
Interpretable Machine Learning Models for Predicting Critical Outcomes in Patients with Suspected Urinary Tract Infection with Positive Urine Culture


Abstract
1. Introduction
2. Materials and Methods
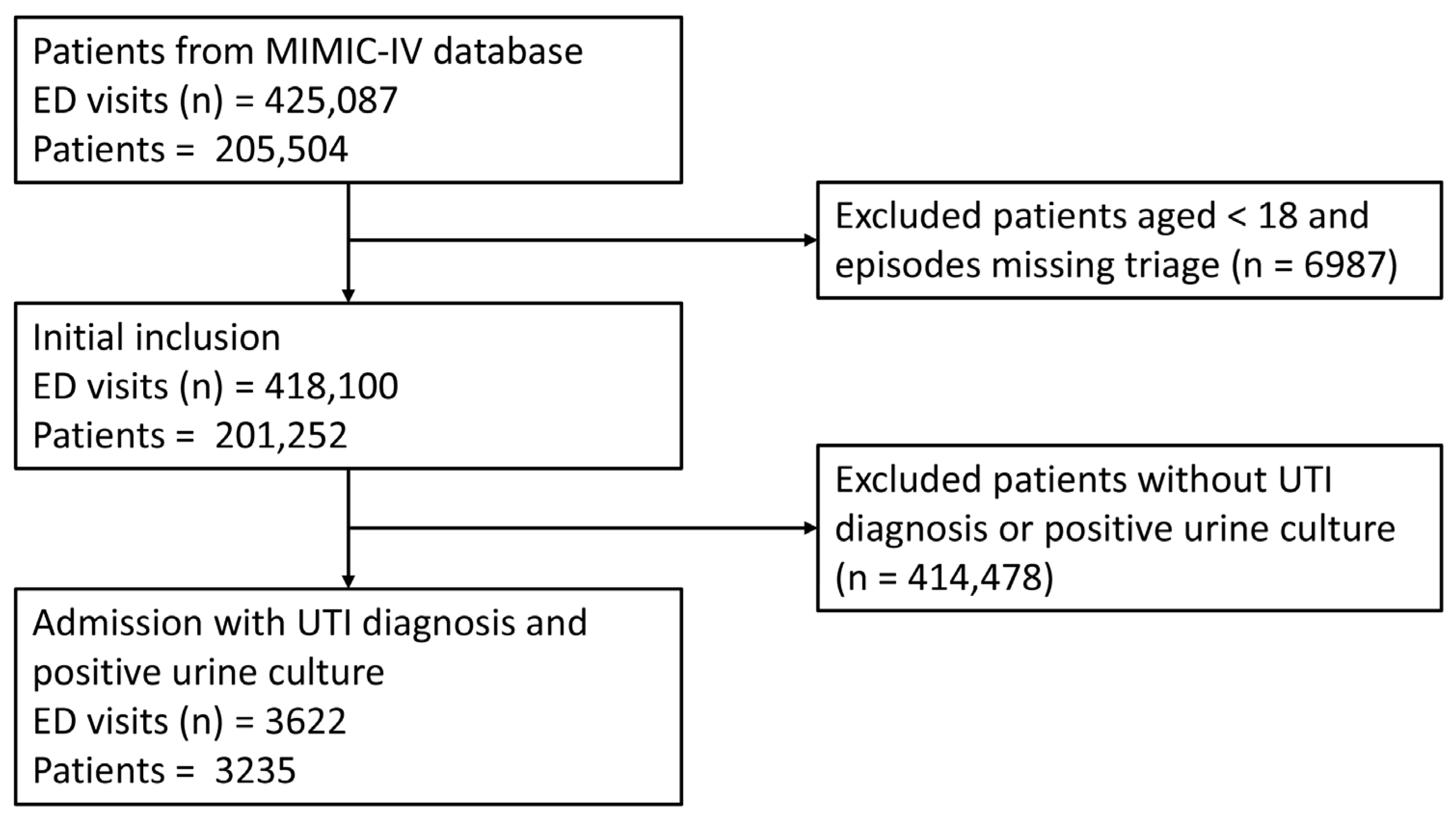
2.1. Data Source and Population
2.2. Variable Extraction and Data Preprocessing
2.3. Model Construction and Comparison
2.4. Statistical Analysis
3. Results
3.1. Patient Characteristics of the Training Group and Validation Group
3.2. Variable Selection and Model Performance Comparisons
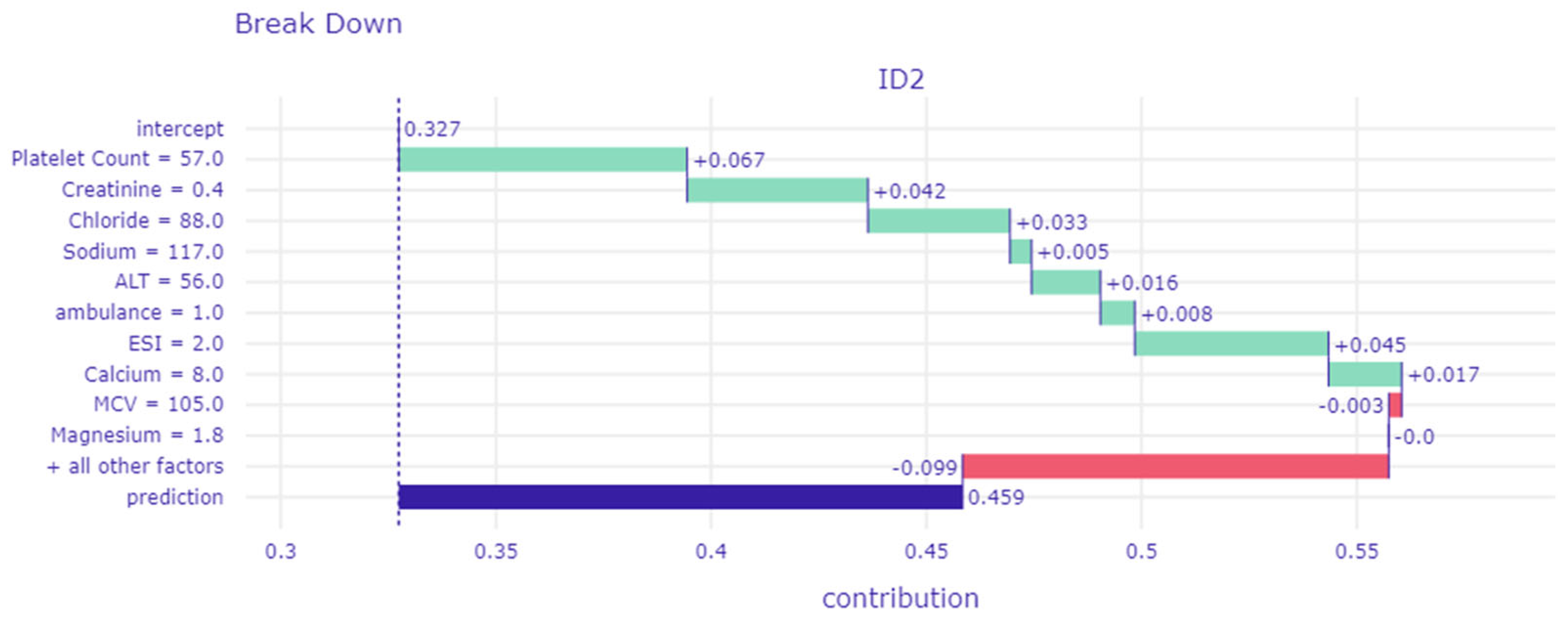
3.3. Interpretation of the Machine Learning Model
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Foxman, B. Urinary tract infection syndromes: Occurrence, recurrence, bacteriology, risk factors, and disease burden. Infect. Dis. Clin. N. Am. 2014, 28, 1–13. (In English) [Google Scholar] [CrossRef] [PubMed]
- Gupta, K.; Grigoryan, L.; Trautner, B. Urinary Tract Infection. Ann. Intern. Med. 2017, 167, Itc49–Itc64. (In English) [Google Scholar] [CrossRef] [PubMed]
- Nicolle, L. Complicated Urinary Tract Infection in Adults. Can. J. Infect. Dis. Med. Microbiol. 2005, 16, 349–360. [Google Scholar] [CrossRef] [PubMed]
- Su, M.; Guo, J.; Chen, H.; Huang, J. Developing a machine learning prediction algorithm for early differentiation of urosepsis from urinary tract infection. Clin. Chem. Lab. Med. 2023, 61, 521–529. (In English) [Google Scholar] [CrossRef] [PubMed]
- Madrazo, M.; López-Cruz, I.; Piles, L.; Artero, S.; Alberola, J.; Aguilera, J.A.; Eiros, J.M.; Artero, A. Risk Factors for Bacteremia and Its Clinical Impact on Complicated Community-Acquired Urinary Tract Infection. Microorganisms 2023, 11, 1995. (In English) [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, F.; Xu, F.; Wang, Z.; Ren, Y.; Han, D.; Lyu, J.; Yin, H. Construction and Evaluation of a Sepsis Risk Prediction Model for Urinary Tract Infection. Front. Med. 2021, 8, 671184. [Google Scholar] [CrossRef]
- Lalueza, A.; Sanz-Trepiana, L.; Bermejo, N.; Yaiza, B.; Morales-Cartagena, A.; Espinosa, M.; García-Jiménez, R.; Jiménez-Rodríguez, O.; Ponce, B.; Lora, D.; et al. Risk factors for bacteremia in urinary tract infections attended in the emergency department. Intern. Emerg. Med. 2018, 13, 41–50. [Google Scholar] [CrossRef] [PubMed]
- Tsai, Y.-C.; Huang, Y.-H.; Niu, K.-Y.; Tsai, Y.-C.; Chen, C.-B.; Yen, C.-C. Development of a Predictive Nomogram for Sepsis in Patients with Urolithiasis-Related Obstructive Pyelonephritis. Medicina 2024, 60, 1113. [Google Scholar] [CrossRef]
- Ngiam, K.Y.; Khor, I.W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. (In English) [Google Scholar] [CrossRef]
- Lu, S.-C.; Swisher, C.L.; Chung, C.; Jaffray, D.; Sidey-Gibbons, C. On the importance of interpretable machine learning predictions to inform clinical decision making in oncology. Front. Oncol. 2023, 13, 1129380. [Google Scholar] [CrossRef]
- Teng, Q.; Liu, Z.; Song, Y.; Han, K.; Lu, Y. A survey on the interpretability of deep learning in medical diagnosis. Multimed. Syst. 2022, 28, 2335–2355. [Google Scholar] [CrossRef] [PubMed]
- Murdoch, W.J.; Singh, C.; Kumbier, K.; Abbasi-Asl, R.; Yu, B. Definitions, methods, and applications in interpretable machine learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22071–22080. [Google Scholar] [CrossRef] [PubMed]
- Ghaderzadeh, M.; Asadi, F.; Ramezan Ghorbani, N.; Almasi, S.; Taami, T. Toward artificial intelligence (AI) applications in the determination of COVID-19 infection severity: Considering AI as a disease control strategy in future pandemics. Iran. J. Blood Cancer 2023, 15, 93–111. [Google Scholar] [CrossRef]
- Fasihfar, Z.; Rokhsati, H.; Sadeghsalehi, H.; Ghaderzadeh, M.; Gheisari, M. AI-driven malaria diagnosis: Developing a robust model for accurate detection and classification of malaria parasites. Iran. J. Blood Cancer 2023, 15, 112–124. (In English). Available online: https://www.magiran.com/paper/2664194 (accessed on 1 November 2023). [CrossRef]
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Horng, S.; Celi, L.A.; Mark, R. MIMIC-IV (Version 2.2). PhysioNet. Available online: https://doi.org/10.13026/6mm1-ek67 (accessed on 1 November 2023).
- Johnson, A.; Bulgarelli, L.; Pollard, T.; Celi, L.A.; Mark, R.; Horng, S. MIMIC-IV-ED (Version 2.2). PhysioNet. Available online: https://doi.org/10.13026/5ntk-km72 (accessed on 1 November 2023).
- Collins, G.S.; Reitsma, J.B.; Altman, D.G.; Moons, K.G.M. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD Statement. BMC Med. 2015, 13, 1. [Google Scholar] [CrossRef] [PubMed]
- Germanos, G.; Light, P.; Zoorob, R.; Salemi, J.; Khan, F.; Hansen, M.; Gupta, K.; Trautner, B.; Grigoryan, L. Validating Use of Electronic Health Data to Identify Patients with Urinary Tract Infections in Outpatient Settings. Antibiotics 2020, 9, 536. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; McDermott, M.B.A.; Chauhan, G.; Ghassemi, M.; Hughes, M.C.; Naumann, T. MIMIC-Extract; ACM: New York, NY, USA, 2019. [Google Scholar]
- Azur, M.J.; Stuart, E.A.; Frangakis, C.; Leaf, P.J. Multiple imputation by chained equations: What is it and how does it work? Int. J. Methods Psychiatr. Res. 2011, 20, 40–49. [Google Scholar] [CrossRef] [PubMed]
- Xie, F.; Zhou, J.; Lee, J.W.; Tan, M.; Li, S.; Rajnthern, L.S.; Chee, M.L.; Chakraborty, B.; Wong, A.-K.I.; Dagan, A.; et al. Benchmarking emergency department prediction models with machine learning and public electronic health records. Sci. Data 2022, 9, 658. [Google Scholar] [CrossRef] [PubMed]
- Subbe, C.P.; Kruger, M.; Rutherford, P.; Gemmel, L. Validation of a modified Early Warning Score in medical admissions. QJM 2001, 94, 521–526. (In English) [Google Scholar] [CrossRef]
- Smith, G.B.; Redfern, O.C.; Pimentel, M.A.; Gerry, S.; Collins, G.S.; Malycha, J.; Prytherch, D.; Schmidt, P.E.; Watkinson, P.J. The National Early Warning Score 2 (NEWS2). Clin. Med. 2019, 19, 260–263. [Google Scholar] [CrossRef]
- Olsson, T.; Terent, A.; Lind, L. Rapid Emergency Medicine score: A new prognostic tool for in-hospital mortality in nonsurgical emergency department patients. J. Intern. Med. 2004, 255, 579–587. [Google Scholar] [CrossRef] [PubMed]
- Baniecki, H.; Kretowicz, W.; PiÄ, P.; WiĹ, J. Dalex: Responsible machine learning with interactive explainability and fairness in python. J. Mach. Learn. Res. 2021, 22, 1–7. [Google Scholar]
- Yamashita, T.; Yamashita, K.; Kamimura, R. A Stepwise AIC Method for Variable Selection in Linear Regression. Commun. Stat.–Theory Methods 2007, 36, 2395–2403. [Google Scholar] [CrossRef]
- Sharman, R. Data Challenges and Societal Impacts—The Case in Favor of the Blueprint for an AI Bill of Rights (Keynote Remarks). In Big Data Analytics, Proceedings of the 10th International Conference, BDA 2022, Hyderabad, India, 19–22 December 2022; Springer: Cham, Switzerland, 2022; pp. 3–15. [Google Scholar]
- Geller, J. Food and Drug Administration Published Final Guidance on Clinical Decision Support Software. J. Clin. Eng. 2023, 48, 3–7. [Google Scholar] [CrossRef]
- Gilboy, N.; Tanabe, P.; Travers, D.; Rosenau, A.M. Emergency Severity Index (ESI): A triage tool for emergency department care, version 4. In Implementation Handbook; Agency for Healthcare Research and Quality (AHRQ): Rockville, MD, USA, 2012. [Google Scholar]
- Phungoen, P.; Khemtong, S.; Apiratwarakul, K.; Ienghong, K.; Kotruchin, P. Emergency Severity Index as a predictor of in-hospital mortality in suspected sepsis patients in the emergency department. Am. J. Emerg. Med. 2020, 38, 1854–1859. (In English) [Google Scholar] [CrossRef]
- Zheng, R.; Pan, H.; Wang, J.F.; Yu, X.S.; Chen, Z.Q.; Pan, J.Y. The association of coagulation indicators with in-hospital mortality and 1-year mortality of patients with sepsis at ICU admissions: A retrospective cohort study. Clin. Chim. Acta 2020, 504, 109–118. (In English) [Google Scholar] [CrossRef]
- Xu, H.; Ploplis, V.; Castellino, F. A coagulation factor VII deficiency protects against acute inflammatory responses in mice. J. Pathol. 2006, 210, 488–496. [Google Scholar] [CrossRef] [PubMed]
- Pawlinski, R.; Pedersen, B.; Schabbauer, G.; Tencati, M.; Holscher, T.; Boisvert, W.; Andrade-Gordon, P.; Frank, R.D.; Mackman, N. Role of tissue factor and protease-activated receptors in a mouse model of endotoxemia. Blood 2004, 103, 1342–1347. [Google Scholar] [CrossRef]
- Shapiro, N.I.; Howell, M.D.; Talmor, D.; Nathanson, L.A.; Lisbon, A.; Wolfe, R.E.; Weiss, J.W. Serum Lactate as a Predictor of Mortality in Emergency Department Patients with Infection. Ann. Emerg. Med. 2005, 45, 524–528. [Google Scholar] [CrossRef]
- Seymour, C.W.; Liu, V.X.; Iwashyna, T.J.; Brunkhorst, F.M.; Rea, T.D.; Scherag, A.; Rubenfeld, G.; Kahn, J.M.; Shankar-Hari, M.; Singer, M.; et al. Assessment of Clinical Criteria for Sepsis. JAMA 2016, 315, 762. [Google Scholar] [CrossRef]
- Kovesdy, C.P.; Anderson, J.E.; Kalantar-Zadeh, K. Association of serum bicarbonate levels with mortality in patients with non-dialysis-dependent CKD. Nephrol. Dial. Transplant. 2008, 24, 1232–1237. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Liu, X.; Liu, Y.; Li, W.; Chen, X.; Chen, Q.; Xiao, C.; Wan, Y.; Li, S.; Li, Q.; et al. Association between base excess and 28-day mortality in sepsis patients: A secondary analysis based on the MIMIC-IV database. Heliyon 2023, 9, e15990. [Google Scholar] [CrossRef] [PubMed]
- Pfortmueller, C.A.; Uehlinger, D.; Von Haehling, S.; Schefold, J.C. Serum chloride levels in critical illness—The hidden story. Intensive Care Med. Exp. 2018, 6, 10. [Google Scholar] [CrossRef] [PubMed]
- Kellum, J.A.; Song, M.; Venkataraman, R. Effects of hyperchloremic acidosis on arterial pressure and circulating inflammatory molecules in experimental sepsis. Chest 2004, 125, 243–248. (In English) [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhang, L.; Wei, C.; Feng, L.; Yang, J.; Zhang, G.; Lu, G.; Gui, X.; Zhou, Y.; Yang, K.; et al. U-shaped association between serum albumin and pediatric intensive care unit mortality in critically ill children. Front. Nutr. 2022, 9, 931599. [Google Scholar] [CrossRef] [PubMed]
- Thongprayoon, C.; Cheungpasitporn, W.; Mao, M.A.; Sakhuja, A.; Kashani, K. U-shape association of serum albumin level and acute kidney injury risk in hospitalized patients. PLoS ONE 2018, 13, e0199153. [Google Scholar] [CrossRef]
- Seymour, C.W. Prediction of Critical Illness During Out-of-Hospital Emergency Care. JAMA 2010, 304, 747. [Google Scholar] [CrossRef] [PubMed]
- Froom, P.; Shimoni, Z. Laboratory Tests, Bacterial Resistance, and Treatment Options in Adult Patients Hospitalized with a Suspected Urinary Tract Infection. Diagnostics 2024, 14, 1078. [Google Scholar] [CrossRef]
- Froom, P.; Shimoni, Z. The uncertainties of the diagnosis and treatment of a suspected urinary tract infection in elderly hospitalized patients. Expert. Rev. Anti Infect. Ther. 2018, 16, 763–770. (In English) [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Training Cohort (n = 2535) | Validation Cohort (n = 1087) | p Value |
|---|---|---|---|
| Age (years), median [IQR] | 72.0 [60.0–81.0] | 71.0 [59.5–81.0] | 0.408 |
| Sex (male), n (%) | 871 (34.4) | 373 (34.3) | 1.000 |
| Race, n (%) | |||
| Asian | 81 (3.2) | 27 (2.5) | 0.326 |
| Black | 361 (14.2) | 181 (16.7) | |
| Hispanic | 108 (4.3) | 46 (4.2) | |
| Other | 192 (7.6) | 77 (7.1) | |
| White | 1793 (70.7) | 756 (69.5) | |
| Insurance, n (%) | 0.226 | ||
| Medicaid | 142 (5.6) | 60 (5.5) | |
| Medicare | 1468 (57.9) | 662 (60.9) | |
| Other | 925 (36.5) | 365 (33.6) | |
| Arrival by ambulance, n (%) | 1689 (66.6) | 736 (67.7) | 0.551 |
| Emergency severity index, n (%) | 0.328 | ||
| Level 1 | 452 (17.8) | 195 (17.9) | |
| Level 2 | 1307 (51.6) | 563 (51.8) | |
| Level 3 | 768 (30.3) | 329 (30.3) | |
| Level 4 | 8 (0.3) | 0 (0.0) | |
| Vital signs at triage, median [IQR] | |||
| Body temperature (°C) | 36.7 [36.4–36.9] | 36.7 [36.4–36.9] | 0.499 |
| Fever † | 170 (6.7) | 72 (6.6) | 0.985 |
| Systolic blood pressure (mmHg) | 133.0 [115.0–146.0] | 133.0 [116.0–148.0] | 0.906 |
| Systolic blood pressure < 100 (mmHg) | 187 (7.4) | 94 (8.6) | 0.214 |
| Diastolic blood pressure (mmHg) | 72.0 [61.0–80.0] | 74.0 [62.0–82.0] | 0.695 |
| Mean arterial pressure (mmHg) | 93.3 [80.8–101.0] | 93.7 [81.5–101.8] | 0.760 |
| Heart rate (beats/min) | 84.0 [73.0–96.0] | 84.0 [74.0–97.5] | 0.250 |
| Respiratory rate (beats/min) | 18.0 [16.0–19.0] | 18.0 [16.0–18.0] | 0.286 |
| O2 saturation (%) | 98.0 [96.0–99.0] | 98.0 [97.0–99.0] | 0.451 |
| Comorbidities, n (%) | |||
| Hypertension | 1386 (54.7) | 590 (54.3) | 0.855 |
| Diabetes mellitus | 739 (29.2) | 341 (31.4) | 0.194 |
| Myocardial infarction | 330 (13.0) | 156 (14.4) | 0.305 |
| Congestive heart failure | 646 (25.5) | 277 (25.5) | 1.000 |
| Prior stroke | 304 (12.0) | 129 (11.9) | 0.960 |
| Liver disease | 282 (11.1) | 106 (9.8) | 0.244 |
| Chronic kidney disease | 672 (26.5) | 291 (26.8) | 0.902 |
| Malignancy | 341 (13.5) | 137 (12.6) | 0.524 |
| Charlson comorbidity index | 5.8 (3.8) | 5.7 (3.9) | 0.590 |
| Laboratory data (serum), median [IQR] | |||
| WBC (103/uL) | 8.7 [6.4–11.9] | 8.6 [6.4–11.8] | 0.115 |
| Neutrophil (%) | 77.5 [67.9–84.7] | 75.8 [66.0–83.5] | 0.098 |
| Monocyte (%) | 6.3 [4.5–8.8] | 6.6 [4.7–9.0] | 0.237 |
| Lymphocyte (%) | 12.1 [7.3–19.6] | 12.9 [8.0–20.9] | 0.129 |
| Hemoglobin (g/dL) | 10.4 [8.9–12.0] | 10.6 [9.0–12.1] | 0.285 |
| MCV (fL) | 92.0 [87.0–96.0] | 92.0 [87.0–96.0] | 0.985 |
| RDW (%) | 14.9 [13.8–16.6] | 14.7 [13.6–16.4] | 0.015 |
| Platelet count (103/uL) | 214.0 [156.0–278.0] | 213.0 [160.0–276.5] | 0.893 |
| PT (s) | 13.2 [11.8–17.4] | 12.9 [11.7–15.8] | 0.384 |
| aPTT (s) | 33.5 [28.7–37.5] | 33.6 [28.6–37.7] | 0.425 |
| Sodium (mEq/L) | 139.0 [136.0–141.0] | 139.0 [135.5–141.0] | 0.846 |
| Potassium (mEq/L) | 4.1 [3.7–4.5] | 4.1 [3.7–4.5] | 0.794 |
| AST (U/L) | 30.2 [19.0–55.0] | 29.5 [18.3–53.0] | 0.123 |
| ALT (U/L) | 22.0 [12.0–42.0] | 20.7 [12.0–38.5] | 0.043 |
| Total bilirubin (mg/dL) | 0.5 [0.3–0.9] | 0.5 [0.3–0.9] | 0.106 |
| Glucose (mg/dL) | 114.0 [94.0–149.0] | 115.0 [95.0–151.5] | 0.331 |
| Blood urea nitrogen (mg/dL) | 22.0 [15.0–37.0] | 22.0 [14.0–35.0] | 0.303 |
| Creatinine (mg/dL) | 1.0 [0.7–1.6] | 1.0 [0.7–1.6] | 0.746 |
| Albumin (g/dL) | 3.2 [2.9–3.5] | 3.2 [2.9–3.5] | 0.503 |
| Calcium (mg/dL) | 8.7 [8.2–9.2] | 8.7 [8.3–9.1] | 0.746 |
| Magnesium (mg/dL) | 1.9 [1.7–2.1] | 1.9 [1.7–2.1] | 0.630 |
| Chloride (mEq/L) | 102.0 [99.0–106.0] | 103.0 [99.0–106.0] | 0.575 |
| Lactate (mmol/L) | 1.7 [1.4–2.0] | 1.7 [1.4–2.0] | 0.340 |
| C-reactive protein (mg/L) | 51.0 [14.0–103.9] | 47.6 [18.9–99.5] | 0.800 |
| pH | 7.4 [7.3–7.4] | 7.4 [7.3–7.4] | 0.596 |
| Bicarbonate (mmol/L) | 24.0 [21.0–27.0] | 24.0 [21.0–27.0] | 0.340 |
| Urinalysis, median [IQR] † | |||
| WBC (/HPF) | 19.0 [6.0–57.0] | 22.0 [6.0–59.0] | 0.303 |
| RBC (/HPF) | 5.0 [2.0–15.0] | 5.0 [2.0–16.5] | 0.128 |
| pH | 6.0 [5.5–6.5] | 6.0 [5.5–6.5] | 0.635 |
| Urine culture, n (%) | 0.068 | ||
| Escherichia coli | 900 (35.5) | 396 (36.4) | |
| Enterococcus sp. | 365 (14.4) | 152 (14.1) | |
| Yeast | 294 (11.6) | 92 (8.5) | |
| Klebsiella sp. | 280 (11.0) | 116 (10.7) | |
| Proteus sp. | 120 (4.8) | 47 (4.3) | |
| Pseudomonas sp. | 113 (4.5) | 50 (4.6) | |
| Other microorganisms | 463 (18.2) | 234 (21.5) | |
| Prediction score | |||
| MEWS | 1.6 (1.0) | 1.6 (1.1) | 0.297 |
| NEWS | 1.4 (1.6) | 1.4 (1.7) | 0.630 |
| REMS | 5.8 (2.2) | 5.8 (2.3) | 0.809 |
| Critical outcomes, n (%) | 836 (33.0) | 358 (32.9) | 1.000 |
| ICU admission | 766 (30.2) | 329 (30.3) | 1.000 |
| In-hospital mortality | 153 (6.0) | 67 (6.2) | 0.942 |
| Without Critical Outcomes (n = 1699) | With Critical Outcomes (n = 836) | p Value | |
|---|---|---|---|
| Emergency severity index, n (%) | <0.001 | ||
| Level 1 | 153 (9.0) | 299 (35.8) | |
| Level 2 | 874 (51.4) | 433 (51.8) | |
| Level 3 | 664 (39.1) | 104 (12.4) | |
| Level 4 | 8 (0.5) | 0 (0.0) | |
| Arrival by ambulance, n (%) | 1118 (65.8) | 571 (68.3) | 0.227 |
| Mean arterial pressure, median [IQR] | 91.7 [81.3–102.7] | 95.7 [80.0–98.1] | 0.289 |
| WBC (103/uL), median [IQR] | 8.2 [5.9–10.9] | 10.2 [7.5–14.1] | <0.001 |
| Hemoglobin (g/dL), median [IQR] | 10.4 [8.9–11.9] | 10.5 [8.8–12.1] | 0.59 |
| MCV (fL), median [IQR] | 92.0 [87.0–96.0] | 92.0 [88.0–97.0] | 0.013 |
| Platelet count (103/uL), median [IQR] | 218.0 [158.0–285.5] | 205.0 [150.0–263.2] | <0.001 |
| aPTT (s), median [IQR] | 35.0 [29.6–37.5] | 31.3 [27.7–37.6] | <0.001 |
| Sodium (mEq/L), median [IQR] | 139.0 [136.0–141.0] | 139.0 [135.0–142.0] | 0.479 |
| Blood urea nitrogen (mg/dL), median [IQR] | 21.0 [14.0–34.0] | 25.0 [16.0–43.0] | <0.001 |
| Creatinine (mg/dL), median [IQR] | 1.0 [0.7–1.6] | 1.1 [0.8–1.7] | 0.059 |
| AST (U/L), median [IQR] | 28.0 [17.0–49.9] | 35.8 [22.0–68.1] | <0.001 |
| ALT (U/L), median [IQR] | 20.0 [11.0–38.0] | 25.6 [15.0–51.0] | <0.001 |
| Calcium (mg/dL), median [IQR] | 8.8 [8.4–9.2] | 8.6 [7.9–9.1] | <0.001 |
| Magnesium (mg/dL), median [IQR] | 1.9 [1.8–2.1] | 1.9 [1.7–2.1] | 0.005 |
| Chloride (mEq/L), median [IQR] | 102.0 [99.0–105.0] | 103.0 [99.0–107.0] | <0.001 |
| Glucose (mg/dL), median [IQR] | 108.0 [92.0–140.0] | 125.0 [102.0–166.0] | <0.001 |
| Albumin (g/dL), median [IQR] | 3.3 [3.0–3.5] | 3.1 [2.7–3.4] | <0.001 |
| Lactate (mmol/L), median [IQR] | 1.7 [1.4–1.9] | 1.8 [1.4–2.3] | <0.001 |
| Bicarbonate (mmol/L), median [IQR] | 25.0 [22.0–27.0] | 23.0 [19.0–26.0] | <0.001 |
| Models | AUC (95% CI) | Accuracy | No-Information Rate | Balanced Accuracy | Kappa | Precision | F1 Score | Sensitivity | Specificity |
|---|---|---|---|---|---|---|---|---|---|
| XGBoost | 0.833 (0.806–0.857) | 0.691 | 0.671 | 0.739 | 0.406 | 0.518 | 0.652 | 0.880 | 0.598 |
| RF | 0.814 (0.785–0.839) | 0.557 | 0.671 | 0.656 | 0.237 | 0.237 | 0.237 | 0.947 | 0.365 |
| SVM | 0.799 (0.771–0.826) | 0.650 | 0.671 | 0.700 | 0.335 | 0.482 | 0.614 | 0.844 | 0.556 |
| GEE LR | 0.793 (0.764–0.820) | 0.615 | 0.671 | 0.676 | 0.288 | 0.455 | 0.594 | 0.858 | 0.495 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yen, C.-C.; Ma, C.-Y.; Tsai, Y.-C. Interpretable Machine Learning Models for Predicting Critical Outcomes in Patients with Suspected Urinary Tract Infection with Positive Urine Culture. Diagnostics 2024, 14, 1974. https://doi.org/10.3390/diagnostics14171974
Yen C-C, Ma C-Y, Tsai Y-C. Interpretable Machine Learning Models for Predicting Critical Outcomes in Patients with Suspected Urinary Tract Infection with Positive Urine Culture. Diagnostics. 2024; 14(17):1974. https://doi.org/10.3390/diagnostics14171974
Chicago/Turabian StyleYen, Chieh-Ching, Cheng-Yu Ma, and Yi-Chun Tsai. 2024. "Interpretable Machine Learning Models for Predicting Critical Outcomes in Patients with Suspected Urinary Tract Infection with Positive Urine Culture" Diagnostics 14, no. 17: 1974. https://doi.org/10.3390/diagnostics14171974
APA StyleYen, C.-C., Ma, C.-Y., & Tsai, Y.-C. (2024). Interpretable Machine Learning Models for Predicting Critical Outcomes in Patients with Suspected Urinary Tract Infection with Positive Urine Culture. Diagnostics, 14(17), 1974. https://doi.org/10.3390/diagnostics14171974