
SDD-YOLO: A Lightweight, High-Generalization Methodology for Real-Time Detection of Strip Surface Defects


Abstract
:1. Introduction
- (1)
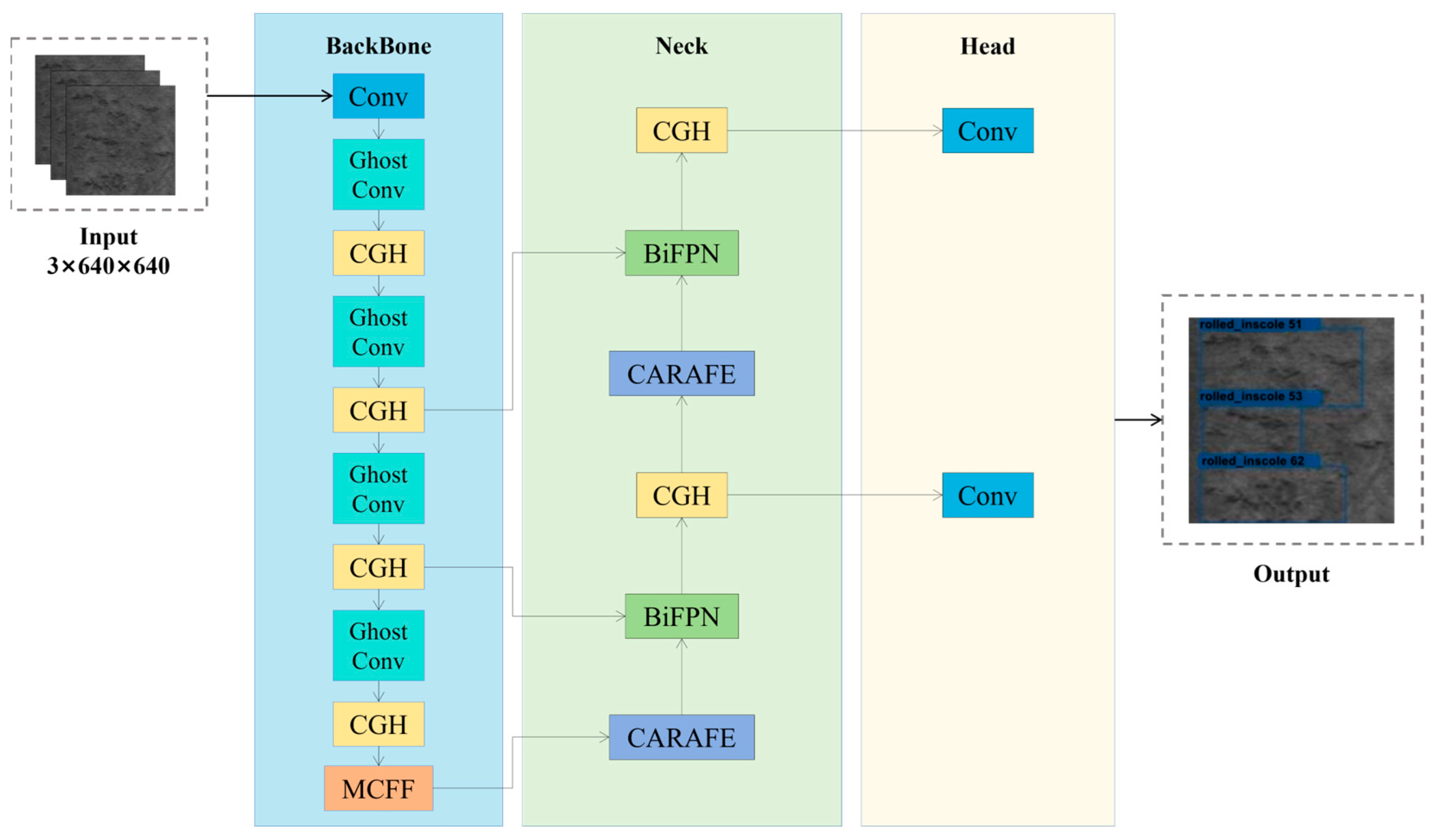
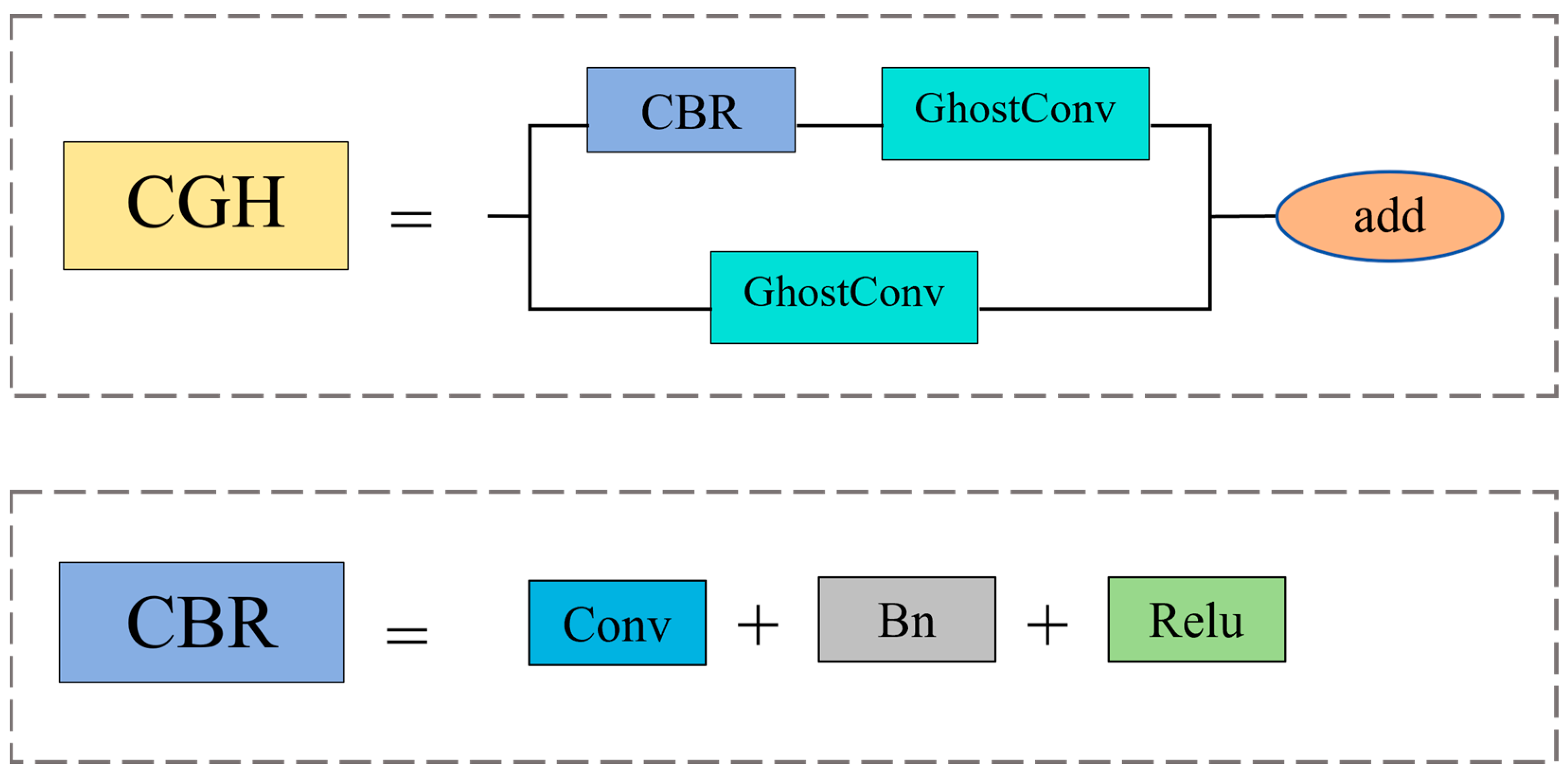
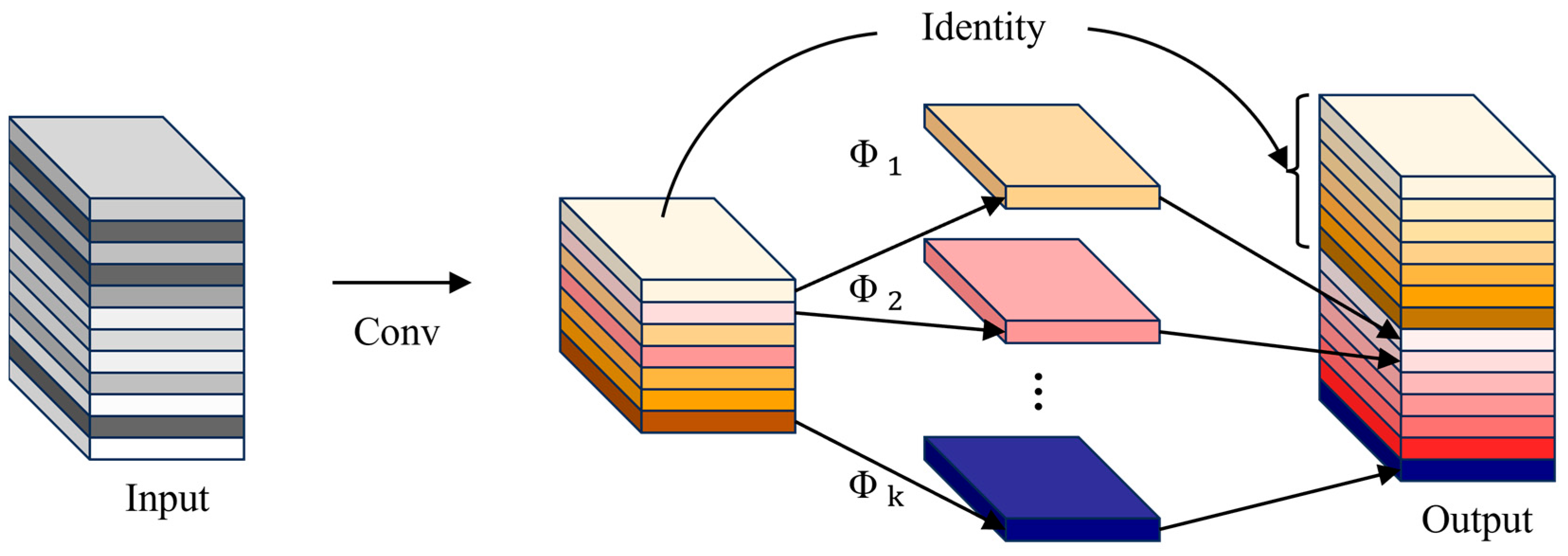
- The proposal of the CGH module, which improves the C3 module of YOLOv5. GhostConv is used to replace conventional convolution layers on bottleneck layers and branches, effectively reducing computational complexity. Meanwhile, residual connections are introduced to replace Concat operations, significantly enhancing the stability of the network. This module combines the low-cost feature map generation of GhostConv with the characteristics of residual connections to reduce memory consumption and improve feature extraction efficiency.
- (2)
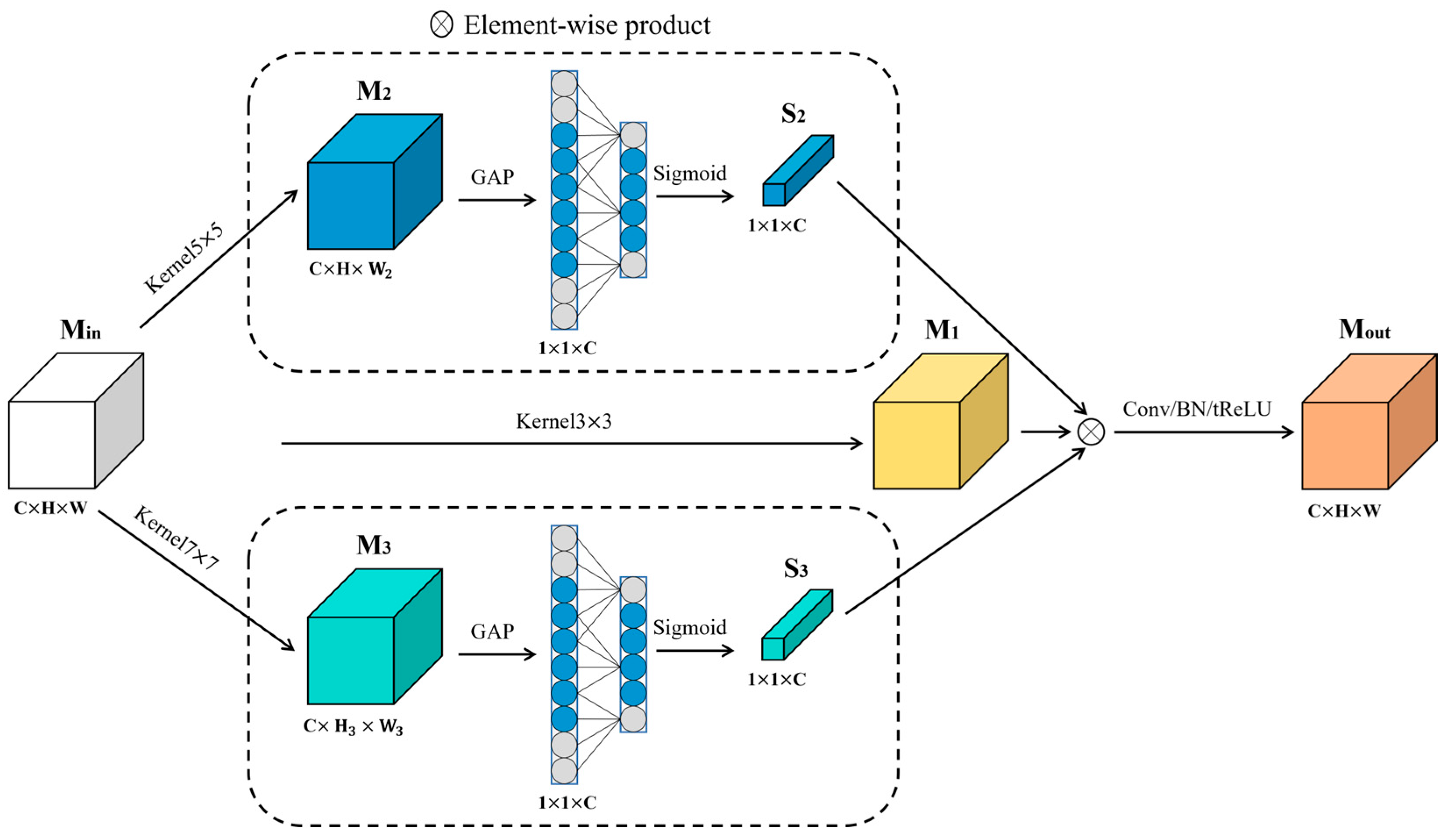
- The proposal of the MCFF module. By employing convolution kernels of different sizes and channel attention mechanisms, the feature expression capability and robustness of the model are effectively enhanced, avoiding gradient disappearance, accelerating the training process, and ensuring that the neural network can accomplish more complex tasks.
- (3)
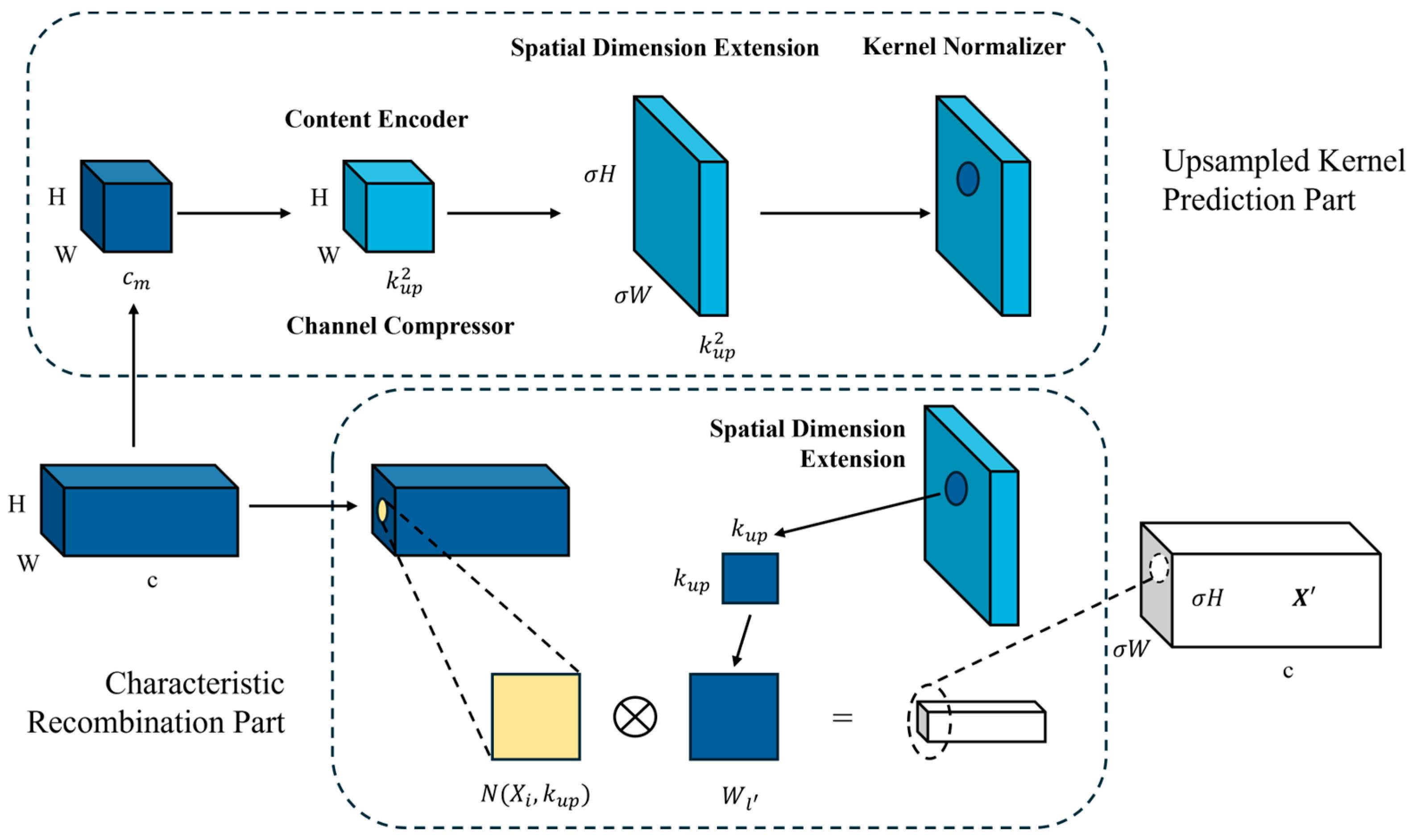
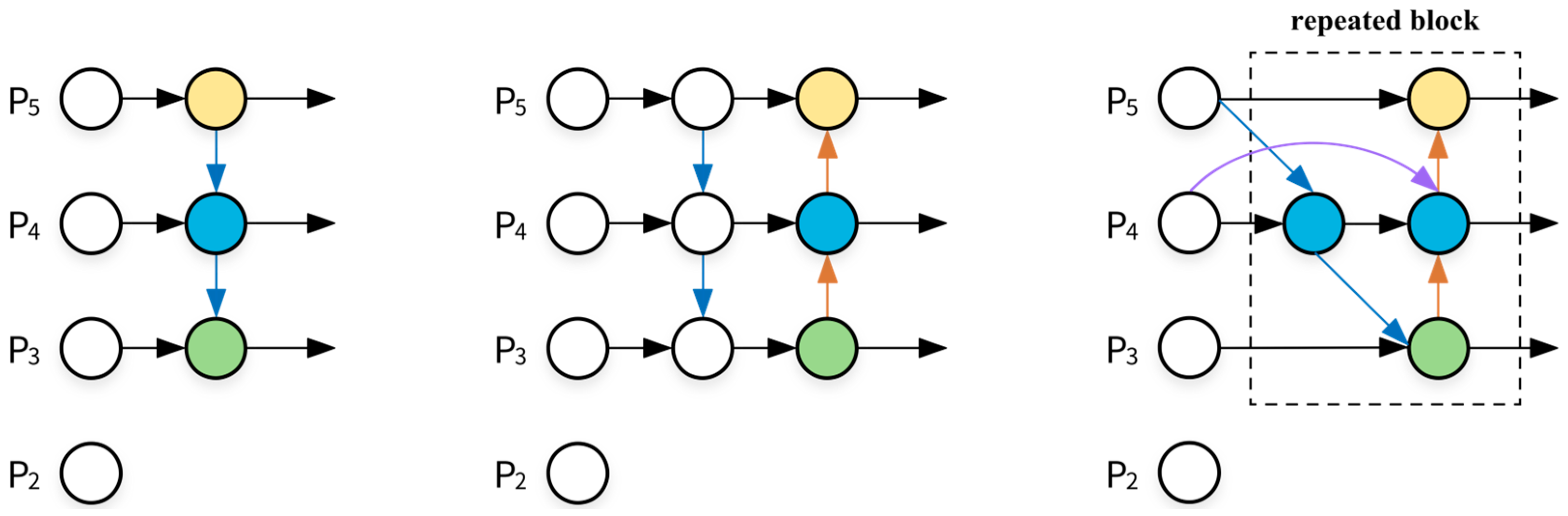
- By simultaneously introducing CARAFE and BiFPNs, the receptive field of convolutional neural networks is enhanced, and the resolution of feature maps is improved, resulting in a more effective upsampling process within convolutional neural networks. Furthermore, the incorporation of the BiFPN into the Neck layer of YOLOv5, in place of traditional FPN and PANet structures, enhances the model’s capability for deep feature fusion.
- (4)
- This study considers disruptive factors in strip steel production and uses three data interference methods—high exposure, low brightness, and Gaussian noise—on the original data to test the robustness of the SDD-YOLO method. The results show that SDD-YOLO has advanced generalization performance, making it suitable for real production environments and effectively improving the quality and efficiency of strip steel production.
2. Related Work
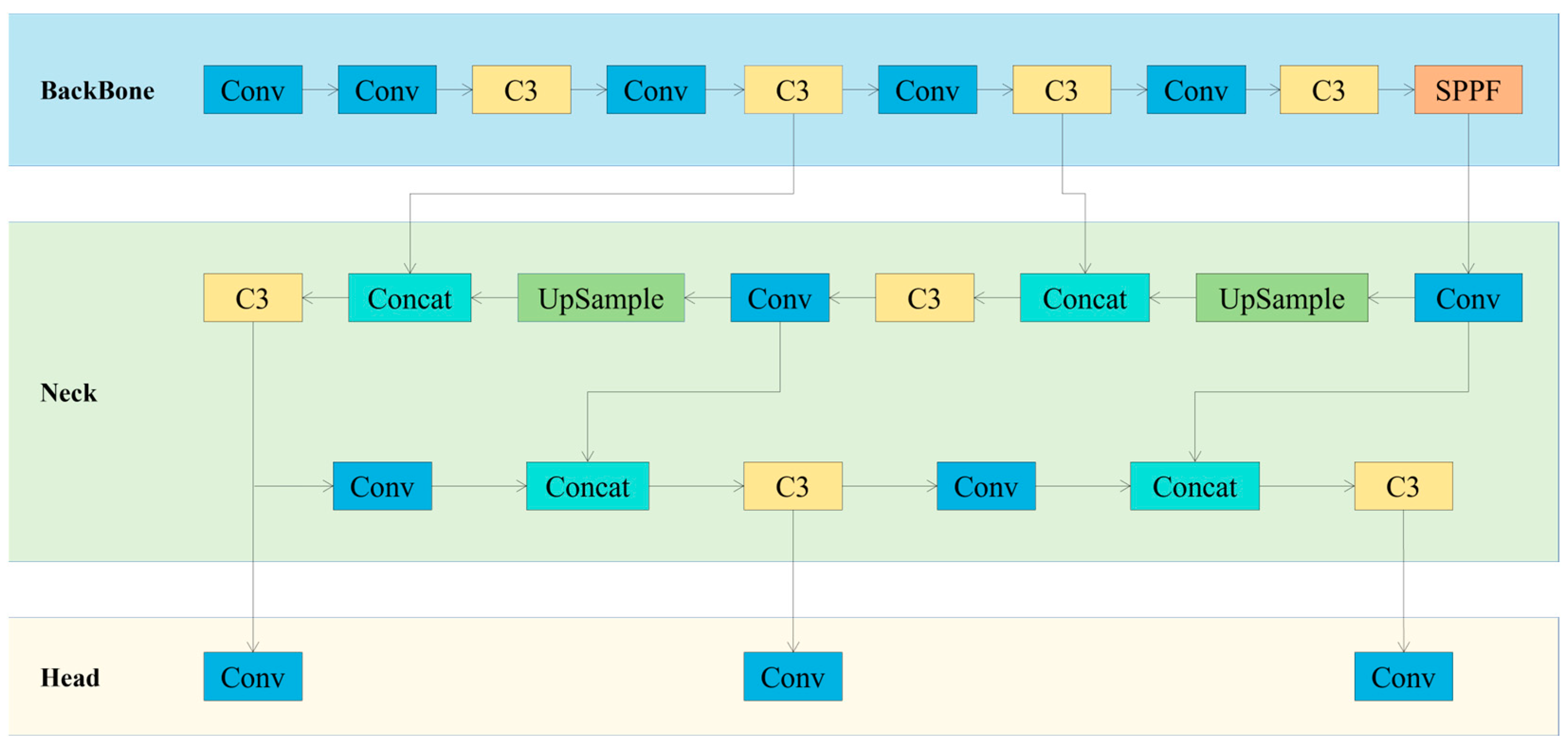
2.1. YOLOv5
2.2. Multi-Scale Feature Fusion
2.3. Lightweight Network
3. Materials and Methods
3.1. Dataset
3.2. Methods
3.2.1. CGH Module
3.2.2. Multi-Convolution Features Fusion Block
3.2.3. CARAFE
3.2.4. BiFPN
3.3. Experimental Parameter Settings
3.4. Model Evaluation Metrics
4. Experimental Result and Discussion
4.1. Performance Evaluation
4.2. Ablation Experiment
4.3. Comparison of Different Modules
4.4. Robustness Testing
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kim, S.; Kim, W.; Noh, Y.-K.; Park, F.C. Transfer learning for automated optical inspection. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2517–2524. [Google Scholar]
- Lv, X.; Duan, F.; Jiang, J.J.; Fu, X.; Gan, L.J.S. Deep metallic surface defect detection: The new benchmark and detection network. Sensors 2020, 20, 1562. [Google Scholar] [CrossRef] [PubMed]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-Based Defect Detection andClassification Approaches for Industrial Applications—A SURVEY. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed]
- Fang, X.; Luo, Q.; Zhou, B.; Li, C.; Tian, L. Research Progress of Automated Visual Surface Defect Detection for Industrial Metal Planar Materials. Sensors 2020, 20, 5136. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Baskaran, P.; Ribeiro, A.L.; Alegria, F.C.; Ramos, H.G. Classification of Corrosion Severity in SPCC Steels Using Eddy Current Testing and Supervised Machine Learning Models. Sensors 2024, 24, 2259. [Google Scholar] [CrossRef] [PubMed]
- Zou, Y.; Fan, Y. An Infrared Image Defect Detection Method for Steel Based on Regularized YOLO. Sensors 2024, 24, 1674. [Google Scholar] [CrossRef] [PubMed]
- Yousaf, J.; Harseno, R.W.; Kee, S.-H.; Yee, J.-J. Evaluation of the Size of a Defect in Reinforcing Steel Using Magnetic Flux Leakage (MFL) Measurements. Sensors 2023, 23, 5374. [Google Scholar] [CrossRef] [PubMed]
- Subramanyam, V.; Kumar, J.; Singh, S.N. Temporal synchronization framework of machine-vision cameras for high-speed steel surface inspection systems. J. Real-Time Image Process. 2022, 19, 445–461. [Google Scholar] [CrossRef]
- Kang, Z.; Yuan, C.; Yang, Q. The fabric defect detection technology based on wavelet transform and neural network convergence. In Proceedings of the 2013 IEEE International Conference on Information and Automation (ICIA), Yinchuan, China, 26–28 August 2013; pp. 597–601. [Google Scholar]
- Hu, S.; Li, J.; Fan, H.; Lan, S.; Pan, Z. Scale and pattern adaptive local binary pattern for texture classification. Expert Syst. Appl. 2024, 240, 122403. [Google Scholar] [CrossRef]
- Abouzahir, S.; Sadik, M.; Sabir, E. Bag-of-visual-words-augmented Histogram of Oriented Gradients for efficient weed detection. Biosyst. Eng. 2021, 202, 179–194. [Google Scholar] [CrossRef]
- Shayeste, H.; Asl, B.M. Automatic seizure detection based on Gray Level Co-occurrence Matrix of STFT imaged-EEG. Biomed. Signal Process. Control 2023, 79, 104109. [Google Scholar] [CrossRef]
- Anter, A.M.; Abd Elaziz, M.; Zhang, Z. Real-time epileptic seizure recognition using Bayesian genetic whale optimizer andadaptive machine learning. Future Gener. Comput. Syst. 2022, 127, 426–434. [Google Scholar] [CrossRef]
- Malek, A.S.; Drean, J.; Bigue, L.; Osselin, J. Optimization of automated online fabric inspection by fast Fourier transform (FFT) and cross-correlation. Text. Res. J. 2013, 83, 256–268. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Y.; Zhu, Q.; Mao, J.; Xiao, C.; Lu, X.; Zhang, H. A Surface Defect Detection Framework for Glass Bottle Bottom Using Visual Attention Model and Wavelet Transform. IEEE Trans. Ind. Inform. 2020, 16, 2189–2201. [Google Scholar] [CrossRef]
- Ma, J.; Wang, Y.; Shi, C.; Lu, C. Fast Surface Defect Detection Using Improved Gabor Filters. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1508–1512. [Google Scholar]
- Kulkarni, R.; Banoth, E.; Pal, P. Automated surface feature detection using fringe projection: An autoregressive modeling-based approach. Opt. Laser Eng. 2019, 121, 506–511. [Google Scholar] [CrossRef]
- Hao, M.; Zhou, M.; Jin, J.; Shi, W. An Advanced Superpixel-Based Markov Random Field Model for Unsupervised Change Detection. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1401–1405. [Google Scholar] [CrossRef]
- Liu, J.; Cui, G.; Xiao, C. A Real-time and Efficient Surface Defect Detection Method Based on YOLOv4. J. Real-Time Image Process. 2023, 20, 1–15. [Google Scholar] [CrossRef]
- Chen, L.; Wu, X.; Sun, C.; Zou, T.; Meng, K.; Lou, P. An intelligent vision recognition method based on deep learning for pointer meters. Meas. Sci. Technol. 2023, 34, 055410. [Google Scholar] [CrossRef]
- Huang, Z.; Hu, H.; Shen, Z.; Zhang, Y.; Zhang, X. Lightweight edge-attention network for surface-defect detection of rubber seal rings. Meas. Sci. Technol. 2022, 33, 085401. [Google Scholar] [CrossRef]
- Lin, Z.; Ye, H.; Zhan, B.; Huang, X. An Efficient Network for Surface Defect Detection. Appl. Sci. 2020, 10, 6085. [Google Scholar] [CrossRef]
- Li, H.; Wang, F.; Liu, J.; Song, H.; Hou, Z.; Dai, P. Ensemble model for rail surface defects detection. PLoS ONE 2023, 18, e0292773. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Lu, Z.; Lv, Z.; Meng, M.; Tan, Y.; Xia, K.; Liu, K.; Zuo, H. Metal surface defect detection based on improved YOLOv5. Sci. Rep. 2023, 13, 20803. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Shen, S.; Xu, S. Strip steel surface defect detection based on lightweight YOLOv5. Front. Neurorobot. 2023, 17, 1263739. [Google Scholar] [CrossRef] [PubMed]
- Lv, B.; Duan, B.; Zhang, Y.; Li, S.; Wei, F.; Gong, S.; Ma, Q.; Cai, M. Research on Surface Defect Detection of Strip Steel Based on Improved YOLOv7. Sensors 2024, 24, 2667. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Xu, S.; Zhu, Z.; Wang, P.; Li, K.; He, Q.; Zheng, Q. EFC-YOLO: An Efficient Surface-Defect-Detection Algorithm for Steel Strips. Sensors 2023, 23, 7619. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2778–2788. [Google Scholar]
- Li, C.; Yan, H.; Qian, X.; Zhu, S.; Zhu, P.; Liao, C.; Tian, H.; Li, X.; Wang, X.; Li, X. A domain adaptation YOLOv5 model for industrial defect inspection. Measurement 2023, 213, 112725. [Google Scholar] [CrossRef]
- Shi, H.; Zhao, D. License Plate Recognition System Based on Improved YOLOv5 and GRU. IEEE Access 2023, 11, 10429–10439. [Google Scholar] [CrossRef]
- Lawal, O.M. YOLOv5-LiNet: A lightweight network for fruits instance segmentation. PLoS ONE 2023, 18, e0282297. [Google Scholar] [CrossRef] [PubMed]
- Cardellicchio, A.; Solimani, F.; Dimauro, G.; Petrozza, A.; Summerer, S.; Cellini, F.; Renò, V. Detection of tomato plant phenotyping traits using YOLOv5-based single stage detectors. Comput. Electron. Agric. 2023, 207, 107757. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Machine Learning and Knowledge Discovery in Databases, Proceedings of the European Conference, ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Part III; Springer Nature Switzerland: Cham, Switzerland, 2022; pp. 443–459. [Google Scholar]
- Sergey, I.; Christian, S. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37, JMLR.org, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Park, S.; Kang, D.; Paik, J. Improved center and scale prediction-based pedestrian detection using convolutional block. In Proceedings of the 2019 IEEE 9th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 8–11 September 2019; pp. 418–419. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, J.; Pan, Q.; Lu, D.; Zhang, Y. An Efficient Ship-Detection Algorithm Based on the Improved YOLOv5. Electronics 2023, 12, 3600. [Google Scholar] [CrossRef]
- Liu, H.; Duan, X.; Chen, H.; Lou, H.; Deng, L. DBF-YOLO: UAV Small Targets Detection Based on Shallow Feature Fusion. IEEJ Trans. Electr. Electron. Eng. 2023, 18, 605–612. [Google Scholar] [CrossRef]
- Zhang, X.; Feng, Y.; Zhang, S.; Wang, N.; Mei, S. Finding Nonrigid Tiny Person With Densely Cropped and Local Attention Object Detector Networks in Low-Altitude Aerial Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 4371–4385. [Google Scholar] [CrossRef]
- Liu, P.; Wang, Q.; Zhang, H.; Mi, J.; Liu, Y. A Lightweight Object Detection Algorithm for Remote Sensing Images Based on Attention Mechanism and YOLOv5s. Remote Sens. 2023, 15, 2429. [Google Scholar] [CrossRef]
- Zha, W.; Hu, L.; Sun, Y.; Li, Y. ENGD-BiFPN: A remote sensing object detection model based on grouped deformable convolution for power transmission towers. Multimed. Tools Appl. 2023, 82, 45585–45604. [Google Scholar] [CrossRef]
- Lu, X.; Lu, X. An efficient network for multi-scale and overlapped wildlife detection. Signal Image Video Process. 2023, 17, 343–351. [Google Scholar] [CrossRef]
- Jiang, M.; Song, L.; Wang, Y.; Li, Z.; Song, H. Fusion of the YOLOv4 network model and visual attention mechanism to detect low-quality young apples in a complex environment. Precis. Agric. 2022, 23, 559–577. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, X.; Jia, C.; Zhao, Z.; Wang, S.; Wang, S. Image and video compression with neural networks: A review. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1683–1698. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADNet: A fast and lightweight network for single-image super resolution. IEEE Trans. Cybern. 2020, 51, 1443–1453. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Gao, H.; Chen, A. A real-time semantic segmentation algorithm based on improved lightweight network. In Proceedings of the 2020 International Symposium on Autonomous Systems (ISAS), Guangzhou, China, 6–8 December 2020; pp. 249–253. [Google Scholar]
- Bao, Y.; Song, K.; Liu, J.; Wang, Y.; Yan, Y.; Yu, H.; Li, X. Triplet-graph reasoning network for few-shot metal generic surface defect segmentation. IEEE Trans. Instrum. Meas. 2021, 70, 5011111. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. Carafe: Content-aware reassembly of features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Value |
| Initial learning rate | 0.01 |
| Momentum | 0.941 |
| Weight decay | 0.0001 |
| Epochs | 160 |
| Batch size | 8 |
| Noautoanchor | FALSE |
| Input image size | 640 |
| Optimizer | SGD |
| Model | P | R | mAP50 (%) | mAP50:95 (%) | Params (M) |
| YOLOv5s | 72.3 | 50.8 | 69.8 | 36.0 | 7.0 |
| SDD-YOLO | 78.6 | 53.9 | 76.1 | 40.3 | 3.4 |
| Number | CGH | GhostConv | MCFF | CARAFE + BiFPN | mAP50 | mAP50:95 | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|---|---|---|---|
| 1 | - | - | - | - | 69.8 | 36.0 | 7.0 | 15.8 | 96 |
| 2 | √ | - | - | - | 71.7 | 37.2 | 3.6 | 7.7 | 147 |
| 3 | - | √ | - | - | 74.3 | 38.3 | 3.9 | 11.4 | 120 |
| 4 | - | - | √ | - | 72.3 | 38.8 | 4.8 | 13.4 | 117 |
| 5 | - | - | - | √ | 72.5 | 38.1 | 4.9 | 13.8 | 103 |
| 6 | √ | √ | - | - | 72.0 | 37.4 | 3.7 | 8.9 | 139 |
| 7 | √ | - | √ | - | 72.3 | 38.2 | 4.0 | 9.5 | 135 |
| 8 | √ | - | - | √ | 71.9 | 37.5 | 3.8 | 9.1 | 136 |
| 9 | - | √ | √ | - | 73.2 | 37.1 | 4.5 | 8.6 | 122 |
| 10 | - | √ | - | √ | 72.5 | 36.5 | 4.3 | 10.3 | 119 |
| 11 | - | - | √ | √ | 71.3 | 36.8 | 4.6 | 8.7 | 112 |
| 12 | √ | √ | √ | - | 74.5 | 39.0 | 4.1 | 8.3 | 130 |
| 13 | √ | √ | - | √ | 74.1 | 39.4 | 3.8 | 8.0 | 125 |
| 14 | √ | - | √ | √ | 75.0 | 39.1 | 4.2 | 7.8 | 122 |
| 15 | - | √ | √ | √ | 73.7 | 39.5 | 4.5 | 8.5 | 127 |
| 16 | √ | √ | √ | √ | 76.1 | 40.3 | 3.4 | 6.4 | 121 |
| Number | FPN | NAS-FPN | BiFPN | mAP50 | mAP50:95 |
|---|---|---|---|---|---|
| 1 | √ | - | - | 70.9 | 37.1 |
| 2 | - | √ | - | 72.3 | 38.2 |
| 3 | - | - | √ | 76.1 | 40.3 |
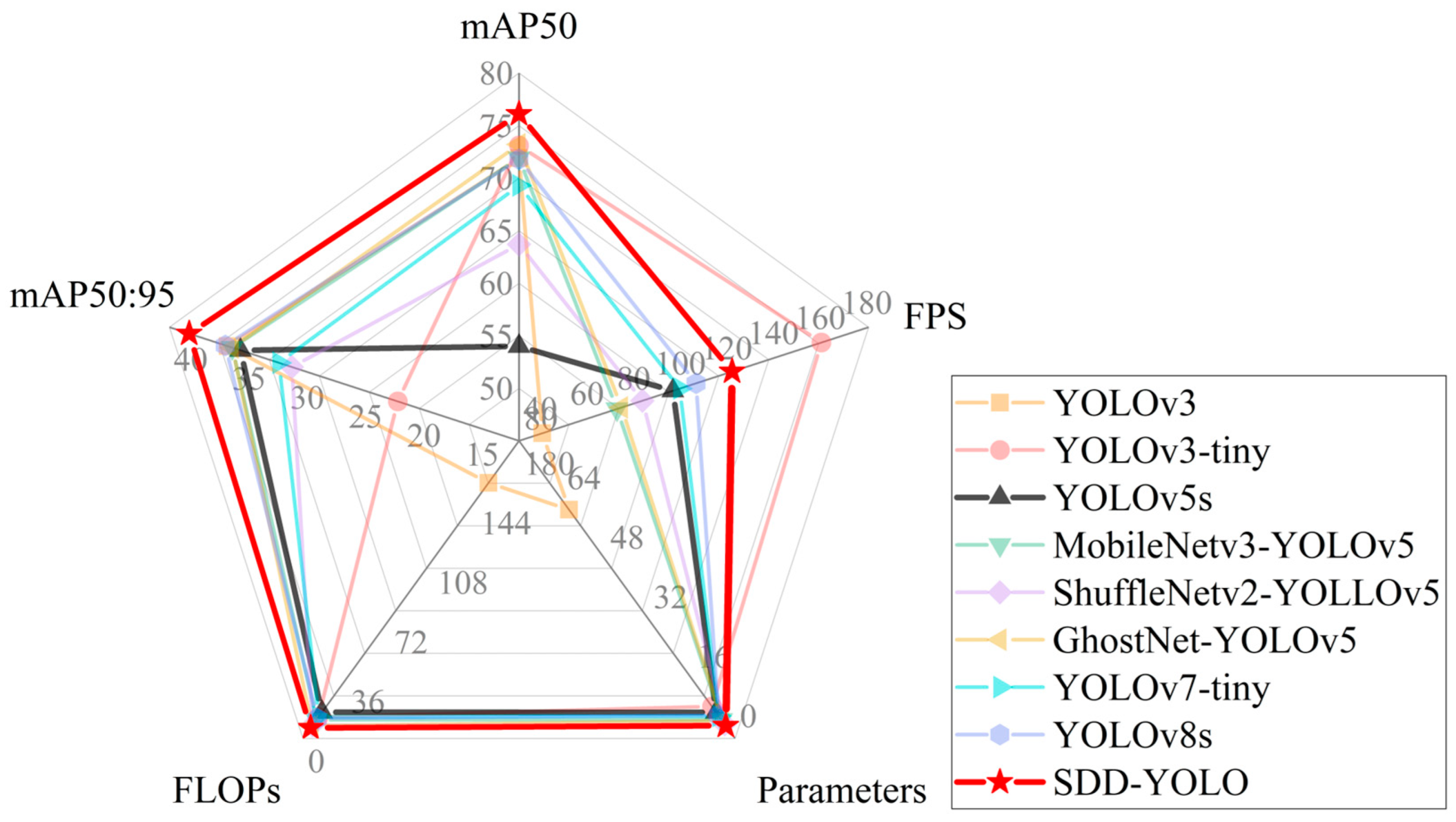
| Method | mAP50 | mAP50:95 | Params (M) | FLOPs (G) | FPS |
|---|---|---|---|---|---|
| YOLOv3 | 73.1 | 37.0 | 61.5 | 154.6 | 40 |
| YOLOv3-tiny | 54 | 22.4 | 8.6 | 12.9 | 160 |
| YOLOv5-s | 69.8 | 36.0 | 7.0 | 15.8 | 96 |
| MobileNetv3-YOLOv5 | 71.9 | 36.6 | 5.0 | 11.3 | 72 |
| ShuffleNetv2-YOLLOv5 | 63.7 | 31.5 | 3.8 | 8.0 | 83 |
| GhostNet-YOLOv5 | 73.2 | 36.6 | 4.7 | 7.6 | 74 |
| YOLOv7-tiny | 69.3 | 32.6 | 6.0 | 13.1 | 99 |
| YOLOv8s | 71.8 | 37.2 | 6.2 | 12.1 | 106 |
| SDD-YOLO | 76.1 | 40.3 | 3.4 | 6.4 | 121 |
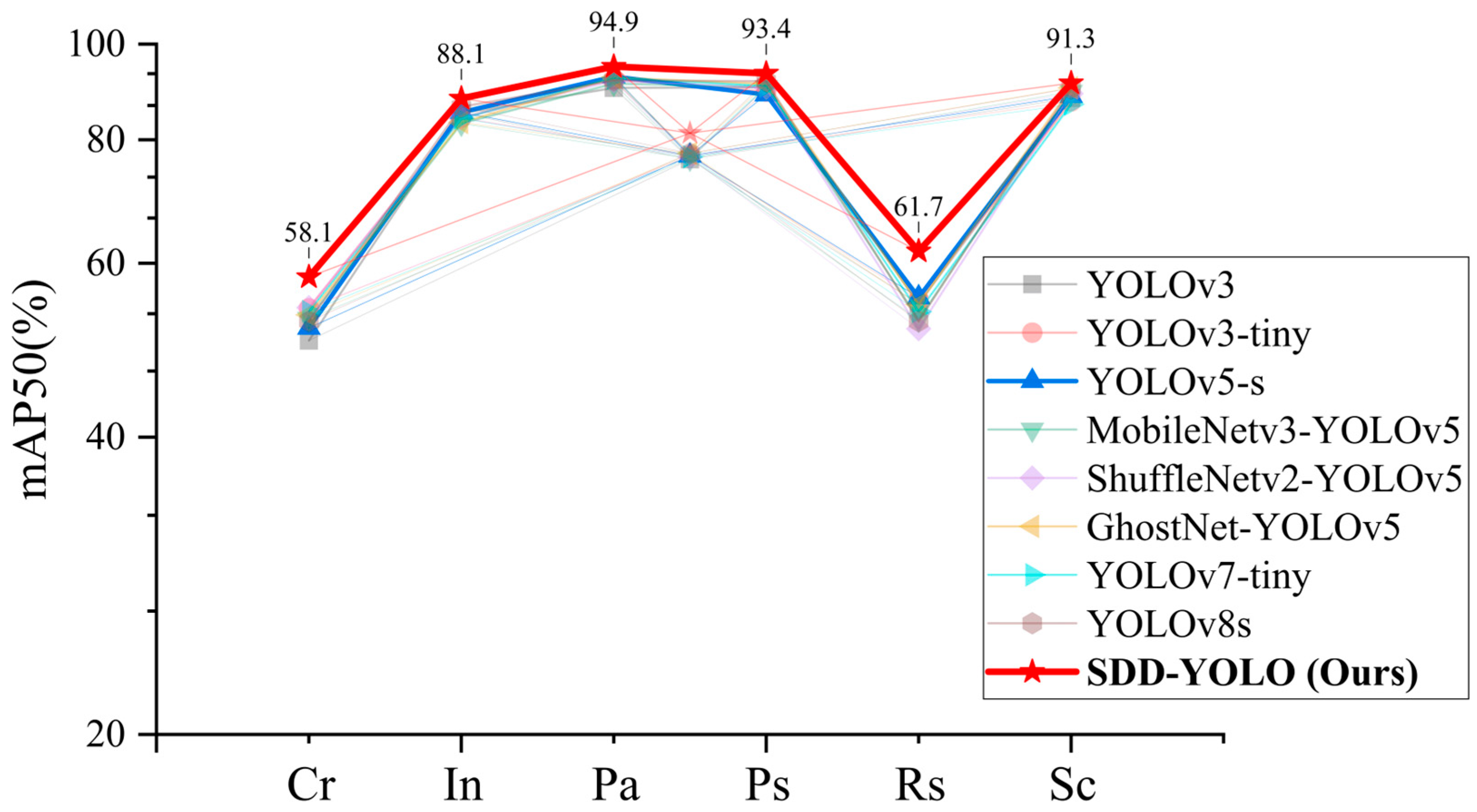
| Method | Cr (%) | In (%) | Pa (%) | Ps (%) | Rs (%) | Sc (%) |
|---|---|---|---|---|---|---|
| YOLOv3 | 50.1 | 85.1 | 90.3 | 90.4 | 54.6 | 88.2 |
| YOLOv3-tiny | 54.0 | 84.2 | 92.2 | 89.5 | 55.1 | 87.5 |
| YOLOv5-s | 51.6 | 85.3 | 92.7 | 88.9 | 55.4 | 88.6 |
| MobileNetv3-YOLOv5 | 52.7 | 83.1 | 91.2 | 90.5 | 52.6 | 89.5 |
| ShuffleNetv2-YOLLOv5 | 54.1 | 84.2 | 91.8 | 90.3 | 51.5 | 89.1 |
| GhostNet-YOLOv5 | 53.2 | 83.3 | 92.5 | 91.1 | 54.5 | 90.3 |
| YOLOv7-tiny | 53.6 | 84.1 | 92.4 | 90.7 | 53.6 | 86.9 |
| YOLOv8s | 52.4 | 86.4 | 91.9 | 91.7 | 52.4 | 90.2 |
| SDD-YOLO | 58.1 | 88.1 | 94.9 | 93.4 | 61.7 | 91.3 |
| Data | Proposed SDD-YOLO | YOLOv5s | ||||
|---|---|---|---|---|---|---|
| mAP50 | mAP50:95 | FPS | mAP50 | mAP50:95 | FPS | |
| Original | 76.1 | 40.3 | 121 | 69.8 | 36.0 | 96 |
| Low brightness | 69.2 | 33.1 | 128 | 57.3 | 26.2 | 107 |
| High exposure | 72.5 | 36.9 | 126 | 62.3 | 29.1 | 104 |
| Gaussian noise | 71.7 | 35.7 | 131 | 62.2 | 28.5 | 112 |
| All processed data | 71.1 | 35.2 | 129 | 59.1 | 27.5 | 108 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Chen, R.; Li, Z.; Ye, M.; Dai, M. SDD-YOLO: A Lightweight, High-Generalization Methodology for Real-Time Detection of Strip Surface Defects. Metals 2024, 14, 650. https://doi.org/10.3390/met14060650
Wu Y, Chen R, Li Z, Ye M, Dai M. SDD-YOLO: A Lightweight, High-Generalization Methodology for Real-Time Detection of Strip Surface Defects. Metals. 2024; 14(6):650. https://doi.org/10.3390/met14060650
Chicago/Turabian StyleWu, Yueyang, Ruihan Chen, Zhi Li, Minhua Ye, and Ming Dai. 2024. "SDD-YOLO: A Lightweight, High-Generalization Methodology for Real-Time Detection of Strip Surface Defects" Metals 14, no. 6: 650. https://doi.org/10.3390/met14060650
APA StyleWu, Y., Chen, R., Li, Z., Ye, M., & Dai, M. (2024). SDD-YOLO: A Lightweight, High-Generalization Methodology for Real-Time Detection of Strip Surface Defects. Metals, 14(6), 650. https://doi.org/10.3390/met14060650