Google Gemini (Formerly Bard). TechTarget. Mar 2024. Available online: https://www.techtarget.com/searchenterpriseai/definition/Google-Bard (accessed on 15 July 2024).
- Saeidnia, H.R. Welcome to the Gemini era: Google DeepMind and the information industry. Libr. Hi Tech News, 2023; ahead-of-print. [Google Scholar] [CrossRef]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Sai, S.; Gaur, A.; Sai, R.; Chamola, V.; Guizani, M.; Rodrigues, J.J.P.C. Generative AI for transformative healthcare: A comprehensive study of emerging models, applications, case studies, and limitations. IEEE Access 2024, 12, 31078–31106. [Google Scholar] [CrossRef]
- Cascella, M.; Montomoli, J.; Bellini, V.; Bignami, E. Evaluating the feasibility of ChatGPT in healthcare: An analysis of multiple clinical and research scenarios. J. Med. Syst. 2023, 47, 33. [Google Scholar] [CrossRef]
- Giannakopoulos, K.; Kavadella, A.; Aaqel Salim, A.; Stamatopoulos, V.; Kaklamanos, E.G. Evaluation of the Performance of Generative AI Large Language Models ChatGPT, Google Bard, and Microsoft Bing Chat in Supporting Evidence-Based Dentistry: Comparative Mixed Methods Study. J. Med. Internet Res. 2023, 25, e51580. [Google Scholar] [CrossRef]
- Hu, K.; Hu, K. ChatGPT Sets Record for Fastest-Growing User Base—Analyst Note. Reuters. Published 2 February 2023. Available online: https://www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/ (accessed on 7 April 2024).
- Sarraju, A.; Bruemmer, D.; Van Iterson, E.; Cho, L.; Rodriguez, F.; Laffin, L. Appropriateness of Cardiovascular Disease Prevention Recommendations Obtained from a Popular Online Chat-Based Artificial Intelligence Model. JAMA 2023, 329, 842–844. [Google Scholar] [CrossRef]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, J.D.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589–596. [Google Scholar] [CrossRef]
- Han, T.; Adams, L.C.; Bressem, K.K.; Busch, F.; Nebelung, S.; Truhn, D. Comparative analysis of multimodal large language model performance on clinical vignette questions. JAMA 2024, 331, 1320–1321. [Google Scholar] [CrossRef] [PubMed]
- Gravina, A.G.; Pellegrino, R.; Cipullo, M.; Palladino, G.; Imperio, G.; Ventura, A.; Auletta, S.; Ciamarra, P.; Federico, A. May ChatGPT be a tool producing medical information for common inflammatory bowel disease patients’ questions? An evidence-controlled analysis. World J. Gastroenterol. 2024, 30, 17–33. [Google Scholar] [CrossRef]
- Hirosawa, T.; Kawamura, R.; Harada, Y.; Mizuta, K.; Tokumasu, K.; Kaji, Y.; Suzuki, T.; Shimizu, T. ChatGPT-generated differential diagnosis lists for complex case-derived clinical vignettes: Diagnostic accuracy evaluation. JMIR Med. Inform. 2023, 11, e48808. [Google Scholar] [CrossRef]
- Hirosawa, T.; Mizuta, K.; Harada, Y.; Shimizu, T. Comparative evaluation of diagnostic accuracy between Google Bard and physicians. Am. J. Med. 2023, 136, 1119–1123.e18. [Google Scholar] [CrossRef]
- Kanjee, Z.; Crowe, B.; Rodman, A. Accuracy of a generative artificial intelligence model in a complex diagnostic challenge. JAMA 2023, 330, 78–80. [Google Scholar] [CrossRef] [PubMed]
- Clinical Classifications Software Refined (CCSR) for ICD-10-CM Diagnoses. Available online: https://hcup-us.ahrq.gov/toolssoftware/ccsr/dxccsr.jsp (accessed on 8 July 2024).
- Department of Health and Human Service. Available online: https://hcup-us.ahrq.gov/toolssoftware/ccsr/ccs_refined.jsp (accessed on 8 July 2024).
- Tipsmark, L.S.; Obel, B.; Andersson, T.; Søgaard, R. Organisational determinants and consequences of diagnostic discrepancy in two large patient groups in the emergency departments: A national study of consecutive episodes between 2008 and 2016. BMC Emerg. Med. 2021, 21, 145. [Google Scholar] [CrossRef]
- Hussain, F.; Cooper, A.; Carson-Stevens, A.; Donaldson, L.; Hibbert, P.; Hughes, T.; Edwards, A. Diagnostic error in the emergency department: Learning from national patient safety incident report analysis. BMC Emerg. Med. 2019, 19, 77. [Google Scholar] [CrossRef]
- Hautz, W.E.; Kämmer, J.E.; Hautz, S.C.; Sauter, T.C.; Zwaan, L.; Exadaktylos, A.K.; Birrenbach, T.; Maier, V.; Müller, M.; Schauber, S.K. Diagnostic error increases mortality and length of hospital stay in patients presenting through the emergency room. Scand. J. Trauma Resusc. Emerg. Med. 2019, 27, 54. [Google Scholar] [CrossRef]
- Wong, K.E.; Parikh, P.D.; Miller, K.C.; Zonfrillo, M.R. Emergency Department and Urgent Care Medical Malpractice Claims 2001–15. West J. Emerg. Med. 2021, 22, 333–338. [Google Scholar] [CrossRef]
- Abe, T.; Tokuda, Y.; Shiraishi, A.; Fujishima, S.; Mayumi, T.; Sugiyama, T.; Deshpande, G.A.; Shiino, Y.; Hifumi, T.; Otomo, Y.; et al. JAAM SPICE Study Group. In-hospital mortality associated with the misdiagnosis or unidentified site of infection at admission. Crit. Care 2019, 23, 202. [Google Scholar] [CrossRef]
- Avelino-Silva, T.J.; Steinman, M.A. Diagnostic discrepancies between emergency department admissions and hospital discharges among older adults: Secondary analysis on a population-based survey. Sao Paulo Med. J. 2020, 138, 359–367. [Google Scholar] [CrossRef]
- Finkelstein, J.; Parvanova, I.; Xing, Z.; Truong, T.T.; Dunn, A. Qualitative Assessment of Implementation of a Discharge Prediction Tool Using RE-AIM Framework. Stud. Health Technol. Inform. 2023, 302, 596–600. [Google Scholar] [CrossRef]
- Peng, A.; Rohacek, M.; Ackermann, S.; Ilsemann-Karakoumis, J.; Ghanim, L.; Messmer, A.S.; Misch, F.; Nickel, C.; Bingisser, R. The proportion of correct diagnoses is low in emergency patients with nonspecific complaints presenting to the emergency department. Swiss. Med. Wkly. 2015, 145, w14121. [Google Scholar] [CrossRef]
- Berner, E.S.; Graber, M.L. Overconfidence as a Cause of Diagnostic Error in Medicine. Am. J. Med. 2008, 121 (Suppl. S5), 2–23. [Google Scholar] [CrossRef]
- Chellis, M.; Olson, J.; Augustine, J.; Hamilton, G. Evaluation of missed diagnoses for patients admitted from the emergency department. Acad. Emerg. Med. 2001, 8, 125–130. [Google Scholar] [CrossRef]
- Kachalia, A.; Gandhi, T.K.; Puopolo, A.L.; Yoon, C.; Thomas, E.J.; Griffey, R.; Brennan, T.A.; Studdert, D.M. Missed and delayed diagnoses in the emergency department: A study of closed malpractice claims from 4 liability insurers. Ann. Emerg. Med. 2007, 49, 196–205. [Google Scholar] [CrossRef]
- Brown, T.W.; McCarthy, M.L.; Kelen, G.D.; Levy, F. An epidemiologic study of closed emergency department malpractice claims in a national database of physician malpractice insurers. Acad. Emerg. Med. Off. J. Soc. Acad. Emerg. Med. 2010, 17, 553–556. [Google Scholar] [CrossRef]
- Trautlein, J.J.; Lambert, R.L.; Miller, J. Malpractice in the emergency department-review of 200 cases. Ann. Emerg. Med. 1984, 13, 709–711. [Google Scholar] [CrossRef]
- Newman-Toker, D.E.; Schaffer, A.C.; Yu-Moe, C.W.; Nassery, N.; Saber Tehrani, A.S.; Clemens, G.D.; Wang, Z.; Zhu, Y.; Fanai, M.; Siegal, D. Serious misdiagnosis-related harms in malpractice claims: The “Big Three”—Vascular events, infections, and cancers. Diagnosis 2019, 6, 227–240. [Google Scholar] [CrossRef]
- Newman-Toker, D.E.; Peterson, S.M.; Badihian, S.; Hassoon, A.; Nassery, N.; Parizadeh, D.; Wilson, L.M.; Jia, Y.; Omron, R.; Tharmarajah, S.; et al. Diagnostic Errors in the Emergency Department: A Systematic Review [Internet]; Report No.: 22-EHC043; Agency for Healthcare Research and Quality (US): Rockville, MD, USA, 2022.
- Cabral, S.; Restrepo, D.; Kanjee, Z.; Wilson, P.; Crowe, B.; Abdulnour, R.E.; Rodman, A. Clinical reasoning of a generative artificial intelligence model compared with physicians. JAMA Intern. Med. 2024, 184, 581–583. [Google Scholar] [CrossRef]
- Hirosawa, T.; Harada, Y.; Yokose, M.; Sakamoto, T.; Kawamura, R.; Shimizu, T. Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study. Int. J. Environ. Res. Public Health 2023, 20, 3378. [Google Scholar] [CrossRef]
- Zhang, P.; Boulos, M.N.K. Generative AI in Medicine and Healthcare: Promises, Opportunities and Challenges. Future Internet 2023, 15, 286. [Google Scholar] [CrossRef]
- Savage, T.; Wang, J.; Shieh, L. A Large Language Model Screening Tool to Target Patients for Best Practice Alerts: Development and Validation. JMIR Med. Inform. 2023, 11, e49886. [Google Scholar] [CrossRef]
- Rojas-Carabali, W.; Sen, A.; Agarwal, A.; Tan, G.; Cheung, C.Y.; Rousselot, A.; Agrawal, R.; Liu, R.; Cifuentes-González, C.; Elze, T.; et al. Chatbots Vs. Human Experts: Evaluating Diagnostic Performance of Chatbots in Uveitis and the Perspectives on AI Adoption in Ophthalmology. Ocul. Immunol. Inflamm. 2023, 1–8. [Google Scholar] [CrossRef]
- Savage, T.; Nayak, A.; Gallo, R.; Rangan, E.; Chen, J.H. Diagnostic reasoning prompts reveal the potential for large language model interpretability in medicine. NPJ Digit. Med. 2024, 7, 20. [Google Scholar] [CrossRef]
- Wada, A.; Akashi, T.; Shih, G.; Hagiwara, A.; Nishizawa, M.; Hayakawa, Y.; Kikuta, J.; Shimoji, K.; Sano, K.; Kamagata, K.; et al. Optimizing GPT-4 Turbo Diagnostic Accuracy in Neuroradiology through Prompt Engineering and Confidence Thresholds. Diagnostics 2024, 14, 1541. [Google Scholar] [CrossRef] [PubMed]
- Cui, W.; Kawamoto, K.; Morgan, K.; Finkelstein, J. Reducing Diagnostic Uncertainty in Emergency Departments: The Role of Large Language Models in Age-Specific Diagnostics. In Proceedings of the 2024 IEEE 12th International Conference on Healthcare Informatics (ICHI), Orlando, FL, USA, 3–6 June 2024; pp. 525–527. [Google Scholar]
- Berg, H.T.; van-Bakel, B.; van-de-Wouw, L.; Jie, K.E.; Schipper, A.; Jansen, H.; O’Connor, R.D.; van-Ginneken, B.; Kurstjens, S. ChatGPT and Generating a Differential Diagnosis Early in an Emergency Department Presentation. Ann. Emerg. Med. 2024, 83, 83–86. [Google Scholar] [CrossRef]
- Shea, Y.F.; Lee, C.M.Y.; Ip, W.C.T.; Luk, D.W.A.; Wong, S.S.W. Use of GPT-4 to Analyze Medical Records of Patients with Extensive Investigations and Delayed Diagnosis. JAMA Netw. Open 2023, 6, e2325000. [Google Scholar] [CrossRef]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission. arXiv 2019, arXiv:1904.05342. [Google Scholar]
- Franz, L.; Shrestha, Y.R.; Paudel, B. A Deep Learning Pipeline for Patient Diagnosis Prediction Using Electronic Health Records. arXiv 2020, arXiv:2006.16926. [Google Scholar]
- Alam, M.M.; Raff, E.; Oates, T.; Matuszek, C. DDxT: Deep Generative Transformer Models for Differential Diagnosis. arXiv 2023, arXiv:2312.01242. [Google Scholar]
- Huo, X.; Finkelstein, J. Analyzing Diagnostic Discrepancies in Emergency Department Using the TriNetX Big Data. In Proceedings of the 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Istanbul, Turkey, 5–8 December 2023; pp. 4896–4898. [Google Scholar]
- Finkelstein, J.; Cui, W.; Ferraro, J.P.; Kawamoto, K. Association of Diagnostic Discrepancy with Length of Stay and Mortality in Congestive Heart Failure Patients Admitted to the Emergency Department. AMIA Jt. Summits Transl. Sci. Proc. 2024, 2024, 155–161. [Google Scholar]
- Shah-Mohammadi, F.; Finkelstein, J. Combining NLP and Machine Learning for Differential Diagnosis of COPD Exacerbation Using Emergency Room Data. Stud. Health Technol. Inform. 2023, 305, 525–528. [Google Scholar] [CrossRef]
- Finkelstein, J.; Cui, W.; Morgan, K.; Kawamoto, K. Reducing Diagnostic Uncertainty Using Large Language Models. In Proceedings of the 2024 IEEE First International Conference on Artificial Intelligence for Medicine, Health and Care (AIMHC), Laguna Hills, CA, USA, 5–7 February 2024; pp. 236–242. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Body System | Category | |||
|---|---|---|---|---|
| GPT-3.5 | GPT-4 | GPT-3.5 | GPT-4 | |
| Percentage (%) | Percentage (%) | Percentage (%) | Percentage (%) | |
| No match | 9.09% | 9.38% | 33.66% | 36.01% |
| Partial match | 79.53% | 81.27% | 65.47% | 63.37% |
| Complete match | 11.38% | 9.35% | 0.87% | 0.62% |
| GPT-4 | GPT-3.5 | Discharge Dx | |
|---|---|---|---|
| Body System | n | n | n |
| Diseases of the circulatory system (CIR) | 4017 | 3523 | 9681 |
| Diseases of the respiratory system (RSP) | 1223 | 1127 | 3791 |
| Diseases of the digestive system (DIG) | 601 | 571 | 3090 |
| Endocrine, nutritional, and metabolic diseases (END) | 330 | 282 | 5076 |
| Diseases of the genitourinary system (GEN) | 269 | 239 | 2449 |
| Certain infectious and parasitic diseases (INF) | 245 | 229 | 2077 |
| Neoplasms (NEO) | 221 | 216 | 983 |
| Diseases of the nervous system (NVS) | 158 | 133 | 1767 |
| Mental, behavioral, and neurodevelopmental disease (MBD) | 133 | 130 | 1465 |
| Diseases of the musculoskeletal system and connective tissue (MUS) | 107 | 90 | 1371 |
| Factors influencing health status and contact with health services (FAC) | 106 | 84 | 1943 |
| Diseases of the blood and blood-forming organs and certain disorders involving the immune mechanism (BLD) | 80 | 80 | 2131 |
| Diseases of the skin and subcutaneous tissue (SKN) | 37 | 35 | 1372 |
| Dental diseases (DEN) | 6 | 5 | 315 |
| External causes of morbidity (EXT) | 5 | 5 | 1802 |
| Congenital malformations, deformations, and chromosomal abnormalities (MAL) | 5 | 4 | 77 |
| Diseases of the eye and adnexa (EYE) | 3 | 2 | 1971 |
| Pregnancy, childbirth, and the puerperium (PRG) | 2 | 1 | 59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shah-Mohammadi, F.; Finkelstein, J. Accuracy Evaluation of GPT-Assisted Differential Diagnosis in Emergency Department. Diagnostics 2024, 14, 1779. https://doi.org/10.3390/diagnostics14161779
Shah-Mohammadi F, Finkelstein J. Accuracy Evaluation of GPT-Assisted Differential Diagnosis in Emergency Department. Diagnostics. 2024; 14(16):1779. https://doi.org/10.3390/diagnostics14161779
Chicago/Turabian StyleShah-Mohammadi, Fatemeh, and Joseph Finkelstein. 2024. "Accuracy Evaluation of GPT-Assisted Differential Diagnosis in Emergency Department" Diagnostics 14, no. 16: 1779. https://doi.org/10.3390/diagnostics14161779