
Developments in Deep Learning Artificial Neural Network Techniques for Medical Image Analysis and Interpretation



Abstract
1. Introduction
1.1. Deep Learning Overview
1.2. Deep Learning in Medical Imaging, Classification, and Segmentation
1.3. Challenges in Utilising Deep Learning in the Medical Field
- Overfitting during training. Overfitting causes poor accuracy when training deep artificial neural networks in recognising images not included during their training dataset (i.e., unseen or test images), even though the images in the training set could have been correctly recognised [6,7,8,9,10]. It has several possible causes that include insufficient training examples to facilitate adequate generalisation and excessive model parameters for the architecture. However, there are techniques that could be valuable to deal with overfitting. One technique is known as dropout [6,11,12,13,14], whereby some nodes in the architecture are temporarily left out during training. Another approach is to artificially extend the number of examples in the training dataset through a process known as data augmentation [15,16,17]. A comparison of different image data augmentation methods was reported in [18]. The technique has been applied to mammograms [19] and CT images [20]. Augmentation can be performed by manipulating the images through processes such as kernel filters, geometric transformation, random erasing, and mixing images. It can also be carried out through deep learning approaches such as adversarial training, neural style transformers, and generative adversarial networks [7]. An issue with performing data augmentation is selecting the best approach for a given set of images [21]. An exploration of the influence of different data augmentation techniques on the explainability of deep learning methods was reported in [22].
- Image annotation. Many deep learning algorithms are supervised, i.e., they require labelled images indicating their categories during their training phase. The labelling requires annotation of images by qualified medical practitioners. Because deep learning requires large datasets for training, this process can be time-consuming. However, there have been reports of automated and interactive image annotation methods that can assist with this operation, e.g., [23,24,25,26,27,28].
- Noisy images. Medical images can be noisy. Noise distorts the quality of images being used to train deep learning networks [29] and can reduce their ability to learn effectively.
- Interpretability. This is an area of great research interest to render decision-making by deep learning artificial neural networks more transparent, i.e., moving away from so-called black box behaviour to more interpretable decision-making. The issue of interpretability has been explored in many studies, e.g., [30,31,32,33,34,35,36]. Interpretability can be considered from multiple perspectives, e.g., user orientation for explanations provided, visualisation through graphs, charts rules etc, user comprehensibility through comprehensive reasoning, simplicity of explanations, local interpretation of a single datum and global interpretation of overall data, consistency in explanations, transparency in decision-making, and ethics and fairness in revealing bias and discrimination [31].
- Data sharing complexities and small datasets. Medical data gathered by a single institution may be insufficient to allow effective training of deep learning algorithms, and thus sharing across many institutions would be required. This, however, could be challenging due to regulatory, technical, and privacy concerns [37] and financial and time constraints, and limited availability of patients can limit the dataset. However, valuable techniques have been devised to address small-dataset problems in deep learning [38,39].
- Trust. There is an ongoing issue of relying on critical medical diagnostic results generated when the manner of their generation is not sufficiently transparent [4].
- Computational requirements and environmental issues. Training deep learning algorithms typically requires high computational capabilities and long durations. Many general-purpose computers do not have the means of delivering the required computational resources, and there is also the issue of the environmental aspects of using so much electricity to perform the required deep learning training [44,45].
2. Materials and Methods
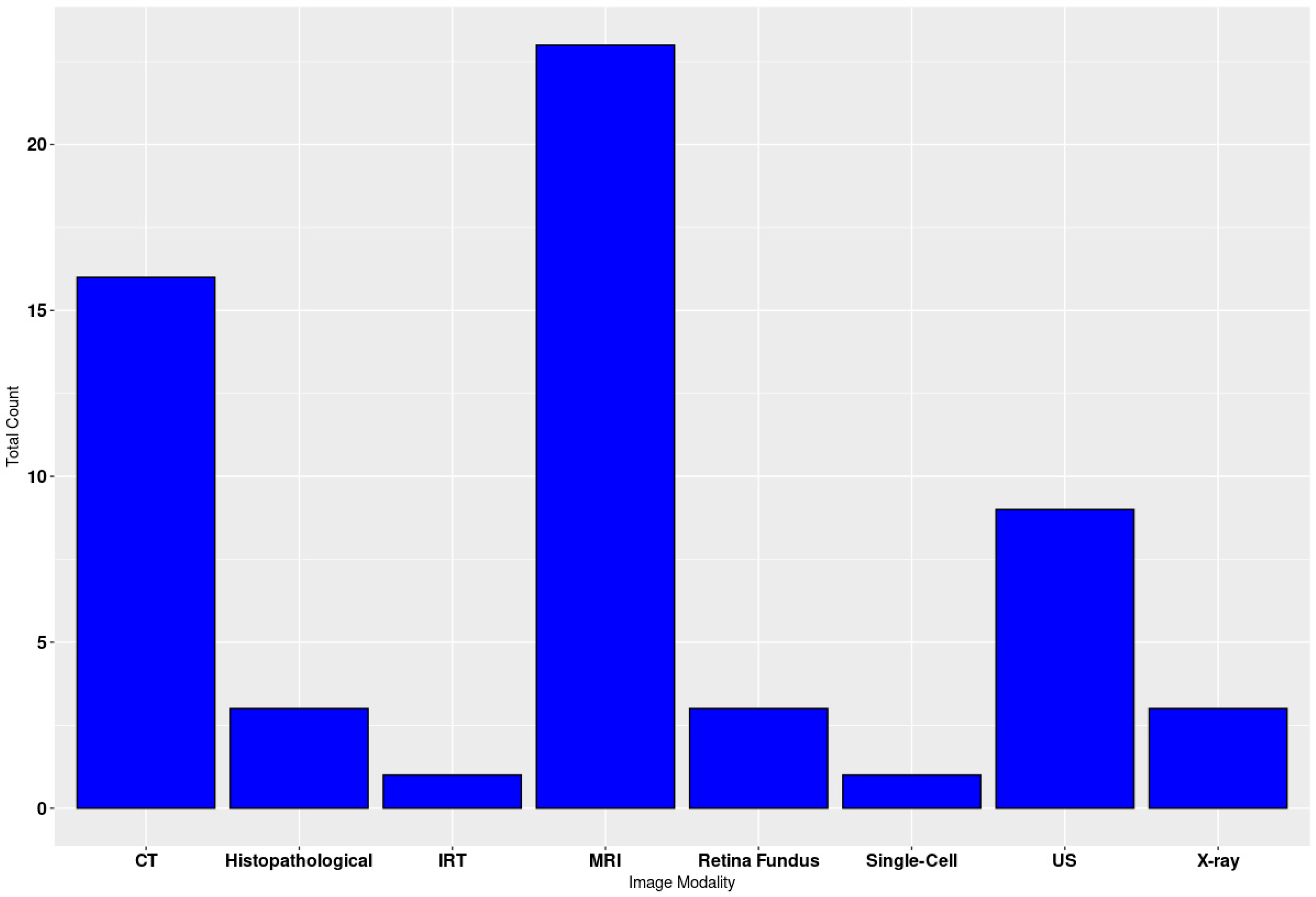
3. Results
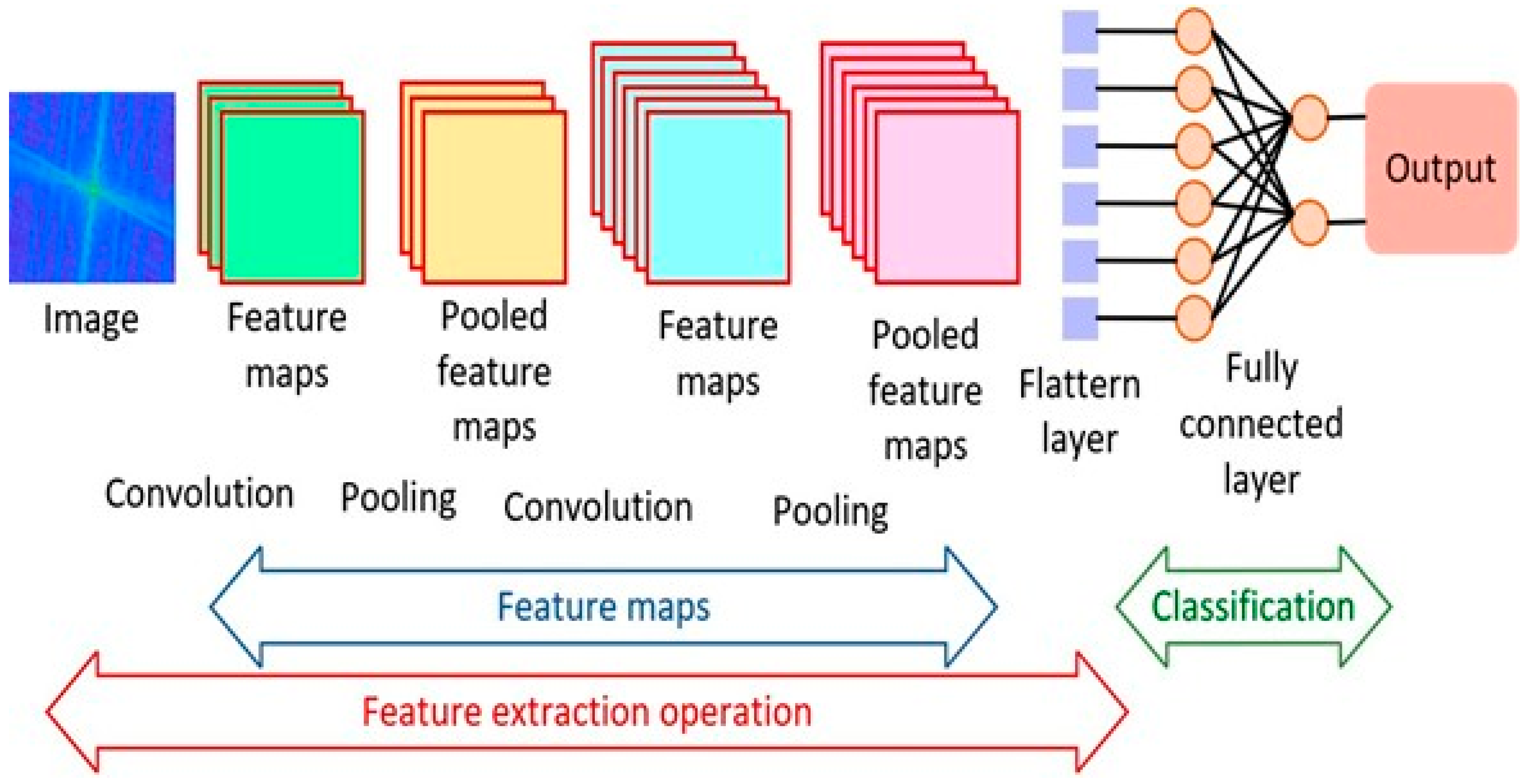
3.1. Convolutional Neural Networks
Literature Review Findings for CNNs
3.2. Recurrent Neural Networks
Literature Review Findings for RNNs
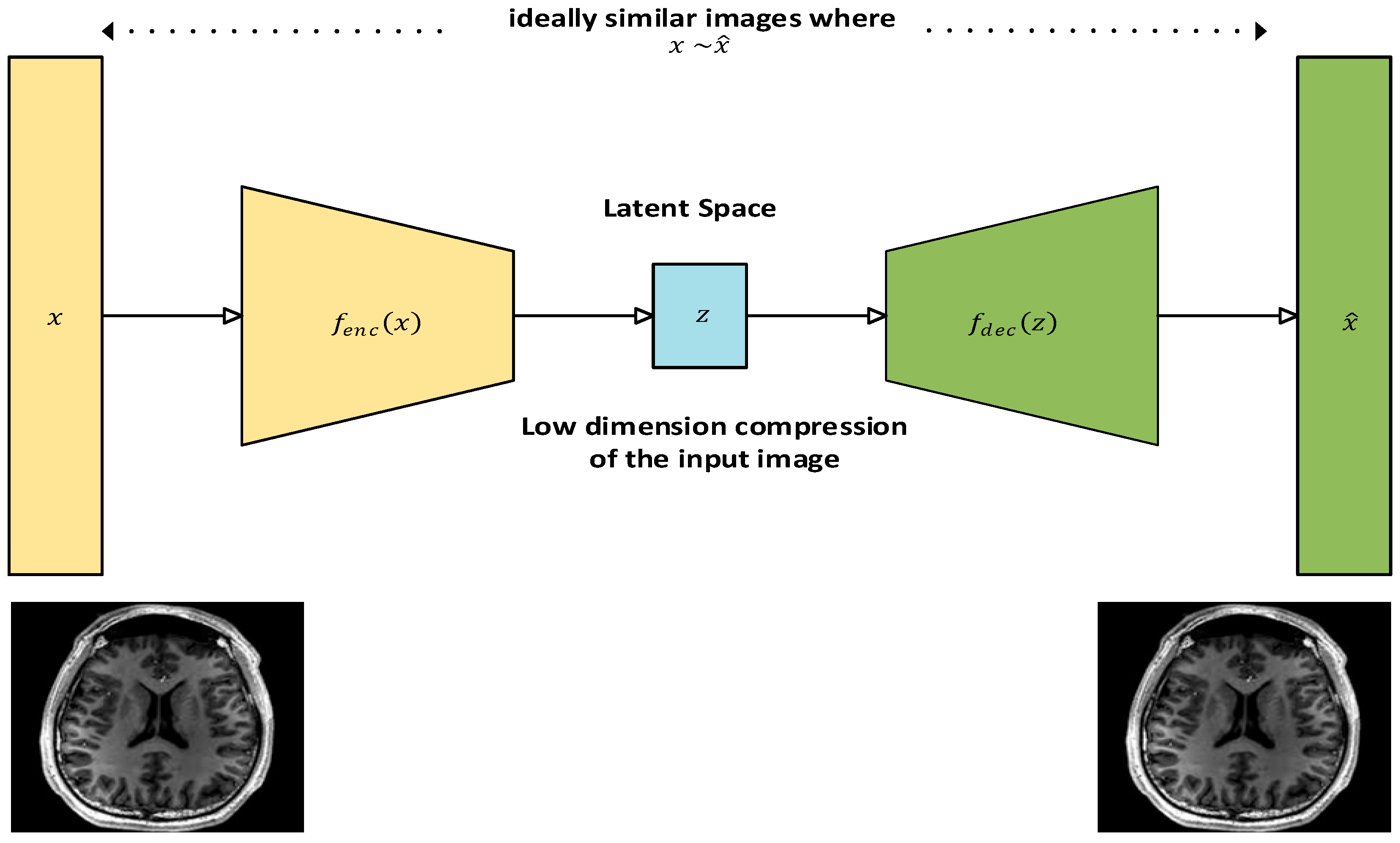
3.3. Autoencoders
Literature Review Findings for Autoencoders
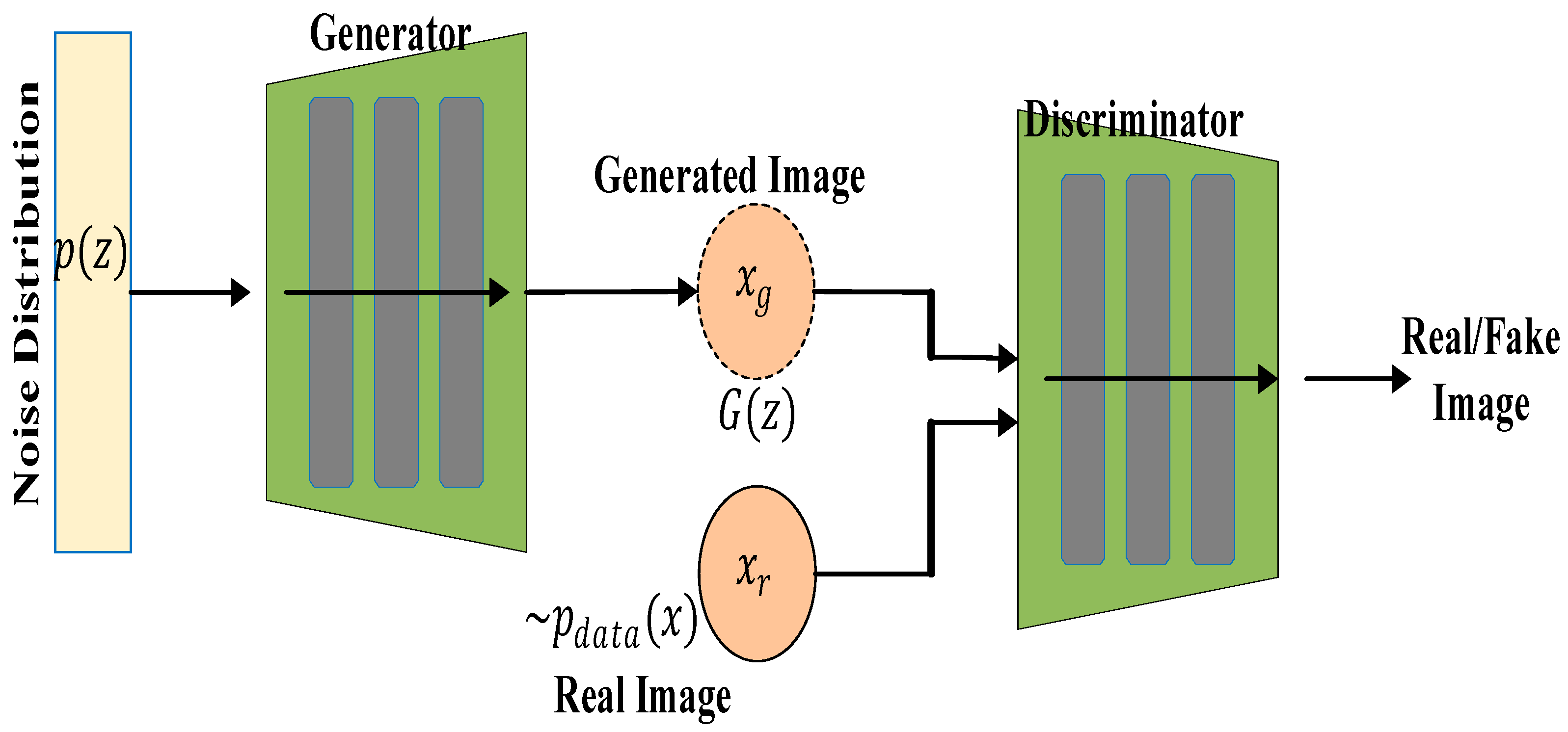
3.4. Generative Adversarial Networks
Literature Review Findings for GANs
3.5. U-Net
Literature Review Findings for U-Net
3.6. Transfer Learning
Findings for Transfer Learning
3.7. Vision Transformers
Literature Review Findings for Vision Transformers
3.8. Hybrid Models
3.8.1. Convolution-Based Hybrid Models
3.8.2. Convolution–Transformer-Based Hybrid Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jeong, J.J.; Tariq, A.; Adejumo, T.; Trivedi, H.; Gichoya, J.W.; Banerjee, I. Systematic Review of Generative Adversarial Networks (GANs) for Medical Image Classification and Segmentation. J. Digit. Imaging 2022, 35, 137–152. [Google Scholar] [CrossRef] [PubMed]
- Yu-Jen Chen, Y.; Hua, K.; Hsu, C.; Cheng, W.; Hidayati, S.C. Computer-aided Classification of Lung Nodules on Computed Tomography Images via deep Learning Technique. OncoTargets Ther. 2015, 8, 2015–2022. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z. Advancements in Automated Classification of Chronic Obstructive Pulmonary Disease based on Computed Tomography Imaging Features Through Deep Learning Approaches. Respir. Med. 2024, 234, 107809. [Google Scholar] [CrossRef] [PubMed]
- Sarmadi, A.; Razavi, Z.S.; Van Wijnen, A.J.; Soltani, M. Comparative Analysis of Vision Transformers and Convolutional Neural Networks in Osteoporosis Detection from X-ray Images. Sci. Rep. 2024, 14, 18007. [Google Scholar] [CrossRef]
- Takahashi, S.; Sakaguchi, Y.; Kouno, N.; Takasawa, K.; Ishizu, K.; Akagi, Y.; Aoyama, R.; Teraya, N.; Bolatkan, A.; Shinkai, N.; et al. Comparison of Vision Transformers and Convolutional Neural Networks in Medical Image Analysis: A Systematic Review. J. Med. Syst. 2024, 48, 84. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, Y. A Comprehensive Survey on Regularization Strategies in Machine Learning. Inf. Fusion 2022, 80, 146–166. [Google Scholar] [CrossRef]
- Xiao, M.; Wu, Y.; Zuo, G.; Fan, S.; Yu, H.; Shaikh, Z.A.; Wen, Z. Addressing Overfitting Problem in Deep Learning-Based Solutions for Next Generation Data-Driven Networks. Hindawi Wirel. Commun. Mob. Comput. 2021, 2021, 8493795. [Google Scholar] [CrossRef]
- Ying, X. An Overview of Overfitting and its Solutions. IOP Conf. Ser. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. Batch Normalization: An Empirical Study of Their Impact to Deep Learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Helmbold, D.P. Surprising Properties of Dropout in Deep Networks. J. Mach. Learn. Res. 2018, 18, 1–28. [Google Scholar]
- Piotrowskia, A.P.; Napiorkowskia, J.J.; Piotrowska, A.E. Impact of Deep Learning-Based Dropout on Shallow Neural Networks Applied to Stream Temperature Modelling. Earth Sci. Rev. 2020, 201, 103076. [Google Scholar] [CrossRef]
- Salehin, I.; Kang, D.-K. A Review on Dropout Regularization Approaches for Deep Neural Networks within the Scholarly Domain. Electronics 2023, 12, 3106. [Google Scholar] [CrossRef]
- Xu, M.; Yoon, S.; Fuentes, A.; Park, D.S. A Comprehensive Survey of Image Augmentation Techniques for Deep Learning. Pattern Recognit. 2023, 137, 109347. [Google Scholar] [CrossRef]
- Kumar, T.; Brennan, R.; Mileo, A.; Bendechache, M. Image Data Augmentation Approaches: A Comprehensive Survey and Future Directions. IEEE Access 2024, 12, 187536–187571. [Google Scholar] [CrossRef]
- Yang, Z.; Sinnott, R.O.; Bailey, J.; Ke, Q. A Survey of Automated Data Augmentation Algorithms for Deep Learning-Based Image Classification Tasks. Knowl. Inf. Syst. 2023, 65, 2805–2861. [Google Scholar] [CrossRef]
- Nanni, L.; Paci, M.; Brahnam, S.; Lumini, A. Comparison of Different Image Data Augmentation Approaches. J. Imaging 2021, 7, 254. [Google Scholar] [CrossRef]
- Oza, P.; Sharma, P.; Patel, S.; Adedoyin, F.; Bruno, A. Image Augmentation Techniques for Mammogram Analysis. J. Imaging 2022, 8, 141. [Google Scholar] [CrossRef]
- Sandfort, V.; Yan, K.; Pickhardt, P.J.; Summers, R.M. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 2019, 9, 16884. [Google Scholar] [CrossRef]
- Wei, J.; Wang, Q.; Song, X.; Zhao, Z. The Status and Challenges of Image Data Augmentation Algorithms. J. Phys. Conf. Ser. 2023, 2456, 012041. [Google Scholar] [CrossRef]
- Liu, X.; Karagoz, G.; Meratnia, N. Analyzing the Impact of Data Augmentation on the Explainability of Deep Learning-Based Medical Image Classification. Mach. Learn. Knowl. Extr. 2025, 7, 1. [Google Scholar] [CrossRef]
- Mamat, N.; Othman, M.F.; Abdulghafor, R.; Alwan, A.A.; Gulzar, Y. Enhancing Image Annotation Technique of Fruit Classification Using a Deep Learning Approach. Sustainability 2023, 15, 901. [Google Scholar] [CrossRef]
- Jayaraj, R.; Lokesh, S. Automatic Image Annotation Using Adaptive Convolutional Deep Learning. Intell. Autom. Soft Comput. 2023, 36, 481–497. [Google Scholar] [CrossRef]
- Zhang, D.; Islam, M.M.; Lu, G. A Review on Automatic Image Annotation Techniques. Pattern Recognit. 2012, 45, 346–362. [Google Scholar] [CrossRef]
- Galbusera, F.; Cina, A. Image Annotation and Curation in Radiology: An Overview for Machine Learning practitioners. Eur. Radiol. Exp. 2024, 8, 11. [Google Scholar] [CrossRef]
- Yin, S.; Bi, J. Medical Image Annotation Based on Deep Transfer Learning. J. Appl. Sci. Eng. 2019, 22, 385–390. [Google Scholar]
- Zhang, Y.; Chen, J.; Xiangxun, M.; Wang, G.; Bhatti, U.A.; Huang, M. Interactive Medical Image Annotation Using Improved Attention U-net With Compound Geodesic Distance. Expert Syst. Appl. 2024, 237 Pt A, 121282. [Google Scholar] [CrossRef]
- Sriwong, K.; Kerdprasop, K.; Kerdprasop, N. The Study of Noise Effect on CNN-Based Deep Learning from Medical Images. Int. J. Mach. Learn. Comput. 2021, 11, 202–207. [Google Scholar] [CrossRef]
- Huang, Z.; Li, F.; Wang, Z.; Wang, Z. Interpretability of Deep Learning. Int. J. Future Comput. Commun. 2022, 11, 34–39. [Google Scholar] [CrossRef]
- Xu, B.; Yang, G. Interpretability Research of Deep Learning: A Literature Survey. Inf. Fusion 2025, 115, 102721. [Google Scholar] [CrossRef]
- Antamis, T.; Drosou, A.; Vafeiadis, T.; Nizamis, A.; Ioannidis, D.; Tzovaras, D. Interpretability of Deep Neural Networks: A Review of Methods, Classification and Hardware. Neurocomputing 2024, 601, 128204. [Google Scholar] [CrossRef]
- Marcinkeviĉs, R.; Vogt, J.E. Interpretable and Explainable Machine Learning: A Methods-Centric Overview with Concrete Examples. WIREs Data Min. Knowl. Discov. 2023, 13, e1493. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Jiang, L.; Xu, C.; Bai, Y.; Liu, A.; Gong, Y.; Wang, Y.-P.; Deng, H.-W. Autosurv: Interpretable deep learning framework for cancer survival analysis incorporating clinical and multi-omics datawas partially supported by previous studies. Npj Precis. Oncol. 2024, 8, 4. [Google Scholar] [CrossRef]
- Balachandar, N.; Chang, K.; Kalpathy-Cramer, J.; Rubin, D.L. Accounting for Data Variability in Multi-Institutional Distributed Deep Learning for Medical Imaging. J. Am. Med. Inform. Assoc. 2020, 27, 700–708. [Google Scholar] [CrossRef]
- Safonova, A.; Ghazaryan, G.; Stiller, S.; Main-Knorn, M.; Nendel, C.; Ryo, M. Ten Deep Learning Techniques to Address Small Data Problems with Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2023, 125, 103569. [Google Scholar] [CrossRef]
- Piffer, S.; Ubaldi, L.; Tangaro, S.; Retico, A.; Talamonti, A. Tackling the Small Data Problem in Medical Image Classification with Artificial Intelligence: A Systematic Review. Prog. Biomed. Eng. 2024, 6, 032001. [Google Scholar] [CrossRef]
- D’Antonoli, T.A. Ethical Considerations for Artificial Intelligence: An Overview of the Current Radiology Landscape. Diagn. Interv. Radiol. 2020, 26, 504–511. [Google Scholar]
- Safdar, N.M.; Banja, J.D.; Meltzer, C.C. Ethical Considerations in Artificial Intelligence. Eur. J. Radiol. 2020, 122, 108768. [Google Scholar] [CrossRef] [PubMed]
- Chen, I.Y.; Pierson, E.; Rose, S.; Joshi, S.; Ferryman, K.; Ghassemi, M. Ethical Machine Learning in Healthcare. Annu. Rev. Biomed. Data Sci. 2021, 4, 123–144. [Google Scholar] [CrossRef] [PubMed]
- Chau, M. Ethical, Legal, and Regulatory Landscape of Artificial Intelligence in Australian Healthcare and Ethical Integration in Radiography: A Narrative Review. J. Med. Imaging Radiat. Sci. 2024, 55, 101733. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhang, P.; Zhang, H.; Dai, J.; Yi, Y.; Zhang, H.; Zhang, Y. Deep Learning on Computational-Resource-Limited Platforms: A Survey. Mob. Inf. Syst. 2020, 1, 8454327. [Google Scholar] [CrossRef]
- Pietrołaj, M.; Blok, M. Resource Constrained Neural Network Training. Sci. Rep. 2024, 14, 2421. [Google Scholar] [CrossRef]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of Medical Image Data Augmentation Techniques for Deep Learning Applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef]
- Masumoto, R.; Eguchi, Y.; Takeuchi, H.; Inage, K.; Narita, M.; Shiga, Y.; Inoue, M.; Toshi, N.; Tokeshi, S.; Okuyama, K.; et al. Automatic Generation of Diffusion Tensor imaging for the Lumbar Nerve using Convolutional Neural Networks. Magn. Reson. Imaging 2024, 114, 110237. [Google Scholar] [CrossRef]
- Shobayo, O.; Saatchi, R.; Ramlakhan, S. Convolutional Neural Network to Classify Infrared Thermal Images of Fractured Wrists in Pediatrics. Healthcare 2024, 12, 994. [Google Scholar] [CrossRef]
- Chauhan, S.; Edla, D.R.; Boddu, V.; Rao, M.J.; Cheruku, R.; Nayak, S.R.; Martha, S.; Lavanya, K.; Nigat, T.D. Detection of COVID-19 Using Edge Devices by a Light-Weight Convolutional Neural Network from Chest X-ray Images. BMC Med. Imaging 2024, 24, 1. [Google Scholar] [CrossRef]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or Deeper: Revisiting the ResNet Model for Visual Recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Zhu, H.; Liu, Y.; Gao, X.; Zhang, L. Combined CNN and Pixel Feature Image for Fatty Liver Ultrasound Image Classification. Comput. Math. Methods Med. 2022, 2022, 9385734. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.; Tseng, Y.; Yang, H.; Liu, C.; Kuo, P.; Lee, M.; Huang, C.; Kuo, L.; Wang, J.; Ho, C.; et al. Deep learning with test-time augmentation for radial endobronchial ultrasound image differentiation: A multicentre verification study. BMJ Open Respir. Res. 2023, 10, e001602. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Zeng, S.; Xu, X.; Li, H.; Yao, S.; Song, K.; Li, X.; Chen, L.; Tang, J.; Xing, H.; et al. Deep learning-enabled pelvic ultrasound images for accurate diagnosis of ovarian cancer in China: A retrospective, multicentre, diagnostic study. Lancet Digit. Health 2022, 4, e179–e187. [Google Scholar] [CrossRef]
- Abdulahi, A.T.; Ogundokun, R.O.; Adenike, A.R.; Shah, M.A.; Ahmed, Y.K. PulmoNet: A Novel Deep learning based Pulmonary Diseases Detection Model. BMC Med. Imaging 2024, 24, 51. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual networks of residual networks: Multilevel residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1303–1314. [Google Scholar] [CrossRef]
- Kim, J.; Hong, J.; Park, H. Prospects of Deep Learning for Medical Imaging. Precis. Future Med. 2018, 2, 37–52. [Google Scholar] [CrossRef]
- Zhang, H.; Qie, Y. Applying Deep Learning to Medical Imaging: A Review. Appl. Sci. 2023, 13, 10521. [Google Scholar] [CrossRef]
- Rajeev, R.; Samath, J.A.; Karthikeyan, N.K. An Intelligent Recurrent Neural Network with Long Short-Term Memory (LSTM) BASED Batch Normalization for Medical Image Denoising. J. Med. Syst. 2019, 43, 234. [Google Scholar] [CrossRef]
- Yao, W.; Bai, J.; Liao, W.; Chen, Y.; Liu, M.; Xie, Y. From CNN to Transformer: A Review of Medical Image Segmentation Models. J. Digit. Imaging Inform. Med. 2024, 37, 1529–1547. [Google Scholar] [CrossRef]
- Cui, R.; Liu, M. RNN-based Longitudinal Analysis for Diagnosis of Alzheimer’s Disease. Comput. Med. Imaging Graph. 2019, 73, 1–10. [Google Scholar] [CrossRef]
- Anbalagan, V.; Balasubramanian, V. HBO-GMRNN: Honey Badger Optimization Based Gain Modulated Recurrent Neural Network for Classification of Breast Cancer. Biomed. Signal Process. Control. 2024, 91, 105910. [Google Scholar] [CrossRef]
- Amarneni, S.; Valarmathi, D.R.S. Diagnosing the MRI Brain Tumour Images Through RNN-LSTM. E Prime Adv. Electr. Eng. Electron. Energy 2024, 9, 100723. [Google Scholar] [CrossRef]
- Zhu, K.; Chen, Y.; Ouyang, X.; White, G.; Agam, G. Fully RNN for Knee Ligament Tear Classification and Localization in MRI scans. Electron. Imaging 2022, 34, 227-1–227-6. [Google Scholar] [CrossRef]
- Gulshan; Arora, A.S. Automated Prediction of Diabetes Mellitus Using Infrared Thermal Foot Images: Recurrent Neural Network Approach. Biomed. Phys. Eng. Express 2024, 10, 025025. [Google Scholar] [CrossRef]
- Ayub, S.; Kannan, R.J.; Alsini, R.; Hasanin, T.; Sasidhar, C. LSTM-Based RNN Framework to Remove Motion Artifacts in Dynamic Multicontrast MR Images with Registration Model. Wirel. Commun. Mob. Comput. 2022, 2022, 5906877. [Google Scholar] [CrossRef]
- Das, T.; Saha, G. Addressing Big Data Issues Using RNN Based Techniques. J. Inf. Optim. Sci. 2020, 40, 1773–1785. [Google Scholar] [CrossRef]
- Zhang, Y. A Better Autoencoder for Image: Convolutional Autoencoder. In Proceedings of the ICONIP17-DCEC, Guangzhou, China, 14–18 October 2017; pp. 11–21. Available online: http://users.cecs.anu.edu.au/Tom.Gedeon/conf/ABCs2018/paper/ABCs2018_paper_58.pdf (accessed on 17 April 2025).
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Edinburgh, UK, 26 June–1 July 2012; JMLR Workshop and Conference Proceedings. pp. 37–49. [Google Scholar]
- Vorontsov, E.; Molchanov, P.; Gazda, M.; Beckham, C.; Kautz, J.; Kadoury, S. Towards Annotation-Efficient Segmentation Via Image-to-Image Translation. Med. Image Anal. 2022, 82, 102624. [Google Scholar] [CrossRef]
- Wang, W.; Huang, Y.; Wang, Y.; Wang, L. Generalized autoencoder: A neural network framework for dimensionality reduction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 490–497. [Google Scholar]
- Juneja, M.; Kaur Saini, S.; Kaul, S.; Acharjee, R.; Thakur, N.; Jindal, P. Denoising of Magnetic Resonance Imaging Using Bayes Shrinkage Based Fused Wavelet Transform and Autoencoder Based Deep Learning Approach. Biomed. Signal Process. Control. 2021, 69, 102844. [Google Scholar] [CrossRef]
- O’ Sullivan, E.; Van De Lande, L.S.; Papaioannou, A.; Breakey, R.W.F.; Jeelani, N.O.; Ponniah, A.; Duncan, C.; Schievano, S.; Khonsari, R.H.; Zafeiriou, S.; et al. Convolutional Mesh Autoencoders for the 3-Dimensional Identification of FGFR-Related Craniosynostosis. Sci. Rep. 2022, 12, 2230. [Google Scholar] [CrossRef]
- Wolf, D.; Payer, T.; Lisson, C.S.; Lisson, C.G.; Beer, M.; Götz, M.; Ropinski, T. Self-supervised Pre-training with Contrastive and Masked Autoencoder Methods for Dealing with Small Datasets in Deep Learning for Medical Imaging. Sci. Rep. 2023, 13, 20260. [Google Scholar] [CrossRef]
- Chen, R.; Song, Y.; Huang, J.; Wang, J.; Sun, H.; Wang, H. Rapid Diagnosis and Continuous Monitoring of Intracerebral Hemorrhage with Magnetic Induction Tomography Based on Stacked Autoencoder. Rev. Sci. Instrum. 2021, 92, 084707. [Google Scholar] [CrossRef] [PubMed]
- Shvetsova, N.; Bakker, B.; Fedulova, I.; Schulz, H.; Dylov, D.V. Anomaly Detection in Medical Imaging with Deep Perceptual Autoencoders. IEEE Access 2021, 9, 118571–118583. [Google Scholar] [CrossRef]
- Elhassan, T.A.; Mohd Rahim, M.S.; Siti Zaiton, M.H.; Swee, T.T.; Alhaj, T.A.; Ali, A.; Aljurf, M. Classification of Atypical White Blood Cells in Acute Myeloid Leukemia Using a Two-Stage Hybrid Model Based on Deep Convolutional Autoencoder and Deep Convolutional Neural Network. Diagnostics 2023, 13, 196. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Guo, W.; Zhang, S.; Lu, H.; Zhao, X. Unsupervised Deep Anomaly Detection for Medical Images Using an Improved Adversarial Autoencoder. J. Digit. Imaging 2022, 35, 153–161. [Google Scholar] [CrossRef]
- Li, D.; Fu, Z.; Xu, J. Stacked-Autoencoder-Based Model for COVID-19 Diagnosis on CT Images. Appl. Intell. 2020, 51, 2805–2817. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, J.; Liao, B.; Wu, F.; Bi, X. Deep Canonical Correlation Fusion Algorithm Based on Denoising Autoencoder for ASD Diagnosis and Pathogenic Brain Region Identification. Interdiscip. Sci. Comput. Life Sci. 2024, 16, 455–468. [Google Scholar] [CrossRef]
- Gao, J.; Zhao, W.; Li, P.; Huang, W.; Chen, Z. LEGAN: A Light and Effective Generative Adversarial Network for medical image synthesis. Comput. Biol. Med. 2022, 148, 105878. [Google Scholar] [CrossRef]
- Singh, N.K.; Raza, K. Medical Image Generation Using Generative Adversarial Networks: A Review; Springer: Singapore, 2021; pp. 77–96. [Google Scholar]
- Xun, S.; Li, D.; Zhu, H.; Chen, M.; Wang, J.; Li, J.; Chen, M.; Wu, B.; Zhang, H.; Chai, X.; et al. Generative adversarial networks in medical image segmentation: A review. Comput. Biol. Med. 2021, 140, 105063. [Google Scholar] [CrossRef]
- Yi, X.; Walia, E.; Babyn, P. Generative adversarial network in medical imaging: A review. Med. Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef]
- Hamghalam, M.; Wang, T.; Lei, B. High tissue contrast image synthesis via multistage attention-GAN: Application to segmenting brain MR scans. Neural Netw. 2020, 132, 43–52. [Google Scholar] [CrossRef]
- Zhu, Q.; Ye, H.; Sun, L.; Li, Z.; Wang, R.; Shi, F.; Shen, D.; Zhang, D. GACDN: Generative adversarial feature completion and diagnosis network for COVID-19. BMC Med. Imaging 2021, 21, 154. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhang, K.; Shi, W.; Miao, Y.; Jiang, Z. A Novel Medical Image Denoising Method Based on Conditional Generative Adversarial Network. Comput. Math. Methods Med. 2021, 2021, 9974017. [Google Scholar] [CrossRef]
- Ahmad, W.; Ali, H.; Shah, Z.; Azmat, S. A new generative adversarial network for medical images super resolution. Sci. Rep. 2022, 12, 9533. [Google Scholar] [CrossRef] [PubMed]
- Mutepfe, F.; Kalejahi, B.K.; Meshgini, S.; Danishvar, S. Generative Adversarial Network Image Synthesis Method for Skin Lesion Generation and Classification. J. Med. Signals Sens. 2021, 11, 237–252. [Google Scholar] [CrossRef]
- Touati, R.; Le, W.T.; Kadoury, S. A feature invariant generative adversarial network for head and neck MRI/CT image synthesis. Phys. Med. Biol. 2021, 66, 095001. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Chen, C.; Wang, L.; Yu, J.; Fu, X.; Zou, Y.; Lin, Z.; Wang, K. A novel hybrid generative adversarial network for CT and MRI super-resolution reconstruction. Phys. Med. Biol. 2023, 68, 135007. [Google Scholar] [CrossRef]
- Mahapatra, D.; Bozorgtabar, B.; Garnavi, R. Image super-resolution using progressive generative adversarial networks for medical image analysis. Comput. Med. Imaging Graph. 2019, 71, 30–39. [Google Scholar] [CrossRef]
- Uzunova, H.; Ehrhardt, J.; Handels, H. Memory-efficient GAN-based domain translation of high resolution 3D medical images. Comput. Med. Imaging Graph. 2020, 86, 101801. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Springer Science + Business Media: Berlin, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Azad, R.; Aghdam, K.; Rauland, A.; Jia, Y.; Avval, H.; Bozorgpour, A.; Karimijafarbigloo, S.; Cohen, J.P.; Adeli, E.; Merhof, D. Medical Image Segmentation Review: The Success of U-Net. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 10076–10095. [Google Scholar] [CrossRef]
- Krithika Alias Anbudevi, M.; Suganthi, K. Review of Semantic Segmentation of Medical Images Using Modified Architectures of UNET. Diagnostics 2022, 12, 3064. [Google Scholar] [CrossRef]
- Ehab, W.; Li, Y. Performance Analysis of UNet and Variants for Medical Image Segmentation. arXiv 2023, arXiv:2309.13013. [Google Scholar]
- Ding, Y.; Chen, F.; Zhao, Y.; Wu, Z.; Zhang, C.; Wu, D. A Stacked Multi-Connection Simple Reducing Net for Brain Tumor Segmentation. IEEE Access 2019, 7, 104011–104024. [Google Scholar] [CrossRef]
- Wang, Z.; Zou, Y.; Liu, P.X. Hybrid dilation and attention residual U-Net for Medical Image Segmentation. Comput. Biol. Med. 2021, 134, 104449. [Google Scholar] [CrossRef]
- Khan, R.A.; Luo, Y.; Wu, F. RMS-UNet: Residual Multi-Scale UNet for Liver and Lesion Segmentation. Artif. Intell. Med. 2022, 124, 102231. [Google Scholar] [CrossRef]
- Kong, Z.; Zhang, M.; Zhu, W.; Yi, Y.; Wang, T.; Zhang, B. Data enhancement based on M2-Unet for liver segmentation in Computed Tomography. Biomed. Signal Process. Control 2022, 79, 104032. [Google Scholar] [CrossRef]
- Chetty, G.; Yamin, M.; White, M. A low resource 3D U-Net based deep learning model for medical image analysis. Int. J. Inf. Technol. 2022, 14, 95–103. [Google Scholar] [CrossRef]
- Huang, K.; Yang, Y.; Huang, Z.; Liu, Y.; Lee, S. Retinal Vascular Image Segmentation Using Improved UNet Based on Residual Module. Bioengineering 2023, 10, 722. [Google Scholar] [CrossRef]
- Lin, Z.; Dall’ara, E.; Guo, L. A novel mean shape based post-processing method for enhancing deep learning lower-limb muscle segmentation accuracy. PLoS ONE 2024, 19, e0308664. [Google Scholar] [CrossRef]
- Ding, T.; Shi, K.; Pan, Z.; Ding, C. AI-based automated breast cancer segmentation in ultrasound imaging based on Attention Gated Multi ResU-Net. PeerJ Comput. Sci. 2024, 10, e2226. [Google Scholar] [CrossRef]
- Henson, W.H.; Li, X.; Lin, Z.; Guo, L.; Mazzá, C.; Dall’ara, E. Automatic segmentation of lower limb muscles from MR images of post-menopausal women based on deep learning and data augmentation. PLoS ONE 2024, 19, e0299099. [Google Scholar] [CrossRef]
- Lin, Z.; Henson, W.H.; Dowling, L.; Walsh, J.; Dall’ara, E.; Guo, L. Automatic segmentation of skeletal muscles from MR images using modified U-Net and a novel data augmentation approach. Front. Bioeng. Biotechnol. 2024, 12, 1355735. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; p. 3. [Google Scholar]
- Garbaz, A.; Oukdach, Y.; Charfi, S.; El Ansari, M.; Koutti, L.; Salihoun, M. MLFA-UNet: A multi-level feature assembly UNet for medical image segmentation. Methods 2024, 232, 52–64. [Google Scholar] [CrossRef]
- Kora, P.; Ooi, C.P.; Faust, O.; Raghavendra, U.; Gudigar, A.; Chan, W.Y.; Meenakshi, K.; Swaraja, K.; Plawiak, P.; Rajendra Acharya, U. Transfer learning techniques for medical image analysis: A review. Biocybern. Biomed. Eng. 2021, 42, 79–107. [Google Scholar] [CrossRef]
- Yu, X.; Wang, J.; Hong, Q.; Teku, R.; Wang, S.; Zhang, Y. Transfer learning for medical images analyses: A survey. Neurocomputing 2022, 489, 230–254. [Google Scholar] [CrossRef]
- Ayana, G.; Dese, K.; Abagaro, A.M.; Jeong, K.C.; Yoon, S.; Choe, S. Multistage Transfer Learning for Medical Images. Artif. Intell. Rev. 2024, 57, 232. [Google Scholar] [CrossRef]
- Atasever, S.; Azginoglu, N.; Terzi, D.S.; Terzi, R. A comprehensive survey of deep learning research on medical image analysis with focus on transfer learning. Clin. Imaging 2022, 94, 18–41. [Google Scholar] [CrossRef]
- Kim, H.E.; Cosa-Linan, A.; Santhanam, N.; Jannesari, M.; Maros, M.E.; Ganslandt, T. Transfer learning for medical image classification: A literature review. BMC Med. Imaging 2022, 22, 69. [Google Scholar] [CrossRef]
- De Santana, M.A.; Pereira, J.M.S.; Silva, F.L.D.; de Lima, N.M.; de Sousa, F.N.; de Arruda, G.M.S.; de Lima, R.d.C.F.; da Silva, W.W.A.; Santos, W.P.d. Breast cancer diagnosis based on mammary thermography and extreme learning machines. Res. Biomed. Eng. 2018, 34, 45–53. [Google Scholar] [CrossRef]
- Kumar, S.; Choudhary, S.; Jain, A.; Singh, K.; Ahmadian, A.; Bajuri, M.Y. Brain Tumor Classification Using Deep Neural Network and Transfer Learning. Brain Topogr. 2023, 36, 305–318. [Google Scholar] [CrossRef]
- Archana, B.; Kalirajan, K. An Intelligent Magnetic Resonance Imagining-Based Multistage Alzheimer’s Disease Classification using Swish-Convolutional Neural Networks. Med. Biol. Eng. Comput. 2024, 63, 885–899. [Google Scholar] [CrossRef]
- Zhu, Y.; Jin, P.; Bao, J.; Jiang, Q.; Wang, X. Thyroid ultrasound image classification using a convolutional neural network. Ann. Transl. Med. 2021, 9, 1526. [Google Scholar] [CrossRef] [PubMed]
- Kalusivalingam, A.K.; Sharma, A.; Patel, N.; Singh, V. Enhancing Diagnostic Accuracy in Medical Imaging through Convolutional Neural Networks and Transfer Learning Algorithms. Int. J. Artif. Intell. Mach. Learn. 2021, 2, 1–24. [Google Scholar]
- Alzubaidi, L.; Al-Amidie, M.; Al-Asadi, A.; Humaidi, A.J.; Al-Shamma, O.; Fadhel, M.A.; Zhang, J.; Santamaría, J.; Duan, Y. Novel Transfer Learning Approach for Medical Imaging with Limited Labeled Data. Cancers 2021, 13, 1590. [Google Scholar] [CrossRef] [PubMed]
- Odusami, M.; Maskeliūnas, R.; Damaševičius, R.; Krilavičius, T. Analysis of Features of Alzheimer’s Disease: Detection of Early Stage from Functional Brain Changes in Magnetic Resonance Images Using a Finetuned ResNet18 Network. Diagnostics 2021, 11, 1071. [Google Scholar] [CrossRef]
- Guan, Q.; Wang, Y.; Du, J.; Qin, Y.; Lu, H.; Xiang, J.; Wang, F. Deep learning based classification of ultrasound images for thyroid nodules: A large scale of pilot study. Ann. Transl. Med. 2019, 7, 137. [Google Scholar] [CrossRef]
- Tian, D.; Jiang, S.; Zhang, L.; Lu, X.; Xu, Y. The role of large language models in medical image processing: A narrative review. Quant. Imaging Med. Surg. 2023, 14, 1108–1121. [Google Scholar] [CrossRef]
- Ogunleye, B.; Sharma, H.; Shobayo, O. Sentiment Informed Sentence BERT-Ensemble Algorithm for Depression Detection. BDCC 2024, 8, 112. [Google Scholar] [CrossRef]
- Bora, A.; Cuayáhuitl, H. Systematic Analysis of Retrieval-Augmented Generation-Based LLMs for Medical Chatbot Applications. Make 2024, 6, 2355–2374. [Google Scholar] [CrossRef]
- Pu, Q.; Xi, Z.; Yin, S.; Zhao, Z.; Zhao, L. Advantages of transformer and its application for medical image segmentation: A survey. Biomed. Eng. OnLine 2024, 23, 14. [Google Scholar] [CrossRef]
- Berroukham, A.; Housni, K.; Lahraichi, M. Vision Transformers: A Review of Architecture, Applications, and Future Directions. In Proceedings of the 2023 7th IEEE Congress on Information Science and Technology (CiSt), Agadir/Essaouira, Morocco, 16–22 December 2023; pp. 205–210. [Google Scholar] [CrossRef]
- Van, M.; Verma, P.; Wu, X. On large visual language models for medical imaging analysis: An empirical study. In Proceedings of the 2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Wilmington, DE, USA, 19–21 June 2024; pp. 172–176. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Tanimola, O.; Shobayo, O.; Popoola, O.; Okoyeigbo, O. Breast Cancer Classification Using Fine-Tuned SWIN Transformer Model on Mammographic Images. Analytics 2024, 3, 461–475. [Google Scholar] [CrossRef]
- Abbaoui, W.; Retal, S.; Ziti, S.; El Bhiri, B. Automated Ischemic Stroke Classification from MRI Scans: Using a Vision Transformer Approach. J. Clin. Med. 2024, 13, 2323. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Frey, E.C.; He, Y.; Segars, W.P.; Li, Y.; Du, Y. TransMorph: Transformer for unsupervised medical image registration. Med. Image Anal. 2022, 82, 102615. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, J.; Liu, S. Medical ultrasound image segmentation with deep learning models. IEEE Access 2022, 11, 10158–10168. [Google Scholar] [CrossRef]
- Ramamurthy, M.; Krishnamurthi, I.; Vimal, S.; Robinson, Y.H. Deep Learning Based Genome Analysis and NGS-RNA LL Identification with a Novel Hybrid Model. Biosystems 2020, 197, 104211. [Google Scholar] [CrossRef]
- Rahman, H.; Bukht, T.F.N.; Imran, A.; Tariq, J.; Tu, S.; Alzahrani, A. A Deep Learning Approach for Liver and Tumor Segmentation in CT Images Using ResUNet. Bioengineering 2022, 9, 368. [Google Scholar] [CrossRef]
- Zhu, Y.; Meng, Z.; Fan, X.; Duan, Y.; Jia, Y.; Dong, T.; Wang, Y.; Song, J.; Tian, J.; Wang, K.; et al. Deep learning radiomics of dual-modality ultrasound images for hierarchical diagnosis of unexplained cervical lymphadenopathy. BMC Med. 2022, 20, 269. [Google Scholar] [CrossRef]
- Vasile, C.M.; Udriștoiu, A.L.; Ghenea, A.E.; Popescu, M.; Gheonea, C.; Niculescu, C.E.; Ungureanu, A.M.; Udriștoiu, Ș.; Drocaş, A.I.; Gruionu, L.G. Intelligent diagnosis of thyroid ultrasound imaging using an ensemble of deep learning methods. Medicina 2021, 57, 395. [Google Scholar] [CrossRef]
- Iqbal, S.; Khan, T.M.; Naqvi, S.S.; Naveed, A.; Meijering, E. TBConvL-Net: A hybrid deep learning architecture for robust medical image segmentation. Pattern Recognit. 2025, 158, 111028. [Google Scholar] [CrossRef]
- Obayya, M.; Saeed, M.K.; Alruwais, N.; Alotaibi, S.S.; Assiri, M.; Salama, A.S. Hybrid Metaheuristics with Deep Learning-Based Fusion Model for Biomedical Image Analysis. IEEE Access 2023, 11, 117149–117158. [Google Scholar] [CrossRef]
- Yan, L.; Ling, S.; Mao, R.; Xi, H.; Wang, F. A deep learning framework for identifying and segmenting three vessels in fetal heart ultrasound images. Biomed. Eng. OnLine 2024, 23, 39. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Article | Imaging Modality | Task | CNN Feature Extraction | Disease/Body Part | Variant Used |
|---|---|---|---|---|---|
| [58] | MRI | Classification | Y | Alzheimer’s | BGRU |
| [59] | Histopathological images | Classification | N | Breast cancer | None |
| [60] | MRI | Classification/segmentation | N | Brain tumour | LSTM |
| [57] | MRI | Segmentation | Y | Aorta | LSTM |
| [61] | MRI | Classification/localisation | Y | Knee ligament | LSTM |
| [62] | IRT | Classification | Y | Diabetes mellitus | LSTM |
| [56] | CT | Image denoising | N | Lungs | LSTM |
| [63] | MRI | Registration | Y | Brain cancer | LSTM |
| Article | Image Modality | Task | Disease/ Body Part |
|---|---|---|---|
| [67] | MRI | Augmentation/ segmentation | Brain |
| [69] | MRI | Denoising | Prostate |
| [70] | CT + others | Classification | Face |
| [71] | CT | Augmentation | Various |
| [72] | MRI and CT | Classification | Intracerebral haemorrhage |
| [73] | X-ray/digital histopathology | Anomaly detection | Various |
| [74] | Single-cell images | Classification | Myeloid leukaemia |
| [75] | None | Anomaly detection | None |
| [76] | CT | Classification | COVID-19 |
| [77] | MRI | Denoising/classification | Autism/brain |
| Article | Imaging Modality | Task | Disease/Body Part | Variant Used |
|---|---|---|---|---|
| [79] | MRI/retina fundus | Image synthesis | - | - |
| [82] | MRI | Image resolution | Brain | Cycle-GAN |
| [83] | CT | Image synthesis | COVID-19 | Enhanced vanilla |
| [84] | X-ray/CT | Image Denoising | Chest/thorax | CGAN |
| [85] | Various | Image resolution | Various | Enhanced vanilla |
| [86] | - | Image synthesis | Skin cancer | DCGAN |
| [87] | MRI/CT | Image synthesis | Head/neck | Vanilla GAN |
| [88] | MRI/CT | Image resolution | Bladder cancer | Enhanced vanilla |
| [89] | Retina fundus/MRI | Image resolution | Various | Vanilla GAN |
| [90] | CT/MRI | Translation | Thorax/brain | CGAN |
| Article | Imaging Modality | Disease/Body Part | Variant Used |
|---|---|---|---|
| [95] | MRI | Brain tumour | Enhanced U-Net |
| [96] | Various | Various | Enhanced U-Net |
| [97] | CT | Hepatocellular carcinoma | Enhanced U-Net |
| [98] | CT | Liver | Enhanced U-Net |
| [99] | MRI | Brain tumour | None |
| [100] | Colour fundus | Diabetic retinopathy | Enhanced U-Net |
| [101] | MRI | Various/musculoskeletal | Enhanced U-Net |
| [102] | MRI | Lower limb muscle | Attention U-Net/SCU-Net |
| [103] | MRI | Musculoskeletal | Various |
| [104] | Various | Various | Enhanced U-Net (U-Net++) |
| [105] | Ultrasound | Breast cancer | Enhanced U-Net (attention gate) |
| Article | Imaging Modality | Disease/Body Part | TL Variant/Best Model |
|---|---|---|---|
| [112] | Histopathological images | Breast cancer | ResNet 50 |
| [113] | MRI | Brain tumour | Improved ResNet 50 |
| [114] | MRI | Alzheimer’s | Various (EffiecientNet) |
| [115] | CT | Pulmonary nodules | Various (DenseNet) |
| [116] | X-ray/CT | COVID-19 | Various (VGG 16) |
| [117] | MRI | Alzheimer’s | Modified ResNET 18 |
| [118] | Ultrasound | Thyroid | VGG-16 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shobayo, O.; Saatchi, R. Developments in Deep Learning Artificial Neural Network Techniques for Medical Image Analysis and Interpretation. Diagnostics 2025, 15, 1072. https://doi.org/10.3390/diagnostics15091072
Shobayo O, Saatchi R. Developments in Deep Learning Artificial Neural Network Techniques for Medical Image Analysis and Interpretation. Diagnostics. 2025; 15(9):1072. https://doi.org/10.3390/diagnostics15091072
Chicago/Turabian StyleShobayo, Olamilekan, and Reza Saatchi. 2025. "Developments in Deep Learning Artificial Neural Network Techniques for Medical Image Analysis and Interpretation" Diagnostics 15, no. 9: 1072. https://doi.org/10.3390/diagnostics15091072
APA StyleShobayo, O., & Saatchi, R. (2025). Developments in Deep Learning Artificial Neural Network Techniques for Medical Image Analysis and Interpretation. Diagnostics, 15(9), 1072. https://doi.org/10.3390/diagnostics15091072