
Identifying Key Information on Life Cycle of Engineering Data by Graph Convolutional Networks and Data Mining

Abstract
:1. Introduction
2. Related Works
2.1. Graph Neural Networks
2.2. Key Nodes Identification
2.3. The Life Cycle of Engineering Data
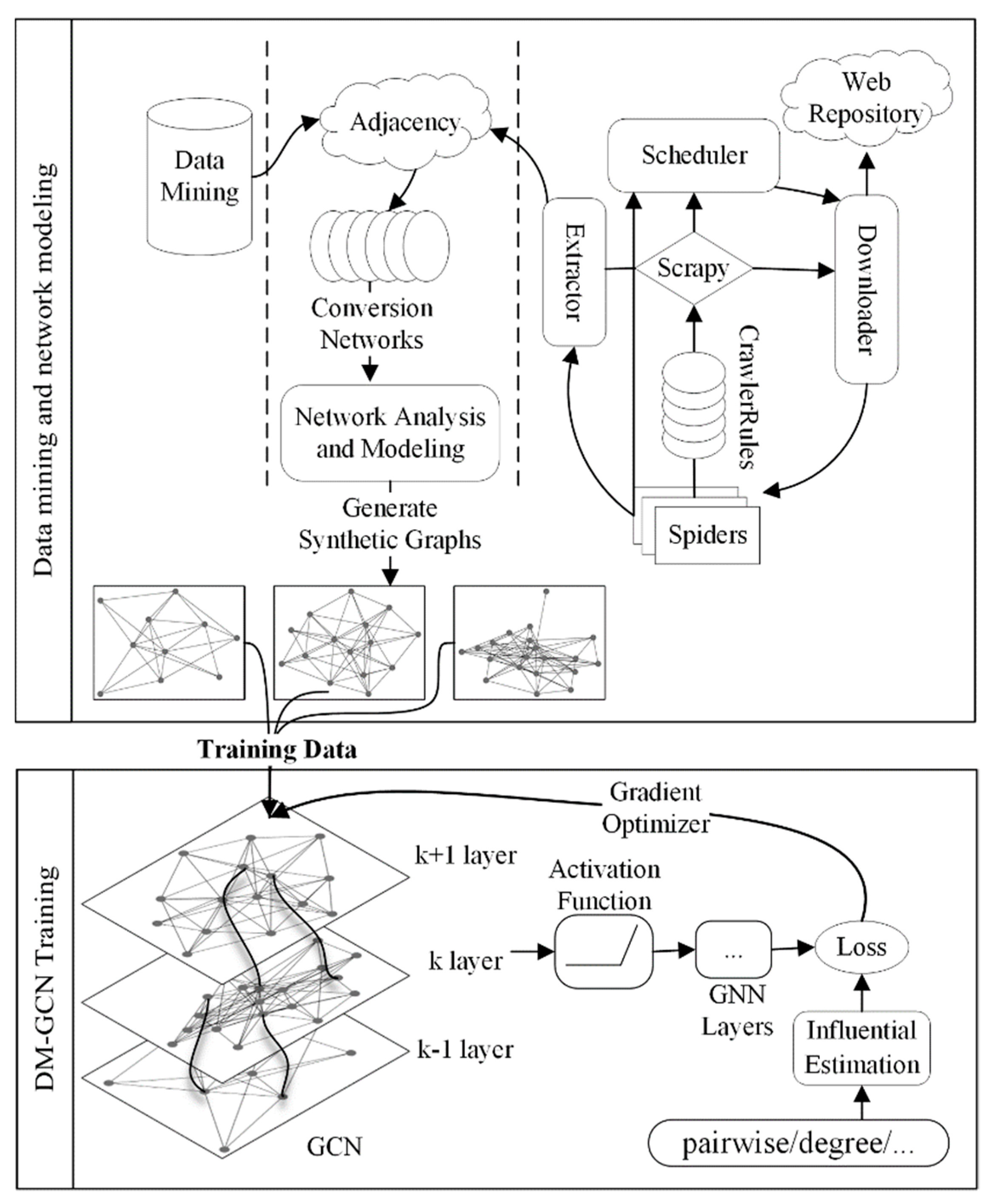
3. Model
3.1. A Data-Mining-Based Graph Convolutional Model
3.2. Complex Network Measures
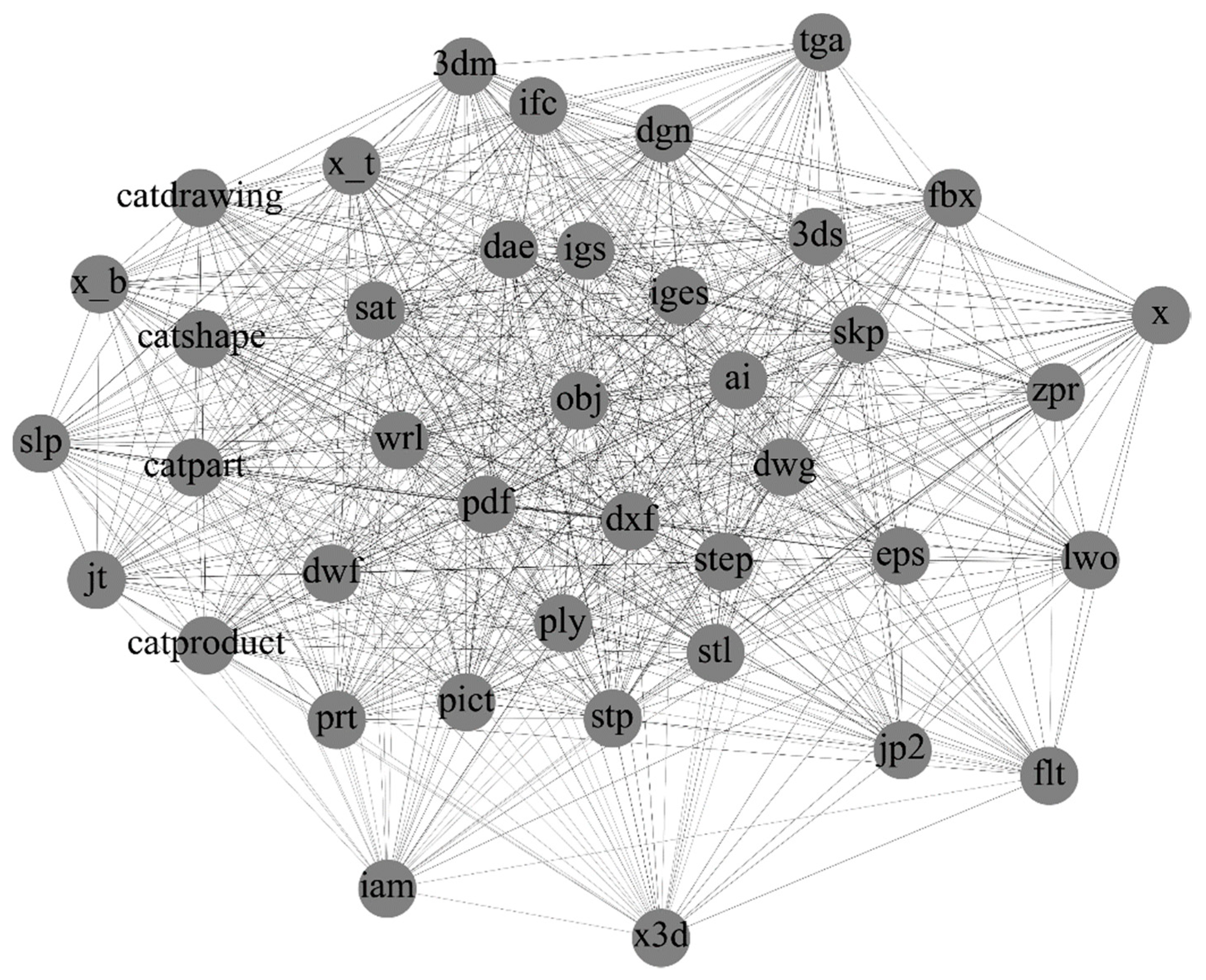
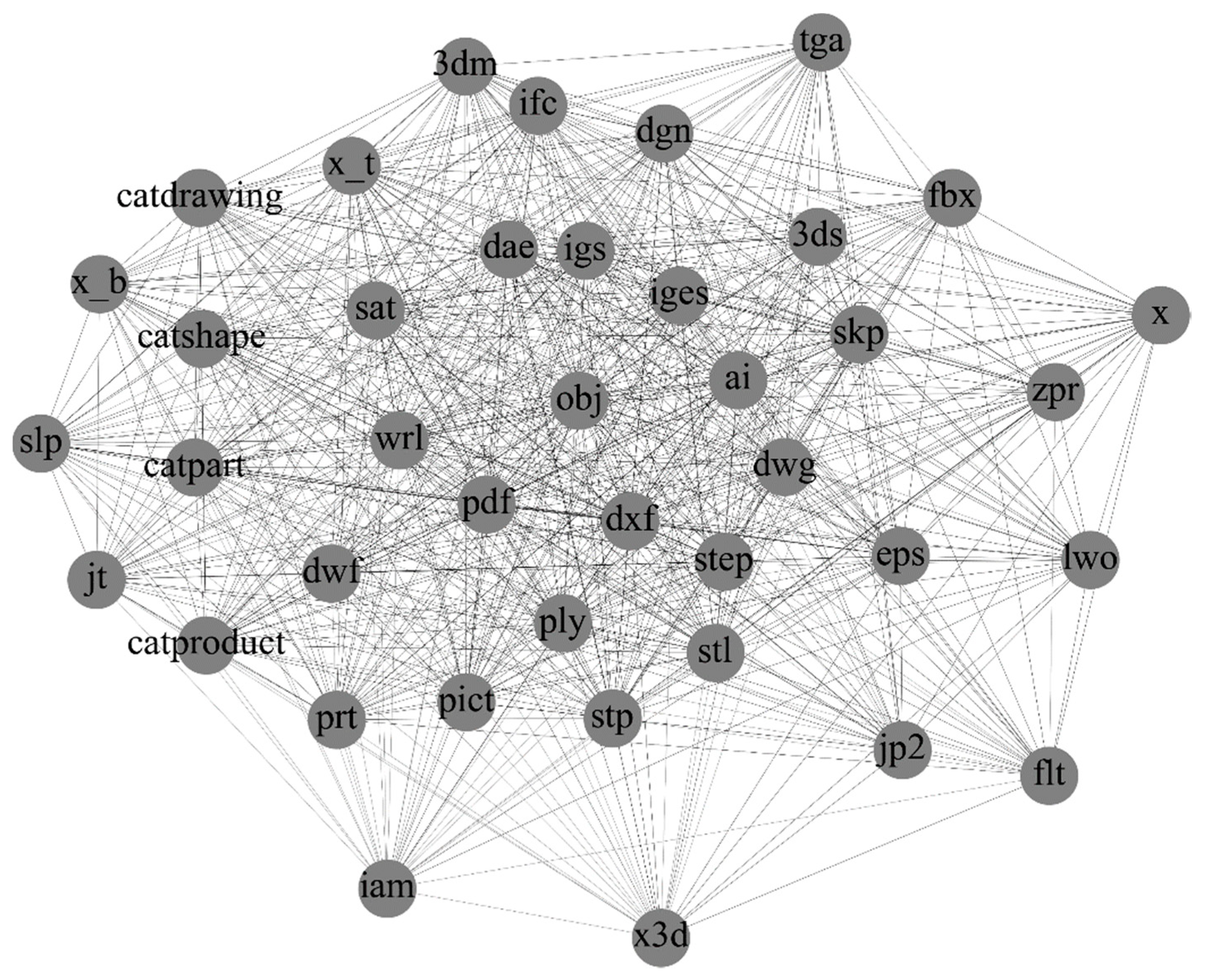
3.3. Case 1: Production Data-Exchange Networks
3.4. Case 2: Operating System Package Dependency Networks
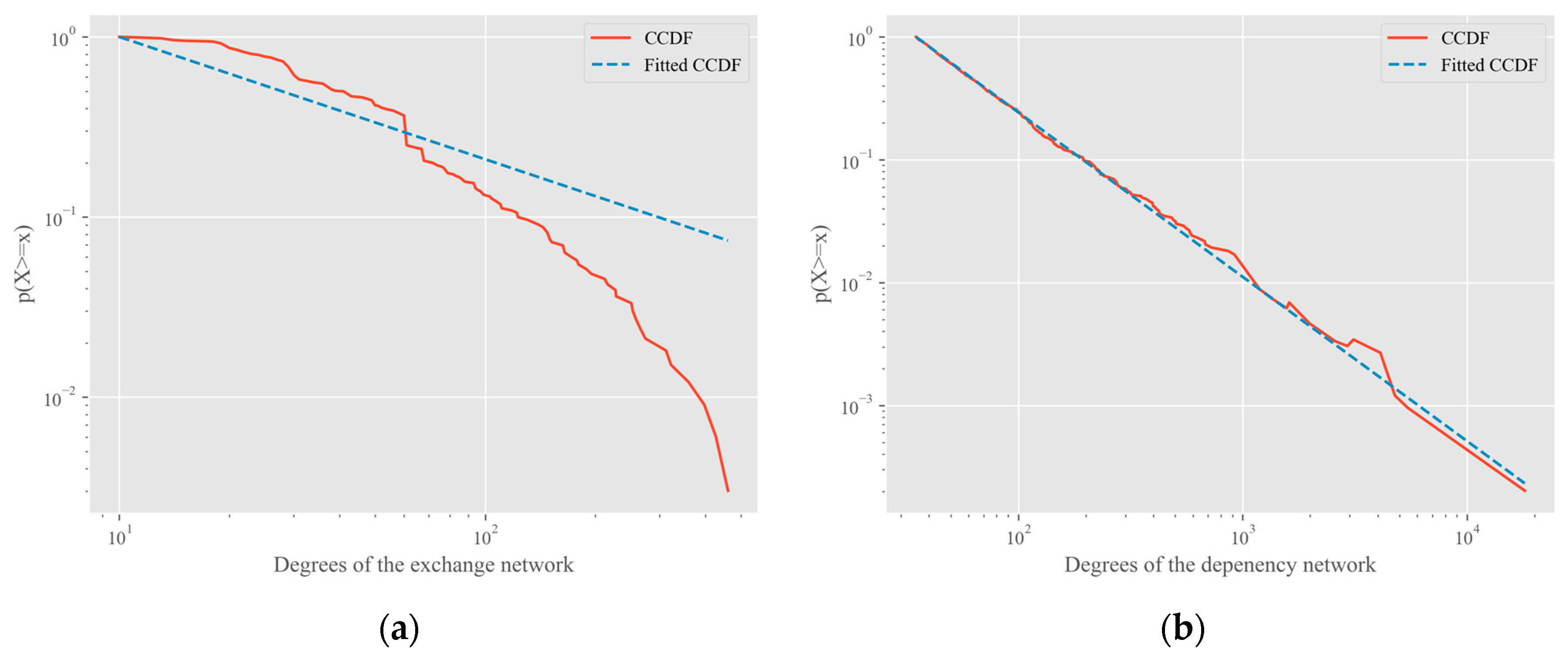
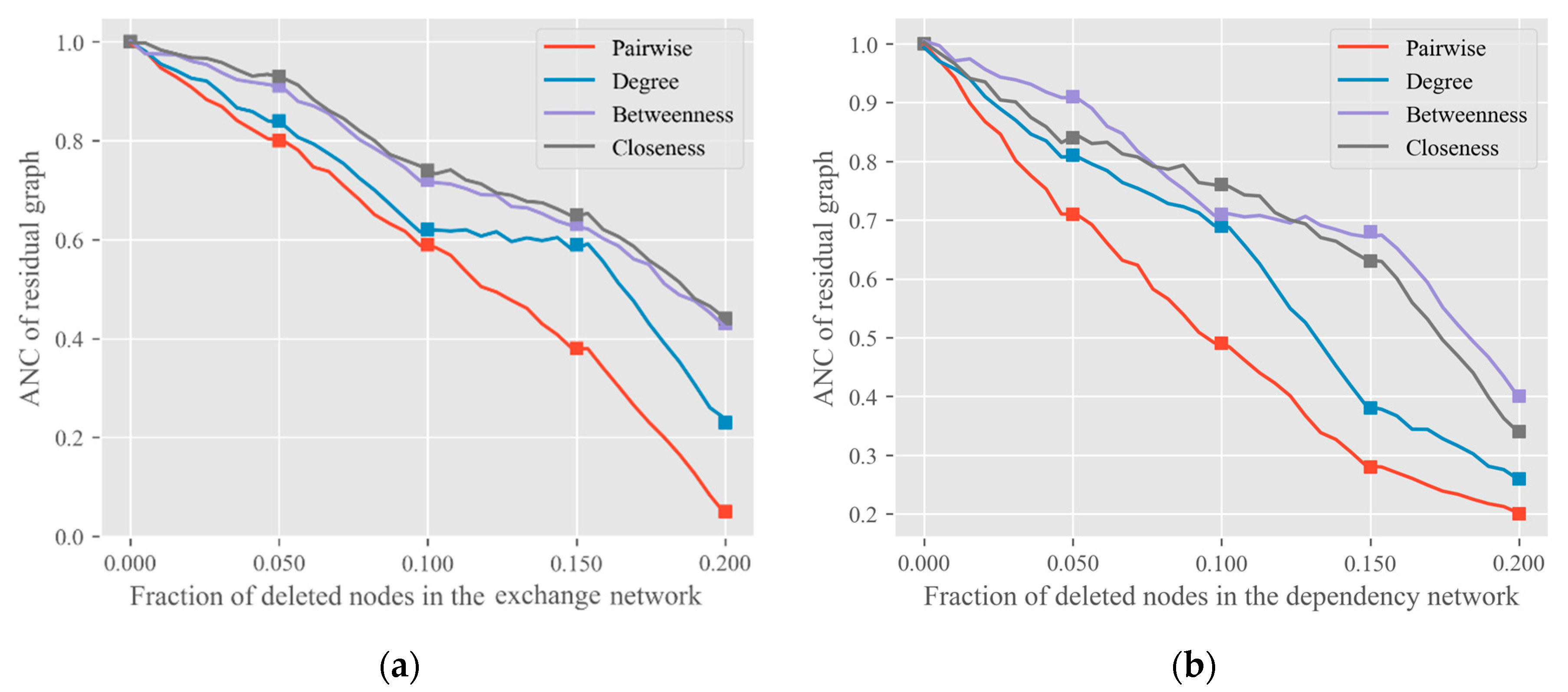
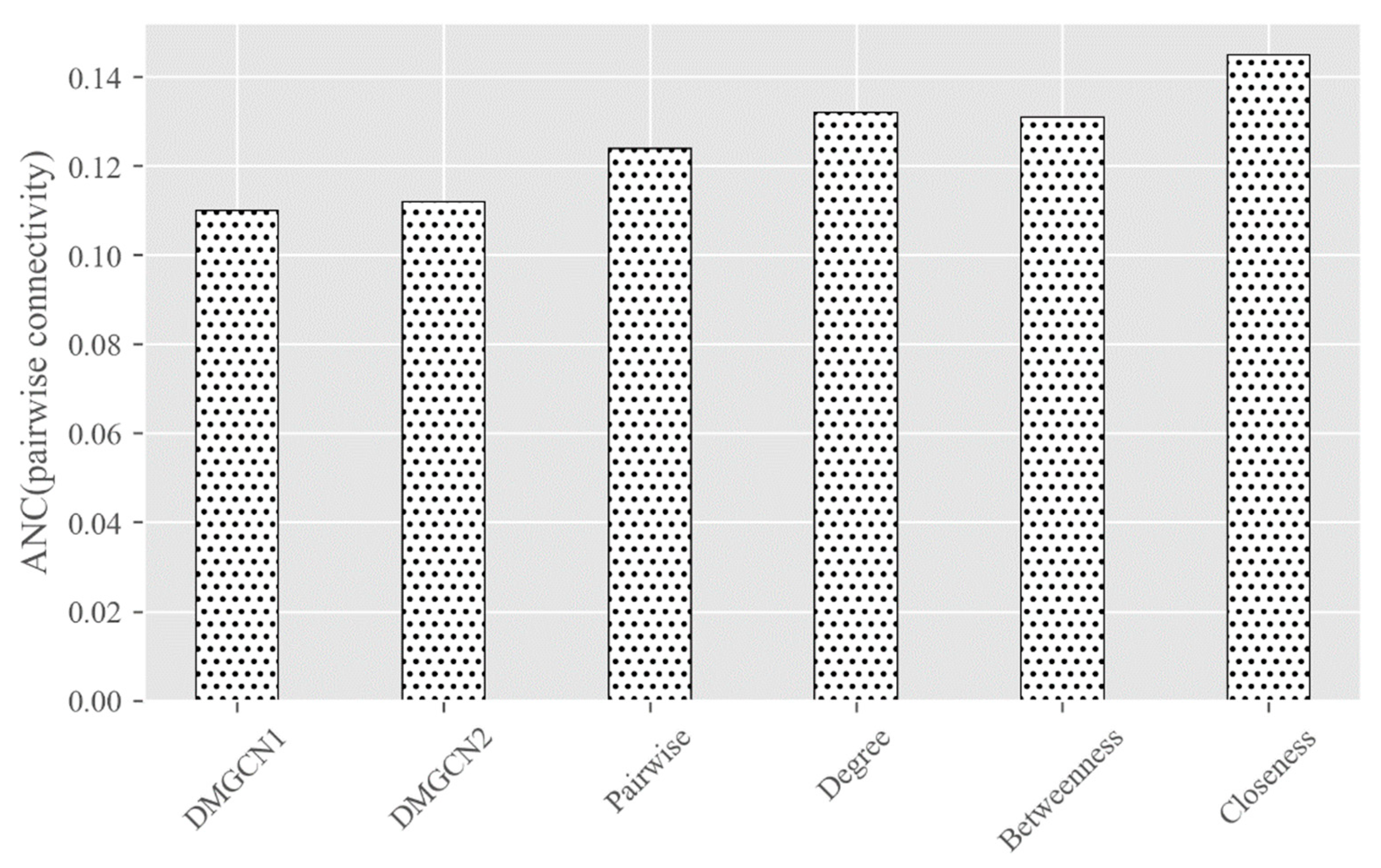
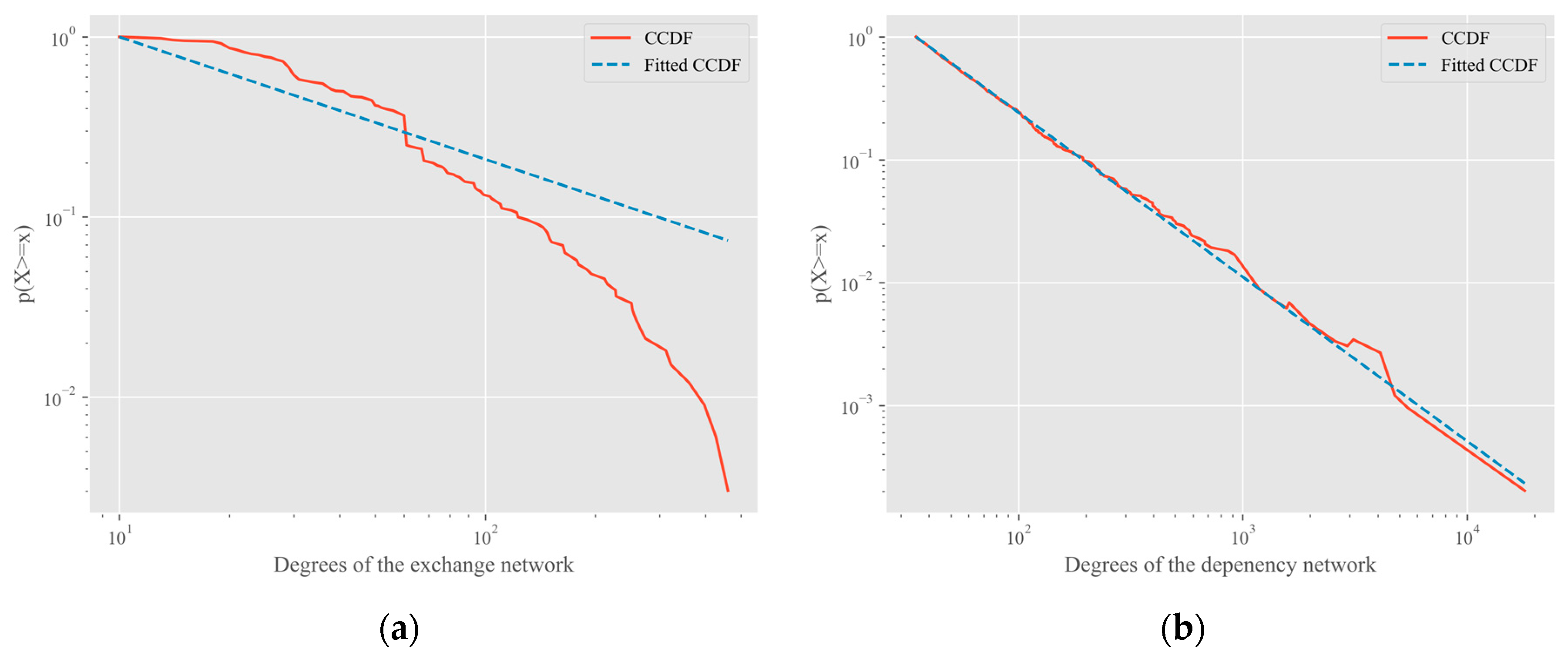
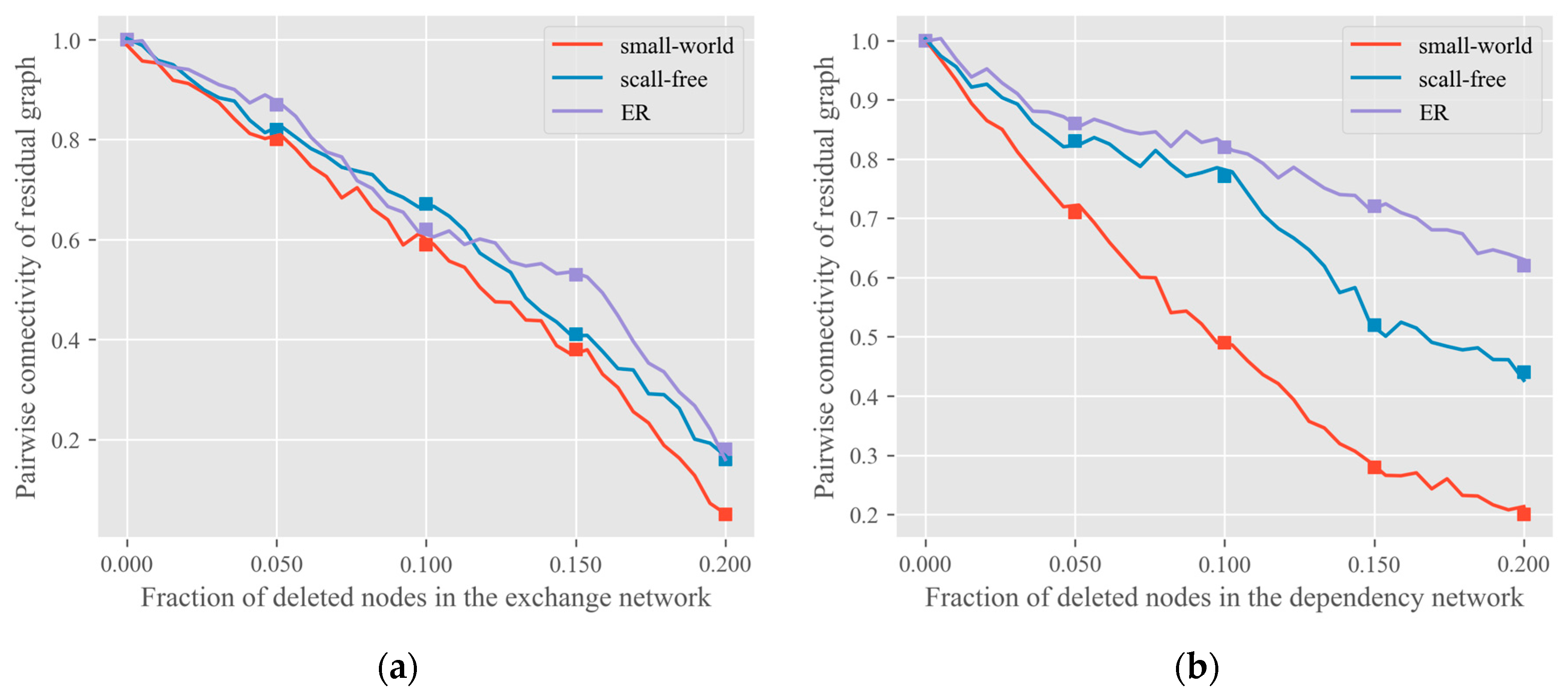
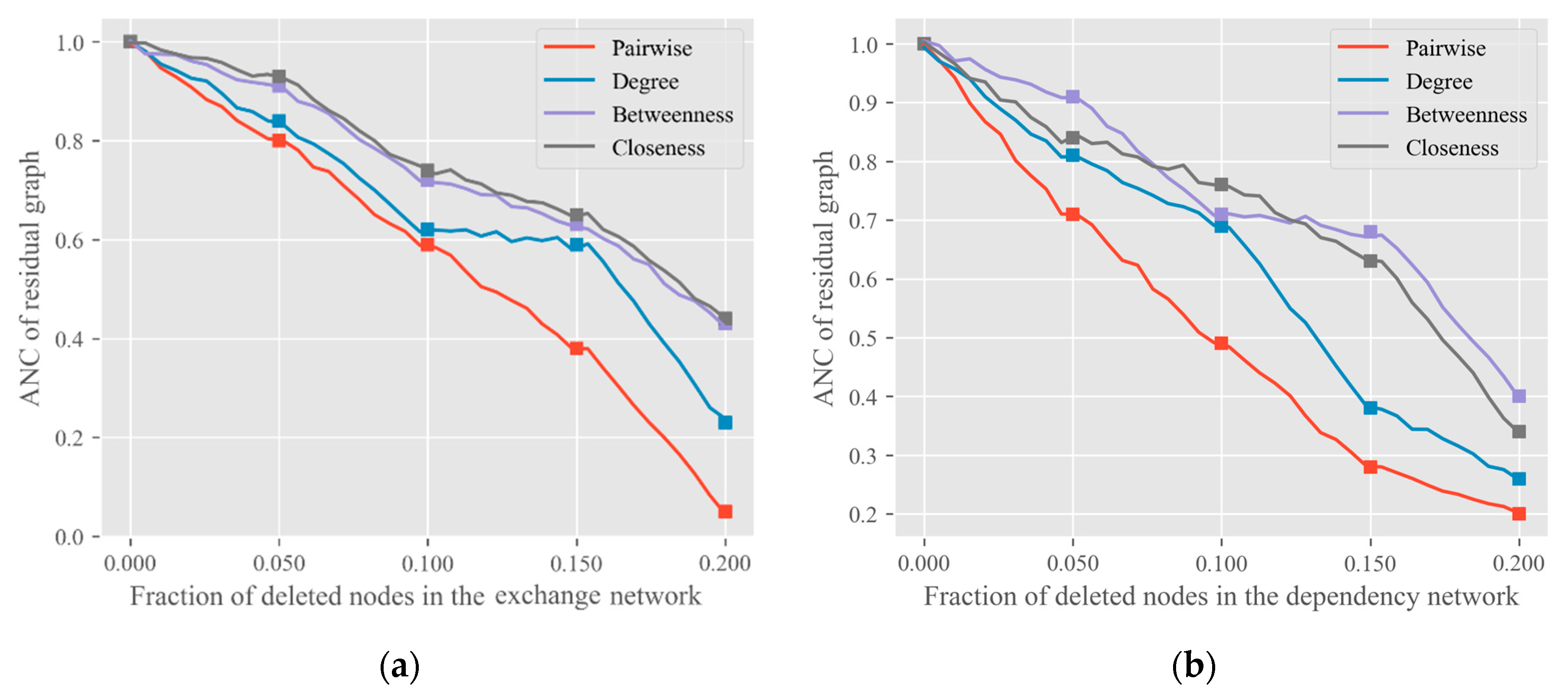
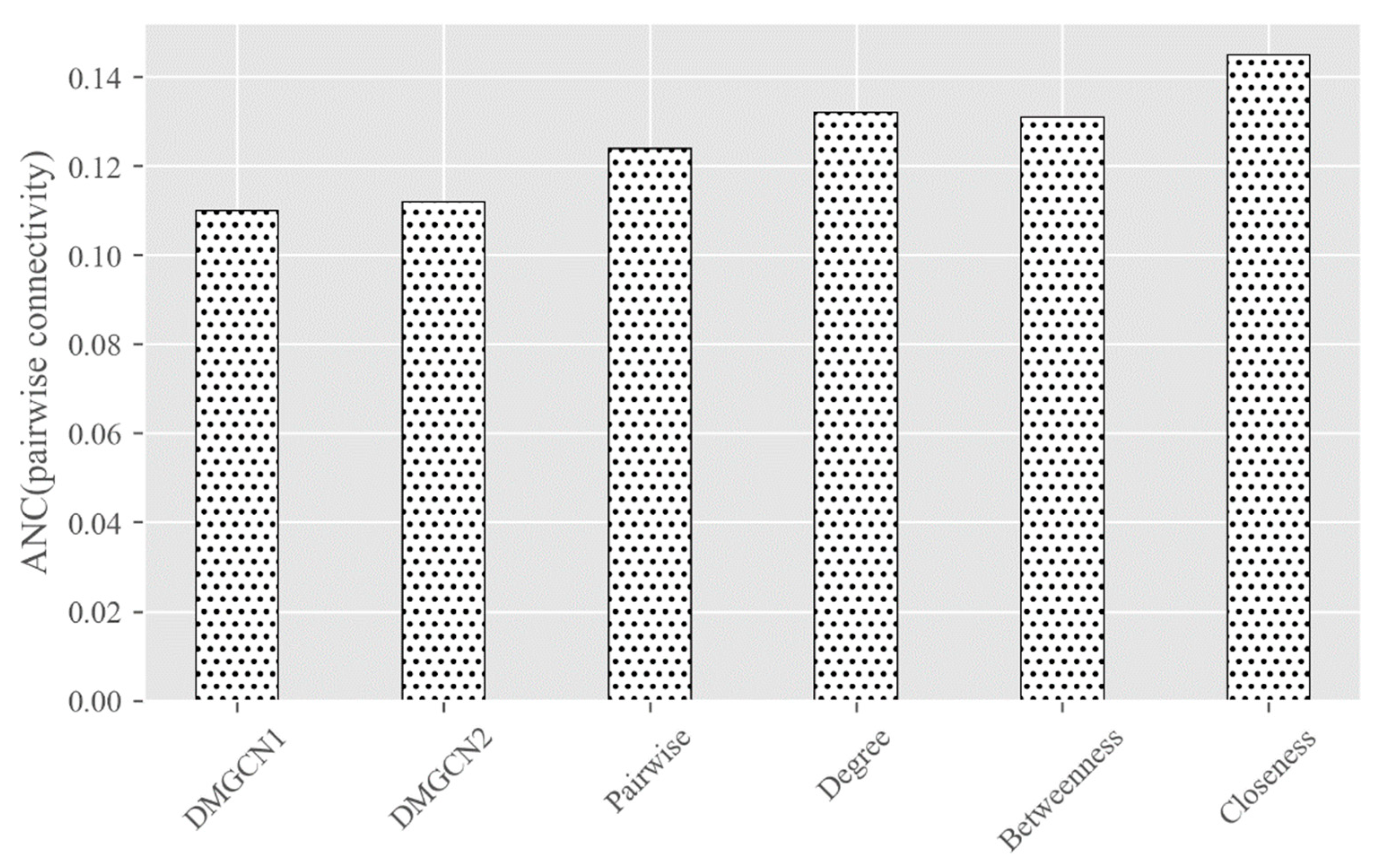
4. Experiments and Discussion
- Begin with a small graph containing nodes. Each step adds a new node.
- Construct () edges by connecting this new node to the original nodes.
- When creating new edges, if a node refers to the degree of in the original network, the probability of new nodes connecting to it is .
- After step t, the process produces a graph with nodes and edges.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ramnath, S.; Haghighi, P.; Venkiteswaran, A.; Shah, J.J. Interoperability of CAD geometry and product manufacturing information for computer integrated manufacturing. Int. J. Comput. Integr. Manuf. 2020, 33, 116–132. [Google Scholar] [CrossRef]
- Denghui, Z.; Zhengxu, Z.; Yiqi, Z.; Yang, G. Migration of Data Format and Formal Specification for Additive Manufacturing. Boletín Técnico 2017, 55, 2. [Google Scholar]
- Blazic, A.J.; Klobucar, T.; Jerman, B.D. Long-term trusted preservation service using service interaction protocol and evidence records. Comput. Stand. Interfaces 2007, 29, 398–412. [Google Scholar] [CrossRef]
- Du, J.; Zhao, D.; Issa, R.R.A.; Singh, N. BIM for Improved Project Communication Networks: Empirical Evidence from Email Logs. J. Comput. Civil. Eng. 2020, 34, 04020027. [Google Scholar] [CrossRef]
- Li, H.; Shang, Q.; Deng, Y. A generalized gravity model for influential spreaders identification in complex networks. Chaos Solitons Fractals 2021, 143, 110456. [Google Scholar] [CrossRef]
- Zhang, D.; Zhao, Z.; Zhou, Y.; Guo, Y. A novel complex network-based modeling method for heterogeneous product design. Clust. Comput. 2019, 22, 7861–7872. [Google Scholar] [CrossRef]
- Cherifi, H.; Palla, G.; Szymanski, B.K.; Lu, X. On community structure in complex networks: Challenges and opportunities. Appl. Netw. Sci. 2019, 4, 117. [Google Scholar] [CrossRef]
- Shen, Y.; Nguyen, N.P.; Xuan, Y.; Thai, M.T. On the Discovery of Critical Links and Nodes for Assessing Network Vulnerability. IEEE/ACM Trans. Netw. 2012, 21, 963–973. [Google Scholar] [CrossRef]
- Wang, D.; Song, C.; Barabási, A.-L. Quantifying long-term scientific impact. Science 2013, 342, 127–132. [Google Scholar] [CrossRef]
- Fan, C.; Zeng, L.; Sun, Y.; Liu, Y.-Y. Finding key players in complex networks through deep reinforcement learning. Nat. Mach. Intell. 2020, 2, 317–324. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; IEEE: New York, NY, USA, 2014; pp. 1701–1708. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. IEEE Trans. Neural. Netw. Learn. Syst. 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Zhao, G.; Jia, P.; Zhou, A.; Zhang, B. InfGCN: Identifying influential nodes in complex networks with graph convolutional networks. Neurocomputing 2020, 414, 18–26. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1025–1035. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Lalou, M.; Tahraoui, M.A.; Kheddouci, H. The Critical Node Detection Problem in networks: A survey. Comput. Sci. Rev. 2018, 28, 92–117. [Google Scholar] [CrossRef]
- Bonato, A.; D’Angelo, D.R.; Elenberg, E.R.; Gleich, D.F.; Hou, Y. Mining and Modeling Character Networks. In Algorithms and Models for the Web Graph; Springer: Cham, Switzerland, 2016; pp. 100–114. [Google Scholar]
- Zhang, Z.; Zhao, Y.; Liu, J.; Wang, S.; Tao, R.; Xin, R.; Zhang, J. A general deep learning framework for network reconstruction and dynamics learning. Appl. Netw. Sci. 2019, 4, 1. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhao, L.Z. Small-world phenomenon: Toward an analytical model for data exchange in Product Lifecycle Management. Int. J. Internet Manuf. Serv. 2008, 1, 213–230. [Google Scholar] [CrossRef]
- Denghui, Z.; Zhengxu, Z.; Yiqi, Z.; Yang, G. Migration of Conventional Model Transfer Format on Additive Manufacturing. In Proceedings of the 3rd International Conference on Material Engineering and Application (ICMEA), Shanghai, China, 12–13 November 2016; pp. 125–130. [Google Scholar]
- Fillinger, S.; Esche, E.; Tolksdorf, G.; Welscher, W.; Wozny, G.; Repke, J.-U. Data Exchange for Process Engineering—Challenges and Opportunities. Chem. Ing. Tech. 2019, 91, 256–267. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Shakibian, H.; Charkari, N.M. Statistical similarity measures for link prediction in heterogeneous complex networks. Phys. A Stat. Mech. Its Appl. 2018, 501, 248–263. [Google Scholar] [CrossRef]
- AlternativeTo—Crowdsourced Software Recommendations. AlternativeTo. Available online: https://alternativeto.net (accessed on 25 July 2022).
- FileInfo.com—The File Information Database. Available online: https://fileinfo.com (accessed on 25 July 2022).
- Akhtar, N. Social network analysis tools. In Proceedings of the 2014 Fourth International Conference on Communication Systems and Network Technologies, Bhopal, India, 7–9 April 2014; pp. 388–392. [Google Scholar]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Li, R.; Dong, L.; Zhang, J.; Wang, X.; Wang, W.X.; Di, Z.; Stanley, H.E. Simple spatial scaling rules behind complex cities. Nat. Commun. 2017, 8, 1841. [Google Scholar] [CrossRef] [PubMed]
- Fey, M.; Lenssen, J.E. Fast graph representation learning with PyTorch Geometric. In Proceedings of the ICLR 2019 Workshop on Representation Learning on Graphs and Manifolds, New Orleans, LA, USA, 6–9 May 2019; pp. 1–9. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| A graph | |
| vertices of | |
| edges of | |
| a vertex or node | |
| The k-th layer embedding of the node | |
| functions such as non-linearity neural layers | |
| a differentiable aggregator function such as | |
| ANC (Accumulated Normalized Connectivity) | |
| the i-th connected subcomponents in G | |
| the initial connectivity of . | |
| The degree of a node | |
| The clustering coefficient of | |
| the probability distribution function |
| Average Degree | 6.15 |
| Network Diameter | 3 |
| Average Path length | 1.92 |
| Average Betweenness Centrality | 247.35 |
| Average Closeness Centrality | 0.00032 |
| Clustering Coefficient | 0.15 |
| Average Degree | 3.72 |
| Network Diameter | 15 |
| Average Path length | 3.84 |
| Average Betweenness Centrality | 163.80 |
| Average Closeness Centrality | 0.00024 |
| Clustering Coefficient | 0.15 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, L.; Zhang, D. Identifying Key Information on Life Cycle of Engineering Data by Graph Convolutional Networks and Data Mining. Buildings 2022, 12, 1105. https://doi.org/10.3390/buildings12081105
Ren L, Zhang D. Identifying Key Information on Life Cycle of Engineering Data by Graph Convolutional Networks and Data Mining. Buildings. 2022; 12(8):1105. https://doi.org/10.3390/buildings12081105
Chicago/Turabian StyleRen, Lijing, and Denghui Zhang. 2022. "Identifying Key Information on Life Cycle of Engineering Data by Graph Convolutional Networks and Data Mining" Buildings 12, no. 8: 1105. https://doi.org/10.3390/buildings12081105
APA StyleRen, L., & Zhang, D. (2022). Identifying Key Information on Life Cycle of Engineering Data by Graph Convolutional Networks and Data Mining. Buildings, 12(8), 1105. https://doi.org/10.3390/buildings12081105