Abstract
Background: Lung cancer remains a significant health concern, and the effectiveness of early detection significantly enhances patient survival rates. Identifying lung tumors with high precision is a challenge due to the complex nature of tumor structures and the surrounding lung tissues. Methods: To address these hurdles, this paper presents an innovative three-step approach that leverages Generative Adversarial Networks (GAN), Long Short-Term Memory (LSTM), and VGG16 algorithms for the accurate reconstruction of three-dimensional (3D) lung tumor images. The first challenge we address is the accurate segmentation of lung tissues from CT images, a task complicated by the overwhelming presence of non-lung pixels, which can lead to classifier imbalance. Our solution employs a GAN model trained with a reinforcement learning (RL)-based algorithm to mitigate this imbalance and enhance segmentation accuracy. The second challenge involves precisely detecting tumors within the segmented lung regions. We introduce a second GAN model with a novel loss function that significantly improves tumor detection accuracy. Following successful segmentation and tumor detection, the VGG16 algorithm is utilized for feature extraction, preparing the data for the final 3D reconstruction. These features are then processed through an LSTM network and converted into a format suitable for the reconstructive GAN. This GAN, equipped with dilated convolution layers in its discriminator, captures extensive contextual information, enabling the accurate reconstruction of the tumor’s 3D structure. Results: The effectiveness of our method is demonstrated through rigorous evaluation against established techniques using the LIDC-IDRI dataset and standard performance metrics, showcasing its superior performance and potential for enhancing early lung cancer detection. Conclusions:This study highlights the benefits of combining GANs, LSTM, and VGG16 into a unified framework. This approach significantly improves the accuracy of detecting and reconstructing lung tumors, promising to enhance diagnostic methods and patient results in lung cancer treatment.
1. Introduction
Lung cancer stands as a critical global health challenge, marking it as one of the deadliest cancers that claim the lives of millions worldwide annually, regardless of gender. For example, there were about 2.09 million new cases in 2018, leading to nearly 1.76 million deaths [1]. Detecting the disease early can substantially improve the chances of survival. However, despite the availability of sophisticated imaging tools such as CT scans, X-rays, and magnetic resonance imaging (MRI), inherent limitations hinder their effectiveness. CT scans offer detailed three-dimensional views of lung tissue; however, their high rates of false positives can lead to unnecessary biopsies and surgeries [2]. Although X-rays are commonly used for initial screenings, they lack the sensitivity to detect early-stage tumors and struggle to differentiate between benign and malignant nodules. MRIs deliver excellent contrast in soft tissues, yet their use in lung imaging is limited due to the lungs’ high air content and motion during breathing [3].
Integrating deep learning in medical imaging presents a promising frontier for overcoming these challenges. Deep learning models, trained on extensively annotated image datasets, have demonstrated remarkable capabilities in identifying subtle patterns that elude human radiologists and traditional machine learning models. These models can enhance the specificity and sensitivity of lung cancer detection, reduce the rate of false positives, and potentially decrease the need for invasive diagnostic procedures. In this article, we present a sophisticated deep-learning model tailored to construct the 3D structures of lung tumors accurately. This model leverages deep learning’s strengths to surpass the limitations of existing imaging technologies. The 3D lung tumor reconstruction process unfolds in three primary steps: lung segmentation, tumor identification and extraction, and reconstructing the tumor’s 3D shape using sequential images. This methodology sharpens the clarity of the tumor’s spatial configuration and provides crucial information that aids effective medical decision-making and treatment planning [4]. Through this research, we aim to showcase the application of deep learning in medical imaging and its potential to transform early detection and treatment.
A variety of methods have been developed for lung segmentation, which includes the use of hand-selected features and the careful tuning of experimental parameters [5]. However, these methods are often explicitly tailored for particular applications and datasets, limiting their generalizability, especially in medical imaging data like CT scans. This limitation is further exacerbated by the tendency to overlook certain features during the feature selection phase [6,7], as practitioners often skip detailed feature selection in favor of more intuitive interactive methods. Traditional machine learning approaches typically adopt a two-step process, beginning with feature selection and then applying a learning algorithm to build an automated system. Initially, experts choose or develop a method specifically for feature selection tailored to the task at hand [8]. In contrast, deep learning models integrate feature selection with the learning process, eliminating the need for separate feature selection algorithms [9,10,11,12]. Deep learning has been particularly effective in lung segmentation, focusing on classifying each pixel as either lung tissue or not. However, this pixel-wise classification approach is challenged by class imbalance, as the number of non-lung pixels significantly outnumbers lung pixels.
To address the class imbalance issue, strategies are employed at both the data handling and algorithmic levels [13,14]. Regarding data handling, techniques include downsampling the overrepresented classes, upsampling the underrepresented classes, or generating synthetic data to balance the dataset. At the algorithmic level, efforts focus on adjusting algorithms to recognize better and weigh the contributions of the less represented classes, which is essential for accurate predictions [15]. The primary problem with data-driven methods lies in their potential to reflect and amplify existing biases in the data, leading to a preference for more common outcomes and overlooking rare but essential cases [16]. From an algorithmic standpoint, the challenge is to adapt learning models to capture these vital, albeit infrequent, phenomena, thereby improving the accuracy and reliability of the model. The advent of RL has garnered considerable attention for its capability to address complex challenges, especially in scenarios marked by class imbalances [17]. RL enhances the efficacy of classification models by filtering out irrelevant details and emphasizing crucial features, demonstrating versatility across various domains. A notable strength of RL is its adaptive learning approach, guided by reward mechanisms, which is particularly effective in managing data imbalance issues [18]. By tailoring the reward system to prioritize accurately identifying underrepresented classes, RL strategies can focus more on these often-neglected segments. This method promotes a more equitable distribution of attention across different courses, significantly improving detection accuracy [19].
The 3D reconstruction from CT images has been thoroughly explored, significantly relying on statistical methodologies [20,21,22]. While these approaches offer considerable value, they encounter several notable limitations. One of the primary challenges is the dependency on extensive annotated datasets, which are notably difficult to obtain in medical imaging due to stringent privacy regulations and the necessity for annotations by medical experts. Additionally, these methods have a heightened risk of overfitting, compromising their ability to be applied effectively across varied medical datasets [23]. The assumptions made about data distribution in statistical methods may only sometimes align with the realities of complex medical environments, potentially leading to reconstruction inaccuracies [24]. The inherently high dimensionality of medical imaging data also presents computational hurdles, often requiring dimensionality reduction techniques that risk excluding crucial information. Moreover, statistical approaches may need help to accurately represent the intricate spatial relationships and textures, which is essential for precise 3D reconstructions in medical imaging [25].
GANs [26] present a transformative approach to overcoming the limitations inherent to traditional statistical methods for the 3D reconstruction of CT images, leveraging their distinctive architecture and learning paradigms. Central to the GAN framework is the symbiotic relationship between two deep neural networks: the generator and the discriminator [27]. The role of the generator is to create synthetic yet plausible data that mimic real CT images, whereas the discriminator evaluates these generated samples, striving to differentiate between the authentic and the synthetic [28]. This adversarial dynamic fosters a continuous learning cycle, driving both networks toward higher performance levels. The generator learns to produce increasingly realistic images, refining details to deceive the discriminator, while the discriminator enhances its ability to detect the subtleties that distinguish real images from fakes. This process generates high-quality, realistic 3D reconstructions that can be difficult to differentiate from actual CT scans.
This study presents an innovative triple-layered methodology for generating three-dimensional models of lung cancer from CT scans. The process begins with segmenting the CT images using a GAN incorporating the U-net architecture, enabling precise pixel-level analysis. To tackle the class imbalance issue, we utilize an RL algorithm that prefers less represented classes, enhancing the sensitivity of the model to rarer but crucial features. The discriminator network, equipped with dilated convolution layers, improves the quality of the generator’s output by effectively differentiating between authentic and synthesized images and emphasizing key features. In the subsequent phase, we employ another GAN setup with the Mask R-CNN framework, which accurately identifies and localizes affected regions within the segmented images, thereby facilitating precise tumor detection and classification. To further refine the accuracy of these identified areas, an error correction component is integrated into the generator’s loss function, and the discriminator continues to use dilated convolution layers for high-quality output validation. The final stage of the process involves 3D modeling, where LSTM networks combined with GAN technology play a pivotal role. Here, features extracted from two-dimensional pulmonary scans by a trained VGG16 network are further processed by an LSTM network, which employs an attention mechanism to highlight critical tumor-related features. The generator then creates a three-dimensional representation based on the output of the LSTM. At the same time, the discriminator evaluates the fidelity of these 3D models against real images, ensuring the reconstructed models closely mirror actual lung structures. The efficacy of our method is validated through comprehensive testing, benchmarked against well-established approaches using the LIDC-IDRI dataset [29] and conventional performance metrics. This comparison highlights our method’s superior capabilities and promising potential to improve the early detection of lung cancer.
The proposed model in this study offers several significant contributions to the field of medical imaging, specifically in the 3D reconstruction of lung cancer from CT scans:
- Addressing class imbalance with RL: Traditional methods for lung segmentation often need help with class imbalance, where certain lung conditions are significantly underrepresented in training datasets. Our approach integrates RL to target this issue specifically. Using RL, the model dynamically adjusts its focus towards these less-represented classes during training, enhancing its sensitivity and specificity in these areas. This targeted focus mitigates the class imbalance problem and improves the model’s generalization capabilities across diverse patient datasets.
- Innovative reward mechanism in RL for enhanced lung segmentation: We have developed an innovative reward mechanism within our RL strategy tailored for lung segmentation. This mechanism provides a higher reward for correctly identifying typically underrepresented classes. This approach ensures that the model pays greater attention to these infrequent classes, promoting a more equitable and balanced segmentation process.
- Utilization of dilated convolution in discriminator network: Our model incorporates a discriminator network that employs dilated convolution layers. This architectural choice allows the network to expand its receptive field without losing resolution, enabling it to better differentiate between real and synthesized images. The ability to focus on more extensive and critical features significantly improves the reconstructed images’ visual clarity and detail resolution.
- Error correction in generator’s loss function for tumor detection: We have integrated an error correction component into the loss function of our generator during the tumor detection phase. This component is specifically designed to fine-tune the detection accuracy and minimize potential errors in the output. By implementing this correction process, the model enhances its reliability and ensures high precision in tumor detection.
2. Related Work
The literature review is divided into three sections: lung segmentation, tumor detection, and 3D tumor reconstruction.
2.1. Lung Segmentation
Hasan et al. [30] delve into deep learning applications for diagnosing diseases such as COVID-19 and tuberculosis by analyzing pulmonary X-rays, explicitly employing the deeplabv3plus CNN-based semantic segmentation model that utilizes “Atrous Convolution” to preserve feature resolution in deeper layers of the network. Swaminathan et al. [31] tackle the pressing issue of diagnosing lung cancer at advanced stages by employing deep learning to improve early detection rates, particularly in high-risk individuals. Their methodology involves initial preprocessing of CT images with the Wiener filter, followed by segmentation using a GAN trained with the Salp Shuffled Shepherd Optimization Algorithm (SSSOA), and subsequent classification via the VGG16 CNN model. Gite et al. [32] present an innovative approach to lung segmentation in X-ray images using U-Net++, aiming to boost tuberculosis detection rates. This novel method surpasses traditional techniques and mitigates data leakage problems, significantly enhancing diagnostic precision. Irawan et al. [33] unveil a modified U-Net architecture tailored for semantic lung segmentation from chest X-rays, integrating multiple dropouts in deconvolutional layers to avoid overfitting, thereby ensuring high accuracy and model generalization with a streamlined framework. Rehman et al. [34] validate the U-Net framework’s capability in segmenting lung areas from X-ray images, attaining a notable average Intersection over Union (IoU) score of 92.82. Shaoyong Guo et al. [35] introduce a sophisticated automated segmentation method that merges radionics with manually selected and algorithmically derived features, achieving a Dice similarity index of 89.42% on the ILD database MedGIFT. Chen Zhou et al. [36] develop an advanced automatic segmentation system that incorporates a 3D V-Net and a Spatial Transform Network (STN) to accurately segment lung tissue in CT scans, facilitating the diagnosis of COVID-19 by examining textures and other critical features. Mizuho Nishio et al. [37] utilize a U-Net framework optimized through Bayesian methods on datasets from Japan and Montgomery, securing high Dice Similarity Coefficients (DSC) of 0.976 and 0.973, respectively. Ferreira et al. [38] propose a unique U-Net variant designed for the automated detection of COVID-19 infections in CT scans, validated on actual patient data from Pedro Ernesto University Hospital in Rio de Janeiro. Feidao Cao [39] enhances the conventional U-Net structure by incorporating a Variational Auto-Encoder (VAE) in each encoder–decoder layer, markedly improving the network’s feature extraction efficiency. This advanced network is evaluated using NIH and JRST datasets, demonstrating exceptional accuracy and F1 scores of 0.9701 and 0.9334 for the former and 0.9750 and 0.9578 for the latter, respectively.
Many current lung segmentation techniques involve classifying each pixel as either lung tissue or not, which presents a challenge due to class imbalance; the overwhelming majority of pixels represent non-lung tissue. Acknowledging this issue, our paper introduces an RL-based innovative approach to lung segmentation that circumvents the problem of unbalanced classification.
2.2. Tumor Detection
Vijh et al. [40] introduced a hybrid bio-inspired algorithm named WOA_APSO, which merges the whale optimization algorithm (WOA) with adaptive particle swarm optimization (APSO) to refine feature selection in a CNN for lung CT image classification, thereby improving tumor detection accuracy. Rathod et al. [41] developed DLCTLungDetectNet, a deep learning framework that employs a CNN with FusionNet, integrating features from ResNet50 and InceptionV3, to enhance early lung cancer detection in CT scans. Their model outperforms traditional architectures like VGG16 and Inception v3, setting a new standard in automated lung tumor detection. Venkatesh et al. [42] proposed a novel method for early lung cancer detection in CT images using patch processing and deep learning to classify tumors efficiently, aiming for accurate detection with less computational time and improved performance metrics. Sundarrajan et al. [43] introduced an advanced lung tumor detection approach leveraging cloud-based IoT for data collection and employing an optimized fuzzy C-means neural network (OFCMNN) for segmentation, followed by classification with a kernel multilayer deep transfer convolutional learning (KM-DTCL) ensemble to provide superior diagnostic performance. Srinivasulu et al. [44] developed a deep learning model, ECNN-ERNN with autoencoders, for early detection of lung malignancies in CT images, utilizing a modified framework to achieve high accuracy and insightful feature extraction. Manickavasagam et al. [45] proposed CNN-5CL. This novel deep learning methodology uses an 11-layer CNN, including five convolutional layers, for precise pulmonary nodule classification in CT images, benchmarked with LIDC/IDRI datasets. Agarwal et al. [46] introduced a method that combines a CNN with the AlexNet Network Model for early lung tumor classification, distinguishing malignant from benign tumors with greater accuracy and addressing the challenge of premature lung cancer diagnosis. Li and Fan [47] unveiled a 3D CNN-based pulmonary nodule detection model featuring an encoder–decoder architecture, a dynamically scaled cross-entropy method for reducing false positives, and a squeeze-and-excitation structure to capitalize on channel dependencies.
2.3. Three-Dimensional Tumor Reconstruction
Recent advancements in the medical field have led to the development of 3D models, significantly enhancing patient treatment strategies [48,49]. A prime example of this application is in liver resection surgeries, where 3D models are crucial in providing surgeons with a detailed understanding of liver anatomy [50]. Furthermore, the creation of 3D brain models using magnetic resonance imaging (MRI) has been investigated [51]. The predominant emphasis in current research revolves around the 3D reconstruction of lung tumors [52,53]. Afshar et al. [21] proposed a method for segmenting lung cancer tumors and reconstructing 3D CT images. Their approach used snake optimization for lung segmentation, Gustafson and Kessel (GK) clustering [54] for tumor detection, and a statistical technique for 3D reconstruction. Hong et al. [22], and Rezaei et al. [55] employed a similar method for lung and tumor detection but with including a GAN-based approach for reconstructing 3D images. However, the accuracy of snake optimization heavily relies on the initial positioning of the contour [56]. If the initial contour placement is correct or deviates from the actual lung boundaries, it can lead to accurate segmentation results. Snake optimization may face challenges when segmenting complex lung structures, such as irregular shapes, nodules, or lesions, as these variations can make it difficult for the contour to adapt and accurately capture their boundaries. Similarly, GK clustering, like other clustering algorithms, is sensitive to the initial selection of cluster centroids. Choosing appropriate initial centroids is crucial to obtain accurate tumor detection. Poorly chosen centroids can cause suboptimal clustering outcomes. GK clustering may also struggle to handle cases where tumors overlap or exhibit heterogeneous characteristics, making it challenging to differentiate between different tumor regions and assign data points accurately to their respective clusters [52].
3. The Proposed Model
Figure 1 illustrates the overall structure of the proposed model, which encompasses three key steps: lung segmentation, tumor detection, and 3D tumor reconstruction. In the subsequent sections, we will discuss each step, elaborating on their functionalities and processes.
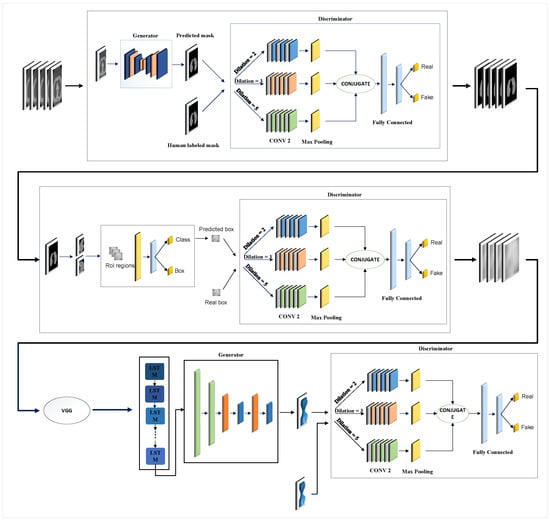
Figure 1.
Overview of the proposed model: In step 1, two lungs are segmented in CT images using the GAN-based model. In step 2, the tumor is detected using the second GAN-based model. After the features are extracted by VGG16, a 3D model of the tumor is reconstructed using the third GAN in step 3.
3.1. Lung Segmentation
The primary objective of segmentation in medical imaging is to produce precise lung outlines that closely mirror the reference or original outline. These outlines are pivotal for many medical uses and further examinations by accurately defining the edges of the lungs. To achieve this, we utilize a duo of neural networks: a generator (G) and a discriminator (D). G is crucial in crafting lung outlines, taking black-and-white CT scans as input. Through its complex structure, G is adept at identifying significant features and patterns within the images, creating outlines that suggest the areas of the lungs. These outlines endeavor to accurately capture the complex shapes and perimeters of the lungs, which is crucial for detailed segmentation. Conversely, D collaborates with G to boost the precision and quality of these outlines. Acting as a rigorous assessor, D examines how closely the created outlines match the reference or original outlines. Utilizing sophisticated methods like the Earth Mover’s (EM) distance, D measures the variance between the predicted and the reference outlines, enhancing G’s output. This motivates G to produce outlines that align with the original, improving the segmentation outcomes. During the training phase, G is fed a lung CT scan image, referred to as , and generates a corresponding outline that highlights the areas of the lungs. D then scrutinizes the created outline for its fidelity and quality, offering critical feedback that aids G’s learning and advancement. This dynamic interaction between G and D, coupled with reference outlines, aids in continuously enhancing the lung outlines generated through the training. In the forthcoming sections, we will explore the intricacies of G and D’s designs, elucidating their structure and functionalities. We will also discuss the loss function utilized during training, which is significant in steering the networks toward yielding more precise and dependable lung segmentation.
3.1.1. Generator Architecture
In our context, segmentation is treated as a task where each pixel in an image is classified as either part of the lung area or not. To perform this task, we rely on the precision of a U-Net-based generator network, as depicted in Figure 2. When processing a CT scan labeled , the generator network (G) meticulously evaluates each pixel to determine its association with the lung region, subsequently generating a mask that accurately reflects this classification. The generator network has two principal components: the encoder and the decoder. The encoder, in its complex task, begins by taking the input image and, through a series of convolution layers, extracts features at multiple scales. These layers enable the encoder to delve into the image, capturing a broad range of details and complex information from the image. Following the feature extraction, the decoder, playing a pivotal role, uses these multi-level features to construct the masks. By leveraging these features, the decoder can accurately reconstruct the intricate structures and contours of the lung area, resulting in detailed and precise masks. Both the encoder and decoder sections include convolution layers, which are crucial in neural network designs for identifying local patterns and spatial correlations, and are key elements for accurate segmentation.
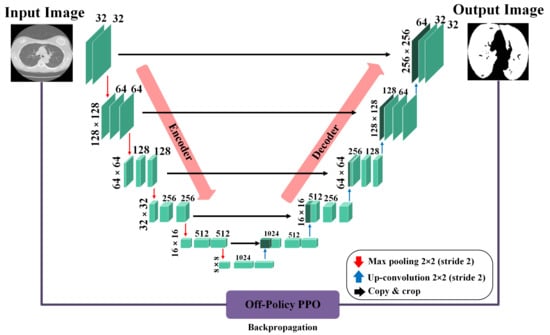
Figure 2.
Architecture of the U-Ne-based generator network used for lung segmentation, illustrating the flow from input CT scan through the encoder and decoder stages to the final mask output.
The generator network is designed as a binary pixel classifier, identifying each pixel as either part of the lung area (labeled as one) or not (labeled as zero). A significant challenge arises due to the overwhelming number of pixels labeled as zero, which is not associated with the lung area and leads to an imbalance. This imbalance causes the classifier to lean towards predicting pixels as non-lung areas, which can drastically reduce the model’s ability to delineate the lung region accurately. To counteract this issue, the training strategy for the generator incorporates an RL algorithm. RL is based on reward and punishment mechanisms, making it an ideal solution for addressing the problem of imbalanced classification. Within this framework, the RL algorithm is customized to assign much higher rewards for accurately identifying pixels within the minority class (the lung region) than those for correctly classifying pixels in the majority class (non-lung area). Conversely, the penalties for incorrectly classifying lung region pixels are more stringent than errors made within the majority class. Despite their scarcity, this strategy shifts the model’s focus towards more accurately recognizing and classifying pixels within the lung region. By amplifying the consequences for the minority class, the RL algorithm motivates the generator network to concentrate more on lung areas, thus mitigating the bias towards the more prevalent non-lung pixels. This adjustment not only equalizes the classifier’s attentiveness to both classes but also significantly boosts the model’s precision and effectiveness in segmenting lung regions from CT scans.
The loss function for the generator is defined as follows [57]:
where and represent the parameters of the generator before and after training, respectively. is the learning rate, while T is a terminal time step. signifies the gradient with respect to the generator parameters. is the logarithm of the policy defined by the generator parameters, which gives the probability of taking action in state . represents the average reward received at time t, calculated across all pixels, where is defined as follows [58]:
where and represent the minority (lung) and majority (no lung) classes, respectively. Correctly/incorrectly classifying a sample from the majority class yields a reward of , where . The pseudocode for our proposed method is outlined in Algorithm 1.
| Algorithm 1 Pseudocode of RL-based model for lung segmentation. |
|
3.1.2. Discriminator Architecture
The discriminator network plays a pivotal role in differentiating between the masks created by the generator and the genuine masks. The Earth Mover’s (EM) distance is used as an effective and smooth measure to gauge the difference between the true and generated mask distributions. The discriminator approximates the EM distance by evaluating the gap in expected values between samples from the model’s distribution and the actual distribution . This is conducted by analyzing the differences in the outputs from and . Unlike the conventional discriminator in a Generative Adversarial Network (GAN), which is typically tasked with classification, our discriminator assumes a regression function. Its goal is to approximate the EM distance function precisely. In tasks like image generation with GANs, the aim is often to create images that closely mimic real ones. However, in lung segmentation, the challenge is different. The mask generated by the generator varies in intensity across a continuum from 0 to 1, in contrast to the mask, which is strictly binary, consisting entirely of 0 s and 1s. This difference could cause the discriminator to focus too narrowly on distinguishing between real and generated masks, possibly missing other important aspects. To avoid this, we do not directly input the generator’s output or the real masks into the discriminator. Instead, we use a modified approach where the discriminator’s input includes lung slice images. These images are altered versions of the original CT scans, modified using segmented and actual masks. This technique allows the discriminator to evaluate the relationship between the generated masks and the original lung images, thus improving its ability to distinguish between real and generated masks accurately. Additionally, a segmentation mask is used as extra information to help maintain the nodule regions in the original image. This different mask selectively retains nodule areas while setting the rest to 0. With this additional detail, the discriminator can better identify important features, enhancing its ability to differentiate effectively. The loss function for the discriminator is articulated using the subsequent equation:
Here, the symbol o represents an operator that performs pixel-wise multiplication.
3.2. Tumor Detection
Figure 1 illustrates the critical component of our research, the generator network, which employs a Mask R-CNN framework. Moving away from the traditional approach of GANs that typically use random noise to create synthetic outputs, our model adopts a more strategic method. Specifically, it utilizes detailed lung data obtained from an earlier phase as its input rather than relying on random noise. This strategic choice of input allows our generator to capitalize on the comprehensive information within the lung data to craft precise and relevant outputs. The generator’s main objective is to deliver outputs that include detailed classification and location data. By processing the lung data, the generator can discern different regions within the lungs, assign appropriate class labels to these regions, and accurately determine their locations with bounding box coordinates. To steer the training of the generator and enhance its output accuracy, we introduce a specialized loss function, noted as Equation (4). This loss function evaluates the difference between the generator’s outputs and the actual verified data. By employing this loss function, our framework methodically improves the generator’s proficiency in producing precise classification and location details for the lung data it processes.
In this context, and are the loss components used within the Mask R-CNN framework, targeting the accuracy of class predictions and the precision of bounding box placements, respectively. Equation (5) introduces the adversarial loss component , which is instrumental in refining the performance of the generator.
Here, N is the mini-batch size, and represents the i-th bounding box prediction. The discriminator is critical in assessing the quality of bounding boxes proposed by the generator. However, evaluating the boxes based solely on their coordinates may not provide a thorough assessment. To overcome this, a method is suggested where feature maps for both authentic and generated boxes are presented together, allowing for a more nuanced evaluation of the bounding box quality. The discriminator’s loss function, as laid out in Equation (6), is crucial for its training. It integrates three Convolutional Neural Networks (CNNs) that collaborate to enhance the discriminator’s ability to differentiate between authentic and fabricated bounding boxes, thereby aiding overall training efficacy.
In this formulation, denotes the actual parameters for the i-th bounding box, while indicates the likelihood that the image is authentic. The adversarial loss incentivizes to create bounding boxes convincing enough to mislead .
3.3. The 3D Reconstruction Method
As Figure 1 shows, segmenting tumors results in N series of 2D slices. These slices undergo feature extraction using the VGG-16 network. The feature vectors from VGG-16 simplify the data by reducing their dimensionality, making them suitable for sequential analysis by the LSTM. This method enables the LSTM to effectively analyze the sequence of slices, which is crucial for accurate 3D tumor reconstruction while avoiding issues like overfitting and the high computational demands associated with processing large image dimensions directly. The outputs from VGG-16 feed into the LSTM, whose results are then employed by a GAN framework for further processing. The GAN framework is designed to create 3D images from the sequences of 2D slices. In this setup, the GAN discriminator differentiates between the images generated by its generator and real images.
4. Empirical Evaluation
In the upcoming section, we describe the dataset, detailing its features and scope as used in our study. This is followed by an explanation of the metrics, where we specify the criteria and measurements employed to assess our models’ performance. The section concludes with the presentation of results, highlighting the key findings from our analysis and model evaluations and discussing their significance in the context of our research objectives.
4.1. Dataset
The Lung Image Database Consortium image collection (LIDC-IDRI) [59] was developed through a collaboration between the Foundation for the National Institutes of Health (FNIH) and the Food and Drug Administration (FDA). This valuable dataset includes 1018 CT scans from 1010 individuals, each paired with an XML file. The XML file holds detailed annotations made by four experienced radiologists to meticulously identify and catalog every nodule visible in the scans. The annotation process is divided into two main phases to ensure thoroughness. In the first phase, known as the blinded-read phase, each radiologist independently reviews the scans to pinpoint lesions, marking those considered as “nodule < 3 mm” and “non-nodule ≥ 3 mm”. Following this, in the unblinded-read phase, they revisit their initial findings and consider their peers’ anonymous annotations. Within this dataset, a total of 7371 lesions were marked as nodules by at least one reviewing radiologist. Of these, 2669 lesions were unanimously classified as “nodule 3 mm” by all four radiologists, with 928 lesions consistently identified by every radiologist involved. These 2669 lesions were then subjected to detailed assessments, including intellectual nodule evaluations and the provision of precise nodule outlines. It is important to note that the original LIDC-IDRI dataset does not include 3D images. To bridge this gap, a meticulous manual process was employed using Rhinoceros 3D software, enabling the creation of 3D representations for these images. Rhinoceros 3D, version 8.0, developed by Robert McNeel, is sourced from Seattle, Washington, United States of America [60].
In addition to the details about the LIDC-IDRI dataset, it is important to outline the preprocessing steps to prepare the data for our analysis. Initially, DICOM images were converted into a more accessible format using the PyDicom library, a Python-based tool that facilitates seamless integration and manipulation within our analysis framework. Each CT scan underwent normalization to standardize pixel intensity values, enhancing data consistency for our machine-learning models.
To enhance the quality and reliability of the data used in training, we applied data augmentation techniques, including rotation, zoom, and horizontal flipping. These methods increased our model’s robustness against new, unseen data variations. Subsequently, each augmented image was resized to uniform dimensions, streamlining processing and ensuring consistency in the input to convolutional neural networks. Additionally, the annotations from the radiologists were precisely converted into mask images that accurately represent the locations of the nodules in the CT scans, providing a reliable ground truth for supervised learning. These crucial preparatory steps ensured that the dataset was optimally prepared for achieving high-performance results in our study.
4.2. Metrics
We employ Intersection over Union (IoU) and Hausdorff Distance (HD) to assess the novel lung segmentation and tumor detection models as our primary evaluation metrics. IoU is particularly apt for segmentation tasks as it quantitatively measures the overlap between the predicted segmentation and the ground truth. This metric highly indicates the accuracy of the model in delineating the boundaries of lung regions and tumors, providing a clear picture of how well the model can identify and segregate the target areas from the surrounding tissues. HD, on the other hand, is utilized to gauge the spatial discrepancy between the predicted and actual boundaries of the tumors. This metric is especially suitable for evaluating the precision of tumor detection models, as it reflects the maximum distance of any point on the predicted boundary from the nearest point on the actual boundary. The smaller the HD value, the closer the prediction of the model is to the true shape of the tumor, indicating a higher level of accuracy in capturing the tumor’s geometric nuances [52].
For the proposed 3D reconstruction model, we continue to use HD along with Euclidean Distance (ED). HD remains a crucial metric due to its effectiveness in measuring the geometric fidelity of the reconstructed tumor shapes compared to real tumors. It ensures that the reconstructed models closely mirror the tumor shapes, maintaining the integrity of critical geometric features. ED complements HD by offering a scalar representation of the straight-line distance between corresponding points on the predicted and true surfaces. This metric is particularly relevant for 3D reconstructions as it provides insight into the average positional accuracy across the entire reconstructed tumor volume. By assessing both the maximum and average deviations (through HD and ED, respectively), we can understand the performance of the model in replicating the complex 3D structures of tumors, ensuring the reconstructions are not only precise in shape but also accurate in spatial positioning.
IoU, HD, and ED metrics are defined as follows:
where A denotes the set of pixels in the ground truth mask, and B represents the pixels in the predicted mask.
where
In this context, A and B are the sets of non-zero pixels in the ground truth and predicted segmentation, respectively, and denotes the Euclidean distance between points a and b.
Here, and represent the coordinates of two points in the 3D space.
4.3. Main Results
To fine-tune parameters for lung delineation, lesion identification, and three-dimensional reconstruction methods, we employed stratified partitioning validation. This highly effective method ensures the resilience and transferability of our approach. This process involved dividing the dataset into equal parts and iterating the training cycle for each division, using one as the test set and the others for training. We conducted systematic experiments to isolate the impact of individual parameters by varying one at a time while keeping others constant. This approach allowed us to identify which parameters most significantly influenced the effectiveness of our methods.
Stratified partitioning validation ensured that each dataset split faithfully, and reflected the entire dataset’s overall variety and class proportions. This meticulous approach to dataset handling enhanced the model’s robustness by training it across a wide range of cases and minimized the potential for overfitting. By exposing the model to diverse yet statistically similar data subsets, we could consistently evaluate its performance across various scenarios. This method of repeated cycles of training and validation allowed us to incrementally refine our model, boosting its accuracy and dependability while preserving its generalization capabilities. Additionally, the stratified approach was crucial for detecting anomalies or biases in the dataset, enabling timely adjustments before the model’s finalization. Thus, this comprehensive validation strategy was pivotal in ensuring that our model delivered a strong performance on training and unseen data, effectively reducing the likelihood of overfitting.
The results of these parameter tuning exercises are summarized in Table 1. This table provides a detailed overview of the optimized parameters, outlining the ranges and specific values that achieved the highest efficacy during the testing phase.

Table 1.
Hyperparameters for lung segmentation, tumor detection, and 3D reconstruction models.
During the training of our GANs and LSTM network, addressing the challenge of local minima was crucial for robust performance. We implemented several strategies to mitigate this risk. Initially, we initialized the GAN models with weights from a truncated normal distribution to stabilize the early training phase and prevent skewed feature influence. We used the Adam optimizer, known for its ability to handle the decay of past gradients and navigate complex parameter spaces effectively, thus avoiding local minima. For the LSTM network, dropout layers were strategically included to prevent overfitting. These approaches, alongside continuous validation checks, ensured our models avoided local minima and maintained excellent generalization across new datasets.
4.3.1. Lung Segmentation
Our GAN-based model performs exceptionally precisely segmenting images, especially in accurately delineating lung regions against the surrounding anatomy. To evaluate its effectiveness, we conducted a detailed comparison with six cutting-edge models: Deeplabv3plus [30], U-Net [33], U-Net++ [32], LDDNet [61], LGAN [62], and 3D Res U-Net [63], with the comparative results encapsulated in Table 2. Within the range of models compared, Deeplabv3plus takes the lead with an IoU score of 0.798, indicating the highest degree of overlap between its predicted segmentation and the actual ground truth. Close contenders, U-Net and U-Net++, exhibit strong segmentation capabilities with IoU scores of 0.762 and 0.750, respectively. In contrast, LDDNet and LGAN show less precision in their segmentations, reflected in lower IoU scores of 0.662 and 0.632. However, when considering the Hausdorff Distance, LGAN and LDDNet outperform others with the lowest scores, suggesting that their segmentations are closer to the ground truth at their furthest point. Interestingly, 3D Res U-Net, despite its lower IoU, presents the highest HD score of 2.835, hinting at potential irregularities in its segmentation boundaries. Our proposed GAN-based model, however, marks a significant advancement with an IoU of 0.972, indicating a 21.8% improvement over the best-performing comparison model, and an HD score of 0.925, the lowest of the group, which translates to a 67.4% improvement from the highest HD score of the compared models. The comparison becomes even more striking when our model is evaluated against its variant without RL. The incorporation of RL has led to a notable IoU increase from 0.726 to 0.972, a leap of 33.9%, signifying a superior match with the ground truth. Similarly, the enhancement in HD from 1.205 to 0.925, a reduction of 23.2%, underscores the heightened accuracy of boundary detection with RL integration.
Table 2.
Performance metrics of the proposed algorithm and various deep learning algorithms for lung segmentation on the LIDC-IDRI dataset.
To ascertain the statistical significance of our proposed model’s superiority over existing models, we conducted paired t-tests on IoU and HD metrics. The tests yielded p-values such as 0.002 for IoU when comparing our model to Deeplabv3plus and 0.005 for HD when comparing to LGAN, indicating significant improvements. These results confirm the enhancements are significant and statistically robust, supporting the model’s superior performance. Additionally, the 95% confidence intervals, like those ranging from 0.15 to 0.21 for IoU differences with Deeplabv3plus, affirm these findings. This statistical evidence strongly validates the proposed model’s utility in clinical settings for more accurate and reliable lung segmentation.
Figure 3 displays three sets of images produced by the proposed lung segmentation model. The top row illustrates the original CT scans from patients, depicting cross-sectional images of the thoracic cavity. These scans provide a clear view of the lung structures, bones, and surrounding tissues, with radiodensity variations allowing these components’ differentiation. In the corresponding images of the bottom row, the results of the segmentation model are evident. Here, the lung regions have been delineated and filled in, starkly contrasting with the non-lung areas, which appear as black space. The segmentation model seems to have successfully extracted the lung regions from the CT images with high accuracy. In the first column, the model accurately identifies the lung boundaries and the separation between the left and right lungs. The second column shows a similarly precise segmentation, with the model correctly excluding the heart and the spine, which are centrally located in the thoracic cavity. In the third column, despite the more complex lung structures due to either a pathological condition or a scanning artifact, the model has managed to delineate the lung region, preserving the intricate details and the shape of the lungs.
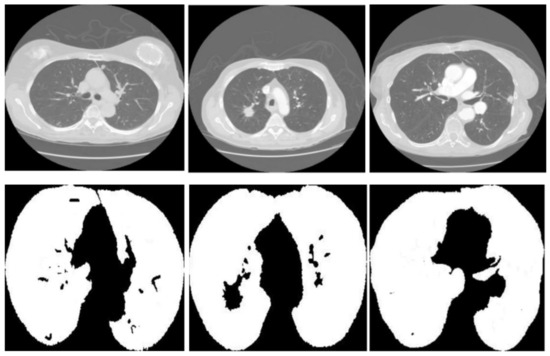
Figure 3.
Comparative visualization of original CT scans and segmented lung regions by the proposed model.
The reward structure of the lung segmentation model differentiates between accurate and inaccurate classifications, assigning values of ±1 and ± for the majority and minority classes, respectively. The optimal is tied to the class ratio and decreases as the majority-to-minority ratio increases. Performance was systematically evaluated over values ranging from 0 to 1 in 0.1 increments, with this assessment graphically represented in Figure 4a. As increases to about 0.4, both IoU and HD improve, indicating better accuracy for minority class predictions. However, beyond a of 0.4, performance declines, suggesting that too high a reward for the minority class may cause bias, leading to model overfitting or underfitting. The performance drop-off becomes significant as approaches 1, where the model heavily penalizes misclassifications of minority class samples, adversely affecting its generalization and accuracy.
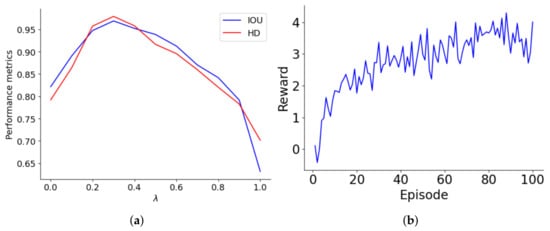
Figure 4.
(a) Optimization of the parameter for lung segmentation model performance, (b) learning trajectory of the reward optimization of the agent on 100 episodes.
Figure 4b illustrates the progression of the agent’s rewards over a series of episodes, highlighting its learning trajectory. Initially, the agent starts with a basic understanding, earning minimal rewards. As the episodes progress, there is a notable increase in rewards, especially between episodes 0 and 20, where the agent quickly learns essential rules and patterns. This phase shows a steep learning curve, transitioning from rudimentary knowledge to a more strategic approach. From episodes 20 to 60, rewards fluctuate but generally trend upwards, indicating the agent’s ongoing adaptation and refinement of strategies. After episode 60, reward variability stabilizes, with values consistently around 3 to 4, suggesting developing a reliable policy. This stability indicates well-established learning, although minor adjustments continue as the agent optimizes its strategies to meet evolving challenges and opportunities for further enhancement.
4.3.2. Tumor Detection
The proposed tumor detection model is compared with five models, DEHA-Net [64], DS-CMSF [65], DA-Net [66], R-CNN [67], PN-SAMPM [68], whose the results are shown Table 3. Within the competitive landscape, DEHA-Net sets a high standard with an IoU of 0.863, signifying a close match with the ground truth in tumor detection. DS-CMSF follows suit with an impressive IoU of 0.842. There is a notable drop in IoU for DA-Net, R-CNN, and PN-SAMPM, with scores of 0.790, 0.768, and 0.752, respectively. This descending trend might imply a diminishing accuracy in capturing the full extent of the tumors. Examining the precision of the tumor boundaries, DEHA-Net again takes the lead with the lowest HD of 0.726, which suggests that its predicted tumor edges are nearest to those in the actual medical images. The subsequent models, DS-CMSF, DA-Net, R-CNN, and PN-SAMPM, exhibit incrementally higher HD values, pointing to less precise boundary detections. The proposed model, however, outperforms all with an IoU of 0.901, surpassing DEHA-Net, the closest competitor, by 4.4%. This indicates that the proposed model detects the presence of tumors more accurately and provides a segmentation that significantly overlaps with the verified ground truth. Moreover, the proposed model achieves an HD of 0.625, an improvement of 13.9% over the best-performing existing model, DEHA-Net. This metric emphasizes the enhanced capability of the proposed model to delineate tumor boundaries with greater exactitude.
Table 3.
Performance metrics of various deep learning algorithms for tumor detection on the LIDC-IDRI dataset.
The statistical significance shows that the proposed model substantially outperforms existing models in tumor detection, with p-values < 0.05 indicating strong statistical significance. For instance, the proposed model’s IoU of 0.901 and HD of 0.625 compared favorably against the next best model, DEHA-Net, which recorded an IoU of 0.863 and HD of 0.726. The confidence intervals for these metrics further reinforce the superiority of the proposed model, illustrating robust improvements in both IoU and HD measures. These data substantiate the claim of our model’s superiority in precise tumor detection.
Figure 5 presents three pairs of images generated by the proposed tumor detection model, where the ground truth annotations are displayed in the top row, and the outputs of the model are shown in the bottom row. A collective analysis of these images suggests that the proposed model demonstrates a commendable level of precision in pinpointing the location of lung tumors. Across the set, the regions marked by the model align well with the ground truth indicators, denoted by squares. This alignment indicates that the model has successfully learned to identify the critical features of lung tumors from CT scans and can consistently distinguish tumor tissue from surrounding anatomical features.
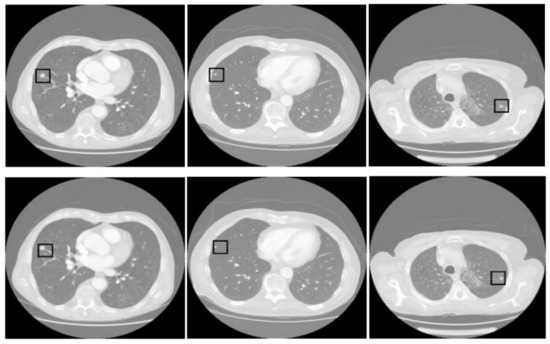
Figure 5.
Comparative analysis of tumor detection. The top row shows the ground truth, while the bottom row presents the model predictions. The black square in every sample shows the tumor extracted by the proposed model.
4.3.3. Three-Dimensional Reconstruction
In our examination of various 3D reconstruction models, we have conducted an in-depth analysis of six distinctive methods: YOLOv4 [20], GAN-LSTM-3D [22], GAN-GK-LSTM [55], GAN-ResNet-3D [52], ANN-GGO [53], alongside our proposed model. To further assess our model, we conducted ablation studies to evaluate the impact of various components: Proposed w/o VGG-16, Proposed w/o SP, Proposed with GANDA, and Proposed with AEDA. The Proposed w/o VGG-16 configuration eliminates the VGG-16 layer, allowing images to be fed directly into the LSTM. The Proposed w/o SP variant does not utilize stratified partitioning for hyperparameter tuning. Additionally, the Proposed with GANDA and Proposed with AEDA models incorporate GAN and autoencoder (AE) for data augmentation purposes. The evaluation results are shown in Table 4.
Table 4.
Performance metrics of the proposed model versus comparator models for lung tumor 3D reconstruction on the LIDC-IDRI dataset.
Within the existing models, YOLOv4 takes the lead, showcasing the lowest values for HD at 1.146 and Euclidean Distance (ED) at 1.236, which serve as indicators of reconstruction accuracy. GAN-LSTM-3D trails just behind, with only marginally higher metrics. A more noticeable increase in ED is seen with GAN-GK-LSTM, particularly its rise to 1.494, signifying a decrease in volumetric precision. GAN-ResNet-3D and ANN-GGO, on the other hand, report the highest HD and ED values, with ANN-GGO deviating most substantially from the actual tumor shapes, as reflected by its HD of 2.630 and ED of 2.023. This diverse performance spectrum suggests that while some models approach the accuracy of our proposed model, there is room for improvement. The proposed model establishes a new standard, exhibiting HD and ED values of 0.986 and 1.126, respectively, thereby eclipsing the performance of all comparator models. Relative to YOLOv4, the nearest rival, our model demonstrates an improvement of approximately 13.9% in HD and 8.9% in ED. The advancements are even more striking against ANN-GGO—the model with the least accuracy among those compared—where we observe improvement rates of 62.5% in HD and 44.3% in ED. This pronounced differentiation emphasizes the refined capability of our model to delineate the complex structures of lung tumors with impressive precision.
The Proposed w/o VGG-16 model showed a significant decrease in performance, where omitting VGG-16 and directly inputting images into LSTM led to increased HD and ED values of 1.342 and 1.438, respectively. This decrease highlights VGG-16’s essential role in extracting image features, which affects the model’s accuracy in 3D lung tumor reconstruction. VGG-16 crucially enhances the interpretation of complex medical images, which could be more effectively handled by the LSTM alone. Additionally, eliminating stratified partitioning from hyperparameter tuning resulted in minor performance reductions, with HD and ED values of 0.975 and 1.186, respectively. This reflects a slight decrease in performance, indicating that while stratified partitioning supports robust training through balanced class representation, its absence subtly affects precision but does not critically reduce overall model effectiveness. Incorporating GAN for data augmentation (Proposed with GANDA) resulted in HD and ED values close to the base model, at 0.983 and 1.132, demonstrating that GANs effectively replicate real data variations and support accurate tumor reconstruction. Conversely, using an autoencoder for data augmentation (Proposed with AEDA) resulted in HD and ED values of 1.035 and 1.205, decreasing performance. Although AEDA enhances data representation, it may not fully capture the critical nuances needed for optimal 3D tumor reconstruction.
The statistical significance shows that the proposed model significantly outperforms the comparator models regarding HD and ED, with p-values consistently below 0.05 across all comparisons. These low p-values confirm that the differences in performance metrics between the proposed and existing models are not due to random chance, indicating a genuine improvement in 3D tumor reconstruction. The robust statistical analysis supports the claim of superiority of the proposed model over traditional approaches.
Table 5 highlights the computational efficiency of various 3D reconstruction models, a critical factor for applications requiring rapid processing. It provides a comparative analysis of runtime and GPU usage, offering key insights for those in the medical imaging and 3D reconstruction fields. The table shows YOLOv4 as moderately efficient with a runtime of 2235 s, indicating a balance between complexity and speed. In contrast, GAN-ResNet-3D has a much higher runtime of 3895 s, suggesting it may not be ideal for time-sensitive applications due to its complex processing. On the GPU usage front, GAN-LSTM-3D uses 10.2 GB, indicating efficiency, while GAN-GK-LSTM, the highest at 15.6 GB, suggests greater complexity. Our proposed model has a balanced runtime of 2475 s and uses 10.7 GB of GPU. It shows a good trade-off between performance and resource usage, making it adaptable for various clinical settings, even those with limited computational resources.
Table 5.
Computational efficiency comparison of models.
Figure 6 presents a side-by-side comparison of the original 3D configurations of ten tumor samples against their digitally reconstructed counterparts. This juxtaposition underscores the complexities involved in replicating the seamless contours that characterize the true forms of the tumors. Traditional methods often falter at this juncture, unable to faithfully reproduce the smooth perimeters, which is crucial for precise reconstructions. However, our proposed method effectively navigates these common pitfalls. Employing advanced techniques and refined algorithms, it adeptly retains the smoothness of the tumor boundaries, thereby ensuring reconstructions that are both accurate and true to the original shapes. This achievement marks a substantial leap forward in 3D tumor imaging reconstruction.
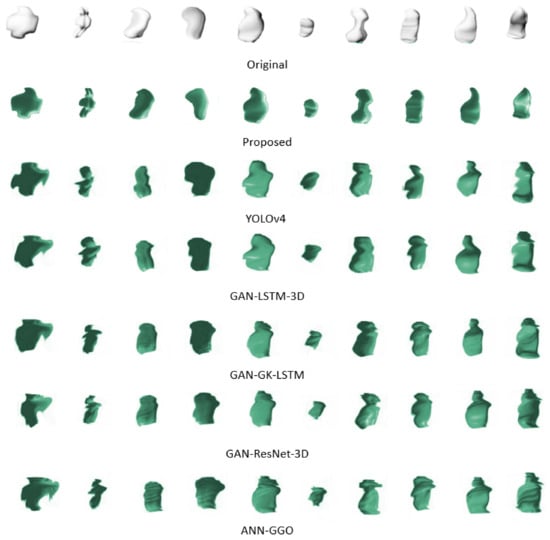
Figure 6.
Comparison of original and reconstructed 3D tumor shapes highlighting the effectiveness of the proposed reconstruction method in preserving boundary smoothness.
Our investigation into the performance of diverse pre-trained models on 3D lung tumor reconstruction has revealed significant variations in accuracy. The experiment encompassed models such as AlexNet, GoogleNet, ResNet, DenseNet, and MobileNet, with VGG-16 as the reference model. According to Table 6, the precision of VGG-16 emerges as the highest, evidenced by its lowest scores in both HD and ED. The contrast is striking when we compare the improvement in precision that VGG-16 offers to that of other models. The HD and ED of AlexNet are elevated by approximately 72.5% and 29%, respectively, over those of VGG-16, underscoring the enhanced capability of the latter to detail tumor contours precisely. As we progress through models from GoogleNet to MobileNet, there is a noticeable regression in precision. The HD and ED measurements of these models exceed those of VGG-16 by substantial margins, ranging from 88% to over 100% for HD and 59% to 104% for ED. This trend makes it clear that the sophistication of the architecture of a model does not inherently translate to superior performance in specialized tasks such as 3D tumor reconstruction. Most strikingly, MobileNet, which is optimized for efficiency on devices with limited computational power, shows more than a doubling of the HD and ED values compared to those of VGG-16, translating to a decline in performance by over 100%. These results illustrate the compromise between efficiency and precision, with the streamlined structure of MobileNet sacrificing the latter.
Table 6.
Performance of different pre-trained models for the reconstruction of 3D lung tumors.
Figure 7 presents the distribution of decision-making times for the proposed 3D reconstruction model utilized in real-time bidding (RTB) environments. The histogram illustrates decision-making times ranging from approximately 350 milliseconds (ms) to 650 ms. A noticeable concentration of decision times falls between 500 ms and 550 ms, signifying the modal interval where the model demonstrates optimal efficiency. The right-skewed distribution suggests that while most decision-making instances are grouped around the median range, fewer significantly prolonged decision times extend toward the upper limit of 650 ms. This skew indicates that the model occasionally experiences delays, possibly due to complex input data or computational constraints within the RTB system. Furthermore, the wide range of the distribution, covering a 300 ms interval, indicates a considerable variability in the model’s response times across different RTB scenarios. This variation could stem from inherent differences like the input data or the model’s computational process dynamics.
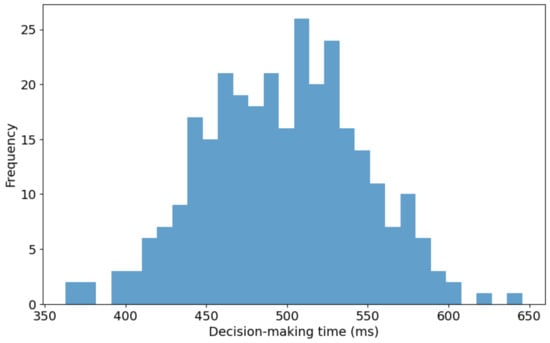
Figure 7.
Distribution of decision-making times for 3D reconstruction in RTB environments.
4.3.4. Analysis of Generalization
To rigorously assess the generalization capabilities of our proposed model, we conducted experiments on the LUng Nodule Analysis (LUNA16) dataset [55] and the Medical Imaging and Data Resource Center (MIDRC) [69], comparing lung segmentation, tumor detection, and 3D reconstruction performance against other models. The results for these categories are detailed in Table 7, Table 8 and Table 9 for both the LUNA16 and MIDRC datasets. For lung segmentation, our model significantly outperformed competitors such as Deeplabv3plus, U-Net, and U-Net++ on both datasets, achieving an IoU 22% higher than Deeplabv3plus on the LUNA16 dataset and 20% higher on the MIDRC dataset. Its HD was reduced by 41% on LUNA16 and 39% on MIDRC, demonstrating superior precision in segmenting lung tissues, which is critical for early detection and accurate medical assessments. In tumor detection, our model excelled on both datasets, outperforming advanced models like DEHA-Net and DS-CMSF with higher IoU and significantly lower HD. It improved IoU by approximately 4.5% over DEHA-Net on LUNA16 and by 4.3% on MIDRC, and it reduced HD by 14% on LUNA16 and 12% on MIDRC, showcasing its precise ability to delineate tumor boundaries. In 3D tumor reconstruction, our model was significantly superior, outperforming GAN-based approaches like GAN-LSTM-3D and GAN-GK-LSTM on both datasets. It improved HD by 21% compared to GAN-LSTM-3D on LUNA16, indicating highly accurate reproduction of 3D tumor structures, and by 20% on MIDRC. These findings consistently underscore our model’s ability to maintain a high performance across different datasets, affirming its strong generalization capability and suitability for deployment in diverse clinical environments.
Table 7.
Performance metrics of various deep learning algorithms for lung segmentation on the LUNA16 and MIDRC datasets.
Table 8.
Performance metrics of various deep learning algorithms for tumor detection on the LUNA16 and MIDRC datasets.
Table 9.
Performance metrics of the proposed model versus comparator models for lung tumor 3D reconstruction on the LUNA16 and MIDRC datasets.
4.3.5. Discussion
The proposed model in this article offers an innovative approach to lung cancer detection by leveraging GANs, LSTM networks, and RL algorithms to tackle significant challenges, including class imbalance. We meticulously executed experiments that underscored the superiority of our model compared to existing advanced technologies and conducted ablation studies to pinpoint the distinct contributions of each component. Table 10 provides a detailed comparative analysis between our method and other existing methods. Our findings reveal that the model excels in lung segmentation tasks, achieving high IoU and low HD, outperforming conventional models such as Deeplabv3plus, U-Net, and U-Net++. The integration of RL adapts the learning process dynamically, which is crucial for effectively managing the class imbalance prevalent in lung imaging datasets. This enhancement not only boosts the accuracy of lung segmentation but also extends the model’s utility across varied imaging scenarios. In tumor detection, the model’s innovative loss function within the GAN framework significantly refines its ability to delineate tumor boundaries, providing substantial improvements over high-performance models such as DEHA-Net and DS-CMSF. This capability is critical for detecting tumors with subtle and intricate imaging patterns. Furthermore, the advanced processing abilities of the LSTM networks significantly improve the model’s performance in the 3D reconstruction of lung tumors, facilitating the creation of detailed and accurate 3D tumor models crucial for effective treatment planning. This advancement represents a significant progression beyond traditional 3D techniques, including YOLOv4 and various GAN-based approaches. These results collectively validate our proposed model’s effectiveness and underscore its potential to transform existing lung cancer detection and treatment planning practices.
Table 10.
Comparative analysis of the proposed method against existing models.
Figure 8 provides a detailed depiction of the loss progression over 250 epochs for lung segmentation, tumor detection, and 3D reconstruction models. Each graph tracks the training and validation loss, shedding light on the dynamics of model learning and its stability over time. In lung segmentation, training, and validation, losses decrease swiftly during the early epochs before stabilizing, demonstrating effective learning with minimal risk of overfitting. The close alignment of training and validation losses throughout the process suggests that the model is well-calibrated and generalizes effectively to new data. For tumor detection, the loss initially plummets, followed by increased fluctuations in the validation loss as training progresses. This pattern may reflect the model’s sensitivity to specific tumor characteristics or variations in the validation data, underscoring potential areas for further optimization or the need for more diverse training examples. The 3D reconstruction model’s loss curve also trends downward steadily, albeit with noticeable volatility in the validation loss. This suggests difficulties in achieving convergence, potentially due to the complexities of processing 3D data or a lack of sufficient diversity in the training data. The frequent oscillations in the validation loss further imply challenges in handling anatomical variations that are not well-represented in the training dataset.
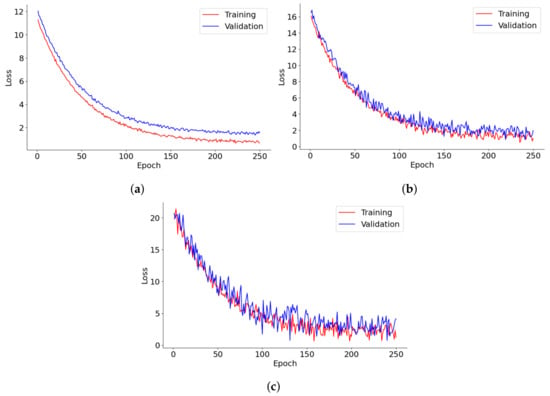
Figure 8.
Loss trends in (a) lung segmentation, (b) tumor detection, and (c) 3D reconstruction models over 250 epochs.
Figure 9 presents the performance trends across 250 epochs for models involved in lung segmentation, tumor detection, and 3D reconstruction utilizing the HD metric. The lung segmentation model shows a consistent reduction in HD throughout the 250 epochs, signaling a steady enhancement in the model’s precision in identifying lung boundaries relative to surrounding tissues. This improvement implies that the model is effectively learning from the training data and becoming increasingly adept at accurately distinguishing lung tissue over time. In contrast, the tumor detection curve demonstrates a sharper decline, especially in the initial epochs. This rapid improvement likely reflects the model’s sensitivity to changes in feature representation or adjustments to the learning rate, which are crucial for detecting smaller and irregularly shaped tumors. The pronounced steepness early in the training indicates that initial adjustments or learning of features significantly impact the model’s performance, with further refinement occurring in later epochs. Meanwhile, the 3D reconstruction process also exhibits a considerable reduction in HD, albeit slower than tumor detection. This slower rate of improvement may stem from the complexities involved in reconstructing three-dimensional structures from segmented images, necessitating more subtle learning and parameter adjustments. Nonetheless, the persistent downward trend indicates that the model is incrementally improving its ability to accurately reconstruct the 3D structures of lungs and tumors.
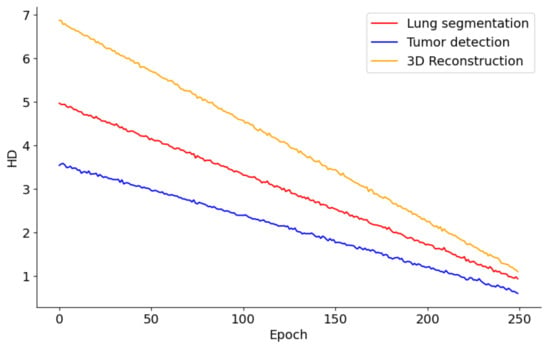
Figure 9.
HD metric trends in lung segmentation, tumor detection, and 3D reconstruction over 250 epochs.
The inclusion of GANs in our model is strategic, leveraging their powerful ability to generate realistic images by pitting two neural networks against each other: a generator that creates images and a discriminator that evaluates them. This dynamic setup enables the generator to produce increasingly accurate representations of the desired output, in this case, lung tissues and tumors. GANs are particularly suited for medical image analysis due to their proficiency in handling complex image data and learning detailed and nuanced representations crucial for accurate medical diagnoses. The adversarial training ensures that the generated images are realistic and consistent with the diverse range of appearances lung tumors can exhibit in CT scans. By employing GANs, our model benefits from their robust image generation capabilities, ensuring that the segmentation and reconstruction of lung tumors are both precise and reliable, which is vital for the early detection and treatment planning of lung cancer.
RL is a critical component of our model, particularly in training the GAN used for lung segmentation. The inclusion of RL is driven by its ability to handle the complex, dynamic environments typical of medical imaging data, especially when dealing with imbalanced datasets such as lung CT images, where non-lung pixels vastly outnumber lung pixels. RL operates on agents learning to make decisions by performing actions in an environment to achieve cumulative rewards. In our GAN model, the generator acts as an agent that receives feedback from the discriminator (environment), which assesses the generated lung segmentation against the real data. The RL approach allows the generator to learn more nuanced strategies for producing realistic segmentations, beyond mere imitation of the training data, by rewarding the generator for segmenting lung regions that challenge the discriminator to distinguish from real lung tissues. The decision to use RL in training the GAN model is motivated by the need to address the class imbalance problem effectively. Traditional training methods might lead the model to overlook minority classes (lung pixels) due to their lesser presence in the training data. RL addresses this by assigning higher rewards for correctly identifying lung pixels, encouraging the model to pay more attention to these critical areas. This method enhances the sensitivity of the model to lung regions, improving segmentation accuracy and, consequently, the reliability of subsequent tumor detection and 3D reconstruction.
The theoretical implications of our research are significant, marking a substantial advancement in medical imaging and automated disease diagnosis. By integrating state-of-the-art machine learning techniques such as GANs, LSTM networks, and the VGG16 algorithm, our model sets a new benchmark in lung tumor detection and 3D reconstruction. Using GANs for segmentation and reconstruction introduces an innovative approach that leverages their generative capabilities to produce highly accurate depictions of lung tumors. Furthermore, applying LSTM networks to process sequential CT scan data underscores the potential of recurrent neural networks in preserving and utilizing temporal information, which is essential for constructing accurate 3D tumor models. Incorporating the VGG16 algorithm enhances the ability of the model to extract detailed and relevant features from complex medical images, laying a solid foundation for the accurate segmentation and detection of lung tumors. This research contributes to improving lung cancer diagnostic processes. It provides a versatile framework that could be adapted for other types of cancer and diseases, showcasing these advanced machine-learning techniques’ broad applicability and impact in healthcare.
The limitations of the proposed model are as follows:
- Data diversity and availability: One of the main limitations of our model is its dependence on the availability and diversity of training data. Medical imaging datasets, especially those for lung cancer, can vary widely in terms of quality, resolution, and the types of imaging equipment used. This variability can affect the ability of the model to generalize across clinical settings and patient populations. To mitigate this limitation, we recommend expanding the training dataset with images from various sources, including hospitals and imaging centers, to cover a broader spectrum of cases and conditions. Additionally, advanced data augmentation techniques can artificially enhance the dataset, introducing variations that simulate different imaging conditions and tumor characteristics, thereby improving the robustness and generalizability of the model.
- Computational complexity: The sophisticated architecture of our model, comprising multiple deep learning components such as GANs and LSTM networks, necessitates substantial computational resources for training and inference. This requirement could limit the accessibility and practicality of the model, especially in resource-constrained environments. To address this challenge, model optimization techniques such as network pruning, quantization, and knowledge distillation can be explored to reduce the model’s computational footprint without significantly compromising its performance. Additionally, adopting cloud computing and specialized hardware accelerators like GPUs and TPUs can offer scalable and cost-effective solutions for deploying the model in diverse clinical settings.
- Interpretability and explainability: The black-box nature of deep learning models, including ours, poses a challenge in clinical applications where understanding the rationale behind diagnostic predictions is crucial. Enhancing the interpretability of the model can foster trust among clinicians and patients by providing insights into the decision-making process. Techniques such as attention mechanisms, which highlight the regions of the image most influential in the predictions of the model, and model-agnostic explanation methods like LIME (Local Interpretable Model-agnostic Explanations) and SHAP (Shapley Additive explanations) can be integrated into our model. These methods can help elucidate the features and patterns the model relies on for segmentation and tumor detection, making its predictions more transparent and understandable for clinical practitioners.
- Adaptation to evolving clinical practices and imaging technologies: The rapid pace of advancement in medical imaging technologies and clinical practices presents a challenge to maintaining the relevance and effectiveness of our model. As new imaging modalities and techniques emerge, the model must be adaptable to leverage these advancements and incorporate new data types. Continuous learning and model updating strategies can be implemented to allow the model to evolve in response to further information and changing clinical environments. Transfer learning techniques can facilitate the integration of new data types and imaging modalities into the model, enabling it to stay current with the latest developments in medical imaging. By ensuring the adaptability of the model, we can maintain its efficacy and utility in clinical practice, supporting ongoing improvements in lung cancer diagnosis and treatment planning.
5. Conclusions
This paper presented an innovative approach for reconstructing 3D lung tumor images using a combination of GAN, LSTM, and VGG16 algorithms. The method addressed the challenge of accurately segmenting lung tissues in CT scans, which was complicated by many non-lung pixels, leading to potential classifier imbalance. This issue was mitigated using a GAN model trained with an RL-based algorithm, enhancing segmentation accuracy. Additionally, a second GAN model with a novel loss function was introduced to improve the precision of tumor detection within the segmented areas. Following successful detection, the VGG16 algorithm was used for feature extraction, which was then processed by an LSTM network for 3D reconstruction using a GAN equipped with dilated convolution layers. This setup allowed for the detailed capture of contextual information, ensuring an accurate tumor reconstruction. The effectiveness of the method was demonstrated through rigorous comparisons with established techniques on the LIDC-IDRI dataset, showcasing its potential to advance early lung cancer detection efforts significantly.
In future developments, we aim to improve our model’s adaptability and real-world performance by implementing real-time data feedback mechanisms. These mechanisms will dynamically adjust essential hyperparameters in response to current performance metrics and environmental changes, enhancing our reinforcement learning framework. Plans include integrating adaptive learning rates and automated hyperparameter tuning algorithms that respond to real-time data. Additionally, we aim to develop a simulation environment that mirrors real clinical settings, which will help us test and evaluate the impact of hyperparameter adjustments on the model’s generalizability and effectiveness. This will be vital for deploying our model in diverse clinical scenarios, ensuring it delivers reliable and effective results regardless of data variability. As another future work, we plan to enhance the interpretability of our model by integrating attention mechanisms that can highlight influential features for diagnostic predictions, aiding clinicians in understanding the decision-making process. Additionally, we will incorporate model-independent interpretation methods such as LIME and SHAP to improve transparency. This approach will enable clinicians and researchers to visually confirm and understand model predictions, ensuring the outputs are reliable and interpretable in real-world healthcare settings.
Author Contributions
H.N., Conceptualization, Software, Data curation, Validation, Methodology, Investigation, Writingt—original draft–review, and editing; K.S., M.M. and S.V.M., Administration, Conceptualization, Data curation, Methodology analysis, Formal analysis, Writing—original draft; R.A., Software, Data curation, Validation, Methodology, Investigation, review, and editing; S.P., Administration, Conceptualization, Supervision, Methodology analysis, writing—review, and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tan, J.; Guo, W.; Yang, S.; Han, D.; Li, H. The multiple roles and therapeutic potential of clusterin in non-small-cell lung cancer: A narrative review. Transl. Lung Cancer Res. 2021, 10, 2683. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, J.F.; Siersma, V.; Malmqvist, J.; Brodersen, J. Psychosocial consequences of false positives in the danish lung cancer ct screening trial: A nested matched cohort study. BMJ Open 2020, 10, e034682. [Google Scholar] [CrossRef] [PubMed]
- Jahani, N.; Choi, S.; Choi, J.; Iyer, K.; Hoffman, E.A.; Lin, C.-L. Assessment of regional ventilation and deformation using 4d-ct imaging for healthy human lungs during tidal breathing. J. Appl. Physiol. 2015, 119, 1064–1074. [Google Scholar] [CrossRef] [PubMed]
- Zareiamand, H.; Darroudi, A.; Mohammadi, I.; Moravvej, S.V.; Danaei, S.; Alizadehsani, R. Cardiac magnetic resonance imaging (cmri) applications in patients with chest pain in the emergency department: A narrative review. Diagnostics 2023, 13, 2667. [Google Scholar] [CrossRef]
- Priya, R.M.; Venkatesan, P. An efficient image segmentation and classification of lung lesions in pet and ct image fusion using dtwt incorporated svm. Microprocess. Microsyst. 2021, 82, 1039581. [Google Scholar]
- Ullah, M.; Akbar, S.; Raza, A.; Zou, Q. Deepavp-tppred: Identification of antiviral peptides using transformed image-based localized descriptors and binary tree growth algorithm. Bioinformatics 2024, 40, btae305. [Google Scholar] [CrossRef]
- Akbar, S.; Raza, A.; Shloul, T.A.; Ahmad, A.; Saeed, A.; Ghadi, Y.Y.; Mamyrbayev, O.; Eldin, E.T. patbp-enc: Identifying anti-tubercular peptides using multi-feature representation and genetic algorithm based deep ensemble model. IEEE Access 2023, 11, 137099–137114. [Google Scholar] [CrossRef]
- Kalinovsky, A.; Kovalev, V. Lung Image Ssgmentation Using Deep Learning Methods and Convolutional Neural Networks; Publishing Center of BSU: Minsk, Belarus, 2016. [Google Scholar]
- Egger, J.; Gsaxner, C.; Pepe, A.; Pomykala, K.L.; Jonske, F.; Kurz, M.; Li, J.; Kleesiek, J. Medical deep learning—A systematic meta-review. Comput. Methods Programs Biomed. 2022, 221, 106874. [Google Scholar] [CrossRef]
- Raza, A.; Uddin, J.; Almuhaimeed, A.; Akbar, S.; Zou, Q.; Ahmad, A. Aips-sntcn: Predicting anti-inflammatory peptides using fasttext and transformer encoder-based hybrid word embedding with self-normalized temporal convolutional networks. J. Chem. Inf. Model. 2023, 63, 6537–6554. [Google Scholar] [CrossRef]
- Akbar, S.; Zou, Q.; Raza, A.; Alarfaj, F.K. iafps-mv-bitcn: Predicting antifungal peptides using self-attention transformer embedding and transform evolutionary based multi-view features with bidirectional temporal convolutional networks. Artif. Intell. Med. 2024, 151, 102860. [Google Scholar] [CrossRef]
- Akbar, S.; Raza, A.; Zou, Q. Deepstacked-avps: Predicting antiviral peptides using tri-segment evolutionary profile and word embedding based multi-perspective features with deep stacking model. BMC Bioinform. 2024, 25, 102. [Google Scholar] [CrossRef] [PubMed]
- de Vargas, V.W.; Aranda, J.A.S.; Costa, R.d.; Pereira, P.R.d.; Barbosa, J.L. Imbalanced data preprocessing techniques for machine learning: A systematic mapping study. Knowl. Inf. Syst. 2023, 65, 31–57. [Google Scholar]
- Moravvej, S.V.; Alizadehsani, R.; Khanam, S.; Sobhaninia, Z.; Shoeibi, A.; Khozeimeh, F.; Sani, Z.A.; Tan, R.; Khosravi, A.; Nahavandi, S.; et al. Rlmd-pa: A reinforcement learning-based myocarditis diagnosis combined with a population-based algorithm for pretraining weights. Contrast Media Mol. Imaging 2022, 2022, 8733632. [Google Scholar] [CrossRef] [PubMed]
- Bostani, A.; Mirzaeibonehkhater, M.; Najafi, H.; Mehrtash, M.; Alizadehsani, R.; Tan, R.; Acharya, U.R. Mlp-rl-crd: Diagnosis of cardiovascular risk in athletes using a reinforcement learning-based multilayer perceptron. Physiol. Meas. 2023, 44, 125012. [Google Scholar] [CrossRef]
- Kasmaee, A.M.M.; Ataei, A.; Moravvej, S.V.; Alizadehsani, R.; Gorriz, J.M.; Zhang, Y.; Tan, R.; Rajendra, A.; Acharya, U. Elrl-md: A deep learning approach for myocarditis diagnosis using cardiac magnetic resonance images with ensemble and reinforcement learning integration. Physiol. Meas. 2024, 45, 055011. [Google Scholar] [CrossRef]
- Danaei, S.; Bostani, A.; Moravvej, S.V.; Mohammadi, F.; Alizadehsani, R.; Shoeibi, A.; Alinejad-Rokny, H.; Nahavandi, S. Myocarditis diagnosis: A method using mutual learning-based abc and reinforcement learning. In Proceedings of the 2022 IEEE 22nd International Symposium on Computational Intelligence and Informatics and 8th IEEE International Conference on Recent Achievements in Mechatronics, Automation, Computer Science and Robotics (CINTI-MACRo), Budapest, Hungary, 21–22 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 000265–000270. [Google Scholar]
- Alarcon, M.L.; Roy, U.; Kambhampati, A.; Nguyen, N.; Attari, M.; Surya, R.; Bunyak, F.; Maschmann, M.; Palaniappan, K.; Calyam, P. Learning-based image analytics in user-ai agent interactions for cyber-enabled manufacturing. In Proceedings of the 2024 IEEE 4th International Conference on Human-Machine Systems (ICHMS), Toronto, ON, Canada, 15–17 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–7. [Google Scholar]
- Kotha, P.R.; Attari, M.; Maschmann, M.; Bunyak, F. Deep style transfer for generation of photo-realistic synthetic images of cnt forests. In Proceedings of the 2023 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Saint Louis, MO, USA, 27–29 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–7. [Google Scholar]
- Dlamini, S.; Chen, Y.-H.; Kuo, J. Complete fully automatic detection, segmentation and 3d reconstruction of tumor volume for non-small cell lung cancer using yolov4 and region-based active contour model. Expert Syst. Appl. 2023, 212, 118661. [Google Scholar] [CrossRef]
- Afshar, P.; Ahmadi, A.; Mohebi, A.; Zarandi, M.H.F. A hierarchical stochastic modelling approach for reconstructing lung tumour geometry from 2d ct images. J. Exp. Theor. Artif. Intell. 2018, 30, 973–992. [Google Scholar] [CrossRef]
- Hong, L.; Modirrousta, M.H.; Nasirpour, M.H.; Chargari, M.; Mohammadi, F.; Moravvej, S.V.; Rezvanishad, L.; Rezvanishad, M.; Bakhshayeshi, I.; Alizadehsani, R.; et al. Gan-lstm-3d: An efficient method for lung tumour 3d reconstruction enhanced by attention-based lstm. CAAI Trans. Intell. Technol. 2023, 1, 1–24. [Google Scholar] [CrossRef]
- Kelkar, V.A.; Gotsis, D.S.; Brooks, F.J.; Prabhat, K.C.; Myers, K.J.; Zeng, R.; Anastasio, M.A. Assessing the ability of generative adversarial networks to learn canonical medical image statistics. IEEE Trans. Med. Imaging 2023, 42, 1799–1808. [Google Scholar] [CrossRef]
- Karanam, S.R.; Srinivas, Y.; Chakravarty, S. A statistical model approach based on the gaussian mixture model for the diagnosis and classification of bone fractures. Int. J. Healthc. Manag. 2023, 12, 1–12. [Google Scholar] [CrossRef]
- Sakshi; Kukreja, V. Image segmentation techniques: Statistical, comprehensive, semi-automated analysis and an application perspective analysis of mathematical expressions. Arch. Comput. Methods Eng. 2023, 30, 457–495. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Dash, A.; Ye, J.; Wang, G. A review of generative adversarial networks (gans) and its applications in a wide variety of disciplines: From medical to remote sensing. IEEE Access 2023, 12, 18330–18357. [Google Scholar] [CrossRef]
- Brophy, E.; Wang, Z.; She, Q.; Ward, T. Generative adversarial networks in time series: A systematic literature review. ACM Comput. Surv. 2023, 55, 1–31. [Google Scholar] [CrossRef]
- Suji, R.J.; Godfrey, W.W.; Dhar, J. Exploring pretrained encoders for lung nodule segmentation task using lidc-idri dataset. Multimed. Tools Appl. 2023, 83, 9685–9708. [Google Scholar] [CrossRef]
- Hasan, D.; Abdulazeez, A.M. Lung segmentation from chest X-ray images using deeplabv3plus-based cnn model. Indones. J. Comput. Sci. 2024, 13, 1. [Google Scholar] [CrossRef]
- Swaminathan, V.P.; Balasubramani, R.; Parvathavarthini, S.; Gopal, V.; Raju, K.; Sivalingam, T.S.; Rajan Thennarasu, S. Gan based image segmentation and classification using vgg16 for prediction of lung cancer. J. Adv. Res. Appl. Sci. Eng. 2024, 35, 45–61. [Google Scholar]
- Gite, S.; Mishra, A.; Kotecha, K. Enhanced lung image segmentation using deep learning. Neural Comput. Appl. 2023, 35, 22839–22853. [Google Scholar] [CrossRef]
- Arvind, S.; Tembhurne, J.V.; Diwan, T.; Sahare, P. Improvised light weight deep cnn based u-net for the semantic segmentation of lungs from chest X-rays. Results Eng. 2023, 17, 100929. [Google Scholar] [CrossRef]
- Rahman, T.; Khandakar, A.; Kadir, M.A.; Islam, K.R.; Islam, K.F.; Mazhar, R.; Hamid, T.; Islam, M.T.; Kashem, S.; Mahbub, Z.B.; et al. Reliable tuberculosis detection using chest x-ray with deep learning, segmentation and visualization. IEEE Access 2020, 8, 191586–191601. [Google Scholar] [CrossRef]
- Pang, T.; Guo, S.; Zhang, X.; Zhao, L. Automatic lung segmentation based on texture and deep features of hrct images with interstitial lung disease. BioMed Res. Int. 2019, 2019, 2045432. [Google Scholar] [CrossRef] [PubMed]
- Zhao, C.; Xu, Y.; He, Z.; Tang, J.; Zhang, Y.; Han, J.; Shi, Y.; Zhou, a.W. Lung segmentation and automatic detection of COVID-19 using radiomic features from chest ct images. Pattern Recognit. 2021, 119, 108071. [Google Scholar] [CrossRef] [PubMed]
- Monshi, M.M.A.; Poon, J.; Chung, V.; Monshi, F.M. Covidxraynet: Optimizing data augmentation and cnn hyperparameters for improved COVID-19 detection from cxr. Comput. Biol. Med. 2021, 133, 104375. [Google Scholar] [CrossRef] [PubMed]
- Diniz, J.a.O.B.; Quintanilha, D.B.P.; Neto, A.C.S.; Silva, G.L.F.; Ferreira, J.L.; Netto, S.M.B.; Araújo, J.D.L.; Cruz, L.B.D.; Silva, T.F.B.; Martins, C.M.d.; et al. Segmentation and quantification of COVID-19 infections in ct using pulmonary vessels extraction and deep learning. Multimed. Tools Appl. 2021, 80, 29367–29399. [Google Scholar] [CrossRef] [PubMed]
- Cao, F.; Zhao, H. Automatic lung segmentation algorithm on chest X-ray images based on fusion variational auto-encoder and three-terminal attention mechanism. Symmetry 2021, 13, 814. [Google Scholar] [CrossRef]
- Vijh, S.; Gaurav, P.; Pandey, H.M. Hybrid bio-inspired algorithm and convolutional neural network for automatic lung tumor detection. Neural Comput. Appl. 2023, 35, 23711–23724. [Google Scholar] [CrossRef]
- Rathod, S.; Ragha, L. Dlctlungdetectnet: Deep learning for lung tumor detection in ct scans. SSRN 2024, 4651122. [Google Scholar]
- Venkatesh, C.; Sivayamini, L.; Sarthika, P.; Hema, M.; Hemalatha, A.; Lakshmi, G. Deep learning and patch processing based lung cancer detection on ct images. In Proceedings of the International Conference on Communications and Cyber Physical Engineering 2018, Hyderabad, India, 28–29 February 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 575–590. [Google Scholar]
- Sundarrajan, M.; Perumal, S.; Sasikala, S.; Ramachandran, M.; Pradeep, N. Lung cancer detection using explainable artificial intelligence in medical diagnosis. In Advances in Explainable AI Applications for Smart Cities; IGI Global: New York, NY, USA, 2024; pp. 352–370. [Google Scholar]
- Srinivasulu, A.; Sreenivasulu, G.; Subramanyam, M.; Rajeyyagari, S.R.; Barua, T.; Pushpa, A. Lung malignant tumor data analytics using fusion ecnn and ernn. In Handbook of Artificial Intelligence Applications for Industrial Sustainability; CRC Press: Boca Raton, FL, USA, 2024; pp. 47–63. [Google Scholar]
- Manickavasagam, R.; Selvan, S.; Selvan, M. Cad system for lung nodule detection using deep learning with cnn. Med. Biol. Eng. Comput. 2022, 60, 221–228. [Google Scholar] [CrossRef]
- Agarwal, A.; Patni, K.; Rajeswari, D. Lung cancer detection and classification based on alexnet cnn. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 8–10 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1390–1397. [Google Scholar]
- Li, Y.; Fan, Y. Deepseed: 3d squeeze-and-excitation encoder–decoder convolutional neural networks for pulmonary nodule detection. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1866–1869. [Google Scholar]
- Pérez-López, A.; Torres-Suárez, A.I.; Martín-Sabroso, C.; Aparicio-Blanco, J. An overview of in vitro 3d models of the blood-brain barrier as a tool to predict the in vivo permeability of nanomedicines. Adv. Drug Deliv. Rev. 2023, 196, 114816. [Google Scholar] [CrossRef]
- Fabbri, R.; Cacopardo, L.; Ahluwalia, A.; Magliaro, C. Advanced 3d models of human brain tissue using neural cell lines: State-of-the-art and future prospects. Cells 2023, 12, 1181. [Google Scholar] [CrossRef]
- Saxton, S.H.; Stevens, K.R. 2d and 3d liver models. J. Hepatol. 2023, 78, 873–875. [Google Scholar] [CrossRef] [PubMed]
- Oh, N.; Kim, J.; Rhu, J.; Jeong, W.K.; Choi, G.; Man Kim, J.; Joh, J. Automated 3d liver segmentation from hepatobiliary phase mri for enhanced preoperative planning. Sci. Rep. 2023, 13, 17605. [Google Scholar] [CrossRef] [PubMed]
- Gu, C.; Gao, H. Combining gan and lstm models for 3d reconstruction of lung tumors from ct scans. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 378–388. [Google Scholar] [CrossRef]
- Kuo, C.J.; Barman, J.; Hsieh, C.W.; Hsu, H. Fast fully automatic detection, classification and 3d reconstruction of pulmonary nodules in ct images by local image feature analysis. Biomed. Signal Process. Control. 2021, 68, 102790. [Google Scholar] [CrossRef]
- Yu, H.; Jiang, L.; Fan, J.; Lan, R. Double-suppressed possibilistic fuzzy gustafson–kessel clustering algorithm. Knowl.-Based Syst. 2023, 276, 110736. [Google Scholar] [CrossRef]
- Rezaei, S.R.; Ahmadi, A. A gan-based method for 3d lung tumor reconstruction boosted by a knowledge transfer approach. Multimed. Tools Appl. 2023, 82, 44359–44385. [Google Scholar] [CrossRef]
- Chen, C.; Fu, Z.; Ye, S.; Zhao, C.; Golovko, V.; Ye, S.; Bai, Z. Study on high-precision three-dimensional reconstruction of pulmonary lesions and surrounding blood vessels based on ct images. Opt. Express 2024, 32, 1371–1390. [Google Scholar] [CrossRef]
- Esmaeili, M.; Goki, S.H.; Masjidi, B.H.K.; Sameh, M.; Gharagozlou, H.; Mohammed, A.S. Ml-ddosnet: Iot intrusion detection based on denial-of-service attacks using machine learning methods and nsl-kdd. Wirel. Commun. Mob. Comput. 2022, 2022, 8481452. [Google Scholar] [CrossRef]
- Gharagozlou, H.; Mohammadzadeh, J.; Bastanfard, A.; Ghidary, S.S. Rlas-biabc: A reinforcement learning-based answer selection using the bert model boosted by an improved abc algorithm. Comput. Intell. Neurosci. 2022, 2022, 7839840. [Google Scholar] [CrossRef]
- Pehrson, L.M.; Nielsen, M.B.; Lauridsen, C. Automatic pulmonary nodule detection applying deep learning or machine learning algorithms to the lidc-idri database: A systematic review. Diagnostics 2019, 9, 29. [Google Scholar] [CrossRef]
- McNeel, R. Rhinoceros 3d. 2024. Available online: https://www.rhino3d.com/ (accessed on 10 September 2024).
- Chen, Y.; Wang, Y.; Hu, F.; Wang, D. A lung dense deep convolution neural network for robust lung parenchyma segmentation. IEEE Access 2020, 8, 93527–93547. [Google Scholar] [CrossRef]
- Tan, J.; Jing, L.; Huo, Y.; Li, L.; Akin, O.; Tian, Y. Lgan: Lung segmentation in ct scans using generative adversarial network. Comput. Med Imaging Graph. 2021, 87, 101817. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Li, J.; Zhang, L.; Cao, Y.; Yu, X.; Sun, J. Design of lung nodules segmentation and recognition algorithm based on deep learning. BMC Bioinform. 2021, 22, 1–21. [Google Scholar] [CrossRef]
- Usman, M.; Shin, Y. Deha-net: A dual-encoder-based hard attention network with an adaptive roi mechanism for lung nodule segmentation. Sensors 2023, 23, 1989. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Gou, F.; Tan, Y.; Wu, J. A cascaded multi-stage framework for automatic detection and segmentation of pulmonary nodules in developing countries. IEEE J. Biomed. Health Informat. 2022, 26, 5619–5630. [Google Scholar] [CrossRef]
- Maqsood, M.; Yasmin, S.; Mehmood, I.; Bukhari, M.; Kim, M. An efficient da-net architecture for lung nodule segmentation. Mathematics 2021, 9, 1457. [Google Scholar] [CrossRef]
- Huang, X.; Sun, W.; Tseng, T.B.; Li, C.; Qian, W. Fast and fully-automated detection and segmentation of pulmonary nodules in thoracic ct scans using deep convolutional neural networks. Comput. Med Imaging Graph. 2019, 74, 25–36. [Google Scholar] [CrossRef]
- Wu, B.; Zhou, Z.; Wang, J.; Wang, Y. Joint learning for pulmonary nodule segmentation, attributes and malignancy prediction. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1109–1113. [Google Scholar]
- Shusharina, N.; Krishnaswamy, D.; Kinahan, P.; Fedorov, A. Integrating deep learning algorithms for the lung segmentation and body-part-specific anatomical classification with medical imaging and data resource center (midrc). In Medical Imaging 2023: Imaging Informatics for Healthcare, Research, and Applications; SPIE: Bellingham, WA, USA, 2023; Volume 12469, pp. 180–186. [Google Scholar]
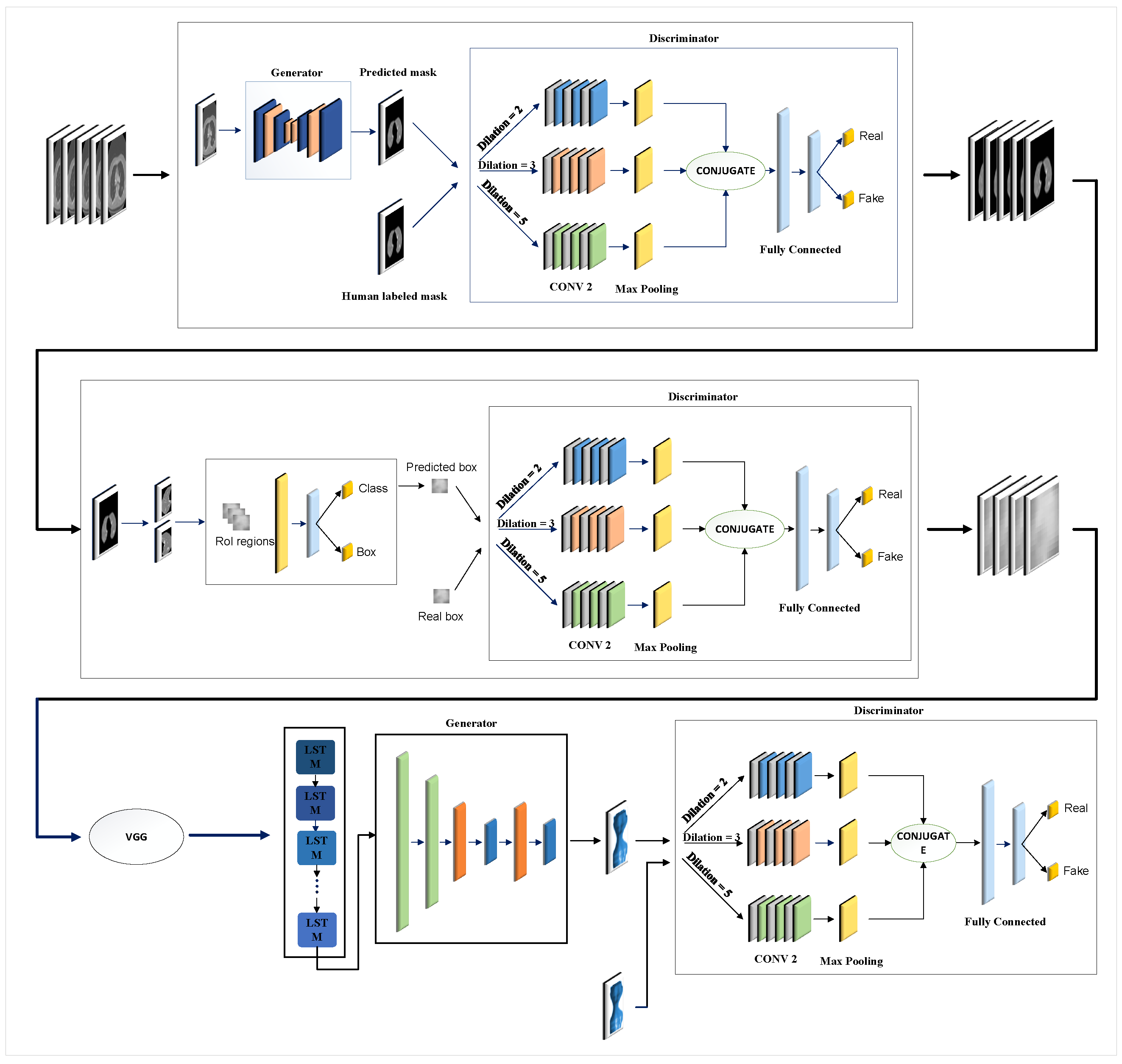
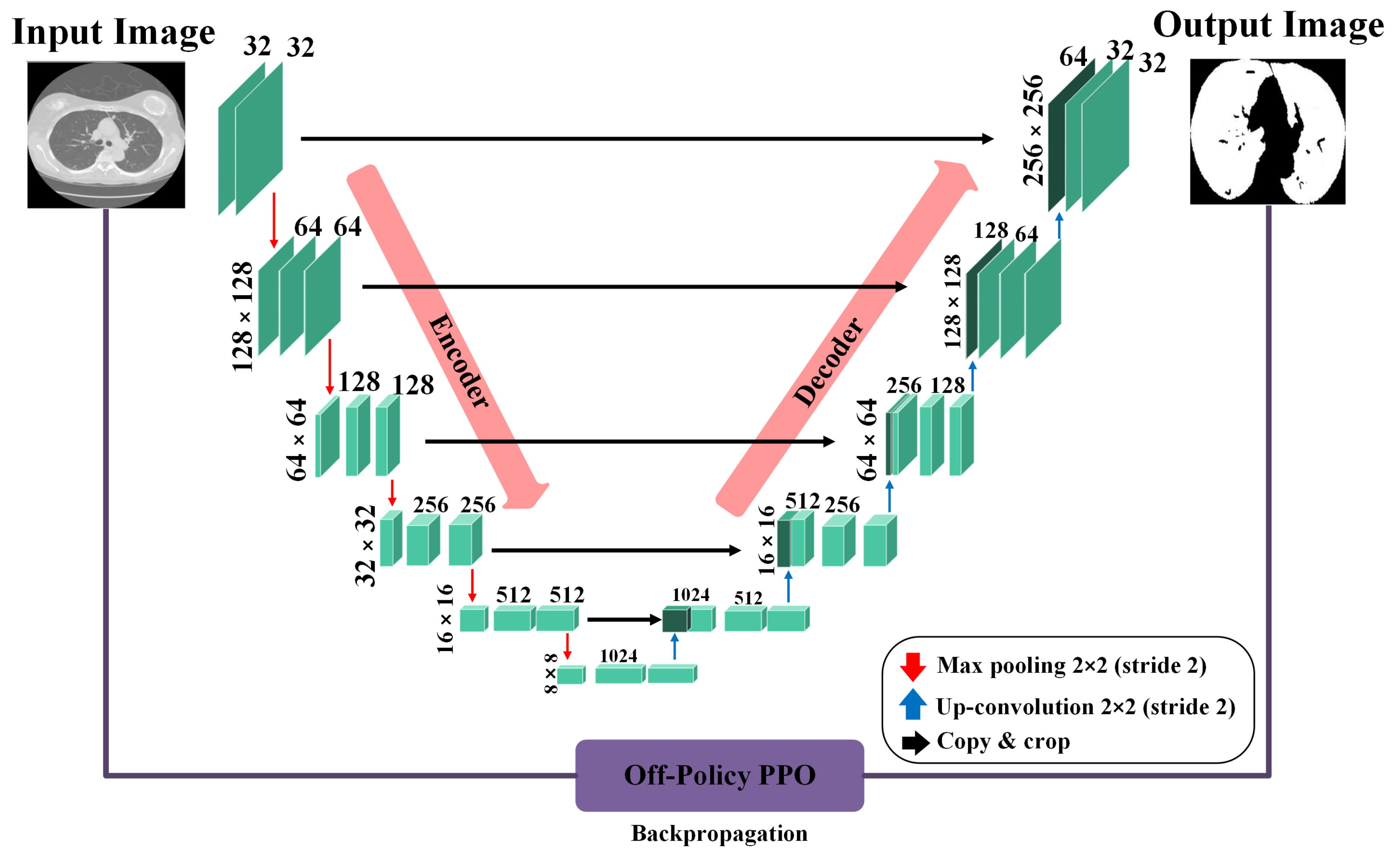
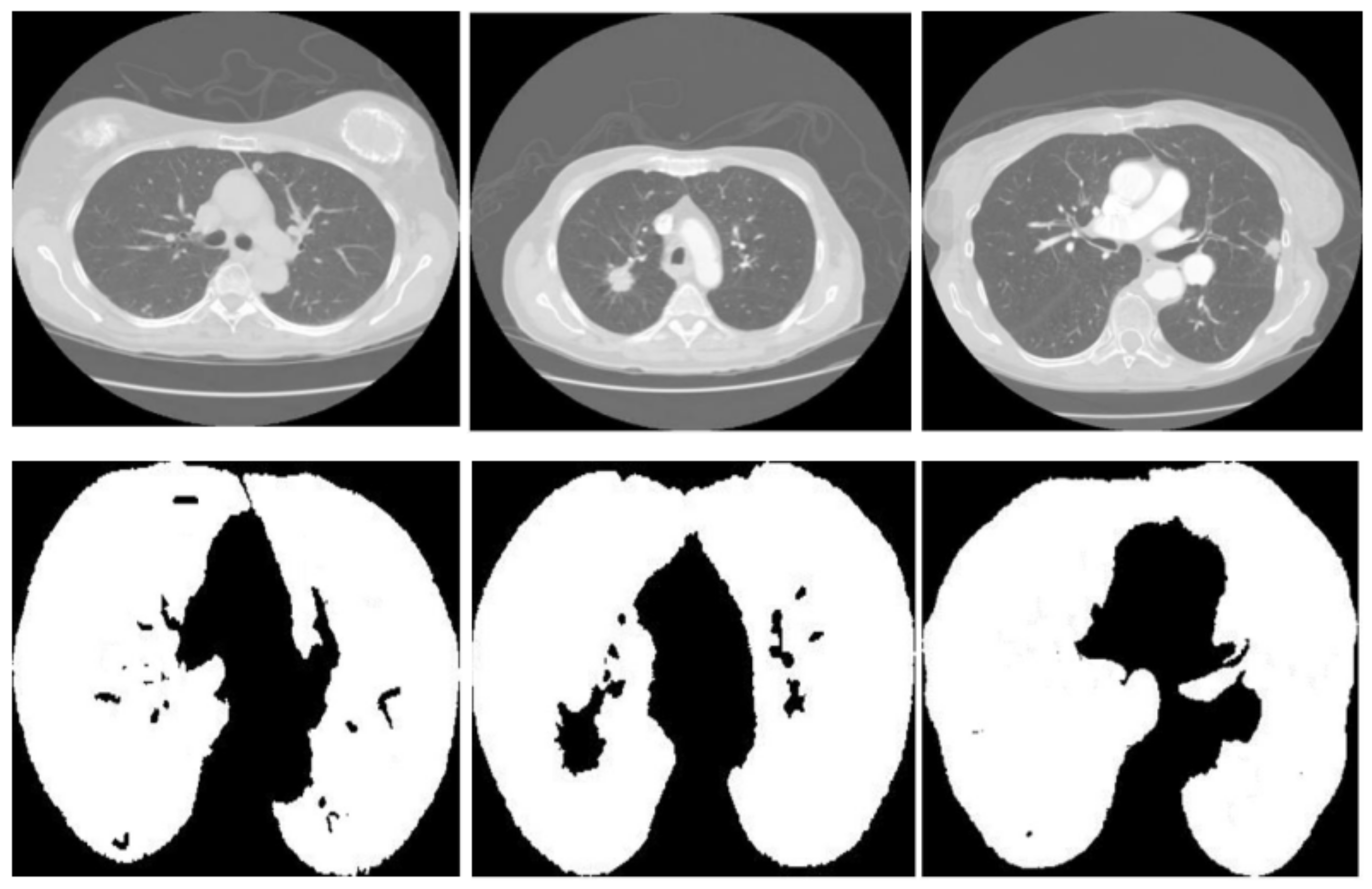
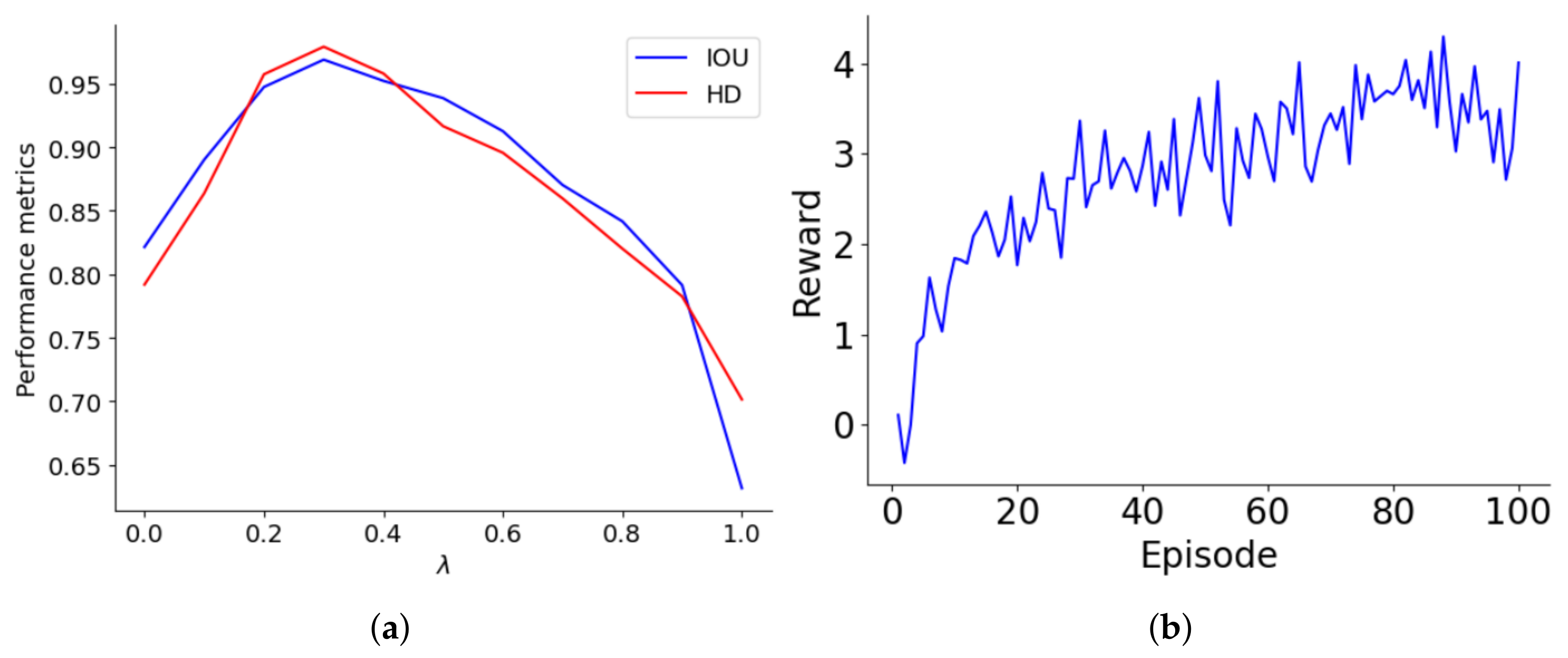
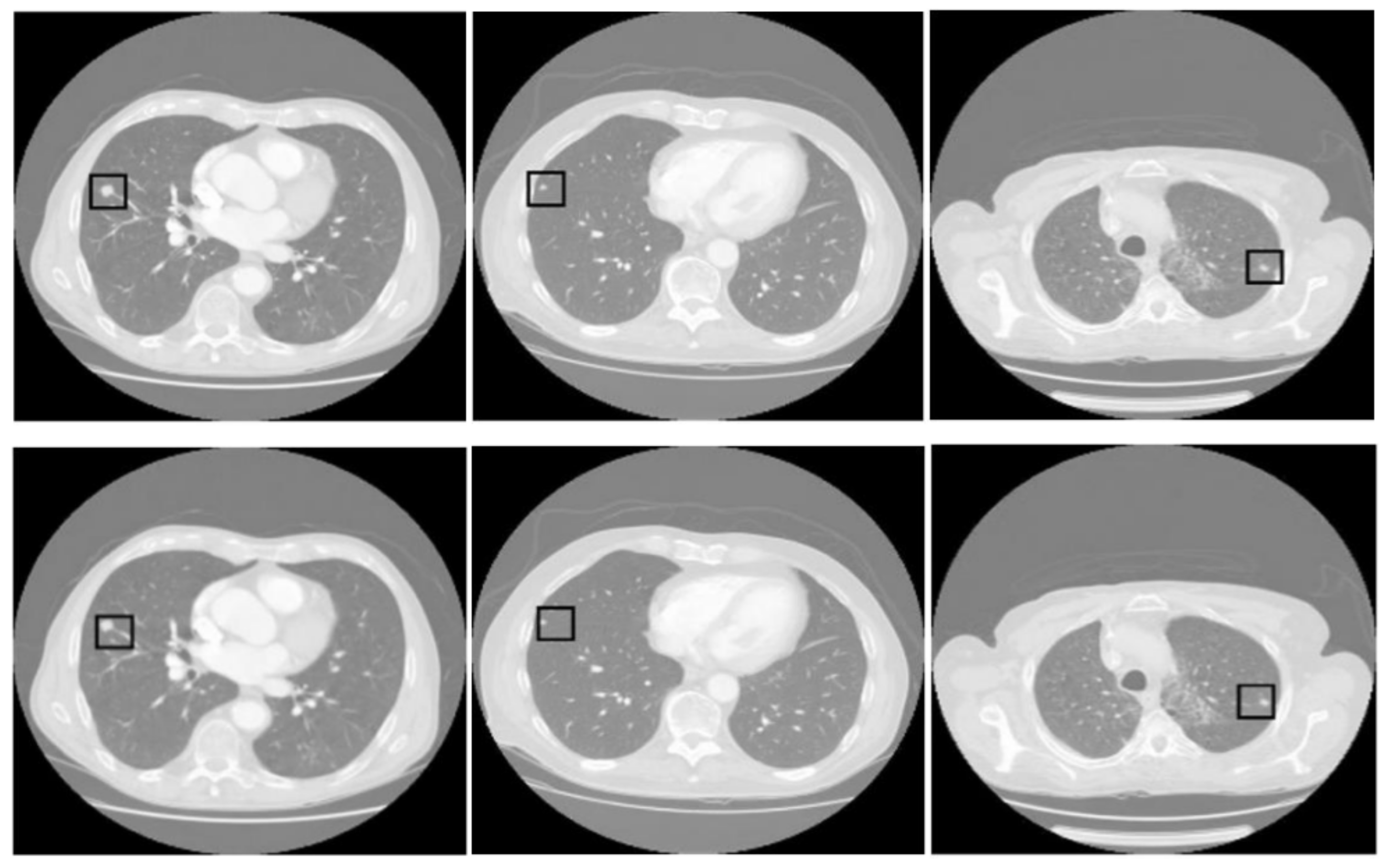
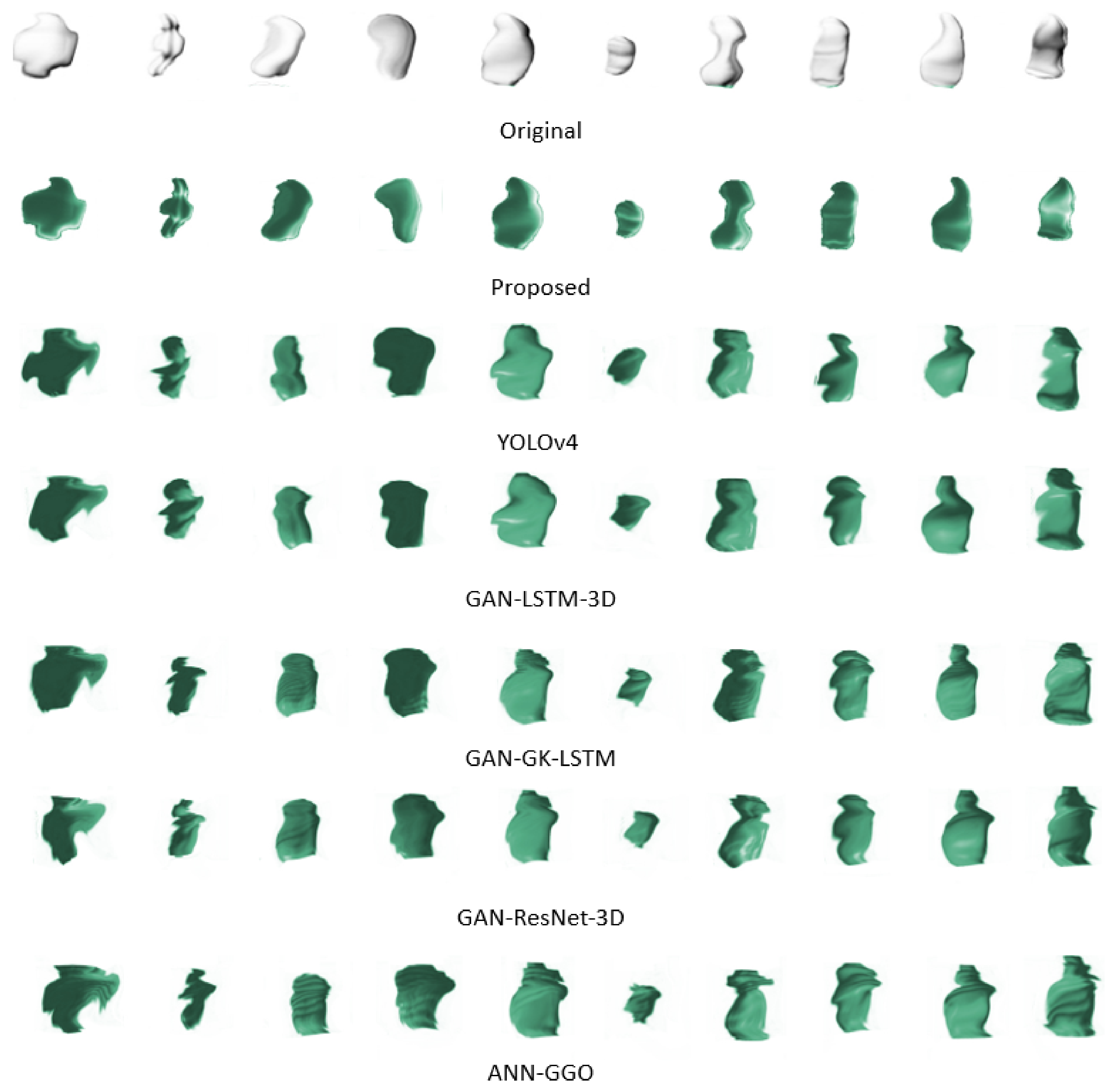
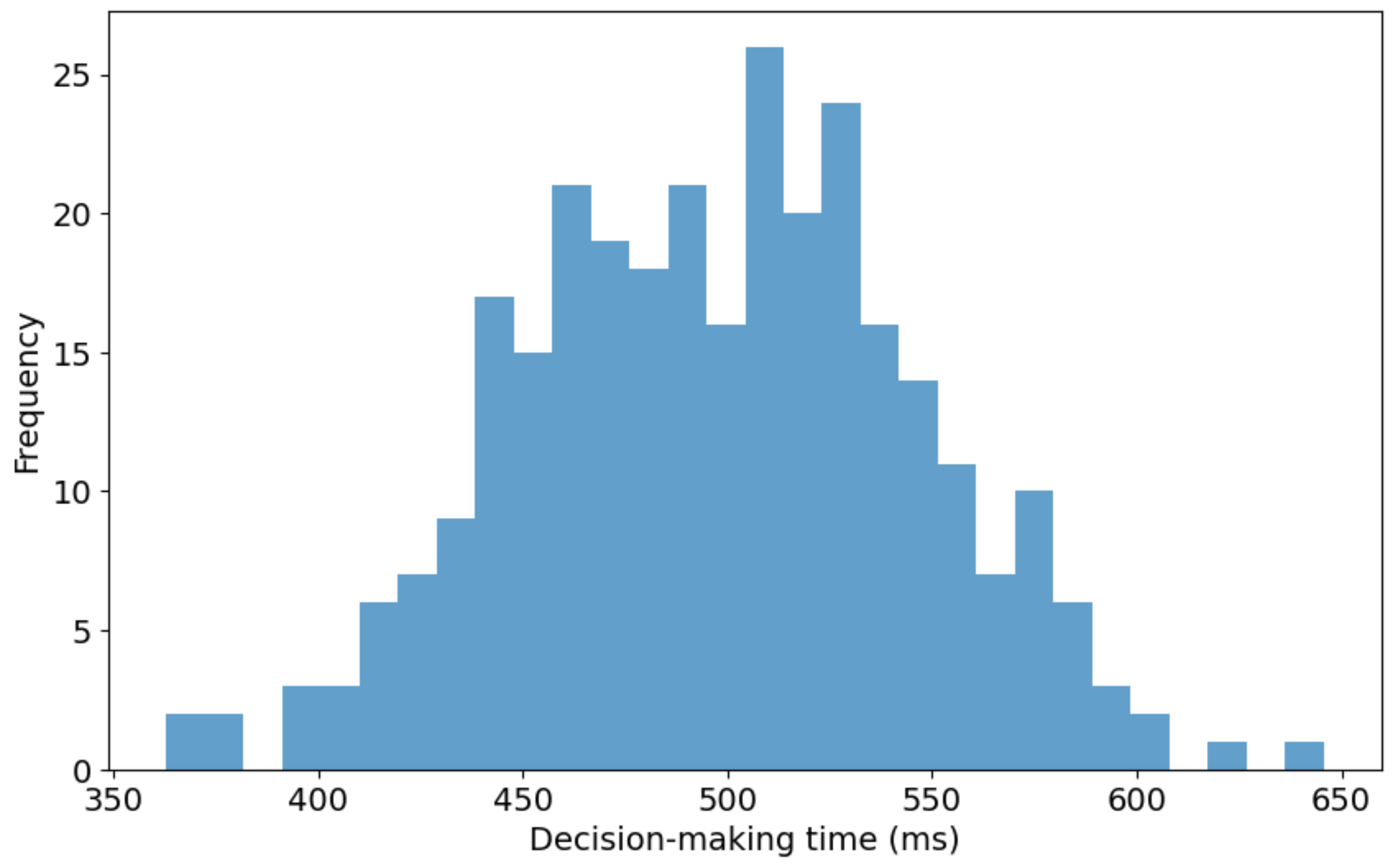
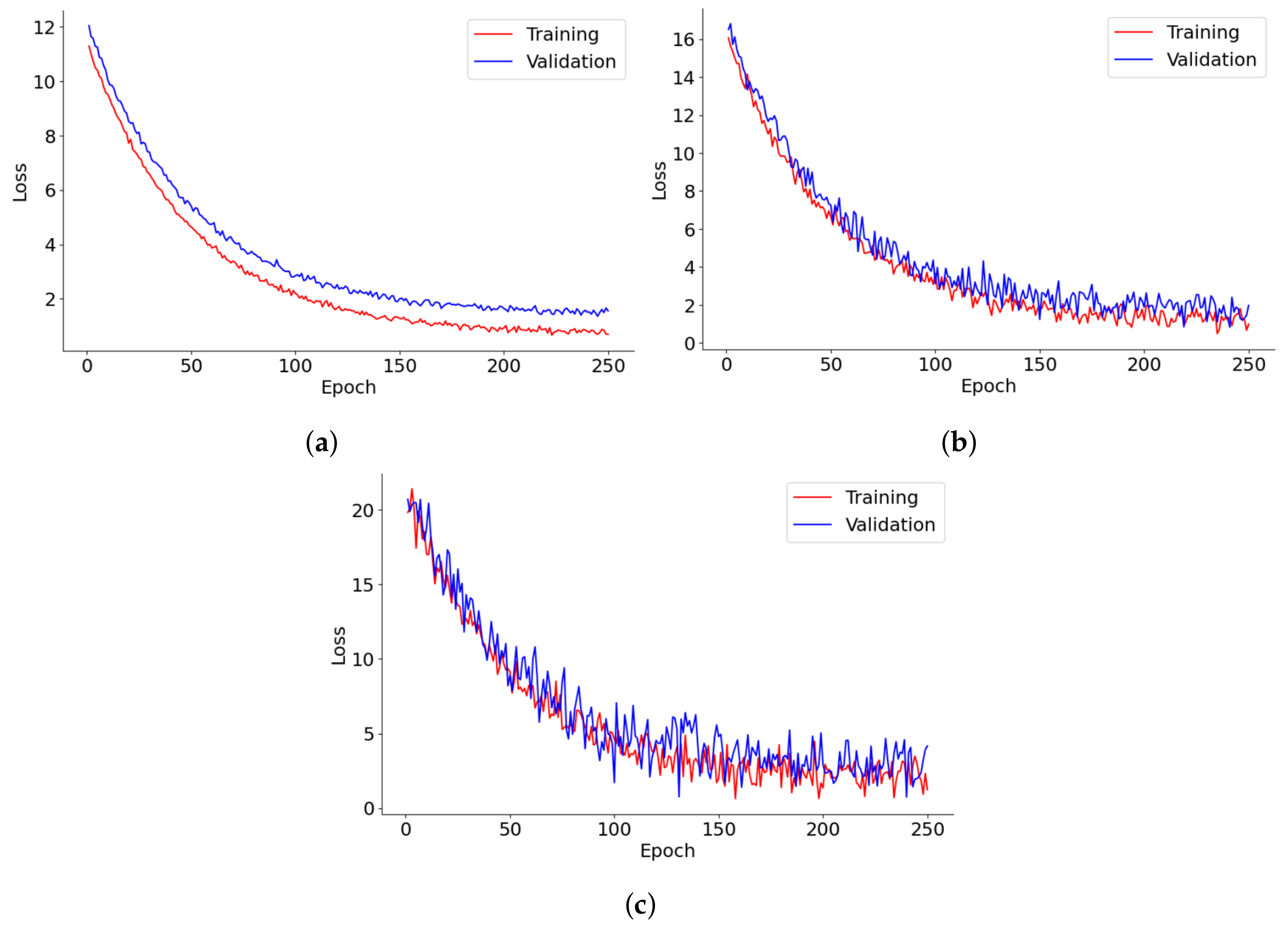
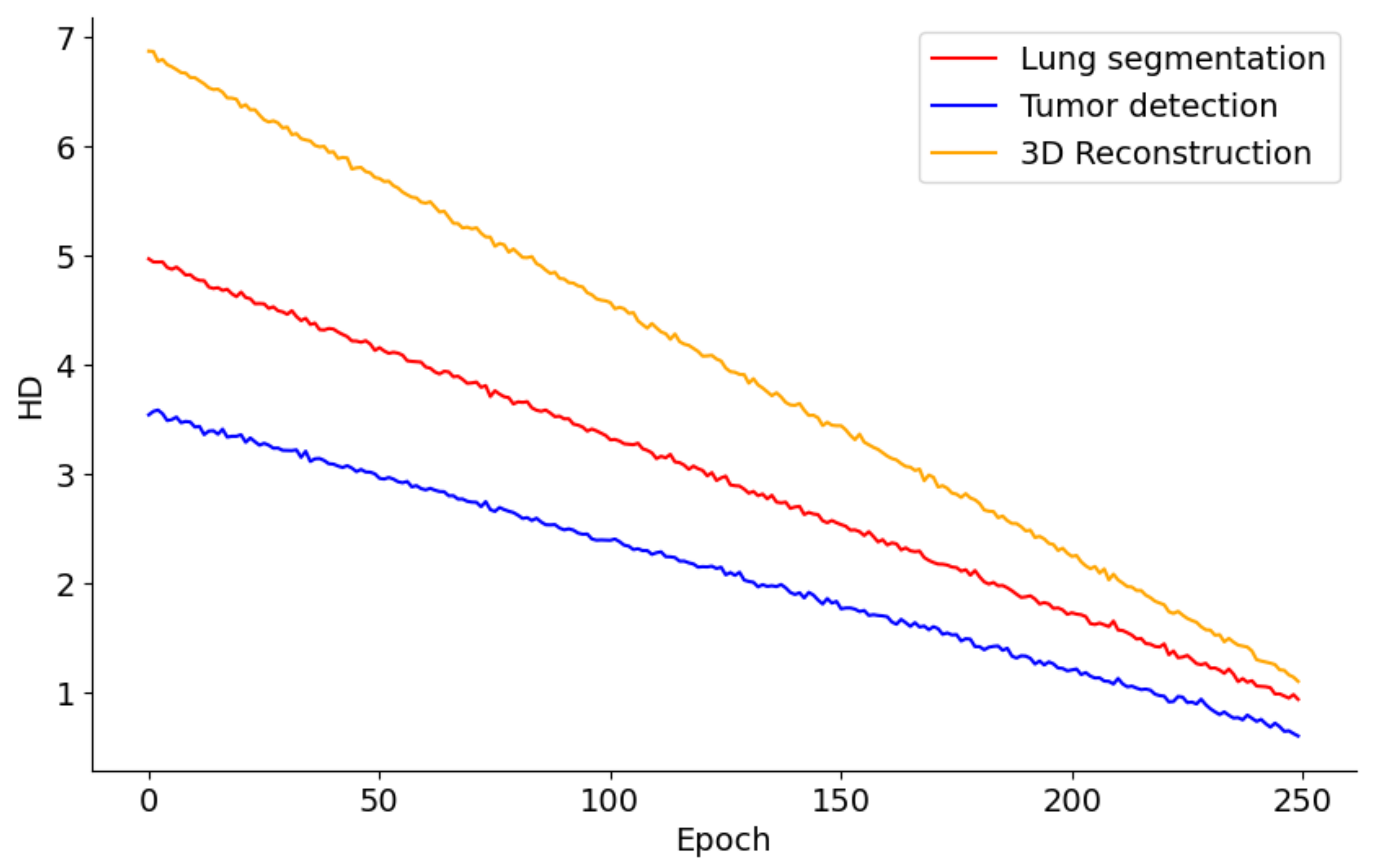
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).