

Feature Identification Using Interpretability Machine Learning Predicting Risk Factors for Disease Severity of In-Patients with COVID-19 in South Florida

 , and
, and
Abstract
1. Introduction
1.1. An Overview of Machine Learning Studies on COVID-19 Disease Severity
1.2. Contributions of the Current Study
2. Materials and Methods
2.1. Dataset Collection and Subject Information
2.2. Study Design Considerations
2.3. Data Classification
2.4. Correlation Check
2.5. Data Splitting
2.6. Resampling Data
3. Results
3.1. Cohort Description
3.2. Statistical Analysis
3.3. Predictive Analysis
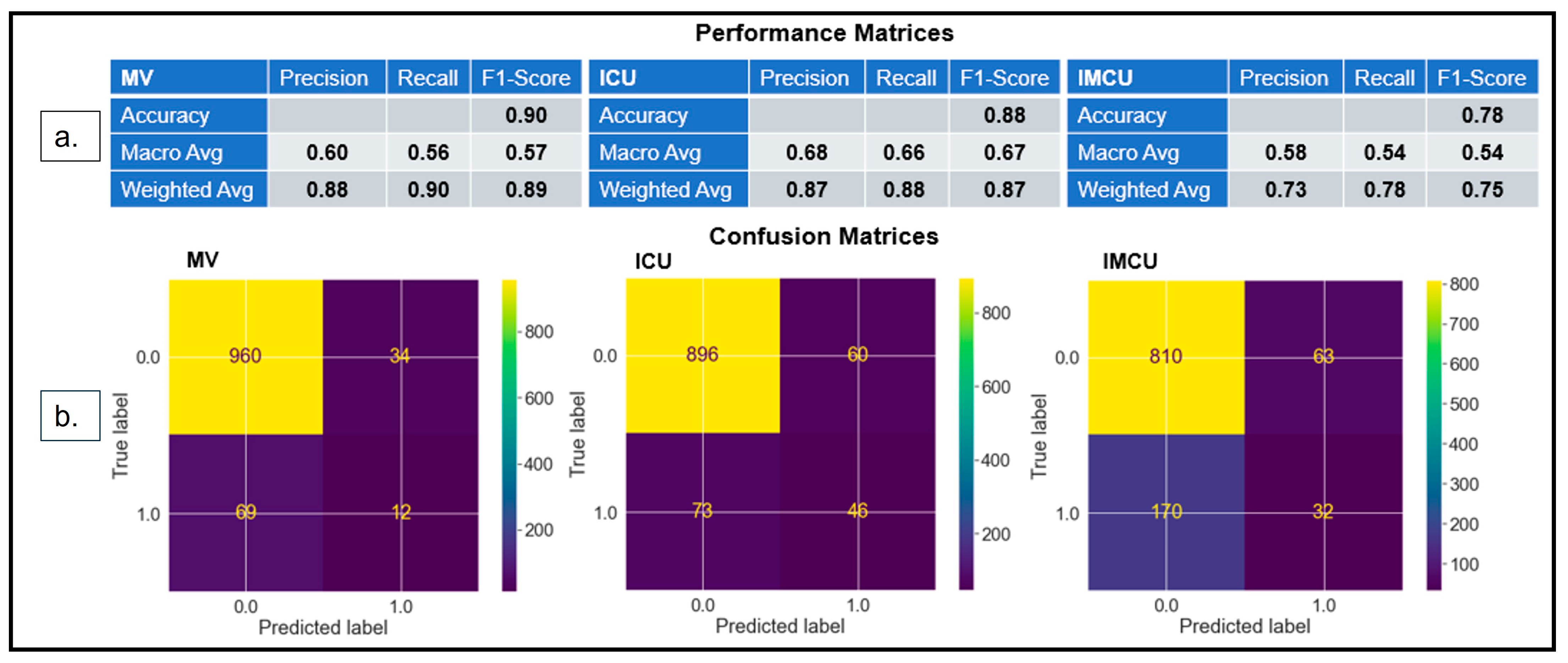
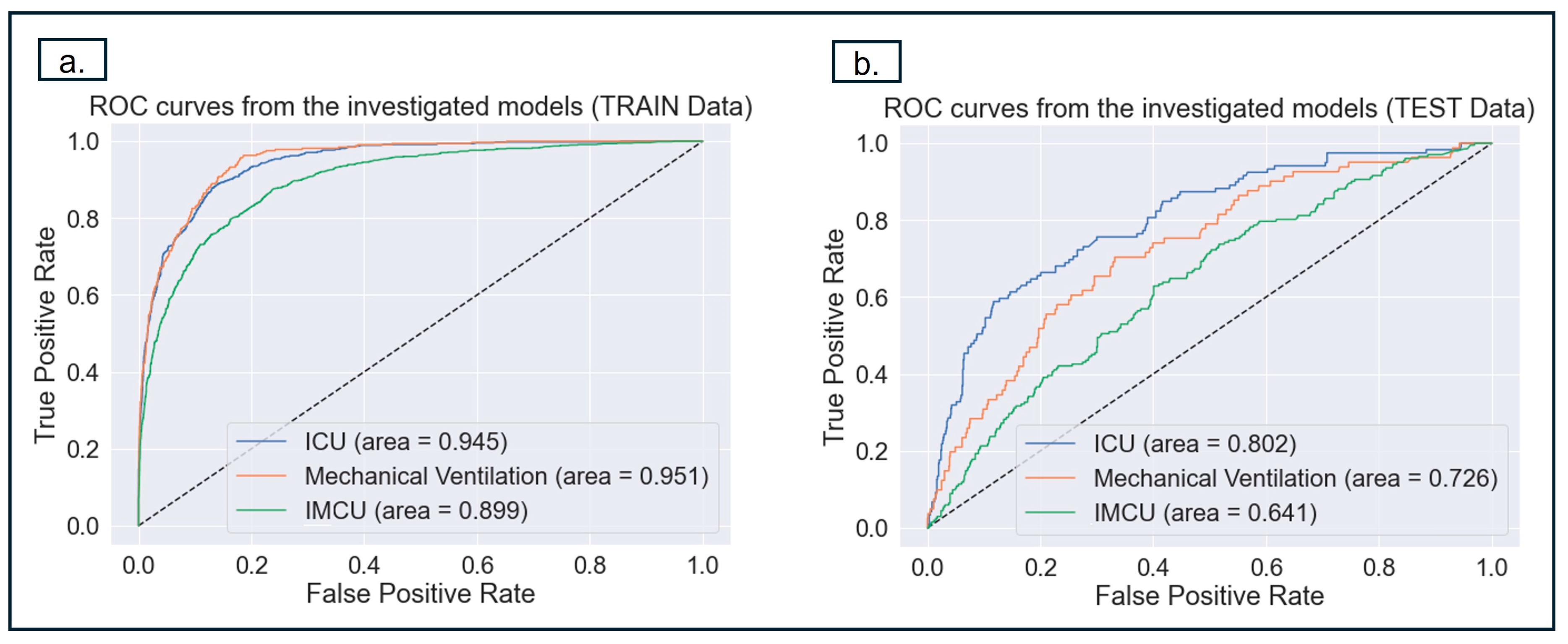
3.3.1. Model Performance
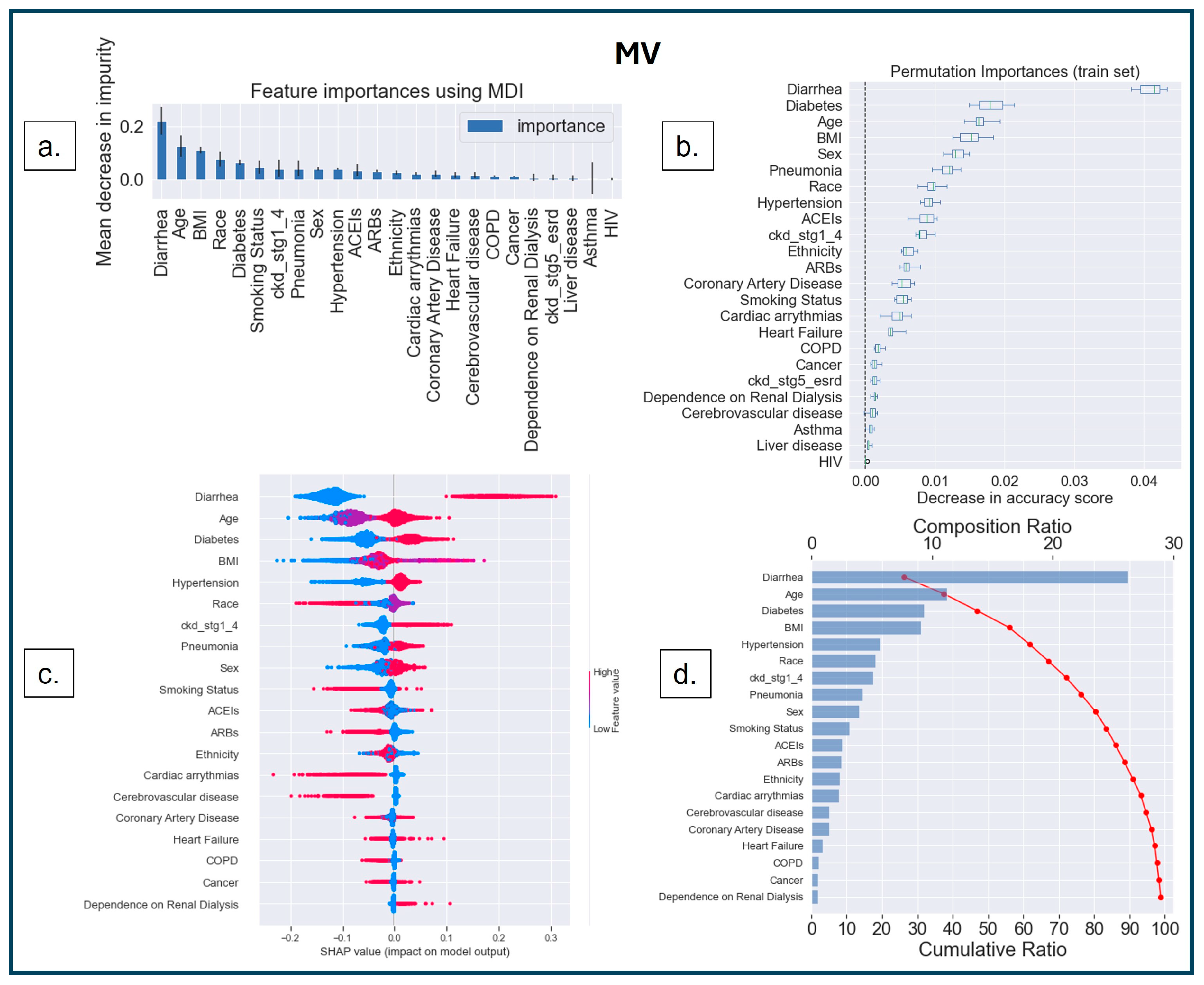
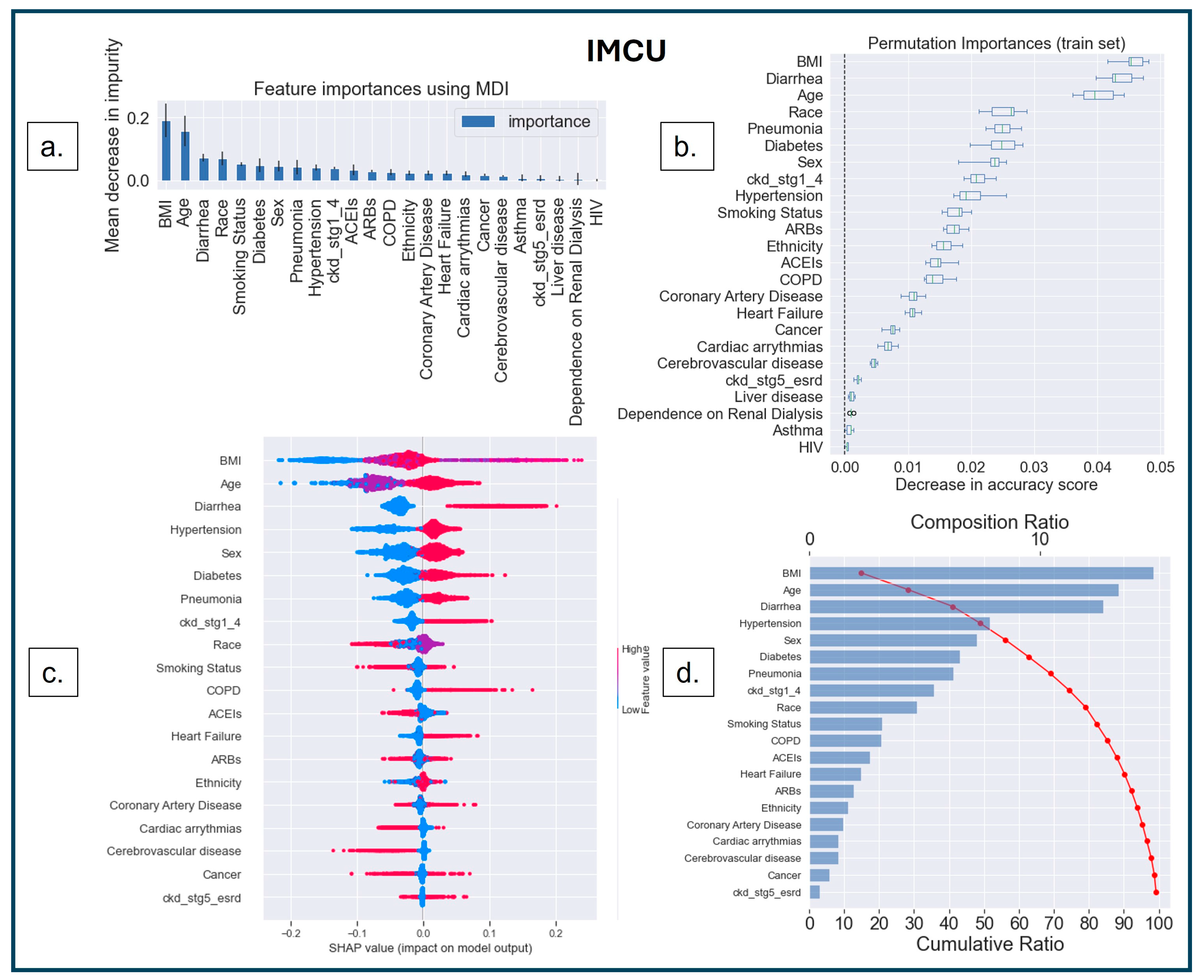
3.3.2. Model Interpretability
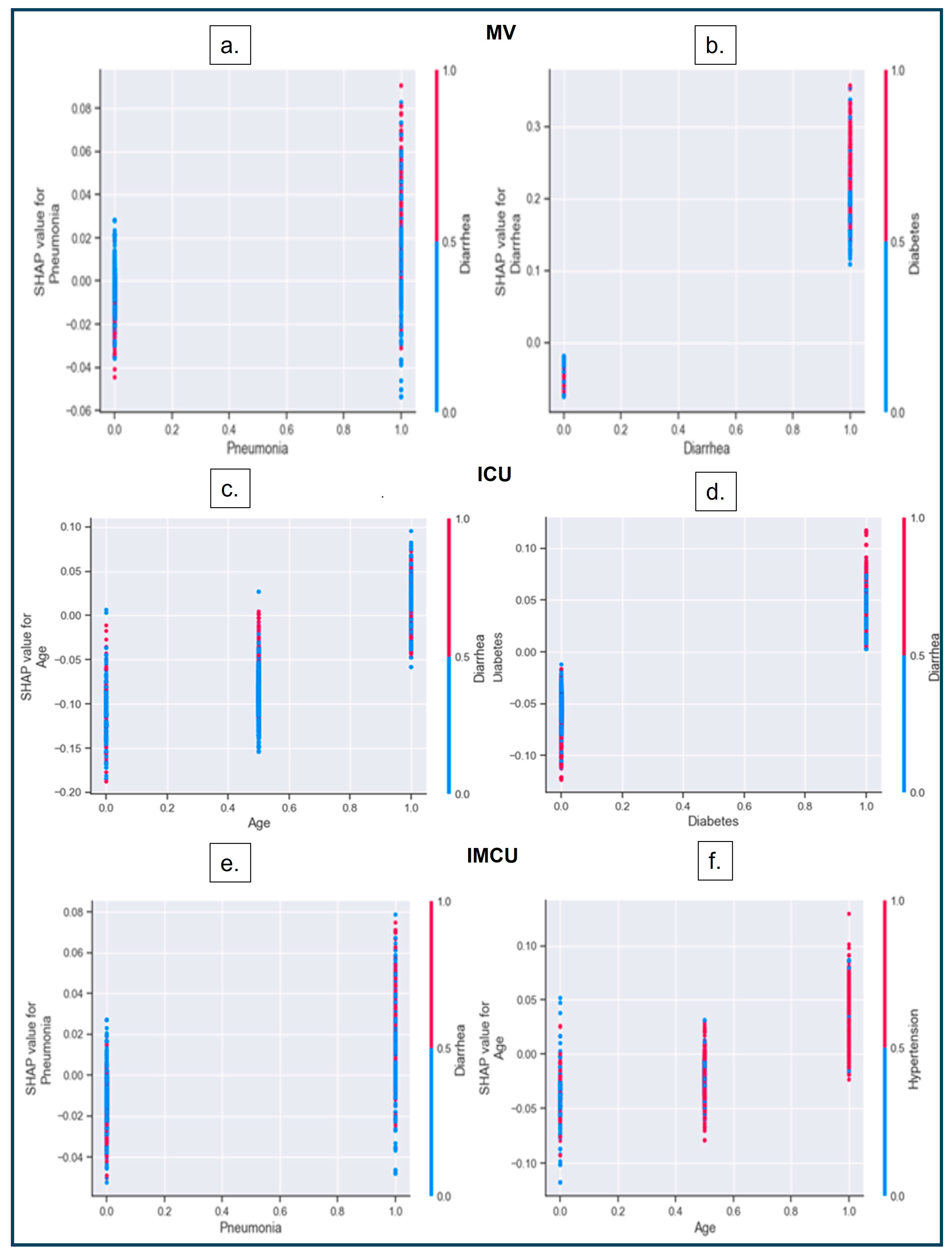
3.3.3. SHAP Dependence Plot
4. Discussion
5. Limitations
6. Future Direction
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miller, I.F.; Becker, A.D.; Grenfell, B.T.; Metcalf, C.J.E. Disease and healthcare burden of COVID-19 in the United States. Nat. Med. 2020, 26, 1212–1217. Available online: https://www.nature.com/articles/s41591-020-0952-y (accessed on 20 August 2024). [CrossRef] [PubMed]
- Worldometer. COVID-19 Coronavirus Pandemic, 2023. World Health Organization (WHO). COVID-19 Weekly Epidemiological Update 2023. Available online: https://www.worldometers.info/coronavirus/ (accessed on 12 July 2024).
- Richardson, S.; Hirsch, J.S.; Narasimhan, M.; Crawford, J.M.; McGinn, T.; Davidson, K.W.; the Northwell COVID-19 Research Consortium. Presenting Characteristics, Comorbidities, and Outcomes among 5700 Patients H Hospitalized with COVID-19 in the New York City Area. JAMA 2020, 323, 2052–2059. [Google Scholar] [CrossRef]
- Meille, G.; Decker, S.L.; Owens, P.L.; Selden, T.M. COVID-19 admission rates and changes in US hospital inpatient and intensive care unit occupancy. In JAMA Health Forum; American Medical Association: Chicago, IL, USA, 2023; Volume 4, p. e234206. [Google Scholar]
- Ranney, M.L.; Griffeth, V.; Jha, A.K. Critical supply shortages—The need for ventilators and personal protective equipment during the COVID-19 pandemic. N. Engl. J. Med. 2020, 382, e41. [Google Scholar] [CrossRef] [PubMed]
- Schwab, P.; DuMont Schütte, A.; Dietz, B.; Bauer, S. Clinical predictive models for COVID-19: Systematic study. J. Med. Internet Res. 2020, 22, e21439. [Google Scholar] [CrossRef] [PubMed]
- Bhatraju, P.K.; Ghassemieh, B.J.; Nichols, M.; Kim, R.; Jerome, K.R.; Nalla, A.K.; Greninger, A.L.; Pipavath, S.; Wurfel, M.M.; Evans, L.; et al. COVID-19 in critically ill patients in the Seattle region—Case series. N. Engl. J. Med. 2020, 382, 2012–2022. [Google Scholar] [CrossRef]
- Cummings, M.J.; Baldwin, M.R.; Abrams, D.; Jacobson, S.D.; Meyer, B.J.; Balough, E.M.; Aaron, J.G.; Claassen, J.; Rabbani, L.E.; Hastie, J.; et al. Epidemiology, clinical course, and outcomes of critically ill adults with COVID-19 in New York City: A prospective cohort study. Lancet 2020, 395, 1763–1770. [Google Scholar] [CrossRef]
- Gupta, S.; Hayek, S.S.; Wang, W.; Chan, L.; Mathews, K.S.; Melamed, M.L.; Brenner, S.K.; Leonberg-Yoo, A.; Schenck, E.J.; Radbel, J.; et al. Factors associated with death in critically ill patients with coronavirus disease 2019 in the US. JAMA Intern. Med. 2020, 180, 1436–1447. [Google Scholar] [CrossRef]
- Zhang, A.; Xing, L.; Zou, J.; Wu, J.C. Shifting machine learning for healthcare from development to deployment and from models to data. Nat. Biomed. Eng. 2022, 6, 1330–1345. [Google Scholar] [CrossRef]
- Abràmoff, M.D.; Lavin, P.T.; Birch, M.; Shah, N.; Folk, J.C. Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices. NPJ Digit. Med. 2018, 1, 39. [Google Scholar] [CrossRef]
- Johnson, K.B.; Wei, W.; Weeraratne, D.; Frisse, M.E.; Misulis, K.; Rhee, K.; Zhao, J.; Snowdon, J.L. Precision medicine, AI, and the future of personalized health care. Clin. Transl. Sci. 2021, 14, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Dixon, D.; Sattar, H.; Moros, N.; Kesireddy, S.R.; Ahsan, H.; Lakkimsetti, M.; Fatima, M.; Doshi, D.; Sadhu, K.; Hassan, M.J. Unveiling the Influence of AI Predictive Analytics on Patient Outcomes: A Comprehensive Narrative Review. Cureus 2024, 16, e59954. [Google Scholar] [CrossRef] [PubMed]
- Hilton, C.B.; Milinovich, A.; Felix, C.; Vakharia, N.; Crone, T.; Donovan, C.; Proctor, A.; Nazha, A. Personalized predictions of patient outcomes during and after hospitalization using artificial intelligence. NPJ Digit. Med. 2020, 3, 51. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Russo, N.W.; Miller, M.M.; Murphy, R.X.; Burmeister, D.B. An observational study to develop a scoring system and model to detect risk of hospital admission due to COVID-19. J. Am. Coll. Emerg. Physicians Open 2021, 2, e12406. [Google Scholar] [CrossRef]
- Liang, W.; Liang, H.; Ou, L.; Chen, B.; Chen, A.; Li, C.; Li, Y.; Guan, W.; Sang, L.; Lu, J.; et al. Development and validation of a clinical risk score to predict the occurrence of critical illness in hospitalized patients with COVID-19. JAMA Intern. Med. 2020, 180, 1081–1089. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, A.; Hou, W.; Graham, J.M.; Li, H.; Richman, P.S.; Thode, H.C.; Singer, A.J.; Duong, T.Q. Prediction model and risk scores of ICU admission and mortality in COVID-19. PLoS ONE 2020, 15, e0236618. [Google Scholar] [CrossRef]
- Noy, O.; Coster, D.; Metzger, M.; Atar, I.; Shenhar-Tsarfaty, S.; Berliner, S.; Rahav, G.; Rogowski, O.; Shamir, R. A machine learning model for predicting deterioration of COVID-19 inpatients. Sci. Rep. 2022, 12, 2630. [Google Scholar] [CrossRef]
- Ferrari, D.; Milic, J.; Tonelli, R.; Ghinelli, F.; Meschiari, M.; Volpi, S.; Faltoni, M.; Franceschi, G.; Iadisernia, V.; Yaacoub, D.; et al. Machine learning in predicting respiratory failure in patients with COVID-19 pneumonia—Challenges, strengths, and opportunities in a global health emergency. PLoS ONE 2020, 15, e0239172. [Google Scholar] [CrossRef] [PubMed]
- Ryan, C.; Minc, A.; Caceres, J.; Balsalobre, A.; Dixit, A.; Ng, B.K.; Schmitzberger, F.; Syed-Abdul, S.; Fung, C. Predicting severe outcomes in COVID-19 related illness using only patient demographics, comorbidities and symptoms. Am. J. Emerg. Med. 2021, 45, 378–384. [Google Scholar] [CrossRef]
- Singh, V.; Kamaleswaran, R.; Chalfin, D.; Buño-Soto, A.; Roman, J.S.; Rojas-Kenney, E.; Molinaro, R.; von Sengbusch, S.; Hodjat, P.; Comaniciu, D.; et al. A deep learning approach for predicting severity of COVID-19 patients using a parsimonious set of laboratory markers. iScience 2021, 24, 103523. [Google Scholar] [CrossRef]
- Chieregato, M.; Frangiamore, F.; Morassi, M.; Baresi, C.; Nici, S.; Bassetti, C.; Bnà, C.; Galelli, M. A hybrid machine learning/deep learning COVID-19 severity predictive model from CT images and clinical data. Sci. Rep. 2022, 12, 4329. [Google Scholar] [CrossRef]
- Li, X.; Ge, P.; Zhu, J.; Li, H.; Graham, J.; Singer, A.; Richman, P.S.; Duong, T.Q. Deep learning prediction of likelihood of ICU admission and mortality in COVID-19 patients using clinical variables. PeerJ 2020, 8, e10337. [Google Scholar] [CrossRef] [PubMed]
- Magunia, H.; Lederer, S.; Verbuecheln, R.; Gilot, B.J.; Koeppen, M.; Haeberle, H.A.; Mirakaj, V.; Hofmann, P.; Marx, G.; Bickenbach, J.; et al. Machine learning identifies ICU outcome predictors in a multicenter COVID-19 cohort. Crit. Care 2021, 25, 295. [Google Scholar] [CrossRef]
- Beiser, D.G.; Jarou, Z.J.; Kassir, A.A.; Puskarich, M.A.; Vrablik, M.C.; Rosenman, E.D.; McDonald, S.A.; Meltzer, A.C.; Courtney, D.M.; Kabrhel, C.; et al. Predicting 30-day return hospital admissions in patients with COVID-19 discharged from the emergency department: A national retrospective cohort study. J. Am. Coll. Emerg. Physicians Open 2021, 2, e12595. [Google Scholar] [CrossRef]
- Garcia-Gutiérrez, S.; Esteban-Aizpiri, C.; Lafuente, I.; Barrio, I.; Quiros, R.; Quintana, J.M.; Uranga, A. Machine learning-based model for prediction of clinical deterioration in hospitalized patients by COVID 19. Sci. Rep. 2022, 12, 7097. [Google Scholar]
- Liu, Q.; Pang, B.; Li, H.; Zhang, B.; Liu, Y.; Lai, L.; Le, W.; Li, J.; Xia, T.; Zhang, X.; et al. Machine learning models for predicting critical illness risk in hospitalized patients with COVID-19 pneumonia. J. Thorac. Dis. 2021, 13, 1215–1229. [Google Scholar] [CrossRef]
- Purkayastha, S.; Xiao, Y.; Jiao, Z.; Thepumnoeysuk, R.; Halsey, K.; Wu, J.; Tran, T.M.L.; Hsieh, B.; Choi, J.W.; Wang, D.; et al. Machine learning-based prediction of COVID-19 severity and progression to critical illness using CT imaging and clinical data. Korean J. Radiol. 2021, 22, 1213. [Google Scholar] [CrossRef]
- Hong, W.; Zhou, X.; Jin, S.; Lu, Y.; Pan, J.; Lin, Q.; Yang, S.; Xu, T.; Basharat, Z.; Zippi, M.; et al. A comparison of XGBoost, random forest, and nomograph for the prediction of disease severity in patients with COVID-19 pneumonia: Implications of cytokine and immune cell profile. Front. Cell. Infect. Microbiol. 2022, 12, 819267. [Google Scholar] [CrossRef] [PubMed]
- Patel, D.; Kher, V.; Desai, B.; Lei, X.; Cen, S.; Nanda, N.; Gholamrezanezhad, A.; Duddalwar, V.; Varghese, B.; AOberai, A. Machine learning based predictors for COVID-19 disease severity. Sci. Rep. 2021, 11, 4673. [Google Scholar] [CrossRef]
- Datta, D.; Dalmida, S.G.; Martinez, L.; Newman, D.; Hashemi, J.; Khoshgoftaar, T.M.; Shorten, C.; Sareli, C.; Eckardt, P. Using machine learning to identify patient characteristics to predict mortality of in-patients with COVID-19 in south Florida. Front. Digit. Health 2023, 5, 1193467. [Google Scholar] [CrossRef]
- Shorten, C.; Cardenas, E.; Khoshgoftaar, T.M.; Hashemi, J.; Dalmida, S.G.; Newman, D.; Datta, D.; Martinez, L.; Sareli, C.; Eckard, P. Exploring Language-Interfaced Fine-Tuning for COVID-19 Patient Survival Classification. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; pp. 1449–1454. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M.; Hashemi, J.; Dalmida, S.G.; Newman, D.; Datta, D.; Martinez, L.; Sareli, C.; Eckard, P. Predicting the Severity of COVID-19 Respiratory Illness with Deep Learning. In Proceedings of the International FLAIRS Conference Proceedings, Jensen Beach, FL, USA, 15–18 May 2022; Volume 35. [Google Scholar]
- Bennett, D.A. How can I deal with missing data in my study? Aust. N. Z. J. Public Health 2001, 25, 464–469. [Google Scholar] [CrossRef]
- Statsenko, Y.; Al Zahmi, F.; Habuza, T.; Almansoori, T.M.; Smetanina, D.; Simiyu, G.L.; Gorkom, K.N.-V.; Ljubisavljevic, M.; Awawdeh, R.; Elshekhali, H.; et al. Impact of Age and Sex on COVID-19 Severity Assessed From Radiologic and Clinical Findings. Front. Cell. Infect. Microbiol. 2022, 11, 777070. [Google Scholar] [CrossRef] [PubMed]
- Romaine, D.S.; Randall, O.S. The Encyclopedia of the Heart and Heart Disease; Facts on File: New York, NY, USA, 2005. [Google Scholar]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef]
- Kubinger, K.D. On artificial results due to using factor analysis for dichotomous variables. Psychol. Sci. 2003, 45, 106–110. [Google Scholar]
- Deb, D.; Smith, R.M. Application of Random Forest and SHAP Tree Explainer in Exploring Spatial (In) Justice to Aid Urban Planning. ISPRS Int. J. Geo Inf. 2021, 10, 629. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Abd El-Raheem, G.O.H.; Mohamed, D.S.I.; Yousif, M.A.A.; Elamin, H.E.S. Characteristics and severity of COVID-19 among Sudanese patients during the waves of the pandemic. Sci. Afr. 2021, 14, e01033. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Steyerberg, E.W.; Eijkemans, M.J.; Habbema, J.F. Stepwise selection in small data sets: A simulation study of bias in logistic regression analysis. J. Clin. Epidemiol. 2018, 101, 76–83. [Google Scholar] [CrossRef]
- Harrell, F.E., Jr. Regression Modeling Strategies: With Applications to Linear Models, Logistic Regression, and Survival Analysis; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Ambler, G.; Brady, A.R.; Royston, P. Simplifying a prognostic model: A simulation study based on clinical data. Stat. Med. 2002, 21, 3803–3822. [Google Scholar] [CrossRef]
- Wang, H.; Li, R.; Tsai, C.L. Tuning parameter selectors for the smoothly clipped absolute deviation method. Biometrika 2007, 94, 553–568. [Google Scholar] [CrossRef]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On evaluation metrics for medical applications of artificial intelligence. Sci. Rep. 2022, 12, 5979. [Google Scholar] [CrossRef] [PubMed]
- Hamida, S.; El Gannour, O.; Cherradi, B.; Ouajji, H.; Raihani, A. Optimization of Machine Learning Algorithms Hyper-Parameters for Improving the Prediction of Patients Infected with COVID-19. In Proceedings of the 2020 IEEE 2nd international conference on electronics, control, optimization and computer science (ICECOCS), Kenitra, Morocco, 2–3 December 2020; pp. 1–6. [Google Scholar]
- Sah, S.; Surendiran, B.; Dhanalakshmi, R.; Yamin, M. COVID-19 cases prediction using SARIMAX Model by tuning hyperparameter through grid search cross-validation approach. Expert Syst. 2023, 40, e13086. [Google Scholar] [CrossRef] [PubMed]
- Liu, B.; Udell, M. Impact of accuracy on model interpretations. arXiv 2020, arXiv:2011.09903. [Google Scholar]
- Ishwaran, H. The effect of splitting on random forests. Mach. Learn. 2015, 99, 75–118. [Google Scholar] [CrossRef] [PubMed]
- Kim, Y.; Kim, Y. Explainable heat-related mortality with random forest and SHapley additive exPlanations (SHAP) models. Sustain. Cities Soc. 2022, 79, 103677. [Google Scholar] [CrossRef]
- Zhai, B.; Perez-Pozuelo, I.; Clifton, E.A.; Palotti, J.; Guan, Y. Making sense of sleep: Multimodal sleep stage classification in a large, diverse population using movement and cardiac sensing. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–33. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, R.; Bajorath, J. Interpretation of compound activity predictions from complex machine learning models using local approximations and shapley values. J. Med. Chem. 2019, 63, 8761–8777. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Van Lissa, C.J.; Stroebe, W.; Leander, N.P.; Agostini, M.; Draws, T.; Grygoryshyn, A.; Gützgow, B.; Kreienkamp, J.; Vetter, C.S.; Abakoumkin, G.; et al. Using machine learning to identify important predictors of COVID-19 infection prevention behaviors during the early phase of the pandemic. Patterns 2022, 3. [Google Scholar] [CrossRef]
- Moncada-Torres, A.; van Maaren, M.C.; Hendriks, M.P.; Siesling, S.; Geleijnse, G. Explainable machine learning can outperform cox regression predictions and provide insights in breast cancer survival. Sci. Rep. 2021, 11, 6968. [Google Scholar] [CrossRef]
- Passarelli-Araujo, H.; Passarelli-Araujo, H.; Urbano, M.R.; Pescim, R.R. Machine learning and comorbidity network analysis for hospitalized patients with COVID-19 in a city in southern Brazil. Smart Health 2022, 26, 100323. [Google Scholar] [CrossRef] [PubMed]
- Batunacun; Wieland, R.; Lakes, T.; Nendel, C. Using SHAP to interpret XGBoost predictions of grassland degradation in Xilingol, China. Geosci. Mod. Dev. Discuss. 2020, 2020, 1–28. [Google Scholar] [CrossRef]
- Gómez-Ramírez, J.; Ávila-Villanueva, M.; Fernández-Blázquez, M.Á. Selecting the most important self-assessed features for predicting conversion to mild cognitive impairment with random forest and permutation-based methods. Sci. Rep. 2020, 10, 20630. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Marques-Silva, J. On the failings of Shapley values for explainability. Int. J. Approx. Reason. 2024, 171, 109112. [Google Scholar] [CrossRef]
- Kumar, I.E.; Venkatasubramanian, S.; Scheidegger, C.; Friedler, S. Problems with Shapley-Value-Based Explanations as Feature Importance Measures. In Proceedings of the International Conference on Machine Learning, Virtual Site, 12–18 July 2020; pp. 5491–5500. [Google Scholar]
- Molnar, C.; Freiesleben, T.; König, G.; Herbinger, J.; Reisinger, T.; Casalicchio, G.; Wright, M.N.; Bischl, B. Relating the Partial Dependence Plot and Permutation Feature Importance to the Data Generating Process. In Proceedings of the World Conference on Explainable Artificial Intelligence, Lisbon, Portugal, 26–28 July 2023; Springer Nature: Cham, Switzerland, 2023; pp. 456–479. [Google Scholar]
- Nohara, Y.; Inoguchi, T.; Nojiri, C.; Nakashima, N. Explanation of Machine Learning Models of Colon Cancer Using SHAP Considering Interaction Effects. arXiv 2022, arXiv:2208.03112. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Qiu, W.; Chen, H.; Dincer, A.B.; Lundberg, S.; Kaeberlein, M.; Lee, S.I. Interpretable machine learning prediction of all-cause mortality. Commun. Med. 2022, 2, 125. [Google Scholar] [CrossRef]
- Molani, S.; Hernandez, P.V.; Roper, R.T.; Duvvuri, V.R.; Baumgartner, A.M.; Goldman, J.D.; Ertekin-Taner, N.; Funk, C.C.; Price, N.D.; Rappaport, N.; et al. Risk factors for severe COVID-19 differ by age for hospitalized adults. Sci. Rep. 2022, 12, 6568. [Google Scholar] [CrossRef]
- Ebinger, J.E.; Achamallah, N.; Ji, H.; Claggett, B.L.; Sun, N.; Botting, P.; Nguyen, T.-T.; Luong, E.; Kim, E.H.; Park, E.; et al. Pre-existing traits associated with COVID-19 illness severity. PLoS ONE 2020, 15, e0236240. [Google Scholar] [CrossRef]
- Şenkal, N.; Meral, R.; Medetalibeyoğlu, A.; Konyaoğlu, H.; Kose, M.; Tukek, T. Association between chronic ACE inhibitor exposure and decreased odds of severe disease in patients with COVID-19. Anatol. J. Cardiol. 2020, 24, 21–29. [Google Scholar]
- Zhang, X.; Cai, H.; Hu, J.; Lian, J.; Gu, J.; Zhang, S.; Ye, C.; Lu, Y.; Jin, C.; Yu, G.; et al. Epidemiological, clinical characteristics of cases of SARS-CoV-2 infection with abnormal imaging findings. Int. J. Infect. Dis. 2020, 94, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Ge, L.; Meng, Y.; Ma, W.; Mu, J. A retrospective prognostic evaluation using unsupervised learning in the treatment of COVID-19 patients with hypertension treated with ACEI/ARB drugs. PeerJ 2024, 12, e17340. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Ruan, W.; Wang, J.; Zheng, D.; Liu, B.; Geng, Y.; Chai, X.; Chen, J.; Li, K.; Li, S.; et al. Interpretable machine learning for covid-19: An empirical study on severity prediction task. IEEE Trans. Artif. Intell. 2021, 4, 764–777. [Google Scholar] [CrossRef]
- Ueda, D.; Kakinuma, T.; Fujita, S.; Kamagata, K.; Fushimi, Y.; Ito, R.; Matsui, Y.; Nozaki, T.; Nakaura, T.; Fujima, N.; et al. Fairness of artificial intelligence in healthcare: Review and recommendations. Jpn. J. Radiol. 2024, 42, 3–15. [Google Scholar] [CrossRef] [PubMed]
- Ghassemi, M.; Naumann, T.; Schulam, P.; Beam, A.L.; Chen, I.Y.; Ranganath, R. A review of challenges and opportunities in machine learning for health. AMIA Summits Transl. Sci. Proc. 2020, 2020, 191. [Google Scholar]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key challenges for delivering clinical impact with artificial intelligence. BMC Med. 2019, 17, 195. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J.P.; Cao, T.; Viviano, J.D.; Huang, C.-W.; Fralick, M.; Ghassemi, M.; Mamdani, M.; Greiner, R.; Bengio, Y. Problems in the deployment of machine-learned models in health care. Can. Med. Assoc. J. 2021, 193, E1391–E1394. [Google Scholar] [CrossRef]
- Laatifi, M.; Douzi, S.; Bouklouz, A.; Ezzine, H.; Jaafari, J.; Zaid, Y.; El Ouahidi, B.; Naciri, M. Machine learning approaches in COVID-19 severity risk prediction in Morocco. J. Big Data 2022, 9, 5. [Google Scholar] [CrossRef]
- Khadem, H.; Nemat, H.; Elliott, J.; Benaissa, M. Interpretable machine learning for inpatient COVID-19 mortality risk assessments: Diabetes mellitus exclusive interplay. Sensors 2022, 22, 8757. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dummy Coding | ||
|---|---|---|
| Patients’ Characteristics | Age | ‘Young adults’: 0, ‘Middle adults’: 1, ‘Older adults’: 2 |
| Sex | ‘Female’: 0, ‘Male’: 1 | |
| Race | ‘Black’: 0, ‘Others’: 1, ‘White’: 2 | |
| Ethnicity | ‘Hispanic’: 0, ‘Not Hispanic’: 1 | |
| Smoking Status | ‘Never’: 0, ‘Former’: 1,‘Current’: 2 | |
| Pre-hospital Comorbidities | COPD | ‘False’: 0, ‘True’: 1 |
| Kidney Disease (stg1_4) | ‘False’: 0, ‘True’: 1 | |
| Kidney Disease (stg5) | ‘False’: 0, ‘True’: 1 | |
| Diarrhea | ‘No Diarrhea’: 0, ‘Diarrhea’: 1 | |
| Hypertension | ‘No Hypertension’: 0, ‘Hypertension‘: 1 | |
| Diabetes | ‘No Diabetes’: 0, ‘Diabetes‘: 1 | |
| Pneumonia | ‘No Pneumonia‘: 0, ‘Pneumonia‘: 1 | |
| Heart Failure | ‘False’: 0, ‘True’: 1 | |
| Cardiac Arrhythmias | ‘False’: 0, ‘True’: 1 | |
| Coronary Artery Disease | ‘False’: 0, ‘True’: 1 | |
| Dependence on Renal Dialysis | ‘No’: 0, ‘Yes’: 1 | |
| Cerebrovascular Disease | ‘No’: 0, ‘Yes’: 1 | |
| BMI | ‘Underweight’: 0, ‘Normal Weight’: 1, ‘Overweight’: 2, ‘Obesity’: 3 | |
| Liver Disease | ‘No’: 0, ‘Yes’: 1 | |
| Asthma | ‘No’: 0, ‘Yes’: 1 | |
| HIV | ‘No’: 0, ‘Yes’: 1 | |
| Cancer | ‘No’: 0, ‘Yes’: 1 | |
| Medications | ARBs | ‘No’: 0, ‘Yes’: 1 |
| ACEIs | ‘No’: 0, ‘Yes’: 1 | |
| Features | No MV (N = 4964) | MV (N = 407) | ||||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | χ2 | df | p | OR | |
| Age | ||||||||
| Young adult | 609 | 12.3 | 22 | 5.4 | 51.43 | 2 | <0.001 | 2.74 |
| Middle Adult | 2353 | 47.4 | 150 | 36.9 | ||||
| Older Adult | 2002 | 40.3 | 235 | 57.7 | ||||
| BMI | ||||||||
| Underweight | 67 | 1.3 | 8 | 2.0 | 4.98 | 3 | 0.173 | 1.77 |
| Normal | 821 | 16.5 | 54 | 13.3 | ||||
| Overweight | 1703 | 34.3 | 134 | 32.9 | ||||
| Obese | 2373 | 47.8 | 211 | 51.8 | ||||
| Sex (Male) | 2478 | 49.9 | 237 | 58.2 | 10.40 | 1 | 0.001 | 1.4 |
| Race | ||||||||
| Black | 1553 | 31.3 | 123 | 30.2 | 5.58 | 2 | 0.061 | 1.09 |
| Other | 2540 | 51.2 | 229 | 56.3 | ||||
| White | 871 | 17.5 | 55 | 13.5 | ||||
| Ethnicity (Not Hispanic) | 3317 | 66.8 | 262 | 64.4 | 1.01 | 1 | 0.314 | 0.9 |
| Smoking Status | ||||||||
| Never | 4121 | 83.0 | 330 | 81.1 | 1.01 | 2 | 0.603 | 1.29 |
| Former | 716 | 14.4 | 65 | 16.0 | ||||
| Current | 127 | 2.6 | 12 | 2.9 | ||||
| Diabetes | 1934 | 39.0 | 240 | 59.0 | 62.50 | 1 | <0.001 | 2.25 |
| Hypertension | 3218 | 64.8 | 340 | 83.5 | 58.90 | 1 | <0.001 | 2.75 |
| COPD | 425 | 8.6 | 46 | 11.3 | 3.53 | 1 | 0.060 | 1.36 |
| Asthma | 151 | 3.0 | 14 | 3.4 | 0.20 | 1 | 0.655 | 1.135 |
| CKD Stages 1 to 4 | 744 | 15.0 | 117 | 28.7 | 52.90 | 1 | <0.001 | 2.89 |
| CKD Stage 5 | 156 | 3.1 | 25 | 6.1 | 10.40 | 1 | 0.001 | 2.02 |
| Heart Failure | 663 | 13.4 | 80 | 19.7 | 12.52 | 1 | <0.001 | 1.59 |
| Cancer | 284 | 5.7 | 29 | 7.1 | 1.35 | 1 | 0.245 | 1.26 |
| Cardiac Arrhythmias | 626 | 12.6 | 48 | 11.8 | 0.23 | 1 | 0.632 | 0.93 |
| Cerebrovascular Disease | 318 | 6.4 | 19 | 4.7 | 1.93 | 1 | 0.165 | 0.72 |
| Coronary Artery Disease | 770 | 15.5 | 90 | 22.1 | 12.19 | 1 | <0.001 | 1.55 |
| Liver Disease | 102 | 2.1 | 16 | 3.9 | 6.16 | 1 | 0.013 | 1.95 |
| HIV | 53 | 1.1 | 3 | 0.7 | 0.40 | 1 | 0.528 | 0.69 |
| Pneumonia | 1992 | 40.1 | 214 | 52.6 | 24.09 | 1 | <0.001 | 1.65 |
| ARBs | 1283 | 25.8 | 110 | 27.0 | 0.27 | 1 | 0.601 | 1.06 |
| ACEIs | 1710 | 34.4 | 150 | 36.9 | 0.96 | 1 | 0.327 | 1.11 |
| Diarrhea | 613 | 12.3 | 205 | 50.4 | 421.16 | 1 | <0.001 | 7.2 |
| Dependence on Renal Dialysis | 4846 | 97.6 | 382 | 93.9 | 20.58 | 1 | <0.001 | 2.69 |
| Features | No ICU (N = 4775) | ICU (N = 596) | ||||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | χ2 | df | p | OR | |
| Age | ||||||||
| Young adult | 600 | 95.1 | 31 | 4.9 | 70.19 | 2 | <0.001 | 3.43 |
| Middle Adult | 2275 | 90.9 | 228 | 9.1 | - | - | - | - |
| Older Adult | 1900 | 84.9 | 337 | 15.1 | - | - | - | - |
| BMI | 0.0 | |||||||
| Underweight | 66 | 88 | 9 | 12.0 | 10.51 | 3 | 0.015 | 0.667 |
| Normal | 801 | 91.5 | 74 | 8.5 | - | - | - | - |
| Overweight | 1642 | 89.4 | 195 | 10.6 | - | - | - | - |
| Obese | 2266 | 87.7 | 318 | 12.3 | - | - | - | - |
| Sex (Male) | 2368 | 87.2 | 347 | 12.8 | 15.79 | 1 | <0.001 | 1.42 |
| Race | 0.0 | |||||||
| Black | 1512 | 90.2 | 164 | 9.8 | 16.76 | 2 | <0.001 | 0.86 |
| Other | 2416 | 87.3 | 353 | 12.7 | - | - | - | - |
| White | 847 | 91.5 | 79 | 8.5 | - | - | - | - |
| Ethnicity (Not Hispanic) | 1578 | 88.1 | 214 | 11.9 | 1.95 | 1 | 0.163 | 0.881 |
| Smoking Status | 0.0 | |||||||
| Never | 3969 | 89.2 | 482 | 10.8 | 1.94 | 2 | 0.379 | 1.23 |
| Former | 685 | 87.7 | 96 | 12.3 | - | - | - | - |
| Current | 121 | 87.1 | 18 | 12.9 | - | - | - | - |
| Diabetes | 1818 | 83.6 | 356 | 16.4 | 103.16 | 1 | <0.001 | 2.41 |
| Hypertension | 3066 | 86.2 | 492 | 13.8 | 79.71 | 1 | <0.001 | 2.64 |
| COPD | 395 | 83.9 | 76 | 16.1 | 13.29 | 1 | <0.001 | 1.62 |
| Asthma | 140 | 84.8 | 25 | 15.2 | 2.84 | 1 | 0.092 | 1.45 |
| CKD Stages 1 to 4 | 699 | 81.2 | 162 | 18.8 | 61.92 | 1 | <0.001 | 2.78 |
| CKD Stage 5 | 150 | 82.9 | 31 | 17.1 | 6.91 | 1 | 0.009 | 1.69 |
| Heart Failure | 623 | 83.8 | 120 | 16.2 | 22.33 | 1 | <0.001 | 1.68 |
| Cancer | 271 | 86.6 | 42 | 13.4 | 1.82 | 1 | 0.178 | 1.26 |
| Cardiac Arrhythmias | 599 | 88.9 | 75 | 11.1 | 0.00 | 1 | 0.978 | 1 |
| Cerebrovascular Disease | 307 | 91.1 | 30 | 8.9 | 1.75 | 1 | 0.185 | 1.23 |
| Coronary Artery Disease | 732 | 85.1 | 128 | 14.9 | 14.89 | 1 | <0.001 | 1.51 |
| Liver Disease | 97 | 82.2 | 21 | 17.8 | 5.49 | 1 | 0.019 | 1.76 |
| HIV | 53 | 94.6 | 3 | 5.4 | 1.89 | 1 | 0.169 | 1.51 |
| Pneumonia | 1907 | 86.4 | 299 | 13.6 | 22.91 | 1 | <0.001 | 1.51 |
| ARBs | 1232 | 88.4 | 161 | 11.6 | 0.41 | 1 | 0.524 | 1.06 |
| ACEIs | 1637 | 88 | 223 | 12.0 | 2.30 | 1 | 0.130 | 1.15 |
| Diarrhea | 511 | 62.5 | 307 | 37.5 | 683.48 | 1 | <0.001 | 8.86 |
| Dependence on Renal Dialysis | 111 | 77.6 | 32 | 22.4 | 18.95 | 1 | <0.001 | 2.38 |
| Features | No IMCU (N = 4361) | IMCU (N = 1010) | ||||||
|---|---|---|---|---|---|---|---|---|
| N | % | N | % | χ2 | df | p | OR | |
| Age | ||||||||
| Young adult | 566 | 89.7 | 65 | 10.3 | 78.79 | 2 | <0.001 | 2.74 |
| Middle Adult | 2094 | 83.7 | 409 | 16.3 | - | - | - | - |
| Older Adult | 1701 | 76.0 | 536 | 24.0 | - | - | - | - |
| BMI | 0.0 | |||||||
| Underweight | 66 | 88.0 | 9 | 12.0 | 5.79 | 3 | 0.122 | 1.78 |
| Normal | 729 | 83.3 | 146 | 16.7 | - | - | - | - |
| Overweight | 1486 | 80.9 | 351 | 19.1 | - | - | - | - |
| Obese | 2080 | 80.5 | 504 | 19.5 | - | - | - | - |
| Sex (Male) | 2221 | 83.6 | 435 | 16.4 | 20.27 | 1 | <0.001 | 1.37 |
| Race | 0.0 | |||||||
| Black | 1372 | 81.9 | 304 | 18.1 | 1.30 | 2 | 0.522 | 1.09 |
| Other | 2232 | 80.6 | 537 | 19.4 | - | - | - | - |
| White | 757 | 81.7 | 169 | 18.3 | - | - | - | - |
| Ethnicity (Not Hispanic) | 1458 | 81.4 | 334 | 18.6 | 0.05 | 1 | 0.825 | 1.02 |
| Smoking Status | 0.0 | |||||||
| Never | 3641 | 81.8 | 810 | 18.2 | 6.84 | 2 | 0.033 | 1.28 |
| Former | 608 | 77.8 | 173 | 22.2 | - | - | - | - |
| Current | 112 | 80.6 | 27 | 19.4 | - | - | - | - |
| Diabetes | 1648 | 75.8 | 526 | 24.2 | 69.50 | 1 | <0.001 | 1.79 |
| Hypertension | 2748 | 77.2 | 810 | 22.8 | 108.31 | 1 | <0.001 | 2.38 |
| COPD | 331 | 70.3 | 140 | 29.7 | 40.32 | 1 | <0.001 | 1.96 |
| Asthma | 129 | 78.2 | 36 | 21.8 | 1.01 | 1 | 0.314 | 1.21 |
| CKD Stages 1 to 4 | 622 | 72.2 | 239 | 27.8 | 53.84 | 1 | <0.001 | 1.86 |
| CKD Stage 5 | 130 | 71.8 | 51 | 28.2 | 10.78 | 1 | 0.001 | 1.73 |
| Heart Failure | 540 | 72.7 | 203 | 27.3 | 40.97 | 1 | <0.001 | 1.78 |
| Cancer | 242 | 77.3 | 71 | 22.7 | 3.28 | 1 | 0.070 | 1.29 |
| Cardiac Arrhythmias | 527 | 78.2 | 147 | 21.8 | 4.56 | 1 | 0.033 | 1.24 |
| Cerebrovascular Disease | 272 | 80.7 | 65 | 19.3 | 0.06 | 1 | 0.815 | 1.03 |
| Coronary Artery Disease | 642 | 74.7 | 218 | 25.3 | 28.72 | 1 | <0.001 | 1.59 |
| Liver Disease | 92 | 78.0 | 26 | 22.0 | 0.82 | 1 | 0.364 | 1.23 |
| HIV | 48 | 85.7 | 8 | 14.3 | 0.76 | 1 | 0.384 | 0.72 |
| Pneumonia | 1706 | 77.3 | 500 | 22.7 | 36.55 | 1 | <0.001 | 1.5 |
| ARBs | 1076 | 77.2 | 317 | 22.8 | 19.24 | 1 | <0.001 | 1.4 |
| ACEIs | 1480 | 79.6 | 380 | 20.4 | 4.92 | 1 | 0.026 | 1.17 |
| Diarrhea | 531 | 64.9 | 287 | 35.1 | 167.52 | 1 | <0.001 | 2.86 |
| Dependence on Renal Dialysis | 108 | 75.5 | 35 | 24.5 | 3.09 | 1 | 0.079 | 1.14 |
| 95% CI for OR | ||||||||
|---|---|---|---|---|---|---|---|---|
| Features | B | SE | Wald | df | p | OR | Lower | Upper |
| Age | 0.43 | 0.11 | 15.27 | 1 | <0.001 | 1.54 | 1.24 | 1.91 |
| BMI | 0.14 | 0.08 | 3.31 | 1 | 0.069 | 1.15 | 0.99 | 1.34 |
| Sex | 0.32 | 0.11 | 7.94 | 1 | 0.005 | 1.38 | 1.10 | 1.72 |
| Black | 9.48 | 2 | 0.009 | |||||
| Other | 0.12 | 0.13 | 0.81 | 1 | 0.369 | 1.12 | 0.87 | 1.44 |
| White | −0.41 | 0.19 | 4.81 | 1 | 0.028 | 0.67 | 0.46 | 0.96 |
| Diabetes | 0.49 | 0.12 | 16.71 | 1 | <0.001 | 1.63 | 1.29 | 2.05 |
| Hypertension | 0.73 | 0.17 | 18.98 | 1 | <0.001 | 2.08 | 1.50 | 2.89 |
| CKD Stages 1 to 4 | 0.57 | 0.14 | 17.47 | 1 | <0.001 | 1.76 | 1.35 | 2.30 |
| Cardiac Arrhythmias | −0.38 | 0.18 | 4.34 | 1 | 0.037 | 0.69 | 0.48 | 0.98 |
| Cerebrovascular Disease | −0.52 | 0.26 | 3.90 | 1 | 0.048 | 0.60 | 0.36 | 1.00 |
| Pneumonia | 0.35 | 0.11 | 10.24 | 1 | 0.001 | 1.43 | 1.15 | 1.77 |
| ARBs | −0.44 | 0.13 | 11.11 | 1 | <0.001 | 0.65 | 0.50 | 0.84 |
| ACEIs | −0.28 | 0.12 | 4.97 | 1 | 0.026 | 0.76 | 0.60 | 0.97 |
| Diarrhea | 1.84 | 0.11 | 268.20 | 1 | <0.001 | 6.31 | 5.06 | 7.87 |
| Dependence on Renal Dialysis | 0.69 | 0.26 | 7.01 | 1 | 0.008 | 1.99 | 1.20 | 3.30 |
| Constant | −4.94 | 0.30 | 267.94 | 1 | <0.001 | 0.01 | ||
| 95% CI for OR | ||||||||
|---|---|---|---|---|---|---|---|---|
| Features | B | SE | Wald | df | p | OR | Lower | Upper |
| Age | 0.46 | 0.10 | 22.70 | 1 | <0.001 | 1.58 | 1.31 | 1.91 |
| BMI | 0.22 | 0.07 | 10.66 | 1 | 0.001 | 1.25 | 1.09 | 1.42 |
| Sex | 0.41 | 0.10 | 16.89 | 1 | <0.001 | 1.51 | 1.24 | 1.83 |
| Black | 23.87 | 2 | <0.001 | |||||
| Other | 0.32 | 0.11 | 7.97 | 1 | 0.005 | 1.38 | 1.10 | 1.72 |
| White | −0.36 | 0.16 | 4.78 | 1 | 0.029 | 0.70 | 0.51 | 0.96 |
| Diabetes | 0.61 | 0.10 | 34.67 | 1 | <0.001 | 1.84 | 1.50 | 2.26 |
| Hypertension | 0.72 | 0.14 | 24.92 | 1 | <0.001 | 2.04 | 1.54 | 2.71 |
| Asthma | 0.57 | 0.25 | 5.08 | 1 | 0.024 | 1.76 | 1.08 | 2.88 |
| CKD Stages 1 to 4 | 0.43 | 0.12 | 12.43 | 1 | <0.001 | 1.54 | 1.21 | 1.95 |
| Heart Failure | 0.41 | 0.14 | 8.63 | 1 | 0.003 | 1.51 | 1.15 | 1.99 |
| Cardiac Arrhythmias | −0.37 | 0.16 | 5.27 | 1 | 0.022 | 0.69 | 0.50 | 0.95 |
| Cerebrovascular Disease | −0.44 | 0.22 | 3.93 | 1 | 0.047 | 0.65 | 0.42 | 1.00 |
| Pneumonia | 0.23 | 0.10 | 5.57 | 1 | 0.018 | 1.26 | 1.04 | 1.52 |
| ARBs | −0.51 | 0.12 | 19.55 | 1 | <0.001 | 0.60 | 0.48 | 0.75 |
| ACEIs | −0.29 | 0.11 | 7.20 | 1 | 0.007 | 0.75 | 0.60 | 0.92 |
| Diarrhea | 2.14 | 0.10 | 463.52 | 1 | <0.001 | 8.52 | 7.01 | 10.36 |
| Constant | −4.98 | 0.27 | 346.66 | 1 | <0.001 | 0.01 | ||
| 95% CI for OR | ||||||||
|---|---|---|---|---|---|---|---|---|
| Features | B | SE | Wald | df | p | OR | Lower | Upper |
| Age | 0.27 | 0.07 | 14.12 | 1 | <0.001 | 1.30 | 1.14 | 1.50 |
| BMI | 0.15 | 0.05 | 9.18 | 1 | 0.002 | 1.16 | 1.06 | 1.28 |
| Sex | 0.32 | 0.07 | 18.76 | 1 | <0.001 | 1.38 | 1.19 | 1.59 |
| Black | 7.04 | 2 | 0.030 | |||||
| Other | 0.22 | 0.11 | 4.22 | 1 | 0.040 | 1.24 | 1.01 | 1.53 |
| White | −0.08 | 0.12 | 0.51 | 1 | 0.476 | 0.92 | 0.74 | 1.15 |
| Ethnicity | 0.17 | 0.10 | 2.88 | 1 | 0.090 | 1.19 | 0.97 | 1.45 |
| Diabetes | 0.27 | 0.08 | 11.75 | 1 | <0.001 | 1.31 | 1.12 | 1.53 |
| Hypertension | 0.59 | 0.10 | 32.14 | 1 | <0.001 | 1.80 | 1.47 | 2.20 |
| COPD | 0.35 | 0.12 | 8.66 | 1 | 0.003 | 1.42 | 1.12 | 1.78 |
| CKD Stage 1 to 4 | 0.22 | 0.10 | 5.17 | 1 | 0.023 | 1.25 | 1.03 | 1.51 |
| Heart Failure | 0.29 | 0.11 | 7.07 | 1 | 0.008 | 1.34 | 1.08 | 1.66 |
| Cardiac Arrhythmias | −0.21 | 0.12 | 3.10 | 1 | 0.078 | 0.81 | 0.64 | 1.02 |
| Pneumonia | 0.29 | 0.07 | 15.54 | 1 | <0.001 | 1.34 | 1.16 | 1.54 |
| ACEIs | −0.24 | 0.08 | 8.40 | 1 | 0.004 | 0.79 | 0.67 | 0.93 |
| Diarrhea | 0.94 | 0.09 | 119.11 | 1 | <0.001 | 2.56 | 2.17 | 3.04 |
| Constant | −3.42 | 0.22 | 249.20 | 1 | <0.001 | 0.03 | ||
| Sex | Age | Ethnicity | |||||
|---|---|---|---|---|---|---|---|
| Features | Female | Male | Young | Middle | Older | Non-Hispanic | Hispanic |
| Male | -- | -- | -- | 1.89 ** | -- | 1.47 * | 1.38 * |
| Age | |||||||
| Young Adult | -- | -- | -- | -- | -- | -- | -- |
| Middle | 0.88 | 1.24 | -- | -- | -- | 2.55 ** | -- |
| Older | 1.72 | 2.02 | -- | -- | -- | 8.43 ** | -- |
| BMI | -- | -- | -- | -- | -- | -- | -- |
| Normal | -- | 0.34 | 0.03 ** | -- | 1.38 | 1.38 | -- |
| Overweight | -- | 0.36 | 0.01 ** | -- | 1.97 | 1.86 | -- |
| Obese | -- | 0.58 | 0.01 ** | -- | 3.06 * | 2.74 * | -- |
| Race | |||||||
| Black | -- | -- | -- | -- | -- | -- | |
| Other | 1.19 | 1.06 | -- | 0.80 | 1.62 * | -- | 1.19 |
| White | 0.76 * | 0.57 * | -- | 0.51 * | 0.82 | -- | 0.70 * |
| Hispanic | -- | -- | 3.36 ** | -- | -- | -- | -- |
| Smoke | |||||||
| Never | -- | -- | -- | -- | -- | -- | -- |
| Former | -- | -- | -- | -- | -- | -- | -- |
| Current | -- | -- | -- | -- | -- | -- | -- |
| Diabetes | 1.88 ** | 1.48 * | 2.16 * | 1.49 * | 1.69 ** | ||
| Hypertension | 1.91 ** | 2.35 ** | 2.52 * | 1.66 | 1.99 * | 2.21 ** | |
| COPD | -- | -- | -- | -- | -- | -- | -- |
| Asthma | -- | -- | -- | -- | -- | -- | -- |
| CKD Stages 1–4 | 1.61 ** | 1.68 ** | -- | -- | 1.95 ** | 1.56 * | 1.82 ** |
| CKD Stage 5 | -- | -- | -- | -- | -- | 0.15 | 1.69 |
| Heart Failure | 1.49 | ||||||
| Cancer | -- | -- | -- | -- | -- | -- | -- |
| Cardiac Arrhythmias | 0.39 | 0.52 ** | |||||
| Cerebrovascular Disease | 0.35 | -- | -- | -- | -- | -- | 0.57 |
| Coronary Artery Disease | 1.43 | -- | 7.95 ** | 1.59 | -- | -- | -- |
| Liver Disease | -- | -- | 8.74 ** | -- | -- | -- | -- |
| HIV | -- | -- | -- | -- | -- | -- | -- |
| Pneumonia | -- | -- | -- | 1.30 | 1.56 ** | -- | -- |
| ARBs | 0.63 | 0.62 | -- | 0.48 ** | 0.707 ** | 0.51 ** | 1.47 ** |
| ACEIs | 0.74 | 0.73 | -- | 0.59 * | -- | 0.67 * | |
| Diarrhea | 5.54 | 7.90 | 43.17 ** | 7.72 ** | 5.18 ** | 5.59 ** | 0.75 |
| Dependence on Renal Dialysis | 2.58 | -- | -- | 3.14 ** | 7.61 ** | 6.88 ** | |
| R2 | 0.18 | 0.24 | 0.43 | 0.22 | 0.18 | 24.6 | 0.20 |
| Correct Classification % | 93.6% | 91.5% | 97.3% | 94.1% | 89.7% | 92.4% | 92.7% |
| Sex | Age | Ethnicity | ||||||
|---|---|---|---|---|---|---|---|---|
| Features | Female | Male | Young | Middle | Older | Non-Hispanic | Hispanic | |
| Male | -- | -- | -- | 1.87 * | 1.91 * | 1.75 ** | 1.39 ** | |
| Age | ||||||||
| Young Adult | -- | -- | -- | -- | -- | -- | -- | |
| Middle | 0.89 | 1.26 | -- | -- | -- | 2.08 | 0.92 | |
| Older | 1.71 | 2.11 | -- | -- | -- | 5.6 ** | 1.29 | |
| BMI | ||||||||
| Normal | -- | 0.29 * | 0.02 ** | -- | -- | -- | -- | |
| Overweight | -- | 0.31 | 0.01 ** | -- | -- | -- | -- | |
| Obese | -- | 0.50 | 0.01 ** | -- | -- | -- | -- | |
| Race | ||||||||
| Black | -- | -- | -- | -- | -- | -- | -- | |
| Other | -- | 1.07 | -- | 1.32 | 1.32 | -- | 1.69 * | |
| White | -- | 0.57 * | -- | 0.65 | 0.65 | -- | 0.69 * | |
| Hispanic | -- | -- | 2.89 * | 1.23 | 1.23 * | -- | -- | |
| Smoke | ||||||||
| Never | -- | -- | -- | -- | -- | -- | -- | |
| Former | -- | -- | -- | -- | -- | -- | -- | |
| Current | -- | -- | -- | -- | -- | -- | -- | |
| Diabetes | 1.91 * | 1.47 * | -- | 2.42 * | 2.41 ** | 2.08 * | 1.76 ** | |
| Hypertension | 1.84 * | 2.37 * | 3.01 * | 2.32 * | 2.32 ** | -- | 2.39 ** | |
| COPD | -- | 0.65 | -- | -- | 1.76* | -- | ||
| Asthma | -- | -- | -- | -- | -- | -- | 1.78 * | |
| CKD Stages 1–4 | 1.60 * | 1.71 * | 10.42 * | 1.70 * | 1.70 * | 1.22 | 1.56 * | |
| CKD Stage 5 | -- | -- | 6.26 * | -- | -- | 0.15 * | -- | |
| Heart Failure | -- | 1.62 * | 3.09 * | 2.24 * | -- | -- | 1.39 * | |
| Cancer | -- | -- | -- | -- | -- | -- | -- | |
| Cardiac Arrhythmias | -- | 0.39 | -- | -- | -- | 0.53 * | -- | |
| Cerebrovascular Disease | 0.39 * | -- | -- | 0.47 * | 0.47 | 0.52 | -- | |
| Coronary Artery Disease | 1.40 | -- | -- | -- | -- | 1.31 | -- | |
| Liver Disease | -- | -- | 3.09* | -- | -- | -- | -- | |
| HIV | -- | -- | -- | -- | -- | -- | -- | |
| Pneumonia | -- | 1.73 | 1.69 | -- | -- | 1.26 | 1.24 * | |
| ARBs | 0.65 * | 0.62 * | 0.44 | 0.52 * | 0.51 * | -- | 0.66 * | |
| ACEIs | 0.73 * | 0.73 | 0.23 | 0.76 | 0.76 | 0.46 ** | 0.69 * | |
| Diarrhea | 5.56 * | 7.93 ** | 41.46 ** | 10.13 ** | 10.13 ** | 7.86 ** | 9.28 ** | |
| Dependence on Renal Dialysis | 2.55 * | -- | -- | -- | -- | 6.39 ** | -- | |
| R2 | 0.18 | 0.24 | 0.46 | 0.48 | 0.27 | 0.29 | 0.26 | |
| Correct Classification% | 93.6% | 91.5% | 95.9% | 95.7% | 97.1% | 89.6% | 89.8% | |
| Sex | Age | Ethnicity | |||||
|---|---|---|---|---|---|---|---|
| Features | Female | Male | Young | Middle | Older | Non-Hispanic | Hispanic |
| Male | -- | -- | -- | 1.64 ** | 1.25 * | 1.40 * | 1.38 * |
| Age | |||||||
| Young Adult | -- | -- | -- | -- | -- | -- | -- |
| Middle | 0.86 | -- | -- | -- | -- | 0.85 | 1.16 |
| Older | 1.44 | -- | -- | -- | -- | 1.32 | 1.46 |
| BMI | -- | -- | -- | -- | -- | -- | -- |
| Normal | 1.52 | -- | -- | -- | 1.58 | 3.14 | -- |
| Overweight | 2.08 | -- | -- | -- | 2.07 * | 5.21 | -- |
| Obese | 2.32 * | -- | -- | -- | 2.16 * | 5.39 | -- |
| Race | |||||||
| Black | -- | -- | -- | -- | -- | -- | -- |
| Other | -- | -- | -- | -- | 1.24 * | -- | 1.12 |
| White | -- | -- | -- | -- | 0.89 | -- | 0.91 |
| Hispanic | -- | -- | -- | -- | -- | -- | -- |
| Smoke | |||||||
| Never | -- | -- | -- | -- | -- | -- | -- |
| Former | -- | -- | 0.00 | -- | -- | -- | -- |
| Current | -- | -- | 2.49 * | -- | -- | -- | -- |
| Diabetes | 1.35 ** | 1.36 ** | 4.46 ** | 1.45 ** | -- | 1.63 ** | 1.25 * |
| Hypertension | 1.53 ** | 2.14 ** | 0.81 * | 1.94 ** | 1.62 ** | 1.89 ** | 1.94 * |
| COPD | 1.34 * | 1.51 ** | -- | 1.59 * | 1.36 * | 1.66 ** | 1.29 * |
| Asthma | -- | -- | 2.79 | -- | -- | -- | -- |
| CKD Stages 1–4 | -- | 1.29 * | 3.48 * | 1.56 * | -- | 1.66 ** | -- |
| CKD Stage 5 | -- | -- | 0.42 | -- | -- | -- | -- |
| Heart Failure | 1.36 * | 1.3 * | 0.52 | 1.44 * | 1.36 * | -- | 1.41 * |
| Cancer | -- | -- | -- | 1.50 | -- | -- | 0.78 |
| Cardiac Arrhythmias | -- | 0.72 * | -- | 0.68 | -- | -- | -- |
| Cerebrovascular Disease | -- | -- | -- | -- | -- | -- | -- |
| Coronary Artery Disease | -- | -- | -- | -- | -- | -- | -- |
| Liver Disease | -- | -- | -- | -- | -- | -- | -- |
| HIV | -- | -- | -- | -- | -- | -- | -- |
| Pneumonia | 1.42 ** | 1.28 * | 2.25 * | 1.2 * | 1.35 ** | 1.40 | 1.32 * |
| ARBs | -- | -- | 4.21 * | -- | 0.81 * | 0.79 | -- |
| ACEIs | -- | 0.72 * | -- | 0.79 ** | 0.74 * | 0.76 | 0.79 * |
| Diarrhea | 2.88 ** | 2.42 * | 2.93 * | 2.81 ** | 2.30 ** | 2.82 ** | 2.52 * |
| Dependence on Renal Dialysis | 0.51 * | -- | -- | -- | -- | -- | 0.76 |
| R2 | 0.11 | 0.09 | 0.23 | 0.11 | 0.07 | 0.15 | 0.09 |
| Correct Classification % | 83.7% | 78.9% | 90.5% | 83.8% | 76.4% | 82.10 | 81.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Datta, D.; Ray, S.; Martinez, L.; Newman, D.; Dalmida, S.G.; Hashemi, J.; Sareli, C.; Eckardt, P. Feature Identification Using Interpretability Machine Learning Predicting Risk Factors for Disease Severity of In-Patients with COVID-19 in South Florida. Diagnostics 2024, 14, 1866. https://doi.org/10.3390/diagnostics14171866
Datta D, Ray S, Martinez L, Newman D, Dalmida SG, Hashemi J, Sareli C, Eckardt P. Feature Identification Using Interpretability Machine Learning Predicting Risk Factors for Disease Severity of In-Patients with COVID-19 in South Florida. Diagnostics. 2024; 14(17):1866. https://doi.org/10.3390/diagnostics14171866
Chicago/Turabian StyleDatta, Debarshi, Subhosit Ray, Laurie Martinez, David Newman, Safiya George Dalmida, Javad Hashemi, Candice Sareli, and Paula Eckardt. 2024. "Feature Identification Using Interpretability Machine Learning Predicting Risk Factors for Disease Severity of In-Patients with COVID-19 in South Florida" Diagnostics 14, no. 17: 1866. https://doi.org/10.3390/diagnostics14171866
APA StyleDatta, D., Ray, S., Martinez, L., Newman, D., Dalmida, S. G., Hashemi, J., Sareli, C., & Eckardt, P. (2024). Feature Identification Using Interpretability Machine Learning Predicting Risk Factors for Disease Severity of In-Patients with COVID-19 in South Florida. Diagnostics, 14(17), 1866. https://doi.org/10.3390/diagnostics14171866