
Detection of Fractured Endodontic Instruments in Periapical Radiographs: A Comparative Study of YOLOv8 and Mask R-CNN


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
- (1)
- FEIs with RCT
- (2)
- FEIs without RCT
- (3)
- Teeth with complete RCT
- (4)
- Teeth without RCT or FEIs
2.2. Ground Truth Determination and Observer Agreement
2.3. Model Selection and Training
2.4. Box Loss Calculation
2.5. Follow-Up Analysis
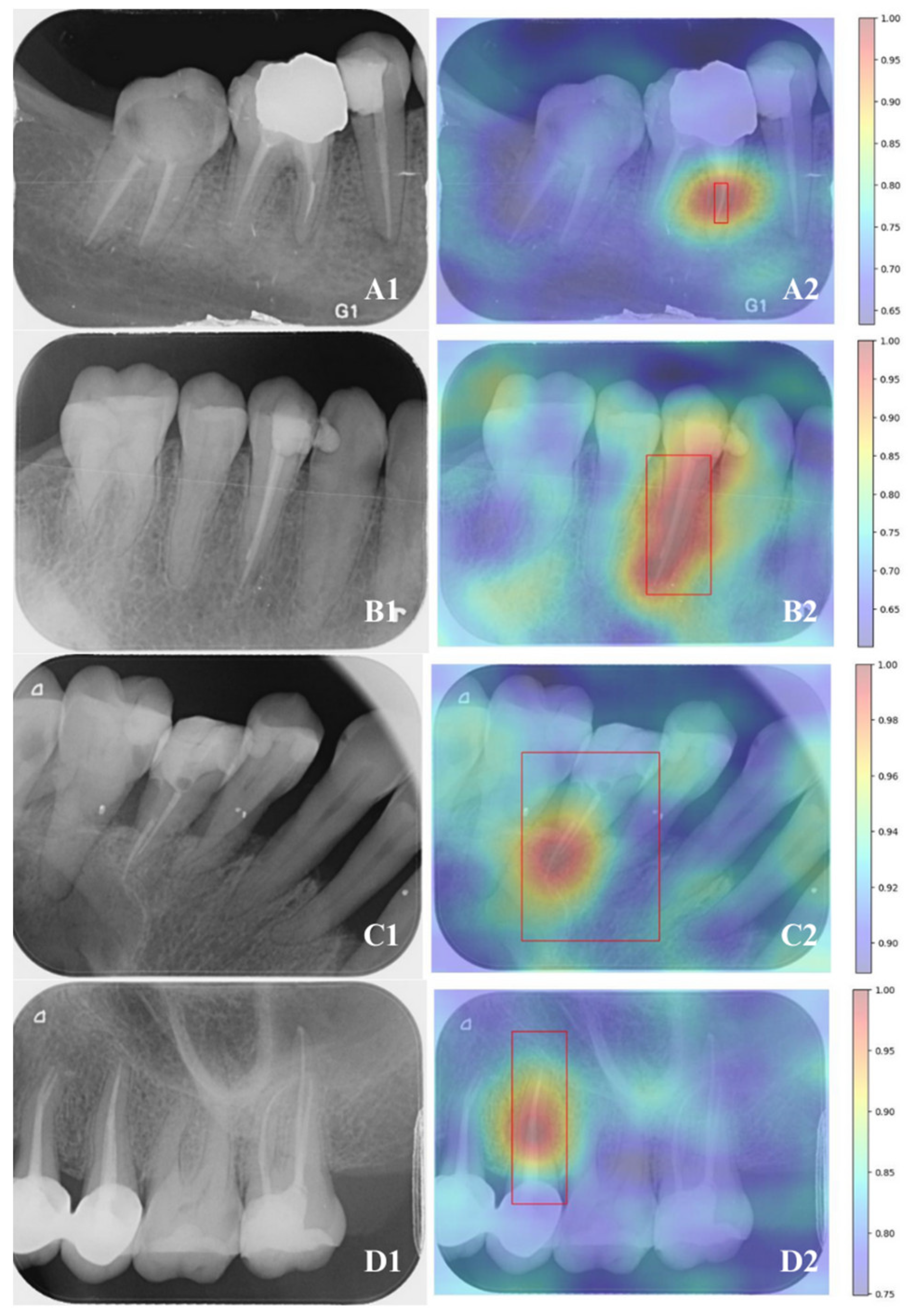
2.6. Methods for Evaluating Model Effectiveness
2.7. Statistical Analysis
3. Results
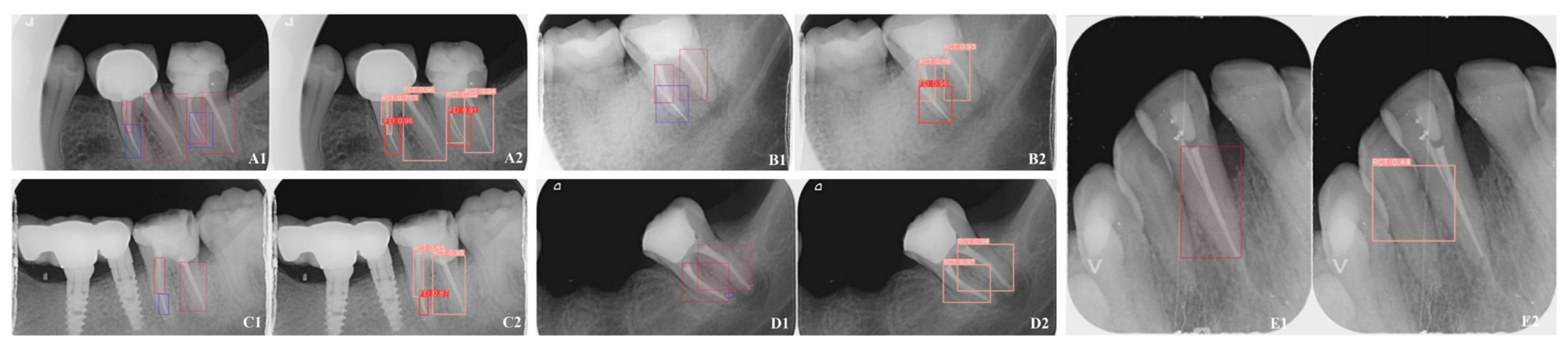
3.1. Model Performance
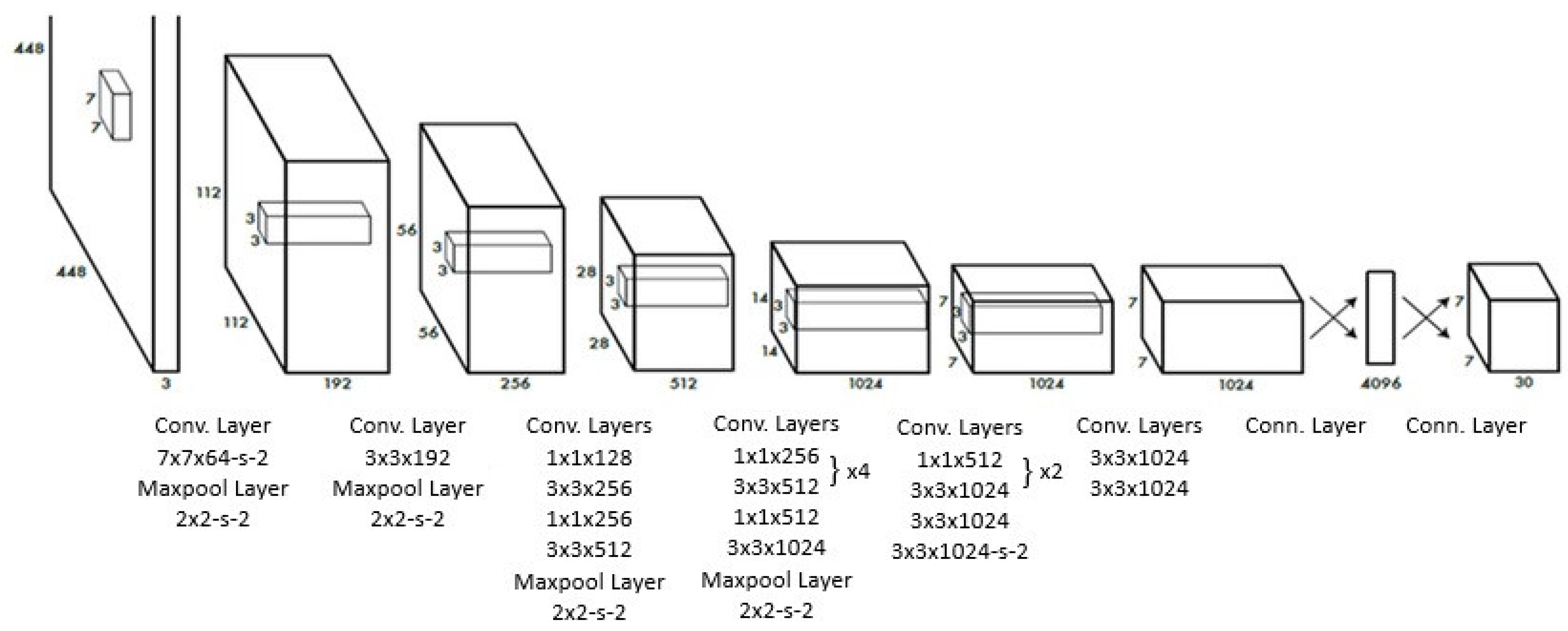
3.2. Algorithmic Overview of YOLOv8 and Mask R-CNN
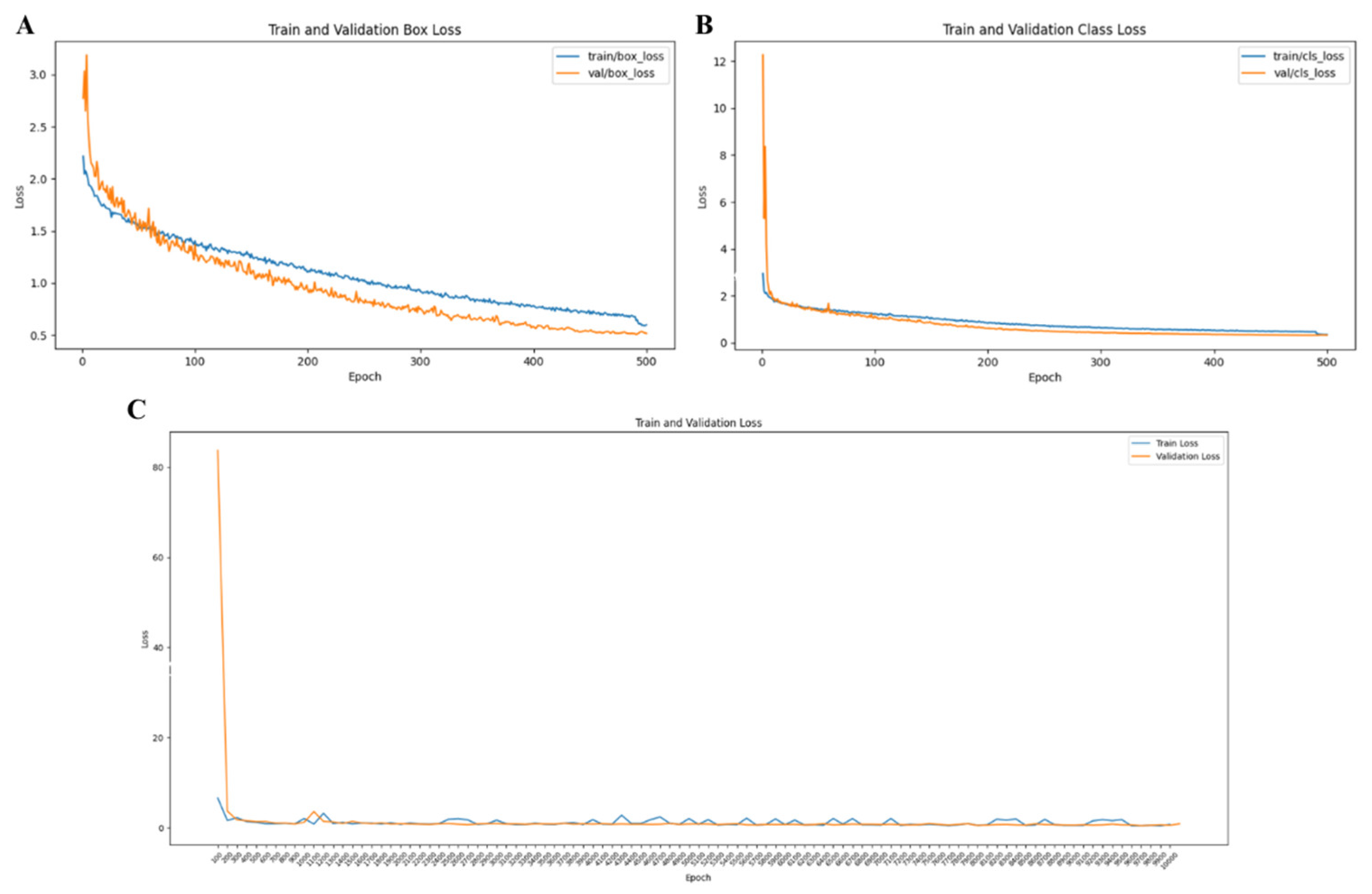
3.3. Training and Validation Stability
3.4. Comparative Performance Between Models and Endodontists
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FEI | Fractured Endodontic Instrument |
| RCT | Root Canal Treatment |
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| MAP | Mean Average Precision |
| PA | Periapical Radiograph |
| ICC | Inter-Class Correlation |
| BG | Background |
| IOU | Intersection Over Union |
| RPN | Region Proposal Network |
| ROI | Region of Interest |
| FC | Fully Connected |
| Conv | Convolutional |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
References
- Panitvisai, P.; Parunnit, P.; Sathorn, C.; Messer, H.H. Impact of a retained instrument on treatment outcome: A systematic review and meta-analysis. J. Endod. 2010, 36, 775–780. [Google Scholar] [CrossRef] [PubMed]
- Gorduysus, M.; Avcu, N. Evaluation of the radiopacity of different root canal sealers. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. Endodontology 2009, 108, e135–e140. [Google Scholar] [CrossRef] [PubMed]
- Brito, A.C.R.; Verner, F.S.; Junqueira, R.B.; Yamasaki, M.C.; Queiroz, P.M.; Freitas, D.Q.; Oliveira-Santos, C. Detection of fractured endodontic instruments in root canals: Comparison between different digital radiography systems and cone-beam computed tomography. J. Endod. 2017, 43, 544–549. [Google Scholar] [CrossRef]
- Jayachandran, S. Digital imaging in dentistry: A review. Contemp. Clin. Dent. 2017, 8, 193–194. [Google Scholar] [CrossRef]
- Özbay, Y.; Kazangirler, B.Y.; Özcan, C.; Pekince, A. Detection of the separated endodontic instrument on periapical radiographs using a deep learning-based convolutional neural network algorithm. Aust. Endod. J. 2024, 50, 131–139. [Google Scholar] [CrossRef]
- Bonfanti-Gris, M.; Herrera, A.; Paraíso-Medina, S.; Alonso-Calvo, R.; Martínez-Rus, F.; Pradíes, G. Performance evaluation of three versions of a convolutional neural network for object detection and segmentation using a multiclass and reduced panoramic radiograph dataset. J. Dent. 2024, 144, 104891. [Google Scholar] [CrossRef] [PubMed]
- Buyuk, C.; Arican Alpay, B.; Er, F. Detection of the separated root canal instrument on panoramic radiograph: A comparison of LSTM and CNN deep learning methods. Dentomaxillofacial Radiol. 2023, 52, 20220209. [Google Scholar] [CrossRef]
- Xue, T.; Chen, L.; Sun, Q. Deep learning method to automatically diagnose periodontal bone loss and periodontitis stage in dental panoramic radiograph. J. Dent. 2024, 150, 105373. [Google Scholar] [CrossRef]
- Anantharaman, R.; Velazquez, M.; Lee, Y. Utilizing mask R-CNN for detection and segmentation of oral diseases. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018. [Google Scholar]
- Sivari, E.; Senirkentli, G.B.; Bostanci, E.; Guzel, M.S.; Acici, K.; Asuroglu, T. Deep learning in diagnosis of dental anomalies and diseases: A systematic review. Diagnostics 2023, 13, 2512. [Google Scholar] [CrossRef]
- Yüksel, A.E.; Gültekin, S.; Simsar, E.; Özdemir, Ş.D.; Gündoğar, M.; Tokgöz, S.B.; Hamamcı, İ.E. Dental enumeration and multiple treatment detection on panoramic X-rays using deep learning. Sci. Rep. 2021, 11, 12342. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Available online: https://xaitk-saliency.readthedocs.io/en/latest/introduction.html#saliency-algorithms (accessed on 23 February 2025).
- Petsiuk, V.; Das, A.; Saenko, K. Rise: Randomized input sampling for explanation of black-box models. arXiv 2018, arXiv:1806.07421. [Google Scholar]
- Rašić, M.; Tropčić, M.; Karlović, P.; Gabrić, D.; Subašić, M.; Knežević, P. Detection and Segmentation of Radiolucent Lesions in the Lower Jaw on Panoramic Radiographs Using Deep Neural Networks. Medicina 2023, 59, 2138. [Google Scholar] [CrossRef]
- Tekin, B.Y.; Ozcan, C.; Pekince, A.; Yasa, Y. An enhanced tooth segmentation and numbering according to FDI notation in bitewing radiographs. Comput. Biol. Med. 2022, 146, 105547. [Google Scholar]
- McGuigan, M.; Louca, C.; Duncan, H. Clinical decision-making after endodontic instrument fracture. Br. Dent. J. 2013, 214, 395–400. [Google Scholar] [CrossRef]
- Souyave, L.; Inglis, A.; Alcalay, M. Removal of fractured endodontic instruments using ultrasonics. Br. Dent. J. 1985, 159, 251–253. [Google Scholar] [CrossRef]
- Souter, N.J.; Messer, H.H. Complications associated with fractured file removal using an ultrasonic technique. J. Endod. 2005, 31, 450–452. [Google Scholar] [CrossRef]
- Hülsmann, M.; Schinkel, I. Influence of several factors on the success or failure of removal of fractured instruments from the root canal. Dent. Traumatol. 1999, 15, 252–258. [Google Scholar] [CrossRef]
- Razaghi, M.; Komleh, H.E.; Dehghani, F.; Shahidi, Z. Innovative Diagnosis of Dental Diseases Using YOLO V8 Deep Learning Model. In Proceedings of the 2024 13th Iranian/3rd International Machine Vision and Image Processing Conference (MVIP), Tehran, Iran, 6–7 March 2024. [Google Scholar]
- Çelik, B.; Çelik, M.E. Root dilaceration using deep learning: A diagnostic approach. Appl. Sci. 2023, 13, 8260. [Google Scholar] [CrossRef]
- Mureșanu, S.; Hedeșiu, M.; Iacob, L.; Eftimie, R.; Olariu, E.; Dinu, C.; Jacobs, R.; on behalf of Team Project Group. Automating Dental Condition Detection on Panoramic Radiographs: Challenges, Pitfalls, and Opportunities. Diagnostics 2024, 14, 2336. [Google Scholar] [CrossRef]
- Yavuz, M.B.; Sali, N.; Bayrakdar, S.K.; Ekşi, C.; İmamoğlu, B.S.; Bayrakdar, İ.Ş.; Çelik, Ö.; Orhan, K. Classification of Periapical and Bitewing Radiographs as Periodontally Healthy or Diseased by Deep Learning Algorithms. Cureus 2024, 16, e60550. [Google Scholar] [CrossRef] [PubMed]
- Wu, P.Y.; Mao, Y.C.; Lin, Y.J.; Li, X.H.; Ku, L.T.; Li, K.C.; Chen, C.A.; Chen, T.Y.; Chen, S.L.; Tu, W.C.; et al. Precision Medicine for Apical Lesions and Peri-Endo Combined Lesions Based on Transfer Learning Using Periapical Radiographs. Bioengineering 2024, 11, 877. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.X.; Zhang, S.B.; Wei, Z.Y.; Fang, X.L.; Liu, F.; Han, M.; Du, M. Deep learning-based efficient diagnosis of periapical diseases with dental X-rays. Image Vis. Comput. 2024, 147, 105061. [Google Scholar] [CrossRef]
- Guo, Y.; Guo, J.; Li, Y.; Zhang, P.; Zhao, Y.-D.; Qiao, Y.; Liu, B.; Wang, G. Rapid detection of non-normal teeth on dental X-ray images using improved Mask R-CNN with attention mechanism. Int. J. Comput. Assist. Radiol. Surg. 2024, 19, 779–790. [Google Scholar] [CrossRef]
- Jayasinghe, H.; Pallepitiya, N.; Chandrasiri, A.; Heenkenda, C.; Vidhanaarachchi, S.; Kugathasan, A.; Rathnayaka, K.; Wijekoon, J. Effectiveness of Using Radiology Images and Mask R-CNN for Stomatology. In Proceedings of the 2022 4th International Conference on Advancements in Computing (ICAC), Colombo, Sri Lanka, 9–10 December 2022. [Google Scholar]
- Widyaningrum, R.; Candradewi, I.; Aji, N.R.A.S.; Aulianisa, R. Comparison of Multi-Label U-Net and Mask R-CNN for panoramic radiograph segmentation to detect periodontitis. Imaging Sci. Dent. 2022, 52, 383–391. [Google Scholar] [CrossRef]
- Abbas, N.M.; Solomon, D.G.; Bahari, M.F. A review on current research trends in electrical discharge machining (EDM). Int. J. Mach. Tools Manuf. 2007, 47, 1214–1228. [Google Scholar] [CrossRef]
- Roganović, J.; Radenković, M.; Miličić, B. Responsible use of artificial intelligence in dentistry: Survey on dentists’ and final-year undergraduates’ perspectives. Healthcare 2023, 11, 1480. [Google Scholar] [CrossRef]
- Gianfrancesco, M.A.; Tamang, S.; Yazdany, J.; Schmajuk, G. Potential biases in machine learning algorithms using electronic health record data. JAMA Intern. Med. 2018, 178, 1544–1547. [Google Scholar] [CrossRef]
- Mörch, C.; Atsu, S.; Cai, W.; Li, X.; Madathil, S.; Liu, X.; Mai, V.; Tamimi, F.; Dilhac, M.; Ducret, M. Artificial intelligence and ethics in dentistry: A scoping review. J. Dent. Res. 2021, 100, 1452–1460. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | IoU (Intersection Over Union) | mAP50 | Interference Time | |
|---|---|---|---|---|
| YOLO v8 | 0.973975 | 1.00 | 0.989 | 14.6 ms |
| Mask-R-CNN | 0.982075 | 0.99 | 0.950 | 88.7 ms |
| p | 0.571 | 0.146 | 0.020 |
| Endodontist A | Endodontist B | Mask-R-CNN | YOLOv8 | A-B (p) | A- Mask-R-CNN (p) | A- YOLOv8 (p) | B- Mask-R-CNN (p) | B- YOLOv8 (p) | Mask-R-CNN-YOLOv8 (p) | |
|---|---|---|---|---|---|---|---|---|---|---|
| BG F1 Score | N/A | N/A | 0.9893 | N/A | --- | --- | --- | --- | --- | --- |
| FEI F1 Score | 0.9947 | 0.9947 | 0.9890 | 1.0000 | 1.000 | 0.640 | 0.447 | 0.640 | 0.447 | 0.272 |
| RCT F1 Score | 0.9944 | 0.9944 | 1.0000 | 0.9964 | 1.000 | 0.447 | 0.832 | 0.447 | 0.832 | 0.542 |
| BG- FEI (p) | --- | --- | 0.971 | --- | ||||||
| BG- RCT (p) | --- | --- | 0.064 | --- | ||||||
| FEI- RCT (p) | 0.967 | 0.967 | 0.126 | 0.382 |
| Feature | YOLOv8 | Mask R-CNN |
|---|---|---|
| Detection Architecture | Single-stage detector that processes the entire image in a single pass. | Two-stage detector that first generates region proposals and then refines detections and segments objects. |
| Network Architecture | Uses a CNN backbone with a unified prediction head for bounding boxes and class probabilities. | Utilizes a CNN backbone with a Region Proposal Network (RPN), followed by RoI Align and separate branches for classification, box regression, and mask prediction. |
| Computational Efficiency | Optimized for speed and efficiency, making it suitable for real-time applications. | More computationally demanding due to its two-stage process, leading to higher precision but slower inference. |
| Detection and Segmentation Output | Outputs bounding boxes and class scores, with instance segmentation added after v8. | Produces bounding boxes, class labels, and masks for pixel-level segmentation. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Çetinkaya, İ.; Çatmabacak, E.D.; Öztürk, E. Detection of Fractured Endodontic Instruments in Periapical Radiographs: A Comparative Study of YOLOv8 and Mask R-CNN. Diagnostics 2025, 15, 653. https://doi.org/10.3390/diagnostics15060653
Çetinkaya İ, Çatmabacak ED, Öztürk E. Detection of Fractured Endodontic Instruments in Periapical Radiographs: A Comparative Study of YOLOv8 and Mask R-CNN. Diagnostics. 2025; 15(6):653. https://doi.org/10.3390/diagnostics15060653
Chicago/Turabian StyleÇetinkaya, İrem, Ekin Deniz Çatmabacak, and Emir Öztürk. 2025. "Detection of Fractured Endodontic Instruments in Periapical Radiographs: A Comparative Study of YOLOv8 and Mask R-CNN" Diagnostics 15, no. 6: 653. https://doi.org/10.3390/diagnostics15060653
APA StyleÇetinkaya, İ., Çatmabacak, E. D., & Öztürk, E. (2025). Detection of Fractured Endodontic Instruments in Periapical Radiographs: A Comparative Study of YOLOv8 and Mask R-CNN. Diagnostics, 15(6), 653. https://doi.org/10.3390/diagnostics15060653