
Lobish: Symbolic Language for Interpreting Electroencephalogram Signals in Language Detection Using Channel-Based Transformation and Pattern

 ,
,  ,
,  ,
,  and
and
Abstract
1. Introduction
1.1. Literature Review
1.2. Literature Gaps
- Deep learning models are widely employed by the researchers. As a result, many deep learning-based models are used to classify the EEG signals with high classification performance. However, these deep learning models often have high time complexities [34].
- There is a limited number of explainable models in this area. Most models have focused solely on classification performance, neglecting the interpretability of the results.
- In feature engineering, there are few specialized classification models. Most researchers have generally relied on well-known classifiers.
1.3. Motivation and the Proposed Feature Engineering Model
1.4. Novelties and Contributions
- We have proposed a new channel-based transformation model that encodes the signals using the channel indices.
- A new channel-based feature extraction function, termed ChannelPat, has been proposed in this work.
- An EEG language dataset was collected for this work.
- The tkNN classifier has been proposed to achieve higher classification performance.
- A channel-based feature engineering model has been presented to demonstrate the classification ability of the proposed channel-based methods.
- Lobish is a new-generation explainable result generator and a symbolic language.
- A novel EEG language dataset was collected. We used two data collection strategies: (1) listening and (2) demonstration.
- We have proposed a new feature engineering model. Two EEG-specific models have been used: channel-based transformation and feature extraction.
- By proposing Lobish, we obtained explainable results related to the cortical area.
2. Material and Method
2.1. Material
2.2. Method
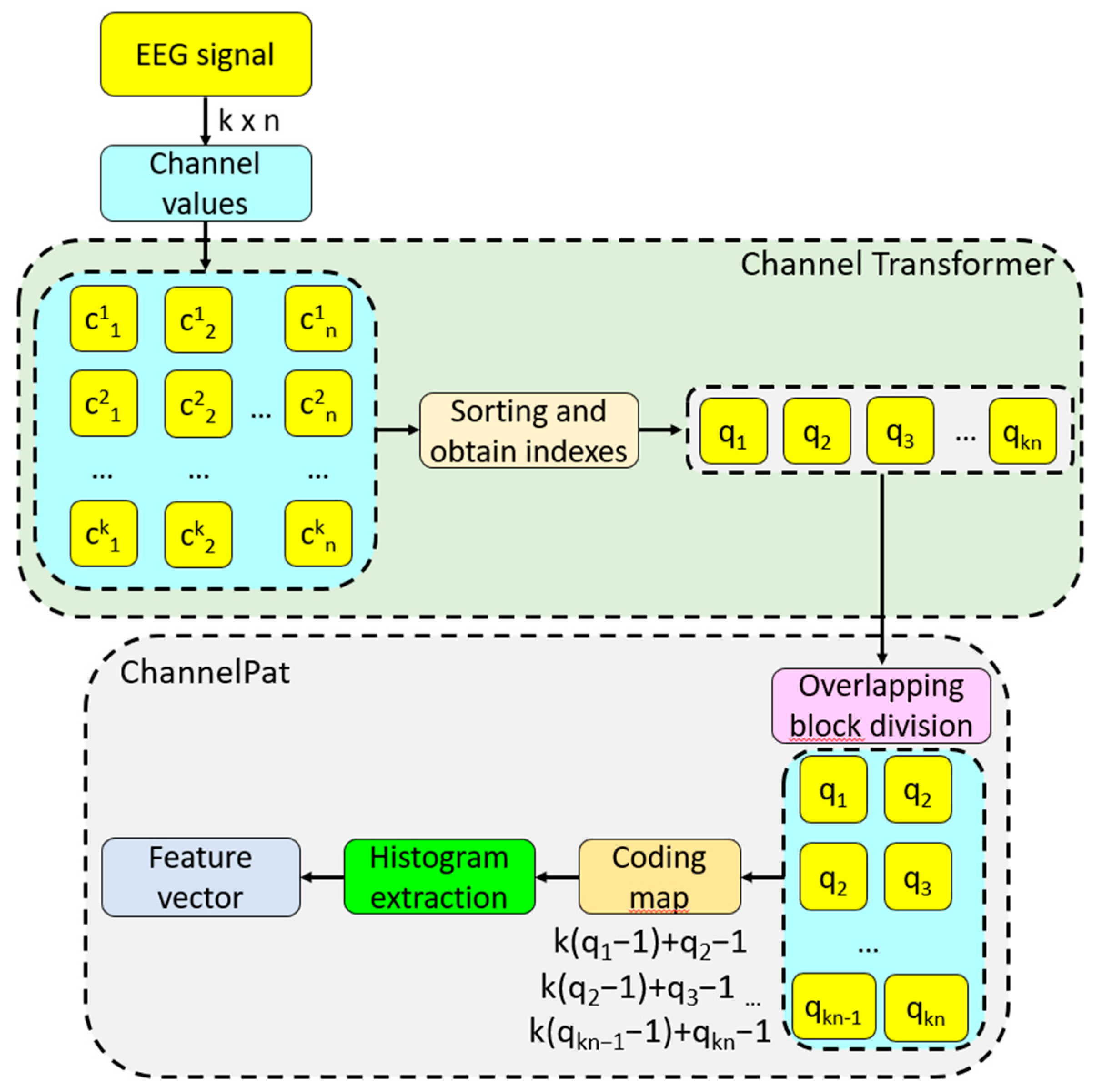
2.2.1. Channel-Based Transformation
| Algorithm 1. Pseudocode of the proposed channel-based transformation. |
| Input: The used EEG signal with 14 channels () with a length of . Output: The transformer signal created () with a length of . |
| 01: ; // Counter definition 02: for i = 1 to do 03: ; // Get values of the channels. 04: : indices of the sorted data. 05: ; // Creating transformer signal 06: ; 07: end for i |
2.2.2. Channel Pattern
- S0: Load the signal.
- S1: Apply the channel-based transformation to the signal.
- S2: Divide the transformed into the overlapping block with a length of 2.
- S3: Create the map signal by deploying base 14 to decimal conversion.
- S4: Extract the histogram of the generated map signal.where is the feature vector with a length of 196 (=142) and is the histogram extraction function.
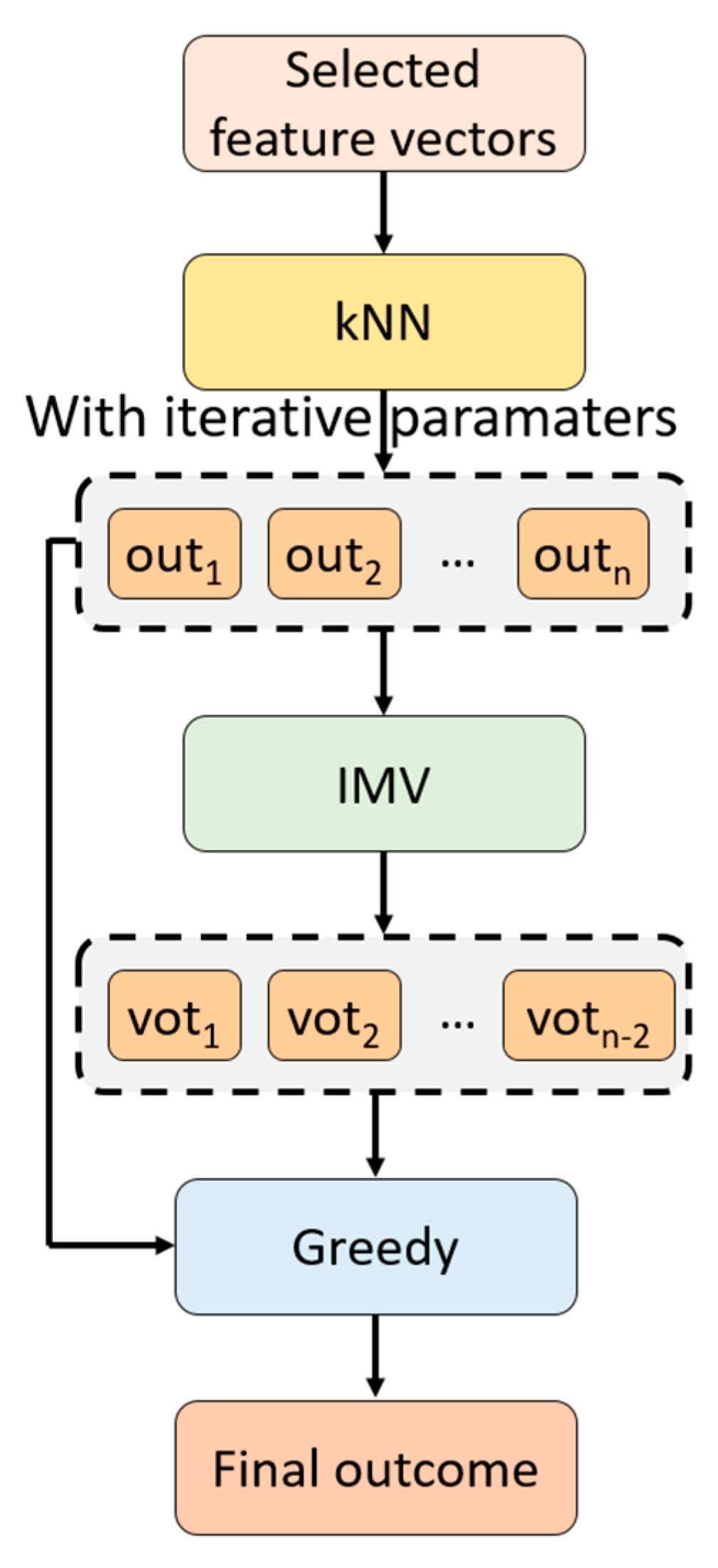
2.2.3. tkNN
- S1: Change the parameters iteratively to create classifier-wise outcomes.where is the classifier-wise outcome, is the kNN classifier, and is the real outcome.
- S2: Apply IMV to the classifier-based outcomes. The mathematical definitions of the IMV algorithm have been given below.
- S3: Choose the final outcome by deploying a greedy algorithm.
2.2.4. Lobish
- F demonstrates cognitive functions.
- P represents sensory processing and spatial awareness.
- T involves auditory processing and memory.
- O indicates visual processing.
- FF defines sustained cognitive effort.
- TT indicates continuous auditory processing or engaging with memory recall.
- PP depicts ongoing sensory integration and spatial processing.
- OO defines continuous visual processing.
- FT defines the transition from planning or decision-making to recalling information or understanding spoken language.
- FP represents moving from cognitive tasks to integrating sensory information.
- FO depicts the transition from planning or thinking to analyzing visual information.
- TP uses auditory information or memory to assist in sensory processing.
- TO defines recalling visual memories or interpreting visual information based on auditory input.
- PO represents integrating sensory and spatial information with visual processing.
- TF uses auditory or memory information for planning or decision-making.
- PF defines transitioning from sensory information to cognitive tasks.
- OF uses visual information for cognitive processes.
- PT integrates sensory information with memory or auditory processing.
- OT defines associating visual stimuli with memory recall or auditory information.
- OP represents using visual information for sensory and spatial awareness.
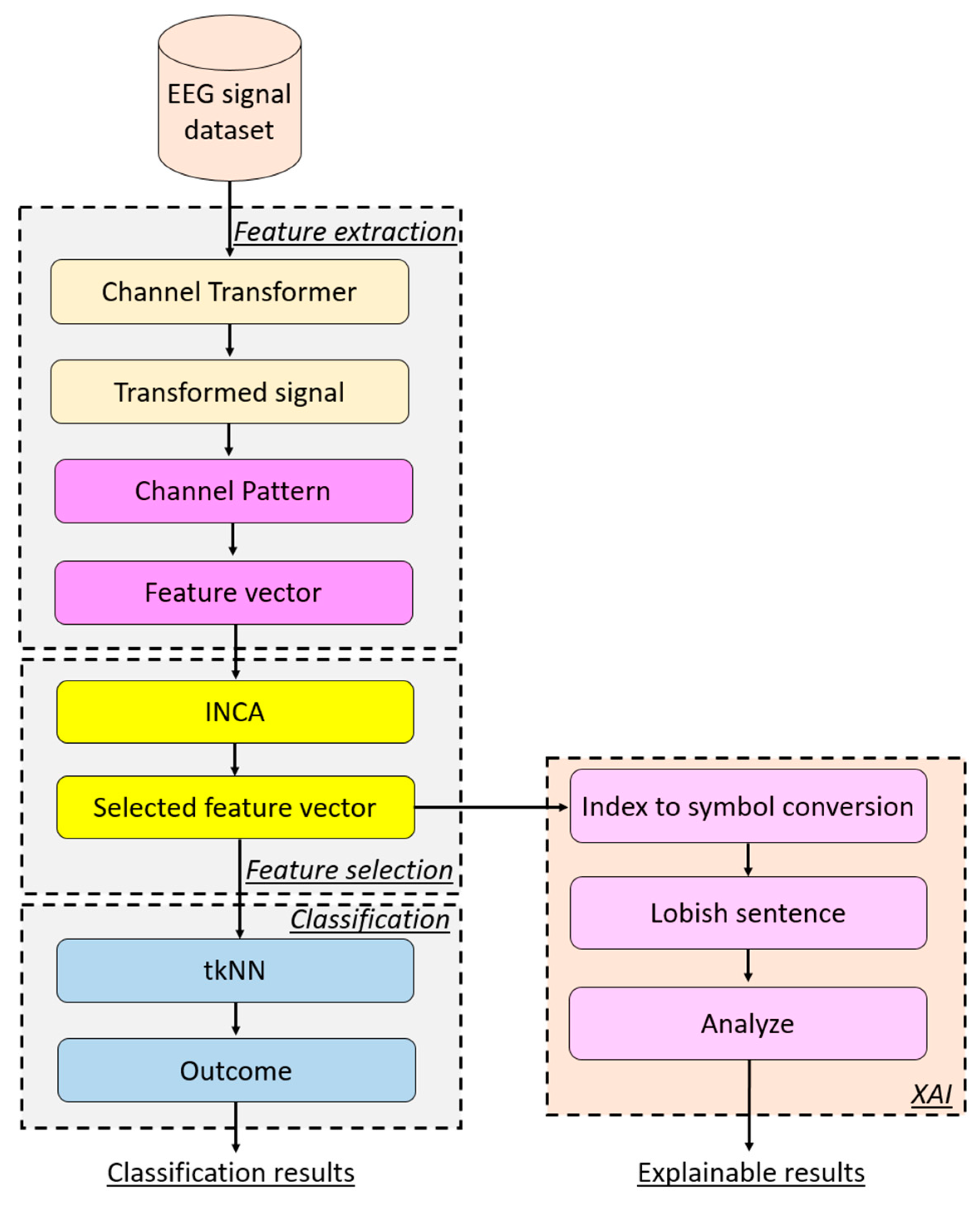
2.2.5. Proposed Feature Engineering Model
- Step 1: Apply channel-based transformation to the EEG signal.
- Step 2: Extract features by deploying the proposed ChannelPat.where is the feature vector and is the proposed ChannelPat. Herein, the length of the feature vector is computed as 196. In this step, 196 (=14 × 14) features have been extracted since the used EEG signal dataset has 14 channels.
- Step 3: Repeat Steps 1–2 until the number of the signals is reached and a feature matrix is created.
- Step 4: Apply the INCA [37] feature selector to choose the most informative features.where is the selected feature vector, is the INCA feature selection function, and is the created feature matrix. By utilizing the selected features, both classification and explainable results have been obtained.
- Step 4 defines the feature selection phase of the proposed feature engineering model.
- Step 5: Classify the selected feature vector by deploying the tkNN classifier.
- Step 6: Extract Lobish symbols by utilizing the indices of the selected features. In this work, we employed a transition table-based feature extraction function, where each selected feature represents a transition between two EEG channels. Consequently, each selected feature corresponds to two Lobish symbols, which are derived based on the specific transitions between the brain lobes represented by those channels. The Lobish symbols provide a symbolic interpretation of the brain’s activity, allowing for both detailed classification and explainable results, as they offer insights into the underlying neural processes associated with the observed EEG patterns. The pseudocode of this step is given in Algorithm 2.
| Algorithm 2. Pseudocode of the proposed Lobish sentence generation method. |
| Input: The indexes of the selected features (id), look up table for Lobish according to used brain cap. LUT = [F,F,F,F,T,P,O,O,P,T,F,F,F,F] Output: Lobish sentence (sen) |
| 01: ; // Counter definition 02: for i = 1 to do 03: ; // Compute values for extracting the Lobish symbol 04: 05: ; // Extraction Lobish symbols from LUT 06: ; // Extraction Lobish symbols from LUT 07: ; 08: end for i |
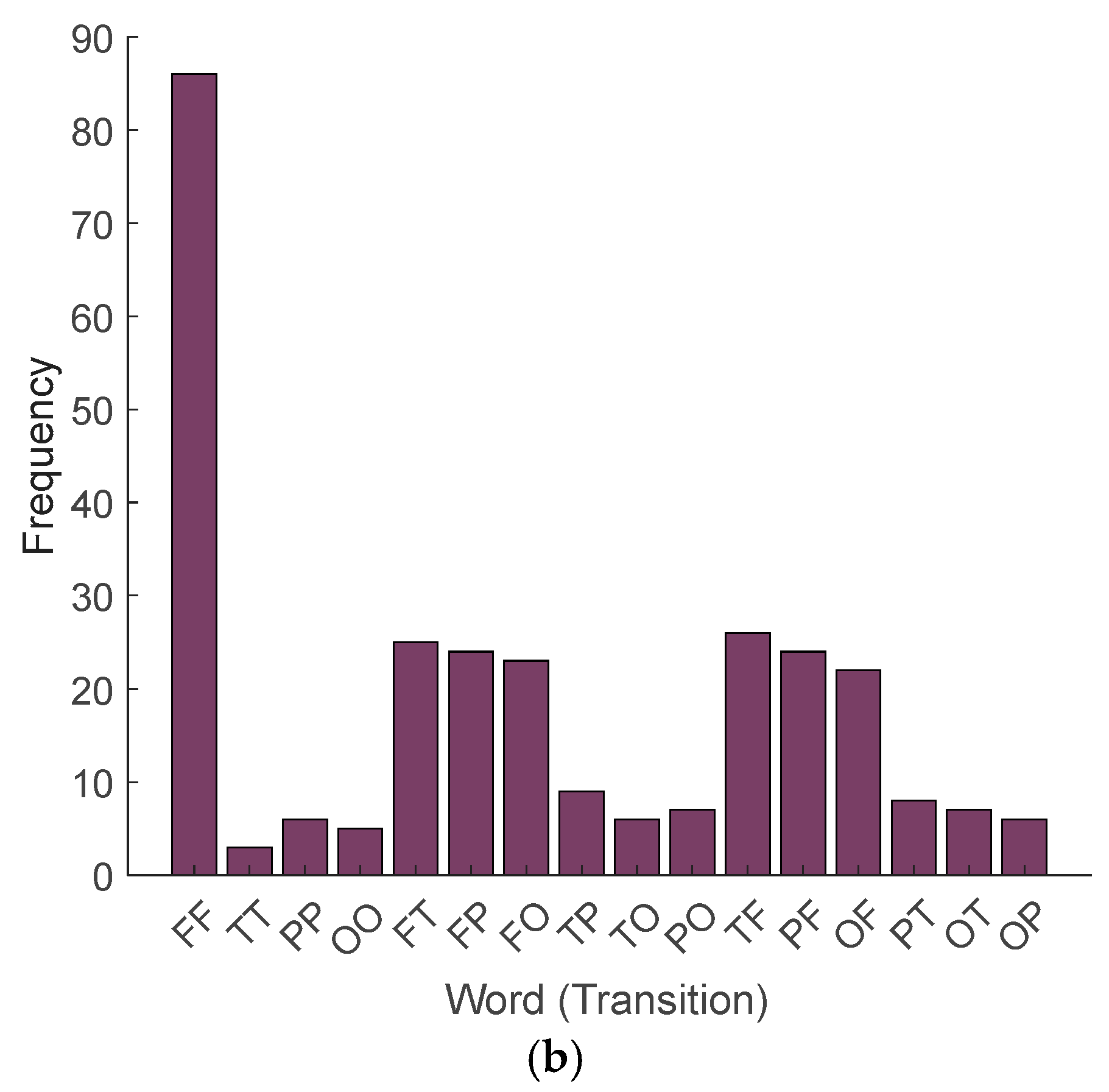
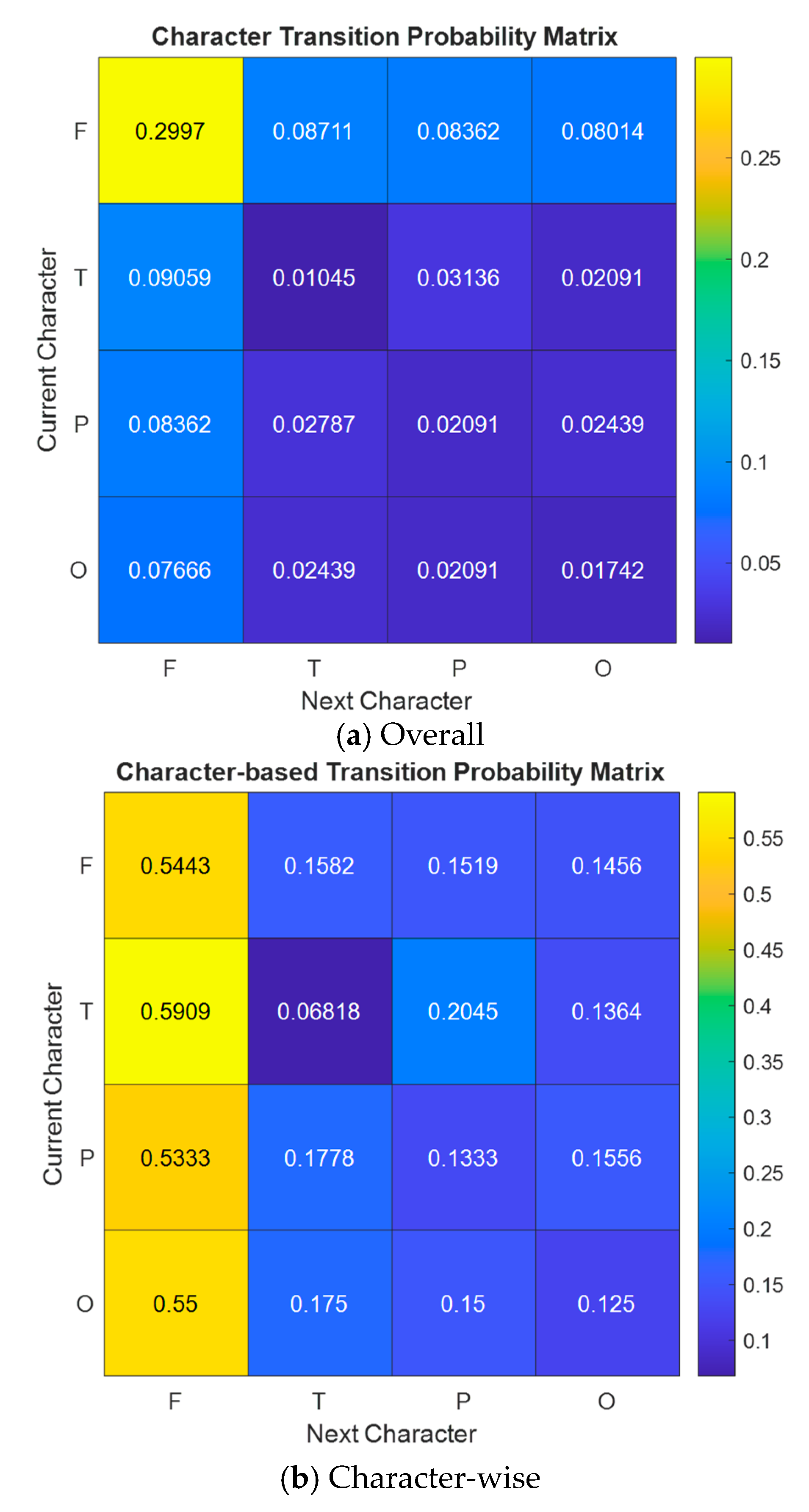
- Step 7: By utilizing the extracted Lobish sentences, obtain explainable results. These sentences, composed of Lobish symbols, provide a structured interpretation of the brain’s activity, translating complex neural processes into a symbolic language. This approach enables a deeper understanding of the EEG data by linking specific brain lobe transitions to cognitive functions, thereby facilitating both the precise classification and meaningful, interpretable explanations of the observed brain dynamics. In this step, histograms of the symbols and transition tables of the symbols have been computed.
3. Experimental Results
- TFTT: Temporal lobe activity indicating memory and auditory processing, and brief cognitive processing, then back to the temporal lobe.
- POO: Transition from parietal to occipital lobes, indicating sensory processing moving into visual processing.
- PPT: Parietal to temporal transition indicating the integration of sensory information with memory.
- FFFF: Sustained frontal lobe activity indicating prolonged cognitive effort and planning.
- POF: Parietal to occipital to frontal transition, indicating sensory and visual information being integrated into cognitive processes.
- TFF: Temporal to frontal transition indicating memory recall being used for planning or decision-making.
- OTT: Occipital to temporal transition, indicating visual information processing leading to memory recall or auditory processing.
- FFFF: Repeated frontal lobe activity, reinforcing cognitive effort.
- TFTOO: Temporal to frontal transition with sustained occipital activity, showing memory integration with visual processing.
- FFFF: Continued cognitive effort in the frontal lobe.
- OOPOFF: Occipital to parietal to frontal transition, indicating visual information moving through sensory integration to cognitive processing.
- OTPTFOO: This complex transition indicates multiple integrations between the occipital, temporal, parietal, and frontal lobes, suggesting intense processing of sensory, memory, and cognitive information.
- FFFFFT: Sustained cognitive effort with a brief switch to the temporal lobe for memory recall.
- FFFFFFT: Continued high-level cognitive processing with brief temporal involvement.
- FP: Simple transition from frontal to parietal lobes, showing cognitive effort translated into sensory integration.
- PFFO: Sensory information is being processed back into cognitive effort and then visual processing.
- FTOTP: Cognitive effort leading to the temporal lobe, then back to occipital and parietal lobes, indicating complex multi-sensory integration.
- FFFFTP: Prolonged cognitive effort with sensory integration.
- TFTPP: Memory recall and cognitive effort leading to sustained sensory processing.
- FTFPO: Cognitive planning integrating memory, sensory, and visual information.
- FFFFO: Sustained cognitive effort with visual processing.
- FOFFF: Visual to cognitive transition showing the integration of visual information into planning.
- TOFFFF: Temporal involvement leading into sustained cognitive effort.
- OF: Simple visual to cognitive processing.
- TPPT: Sensory to memory transitions indicating the integration of external stimuli into memory.
- FFFFP: Prolonged cognitive effort with brief sensory integration.
- FFFOTF: Sustained cognitive effort with visual integration and brief memory recall.
- FFFTF: Continuous cognitive effort with brief memory recall.
- FP: Cognitive to sensory integration.
- FFFFFO: Sustained cognitive effort with visual processing.
- FTFO: Cognitive planning integrating memory and visual processing.
- FFTFF: Cognitive effort with brief sensory and memory processing.
- TPFF: Sensory to memory to cognitive processing.
- FPOFFP: Sensory and visual integration into cognitive processes.
- TFFTFFF: Memory recall leading to sustained cognitive effort.
- FOFFTFF: Visual to cognitive transitions indicating the complex integration of visual information into planning.
- FTFPPF: Cognitive to sensory transitions showing continuous cognitive effort and the integration of sensory information.
- FTOTPFF: Cognitive to memory, visual, and sensory integration showing complex processing.
- FFFFTP: Prolonged cognitive effort with sensory integration.
- TFTPPF: Memory recall leading to sensory processing and cognitive integration.
- TFFPFO: Memory to cognitive, sensory, and visual processing, indicating complex integration.
- FFOTF: Cognitive planning with visual and brief memory recall.
- FFFF: Sustained cognitive effort.
- FOFT: Integration of visual information into cognitive planning and memory recall.
- FOFO: Indicates a task requiring continuous alternation between thinking and a visual analysis, such as reading, planning, or visual problem-solving.
4. Discussions
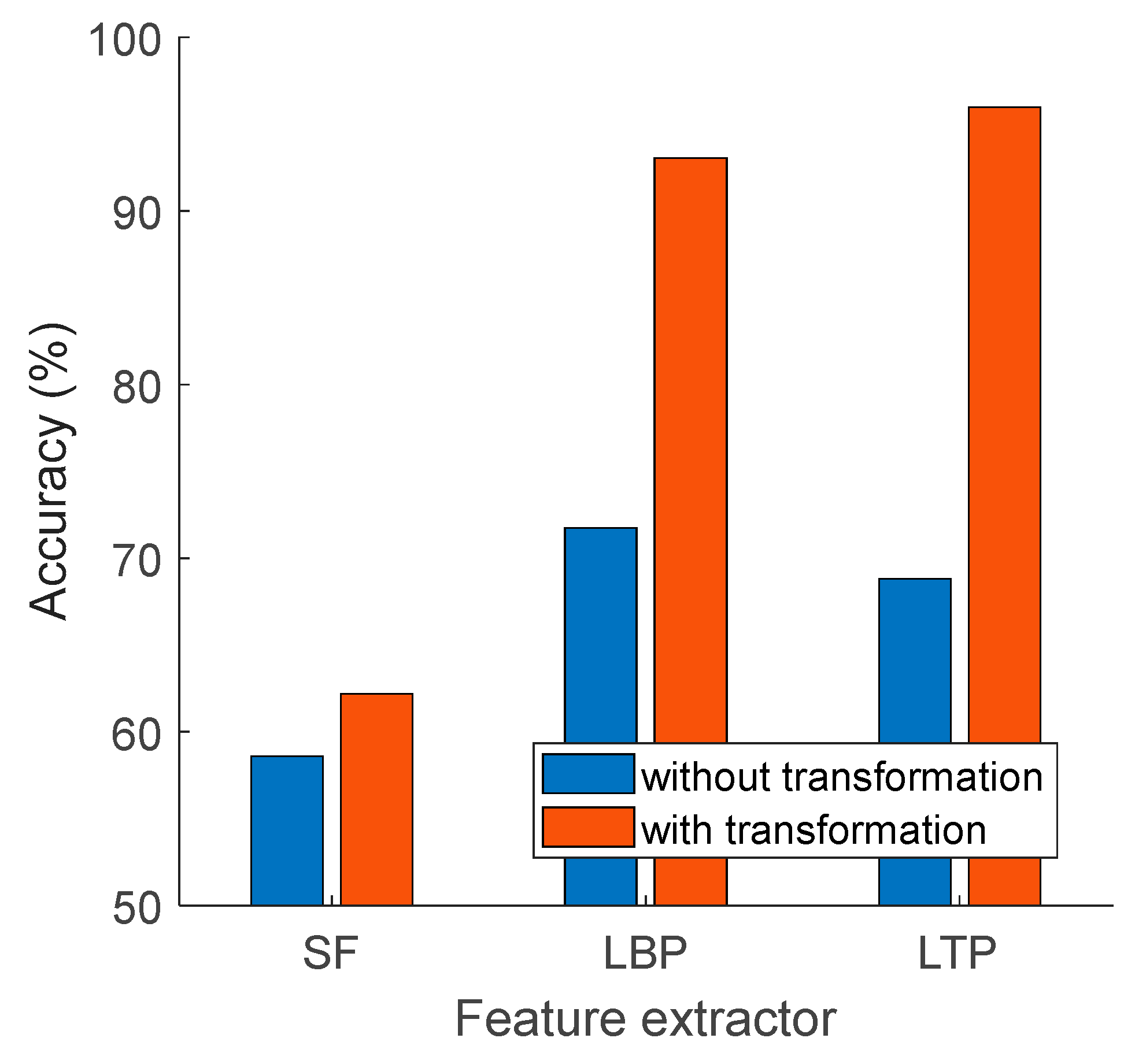
- A novel channel-based transformation function was proposed to obtain higher classification accuracy than the traditional feature extractors like LBP, LTP, and SF.
- The ChannelPat feature extraction function used channel-based transformation to create a map signal, achieving a high classification accuracy of 98.59%.
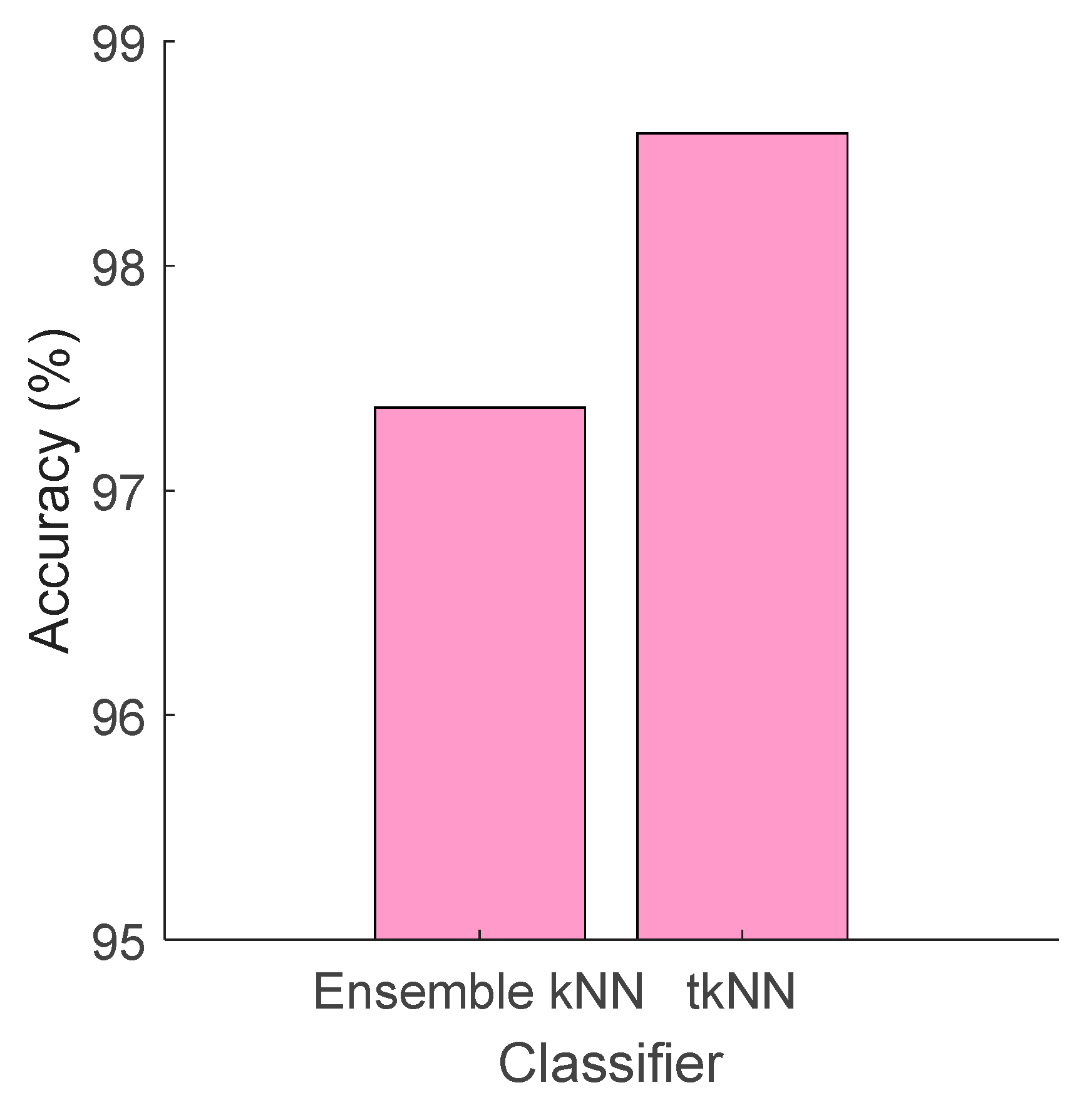
- The innovative tkNN classifier outperformed the ensemble kNN tool, achieving a classification accuracy of 98.59% compared to 97.37%.
- Lobish, a new symbolic language, was introduced to obtain explainable results.
- The proposed channel-based feature engineering model attained over 98% classification performance.
- This model is a lightweight EEG language detection model since this model has linear time complexity.
- A new EEG language detection dataset was collected, and this dataset includes two languages, which are (1) Arabic and (2) Turkish.
- Lobish has identified the necessity of integrating sensory, auditory, and visual information and high frontal lobe activity for language detection.
- By translating EEG signals into symbolic representations, Lobish has provided deeper insights into the neural processes underlying language perception and processing, paving the way for advanced research in neuroscience and cognitive science.
- The ability to generate Lobish sentences from EEG data opens up new avenues/ways for exploring how different brain regions interact during specific tasks, providing insights that were previously difficult to obtain.
- Lobish serves as a bridge between neuroscience, cognitive science, and artificial intelligence. Its symbolic nature makes it accessible to researchers from different disciplines.
- Lobish can be used to develop personalized learning strategies that align with a student’s cognitive strengths and weaknesses, optimizing learning outcomes.
- The creation of Lobish represents a shift towards a more human-centric approach in EEG analyses.
- Lobish has the potential to transform the way EEG data are used in both research and practical applications, making brain–computer interaction more intuitive and accessible.
5. Conclusions
6. Future Directions
- Lobish can be used in neurology, neurosurgery, and neuroscience to understand brain activities better.
- Lobish-based diagnostic and education tools coupled with visualization platforms can be proposed.
- To increase the explainability of Lobish, new letters can be added to represent more specific lobes or parts of the lobes.
- The proposed channel-based transformation can be integrated with deep learning models to achieve higher classification performances.
- The t algorithm can be applied to machine learning algorithms, such as decision trees, naïve Bayes, support vector machines, etc.
- In this work, we proposed ChannelPat to extract features. To obtain more meaningful features, new-generation and effective feature extraction methods can be proposed.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Malmasi, S.; Dras, M. Multilingual native language identification. Nat. Lang. Eng. 2017, 23, 163–215. [Google Scholar] [CrossRef]
- Jauhiainen, T.; Lui, M.; Zampieri, M.; Baldwin, T.; Lindén, K. Automatic language identification in texts: A survey. J. Artif. Intell. Res. 2019, 65, 675–782. [Google Scholar] [CrossRef]
- Babaee, E.; Anuar, N.B.; Abdul Wahab, A.W.; Shamshirband, S.; Chronopoulos, A.T. An overview of audio event detection methods from feature extraction to classification. Appl. Artif. Intell. 2017, 31, 661–714. [Google Scholar] [CrossRef]
- Ambikairajah, E.; Li, H.; Wang, L.; Yin, B.; Sethu, V. Language identification: A tutorial. IEEE Circuits Syst. Mag. 2011, 11, 82–108. [Google Scholar] [CrossRef]
- Amogh, A.M.; Hari Priya, A.; Kanchumarti, T.S.; Bommilla, L.R.; Regunathan, R. Language Detection Based on Audio for Indian Languages. Autom. Speech Recognit. Transl. Low Resour. Lang. 2024, 275–296. [Google Scholar] [CrossRef]
- Rustamov, S.; Bayramova, A.; Alasgarov, E. Development of dialogue management system for banking services. Appl. Sci. 2021, 11, 10995. [Google Scholar] [CrossRef]
- Sabol, R.; Horák, A. New Language Identification and Sentiment Analysis Modules for Social Media Communication; Springer International Publishing: Cham, Switzerland, 2022; pp. 89–101. [Google Scholar]
- Rivera-Trigueros, I. Machine translation systems and quality assessment: A systematic review. Lang. Resour. Eval. 2022, 56, 593–619. [Google Scholar] [CrossRef]
- Burke, M.; Zavalina, O.L.; Phillips, M.E.; Chelliah, S. Organization of knowledge and information in digital archives of language materials. J. Libr. Metadata 2020, 20, 185–217. [Google Scholar] [CrossRef]
- Shirmatov, S.T.; Akhmedova, G.M. Revolutionizing Language Learning with Smart Technologies. Excell. Int. Multi-Discip. J. Educ. (2994-9521) 2024, 2, 1165–1179. [Google Scholar]
- Nguyen, T.-C.-H.; Le-Nguyen, M.-K.; Le, D.-T.; Nguyen, V.-H.; Tôn, L.-P.; Nguyen-An, K. Improving web application firewalls with automatic language detection. SN Comput. Sci. 2022, 3, 446. [Google Scholar] [CrossRef]
- McFarland, D.J.; Wolpaw, J.R. EEG-based brain–computer interfaces. Curr. Opin. Biomed. Eng. 2017, 4, 194–200. [Google Scholar] [CrossRef] [PubMed]
- Rahman, M.M.; Sarkar, A.K.; Hossain, M.A.; Hossain, M.S.; Islam, M.R.; Hossain, M.B.; Quinn, J.M.W.; Moni, M.A. Recognition of human emotions using EEG signals: A review. Comput. Biol. Med. 2021, 136, 104696. [Google Scholar] [CrossRef] [PubMed]
- Dadebayev, D.; Goh, W.W.; Tan, E.X. EEG-based emotion recognition: Review of commercial EEG devices and machine learning techniques. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4385–4401. [Google Scholar] [CrossRef]
- Patel, U.K.; Anwar, A.; Saleem, S.; Malik, P.; Rasul, B.; Patel, K.; Yao, R.; Seshadri, A.; Yousufuddin, M.; Arumaithurai, K. Artificial intelligence as an emerging technology in the current care of neurological disorders. J. Neurol. 2021, 268, 1623–1642. [Google Scholar] [CrossRef]
- Saeidi, M.; Karwowski, W.; Farahani, F.V.; Fiok, K.; Taiar, R.; Hancock, P.A.; Al-Juaid, A. Neural decoding of EEG signals with machine learning: A systematic review. Brain Sci. 2021, 11, 1525. [Google Scholar] [CrossRef]
- Vempati, R.; Sharma, L.D. A systematic review on automated human emotion recognition using electroencephalogram signals and artificial intelligence. Results Eng. 2023, 18, 101027. [Google Scholar] [CrossRef]
- Górriz, J.M.; Ramírez, J.; Ortíz, A.; Martinez-Murcia, F.J.; Segovia, F.; Suckling, J.; Leming, M.; Zhang, Y.-D.; Álvarez-Sánchez, J.R.; Bologna, G. Artificial intelligence within the interplay between natural and artificial computation: Advances in data science, trends and applications. Neurocomputing 2020, 410, 237–270. [Google Scholar] [CrossRef]
- Fowler, R. Understanding Language: An Introduction to Linguistics; Routledge: London, UK, 2022. [Google Scholar]
- Ballard, K. The Frameworks of English: Introducing Language Structures; Bloomsbury Publishing: London, UK, 2022. [Google Scholar]
- Hollenstein, N.; Renggli, C.; Glaus, B.; Barrett, M.; Troendle, M.; Langer, N.; Zhang, C. Decoding EEG brain activity for multi-modal natural language processing. Front. Hum. Neurosci. 2021, 15, 659410. [Google Scholar] [CrossRef]
- Jolles, J.; Jolles, D.D. On neuroeducation: Why and how to improve neuroscientific literacy in educational professionals. Front. Psychol. 2021, 12, 752151. [Google Scholar] [CrossRef]
- Gkintoni, E.; Dimakos, I. An overview of cognitive neuroscience in education. In Proceedings of the EDULEARN22 Proceedings, Palma, Spain, 4–6 July 2022; pp. 5698–5707. [Google Scholar] [CrossRef]
- Kirik, S.; Dogan, S.; Baygin, M.; Barua, P.D.; Demir, C.F.; Keles, T.; Yildiz, A.M.; Baygin, N.; Tuncer, I.; Tuncer, T. FGPat18: Feynman graph pattern-based language detection model using EEG signals. Biomed. Signal Process. Control 2023, 85, 104927. [Google Scholar] [CrossRef]
- Sakthi, M.; Tewfik, A.; Chandrasekaran, B. Native language and stimuli signal prediction from eeg. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3902–3906. [Google Scholar]
- García-Salinas, J.S.; Villaseñor-Pineda, L.; Reyes-García, C.A.; Torres-García, A.A. Transfer learning in imagined speech EEG-based BCIs. Biomed. Signal Process. Control 2019, 50, 151–157. [Google Scholar] [CrossRef]
- Becerra, M.A.; Londoño-Delgado, E.; Botero-Henao, O.I.; Marín-Castrillón, D.; Mejia-Arboleda, C.; Peluffo-Ordóñez, D.H. Low Resolution Electroencephalographic-Signals-Driven Semantic Retrieval: Preliminary Results. In Bioinformatics and Biomedical Engineering: 7th International Work-Conference, IWBBIO 2019, Granada, Spain, 8–10 May 2019, Proceedings, Part II 7; Springer International Publishing: Cham, Switzerland, 2019; pp. 333–342. [Google Scholar]
- Vorontsova, D.; Menshikov, I.; Zubov, A.; Orlov, K.; Rikunov, P.; Zvereva, E.; Flitman, L.; Lanikin, A.; Sokolova, A.; Markov, S. Silent EEG-speech recognition using convolutional and recurrent neural network with 85% accuracy of 9 words classification. Sensors 2021, 21, 6744. [Google Scholar] [CrossRef]
- Bakhshali, M.A.; Khademi, M.; Ebrahimi-Moghadam, A.; Moghimi, S. EEG signal classification of imagined speech based on Riemannian distance of correntropy spectral density. Biomed. Signal Process. Control 2020, 59, 101899. [Google Scholar] [CrossRef]
- Sarmiento, L.C.; Villamizar, S.; López, O.; Collazos, A.C.; Sarmiento, J.; Rodríguez, J.B. Recognition of EEG signals from imagined vowels using deep learning methods. Sensors 2021, 21, 6503. [Google Scholar] [CrossRef] [PubMed]
- Dash, S.; Tripathy, R.K.; Panda, G.; Pachori, R.B. Automated recognition of imagined commands from EEG signals using multivariate fast and adaptive empirical mode decomposition based method. IEEE Sens. Lett. 2022, 6, 7000504. [Google Scholar] [CrossRef]
- Keles, T.; Yildiz, A.M.; Barua, P.D.; Dogan, S.; Baygin, M.; Tuncer, T.; Demir, C.F.; Ciaccio, E.J.; Acharya, U.R. A new one-dimensional testosterone pattern-based EEG sentence classification method. Eng. Appl. Artif. Intell. 2023, 119, 105722. [Google Scholar] [CrossRef]
- Barua, P.D.; Keles, T.; Dogan, S.; Baygin, M.; Tuncer, T.; Demir, C.F.; Fujita, H.; Tan, R.-S.; Ooi, C.P.; Acharya, U.R. Automated EEG sentence classification using novel dynamic-sized binary pattern and multilevel discrete wavelet transform techniques with TSEEG database. Biomed. Signal Process. Control 2023, 79, 104055. [Google Scholar] [CrossRef]
- Montaha, S.; Azam, S.; Rafid, A.R.H.; Islam, S.; Ghosh, P.; Jonkman, M. A shallow deep learning approach to classify skin cancer using down-scaling method to minimize time and space complexity. PLoS ONE 2022, 17, e0269826. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Dogan, S.; Baygin, M.; Tasci, B.; Loh, H.W.; Barua, P.D.; Tuncer, T.; Tan, R.-S.; Acharya, U.R. Primate brain pattern-based automated Alzheimer’s disease detection model using EEG signals. Cogn. Neurodynamics 2023, 17, 647–659. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Acharya, U.R. Automated accurate speech emotion recognition system using twine shuffle pattern and iterative neighborhood component analysis techniques. Knowl.-Based Syst. 2021, 211, 106547. [Google Scholar] [CrossRef]
- Zhu, E.; Wang, H.; Zhang, Y.; Zhang, K.; Liu, C. PHEE: Identifying influential nodes in social networks with a phased evaluation-enhanced search. Neurocomputing 2024, 572, 127195. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Tan, X.; Triggs, B. Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 2010, 19, 1635–1650. [Google Scholar] [PubMed]
- Dixit, A.; Thakur, M.K. RVM-MR image brain tumour classification using novel statistical feature extractor. Int. J. Inf. Technol. 2023, 15, 2395–2407. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Pławiak, P.; Acharya, U.R. Automated arrhythmia detection using novel hexadecimal local pattern and multilevel wavelet transform with ECG signals. Knowl.-Based Syst. 2019, 186, 104923. [Google Scholar] [CrossRef]
- Tasci, G.; Loh, H.W.; Barua, P.D.; Baygin, M.; Tasci, B.; Dogan, S.; Tuncer, T.; Palmer, E.E.; Tan, R.-S.; Acharya, U.R. Automated accurate detection of depression using twin Pascal’s triangles lattice pattern with EEG Signals. Knowl.-Based Syst. 2023, 260, 110190. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Aim | Dataset | Method | Result(s) (%) | XAI |
|---|---|---|---|---|---|
| Sakthi et al. [25] | Native language detection | 15 native English and 14 non-native Mandarin Chinese speakers | LSTM-based recurrent neural network | Acc. = 95.0 | No |
| Garcia-Salinas et al. [26] | Automatic Spanish word identification | 27 participants and 5 words | Bag of features, codebook and histogram generation, naïve Bayes | Acc. = 68.9 | No |
| Becerra et al. [27] | Automatic Spanish word identification | 3 participants and 36 words | Signal decomposition, discrete wavelet transform, linear and non-linear statistical measures, kNN | Acc. ≥ 95.0 | No |
| Vorontsova et al. [28] | Automatic Russian word identification | 268 participants and 8 words | Convolutional and recurrent neural network | Acc. = 84.5 | No |
| Bakhshali et al. [29] | Automatic word identification | 8 participants and 4 English words | Correntropy spectral density, Riemann distance, kNN | Acc. = 90.25 | No |
| Sarmiento et al. [30] | Automatic vowel identification | 50 participants and 5 vowels | Custom-designed CNN (CNNeeg1-1) | Acc. = 85.66 | No |
| Dash et al. [31] | Automatic word identification | 15 participants and 6 words | Multivariate fast and adaptive empirical mode decomposition, kNN | Acc. = 60.72 | No |
| Keles et al. [32] | Automatic Turkish sentence identification | 20 participants (Turkish and Nigerian volunteers) and 20 sentences (Turkish and English sentences) | Wavelet packet decomposition, TesPat, statistical feature extractor, NCA, kNN, IHMV | Acc. = 95.38 | No |
| Barua et al. [33] | Automatic Turkish sentence identification | 20 Turkish participants and 20 Turkish sentences | Multilevel discrete wavelet transform, dynamic-sized binary pattern, statistical feature extractor, NCA, kNN, SVM | Acc. = 95.25 | No |
| Method | Parameters |
|---|---|
| Channel transformer | Sorting function: descending, number of channels: 14, coding: indices. |
| Channel pattern | Length of overlapping block: 2, base: 14, feature generation function: histogram extraction, length of feature vector: 196. |
| INCA | Range of iteration: from 10 to 196, selection function: maximum accurate selected feature vector, the number of selected feature vectors: 187, loss function: kNN classifier with 10-fold cross-validation. |
| tkNN | k value: 1–10, weight: {equal, inverse, squared inverse}, distance: {Manhattan and Euclidean}, number of the generated prediction vectors: 60, validation: 10-fold cross-validation. IMV: Sorting function: accuracy by descending order, range: from 3 to 60, number of voted outcomes: 58. Greedy: Selection outcome with maximum accuracy from the generated 118 outcomes. |
| Performance Evaluation Metric | Class | Result (%) |
|---|---|---|
| Classification accuracy | Arabic | - |
| Turkish | - | |
| Overall | 98.59 | |
| Sensitivity | Arabic | 98.55 |
| Turkish | 98.63 | |
| Overall | 98.59 | |
| Specificity | Arabic | 98.63 |
| Turkish | 98.55 | |
| Overall | 98.59 | |
| Precision | Arabic | 98.48 |
| Turkish | 98.69 | |
| Overall | 98.59 | |
| F1-score | Arabic | 98.52 |
| Turkish | 98.66 | |
| Overall | 98.59 | |
| Geometric mean | Arabic | - |
| Turkish | - | |
| Overall | 98.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tuncer, T.; Dogan, S.; Tasci, I.; Baygin, M.; Barua, P.D.; Acharya, U.R. Lobish: Symbolic Language for Interpreting Electroencephalogram Signals in Language Detection Using Channel-Based Transformation and Pattern. Diagnostics 2024, 14, 1987. https://doi.org/10.3390/diagnostics14171987
Tuncer T, Dogan S, Tasci I, Baygin M, Barua PD, Acharya UR. Lobish: Symbolic Language for Interpreting Electroencephalogram Signals in Language Detection Using Channel-Based Transformation and Pattern. Diagnostics. 2024; 14(17):1987. https://doi.org/10.3390/diagnostics14171987
Chicago/Turabian StyleTuncer, Turker, Sengul Dogan, Irem Tasci, Mehmet Baygin, Prabal Datta Barua, and U. Rajendra Acharya. 2024. "Lobish: Symbolic Language for Interpreting Electroencephalogram Signals in Language Detection Using Channel-Based Transformation and Pattern" Diagnostics 14, no. 17: 1987. https://doi.org/10.3390/diagnostics14171987
APA StyleTuncer, T., Dogan, S., Tasci, I., Baygin, M., Barua, P. D., & Acharya, U. R. (2024). Lobish: Symbolic Language for Interpreting Electroencephalogram Signals in Language Detection Using Channel-Based Transformation and Pattern. Diagnostics, 14(17), 1987. https://doi.org/10.3390/diagnostics14171987