
Hybrid CNN-Transformer Model for Accurate Impacted Tooth Detection in Panoramic Radiographs

 ,
,  , , , and
, , , and
Abstract
1. Introduction
- Integration of deep learning algorithms, including super-resolution techniques, CNNs, transformer-based models, and the Weighted Boxes Fusion (WBF) component, to improve the accuracy and efficiency of object detection in panoramic radiography images.
- Optimization of the model for accurate and real-time detection of impacted teeth in panoramic radiographs, assisting dentists in their clinical decision-making processes and contributing to more effective patient care.
- High detection accuracy validated through experimental studies, demonstrating that the model can reliably detect impacted teeth in panoramic images.
- Highlighting the potential of AI-based tools in dentistry to automate manual analysis processes, reduce the workload of experts, and minimize human error. These contributions show that the proposed model can have a wide range of applications in both academic and clinical settings, establishing a future reference point for artificial intelligence-based solutions in dentistry.
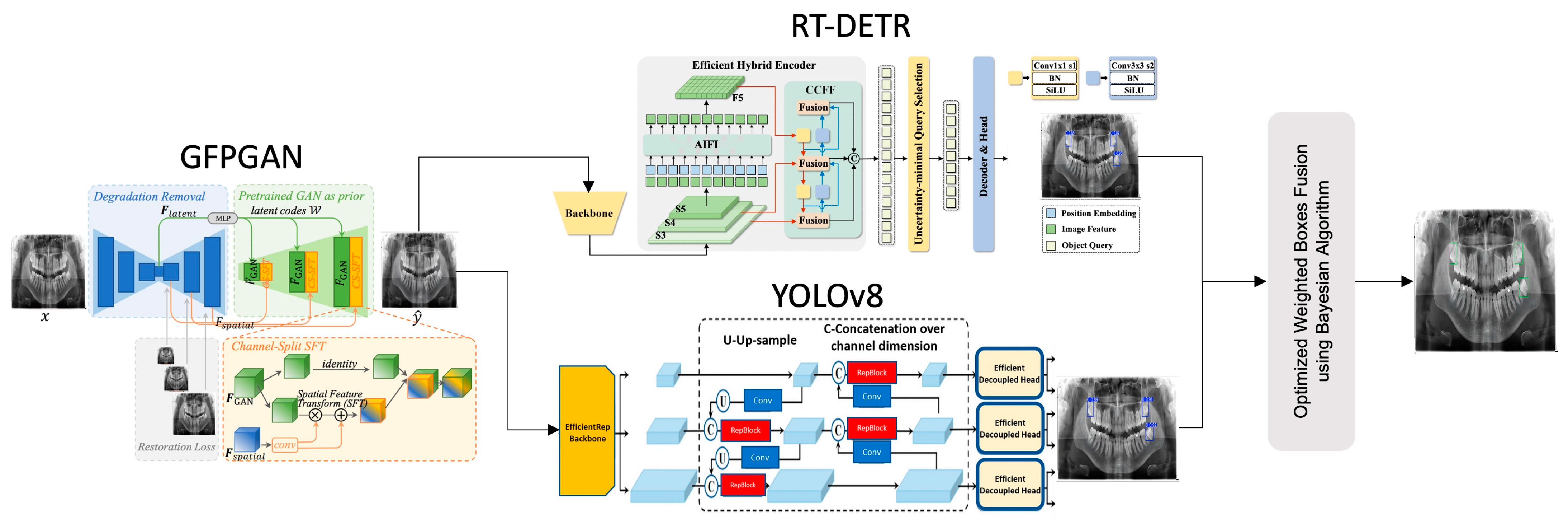
2. Materials and Methods
- The Generative Facial Prior (GFP-GAN) module improves the clarity of the input image by enhancing low-resolution panoramic images with a super-resolution method. This process provides higher quality data for the next steps and contributes significantly to the overall performance of the model. GFP-GAN reconstructs the detail in low-resolution images, producing a sharper and more meaningful input.
- In the second phase, the RT-DETR module uses a transformer-based approach to regionally detect dental structures in panoramic images. This module extracts meaningful features from complex image structures and accurately labels target regions. In particular, it provides high accuracy in dental radiographs thanks to its ability to model sequential relationships and improve positional accuracy.
- In the third stage, the YOLOv8 model classifies the detected tooth regions in detail and marks them more precisely. YOLOv8 is one of the most efficient object detection algorithms, delivering fast and accurate results. This component allows detailed analysis of important structures in dental radiographs and optimizes the detected areas, improving overall accuracy.
- In the final stage, the detection results from the different modules are combined with the WBF method, enhanced with Bayesian optimization. This method combines the strengths of the models and provides a more accurate and integrated output. By combining the predictions of different modules, WBF minimizes the false positive and false negative rates. Finally, the analysis of the dental structures is complete, and the results are presented with high accuracy.
2.1. Generative Facial Prior
2.2. CNN (YOLO)
- Main Network: YOLOv8 uses a modified version of CSPDarknet53 as its main network. CSPDarknet53 is replaced by the C2f Module, which uses gradient shunt connectivity to enrich the information flow and maintains a lightweight structure. Furthermore, the GIS Module performs processing using convolution, group normalization, and SiLU activation. YOLOv8 also uses the SPPF Module to convert the input feature maps into a fixed-size map, which reduces computational effort and lowers latency.
- Neck: The neck structure of YOLOv8 uses the PAN-FPN structure. Inspired by PANet, this structure improves location information by combining features at different scales and provides feature diversity and completion.
- Head: YOLOv8 uses two separate branches for segmentation and bounding box regression. For classification purposes, binary cross-entropy loss (BCE Loss) is applied, whereas distribution focal loss (DFL) and CIoU are utilized for tasks involving bounding box regression. The model also uses a non-anchor detection model and improves detection accuracy and robustness by assigning by task.
2.3. Transformer (RT-DETR)
- Backbone Network: RT-DETR uses convolution-based networks such as ResNet or HGNetv2 as the backbone. The last three stages of the backbone (S3, S4, S5) serve as the input for the hybrid encoder and enable efficient processing of multi-scale features. This design allows the model to be built on a strong foundation and provides a suitable structure for modeling multi-scale information.
- Neck: The neck structure of RT-DETR is not designed as a distinct intermediate layer as in conventional models but instead offers an innovative structure integrated within the Hybrid Encoder. The Neck function is realized by the following two modules:
- Attention in Feature Interaction (AIFI): This module is specifically designed to improve semantic information in deep feature maps (S5). AIFI enhances information flow by modeling dependencies between features. This approach provides high performance with a more minimal design unlike classical neck structures.
- Cross-Scale Feature-Fusion Module (CCFM): Combining features at different scales (S4 and S5) enables the model to effectively use multi-scale information. Instead of a classical feature pyramid, CCFM offers a lighter and more flexible fusion mechanism.
- 3.
- Head: Unlike conventional object detection models, RT-DETR’s head structure is designed to be more dynamic and integrated with the encoder. This structure works as follows:
- Decoder: The IoU-aware Query Selection mechanism selects the most relevant object queries from the features received from the encoder and optimizes them to generate class information and bounding boxes. This mechanism reduces redundant computations and improves accuracy by focusing on the most important objects in the scene.
- Auxiliary Prediction Heads: These heads enable the model to learn faster and more accurately by making intermediate predictions. Unlike the separate classification and regression heads in classical models, it works while integrated into the decoder and does not require an extra ‘head’ layer.
2.4. Ensemble Strategy
- The combined confidence score of the fused bounding box is calculated as the average of the confidence scores of all participating bounding boxes:
- The coordinates of the fused bounding box are computed as weighted averages of the corresponding coordinates of the individual bounding boxes:
2.5. Optimization
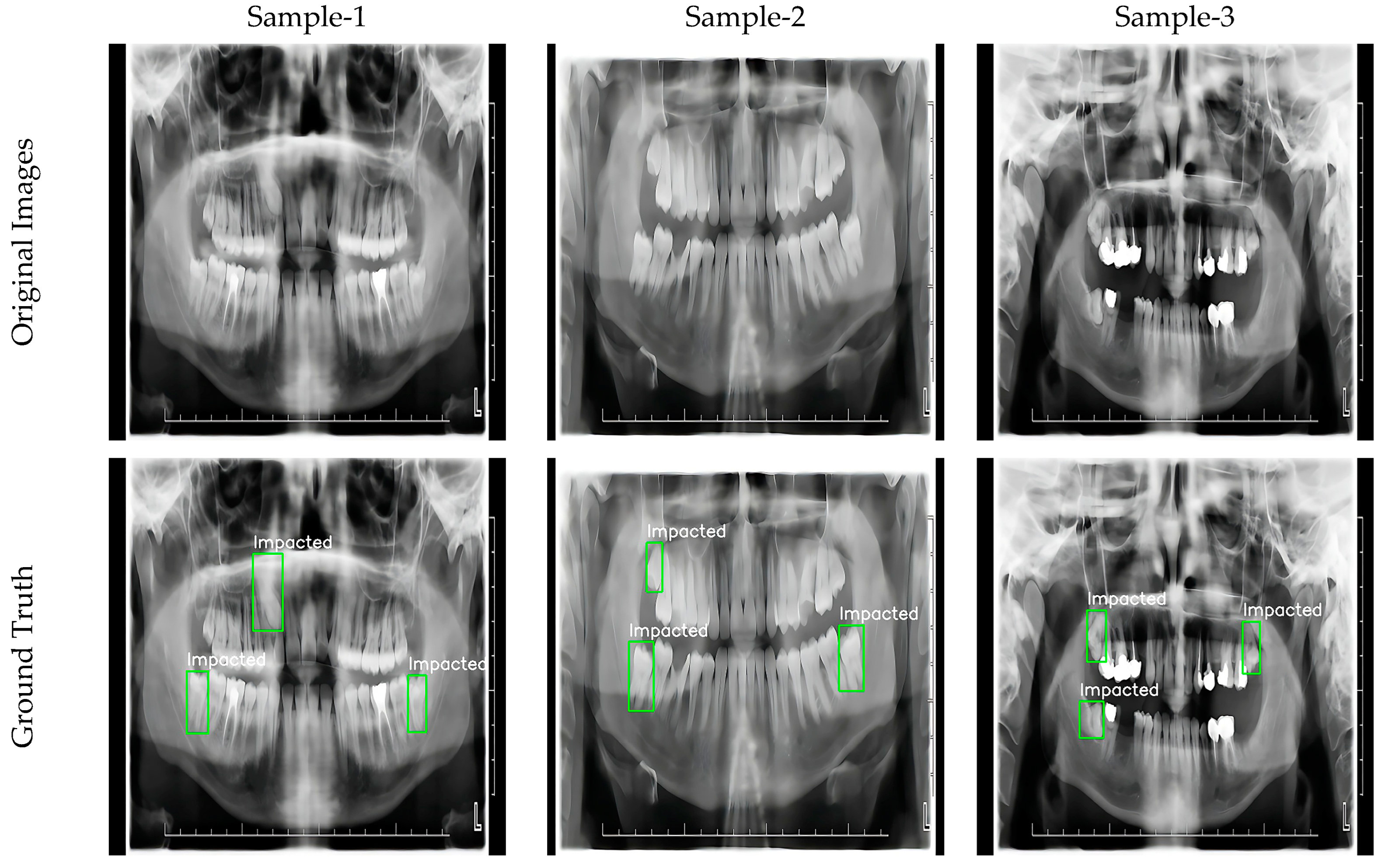
2.6. Dataset
2.7. Implementation Details
2.8. Performance Metrics
3. Experimental Results and Analysis
3.1. Individual Results
- The YOLOv8L model achieved the highest F1 values (94.6% and 94.5%) with both normal and GAN-based super-resolution images. It was also observed that mAP@0.5 (96.5%) improved with GAN-based images. These results show that YOLOv8L performs well with both image types. On the other hand, the YOLOv8X model performed similarly on normal and GAN-based images (88.8% mAP@0.5 and 93.7% F1). This suggests that the effect of GAN-based super-resolution on this model is limited.
- RT-DETR-L achieved the highest IoU score of 95.2% mAP@0.5 for normal images. However, this value decreased slightly to 94.7% for GAN-based images. In contrast, the GAN enhancement resulted in a significant increase in the F1 score (from 88.2% to 92.3%). On the other hand, RT-DETR-X showed a balanced performance on both normal and GAN-based images. However, there was a slight decrease in mAP@0.5 (92.3%) and F1 (91.7%) after GAN enhancement.
3.2. Ensemble Results
- In tests on normal images, the model combinations YOLOv8L + RT-DETR-X and YOLOv8X + RT-DETR-X achieved the highest F1 values (94.9% and 94.8%) and precision values (93.0% and 94.4%). These results indicate that the RT-DETR-X component provides high precision in normal images. On the other hand, the YOLOv8X + RT-DETR-L combination achieved the highest IoU value (95.6%) on normal images, but the recall rate (96.0%) remained similar to the other models.
- For GAN-enhanced images, the YOLOv8L + RT-DETR-X and YOLOv8L + RT-DETR-L combinations achieved the highest IoU and F1 scores (97.5% and 93.5%, 97.4% and 92.3%, respectively). YOLOv8L + RT-DETR-X performed particularly well in terms of precision (89.1%) and recall (98.4%). The combination YOLOv8X + RT-DETR-X showed a balanced performance on both normal and GAN-enhanced images, but the performance improvement after GAN enhancement was limited compared to the other combinations.
3.3. Optimized Results
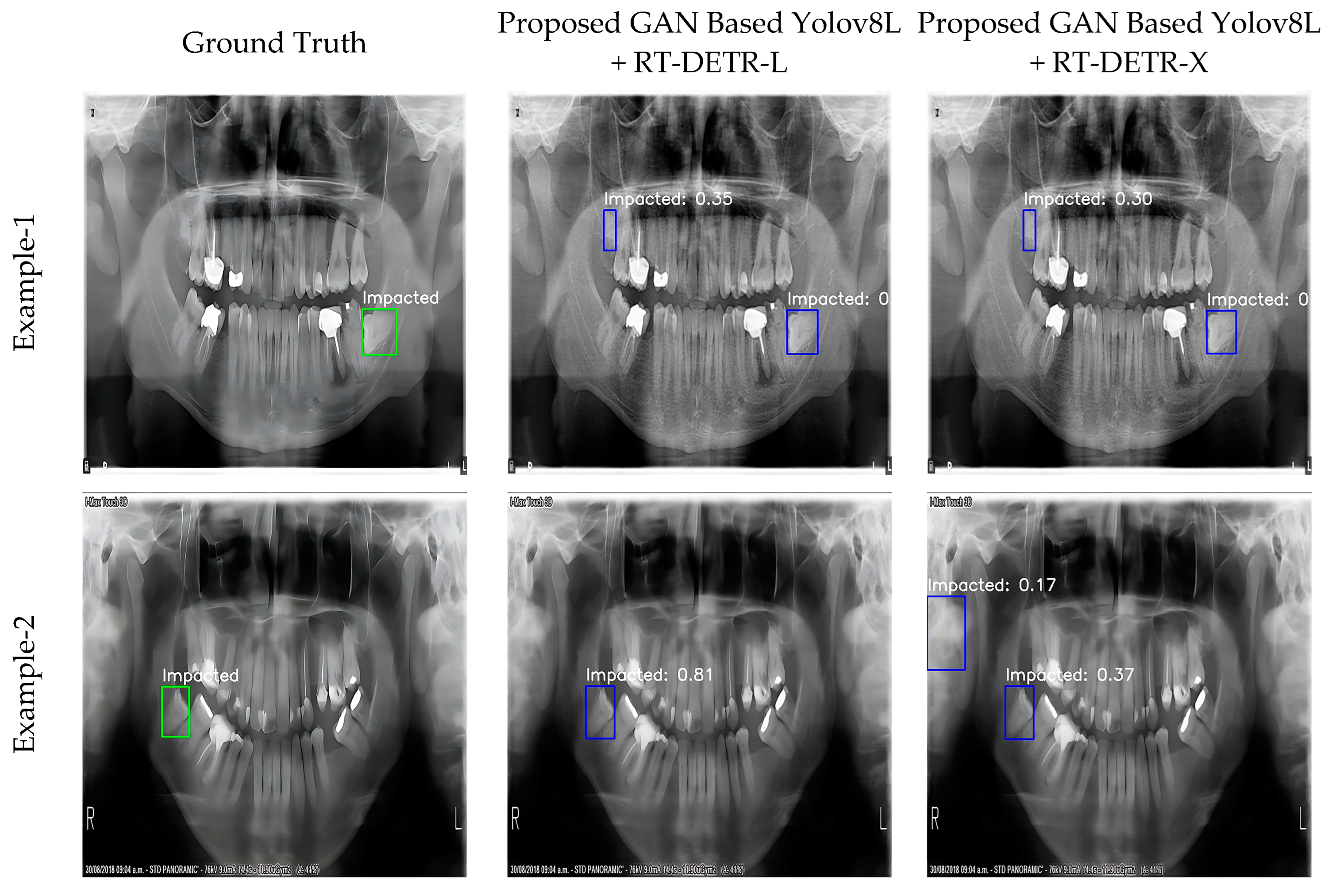
- YOLOv8L + RT-DETR-L: This model showed the highest accuracy of 98.3% with mAP@0.5. This means that the overall recognition accuracy of the model is quite high. The recall rate reached a remarkable 99.2%, indicating that the model was able to correctly detect almost all target objects. However, the precision remained relatively low compared to the other metrics at 86.7%. This suggests that the model’s false positive prediction rate could be improved. The F1 score reached 92.5% in the balance of precision and recall. The optimized parameters of the WBF algorithm for this model were determined as follows:
- IoU Threshold (iou_thr): 0.3466;
- Skip Box Threshold (skip_box_thr): 0.0340;
- YOLOv8L Weight (weight1): 4.2111;
- RT-DETR-L Weight (weight2): 2.9897.
- YOLOv8L + RT-DETR-X: This model achieved a high accuracy of 97.5% mAP@0.5 and a remarkable performance with an F1 score of 96.0%. The precision was 93.8% and the recall 98.4%. This shows that the model provides a balanced and reliable performance. The optimized parameters of the WBF algorithm for this model were determined as follows:
- IoU Threshold (iou_thr): 0.3597;
- Skip Box Threshold (skip_box_thr): 0.0843;
- YOLOv8L Weight (weight1): 7.7882;
- RT-DETR-L Weight (weight2): 7.6551.
3.4. Visualization
4. Discussion
4.1. Comparison of Previous Studies with Proposed Model
4.2. Limitations
4.3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Göksu, V.C.; Ersoy, H.E.; Eberliköse, H.; Yücel, E. Gömülü Mandibular Üçüncü Molar Diş Pozisyonlarının Demografik Olarak İncelenmesi: Retrospektif Çalışma. Ado Klin. Bilim. Derg. 2021, 10, 165–171. [Google Scholar]
- Kaczor-Urbanowicz, K.; Zadurska, M.; Czochrowska, E. Impacted Teeth: An Interdisciplinary Perspective. Adv. Clin. Exp. Med. Off. Organ Wroclaw Med. Univ. 2016, 25, 575–585. [Google Scholar] [CrossRef]
- Başaran, M.; Çelik, Ö.; Bayrakdar, I.S.; Bilgir, E.; Orhan, K.; Odabaş, A.; Jagtap, R. Diagnostic charting of panoramic radiography using deep-learning artificial intelligence system. Oral Radiol. 2022, 38, 363–369. [Google Scholar] [CrossRef] [PubMed]
- Orhan, K.; Bilgir, E.; Bayrakdar, I.S.; Ezhov, M.; Gusarev, M.; Shumilov, E. Evaluation of artificial intelligence for detecting impacted third molars on cone-beam computed tomography scans. J. Stomatol. Oral Maxillofac. Surg. 2021, 122, 333–337. [Google Scholar] [CrossRef] [PubMed]
- Zhicheng, H.; Yipeng, W.; Xiao, L. Deep Learning-Based Detection of Impacted Teeth on Panoramic Radiographs. Biomed. Eng. Comput. Biol. 2024, 15, 11795972241288319. [Google Scholar] [CrossRef] [PubMed]
- Faure, J.; Engelbrecht, A. Impacted tooth detection in panoramic radiographs. In Proceedings of the Advances in Computational Intelligence: 16th International Work-Conference on Artificial Neural Networks, IWANN 2021, Virtual Event, 16–18 June 2021; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 525–536, Part I 16. [Google Scholar]
- Sheiham, A. Editorials Oral Health, General Health and Quality of Life. Bull. World Health Organ. 2005, 83, 644. [Google Scholar]
- Sultan, A.S.; Elgharib, M.A.; Tavares, T.; Jessri, M.; Basile, J.R. The use of artificial intelligence, machine learning and deep learning in oncologic histopathology. J. Oral Pathol. Med. 2020, 49, 849–856. [Google Scholar] [CrossRef]
- Alhazmi, A.; Alhazmi, Y.; Makrami, A.; Masmali, A.; Salawi, N.; Masmali, K.; Patil, S. Application of artificial intelligence and machine learning for prediction of oral cancer risk. J. Oral Pathol. Med. 2021, 50, 444–450. [Google Scholar] [CrossRef]
- Takahashi, T.; Nozaki, K.; Gonda, T.; Mameno, T.; Wada, M.; Ikebe, K. Identification of dental implants using deep learning—Pilot study. Int. J. Implant. Dent. 2020, 6, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.W.; Kim, S.Y.; Jeong, S.N.; Lee, J.H. Artificial intelligence in fractured dental implant detection and classification: Evaluation using dataset from two dental hospitals. Diagnostics 2021, 11, 233. [Google Scholar] [CrossRef]
- Imak, A.; Çelebi, A.; Türkoğlu, M.; Şengür, A. Dental material detection based on faster regional convolutional neural networks and shape features. Neural Process. Lett. 2022, 54, 2107–2126. [Google Scholar] [CrossRef]
- Tuzoff, D.V.; Tuzova, L.N.; Bornstein, M.M.; Krasnov, A.S.; Kharchenko, M.A.; Nikolenko, S.I.; Bednenko, G.B. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dentomaxillofac. Radiol. 2019, 48, 20180051. [Google Scholar] [CrossRef] [PubMed]
- Putra, R.H.; Astuti, E.R.; Putri, D.K.; Widiasri, M.; Laksanti, P.A.M.; Majidah, H.; Yoda, N. Automated permanent tooth detection and numbering on panoramic radiograph using a deep learning approach. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2024, 137, 537–544. [Google Scholar] [CrossRef] [PubMed]
- Brahmi, W.; Jdey, I. Automatic tooth instance segmentation and identification from panoramic X-Ray images using deep CNN. Multimed. Tools Appl. 2024, 83, 55565–55585. [Google Scholar] [CrossRef]
- Sadr, S.; Mohammad-Rahimi, H.; Motamedian, S.R.; Zahedrozegar, S.; Motie, P.; Vinayahalingam, S.; Dianat, O.; Nosrat, A. Deep Learning for Detection of Periapical Radiolucent Lesions: A Systematic Review and Meta-analysis of Diagnostic Test Accuracy. J. Endod. 2023, 49, 248–261.e3. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, F.; Xie, Y.; Li, W.; Wang, X.; Liu, J. Periodontitis auxiliary diagnosis based on deep learning and oral dental x-ray images. Russ. J. Nondestruct. Test. 2023, 59, 487–500. [Google Scholar] [CrossRef]
- Bayrakdar, I.S.; Orhan, K.; Çelik, Ö.; Bilgir, E.; Sağlam, H.; Kaplan, F.A.; Różyło-Kalinowska, I. AU-net approach to apical lesion segmentation on panoramic radiographs. BioMed Res. Int. 2022, 2022, 7035367. [Google Scholar] [CrossRef] [PubMed]
- Shon, H.S.; Kong, V.; Park, J.S.; Jang, W.; Cha, E.J.; Kim, S.Y.; Kim, K.A. Deep learning model for classifying periodontitis stages on dental panoramic radiography. Appl. Sci. 2022, 12, 8500. [Google Scholar] [CrossRef]
- Jiang, L.; Chen, D.; Cao, Z.; Wu, F.; Zhu, H.; Zhu, F. A two-stage deep learning architecture for radiographic staging of periodontal bone loss. BMC Oral Health 2022, 22, 106. [Google Scholar] [CrossRef] [PubMed]
- Mori, M.; Ariji, Y.; Katsumata, A.; Kawai, T.; Araki, K.; Kobayashi, K.; Ariji, E. A deep transfer learning approach for the detection and diagnosis of maxillary sinusitis on panoramic radiographs. Odontology 2021, 109, 941–948. [Google Scholar] [CrossRef] [PubMed]
- Murata, M.; Ariji, Y.; Ohashi, Y.; Kawai, T.; Fukuda, M.; Funakoshi, T.; Kise, Y.; Nozawa, M.; Katsumata, A.; Fujita, H.; et al. Deep-learning classification using convolutional neural network for evaluation of maxillary sinusitis on panoramic radiography. Oral Radiol. 2019, 35, 301–307. [Google Scholar] [CrossRef]
- Çelebi, A.; Imak, A.; Üzen, H.; Budak, Ü.; Türkoğlu, M.; Hanbay, D.; Şengür, A. Maxillary sinus detection on cone beam computed tomography images using ResNet and Swin Transformer-based UNet. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2024, 138, 149–161. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.G.; Lee, K.M.; Kim, E.J.; Lee, J.S. Improvement diagnostic accuracy of sinusitis recognition in paranasal sinus X-ray using multiple deep learning models. Quant Imaging Med. Surg. 2019, 9, 942. [Google Scholar] [CrossRef]
- Kuwana, R.; Ariji, Y.; Fukuda, M.; Kise, Y.; Nozawa, M.; Kuwada, C.; Muramatsu, C.; Katsumata, A.; Fujita, H.; Ariji, E. Performance of deep learning object detection technology in the detection and diagnosis of maxillary sinus lesions on panoramic radiographs. Dentomaxillofac. Radiol. 2020, 50, 20200171. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, K.J.; Sunwoo, L.; Choi, D.; Nam, C.M.; Cho, J.; Kim, J.; Bae, Y.J.; Yoo, R.E.; Choi, B.S.; et al. Deep Learning in Diagnosis of Maxillary Sinusitis Using Conventional Radiography. Investig. Radiol. 2019, 54, 7–15. [Google Scholar] [CrossRef] [PubMed]
- Ohashi, Y.; Ariji, Y.; Katsumata, A.; Fujita, H.; Nakayama, M.; Fukuda, M.; Nozawa, M.; Ariji, E. Utilization of computer-aided detection system in diagnosing unilateral maxillary sinusitis on panoramic radiographs. Dentomaxillofac. Radiol. 2016, 45, 20150419. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Wang, K.; Wang, C.; Chen, R.; Zhu, F.; Long, H.; Guan, Q. Iterative learning for maxillary sinus segmentation based on bounding box annotations. Multimed. Tools Appl. 2024, 83, 33263–33293. [Google Scholar] [CrossRef]
- Yoo, Y.S.; Kim, D.; Yang, S.; Kang, S.R.; Kim, J.E.; Huh, K.H.; Yi, W.J. Comparison of 2D, 2.5 D, and 3D segmentation networks for maxillary sinuses and lesions in CBCT images. BMC Oral Health 2023, 23, 866. [Google Scholar] [CrossRef] [PubMed]
- Zeng, P.; Song, R.; Lin, Y.; Li, H.; Chen, S.; Shi, M.; Chen, Z. Abnormal maxillary sinus diagnosing on CBCT images via object detection and ‘straight-forward’classification deep learning strategy. J. Oral Rehabil. 2023, 50, 1465–1480. [Google Scholar] [CrossRef]
- Chen, I.D.S.; Yang, C.M.; Chen, M.J.; Chen, M.C.; Weng, R.M.; Yeh, C.H. Deep learning-based recognition of periodontitis and dental caries in dental x-ray images. Bioengineering 2023, 10, 911. [Google Scholar] [CrossRef]
- Khan, M.H.; Giri, P.S.; Jothi, J.A.A. Detection of cavities from oral Images using convolutional neural networks. In Proceedings of the 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), Prague, Czech Republic, 20–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- ForouzeshFar, P.; Safaei, A.A.; Ghaderi, F.; Hashemikamangar, S.S. Dental Caries diagnosis from bitewing images using convolutional neural networks. BMC Oral Health 2024, 24, 211. [Google Scholar] [CrossRef] [PubMed]
- Esmaeilyfard, R.; Bonyadifard, H.; Paknahad, M. Dental Caries Detection and Classification in CBCT Images Using Deep Learning. Int. Dent. J. 2024, 74, 328–334. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Xia, K.; Cen, Y.; Ying, S.; Zhao, Z. Artificial intelligence for caries detection: A novel diagnostic tool using deep learning algorithms. Oral Radiol. 2024, 40, 375–384. [Google Scholar] [CrossRef]
- Szabó, V.; Szabo, B.T.; Orhan, K.; Veres, D.S.; Manulis, D.; Ezhov, M.; Sanders, A. Validation of Artificial Intelligence Application for Dental Caries Diagnosis on Intraoral Bitewing and Periapical Radiographs. J. Dent. 2024, 147, 105105. [Google Scholar] [CrossRef] [PubMed]
- Haghanifar, A.; Majdabadi, M.M.; Haghanifar, S.; Choi, Y.; Ko, S.B. PaXNet: Tooth segmentation and dental caries detection in panoramic X-ray using ensemble transfer learning and capsule classifier. Multimed. Tools Appl. 2023, 82, 27659–27679. [Google Scholar] [CrossRef]
- Pérez de Frutos, J.; Holden Helland, R.; Desai, S.; Nymoen, L.C.; Langø, T.; Remman, T.; Sen, A. AI-Dentify: Deep learning for proximal caries detection on bitewing x-ray-HUNT4 Oral Health Study. BMC Oral Health 2024, 24, 344. [Google Scholar] [CrossRef]
- Imak, A.; Celebi, A.; Siddique, K.; Turkoglu, M.; Sengur, A.; Salam, I. Dental caries detection using score-based multi-input deep convolutional neural network. IEEE Access 2022, 10, 18320–18329. [Google Scholar] [CrossRef]
- Basri, K.N.; Yazid, F.; Zain, M.N.M.; Yusof, Z.M.; Rani, R.A.; Zoolfakar, A.S. Artificial neural network and convolutional neural network for prediction of dental caries. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2024, 312, 124063. [Google Scholar] [CrossRef] [PubMed]
- Chaves, E.T.; Vinayahalingam, S.; van Nistelrooij, N.; Xi, T.; Romero, V.H.D.; Flügge, T.; Cenci, M.S. Detection of caries around restorations on bitewings using deep learning. J. Dent. 2024, 143, 104886. [Google Scholar] [CrossRef]
- Kuwada, C.; Ariji, Y.; Fukuda, M.; Kise, Y.; Fujita, H.; Katsumata, A.; Ariji, E. Deep learning systems for detecting and classifying the presence of impacted supernumerary teeth in the maxillary incisor region on panoramic radiographs. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2020, 130, 464–469. [Google Scholar] [CrossRef]
- Durmuş, M.; Ergen, B.; Çelebi, A.; Türkoğlu, M. Panoramik diş görüntülerinde derin evrişimsel sinir ağına dayalı gömülü diş tespiti ve segmentasyonu. Çukurova Üniv. Mühendis. Fak. Derg. 2023, 38, 713–724. [Google Scholar] [CrossRef]
- Imak, A.; Çelebi, A.; Polat, O.; Türkoğlu, M.; Şengür, A. ResMIBCU-Net: An encoder–decoder network with residual blocks, modified inverted residual block, and bi-directional ConvLSTM for impacted tooth segmentation in panoramic X-ray images. Oral Radiol. 2023, 39, 614–628. [Google Scholar] [CrossRef] [PubMed]
- Celik, M.E. Deep learning based detection tool for impacted mandibular third molar teeth. Diagnostics 2022, 12, 942. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Li, Y.; Zhang, H.; Shan, Y. Towards real-world blind face restoration with generative facial prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9168–9178. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8110–8119. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 694–711, Part II 14. [Google Scholar]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Widayani, A.; Putra, A.M.; Maghriebi, A.R.; Adi, D.Z.C.; Ridho, M.H.F. Review of Application YOLOv8 in Medical Imaging. Indones. Appl. Phys. Lett. 2024, 5, 23–33. [Google Scholar] [CrossRef]
- Ju, R.Y.; Cai, W. Fracture Detection in Pediatric Wrist Trauma X-Ray Images Using YOLOv8 Algorithm. Sci. Rep. 2023, 13, 20077. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Yu, C.; Shin, Y. An Enhanced RT-DETR with Dual Convolutional Kernels for SAR Ship Detection. In Proceedings of the 2024 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Osaka, Japan, 19–22 February 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 425–428. [Google Scholar]
- Solovyev, R.; Wang, W.; Gabruseva, T. Weighted boxes fusion: Ensembling boxes from different object detection models. Image Vis. Comput. 2021, 107, 104117. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, L.; Zhang, D. An Ensemble Learning and Slice Fusion Strategy for Three-Dimensional Nuclei Instance Segmentation in Medical Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 1–10. [Google Scholar]
- Xiong, Y.; Deng, L.; Wang, Y. Pulmonary nodule detection based on model fusion and adaptive false positive reduction. Expert Syst. Appl. 2024, 238, 121890. [Google Scholar] [CrossRef]
- Pelikan, M.; Goldberg, D.E.; Cantú-Paz, E. BOA: The Bayesian optimization algorithm. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), Orlando, FL, USA, 13–17 July 1999; pp. 525–532. [Google Scholar]
- Frazier, P.I. A tutorial on Bayesian optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar]
- Victoria, A.H.; Maragatham, G. Automatic tuning of hyperparameters using Bayesian optimization. Evol. Syst. 2021, 12, 217–223. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Klein, A.; Falkner, S.; Bartels, S.; Hennig, P.; Hutter, F. Fast bayesian optimization of machine learning hyperparameters on large datasets. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 528–536. [Google Scholar]
- Román, J.C.M.; Fretes, V.R.; Adorno, C.G.; Silva, R.G.; Noguera, J.L.V.; Legal-Ayala, H.; Mello-Román, J.D.; Torres, R.D.E.; Facon, J. Panoramic dental radiography image enhancement using multiscale mathematical morphology. Sensors 2021, 21, 3110. [Google Scholar] [CrossRef] [PubMed]
- Abdi, A.H.; Kasaei, S.; Mehdizadeh, M. Automatic segmentation of mandible in panoramic X-ray. J. Med. Imaging 2015, 2, 044003. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Search Ranges |
|---|---|
| IoU threshold | 0.1–0.9 |
| Skip box threshold | 0.001–0.1 |
| Weight1 (YOLO weight) | 1–10 |
| Weight2 (RT-DETR weight) | 1–10 |
| Models | Normal Images | GAN Images | ||
|---|---|---|---|---|
| mAP@0.5 | F1 | mAP@0.5 | F1 | |
| Yolov8L | 91.3 | 94.6 | 96.5 | 94.5 |
| Yolov8X | 88.8 | 93.7 | 88.8 | 93.7 |
| RT-DETR-L | 95.2 | 88.2 | 94.7 | 92.3 |
| RT-DETR-X | 94.2 | 92.2 | 92.3 | 91.7 |
| Input | Hybrid Models | mAP@0.5 | F1 | Precision | Recall |
|---|---|---|---|---|---|
| Normal Images | Yolov8L + RT-DETR-L | 95.4 | 88.8 | 82.7 | 96 |
| Yolov8X + RT-DETR-L | 95.6 | 89.5 | 83.9 | 96 | |
| Yolov8L + RT-DETR-X | 95.3 | 94.9 | 93 | 96.8 | |
| Yolov8X + RT-DETR-X | 94.6 | 94.8 | 94.4 | 95.2 | |
| GAN Images | Yolov8L + RT-DETR-L | 97.4 | 92.3 | 86.6 | 98.4 |
| Yolov8X + RT-DETR-L | 95.5 | 93 | 89.6 | 96.8 | |
| Yolov8L + RT-DETR-X | 97.5 | 93.5 | 89.1 | 98.4 | |
| Yolov8X + RT-DETR-X | 94.6 | 94.8 | 94.4 | 95.2 |
| Input | Hybrid Models | mAP@0.5 | F1 | Precision | Recall |
|---|---|---|---|---|---|
| GAN Images | Yolov8L + RT-DETR-L | 98.3 | 92.5 | 86.7 | 99.2 |
| Yolov8L + RT-DETR-X | 97.5 | 96 | 93.8 | 98.4 |
| Reference | Dataset | Models | Performance Results |
|---|---|---|---|
| [3] | 1084 panoramic radiographs | Faster R-CNN Inception v2 | F1 score: 86.25% |
| [44] | 440 panoramic radiographs | AlexNet-Faster R-CNN | mAP: 86% |
| VGG16-Faster R-CNN | mAP: 87% | ||
| ResNet50-Faster R-CNN | mAP: 91% | ||
| YOLO v3 | mAP: 96% | ||
| Our model | 407 panoramic radiographs | GAN based Yolov8L + RT-DETR-L | mAP: 98.3% F1 score: 92.5% |
| GAN based Yolov8L + RT-DETR-X | mAP: 97.5% F1 score: 96% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Küçük, D.B.; Imak, A.; Özçelik, S.T.A.; Çelebi, A.; Türkoğlu, M.; Sengur, A.; Koundal, D. Hybrid CNN-Transformer Model for Accurate Impacted Tooth Detection in Panoramic Radiographs. Diagnostics 2025, 15, 244. https://doi.org/10.3390/diagnostics15030244
Küçük DB, Imak A, Özçelik STA, Çelebi A, Türkoğlu M, Sengur A, Koundal D. Hybrid CNN-Transformer Model for Accurate Impacted Tooth Detection in Panoramic Radiographs. Diagnostics. 2025; 15(3):244. https://doi.org/10.3390/diagnostics15030244
Chicago/Turabian StyleKüçük, Deniz Bora, Andaç Imak, Salih Taha Alperen Özçelik, Adalet Çelebi, Muammer Türkoğlu, Abdulkadir Sengur, and Deepika Koundal. 2025. "Hybrid CNN-Transformer Model for Accurate Impacted Tooth Detection in Panoramic Radiographs" Diagnostics 15, no. 3: 244. https://doi.org/10.3390/diagnostics15030244
APA StyleKüçük, D. B., Imak, A., Özçelik, S. T. A., Çelebi, A., Türkoğlu, M., Sengur, A., & Koundal, D. (2025). Hybrid CNN-Transformer Model for Accurate Impacted Tooth Detection in Panoramic Radiographs. Diagnostics, 15(3), 244. https://doi.org/10.3390/diagnostics15030244