Abstract
The integration of artificial intelligence (AI) in medical diagnostics represents a significant advancement in managing upper gastrointestinal (GI) cancer, which is a major cause of global cancer mortality. Specifically for gastric cancer (GC), chronic inflammation causes changes in the mucosa such as atrophy, intestinal metaplasia (IM), dysplasia, and ultimately cancer. Early detection through endoscopic regular surveillance is essential for better outcomes. Foundation models (FMs), which are machine or deep learning models trained on diverse data and applicable to broad use cases, offer a promising solution to enhance the accuracy of endoscopy and its subsequent pathology image analysis. This review explores the recent advancements, applications, and challenges associated with FMs in endoscopy and pathology imaging. We started by elucidating the core principles and architectures underlying these models, including their training methodologies and the pivotal role of large-scale data in developing their predictive capabilities. Moreover, this work discusses emerging trends and future research directions, emphasizing the integration of multimodal data, the development of more robust and equitable models, and the potential for real-time diagnostic support. This review aims to provide a roadmap for researchers and practitioners in navigating the complexities of incorporating FMs into clinical practice for the prevention/management of GC cases, thereby improving patient outcomes.
1. Introduction
Artificial intelligence (AI) is transforming medical imaging, particularly in the detection and surveillance of upper gastrointestinal (GI) cancers. Traditional diagnostic methods rely heavily on the expertise of medical professionals, which, although critical, can be time-consuming and variable. AI addresses these challenges by providing accurate, real-time analysis of endoscopic and pathology images, improving the early detection of premalignant lesions and optimizing patient risk stratification and surveillance intervals. The emergence of foundation models (FMs) further enhances this capability by offering automated, scalable solutions for image analysis. Trained on vast and diverse datasets, FMs can be fine-tuned for specific tasks, such as the interpretation of endoscopy and pathology images. These models can utilize textual or visual prompts to focus on relevant aspects of medical images, thereby improving diagnostic accuracy and efficiency. This review explores these advancements, highlighting their potential impact on GI cancer detection and the broader field of medical imaging. In the following section, we discuss how AI is transforming the detection and management of upper GI cancer (Section 1.1), and it then delves into the role of FMs in endoscopy and pathology imaging (Section 1.2).
1.1. AI in Upper GI Cancer: Transforming Detection and Surveillance
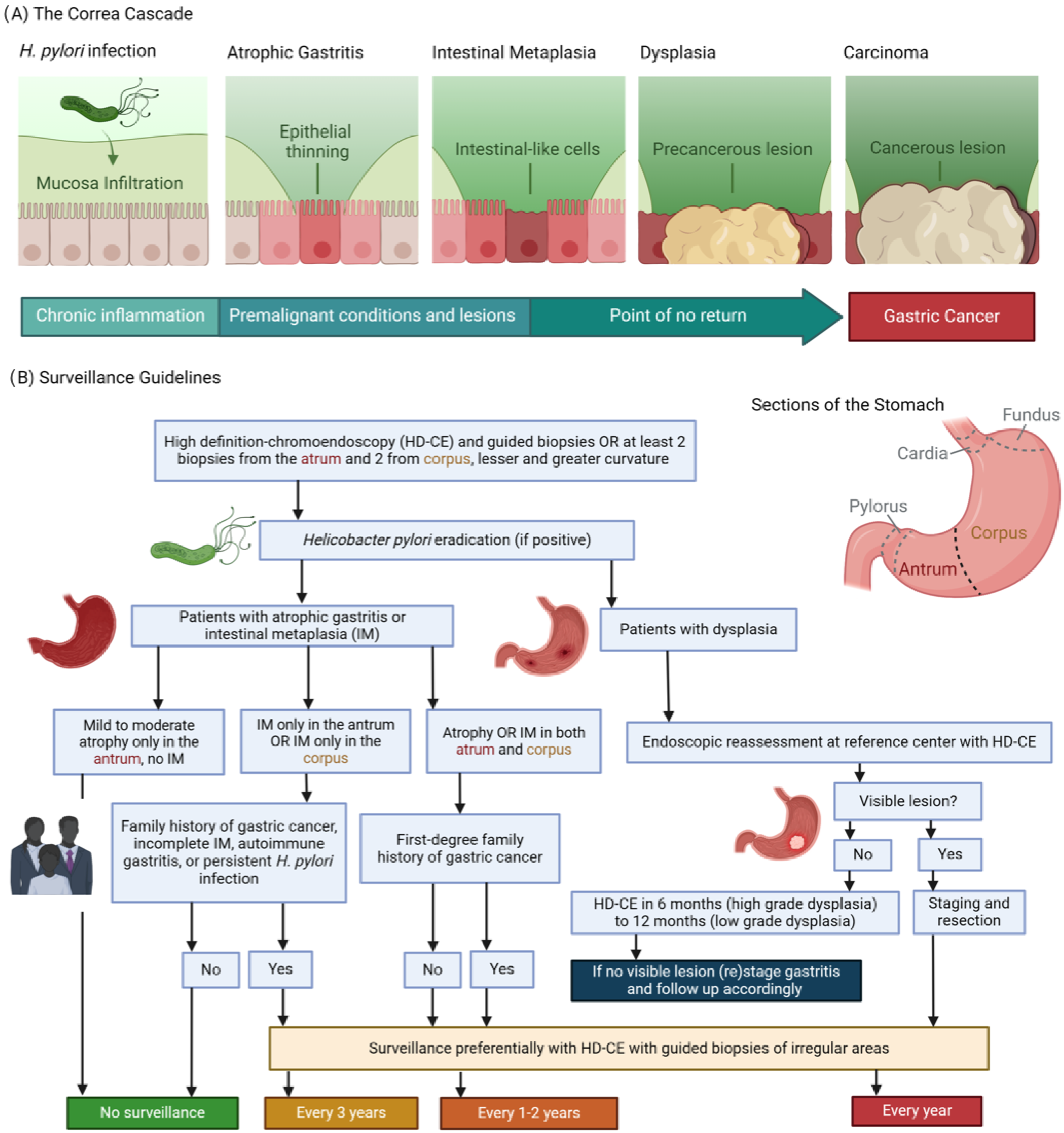
Gastric cancer (GC) is one of the leading causes of cancer mortality globally. Its pathogenesis is related with chronic inflammation, which causes changes in the mucosa, including atrophy, intestinal metaplasia (IM), and dysplasia [1], as shown in Figure 1A. Recognizing these conditions early through regular and precise endoscopic surveillance, as presented in Figure 1B, is pivotal for enhancing early diagnosis and treatment outcomes [2,3]. The advent of AI in medical imaging and diagnostics brings a promising solution to these challenges, especially in the realm of GI endoscopy. AI and FM offer a revolutionary approach to interpreting endoscopy and pathology images for risk stratification and determination of the appropriate surveillance intervals for patients with upper GI precancerous conditions. These AI-driven models can potentially transform the management of patients at risk for upper GI cancers by providing precise, real-time analysis of endoscopic images, identifying premalignant lesions with high accuracy, and predicting the risk levels of patients based on the characteristics of detected lesions. This emphasis on AI’s role in enhancing the identification and surveillance of high-risk patients marks a significant step forward. By leveraging AI for the interpretation of endoscopic and pathology images, healthcare providers can achieve more accurate risk stratification and timely intervention, ultimately aiming to increase the surveillance rate among high-risk patients. This not only addresses the current shortfall in surveillance adherence but also paves the way for a more proactive and prevention-oriented approach in managing the risk of upper GI cancers.
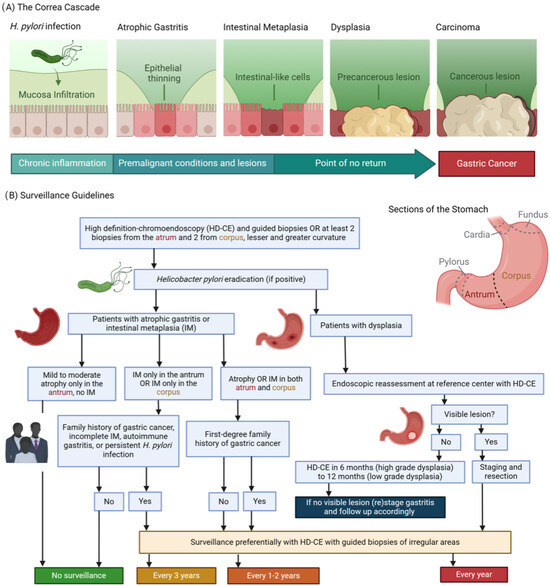
Figure 1.
(A) The Correa’s cascade of intestinal type gastric carcinogenesis: a sequence of gastric changes from chronic gastritis to atrophic gastritis, then to intestinal metaplasia and dysplasia, culminating in gastric cancer, highlighting a progressive, stepwise development toward malignancy. (B) Surveillance guidelines overview [2]: (1) Detection and Diagnosis: Endoscopy provides a direct view of the stomach lining, enabling the identification of areas that may exhibit precancerous alterations. During this examination, targeted biopsies are collected from visually abnormal or suspicious regions. (2) Pathological Analysis: These biopsies are meticulously analyzed by pathologists to categorize the cellular composition of the tissue. This examination distinguishes between normal cells, atrophic gastritis, intestinal metaplasia, dysplasia, or the early stages of gastric cancer. The results are used for confirming the diagnosis and assessing the condition’s severity. (3) Guiding Management: Insights derived from endoscopic findings and pathological reports are integral to formulating a management strategy. Decisions regarding the frequency of surveillance, the need for further medical interventions, and evaluations of the risk for progression to gastric cancer are based on these combined observations and individual risk factors such as genetic predispositions.
1.2. Expanding Horizons: Foundation Models in Endoscopy and Pathology Imaging
The advent of FMs has marked a pivotal shift in the landscape of medical imaging analysis, particularly in the domains of pathology and endoscopy. These models undergo training on large and varied datasets, often employing self-supervision methods on an extensive scale. After this initial training, they can be further refined—through processes like fine-tuning—to perform a broad spectrum of related downstream tasks, enhancing their applicability based on the original dataset. By leveraging vast amounts of data to learn rich representations, they have the potential to facilitate the diagnosis for a personalized treatment approach. This review aims to explore the cutting-edge advancements in FMs applied to pathology and endoscopy imaging, elucidating their impact, challenges, and the promising avenues they pave for future research.
Pathology and endoscopy, two critical fields in medical diagnostics, generate a wealth of image data that encapsulate intricate details vital for accurate disease diagnosis and management. Traditionally, the analysis of such images has been heavily reliant on the expertise of highly trained professionals. While indispensable, this approach is time-consuming, subject to variability, and scales linearly with the volume of data. FMs emerge as a powerful solution to these challenges, offering a way to automate and enhance the analysis process through textually and visually prompted models. In the context of pathology, textually prompted models leverage textual data as prompts to guide the analysis of images. These textual prompts could be descriptions of histological features, diagnostic criteria, or other relevant annotations that guide the model’s interpretation of the images. On the other hand, visually prompted models operate by utilizing visual cues, such as points, boxes, or masks, to guide the model’s focus within an image. For a pathology image, a visually prompted model could be prompted to concentrate on specific areas of a tissue slide that are marked by a pathologist or identified by preliminary analysis. In the context of endoscopy, only visually prompted models are utilized, since clinical routines for endoscopy videos do not involve text data. However, the integration of FMs into pathology and endoscopy poses unique challenges. These include ensuring model interpretability, managing the privacy and security of sensitive medical data, and addressing the potential biases inherent in the training datasets. Moreover, the dynamic nature of medical knowledge and the continuous evolution of diseases necessitate that these models are adaptable and capable of learning from new data while incorporating previously acquired knowledge. This paper provides an introductory overview, followed by an in-depth analysis of the principles underlying FMs for medical imaging, with a focus on pathology and endoscopy (see Figure 2A for a taxonomy of vision language FMs). We classify the current state-of-the-art (SOTA) models based on their architectural designs, training objectives, and application areas. Furthermore, we discuss the recent works in the field, highlighting the innovative approaches that have been developed to address the specific needs of pathology and endoscopy image analysis. Finally, we outline the challenges faced by current models and propose several directions for future research, aiming to guide and inspire further advancements in this rapidly evolving field. Our major contributions include the following:
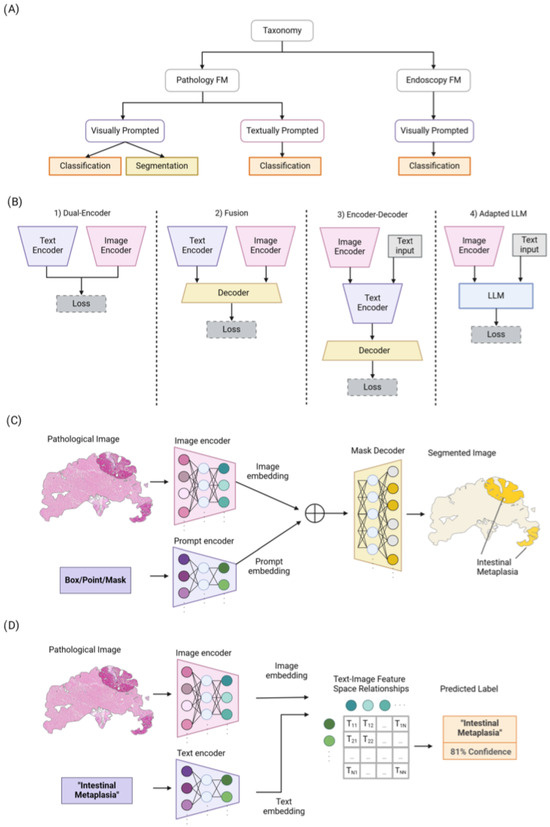
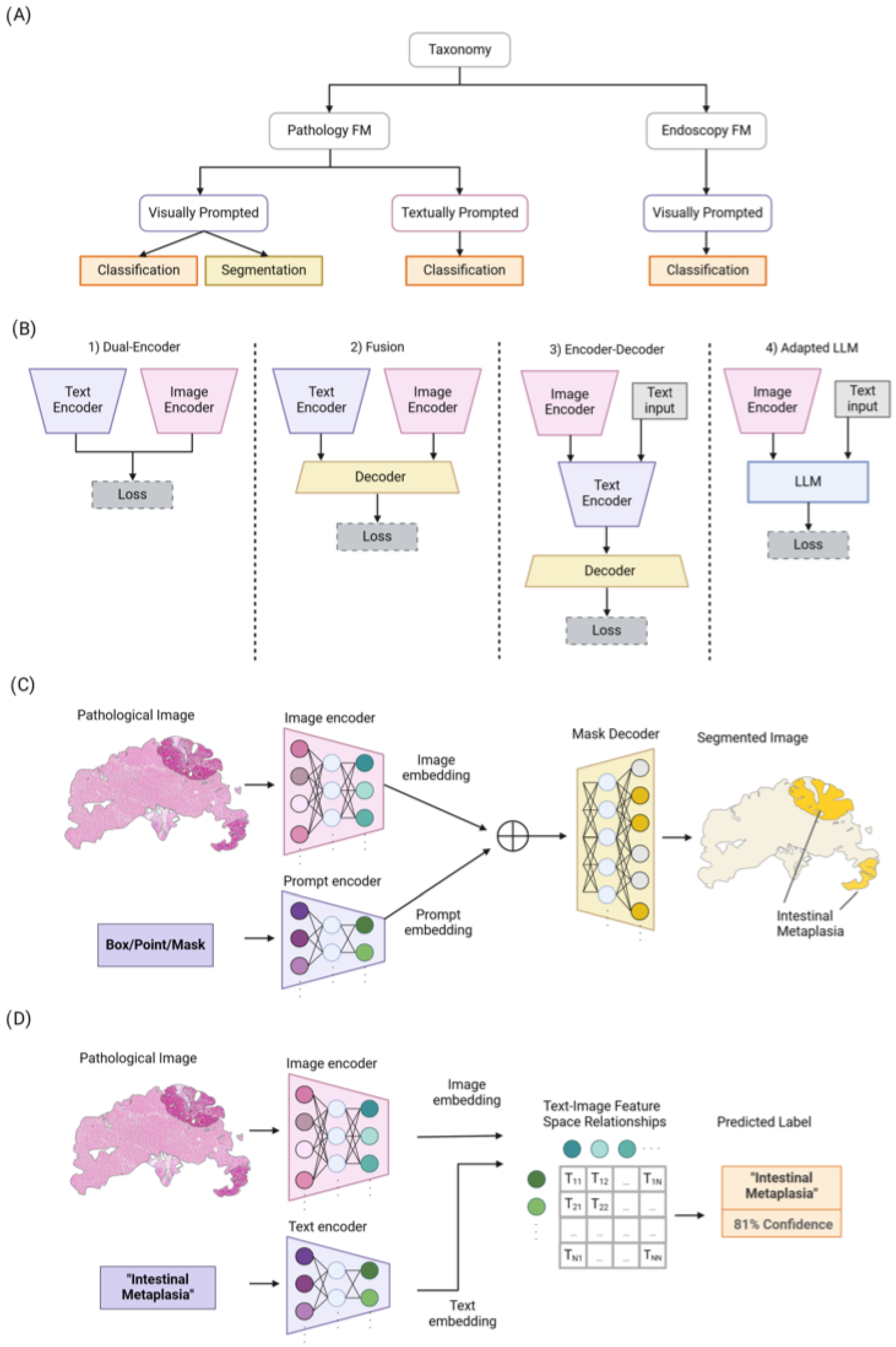
Figure 2.
(A) An overview of our taxonomy for pathology and endoscopy FMs. They are categorized based on the prompt types (i.e., visually or textually prompted models) and their utilization. (B) Overview of four different common architecture styles used in vision language models: (1) Dual-Encoder designs use a parallel image and text encoder with aligned representations. (2) Fusion designs jointly process both image and text representations via a decoder. (3) Encoder–Decoder designs apply joint feature encoding and decoding sequentially. (4) Adapted Large Language Model (LLM) designs input visual and text prompts to the LLMs to leverage their superior generalization ability. (C) Overview of Segment Anything Model (SAM) for pathology image segmentation. (D) The process of training textually prompted models with paired image–text dataset via contrastive learning.
- We conduct a thorough review of FMs applied in the field of pathology and endoscopy imaging, beginning with their architecture types, training objectives, and large-scale training. Then, they are classified into visually and textually prompted models (based on prompting type), and then their subsequent application/utilization is discussed.
- We also discuss the challenges and unresolved aspects linked to FMs in pathology and endoscopy imaging.
2. Inclusion and Search Criteria
This study was conducted as a systematic review to identify and evaluate studies related to the application of FMs in pathology and endoscopy imaging, particularly in the context of gastric inflammation and cancer. The inclusion criteria for this review comprised original research articles, review articles, and preprints that focused on the development, validation, and application of FMs in these specific areas. To maintain consistency and accessibility, only articles published in English were considered. We included studies that addressed the use of FMs in the detection, diagnosis, and management of GI conditions, particularly those involving pathology and endoscopy.
The literature search was comprehensive, utilizing multiple databases such as PubMed, Scopus, IEEE Xplore, Web of Science, Google Scholar, and Embase, which is specialized for medical and biomedical literature. The search strategy incorporated specific keywords and Medical Subject Headings (MeSHs) terms, including “foundation models”, “deep learning”, “machine learning”, “pathology”, “endoscopy”, “AI diagnostics”, “pretrained models”, and “transfer learning”. Boolean operators were employed to refine the search results; for instance, “AND” was used to combine concepts (e.g., “foundation models” AND “pathology”), “OR” was used to include synonyms or related terms, and “NOT” was used to exclude irrelevant topics. Filters were applied to limit results to human studies, recent publications, and primary research articles, with editorials and reviews excluded unless they provided critical foundational insights.
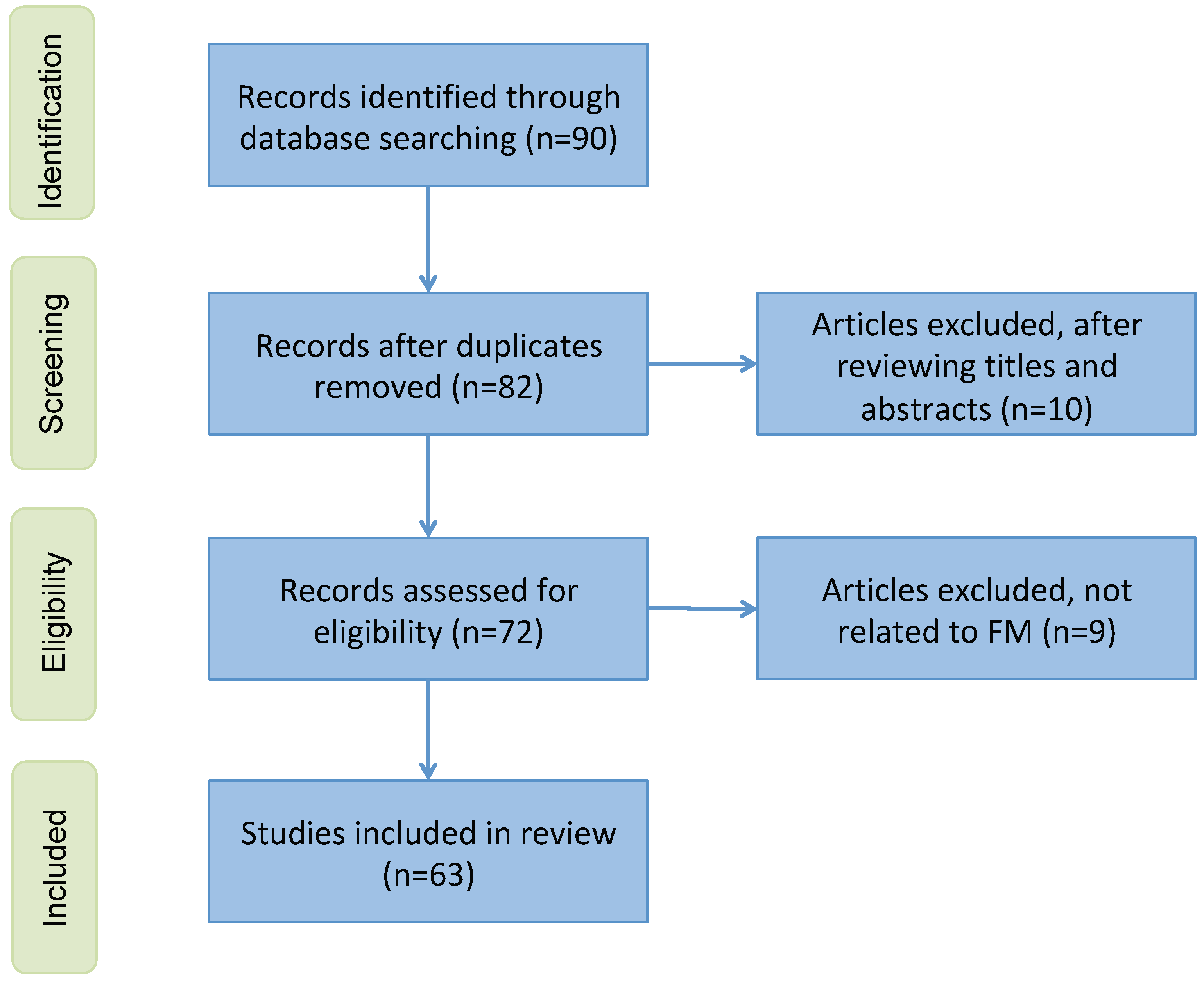
The literature search and selection process were performed by a team of researchers with substantial experience in medical imaging and artificial intelligence. The team consisted of three researchers, each with over 10 years of experience in medical imaging and AI diagnostics. During the selection process, the researchers independently screened the titles and abstracts of the retrieved articles to determine their relevance based on the predefined inclusion criteria. In instances where there were disagreements regarding the inclusion or exclusion of a study, these were resolved through consensus discussions among the researchers. The proportion of cases requiring consensus resolution was approximately 10%, demonstrating a high level of initial agreement among the reviewers. To ensure transparency in the study selection process, a preferred reporting items for systematic reviews and meta-analyses (PRISMA) flowchart (see Figure A1) is presented in the Appendix A.
3. Foundation Models in Computer Vision
3.1. Architecture Type
Vision language models primarily utilize four distinct architectural frameworks, as depicted in Figure 2B. The initial framework, known as Dual-Encoder, employs parallel visual and textual encoders to produce aligned representations. The second framework, Fusion, integrates image and text representations through a fusion decoder, facilitating the learning of combined representations. The third framework, Encoder–Decoder, features a language model based on encoder–decoder mechanisms alongside a visual encoder, enabling sequential joint feature encoding and decoding. Finally, the Adapted LLM framework incorporates an LLM as its foundation element, with a visual encoder that transforms images into a format that the LLM can understand, thus capitalizing on the LLM’s enhanced generalization capabilities. Following this overview, we will explore the loss functions utilized to train these various architectural types.
3.2. Training Objectives
3.2.1. Contrastive Objectives
Contrastive objectives train models to form distinct representations, effectively narrowing the gap between similar sample pairs and widening it between dissimilar ones in the feature space [4]. Image contrastive loss is designed to enhance the uniqueness of image features. It achieves this by aligning a target image more closely with its positive keys—essentially, versions of itself that have undergone data augmentation—and ensuring that it remains clearly differentiated from its negative keys, which are distinct, unrelated images, within the embedding space. Image–Text Contrastive (ITC) loss is a type of contrastive loss function that aims to create distinctive image–text pair representations. This is accomplished by bringing together the embeddings of matched images and texts and pushing apart those that do not match [5]. Given a batch of N examples, ITC loss aims to match correct image–text pairs among N × N possible configurations. ITC loss maximizes the cosine similarity between N correct pairs and minimizes it among incorrect pairs. Let be the i-th image–text example and be its corresponding representations; then, Image–Text Contrastive (ITC) loss is calculated as follows:
This loss is calculated by concentrating on the relationship between images and texts, taking into account the temperature parameter . ITC loss was used by [5,6] to learn to predict correct image–text pairs.
Image–Text Matching (ITM) loss [7] is another type of contrastive loss that aims to correctly predict whether a pair of images and text is positively or negatively matched. To achieve this, a series of perceptron layers are introduced to estimate the likelihood of a pair being matched. Subsequently, the loss is computed using the cross-entropy loss function. Additionally, several other contrastive loss functions have been utilized for various applications. They include variants of ITC losses such as FILIP loss [8], Text-to-Pixel Contrastive loss [9], Region–Word Alignment [10], Multi-label Image–Text Contrastive [11], Unified Contrastive Learning [12], Region–Word Contrastive loss [13], and image-based self-supervision loss like simple contrastive learning of representations (SimCLR) [4].
3.2.2. Generative Objectives
Generative objectives focus on training networks to create images or textual contents, enabling them to learn semantic attributes through activities such as image generation [14] and language production [15]. A prevalent generative loss function in computer vision is Masked Image Modeling (MIM) [16]. This approach involves the acquisition of cross-patch correlations by employing masking and image reconstruction methods. In MIM, certain patches of an input image are randomly obscured, and the network’s encoder is tasked with reconstructing these hidden patches using the visible sections as a reference. For a given batch of N images, the loss function is computed as follows:
where and represent the masked and unmasked patches within , respectively. Similarly, Masked Language Modeling (MLM) [16] is a widely adopted generative loss technique in Natural Language Processing (NLP). In MLM, a certain percentage of input text tokens are randomly masked, and the model is trained to predict these masked tokens based on the context provided by the unmasked tokens. The loss function used in MLM is akin to that of the MIM, focusing on the reconstruction of masked elements. However, the difference lies in the elements being reconstructed: in MLM, the focus is on masked and unmasked tokens, as opposed to the masked and unmasked patches in MIM. In similar fashion, various other generative loss techniques have been proposed. Examples include Masked Multi-Modal Modeling (MMM) loss [17], Semi-Casual Language Modeling [18], Image-Conditioned Masked Language Modeling (IMLM) loss [16], Image-Grounded Text Generation (ITG) loss [19], and Captioning with Parallel Prediction (CapPa) loss [20].
3.3. Large-Scale Training
Large-scale data are central to the development of vision and language foundation models. The datasets used for pre-training these models are categorized into three main types: image–text datasets, partially synthetic datasets, and combination datasets. Among these, image–text datasets like WebImageText, which were used in CLIP [5], demonstrate the significant impact of web-scale image–text data in training FM. Such data are typically extracted from web crawls, and the final dataset emerges from a rigorous filtering process designed to eliminate noisy, irrelevant, or detrimental data points. Unlike image–text datasets, partially synthetic datasets are not readily available on the web and require significant human annotation effort. A cost-effective approach is to utilize a proficient teacher model to transform image–text datasets into mask–description datasets [10]. To address the challenge of curating and training on web-scale datasets, combination datasets have been employed [21,22,23]. These datasets amalgamate standard vision datasets, including those featuring image–text pairs such as captioning and visual question answering, and sometimes modify non-image–text datasets using template-based prompt engineering to transform labels into descriptions.
Furthermore, large-scale training, coupled with effective fine-tuning and strategic prompting at the inference stage, has been an essential component of vision foundation models. Fine-tuning adjusts the model’s parameters on a task-specific dataset, optimizing it for particular applications like image captioning or visual question answering. It enables leveraging the vast knowledge captured by pre-trained vision language models, making them highly effective for a wide range of applications with relatively less data and computational resources than required for training from scratch. Prompt engineering, meanwhile, involves the strategic creation of input prompts to guide the model in generating accurate and relevant responses, leveraging its pre-trained capabilities. Both practices are vital for customizing vision language models to specific needs, enabling their effective application across various domains that require nuanced interpretations of visual and textual information.
4. Pathology Foundation Models
4.1. Visually Prompted Models
This section reviews visually prompted pathology foundation models that have been designed for segmentation and classification of pathology images.
4.1.1. Pathology Image Segmentation
Semantic segmentation plays a crucial role in digital pathology, involving the division of images into distinct regions that represent different tissue structures, cell types, or subcellular components. The segment anything model (SAM) [24] emerges as the first promptable foundation model specifically designed for image segmentation tasks. Trained on the SA-1B dataset, the SAM benefits from a vast amount of images and annotations, granting it outstanding zero-shot generalization capabilities. Utilizing a vision transformer-based image encoder, the SAM extracts image features and computes image embeddings. Additionally, its prompt encoder embeds user prompts, enhancing interaction. The combined outputs from both encoders are then processed by a lightweight mask decoder, which generates segmentation results by integrating the image and prompt embedding with output tokens as illustrated in Figure 2C. While the SAM has proven effective for segmenting natural images, its potential for navigating the complexities of medical image segmentation, particularly in pathology, invites further investigation. Pathology images present unique challenges, such as structural complexity, low contrast, and inter-observer variability. To address these, the research community has explored various extensions of the SAM, aiming to unlock its capabilities for pathology image segmentation tasks.
For example, Deng et al. [25] evaluated the SAM in the context of cell nuclei segmentation on whole-slide imaging (WSI). Their evaluation encompassed various scenarios, including the application of the SAM with a single positive point prompt, with 20 point prompts comprising an equal number of positive and negative points, and with comprehensive annotations (points or bounding boxes) for every individual instance. The findings indicated that the SAM delivers exceptional performance in segmenting large, connected objects. However, it falls short in accurately segmenting densely packed instances, even when 20 prompts (clicks or bounding boxes) are used for each image. This shortfall could be attributed to the significantly higher resolution of WSI images relative to the resolution of images used to train the SAM, coupled with the presence of tissue types of varying scales in digital pathology. Additionally, manually annotating all the boxes during inference remains time-consuming. To address this issue, Cui et al. [26] introduced a pipeline for label-efficient fine-tuning of the SAM, with no requirement for annotation prompts during inference. Such a pipeline surpasses previous SOTA methods in nuclei segmentation and achieves competitive performance compared to using strong pixelwise annotated data. Zhang et al. [27] introduced the SAM-Path for semantic segmentation of pathology images. This approach extends the SAM by incorporating trainable class prompts, augmented further with a pathology-specific encoder derived from a pathology FM. The SAM-Path improves upon the SAM’s capability for performing semantic segmentation in digital pathology, eliminating the need for human-generated input prompts. The findings highlight the SAM-Path’s promising potential for semantic segmentation tasks in pathology. In another study, using the CellSAM [28], the authors proposed as a foundation model for cell segmentation, which generalizes across a wide range of cellular imaging data. This model enhances the capabilities of the SAM by introducing a novel prompt engineering technique for mask generation. To facilitate this, an object detector named CellFinder was developed, which automatically detects cells and cues the SAM to produce segmentations. They demonstrated that this approach allows a single model to achieve SOTA performance in segmenting images of mammalian cells (both in tissues and cell cultures), yeast, and bacteria—across different imaging modalities. Archit et al. [29] presented segment anything for microscopy as a tool for interactive and automatic segmentation and for the tracking of objects in multi-dimensional microscopy data. They extended the SAM by training specialized models for microscopy data that significantly improved segmentation quality for a wide range of imaging conditions.
In addition to image segmentation, the SAM was also utilized to generate pixel-level annotations to train a segmentation model for pathology images. Li et al. [30] investigated the feasibility of bypassing pixel-level delineation through the utilization of the SAM applied to weak box annotations in a zero-shot learning framework. Specifically, the SAM’s capability was leveraged to generate pixel-level annotations from mere box annotations, and these SAM-derived labels were employed to train a segmentation model. The results demonstrated that the proposed SAM-assisted model significantly reduced the labeling workload for non-expert annotators by relying solely on weak box annotations. A summary of the mentioned FMs used in pathology image segmentation is presented in Table 1A.

Table 1.
Review of FMs for pathology visually prompted (i.e., Image segmentation (A) and image classification (B)) and textually prompted (Image classification (C)) models.
To conclude, the SAM delivers satisfactory performance on histopathological images, particularly with objects that are sharply defined, and it significantly facilitates the annotation process in segmentation tasks where dedicated deep learning models are either unavailable or inaccessible. However, the SAM’s application in annotating histopathological images encounters several challenges. Firstly, the SAM faces difficulties with objects that are interconnected or have indistinct borders (e.g., vascular walls), are prone to prompt ambiguity (e.g., distinguishing between an entire vessel and its lumen), or blend into the background due to low contrast (e.g., sparse tumor cells within an inflammatory backdrop). These limitations can be attributed not only to the absence of microscopic images in the training set but also to the intrinsic characteristics of histopathological images compared to conventional images: (1) the color palette is often limited and similar across different structures, and (2) histopathological tissues are essentially presented on a single plane, contrasting with the three-dimensional perspectives captured in real-world photography, which naturally enhances object delineation. Additionally, generating accurate masks for non-object elements, such as the stroma or interstitial spaces, remains challenging even with extensive input. Technical artifacts such as edge clarification in biopsy samples and tearing artifacts further impair segmentation performance. Secondly, the SAM’s overall efficacy falls short of the benchmarks set by SOTA models specifically designed for tasks like nuclei segmentation, particularly in semantic segmentation tasks.
4.1.2. Pathology Image Classification
Pathology image classification leverages computational methods to categorize and diagnose diseases from medical images acquired during pathology examinations. This process plays a vital role in medical diagnostics, as the precise and prompt classification of diseases can greatly influence the outcomes of patient treatments. The images used in pathology, often derived from biopsies, are intricate, featuring detailed cellular and tissue structures that signify a range of health conditions, such as cancers, inflammatory diseases, and infections. Table 1B presents a summary of recent FMs used in pathology image classification. The subsequent paragraph provides detailed explanations of these models.
In recent years, numerous self-supervised techniques for computational pathology image classification have been proposed. For example, the Hierarchical Image Pyramid Transformer (HIPT) [31] is a vision transformer (ViT) with less than 10 million parameters, which was trained on approximately 100 million patches extracted from 11,000 WSIs from The Cancer Genome Atlas (TCGA) [50]. The HIPT utilized student–teacher knowledge distillation [51] at two successive representation levels: initially at the local image patch level and subsequently at the regional image patch level, which was derived from the learned representations of multiple local patches. The CTransPath, a Swin transformer equipped with a convolutional backbone featuring 28 million parameters, was proposed by [32]. It was trained on 15 million patches extracted from 30,000 WSIs sourced from both the TCGA and the Pathology AI Platform (PAIP) [52]. Similarly, Ciga et al. [33] trained a 45 million parameter ResNet on 25,000 WSIs with the addition of 39,000 patches, which were all collected from the TCGA and 56 other small datasets. Recently, Filiot et al. [39] utilized a ViT-Base architecture, which has 86 million parameters, and employed the Image BERT pre-training with the Online Tokenizer (iBOT) framework [53] for its pre-training. This model was pre-trained on 43 million patches derived from 6000 WSIs from the TCGA and surpassed both the HIPT and CTransPath in performance across various TCGA evaluation tasks. In a similar endeavor, Azizi et al. [34] developed a model with 60 million parameters using the SimCLR framework [4] and trained it on 29,000 WSIs, covering nearly the entire TCGA dataset.
The mentioned studies highlight models that possess up to 86 million parameters and incorporate a teacher distillation objective for training on the extensive TCGA dataset, which includes over 30,000 WSIs. In contrast, Virchow [36] distinguishes itself by its significantly larger scale and more extensive training data. It boasts 632 million parameters, marking a 69-fold increase in size compared to the largest models mentioned in the previous studies. Virchow employs the vision transformer and was trained using the DINOv2 [35] self-supervised algorithm, which is based on a student–teacher paradigm. When evaluated on downstream tasks, such as tile-level pan-cancer detection and subtyping, as well as slide-level biomarker prediction, Virchow surpassed SOTA systems. UNI [38], a ViT-large model trained on 100,000 proprietary slides (Mass-100k: a large and diverse pretraining dataset containing over 100 million tissue patches from 100,426 WSIs across 20 major organ types, including normal tissue, cancerous tissue, and other pathologies) is another foundation model for pathology image classification. They assessed the downstream performance on 33 tasks, including tile-level tasks for classification, segmentation, and retrieval, as well as slide-level classification tasks, and demonstrated the generalizability of the model in anatomic pathology. Roth et al. [37] benchmarked the most popular pathology vision FMs like DINOv2 ViT-S, DINOv2 ViT-S finetuned, CTransPath, and RetCCL [54] as feature extractors for histopathology data. The models were evaluated in two settings: slide-level classification and patch-level classification. The results showed that fine-tuning a DINOv2 ViT-S yielded at least equal performance compared to the CTransPath and RetCCL but in a fraction of the domain-specific training time. Campanella et al. [40] trained the largest academic foundation model on 3 billion image patches from over 400,000 slides. They compared the pre-training of visual transformer models using the masked autoencoder (MAE) and DINO algorithms. The results demonstrate that pre-training on pathology data is beneficial for downstream performance compared to pre-training on natural images. Also, the DINO algorithm achieved better generalization performance across all tasks tested. Furthermore, Dippel et al. [41] demonstrated that integrating pathological domain knowledge carefully can significantly enhance pathology foundation model performance, achieving superior results with the best available performing pathology foundation model. This achievement came despite using considerably fewer slides and a model with fewer parameters than competing models. Although the mentioned studies successfully applied FMs for pathology image analysis, Prov-GigaPath [42] stands out from them due to its unique combination of a larger and more diverse dataset (1.3 billion 256 × 256 pathology image tiles in 171,189 whole slides), as well as its innovative use of vision transformers with dilated self-attention.
4.2. Textually Prompted Models
Textually prompted models are increasingly recognized as foundational in the field of medical imaging, particularly in computational pathology. These models learn representations that capture the semantics and relationships between pathology images and their corresponding textual prompts (shown in Figure 2D). By leveraging contrastive learning objectives, they bring similar image–text pairs closer together in the feature space while pushing dissimilar pairs apart. Such models are crucial for tasks related to pathology image classification and retrieval. Architectural explorations have included Dual-Encoder designs—with separate visual and language encoders—as well as Fusion designs that integrate image and text representations using decoder and transformer-based architectures. The potential of these models for pathology image classification has been highlighted in numerous studies, which are discussed in the following section and summarized in Table 1C.
Pathology Image Classification
In the context of pathology image classification, TraP-VQA [43] represents the pioneering effort to utilize a vision language transformer for processing pathology images. This approach was evaluated using the PathVQA dataset [44] to generate interpretable answers. More recently, Huang et al. [45] compiled a comprehensive dataset of image–text paired pathology data sourced from public platforms, including Twitter. They employed a contrastive language–image pre-training model to create a foundation framework for both pathology text-to-image and image-to-image retrieval tasks. Their methodology showcased promising zero-shot capabilities in classifying new pathological images. PathAsst [46] utilizes FMs, functioning as a generative AI assistant, to revolutionize predictive analytics in pathology. It employs ChatGPT/GPT-4 to produce over 180,000 samples that follow instructions, thereby activating pathology-specific models and enabling efficient interactions based on input images and user queries. PathAsst is developed using the Vicuna-13B language model in conjunction with the CLIP vision encoder. The outcomes from PathAsst underscore the capability of leveraging AI-powered generative FMs to enhance pathology diagnoses and the subsequent treatment processes. Lu et al. [47] introduced MI-Zero, an intuitive framework designed to unlock the zero-shot transfer capabilities of contrastively aligned image and text models for gigapixel histopathology whole-slide images. This framework allows multiple downstream diagnostic tasks to be performed using pre-trained encoders without the need for additional labeling. MI-Zero reimagines zero-shot transfer within the context of multiple instance learning, addressing the computational challenges associated with processing extremely large images. To pre-train the text encoder, they utilized over 550,000 pathology reports, along with other available in-domain text corpora. By harnessing the power of strong pre-trained encoders, their top performing model, which was pre-trained on more than 33,000 histopathology image–caption pairs, achieved an average median zero-shot accuracy of 70.2% across three distinct real-world cancer subtyping tasks. Lu et al. [48] proposed CONCH, a foundation model framework for pathology that integrates a vision language joint embedding space. Initially, they trained a ViT on a dataset comprising 16 million tiles from 21,442 proprietary in-house WSIs using the iBOT [53] self-supervised learning framework. Subsequently, leveraging the ViT backbone, they developed a vision language model utilizing the CoCa framework [55], which was trained on 1.17 million image–caption pairs derived from educational materials and PubMed articles. The model’s efficacy was evaluated across 13 downstream tasks, including tile and slide classification, cross-modal image-to-text and text-to-image retrieval, coarse WSI segmentation, and image captioning. Another study [49] proposed the Connect Image and Text Embeddings (CITE) method to improve pathological image classification. The CITE leverages insights from language models pre-trained on a wide array of biomedical texts to enhance FMs for a better understanding of pathological images. This approach has been shown to achieve superior performance on the PatchGastric stomach tumor pathological image dataset, outperforming various baseline methods, particularly in scenarios with limited training data. The CITE underscores the value of incorporating domain-specific textual knowledge to bolster efficient pathological image classification.
5. Endoscopy Foundation Models
Endoscopic video has become a standard imaging modality and is increasingly being studied for the diagnosis of gastrointestinal diseases. Developing an effective foundation model shows promise in facilitating downstream tasks requiring analysis of endoscopic videos.
Visually Prompted Models
Since clinical routines for endoscopy videos typically do not involve text data, and a purely image-based foundation model is currently more feasible.
In response to this need, Wang et al. [56] developed the first foundation model, Endo-FM, which is specifically designed for analyzing endoscopy videos. Endo-FM utilizes a video transformer architecture to capture rich spatial–temporal information and is pre-trained to be robust against diverse spatial–temporal variations. A large-scale endoscopic video dataset, comprising over 33,000 video clips, was constructed for this purpose. Extensive experimental results across three downstream tasks demonstrate Endo-FM’s effectiveness, significantly surpassing other SOTA video-based pre-training methods and showcasing its potential for clinical application. Additionally, Cui et al. [57] demonstrated the effectiveness of vision-based FMs for depth estimation in endoscopic videos. They developed a foundation model-based depth estimation method named Surgical-DINO, which employs a Low-Rank Adaptation (LoRA) [58] of DINOv2 specifically for depth estimation in endoscopic surgery. The LoRA layers, rather than relying on conventional fine-tuning, were designed and integrated into DINO to incorporate surgery-specific domain knowledge. During the training phase, the image encoder of DINO was frozen to leverage its superior visual representation capabilities, while only the LoRA layers and the depth decoder were optimized to assimilate features from the surgical scene. The results indicated that Surgical-DINO significantly surpassed all other SOTA models in tasks related to endoscopic depth estimation. Furthermore, trends in the development of video FMs indicate promising applications for endoscopy, such as video segmentation [59] for identifying lesions in endoscopy footage and enhancing endoscopy videos by reconstructing masked information [60] to reveal obscured lesions.
6. Challenges and Future Work
The pathology and endoscopy FMs discussed in this review have their respective shortcomings and open challenges. This section aims to provide a comprehensive overview of the common challenges these approaches face, as well as highlight the future directions of FMs in pathology and endoscopy analysis, along with FUTURE-AI guidelines that guide their deployments.
Despite the potential of FMs for disease diagnosis, their application in the medical domain, including pathology and endoscopy image analysis, faces several challenges. Firstly, FMs are susceptible to “hallucination” [61], where they generate incorrect or misleading information. In the medical domain, such hallucinations can lead to the dissemination of incorrect medical information, resulting in misdiagnoses and consequently, inappropriate treatments. Secondly, FMs in vision and language can inherit and amplify “biases” [62] present in the training data. Biases related to race, underrepresented groups, minority cultures, and gender can result in biased predictions or skewed behavior from the models. Addressing these biases is crucial to ensure fairness, inclusivity, and the ethical deployment of these systems. Additionally, patient privacy and ethical considerations present significant hurdles that must be overcome to ensure the ethical and equitable use of FMs in medical practice. Moreover, training large-scale vision and language models demands substantial computational resources and large datasets, which can limit their application in real-time inference or on edge devices with limited computing capabilities. The lack of evaluation benchmarks and metrics for FMs also poses a challenge, hindering the assessment of their overall capabilities, particularly in the medical domain. Developing domain-specific and FM-specific benchmarks and metrics is essential.
Despite these challenges, the future direction of FMs in pathology and endoscopy analysis is likely to include several innovative and transformative approaches. These models are set to significantly enhance diagnostic accuracy, efficiency, and the overall understanding of disease processes. A key future direction is the integration with multi-modal data. FMs are expected to evolve beyond text and incorporate the integration of multi-modal data, combining pathology images, endoscopic video data, genomic information, and clinical notes. This will enable a more comprehensive and nuanced understanding of patient cases, facilitating more accurate diagnoses and personalized treatment plans. FMs could also automate the generation of pathology and endoscopy reports, synthesizing findings from images, patient history, and test results into coherent, standardized, and clinically useful reports. This would streamline workflows, reduce human error, and allow pathologists and endoscopists to concentrate on complex cases. In endoscopy, FMs could provide real-time analysis and guidance, identifying areas of interest or concern during a procedure, which could assist less experienced endoscopists and potentially reduce the rate of missed lesions or abnormalities. Future FMs are likely to feature more sophisticated algorithms for detecting and classifying diseases from pathology slides and endoscopy videos, which would be trained on vast datasets to recognize rare conditions, subtle abnormalities, and early disease stages with high accuracy.
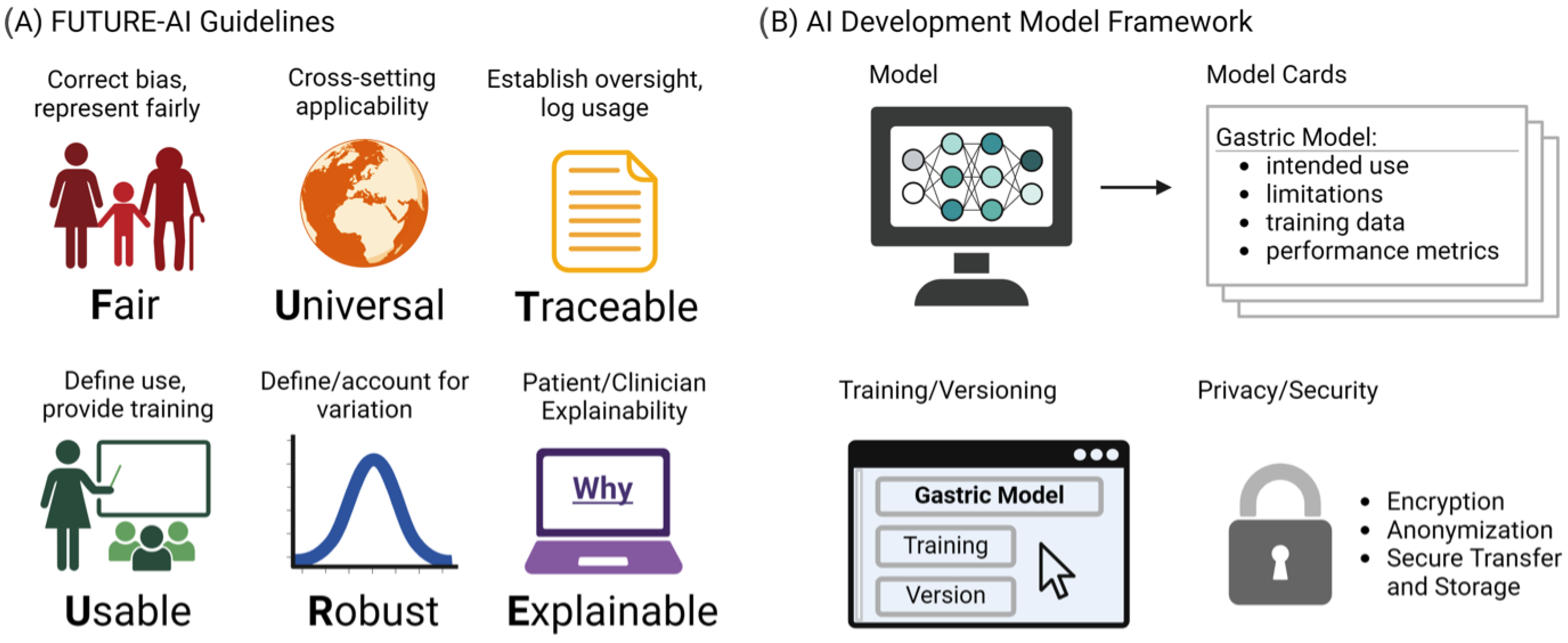
Despite their major advances, the deployment and adoption of FMs—like other medical AI tools—remain limited in real-world clinical practice. To increase adoption in the real world, it is essential that medical AI tools are accepted by patients, clinicians, health organizations, and authorities. However, there is a lack of widely accepted guidelines on how medical AI tools should be designed, developed, evaluated, and deployed to be trustworthy, ethically sound, and legally compliant. To address this challenge, the FUTURE-AI guidelines [63] were proposed that aim to guide the development and deployment of AI tools in healthcare that are ethical, legally compliant, technically robust, and clinically safe. They consist of six guiding principles for trustworthy AI, including Fairness, Universality, Traceability, Usability, Robustness, and Explainability, as shown in Figure 3A. This initiative is crucial, especially in domains like gastric cancer detection, where AI’s potential for early detection and improved patient outcomes is significant. The specificity of vision FMs in detecting such conditions necessitates adherence to guidelines ensuring the models’ ethical use, fairness, and transparency. By adopting FUTURE-AI’s guidelines, researchers and developers can mitigate risks like biases and errors in AI models, ensuring these tools are trustworthy and can be seamlessly integrated into clinical practice. The structured approach provided by FUTURE-AI facilitates the creation of AI tools that are ready for real-world deployment, encouraging their acceptance among patients, clinicians, and health authorities. Additionally, Figure 3B shows our proposed AI development framework, which provides a structured outline for documenting AI models for the transparency and reliability of gastric cancer detection tools. The Model Cards section details the model’s purpose, its limitations, the nature of the training data, and how the model’s performance is measured. Training and Versioning are recorded, tracing the evolution of the model through updates and refinements. Privacy and Security considerations are paramount, detailing the protective measures such as encryption and anonymization to ensure patient data confidentiality during model training and deployment. This multi-dimensional approach to documentation is essential for the end users and developers to understand the model’s capabilities, limitations, and to ensure its responsible use in the future healthcare settings.
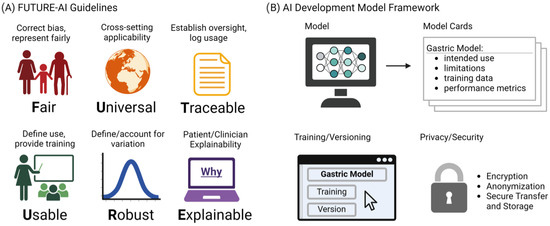
Figure 3.
(A) The FUTURE-AI guidelines. (B) Proposed Model Cards Framework.
7. Conclusions
In this survey, we have conducted a comprehensive review of the recent advancements in FM for pathology and endoscopy imaging. Our survey begins with an introductory section, followed by a discussion on the principles of vision FM, including architecture types, training objectives (i.e., contrastive and generative), and large-scale training. Section 4 delves into pathology FMs, which are classified into visually (Section 4.1) and textually (Section 4.2) prompted models. Visually prompted models are applied to pathology image segmentation and classification, whereas textually prompted models are utilized solely for pathology image classification. Section 5 describes recent works on endoscopy FMs, which are exclusively visually prompted models. In conclusion, our survey not only reviews recent developments but also lays the groundwork for future research in FMs. We propose several directions for future investigations (Section 6), offering a roadmap for researchers aiming to excel in the field of FMs for pathology and endoscopy imaging.
Author Contributions
Conceptualization, K.V. and H.K.; methodology, H.K., I.L., D.V., I.P., M.C. and K.H.; software, H.K., I.L., D.V. and K.H.; validation, H.K., K.V. and I.L.; formal analysis, investigation, and interpretation, H.K., I.L., D.V., M.C., I.P., M.L., T.F.K., M.D.-R. and K.V.; resources, H.K.; data curation, H.K., I.L., D.V. and K.H.; writing—original draft preparation, H.K.; writing—review and editing, H.K., K.H., I.L., D.V., M.C., I.P., M.L., M.L., M.D.-R., T.F.K., J.A.P. and K.V.; visualization, H.K., I.L. and K.H.; supervision, K.V. and T.F.K.; project administration, K.V. and T.F.K.; funding acquisition, K.V., D.V. and T.F.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research is part of the AIDA project, which has been funded by the European Union (grant number 101095359) and UK Research and Innovation (grant number 10058099). The open access fee was paid from the Imperial College London Open Access Fund.
Conflicts of Interest
Author Junior Andrea Pescino was employed by the company StratejAI. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationship that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| GI | Gastrointestinal |
| GC | Gastric Cancer |
| IM | Intestinal Metaplasia |
| SOTA | State-Of-The-Art |
| FM | Foundation Model |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| LLM | Large Language Model |
| SAM | Segment Anything Model |
| WSI | Whole-Slide Imaging |
| TCGA | The Cancer Genome Atlas |
| MeSH | Medical Subject Headings |
| ITC | Image–Text Contrastive |
| ITM | Image–Text Matching |
| SimCLR | Simple Contrastive Learning of Representations |
| MIM | Masked Image Modeling |
| MLM | Masked Language Modeling |
| NLP | Natural Language Processing |
| MMM | Masked Multi-Modal Modeling |
| IMLM | Image-conditioned Masked Language Modeling |
| ITG | Image-grounded Text Generation |
| CapPa | Captioning with Parallel Prediction |
| HIPT | Hierarchical Image Pyramid Transformer |
| ViT | Vision Transformer |
| TCGA | The Cancer Genome Atlas |
| PAIP | Pathology AI Platform |
| MAE | Masked AutoEncoder |
| CITE | Connect Image and Text Embeddings |
| LoRA | Low-Rank Adaptation |
Appendix A
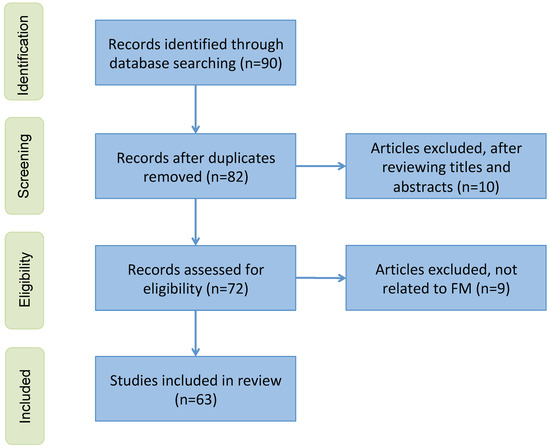
Figure A1.
A PRISMA flowchart showing the inclusion and exclusion criteria.
Figure A1.
A PRISMA flowchart showing the inclusion and exclusion criteria.
References
- Yoon, H.; Kim, N. Diagnosis and management of high risk group for gastric cancer. Gut Liver 2015, 9, 5. [Google Scholar] [CrossRef]
- Pimentel-Nunes, P.; Libânio, D.; Marcos-Pinto, R.; Areia, M.; Leja, M.; Esposito, G.; Garrido, M.; Kikuste, I.; Megraud, F.; Matysiak-Budnik, T.; et al. Management of epithelial precancerous conditions and lesions in the stomach (maps II): European Society of gastrointestinal endoscopy (ESGE), European Helicobacter and microbiota Study Group (EHMSG), European Society of pathology (ESP), and Sociedade Portuguesa de Endoscopia Digestiva (SPED) guideline update 2019. Endoscopy 2019, 51, 365–388. [Google Scholar]
- Matysiak-Budnik, T.; Camargo, M.; Piazuelo, M.; Leja, M. Recent guidelines on the management of patients with gastric atrophy: Common points and controversies. Dig. Dis. Sci. 2020, 65, 1899–1903. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Radford, A.; Kim, J.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.-T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.-H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 9694–9705. [Google Scholar]
- Yao, L.; Huang, R.; Hou, L.; Lu, G.; Niu, M.; Xu, H.; Liang, X.; Li, Z.; Jiang, X.; Xu, C. Filip: Fine-grained interactive language-image pre-training. arXiv 2021, arXiv:2111.07783. [Google Scholar]
- Wang, Z.; Lu, Y.; Li, Q.; Tao, X.; Guo, Y.; Gong, M.; Liu, T. Cris: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11686–11695. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.-N.; et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10965–10975. [Google Scholar]
- Xu, J.; De Mello, S.; Liu, S.; Byeon, W.; Breuel, T.; Kautz, J.; Wang, X. Groupvit: Semantic segmentation emerges from text supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Yang, J.; Li, C.; Zhang, P.; Xiao, B.; Liu, C.; Yuan, L.; Gao, J. Unified contrastive learning in image-text-label space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 19163–19173. [Google Scholar]
- Zhang, H.; Zhang, P.; Hu, X.; Chen, Y.-C.; Li, L.; Dai, X.; Wang, L.; Yuan, L.; Hwang, J.-N.; Gao, J. Glipv2: Unifying localization and vision-language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36067–36080. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F. Beit: Bert pre-training of image transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zhang, X.; Zeng, Y.; Zhang, J.; Li, H. Toward building general foundation models for language, vision, and vision-language understanding tasks. arXiv 2023, arXiv:2301.05065. [Google Scholar]
- Singh, A.; Hu, R.; Goswami, V.; Couairon, G.; Galuba, W.; Rohrbach, M.; Kiela, D. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15638–15650. [Google Scholar]
- Hao, Y.; Song, H.; Dong, L.; Huang, S.; Chi, Z.; Wang, W.; Ma, S.; Wei, F. Language models are general-purpose interfaces. arXiv 2022, arXiv:2206.06336. [Google Scholar]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv 2023, arXiv:2301.12597. [Google Scholar]
- Tschannen, M.; Kumar, M.; Steiner, A.; Zhai, X.; Houlsby, N.; Beyer, L. Image captioners are scalable vision learners too. arXiv 2023, arXiv:2306.07915. [Google Scholar]
- Chen, Y.-C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Computer Vision—ECCV 2020: 16th European Conference, Part XXX; Springer: Cham, Switzerland, 2020; pp. 104–120. [Google Scholar]
- Tsimpoukelli, M.; Menick, J.L.; Cabi, S.; Eslami, S.M.; Vinyals, O.; Hill, F. Multimodal few-shot learning with frozen language models. Adv. Neural Inf. Process. Syst. 2021, 34, 200–212. [Google Scholar]
- Xu, H.; Zhang, J.; Cai, J.; Rezatofighi, H.; Yu, F.; Tao, D.; Geiger, A. Unifying flow, stereo and depth estimation. arXiv 2022, arXiv:2211.05783. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]
- Deng, R.; Cui, C.; Liu, Q.; Yao, T.; Remedios, L.W.; Bao, S.; Landman, B.A.; Wheless, L.E.; Coburn, L.A.; Wilson, K.T.; et al. Segment anything model (sam) for digital pathology: Assess zero-shot segmentation on whole slide imaging. arXiv 2023, arXiv:2304.04155. [Google Scholar]
- Cui, C.; Deng, R.; Liu, Q.; Yao, T.; Bao, S.; Remedios, L.W.; Tang, Y.; Huo, Y. All-in-sam: From weak annotation to pixel-wise nuclei segmentation with prompt-based finetuning. arXiv 2023, arXiv:2307.00290. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, K.; Kapse, S.; Saltz, J.; Vakalopoulou, M.; Prasanna, P.; Samaras, D. Sam-path: A segment anything model for semantic segmentation in digital pathology. arXiv 2023, arXiv:2307.09570. [Google Scholar]
- Israel, U.; Marks, M.; Dilip, R.; Li, Q.; Yu, C.; Laubscher, E.; Li, S.; Schwartz, M.; Pradhan, E.; Ates, A.; et al. A foundation model for cell segmentation. bioRxiv 2023, preprint. [Google Scholar]
- Archit, A.; Nair, S.; Khalid, N.; Hilt, P.; Rajashekar, V.; Freitag, M.; Gupta, S.; Dengel, A.; Ahmed, S.; Pape, C. Segment anything for microscopy. bioRxiv 2023, preprint. [Google Scholar]
- Li, X.; Deng, R.; Tang, Y.; Bao, S.; Yang, H. and Huo, Y. Leverage Weakly Annotation to Pixel-wise Annotation via Zero-shot Segment Anything Model for Molecular-empowered Learning. arXiv 2023, arXiv:2308.05785. [Google Scholar]
- Chen, R.J.; Chen, C.; Li, Y.; Chen, T.Y.; Trister, A.D.; Krishnan, R.G.; Mahmood, F. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16144–16155. [Google Scholar]
- Wang, X.; Yang, S.; Zhang, J.; Wang, M.; Zhang, J.; Yang, W.; Huang, J.; Han, X. Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 2022, 81, 102559. [Google Scholar] [CrossRef]
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 2022, 7, 100198. [Google Scholar] [CrossRef]
- Azizi, S.; Culp, L.; Freyberg, J.; Mustafa, B.; Baur, S.; Kornblith, S.; Chen, T.; Tomasev, N.; Mitrović, J.; Strachan, P.; et al. Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging. Nat. Biomed. Eng. 2023, 7, 756–779. [Google Scholar] [CrossRef]
- Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.; Szafraniec, M.; Khalidov, V.; Fernandez, P.; Haziza, D.; Massa, F.; El-Nouby, A.; et al. Dinov2: Learning robust visual features without supervision. arXiv 2023, arXiv:2304.07193. [Google Scholar]
- Vorontsov, E.; Bozkurt, A.; Casson, A.; Shaikovski, G.; Zelechowski, M.; Liu, S.; Severson, K.; Zimmermann, E.; Hall, J.; Tenenholtz, N.; et al. Virchow: A million-slide digital pathology foundation model. arXiv 2023, arXiv:2309.07778. [Google Scholar]
- Roth, B.; Koch, V.; Wagner, S.J.; Schnabel, J.A.; Marr, C.; Peng, T. Low-resource finetuning of foundation models beats state-of-the-art in histopathology. arXiv 2024, arXiv:2401.04720. [Google Scholar]
- Chen, R.J.; Ding, T.; Lu, M.Y.; Williamson, D.F.K.; Jaume, G.; Chen, B.; Zhang, A.; Shao, D.; Song, A.H.; Shaban, M.; et al. A general-purpose self-supervised model for computational pathology. arXiv 2023, arXiv:2308.15474. [Google Scholar]
- Filiot, A.; Ghermi, R.; Olivier, A.; Jacob, P.; Fidon, L.; Mac Kain, A.; Saillard, C.; Schiratti, J.-B. Scaling self-supervised learning for histopathology with masked image modeling. medRxiv 2023. 2023-07. [Google Scholar] [CrossRef]
- Campanella, G.; Kwan, R.; Fluder, E.; Zeng, J.; Stock, A.; Veremis, B.; Polydorides, A.D.; Hedvat, C.; Schoenfeld, A.; Vanderbilt, C.; et al. Computational pathology at health system scale–self-supervised foundation models from three billion images. arXiv 2023, arXiv:2310.07033. [Google Scholar]
- Dippel, J.; Feulner, B.; Winterhoff, T.; Schallenberg, S.; Dernbach, G.; Kunft, A.; Tietz, S.; Jurmeister, P.; Horst, D.; Ruff, L.; et al. RudolfV: A Foundation Model by Pathologists for Pathologists. arXiv 2024, arXiv:2401.04079. [Google Scholar]
- Xu, H.; Usuyama, N.; Bagga, J.; Zhang, S.; Rao, R.; Naumann, T.; Wong, C.; Gero, Z.; González, J.; Gu, Y.; et al. A whole-slide foundation model for digital pathology from real-world data. Nature 2024, 630, 181–188. [Google Scholar] [CrossRef] [PubMed]
- Naseem, U.; Khushi, M.; Kim, J. Vision-language transformer for interpretable pathology visual question answering. IEEE J. Biomed. Health Inform. 2022, 27, 1681–1690. [Google Scholar] [CrossRef]
- He, X.; Zhang, Y.; Mou, L.; Xing, E.; Xie, P. Pathvqa: 30,000+ questions for medical visual question answering. arXiv 2020, arXiv:2003.10286. [Google Scholar]
- Huang, Z.; Bianchi, F.; Yuksekgonul, M.; Montine, T.; Zou, J. Leveraging medical twitter to build a visual–language foundation model for pathology ai. bioRxiv 2023. 2023-03. [Google Scholar] [CrossRef]
- Sun, Y.; Zhu, C.; Zheng, S.; Zhang, K.; Shui, Z.; Yu, X.; Zhao, Y.; Li, H.; Zhang, Y.; Zhao, R.; et al. Pathasst: Redefining pathology through generative foundation ai assistant for pathology. arXiv 2023, arXiv:2305.15072. [Google Scholar]
- Lu, M.Y.; Chen, B.; Zhang, A.; Williamson, D.F.; Chen, R.J.; Ding, T.; Le, L.P.; Chuang, Y.S.; Mahmood, F. Visual Language Pretrained Multiple Instance Zero-Shot Transfer for Histopathology Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Lu, M.Y.; Chen, B.; Williamson, D.F.; Chen, R.J.; Liang, I.; Ding, T.; Jaume, G.; Odintsov, I.; Zhang, A.; Le, L.P.; et al. Towards a visual-language foundation model for computational pathology. arXiv 2023, arXiv:2307.12914. [Google Scholar]
- Zhang, Y.; Gao, J.; Zhou, M.; Wang, X.; Qiao, Y.; Zhang, S.; Wang, D. Text-guided foundation model adaptation for pathological image classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2023; pp. 272–282. [Google Scholar]
- Weinstein, J.N.; Collisson, E.A.; Mills, G.B.; Shaw, K.R.; Ozenberger, B.A.; Ellrott, K.; Shmulevich, I.; Sander, C.; Stuart, J.M. The cancer genome atlas pan-cancer analysis project. Nat. Genet. 2013, 45, 1113–1120. [Google Scholar] [CrossRef]
- Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P.; Joulin, A. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 9650–9660. [Google Scholar]
- Kim, Y.J.; Jang, H.; Lee, K.; Park, S.; Min, S.-G.; Hong, C.; Park, J.H.; Lee, K.; Kim, J.; Hong, W.; et al. Paip 2019: Liver cancer segmentation challenge. Med. Image Anal. 2021, 67, 101854. [Google Scholar] [CrossRef]
- Zhou, J.; Wei, C.; Wang, H.; Shen, W.; Xie, C.; Yuille, A.; Kong, T. ibot: Image bert pre-training with online tokenizer. arXiv 2021, arXiv:2111.07832. [Google Scholar]
- Wang, X.; Du, Y.; Yang, S.; Zhang, J.; Wang, M.; Zhang, J.; Yang, W.; Huang, J.; Han, X. Retccl: Clustering-guided contrastive learning for whole-slide image retrieval. Med. Image Anal. 2023, 83, 102645. [Google Scholar] [CrossRef]
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. Coca: Contrastive captioners are image-text foundation models. arXiv 2022, arXiv:2205.01917. [Google Scholar]
- Wang, Z.; Liu, C.; Zhang, S.; Dou, Q. Foundation model for endoscopy video analysis via large-scale self-supervised pre-train. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2023; pp. 101–111. [Google Scholar]
- Cui, B.; Mobarakol, I.; Bai, L.; Ren, H. Surgical-DINO: Adapter Learning of Foundation Model for Depth Estimation in Endoscopic Surgery. arXiv 2024, arXiv:2401.06013. [Google Scholar] [CrossRef] [PubMed]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Cheng, Y.; Li, L.; Xu, Y.; Li, X.; Yang, Z.; Wang, W.; Yang, Y. Segment and track anything. arXiv 2023, arXiv:2305.06558. [Google Scholar]
- Song, Y.; Yang, M.; Wu, W.; He, D.; Li, F.; Wang, J. It takes two: Masked appearance-motion modeling for self-supervised video transformer pre-training. arXiv 2022, arXiv:2022. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 248. [Google Scholar] [CrossRef]
- Hoelscher-Obermaier, J.; Persson, J.; Kran, E.; Konstas, I.; Barez, F. Detecting edit failures in large language models: An improved specificity benchmark. arXiv 2023, arXiv:2305.17553. [Google Scholar]
- Lekadir, K.; Feragen, A.; Fofanah, A.J.; Frangi, A.F.; Buyx, A.; Emelie, A.; Lara, A.; Porras, A.R.; Chan, A.; Navarro, A.; et al. FUTURE-AI: International consensus guideline for trustworthy and deployable artificial intelligence in healthcare. arXiv 2023, arXiv:2309.12325. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).