1. Introduction
The electric arc furnace (EAF) is the second most important process for the production of crude steel [
1]. Historically, it was primarily used for the melting of scrap metal. However, with the ongoing decarbonization of the steel industry, other input materials such as biogenic carbon carriers or direct reduced iron (DRI) are being used more frequently in the EAF [
2,
3]. Meanwhile, the energy costs as well as the requirements on the composition of the crude steel are increasing, posing an unprecedented challenge for the furnace operation. Due to the extreme condition within the arc furnace, the measurements, however, are highly complicated and cost-intensive. As a result, the available data are often limited to ingoing and outgoing energy and material flows, with no direct information on the occurring processes. In addition, there is often a significant delay between taking a sample of the steel and the determination of the result. A common way to analyze and improve the operation of metallurgical processes is, therefore, through the application of mathematical models. In doing so, the costs and risks connected with subsequent plant trials can be decreased. A comprehensive review of the available models of the EAF was published by Hay et al. [
4] as well as Carlsson et al. [
5]. Carlsson focused on statistical models, while Hay et al. discussed the purpose, modeling approach, and limitations of dynamic process models. A comprehensive and well-documented process model of the EAF was developed by Meier [
6] based on the previous work by Logar et al. [
7,
8]. Within the model, the furnace is divided into several homogenous zones, including the liquid steel and slag, as well as the gas phase. The arc furnace process is simulated by calculating the energy and mass transfer between these zones. In this regard, the chemical reactions are a key aspect in simulating the EAF process, as they determine the composition of the molten steel, slag, and off-gas. Moreover, chemical reactions contribute a significant amount of energy to the process [
9]. A well-conditioned slag also improves the stability of the arc, reduces the refractory corrosion, and reduces heat losses by building a slag coating on the furnace walls. In later stages of the process, it is advantageous to promote a foaming slag by injecting carbon and oxygen. The carbon reacts with the oxygen and oxides in the slag, forming CO, which leads to the foaming of the slag. The foaming slag encapsulates the arc and shields the furnace roof and walls from its thermal radiation, further reducing heat losses and preventing damage [
10]. For the presented reasons, an accurate modelling of the slag phase as well as the reactions in the interphase between the melt and slag is detrimental for a simulation of the EAF process.
The reaction rates are subject to the melt and slag composition, and the activity of the species, as well as the reaction kinetics and the mass transfer within the adjacent zones. Although the slag activity is only calculated for a limited number of species, the computation takes up a significant fraction of the total runtime of the process model. The overall computation time is still short enough to allow for the real-time monitoring of the process. However, when running optimization tasks on multiple heats, the computation time can increase drastically. A possible future application of the model is the optimization of the operating chart in order to minimize energy and resource consumption as well as climate gas emissions while maintaining a desirable composition of the melt and a safe operation of the furnace. However, searching the high-dimensional solution space using the process model in its default state is not possible in a reasonable time. In this regard, a further reduction in the computation time is imperative. The main objective of this work is, therefore, to implement a surrogate model for the calculation of the activity of the reacting species by utilizing supervised machine learning. In this regard, neural networks allow for the representation of complex relationships between the input and output data. A shallow neural network is used, as it provides a sufficient approximation of the reference model, yet retains an efficient architecture. This way, by applying the surrogate model, the computation time of the EAF model can be significantly decreased. The described approach of substituting particularly demanding sub-models is not limited to the domain of the chemical activity calculation. It can also be applied to other model aspects or even different processes. The necessary training data can be generated by means of measurement or by the application of an accurate but computationally more demanding model.
2. Materials and Methods
In general, most relevant metallurgical reactions take place at the boundaries between immiscible phases. In the context of the EAF, those are primarily the injection zones of oxygen and carbon, as well as the interface between melt and slag [
11]. Within these zones, the overall reaction rates are governed by the transport of reactants and products towards and from the interface, as well as the chemical reaction rates at the interface itself. However, with temperatures above the melting point of steel, a local equilibrium is often assumed for the interface, with the transport rates considered as the limiting factor [
11]. Among others, this approach is used within the process models by MacRosty [
12] and Hay [
6,
13]. The latter is the primary object of consideration for this work. Hay incorporates separate reactions zones for the sites of oxygen and carbon injection, as well as the metal–slag interface. However, for the purpose of demonstration, the surrogate model is only applied for the interaction zone between liquid metal and slag. Within the model, the reaction zone contains the entire liquid slag phase and a limited amount of melt. Consequently, in terms of mass transport, the reaction rates are only limited by the diffusion rates between the melt and the metal–slag interface (
) in accordance to Equation (1)
, where the current mass fractions of species i within the melt and interface are given by
and
, respectively, and kd
i denoting empirical factors. The equilibrium composition within the interaction zone is governed by Equation (2). As such, the equilibrium constant
can be determined as a function of the standard Gibbs free energy change −ΔG
0, temperature T, and the gas constant R, as well as the activity
and the stoichiometric coefficient
for each species. The equilibrium concentration of the elements in the interface can then be calculated using the equilibrium constants and activities. Ultimately, the reaction rates within the model are implemented as a function of the difference between the current mass fractions and the equilibrium concentration. The size of the time steps within the process model is controlled globally for the entire system of differential equations by means of the solver (BDF) in use [
14]. A more detailed description can be found in the corresponding work by Hay [
13]:
For calculation of the reaction rate as previously described, it is necessary to compute the activity of the species within the liquid melt and slag. Computation of the melt activities is comparably simple, as the melt is largely made of liquid iron with low concentration of dissolved species. In this regard, Hay incorporated both the Wagner interaction parameter formalism (WIPF) [
15] and the unified interaction parameter formalism (UIP) [
16]. The slag can, however, vary over a wide range. It consists, in part, of metallic oxides (mainly iron oxide) and silica from adhesives of the charged scrap. From a metallurgy point of view, the main requirement on the slag is to promote dephosphorization as well as desulphurization. Both metals are often present in the scrap and coal, yet are undesirable in produced steel [
17]. In order to facilitate oxidation of phosphor and sulphur, it is customary to charge basic material such as chalk, lime, or dolomite alongside the scrap in order to raise the activity of oxygen within the slag and lower the activity of oxygen within the liquid melt [
18,
19]. For this reason, a large portion of the slag is made up of calcium and magnesium oxide from the slag formers. In addition, magnesium oxide is also released into the liquid slag from disintegration of the refractory material. Oversaturation of the slag with CaO and MgO can ultimately lead to the formation of another phase, further increasing the complexity of the system [
20]. In addition to the aforementioned species, the slag also contains various sulfides and fluorites to a lesser extent. That being said, due to the high complexity and unavailability of interaction parameters for these species, the EAF model focuses purely on oxides. In
Table 1, an exemplary composition of the EAF slag from a steel plant producing structural and engineering steels is listed. Below that, the upper and lower limits (UL and LL) on the mass fractions of each species for the subsequent creation of the data for training of the neural network are shown. The first scenario is intended to match the composition of the slag at the time of tapping, while the second scenario is provided for a more general description. For the calculation of the activities within the slag, the regular solution (RS) model published by Ban-Ya [
21] as well as the cell model by Gaye et al. [
22] are implemented. Within the RS model, cations are assumed to be randomly distributed within an oxygen–anion matrix. In contrast, the cell model describes the slag in terms of cells composed of a single central anion surrounded by cations [
23]. Unfortunately, the interaction parameters published by Ban-Ya are missing information for chromium oxide. These have been partially supplemented by the work of Xiao and Holappa [
24]. However, when compared to the results of the commercial software FactSage 6.4 (Version 6.4, GTT Technologies Herzogenrath, Germany) [
25], the deviation of both models necessitated the usage of further parameters for correction. Furthermore, while the cell model yields better results than the regular solution model, the computation time is significantly higher, accounting for up to 40% of the EAF model’s total runtime. For this reason, estimation of the slag activities using a neural network is investigated. Within this work, the calculation of the slag activity is treated as a pure regression task.
The necessary data for training of the model are generated by using the FactSage Equilib module on a dataset generated corresponding to the aforementioned upper and lower bounds. The temperature values are drawn from a uniform distribution. For the composition, two separate scenarios are considered. For the first case the composition range is aimed to match the composition of the slag at tapping. However, depending on the melting rates of the input material, the slag composition varies throughout the process. For this reason, in the second scenario, broader boundaries are chosen, ranging from 0 to 100 percent for each species. Phosphorus oxide is set to zero in both cases, as it is not included in the version 6.4 of the FToxid or FTstel databases used for generation of the training data [
26]. In the first scenario, individual mole fractions are drawn from a uniform distribution by applying the stated lower and upper bounds. The composition array is then normalized by division with the overall sum. However, in the second scenario, this method cannot be used. Since all species range from 0 to 100%, by normalizing, all mol fractions are likely to be on a similar level. This way, creating a composition with only one or two major components is virtually impossible, as it would require all other fractions to be very small. To address this issue, the composition array is created in multiple steps. In the first step a single value between 0 and 1 is drawn from a uniform distribution. Subsequently, other (n−1) values are drawn that range from 0 to (1−x) where n denotes the number of species and x denotes the result of the first sample. Using all values, as well as 0 and 1, an array is created. Ultimately, the array is sorted, and the difference between each element and its successor is calculated. The result is assigned to the species at random. This way, the sum of all entries is equal to one, while a single species is likely to have a higher mole fraction than the others. For each scenario, a total of 10,000 compositions is created, 40% of which is used for training of the neural network. In
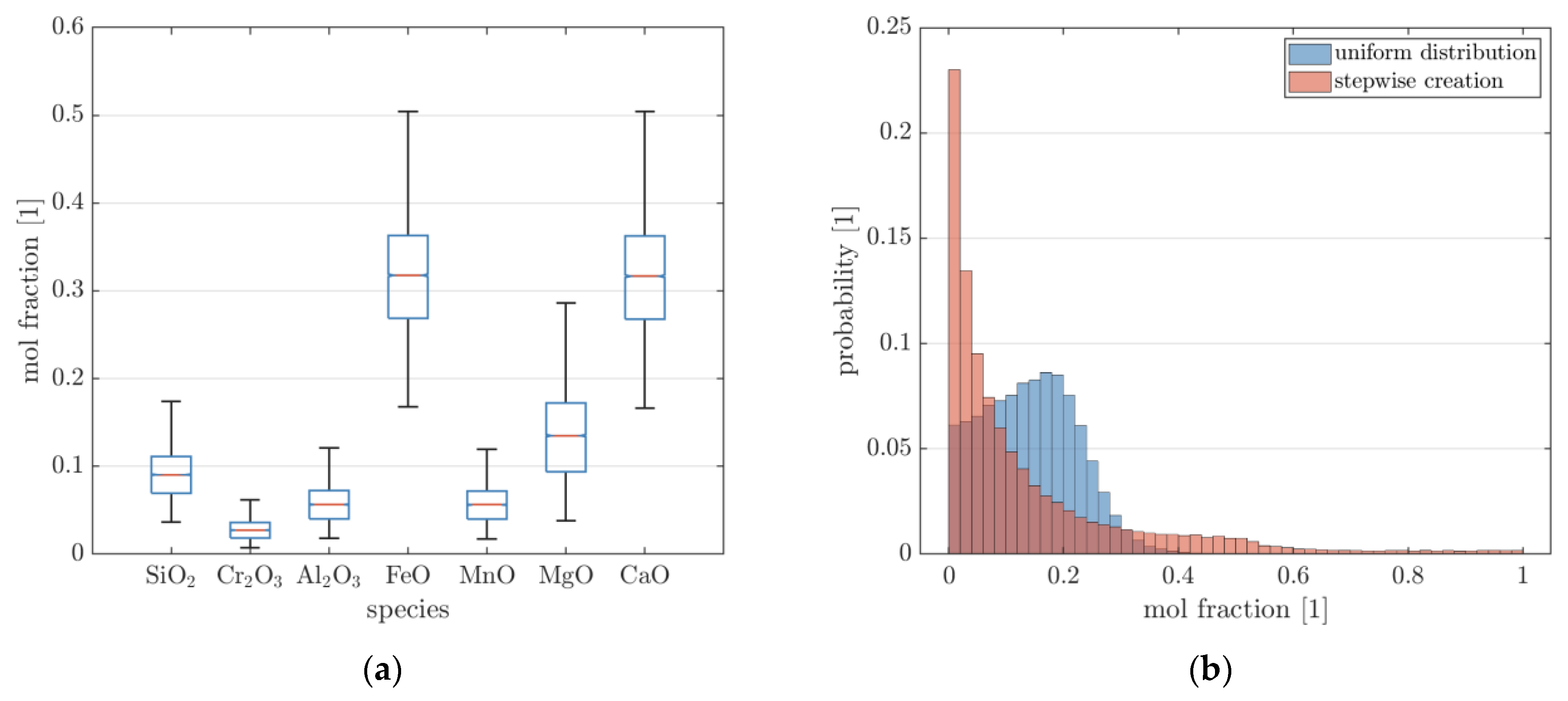
Figure 1a, the generated slag composition of the tapping scenario is shown in the form of a box plot. The slag consists mainly of FeO, CaO, and MgO with lower percentages of the remaining species.
Figure 1b also shows the probability distribution of the molar fractions for the second scenario. As can be seen, when drawing from a uniform distribution with subsequent normalization, almost no samples exceed a mole fraction of 0.4. In contrast, when stepwise-creating the composition array, mole fractions of up to 1 can be reached. By nature, this results in a higher overall number of small mole fractions. The composition matrices from scenario 1 and 2 (with stepwise creation) are used in conjunction when training the model to prevent overfitting of the neural network to a specific situation.
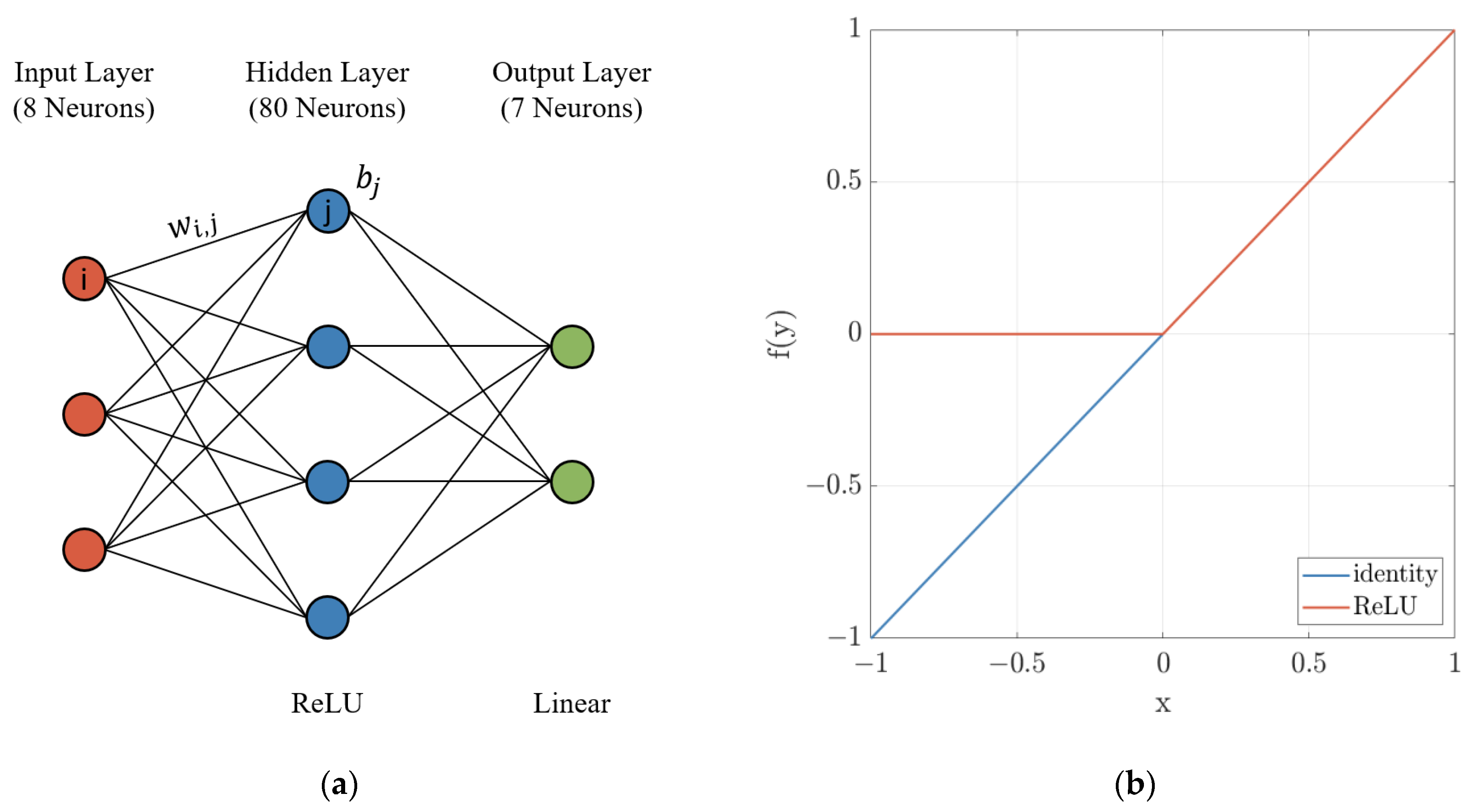
For approximation of the chemical activity, a shallow feedforward neural network was chosen. When applying neural nets, most computational effort is during training of the model weights. Predicting the output using the trained model is as simple as matrix multiplication and summation, as such computation of the prediction is not reliant on third-party libraries and can be implemented very efficiently. The network is composed of an input and output layer, as well as a single hidden layer with 80 neurons. The layout of the neural network is depicted in
Figure 2a.
As shown in Equation (3), at each node, the input from the previous layer denoted by v
j is first multiplied by a set of weights w
ij specific to the neuron i. Afterwards, the corresponding vector is cumulated, and a bias bi is added. The result x is passed onto the next layer by application of an activation function f(x). The output layer utilizes a linear activation function (identity) with a constant value as given by Equation (4), while the neurons within the hidden layer uses a rectified linear unit (ReLU) as stated in Equation (5). Both functions are visualized in
Figure 2b. In the recent past, the ReLU has become the default choice for most feedforward networks [
27]. While the advantages of the ReLU in terms of the learning rate are neglectable for small networks, it has been chosen in order to introduce a nonlinear transformation to the model. Stacking linear layers, the output would otherwise still be equivalent to a linear combination of the input arguments [
28]. The model input consists of the temperature and composition of the slag. In theory, the chemical activity is also dependent on pressure. However, the melt–slag interface is located above the melt, with the pressure inside the EAF being reasonably close to atmospheric pressure. For this reason, the pressure dependency of the activity can be neglected. The output contains the activities of each species at the given temperature and composition.
Both the weights and biases of each neuron can be seen as parameters of the neural network. Starting from their initial values, during training, the parameters are adjusted such that the output of the network best matches the reference values. To achieve this, a backpropagation algorithm is applied. Starting from the output layer, the effect of each individual weight on the result is calculated by partial derivation of the obtained overall error. The weights can then be adjusted accordingly before the next iteration [
29]. This process is repeated until the output is within a specified tolerance or the maximum number of iterations is reached. In the upcoming section, the results of the surrogate model are compared to the previously used models. In this regard, the results are evaluated based on several metrics. A major aspect is the accuracy of the model prediction. As such, the deviation between the chemical activity calculated by each model and the reference values obtained with FactSage is assessed using the mean absolute error (MAE) as stated in Equation (6). Additionally, the adjusted coefficient of determination (
) given in Equation (7) is calculated from the ratio of the residual (RSS) and total sum of squares (TSS). The coefficient is a popular measure for the quality of a fit and is often presented as the percentage of variance of the result which is explained by the linear relationship with the explanatory variables [
30]. Finally, the 95% percentile is provided, representing the threshold within which 95% of the results fall. Likewise, 5% of the results have a deviation greater than the threshold. This metric can be interpreted as a worst-case analysis. Due to the dynamic nature of the EAF process, small deviations from the actual result can cancel each other out, while large deviations will significantly affect the overall result of the simulation.
On the other hand, the computation speed of the models is relevant, as the purpose of the surrogate model is not only to closely reproduce the reference value, but to do so in significantly less time than the previous models. In order to eliminate random fluctuations, the execution time is averaged for all samples within the validation set. The calculations are performed in serial, as this resembles the later usage in the EAF model. Furthermore, the computation time of the surrogate model is multiplied by a factor of as it is missing the activity of phosphorus oxide. However, it can be argued that the complexity of the neural network remains largely unchanged, as the additional output only affects the size of matrices used for calculation but not the overall structure of the model.



{kind=link}
{kind=link}
{kind=link}