



Detection of Intracranial Hemorrhage from Computed Tomography Images: Diagnostic Role and Efficacy of ChatGPT-4o


Abstract
:1. Introduction
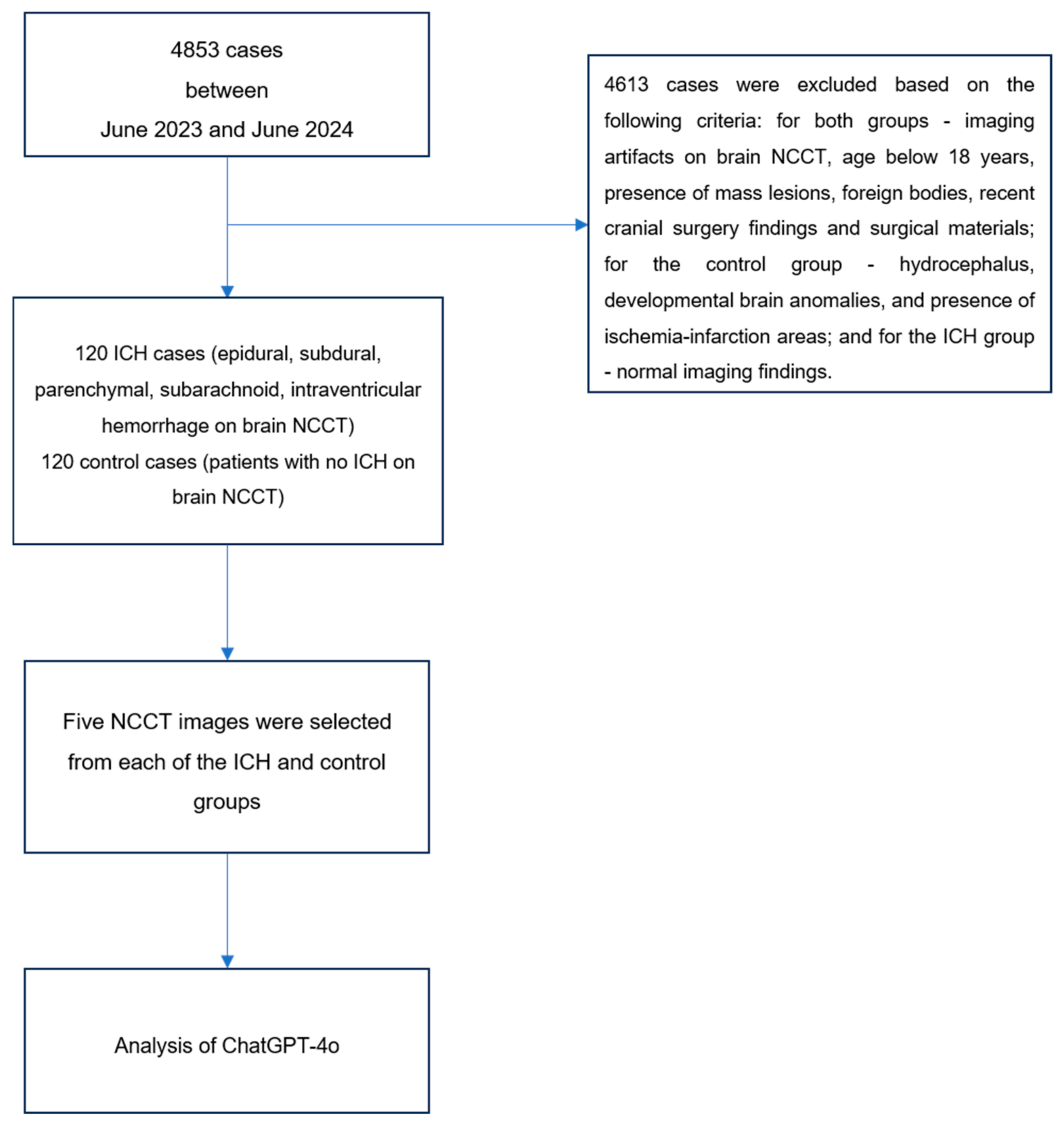
2. Materials and Methods
2.1. Study Design and Case Selection
2.2. Inclusion and Exclusion Criteria
2.3. Brain NCCT Images
2.4. Image Selection and Evaluation
2.5. Prompt Selection and Testing
2.6. ChatGPT Interaction and Prompting
- What is the name of this radiological imaging method? Are there any hemorrhages in these images? Please answer “Yes” or “No”.
- What type(s) of hemorrhage(s) are present? Please answer this question with “subdural”, “epidural”, “subarachnoid”, “intraparenchymal”, or “intraventricular”. If there are multiple hemorrhages in these images, please answer this question separately for each hemorrhage.
- If the type of hemorrhage(s) is “subdural” or “epidural”, what is the location of the hemorrhage(s)? Please specify the location with “on the patient’s right” or “on the patient’s left” followed by “frontal”, “parietal”, “temporal”, “occipital”, “frontoparietal”, “frontotemporal”, “temporoparietal”, “temporooccipital”, “posterior fossa”, etc. If there are multiple hemorrhages in these images, please answer this question separately for each hemorrhage.
- If the type of hemorrhage(s) is “intraparenchymal”, what is the location of the hemorrhage(s)? Please specify the location with “on the patient’s right” or “on the patient’s left” followed by “frontal”, “parietal”, “temporal”, “occipital”, “frontoparietal”, “frontotemporal”, “temporoparietal”, “temporooccipital”, “cerebellar”, “thalamus”, “pons”, “mesencephalon”, etc.
- If there are multiple hemorrhages in these images, please answer this question separately for each hemorrhage.
- If the type of hemorrhage(s) is “subarachnoid”, what is the location of the hemorrhage(s) in relation to the patient? Please specify the location with “on the patient’s right” or “on the patient’s left” followed by “frontal”, “parietal”, “temporal”, “occipital”, “frontoparietal”, “frontotemporal”, “temporoparietal”, “temporooccipital”, “cerebellar”. If there are multiple hemorrhages in these images, please answer this question separately for each hemorrhage.
- If the type of hemorrhage(s) is “intraventricular”, what is the location of the hemorrhage(s) in relation to the patient? Please specify the location as “3rd ventricle”, “4th ventricle”, “right lateral ventricle”, or “left lateral ventricle”. If there are multiple hemorrhages in these images, please answer this question separately for each hemorrhage.
- What is the phase of the hemorrhage(s)? Please answer this question with “acute”, “subacute”, or “chronic”. If there are multiple hemorrhages in these images, please answer this question separately for each hemorrhage.
- Are there any additional pathological findings related to the hemorrhage(s) in these images? If so, please specify the pathology/ies as “right shift”, “left shift”, “brain edema”, “3rd ventricle compression”, “right lateral ventricle compression”, “left lateral ventricle compression”, etc.
2.7. Executors and Readers
2.8. Statistical Analysis
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1
Appendix A.2

References
- Van Asch, C.J.; Luitse, M.J.; Rinkel, G.J.; van der Tweel, I.; Algra, A.; Klijn, C.J. Incidence, case fatality, and functional outcome of intracerebral haemorrhage over time, according to age, sex, and ethnic origin: A systematic review and meta-analysis. Lancet Neurol. 2010, 9, 167–176. [Google Scholar] [CrossRef] [PubMed]
- Heit, J.J.; Iv, M.; Wintermark, M. Imaging of intracranial hemorrhage. J. Stroke 2016, 19, 11. [Google Scholar] [CrossRef] [PubMed]
- Ginat, D.T. Analysis of head CT scans flagged by deep learning software for acute intracranial hemorrhage. Neuroradiology 2020, 62, 335–340. [Google Scholar] [CrossRef] [PubMed]
- Kidwell, C.S.; Chalela, J.A.; Saver, J.L.; Starkman, S.; Hill, M.D.; Demchuk, A.M.; Butman, J.A.; Patronas, N.; Alger, J.R.; Latour, L.L.; et al. Comparison of MRI and CT for detection of acute intracerebral hemorrhage. JAMA 2004, 292, 1823–1830. [Google Scholar] [CrossRef]
- Zahuranec, D.B.; Lisabeth, L.D.; Sánchez, B.N.; Smith, M.A.; Brown, D.L.; Garcia, N.M.; Skolarus, L.E.; Meurer, W.J.; Burke, J.F.; Adelman, E.E.; et al. Intracerebral hemorrhage mortality is not changing despite declining incidence. Neurology 2014, 82, 2180–2186. [Google Scholar] [CrossRef]
- Elliott, J.; Smith, M. The acute management of intracerebral hemorrhage: A clinical review. Anesth. Analg. 2010, 110, 1419–1427. [Google Scholar] [CrossRef]
- Fugate, J.E.; Rabinstein, A.A. Absolute and relative contraindications to IV rt-PA for acute ischemic stroke. Neurohospitalist 2015, 5, 110–121. [Google Scholar] [CrossRef]
- Qureshi, A.I.; Mendelow, A.D.; Hanley, D.F. Intracerebral haemorrhage. Lancet 2009, 373, 1632–1644. [Google Scholar] [CrossRef]
- Morotti, A.; Goldstein, J.N. Diagnosis and management of acute intracerebral hemorrhage. Emerg. Med. Clin. N. Am. 2016, 34, 883–899. [Google Scholar] [CrossRef]
- McDonald, R.J.; Schwartz, K.M.; Eckel, L.J.; Diehn, F.E.; Hunt, C.H.; Bartholmai, B.J.; Erickson, B.J.; Kallmes, D.F. The effects of changes in utilization and technological advancements of cross-sectional imaging on radiologist workload. Acad. Radiol. 2015, 22, 1191–1198. [Google Scholar] [CrossRef]
- Sellers, A.; Hillman, B.J.; Wintermark, M. Survey of after-hours coverage of emergency department imaging studies by US academic radiology departments. J. Am. Coll. Radiol. 2014, 11, 725–730. [Google Scholar] [CrossRef] [PubMed]
- Spitler, K.; Vijayasarathi, A.; Salehi, B.; Dua, S.; Azizyan, A.; Cekic, M.; Yaghmai, N.; Homer, R.; Salamonet, N. Neuroradiologist coverage improves resident perception of educational experience, referring physician satisfaction, and turnaround time. Curr. Probl. Diagn. Radiol. 2020, 49, 168–172. [Google Scholar] [CrossRef] [PubMed]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef]
- Almeida, L.C.; Farina, E.M.J.M.; Kuriki, P.E.A.; Abdala, N.; Kitamura, F.C. Performance of ChatGPT on the Brazilian radiology and diagnostic imaging and mammography board examinations. Radiol. Artif. Intell. 2024, 6, e230103. [Google Scholar] [CrossRef]
- Lee, J.Y.; Kim, J.S.; Kim, T.Y.; Kim, Y.S. Detection and classification of intracranial haemorrhage on CT images using a novel deep-learning algorithm. Sci. Rep. 2020, 10, 20546. [Google Scholar] [CrossRef]
- Yun, T.J.; Choi, J.W.; Han, M.; Jung, W.S.; Choi, S.H.; Yoo, R.E.; Hwang, I.P. Deep learning based automatic detection algorithm for acute intracranial haemorrhage: A pivotal randomized clinical trial. NPJ Digit. Med. 2023, 6, 61. [Google Scholar] [CrossRef]
- Dawud, A.M.; Yurtkan, K.; Oztoprak, H. Application of deep learning in neuroradiology: Brain haemorrhage classification using transfer learning. Comput. Intell. Neurosci. 2019, 2019, 4629859. [Google Scholar] [CrossRef]
- Kaluarachchi, T.; Reis, A.; Nanayakkara, S. A review of recent deep learning approaches in human-centered machine learning. Sensors 2021, 21, 2514. [Google Scholar] [CrossRef]
- Lewick, T.; Kumar, M.; Hong, R.; Wu, W. Intracranial hemorrhage detection in ct scans using deep learning. In Proceedings of the 2020 IEEE Sixth International Conference on Big Data Computing Service and Applications (BigDataService), Oxford, UK, 3–6 August 2020; Volume 2020, pp. 169–172. [Google Scholar]
- Heit, J.J.; Coelho, H.; Lima, F.O.; Granja, M.; Aghaebrahim, A.; Hanel, R.; Kwok, K.; Haerian, H.; Cereda, C.W.; Venkatasubramanian, C.; et al. Automated cerebral hemorrhage detection using RAPID. Am. J. Neuroradiol. 2021, 42, 273–278. [Google Scholar] [CrossRef]
- Kuo, W.; Häne, C.; Mukherjee, P.; Malik, J.; Yuh, E.L. Expert-level detection of acute intracranial hemorrhage on head computed tomography using deep learning. Proc. Natl. Acad. Sci. USA 2019, 116, 22737–22745. [Google Scholar] [CrossRef]
- Voter, A.F.; Meram, E.; Garrett, J.W.; Yu, J.P.J. Diagnostic accuracy and failure mode analysis of a deep learning algorithm for the detection of intracranial hemorrhage. J. Am. Coll. Radiol. 2021, 18, 1143–1152. [Google Scholar] [CrossRef] [PubMed]
- Rahsepar, A.A.; Tavakoli, N.; Kim, G.H.J.; Hassani, C.; Abtin, F.; Bedayat, A. How AI responds to common lung cancer questions: ChatGPT versus Google Bard. Radiology 2023, 307, e230922. [Google Scholar] [CrossRef] [PubMed]
- Temperley, H.C.; O’Sullivan, N.J.; Mac Curtain, B.M.; Corr, A.; Meaney, J.F.; Kelly, M.E.; Brennan, I. Current applications and future potential of ChatGPT in radiology: A systematic review. J. Med. Imaging Radiat. Oncol. 2024, 68, 257–264. [Google Scholar] [CrossRef]
- Haver, H.L.; Bahl, M.; Doo, F.X.; Kamel, P.I.; Parekh, V.S.; Jeudy, J.; Yi, P.H. Evaluation of multimodal ChatGPT (GPT-4V) in describing mammography image features. Can. Assoc. Radiol. J. 2024, 75, 947–949. [Google Scholar] [CrossRef]
- Mert, S.; Stoerzer, P.; Brauer, J.; Fuchs, B.; Haas-Lützenberger, E.M.; Demmer, W.; Giunta, R.E.; Nuernberger, T. Diagnostic power of ChatGPT 4 in distal radius fracture detection through wrist radiographs. Arch. Orthop. Trauma. Surg. 2024, 144, 2461–2467. [Google Scholar] [CrossRef]
- Dehdab, R.; Brendlin, A.; Werner, S.; Almansour, H.; Gassenmaier, S.; Brendel, J.M.; Nikolaou, K.; Afat, S. Evaluating ChatGPT-4V in chest CT diagnostics: A critical image interpretation assessment. Jpn. J. Radiol. 2024, 42, 1168–1177. [Google Scholar] [CrossRef]
- Kuzan, B.N.; Meşe, İ.; Yaşar, S.; Kuzan, T.Y. A retrospective evaluation of the potential of ChatGPT in the accurate diagnosis of acute stroke. Diagn. Interv. Radiol. 2024. online ahead of print. [Google Scholar] [CrossRef]
- Zhang, D.; Ma, Z.; Gong, R.; Lian, L.; Li, Y.; He, Z.; Han, Y.; Hui, J.; Huang, J.; Jiang, J.; et al. Using natural language processing (GPT-4) for computed tomography image analysis of cerebral hemorrhages in radiology: Retrospective analysis. J. Med. Internet Res. 2024, 26, e58741. [Google Scholar] [CrossRef]
- Arbabshirani, M.R.; Fornwalt, B.K.; Mongelluzzo, G.J.; Suever, J.D.; Geise, B.D.; Patel, A.A.; Moore, G.J. Advanced machine learning in action: Identification of intracranial hemorrhage on computed tomography scans of the head with clinical workflow integration. NPJ Digit. Med. 2018, 1, 9. [Google Scholar] [CrossRef]
- Mongan, J.; Moy, L.; Kahn, C.E. Checklist for artificial intelligence in medical imaging (CLAIM): A guide for authors and Reviewers. Radiol. Artif. Intell. 2020, 2, e200029. [Google Scholar] [CrossRef]
- ChatGPT. Available online: https://chatgpt.com/ (accessed on 22 August 2024).
- Ojeda, P.; Zawaideh, M.; Mossa-Basha, M.; Haynor, D. The utility of deep learning: Evaluation of a convolutional neural network for detection of intracranial bleeds on non-contrast head computed tomography studies. Proc. SPIE 2019, 10949, 899–906. [Google Scholar] [CrossRef]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef] [PubMed]
- Kundisch, A.; Hönning, A.; Mutze, S.; Kreissl, L.; Spohn, F.; Lemcke, J.; Sitz, M.; Sparenberg, P.; Goelz, L. Deep learning algorithm in detecting intracranial hemorrhages on emergency computed tomographies. PLoS ONE 2021, 16, e0260560. [Google Scholar] [CrossRef] [PubMed]
- Jung, J.; Dai, J.; Liu, B.; Wu, Q. Artificial intelligence in fracture detection with different image modalities and data types: A systematic review and meta-analysis. PLoS Digit. Health 2024, 3, e0000438. [Google Scholar] [CrossRef] [PubMed]
- Rea, G.; Sverzellati, N.; Bocchino, M.; Lieto, R.; Milanese, G.; D’Alto, M.; Bocchini, G.; Maniscalco, M.; Valente, T.; Sica, G. Beyond visual interpretation: Quantitative analysis and artificial intelligence in interstitial lung disease diagnosis “expanding horizons in radiology”. Diagnostics 2023, 13, 2333. [Google Scholar] [CrossRef]
- Ozkara, B.B.; Chen, M.M.; Federau, C.; Karabacak, M.; Briere, T.M.; Li, J.; Wintermark, M. Deep learning for detecting brain metastases on MRI: A systematic review and meta-analysis. Cancers 2023, 15, 334. [Google Scholar] [CrossRef]
- Obuchowicz, R.; Strzelecki, M.; Piórkowski, A. Clinical applications of artificial intelligence in medical imaging and image processing—A review. Cancers 2024, 16, 1870. [Google Scholar] [CrossRef]
- Fathi, M.; Eshraghi, R.; Behzad, S.; Tavasol, A.; Bahrami, A.; Tafazolimoghadam, A.; Bhatt, V.; Ghadimi, D.; Gholamrezanezhad, A. Potential strength and weakness of artificial intelligence integration in emergency radiology: A review of diagnostic utilizations and applications in patient care optimization. Emerg. Radiol. 2024, 31, 887–901. [Google Scholar] [CrossRef]
- Morales, H. Pitfalls in the imaging interpretation of intracranial hemorrhage. Semin. Ultrasound CT MR 2018, 39, 457–468. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author and Year | AI Model Used | Study Objective | Sample Size | Main Findings |
|---|---|---|---|---|
| Ginat et al., 2020 [3] | Deep learning | ICH detection from NCCT images | 373 cases | ICH detection Sensitivity: 88.7%, Specificity: 94.2% |
| Yun et al., 2023 [16] | Deep learning | ICH detection from NCCT images | 49,841 cases | ICH detection Sensitivity: 95.9%, Specificity: 95.3% |
| Heit et al., 2024 [20] | Deep learning | ICH detection from NCCT images | 308 cases | ICH detection Sensitivity: 95.6%, Specificity: 95.3% |
| Daiwen et al., 2024 [29] | ChatGPT-4 | ICH detection from NCCT images | 208 cases | 72.6% ICH detection rate |
| Arbabshirani et al., 2018 [30] | Deep learning | ICH detection from NCCT images | 46,583 cases | ICH detection Sensitivity: 78%, Specificity: 80% |
| ICH Group (n = 120) | Healthy Control Group (n = 120) | p Value | |
|---|---|---|---|
| Gender *, n (%) | |||
| Female | 39 (32.5) | 40 (33.3) | 0.891 |
| Male | 81 (67.5) | 80 (66.7) | |
| Age **, years, Mean ± SD | 63.95 ± 19.58 | 63.73 ± 18.81 | 0.877 |
| n (%) | |
|---|---|
| Hemorrhage type (hemorrhagic areas, n = 150) | |
| Subdural | 78 (52) |
| Epidural | 12 (8) |
| Intraventricular | 7 (4.7) |
| Intraparenchymal | 35 (23.3) |
| Subarachnoid | 18 (12) |
| Hemorrhage location (cases, n = 120) | |
| Unifocal | 92 (76.7) |
| Multifocal | 28 (23.3) |
| Associated pathologies (n = 85) | |
| Cerebral edema | 44 (51.8) |
| Midline shift | 23 (27) |
| Right lateral ventricle compression | 8 (9.4) |
| Left lateral ventricle compression | 10 (11.8) |
| Hemorrhage Stage | Subdural n (%) | Epidural n (%) | Intraventricular n (%) | Intraparenchymal n (%) | Subarachnoid n (%) | Total n (%) |
|---|---|---|---|---|---|---|
| Acute | 38 (25.3) | 10 (6.7) | 7 (4.7) | 32 (21.3) | 18 (12) | 105 (70) |
| Subacute | 11 (7.3) | 1 (0.7) | 0 (0) | 1 (0.7) | 0 (0) | 13 (8.7) |
| Chronic | 24 (16) | 1 (0.7) | 0 (0) | 2 (1.3) | 0 (0) | 27 (18) |
| Acute–subacute | 2 (1.3) | 0 (0) | 0 (0) | 0 (0) | 0 (0) | 2 (1.3) |
| Acute–chronic | 3 (2) | 0 (0) | 0 (0) | 0 (0) | 0 (0) | 3 (2) |
| Total | 78 (52) | 12 (8) | 7 (4.7) | 35 (23.3) | 18 (12) | 150 (100) |
| True Positive, n (%) | False Positive, n (%) | True Negative, n (%) | False Negative, n (%) | Sensitivity, % | Specificity, % | PPV, % | NPV, % | Diagnostic Accuracy, % | |
|---|---|---|---|---|---|---|---|---|---|
| ChatGPT-4o, Round 1 | 95 (79.2) | 51 (42.5) | 69 (57.5) | 25 (20.8) | 79.2 | 57.5 | 65.1 | 73.4 | 68.3 |
| ChatGPT-4o, Round 2 | 104 (86.7) | 48 (40) | 72 (60) | 16 (13.3) | 86.7 | 60.0 | 68.4 | 81.8 | 73.3 |
| Hemorrhage Presence Assessment | |||||||
|---|---|---|---|---|---|---|---|
| ICH Group (n = 120) | Healthy Control Group (n = 120) | ||||||
| ChatGPT-4o, Round 1 | ChatGPT-4o, Round 1 | ||||||
| Negative | Positive | Negative | Positive | ||||
| ChatGPT-4o, Round 2 | Negative | 9 | 7 | ChatGPT-4o, Round 2 | Negative | 52 | 20 |
| Positive | 16 | 88 | Positive | 17 | 31 | ||
| Hemorrhage Type (n = 150) | Correct, n (%) | Partially Correct, n (%) | Incorrect, n (%) | False Negative Cases, n (%) | Total, n (%) |
|---|---|---|---|---|---|
| Subdural | 21 (14) | 7 (4.7) | 26 (17.3) | 24 (16) | 78 (52) |
| Epidural | 1 (0.7) | 0 (0) | 10 (6.6) | 1 (0.7) | 12 (8) |
| Intraventricular | 3 (2) | 0 (0) | 4 (2.7) | 0 (0) | 7 (4.7) |
| Intraparenchymal | 25 (16.6) | 0 (0) | 9 (6) | 1 (0.7) | 35 (23.3) |
| Subarachnoid | 1 (0.7) | 0 (0) | 15 (10) | 2 (1.3) | 18 (12) |
| Total | 51 (34) | 7 (4.7) | 64 (42.6) | 28 (18.7) | 150 (100) |
| Associated Pathologies | True Positive, n (%) | False Negative, n (%) |
|---|---|---|
| Midline shift, n = 23 | 11 (47.8) | 12 (52.2) |
| Cerebral edema, n = 44 | 29 (65.9) | 15 (34.1) |
| Right lateral ventricle compression, n = 8 | 0 (0) | 8 (100) |
| Left lateral ventricle compression, n = 10 | 0 (0) | 10 (100) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koyun, M.; Cevval, Z.K.; Reis, B.; Ece, B. Detection of Intracranial Hemorrhage from Computed Tomography Images: Diagnostic Role and Efficacy of ChatGPT-4o. Diagnostics 2025, 15, 143. https://doi.org/10.3390/diagnostics15020143
Koyun M, Cevval ZK, Reis B, Ece B. Detection of Intracranial Hemorrhage from Computed Tomography Images: Diagnostic Role and Efficacy of ChatGPT-4o. Diagnostics. 2025; 15(2):143. https://doi.org/10.3390/diagnostics15020143
Chicago/Turabian StyleKoyun, Mustafa, Zeycan Kubra Cevval, Bahadir Reis, and Bunyamin Ece. 2025. "Detection of Intracranial Hemorrhage from Computed Tomography Images: Diagnostic Role and Efficacy of ChatGPT-4o" Diagnostics 15, no. 2: 143. https://doi.org/10.3390/diagnostics15020143
APA StyleKoyun, M., Cevval, Z. K., Reis, B., & Ece, B. (2025). Detection of Intracranial Hemorrhage from Computed Tomography Images: Diagnostic Role and Efficacy of ChatGPT-4o. Diagnostics, 15(2), 143. https://doi.org/10.3390/diagnostics15020143